Federated Learning in Smart Healthcare: A Survey of Applications, Challenges, and Future Directions


 ,
,  , ,
, ,  , and
, and
Abstract
1. Introduction
1.1. Motivation
1.2. Methodology
1.2.1. Research Questions
1.2.2. Search Strategy
- Selection and Screening: Initially, we screened papers based on their titles and abstracts, focusing on those related to federated learning and its application in healthcare. We applied the following inclusion criteria: (1) peer-reviewed articles, (2) studies that explicitly discuss federated learning or related techniques, and (3) research relevant to healthcare applications.
- Exclusion Criteria: We excluded papers that were not directly related to healthcare, those without empirical analysis or practical applications, and those published in languages other than English.
- Evaluation: After screening, we evaluated the full texts of the selected papers for quality and relevance, considering factors such as research methodology, sample size, and applicability to current trends in the field.
1.3. Difference with Other Review Papers
1.4. Outline
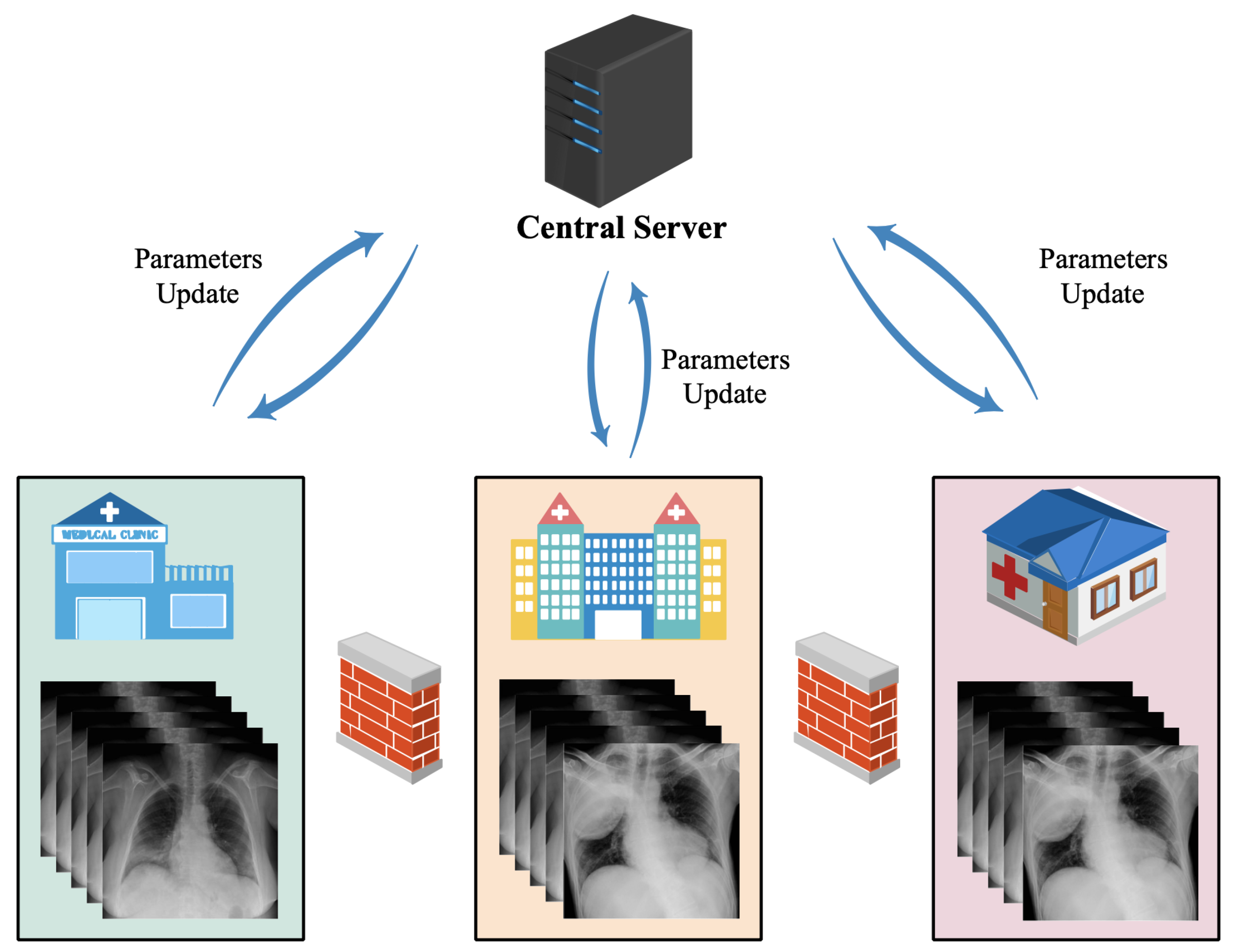
2. Architectures
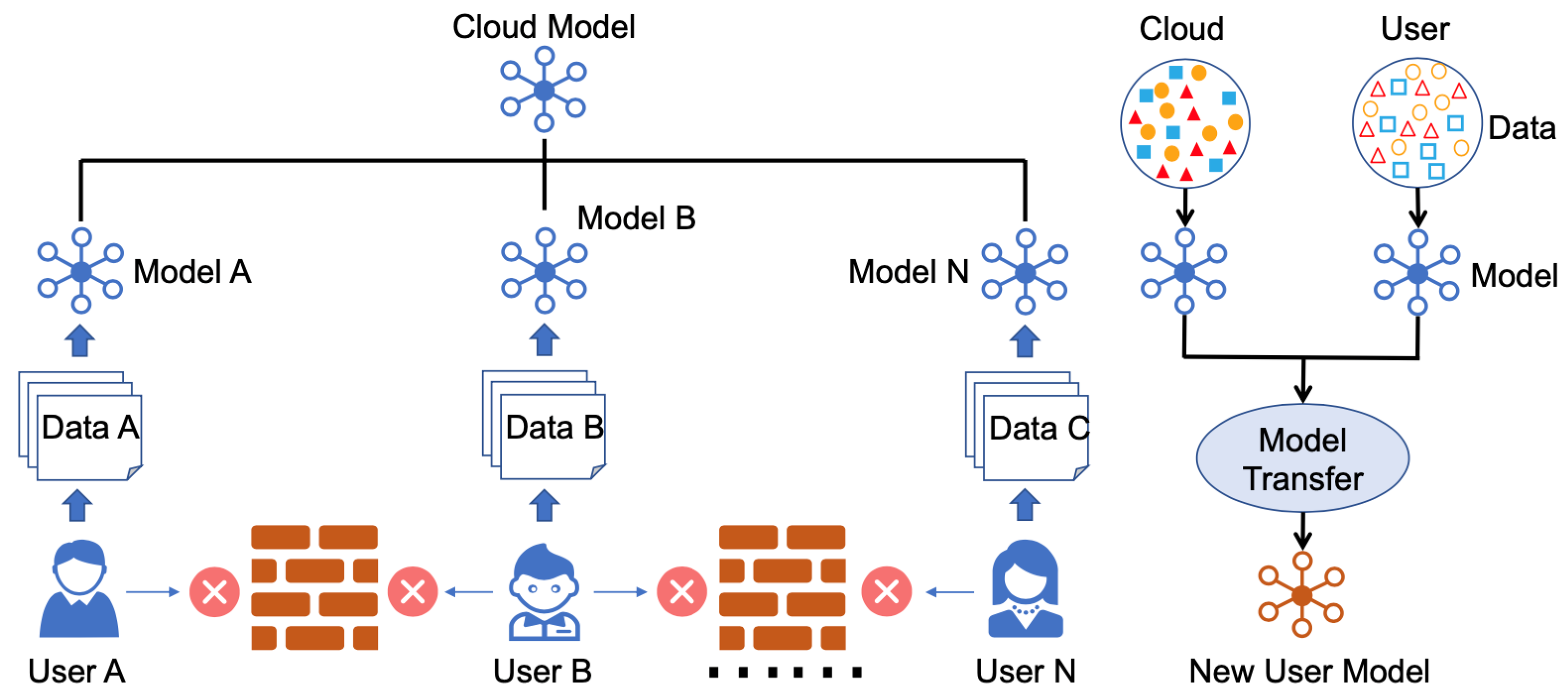
2.1. FedHealth
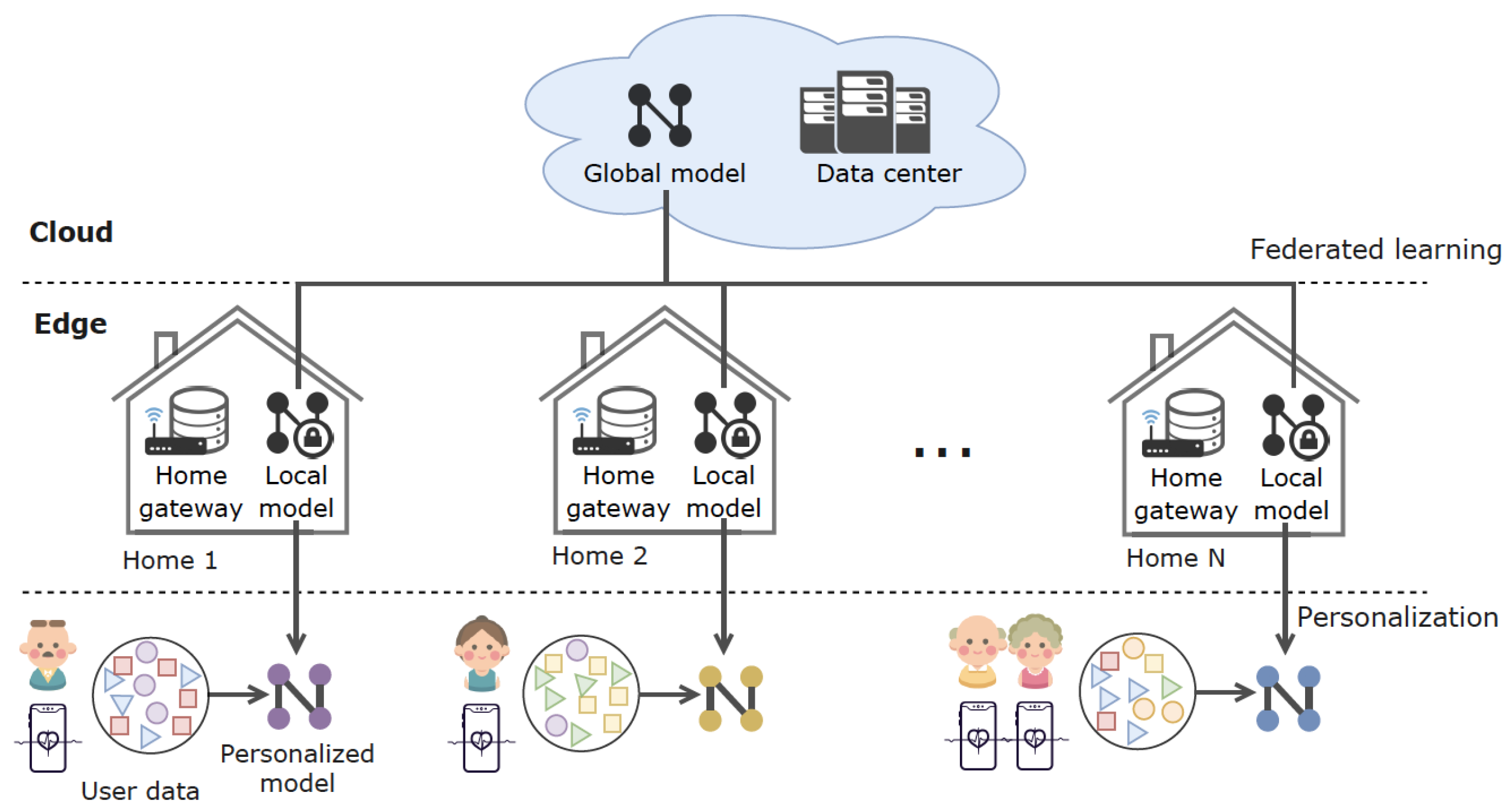
2.2. PerFit
2.2.1. Heterogeneity of Devices
2.2.2. Statistical Heterogeneity
2.2.3. Model Heterogeneity
Unloading
Learning
Personalization
2.3. FedHome
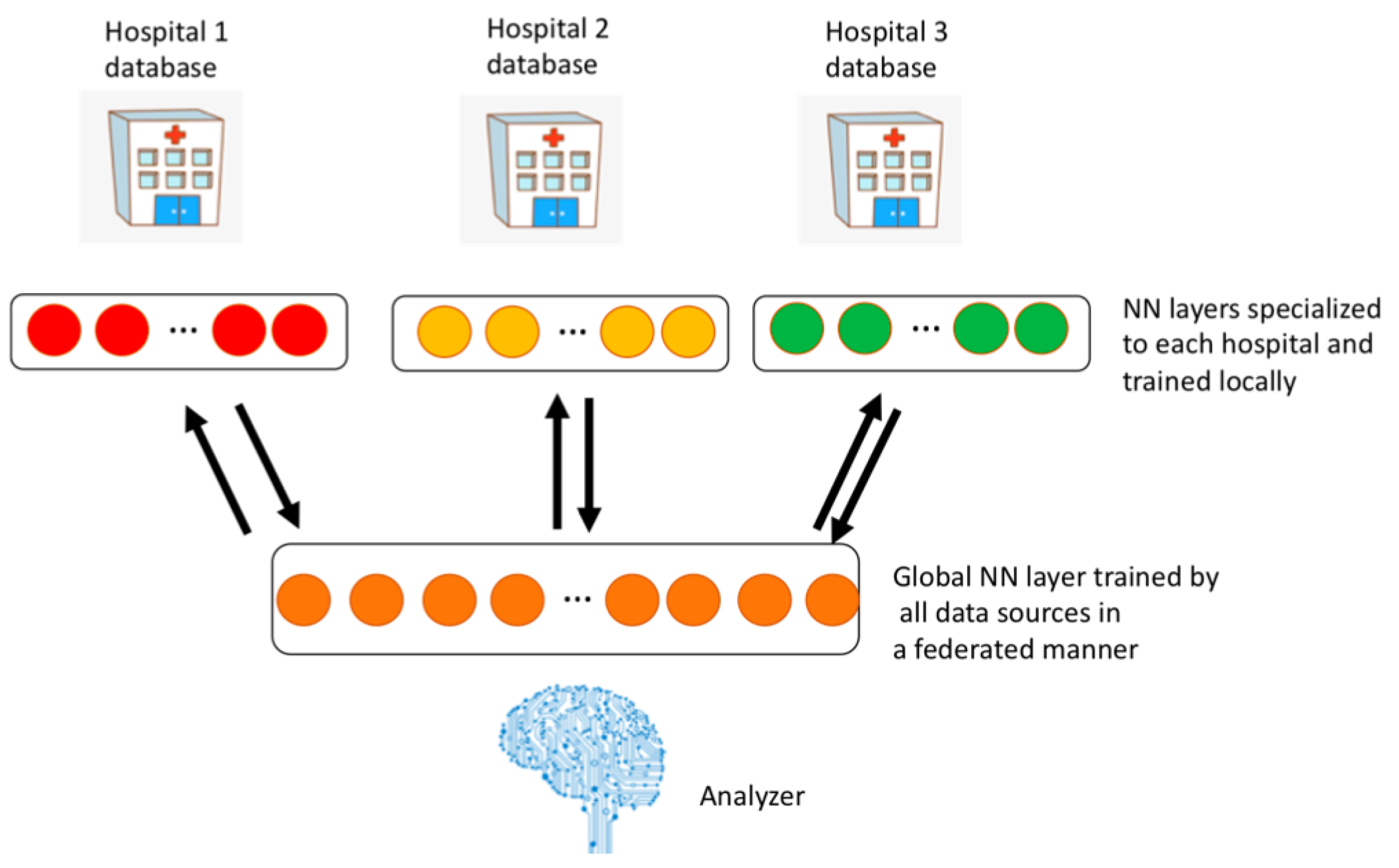
2.4. FADL
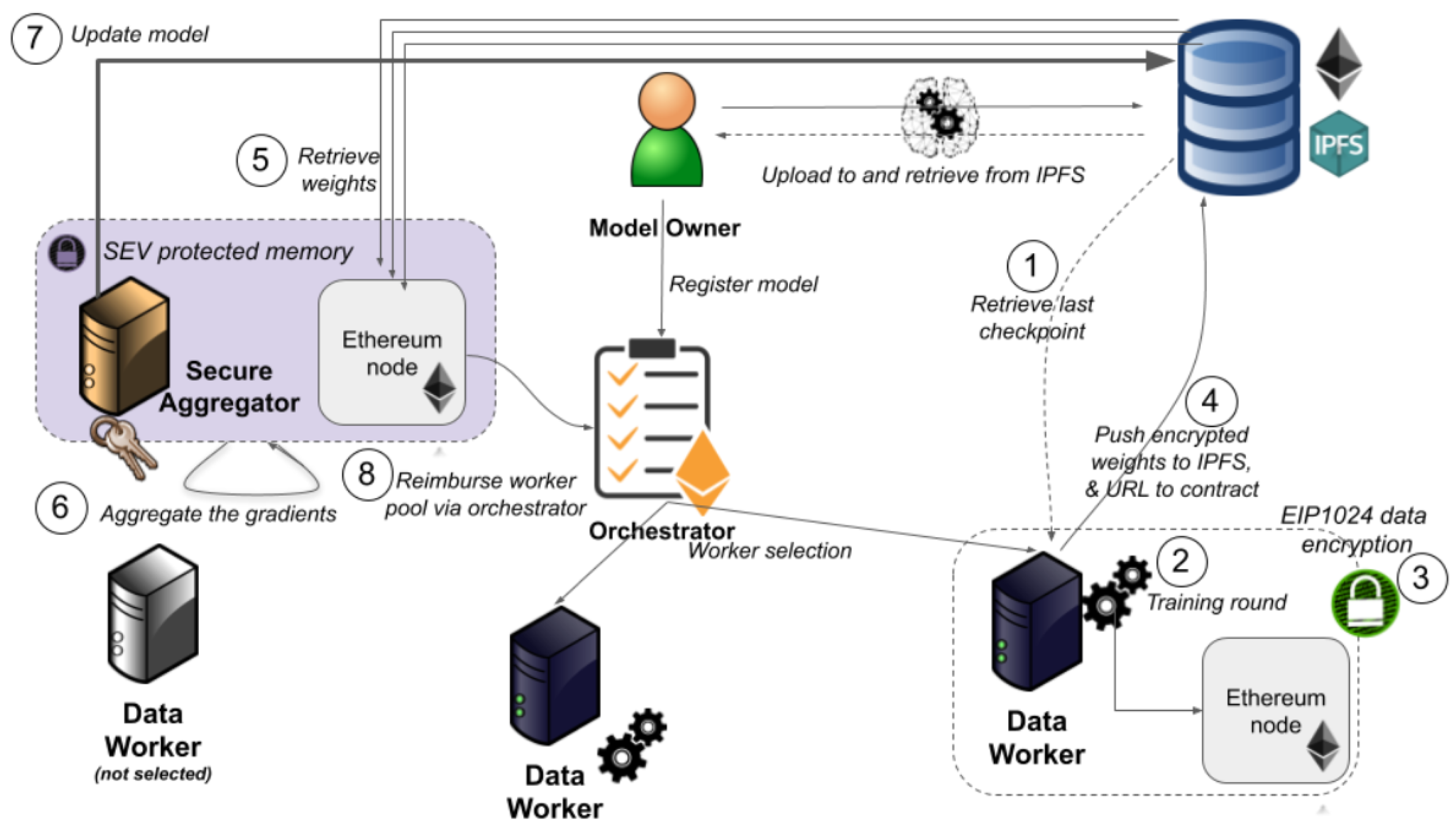
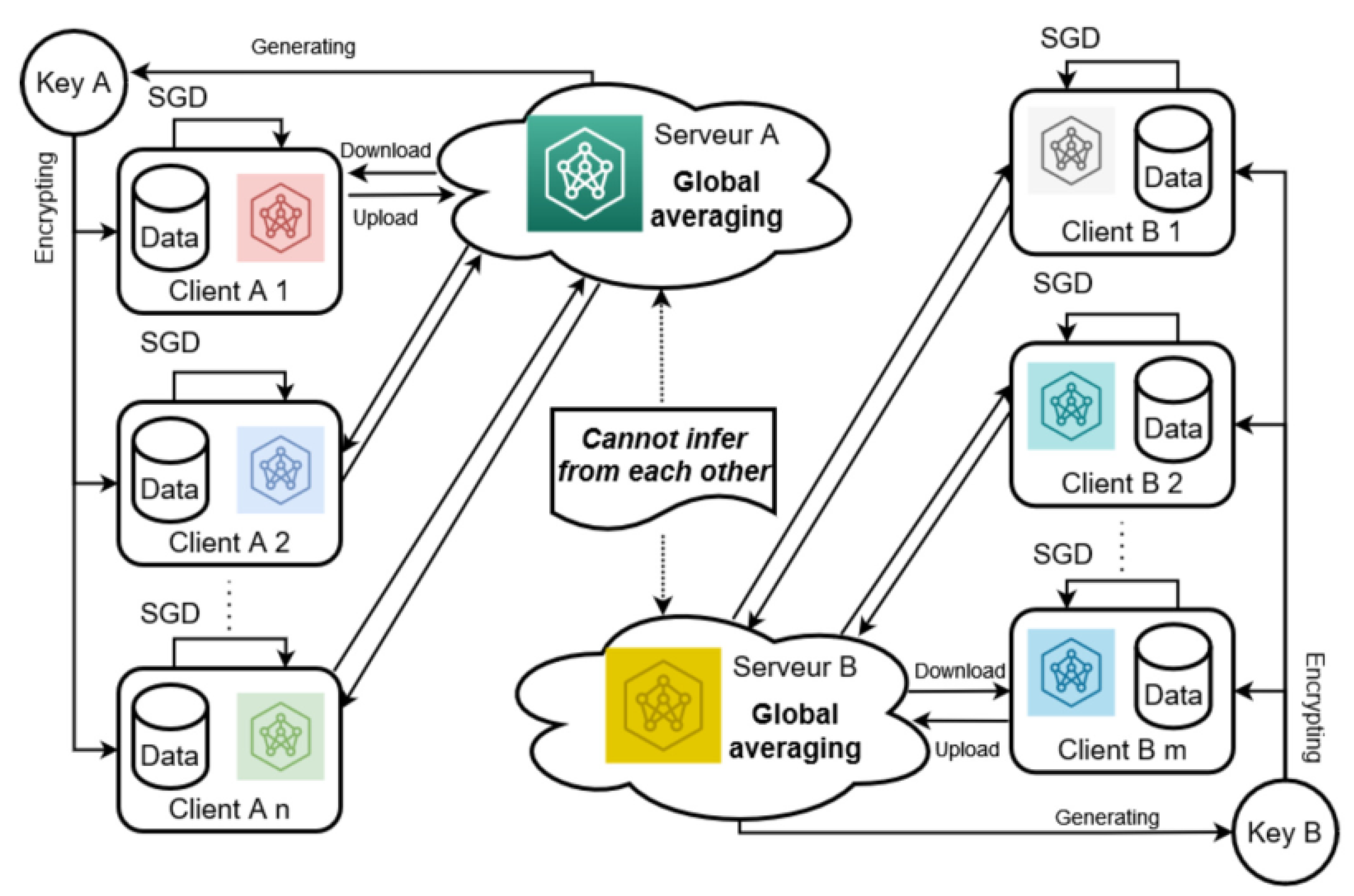
2.5. Blockchain-Based Ethereum
2.5.1. Data Policy
2.5.2. Secure Aggregation
2.5.3. Peer-to-Peer Transition
Selecting Randomly
Audit Trail
2.6. FEEL
- Mobile Healthcare Devices,
- Hospital Private Server,
- Cloud Data Center.
2.7. DMFL-Net
2.8. FedCare
2.9. Sensor-Based HAR
3. Applications
3.1. Drug Discovery
3.1.1. Cross-Silo FL
3.1.2. FL-QSAR
3.1.3. Adverse Drug Reaction
3.2. Prediction
3.2.1. Mortality and Stay Time Prediction
CBFL
Privacy of EHRs
Data Privacy
3.2.2. Hospitalization Prediction
COVID-19
Cardiac Events
3.2.3. Preterm Birth Prediction-Federated Uncertainty-Aware Learning Algorithm (FUALA)
3.3. Medical Imaging
3.3.1. Brain Segmentation
Whole Brain Segmentation
Brain Tumor Segmentation
3.3.2. fMRI—Autism Spectrum Disorders
3.3.3. COVID-19 Detection
CT Scan
Chest X-Ray Images
Dynamic Fusion
3.3.4. Lung Nodules
3.3.5. Cardiovascular Disease Detection
3.3.6. Thyroid Image Recognition
3.4. Patient Similarity Learning
Privacy Preserving
FPH
3.5. Phenotype Discovery
3.5.1. Federated Tensor Factorization
3.5.2. Clinical Data
3.6. Arrhythmia Detection
3.7. Large-Scale Medical Data
3.8. Critical Assessment
4. Challenges
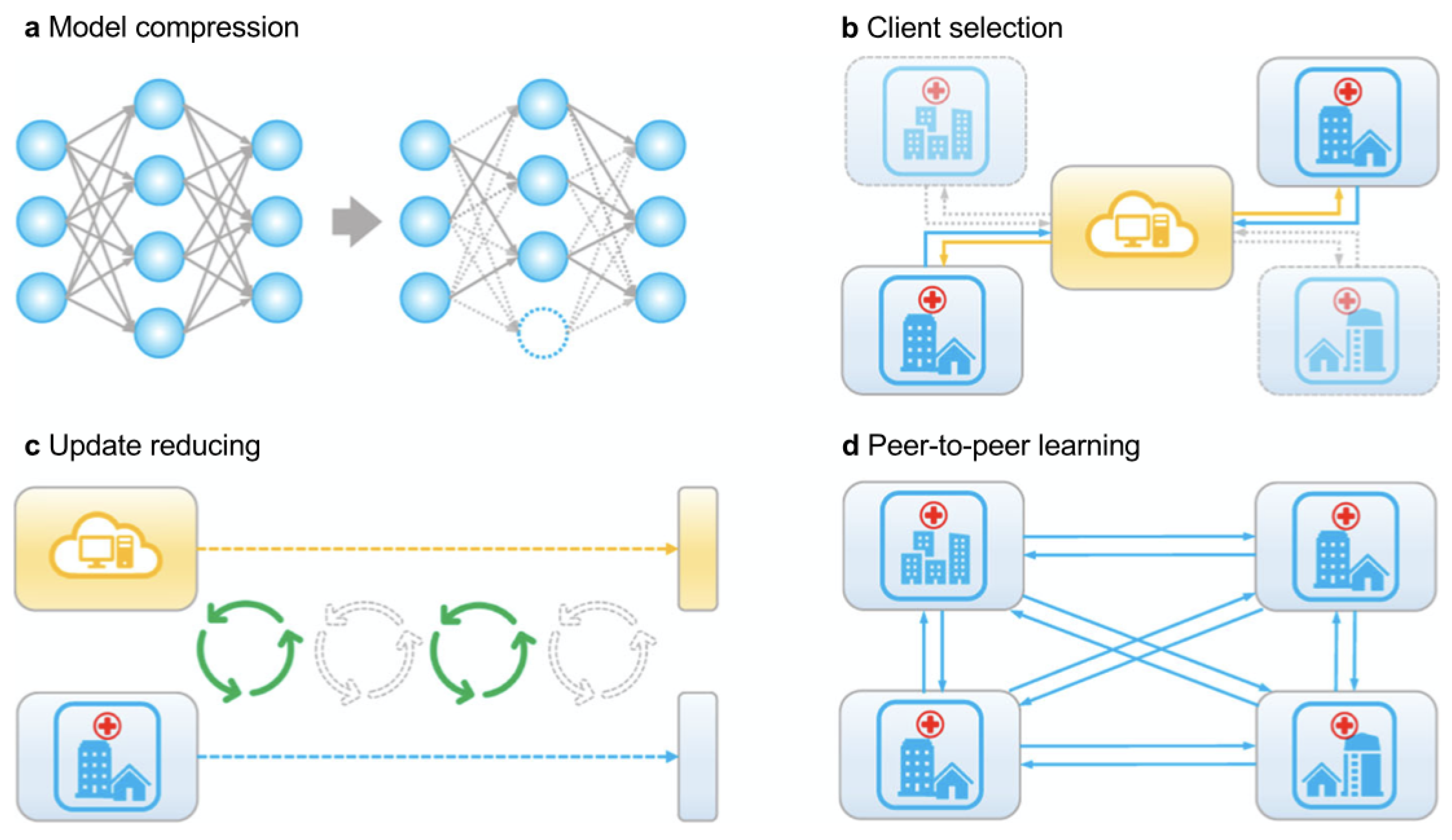
4.1. Communication Efficiency
4.1.1. Client Section
4.1.2. Model Compression
4.1.3. Update Reduction
4.1.4. Peer-to-Peer Learning
4.2. Privacy
4.2.1. Performance
4.2.2. Level of Trust
- Trusted
- Non-Trusted
4.2.3. Information Leakage
4.3. Data Skewing
4.4. Traceability
4.5. System Architecture
4.6. Data Heterogeneity
4.7. Scalability
4.8. Interoperability
5. Future Directions
5.1. Privacy and Security Issues
5.2. Communication Cost
5.3. Heterogeneity Data
5.4. Scalability
5.5. Standardization
5.6. Model Explainability
5.7. Integrating FL with Emerging Technologies
5.8. Hyperparameter Optimization
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 12 March 2025).
- Mitchell, R.; Michalski, J.; Carbonell, T. An Artificial Intelligence Approach; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Ghoddusi, H.; Creamer, G.G.; Rafizadeh, N. Machine learning in energy economics and finance: A review. Energy Econ. 2019, 81, 709–727. [Google Scholar] [CrossRef]
