1. Introduction
Recently, recommendation systems driven by deeper and larger deep neural network models have achieved remarkable success [
1,
2]. However, in practice, due to the limited computing power and memory of mobile devices, it is a great challenge to deploy deep recommendation systems on mobile devices [
3,
4] and embedded systems. Training complex models or ensembles of multiple models can result in significant parameter redundancy in deep recommendation systems, and computationally intensive forward prediction conflicts with model effectiveness. In addition, the conflict between model effectiveness and performance becomes particularly acute when selecting items of greatest interest to users from millions of candidates. In practice, online models in recommendation systems should be as compact as possible to meet very stringent response time requirements [
5,
6]. As a result, model compression [
7] has become an important issue that can reduce the number of parameters and the size of the model while maintaining performance.
To address these issues, the concept of knowledge distillation (KD), introduced by Hinton et al. [
8], has been applied to the design of recommendation algorithms. Knowledge distillation is a method for condensing knowledge from complex models into simpler ones, and early applications focused on creating smaller, more efficient models that can be deployed on resource-limited devices. This not only enhances model accuracy, but also reduces model latency and compresses network parameters, which in turn also enables domain transfer between image tags (integrating and transferring datasets from two different domains) and reduces annotation volume. In recommendation systems, by learning user behavior data, building mathematical models, and predicting user’s interest points, we eventually recommend items that users may prefer to satisfy their passive needs and improve user experience. Therefore, knowledge distillation is applied in the design of recommendation algorithms, making the recommendation model more efficient, accurate, and effective in resource utilization.
There have been many surveys on recommendation systems, or from the perspective of the topic being studied, e.g.,cross-domain recommendation [
9,
10,
11], conversational recommendation [
12,
13], the bias and debias problem [
14,
15], multimodal recommendation [
16,
17,
18], bundle recommendation [
19], sequential recommendation [
20,
21], etc. Or from the perspective of the techniques and methods applied, e.g., causal inference [
22,
23,
24,
25], graph neural networks [
26,
27,
28,
29], federated learning [
30,
31,
32], reinforcement learning [
33], AutoML (or Automated Machine Learning) [
34,
35], large language models [
36,
37,
38], diffusion models [
39,
40], etc. Knowledge distillation and the ideas and methods derived from it have more or less penetrated into the above-mentioned topics, techniques, and methods of recommendation systems. Currently, there are also several surveys on knowledge distillation [
41,
42,
43,
44] from different perspectives, and its application in different fields [
45,
46,
47,
48,
49].
Currently, knowledge distillation has been progressively used in recommendation systems. However, although surveys on recommendation systems continue to emerge, the current surveys on knowledge distillation and recommendation systems are discussed in isolation—none of these surveys focus on the applications of knowledge distillation for recommendation. There is a lack of a bird’s eye view of how recommendation systems can incorporate knowledge distillation and integrate it into different parts of the recommendation pipeline, which is crucial for building a technology roadmap/route for recommendation systems empowered by knowledge distillation. The primary focus of this paper is to provide a timely and survey of the application of knowledge distillation in recommendation systems.
The rest of this paper is arranged as follows.
Section 2 discusses the basic concept, necessity and operation mechanism of knowledge distillation recommendation systems.
Section 3 provides a detailed study of the recommended methods of knowledge distillation and classifies them from the perspectives of knowledge types, distillation schemes, and Teacher–Student structure.
Section 4 introduces the discussions on the application of knowledge distillation in industrial recommendation systems.
Section 5 presents some prospective research directions for knowledge distillation recommendation systems. Finally,
Section 6 concludes this study.
2. Overview of Knowledge Distillation Recommendation Systems
The intent here is to explore the basic concepts, necessity, and operational mechanisms related to knowledge distillation recommendation systems.
Knowledge distillation recommendation systems apply knowledge distillation techniques to simplify large and complex models into small, effective and low-cost simple models. By extracting simple and easy-to-understand knowledge from large models and transferring it to small models, small models can learn the representational capabilities of large models. As a result, the simplified models operate faster, reduce computational costs and storage resource consumption, and hence enhance the efficiency, accuracy, and flexibility of the recommendation systems. Further, recommendation systems are highly scalable and portable for different scenarios and platforms.
Knowledge distillation recommendation systems are a new class of recommendation systems. Firstly, complex recommendation algorithms (e.g., deep neural networks, etc.) require lots of computational resources and time for training and prediction, while knowledge distillation recommendation systems can transform a complex model into a simple one, then save computational resources and training times, and hence improve the efficiency of the recommendation systems. Secondly, complex models need more memory and storage space to store weights and features, resulting in increased system complexity. Knowledge distillation recommendation systems can reduce the complexity of complex models to simple ones through model compression and thus improve the interpretability of recommendation systems. Finally, knowledge distillation recommendation systems can enhance the accuracy of the recommendation system by transferring knowledge from complex models to simple ones using transfer learning techniques. For example, when data are sparse, the original complex model will face interference and errors, and knowledge distillation makes the prediction results more accurate by narrowing the model distribution in the target simple model.
The operational mechanism of the knowledge distillation recommendation system is summarized as follows. Firstly, original model training uses a more complex primitive model (e.g., deep neural network) for training to obtain predictions and parameters for each layer. Secondly, the distillation target setting chooses a simple model (e.g., linear model) and defines the distillation target to distill the predictions of the original model into a simple one as accurately as possible. Finally, distillation training uses the prediction results of the original model and the parameters of each layer, as well as the input and output data of the simple model, for distillation training. During the training process, some essential components required for training, such as different loss functions, hyperparameters, etc., can be set as needed. Finally, the recommendation service deploys the trained simple model to recommendation systems, receives user requests, and outputs recommendation results. In summary, knowledge distillation recommendation systems improve the performance and efficiency of recommendation systems by distilling complex models into simple ones, and achieve efficient recommendation services.
In practice, in the work of knowledge distillation recommendation systems, the mechanism of knowledge distillation is mainly reflected in matching recommendation results from the teacher model (abbreviated Teacher, the same as in full text) and the student model (abbreviated Student, the same as in full text), where Teacher’s prediction transmits more information about the subtle differences between items and helps Student to better generalize. If the predictions do not fully reveal Teacher’s knowledge, then the latent knowledge is extracted from the intermediate layer of Teacher. Moreover, given that users’ preferences are represented by relationships with other users and items, Student can utilize the relationship space found in Teacher, where each entity finds more accurate knowledge among entities through its relationships with other entities, thus improving recommendation performance. The framework for knowledge distillation recommendation systems is shown in
Figure 1.
3. Categories of Knowledge Distillation Recommendation Systems
In knowledge distillation, knowledge types, distillation schemes, and Teacher–Student architectures all play a essential role in Student learning. In this section, knowledge distillation recommendation methods are summarized and classified, respectively, from the perspectives of knowledge types, distillation schemes, and Teacher–Student architecture, as shown in
Figure 2.
3.1. Knowledge Types
According to the way of information collected from Teacher, there are three types of knowledge [
41,
42]: response-based knowledge, feature-based knowledge, and relation-based knowledge. This subsection introduces knowledge distillation recommendation methods around this topic.
3.1.1. Response-Based Knowledge Distillation Recommendation Systems
In response-based knowledge distillation recommendation systems, response-based knowledge distillation concentrates on learning knowledge from the final output layer of Teacher as a response. The aim is to match the final predictions between Teacher and Student. Using this approach, Student can be trained to generalize in the same way as Teacher, that is, the output of Student is approximating as much as possible to that of Teacher. The distillation loss function is used to capture the difference in prediction results between Student and Teacher, and minimizing the loss function allows Student to better fit the prediction results of Teacher. In general, given vectors
,
of logits as the output of the last fully connected layer of Teacher and Student separately, the distillation loss of response-based knowledge can be expressed as:
where
denotes the divergence loss of logits,
, and
[
44]. In recommendation systems, response-based knowledge distillation can be used to calculate vector similarity, rank the model, and other tasks to improve model performance. Typically, the prediction result of the final output layer of Teacher is ranking information.
For example, Tang et al. [
50] propose a ranking distillation (RD), which applies pairwise distillation to minimize two loss functions: the ranking loss relative to the ground truth ranking in the training dataset, that is, collaborative filtering loss, and the distillation loss of the top k ranking for unlabeled items, which is used to bootstrap Student. Unlike RD, Lee et al. [
51,
52] propose a new collaborative filtering method, namely collaborative distillation (CD), and apply a point-wise distillation approach to minimize two loss functions: collaborative filtering loss function, which can provide more accurate feedback and avoid the ambiguity of unknown feedback, and the sampling-based knowledge distillation loss function, which can not only distinguish between positive/negative and missing feedback, but also capture users’ relative preferences for different items. Both methods use a negative log-likelihood cross-entropy loss function.
Lee et al. [
53] propose the dual correction strategy for distillation (DCD) based on listwise distillation, and the loss function is divided into two parts. The ranking knowledge distillation (RKD) loss consists of base loss and relaxed ranking distillation (RRD) loss, which are applied to guide Student training. The other part of the dual correction distillation loss consists of the user-side correction distillation (UCD) loss and item-side correction distillation (ICD) loss, which are used to correct the user-side and item-side prediction inconsistencies. It is worth noting that the RKD loss is calculated for the same integer ground-truths, whereas the dual correction loss provides a guide to dynamic changes to train Student more effectively. Thus, the DCD distillation loss is composed of a linear combination of these two components of the loss function.
In summary, response-based knowledge distillation recommendation systems can help to retain the knowledge of large models (Teacher) and effectively transfer it to smaller models (Student), enhance the performance of the recommendation, and hence, enable model compression and acceleration while maintaining high recommendation accuracy. However, even if response-based knowledge distillation has successful applications in many fields, the performance gap remains an unresolved issue. If there is a significant capability gap between Teacher and Student, Student may fail to absorb meaningful knowledge, leading to unfavorable supervision effects. Moreover, response-based knowledge is based on predefined categories whose application is confined to supervised learning, and match the final layer’s predictions, which leads to neglecting intermediate layer’s information, affecting limited recommendation performance enhancement. In addition, for Student, it is a challenge to learn effectively only from the final output of Teacher, especially when the network structure between Teacher and Student is different.
3.1.2. Feature-Based Knowledge Distillation Recommendation Systems
In feature-based knowledge distillation recommendation systems, feature-based knowledge distillation focuses on exploring intermediate feature information distilled from Teacher and is a good complement to response-based knowledge distillation, especially for training shallower and deeper networks [
41,
42]. The basic idea is to fit Student to the representations of the hidden layer of Teacher, i.e., the features distilled from Teacher. Specifically, this is achieved by minimizing the difference in features between Teacher and Student to match the intermediate features, as well as the activation values. In general, the distillation loss of feature-based knowledge can be expressed as
where
and
are the feature maps of the hidden layers of Teacher and Student respectively, the transformation functions
and
are usually applied when Teacher and Student have different shapes of feature maps,
denotes the similarity function used to match the feature maps of Teacher and Student [
41,
44]. The type of feature-based knowledge varies between tasks and applications, such as feature representation, sharing parameters, knowledge amalgamation, parameter distribution, activation boundaries, feature maps, etc.
