1. Introduction
With the rapid and pervasive advancement of digitalization across industries, enterprise operations have increasingly relied on crucial, competitive data assets. The exponential growth in data generation across various domains necessitates its transformation into structured data assets through processing and analysis, underscoring the critical role of data lineage in operational efficiency and governance. Data lineage, the focus of our research, refers to the detailed trail that data follow as they navigate through an array of systems and processes. It serves as an indispensable cornerstone for accurately discerning data origin, maintaining high-quality data, and enabling comprehensive auditing. In the domain of data lineage parsing, numerous research efforts have been dedicated to developing innovative solutions. For instance, Michael Backes et al. introduced the LIME framework, a pioneering solution for tracking data flow across multiple entities, which set a benchmark for data lineage research [
1]. Similarly, Mingjie Tang et al. proposed the SAC system, a groundbreaking approach for data lineage tracking on distributed computing platforms such as Spark, which has been widely adopted in big data ecosystems [
2]. These contributions have laid a solid foundation for contemporary data lineage solutions, which can be broadly categorized into embedded and parsed lineage acquisition techniques.
Embedded lineage acquisition involves integrating plug-ins or hooks into the underlying architecture of computation engines or databases to automatically capture data lineage during execution. This approach leverages the inherent capabilities of modern data processing frameworks to seamlessly extract lineage information without significant overhead [
3]. For example, the Spark big data processing framework, renowned for its scalability and performance, allows the seamless deployment of external plug-ins to effectively capture lineage information during task execution. A notable case in point is the DataHub-based metadata lineage management solution, which ingests extensive datasets into a database and maintains direct upstream/downstream table correlations in memory. This architecture enables efficient lineage retrieval through the recursive traversal of dependent tables, facilitating the rapid construction of a comprehensive lineage tree. Such solutions are particularly advantageous in environments where real-time lineage tracking is essential for operational decision-making and compliance. Conversely, parsed lineage acquisition delves into metadata, system logs, and other key information sources to extract implicit lineage relationships that are not explicitly captured during execution. This approach often involves sophisticated algorithms and tools to reconstruct lineage logic from disparate data sources [
4]. Solutions based on Neo4j graph databases, for instance, enable lineage modifications via RESTful APIs, allowing specialized algorithms to process lineage parsing independently. Additionally, by deeply analyzing Spark’s event logs, it is possible to reconstruct lineage logic for task execution, providing valuable insights into data flow and dependencies. These techniques are particularly useful in scenarios where embedded lineage acquisition is not feasible or historical lineage reconstruction is required.
While these solutions offer improved accuracy and update efficiency, they still present considerable challenges. Firstly, they entail high costs and lengthy development cycles for customization. Enterprises with specific business requirements often require extensive system modifications, involving a deep understanding of intricate business logic, restructuring, and significant architectural adjustments [
5]. These modifications inevitably escalate costs and extend the development timeline, making it difficult for organizations to achieve timely implementation [
6]. Additionally, ongoing adjustments necessitated by evolving business demand further prolong the implementation cycle, potentially resulting in lost market opportunities and reduced competitive advantage. Secondly, existing approaches suffer from limited generalization capabilities, particularly when dealing with diverse scripting environments. While SQL, with its well-structured syntax, is relatively straightforward to parse, non-SQL languages such as Python and Shell pose substantial challenges due to their flexibility and complexity. Scripts in these languages often incorporate complex logical structures, nested function calls, and dynamic runtime behaviors, requiring precise syntactic understanding and adaptability. The inability of current tools to effectively handle these variations significantly restricts their applicability across diverse scripting environments, limiting their utility in modern data ecosystems [
7].
In recent years, the field of artificial intelligence has witnessed a surge in the adoption of large language models (LLMs), which have demonstrated promising potential for addressing the challenges of data lineage parsing. LLMs, with their ability to process and generate human-like text, have shown remarkable capabilities to understand and infer complex relationships within data. Particularly in the context of few-shot prompting, pre-trained LLMs exhibit exceptional proficiency in discerning intricate correlations and data flow pathways under conditions of limited information. By leveraging advanced prompt engineering techniques—such as structured querying, guided inference, and scientific prompting—LLMs can generate more human-aligned outputs, bridging the gap between machine-generated and human-interpretable lineage information [
8]. The incorporation of methodologies such as Chain of Thought (CoT) has further enhanced the logical inference capabilities of LLMs, proving beneficial for complex task decomposition in AI agent scenarios [
9]. For example, in the GSM8K dataset, CoT-based prompting with only eight examples yielded superior results compared to full dataset fine-tuning [
10], reinforcing the effectiveness of CoT techniques in reasoning tasks. Moreover, CoT improves the interpretability of model outputs by offering step-by-step inferences, enhancing credibility in lineage parsing and making the results more transparent and actionable [
11]. Various refinements, such as Least-to-Most [
12], Self-Consistency [
13], and Diverse prompting [
14], have been proposed to strengthen LLM inference performance, further expanding their applicability in data lineage parsing.
