Lightweight Underwater Target Detection Algorithm Based on YOLOv8n


Abstract
1. Introduction
- 1.
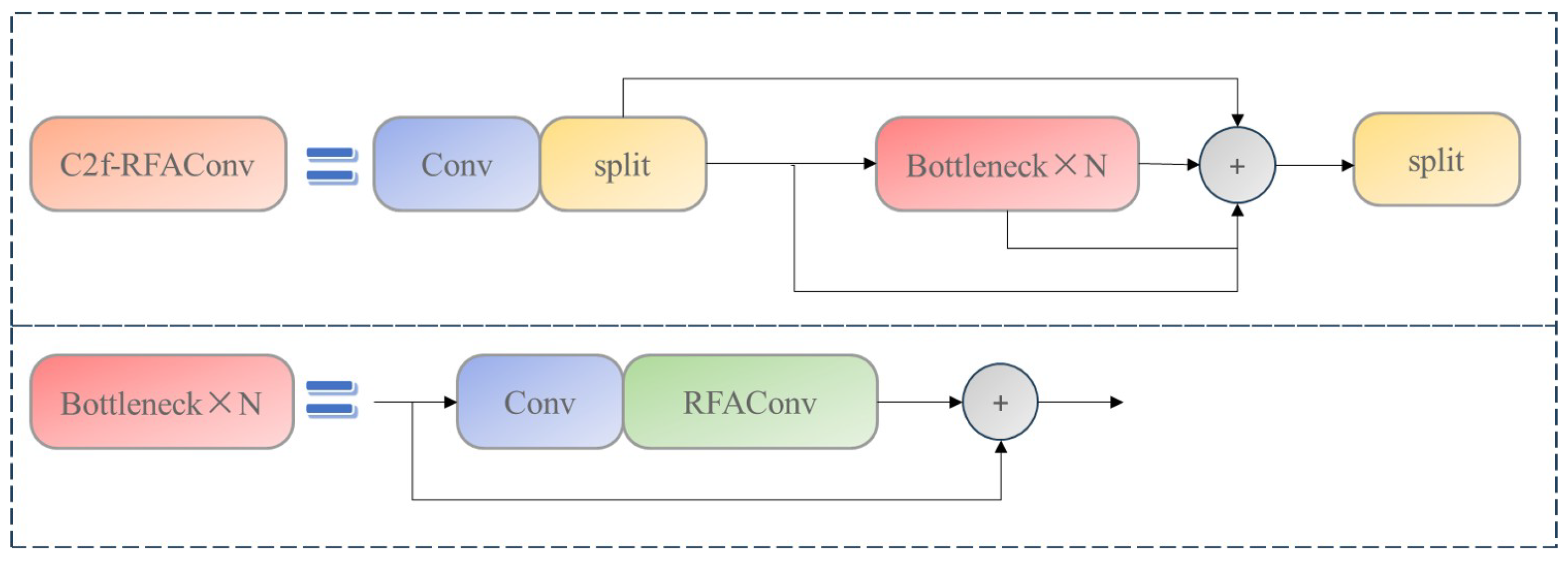
- The introduction of the Introduce RFAConv module optimizes the backbone network, effectively suppressing interference from complex underwater backgrounds and enhancing the capacity to extract features for underwater targets.
- 2.
