
Detection of Exoplanets in Transit Light Curves with Conditional Flow Matching and XGBoost

 , , ,
, , ,  ,
,  , and
, and
Abstract
1. Introduction
- Feature extraction, performed using the widely adopted CNN VGG19, which transforms input signals into high-dimensional feature vectors;
- Dimensionality reduction, performed by the t-SNE method, which maps the high-dimensional features to a lower dimensional space, where they can be most effectively classified;
- Classification, implemented by Conditional Flow Matching (CFM) and XGBoost [36].
2. Related Works

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model [Ref.] | Architecture | Task | St.f. | Pl.f. | C | Pff | Odd–Even | Sv | Diff.img. |
|---|---|---|---|---|---|---|---|---|---|
| Robovetter | Decision Tree | 3c | × | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Autovetter | Decision Tree | 3c | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Armstrong D. et al. [39] | SOM | 2c | × | × | × | ✓ | × | × | × |
| Armstrong D. et al. [30] | RFC + SOM | 2c | × | ✓ | × | × | × | × | × |
| Astronet | CNN | 2c | × | × | × | ✓ | × | × | × |
| Astronet-K2 [11] | CNN | 2c | ✓ | ✓ | × | ✓ | × | × | × |
| Exonet [41] | CNN | 2c | ✓ | × | ✓ | ✓ | × | × | × |
| Genesis [43] | CNN | 2c | ✓ | × | ✓ | ✓ | × | × | × |
| Astronet-Triage [13] | CNN | 2c | × | × | × | ✓ | × | × | × |
| Astronet-Vetting [13] | CNN | 2c | × | ✓ | × | ✓ | × | ✓ | × |
| Astronet-Triage-v2 | CNN | 5c | ✓ | ✓ | × | ✓ | × | ✓ | × |
| Exominer | CNN | 2c | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Salinas H. et al. [42] | Transformer | 2c | ✓ | ✓ | ✓ | ✓ | × | × | × |
| This work | CNN + DR + CFM + XGBoost | 3c | × | × | × | ✓ | × | × | × |
3. Background
3.1. Data
3.1.1. From Light Curves to Threshold Crossing Events
3.1.2. Catalogs of Threshold Crossing Events Used in This Work
- Kepler Q1–Q17 Data Release 24 (). This catalog comprises 20,367 TCEs identified by the KSOC pipeline in Kepler light curves. These TCEs were automatically classified by Autovetter [29,49] into planet candidates (PCs), astrophysical false positives (AFPs), non-transiting phenomena (NTP), and unknown (UNK). To minimize the uncertainty of our dataset labels, we adopted the approach employed for the first time by SV18 by discarding all TCEs labeled as UNK. This filtering resulted in a final dataset of 3600 PCs, 9596 AFPs, and 2541 NTPs.
- Kepler Q1–Q17 Data Release 25 (). This set is the final version of TCEs detected by the Kepler mission [50], comprising 34,032 TCEs automatically dispositioned by the Robovetter algorithm [37], that is an ensemble of decision trees trained on a dataset of labeled transits.The primary distinction between this catalog and lies in a higher number of long-period TCEs (approximately 372 days), resulting in being a TCE dataset characterized by a lower SNR. With longer orbital periods, the number of observed transits decreases, limiting the increase in SNR during our data preparation pipeline.Before generating model inputs from this catalog, we performed the following filtering operation. We removed all TCEs with the rogue flag set to 1, which correspond to cases with fewer than three detected transits, erroneously included in this catalog due to a bug in the Kepler pipeline. For our PC class, we selected the 2726 confirmed and 1382 candidate planets from the Cumulative KOI catalog (The Cumulative KOI catalog contains the most precise information on all the Kepler TCEs labeled as confirmed and candidate planet, as well as false positive. Further information about Kepler tables of TCEs can be found at the following link: https://exoplanetarchive.ipac.caltech.edu/docs/Kepler_KOI_docs.html, accessed on 9 August 2024). Our AFP class includes the 3946 TCEs labeled as false positive in the Cumulative KOI table, while the NTP class contains the 21,098 TCEs from the Kepler Data Release (DR) 25 catalog that do not appear in the Cumulative KOI table.
- TESS TEY23 (). This catalog contains a subset of 24,952 TCEs detected by QLP in TESS long cadence data for which Tey E. et al. [22] (hereafter TEY23) provided dispositions across a three-year vetting process. The authors used five labels to classify these TCEs: “periodic eclipsing signal”, “single transit”, “contact eclipsing binaries”, “junk”, and “not-sure” (see Section 2.4 of their paper for further details on the labeling process). To improve the reliability of our dataset, we filtered out (i) 5340 TCEs for which the authors did not provide a consensus label and (ii) all the TCEs labeled as “single transit” and “not-sure”, thus obtaining 2613 periodic eclipsing signals (we will identify as E), which include both planet candidates and non-contact eclipsing binaries, 738 contact eclipsing binaries (B) and 15,791 junk (J).