In this paper, we introduce an innovative approach leveraging pre-trained LLMs for data lineage parsing, systematically addressing the limitations of existing methodologies. Through comparative analytics, empirical research, and advanced modeling techniques, we aim to reduce customization costs, expedite development cycles, and enhance the generalizability of parsing solutions. Notably, this approach is designed to tackle the inherent complexities of non-SQL script parsing, thereby advancing data management frameworks and enabling more robust and scalable lineage tracking. The findings offer valuable insights for industry practitioners, including data engineers and governance teams, by providing efficient, scalable tools to enhance workflow automation and improve data governance practices. Furthermore, this research contributes novel interdisciplinary perspectives at the intersection of artificial intelligence and data management, fostering technological advancements in enterprise data governance. The proposed methodology and experimental results provide a valuable reference for researchers and practitioners in data lineage parsing and optimized data management, ultimately driving improvements in enterprise data governance and the broader technological landscape. By addressing the challenges of high customization costs, limited generalization, and complex script parsing, this study paves the way for more efficient and effective data lineage solutions and enables organizations to harness the full potential of their data assets in an increasingly digital world.
5. Evaluation
5.1. Datasets and Evaluation Criteria
The characteristics of the data, features of the model, and business scenarios were fully taken into account and targeted strategies were formulated to ensure that there were no misjudgments in the overall experimental results. In terms of dataset selection, this paper study chose a total of five types of scripts, including SQL scripts, Python scripts, Shell scripts, and Flume configuration scripts. Regarding scenario design, this study comprehensively considered two methods: industry standards (TPC-H) and custom rules, and used large language models for synthetic expansion. TPC-H serves as a benchmark testing suite for decision support systems (DSSs), developed by the Transaction Processing Performance Council (TPC) and designed to simulate complex decision-making environments and assess the performance of database management systems (DBMSs) in executing queries and generating reports. The customized scenarios defined the input and output data sources, as well as the data processing logic. Once the scenarios were selected, the test dataset was expanded using synthetic data generated by LLMs. The datasets are presented in
Table 1, with a comprehensive description of use cases provided in
Appendix A.
The accuracy metric was used to evaluate the effectiveness of the lineage parsing by LLMs, calculated as follows:
5.2. Model Parameters
The experiments in this study did not involve the private deployment of LLMs. Instead, we directly invoked the SaaS service APIs provided by cloud service providers for LLMs, thus eliminating the need to prepare dedicated computational resources for LLMs.
The models involved in the experiments of this study are all publicly available models. In order to ensure the consistency of the model names being cited, this paper standardizes the naming criteria for the models: Model Name-Version Number-Parameter Scale. For example, Llama-3.1-405B indicates that the model name is Llama, the version number is 3.1, and the parameter scale is 405 billion.
The experiment employed four LLMs: Qwen-2-7B-Instruct (Qwen-2-7b), Llama-3.1-8B-Instruct (Llama-3.1-8b), Qwen-2-72b-instruct-gptq-int4 (Qwen-2-72b), and Llama-3.1-405B-Instruct (Llama-3.1-405b). The context length was fixed at 10K and the temperature parameter was set at 0.1. The details of these models are summarized in
Table 2.
5.3. Compared Methods
This study employed zero-shot, one-shot, and few-shot prompting as baseline comparisons to assess improvements in lineage parsing performance. The few-shot prompting with error cases and collaborative CoT and multi-expert prompting framework were evaluated for their efficacy. In addition, to compare the performance of the LLM-based method proposed in this paper with that of traditional lineage parsing methods, an additional lineage parsing method based on the fusion of abstract syntax trees and metadata [
7] was included as a comparison baseline. However, this baseline was only applicable to SQL scripts and Python scripts. The baselines of all experiments are listed in
Table 3.