For example, Kang et al. [
54] proposes a new RS knowledge distillation framework, called DE-RRD, which is composed of two parts: distillation experts (DE) and relaxed ranking distillation (RRD), where DE distillates the corresponding representation space of Student from the intermediate representation space of Teacher (i.e., the output of the middle layer). Distillation Experts Distillation loss is the
(
-norm, which is used frequently, is justified by the fact that it selects more features that are close to zero, thus better improving overfitting) distance between the output of the mapping function to Teacher space (i.e., nested function in the middle layer of Teacher) and the mapping function to Student space. In addition, Zhou et al. [
55] propose a general framework called Rocket Launching, where the Booster Net (Teacher) and the Light Net (Student) share some low-level layers (some lower-level layers) and some parameters, learn category labels, reduce the parameters of the neural network, and improve its generalization ability. The hint loss function is used as the mean square error (MSE) between the Booster Net output and Light Net output, and the distillation loss is a minimized hint loss function.
In summary, feature-based knowledge distillation recommendation systems can effectively retain the key feature information in the original Teacher and transfer it to the simplified Student while reducing the model complexity. This can be done to improve the speed and efficiency of the recommendation while maintaining the quality of the recommendations. In general, feature-based knowledge distillation serves as an advantageous complement to response-based knowledge distillation, offering intermediate features that encapsulate the learning process. However, if there is a significant capability gap or architectural difference, simply aligning feature information at the same stage between Teacher and Student can lead to negative supervision and affect the effectiveness and quality of recommendations. A more valuable effort might be feature-based knowledge distillation that is Student-friendly, providing semantically consistent supervision [
42].
3.1.3. Relation-Based Knowledge Distillation Recommendation Systems
In relation-based knowledge distillation recommendation systems, relation-based knowledge distillation further extends response-based knowledge and feature-based knowledge by extracting and transmitting relations or interaction information between different entities or users in a more comprehensive and in-depth way, and these relationships or interaction information are denoted as knowledge. In general, relationship-based knowledge distillation extracts and transmits cross-sample or cross-layer relationships as meaningful knowledge, rather than aiming to distill knowledge from individual samples [
42].
The idea behind relation-based knowledge RS is that: the interrelationships of data samples in Teacher output representations are applied to mimic the structural relationships between Teacher learning representations, which does not require Student to imitate the Teacher’s representation space, thus providing Student with greater flexibility [
56]. In general, the distillation loss of relationship-based knowledge can be expressed as:
where
and
are the feature maps (or representations) of Teacher and Student respectively,
and
are the similarity functions of the feature maps (or representations) pairs (or sets) from Teacher and Student,
denotes the relation function of the feature maps (or representations) between Teacher and Student [
41,
44]. Relation-based knowledge can be modeled as feature mappings, graphs, similarity matrices, feature embeddings, or correlations between probability distributions based on feature representations, etc., for different tasks and applications.
For example, Kang et al. [
57] propose a general topology distillation method, namely hierarchical topology distillation (HTD), to adaptively find the preference group(s) of the entities, so that the entities within each group have similar preferences. The topology is hierarchical at both the group-level and the entity-level. The group-level topology represents the aggregated relationships between groups and provides a profile of the overall topology. The entity-level topology, on the other hand, represents the relationships between entities within the same group. The loss of distillation in both group-level topology and entity-level topology is the
(
-norm) distance between Teacher topology (matrix) and Student topology (matrix). Chen et al. [
58] propose a scene-adaptive knowledge distillation-based model compression method, called AdaRec, where AdaRec is specified to use NextItNet [
59], SASRec [
60] and BERT4Rec [
61] as Teacher. The general framework of Teacher consists of a bottom embedding layer, hidden layers, and a prediction layer. Embedding layer distillation loss is achieved by minimizing the mean square error (MSE) between Teacher and Student. The loss of prediction layer distillation is achieved by the Kullback–Leibler (KL) divergence between the probability logits of Teacher and Student. The loss of distillation of hidden layers is achieved by using Earth Mover’s Distance (EMD) [
62] metric to measure the distance between Teacher and Student as the minimum cumulative cost of knowledge transfer.
In summary, relationship-based knowledge distillation recommendation systems can help to retain complex relationship information from Teacher, improve the recommendation for Student learning to speed up model training and inference, and hence, reduce the complexity of the model, enabling recommendation systems to make predictions and recommendations more efficient quality of recommendation, which is especially advantageous in scenarios that deal with complex relationships between items. However, modeling and distilling complex relational knowledge may require more computational resources and time for training and reasoning. Effective relational knowledge transfer requires high-quality data and appropriate distillation strategies, which can lead to the loss or misinterpretation of relational information, affecting the accuracy of recommendations. Updating relational knowledge may require constant retraining of the model, which increases the complexity of maintenance and thus affects the quality of recommendations. As a result, how to use more meaningful node transformation and metric function or aggregate appropriate layer information to establish a better relationship model is still the core problem that needs further research [
42].
3.2. Distillation Schemes
According to whether Teacher and Student are updated simultaneously, the knowledge distillation scheme can be directly classified into three categories [
41,
42,
44]: offline distillation, online distillation and self-distillation.
3.2.1. Offline Distillation Recommendation Systems
In offline distillation recommendation systems, the focus of offline distillation is to use a large pre-trained Teacher with excellent performance to guide the training of smaller and faster Student. In practice, offline distillation typically employs a two-stage training pipeline: (1) pretraining Teacher to achieve outstanding performance; and (2) guiding Student to mimic the Teacher’s information during the training phase [
42]. Influenced by the idea of vanilla knowledge distillation, where knowledge in the form of intermediate features or logits is extracted from Teacher and then used to guide Student training. Currently, offline distillation mainly focuses on improving different pipelines of Teacher, including knowledge form, design of loss function, and the matching of probability distribution or expectation.
For example, Xia et al. [
63] proposes a self-supervised knowledge distillation framework, called on-device recommendation (OD-Rec), and designed three types of distillation tasks: the traditional distillation task based on soft targets adopts an embedding recombination strategy where embedding fragments of Teacher and Student are exchanged and combined to distill knowledge, freezes the parameters of Teacher to enable direct information transfer, and produces representation-level augmentation to inherit features from both sides; the contrastive self-supervised distillation tasks facilitate the transfer of information about the Teacher’s representation, not just the output probabilities; and the predictive self-supervised distillation task, guided by Teacher, improves Student’s ability to predict the Ground Truth. The loss function applies the cross-entropy of the negative log likelihood loss function and the Kullback–Leibler (KL) divergence to make Student produce a probability distribution similar to that of Teacher.
Xu et al. [
64] propose a new framework for recommendation systems, called graph structure aware incremental learning (GraphSAIL), and designs three generic components. Firstly, the distillation mechanism of the local structure facilitates the transfer of local topological information from Teacher to Student by regularizing the local neighborhood representation of each node, whose distillation loss minimizes the mean square error of the difference in dot product between Teacher trained with time interval
data and Student trained with time interval
t data. Secondly, the distillation strategy of the global structure encodes the global position of each user and item node, whose distillation loss minimizes the sum of the Kullback–Leibler (KL) divergence between the global structural probability distributions of Teacher and Student. Finally, the degree-aware self-embedding distillation strategy establishes a fixed quadratic constraint between embeddings on historical data and embeddings on new data, and regularizes the learned user and item embeddings, whose distillation loss minimizes
(
-norm) distance of the difference between Teacher trained with time interval
data and Student trained with time interval
t data.
In summary, offline distillation recommendation systems can help reduce model complexity, accelerate inference, and save resource consumption while maintaining the accuracy of the original model. In this way, recommendation systems can better balance the accuracy and efficiency of the model, provide more personalized and efficient recommendation services, and achieve better recommendations in practice. However, offline distillation may not reflect the latest user behavior or market changes in a timely manner, resulting in models that may be outdated. If practice data are not sufficiently comprehensive or biased, Student may not be able to effectively generalize to unseen new data, which may affect recommendation performance. Offline distillation does not adapt to new user behaviors or preferences in real time, especially in dynamically changing environments, which may lead to poor recommendation performance.
3.2.2. Online Distillation Recommendation Systems
In online distillation recommendation systems, online distillation denotes the simultaneous updating of Teacher and Student parameters, and the entire knowledge distillation framework is an end-to-end optimization process, i.e., a group of Students are simultaneously trained from scratch and transfer knowledge to each other during the training phase. In practice, online distillation implementation forms include mutual learning, where two or more Students are trained together and their output knowledge is used as the learning target for each other, and Student plays the role of Teacher for the other Students [
65]; Or ensemble learning, where virtual Teacher is constructed by integrating the output of Student and then distilling it to train Student [
66]; Or collaborative learning, where knowledge integration and transfer are achieved after training multiple independent branches on a task, and simultaneous updating of Student is achieved [
67], etc.
For example, Kweon et al. [
68] propose a new bidirectional knowledge distillation framework, namely bidirectional distillation (BD), for Top-N recommendation systems. The framework adopts each other’s knowledge and binary training sets to train Teacher and Student end-to-end. Specifically, firstly, Teacher and Student generate recommendation lists for each user. Secondly, the proposed rank discrepancy-aware sampling scheme is used for bidirectional distillation, where only distillation fully enhances the knowledge of each other’s information and determines the knowledge transferred in each distillation direction. Finally, two-way training is achieved by training on the distillation loss and original collaborative filtering loss, which in turn enables Teacher and Student to collaborate with each other on the basis of complementarity to improve recommendation accuracy.
Yang et al. [
69] propose a cross-task knowledge distillation framework for multitask recommendation, called cross-task knowledge distillation (CrossDistil). Specifically, augmented ranking-based tasks are designed to introduce secondary tasks with quadruplet loss functions to capture fine-grained ranking information across tasks and prevent task conflicts, alleviating the negative transfer problem, as well as preparation for subsequent knowledge distillation. Calibrated knowledge distillation is applied to transfer knowledge from augmented tasks (Teacher) to original tasks (Student), and accompanied by a bi-level training algorithm that optimizes the parameters of prediction and calibration, respectively. A new error correction mechanism is proposed to implement end-to-end training of teacher and student to speed up the model convergence and further improve the knowledge quality.
In summary, in online distillation recommendation systems, online distillation is able to adapt to the latest user behavior and preferences in real time, adjusting the recommendation strategy in a timely manner to provide more personalized and relevant recommendation results. The online distillation process can be automated, making models typically lighter and more efficient to update and optimize, which allows them to run efficiently on resource-constrained devices (e.g., mobile devices) while maintaining better recommendation performance. Online learning can form a feedback mechanism in which the system can learn based on real-time feedback, enabling continuous improvement of the model and improving the adaptability of the recommendation system in changing environments. However, the implementation of online distillation is usually complex and requires the design of suitable algorithms and frameworks to deal with various challenges in online learning (e.g., data imbalance, noise, etc.). The problem of data sparsity may occur during online learning, especially when the user first uses the recommendation system and lacks sufficient interaction data. Online update may cause the model to be unstable in the short term, especially in the case of high data mobility, and the model may suffer from overfitting or performance fluctuations.
3.2.3. Self-Distillation Recommendation Systems
In self-distillation recommendation systems, self-distillation is centered on the fact that Student does not need a pre-trained Teacher, but instead guides its own training through its own middle-layer features or outputs. In practice, it can adopt two ideas: data-centric self-distillation which uses the same model for mutual regularization during training and considers the output prediction of the model at step
t as the input of the model at step
, and distribution-centric self-distillation which replaces the prior of a given step
t with the posterior of the previous step
[
70]. In addition, the target neural network can be divided into several shallow layers according to its depth and original structure, and the shallow part is trained as Student by distillation of the deepest part in the training phase, or the knowledge of the previous Teacher is transferred to the Student later trained to improve the model performance and reduce the risk of gradient disappearance [
71].
