
Joint Optimization of Model Partitioning and Resource Allocation for Multi-Exit DNNs in Edge-Device Collaboration


Abstract
1. Introduction
- We establish a joint optimization model for model partitioning and resource allocation in end–edge collaborative computing based on multi-exit DNNs.
- We design an efficient algorithm to determine the optimal partitioning points and resource allocation ratios.
- We conduct experiments to verify the proposed method’s superiority in terms of latency and energy consumption.
2. Related Work
3. System Model and Optimization Problem
3.1. System Model
3.2. Latency Model
3.2.1. Expected Local Inference Latency on End Device i
3.2.2. Expected Transmission Latency
3.2.3. Expected Inference Latency at the Edge Server
3.2.4. Total Expected Inference Latency
3.3. Energy Consumption Model
3.3.1. Expected Local Inference Energy Consumption on End Device i
3.3.2. Expected Network Transmission Energy Consumption on End Device i
3.3.3. Total Expected Inference Energy Consumption
3.4. Optimization Problem
4. Algorithm Design
- The Actor network generates the optimal actions under the current system state (i.e., model partitioning and resource allocation decisions); and
- The Critic network evaluates the value of the current state and guides policy improvement.
4.1. Mapping the Optimization Problem to DRL
4.2. State Space
4.3. Action Space
4.4. Reward Function Design
4.5. Policy Optimization Using PPO
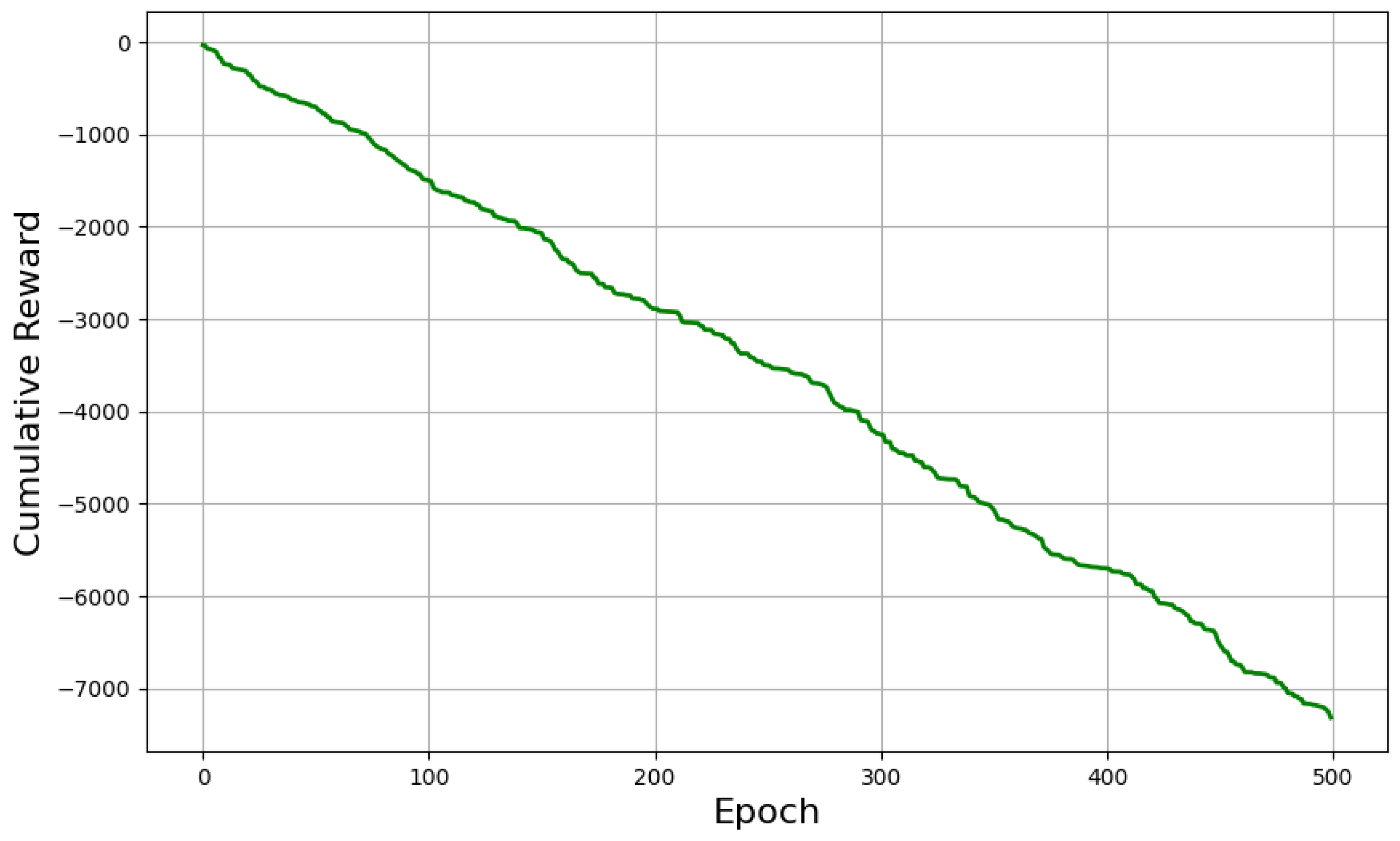
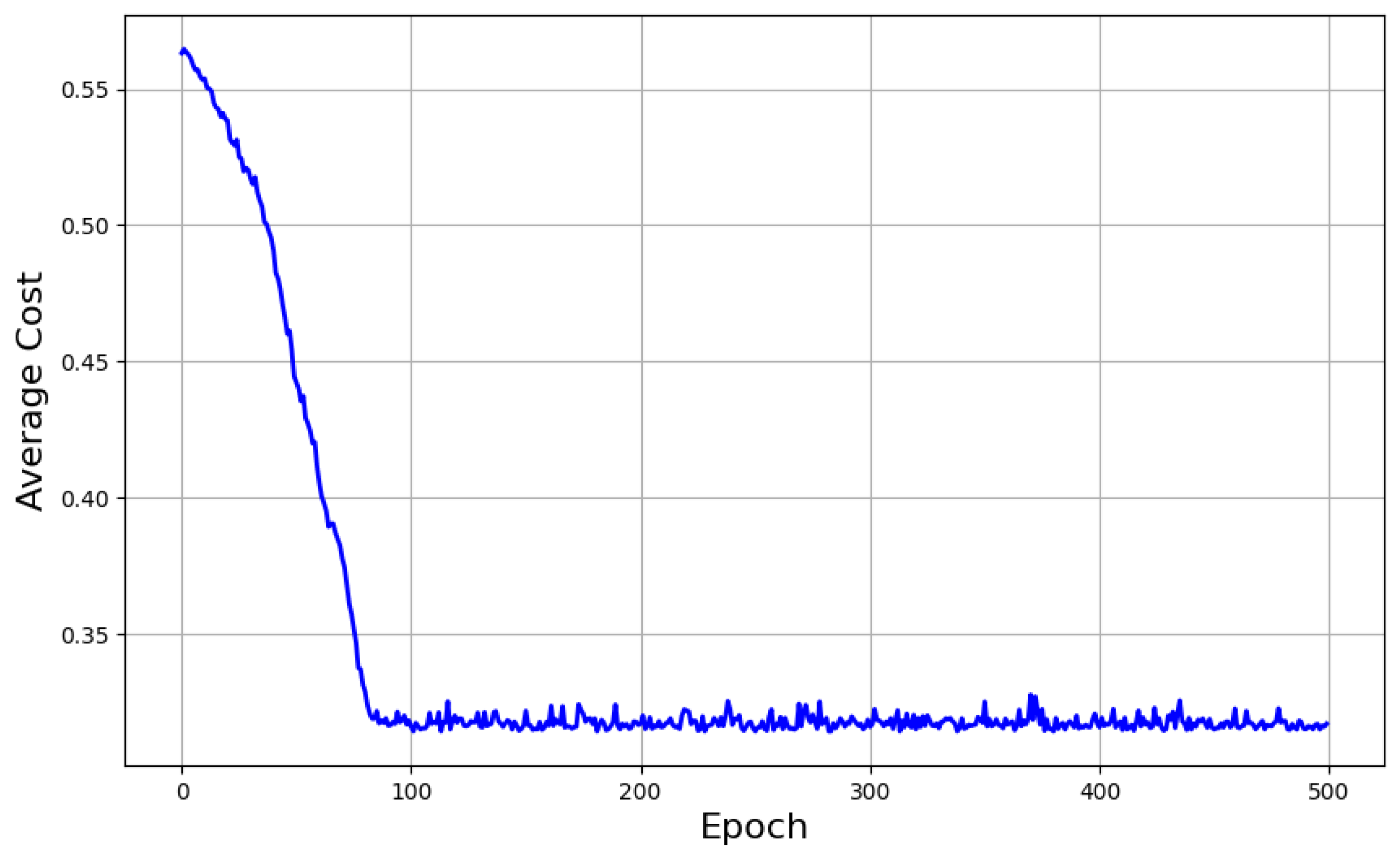
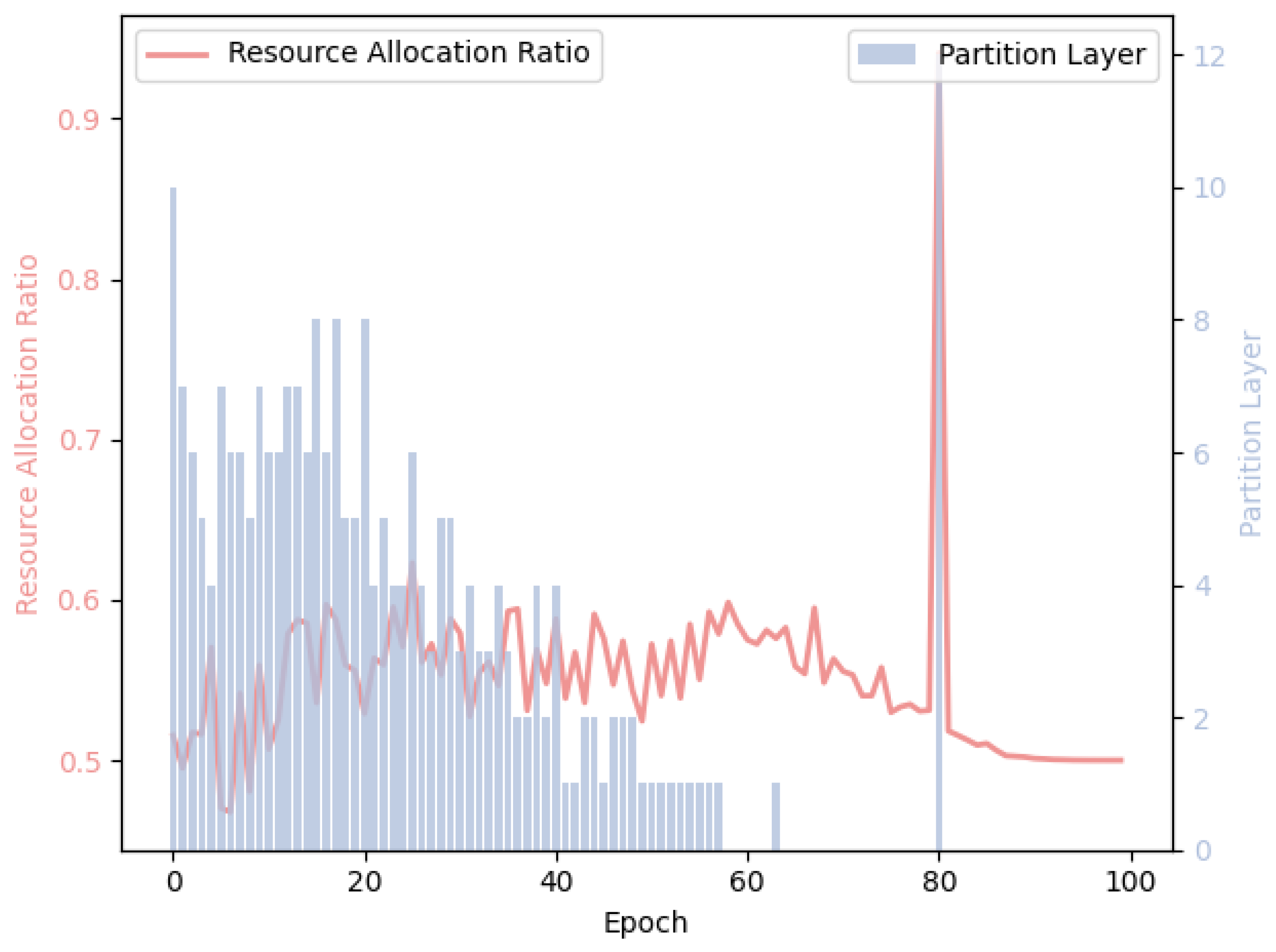
4.6. Training Process
| Algorithm 1 DRL-Based Joint Optimization Algorithm |
| Input: |
|
| Output: |
|
5. Experimental Evaluation
5.1. Experimental Setup
5.2. Baseline Comparisons
- 1.