3.1.3. Data Preparation
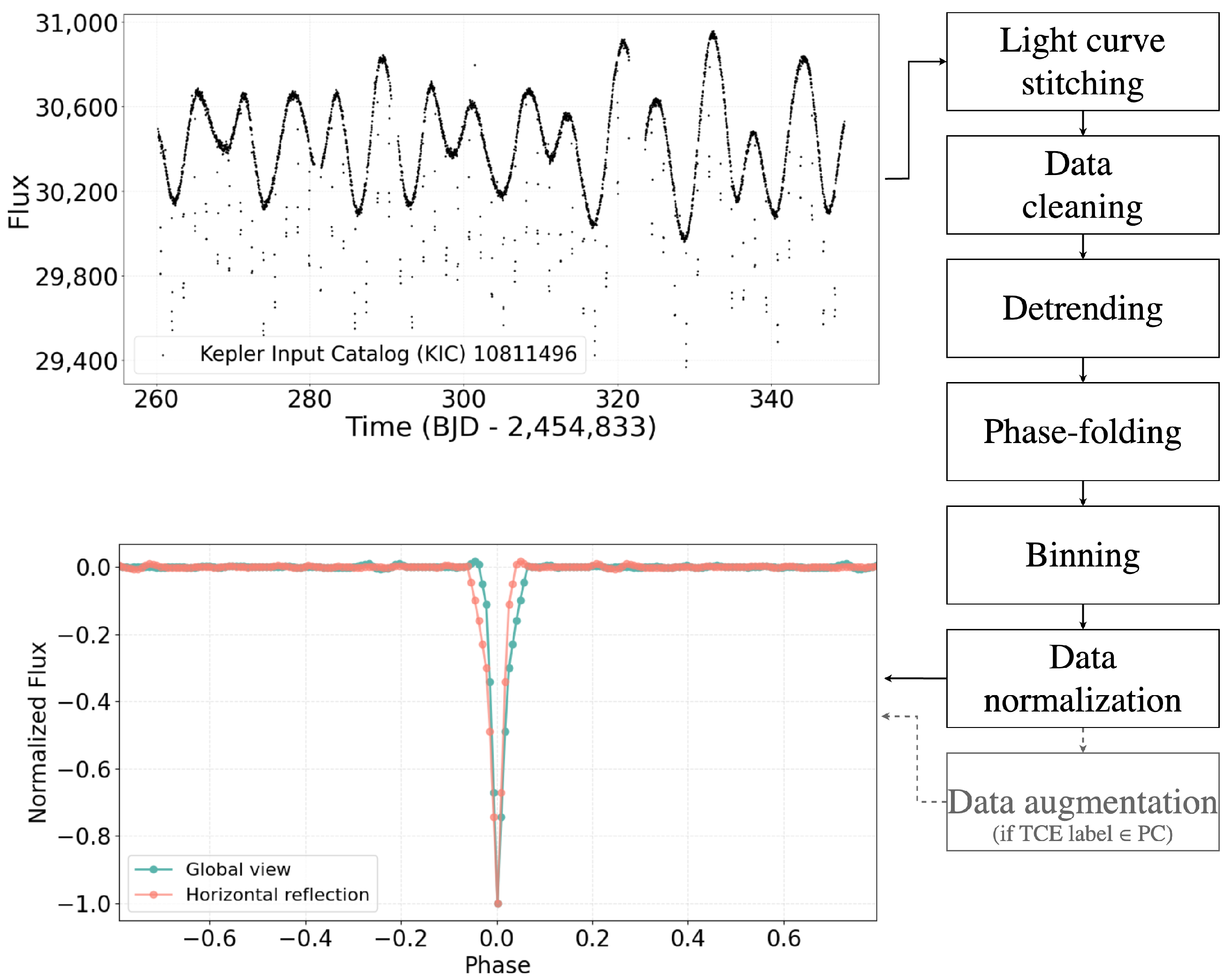
- Stitching the light curves. A TCE can be associated with multiple segments (Kepler quarters or TESS sectors) of the light curve of its host star. This depends mainly on the observing strategy of the telescope. We generate a single light curve by sequentially appending segments, which we then normalize by the median value calculated over the entire signal;
- Data cleaning. From the resulting light curve, we discard all not-a-numbers and outliers beyond of the stellar flux;
- Detrending. In order to remove any non-TCE-related variability, we divide the cleaned flux data by an interpolating polynomial of degree 3 computed using the Savitzky–Golay method with filter window set to 11. During detrending, we preserve flux measurements related to TCE transit by applying a mask calculated based on TCE transit period and duration;
- Phase-folding and binning. This detrended signal is folded on the relative TCE period and binned with a time bin size of 30 min (When developing this data pre-processing pipeline, we tested time bin sizes of 2, 10, and 30 min, which correspond to the data sampling rates of the Kepler and TESS telescopes. The best results in terms of the shape of the resulting transit were obtained using the 30 min value).Following the same methodology used by SV18 and Yu L. et al. [13], we linearly interpolate any empty bin so as to generate an input signal of length 201;
- Normalizing the binned signal. The binned signal is then normalized to 0-median and maximum transit depth to −1. We define the binned and normalized transit as global view, consisting of the one-dimensional input we fed to our model;
- Data augmentation on the PC class. Since our main goal is to train a model able to minimize the number of misclassified planets, we double the number of samples belonging to this class in the and datasets. More precisely, we apply a horizontal reflection to the global views of the PC TCEs. We decided to not adopt the same procedure to the eclipsing signals (E class) of since Tey E. et al. [22] declared that this set of planets also contains a fraction of non-contact eclipsing binaries, and we want to minimize the risk of increasing the number of eclipsing binaries contaminating the E class because of our purpose of identifying exoplanets.