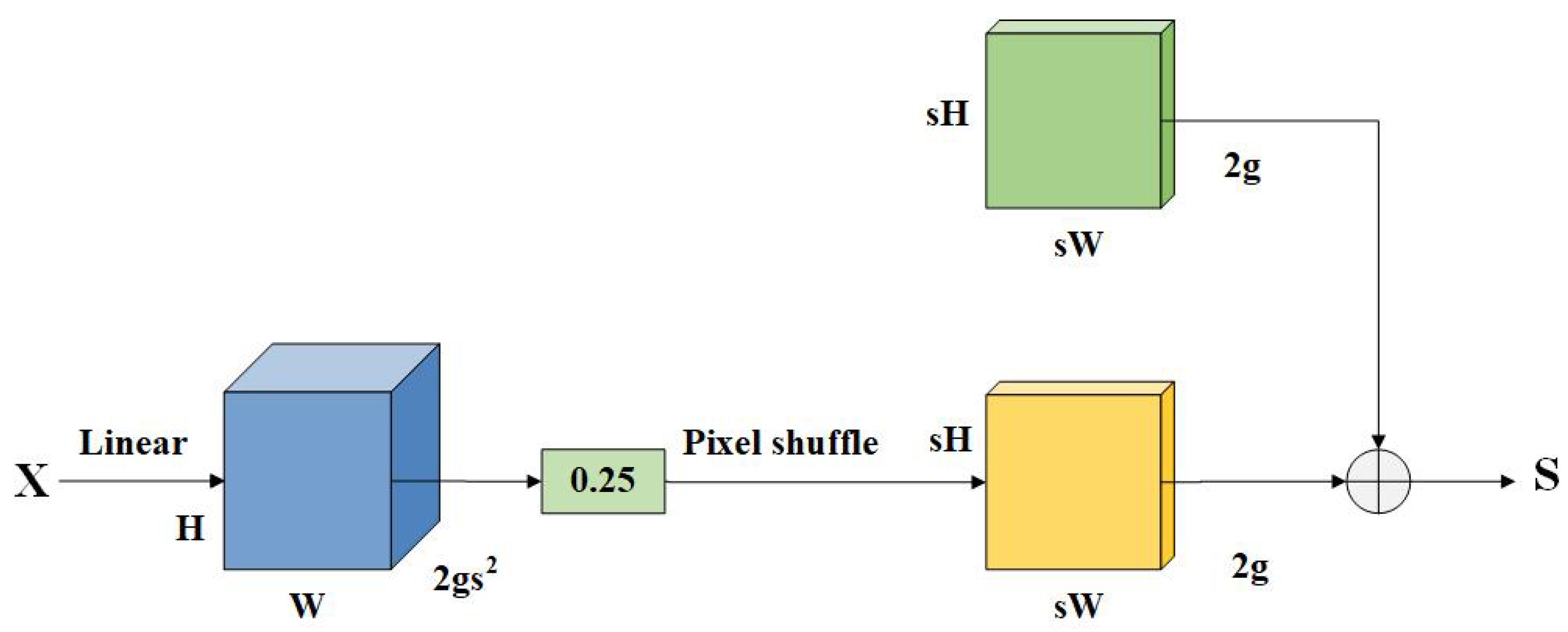
- The DySample dynamic upsampler is adopted in the neck network to effectively reduce the loss of edge detail information during upsampling.
- 3.
- A lightweight shared convolution detection head is designed, which preserves detection efficiency while significant reducing the number of parameters and computational complexity.
- 4.
- By combining the NWD and CIoU loss functions, the NWD-CIoU loss function is constructed, improving the accuracy of bounding box localization for small underwater targets.
2. Materials and Methods
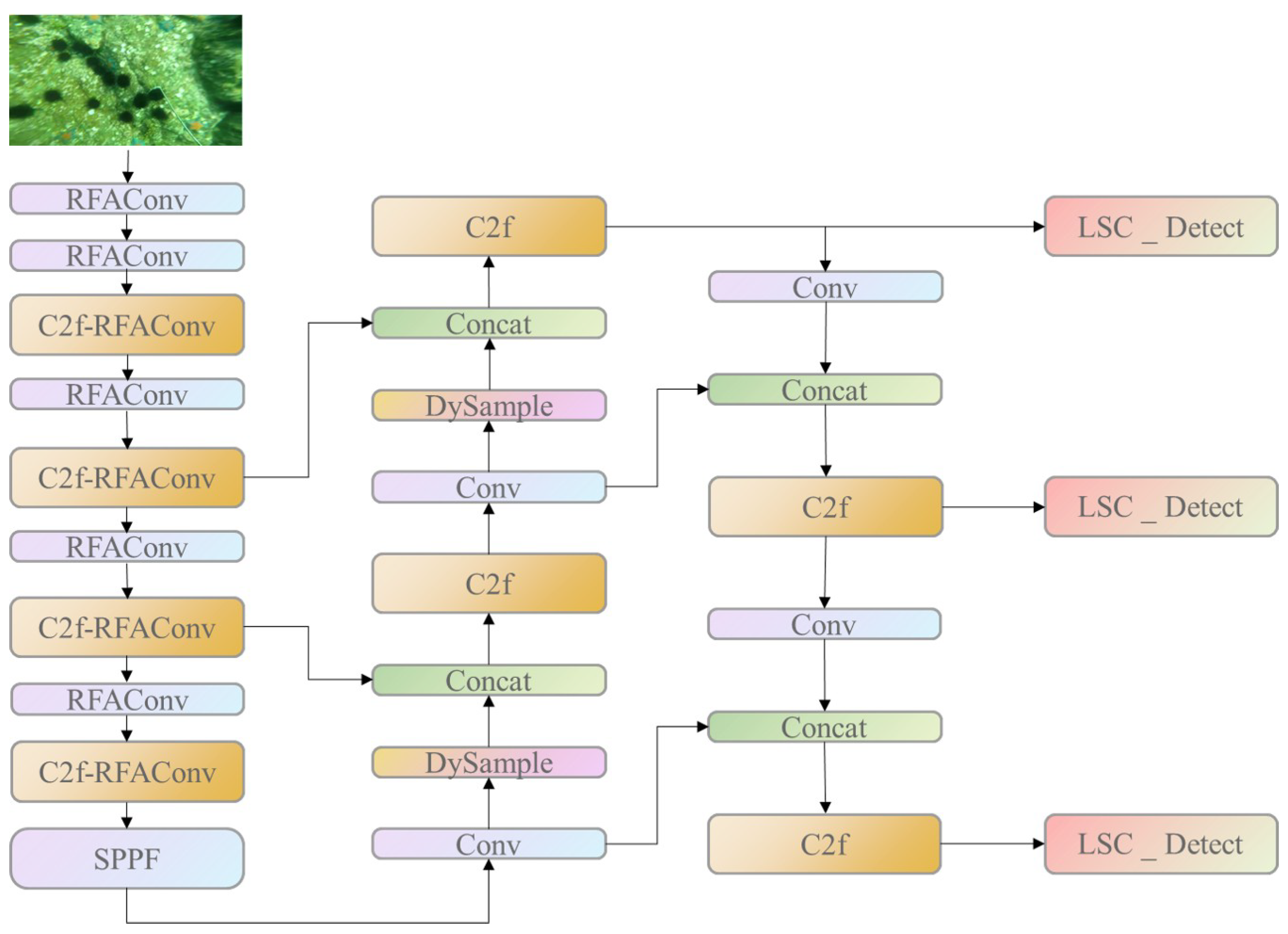
2.1. Object Detection Algorithm
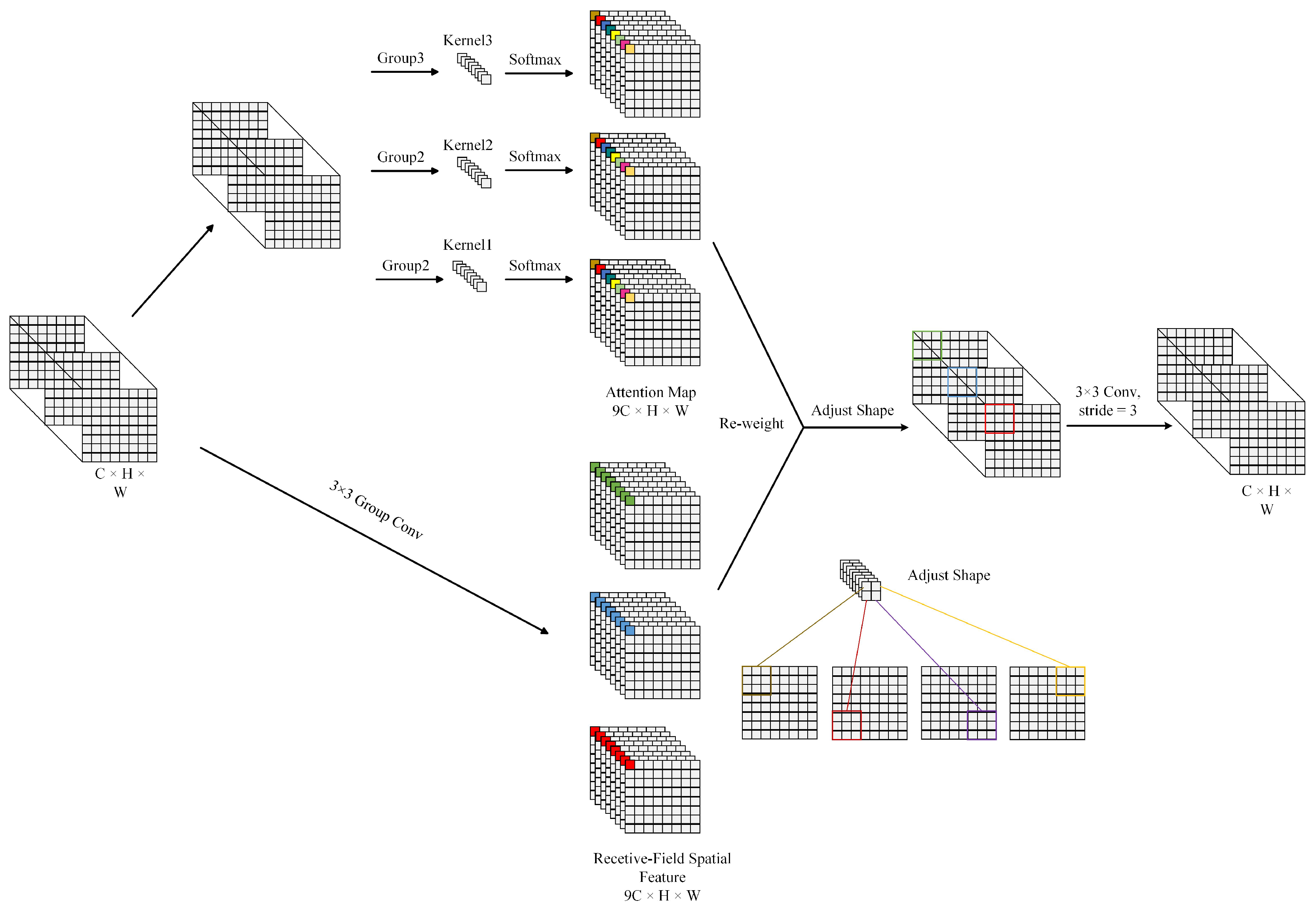
2.2. Receptive-Field Attention Convolution
2.3. DySample Upsampling Module
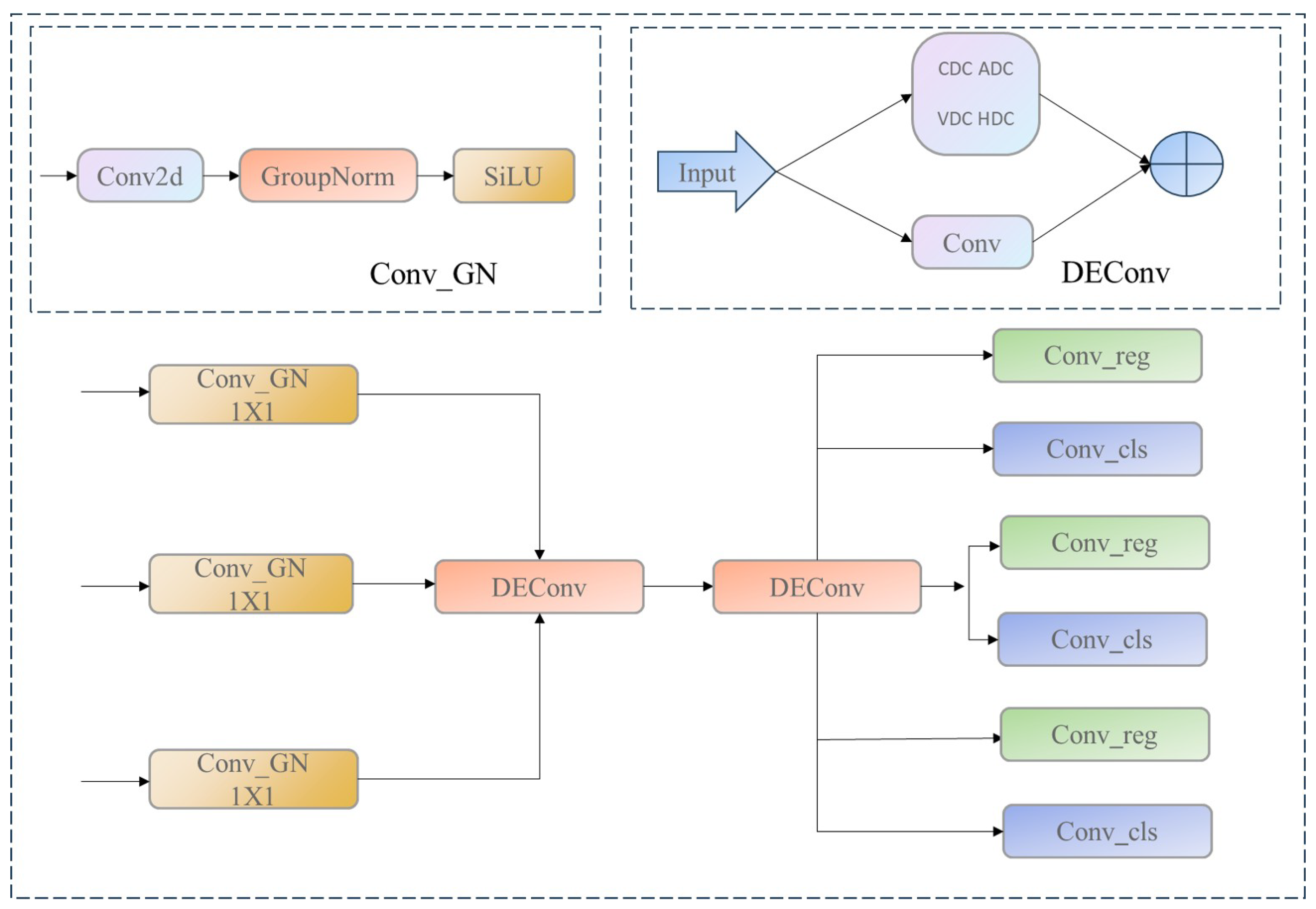
2.4. Shared Convolution Detection Head
2.5. Loss Function Improvement
3. Experimental Results and Analysis
3.1. Dataset Introduction
3.2. Experimental Environment
3.3. Evaluation Metrics
3.4. Ablation Experiment
3.5. Loss Function Weight Assignment Comparison
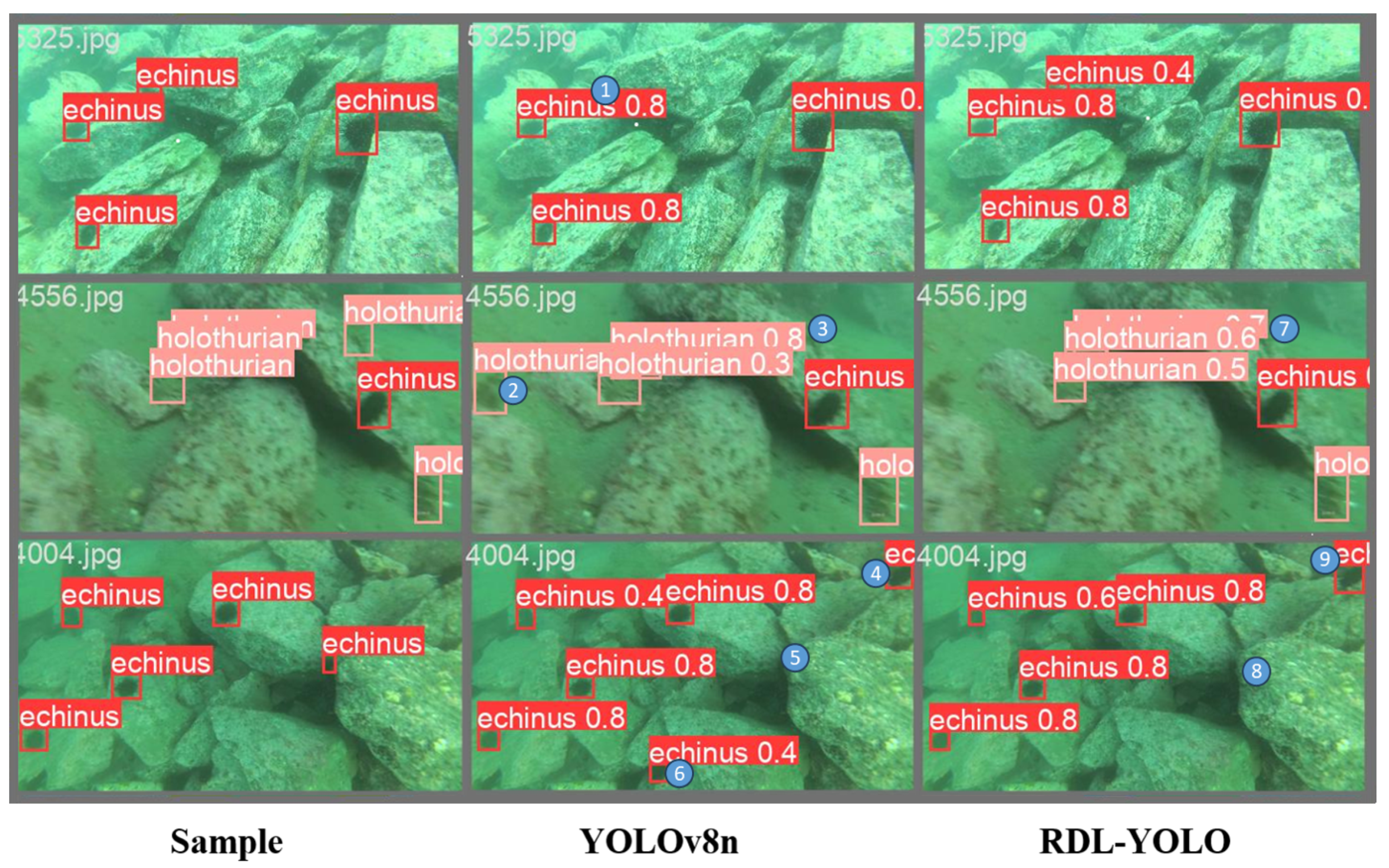
3.6. Comparison Experiment
3.7. Generalization Experiment
4. Discussion
4.1. Findings
4.2. Limitations and Future Works
- 1.