- Athey, S. The impact of machine learning on economics. In The Economics of Artificial Intelligence: An Agenda; University of Chicago Press: Chicago, IL, USA, 2018; pp. 507–547. [Google Scholar]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef]
- Sharp, M.; Ak, R.; Hedberg, T., Jr. A survey of the advancing use and development of machine learning in smart manufacturing. J. Manuf. Syst. 2018, 48, 170–179. [Google Scholar] [CrossRef]
- Bhavsar, P.; Safro, I.; Bouaynaya, N.; Polikar, R.; Dera, D. Machine learning in transportation data analytics. In Data Analytics for Intelligent Transportation Systems; Elsevier: Amsterdam, The Netherlands, 2017; pp. 283–307. [Google Scholar]
- Nguyen, H.; Kieu, L.M.; Wen, T.; Cai, C. Deep learning methods in transportation domain: A review. IET Intell. Transp. Syst. 2018, 12, 998–1004. [Google Scholar] [CrossRef]
- Bhardwaj, R.; Nambiar, A.R.; Dutta, D. A study of machine learning in healthcare. In Proceedings of the 2017 IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), Turin, Italy, 4–8 July 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 2, pp. 236–241. [Google Scholar]
- Shailaja, K.; Seetharamulu, B.; Jabbar, M. Machine Learning in Healthcare: A Review. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 910–914. [Google Scholar]
- Saharkhizan, M.; Azmoodeh, A.; Dehghantanha, A.; Choo, K.K.R.; Parizi, R.M. An Ensemble of Deep Recurrent Neural Networks for Detecting IoT Cyber Attacks Using Network Traffic. IEEE Internet Things J. 2020, 7, 8852–8859. [Google Scholar] [CrossRef]
- Al-Abassi, A.; Karimipour, H.; Dehghantanha, A.; Parizi, R.M. An Ensemble Deep Learning-Based Cyber-Attack Detection in Industrial Control System. IEEE Access 2020, 8, 83965–83973. [Google Scholar] [CrossRef]
- El Naqa, I.; Murphy, M.J. What is Machine Learning? Springer: Berlin/Heidelberg, Germany, 2015; pp. 3–11. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- The HIPAA Privacy Rule. 2020. Available online: https://www.hhs.gov/hipaa/for-professionals/privacy/index.html (accessed on 8 December 2020).
- General Data Protection Regulation (GDPR). 2018. Available online: https://gdpr-info.eu (accessed on 29 December 2020).
- Rumbold, J.M.; Pierscionek, B.K. What are data? A categorization of the data sensitivity spectrum. Big Data Res. 2018, 12, 49–59. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (Tist) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Chen, Y.; Qin, X.; Wang, J.; Yu, C.; Gao, W. Fedhealth: A federated transfer learning framework for wearable healthcare. IEEE Intell. Syst. 2020, 35, 83–93. [Google Scholar] [CrossRef]
- Voigt, P.; von dem Bussche, A. The EU General Data Protection Regulation (GDPR): A Practical Guide, 1st ed.; Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Ghassemi, M.; Naumann, T.; Schulam, P.; Beam, A.L.; Chen, I.Y.; Ranganath, R. A review of challenges and opportunities in machine learning for health. AMIA Summits Transl. Sci. Proc. 2020, 2020, 191. [Google Scholar] [PubMed]
- Rajkomar, A.; Dean, J.; Kohane, I. Machine learning in medicine. New Engl. J. Med. 2019, 380, 1347–1358. [Google Scholar] [CrossRef]