3.2. Components of Our Model
3.2.1. Convolutional Neural Network and VGG19
3.2.2. Dimensionality Reduction and t-SNE
3.2.3. Gradient-Boosted Trees and XGBoost
3.2.4. Diffusion Models and Conditional Flow Matching
4. Method
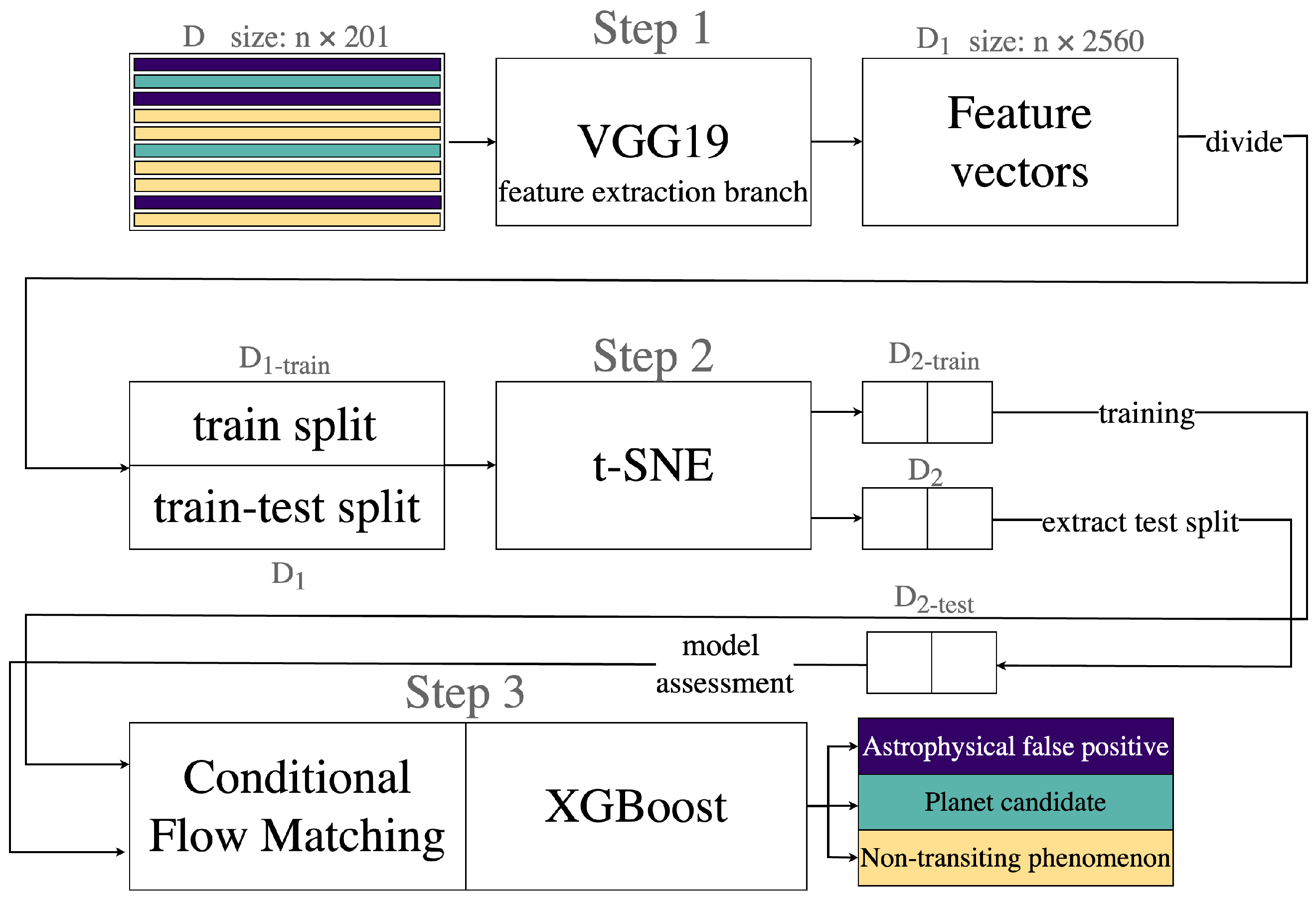
- Feature extraction. We extract the features from the global views with the feature extraction block of VGG19. This model is independently trained on each dataset until overfitting on the global views. Since VGG19 is exclusively used as feature extractor, its training can be extended until overfitting the dataset in order to guarantee the most representative features are extracted. For each of the n global views, the VGG19’s feature extraction branch produces a one-dimensional feature map of size 2560, once flattened. We trained VGG19 for 300 epochs on each dataset, with a learning rate of , batch size of 128, and pooling size and stride fixed to 3 and 2, respectively, by using Adam [67] as the optimization algorithm. As highlighted from the number of TCEs for each class in Table 2, all our datasets are imbalanced toward one of the three classes. Typically, such an imbalance is toward the class of non-astrophysical transits (classes NTP and J). To address class imbalance, we used class weighting when training VGG19. The weights for each class were computed using the Inverse Class Frequency technique [68].The n 2560-length feature vectors, we denote as , are saved at the end of the last training epoch.
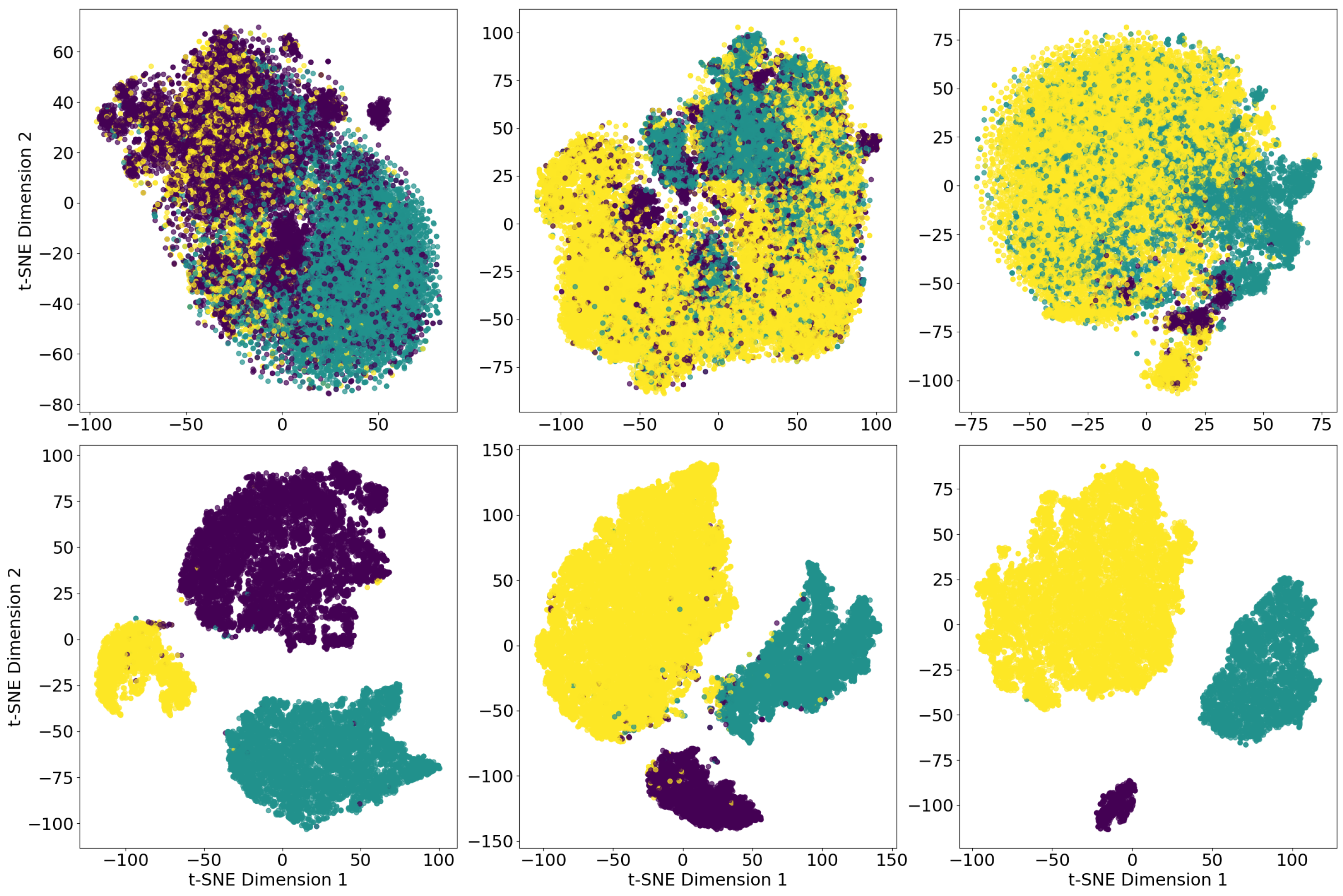
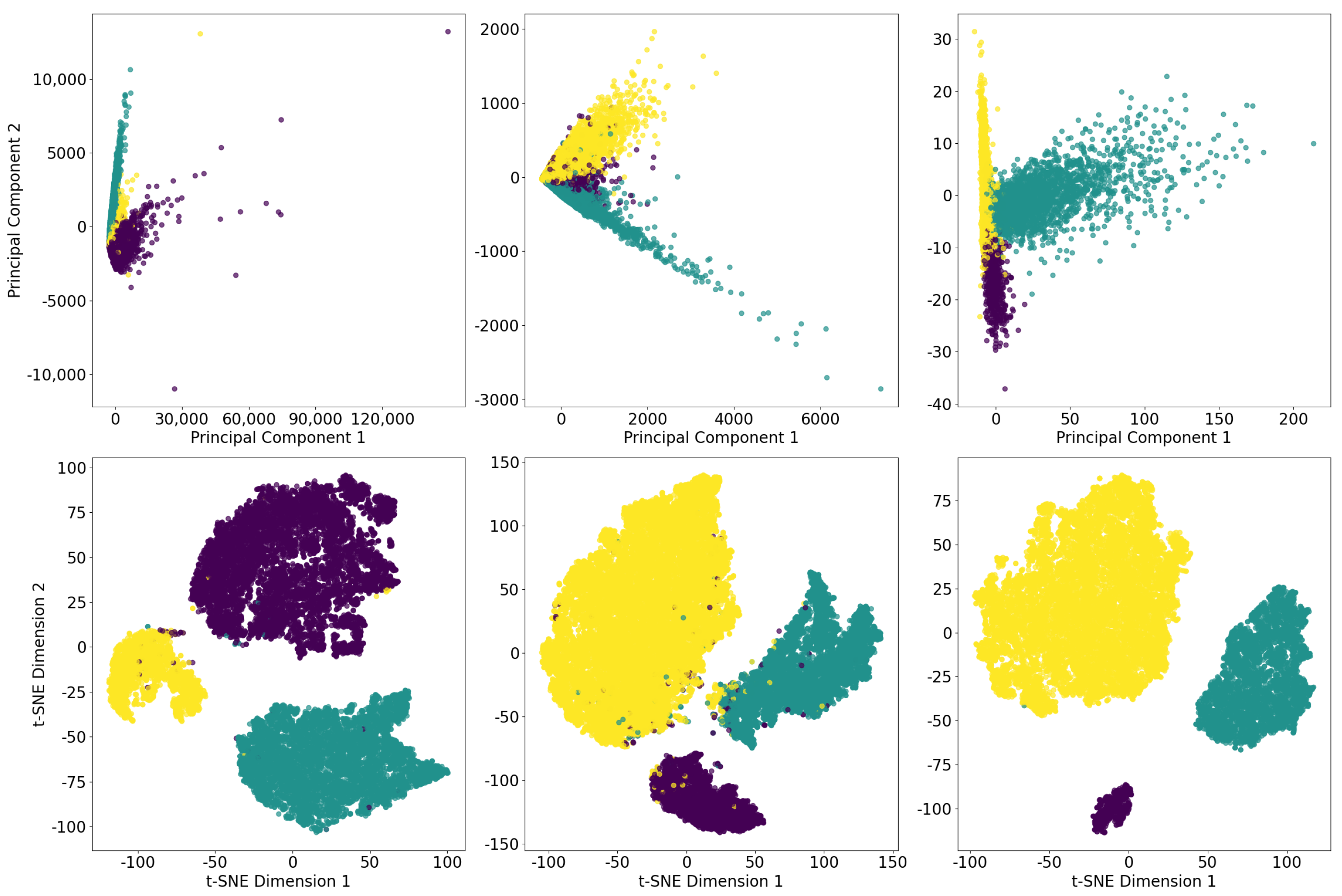
- Dimensionality reduction. The resulting feature vectors are projected into a two-dimensional embedding defined by t-SNE. By processing , t-SNE produces (In our experiments, we also evaluated the classification performance of our model by processing three-dimensional data produced by t-SNE, rather than exclusively two-dimensional data. However, the best performance was obtained by processing data in two dimensions) a representation .As shown in Step 2 of Figure 3, the input of t-SNE is divided in two subsets (We discuss the application of this strategy in Section 6.5):
