1. Introduction
The increasing reliance on biometric authentication systems, particularly those utilizing fingerprints [
1,
2], underscores the critical need for advanced spoof detection and prevention mechanisms. This necessity arises from the fact that commonly available materials such as gelatin, silicone, and Play-Doh can be utilized to create spoof fingerprints capable of bypassing fingerprint recognition systems [
3,
4], with a reported success rate exceeding
[
5]. To counteract such vulnerabilities, a variety of anti-spoofing techniques have been proposed, which can be broadly classified into hardware-based and software-based solutions [
6,
7]. Although hardware-based solutions are highly effective [
8], they are also prohibitively expensive due to the need for multiple sensors. In contrast, software-based solutions offer a cost-effective alternative, achieving comparable efficacy by extracting features from fingerprint images captured by sensors, thereby distinguishing between live and spoof fingerprints without incurring additional hardware costs.
The application of CNNs has recently gained prominence in addressing the problem of spoof fingerprint detection. CNN-based approaches have consistently produced top-performing algorithms in various competitions, such as the Liveness Detection (LivDet) competition [
9], over the past several years. To enhance accuracy and prevent overfitting on small datasets, pre-trained models are commonly used [
10,
11]. Additionally, patch extraction is often employed as a strategy to expand the training dataset, mitigating overfitting by increasing the number of training samples [
12]. Furthermore, to improve model generalization, generative adversarial networks (GANs) have been used to generate synthetic fingerprint data, enriching the diversity of training samples [
10,
13].
CNN-based methods identify local patterns and structures in fingerprint images using convolutional filters [
14]. However, one of their inherent limitations is the lack of spatial awareness, meaning they do not explicitly consider how these local features relate to each other across the entire image; this can hinder accuracy in fingerprint liveness detection, particularly in cases where the relationship between different fingerprint features plays a crucial role [
15,
16]. To overcome this challenge, attention-based approaches have been introduced, enabling models to capture and utilize spatial dependencies more effectively. By incorporating attention mechanisms, these methods enhance feature representation and improve overall detection performance. Attention-based methods have demonstrated high accuracy in fingerprint liveness detection by learning the global context of fingerprint images and directing focus toward important regions [
17,
18,
19]. However, most existing approaches require significant computational resources or have long processing times due to their large number of parameters or intricate preprocessing steps. For example, some methods [
15,
20] rely on complex preprocessing techniques, such as patch extraction, minutiae detection, and synthetic fingerprint generation, which add computational overhead. While these methods perform well in controlled environments with high-end hardware, their reliance on large-scale models makes them impractical for resource-constrained devices [
16,
21,
22]. Fingerprint liveness detection plays an essential role in on-device authentication, where both accuracy and speed are essential for a seamless user experience [
19,
23]. This creates a need for optimized fingerprint liveness detection techniques that maintain a balance between model accuracy and number of parameters. While some lightweight models with fewer parameters have made advancements in minimizing computational demands [
13,
19], further research is needed to provide lightweight models while enhancing accuracy and generalization.
In this work, we propose a lightweight model with a parameter count of only 0.14 million (M) for spoof fingerprint detection on LivDet-2015 [
24] and LivDet-2017 [
25] by guiding attention to essential features across different levels of detail. In our work, we did not use pre-trained models, trained on natural images, rather we provided an architecture tailored specifically for fingerprint data. In our proposed model, we avoid a fully connected prediction layer, as such a layer with our architecture may lead to overfitting on these small fingerprint datasets. In contrast, in our proposed model, the final feature map is averaged to a single value for classification. This architectural choice highlights the importance of spatial discriminability and motivates the integration of a spatial attention module [
26] to guide the network’s focus toward the most informative regions. A spatial attention module integrated before the final convolutional layers ensures the preservation of critical spatial relationships, preventing the loss of intricate dependencies essential for effective spoof detection. Unlike conventional CNN architectures that assign uniform importance to all features, this attention module dynamically emphasizes spatial regions based on their discriminative relevance. Specifically, it directs the model’s focus towards informative regions containing high-quality ridge structures and subtle textural cues, significantly improving the model’s ability to differentiate between live and spoof fingerprints, even under challenging imaging conditions or when presented with previously unseen spoof materials. This targeted attention helps the network ignore irrelevant regions, improving generalization by guiding learning toward consistently discriminative spatial features. The initial convolutional layer employs a large
kernel to capture broader contextual information, ensuring that each pixel in the feature map corresponds to a larger receptive field. To enhance robustness, the hyperbolic tangent activation applied to the final feature map prevents any single feature from dominating. The averaging operation leverages information from all regions of the fingerprint image, integrating subtle spatial patterns to improve classification accuracy. Furthermore, error calculation on the averaged CNN response effectively incorporates receptive field-wise labels, allowing the model to be trained with fewer parameters, thereby helping to prevent overfitting while maximizing accuracy.
