1. Introduction
The e-commerce industry has experienced rapid growth with the development of information and communication technology along with a continuous increase in the number of users and items [
1,
2]. The proportion of e-commerce transactions in the global retail market exceeds 20% [
3]. Users can easily access item-related information through online platforms. However, a vast amount of information often leads to information overload. As a result, the user’s purchase decision-making process becomes increasingly complex, which can lead to inefficiencies such as higher marketing costs [
4,
5]. Recommender systems have been actively studied as a solution to these challenges, as they provide users with personalized item suggestions based on their past behavior. Simultaneously, they support sellers by enhancing their sales performance and customer retention [
6].
Collaborative filtering (CF) has traditionally been one of the most widely adopted approaches in recommender systems [
4]. CF infers user preferences by analyzing the similarity between users or items. Although effective in many cases, CF-based methods suffer from scalability and sparsity issues as the number of users and items increase. To overcome these challenges, matrix factorization (MF) was introduced, which learns latent features from user–item interaction matrices [
7]. MF improves both scalability and accuracy compared to traditional CF but still models user–item interactions linearly. To capture more complex relationships, neural collaborative filtering (NCF) was proposed, which combines embedding layers with multilayer perceptrons to learn nonlinear interactions [
8]. Further advancements such as neural graph collaborative filtering (NGCF) leverage graph structures to model higher-order connections among users and items [
9]. These approaches have improved recommendation performance by enriching the representation of preferences and interactions.
However, these general recommendation models generally assume that user preferences are static and inferred from the entire history of interactions without considering temporal ordering. This study has several limitations. First, they treat all past interactions as equally important and overlook the potential relevance of recent purchases. Second, user preferences can change over time and are influenced by evolving interests and trends [
10]. Third, the absence of order awareness in these models makes it difficult to provide timely and context-sensitive recommendations. To address these issues, sequential recommender systems have been developed that focus on learning temporal patterns in purchase behavior to predict the next likely item [
11].
Sequential recommender systems treat a user’s interaction history as a sequence and model the dependencies between items sequentially. This perspective aligns with natural language processing (NLP), in which sequences of words are learned to predict context or generate language. Deep learning techniques developed for NLP have been successfully adapted to sequential recommendations. For example, Hidasi et al. [
12] introduced a session-based recommendation model using gated recurrent units (GRUs). Kang et al. [
13] proposed a model based on the transformer architecture with self-attention, which effectively captures the relative importance of items in a sequence. Sun et al. [
14] further extended this method to Bert4Rec by incorporating bidirectional encoding and masked learning to capture complex patterns. These studies highlight that the recommendation performance can be significantly improved by learning sequential patterns using techniques inspired by NLP.
Despite this progress, many sequential recommendation models rely solely on item IDs as inputs. This limits their ability to capture deeper semantic features or contextual information associated with the items. In reality, user decision-making is influenced not only by purchase history, but also by the content of items, including textual elements that describe product characteristics or convey user sentiment. Item-related texts (e.g., titles, descriptions, reviews) offer valuable information about an item’s features, usage, and perceived value [
15,
16,
17]. Prior research has shown that user-generated content plays an essential role in purchasing behavior; however, the use of such information in sequential recommendations remains limited [
18,
19].
The integration of textual information into sequential recommendations offers several advantages. First, item-related texts provide a rich semantic context that helps to disambiguate similar items and captures subtle differences that item IDs alone cannot represent. This is particularly effective in alleviating sparsity issues, particularly in cold-start or long-tail scenarios. Moreover, text embeddings can complement sequential patterns by introducing content-aware signals into the recommendation process [
15,
16,
17]. While item sequences reflect behavioral dynamics over time, textual features offer insights into item properties and user sentiments, thereby enabling a more accurate understanding of user intent.