- Razzak, M.I.; Naz, S.; Zaib, A. Deep learning for medical image processing: Overview, challenges and the future. In Classification in BioApps: Automation of Decision Making; Springe: Berlin/Heidelberg, Germany, 2017; pp. 323–350. [Google Scholar]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Aledhari, M.; Razzak, R.; Parizi, R.M.; Saeed, F. Federated Learning: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Access 2020, 8, 140699–140725. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics; PMLR: Cambridge, MA, USA, 2017; pp. 1273–1282. [Google Scholar]
- Hu, F.; Yang, H.; Qiu, L.; Wei, S.; Hu, H.; Zhou, H. Spatial structure and organization of the medical device industry urban network in China: Evidence from specialized, refined, distinctive, and innovative firms. Front. Public Health 2025, 13, 1518327. [Google Scholar] [CrossRef]
- Xu, J.; Glicksberg, B.S.; Su, C.; Walker, P.; Bian, J.; Wang, F. Federated learning for healthcare informatics. J. Healthc. Inform. Res. 2020, 5, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Rieke, N.; Hancox, J.; Li, W.; Milletari, F.; Roth, H.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.; Maier-Hein, K.; et al. The future of digital health with federated learning. arXiv 2020, arXiv:2003.08119. [Google Scholar] [CrossRef]
- Kaissis, G.A.; Makowski, M.R.; Rückert, D.; Braren, R.F. Secure, privacy-preserving and federated machine learning in medical imaging. Nat. Mach. Intell. 2020, 2, 305–311. [Google Scholar] [CrossRef]
- Liu, Y.; Kang, Y.; Xing, C.; Chen, T.; Yang, Q. Secure federated transfer learning. arXiv 2018, arXiv:1812.03337. [Google Scholar]
- Wu, Q.; He, K.; Chen, X. Personalized federated learning for intelligent iot applications: A cloud-edge based framework. IEEE Comput. Graph. Appl. 2020, 1, 35–44. [Google Scholar] [CrossRef]
- Wu, Q.; Chen, X.; Zhou, Z.; Zhang, J. FedHome: Cloud-Edge based Personalized Federated Learning for In-Home Health Monitoring. IEEE Trans. Mob. Comput. 2020, 21, 2818–2832. [Google Scholar] [CrossRef]
- Liu, D.; Miller, T.; Sayeed, R.; Mandl, K.D. Fadl: Federated-autonomous deep learning for distributed electronic health record. arXiv 2018, arXiv:1811.11400. [Google Scholar]
- Passerat-Palmbach, J.; Farnan, T.; Miller, R.; Gross, M.S.; Flannery, H.L.; Gleim, B. A blockchain-orchestrated Federated Learning architecture for healthcare consortia. arXiv 2019, arXiv:1910.12603. [Google Scholar]
- Guo, Y.; Liu, F.; Cai, Z.; Chen, L.; Xiao, N. FEEL: A Federated Edge Learning System for Efficient and Privacy-Preserving Mobile Healthcare. In Proceedings of the 49th International Conference on Parallel Processing-ICPP, Edmonton, AB, Canada, 17–20 August 2020; pp. 1–11. [Google Scholar]
- Malik, H.; Naeem, A.; Naqvi, R.A.; Loh, W.K. DMFL_Net: A Federated Learning-Based Framework for the Classification of COVID-19 from Multiple Chest Diseases Using X-rays. Sensors 2023, 23, 743. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Misra, S.; Pathak, N.; Das, D. Fedcare: Federated learning for resource-constrained healthcare devices in iomt system. IEEE Trans. Comput. Soc. Syst. 2023, 10, 1587–1596. [Google Scholar] [CrossRef]
- Pham, C.H.; Huynh-The, T.; Sedgh-Gooya, E.; El-Bouz, M.; Alfalou, A. Extension of physical activity recognition with 3D CNN using encrypted multiple sensory data to federated learning based on multi-key homomorphic encryption. Comput. Methods Programs Biomed. 2024, 243, 107854. [Google Scholar] [CrossRef]
- Al-Turjman, F.; Baali, I. Machine learning for wearable IoT-based applications: A survey. Trans. Emerg. Telecommun. Technol. 2019, 33, e3635. [Google Scholar] [CrossRef]
- Liang, P.P.; Liu, T.; Ziyin, L.; Salakhutdinov, R.; Morency, L.P. Think locally, act globally: Federated learning with local and global representations. arXiv 2020, arXiv:2001.01523. [Google Scholar]