This task-specific approach effectively mitigates the shortcomings commonly associated with excessive parameter counts and model complexity, which often compromise efficiency in resource-constrained deployments. This compactness makes our model exceptionally suitable for real-time and resource-constrained deployments. In contrast, existing methods such as FLDNet [
13] and LFLDNet [
19] utilize approximately 0.48 M and 0.83 M parameters, respectively, while even more resource demanding architectures like Slim-ResCNN [
17] and ALDRN [
27] employ over 2 million parameters. The substantial computational overhead of these methods significantly limits their practical deployment, especially in environments with strict computational constraints. Our model achieves superior average classification accuracy compared to many existing methods, such as [
10,
11], which rely on pre-trained models. Specifically, in challenging cross-material evaluations, our model significantly outperforms state-of-the-art methods such as Fingerprint Spoof Buster (FSB) [
28], LivDet15 winner [
29], CFD-PAD [
30], RTK-PAD [
30], and Siamese Attention Res-CNN (SA-R-CNN) [
31], achieving ACE values of 0.81% on LivDet-2015 and 1.91% on LivDet-2017. Thus, our results demonstrate both superior accuracy and enhanced generalization capability while having significantly fewer parameters, highlighting our architecture’s efficiency for resource-constrained devices. The primary two contributions of this paper can be summarized as follows:
Proposing a lightweight fingerprint liveness detection approach that guides attention to essential features across multiple levels of detail, reducing model complexity while maintaining high accuracy.
Validating the generalization capability of the proposed method through comprehensive testing to ensure robustness.
2. Related Work
In software-based liveness detection, the distinction between live and spoof fingerprints depends heavily on effective feature extraction. The texture properties of live and spoof fingerprints differ significantly, particularly in terms of continuity and sharpness. These variations result from the inherent material and structural differences between authentic skin and synthetic materials, which influence the ridge patterns and fine details of fingerprints. As a result, texture-based feature extraction techniques have become widely used in static feature-based approaches. These techniques also highlight the use of traditional machine learning methods to enhance classification performance.
2.1. Static Feature-Based Approaches
Sharma et al. [
32] introduced a texture-based fingerprint liveness detection method using handcrafted features like ridge-width smoothness, valley-width smoothness, and ridge–valley clarity to capture differences between live and spoof fingerprints. Feature selection techniques are employed to optimize extracted features, which are classified using traditional machine learning models such as SVM and Random Forest. The local phase quantization descriptor, which utilizes the short-time Fourier transform, was introduced as a method to capture the information loss that occurs during the fabrication process of spoof fingerprints, enabling the distinction between live and spoof fingerprints [
33]. Gragnaniello et al. [
34] explored Weber local descriptors to mitigate spoofing attacks on fingerprint sensors, leveraging their ability to extract local texture information to improve detection accuracy. Building on this, Gragnaniello et al. [
35] developed the local contrastive phase descriptor, which enhances spoof detection by integrating gradient information with local phase data, achieving commendable accuracy. Xia et al. [
36] proposed the Weber local binary descriptor, which introduced a novel approach to analyzing texture features and explored the benefits of feature fusion techniques, combining multiple features to improve performance and robustness in fingerprint liveness detection.
Although these methods deliver satisfactory classification accuracy, their generalization and robustness remain limited, especially when dealing with images captured in complex or challenging conditions, such as those affected by excessive noise, variations in sensor quality, or disruptions caused by inconsistent pressure during fingerprint acquisition. To overcome these limitations, recent research has increasingly focused on deep learning techniques, with CNNs such as DenseNet, MobileNet, ResNet, and VGG. These methods have achieved significant attention as they eliminate the need for extensive manual feature design, enabling models to autonomously learn patterns and features directly from the data while improving classification accuracy.