To address this gap, we propose an item textual information-based sequential recommendation (ITS-Rec) model that integrates textual information to enhance item representation. The model aims to capture user preferences more accurately by combining traditional sequence modeling with semantic item features. ITS-Rec consists of two main stages. First, item representations were generated using Bidirectional Encoder Representations from Transformers (BERT) to extract semantic information from product titles, descriptions, and reviews. Subsequently, a self-attention-based sequential learning module extended from SASRec [
13] models user behavior over time. This combination enables ITS-Rec to reflect both the long-term item semantics and short-term user preferences. BERT provides rich contextual embeddings of the item content, whereas self-attention captures the temporal importance of previous interactions. Unlike previous models that rely only on item IDs, ITS-Rec leverages textual features to provide a more informative and context-aware representation. Experiments on the Amazon.com dataset demonstrate that ITS-Rec outperforms strong baselines, and ablation studies confirm the effectiveness of incorporating different types of textual information. The main contributions of this study are as follows:
We propose ITS-Rec, which comprehensively integrates item-related textual data (e.g., titles, descriptions, and reviews) to model detailed item characteristics and user purchase motivation.
We investigated the effect of each type of textual information within an attention-based sequential recommendation model, offering insights into the most effective data sources.
Through experiments on real-world datasets, we demonstrated that ITS-Rec achieves superior performance compared with existing sequential recommendation models.
The remainder of this paper is structured as follows:
Section 2 reviews the related work,
Section 3 presents the proposed model,
Section 4 details the experimental setup and results, and
Section 5 concludes the study and discusses future work.
3. Problem Definition
The recommendation model proposed in this study predicts the next purchased item based on the previous item purchase sequence of a user. The problem is formally defined as follows: Let and denote the sets of users and items, respectively, where and represent the total number of users and items. The item purchase sequence for user is represented as , where is the item interacted with by user at time , and is the total number of items purchased by user . Textual information embedding is denoted by , where is a vector that integrates the item’s title, description, and online reviews.
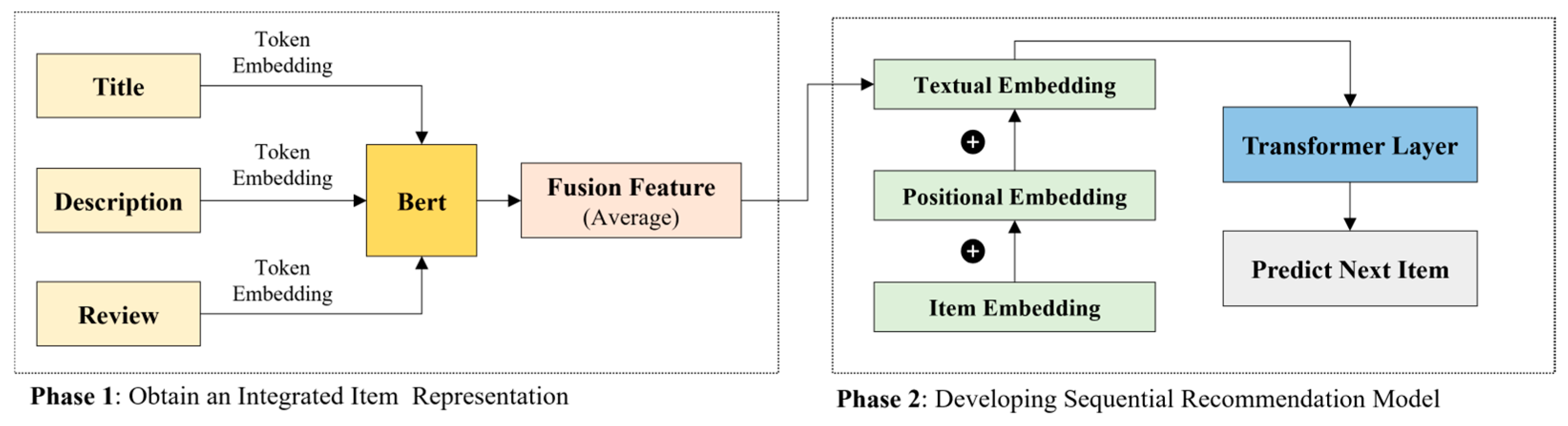
The proposed ITS-Rec model comprises two main stages, as illustrated in
Figure 1. In the first stage, the title, description, and online reviews of each item, which may influence a user’s purchase decision, were converted into vector representations using BERT, a pre-trained NLP model. These three vectors were then integrated to construct the textual information embedding for each item. Textual embedding captures rich semantic features that reflect item properties, usage contexts, and sentiments, providing a more informative representation than item IDs alone.