- Combining lightweight image enhancement modules with the detector for joint training to improve detection accuracy under low-light and high-noise conditions.
- 2.
- Integrating optical and sonar image information to use multimodal data to enhance the model’s robustness and enhance detection efficacy in intricate underwater settings.
- 3.
- Deploying and testing the model in real underwater environments to evaluate its performance and further optimize the model structure and parameter configuration.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Joshi, R.; Usmani, K.; Krishnan, G.; Blackmon, F.; Javidi, B. Underwater object detection and temporal signal detection in turbid water using 3D-integral imaging and deep learning. Opt. Express 2024, 32, 1789–1801. [Google Scholar] [CrossRef] [PubMed]
- Xu, S.; Zhang, M.; Song, W.; Mei, H.; He, Q.; Liotta, A. A systematic review and analysis of deep learning-based underwater object detection. Neurocomputing 2023, 527, 204–232. [Google Scholar] [CrossRef]
- Shen, L.; Reda, M.; Zhang, X.; Zhao, Y.; Kong, S.G. Polarization-driven solution for mitigating scattering and uneven illumination in underwater imagery. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4202615. [Google Scholar] [CrossRef]
- Yi, X.; Jiang, Q.; Zhou, W. No-reference quality assessment of underwater image enhancement. Displays 2024, 81, 102586. [Google Scholar] [CrossRef]