2.2. CNN-Based Approaches
Building upon this, and shifting away from manually extracted features to learning-based approaches, recent studies have proposed various CNN-based architectures for fingerprint liveness detection. Nogueira et al. [
37] introduced one of the earliest CNN-based approaches for fingerprint liveness detection by leveraging a pre-trained VGG network. Their method achieved state-of-the-art performance and was recognized as the winning solution in the 2015 Fingerprint Liveness Detection Competition, marking a significant shift toward deep learning in the field. Rai et al. [
10] proposed a presentation attack detection method based on an Open Patch Generator (OPG) that uses GANs to create synthetic spoof fingerprint patches. These synthetic patches are used to augment the training dataset, while DenseNet classifiers are trained to distinguish between live and spoof fingerprints, showing strong performance in generalization across datasets. Similarly, the MoSFPAD model by Rai et al. [
11] combines MobileNet for feature extraction with an SVM to deliver a hybrid architecture. This model focuses on patch-based feature extraction for detecting spoof attacks. To enhance efficiency, Slim-ResCNN [
17] takes an approach of using improved residual blocks with dropout layers to prevent overfitting. Sharma et al. [
38] introduced the HyFiPAD model, which combines multiple texture analysis methods, including local adaptive binary pattern, complete local adaptive binary pattern, and binarized statistical image features. By using a combination of SVM and CNNs with majority voting, this method improves classification accuracy, particularly in identifying texture details in fingerprint images. The Adaptive-Learning-Based Deep Residual Network (ALDRN) proposed by Yuan et al. [
27] addresses the challenge of fingerprint liveness detection by utilizing region-of-interest (ROI) extraction to remove noise and isolate key minutiae. Additionally, the use of deep residual networks mitigates degradation issues through shortcut connections.
CNN-based methods lack spatial awareness, as they do not explicitly capture relationships between local features across the entire image. This limitation can affect fingerprint liveness detection, particularly when the spatial dependencies between fingerprint features are crucial. To address this, attention-based approaches have been introduced, allowing models to effectively learn and utilize these dependencies [
17].
2.3. Attention-Based Approaches
In an effort to enhance feature discrimination and reduce noise in fingerprint spoof detection, various attention-based methods have been incorporated, including Convolutional Block Attention Module (CBAM)-based [
39,
40], multi-head attention-based [
19], and self-attention-based approaches [
41]. To enhance feature discrimination in fingerprint spoof detection, Aluvala et al. [
40] proposed a CNN-based architecture augmented with a CBAM. Their work leverages both channel and spatial attention mechanisms to enable the model to adaptively emphasize the most informative fingerprint regions while suppressing irrelevant patterns. To strengthen its attention capacity, the architecture applies CBAM at multiple layers, using local binary pattern descriptors as input features. The channel attention mechanism focuses on inter-channel relationships, while the spatial attention module learns spatially salient regions. This dual-attention design improves the model’s ability to highlight fabricated texture patterns, an important factor in spoof detection.
On the other hand, Grosz et al. [
41] proposed a unified Vision Transformer (ViT)-based architecture that simultaneously performs fingerprint presentation attack detection and identity recognition. Unlike conventional CNN-based approaches that rely heavily on patch-level analysis or separate models for PAD and recognition, their method leverages the global and local attention mechanisms intrinsic to ViT. The model captures global contextual representations for fingerprint recognition and local patch-based attention features for spoof detection. This dual use of self-attention allows the architecture to efficiently extract discriminative features across spatial hierarchies. While promising, ViT demands significant computational resources and requires large-scale datasets for training, posing challenges for practical implementation in real-time fingerprint authentication systems that prioritize efficiency and speed [
42].
In contrast, our architecture incorporates a spatial attention module to enhance discriminative feature learning. Rather than relying on fully connected layers, we employ global average pooling to aggregate the final feature map into a single scalar output, allowing each spatial location to contribute equally to the classification. The spatial attention module further guides the model to focus on the most informative regions, capturing pixel-level significance.