In the second stage, a self-attention mechanism was used to model user behavior over time, allowing the model to identify past items that are most relevant for predicting the next interaction. By combining BERT-based semantic encoding with self-attention-based sequence modeling, ITS-Rec effectively captures both long-term and short-term user intentions. The main distinction between the proposed model and previous sequential recommendation models is the use of integrated textual information, item ID, and positional embedding. This richer representation enables more effective modeling of items in sequential contexts. In summary, the proposed two-stage ITS-Rec model aims to capture user purchase patterns accurately and predict the next item to be purchased based on a sequence of previous interactions. A detailed explanation of the model architecture is provided in
Section 4.
4. ITS-Rec Framework
The ITS-Rec framework is illustrated in
Figure 2. First, item ID, positional information, and item textual information embeddings were input into the model. Using these embeddings, item sequence vectors were constructed for each user, and the model learned the item patterns in sequence using a self-attention mechanism. Based on this learning process, the proposed model predicts the next item to be purchased. The ITS-Rec model consists of three main components: an embedding layer, self-attention layer, and prediction layer.
4.1. Embedding Layer
The proposed model predicts the next purchased item based on the item sequence with which the user has previously interacted. In the first step, the model generates item ID, positional, and textual information embeddings. Item ID embedding represents the unique identity of each item, whereas positional embedding captures the position of each item within the user’s purchase sequence. To construct a rich item representation from textual content, embeddings were created for item titles, descriptions, and online reviews. These vectors are then integrated to form a unified textual information embedding that represents an item in detail. Consequently, the embedding layer generates three types of embeddings for each item in the sequence.
First, item ID embedding was generated by applying an embedding function to each item ID, where denotes the total number of items and is the embedding dimension. Second, positional embedding was used to encode the position of each item in the sequence. This is necessary because the attention-based model lacks a recursive structure; denotes the maximum sequence length considered in the model.
Next, the item titles, descriptions, and online reviews were vectorized to generate the textual representation of each item. To extract meaningful information, we utilized BERT, a pre-trained language model, to obtain token-level embeddings for each type of textual content. The resulting vectors for item titles, descriptions, and online reviews are denoted as , , and , respectively, where is the text embedding dimension and is the total number of reviews.
Because the number of online reviews per item varies, we computed the average of all review embeddings associated with each item to align the dimensionality with other textual features. This averaging process is expressed in Equation (1).
where
is the average vector of online reviews generated through the interaction between the item and user, and
is the number of online reviews included for each item.
The final input embedding for each item at time
is obtained by combining the item ID embedding, positional embedding, and textual information embedding, as shown in Equation (2).
The complete item sequence for each user is then represented as shown in Equation (3). If a user’s sequence exceeds the maximum length
, only the most recent
items are retained. If the sequence is shorter than
, it is padded with zero vectors from the past.
Each row of is composed of the user’s purchase item by time order, and it represents an input of the model to predict the user’s next purchase item.
4.2. Self-Attention Layer
The attention mechanism is defined by Equation (4). Self-attention is a method in which the same vector is used as the query, key, and value [
35].
where
,
, and
represent the query, key, and value matrices, respectively, and
denotes the dimension used for scaling. The attention operation computes a weighted sum of values based on the relevance between the query and key. When applied to sequential recommendations, it determines the importance of each item in the sequence. Therefore, item sequence embeddings are passed through the self-attention operation.
where
,
, and
are the weight matrices for the query, key, and value transformations, respectively. The resulting
is an item sequence vector derived through self-attention.
