1. Introduction
With the rapid development of wireless communication and intelligent sensing technologies, Internet of Things (IoT) devices have become integral to various sectors [
1], such as energy [
2,
3,
4], industry [
5,
6,
7], transportation [
8,
9], healthcare [
10,
11], and smart homes [
12,
13]. Although the pervasiveness of IoT devices has greatly improved convenience, their inadequate security design and insufficient testing can lead to exploitable security vulnerabilities, leading to security attacks. According to Nokia’s 2023 Threat Intelligence Report, IoT devices involved in distributed denial of service (DDoS) attacks surged from 200,000 to 1 million, leading to an estimated global financial loss of USD 2.5 billion. Therefore, detecting security attack behaviors in IoT networks has become crucial for ensuring IoT security.
Common attack detection models are designed by analyzing whether network traffic is benign or malicious to detect attack behaviors in the network. Such malicious traffic detection methods have been validated as effective methods for maintaining the security of IoT systems [
14]. Initially, centralized training approaches were widely adopted for developing IoT malicious traffic detection models [
15,
16]. In this paradigm, raw traffic data are transferred to the cloud [
15] for model training, leveraging extensive computational resources. However, due to the increased emphasis on privacy protection, such approaches have faced increasing scrutiny due to concerns over potential privacy breaches [
17], especially in regions with strict data protection regulations. For instance, the European Union’s General Data Protection Regulation (GDPR) [
18] imposes severe restrictions on cross-border data transfers, prompting a search for alternative solutions.
Subsequently, with advancements in chip technology and edge computing, distributed training methods like Federated Learning have become more popular as a promising alternative [
17,
19,
20,
21]. Federated Learning enables model training to occur directly on local edge devices, with only model parameter updates being transmitted to the cloud. This method eliminates the need for raw data transmission, thereby reducing privacy risks and bandwidth consumption [
22].
Despite its promises, existing Federated-Learning-based approaches to IoT malicious traffic detection have two key challenges.
First, training on complex model structures and redundant high-dimensional input features often requires significant computational overheads, especially for resource-constrained edge devices. To address this problem, an increasing number of researchers are committed to exploring lightweight neural networks and feature downscaling techniques for malicious traffic detection [
14,
23,
24,
25]. For instance, for developing a lightweight model for IoT malicious traffic detection in Federated Learning environments, MobileNet-Tiny [
14] and LwResnet [
24] achieve model complexity reduction by decreasing the number of convolutional layers and kernels. Despite their achievements, they have all neglected lightweighting in the classification phase, where a fully connected layer is used to classify the extracted features, resulting in substantial parameter and computation overhead. To efficiently handle redundant high-dimensional input features, works [