2.4. Lightweight Methods
As fingerprint liveness detection plays a critical role in on-device authentication, where both accuracy and speed are essential for a seamless user experience [
19,
23], several recent studies have proposed lightweight architectures aimed at reducing model complexity while maintaining competitive accuracy in spoof detection. One lightweight approach is Slim-ResCNN, proposed by Zhang et al. [
17], which introduces a residual convolutional neural network architecture specifically optimized for fingerprint liveness detection. Unlike traditional deep models adapted from natural image processing, Slim-ResCNN is tailored to the unique properties of fingerprint images, incorporating nine improved residual blocks with design simplifications to reduce parameter count and training complexity. They use dropout-enhanced residual connections to mitigate overfitting. Additionally, the model adopts a patch-based training strategy that leverages local fingerprint regions extracted via center-of-gravity-based segmentation, thereby reducing execution time and enabling better adaptability to varying fingerprint sample sizes. Slim-ResCNN with 2.5 M parameters achieves competitive performance, securing the top position in the LivDet 2017 competition.
To further provide a lightweight network, Zhang et al. [
13] proposed FLDNet that comprises only 0.48 million parameters, significantly reducing the computational and storage burden compared to conventional CNNs, while maintaining classification performance across various spoofing scenarios. Additionally, FLDNet incorporates a building block design, combining dense connectivity with residual paths. This dual-path structure enables both feature reuse and the continuous discovery of new discriminative features, effectively balancing performance and efficiency. The architecture also benefits from ROI extraction and multi-patch sampling during training, which enhances robustness without incurring significant overhead. FLDNet offers a fully end-to-end solution that processes fingerprint patches with minimal architectural complexity. Its efficiency, accuracy, and task-specific design highlight FLDNet as a strong benchmark in the lightweight fingerprint spoof detection literature.
On the other hand, LFLDNet by Kang et al. [
19] introduces an architecture for fingerprint liveness detection by integrating a modified ResNet backbone with a Transformer-based attention mechanism. To reduce complexity, the authors design a shallow residual network with fewer convolutional kernels and employ dropout layers after each convolution to prevent overfitting on small grayscale fingerprint datasets. A notable contribution is the inclusion of multi-head self-attention in place of the final convolution block, allowing the model to capture long-range dependencies and global ridge structures. To further enhance generalization, especially under unknown material attacks, the authors incorporate synthetic spoof fingerprints using CycleGAN-based style transfer augmentation. Despite these additions, the model remains efficient, with only 0.83 million parameters.
Although these models are lightweight, with fewer parameters compared to conventional CNN-based methods, there is still a need for more efficient architectures, maximizing the classification accuracy, that are suitable for resource-constrained devices. Our proposed model consists of only 0.14 million parameters, which is significantly lower than those of the aforementioned lightweight models, while achieving higher classification accuracy. The model operates on full-fingerprint images and produces a single scalar value through global average pooling. This strategy increases the number of effective labels and helps reduce overfitting. We deliberately avoided using any fully connected layers. To further improve generalization, we integrated a spatial attention module, which added only a negligible number of additional parameters.
According to our observation, GANs for style transfer, as employed in [
10,
13], have become a common approach to enhance generalization. However, many of these methods rely on CNN models pre-trained on natural images rather than architectures specifically designed for fingerprint data. This oversight hampers accuracy improvement. In contrast, our proposed model is designed to reduce computational overhead by minimizing the parameter count while improving both accuracy and generalization. The experimental results demonstrate that our architecture achieves superior performance with high average accuracy, while also delivering state-of-the-art cross-material ACE, confirming the proposed method’s suitability as a practical solution.