For example, Mi et al. [
72] propose the adaptively distilled exemplar replay (ADER) method to support continuous learning from exemplars by using knowledge distillation loss [
8], periodically repopulating exemplars into the current model with adaptive distillation loss to avoid forgetting the constraints of old user preference patterns, which can effectively avoid catastrophic forgetting in continuous learning. ADER uses a cross-entropy loss function that measures the difference between the output of the previous model and the current model on the samples. In addition, Xu et al. [
73] propose privileged feature distillation (PFD), which applies the same model but different inputs to improve prediction accuracy by distilling the knowledge from the more accurate Teacher into Student, while the implementation of PFD utilizes the privileged feature.
In summary, in self-distillation recommendation systems, self-distillation techniques can help recommendation systems learn and adapt quickly to changes in users and content, thus improving recommendation effectiveness. Through self-learning and iteration, the system can improve its understanding of user interests and behaviors, thus boosting the accuracy and personalization of recommendations. Self-distillation helps recommendation systems avoid over-reliance on specific data or user behavior patterns, thereby enhancing the model’s generalization ability. However, implementing self-distillation requires substantial computational resources and complex algorithm support, which can pose challenges for systems with limited resources. The success of self-distillation depends largely on the quality and diversity of available data; if the data is incomplete or have significant bias, it may affect the quality and stability of recommendations. Self-distillation involves multiple complex algorithms and models, and their tuning and maintenance require continuous fine-tuning work, posing challenges to the management and operation of recommendation systems.
3.3. Teacher–Student Architecture
The Teacher–Student architecture plays an important role in knowledge distillation by which it ensures that Student obtains high-quality knowledge from Teacher [
41]. However, there is often a capacity gap between Teacher and Student, and in order to optimize knowledge transfer, an efficient Teacher–Student architecture needs to be designed. In addition, for better knowledge transfer, a multiple teachers architecture is also developed, in which multiple Teachers may supervise single Student or multiple Students simultaneously, including multiple teachers-single student architecture and multiple teachers-multiple students architecture. This approach is expected to further improve the efficiency of knowledge distillation. This subsection will introduce the knowledge distillation recommendation methods around this topic.
3.3.1. Single Teacher-Single Student Architecture Recommendation Systems
In knowledge distillation, the single (or one) teacher-single (or one) student architecture (STSSA) is a simple model architecture. Recommendation systems generally adopt STSSA, which is influenced by the idea of vanilla knowledge distillation [
8], as shown in
Figure 3. In this recommendation systems, ‘single teacher’ refers to an expert or ‘mentor’ who provides personalized guidance to the user, which can be a recommendation system or an algorithmic model responsible for providing personalized learning content and advice based on the learner’s needs, interests, and behavioral characteristics. ‘single student’ represents each user or learner, which is provided with dynamic support and recommendations by Teacher. The STSSA can be understood as a close connection between each user and a specific recommendation algorithm, model, or content ‘mentor’, and the system will continuously optimize the recommended content that matches the user based on the user’s historical behavior, preferences, needs, and other information. This architecture essentially emphasizes the deep understanding of the individual to provide each user with exclusive customized recommendations, rather than a large-scale unified push of information. Similarly to a personal trainer, the recommendation system gradually adjusts its strategy through a feedback mechanism to make the recommendation results more closely match the specific needs and changes of the user.
In practice, this idea has also been extended. For example, Wang et al. [
74] propose the privileged graph distillation (PGD) model, which consists of three main components. Firstly, Teacher generates comprehensive user and item information, embeddings, and predicts the ratings of items by users. The existing user–item interaction is used to learn the user preference representations and the item representations. Secondly, user Student focuses on new user preference modeling and takes user attributes and items as input. Finally, item Student focuses on new item modeling and takes item attributes and users as input. Xie et al. [
75] propose a new distilled reinforcement learning recommendation framework, namely distilled reinforcement learning framework for recommendation (DRL-Rec), which contains three modules: Teacher and Student module, which applies two RL-based RL-based models to make recommendations and predict the scores of certain items; the exploring and filtering module, which determines the criteria by which unlabeled user–item exploration should be delivered, and selects informative items to solve the problem of “what to deliver” from Teacher to Student; and the confidence-guided distillation module, which uses Kullback–Leibler (KL) divergence-based list-wise to distill Q values in lists and hint loss for intermediate distillations, while learning from real training examples and exploration candidates filtered by knowledge distillation. This approach allows for more efficient distillation between RL-based models and addresses the problem of “how much to learn” for Student.
In summary, in the STSSA recommendation systems, this one-to-one model allows each user to get accurate recommendations, avoiding the cold start problem (e.g., new users do not have historical data and information cannot be accurately matched) that is common in traditional recommendation systems. Through real-time tracking of user behavior changes and feedback, the system can adjust the recommendation strategy in a short time to make the recommended content more accurate and improve the user experience. The recommendation system is more personalized, and users are more likely to feel attentive service, which helps to enhance user trustworthiness and retention rate. Through this deeply customized recommendation, the value of the content or product can be maximized to show that the potential user demand will not be lost due to the generalization of the recommendation. However, one-to-one personalized recommendations require collecting and analyzing large amounts of user behavior data, which consumes significant computing resources and can also lead to data privacy issues. Over-reliance on historical user behavior data may result in overfitting, making it difficult to effectively handle changes in user interests. The one-to-one architecture can alleviate the cold start problem to some extent, but for new users or new content, the system still lacks sufficient information for precise recommendations. Personalized recommendation system models are generally complex, and as the number of users and data volumes increases, maintaining model maintainability and scalability becomes a major challenge.
3.3.2. Multiple Teachers-Single Student Architecture Recommendation Systems
In knowledge distillation, the core idea of multiple (or many) teachers single (or one) student architecture (MTSSA) is to use multiple Teachers to co-direct the training of single Student, so that single Student can incorporate the advantages of different Teachers to improve the generalization ability and robustness. Recommendation systems adopt MTSSA, as shown in
Figure 4. In this recommendation systems, ‘multiple teachers’ means that the system not only relies on a single recommendation algorithm or model but also combines many ‘mentors’, such as expert systems in different domains, collaborative filtering models, deep learning models, etc., to work together to provide recommendations for users. ‘Single student’ means that the system makes personalized recommendations for each user or learner. The design concept of MTSSA is that by aggregating the knowledge and opinions of experts from multiple domains, the system will select the most suitable Teacher (or algorithm) or integrate multiple Teachers (or algorithms) based on Student’s learning history, interests, ability level, etc., so as to improve the diversity, accuracy, and depth of recommendations.
For example, Ding et al. [
76] propose the interpolation distillation (InterD) framework, treating biased and unbiased models as Teachers for label-based distillation. InterD distills knowledge from both environments to Students and automatically adjusts the coefficients of each Teacher at the user–item pair level. The consideration in assigning coefficients is that Students should trust more reliable Teachers in each user–item pair. Therefore, the setting of coefficients is based on the distance between Teacher’s predictions and the observed ratings of the user–item pairs. Furthermore, non-observed data (i.e., missing data) are considered to be included in the InterD, and the coefficients of the non-observed pairs are set as the distance between Student’s prediction and Teachers’ predictions.
In summary, in MTSSA recommendation systems, multiple Teachers guide single Student in learning and recommendation tasks through their specific experience and knowledge. Specifically, the multiple Teachers can be different neural network models, each of which produces different predictions or recommendations based on its own training data and experience. Student, on the other hand, integrates and refines the knowledge of multiple Teachers through distillation techniques to learn a more generalized and efficient knowledge representation to improve the performance and effectiveness of the recommendation systems. The advantage of this architecture is that it can combine the advantages of multiple Teachers to make up for the shortcomings of a single model, and help Student better understand and generalize the knowledge of Teacher through knowledge distillation. However, integrating multiple Teachers requires large computational resources and complex architectural design. The system needs to obtain information from multiple domain models, and it is a challenge to effectively synchronize user data among different models and make reasonable trade-offs in the recommendation process. If a multiple teachers recommendation system relies too much on certain domain models and ignores the contributions of other models, it may run the risk of overfitting, which may affect the diversity and accuracy of recommendations.
3.3.3. Multiple Teachers-Multiple Students Architecture Recommendation Systems
In knowledge distillation, the core idea of multiple (or many) teachers-multiple (or many) students architecture (MTMSA) is to utilize multiple Teachers to collaboratively train multiple Students and to build a more powerful and flexible application system through knowledge complementarity among Teachers and collaborative learning among Students. Recommendation systems adopt MTMSA, as shown in
Figure 5. In this recommendation systems, ‘multiple teachers’ indicates that the system employs multiple recommendation algorithms, content providers, or experts to generate recommendations. These Teachers are tasked with providing accurate outputs or making predictions about user interests, and can have expertise in different domains or topics to be able to provide diverse and specialized recommendations. ‘Multiple students’ indicates that the system serves many users or learners. Multiple Students then learn from these Teachers and gradually adjust their parameters so that they can show better performance in specific tasks. The design concept of MTMSA is that each Student aims to mimic the behavior of multiple Teachers, which are typically trained by different algorithms (e.g., collaborative filtering, deep learning, matrix factorization, etc.). During the training process, Students constantly adjust their parameters in order to make their outputs as close as possible to the outputs of Teachers.
For example, Du et al. [
77] propose an ensemble modeling and contrastive knowledge distillation (EMKD) approach for sequential recommendation that employs multiple parallel networks as an ensemble of sequential encoders to improve the overall prediction accuracy and recommends items based on the distribution of outputs from all these networks. To facilitate knowledge transfer between parallel networks, a novel contrastive knowledge distillation approach is introduced to achieve knowledge transfer at the representational level through intra-network contrastive learning (ICL) and cross-network contrastive learning (CCL), and to complete knowledge distillation at the logit level by minimizing the Kullback–Leibler (KL) divergence between the output distributions of Teacher network and Student network. All networks at the logit level can simultaneously act as Students, learning knowledge from other peer networks, and as Teachers, transferring knowledge to other peer networks. Thus, knowledge at the logit level can be efficiently shared and transferred between all parallel networks.
In summary, multiple Teachers provide multi-perspective knowledge (e.g., collaborative filtering, content features, graph structure), and multiple Students integrate this knowledge through collaborative learning to improve generalization. Different Students can be optimized independently for different tasks (e.g., click-through prediction, cold-start processing, diversity control) to avoid multi-objective conflicts of a single model. Local failures (e.g., overfitting, data bias) of Teachers or Students can be compensated by other models, resulting in a more stable system as a whole. Supports dynamic addition of new Teachers or Students (e.g., introduction of new modal Teachers), which is suitable for rapid business iteration. Different Teachers/Students can be deployed at different privacy levels (e.g., edge devices, center servers) to meet data isolation requirements. However, MTMSA tends to require more computational resources and storage space, especially when the models are large or the number of Teachers is high, and the time overhead for training and inference may increase significantly. Managing the training process of multiple Teachers and Students, how to appropriately distribute weights and influence, and how to coordinate learning among different models may bring increased complexity to the system. The opinions of different Teachers may be conflicting, and it is a challenge to allow the knowledge and advice of multiple Teachers to be effectively transferred to Students to avoid conflicting information or divergence in model learning. The MTMSA represents the evolution of recommendation systems towards modularity and collaboration, but its complexity requires strong algorithmic and engineering skills from the team. In the future, AutoML technology may be combined to achieve automated architecture design.