- SÜZEN, A.A.; ŞİMŞEK, M.A. A Novel Approach to Machine Learning Application to Protection Privacy Data in Healthcare: Federated Learning. Namik Kemal Tip Derg. 2020, 8, 22–30. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. Human activity recognition on smartphones using a multiclass hardware-friendly support vector machine. In Proceedings of the International Workshop on Ambient Assisted Living, Vitoria-Gasteiz, Spain, 3–5 December 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 216–223. [Google Scholar]
- Vavoulas, G.; Chatzaki, C.; Malliotakis, T.; Pediaditis, M.; Tsiknakis, M. The MobiAct Dataset: Recognition of Activities of Daily Living using Smartphones. In Proceedings of the ICT4AgeingWell, Rome, Italy, 21–22 April 2016; pp. 143–151. [Google Scholar]
- CMS. Electronic Health Records. 2012. Available online: https://web.archive.org/web/20120915155253/http://www.cms.gov/Medicare/E-Health/EHealthRecords/index.html (accessed on 23 April 2025).
- Pollard, T.J.; Johnson, A.E.; Raffa, J.D.; Celi, L.A.; Mark, R.G.; Badawi, O. The eICU Collaborative Research Database, a freely available multi-center database for critical care research. Sci. Data 2018, 5, 180178. [Google Scholar] [CrossRef]
- Jones, R. Hyperledger Besu. 2020. Available online: https://wiki.hyperledger.org/display/BESU/Hyperledger+Besu (accessed on 15 December 2021).
- Shbair, W.; Steichen, M.; François, J. Blockchain orchestration and experimentation framework: A case study of KYC. In Proceedings of the IEEE/IFIP Man2Block 2018-IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018. [Google Scholar]
- Alabi, T. Ethereum Improvement Proposal-1024 - Add web3.eth.encrypt and web3.eth.decrypt Functions. Technical Report. 2018. Available online: https://github.com/ethereum/EIPs/pull/1098 (accessed on 15 December 2020).
- Melis, L.; Song, C.; De Cristofaro, E.; Shmatikov, V. Exploiting unintended feature leakage in collaborative learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 691–706. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 25–27 October 2016; pp. 308–318. [Google Scholar]
- Boneh, D. The decision diffie-hellman problem. In Proceedings of the International Algorithmic Number Theory Symposium, Portland, OR, USA, 13–18 June 2004; Springer: Berlin/Heidelberg, Germany, 1998; pp. 48–63. [Google Scholar]
- Mangasarian, O.L.; Wolberg, W.H. Cancer diagnosis via linear programming. In Technical Report; University of Wisconsin-Madison Department of Computer Sciences: Madison, WI, USA, 1990. [Google Scholar]
- Bilal, A.; Shafiq, M.; Obidallah, W.J.; Alduraywish, Y.A.; Long, H. Quantum computational infusion in extreme learning machines for early multi-cancer detection. J. Big Data 2025, 12, 1–48. [Google Scholar] [CrossRef]
- Rhodes, C. Perfect Harmony: Pharma’s MELLODDY Consortium Joins Forces with NVIDIA to Supercharge AI Drug Discovery. 2019. Available online: https://blogs.nvidia.com/blog/2019/08/08/pharma-melloddy-ai-drug-discovery-consortium/ (accessed on 3 November 2020).
- nvidia. King’s College London is Working to Bring AI Benefits to the Point of Care. 2019. Available online: https://www.nvidia.com/content/dam/en-us/Solutions/data-center/gated-resources/hc-casestudy-kings-college-london.pdf (accessed on 3 November 2020).
- Xiong, Z.; Cheng, Z.; Liu, X.; Wang, D.; Luo, X.; Chen, K.; Jiang, H.; Zheng, M. Facing small and biased data dilemma in drug discovery with federated learning. BioRxiv 2020. [Google Scholar]