26,
27,
28] utilize autoencoders to reduce the dimensionality of the features. Although effective in reducing computational overhead, these methods necessitate a separate training process for the feature reduction module. This extra step introduces complexity and constrains the overall performance of the model. To address this issue, Wang et al. [
29] and Rey et al. [
30] utilized a semi-supervised training approach, where the autoencoder extracts features from a large amount of unlabeled data and the classifier utilizes these features to classify the labeled data. This approach allows the autoencoder to be trained simultaneously with the classifier. Moreover, to eliminate the need for training autoencoders, works [
31,
32] utilize a mayfly optimization algorithm and PCA to reduce the dimensionality of the features. However, these methods still require manual tuning to determine the optimal output dimension and thus remain outside the end-to-end category. These onerous tuning processes, especially when applied to different datasets, such as different participants in Federated Learning (where participants operate in varying network environments and use heterogeneous IoT devices that generate network traffic), hinder the model’s performance and adaptability.
Second, to improve the accuracy of lightweight IoT malicious traffic detection models in Federated Learning environments, current methods typically focus on extracting time-series features from network traffic but neglect the importance of dynamically selecting valid long-term dependencies. For instance, Jin et al. [
33] utilize a 1D CNN to transform network traffic into one-dimensional traffic time series and apply one-dimensional convolutions for classification. Yang et al. [
26] enhance this approach by using the TCN’s dilated convolutions to expand the receptive field, which allows the network to view further historical information at each time step, thus enabling the capture of longer-range dependencies between traffic time series. However, since the models lack a mechanism for selecting important information after extracting long-term dependencies from the input series, they remain vulnerable to noise interference during classification, which ultimately compromises model performance.
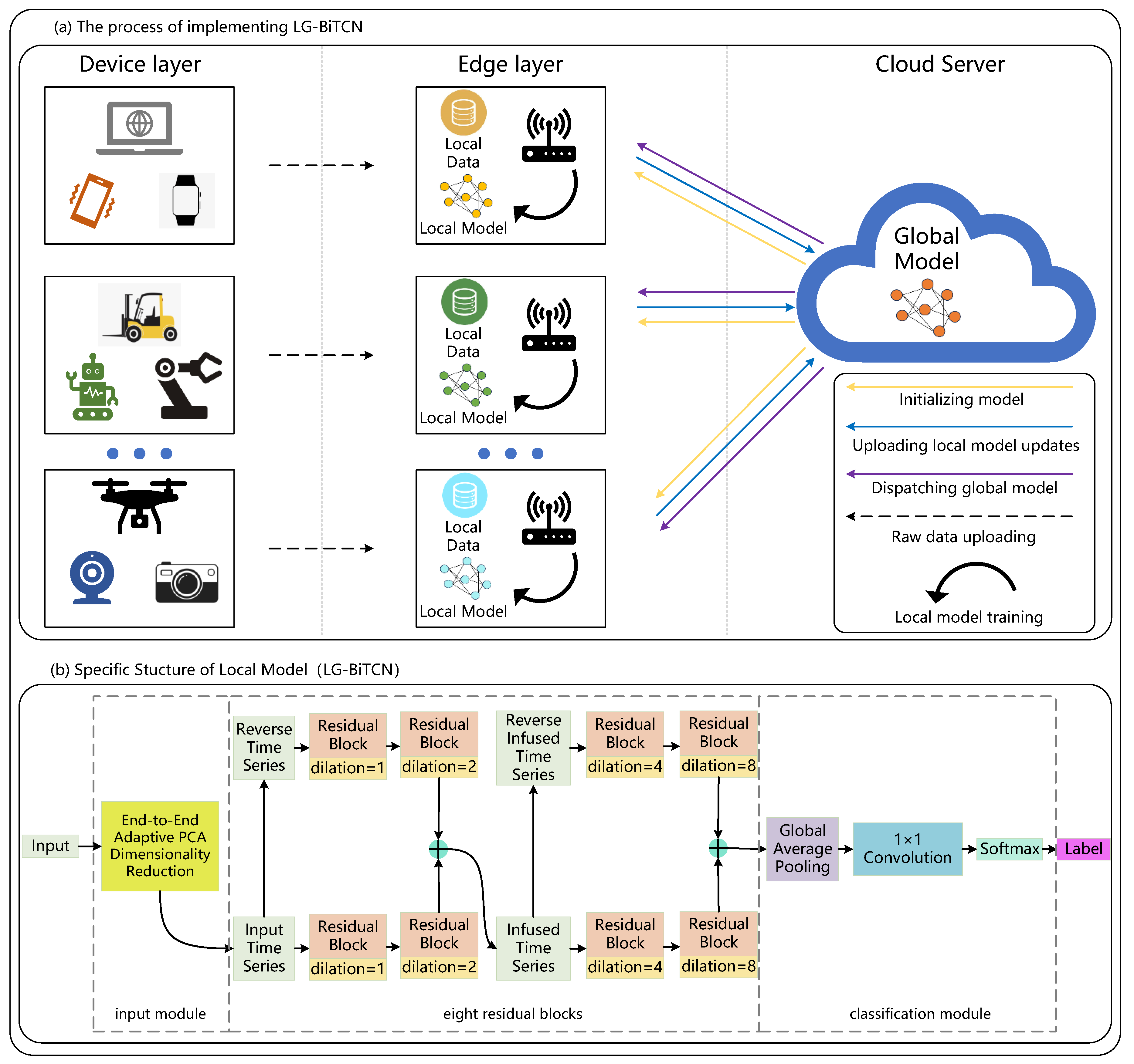
In response, in order to address the two issues discussed above, we propose a lightweight gated-bidirectional temporal convolutional network (LG-BiTCN) framework designed to detect IoT malicious traffic using a lightweight and efficient method. The contributions of this paper are presented as follows:
- (1)