- Guo, Q.; Liu, N.; Wang, Z.; Sun, Y. Review of deep learning based object detection algorithms. J. Detect. Control 2023, 45, 10–20. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Cao, R.; Zhang, R.; Yan, X.; Zhang, J. BG-YOLO: A bidirectional-guided method for underwater object detection. Sensors 2024, 24, 7411. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Zhao, K.; Liu, C.; Chen, L. Bi2F-YOLO: A novel framework for underwater object detection based on YOLOv7. Intell. Mar. Technol. Syst. 2025, 3, 9. [Google Scholar] [CrossRef]
- Zhou, S.; Wang, L.; Chen, Z.; Zheng, H.; Lin, Z.; He, L. An improved YOLOv9s algorithm for underwater object detection. J. Mar. Sci. Eng. 2025, 13, 230. [Google Scholar] [CrossRef]
- Guo, A.; Sun, K.; Zhang, Z. A lightweight YOLOv8 integrating FasterNet for real-time underwater object detection. J. Real-Time Image Process. 2024, 21, 49. [Google Scholar] [CrossRef]
- Liu, K.; Peng, L.; Tang, S. Underwater object detection using TC-YOLO with attention mechanisms. Sensors 2023, 23, 2567. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, Z.; Song, W.; Zhao, D.; Zhao, H. Efficient small-object detection in underwater images using the enhanced yolov8 network. Appl. Sci. 2024, 14, 1095. [Google Scholar] [CrossRef]