- ACO-device only-EAR: The DNN exits are configured as in [19], with all tasks processed by the end devices and the resources of the edge server evenly distributed across all devices.
- 2.
- ACO-edge only-EAR: The DNN exits are configured as in [19], with all inference tasks offloaded to the edge server for processing, and the resources of the edge server are evenly allocated among the devices.
- 3.
- SPINN [9]-EAR: Exits are set at intervals of 15% FLOPs computation, and the model is partitioned accordingly. Since the resource allocation issue is not considered, it is assumed that the resource allocation follows an even distribution.
- 4.
- 5.
- FP-AR (Fixed Partitioning-Resource Allocation): This method optimizes resource allocation based on a fixed model partitioning scheme (in this experiment, the partitioning layer for each model is randomly set to 6). A total of 1000 exhaustive search iterations are conducted, and the optimal resource allocation scheme is selected.
5.3. Performance Evaluation
5.3.1. Performance Evaluation of Image Experiments
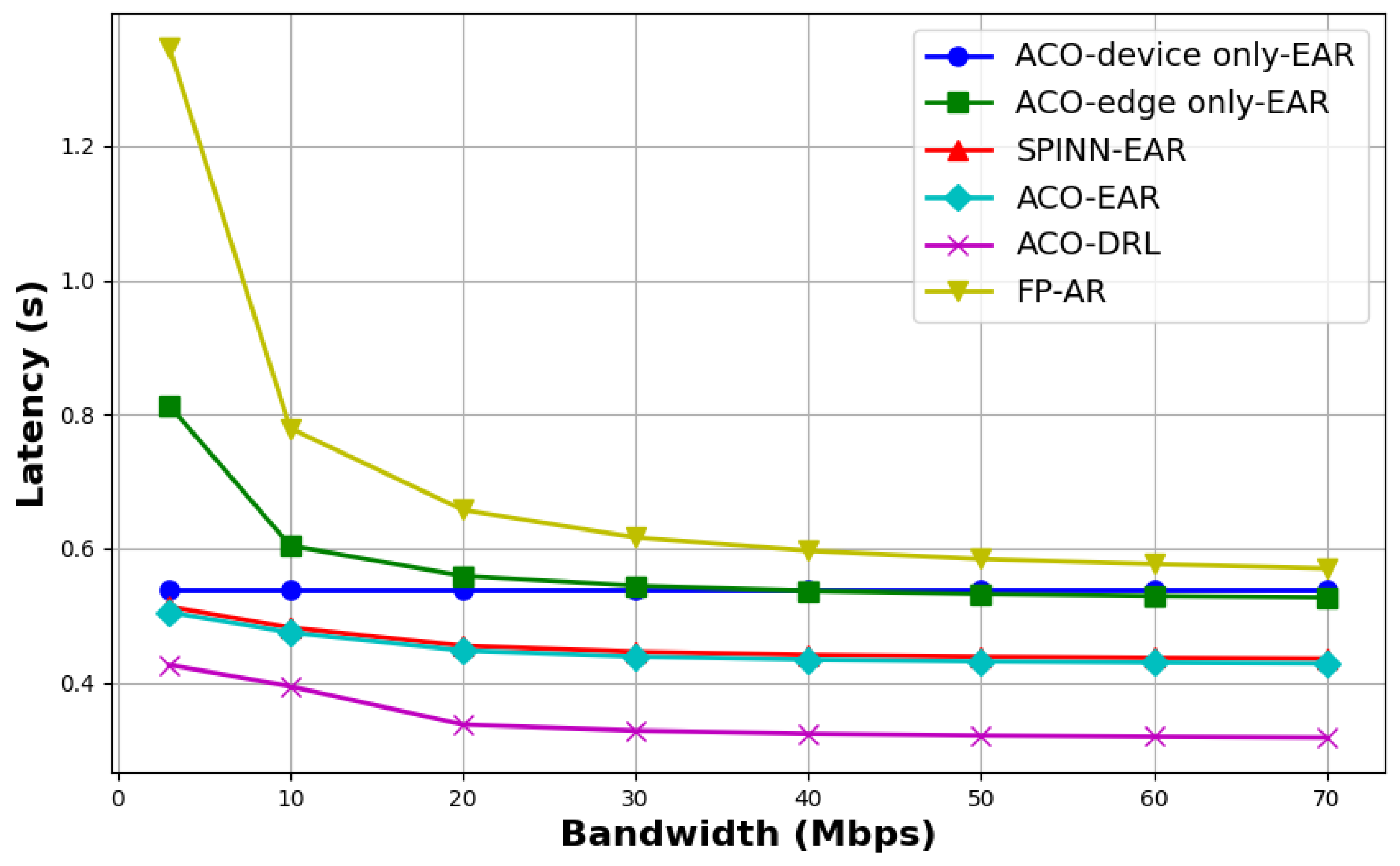
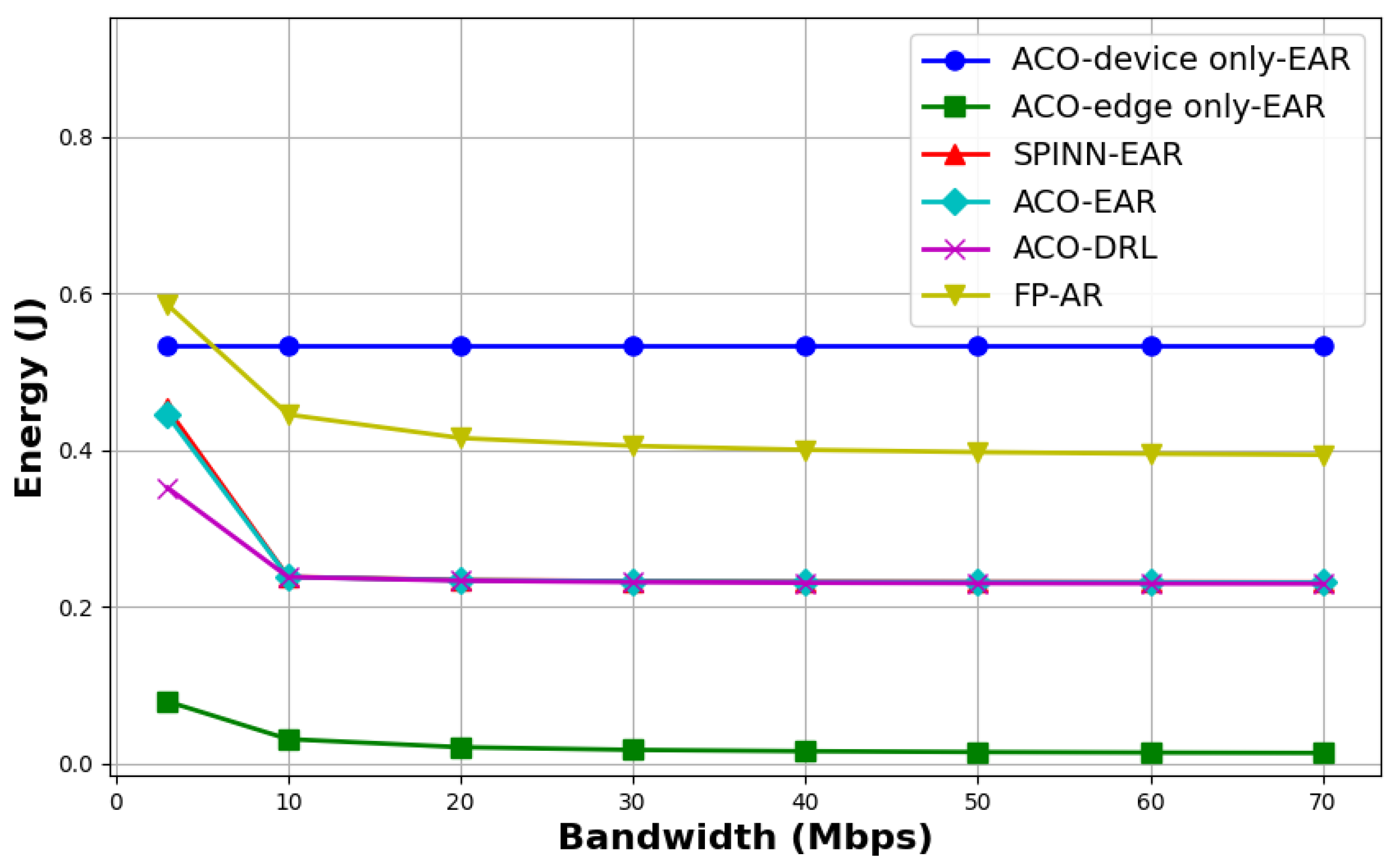
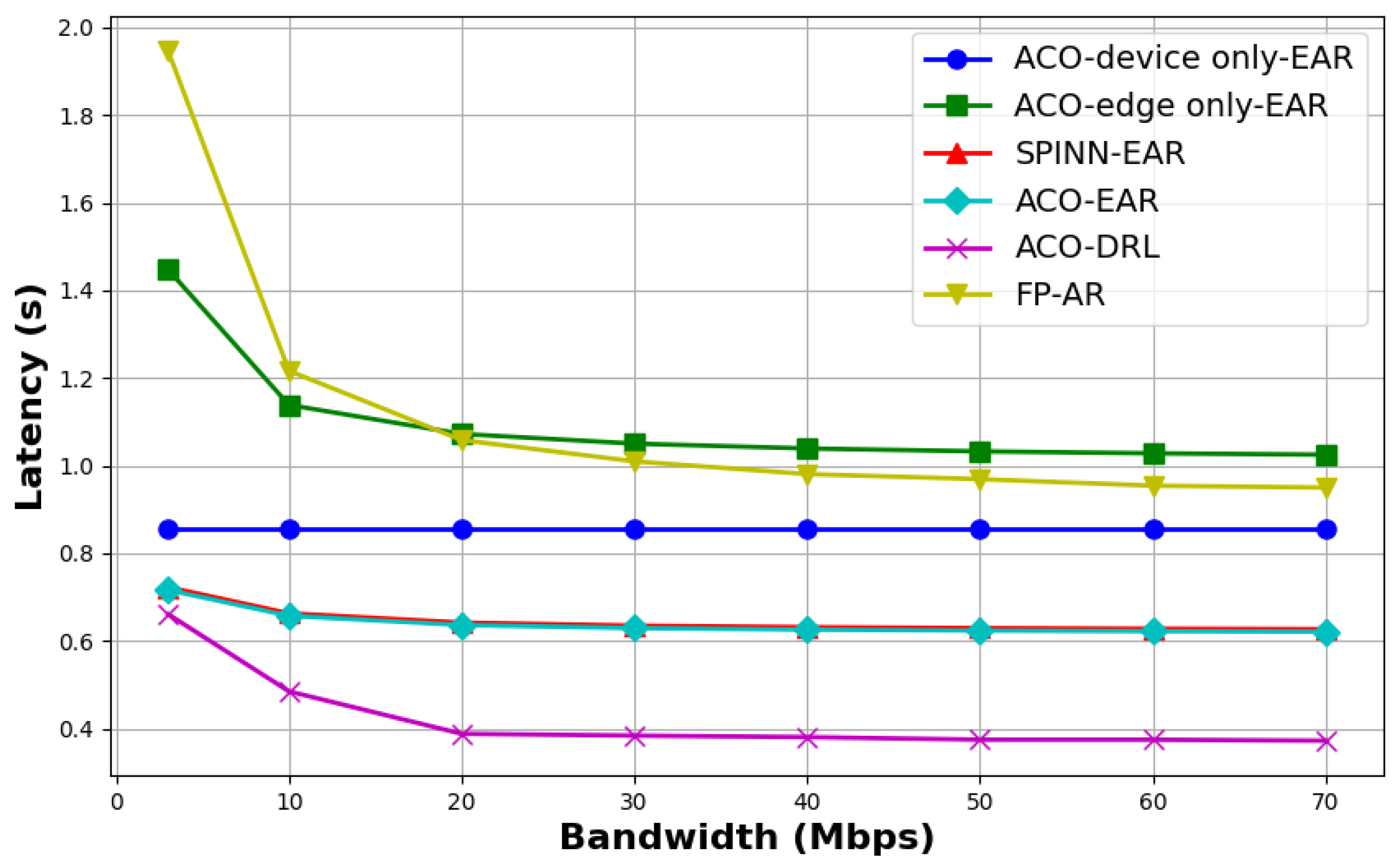
- “ACO-EAR” and “SPINN-EAR” adopt the same model partitioning strategy but are based on different exit-setting algorithms, with both employing an average resource allocation strategy. The experimental results indicate that “ACO-EAR” consistently achieves slightly lower inference delay, energy consumption, and cost compared with “SPINN-EAR”, demonstrating the impact of the exit-setting strategy on the inference performance of multi-exit DNNs.
- Compared with the method adopting equal distribution of resources, “ACO-DRL” demonstrates superior performance in both inference latency and overall cost control, clearly highlighting the critical role of resource allocation strategies in enhancing inference efficiency.