To reduce the model parameter count, we improve BiTCN’s classification module with GAP and pointwise convolutional layers, and we propose an end-to-end adaptive principal components analysis (PCA) dimensionality reduction algorithm that can automatically reduce the feature dimension to its optimal state. GAP effectively preserves the spatial structure of input data while significantly reducing feature dimensionality; meanwhile, the end-to-end adaptive PCA dimensionality reduction algorithm can automatically compare the accuracy of different feature dimensions on a dataset to determine an optimal input feature dimension, therefore eliminating the manual intervention and improving the generalizability and detection efficiency of the model.
- (2)
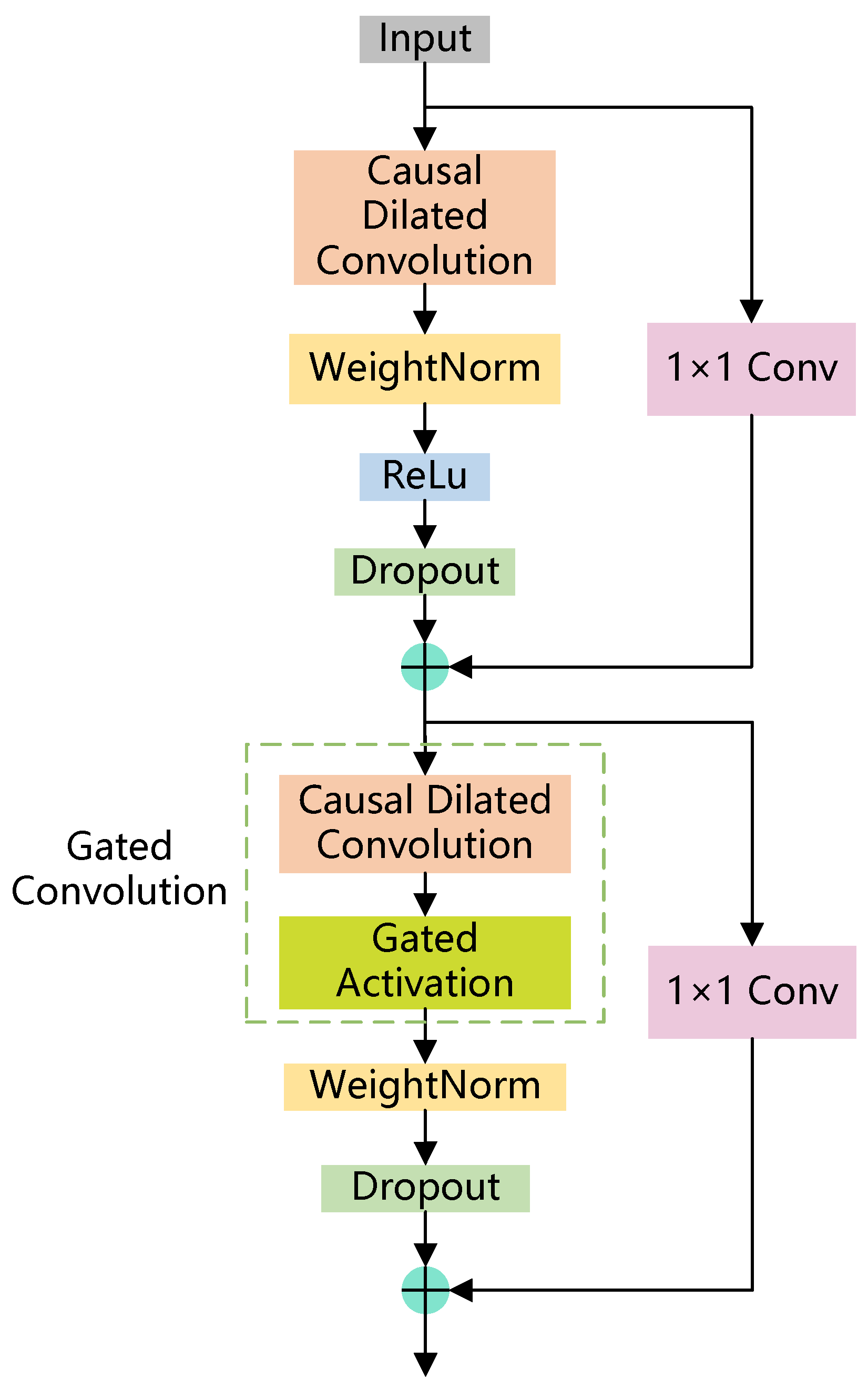
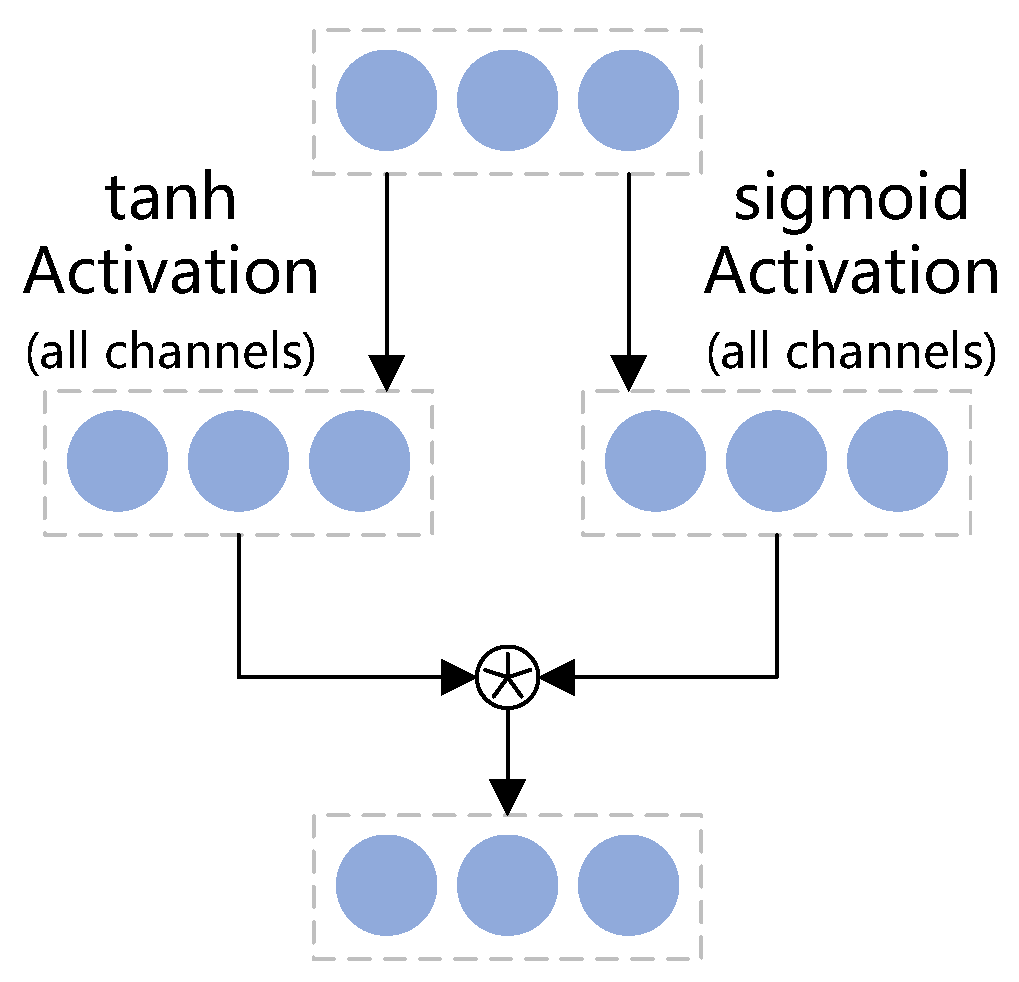
We integrate a gated convolution mechanism into the LG-BiTCN to address the issue of BiTCN’s inability to dynamically select long-term dependencies. This mechanism acts as an information selector, allowing the model to retain only the most essential long-term dependencies by dynamically controlling the flow of information.
- (3)
We compare the LG-BiTCN against three state-of-the-art models on three datasets. The experiments demonstrate our method’s excellence in accuracy and computational overhead. On the Edge-IIoTset dataset with 280,000 samples selected and the ToN-IoT dataset with 191,789 samples selected, our model achieves the highest accuracy with the lowest FLOPs and parameter count. On the CIC-IoT2023 dataset with 180,000 samples selected, our model’s accuracy is only 0.07% lower than the top performer, while using just 6.69% of the FLOPs. Thus, it demands minimal computational overhead while achieving outstanding detection performance.
3. Preliminaries
This section presents background knowledge about our proposed method, i.e., the specific structure of the BiTCN model.
The bidirectional temporal convolutional network (BiTCN) is a predictive architecture that utilizes two temporal convolutional networks (TCNs). The first network processes future covariates of the traffic time series while the second focuses on past observations and covariates. This approach maintains the traffic time series’s temporal structure and is computationally more efficient than traditional RNN methods like LSTM and GRUs. Compared to Transformer-based models, the BiTCN significantly reduces space complexity, requiring a far lower parameter count.
To effectively process long time series, the BiTCN employs causal dilated convolution, an innovative approach for extracting global information from extended traffic time series. This architecture implements strategic padding of the input traffic time series prior to convolution, ensuring two critical properties: first, the output at any given time step is determined exclusively by elements from previous time steps, maintaining temporal causality; and, second, the output time-series length precisely matches the input time-series length, preserving temporal dimensionality. The dilated convolution mechanism introduces systematic gaps in the convolution kernel, significantly expanding the receptive field of each convolution operation without the need for deeper layers. This sophisticated structure enables the BiTCN to effectively handle traffic time series while maintaining relatively low computational overhead, offering a more efficient alternative to traditional recurrent architectures.