- Sorkun, M.C.; Khetan, A.; Er, S. AqSolDB, a curated reference set of aqueous solubility and 2D descriptors for a diverse set of compounds. Sci. Data 2019, 6, 143. [Google Scholar] [CrossRef]
- Chen, S.; Xue, D.; Chuai, G.; Yang, Q.; Liu, Q. FL-QSAR: A federated learning based QSAR prototype for collaborative drug discovery. bioRxiv 2020. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Sheridan, R.P.; Liaw, A.; Dahl, G.E.; Svetnik, V. Deep neural nets as a method for quantitative structure–activity relationships. J. Chem. Inf. Model. 2015, 55, 263–274. [Google Scholar] [CrossRef]
- Choudhury, O.; Park, Y.; Salonidis, T.; Gkoulalas-Divanis, A.; Sylla, I.; k Das, A. Predicting Adverse Drug Reactions on Distributed Health Data using Federated Learning. In Proceedings of the AMIA Annual Symposium Proceedings. American Medical Informatics Association, Washington, DC, USA, 16–20 November 2019; Volume 2019, p. 313. [Google Scholar]
- IBM. IBM Explorys Electronic Health Record (EHR) Database. Available online: https://pophealth.ucsf.edu/ibm-marketscan-research-databases-access (accessed on 23 April 2025).
- Huang, L.; Shea, A.L.; Qian, H.; Masurkar, A.; Deng, H.; Liu, D. Patient clustering improves efficiency of federated machine learning to predict mortality and hospital stay time using distributed electronic medical records. J. Biomed. Inform. 2019, 99, 103291. [Google Scholar] [CrossRef]
- Pfohl, S.R.; Dai, A.M.; Heller, K. Federated and Differentially Private Learning for Electronic Health Records. arXiv 2019, arXiv:1911.05861. [Google Scholar]
- Sharma, P.; Shamout, F.E.; Clifton, D.A. Preserving patient privacy while training a predictive model of in-hospital mortality. arXiv 2019, arXiv:1912.00354. [Google Scholar]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Li-Wei, H.L.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef]
- Vaid, A.; Jaladanki, S.K.; Xu, J.; Teng, S.; Kumar, A.; Lee, S.; Somani, S.; Paranjpe, I.; De Freitas, J.K.; Wanyan, T.; et al. Federated learning of electronic health records to improve mortality prediction in hospitalized patients with COVID-19: Machine learning approach. JMIR Med. Inform. 2021, 9, e24207. [Google Scholar] [CrossRef]
- Liu, B.; Yan, B.; Zhou, Y.; Yang, Y.; Zhang, Y. Experiments of federated learning for covid-19 chest x-ray images. arXiv 2020, arXiv:2007.05592. [Google Scholar]
- Brisimi, T.S.; Chen, R.; Mela, T.; Olshevsky, A.; Paschalidis, I.C.; Shi, W. Federated learning of predictive models from federated electronic health records. Int. J. Med. Inform. 2018, 112, 59–67. [Google Scholar] [CrossRef]
- Boughorbel, S.; Jarray, F.; Venugopal, N.; Moosa, S.; Elhadi, H.; Makhlouf, M. Federated Uncertainty-Aware Learning for Distributed Hospital EHR Data. arXiv 2019, arXiv:1910.12191. [Google Scholar]
- Roy, A.G.; Siddiqui, S.; Pölsterl, S.; Navab, N.; Wachinger, C. Braintorrent: A peer-to-peer environment for decentralized federated learning. arXiv 2019, arXiv:1905.06731. [Google Scholar]
- Landman, B.; Warfield, S. MICCAI 2012 workshop on multi-atlas labeling. In Proceedings of the MICCAI Grand Challenge and Workshop on Multi-Atlas Labeling, CreateSpace Independent Publishing Platform, Marrakesh, Morocco, 7–11 October 2012. [Google Scholar]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.S.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Segmentation Labels for the Pre-operative Scans of the TCGA-GBM collection [Data Set]. 2017. Available online: https://www.cancerimagingarchive.net/analysis-result/brats-tcga-gbm/ (accessed on 12 March 2025).
