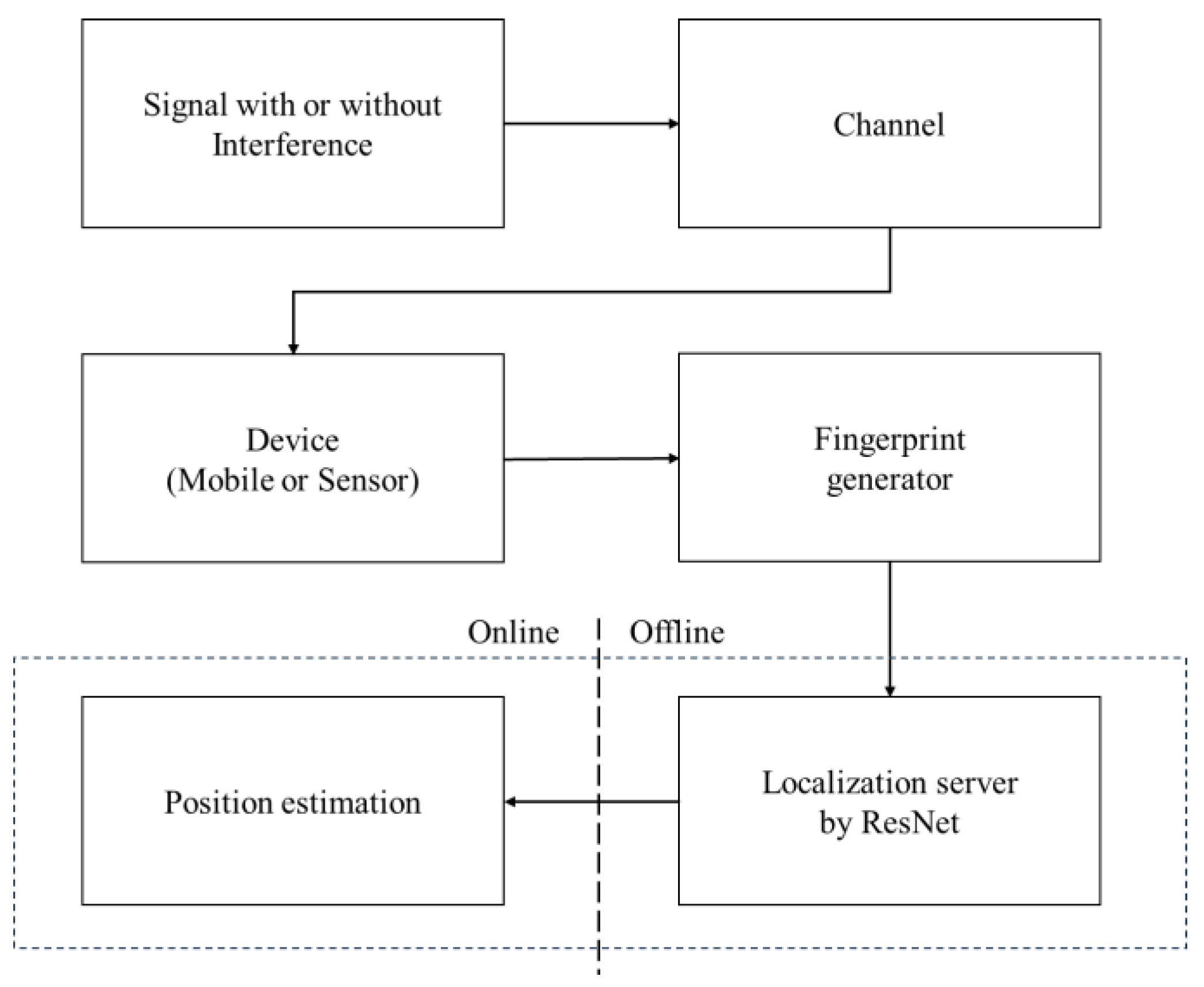
1. Introduction
Positioning technology plays a crucial role in modern 6G information processing, with applications ranging from indoor navigation to environmental monitoring [
1,
2]. From a research perspective, positioning methods can generally be categorized into two types: frequency-domain and time-domain. Frequency-domain methods typically extract positioning information by analyzing the frequency characteristics of signals. In contrast, time-domain methods directly utilize the temporal characteristics of signals, such as time delay estimation for positioning. Frequency-domain methods involve analyzing signals in terms of their frequency content, and they make it easier to isolate frequencies and remove noise. However, the time resolution is poor for these methods. On the contrary, time-domain methods provide better time resolution because they analyze the signal directly as it varies over time. Nevertheless, the methods suffer from poor frequency discrimination as well as being noise-sensitive. Existing literature has extensively explored these two approaches, each demonstrating unique advantages and limitations [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17].