3.4. Summary of Knowledge Distillation Recommended Methods
In different scenarios for the application of recommendation systems, knowledge distillation recommendation methods are used to solve different problems, and the corresponding knowledge types should be selected. To acquire the corresponding types of knowledge, the appropriate distillation schemes need to be selected. To implement the selected distillation schemes, the suitable Teacher–Student architecture has to be designed. Conversely, the designed and selected Teacher–Student architecture affects the implementation of distillation schemes, which in turn affects the quality of the generated knowledge, and finally affects the performance of the selected recommendation method in problem solving. Currently, the main methods of recommendation for knowledge distillation in the existing literature, including the representative methods introduced above, are classified and summarized according to knowledge types, distillation schemes, and Teacher–Student architecture, as shown in
Table 1,
Table 2,
Table 3.
4. Applications of Knowledge Distillation in Industrial Recommendation Systems
Recommendation systems are significantly different between academia and industry, yet there is a close relationship between them. Theoretical research in academia provides the foundation and innovation for industry, while practical applications in industry provide real problems and data for academic research. Recommendation systems in industry generally have three cascading links: recall, pre-ranking, and ranking. This section presents an exploration of applications of knowledge distillation in industrial recommendation systems in terms of three cascading links of recommendation systems [
90,
91].
4.1. Knowledge Distillation Adopted in Ranking
The idea behind knowledge distillation adopted in ranking is that: in offline training, a complex fine-ranking model can be used as Teacher and a simpler deep neural networks (DNN) ranking model as Student to enhance Student’s expressiveness and recommendation effectiveness. In addition to adopting the conventional Ground Truth training data, Teacher can also assist Student training and transfer some knowledge learned by the complex Teacher to Student to enhance the expression ability of the model and strengthen its recommendation effect. When the model is served online, a small Student is used as the online service to improve the speed of online reasoning and ensure recommendation quality. The knowledge distillation technique thus not only improves the model recommendation quality, but also speeds up online reasoning.
Currently, in the recommendation field, knowledge distillation is adopted in ranking stage, mainly using the method of joint training (i.e., the complex Teacher is used to guide Student trained offline, and both are trained simultaneously) between Teacher and Student, while the purpose is to guide the training of small Student by complex Teacher, promoting Student online service performance and increasing the model response speed. For example, Zhou et al. [
55] propose a general framework, called Rocket Launching, which has three main points: first, two models are trained simultaneously; second, Teacher and Student share feature embedding; and third, knowledge distillation is performed through Logits. Moreover, iQIYI proposes a dual-towers DNN ranking model in the ranking stage [
92], which can be seen as a further improvement of the Rocket Launching model, where Teacher of the dual-DNN ranking model can be more flexible to integrate various different methods between the feature embedding layer and the multi-layer perceptron (MLP) layer, so that the feature combination function reflects the stronger model expression and generalization ability of Teacher.
4.2. Knowledge Distillation Adopted in Recall/Pre-Ranking
The idea behind knowledge distillation adopted in recall/pre-ranking is that: the complex ranking model is used as Teacher, and the recall or pre-ranking model is used as small Student, such as the dual-towers DNN model [
92], etc.; the knowledge distillation makes Student not only close to the effect of Teacher, but also satisfies the speed requirement of the recall or pre-ranking, so as to guide the optimization process of the recall or pre-ranking Student. By simulating the ranking results of the ranking model, Student can be applied to align the optimization goals of the recall or ranking with the final optimization goals of the recommendation task. Note that if the recall or pre-ranking model is single-objective, the Ground Truth optimization objective is included. If the recall or pre-ranking model is multi-objective, the new model distillation objective needs to be added to the original multi-objective, or only the distillation model needs to be used to replace the previous multi-objective model.
For example, Tang et al. [
50] proposes Ranking Distillation (RD), which utilizes point-wise (reducing the learning problem to a single item ranking problem) loss and pair-wise (modeling training data pairs that can maintain ordinal relationships) loss, and adds teacher’s top-K items as positive examples, but no negative examples were selected and added to Student for training together. Besides, the Instagram recommendation system adopts knowledge distillation in the pre-ranking, and applies the ranking model as Teacher to guide the optimization of Student, whose optimization objective employs the widely used list-wise (modeling the order relationship of the whole ranking list) loss function NDCG (Normalized Discounted Cumulative Gain) [
93].
4.3. Assumption of Applying Knowledge Distillation to Jointly Train Recall, Pre-Ranking and Ranking Models
Joint training means that Teacher and Student are trained on the same training sample in the same training process, and Teacher and Student update the parameters (forward reasoning plus backpropagation) simultaneously. The idea of applying knowledge distillation to jointly train recall, pre-ranking and ranking models is that: a very complex but effective ranking model can be designed as Teacher, and then trained jointly with three Students: recall Student, pre-ranking Student and ranking Student. The ranking Student can apply logits and hidden layer feature responses to optimize the results, while the recall Student and pre-ranking Student pursue the best possible results with a small model. By means of knowledge distillation, the effectiveness of each link can be improved simultaneously and the consistency of the goals of each link of the recommendation system can be maintained. This joint training model design can maximize the effect of multi-link gain from one training.
In summary, the academic community typically focuses on theoretical research and algorithm innovation, emphasizing the establishment of fundamental theories, model optimization, interpretability of algorithms, and the effectiveness of various recommendation strategies, which provides new ideas and tools for industrial development. In contrast, industry places greater emphasis on practical applications and commercial value, with the aim of developing recommendation systems that can function effectively in real-world environments. Industry provides large-scale authentic user behavior data for empirical research and algorithm validation by academia, which in turn leads to optimization and improvement; the actual needs and challenges posed by industry also offer new challenges and research directions for academic studies. As a result, exploring the application of knowledge distillation in industrial recommendation systems is a research direction of practical significance and value in the recommendation systems field.
5. Future Directions
Research has been conducted to show that knowledge distillation recommendation systems are of great interest, but several issues still need to be addressed to meet the challenges of practical applications. Future research directions include the following areas.
5.1. Neural Architecture Search-Based Distillation Recommendation
In knowledge distillation recommendation systems, the success of knowledge transfer is dependent not only on the knowledge of Teacher, but also on the Teacher–Student architecture. The relationship between the Teacher–Student architecture can significantly affect the performance of knowledge distillation [
41]. Recent research has found that the model capacity gap between Teacher and Student allows Student to learn very little from some Teachers [
71], therefore, it is necessary to design adaptive Teacher–Student learning architecture. Neural architecture search (NAS) aims at automatically identifying deep neural models and adaptively learning the appropriate deep neural structures. The NAS idea is applied in knowledge distillation recommendation methods [
58]. NAS-based distillation recommendation, that is, the joint search for Student structure and knowledge transfer under the guidance of Teacher, bridges the possible capacity gap between Teacher and Student, finds the suitable Teacher–Student architecture, and improves the performance of the knowledge distillation recommendation method, which will be a topic of interest and research.
5.2. Attention-Based Distillation Recommendation
In knowledge distillation recommendation systems, it is crucial to transfer the rich knowledge of Teacher to Student. Due to the limitation of computational power, attention mechanisms are introduced into knowledge distillation to help allocate limited computational resources to process more important information, thus solving the problem of information overload and defining different attention transfer mechanisms [
94,
95]. The core of attention transfer is to define attention mapping for the features embedded in the neural network layers, namely, knowledge about the feature embedding is transferred through an attention mapping function [
41]. Attention-based distillation recommendation, which introduces the attention transfer mechanism to enhance the performance of knowledge distillation recommendation methods, is also a topic worth investigating.
5.3. Cross-Modal Distillation Recommendation
Multimodal fusion is currently introduced to recommendation systems for solving problems such as data sparsity and cold starts [
17]. Multimodal fusion is used in recommendation systems where data or labels for certain modalities may not be available during training or testing [
96]. When there are modal differences, such as lack of paired samples between different modes, or in order to complement the features of different modes, cross-modal knowledge transfer is needed [
41]. Therefore, it is important to transfer knowledge between different modalities, and knowledge distillation in the Teacher–Student architecture allows for the transfer and preservation of cross-modal knowledge, which in turn leads to cross-modal distillation and the transfer of knowledge between multiple domains [
97,
98]. In addition, how to enable machine learning models to accept information from different modal types, and to complement knowledge and information for more fully understanding entities or behaviors, is also a trend in ranking model discovery in the recommendation field, so cross-modal distillation recommendation deserves further study.
5.4. Lifelong Learning-Based Distillation Recommendation
In practice, recommendation systems need to constantly adapt to consider new and outdated items and users, and require lifelong learning (a.k.a.incremental learning/continuous or continual learning), while lifelong learning using neural network models suffers from catastrophic forgetting, that is, a model trained by lifelong learning forgets the users’ preference patterns it has learned before [
72]. In knowledge distillation recommendation systems, to address catastrophic forgetting of lifelong learning using neural network models [
99], knowledge distillation is used to maintain the performance of old tasks and adapt to new tasks, with a focus on how to maintain the performance of old tasks when training new data to alleviate catastrophic forgetting, thus lifelong learning-oriented distillation came into being. Recently, some lifelong learning-based knowledge distillation methods have been proposed to address catastrophic forgetting in lifelong learning, e.g., Global Distillation [
100], Lifelong GAN [
101], with M2KD [
102], and other methods [
103], etc. At present, as deep neural networks have been applied on a large scale in recommendation systems, lifelong learning-oriented distillation recommendation is also a promising and worthy direction to explore in depth to address the practical challenges of recommendation methods in the future.
5.5. Federated Learning-Based Distillation Recommendation
Recently, federated learning has been introduced into recommendation systems to form federated recommendation systems, which have attracted attention due to their ability to protect user privacy by retaining private data on client devices [
30,
31,
32]. At the same time, knowledge distillation has been widely used in federated learning to form federated distillation [
47,
48], which provides a new approach to personalized and efficient model training while protecting user privacy by leveraging knowledge distillation to aggregate features of client models and facilitate collaborative model training. However, federated recommendation systems also suffer from some issues, including privacy risks, communication costs, unbalanced data, system heterogeneity, etc. To address these issues, federated distillation is expected to be used more widely in the field of federated recommendation systems in the future.
5.6. Graph-Based Distillation Recommendation
Recently, graph neural networks have been widely applied in recommendation systems, because most of the data in recommendation systems essentially have a graph structure and graph neural networks have advantages in graph representation learning [
26,
27,
28]. However, graph neural networks are difficult to deploy in resource-limited devices due to scalability constraints imposed by model size and multi-hop data dependency, making their performance highly dependent on high-quality labeled data. To address the scarcity of labeled data and the high complexity of graph neural networks, knowledge distillation has been introduced to advance existing graph neural networks [
45,
46]. In recommendation systems, with the development of graph scale, the design of the existing graph model is increasingly complex, which brings some challenges to graph model calculation and graph storage, it is also faced with the problem that model calculation is expensive and cannot be run on mobile or embedded devices [
46]. To solve the contradiction between model effect and response speed, graph distillation came into being. Currently, graph-based distillation algorithms can be used to solve cold start [
74], collaborative filtering [
88], tail generalization [
104], and incremental learning [
105], etc. As a result, graph-based distillation recommendation should be a natural and compelling choice.