- Li, W.; Milletarì, F.; Xu, D.; Rieke, N.; Hancox, J.; Zhu, W.; Baust, M.; Cheng, Y.; Ourselin, S.; Cardoso, M.J.; et al. Privacy-preserving federated brain tumour segmentation. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Shenzhen, China, 17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 133–141. [Google Scholar]
- Bakas, S.; Reyes, M.; Jakab, A.; Bauer, S.; Rempfler, M.; Crimi, A.; Shinohara, R.T.; Berger, C.; Ha, S.M.; Rozycki, M.; et al. Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge. arXiv 2018, arXiv:1811.02629. [Google Scholar]
- Li, X.; Gu, Y.; Dvornek, N.; Staib, L.; Ventola, P.; Duncan, J.S. Multi-site fmri analysis using privacy-preserving federated learning and domain adaptation: Abide results. arXiv 2020, arXiv:2001.05647. [Google Scholar] [CrossRef]
- Di Martino, A.; Yan, C.G.; Li, Q.; Denio, E.; Castellanos, F.X.; Alaerts, K.; Anderson, J.S.; Assaf, M.; Bookheimer, S.Y.; Dapretto, M.; et al. The autism brain imaging data exchange: Towards a large-scale evaluation of the intrinsic brain architecture in autism. Mol. Psychiatry 2014, 19, 659–667. [Google Scholar] [CrossRef]
- Kumar, R.; Khan, A.A.; Zhang, S.; Wang, W.; Abuidris, Y.; Amin, W.; Kumar, J. Blockchain-federated-learning and deep learning models for COVID-19 detection using CT imaging. arXiv 2020, arXiv:2007.06537. [Google Scholar] [CrossRef]
- RSNA. RSNA Pneumonia Detection Challenge. 2018. Available online: https://www.kaggle.com/c/rsna-pneumonia-detection-challenge/ (accessed on 24 December 2020).
- Zhang, W.; Zhou, T.; Lu, Q.; Wang, X.; Zhu, C.; Wang, Z.; Wang, F. Dynamic Fusion based Federated Learning for COVID-19 Detection. arXiv 2020, arXiv:2009.10401. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, Y.; He, X.; Xie, P. COVID-CT-Dataset: A CT scan dataset about COVID-19. arXiv 2020, arXiv:2003.13865. [Google Scholar]
- Kaggle. COVID-19 Radiography Database. 2018. Available online: https://www.kaggle.com/tawsifurrahman/covid19-radiography-database (accessed on 24 December 2020).
- Figure 1 COVID-19 Chest X-ray Dataset Initiative. 2020. Available online: https://github.com/agchung/Figure1-COVID-chestxray-dataset (accessed on 24 December 2020).
- Baheti, P.; Sikka, M.; Arya, K.; Rajesh, R. Federated Learning on Distributed Medical Records for Detection of Lung Nodules. In Proceedings of the VISIGRAPP (4: VISAPP), Valletta, Malta, 27–29 February 2020; pp. 445–451. [Google Scholar]
- Armato, S.G., III; McLennan, G.; Bidaut, L.; McNitt-Gray, M.F.; Meyer, C.R.; Reeves, A.P.; Zhao, B.; Aberle, D.R.; Henschke, C.I.; Hoffman, E.A.; et al. The lung image database consortium (LIDC) and image database resource initiative (IDRI): A completed reference database of lung nodules on CT scans. Med. Phys. 2011, 38, 915–931. [Google Scholar] [PubMed]
- Linardos, A.; Kushibar, K.; Walsh, S.; Gkontra, P.; Lekadir, K. Federated learning for multi-center imaging diagnostics: A simulation study in cardiovascular disease. Sci. Rep. 2022, 12, 3551. [Google Scholar] [CrossRef] [PubMed]
- Bernard, O.; Lalande, A.; Zotti, C.; Cervenansky, F.; Yang, X.; Heng, P.A.; Cetin, I.; Lekadir, K.; Camara, O.; Ballester, M.A.G.; et al. Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: Is the problem solved? IEEE Trans. Med. Imaging 2018, 37, 2514–2525. [Google Scholar] [CrossRef]
- Campello, V.M.; Gkontra, P.; Izquierdo, C.; Martin-Isla, C.; Sojoudi, A.; Full, P.M.; Maier-Hein, K.; Zhang, Y.; He, Z.; Ma, J.; et al. Multi-centre, multi-vendor and multi-disease cardiac segmentation: The M&Ms challenge. IEEE Trans. Med. Imaging 2021, 40, 3543–3554. [Google Scholar]
- Lee, H.; Chai, Y.J.; Joo, H.; Lee, K.; Hwang, J.Y.; Kim, S.M.; Kim, K.; Nam, I.C.; Choi, J.Y.; Yu, H.W.; et al. Federated learning for thyroid ultrasound image analysis to protect personal information: Validation study in a real health care environment. JMIR Med. Inform. 2021, 9, e25869. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Sun, J.; Wang, F.; Wang, S.; Jun, C.H.; Jiang, X. Privacy-preserving patient similarity learning in a federated environment: Development and analysis. JMIR Med. Inform. 2018, 6, e20. [Google Scholar] [CrossRef]
- Xu, J.; Xu, Z.; Walker, P.; Wang, F. Federated patient hashing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6486–6493. [Google Scholar]
- Kim, Y.; Sun, J.; Yu, H.; Jiang, X. Federated tensor factorization for computational phenotyping. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 887–895. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset. California Institute of Technology, CNS-TR-2011-001. 2011. Available online: http://www.vision.caltech.edu/datasets/cub_200_2011/ (accessed on 12 March 2025).
- Liu, D.; Dligach, D.; Miller, T. Two-stage federated phenotyping and patient representation learning. arXiv 2019, arXiv:1908.05596. [Google Scholar]
- Yuan, B.; Ge, S.; Xing, W. A Federated Learning Framework for Healthcare IoT devices. arXiv 2020, arXiv:2005.05083. [Google Scholar]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef]
- Silva, S.; Gutman, B.A.; Romero, E.; Thompson, P.M.; Altmann, A.; Lorenzi, M. Federated learning in distributed medical databases: Meta-analysis of large-scale subcortical brain data. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 270–274. [Google Scholar]
- Alzheimer’s Disease Neuroimaging Initiative. 2020. Available online: http://adni.loni.usc.edu (accessed on 26 December 2020).
- Malone, I.B.; Cash, D.; Ridgway, G.R.; MacManus, D.G.; Ourselin, S.; Fox, N.C.; Schott, J.M. MIRIAD—Public release of a multiple time point Alzheimer’s MR imaging dataset. NeuroImage 2013, 70, 33–36. [Google Scholar] [CrossRef]
- Parkinson’s Progression Markers Initiative. 2018. Available online: https://www.ppmi-info.org (accessed on 26 December 2020).
- Biobank UK: Enabling Scientific Discoveries that Improve Human Health. 2018. Available online: https://www.ukbiobank.ac.uk (accessed on 26 December 2020).
- McMahan, H.B.; Ramage, D.; Talwar, K.; Zhang, L. Learning differentially private recurrent language models. arXiv 2017, arXiv:1710.06963. [Google Scholar]
- coMind Collaborative Machine Learning. 2018. Available online: https://medium.com/@Acuratio/collaborative-machine-learning-ba7961a75f3a (accessed on 18 December 2020).
- Behrman, R.E.; Butler, A.S. Preterm Birth: Causes, Consequences, and Prevention; National Academies Press: Washington, DC, USA, 2007. [Google Scholar]
- Bluemke, E. Privacy-Preserving AI in Medical Imaging: Federated Learning, Differential Privacy, and Encrypted Computation. 2019. Available online: https://blog.openmined.org/federated-learning-differential-privacy-and-encrypted-computation-for-medical-imaging/ (accessed on 3 November 2020).