- Wu, D.; Luo, L. SVGS-DSGAT: An IoT-enabled innovation in underwater robotic object detection technology. Alex. Eng. J. 2024, 108, 694–705. [Google Scholar] [CrossRef]
- Lian, S.; Li, H.; Cong, R.; Li, S.; Zhang, W.; Kwong, S. Watermask: Instance segmentation for underwater imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 1305–1315. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhao, H.; Xu, C.; Chen, J.; Zhang, Z.; Wang, X. BGLE-YOLO: A Lightweight Model for Underwater Bio-Detection. Sensors 2025, 25, 1595. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, C.; Yang, D.; Song, T.; Ye, Y.; Li, K.; Song, Y. RFAConv: Innovating spatial attention and standard convolutional operation. arXiv 2023, arXiv:2304.03198. [Google Scholar]
- Xie, G.; Liang, L.; Lin, Z.; Lin, S.; Su, Q. Lightweight Underwater Target Detection Algorithm Based on Improved YOLOv8n. Laser Optoelectron. Prog. 2024, 61, 2437006. [Google Scholar]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to upsample by learning to sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6027–6037. [Google Scholar]
- Chen, Z.; He, Z.; Lu, Z.M. DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, Y.; Bai, Y.; Li, Y.; Liu, M. Convolutional graph neural networks-based research on estimating heavy metal concentrations in a soil-rice system. Environ. Sci. Pollut. Res. 2023, 30, 44100–44111. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A normalized Gaussian Wasserstein distance for tiny object detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]
- Lieberman, B.; Dahbi, S.E.; Mellado, B. The use of Wasserstein Generative Adversarial Networks in searches for new resonances at the LHC. J. Phys. Conf. Ser. 2023, 2586, 012157. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Zhou, H.; Kong, M.; Yuan, H.; Pan, Y.; Wang, X.; Chen, R.; Lu, W.; Wang, R.; Yang, Q. Real-time underwater object detection technology for complex underwater environments based on deep learning. Ecol. Inform. 2024, 82, 102680. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, H.; Yan, X.; Zhou, K.; Zhang, J.; Zhang, Y.; Jiang, H.; Shao, B. An improved yolov5 underwater detector based on an attention mechanism and multi-branch reparameterization module. Electronics 2023, 12, 2597. [Google Scholar] [CrossRef]
- Jia, R.; Lv, B.; Chen, J.; Liu, H.; Cao, L.; Liu, M. Underwater object detection in marine ranching based on improved YOLOv8. J. Mar. Sci. Eng. 2023, 12, 55. [Google Scholar] [CrossRef]
- Cheng, S.; Han, Y.; Wang, Z.; Liu, S.; Yang, B.; Li, J. An Underwater Object Recognition System Based on Improved YOLOv11. Electronics 2025, 14, 201. [Google Scholar] [CrossRef]