5.7. Diffusion-Based Distillation Recommendation
Precisely because diffusion models in recommendation systems excel in managing complex user and item distributions and do not suffer from mode collapse, diffusion-based recommendation systems have recently been shown to be superior to traditional generative recommendation methods (e.g., Variational Auto Encoders and Generative Adversarial Networks). [
39,
40], such as DiffRec [
106,
107], DMI [
108], CDiff4Rec [
109], DiffuRecSys [
110], DRGO [
111], and DMCDR [
112], etc. However, as a typical real-time service, recommendation systems are extremely time sensitivity and resource constraints in terms of large-scale users/projects, which poses a great challenge to the efficiency and scalability of diffusion-based recommendations; in the training phase of diffusion-based recommendation systems, slow generation will limit the training efficiency of downstream recommendation models, which typically requires a large amount of training data and update frequency; the diffusion-based recommendation are directly deployed for real-time online services, where the user request should be responded to within around tens of milliseconds [
39,
40]. To address the above issues, it is crucial and beneficial to develop better strategies to achieve better model compression and explore how to distill the knowledge of diffusion models, and thus diffusion-based distillation has come into being [
113]. Given that diffusion models can successfully obtain fine-grained knowledge (i.e., marginal score functions) of the underlying distribution in recommendation systems, diffusion-based distillation recommendation is worthwhile to invest future efforts in recommendation systems.
5.8. Large Language Models-Based Distillation Recommendation
Recently, large language models (LLMs) have been used effectively for recommendation due to their powerful semantic reasoning ability, and remarkable results have been achieved [
36,
38]. The main advantage of incorporating LLMs into recommendation systems is that they can extract high-quality representations of textual features and utilize the large amount of external knowledge encoded therein, which is usually attributed to the increase in training data and model parameters [
114,
115]. However, scaling up of parameter sizes and the increase in training data bring significant drawbacks, especially inference costs and large memory requirements, which create challenges for practical deployment and require recommendation systems with high inference memory and latency. To address these issues, knowledge distillation is used to reduce the number of parameters while maintaining the highest performance, lowering the computational resource requirements and increasing the speed of inference without drastically sacrificing performance [
49], thereby LLMs-based distillation recommendation came into being, such as, DLLM2Rec [
116], SLMRec [
117], ALKDRec [
118], and KEDRec-LM [
119], etc. Given that LLMs have successfully become the cornerstone of augmented recommendation systems with their powerful generalization capabilities and inference skills, LLMs-based distillation recommendation is expected to revolutionize the traditional recommendation framework and lay the foundation for a new era of recommendation [
120].
6. Conclusions
Knowledge distillation recommendation system is a technique to improve the performance of recommendation models through transfer learning. This survey firstly introduces in detail the background of knowledge distillation technology applied to recommendation systems, which also cites some survey papers related to some hot topics and technologies of recommendation systems, not only to expand the research field of knowledge distillation applied to recommendation systems, but also to cite some ideas, opinions, and methods from these papers, in order to facilitate the subsequent introduction of various types of recommendation methods and to summarize the future research direction. It then provides an overview of knowledge distillation recommendation systems, which discusses in detail the basic concepts, necessity, and operational mechanisms related to knowledge distillation recommendation systems. Next, it elaborates on various types of recommendation methods based on the three elements of knowledge distillation (i.e., knowledge types, distillation mechanism, and Teacher–Student architecture), discussing in particular the viewpoints, ideas, and design concepts of each type of recommendation method, as well as presenting some representative related work as examples. Next, it elaborates on various types of recommendation methods based on the three elements of knowledge distillation (i.e., knowledge types, distillation schemes, and Teacher–Student architectures), discussing in particular the viewpoints, ideas, and design concepts of each type of recommendation method, as well as presenting some representative related work as examples. Knowledge distillation recommendation systems are at the forefront of lightweight AI model and knowledge transfer, and are particularly suitable for industrial-scale large-scale recommendation scenarios, but their success relies on the quality of Teacher and the design of the distillation strategy. Thus, it explores the idea of applying knowledge distillation in industrial recommendation systems from the viewpoint of recall, pre-ranking, and ranking. Finally, it identifies some open research directions worthy of further efforts to advance the field of knowledge distillation recommendation systems. It should be noted that machine learning is the underlying methodology, deep learning is a subset of it, and knowledge distillation is an advanced technique for model optimization. Deep learning solves the bottleneck of traditional machine learning on high-dimensional data, and knowledge distillation further solves the problem of high computational cost of deep learning models. In addition, knowledge distillation can be regarded as a technical application of deep learning, which takes advantage of the properties of complex model learning and representation learning in deep learning. Thus, knowledge distillation is both a part of machine learning and an optimization strategy in deep learning that aims to improve and simplify models by transferring knowledge. As a result, it is hoped that this survey could serve as an informative background and a foundational roadmap for researchers and practitioners to advance recommendation systems through technological updates and innovative application of knowledge distillation.
Author Contributions
Conceptualization, H.S. and L.C.; methodology, H.S.; software, H.S.; validation, H.S., Y.Z. (Yibowen Zhao) and Y.Z. (Yixin Zhang); formal analysis, H.S.; investigation, H.S.; resources, H.S., Y.Z. (Yibowen Zhao) and Y.Z. (Yixin Zhang); data curation, H.S., Y.Z. (Yibowen Zhao) and Y.Z. (Yixin Zhang); writing—original draft preparation, H.S.; writing—review and editing, H.C. and H.S.; visualization, H.S. and Y.Z. (Yixin Zhang); supervision, H.C. and L.C.; project administration, L.C.;funding acquisition, L.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research is partially supported by the Natural Science Foundation of China (No. 92367202).