3. Method
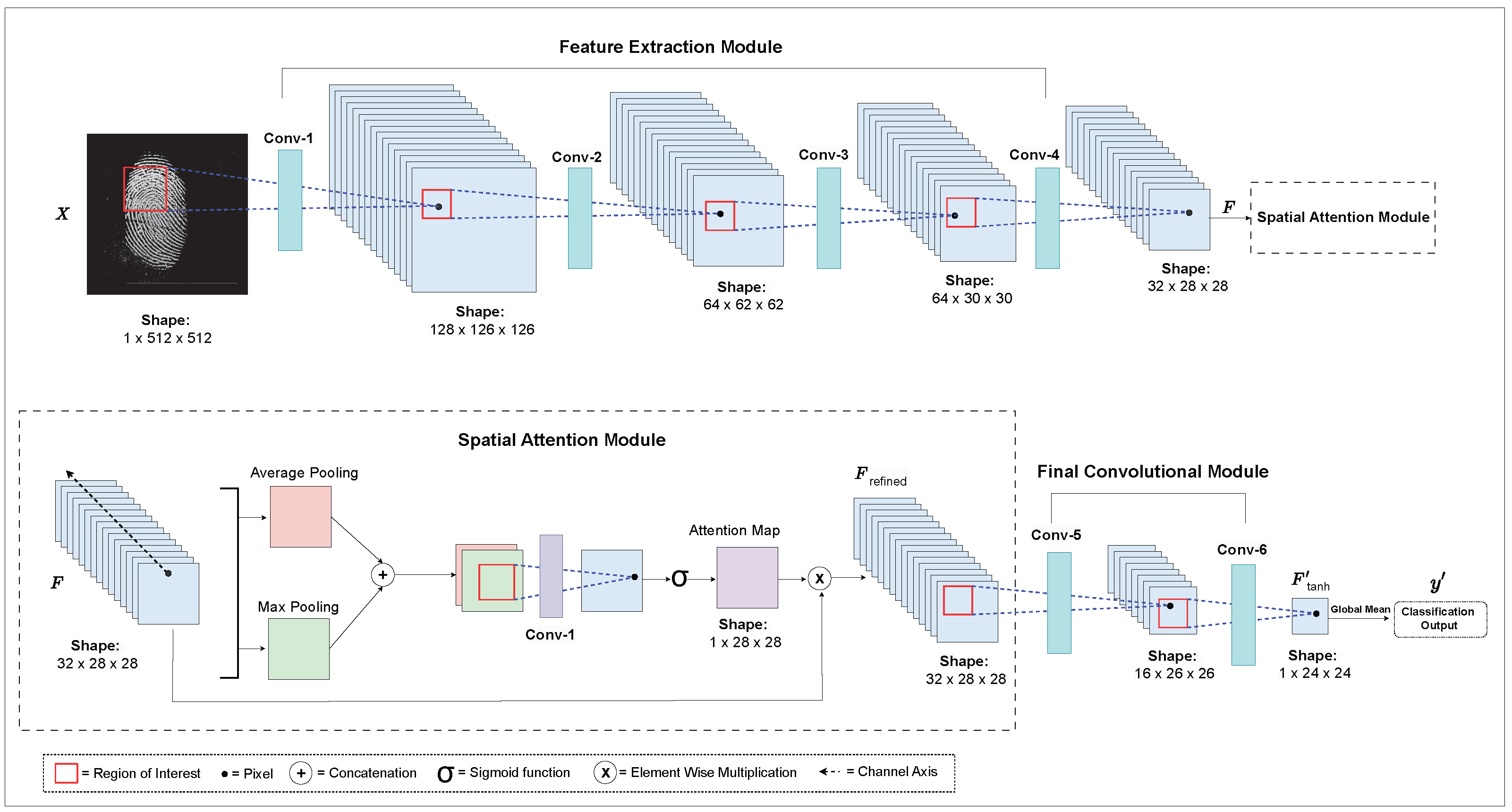
The proposed methodology, shown in
Figure 1, leverages a moderately deep CNN architecture comprising six convolutional layers. These layers are optimized to ensure comprehensive feature extraction while mitigating the risk of overfitting. The layer-wise details of the proposed CNN architecture are presented in
Table 1, and the detailed methodology is outlined below.
We denote the feature extraction module as
, consisting of four convolutional layers, and the final convolutional module as
, which includes two convolutional layers. The input image
X is processed by the feature extraction module, which is expressed as
where
F represents the extracted feature map. In this module, the first convolutional layer employs a large
kernel with stride
, capturing broader contextual information from the input image
X. This ensures that each pixel in the final feature map corresponds to a large receptive field. The initial feature map is then reduced in dimensions using a
max-pooling layer. Subsequent layers (Conv2d-2 to Conv2d-4) utilize smaller
kernels to extract hierarchical features produced by the initial layer. Each layer is followed by a max-pooling operation to progressively downsample the feature maps while retaining essential spatial information.