5.4. Results Analysis
5.4.1. Table-Level Lineage Parsing
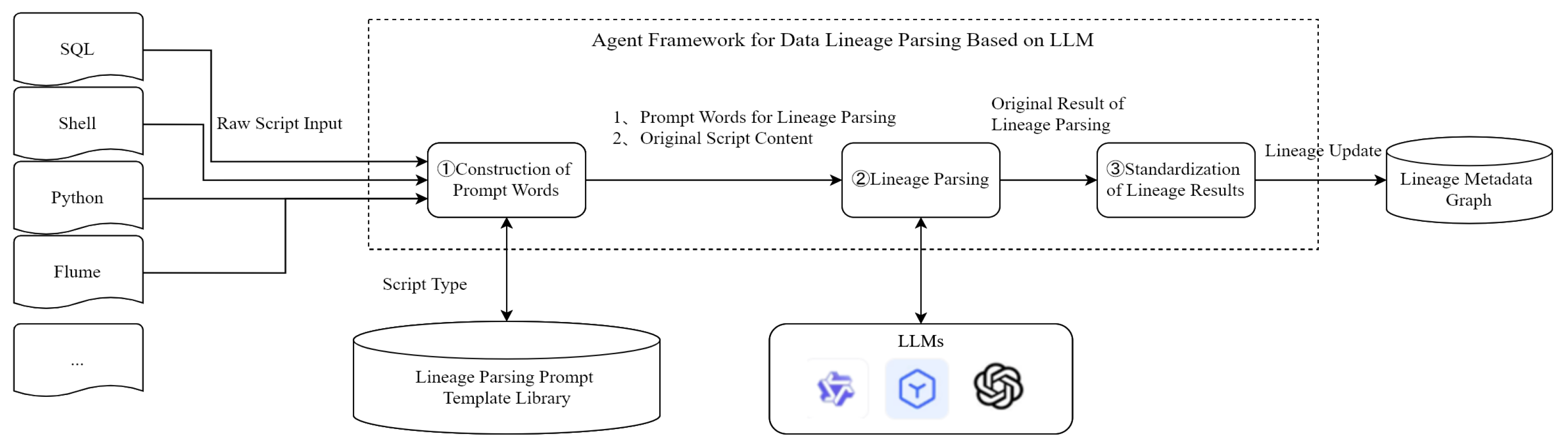
Table-level lineage parsing captured input and output table-related information, such as table names, catalog names, and extended attributes, while ignoring mapping relationships, subqueries, and filtering conditions. The experimental framework is illustrated in
Figure 5.
The statistical results of table-level lineage parsing are presented in
Table 4 below.
The findings indicated that Qwen-2-72b and Llama-3.1-405B achieved over 90% accuracy in table-level lineage parsing across all four script types, even with zero-shot prompting. The one-shot and few-shot prompting techniques yielded marginal accuracy improvements of approximately 0–3%. The proposed method of few-shot with error cases enhanced accuracy by approximately 2–4% compared to the most effective baseline (B3). Specifically, Qwen-2-72b surpassed 95% accuracy across all script types, while Llama-3.1-405B achieved over 97% accuracy. The traditional data lineage parsing method based on abstract syntax trees (AST) achieved an accuracy rate of over 99% in scenarios involving SQL scripts and Python scripts, which still gives it an advantage over the LLM-based method proposed in this paper. However, it is incapable of parsing Flume scripts, Shell scripts, and others. Therefore, in terms of scenario coverage, it is slightly inferior to the method proposed in this paper.
Conversely, Llama-3.1-8B and Qwen-2-7B demonstrated poor parsing performance, with an accuracy below 50% in most cases. The primary sources of error included the misinterpretation of script content, resulting in extraneous nodes within lineage graphs, and incorrect formatting that deviated from predefined templates. Despite incremental improvements using one-shot and few-shot prompting, the overall performance of these models remained suboptimal. Consequently, further operator-level lineage experiments excluded small-scale LLMs such as Llama-3.1-8B and Qwen-2-7B.