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest. The funding sponsor provides financial support, constructive guidance on the conception of the paper and professional reviews of the writing of the paper in the study.
References
- Gkillas, A.; Kosmopoulos, D. A cross-domain recommender system using deep coupled autoencoders. arXiv 2022, arXiv:2112.07617. [Google Scholar]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional Matrix Factorization for Document Context-Aware Recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems (RecSys’16). Association for Computing Machinery, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- He, X.; Du, X.; Wang, X.; Tian, F.; Tang, J.; Chua, T.-S. Outer Product-based NeuralCollaborativeFiltering. arXiv 2018, arXiv:1808.03912. [Google Scholar]
- Xue, H.-J.; Dai, X.; Zhang, J.; Huang, S.; Chen, J. Deep Matrix FactorizationModelsfor Recommender Systems. In Proceedings of the 26th International Joint Conferenceon Artificial Intelligence (IJCAI’17), Melbourne, Australia, 19–25 August 2017; pp. 3203–3209. [Google Scholar]
- Chen, X.; Yao, L.; McAuley, J.; Hou, G.; Wang, X. A Survey of Deep Reinforcement Learning in Recommender Systems: A Systematic Review and Future Directions. arXiv 2016, arXiv:2109.03540. [Google Scholar]
- Wu, Y.; DuBois, C.; Zheng, A.; Ester, M. Collaborative Denoising Auto-Encoders for Top-N Recommender Systems. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining (WSDM’16), San Francisco, CA, USA, 22–25 February 2016; pp. 153–162. [Google Scholar]
- Buciluundefined, C.; Caruana, R.; Niculescu-Mizil, A. Model Compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’06), Philadelphia, PA, USA, 20–23 August 2006; pp. 535–541. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zang, T.; Zhu, Y.; Liu, H.; Zhang, R.; Yu, J. A Survey on Cross-domain Recommendation: Taxonomies, Methods, and Future Directions. arXiv 2022, arXiv:2108.03357. [Google Scholar] [CrossRef]
- Chen, S.; Xu, Z.; Pan, W.; Yang, Q.; Ming, Z. A Survey on Cross-Domain Sequential Recommendation. arXiv 2024, arXiv:2401.04971. [Google Scholar]
- Zhang, H.; Cheng, M.; Liu, Q.; Jiang, J.; Wang, X.; Zhang, R.; Lei, C.; Chen, E. A Comprehensive Survey on Cross-Domain Recommendation: Taxonomy, Progress, and Prospects. arXiv 2025, arXiv:2503.14110. [Google Scholar]
- Jannach, D.; Manzoor, A.; Cai, W.; Chen, L. A Survey on Conversational Recommender Systems. arXiv 2020, arXiv:2004.00646. [Google Scholar] [CrossRef]
- Gao, C.; Lei, W.; He, X.; Rijke, M.; Chua, T.-S. Advances and Challenges in Conversational Recommender Systems: A Survey. arXiv 2021, arXiv:2101.09459. [Google Scholar] [CrossRef]
- Chen, J.; Dong, H.; Wang, X.; Feng, F.; Wang, M.; He, X. Bias and Debias in Recommender System: A Survey and Future Directions. arXiv 2021, arXiv:2010.03240. [Google Scholar] [CrossRef]
- Klimashevskaia, A.; Jannach, D.; Elahi, M.; Trattner, C. A Survey on Popularity Bias in Recommender Systems. arXiv 2023, arXiv:2308.01118. [Google Scholar] [CrossRef]
- Liu, Q.; Hu, J.; Xiao, Y.; Gao, J.; Zhao, X. Multimodal Recommender Systems: A Survey. arXiv 2023, arXiv:2302.03883. [Google Scholar] [CrossRef]
- Zhou, H.; Zhou, X.; Zeng, Z.; Zhang, L.; Shen, Z. A Comprehensive Survey on Multimodal Recommender Systems: Taxonomy, Evaluation, and Future Directions. arXiv 2023, arXiv:2302.04473. [Google Scholar]
- Liu, Q.; Zhu, J.; Yang, Y.; Dai, Q.; Du, Z.; Wu, X.; Zhao, Z.; Zhang, R.; Dong, Z. Multimodal Pretraining, Adaptation, and Generation for Recommendation: A Survey. arXiv 2024, arXiv:2404.00621. [Google Scholar]
- Sun, M.; Li, L.; Li, M.; Tao, X.; Zhang, D.; Wang, P.; Huang, J.X. A Survey on Bundle Recommendation: Methods, Applications, and Challenges. arXiv 2024, arXiv:2411.00341. [Google Scholar]
- Dang, Y.; Yang, E.; Liu, Y.; Guo, G.; Jiang, L.; Zhao, J.; Wang, X. Data Augmentation for Sequential Recommendation: A Survey. arXiv 2024, arXiv:2409.13545. [Google Scholar]
- Pan, L.; Pan, W.; Wei, M.; Yin, H.; Ming, Z. A Survey on Sequential Recommendation. arXiv 2024, arXiv:2412.12770. [Google Scholar]
- Luo, H.; Zhuang, F.; Xie, R.; Zhu, H.; Wang, D. A Survey on Causal Inference for Recommendation. arXiv 2023, arXiv:2303.11666. [Google Scholar] [CrossRef]
- Xu, S.; Ji, J.; Li, Y.; Ge, Y.; Tan, J.; Zhang, Y. Causal Inference for Recommendation: Foundations, Methods and Applications. arXiv 2023, arXiv:2301.04016cs. [Google Scholar] [CrossRef]
- Gao, C.; Zheng, Y.; Wang, W.; Feng, F.; He, X.; Li, Y. Causal Inference in Recommender Systems: A Survey and Future Directions. arXiv 2023, arXiv:2208.12397. [Google Scholar] [CrossRef]
- Zhu, Y.; Ma, J.; Li, J. Causal Inference in Recommender Systems: A Survey of Strategies for Bias Mitigation, Explanation, and Generalization. arXiv 2023, arXiv:2301.00910. [Google Scholar]
- Gao, C.; Zheng, Y.; Li, N.; Li, Y.; Qin, Y.; Piao, J.; Quan, Y.; Chang, J.; Jin, D.; He, X.; et al. A Survey of Graph Neural Networks for Recommender Systems: Challenges, Methods, and Directions. arXiv 2021, arXiv:2109.12843. [Google Scholar] [CrossRef]
- Wu, S.; Sun, F.; Zhang, W.; Xie, X.; Cui, B. Graph Neural Networks in Recommender Systems: A Survey. arXiv 2022, arXiv:2011.02260. [Google Scholar] [CrossRef]
- Wang, S.; Hu, L.; Wang, Y.; He, X.; Sheng, Q.Z.; Orgun, M.A.; Cao, L.; Ricci, F.; Yu, P.S. Graph Learning based Recommender Systems: A Review. arXiv 2021, arXiv:2105.06339. [Google Scholar]
- Wu, B.; Wang, Y.; Zeng, Y.; Liu, J.; Zhao, J.; Yang, C.; Li, Y.; Xia, L.; Yin, D.; Shi, C. Graph Foundation Models for Recommendation: A Comprehensive Survey. arXiv 2025, arXiv:2502.08346. [Google Scholar]
- Sun, Z.; Xu, Y.; Liu, Y.; He, W.; Kong, L.; Wu, F.; Jiang, Y.; Cui, L. A Survey on Federated Recommendation Systems. arXiv 2023, arXiv:2301.00767. [Google Scholar] [CrossRef]
- Jiang, J.; Zhang, C.; Zhang, H.; Li, Z.; Li, Y.; Yang, B. A Tutorial of Personalized Federated Recommender Systems: Recent Advances and Future Directions. arXiv 2024, arXiv:2412.08071. [Google Scholar]
- Li, Z.; Long, G.; Zhang, C.; Zhang, H.; Jiang, J.; Zhang, C. Navigating the Future of Federated Recommendation Systems with Foundation Models. arXiv 2024, arXiv:2406.00004. [Google Scholar]
- Lin, Y.; Liu, Y.; Lin, F.; Zou, L.; Wu, P.; Zeng, W.; Chen, H.; Miao, C. A Survey on Reinforcement Learning for Recommender Systems. arXiv 2022, arXiv:2109.10665. [Google Scholar] [CrossRef]
- Zheng, R.; Qu, L.; Cui, B.; Shi, Y.; Yin, H. AutoML for Deep Recommender Systems: A Survey. arXiv 2022, arXiv:2203.13922. [Google Scholar] [CrossRef]
- Chen, B.; Zhao, X.; Wang, Y.; Fan, W.; Guo, H.; Tang, R. A Comprehensive Survey on Automated Machine Learning for Recommendations. arXiv 2023, arXiv:2204.01390. [Google Scholar] [CrossRef]
- Liu, Q.; Zhao, X.; Wang, Y.; Wang, Y.; Zhang, Z.; Sun, Y.; Li, X.; Wang, M.; Jia, P.; Chen, C.; et al. Large Language Model Enhanced Recommender Systems: Taxonomy, Trend, Application and Future. arXiv 2024, arXiv:2412.13432. [Google Scholar]
- Zhang, W.; Bei, Y.; Yang, L.; Zou, H.P.; Zhou, P.; Liu, A.; Li, Y.; Chen, H.; Wang, J.; Wang, Y.; et al. Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap. arXiv 2025, arXiv:2501.01945. [Google Scholar]
- Yu, P.; Xu, Z.; Wang, J.; Xu, X. The Application of Large Language Models in Recommendation Systems. arXiv 2025, arXiv:2501.02178. [Google Scholar]
- Lin, J.; Liu, J.; Zhu, J.; Xi, Y.; Liu, C.; Zhang, Y.; Yu, Y.; Zhang, W. A Survey on Diffusion Models for Recommender Systems. arXiv 2024, arXiv:2409.05033. [Google Scholar]