The extracted feature map is then processed through the spatial attention module [
26], introduced before the final convolutional module to enhance the model’s ability to distinguish spoofed and live fingerprints. This spatial attention module computes a spatial attention map, which highlights critical regions for classification and improves feature representation. In this module, the attention map is first generated by applying average pooling and max pooling along the channel axis, resulting in two spatial descriptors: an average-pooled descriptor
and a max-pooled descriptor
. These descriptors are concatenated and passed through a
convolution, followed by a sigmoid activation, yielding the spatial attention map. Once the attention map is obtained, it is element-wise-multiplied with the original feature map
F within this module, producing the refined feature map:
The refined feature map
is next directed to the final convolutional module
, where the final convolutional layer in this module uses a
kernel, producing a single-channel feature map
. A hyperbolic tangent activation is subsequently applied to this feature map, bounding the output feature values between
, normalizing the response, and reducing the dominance of any single feature.
where
is the feature map obtained by applying the hyperbolic tangent activation to the convolutional features. This normalized feature map
is later averaged across all pixels to generate the final output
, which is expressed as
where the output
represents the liveness score for classification. The model is trained using the binary cross-entropy loss:
where
y represents the ground truth label,
denotes the predicted probability, and
N is the number of samples.
3.1. Datasets and Preprocessing
We evaluated our approach using the LivDet-2015 [
24] and LivDet-2017 [
25] fingerprint datasets. The training set for the LivDet-2015 dataset contained approximately 1000 to 1500 live and spoofed fingerprint images per sensor, including CrossMatch, DigitalPersona, GreenBit, and HiScan. For the LivDet-2017 dataset, the training set contained around 1000 to 1200 live and spoofed fingerprint images per sensor, including DigitalPersona, GreenBit, and Orcanthus. In the test data for LivDet-2015, each sensor contained between 1050 and 1500 spoof images and between 1000 and 1500 live images, along with 500 unknown material images. For LivDet-2017, the test data included approximately 2000 spoof images and 1700 live images per sensor, all of which were from unknown materials. To ensure consistency across different sensors and resolutions, all fingerprint images were first converted to grayscale and inverted so that fingerprint ridges appeared bright. Next, we performed connected component analysis to extract the main fingerprint region by detecting the largest foreground area after binarization and morphological dilation. The extracted region was centrally placed on a fixed-size black background of
pixels, ensuring a uniform input size. Images smaller than
were padded with zeros, and larger ones were centrally cropped. This preprocessing standardizes spatial scale and alignment across all inputs. In addition, we applied data augmentation during training. Specifically, we used random horizontal and vertical flipping as well as random rotations in the range of
to
.
3.2. Training Protocol
The model was trained using the Stochastic Gradient Descent (SGD) optimizer with a learning rate of 0.01, no momentum, and no weight decay, using a batch size of 2. The training process was conducted over 1500 epochs. A large number of epochs was necessary because the number of training samples was small. However, due to the proposed architecture, overfitting was not an issue. The proposed approach helps prevent overfitting by increasing the number of effective labels. And our proposed model only consists of 140,353 parameters, maintaining computational efficiency while achieving improved accuracy. The details of the network architecture are presented in
Table 1. The detailed results on the LivDet-2015 and LivDet-2017 datasets demonstrate the efficacy of this approach.
4. Results
In this study, we employed multiple evaluation metrics to comprehensively assess model performance, including classification accuracy, average classification error (ACE), precision, recall, and F1-score. These metrics are particularly critical in fingerprint liveness detection, where misclassifying spoof images as live can compromise system security.
True positive (TP): The case where a spoof fingerprint is correctly classified as a spoof.
False positive (FP): The case where a live fingerprint is incorrectly classified as a spoof.
True negative (TN): The case where a live fingerprint is correctly classified as live.
False negative (FN): The case where a spoof fingerprint is incorrectly classified as live.
Classification accuracy: Accuracy measures the overall effectiveness of the model by calculating the ratio of correctly classified samples to the total number of samples.
ACE: The ACE is commonly used in fingerprint liveness detection tasks and quantifies the overall classification error. The ACE is calculated as the mean of the error rates for live samples and spoof samples.