- Despotović, I.; Goossens, B.; Philips, W. MRI segmentation of the human brain: Challenges, methods, and applications. Comput. Math. Methods Med. 2015, 2015, 450341. [Google Scholar] [CrossRef]
- de Brebisson, A.; Montana, G. Deep neural networks for anatomical brain segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 20–28. [Google Scholar]
- Roy, A.G.; Conjeti, S.; Navab, N.; Wachinger, C.; Alzheimer’s Disease Neuroimaging Initiative. QuickNAT: A fully convolutional network for quick and accurate segmentation of neuroanatomy. NeuroImage 2019, 186, 713–727. [Google Scholar]
- Sheller, M.J.; Reina, G.A.; Edwards, B.; Martin, J.; Bakas, S. Multi-institutional deep learning modeling without sharing patient data: A feasibility study on brain tumor segmentation. In Proceedings of the International MICCAI Brainlesion Workshop, Granada, Spain, 16 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 92–104. [Google Scholar]
- Rumbold, J.M.M.; Pierscionek, B. The effect of the general data protection regulation on medical research. J. Med. Internet Res. 2017, 19, e47. [Google Scholar] [CrossRef]
- Portability, I.; Act, A. Guidance Regarding Methods for de-Identification of Protected Health Information in Accordance with the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule; Human Health Services: Washington, DC, USA, 2012. [Google Scholar]
- Chaudhuri, K.; Imola, J.; Machanavajjhala, A. Capacity bounded differential privacy. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 3474–3483. [Google Scholar]
- WHO. WHO Coronavirus Disease (COVID-19). 2021. Available online: https://covid19.who.int (accessed on 18 January 2021).
- Vaishya, R.; Javaid, M.; Khan, I.H.; Haleem, A. Artificial Intelligence (AI) applications for COVID-19 pandemic. Diabetes Metab. Syndr. Clin. Res. Rev. 2020, 14, 337–339. [Google Scholar] [CrossRef] [PubMed]
- Shahid, O.; Nasajpour, M.; Pouriyeh, S.; Parizi, R.M.; Han, M.; Valero, M.; Li, F.; Aledhari, M.; Sheng, Q.Z. Machine Learning Research Towards Combating COVID-19: Virus Detection, Spread Prevention, and Medical Assistance. arXiv 2020, arXiv:2010.07036. [Google Scholar] [CrossRef] [PubMed]
- Bragazzi, N.L.; Dai, H.; Damiani, G.; Behzadifar, M.; Martini, M.; Wu, J. How Big Data and Artificial Intelligence Can Help Better Manage the COVID-19 Pandemic. Int. J. Environ. Res. Public Health 2020, 17, 3176. [Google Scholar] [CrossRef]
- Nasajpour, M.; Pouriyeh, S.; Parizi, R.M.; Dorodchi, M.; Valero, M.; Arabnia, H.R. Internet of Things for current COVID-19 and future pandemics: An exploratory study. J. Healthc. Inform. Res. 2020, 4, 325–364. [Google Scholar] [CrossRef]
- Sun, J.; Wang, F.; Hu, J.; Edabollahi, S. Supervised patient similarity measure of heterogeneous patient records. Acm Sigkdd Explor. Newsl. 2012, 14, 16–24. [Google Scholar] [CrossRef]
- Carroll, R.J.; Eyler, A.E.; Denny, J.C. Naïve electronic health record phenotype identification for rheumatoid arthritis. In Proceedings of the AMIA Annual Symposium Proceedings. American Medical Informatics Association, Washington DC, USA, 22–26 October 2011; Volume 2011, p. 189. [Google Scholar]
- Ho, J.C.; Ghosh, J.; Steinhubl, S.R.; Stewart, W.F.; Denny, J.C.; Malin, B.A.; Sun, J. Limestone: High-throughput candidate phenotype generation via tensor factorization. J. Biomed. Inform. 2014, 52, 199–211. [Google Scholar] [CrossRef]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Xi’an, China, 25–29 April 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–19. [Google Scholar]
- Boyd, S.; Parikh, N.; Chu, E. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers; Now Publishers Inc.: Hanover, MA, USA, 2011. [Google Scholar]
- Dligach, D.; Miller, T. Learning Patient Representations from Text. In Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics, New Orleans, LA, USA, 5–6 June 2018; pp. 119–123. [Google Scholar] [CrossRef]
- Miotto, R.; Li, L.; Kidd, B.A.; Dudley, J.T. Deep patient: An unsupervised representation to predict the future of patients from the electronic health records. Sci. Rep. 2016, 6, 26094. [Google Scholar] [CrossRef]
- Islam, S.R.; Kwak, D.; Kabir, M.H.; Hossain, M.; Kwak, K.S. The internet of things for health care: A comprehensive survey. IEEE Access 2015, 3, 678–708. [Google Scholar] [CrossRef]
- Firouzi, F.; Rahmani, A.M.; Mankodiya, K.; Badaroglu, M.; Merrett, G.V.; Wong, P.; Farahani, B. Internet-of-Things and big data for smarter healthcare: From device to architecture, applications and analytics. Future Gener. Comput. Syst. 2018, 78, 583–586. [Google Scholar] [CrossRef]
- Lipsey, M.W.; Wilson, D.B. Practical Meta-Snalysis; SAGE publications, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Wei, E.; Ozdaglar, A. Distributed alternating direction method of multipliers. In Proceedings of the 2012 IEEE 51st IEEE Conference on Decision and Control (CDC), Maui, HI, USA, 10–13 December 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 5445–5450. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Kamp, M.; Adilova, L.; Sicking, J.; Hüger, F.; Schlicht, P.; Wirtz, T.; Wrobel, S. Efficient decentralized deep learning by dynamic model averaging. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 393–409. [Google Scholar]
- Lin, Y.; Han, S.; Mao, H.; Wang, Y.; Dally, W.J. Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, S.Q.; Lin, J.; Zhang, Q.; McDanel, B.; Kim, S.W. Field-Aware Adaptive Communication for Collaborative Learning. IEEE Trans. Mob. Comput. 2021, 20, 2981–2994. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. arXiv 2019, arXiv:1912.04977. [Google Scholar]
- Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; Naor, M. Our data, ourselves: Privacy via distributed noise generation. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, St. Petersburg, Russia, 28 May 28–1 June 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 486–503. [Google Scholar]
- Goldreich, O. Secure multi-party computation. Manuscript. Prelim. Version 1998, 78, 1–108. [Google Scholar]
- Ma, C.; Li, J.; Ding, M.; Yang, H.H.; Shu, F.; Quek, T.Q.; Poor, H.V. On Safeguarding Privacy and Security in the Framework of Federated Learning. IEEE Netw. 2020, 34, 242–248. [Google Scholar] [CrossRef]
- Wu, B.; Zhao, S.; Sun, G.; Zhang, X.; Su, Z.; Zeng, C.; Liu, Z. P3sgd: Patient privacy preserving sgd for regularizing deep cnns in pathological image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2099–2108. [Google Scholar]
- Zhu, L.; Liu, Z.; Han, S. Deep leakage from gradients. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 14774–14784. [Google Scholar]
- Wang, Z.; Song, M.; Zhang, Z.; Song, Y.; Wang, Q.; Qi, H. Beyond inferring class representatives: User-level privacy leakage from federated learning. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2512–2520. [Google Scholar]
- Sindhusaranya, B.; Yamini, R.; Manimekalai, M.A.P.; Geetha, K. Homomorphic Encryption-Based Privacy-Preserving Federated Learning in IoT-Enabled Healthcare System. IEEE Trans. Netw. Sci. Eng. 2022, 10, 2864–2880. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.S.; Poor, H.V. Personalized Federated Learning with Differential Privacy. IEEE Internet Things J. 2020, 7, 9650–9662. [Google Scholar] [CrossRef]
- Verma, D.C.; White, G.; Julier, S.; Pasteris, S.; Chakraborty, S.; Cirincione, G. Approaches to address the data skew problem in federated learning. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications. International Society for Optics and Photonics, Baltimore, MD, USA, 15–17 April 2019; Volume 11006, p. 110061. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated Learning with Non-IID Data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated Optimization in Heterogeneous Networks. In Proceedings of the Machine Learning and Systems (MLSys), Austin, TX, USA, 2–4 March 2020. [Google Scholar]
- Li, Z.; Huang, L. Tracing requirements as a problem of machine learning. Int. J. Softw. Eng. Appl. (IJSEA) 2018, 9, 21–36. [Google Scholar] [CrossRef]
- Rodriguez, R.; Svensson, G.; Wood, G. Sustainability trends in public hospitals: Efforts and priorities. Eval. Program Plan. 2020, 78, 101742. [Google Scholar] [CrossRef]
- Trichelair, P.; Andreux, M.; Trower, A. Data Heterogeneity in Healthcare. Available online: https://owkin.com/federated-learning/heterogeneity-in-healthcare/ (accessed on 3 December 2020).
