
Pose Measurement of Non-Cooperative Space Targets Based on Point Line Feature Fusion in Low-Light Environments


Abstract
1. Introduction
- (1)
- Improved traditional point feature algorithms to reduce the impact of illumination on feature extraction performance. By combining point feature matching with epipolar constraint, we narrow the matching range of points from two dimensions to the epipolar line, greatly improving matching speed and accuracy.
- (2)
- Introduced line features based on the structural information of the spacecraft. These features are extracted and matched in parallel with point features to achieve preliminary pose measurement, greatly ensuring the precision and accuracy of the pose measurement results.
- (3)
- Introduced an adaptive weighted multi-feature pose fusion based on illumination, fully integrating point-line matching features to obtain the optimal pose estimation result.
2. Related Work
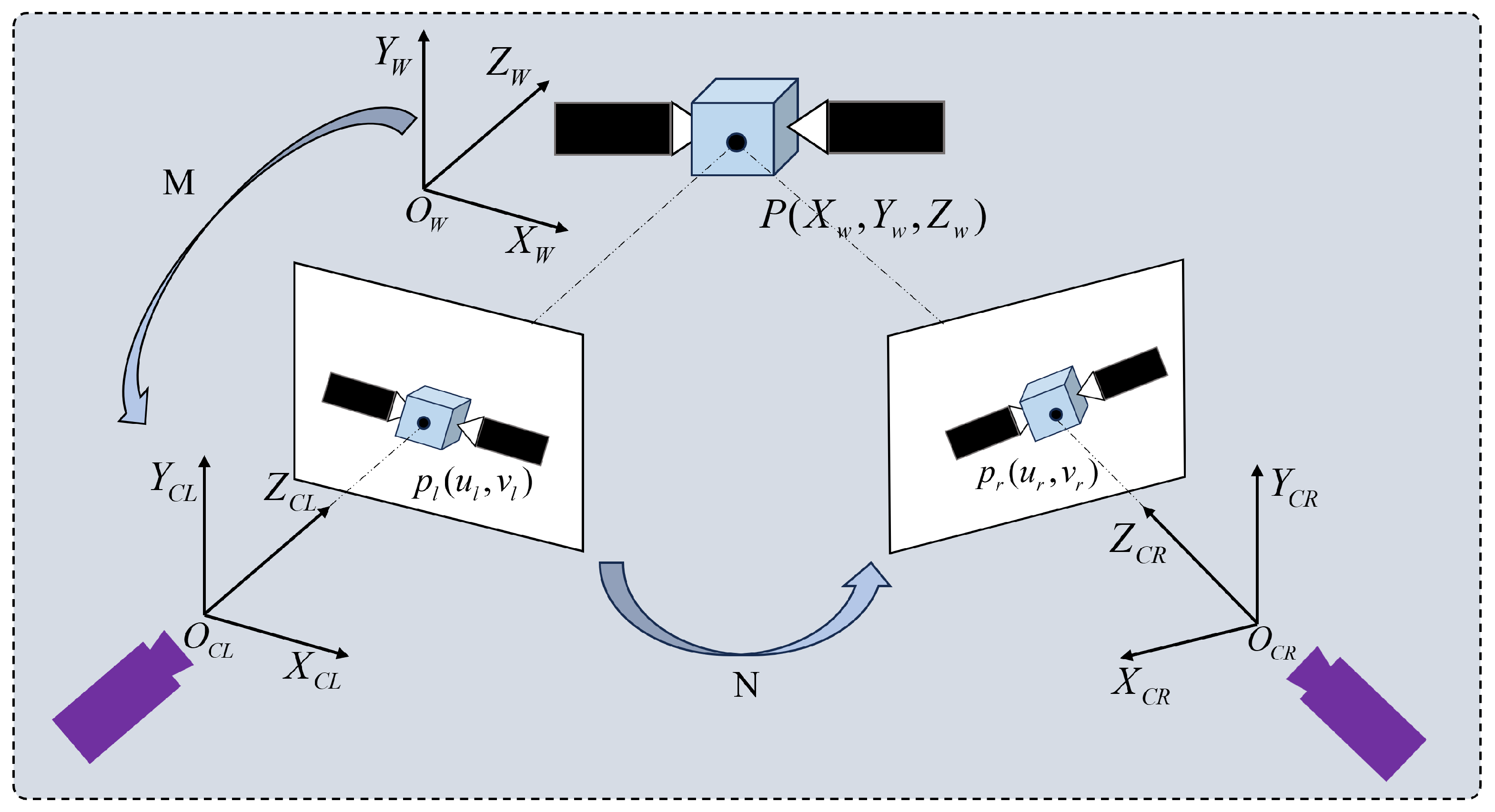
2.1. Binocular Vision System
2.2. Pose Estimation Algorithm
3. Point-Line Feature Fusion Extraction Matching Algorithm
3.1. Overall Structure of the Algorithm
3.2. Improved Feature Extraction and Matching Algorithm
- (1)
- Taking image processing as the detection area, we set a certain pixel point P in the detection area, with its corresponding grayscale value as . With P as the center and a radius of r, we select the 16 pixels in the region corresponding to P, which are located around point P.