5.4.2. Operator-Level Lineage Parsing
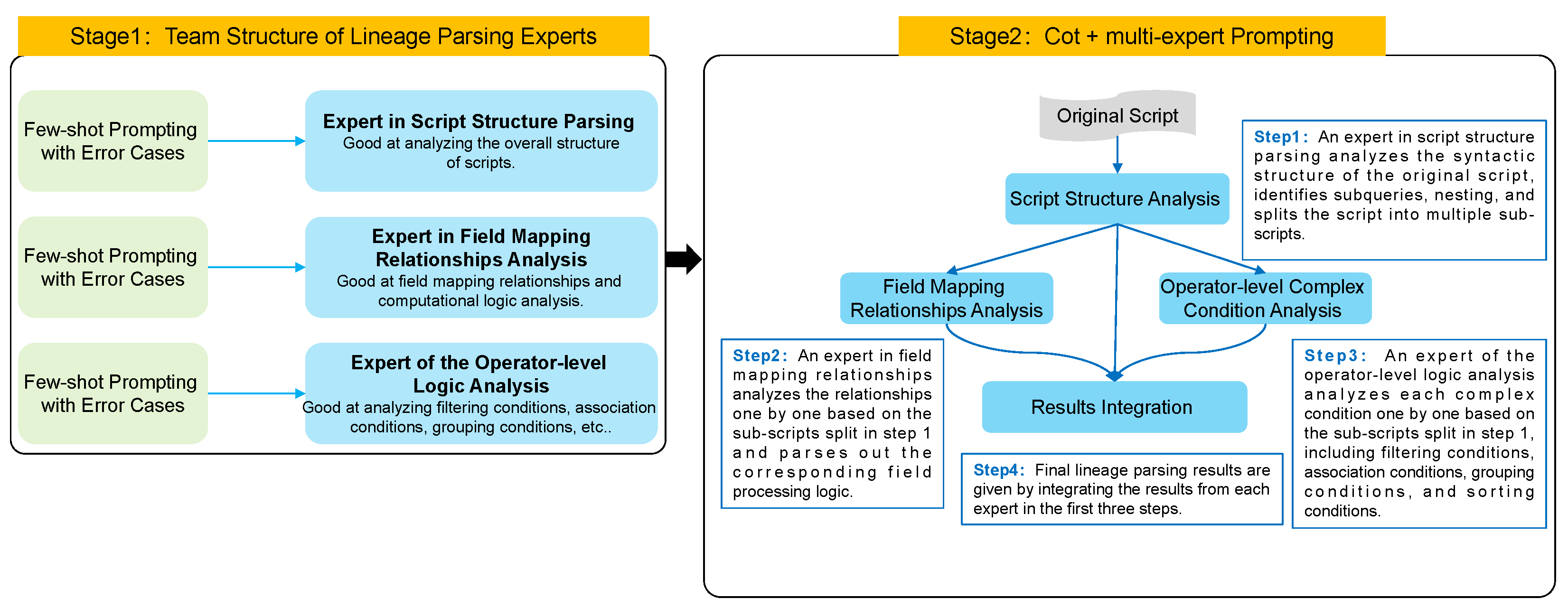
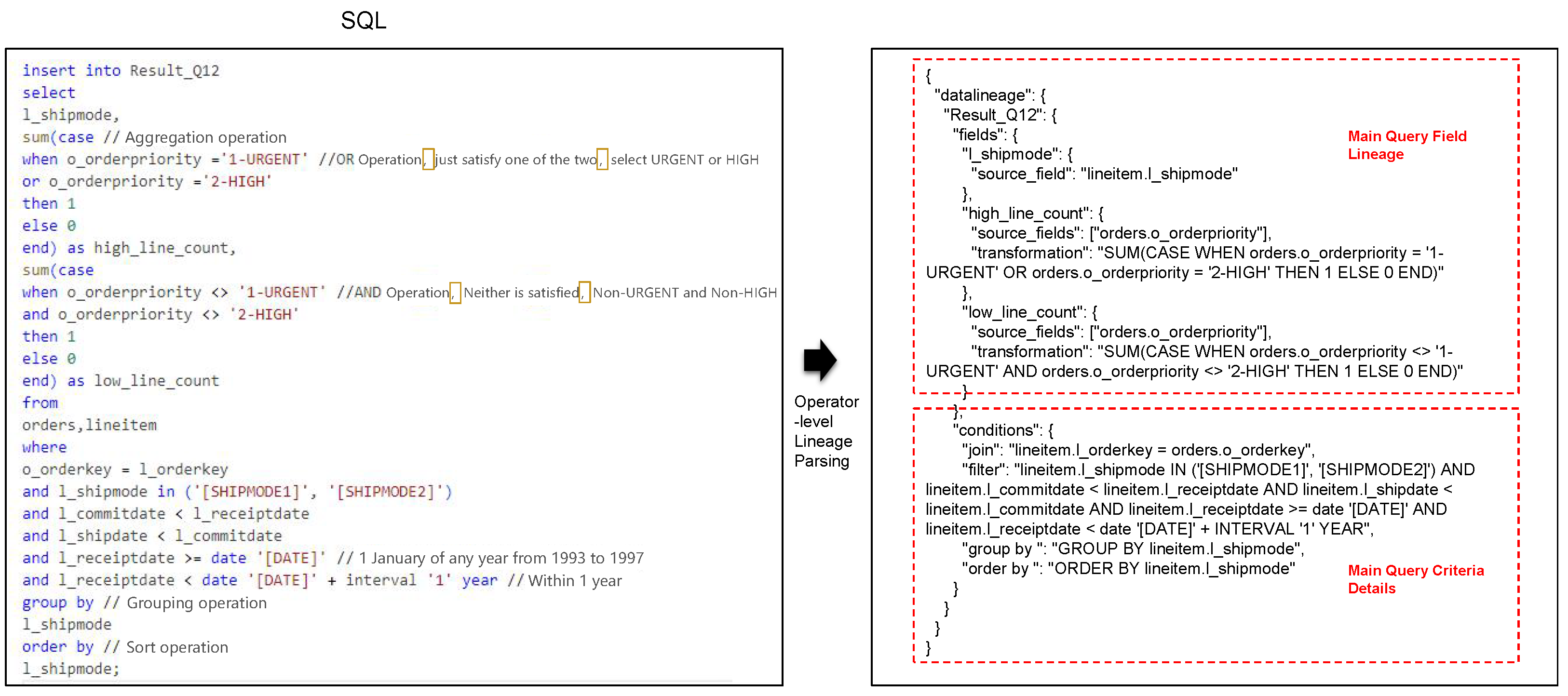
Operator-level lineage parsing extended beyond table-level parsing to include mapping relationships between fields, aggregation and mathematical computations, and detailed information such as subqueries, filtering conditions, grouping, and sorting. An example of SQL-script operator-level lineage parsing using few-shot prompting is illustrated in
Figure 6.