- (80% of data), used to generate , which will be used as training set for the Conditional Flow Matching;
- The entire dataset , from which is obtained. We extract from this representation the set , containing the data that will be used when assessing the Conditional Flow Matching performance.
Our experiments revealed that running t-SNE for 3000 iterations, with a perplexity of 50, best maximized the separation of TCEs classes in the two-dimensional space.The two-dimensional projections obtained by t-SNE for training and test data are shown in middle and right panels of Figure 2, respectively.We emphasize that a quantitative assessment of how well t-SNE preserves the clustering structure of the data—particularly in terms of local and global neighborhood relationships—is thoroughly discussed in the original work by Van der Maaten L. and Hinton G. [33]. In our study, we focus on the practical impact this dimensionality reduction has in the context of TCE classification, showing the related evidence in Figure 2 and Figure 4 and Table 3. - Classification with CFM and XGBoost. Following the methodology described in Jolicoeur-Martineau A. et al. [36] and Li A. et al. [65], we performed TCE classification by processing with CFM and XGBoost (Step 3). Each sample of is mapped into the vector field of the CFM from to in steps. At each step, an XGBoost is trained to estimate the vector field. The sample at time is processed with an ODE, returning the output sample that is fed to an additional XGBoost, responsible for the TCE classification [65].Due to the low dimensionality of the input and the good separability between classes of TCEs provided by t-SNE, a very accurate classification performance is obtained as early as = 50 noise levels. Each of the XGBoosts has 100 decision trees of maximum depth of 2 and has been trained for 30 epochs with 63 steps per epoch. An extended discussion on finding the sub-optimal hyperparameters configuration is provided in Section 6.