This self-attention-based sequence vector effectively integrates the item information by reflecting the relative importance of each item. However, because the operation is linear, it may have limitations in capturing complex patterns within the user’s item sequence. To address this, a pointwise feed-forward network (FFN) was applied to introduce nonlinearity, as shown in Equation (6).
The FFN performs two linear transformations with a nonlinear activation function in between. Here, and are weight matrices, and are bias terms, and is the resulting item sequence representation that integrates contextual information across all positions.
To ensure stable training and prevent overfitting, the proposed model incorporates three regularization techniques: dropout, layer normalization, and residual connections [
13]. First, dropout was applied to input
, randomly excluding elements in the network with a given probability
to reduce overfitting during training [
36]. This enhances generalization and mitigates performance degradation. Second, layer normalization is used to stabilize the training by normalizing each input vector independently of the other samples in the batch [
37]. Unlike batch normalization, which uses statistics across batches, layer normalization computes the mean and variance from individual instances, allowing for more robust training in sequence models. Third, residual connections are employed to preserve the information from the earlier layers and prevent it from vanishing during training in deep networks [
38]. Because items at later positions in the sequence often play a crucial role in next-item prediction, residual connections ensure that earlier learned representations are retained throughout the learning process. In summary, the proposed model performs item sequence learning by applying self-attention and FFN, supported by dropout, layer normalization, and residual connections, to enhance the training stability and model performance.
4.3. Prediction Layer
Based on
, which incorporates the item sequence embedding up to time
, the proposed model predicts the next item to be purchased at time
. To achieve this, the model applies a matrix decomposition approach, as shown in Equation (7). The model calculates the relevance between
and each item embedding to identify the most relevant item at the next time step.
where
denotes the embedding matrix of item
, and
indicates the level of relation between item
and the item sequence. It may be understood that an item with a high
relates highly with the item sequence
. Accordingly, the model can provide recommendations based on ranking the scores of the items. In the learning process of the deep learning model, the loss function utilizes binary cross-entropy, which is shown in Equation (8), and the optimization function operates the adaptive moment estimation (Adam) [
39,
40]. In addition, the proposed model selects a random negative item from each epoch and uses it for learning.
5. Experiments
5.1. Datasets
This study used data collected from Amazon.com to verify the performance of the proposed model [
41]. The Amazon dataset was categorized by item type and included user purchase histories from May 1996 to July 2018. It contains various types of item-related textual information, such as item titles, descriptions, and online reviews. This study utilized the Movies and TV subset, a representative dataset frequently used in prior research, to examine the effect of textual information on sequential recommendation models [
13,
14,
42]. The following data preprocessing steps were performed based on the strategy used in a previous study [
14]. First, for textual information, spaces and non-English characters were removed. The remaining text was converted to lowercase and word-level tokenization was applied [
43]. Second, the interactions between users and items are converted into implicit feedback [
33]. Third, the users’ purchase records were sorted in chronological order, and item sequences were generated for each user. To effectively evaluate the recommendation performance, only users with more than four purchase records were included, and data containing missing values were removed [
14]. The basic statistics of the preprocessed data are summarized in
Table 1.
5.2. Evaluation Metric
This study used a leave-one-out evaluation method to measure the performance of the sequential recommendation model [
13,
14]. Specifically, the most recently purchased item in each user’s purchase history was used as the test data. Items purchased immediately before the test item were used as validation data, and the remaining purchase records were used as training data. A common evaluation strategy widely adopted in sequential recommendation studies was employed to ensure a fair and consistent performance comparison.
To reduce the computational cost, 100 negative items that each user had not purchased were randomly sampled. These items were ranked along with the actual purchased item (used as test data) according to the purchase probability predicted by the model. Therefore, model performance was evaluated by ranking 101 items, and the following evaluation metrics were used.