Consider the forward TCN model, where the network traffic one-dimensional time series obtained from past time steps is denoted as
with
T representing the length of the time series. Let
represent the convolutional kernel. The dilated convolution operation at timestamp
t can be expressed as follows:
where
is the feature of the forward network traffic,
d represents the dilation rate (when
d = 1, the dilated convolution degenerates to normal convolution),
k is the size of the convolution kernel, and
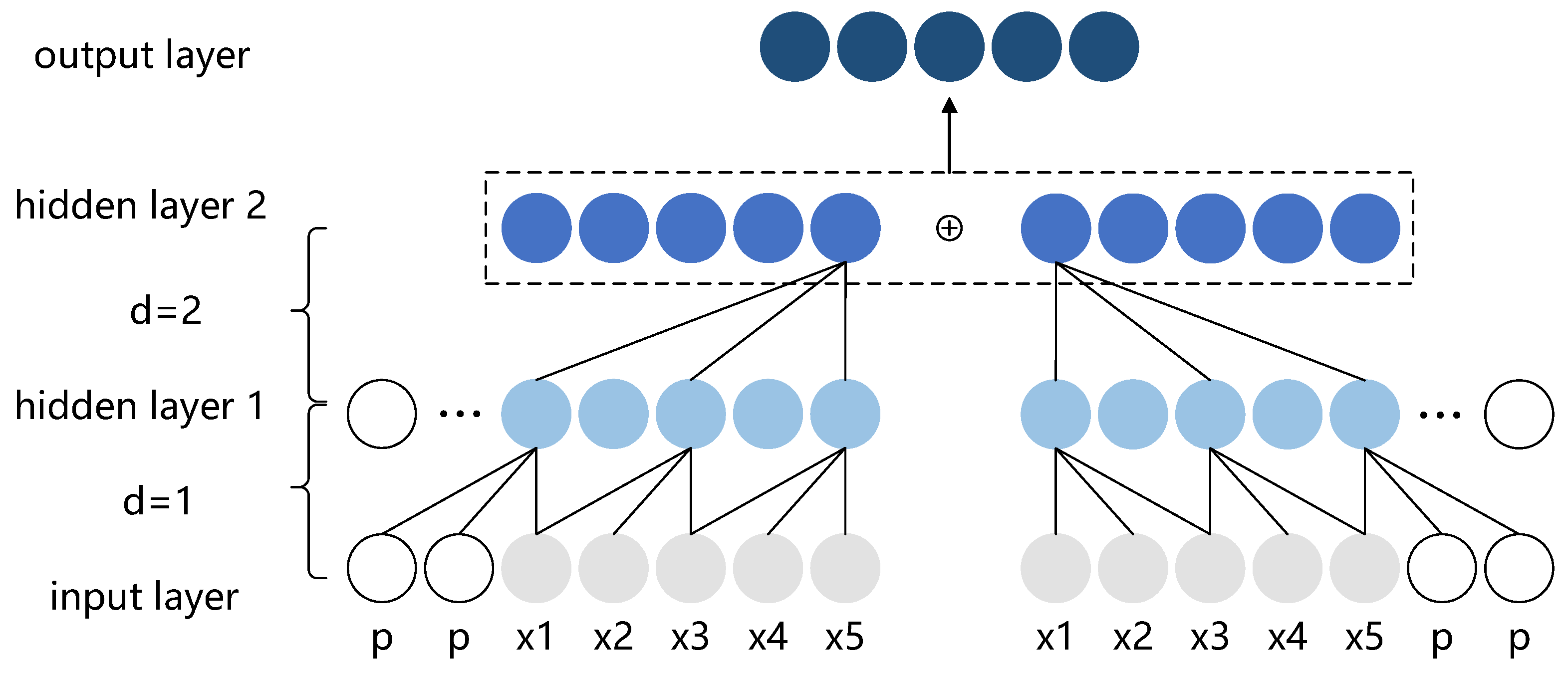
represents the information from past time steps. As an example illustrated in
Figure 1, we input a traffic time series with a time step of 5 into the forward TCN, which captures global features in the future time direction. Meanwhile, we reverse the traffic time series along the time dimension, and input it into the backward TCN, capturing global features in the past time direction. Furthermore, by infusing the results of both the forward and backward TCN, the network can comprehensively learn the characteristics of the traffic time series from both future and past perspectives. After obtaining the infused features from the forward and backward TCN, the BiTCN applies a fully connected layer to integrate all the features extracted in the previous layers and map the extracted features to the final output space to produce the final output.
Although the BiTCN has shown promise in previous traffic detection tasks, it requires substantial improvements to meet the stringent computational and accuracy demands of Federated Learning environments. First, the fully connected layer in the classification module, which contains the highest number of parameters, imposes a significant computational burden on IoT edge devices. Optimizing this component is essential for ensuring feasibility in resource-constrained settings. Furthermore, the absence of an information selection module that does not introduce additional parameters limits the model’s ability to achieve high classification performance, particularly after the fully connected layer has been removed as part of the model lightweighting. In such cases, the model becomes more vulnerable to noise, as operations such as global average pooling—often used as a replacement—tend to aggregate both informative and irrelevant features, thereby diluting the quality of the final representation.
5. Experiments
5.1. Description of Datasets
In our study, we mainly focus on three datasets: Edge-IIoT [
44], the CIC IoT dataset 2023 [
45], and the ToN-IoT [
46,
47,
48,
49] dataset. The Edge-IIoT dataset was released in 2022 and was generated through a purposely constructed testbed. The IoT data come from more than 10 types of IoT devices, such as ultrasonic sensors, heart rate sensors, etc. This dataset includes 13 attacks and benign ones related to IoT and IIoT connectivity protocols. The number of traffic samples in the training set is 211,131 and, in the test set, it is 90,350; each traffic sample has 61 recorded features and 1 label.
The CIC IoT dataset 2023 was released in 2023, and is a novel and extensive IoT attack dataset specifically designed for security analytics in real-world IoT deployments. It collects 33 attacks from 105 IoT devices, categorized into 7 main categories of traffic. We selected 7 of the representative attack categories for our study, such as DNS spoofing and OS scanning. The number of traffic samples in the training set is 160,000 and, in the test set, it is 40,000; each traffic sample has 46 recorded features and 1 label.
Another dataset, ToN-IoT, was released in 2021, collected from a realistic network environment designed at the IoT Lab of the University of New South Wales. The dataset contains normal traffic and nine attack classes, such as MITM, XSS, and ransomware. The number of traffic samples in the training set is 151,439 and, in the test set, it is 40,350; each traffic sample has 44 recorded features and 1 label.
We list all the categories associated with each task for all datasets in
Table 1.
5.2. Experimental Environment and Hyperparameters
We organized our experiments on a Windows 10 operating system with an Intel Xeon(R) Gold 5120 CPU (2.20 GHz, 14 cores, 32 GB) (Intel Corporation, Santa Clara, CA, USA), Python 3.8, Pytorch 2.2.2 deep learning framework. The hyperparameters are set as follows: the loss function is a cross-entropy loss function, the optimizer is the Adam-Optimizer, the learning rate is 0.001, the batch size is 64, and the number of epochs is 10. The model contains 8 residual blocks, each of which consists of one layer of dilated causal convolution and one layer of gated convolution, the dilation rate is (1, 2, 4, 8), and the kernel size is 3.