- (2)
- The lighting-based adaptive threshold M is set for the detection area, and the formula for calculating the adaptive threshold M is as follows:where represents the grayscale value of the i-th pixel point in the detection area, is the average grayscale value of the pixel points in the detection area, is the number of pixel points in the detection area, and is the scaling factor.
- (3)
- If there are N consecutive (can be adjusted based on the actual situation) pixel points among the 16 pixel points whose pixel values are greater than or equal to K or less than or equal to K, then p is considered as a corner point.
- (4)
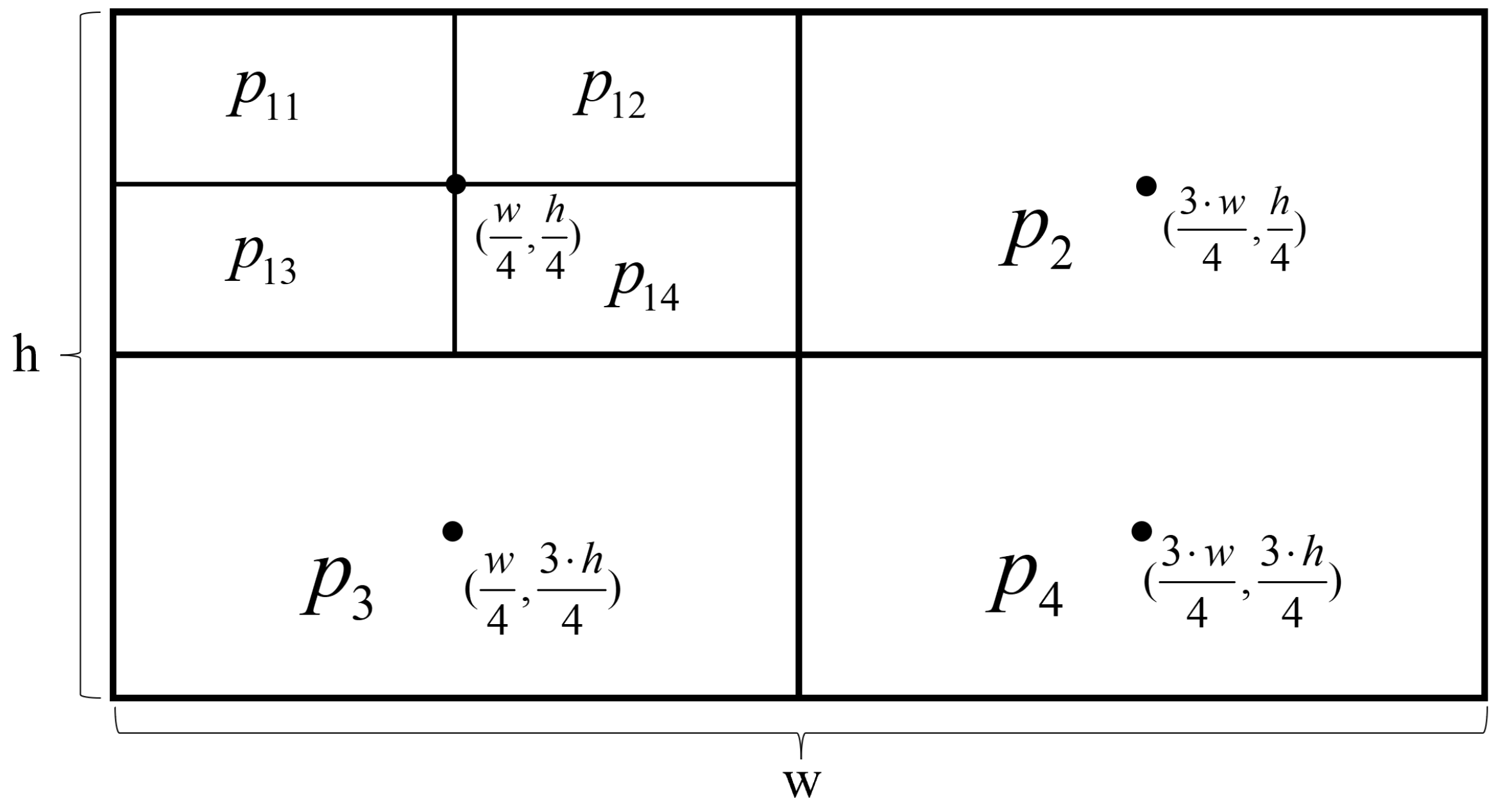
- Repeat the above three steps to perform feature point extraction. Assuming the image has a pixel size of , regions are divided equally around pixel points ,, , and , in the upper left, bottom left, upper right, and bottom right directions, resulting in the following 16 regions: , , … . The specific arrangement is shown in Figure 3:
- (5)
- Let Y be the number of feature points obtained. If the number of feature points in the corresponding region is greater than G, all points are directly retained.