- Wei, T.-R.; Fang, Y. Diffusion Models in Recommendation Systems: A Survey. arXiv 2025, arXiv:2501.10548. [Google Scholar]
- Gou, J.; Yu, B.; JohnMaybank, S.; Tao, D. Knowledge Distillation: A Survey. arXiv 2021, arXiv:2006.05525. [Google Scholar] [CrossRef]
- Yang, C.; Yu, X.; An, Z.; Xu, Y. Categories of Response-Based, Feature-Based, and Relation-Based Knowledge Distillation. arXiv 2023, arXiv:2306.10687. [Google Scholar]
- Hu, C.; Li, X.; Liu, D.; Wu, H.; Chen, X.; Wang, J.; Liu, X. Teacher-Student Architecture for Knowledge Distillation: A Survey. arXiv 2023, arXiv:2308.04268. [Google Scholar]
- Mansourian, A.M.; Ahmadi, R.; Ghafouri, M.; Babaei, A.M.; Golezani, E.B.; Ghamchi, Z.Y.; Ramezanian, V.; Taherian, A.; Dinashi, K.; Miri, A.; et al. A Comprehensive Survey on Knowledge Distillation. arXiv 2025, arXiv:2503.12067. [Google Scholar]
- Tian, Y.; Pei, S.; Zhang, X.; Zhang, C.; Chawla, N.V. Knowledge Distillation on Graphs: A Survey. arXiv 2023, arXiv:2302.00219. [Google Scholar] [CrossRef]
- Liu, J.; Zheng, T.; Zhang, G.; Hao, Q. Graph-based Knowledge Distillation: A survey and experimental evaluation. arXiv 2023, arXiv:2302.14643. [Google Scholar]
- Li, L.; Gou, J.; Yu, B.; Du, L.; Yi, Z.; Tao, D. Federated Distillation: A Survey. arXiv 2024, arXiv:2404.08564. [Google Scholar]
- Qin, L.; Zhu, T.; Zhou, W.; Yu, P.S. Knowledge Distillation in Federated Learning: A Survey on Long Lasting Challenges and New Solutions. arXiv 2024, arXiv:2406.10861. [Google Scholar]
- Yang, C.; Lu, W.; Zhu, Y.; Wang, Y.; Chen, Q.; Gao, C.; Yan, B.; Chen, Y. Survey on Knowledge Distillation for Large Language Models: Methods, Evaluation, and Application. arXiv 2024, arXiv:2407.01885. [Google Scholar] [CrossRef]
- Tang, J.; Wang, K. Ranking Distillation: Learning Compact Ranking Models with High Performance for Recommender System. arXiv 2018, arXiv:1809.07428. [Google Scholar]
- Lee, J.; Choi, M.; Lee, J.; Shim, H. Collaborative Distillation for Top-N Recommendation. arXiv 2019, arXiv:1911.05276. [Google Scholar]
- Lee, J.W.; Choi, M.; Sael, L.; Shim, H.; Lee, J. Knowledge distillation meets recommendation: Collaborative distillation for top-N recommendation. Knowl. Inf. Syst. 2022, 64, 1323–1348. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, K.-E. Dual Correction Strategy for Ranking Distillation in Top-N Recommender System. arXiv 2021, arXiv:2109.03459. [Google Scholar]
- Kang, S.; Hwang, J.; Kweon, W.; Yu, H. DE-RRD: A Knowledge Distillation Framework for Recommender System. arXiv 2020, arXiv:2012.04357. [Google Scholar]
- Zhou, G.; Fan, Y.; Cui, R.; Bian, W.; Zhu, X.; Gai, K. Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net. arXiv 2018, arXiv:1708.04106. [Google Scholar] [CrossRef]
- Sarfraz, F.; Arani, E.; Zonooz, B. Knowledge Distillation Beyond Model Compression. arXiv 2020, arXiv:2007.01922. [Google Scholar]
- Kang, S.; Hwang, J.; Kweon, W.; Yu, H. Topology Distillation for Recommender System. arXiv 2021, arXiv:2106.08700. [Google Scholar]
- Chen, L.; Yuan, F.; Yang, J.; Yang, M.; Li, C. Scene-adaptive Knowledge Distillation for Sequential Recommendation via Differentiable Architecture Search. arXiv 2021, arXiv:2107.07173. [Google Scholar]
- Yuan, F.; Karatzoglou, A.; Arapakis, I.; Jose, J.M.; He, X. A Simple Convolutional Generative Network for Next Item Recommendation. arXiv 2018, arXiv:1808.05163. [Google Scholar]
- Kang, W.C.; McAuley, J. Self-Attentive Sequential Recommendation. arXiv 2018, arXiv:1808.09781. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. arXiv 2019, arXiv:1904.06690. [Google Scholar]
- Rubner, Y.; Tomasi, C.; Guibas, L. The Earth Mover’s Distance as a Metric for Image Retrieval. Inter-Natl. J. Computer Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Xia, X.; Yin, H.; Yu, J.; Wang, Q.; Xu, G.; Hung, N.Q.V. On-Device Next-Item Recommendation with Self-Supervised Knowledge Distillation. arXiv 2022, arXiv:2204.11091. [Google Scholar]
- Xu, Y.; Zhang, Y.; Guo, W.; Guo, H.; Tang, R.; Coates, M. GraphSAIL: Graph Structure Aware Incremental Learning for Recommender Systems. arXiv 2008, arXiv:2008.13517. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep Mutual Learning. arXiv 2017, arXiv:1706.00384. [Google Scholar]
- Lan, X.; Zhu, X.; Gong, S.; Lan, X.; Zhu, X.; Gong, S. Knowledge Distillation by On-the-Fly Native Ensemble. arXiv 2018, arXiv:1806.04606. [Google Scholar]
- Guo, Q.; Wang, X.; Wu, Y.; Yu, Z.; Liang, D.; Hu, X.; Luo, P. Online Knowledge Distillation via Collaborative Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR’20), Seattle, WA, USA, 13–19 June 2020; pp. 11017–11026. [Google Scholar]
- Kweon, W.; Kang, S.; Yu, H. Bidirectional Distillation for Top-K Recommender System. arXiv 2021, arXiv:2106.02870. [Google Scholar]
- Yang, C.; Pan, J.; Gao, X.; Jiang, T.; Liu, D.; Chen, G. Cross-Task Knowledge Distillation in Multi-Task Recommendation. arXiv 2022, arXiv:2202.09852. [Google Scholar] [CrossRef]
- Borup, K.; Andersen, L.N. Self-Distillation for Gaussian Process Regression and Classification. arXiv 2023, arXiv:2304.02641. [Google Scholar]
- Zhang, L.; Song, J.; Gao, A.; Chen, J.; Bao, C.; Ma, K. Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation. arXiv 2019, arXiv:1905.08094. [Google Scholar]
- Mi, F.; Lin, X.; Faltings, B. ADER: Adaptively Distilled Exemplar Replay Towards Continual Learning for Session-based Recommendation. arXiv 2020, arXiv:2007.12000. [Google Scholar]
- Xu, C.; Li, Q.; Ge, J.; Gao, J.; Yang, X.; Pei, C.; Sun, F.; Wu, J.; Sun, H.; Ou, W. Privileged Features Distillation at Taobao Recommendations. arXiv 2020, arXiv:1907.05171. [Google Scholar]
- Wang, S.; Zhang, K.; Wu, L.; Ma, H.; Hong, R.; Wang, M. Privileged Graph Distillation for Cold Start Recommendation. arXiv 2021, arXiv:2105.14975. [Google Scholar]
- Xie, R.; Zhang, S.; Wang, R.; Xia, F.; Lin, L. Explore, Filter and Distill: Distilled Reinforcement Learning in Recommendation. In Proceedings of the 30th ACM International Conference on Information and Knowledge Management (CIKM’21), Virtual Event, QLD, Australia, 1–5 November 2021; pp. 4243–4252. [Google Scholar]
- Ding, S.; Feng, F.; He, X.; Jin, J.; Wang, W.; Liao, Y.; Zhang, Y. Interpolative Distillation for Unifying Biased and Debiased Recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’22), Madrid, Spain, 11–15 July 2022; pp. 40–49. [Google Scholar]
- Du, H.; Yuan, H.; Zhao, P.; Zhuang, F.; Liu, G.; Zhao, L.; Liu, Y.; Sheng, V.S. Ensemble Modeling with Contrastive Knowledge Distillation for Sequential Recommendation. arXiv 2023, arXiv:2304.14668. [Google Scholar]
- Eren, M.E.; Richards, L.E.; Bhattarai, M.; Yus, R.; Nicholas, C.; Alexandrov, B.S. FedSPLIT: One-Shot Federated Recommendation System Based on Non-negative Joint Matrix Factorization and Knowledge Distillation. arXiv 2022, arXiv:2205.02359 9. [Google Scholar]
- Liu, X.; Li, L.; Hsieh, P.; Xie, M.; Ge, Y.; Chen, R. Developing Multi-Task Recommendations with Long-Term Rewards via Policy Distilled Reinforcement Learning. arXiv 2020, arXiv:2001.09595. [Google Scholar]
- Kang, S.; Lee, D.; Kweon, W.; Yu, H. Personalized Knowledge Distillation for Recommender System. Knowl.-Based Syst. 2022, 239, 107958. [Google Scholar] [CrossRef]
- Chen, G.; Chen, J.; Feng, F.; Zhou, S.; He, X. Unbiased Knowledge Distillation for Recommendation. arXiv 2022, arXiv:2211.14729. [Google Scholar]