5.3. Selection of Baselines
To evaluate the performance of the LG-BiTCN model, we selected the following models for experimentation as a comparison.
The bidirectional temporal convolutional network (BiTCN) [
50] utilizes dilated causal convolution to extract local patterns in time series, and uses a bidirectional processing mechanism that is able to efficiently capture the dynamic properties of time series data.
The bidirectional gated recurrent unit (BiGRU) [
51] simplifies the structure of gates, including the update gate and reset gate. The GRU has a simpler structure and lower parameter count than previous gating units, but still handles the retention and transfer of information efficiently. This model is commonly used for traffic time-series prediction, and is capable of capturing long-term dependencies in time series.
Adaptive clustering intrusion detection (ACID) [
52] is an architecture specifically optimized for network edge deployment. The framework presents an edge-optimized architecture featuring a novel adaptive clustering methodology for enhanced feature space representation. The model achieves a perfect accuracy and F1-score (100%) with zero false alarms across four distinct datasets spanning two decades, significantly outperforming conventional clustering network intrusion detection approaches.
5.4. Evaluation Metrics
In order to evaluate the performance of LG-BiTCN in detecting malicious traffic, four metrics are used in this paper: accuracy, precision, recall and F1-measurement. Among them, accuracy indicates the proportion of correctly classified samples to all tested samples and is a measure of the overall performance of the model. Precision indicates the proportion of true positive samples to all samples classified as positive. Recall indicates the proportion of correctly classified positive samples among all true positive samples. F1-measure is the harmonic mean of precision and recall, and is used to comprehensively evaluate the precision and recall of the model. These four metrics are calculated as follows:
where TP denotes the number of positive samples correctly categorized as positive, TN denotes the number of negative samples correctly categorized as negative, FP denotes the number of negative samples categorized as positive, and FN denotes the number of positive samples categorized as negative.
In addition, we use parameter count, floating point operations (FLOPs), and model size to measure the operational performance of the method. The parameter count is related to the kernel size and the number of input and output channels of the model, and measures the use of computational resources such as memory during model training and detection. FLOPs are the number of multiplication and addition operations in the model, which measure the computational overhead of the model. The model size provides a more intuitive reflection of the parameter count and computational resources used in the detection phase, and measures the portability of the method on edge computing devices.
5.5. Ablation Experiment