Here, is the proportion of live fingerprints misclassified as spoofs, and is the proportion of spoof fingerprints misclassified as live.
Precision: Precision indicates the proportion of predicted positive samples that are correctly classified. It reflects how accurate the model is when it predicts a sample as positive.
Recall: Recall measures the proportion of actual positive samples that are correctly identified by the model. In the context of spoof detection, it shows the effectiveness of detecting actual spoofs.
F1-score: F1-score is the harmonic mean of precision and recall, balancing both metrics, especially when the dataset is imbalanced. It provides a single measure of a test’s accuracy.
Classification performance comparison: The evaluation was conducted on the test set for each sensor in the LivDet-2015 and LivDet-2017 datasets.
Table 2 shows that on the LivDet-2015 dataset, our proposed model, despite its simplicity, achieved an impressive average accuracy of 98.30%, surpassing several existing methods. The model particularly excelled on sensors such as GreenBit, CrossMatch, and HiScan, with accuracies of 99.31%, 99.79%, and 98.04%, respectively, illustrating its capability in capturing and utilizing relevant fingerprint features. However, on the DigitalPersona sensor, the model’s accuracy was slightly lower at 96.07%. This small drop in performance can be attributed to the smaller image size, as the lower resolution of DigitalPersona images made it more challenging to distinguish fine fingerprint details. The results on the LivDet-2017 dataset are presented in
Table 3, which shows that the model achieved comparable accuracies of 94.89%, 96.06%, and 95.77% across the three sensors, including DigitalPersona, GreenBit, and Orcanthus. In terms of average accuracy, the proposed model achieved 95.57% accuracy, exceeding existing methods.
Cross-material generalization performance:
Table 4 and
Table 5 provide a comprehensive comparison of the proposed model’s cross-material robustness against several state-of-the-art methods on the LivDet-2015 and LivDet-2017 datasets. These evaluations were conducted under the challenging condition where spoof materials used for testing were excluded from the training phase, thereby assessing the model’s ability to generalize to unseen attacks.
On the LivDet-2015 dataset, the proposed model achieved an average ACE of 0.81 percent, outperforming LivDet15-Winner [
29] at 5.72 percent, FSB [
28] at 1.48 percent, and SA-R-CNN [
31] at 5.17 percent. Across individual sensors such as GreenBit and CrossMatch, our method achieved remarkably low ACE values of 0.20 percent and 0.16 percent, respectively, indicating strong generalization across different sensor types and spoof materials.
Likewise, on the LivDet-2017 dataset, our model continued to exhibit robust generalization performance, achieving an average ACE of 1.91 percent. This outperformed all compared approaches including RTK-PAD [
47] at 2.28 percent, CFD-PAD [
47] at 2.53 percent, FSB [
28] at 4.56 percent, and SA-R-CNN [
31] at 3.12 percent. Across all sensors, the proposed model consistently achieved the lowest or highly competitive ACE values, underscoring its strong capability in detecting spoof attacks fabricated from previously unseen materials.
Comprehensive metric evaluation: To comprehensively evaluate the classification performance of the proposed model, we analyze precision, recall, and F1-score across different sensors in the LivDet-2015 and LivDet-2017 datasets. As shown in
Table 6, the model achieves consistently high performance on the LivDet-2015 dataset, with an average precision, recall, and F1-score of 0.979, 0.976, and 0.977, respectively. Notably, on sensors such as CrossMatch and HiScan, the model reaches F1-scores of 0.998 and 0.974, indicating its strong capability to balance between sensitivity and specificity. Even on the more challenging DigitalPersona sensor, the model maintains a robust F1-score of 0.948, demonstrating reliable spoof detection under lower-resolution input conditions. Similarly, on the LivDet-2017 dataset, as shown in
Table 7 the proposed model continues to exhibit strong generalization, achieving an average precision of 0.954, recall of 0.949, and F1-score of 0.952 across all sensors. These high values reflect the model’s effectiveness in correctly identifying both live and spoof fingerprints while minimizing misclassification. The consistently high F1-scores across diverse sensors further substantiate the robustness and reliability of the proposed lightweight architecture for fingerprint liveness detection.