This study assessed recommendation performance using the Hit Ratio (HR) and Normalized Discounted Cumulative Gain (NDCG) [
12,
13,
14]. HR@K determines whether the actual purchased item appears among the top K items with the highest predicted probability of purchase. HR@K is equivalent to recall @K and is proportional in nature to precision @K [
14]. HR@K is presented in Equation (9).
Here, denotes the total number of users, is the ranking position of the ground-truth item purchased by user, and is the top K ranking threshold used as a measurement criterion.
NDCG is a ranking-aware evaluation metric that considers the position of the actual purchased item in the recommendation list and assigns higher weights to items that are ranked higher. NDCG@K is presented in Equation (10). In this study, K values of 1, 5, 10, and 20 were used to obtain a range of experimental results.
5.3. Baseline Model
This study aimed to address the limitations of previous sequential recommendation models that relied solely on item IDs. The proposed ITS-Rec model incorporates textual information containing detailed item characteristics and features that influence user purchase decisions. To verify the effectiveness of the proposed model, its recommendation performance was compared with representative sequential recommendation models based on recurrent neural networks (RNNs), convolutional neural networks (CNNs), and transformer architectures. The baseline models used in this study are summarized as follows:
5.4. Parameter Settings
The baseline models were implemented using the parameter settings presented in their original studies, whereas the proposed ITS-Rec model was fine-tuned through a parameter adjustment process to optimize performance.
For BPR-MF, the item embedding size was set to 50 with a dropout ratio of 0.5, and the Adam optimizer was used. GRU4Rec was configured with a learning rate of 0.01, embedding size of 50, L2 regularization of 0.01, and Adam optimizer. Caser used a learning rate of 0.001, dropout ratio of 0.5, L2 regularization of 0.01, and Adam optimizer. The model was trained to predict the next three items based on the previous five items. SASRec employed two self-attention layers and two FFN layers with the Adam optimizer, a learning rate of 0.001, and a dropout ratio of 0.5.
The proposed ITS-Rec model was designed with reference to the SASRec structure. It consisted of two self-attention layers and two FFN layers, and learnable positional embeddings were applied to enhance sequential understanding [
13]. To process textual information, a pre-trained BERT-based model from the Hugging Face Transformers library was used. The BERT encoder was used in a frozen state, without fine-tuning, to reduce the training complexity and prevent overfitting on limited textual data. A bert-based uncased tokenizer was employed for tokenization. The maximum input length for each textual field (i.e., title, description, and review) was set to 100 tokens. Texts shorter than this limit were padded, and longer ones were truncated from the end.
All experiments were implemented using the PyTorch framework and conducted on a system equipped with an Intel Core i9-11900F CPU, 128 GB RAM (Intel Corporation, Santa Clara, CA, USA), and an NVIDIA GeForce RTX 3080 Ti GPU (Nvidia Corporation, Santa Clara, CA, USA). Under these settings, each training epoch consisted of 373 mini-batches and required approximately 16 min and 19 s (979 s). Given a batch size of 1024, this corresponds to processing 381,952 training samples per epoch, with an average throughput of approximately 390 samples per second. Although the integration of BERT increases the computational load compared with lightweight ID-based models, the overall training cost remains acceptable for practical applications.
6. Experiments
6.1. Performance Comparison to Baseline Models
Table 2 shows the performance comparison results between the ITS-Rec and baseline models.
First, POP, which recommends popular items, showed the lowest performance among all models. As a basic recommendation method, POP does not require complex operations and can quickly provide item suggestions to all users, even in the absence of user–item interactions. However, it provides the same items to all users based on popularity and cannot reflect individual user preferences. As a result, it performs poorly compared to sequential recommendation models that use personalized purchase history.
Second, RNN-based GRU4Rec can capture long-term dependencies in item sequences. However, its learning is limited to sparse data owing to the long-term dependency problem. In the Amazon.com dataset, the interaction matrix is sparse because the number of purchase records is relatively small. Consequently, GRU4Rec showed a lower performance than the other baselines, excluding POP. This result emphasizes the need to choose learning strategies suited for sparse e-commerce environments.