By means of the frequency-domain, in 2021, Wu introduced a deep learning approach called Structured Intra-Attention Bidirectional Recurrent (SIABR) for CSI-based (Channel State Information) 3D THz indoor localization, which improved stability and performance in challenging conditions [
3]. In 2022, Shubham introduced a novel approach to address the localization challenge in IEEE 802.11ay WLAN systems, specifically tailored for indoor environments. The proposed method integrates advanced signal processing with machine learning techniques, utilizing Doppler and angular domain analysis to effectively differentiate between multipath signals. This differentiation is based on variations in range, velocity, and angular orientation of reflected signals [
4].
In 2023, Pu proposed an indoor Wi-Fi localization scheme that extracts both spatial and temporal features from signal data. By incorporating a fusion neural network, the proposed method significantly enhanced signal reconstruction accuracy, as demonstrated by numerical evaluations [
5]. In the same year, Alitaleshi introduced a hybrid approach that integrates an autoencoder-based learning framework with a two-dimensional convolutional neural network (2D-CNN). This method achieved superior performance in terms of both positioning accuracy and floor-level estimation [
6]. In 2024, Zhou developed a cost-efficient indoor positioning system leveraging 5G downlink multibeam signals. The system demonstrated strong performance in multi-floor environments, achieving a root-mean-square positioning error of under 1.5 m. These results highlight its potential for practical deployment in mobile localization applications [
7]. In 2024, Wan proposed a novel deep learning model for solving the MIMO positioning problem, which incorporated two types of attention mechanisms and an improved training scheme to further enhance positioning accuracy [
8]. Later, Stavros presented a positioning system that extracted and processed CSI from a single Access Point (AP) to localize commercial smartphones [
9]. In the same year, Chiu explored 6G technology for indoor positioning, focusing on accuracy and reliability using Convolutional Neural Networks (CNNs) with CSI at terahertz frequencies and advanced AI algorithms, which achieved centimeter-level accuracy [
10].
By means of the time-domain, in 1999, Chiu employed a site-specific model to analyze the performance of millimeter-wave Binary Phase-Shift Keying (BPSK) systems with single cochannel interference. Impulse responses for different room types were computed via the shooting and bouncing rays technique. The Bit Error Rates (BER) and carrier-to-interference ratios were calculated, with findings indicating that interference was more significant in rooms with plasterboard-wall partitions compared to those with concrete-wall partitions [
11]. An attention-assisted Ultra-Wideband (UWB) ranging error compensation algorithm was proposed by He in 2023, enabling the reevaluation of the significance of extracted UWB channel characteristics across different environments. This approach enhanced the performance of the Deep Neural Network (DNN) model [
12]. In 2024, Lv proposed a dual-channel neural network to accurately recognize Non-Line-Of-Sight (NLOS) and Line-Of-Sight (LOS) signals in UWB positioning systems. By integrating both time-domain and time–frequency-domain features, the network processed UWB Channel Impulse Response (CIR) signals using a combination of CNN, Time Convolutional Networks (TCNs), and self-attention, achieving high classification accuracy across various complex environments and enhancing positioning performance [
13]. In 2024, Carlos compared classical fingerprinting with Decision Tree Regressor (DTR)-based algorithms to improve indoor localization in 5G and WiFi environments. This paper demonstrated how machine learning enhanced robustness when radio maps were incomplete during training and discussed the benefits of technology fusion for precise positioning. [
14]. In 2024, Gao proposed a paradigm of Localization-oriented Digital Twins (LocDT) with a compound architecture of seven sub-DT layers to characterize the 6G Integrated-Localization-And-Communication (ILAC) feature. LocDT started from a physical environment sublayer to mirror 6G signal interactions within a real-world scenario, along with an ILAC baseband sublayer and a channel frequency polar-coordinate image construction method to provide finer-grained fingerprints [
15].
In 2025, Sun constructed a high-precision indoor positioning system by integrating Wi-Fi round-trip time, magnetic field sensing, and pedestrian dead reckoning. Numerical results demonstrated that the proposed fusion model achieved a localization accuracy ranging from 0.64 to 0.91 m [
16]. In the same year, Lu proposed an ultra-wideband positioning approach based on a novel position fingerprinting technique and a parallel convolutional neural network. The proposed scheme achieved a mean absolute error of just 0.173 m, indicating high precision in indoor localization tasks [
17]. However, we notice that the accuracy of existing methods decreases under high noise and interference, and the CLAB and SLAB mechanisms effectively overcome this problem. Experimental results have demonstrated improvements in stability and anti-interference capabilities.