- “ACO-DRL” achieves joint optimization of both resource allocation and model partitioning strategies, whereas “FP-AR” only optimizes resource allocation based on a predefined fixed model partitioning scheme. Experimental results indicate that “ACO-DRL” consistently outperforms other methods in terms of latency and overall cost. In contrast, “FP-AR” shows inferior performance in both latency and cost control, and also exhibits higher energy consumption compared with most baseline methods. These findings validate the significant impact of model partitioning strategies on inference performance.
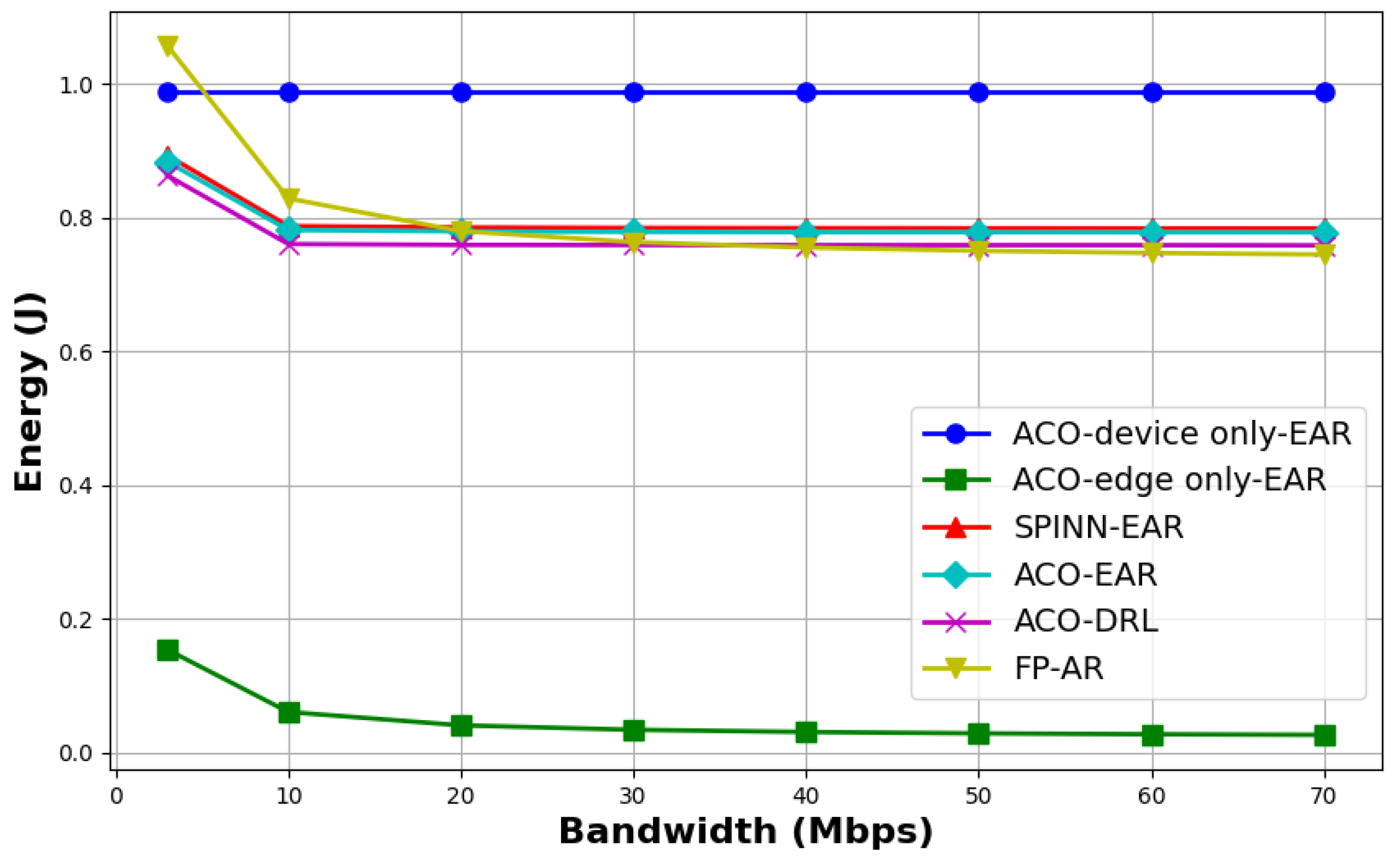