Parameter efficiency: The comparison shown in
Table 8 highlights the efficiency of the proposed model on the LivDet-2015 dataset. With only 0.14 M parameters, it achieves the highest accuracy of 98.30%, significantly outperforming other methods such as Slim-ResCNN (2.15 M parameters), LFLDNet (0.83M parameters), and FLDNet (0.48 M parameters). This demonstrates that the proposed model produces better results with 70% fewer parameters compared to the FLDNet lightweight model.
4.1. Visual Analysis
To improve interpretability and provide insight into the model’s decision-making process, we visualize the liveness maps generated from the final feature map prior to global average pooling, as shown in
Figure 2. These liveness maps are derived from the output of the final convolutional layer and are globally averaged for classification. The original resolution of each map is 24 × 24, which we resized to 512 × 512 for visualization purposes. In these maps, the background is represented by a value of 0. For live fingerprints, the foreground regions exhibit positive values, whereas for spoof fingerprints, the corresponding values tend to be negative. We applied normalization to scale all values between 0 and 1 to enhance visual contrast. As illustrated, live fingerprints generate liveness maps with high values, appearing brighter, while fake fingerprints yield lower values, resulting in darker regions. This clearly reflects how the model differentiates between live and spoof fingerprints and confirms that the liveness map carries meaningful and class-discriminative spatial patterns, validating our design choice.
4.2. Ablation Study
The ablation study in
Table 9 evaluates the impact of key architectural components, the spatial attention module and hyperbolic tangent activation, on the performance of our proposed model using the DigitalPersona of LivDet-2015 and LivDet-2017 datasets. Importantly, the removal of the dense layer and the inclusion of global average pooling result in a significant accuracy improvement from 89.48% to 95.20% on the LivDet-2015 dataset and from 90.81% to 94.11% on the LivDet-2017 dataset, compared to the base CNN with a fully connected dense layer, despite having a lower parameter count. These improvements demonstrate that our lightweight architecture reduces overfitting while maintaining strong classification performance. In our study, we consider our proposed model without the spatial attention module and hyperbolic tangent activation as the base CNN. Introducing the spatial attention module before the last two convolutional layers of our architecture improves performance by enabling the model to focus on discriminative regions, enhancing feature extraction. The spatial attention module alone adds only a negligible increase of fewer than 100 parameters, yet guides the network to focus on informative spatial regions. While its standalone use achieves lower accuracy than the baseline model on LivDet-2015, its integration with global pooling and tanh activation leads to performance improvement. This shows that the spatial attention module is effective when combined with other components in the architecture. Furthermore, instead of using a fully connected layer for classification, we average the feature map to obtain a single value, allowing the model to evaluate receptive field-wise features equally. The hyperbolic tangent activation enhances robustness by preventing any single feature from dominating. The full architecture, incorporating both enhancements, achieves the highest accuracy, with 96.08 percent on LivDet-2015 and 94.89 percent on LivDet-2017, respectively, demonstrating the efficiency of our lightweight architecture in improving spoof fingerprint detection while maintaining a low parameter count.
Furthermore, to examine the impact of spatial attention placement within the network, we conducted an ablation study that is summarized in
Table 10. Three configurations were tested: placing the spatial attention module after the final convolution layer; before the final convolution layer; and in the middle of the architecture, as proposed. The results demonstrate that integrating the attention module in the middle yields the highest classification accuracy of 96.07%, outperforming other placements. This suggests that introducing spatial attention earlier allows the network to better refine intermediate feature representations, enhancing its discriminative capacity.
Moreover, to evaluate the effectiveness of our attention strategy, we conducted a comparative study by integrating different attention modules into the same backbone architecture and testing them on the DigitalPersona sensor from the LivDet-2015 dataset. As shown in
Table 11, our proposed method with spatial attention module achieves the highest classification accuracy of 96.07%, outperforming both the Convolutional Block Attention Module (CBAM) at 94.28% and the Squeeze-and-Excitation (SE) block at 92.40%. Even without any attention mechanism, the model achieved 95.20% accuracy. These results highlight the superiority of our proposed architecture with this attention design in enhancing discriminative feature learning specifically tailored for fingerprint spoof detection.





{kind=link}
{kind=link}