The statistical results are summarized in
Table 5 for Python and SQL script operator-level lineage parsing across different baselines.
The experimental results indicated that Qwen-2-72b achieved an accuracy below 85% across all baselines, including zero-shot, one-shot, few-shot, and few-shot with error cases. However, the proposed multi-expert with CoT significantly improved accuracy, exceeding 90% for Python and 85% for SQL, representing improvements of 5% and 10% compared to the B4 baseline, respectively. Llama-3.1-405B consistently outperformed other models, achieving nearly 90% accuracy with zero-shot prompting. The progressive improvements from B2 to B4 further increased accuracy to approximately 95%. Notably, the multi-expert with CoT approach enhanced lineage parsing accuracy to over 97% for both script types.
Taking the Llama-3.1-405B model as an example, when compared with the traditional lineage parsing method based on abstract syntax trees (AST), it can be observed that for Python scripts, the accuracy rate of the method proposed in this paper was about 1.5% lower than that of the traditional method. However, for SQL scripts, the method proposed in this paper was slightly higher than the traditional method. From the analysis of error cases, it was found that there were a small number of SQL dialects in the experimental cases. The traditional method, which did not extend its parsing rules to cover SQL dialects, failed to parse these cases. In contrast, the LLM-based method proposed in this paper still correctly parsed a significant proportion of the SQL dialect cases, resulting in an overall accuracy rate that was slightly higher than that of the traditional method.
5.4.3. Ablation Analysis
To investigate the impact of prompt strategies such as sample size, negative samples, Chain of Thought (COT), and multi-expert mechanisms on performance, additional baselines were added to the previous ones, as shown in
Table 6 below.
Additional operator-level lineage experiments with baselines were conducted for the Llama-3.1-405B large model, and the results are shown in
Table 7 below.
By comparing the parsing results of the baselines, it can be seen that in the SQL scenario, removing the multi-expert and COT led to a decrease of 0.62% and 2.0% in the accuracy rate of operator-level lineage parsing, respectively. In the Python scenario, removing the multi-expert and COT resulted in a decrease of 0.46% and 1.23% in the accuracy rate of lineage parsing, respectively, as shown in
Figure 7 below. The ablation comparison in both scenarios indicated that COT had a greater impact on the accuracy of lineage parsing than multi-expert. Comparing baseline B5 and B4 revealed that removing both multi-expert and COT simultaneously resulted in a more significant decrease in accuracy: 3.38% for SQL and 1.85% for Python. These decreases were greater than the sum of the individual decreases when each strategy was removed separately (SQL: 2.0% + 0.62% = 2.62%, Python: 1.23% + 0.46% = 1.69%). This suggests that using both multi-expert and COT prompt strategies together is more effective than using them individually (1 + 1 > 2).