To the best of our knowledge, there has been no research on a time-domain positioning system using ResNet with Channel Local Attention Block (CLAB) and Spatial Local Attention Block (SLAB). This paper first introduces ResNet with CLAB and SLAB for localization by means of time-domain data. The distinctive features of this work include the following:
We employ the time-domain approach using the ResNet to effectively leverage channel information, further enhancing the accuracy of the localization results;
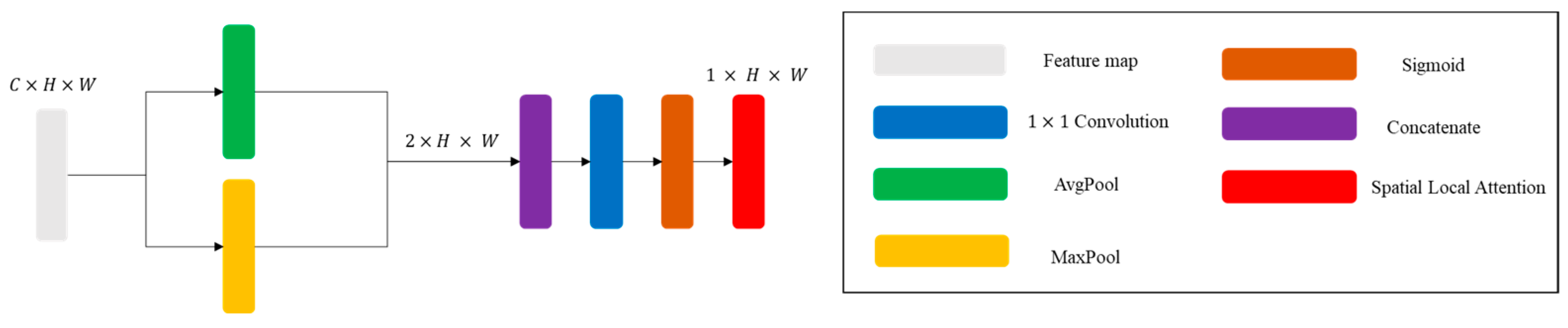
We introduce two advanced attention mechanisms, CLAB and SLAB, that significantly boost model performance, elevating its effectiveness to a new level;
Existing localization methods often struggle under severe noise and interference, leading to significant accuracy degradation. This paper addresses such limitations by integrating CLAB and SLAB into the ResNet framework, enhancing noise robustness. Experimental results show that under 20% Gaussian noise and an additional 20% interference, our proposed method reduces RMSE by up to 56.5% compared to baseline ResNet, clearly demonstrating superior stability and accuracy in harsh environments.
Section 2 discusses the 6G channel model and system design.
Section 3 details the proposed ResNet architecture with CLAB and SLAB.
Section 4 presents experimental results.
Section 5 concludes the study.
4. Numerical Results
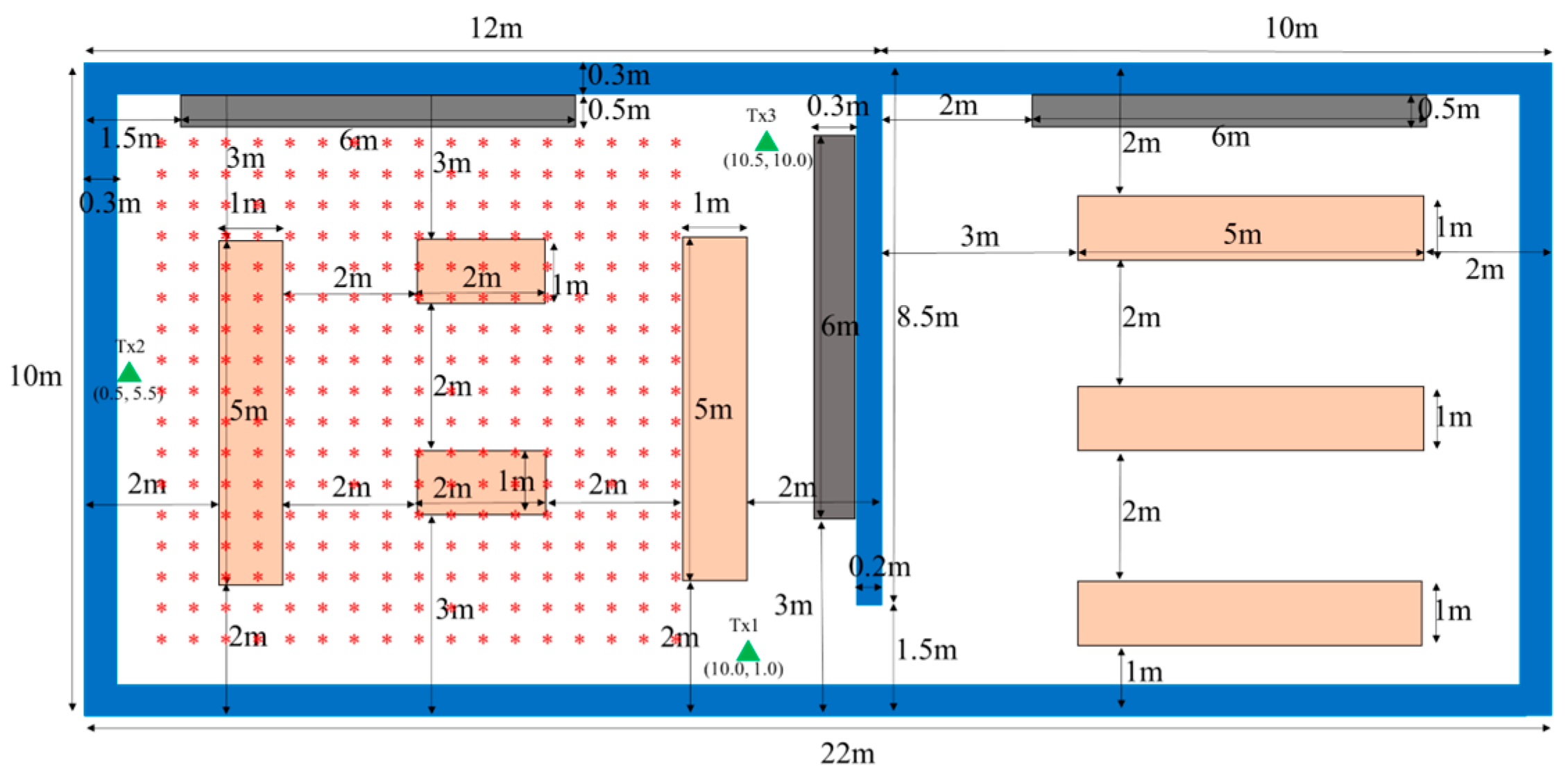
Figure 5 is the layout of the environment. A typical laboratory with
is simulated to test the positioning algorithm. CIR data from terahertz sensors is collected to extract the fingerprint. The dataset includes data from 289 receiving antennas, 3 transmitters, and 1024 frequency points, spanning a frequency range from 120 GHz to 130.23 GHz, with a frequency resolution of 0.01 GHz. The half-wave dipoles are used for transmitting and receiving antennas. The maximum number of reflections is set to 5, and the number of diffractions is 1. The CIR data are measured 200 times per receiver, with