- Since “ACO-edge only-EAR” offloads all tasks to the edge server for inference, it consistently maintains the lowest energy consumption. However, under limited bandwidth conditions, this method results in considerable inference delay.
- When the bandwidth exceeds 10 Mbps, the energy consumption of “ACO-EAR” becomes comparable to that of “ACO-DRL”, suggesting that their model partitioning schemes are similar or identical. Nevertheless, since “ACO-DRL” further optimizes the resource allocation strategy, it achieves significantly better performance in terms of inference delay and overall cost than “ACO-EAR.”
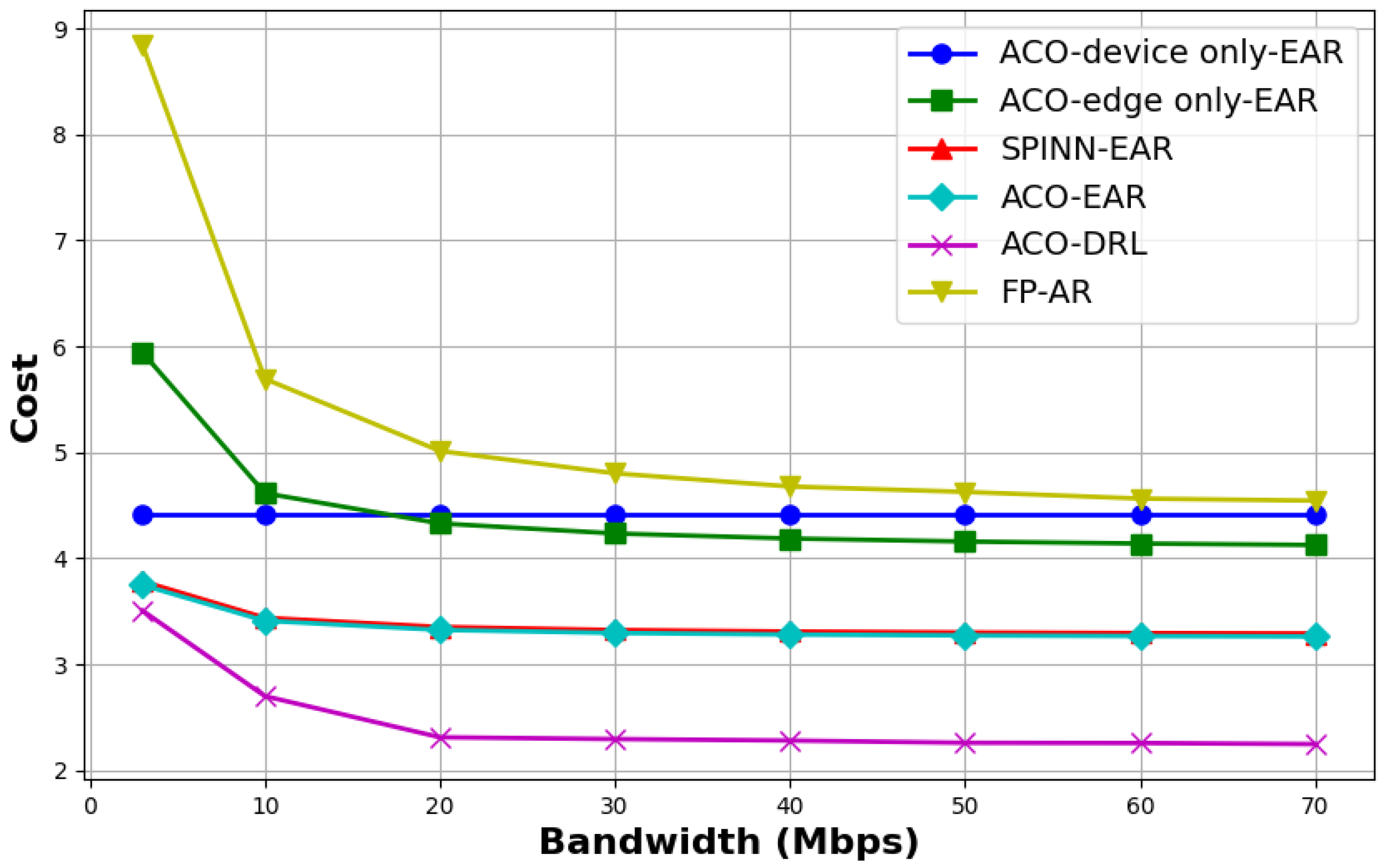
- When the bandwidth exceeds 30 Mbps, the inference cost for all methods tends to stabilize. Among them, the proposed joint optimization method (“ACO-EAR”) consistently maintains the lowest inference cost, fully demonstrating the effectiveness of the proposed joint optimization algorithm for model partitioning and resource allocation.