- Fu, C.; Liu, R.; Fan, X.; Chen, P.; Fu, H.; Yuan, W.; Zhu, M.; Luo, Z. Rethinking general underwater object detection: Datasets, challenges, and solutions. Neurocomputing 2023, 517, 243–256. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiments | C2f-RFA | RFAConv | LSC_Detect | DySample | NWD-CIoU | mAP50/% | Params/M | FLOPs/G |
|---|---|---|---|---|---|---|---|---|
| 1 | 82.5 | 3.01 | 8.1 | |||||
| 2 | ✓ | 83.4 | 3.04 | 8.4 | ||||
| 3 | ✓ | 83.2 | 3.03 | 8.4 | ||||
| 4 | ✓ | 82.3 | 2.36 | 6.5 | ||||
| 5 | ✓ | 82.9 | 3.01 | 8.1 | ||||
| 6 | ✓ | 82.8 | 3.01 | 8.1 | ||||
| 7 | ✓ | ✓ | 83.6 | 3.07 | 8.7 | |||
| 8 | ✓ | ✓ | ✓ | 83.3 | 2.43 | 6.9 | ||
| 9 | ✓ | ✓ | ✓ | ✓ | 83.7 | 2.43 | 6.9 | |
| 10 | ✓ | ✓ | ✓ | ✓ | ✓ | 83.9 | 2.43 | 6.9 |
| Weight Assignment | Precision/% | Recall/% | mAP50/% |
|---|---|---|---|
| 1.0 | 83.3 | 76.5 | 83.7 |
| 0.8 | 83.1 | 76.7 | 83.6 |
| 0.6 | 82.6 | 77.2 | 83.7 |
| 0.4 | 83.0 | 77.9 | 83.9 |
| 0.2 | 82.8 | 77.5 | 83.8 |
| 0 | 82.7 | 77.4 | 83.5 |
| Model | mAP50/% | Params/M | FLOPs/G |
|---|---|---|---|
| Faster R-CNN | 75.2 | 41.14 | 63.3 |
| YOLOv3-Tiny [29] | 79.6 | 12.13 | 18.9 |
| YOLOX-Tiny [30] | 80.1 | 5.06 | 15.4 |
| YOLOv5n | 81.5 | 2.50 | 7.1 |
| YOLOv8n | 82.5 | 3.01 | 8.1 |
| YOLOv10 [31] | 81.6 | 2.69 | 8.2 |