data from 289 receiving antennas, resulting in a significant dataset for training the model. The CIR features are extracted, normalized, and reshaped for model convergence. A database of pre-collected signals is created across the environment to generate fingerprint data. The fingerprint data includes the first path amplitude, time of arrival of the first path, channel impulse response power, root mean square delay spread, and RSSI from CIR. These features are normalized to standardize the input, thereby improving model training.
There are three metal bookcases, with a height of 2 m, and seven desks with a height of 0.7 m in the laboratory. Three transmitters, of 1 m tall, located at Tx1(10, 1) m, Tx2(0.5, 5.5) m and Tx3(10.5, 10) m are used to transmit the signal. 289 receivers, all 1 m in height, are uniformly distributed from (1, 1) m to (9, 9) m as shown in
Figure 5. The Adam optimizer is used for training, including 200 epochs with a mini-batch size of 128, and an initial learning rate of 0.002. The training is conducted on a GPU. L2 regularization and gradient clipping are employed to improve performance.
This paper primarily focuses on the time-domain to assess the accuracy of position prediction models for indoor positioning systems. The errors in predicted positions are typically computed as the Euclidean distance between the predicted and actual positions at each time point. The overall positioning error across all data points can be represented by the Root Mean Square Error (RMSE), which is calculated as follows:
where
N denotes the total number of data points.
and
are the predicted x- and y-coordinates of the i-th data point.
and
are the true x- and y-coordinates of the i-th data point. The RMSE provides a more intuitive understanding of the error, with units equivalent to those of the original data (e.g., meters), making it suitable for real-world applications. Lower RMSE values indicate better accuracy, and the RMSE is particularly useful for understanding how well the model generalizes its predictions.