5.3.2. Performance Evaluation of Video Experiments
- The performance of “ACO-EAR” and “SPINN-EAR” in terms of inference delay, energy consumption, and cost is comparable. However, owing to the more flexible exit-setting strategy adopted by “ACO-EAR,” it consistently achieves slightly better overall performance than “SPINN-EAR.”
- Compared with methods that do not incorporate resource optimization, “ACO-DRL” demonstrates superior performance in both inference latency and overall cost control, further confirming the significant impact of resource allocation strategies on the total system cost.
- Although the energy consumption of “FP-AR” is slightly lower than that of most methods when the bandwidth exceeds 40 Mbps, its latency is significantly higher than that of the majority of the other approaches, thereby demonstrating the critical importance of optimizing model partitioning decisions for inference performance.
- The “ACO-device only-EAR” and “ACO-edge only-EAR” methods underutilize the computational capabilities of either the edge server or the end device, respectively. As a result, their performance in terms of latency and overall cost is inferior to that of most other approaches.
- Under bandwidth-constrained conditions, the proposed method “ACO-DRL” achieves inference delay and cost comparable to or even better than other methods under sufficient bandwidth conditions. This further demonstrates the excellent adaptability of the proposed joint optimization method in varying network environments, effectively reducing inference costs and enhancing overall system performance.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Teerapittayanon, S.; McDanel, B.; Kung, H.T. Branchynet: Fast Inference via Early Exiting from Deep Neural Networks. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2464–2469. [Google Scholar]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Zhu, L.; Li, B.; Tan, L. A Digital Twin-based Multi-objective Optimized Task Offloading and Scheduling Scheme for Vehicular Edge Networks. Future Gener. Comput. Syst. 2025, 163, 107517. [Google Scholar] [CrossRef]
- Ebrahimi, M.; Veith, A.D.; Gabel, M.; de Lara, E. Combining DNN Partitioning and Early Exit. In Proceedings of the 5th International Workshop on Edge Systems, Analytics and Networking, Rennes, France, 5–8 April 2022; pp. 25–30. [Google Scholar]
- Li, N.; Iosifidis, A.; Zhang, Q. Graph Reinforcement Learning-based CNN Inference Offloading in Dynamic Edge Computing. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Rio de Janeiro, Brazil, 4–8 December 2022; pp. 982–987. [Google Scholar]
- Xie, Z.; Xu, Y.; Xu, H.; Liao, Y.; Yao, Z. Collaborative Inference for Large Models with Task Offloading and Early Exiting. arXiv 2024, arXiv:2412.08284. [Google Scholar]
- Bajpai, D.J.; Jaiswal, A.; Hanawal, M.K. I-splitee: Image Classification in Split Computing DNNs with Early Exits. In Proceedings of the IEEE International Conference on Communications (ICC), Denver, CO, USA, 9–13 June 2024; pp. 2658–2663. [Google Scholar]
- Laskaridis, S.; Venieris, S.I.; Almeida, M.; Leontiadis, I.; Lane, N.D. SPINN: Synergistic Progressive Inference of Neural Networks Over Device and Cloud. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking (MobiCom), London, UK, 21–25 September 2020; ACM: New York, NY, USA, 2020; pp. 1–15. [Google Scholar]
- Matsubara, Y.; Levorato, M.; Restuccia, F. Split Computing and Early Exiting for Deep Learning Applications: Survey and Research Challenges. ACM Comput. Surv. 2022, 55, 1–30. [Google Scholar] [CrossRef]
- Zhou, M.; Zhou, B.; Wang, H.; Dong, F.; Zhao, W. Dynamic Path Based DNN Synergistic Inference Acceleration in Edge Computing Environment. In Proceedings of the 27th International Conference on Parallel and Distributed Systems (ICPADS), Beijing, China, 14–16 December 2021; pp. 567–574. [Google Scholar]
- Kang, Y.; Hauswald, J.; Gao, C.; Rovinski, A.; Mudge, T.; Mars, J.; Tang, L. Neurosurgeon: Collaborative Intelligence Between the Cloud and Mobile Edge. In Proceedings of the 22nd International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Xi’an, China, 8–12 April 2017; pp. 615–629. [Google Scholar]
- Liu, Z.; Lan, Q.; Huang, K. Resource Allocation for Batched Multiuser Edge Inference with Early Exiting. In Proceedings of the IEEE International Conference on Communications (ICC), Rome, Italy, 28 May–1 June 2023; pp. 3614–3620. [Google Scholar]