5. Results
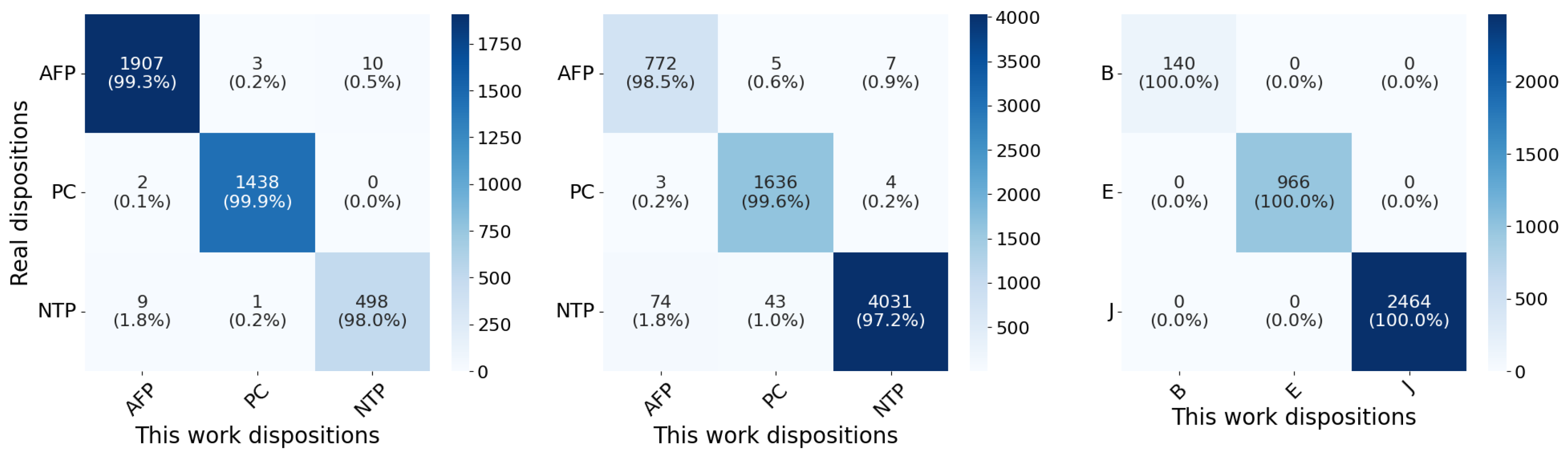
5.1. Application on Kepler Q1–Q17 Data Release 24
5.2. Application on Kepler Q1–Q17 Data Release 25
5.3. Application on TESS TEY23
6. Discussion
6.1. The Contribution of VGG19 and t-SNE in TCEs Classification
6.2. Reducing the High Computational Complexity and Memory Demand When Training the Conditional Flow Matching with XGBoost
6.3. Finding the Hyperparameter Configuration Optimizing Classification Accuracy
6.4. Comparison with State-of-the-Art Vetting Models
6.5. Current Limitations of Our Model
6.6. The Noise Affecting TCE Labels and Lack of Benchmark Dataset
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mayor, M.; Queloz, D. A Jupiter-mass companion to a solar-type star. Nature 1995, 378, 355–359. [Google Scholar] [CrossRef]
- Giordano Orsini, M.; Ferone, A.; Inno, L.; Giacobbe, P.; Maratea, A.; Ciaramella, A.; Bonomo, A.S.; Rotundi, A. A data-driven approach for extracting exoplanetary atmospheric features. Astron. Comput. 2025, 52, 100964. [Google Scholar] [CrossRef]
- Koch, D.G.; Borucki, W.J.; Basri, G.; Batalha, N.M.; Brown, T.M.; Caldwell, D.; Christensen-Dalsgaard, J.; Cochran, W.D.; DeVore, E.; Dunham, E.W.; et al. Kepler mission design, realized photometric performance, and early science. Astrophys. J. Lett. 2010, 713, L79. [Google Scholar] [CrossRef]
- Ricker, G.R.; Winn, J.N.; Vanderspek, R.; Latham, D.W.; Bakos, G.Á.; Bean, J.L.; Berta-Thompson, Z.K.; Brown, T.M.; Buchhave, L.; Butler, N.R.; et al. Transiting exoplanet survey satellite. J. Astron. Telesc. Instrum. Syst. 2015, 1, 014003. [Google Scholar] [CrossRef]
- Deeg, H.J.; Alonso, R. Transit photometry as an exoplanet discovery method. arXiv 2018, arXiv:1803.07867. [Google Scholar]
- Cacciapuoti, L.; Kostov, V.B.; Kuchner, M.; Quintana, E.V.; Colón, K.D.; Brande, J.; Mullally, S.E.; Chance, Q.; Christiansen, J.L.; Ahlers, J.P.; et al. The TESS Triple-9 Catalog: 999 uniformly vetted exoplanet candidates. Mon. Not. R. Astron. Soc. 2022, 513, 102–116. [Google Scholar] [CrossRef]
- Magliano, C.; Kostov, V.; Cacciapuoti, L.; Covone, G.; Inno, L.; Fiscale, S.; Kuchner, M.; Quintana, E.V.; Salik, R.; Saggese, V.; et al. The TESS Triple-9 Catalog II: A new set of 999 uniformly vetted exoplanet candidates. Mon. Not. R. Astron. Soc. 2023, 521, 3749–3764. [Google Scholar] [CrossRef]
- Kostov, V.B.; Kuchner, M.J.; Cacciapuoti, L.; Acharya, S.; Ahlers, J.P.; Andres-Carcasona, M.; Brande, J.; de Lima, L.T.; Di Fraia, M.Z.; Fornear, A.U.; et al. Planet Patrol: Vetting Transiting Exoplanet Candidates with Citizen Science. Publ. Astron. Soc. Pac. 2022, 134, 044401. [Google Scholar] [CrossRef]
- Tenenbaum, P.; Jenkins, J.M. TESS Science Data Products Description Document: EXP-TESS-ARC-ICD-0014 Rev D; No. ARC-E-DAA-TN61810; NASA: Washington, DC, USA, 2018. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Dattilo, A.; Vanderburg, A.; Shallue, C.J.; Mayo, A.W.; Berlind, P.; Bieryla, A.; Calkins, M.L.; Esquerdo, G.A.; Everett, M.E.; Howell, S.B.; et al. Identifying exoplanets with deep learning. II. Two new super-Earths uncovered by a neural network in K2 data. Astron. J. 2019, 157, 169. [Google Scholar] [CrossRef]
- Chaushev, A.; Raynard, L.; Goad, M.R.; Eigmüller, P.; Armstrong, D.J.; Briegal, J.T.; Burleigh, M.R.; Casewell, S.L.; Gill, S.; Jenkins, J.S.; et al. Classifying exoplanet candidates with convolutional neural networks: Application to the Next Generation Transit Survey. Mon. Not. R. Astron. Soc. 2019, 488, 5232–5250. [Google Scholar] [CrossRef]
- Yu, L.; Vanderburg, A.; Huang, C.; Shallue, C.J.; Crossfield, I.J.; Gaudi, B.S.; Daylan, T.; Dattilo, A.; Armstrong, D.J.; Ricker, G.R.; et al. Identifying exoplanets with deep learning. III. Automated triage and vetting of TESS candidates. Astron. J. 2019, 158, 25. [Google Scholar] [CrossRef]
- Osborn, H.P.; Ansdell, M.; Ioannou, Y.; Sasdelli, M.; Angerhausen, D.; Caldwell, D.; Jenkins, J.M.; Räissi, C.; Smith, J.C. Rapid classification of TESS planet candidates with convolutional neural networks. Astron. Astrophys. 2020, 633, A53. [Google Scholar] [CrossRef]
- Fiscale, S.; Inno, L.; Ciaramella, A.; Ferone, A.; Rotundi, A.; De Luca, P.; Galletti, A.; Marcellino, L.; Covone, G. Identifying Exoplanets in TESS Data by Deep Learning. In Applications of Artificial Intelligence and Neural Systems to Data Science; Springer Nature: Singapore, 2023; pp. 127–135. [Google Scholar]
- Shallue, C.J.; Vanderburg, A. Identifying exoplanets with deep learning: A five-planet resonant chain around Kepler-80 and an eighth planet around Kepler-90. Astron. J. 2018, 155, 94. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Valizadegan, H.; Martinho, M.J.; Wilkens, L.S.; Jenkins, J.M.; Smith, J.C.; Caldwell, D.A.; Twicken, J.D.; Gerum, P.C.; Walia, N.; Hausknecht, K.; et al. ExoMiner: A highly accurate and explainable deep learning classifier that validates 301 new exoplanets. Astrophys. J. 2022, 926, 120. [Google Scholar] [CrossRef]