In this section, we analyze the numerical results obtained from four different models under various noise conditions. The four models include the ResNet, ResNet with CLAB, ResNet with SLAB, and ResNet with CLAB and SLAB. The evaluation is based on RMSE, which measures the positioning accuracy of each model. The networks are trained with 10% noise.
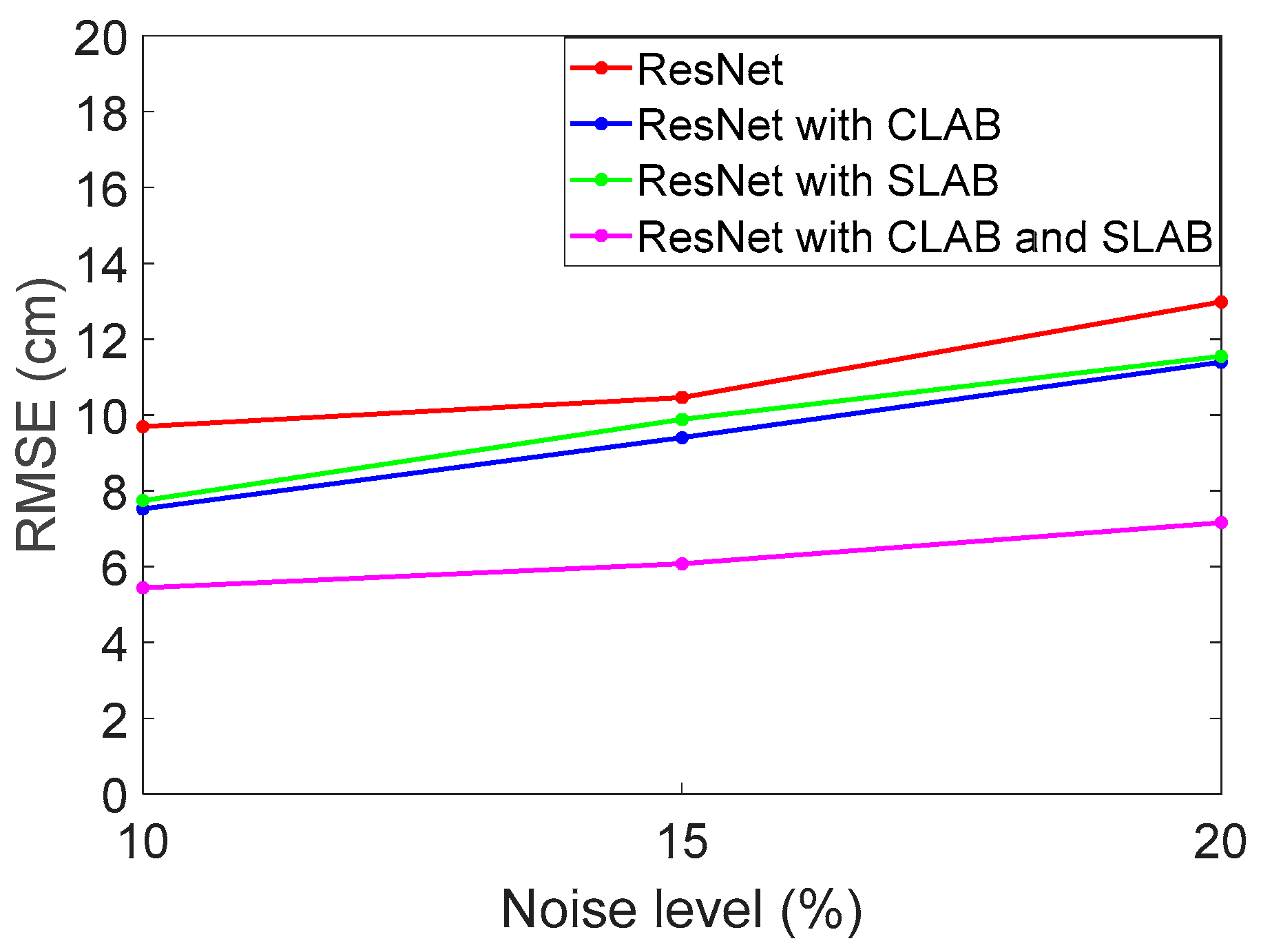
Figure 6 shows the RMSE performance under different noise levels.
Table 1 provides a summary of the results for different noise levels.