- (6)
- If the number of feature points in the corresponding region is equal to 0, adjust the pixel adaptive threshold, with as the threshold and as the scaling factor. We set it at 0.5. If there are still no feature points after adjusting the threshold, detection is stopped.
- (7)
- The points obtained in the above steps are candidate feature points. They may exhibit edge clustering. We use non-maximum suppression to remove duplicates and filter the candidate feature points. This allows us to obtain the final set of feature points.
- (1)
- First, compute the BRIEF descriptor for each feature point in the left image and right image to obtain the BRIEF descriptor vector of each feature point. Then, compare the BRIEF descriptor vector of a specific feature point in the left image with the BRIEF descriptor vectors of all feature points on the corresponding epipolar line in the right image. Calculate the Hamming distance between the descriptors and select the pair with the smallest distance as the correct match.
- (2)
- When all feature points in the left image have been traversed, we iterate through all corresponding feature points on the constrained epipolar line in the right image, based on the right image. We perform reverse matching, keeping the matches if they coincide and discarding them if they do not match.
3.3. Improved Line Feature Extraction and Matching Algorithm
- (1)
- Calculate the angle between pixels and pixels, and compute their corresponding gradients using the following formula, as Equations (3)–(6):represents the gradient value in the horizontal direction, represents the gradient value in the vertical direction, represents the total gradient value, and represents the gradient direction. In the equation, represents the grayscale value of the pixel .
- (2)
- When all feature points in the left image have been traversed, we iterate through all corresponding feature points on the constrained epipolar line in the right image, based on the right image. We perform reverse matching, keeping the matches if they coincide and discarding them if they do not match.
- (3)
- If two line segments are non-parallel and , they are considered as one line segment when the angle between them is smaller than the angle threshold.
- (4)
- If two line segments are parallel and one end of one line segment falls between the two ends of the other line segment, meaning the shortest distance between the two line segments does not exceed the distance threshold, they can be considered as one line segment.
- (5)
- The brute force matching algorithm is used to calculate the Hamming distance between the LBD descriptor of a certain valid line segment in the left image and the binary LBD feature descriptors of all valid line segments in the right image. The pair of valid line segments with the smallest Hamming distance value is determined as the preliminary matching feature segments.
- (6)
- The nearest and second nearest distance ratio method is used for fine matching to eliminate false matches and obtain precise matching feature segments.