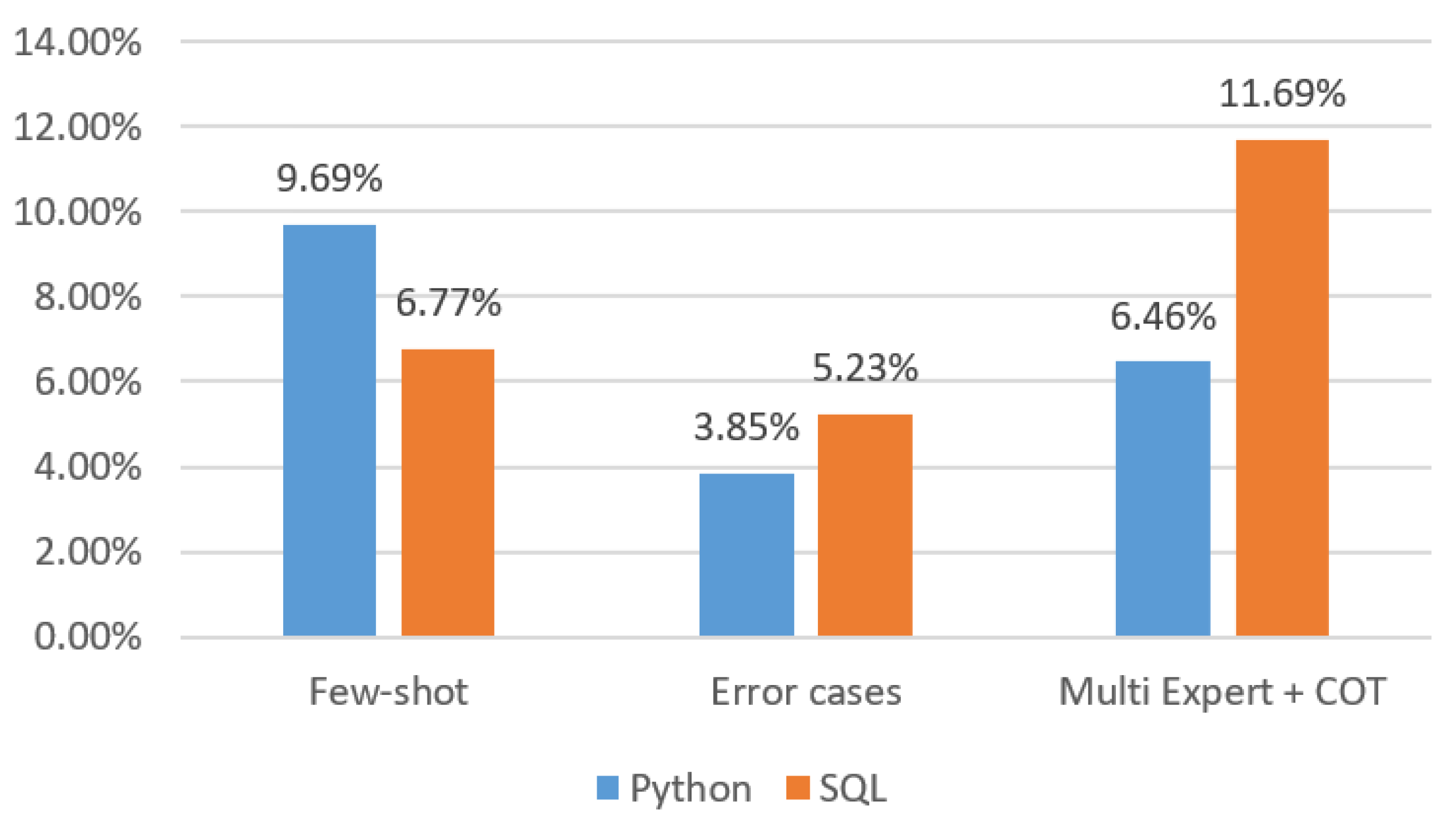
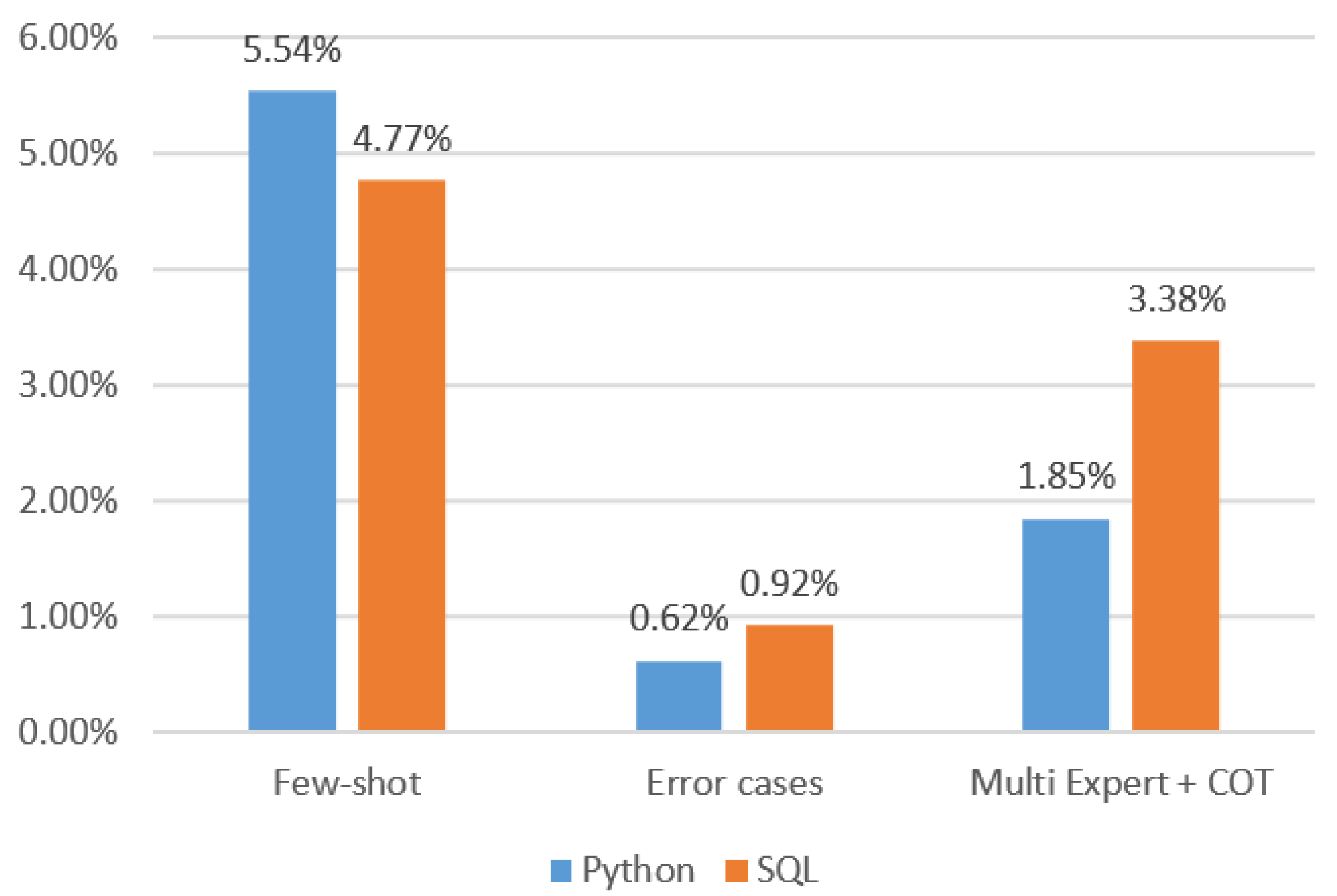
In addition, by analyzing
Table 5 and comparing the accuracy rates of the baselines in pairs such as B3 and B1, B4 and B3, and B5 and B4, we could approximately determine the individual improvement rates brought by the prompt strategies of few-shot, error cases, and multi-expert + COT. The relevant data are shown in
Figure 8 and
Figure 9.
As can be seen from
Figure 8, for Qwen-2-72b, the mainstream few-shot prompting strategy in the industry significantly contributed to the improvement of accuracy. The multi-expert + COT method proposed in this paper achieved the greatest improvement in the SQL scenario, but its contribution in the Python scenario was lower than that of few-shot. In both scenarios, the improvement rate of the negative sample strategy was relatively small.
From
Figure 9, it can be observed that for the large model Llama-3.1-405B with hundreds of billions of parameters, few-shot remained the most effective strategy for improvement. The multi-expert + COT strategy proposed in this paper had a slightly lower improvement rate than the former, and the improvement rate of the negative sample strategy was also small.
5.5. Discussion
Data in the telecommunications industry are characterized by their large scale, high real-time requirements, and complex and diverse business scenarios. A vast amount of data are generated daily, including network operation and maintenance data, user call and data traffic information, and business package data, among others. In the scenario of network operation and maintenance data management for telecommunications