As shown, the ResNet with CLAB model outperforms ResNet in all noise scenarios, demonstrating its ability to improve feature selection. For a 10% noise level, RMSE is reduced from 0.0969 m to 0.0752 m, achieving a 22.4% improvement. However, the performance gain varies more significantly with different noise levels.
Next, the ResNet with the SLAB model consistently achieves lower RMSE values compared to the baseline ResNet, indicating that spatial attention enhances feature extraction and improves noise robustness. For a 10% noise level, RMSE is reduced from 0.0969 m to 0.0774 m, reflecting a 20.2% improvement. For a 15% noise level, RMSE reduction is 5.5%, showing that SLAB remains effective at moderate noise levels. This indicates that SLAB is particularly effective in reducing errors under varying noise conditions, likely due to its ability to capture spatial dependencies more effectively.
Lastly, the ResNet with CLAB and SLAB models achieves the lowest RMSE values under all noise conditions, verifying that the combination of spatial and channel attention mechanisms results in superior performance. Compared to ResNet, RMSE reductions of 43.9%, 42%, and 44.8% are observed at 10%, 15%, and 20% noise levels, respectively. From
Table 1, it is evident that integrating both attention mechanisms, CLAB and SLAB, significantly enhances positioning accuracy. The RMSE can be reduced to 7 cm.
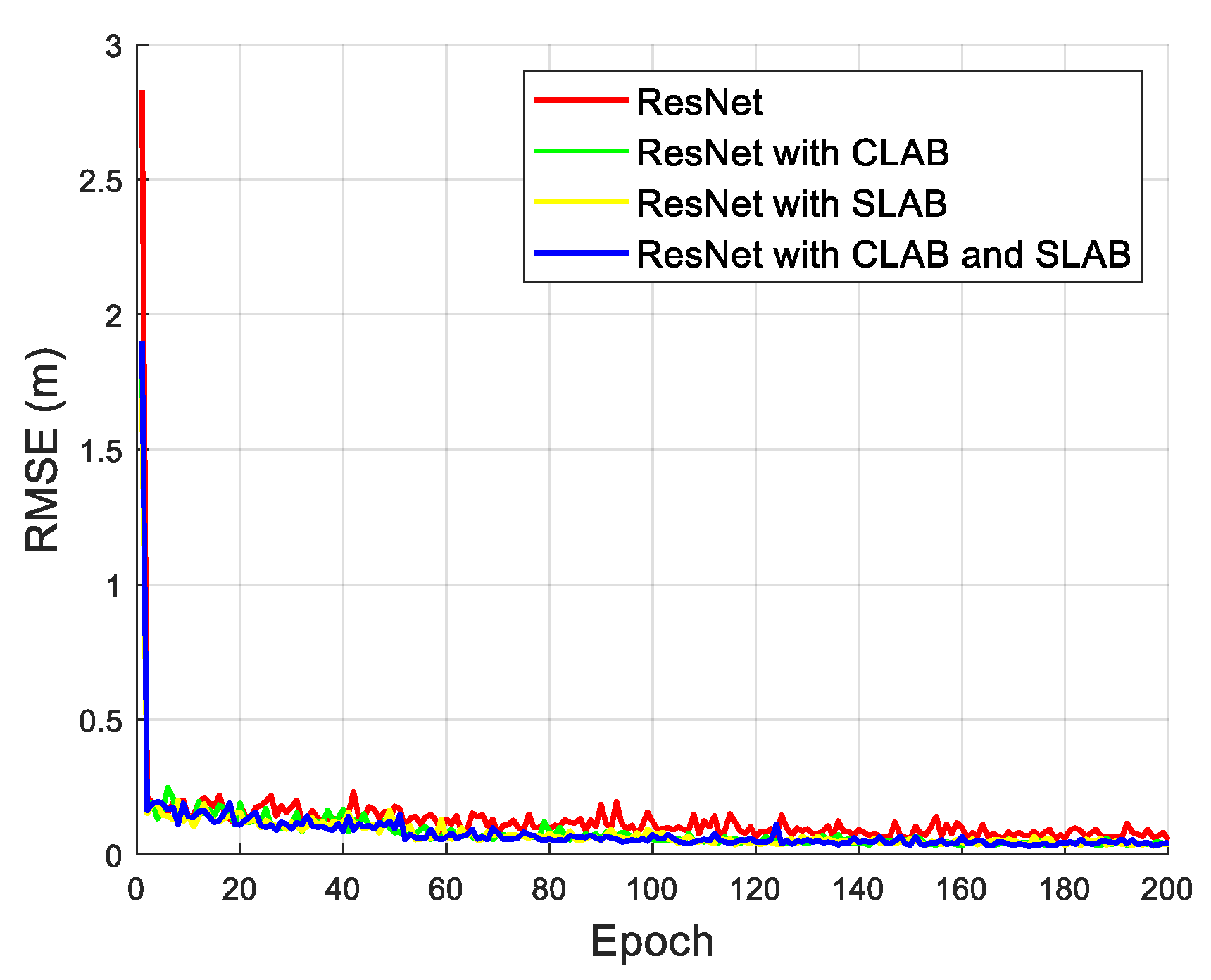