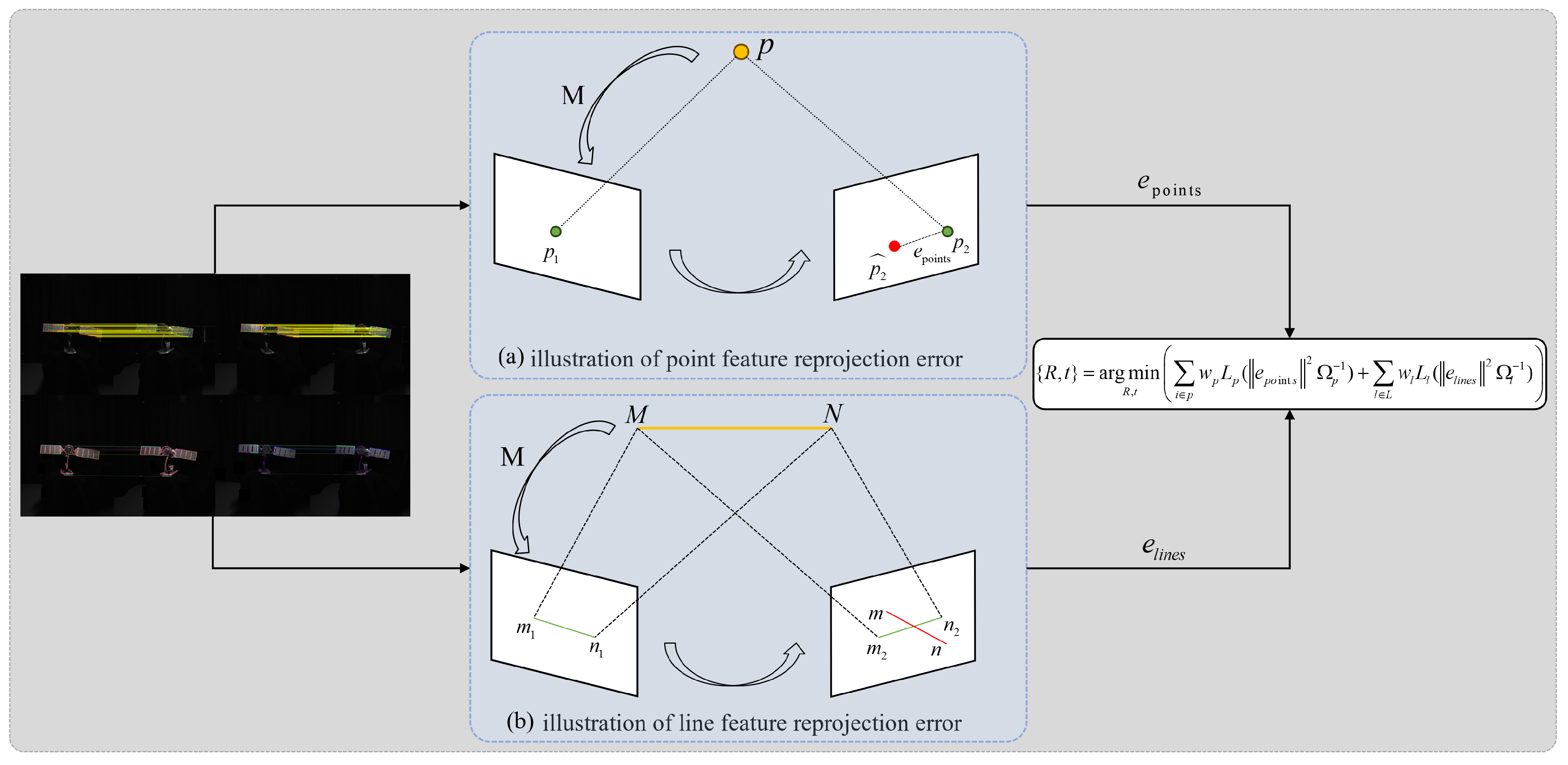
3.4. Pose Estimation
4. Physical Experiment Results
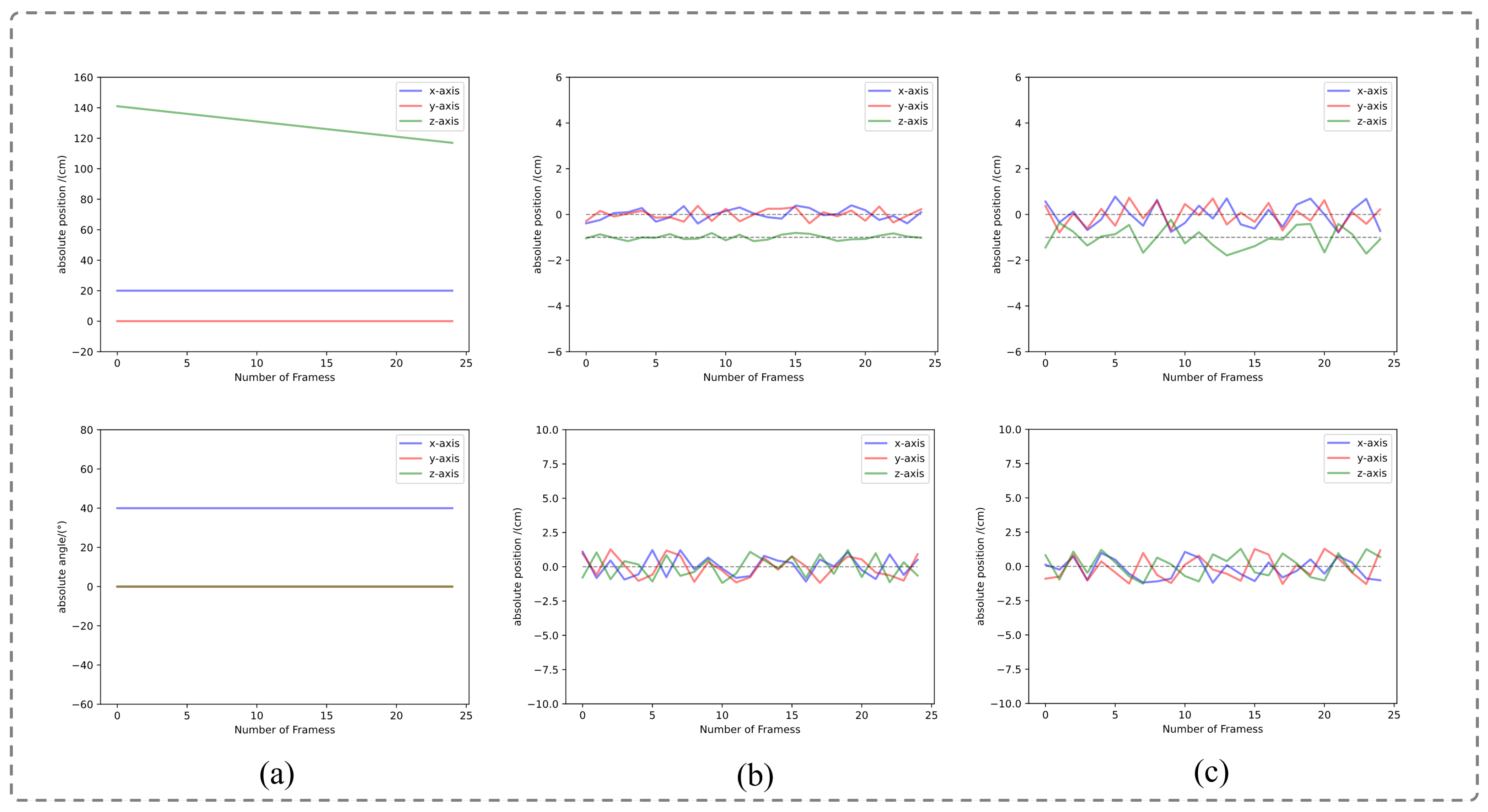
4.1. Experimental Environment
4.2. Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, F.; Zhang, H.; Zhang, G.; Shan, F.; Ren, L.; Ai, H.; Cao, J. High-precision pose measurement method based on binocular vision in dark lighting environments. Opt. Eng. 2023, 62, 024105. [Google Scholar] [CrossRef]
- Pan, H.; Huang, J.; Qin, S. High accurate estimation of relative pose of cooperative space targets based on measurement of monocular vision imaging. Optik 2014, 125, 3127–3133. [Google Scholar] [CrossRef]
- Zhang, Y.; Qin, S.; Hu, X. High-precision and real-time algorithms of multi-object detection, recognition and localization toward ARVD of cooperative spacecrafts. Optik 2015, 126, 5797–5805. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, H.; Zhu, Z.; Sun, C.; Song, J. Three-dimensional shape reconstruction of uncooperative spacecraft with texture-guided depth upsampling. Meas. Sci. Technol. 2021, 32, 095006. [Google Scholar] [CrossRef]
- Zhao, G.; Xu, S.; Bo, Y. LiDAR-Based Non-Cooperative Tumbling Spacecraft Pose Tracking by Fusing Depth Maps and Point Clouds. Sensors 2018, 18, 3432. [Google Scholar] [CrossRef]
- Capuano, V.; Kim, K.; Harvard, A.; Chung, S.J. Monocular-based pose determination of uncooperative space objects. Acta Astronaut. 2020, 166, 493–506. [Google Scholar] [CrossRef]
- Peng, J.; Xu, W.; Yan, L.; Pan, E.; Liang, B.; Wu, A.G. A Pose Measurement Method of a Space Noncooperative Target Based on Maximum Outer Contour Recognition. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 512–526. [Google Scholar] [CrossRef]
- Sharma, S.; Beierle, C.; D’Amico, S. Pose estimation for non-cooperative spacecraft rendezvous using convolutional neural networks. In Proceedings of the 2018 IEEE Aerospace Conference, Big Sky, MO, USA, 3–10 March 2018; pp. 1–12. [Google Scholar] [CrossRef]
- Huan, W.; Liu, M.; Hu, Q. Pose Estimation for Non-cooperative Spacecraft based on Deep Learning. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 3339–3343. [Google Scholar] [CrossRef]