- Cao, Y.; Fu, S.; He, X.; Hu, H.; Shan, H.; Yu, L. Video Surveillance on Mobile Edge Networks: Exploiting Multi-Exit Network. In Proceedings of the IEEE International Conference on Communications (ICC), Rome, Italy, 28 May–1 June 2023; pp. 6621–6626. [Google Scholar]
- Dong, F.; Wang, H.; Shen, D.; Huang, Z.; He, Q.; Zhang, J.; Wen, L.; Zhang, T. Multi-exit DNN Inference Acceleration Based on Multi-dimensional Optimization for Edge Intelligence. IEEE Trans. Mob. Comput. 2022, 22, 5389–5405. [Google Scholar] [CrossRef]
- Kim, J.W.; Lee, H.S. Early Exiting-aware Joint Resource Allocation and DNN Splitting for Multi-sensor Digital Twin in Edge-cloud Collaborative System. IEEE Internet Things J. 2024, 11, 36933–36949. [Google Scholar] [CrossRef]
- Liu, Z.; Song, J.; Qiu, C.; Wang, X.; Chen, X.; He, Q.; Sheng, H. Hastening Stream Offloading of Inference via Multi-exit DNNs in Mobile Edge Computing. IEEE Trans. Mob. Comput. 2022, 23, 535–548. [Google Scholar] [CrossRef]
- Li, E.; Zeng, L.; Zhou, Z.; Chen, X. Edge AI: On-demand Accelerating Deep Neural Network Inference via Edge Computing. IEEE Trans. Wirel. Commun. 2019, 19, 447–457. [Google Scholar] [CrossRef]
- Ma, Y.; Tang, B. Correlation-Aware Exit Setting for Deep Neural Network Inference. In Proceedings of the 2024 4th International Conference on Digital Society and Intelligent Systems (DSIns), Sydney, Australia, 20–22 November 2024. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| The number of logical layers in the complete multi-exit DNN deployed on end device i. | |
| The FLOPs required to infer a task at exit branch j of the multi-exit DNN deployed on end device i. | |
| The FLOPs required to infer a task at logical layer j of the multi-exit DNN deployed on end device i. | |
| The probability that a task produces computation at logical layer j. | |
| The probability that a task produces computation at exit branch j. | |
| The computational capability of end device i. | |
| The computational capability of the edge server. | |
| The power consumption of end device i. | |
| The transmission power from end device i to the edge server. | |
| B | The bandwidth size for data transmission. |
| The size of intermediate data passed between layers. | |
| The proportion of resources allocated by the edge server for offloading tasks from end device i. | |
| The splitting point of the DNN on end device i. | |
| The overall cost function for end device i. |
| (W) | (W) | (GFLOPS) | |
|---|---|---|---|
| 0.5 | 0.1 | 50 | {10%, 8%, 2%, 15%, 0%, 7%, 5%, 6%, 3%, 2%, 28%, 12%, 2%} |
| 0.8 | 0.15 | 80 | {12%, 6%, 3%, 10%, 1%, 8%, 4%, 7%, 2%, 1%, 25%, 15%, 6%} |
| 1.2 | 0.2 | 100 | {9%, 7%, 4%, 14%, 0%, 6%, 5%, 8%, 3%, 2%, 27%, 10%, 5%} |
| 1.5 | 0.3 | 150 | {11%, 5%, 2%, 13%, 1%, 9%, 4%, 6%, 3%, 1%, 26%, 14%, 5%} |
| 2.0 | 0.4 | 200 | {11%, 1%, 0%, 0%, 0%, 0%, 4%, 6%, 3%, 30%, 26%, 14%, 5%} |
| (W) | (W) | (GFLOPS) | |
|---|---|---|---|
| 0.3 | 0.08 | 30 | {15%, 10%, 5%, 20%, 2%, 8%, 6%, 7%, 4%, 3%, 30%, 15%, 1%} |
| 0.6 | 0.12 | 60 | {12%, 8%, 4%, 15%, 1%, 9%, 7%, 6%, 5%, 3%, 25%, 14%, 2%} |
| 1.2 | 0.2 | 100 | {10%, 7%, 3%, 14%, 2%, 8%, 6%, 5%, 4%, 3%, 26%, 12%, 3%} |
| 2.0 | 0.3 | 120 | {9%, 6%, 2%, 13%, 1%, 10%, 5%, 7%, 4%, 2%, 27%, 13%, 3%} |
| 3.0 | 0.4 | 200 | {8%, 5%, 1%, 12%, 0%, 11%, 7%, 6%, 3%, 2%, 28%, 14%, 2%} |
| 4.0 | 0.5 | 250 | {7%, 4%, 1%, 10%, 0%, 12%, 6%, 5%, 3%, 1%, 29%, 15%, 2%} |
| 5.0 | 0.6 | 300 | {6%, 3%, 0%, 8%, 0%, 13%, 7%, 5%, 2%, 1%, 30%, 16%, 2%} |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Wang, Y.; Tang, B. Joint Optimization of Model Partitioning and Resource Allocation for Multi-Exit DNNs in Edge-Device Collaboration. Electronics 2025, 14, 1647. https://doi.org/10.3390/electronics14081647
Ma Y, Wang Y, Tang B. Joint Optimization of Model Partitioning and Resource Allocation for Multi-Exit DNNs in Edge-Device Collaboration. Electronics. 2025; 14(8):1647. https://doi.org/10.3390/electronics14081647
Chicago/Turabian StyleMa, Yuer, Yanyan Wang, and Bin Tang. 2025. "Joint Optimization of Model Partitioning and Resource Allocation for Multi-Exit DNNs in Edge-Device Collaboration" Electronics 14, no. 8: 1647. https://doi.org/10.3390/electronics14081647
APA StyleMa, Y., Wang, Y., & Tang, B. (2025). Joint Optimization of Model Partitioning and Resource Allocation for Multi-Exit DNNs in Edge-Device Collaboration. Electronics, 14(8), 1647. https://doi.org/10.3390/electronics14081647