Figure 7 illustrates the RMSE variation over epochs without additional interference sources for different models under a 15% noise level. The results indicate that all models experience an initial sharp decline in RMSE, followed by stabilization as training progresses. The ResNet model with CLAB and SLAB mechanisms achieves the lowest RMSE and demonstrates the best convergence stability, suggesting that combining both channel and spatial attention mechanisms effectively enhances feature extraction and noise resilience. In brief, it has been observed that the standalone CLAB and SLAB models show improvement over the baseline ResNet. Additionally, the hybrid model outperforms both, confirming the complementary benefits of integrating both attention mechanisms. We are currently developing tools to visualize the learned attention weights from CLAB and SLAB in different indoor scenes. Preliminary results show that CLAB tends to emphasize frequency-domain feature channels that correspond to dominant signal components. SLAB highlights regions that spatially align with the anchor point, likely correlating with areas of signal strength variation due to multipath effects.
In some wireless communication systems, interference may come from multiple independent radio sources. The impact of these interference sources can be approximated as a Gaussian distribution. As a result, we use 20% Gaussian interference to evaluate our model.
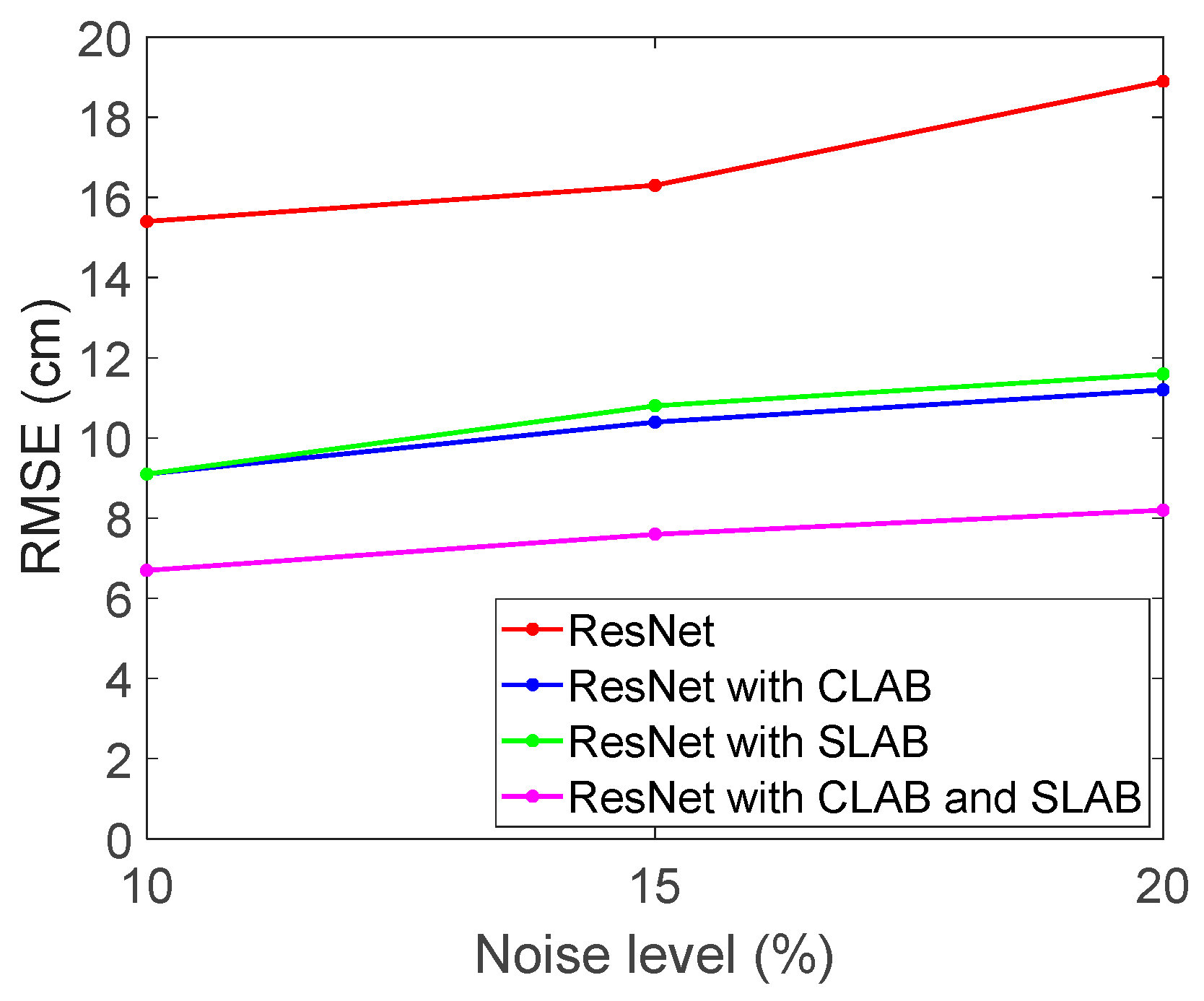
Figure 8 shows the RMSE performance with 20% interference under different noise levels.