operators, various types of script are used in collaboration to process data from different sources. Similarly, in user behavior data analysis, different types of script are employed to mine and analyze user data related to calls, data traffic, and text messages.
The experimental results demonstrate that the proposed approach effectively addresses the key challenges associated with current data lineage parsing methods, namely, high customization costs, lengthy development cycles, and limited generalization, particularly demonstrating significant application value and broad prospects in the telecommunications operator industry.
First, the LLM-based lineage parsing framework significantly enhances the generalizability of parsing solutions across both SQL and non-SQL scripts. At the table-level granularity, open-source LLMs such as Qwen-2-72b and Llama-3.1-405B achieve over 95% parsing accuracy across multiple script types, including Shell, Flume, Python, and SQL. In contrast, smaller models such as Qwen-2-7B and Llama-3.1-8B perform poorly, with an average accuracy below 50%, even after multiple rounds of prompt optimization. Consequently, LLMs with more than 10 billion parameters are recommended for practical implementation.
Second, the proposed LLM-based approach relies solely on prompt engineering, eliminating the need for additional training, parameter fine-tuning, or customized code development. Minor prompt optimizations can be applied to adapt to new business scenarios, reducing development cycles and computational resource consumption compared to traditional lineage parsing solutions and fine-tuned LLM-based applications.