- Tey, E.; Moldovan, D.; Kunimoto, M.; Huang, C.X.; Shporer, A.; Daylan, T.; Muthukrishna, D.; Vanderburg, A.; Dattilo, A.; Ricker, G.R.; et al. Identifying exoplanets with deep learning. V. Improved light-curve classification for TESS full-frame image observations. Astrophys. J. 2023, 165, 95. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Royden, H.L.; Fitzpatrick, P. Real Analysis; Macmillan: New York, NY, USA, 1968; Volume 2. [Google Scholar]
- Shwartz-Ziv, R.; Armon, A. Tabular data: Deep learning is not all you need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- McCauliff, S.D.; Jenkins, J.M.; Catanzarite, J.; Burke, C.J.; Coughlin, J.L.; Twicken, J.D.; Tenenbaum, P.; Seader, S.; Li, J.; Cote, M. Automatic classification of Kepler planetary transit candidates. Astrophys. J. 2015, 806, 6. [Google Scholar] [CrossRef]
- Armstrong, D.J.; Günther, M.N.; McCormac, J.; Smith, A.M.; Bayliss, D.; Bouchy, F.; Burleigh, M.R.; Casewell, S.; Eigmüller, P.; Gillen, E.; et al. Automatic vetting of planet candidates from ground-based surveys: Machine learning with NGTS. Mon. Not. R. Astron. Soc. 2018, 478, 4225–4237. [Google Scholar] [CrossRef]
- Caceres, G.A.; Feigelson, E.D.; Babu, G.J.; Bahamonde, N.; Christen, A.; Bertin, K.; Meza, C.; Curé, M. Autoregressive planet search: Application to the Kepler mission. Astrophys. J. 2019, 158, 58. [Google Scholar] [CrossRef]
- Schanche, N.; Cameron, A.C.; Hébrard, G.; Nielsen, L.; Triaud, A.H.; Almenara, J.M.; Alsubai, K.A.; Anderson, D.R.; Armstrong, D.J.; Barros, S.C.; et al. Machine-learning approaches to exoplanet transit detection and candidate validation in wide-field ground-based surveys. Mon. Not. R. Astron. Soc. 2019, 483, 5534–5547. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Wheatley, P.J.; West, R.G.; Goad, M.R.; Jenkins, J.S.; Pollacco, D.L.; Queloz, D.; Rauer, H.; Udry, S.; Watson, C.A.; Chazelas, B.; et al. The next generation transit survey (NGTS). Mon. Not. R. Astron. Soc. 2018, 475, 4476–4493. [Google Scholar] [CrossRef]
- Pollacco, D.L.; Skillen, I.; Cameron, A.C.; Christian, D.J.; Hellier, C.; Irwin, J.; Lister, T.A.; Street, R.A.; West, R.G.; Anderson, D.; et al. The WASP project and the SuperWASP cameras. Publ. Astron. Soc. Pac. 2006, 118, 1407. [Google Scholar] [CrossRef]
- Jolicoeur-Martineau, A.; Fatras, K.; Kachman, T. Generating and imputing tabular data via diffusion and flow-based gradient-boosted trees. In International Conference on Artificial Intelligence and Statistics; PMLR: Birmingham, UK, 2024; pp. 1288–1296. [Google Scholar]
- Coughlin, J.L.; Mullally, F.; Thompson, S.E.; Rowe, J.F.; Burke, C.J.; Latham, D.W.; Batalha, N.M.; Ofir, A.; Quarles, B.L.; Henze, C.E.; et al. Planetary candidates observed by Kepler. VII. The first fully uniform catalog based on the entire 48-month data set (Q1–Q17 DR24). Astrophys. J. Suppl. Ser. 2016, 224, 12. [Google Scholar] [CrossRef]
- Howell, S.B.; Sobeck, C.; Haas, M.; Still, M.; Barclay, T.; Mullally, F.; Troeltzsch, J.; Aigrain, S.; Bryson, S.T.; Caldwell, D.; et al. The K2 mission: Characterization and early results. Publ. Astron. Soc. Pac. 2014, 126, 398. [Google Scholar] [CrossRef]
- Armstrong, D.J.; Pollacco, D.; Santerne, A. Transit shapes and self organising maps as a tool for ranking planetary candidates: Application to kepler and k2. Mon. Not. R. Astron. Soc. 2016, 461, 2461–2473. [Google Scholar]
- Poleo, V.T.; Eisner, N.; Hogg, D.W. NotPlaNET: Removing False Positives from Planet Hunters TESS with Machine Learning. Astron. J. 2024, 168, 100. [Google Scholar] [CrossRef]
- Ansdell, M.; Ioannou, Y.; Osborn, H.P.; Sasdelli, M.; Smith, J.C.; Caldwell, D.; Jenkins, J.M.; Räissi, C.; Angerhausen, D. Scientific domain knowledge improves exoplanet transit classification with deep learning. Astrophys. J. Lett. 2018, 869, L7. [Google Scholar] [CrossRef]
- Salinas, H.; Pichara, K.; Brahm, R.; Pérez-Galarce, F.; Mery, D. Distinguishing a planetary transit from false positives: A Transformer-based classification for planetary transit signals. Mon. Not. R. Astron. Soc. 2023, 522, 3201–3216. [Google Scholar] [CrossRef]
- Visser, K.; Bosma, B.; Postma, E. Exoplanet detection with Genesis. J. Astron. Instrum. 2022, 11, 2250011. [Google Scholar] [CrossRef]
- Jenkins, J.M.; Caldwell, D.A.; Chandrasekaran, H.; Twicken, J.D.; Bryson, S.T.; Quintana, E.V.; Clarke, B.D.; Li, J.; Allen, C.; Tenenbaum, P.; et al. Overview of the Kepler science processing pipeline. Astrophys. J. Lett. 2010, 713, L87. [Google Scholar] [CrossRef]