Table 2 presents the RMSE performance under different noise levels with an additional 20% interference. The results also indicate that both CLAB and SLAB mechanisms contribute to reducing the RMSE value. Compared to
Table 1, the presence of interference significantly increases the RMSE across all models, indicating that interference degrades positioning accuracy. Nevertheless, ResNet integrated with the CLAB and SLAB model still achieves the best performance, demonstrating its robustness against interference.
In the 10% noise scenario, RMSE for ResNet increases from 0.0969 m (
Table 1) to 0.1546 m (
Table 2) due to interference, reflecting the impact of interference. However, applying CLAB or SLAB reduces RMSE, and their combination, CLAB and SLAB, achieves the lowest RMSE at 0.0673, an improvement of 50.5% compared to the baseline ResNet. At the 15% noise level, RMSE for the baseline ResNet rises from 0.1046 m (
Table 1) to 0.1631 m (
Table 2), further confirming the negative effect of interference. Even so, the CLAB and SLAB mechanisms still provide improvements by reducing RMSE to 0.0768, achieving a 54.3% improvement over the baseline ResNet. At 20% noise, RMSE degradation is most pronounced, with ResNet increasing from 0.1298 m (
Table 1) to 0.1898 m (
Table 2). Despite this, ResNet with CLAB and SLAB still effectively suppresses the error, achieving an RMSE of 0.0825 m, which represents a 56.5% improvement compared to ResNet. The above results demonstrate that both CLAB and SLAB effectively mitigate noise interference, and their combination provides the most significant improvement in positioning accuracy. The findings highlight the importance of integrating spatial and channel attention mechanisms in challenging environments.
Figure 9 presents the RMSE versus epoch results for the same models under a 15% noise level, with an additional 20% interference source. Compared to
Figure 7, the RMSE values are generally higher in the initial training phase due to the added interference, which introduces additional challenges in learning accurate feature representations. However, as training progresses, RMSE stabilizes, with the ResNet model incorporating CLAB and SLAB still achieving the best overall performance. The gap between the baseline ResNet and the models utilizing attention mechanisms widens, highlighting that attention-based architectures are more robust against interference. Notably, the hybrid CLAB and SLAB model not only achieves lower RMSE but also maintains a more stable convergence trend, indicating its superior capacity to mitigate interference effects while preserving localization accuracy. As shown in
Figure 7 and
Figure 9, models equipped with CLAB and SLAB exhibit faster and more stable convergence trends compared to the baseline ResNet. In particular, the hybrid model with both CLAB and SLAB not only achieves the lowest RMSE but also shows less fluctuation during training, indicating better learning stability and robustness to noise and interference. The loss consistently decreases within the first 50 epochs and stabilizes afterwards, suggesting that our attention-augmented architectures can converge effectively and reliably.
In relation to the overall training duration for deep learning, our experiments are conducted on the same hardware configuration: a personal computer equipped with a 3.8 GHz Intel Core i7 processor, 64 GB RAM, and an NVIDIA RTX 4060 12 GB GPU. The training time for the baseline ResNet model is approximately 150 minutes. In comparison, the ResNet with CLAB requires an average of 155 min, and the model with SLAB needs the training time to approximately 160 min. The model with both CLAB and SLAB needs the training time to approximately 165 min. The computation time for training each model is shown in
Table 3. Although training requires several hours, once the models are trained, they can perform inference in less than 1 s, making the proposed method suitable for real-time indoor localization applications.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}