In this ablation study, we discuss how each of our designed component in the LG-BiTCN model contributes to the overall performance. We conducted ablation experiments on 14 types of tasks on the Edge-IIoTset dataset. The results of the experiments are shown in
Table 2, where (0) represents replacing the gated convolutions in the LG-BiTCN with ordinary causal dilation convolutions, (1) refers to replacing the classification module in the LG-BiTCN, which utilizes a 1 × 1 convolutional layer followed by a hidden layer with 60 neurons after GAP, with a conventional fully connected layer that includes a hidden layer of 600 neurons, (2) represents removing the end-to-end adaptive PCA dimensionality reduction module in the LG-BiTCN, and (3) represents the LG-BiTCN proposed in this paper.
It is evident that our structural design for the LG-BiTCN significantly reduces model complexity while enhancing detection performance. When the end-to-end adaptive PCA dimensionality reduction algorithm in the LG-BiTCN is replaced, the FLOPs, parameter count and model size of the model increase by 43.91%, 41.05% and 37.7%, respectively. However, the accuracy and F1-measure of the model are lower than before. After replacing the lightweight classification module in the LG-BiTCN, the parameter count increases to more than ten times that observed before the modification, the model size grows to more than five times its previous size, and the FLOPs rise by 37.25%. Nonetheless, the detection performance of the model is diminished. All of this proves that the two aforementioned modules not only effectively serve a lightweighting role but also confirm the model’s suitability for real-world IoT malicious traffic detection applications. After replacing the gated convolution, although the FLOPs and parameter count are reduced by 33.2% and 30.7%, respectively, there is a raise of 0.15% for both the accuracy and F1-measure. This indicates that gated convolution can indeed enhance model detection performance while maintaining an acceptable level of computational overhead.
In summary, the architectural design of the LG-BiTCN successfully reconciles the competing demands of computational efficiency and detection accuracy, exhibiting superior performance metrics while maintaining reduced computational overhead.
5.6. Comparison of Detection Results
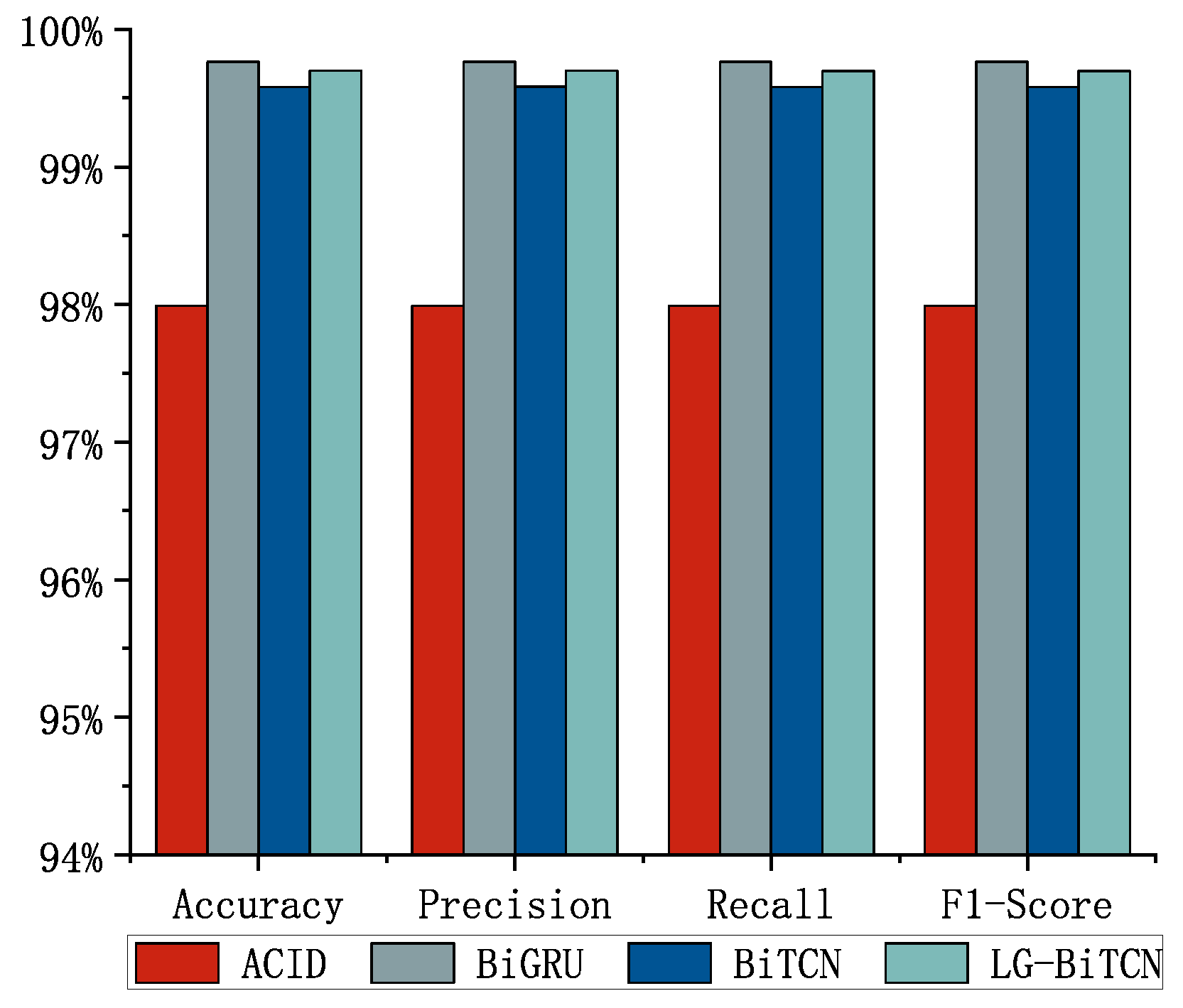
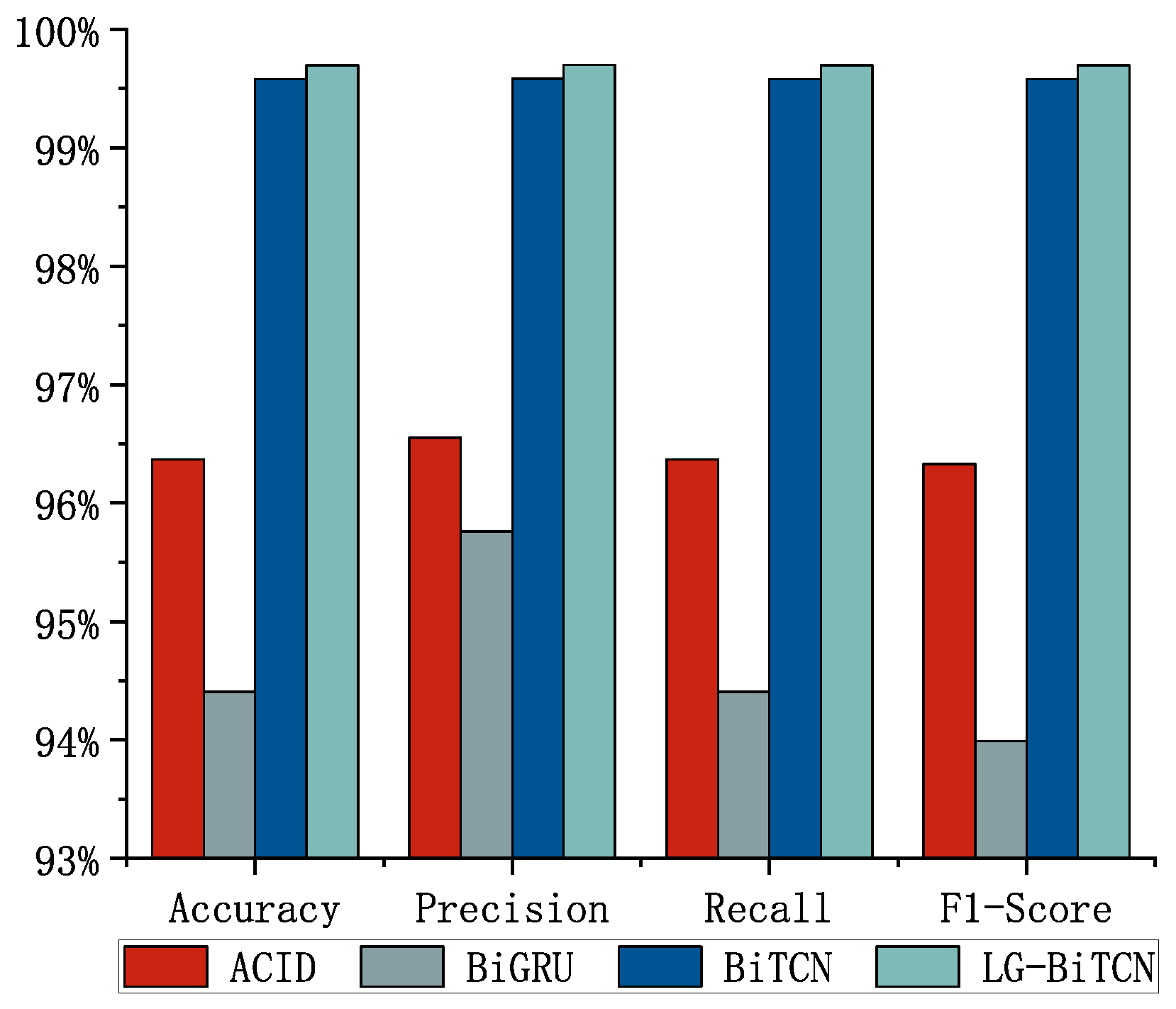
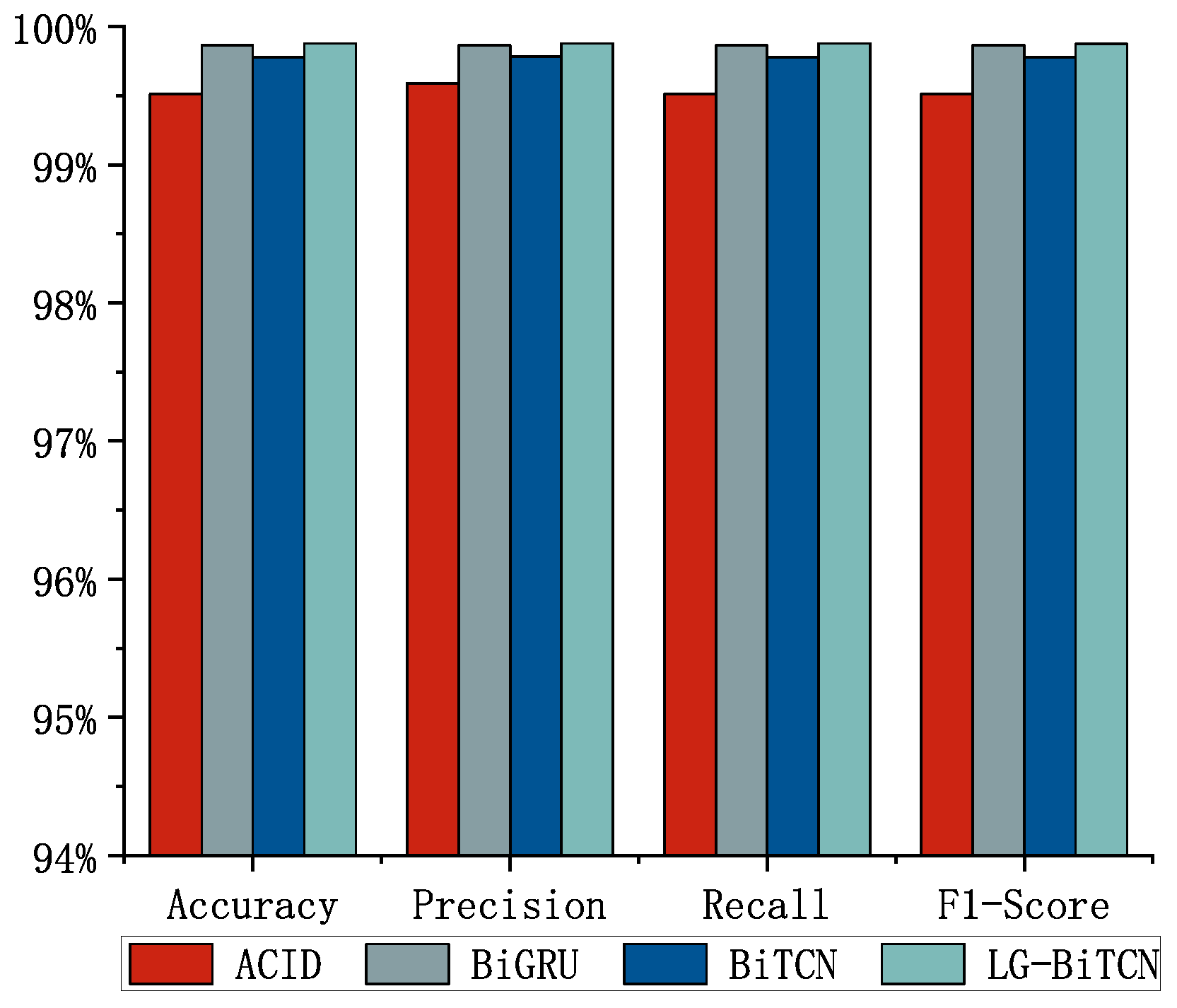
We compared the LG-BiTCN with the other four models on three datasets;
Figure 5,
Figure 6 and
Figure 7 shows the average detection results of 10 experiments, and
Table 3 demonstrates the comparison of the computational overhead of different models. In the 14 classes of tasks on the Edge-IIoT dataset and the 10 classes of tasks on the ToN-IoT, the LG-BiTCN outperforms the other compared models in terms of accuracy, precision, recall, and F1-measure by 99.69% and 99.88%; moreover, it exhibits significantly lower model complexity than the other models.