- Pauly, L.; Rharbaoui, W.; Shneider, C.; Rathinam, A.; Gaudillière, V.; Aouada, D. A survey on deep learning-based monocular spacecraft pose estimation: Current state, limitations and prospects. Acta Astronaut. 2023, 212, 339–360. [Google Scholar] [CrossRef]
- Davis, J.; Pernicka, H. Proximity operations about and identification of non-cooperative resident space objects using stereo imaging. Acta Astronaut. 2019, 155, 418–425. [Google Scholar] [CrossRef]
- De Jongh, W.; Jordaan, H.; Van Daalen, C. Experiment for pose estimation of uncooperative space debris using stereo vision. Acta Astronaut. 2020, 168, 164–173. [Google Scholar] [CrossRef]
- Jiang, C.; Hu, Q. Constrained Kalman filter for uncooperative spacecraft estimation by stereovision. Aerosp. Sci. Technol. 2020, 106, 106133. [Google Scholar] [CrossRef]
- Pasqualetto Cassinis, L.; Fonod, R.; Gill, E. Review of the robustness and applicability of monocular pose estimation systems for relative navigation with an uncooperative spacecraft. Prog. Aerosp. Sci. 2019, 110, 100548. [Google Scholar] [CrossRef]
- Sun, D.; Hu, L.; Duan, H.; Pei, H. Relative Pose Estimation of Non-Cooperative Space Targets Using a TOF Camera. Remote Sens. 2022, 14, 6100. [Google Scholar] [CrossRef]
- Gómez Martínez, H.; Giorgi, G.; Eissfeller, B. Pose estimation and tracking of non-cooperative rocket bodies using Time-of-Flight cameras. Acta Astronaut. 2017, 139, 165–175. [Google Scholar] [CrossRef]
- Peng, J.; Xu, W.; Liang, B.; Wu, A.G. Pose Measurement and Motion Estimation of Space Non-Cooperative Targets Based on Laser Radar and Stereo-Vision Fusion. IEEE Sens. J. 2019, 19, 3008–3019. [Google Scholar] [CrossRef]
- Liu, Q.; Tang, X.; Huo, J. Attitude measurement of ultraclose-range spacecraft based on improved YOLOv5s and adaptive Hough circle extraction. Appl. Opt. 2024, 63, 1364–1376. [Google Scholar] [CrossRef]
- Wang, F.; Xu, W.; Yan, L.; Xie, C.; Pu, W. Rectangular Natural Feature Recognition and Pose Measurement Method for Non-Cooperative Spacecraft. Aerospace 2024, 11, 125. [Google Scholar] [CrossRef]
- Yuan, H.; Chen, H.; Wu, J.; Kang, G. Non-Cooperative Spacecraft Pose Estimation Based on Feature Point Distribution Selection Learning. Aerospace 2024, 11, 526. [Google Scholar] [CrossRef]