Third, BPR-MF uses Bayesian inference to optimize MF and predict the next likely item. This method has demonstrated good scalability and is widely used in general recommender systems. However, because it models item sequences linearly, it struggles to capture complex relationships, resulting in lower performance compared to Caser and SASRec in most metrics, except for HR@1.
Fourth, Caser captures higher-order Markov chains through CNN-based operations on item sequences. It effectively predicts the next item using limited historical data, making it suitable for sparse environments. In this experiment, Caser outperformed BPR-MF and GRU4Rec, which are limited by linearity and bottlenecks. However, Caser does not fully utilize long-term item dependencies, which limits its overall performance.
Fifth, SASRec uses a self-attention mechanism to weigh the importance of each item in a sequence, considering both recent and earlier purchases. This allows for the effective modeling of sequential patterns and enables SASRec to achieve the best performance among the baseline models. However, it relies only on item IDs to represent sequences, which limits its ability to capture detailed item features or to reflect the underlying context of user behavior.
Sixth, the proposed ITS-Rec achieved the best performance among all the models. The reasons for this are as follows: (1) Unlike POP and BPR-MF, ITS-Rec can learn complex sequential patterns using deep learning, thereby enabling more sophisticated personalization. (2) Compared with GRU4Rec and Caser, which are limited in capturing overall historical information, ITS-Rec leverages self-attention to integrate both long- and short-term patterns. (3) Unlike SASRec, which uses only item IDs, ITS-Rec incorporates rich textual information to represent item features and user behavior contexts. These findings demonstrate that using detailed textual features, including item descriptions and online reviews, helps the model better understand user preferences. Representing items with informative textual embeddings enables the model to capture user purchase patterns more accurately and improve recommendation performance.
6.2. Impact of Textual Information Types on Recommendation Performance
The proposed ITS-Rec model integrates item representations extracted from various textual sources and learns sequential patterns based on the detailed features obtained from these representations. Item titles, descriptions, and online reviews capture different aspects of an item, and their impact on recommendation performance may vary. To examine the effects of each type of textual information, an ablation study was conducted by systematically removing one component at a time. The results, shown in
Table 3, present the performance for each feature combination in terms of HR@10 and NDCG@10.
First, when online reviews were excluded, recommendation performance decreased the most, indicating that they were the most influential feature among the textual components. Online reviews often contain user experiences, opinions, and purchase motivations, which are highly relevant to user preferences and decision-making. Therefore, incorporating online reviews helps the model better understand user intent and item characteristics, leading to improved performance. Second, item description contributed more to performance than item title. Although the title may capture the basic or high-level features of the item, it lacks the detailed context provided in the description. Because item descriptions typically include specific attributes and functionalities, they play a greater role in enhancing recommendation accuracy. In summary, online reviews were found to have the most significant impact on recommendation performance, followed by item descriptions and titles.
6.3. Impact of Review Selection Strategies on Performance
To generate item representations, the proposed ITS-Rec model calculates the average embedding of all online reviews for each item. Although this approach captures rich textual signals, it may also introduce noise from irrelevant or low-quality reviews, potentially degrading item embedding quality. To address this, we conducted additional experiments to assess the impact of various review selection strategies on recommendation performance with the aim of striking a balance between representational quality and computational efficiency.
Specifically, we compared the full review set with three filtered subsets: (1) the top-20 helpful reviews based on user votes, (2) the most recent 20 reviews, and (3) 20 randomly selected reviews. The results, summarized in
Table 4, show that using all available reviews yielded the highest performance, as it provided the most comprehensive item-level information. However, among the selection strategies, helpful reviews achieved the best performance, confirming that user-evaluated quality serves as an effective proxy for noise reduction. Recent reviews have also outperformed random selections, suggesting that recency is a meaningful signal in dynamic environments where user preferences and product characteristics are constantly evolving.