The best performing model on the CIC IoT 2023 dataset is the BiGRU, which is able to achieve 99.76% accuracy, precision, recall, and F1-score. This is followed by the LG-BiTCN, with metrics 0.07% lower than the BiGRU’s for each of the above four measures. However, it is worth noting that the FLOPs, parameter counts, and model size of the LG-BiTCN are only 6.69%, 7.82%, and 16.67% those of the BiGRU, respectively. Therefore, the LG-BiTCN is still the most suitable model to be deployed on edge devices for cloud–edge cooperative training.
5.7. Effectiveness of Federated-Learning-Based Malicious Traffic Detection
The aforementioned experiments validate the efficacy of the LG-BiTCN in resource-constrained edge environments. To further evaluate its detection capabilities within a Federated Learning framework, we implemented a cloud–edge architecture based on the canonical FedAvg [
53] algorithm. In this setup, edge devices first use the model parameters from the cloud to perform local training, and then transmit the updated parameters back to the cloud for global aggregation. This process is repeated several times to obtain the final global model. The experimental evaluation was conducted using the Edge-IIoT dataset. We set 10 participants representing edge devices to divide the training set into 10 parts, and set the number of local training rounds to 10 and the number of communication rounds between the cloud server and edge devices to 10.
By comparing the F1-scores of the final model under both cloud-centric and Federated Learning approaches, as well as the number of communication rounds required for convergence—where, in Federated Learning, this refers to the communication rounds between the cloud and edge, and, in the cloud-centric approach, it corresponds to the total number of training epochs—we can evaluate their efficiency and effectiveness.
Given that individual edge devices can only capture a limited subset of IoT malicious traffic types, detection models trained exclusively on their local datasets inherently lack the capability to identify the complete spectrum of potential IoT cyberattacks. However, detection models can be trained by sharing intelligence among participants to discover cyberattacks unknown to them. In this study, we assume that the 10 edge devices are E0, E1, E2, E3, E4, E5, E6, E7, E8, and E9, and our experiments are divided into two main scenarios:
Scenario (i): all 10 edge devices are given training samples of all malicious traffic categories.
Scenario (ii): each edge device is given training samples that are missing one malicious traffic category each.
Table 4 and
Table 5 explain the local training sample distribution for the two specific cases considered in our study.
Table 6, on the other hand, shows the distribution of test samples used for evaluating the performance of the global model. Specifically, for scenario (ii), the samples obtained by
E0,
E1,
E2,
E3,
E4,
E5,
E6,
E7,
E8, and
E9 do not contain Ransomware, XSS, PortScanning, Backdoor, Uploading, DDosTCP, VulnerabilityScan, Password, SQLinjection, and Normal, respectively. Furthermore, we also consider the cloud-centric scenario wherein a cloud center performs model training on a comprehensive dataset encompassing all categories of malicious network traffic.