- Crelier, B.; Streit, S.; Donzé, J. Patient Complexity Characteristics in the Hospital Setting. Am. J. Accountable Care 2018, 9, 3–8. [Google Scholar]
- Laguel, Y.; Pillutla, K.; Malick, J.; Harchaoui, Z. Device Heterogeneity in Federated Learning: A Superquantile Approach. arXiv 2020, arXiv:2002.11223. [Google Scholar]
- Hahn, S.J.; Lee, J. Privacy-preserving Federated Bayesian Learning of a Generative Model for Imbalanced Classification of Clinical Data. arXiv 2019, arXiv:1910.08489. [Google Scholar]
- Liu, L.; Cao, J.; Liu, M.; Liu, Y. Client-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Xie, C.; Koyejo, S.; Ray, I. Asynchronous Federated Optimization. arXiv 2019, arXiv:1903.03934. [Google Scholar]
- Reina, G.A.; Gruzdev, A.; Foley, P.; Perepelkina, O.; Sharma, M.; Davidyuk, I.; Trushkin, I.; Radionov, M.; Mokrov, A.; Agapov, D.; et al. OpenFL: An Open-Source Framework for Federated Learning. arXiv 2021, arXiv:2105.06413. [Google Scholar]
- Shen, Y.; Yuan, K.; Yang, M.; Tang, B.; Li, Y. Ontology-Based Data Integration for Federated Learning in Healthcare. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Republic of Korea, 16–19 December 2020; pp. 1483–1488. [Google Scholar] [CrossRef]
- Hashash, O.; Sharafeddine, S.; Dawy, Z. MEC-based energy-aware distributed feature extraction for mHealth applications with strict latency requirements. In Proceedings of the 2021 IEEE International Conference on Communications Workshops (ICC Workshops), Montreal, QC, Canada, 14–23 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Patel, V.A.; Bhattacharya, P.; Tanwar, S.; Gupta, R.; Sharma, G.; Bokoro, P.N.; Sharma, R. Adoption of federated learning for healthcare informatics: Emerging applications and future directions. IEEE Access 2022, 10, 90792–90826. [Google Scholar] [CrossRef]
- Fu, L.; Zhang, H.; Gao, G.; Zhang, M.; Liu, X. Client selection in federated learning: Principles, challenges, and opportunities. IEEE Internet Things J. 2023, 10, 21811–21819. [Google Scholar] [CrossRef]
- Smith, V.; Chiang, C.K.; Sanjabi, M.; Talwalkar, A.S. Federated multi-task learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4424–4434. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Jiang, S.; Xuan, S. Decentralized federated learning based on blockchain: Concepts, framework, and challenges. Comput. Commun. 2024, 216, 140–150. [Google Scholar] [CrossRef]
- Abreha, H.G.; Hayajneh, M.; Serhani, M.A. Federated learning in edge computing: A systematic survey. Sensors 2022, 22, 450. [Google Scholar] [CrossRef]
- Holly, S.; Hiessl, T.; Lakani, S.R.; Schall, D.; Heitzinger, C.; Kemnitz, J. Evaluation of hyperparameter-optimization approaches in an industrial federated learning system. In Data Science—Analytics and Applications, Proceedings of the 4th International Data Science Conference–iDSC2021, Online, 21–22 May 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 6–13. [Google Scholar]
- Deng, Y.; Lyu, F.; Ren, J.; Wu, H.; Zhou, Y.; Zhang, Y.; Shen, X. AUCTION: Automated and quality-aware client selection framework for efficient federated learning. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 1996–2009. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Methodology | Context of Application | Strengths | Limitations | Dataset | Perf. Metrics | Baseline Comparison |
|---|---|---|---|---|---|---|---|
| FedHealth [19] | FL + Transfer Learning (TL) | Wearable healthcare (e.g., activity monitoring) | Higher accuracy, personalization | Computationally intensive | UCI Smartphone | Acc = 98.8 | Acc = 85 (CNN baseline) |
| PerFit [32] | FL + TL, Distillation | IoT healthcare (e.g., activity recognition) | Handles heterogeneity, high performance | Complex personalization process | MobiAct | Acc = 95.37 > FedAvg | Acc = 85 (cCNN baseline) |
| FedHome [33] | FL + Generative CNN Autoencoder | In-home elderly monitoring | Good performance, privacy | Imbalanced data handling | N/A | Acc = 95.41 | Acc = 87.92 (CNN baseline) |
| FADL [34] | FL + Neural Network | EHR-based mortality prediction | Higher accuracy, balanced models | Limited to structured EHR data | eICU | AUC = 0.79 | AUC=0.75 (FL-Avg baseline) |
| Ethereum Blockchain [35] | FL + Blockchain, Encryption | Healthcare consortium data sharing | Strong privacy protection | High computational cost | N/A | Not specified | N/A |
| FEEL [36] | FL + Differential Privacy | Mobile healthcare (e.g., cancer detection) | High efficiency, privacy | Potential accuracy trade-off | Breast cancer | Acc = 86, F1 = 0.90 | Acc = 88, F1 = 0.91 (Centralized Learning baseline) |
| DMFL-Net [37] | FL + Neural Network | COVID-19 and chest disease detection | High accuracy, fast classification | Specific to imaging data | CXR images | Acc = 92.25, F1 = 92.21 | Acc = 90, F1 = 90 (default FL baselines) |
| FedCare [38] | FL + Split Learning | IoMT for rural/elderly monitoring | Reduced training time, scalability | Limited evaluation scope | N/A | Acc = 90.32 | N/A |
| Sensor-based HAR [39] | FL + Homomorphic Encryption | Wearable devices (e.g., activity recognition) | Strong privacy, high accuracy | Encryption overhead | Sport, DaLiAC | Acc = 89.5 | Acc = 94.6 (3D CNN baseline) |
| Focus | Reference | Approach | Technique | Dataset |
|---|---|---|---|---|
| Drug | [57] | Cross-silo FL | DNN | AqSolDB [58] |
| [59] | FL-QSAR | QSAR, HFL | Kaggle datasets [60] | |
| [61] | Adverse drug reactions | SVM, LM | LCED [62] | |
| Mortality and stay time | [63] | CBFL | Encoder, K-means | eICU [46] |
| [64] | Privacy of EHRs | DP-SGD | eICU [46] | |
| [65] | Data privacy | DP, LR, MLP | MIMIC-III [66] | |
| Hospitalization | [67] | COVID-19 | LASSO, MLP | MSHS [67] |
| [68] | Cardiac events | SVM, cPDS | Boston Medical Center [69] | |
| Preterm birth prediction | [70] | FUALA | RNN | Center Health Facts [70] |
| Brain segmentation | [71] | Whole brain segmentation | DNN | MALC [72] |
| [61] | Brain tumor segmentation | FL, IIL, CIIL | BraTS [73] | |
| [74] | Brain tumor segmentation | DP, DNN | BraTS [75] | |
| Functional MRI | [76] | Autism Spectrum Disorders | DP, MLP | ABIDE [77] |
| COVID-19 detection | [78] | CT scan | VGG, Resnet, etc. | CC-19 [78] |
| [68] | Chest X-ray images | MobileNet, ResNet18, etc. | COVIDx [79] | |
| [80] | Dynamic fusion | GhostNet, ResNet50, ResNet101 | CT, Radiography, Xray [81,82,83] | |
| Medical records | [84] | Lung nodules detection | Vnet 3D, ResNet | LIDC [85] |
| [86] | Cardiovascular detection | 3D-CNN | ACDC, M&M [87,88] | |
| [89] | Thyroid image recognition | DNN | Thyroid Nodule Clinical Data [89] | |
| Patient similarity learning | [90] | Privacy preserving | Hashing | MIMIC-III [66] |
| [91] | Federated Patient Hashing | Hashing | MIMIC-III [66] | |
| Phenotyping | [92] | Privacy preserving | Tensor Factorization, ADMM | MIMIC-III, UCSD [66,93] |
| [94] | Clinical data | NLP, SVM | MIMIC-III [66] | |
| Communication overhead | [95] | Arrhythmia detection | DNN | PhysioNet 2017 [96] |
| Meta-analysis of brain data | [97] | PCA | ADMM | ADNI, PPMI |
| MIRIAD, UK Biobank [98,99,100,101] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nasajpour, M.; Pouriyeh, S.; Parizi, R.M.; Han, M.; Mosaiyebzadeh, F.; Liu, L.; Xie, Y.; Batista, D.M. Federated Learning in Smart Healthcare: A Survey of Applications, Challenges, and Future Directions. Electronics 2025, 14, 1750. https://doi.org/10.3390/electronics14091750
Nasajpour M, Pouriyeh S, Parizi RM, Han M, Mosaiyebzadeh F, Liu L, Xie Y, Batista DM. Federated Learning in Smart Healthcare: A Survey of Applications, Challenges, and Future Directions. Electronics. 2025; 14(9):1750. https://doi.org/10.3390/electronics14091750
Chicago/Turabian StyleNasajpour, Mohammad, Seyedamin Pouriyeh, Reza M. Parizi, Meng Han, Fatemeh Mosaiyebzadeh, Liyuan Liu, Yixin Xie, and Daniel Macêdo Batista. 2025. "Federated Learning in Smart Healthcare: A Survey of Applications, Challenges, and Future Directions" Electronics 14, no. 9: 1750. https://doi.org/10.3390/electronics14091750
APA StyleNasajpour, M., Pouriyeh, S., Parizi, R. M., Han, M., Mosaiyebzadeh, F., Liu, L., Xie, Y., & Batista, D. M. (2025). Federated Learning in Smart Healthcare: A Survey of Applications, Challenges, and Future Directions. Electronics, 14(9), 1750. https://doi.org/10.3390/electronics14091750