The results suggest that, although it is preferable to utilize all reviews, filtering based on helpfulness or recency can be an effective alternative when resources are limited. They also demonstrated that our model is robust to variations in review selection and benefits from quality-aware filtering mechanisms.
6.4. Hyperparameter Analysis
The sequential recommendation model predicts the next item to be purchased based on a user’s past purchase history. The number of past purchases used for prediction significantly influences the performance of the sequential recommendations. For example, RNN-based sequential recommendation models may exhibit degraded performance with long sequences owing to bottleneck problems. In contrast, the self-attention mechanism can effectively address this issue, and its effectiveness has been validated in previous studies [
13,
14]. The proposed ITS-Rec model adopts a self-attention-based approach. To evaluate the impact of sequence length, an experiment was conducted to compare the recommendation performance across different sequence lengths.
Table 5 presents the results.
The experiment showed that shorter sequences resulted in lower performance, whereas longer sequences improved performance. This is because previously purchased items provide meaningful information to learn about user purchase patterns. However, overly long sequences may include outdated or irrelevant items that introduce noise. The proposed model alleviates this issue by applying a self-attention mechanism that assigns varying degrees of importance to each item in a sequence. This allows the model to appropriately reflect relevant information from long sequences, thereby enhancing performance.
The model also employs multi-head attention and an FFN to capture complex patterns in item sequences. These components enable learning through both linear and nonlinear operations, allowing the model to estimate purchase behavior more effectively. However, an excessively deep architecture can lead to overfitting, whereas insufficient depth may hinder learning. Therefore, it is necessary to optimize the number of multi-head attention and FFN layers. To identify the optimal configuration, an experiment was conducted to compare the recommendation performance across different layer depths.
The results shown in
Table 6 indicate that using one or two layers yields the best performance. Because the proposed model simultaneously processes diverse item features, excessive computation can easily lead to overfitting. When three or more layers were applied, the performance gradually declined, indicating that deeper architectures may negatively impact model generalization.
7. Conclusions and Future Works
The scale of the e-commerce industry and the number of users and items continue to grow, making it increasingly difficult to estimate user purchase patterns. Item textual information can assist in capturing these patterns and enhancing the learning process in recommendation systems. However, many sequential recommendation studies have focused primarily on developing models that learn item sequences using NLP methodologies, often without incorporating rich item-related content. To address this limitation, this study proposes ITS-Rec, a model that utilizes various types of textual information to reflect detailed item characteristics and user purchasing motivations. By integrating this information into item representations, the proposed model achieved superior performance compared to various baseline models. The experimental results demonstrate the effectiveness of incorporating textual information into sequential recommendation tasks. This study provides meaningful insights into how such information can be used to improve recommendation accuracy in a rapidly growing e-commerce environment.
Several directions for future research are suggested based on the limitations of this study. First, this study was conducted using only the Amazon Movies and TV dataset, which may have led to domain-specific bias. Because product categories differ in review content, user behavior, and metadata, results from a single domain may not generalize well. Future work should evaluate the model using additional datasets to assess its robustness across different domains. Second, future studies should explore the integration of the proposed approach into more advanced sequential recommendation models. The ITS-Rec model is based on SASRec, which uses a self-attention mechanism. Recently, more sophisticated models, such as Bert4Rec and GNN-based recommender systems, have been introduced. Investigating whether item textual information can also enhance the performance of these state-of-the-art models would be a valuable next step. Third, it is necessary to consider additional types of item-related information beyond the text, such as images, prices, and vendor details. While this study focused on textual information to construct item representations, other modalities, such as visual data, can provide further complementary information. Many multimodal recommendation studies have demonstrated the benefits of combining diverse data types. Therefore, future studies could enhance the ITS-Rec model by integrating multiple modalities to represent items more comprehensively.





{kind=link}
{kind=link}