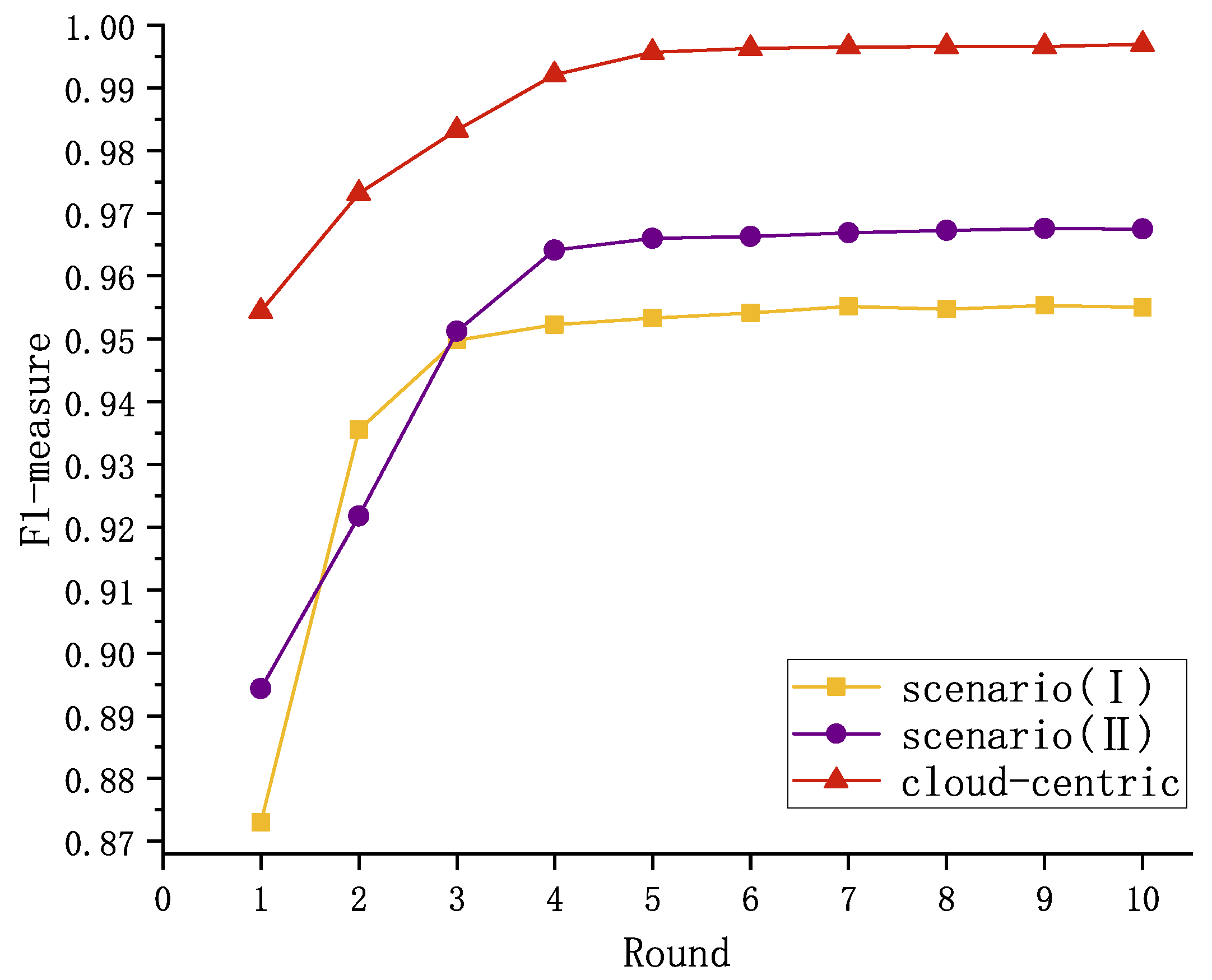
The models obtained through both scenarios were tested on a test set containing the complete set of types; a comparison of the models based on different experimental scenarios is shown in
Figure 8. It is clear that the LG-BiTCN has excellent detection results as well as fast convergence speed in the process of aggregating into the final global model. In scenario (i), although both the anomaly detection performance of the global model in a Federated Learning setting and the convergence speed are affected, the LG-BiTCN model still achieves a classification accuracy of 96.75% after just six rounds of cloud–edge training. Furthermore, starting from the fourth round, the F1-measure is only 3% lower than that observed in the cloud-centric scenario. In scenario (ii), although the model’s final F1-measure and convergence speed were not as good as the other two scenarios, it still reached and stabilized above 95.22% after only four rounds of training, and, considering its ability to share attack intelligence among edge devices to avoid unknown attacks, we conclude that this marginal performance trade-off is acceptable within the context of distributed threat detection. Therefore, the proposed LG-BiTCN demonstrates its viability as a Federated-Learning-based intrusion detection solution for IoT environments. Through federated training, the LG-BiTCN empowers edge devices with enhanced capabilities in detecting previously unseen attack patterns, thereby improving the overall security posture of distributed IoT systems.
6. Conclusions
In this paper, we propose an end-to-end lightweight deep learning model LG-BiTCN based on Federated Learning for IoT malicious traffic detection in order to achieve a robust traffic detection performance within the constraints of rigorous user privacy protection frameworks. We propose an end-to-end adaptive PCA dimensionality reduction algorithm and introduce gated convolution for the BiTCN, as well as optimize the classification layer in the BiTCN with global average pooling and pointwise convolution to ensure the accuracy of the model and to reduce the parameter count of the model as well as the computational resources required and the model size. Th experimental results on the Edge-IIoT dataset, CIC IoT dataset 2023, and ToN-IoT show that the LG-BiTCN not only has lower computational overhead and minimized model size but also has an excellent detection accuracy as well as F1-score. In the experiments on Federated Learning, the LG-BiTCN can converge with very few rounds and achieve detection results higher than 96.75%.
In real-world IoT networks, only a limited proportion of network traffic is labeled. Our future work will explore the integration of active and semi-supervised learning with resource-efficient models to enhance practical malicious traffic detection, addressing both the computational constraints of IoT devices and the challenge of detecting unknown malicious variants.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}