| YOLOv11n | 82.0 | 2.60 | 6.5 |
| reference [32] | 84.0 | 19.0 | 6.5 |
| reference [33] | 82.0 | 13.7 | 27.3 |
| reference [34] | 83.3 | 3.10 | 8.0 |
| reference [35] | 83.6 | 2.55 | 7.5 |
| RDL-YOLO | 83.9 | 2.43 | 6.9 |
| Model | mAP50/% | Params/M | FLOPs/G |
|---|---|---|---|
| Faster R-CNN | 65.2 | 41.14 | 63.3 |
| YOLOv3-Tiny | 80.6 | 12.13 | 18.9 |
| YOLOX-Tiny | 82.1 | 5.06 | 15.4 |
| YOLOv5n | 83.5 | 2.50 | 7.1 |
| YOLOv8n | 84.1 | 3.01 | 8.1 |
| YOLOv10 | 83.7 | 2.69 | 8.2 |
| YOLOv11n | 84.0 | 2.60 | 6.5 |
| RDL-YOLO | 85.1 | 2.43 | 6.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, D.; Huo, H. Lightweight Underwater Target Detection Algorithm Based on YOLOv8n. Electronics 2025, 14, 1810. https://doi.org/10.3390/electronics14091810
Song D, Huo H. Lightweight Underwater Target Detection Algorithm Based on YOLOv8n. Electronics. 2025; 14(9):1810. https://doi.org/10.3390/electronics14091810
Chicago/Turabian StyleSong, Dengke, and Hua Huo. 2025. "Lightweight Underwater Target Detection Algorithm Based on YOLOv8n" Electronics 14, no. 9: 1810. https://doi.org/10.3390/electronics14091810
APA StyleSong, D., & Huo, H. (2025). Lightweight Underwater Target Detection Algorithm Based on YOLOv8n. Electronics, 14(9), 1810. https://doi.org/10.3390/electronics14091810