- Jenkins, J.M.; Twicken, J.D.; McCauliff, S.; Campbell, J.; Sanderfer, D.; Lung, D.; Mansouri-Samani, M.; Girouard, F.; Tenenbaum, P.; Klaus, T.; et al. The TESS science processing operations center. In Software and Cyberinfrastructure for Astronomy IV; SPIE: Bellingham, WA, USA, 2016; Volume 9913, pp. 1232–1251. [Google Scholar]
- Jenkins, J.M.; Tenenbaum, P.; Seader, S.; Burke, C.J.; McCauliff, S.D.; Smith, J.C.; Twicken, J.D.; Chandrasekaran, H. Kepler Data Processing Handbook: Transiting Planet Search; Kepler Science Document KSCI-19081-002; NASA Ames Research Center: Mountain View, CA, USA, 2017; p. 9. [Google Scholar]
- Kunimoto, M.; Huang, C.; Tey, E.; Fong, W.; Hesse, K.; Shporer, A.; Guerrero, N.; Fausnaugh, M.; Vanderspek, R.; Ricker, G. Quick-look pipeline lightcurves for 9.1 million stars observed over the first year of the TESS Extended Mission. RNAAS 2021, 5, 234. [Google Scholar] [CrossRef]
- Kostov, V.B.; Mullally, S.E.; Quintana, E.V.; Coughlin, J.L.; Mullally, F.; Barclay, T.; Colón, K.D.; Schlieder, J.E.; Barentsen, G.; Burke, C.J. Discovery and Vetting of Exoplanets. I. Benchmarking K2 Vetting Tools. Astron. J. 2019, 157, 124. [Google Scholar] [CrossRef]
- Catanzarite, J.H. Autovetter Planet Candidate Catalog for Q1–Q17 Data Release 24; NASA Ames Research Center: Mountain View, CA, USA, 2015. [Google Scholar]
- Thompson, S.E.; Coughlin, J.L.; Hoffman, K.; Mullally, F.; Christiansen, J.L.; Burke, C.J.; Bryson, S.; Batalha, N.; Haas, M.R.; Catanzarite, J.; et al. Planetary candidates observed by Kepler. VIII. A fully automated catalog with measured completeness and reliability based on data release 25. Astrophys. J. Suppl. Ser. 2018, 235, 38. [Google Scholar] [CrossRef] [PubMed]
- Fiscale, S.; De Luca, P.; Inno, L.; Marcellino, L.; Galletti, A.; Rotundi, A.; Ciaramella, A.; Covone, G.; Quintana, E. A GPU algorithm for outliers detection in TESS light curves. In International Conference on Computational Science; Springer: Cham, Switzerland, 2021; pp. 420–432. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; Silva, V.D.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P. Using manifold stucture for partially labeled classification. Adv. Neural Inf. Process. Syst. 2002, 15, 1505–1512. [Google Scholar]
- Hinton, G. Stochastic neighbor embedding. Adv. Neural Inf. Process. Syst. 2003, 15, 857–864. [Google Scholar]
- Csiszár, I. I-divergence geometry of probability distributions and minimization problems. Ann. Probab. 1975, 3, 146–158. [Google Scholar] [CrossRef]
- Jacobs, R.A. Increased rates of convergence through learning rate adaptation. Neural Netw. 1988, 1, 295–307. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, C.; Zhang, X.; Almpanidis, G. An up-to-date comparison of state-of-the-art classification algorithms. Expert Syst. Appl. 2017, 82, 128–150. [Google Scholar] [CrossRef]
- Touzani, S.; Granderson, J.; Fernandes, S. Gradient boosting machine for modeling the energy consumption of commercial buildings. Energy Build. 2018, 158, 1533–1543. [Google Scholar] [CrossRef]
- Machado, M.R.; Karray, S.; De Sousa, I.T. LightGBM: An effective decision tree gradient boosting method to predict customer loyalty in the finance industry. In Proceedings of the 2019 14th International Conference on Computer Science & Education (ICCSE), Toronto, ON, Canada, 19–21 August 2019; pp. 1111–1116. [Google Scholar]
- Ma, B.; Meng, F.; Yan, G.; Yan, H.; Chai, B.; Song, F. Diagnostic classification of cancers using extreme gradient boosting algorithm and multi-omics data. Comput. Biol. Med. 2020, 121, 103761. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T. Xgboost: Extreme gradient boosting. In R Package Version 0.4-2; The R Project for Statistical Computing: Vienna, Austria, 2015; Volume 1, pp. 1–4. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Li, A.C.; Prabhudesai, M.; Duggal, S.; Brown, E.; Pathak, D. Your diffusion model is secretly a zero-shot classifier. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 2206–2217. [Google Scholar]
- Chen, R.T.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D.K. Neural ordinary differential equations. Adv. Neural Inf. Process. Syst. 2018, 31, 6572–6583. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lertnattee, V.; Theeramunkong, T. Analysis of inverse class frequency in centroid-based text classification. In Proceedings of the IEEE International Symposium on Communications and Information Technology, 2004. ISCIT 2004, Sapporo, Japan, 26–29 October 2004; Volume 2, pp. 1171–1176. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1, No. 2. [Google Scholar]
- Visser, K.; Bosma, B.; Postma, E. Size does matter: Exoplanet detection with a sparse convolutional neural network. Astron. Comput. 2022, 41, 100654. [Google Scholar] [CrossRef]