- Gao, X.; Yu, J.; Tan, M. An Online 3D Modeling Method for Pose Measurement under Uncertain Dynamic Occlusion Based on Binocular Camera. Sensors 2023, 23, 2871. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. In Readings in Computer Vision; Fischler, M.A., Firschein, O., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1987; pp. 726–740. [Google Scholar] [CrossRef]
- Strutz, T. Data Fitting and Uncertainty: A Practical Introduction to Weighted Least Squares and Beyond; Vieweg+Teubner: Wiesbaden, Germany, 2010. [Google Scholar]
- Legrand, A.; Detry, R.; Vleeschouwer, C.D. End-to-end Neural Estimation of Spacecraft Pose with Intermediate Detection of Keypoints. In Proceedings of the ECCV Workshops, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EPnP: An accurate O(n) solution to the PnP problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef]
- Kleeberger, K.; Huber, M.F. Single Shot 6D Object Pose Estimation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 6239–6245. [Google Scholar] [CrossRef]
- Chen, B.; Cao, J.; Parra, Á.; Chin, T.J. Satellite Pose Estimation with Deep Landmark Regression and Nonlinear Pose Refinement. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 2816–2824. [Google Scholar]
- Kendall, A.; Cipolla, R. Geometric Loss Functions for Camera Pose Regression with Deep Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6555–6564. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Park, T.H.; D’Amico, S. Robust Multi-Task Learning and Online Refinement for Spacecraft Pose Estimation across Domain Gap. arXiv 2022, arXiv:2203.04275. [Google Scholar] [CrossRef]
- Garcia, A.; Musallam, M.A.; Gaudilliere, V.; Ghorbel, E.; Al Ismaeil, K.; Perez, M.; Aouada, D. LSPnet: A 2D Localization-oriented Spacecraft Pose Estimation Neural Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 2048–2056. [Google Scholar] [CrossRef]
- Musallam, M.A.; Gaudillière, V.; Del Castillo, M.O.; Al Ismaeil, K.; Aouada, D. Leveraging Equivariant Features for Absolute Pose Regression. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6866–6876. [Google Scholar] [CrossRef]