Additionally, the proposed method enhances the depth of lineage parsing without necessitating complex, deep customization. While Qwen-2-72b achieves suboptimal results for operator-level lineage parsing, with accuracy below 85%, the multi-expert with CoT approach improves accuracy beyond 90% for Python and 85% for SQL. Meanwhile, Llama-3.1-405B performs well across all baselines, achieving nearly 90% accuracy with zero-shot prompting. With the application of multi-expert with CoT, lineage parsing accuracy exceeds 97%. Compared with traditional lineage parsing methods, the method proposed in this paper achieved accuracy in table-level lineage that is close to that of traditional methods. However, it outperforms traditional methods when dealing with scenarios involving SQL dialects and multiple types of scripts.
From the results of the ablation analysis, it is evident that the currently well-developed few-shot prompting strategies have a significant impact on lineage accuracy and are indispensable. The multi-expert + COT prompting strategy proposed in this paper can notably improve lineage accuracy, with more pronounced effects observed in models with smaller parameter scales. Among the combined strategies, the COT strategy appears to be more important than the multi-expert strategy. Additionally, incorporating negative samples into the prompts can slightly enhance the final accuracy of lineage parsing.
In summary, the results indicate that LLMs, particularly those with large parameter scales, offer a highly effective and scalable solution for data lineage parsing. The multi-expert with CoT approach further enhances accuracy and interpretability, demonstrating substantial potential for improving enterprise data management and governance frameworks.
6. Conclusions
This study demonstrated the feasibility of employing a large language model (LLM)-based approach for data lineage parsing across various data processing script types through advanced prompt engineering techniques. This research comprehensively evaluated parsing performance under multiple dimensions, including LLM parameter scales, script types, different prompting methods, and varying levels of lineage granularity. By systematically analyzing these factors, this study provides a nuanced understanding of the capabilities and limitations of LLMs in the context of data lineage parsing. Furthermore, this research introduces significant enhancements to traditional LLM prompting methods, such as few-shot prompting and expert prompting, by incorporating innovative strategies like few-shot prompting with error cases and collaborative Chain-of-Thought (CoT) and multi-expert prompting. The effectiveness of these enhancements has been rigorously validated through empirical experimentation, demonstrating their potential to improve the accuracy and reliability of data lineage parsing.
The findings of this study offer valuable insights into the application of LLMs for data lineage parsing, particularly in scenarios involving multi-type, script-based lineage parsing and operator-level lineage tracking. The results underscore the potential of LLMs to enhance accuracy, efficiency, and adaptability in data lineage management, making them a powerful tool for organizations seeking to improve their data governance practices. By leveraging the generalization capabilities of LLMs, this research highlights how complex data lineage tasks can be streamlined, reducing the need for extensive manual intervention and enabling more scalable and efficient data management solutions.
However, despite the promising results, several challenges remain, particularly in handling complex stored procedures. Even large-scale LLMs, such as those with 100 billion parameters, exhibit various errors when parsing stored procedures. These errors often arise because stored procedures frequently depend on external scripts, and LLMs may generate speculative parsing results in the absence of explicit script content. This limitation underscores the need for further research to address the complexities associated with stored procedures and develop more robust parsing methodologies. Due to time and resource constraints, this study did not extensively explore lineage parsing for stored procedures, leaving this as an important area for future investigation.
In the future, we should focus on the deeper integration of AI Agent and Retrieval-Augmented Generation (RAG) techniques to enhance the accuracy and reliability of lineage extraction and interpretation. AI agents, with their ability to autonomously perform complex tasks, could be leveraged to dynamically retrieve and integrate relevant information from external sources, thereby improving the context-awareness and precision of LLM-based lineage parsing. Similarly, RAG techniques, which combine retrieval mechanisms with generative models, could be employed to augment an LLM’s knowledge base, enabling it to generate more accurate and contextually relevant lineage information. By integrating these advanced techniques, future research could address the current limitations and further advance the state of the art in data lineage parsing.
In conclusion, this study provides a foundational framework for leveraging LLMs in data lineage parsing, demonstrating their potential to transform data governance practices. Our contributions offer valuable guidance for researchers and practitioners in the field, highlighting both the opportunities and challenges associated with LLM-based approaches. Along with the continued exploration of stored procedure parsing, further advancements in AI agent and RAG integration will be critical for realizing the full potential of LLMs in data lineage management. This research contributes to the growing body of knowledge at the intersection of artificial intelligence and data governance, paving the way of more efficient, accurate, and scalable data lineage solutions in the future.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}