- Gisbrecht, A.; Schulz, A.; Hammer, B. Parametric nonlinear dimensionality reduction using kernel t-SNE. Neurocomputing 2015, 147, 71–82. [Google Scholar] [CrossRef]
- Guerrero, N.M.; Seager, S.; Huang, C.X.; Vanderburg, A.; Soto, A.G.; Mireles, I.; Hesse, K.; Fong, W.; Glidden, A.; Shporer, A.; et al. The TESS objects of interest catalog from the TESS prime mission. Astrophys. J. Suppl. Ser. 2021, 254, 39. [Google Scholar] [CrossRef]
- Imambi, S.; Prakash, K.B.; Kanagachidambaresan, G.R. PyTorch. In Programming with TensorFlow: Solution for Edge Computing Applications; Springer Nature: Cham, Switzerland, 2021; pp. 87–104. [Google Scholar]
- Braga, F.C.; Roman, N.T.; Falceta-Gonçalves, D. The Effects of Under and Over Sampling in Exoplanet Transit Identification with Low Signal-to-Noise Ratio Data. In Brazilian Conference on Intelligent Systems; Springer International Publishing: Cham, Switzerland, 2022; pp. 107–121. [Google Scholar]
- Rauer, H.; Catala, C.; Aerts, C.; Appourchaux, T.; Benz, W.; Brandeker, A.; Christensen-Dalsgaard, J.; Deleuil, M.; Gizon, L.; Goupil, M.J.; et al. The PLATO 2.0 mission. Exp. Astron. 2014, 38, 249–330. [Google Scholar] [CrossRef]

| Dataset [Ref.] | Class | Total | Training | Test |
|---|---|---|---|---|
| Kepler Q1–Q17 DR24 [49] | PC | a 7200 | 5760 | 1440 |
| AFP | 9596 | 7676 | 1920 | |
| NTP | 2541 | 2033 | 508 | |
| Total | 19,337 | 15,469 | 3868 | |
| Kepler Q1–Q17 DR25 [50] | PC | a 8216 | 6573 | 1643 |
| AFP | 3946 | 3162 | 784 | |
| NTP | 21,098 | 16,950 | 4148 | |
| Total | 33,260 | 26,685 | 6575 | |
| TESS TEY23 [22] | E | 2613 | 1647 | 966 |
| B | 738 | 598 | 140 | |
| J | 15,791 | 13,327 | 2464 | |
| Total | 19,142 | 15,572 | 3570 |
| Model [Ref.] | Survey | Precision | Recall | F1-Score |
|---|---|---|---|---|
| SOM [39] | Kepler | 0.864 | 0.865 | 0.864 |
| SOM [39] | K2 | 0.945 | 0.972 | 0.958 |
| RFC + SOM [30] | NGTS | 0.901 | 0.914 | 0.907 |
| Exominer [21] | Kepler | 0.968 | 0.974 | 0.971 |
| Exominer-Basic [21] | TESS | 0.88 | 0.73 | 0.79 |
| Astronet-Triage-v2 [22] | TESS | 0.84 | 0.99 | 0.909 |
| Transformer [42] | TESS | 0.809 | 0.8 | 0.805 |
| This work | Kepler | 0.974 | 0.987 | 0.980 |
| This work | TESS | 1.0 | 1.0 | 1.0 |
| Dataset | Class | Precision | Recall | F1-Score | Misclass. Rate (%) |
|---|---|---|---|---|---|
| Kepler Q1–Q17 DR24 | AFP | 0.9943 | 0.9932 | 0.9937 | 1.25 |
| PC | 0.9972 | 0.9986 | 0.9979 | 0.42 | |
| NTP | 0.9803 | 0.9803 | 0.9803 | 3.93 | |
| Kepler Q1–Q17 DR25 | AFP | 0.910 | 0.985 | 0.946 | 2.1 |
| PC | 0.971 | 0.996 | 0.983 | ||
| NTP | 0.997 | 0.972 | 0.984 | ||
| TESS TEY23 | B | 1.000 | 1.000 | 1.000 | 0.0 |
| E | 1.000 | 1.000 | 1.000 | ||
| J | 1.000 | 1.000 | 1.000 |
| Hyperparameters | Models | ||
|---|---|---|---|
| Exominer | Astronet-Triage-v2 | Salinas H. et al. [42] | |
| Architecture | CNN | CNN | Transformer |
| Figure Ref. | Figure 9 | Figure 8 | Figure 2 |
| Input branches | 8 | 7 | 3 |
| Activation | ReLU | ReLU | Attention Mechanism * |
| Regularization | Dropout | Dropout | Dropout |
| Fully-connected | 4 × 128 | 4 × 512 | Linear (X → 2) * |
| Output | Sigmoid | Sigmoid | Softmax * |
| Optimizer | Adam | Adam | Adam |
| Training | - | 20,000 steps | 60 epochs |
| Learning rate | 6.73 | 1 | 1 |
| Batch size | - | 64 | 100 |
| Model selection | 10-fold CV | 10-fold CV | 10-fold CV |
| Armstrong D. et al. [39] | Armstrong D. et al. [30] | ||
| Kepler | K2 | ||
| Architecture | SOM | SOM | RFC + SOM |
| Grid dimension | 20 × 20 | 8 × 8 | 20 × 20 |
| Radius | 20 | <20 | 20 |
| Training epochs | 500 | 500 | 300 |
| Learning rate | 0.1 | 0.1 | 0.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fiscale, S.; Ferone, A.; Ciaramella, A.; Inno, L.; Giordano Orsini, M.; Covone, G.; Rotundi, A. Detection of Exoplanets in Transit Light Curves with Conditional Flow Matching and XGBoost. Electronics 2025, 14, 1738. https://doi.org/10.3390/electronics14091738
Fiscale S, Ferone A, Ciaramella A, Inno L, Giordano Orsini M, Covone G, Rotundi A. Detection of Exoplanets in Transit Light Curves with Conditional Flow Matching and XGBoost. Electronics. 2025; 14(9):1738. https://doi.org/10.3390/electronics14091738
Chicago/Turabian StyleFiscale, Stefano, Alessio Ferone, Angelo Ciaramella, Laura Inno, Massimiliano Giordano Orsini, Giovanni Covone, and Alessandra Rotundi. 2025. "Detection of Exoplanets in Transit Light Curves with Conditional Flow Matching and XGBoost" Electronics 14, no. 9: 1738. https://doi.org/10.3390/electronics14091738
APA StyleFiscale, S., Ferone, A., Ciaramella, A., Inno, L., Giordano Orsini, M., Covone, G., & Rotundi, A. (2025). Detection of Exoplanets in Transit Light Curves with Conditional Flow Matching and XGBoost. Electronics, 14(9), 1738. https://doi.org/10.3390/electronics14091738