- Leon, V.; Lentaris, G.; Soudris, D.; Vellas, S.; Bernou, M. Towards Employing FPGA and ASIP Acceleration to Enable Onboard AI/ML in Space Applications. In Proceedings of the 2022 IFIP/IEEE 30th International Conference on Very Large Scale Integration (VLSI-SoC), Patras, Greece, 3–5 October 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Cai, H. Experiment Research of Non-cooperative Space Target Relative Measurement Based on Binocular Vision. Master’s Thesis, Beijing Institute of Technology, Beijing, China, 2015. [Google Scholar]
- Zhao, Z.Q. Research on Key Technologies of Visual Pose Measurement System with Large Vision Range for Non-cooperative Target. Ph.D. Thesis, Harbin Institute of Technology, Harbin, China, 2016. [Google Scholar]
- Wen, H.; Tian, J.; Li, D. PLS-VIO: Stereo Vision-inertial Odometry Based on Point and Line Features. In Proceedings of the 2020 International Conference on High Performance Big Data and Intelligent Systems, Shenzhen, China, 23 May 2020; pp. 1–7. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Extracted Points | Matches Points (Pairs) | Mismatch Rate | Time (s) | |
|---|---|---|---|---|
| Wang’s algorithm | 1230 | 53 | 5.4% | 0.229 |
| ORB algorithm | 1433 | 149 | 9.1% | 0.427 |
| Our algorithm | 1973 | 106 | 3.7% | 0.552 |
| Extracted Lines | Matches Lines (Pairs) | Mismatch Rate | Time(s) | |
|---|---|---|---|---|
| LSD + LBD | 316 | 18 | 11.5% | 0.634 |
| Our algorithm | 154 | 13 | 6.1% | 0.671 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Wu, J.; Ai, H.; Liu, D.; Mei, C.; Xiao, M. Pose Measurement of Non-Cooperative Space Targets Based on Point Line Feature Fusion in Low-Light Environments. Electronics 2025, 14, 1795. https://doi.org/10.3390/electronics14091795
Zhang H, Wu J, Ai H, Liu D, Mei C, Xiao M. Pose Measurement of Non-Cooperative Space Targets Based on Point Line Feature Fusion in Low-Light Environments. Electronics. 2025; 14(9):1795. https://doi.org/10.3390/electronics14091795
Chicago/Turabian StyleZhang, Haifeng, Jiaxin Wu, Han Ai, Delian Liu, Chao Mei, and Maosen Xiao. 2025. "Pose Measurement of Non-Cooperative Space Targets Based on Point Line Feature Fusion in Low-Light Environments" Electronics 14, no. 9: 1795. https://doi.org/10.3390/electronics14091795
APA StyleZhang, H., Wu, J., Ai, H., Liu, D., Mei, C., & Xiao, M. (2025). Pose Measurement of Non-Cooperative Space Targets Based on Point Line Feature Fusion in Low-Light Environments. Electronics, 14(9), 1795. https://doi.org/10.3390/electronics14091795