- Jiang, J.; Luo, Y.; Kim, J.B.; Zhang, K.; Kim, S. Sequential Recommendation with Bidirectional Chronological Augmentation of Transformer. arXiv 2022, arXiv:2112.06460. [Google Scholar]
- Kang, S.; Kweon, W.; Lee, D.; Lian, J.; Xie, X.; Yu, H. Distillation from Heterogeneous Models for Top-K Recommendation. arXiv 2023, arXiv:2303.01130. [Google Scholar]
- Chen, X.; Zhang, Y.; Xu, H.; Qin, Z.; Zha, H. Adversarial Distillation for Efficient Recommendation with External Knowledge. ACM Trans. Inf. Syst. 2018, 37, 12. [Google Scholar] [CrossRef]
- Pan, Y.; He, F.; Yan, X.; Li, H. A synchronized heterogeneous autoencoder with feature-level and label-level knowledge distillation for the recommendation. Eng. Appl. Artif. Intell. 2021, 106, 104494. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, X.; Zhou, H.; Zhang, Y. Distilling Structured Knowledge into Embeddings for Explainable and Accurate Recommendation. arXiv 2019, arXiv:1912.08422. [Google Scholar]
- Pan, Y.; He, F.; Yu, H. A novel Enhanced Collaborative Autoencoder with knowledge distillation for top-N recommender systems. Neurocomputing 2019, 332, 137–148. [Google Scholar] [CrossRef]
- Xia, L.; Huang, C.; Shi, J.; Xu, Y. Graph-less Collaborative Filtering. arXiv 2023, arXiv:2303.08537. [Google Scholar]
- Wan, S.; Gao, D.; Gu, H.; Hu, D. FedPDD: A Privacy-preserving Double Distillation Framework for Cross-silo Federated Recommendation. arXiv 2023, arXiv:2305.06272. [Google Scholar]
- Zhang, J. Recommendation Systems Technology Evolution Trend: From Recall to Ranking, Next to ReRanker. 2019. Available online: https://zhuanlan.zhihu.com/p/100019681 (accessed on 6 July 2023).
- Zhang, J. Application of Knowledge Distillation in Recommendation Systems. 2020. Available online: https://zhuanlan.zhihu.com/p/143155437 (accessed on 10 September 2023).
- iQIYI. Dual DNN Ranking Model: Online Knowledge Distillation in Practice for iQIYI Recommendations. 2020. Available online: https://www.infoq.cn/article/pUfNBe1o6FwiiPkxQy7C (accessed on 15 October 2023).
- Facebook. Instagram Recommendation System: How Is It Possible to Predict 90 Million Models per Second? 2021. Available online: https://blog.51cto.com/u_15060462/2677067 (accessed on 30 December 2023).
- Huang, Z.; Wang, N. Like What You Like: Knowledge Distill via Neuron Selectivity Transfer. arXiv 2017, arXiv:1707.01219. [Google Scholar]
- Srinivas, S.; Fleuret, F. Knowledge Transfer with Jacobian Matching. arXiv 2018, arXiv:1803.00443. [Google Scholar]
- Zhao, L.; Peng, X.; Chen, Y.; Kapadia, M.; Metaxas, D. Knowledge as Priors: Cross-Modal Knowledge Generalization for Datasets without Superior Knowledge. arXiv 2020, arXiv:2004.00176. [Google Scholar]
- Kundu, J.; Lakkakula, N.; Babu, V. UM-Adapt: Unsupervised Multi-Task Adaptation Using Adversarial Cross-Task Distillation. arXiv 2019, arXiv:1908.03884. [Google Scholar]
- Chen, Y.-C.; Lin, Y.-Y.; Yang, M.-H.; Huang, J.-B. CrDoCo: Pixel-level Domain Transfer with Cross-Domain Consistency. arXiv 2020, arXiv:2001.03182. [Google Scholar]
- Parisi, G.; Kemker, R.; Part, J.; Kanan, C.; Wermter, S. Continual Lifelong Learning with Neural Networks: A Review. arXiv 2018, arXiv:1802.07569. [Google Scholar] [CrossRef]
- Lee, K.; Lee, K.; Shin, J.; Lee, H. Overcoming Catastrophic Forgetting with Unlabeled Data in the Wild. arXiv 2019, arXiv:1903.12648. [Google Scholar]
- Zhai, M.; Chen, L.; Tung, F.; He, J.; Nawhal, M.; Mori, G. Lifelong GAN: Continual Learning for Conditional Image Generation. arXiv 2019, arXiv:1907.10107. [Google Scholar]
- Zhou, P.; Mai, L.; Zhang, J.; Xu, N.; Wu, Z.; Davis, L.S. M2KD: Multi-model and Multi-level Knowledge Distillation for Incremental Learning. arXiv 2019, arXiv:1904.01769. [Google Scholar]
- Shmelkov, K.; Schmid, C.; Alahari, K. Incremental Learning of Object Detectors without Catastrophic Forgetting. arXiv 2017, arXiv:1708.06977. [Google Scholar]
- Zheng, W.; Huang, E.W.; Rao, N.; Katariya, S.; Wang, Z.; Subbian, K. Cold Brew: Distilling Graph Node Representations with Incomplete or Missing Neighborhoods. arXiv 2021, arXiv:2111.04840. [Google Scholar]
- Wang, Y.; Zhang, Y.; Coates, M. Graph Structure Aware Contrastive Knowledge Distillation for Incremental Learning in Recommender Systems. In Proceedings of the CIKM ’21: The 30th ACM International Conference on Information and Knowledge Management, Virtual Event, Gold Coast, QLD, Australia, 1–5 November 2021; pp. 3518–3522. [Google Scholar]
- Wang, W.; Xu, Y.; Feng, F.; Lin, X.; He, X.; Chua, T.-S. Diffusion Recommender Model. arXiv 2023, arXiv:2304.04971. [Google Scholar]
- Malitesta, D.; Medda, G.; Purificato, E.; Boratto, L.; Malliaros, F.D.; Marras, M.; Luca, E.W.D. How Fair is Your Diffusion Recommender Model? arXiv 2024, arXiv:2409.04339. [Google Scholar]
- Le, Y.; Li, H.; Ou, B.; Qin, Y.; Yang, Z.; Su, R.; Zhang, F. Diffusion Model for Interest Refinement in Multi-Interest Recommendation. arXiv 2025, arXiv:2502.05561. [Google Scholar]
- Lee, G.; Zhu, Y.; Yu, H.; Zhou, Y.; Li, J. Collaborative Diffusion Model for Recommender System. arXiv 2025, arXiv:2501.18997. [Google Scholar]
- Zolghadr, S.; Winther, O.; Jeha, P. Generative Diffusion Models for Sequential Recommendations. arXiv 2024, arXiv:2410.19429. [Google Scholar]
- Zhao, C.; Yang, E.; Liang, Y.; Zhao, J.; Guo, G.; Wang, X. Distributionally Robust Graph Out-of-Distribution Recommendation via Diffusion Model. arXiv 2025, arXiv:2501.15555. [Google Scholar]
- Li, X.; Tang, H.; Sheng, J.; Zhang, X.; Gao, L.; Cheng, S.; Yin, D.; Liu, T. Exploring Preference-Guided Diffusion Model for Cross-Domain Recommendation. arXiv 2025, arXiv:2501.11671. [Google Scholar]
- Luo, W. A Comprehensive Survey on Knowledge Distillation of Diffusion Models. arXiv 2023, arXiv:2304.04262. [Google Scholar]
- Liu, P.; Zhang, L.; Gulla, J.A. Pre-train, Prompt and Recommendation: A Comprehensive Survey of Language Modelling Paradigm Adaptations in Recommender Systems. arXiv 2023, arXiv:2302.03735. [Google Scholar] [CrossRef]
- Wu, L.; Zheng, Z.; Qiu, Z.; Wang, H.; Gu, H.; Shen, T.; Qin, C.; Zhu, C.; Zhu, H.; Liu, Q.; et al. A Survey on Large Language Models for Recommendation. arXiv 2023, arXiv:2305.19860. [Google Scholar] [CrossRef]
- Cui, Y.; Liu, F.; Wang, P.; Wang, B.; Tang, H.; Wan, Y.; Wang, J.; Chen, J. Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model. arXiv 2024, arXiv:2405.00338. [Google Scholar]
- Xu, W.; Wu, Q.; Liang, Z.; Han, J.; Ning, X.; Shi, Y.; Lin, W.; Zhang, Y. SLMRec: Distilling Large Language Models into Small for Sequential Recommendation. arXiv 2024, arXiv:2405.17890. [Google Scholar]
- Du, Y.; Sun, Z.; Wang, Z.; Chua, H.; Zhang, J.; Ong, Y.-S. Active Large Language Model-based Knowledge Distillation for Session-based Recommendation. arXiv 2025, arXiv:2502.15685. [Google Scholar]
- Zhang, K.; Zhu, R.; Ma, S.; Xiong, J.; Kim, Y.; Murai, F.; Liu, X. KEDRec-LM: A Knowledge-distilled Explainable Drug Recommendation Large Language Model. arXiv 2025, arXiv:2502.20350. [Google Scholar]
- Wang, Q.; Li, J.; Wang, S.; Xing, Q.; Niu, R.; Kong, H.; Li, R.; Long, G.; Chang, Y.; Zhang, C. Towards Next-Generation LLM-based Recommender Systems: A Survey and Beyond. arXiv 2024, arXiv:2410.19744. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



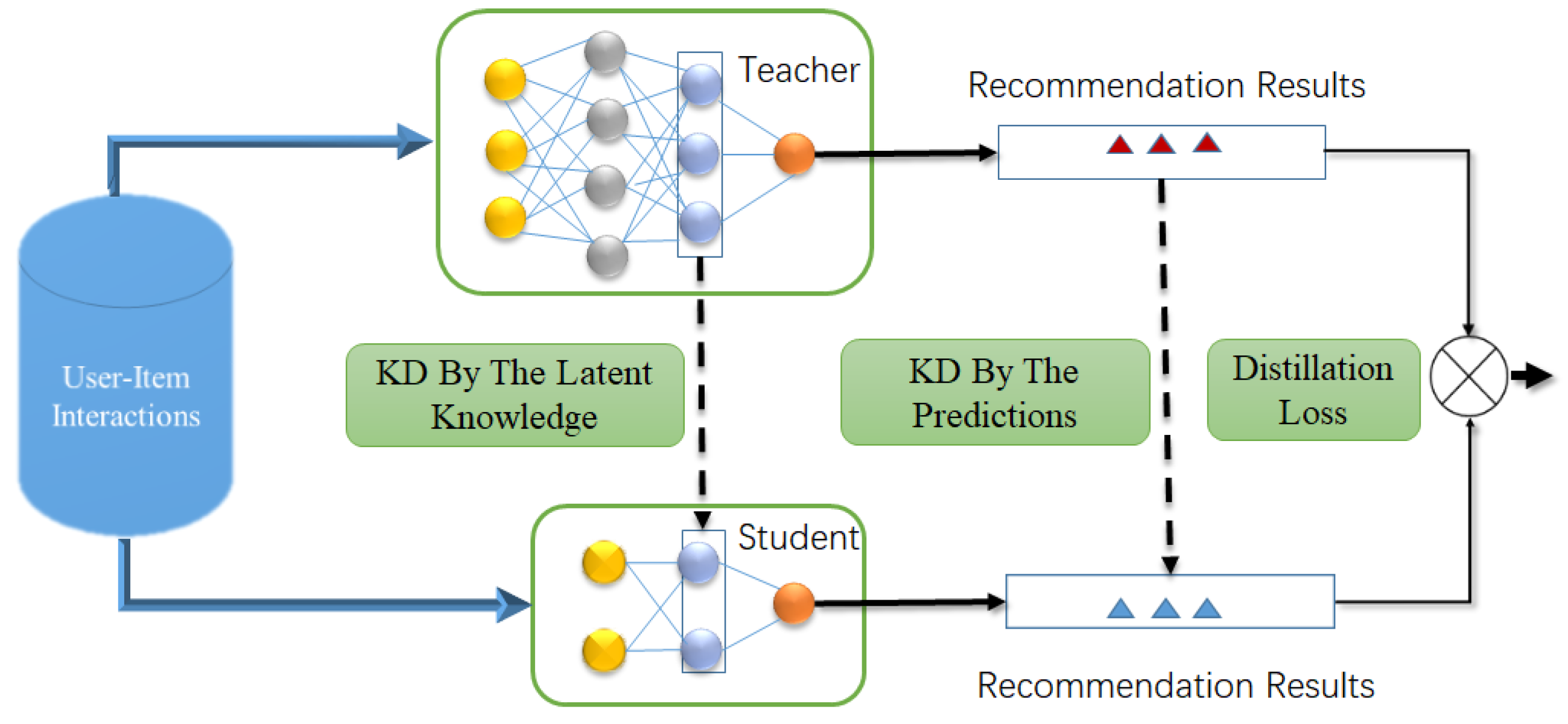

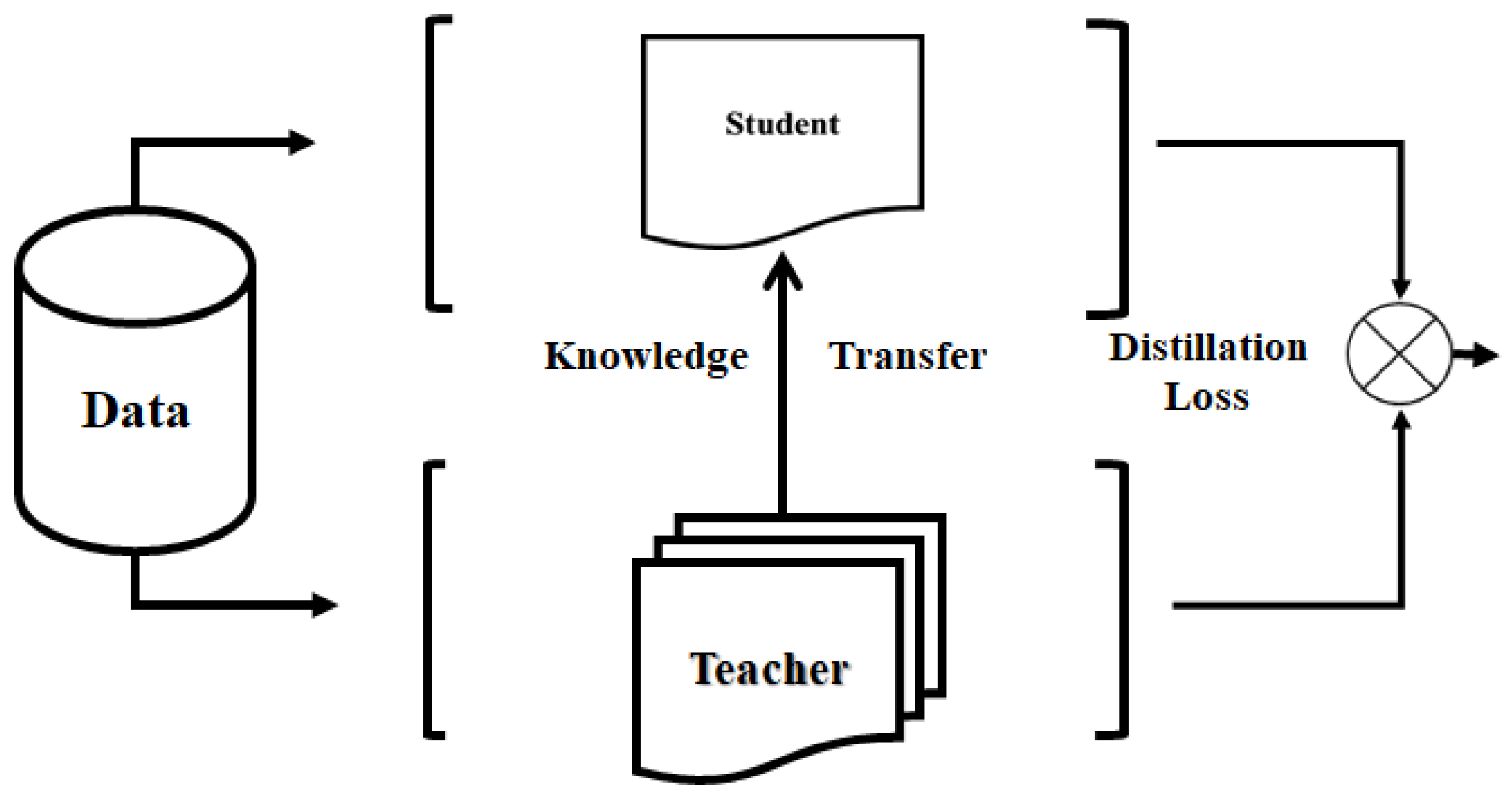
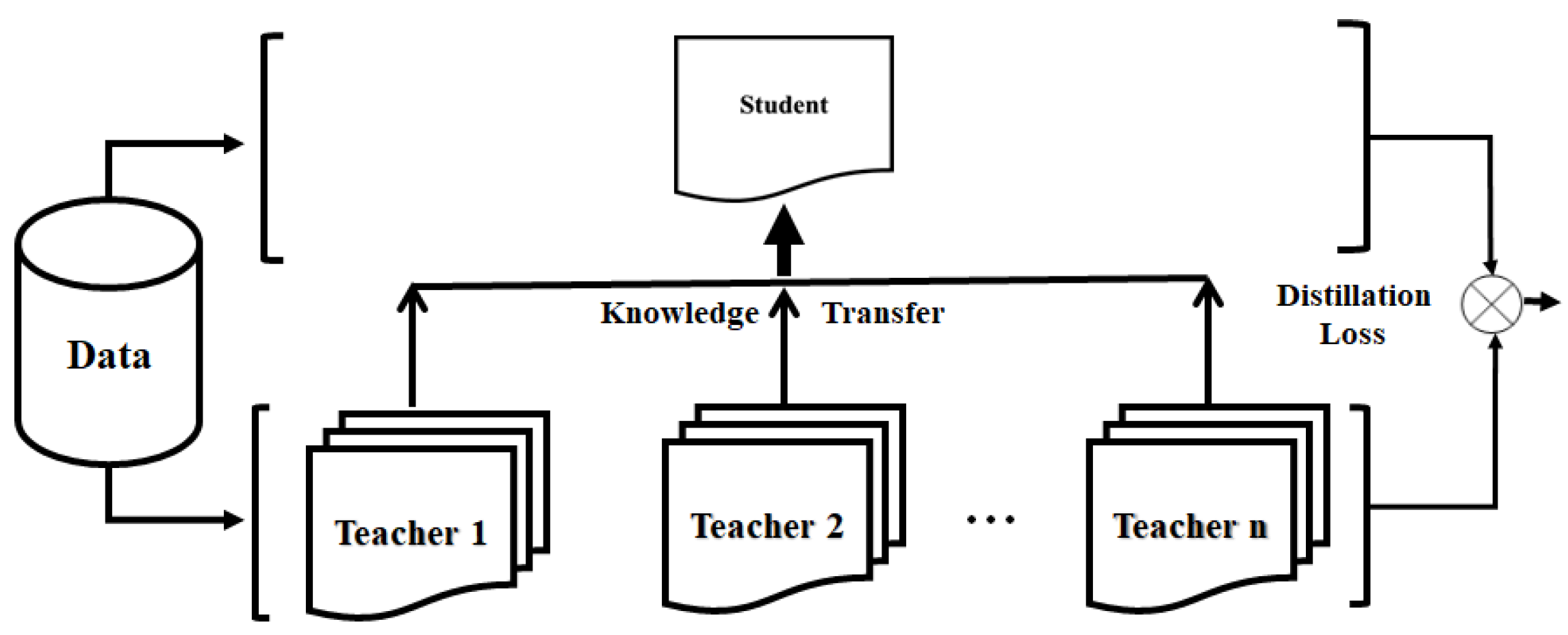


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}