Abstract
Human motion recognition is crucial for applications like navigation, health monitoring, and smart healthcare, especially in weak GNSS scenarios. Current methods face challenges such as limited sensor diversity and inadequate feature extraction. This study proposes a CNN–Transformer–Attention framework with multimodal enhancement to address these challenges. We first designed a lightweight wearable system integrating synchronized accelerometer, gyroscope, and magnetometer modules at wrist, chest, and foot positions, enabling multi-dimensional biomechanical data acquisition. A hybrid preprocessing pipeline combining cubic spline interpolation, adaptive Kalman filtering, and spectral analysis was developed to extract discriminative spatiotemporal-frequency features. The core architecture employs parallel CNN pathways for local sensor feature extraction and Transformer-based attention layers to model global temporal dependencies across body positions. Experimental validation on 12 motion patterns demonstrated 98.21% classification accuracy, outperforming single-sensor configurations by 0.43–7.98% and surpassing conventional models (BP-Network, CNN, LSTM, Transformer, KNN) through effective cross-modal fusion. The framework also exhibits improved generalization with 3.2–8.7% better accuracy in cross-subject scenarios, providing a robust solution for human activity recognition and accurate positioning in challenging environments such as autonomous navigation and smart cities.
1. Introduction
As a pivotal biometric modality, gait recognition through wearable devices has gained significant traction in smart healthcare [1], consumption and consumer behavior analysis [2], social security [3], and human–computer interaction systems [4], particularly for applications requiring continuous health monitoring and emergency response [5]. The proliferation of lightweight micro-electromechanical systems (MEMS)—including triaxial accelerometers, gyroscopes, and magnetometers—has facilitated non-invasive gait capture through compact wearable form factors [6], thereby enabling its widespread application in the monitoring and recognition of human motion states [7]. The advancement of MEMS concurrently enhances the potential for human–robot interaction (HRI) applications, particularly in domains such as exoskeleton robotics [8]. However, existing implementations predominantly rely on single-node sensing architectures (typically wrist-worn devices) that fundamentally limit their ability to characterize whole-body kinematic patterns. Despite the widespread adoption of existing detection methodologies (e.g., SVM [9], LSTM [10], KNN [11]) for gait recognition, the action recognition accuracy remains suboptimal and requires enhancement.
Current technical barriers manifest in three dimensions: First, homogeneous data streams from isolated MEMS sensors fail to capture inter-limb coordination critical for distinguishing ambulatory patterns [12] (e.g., stair ascent vs. normal walking). Second, conventional feature extraction pipelines overemphasize time-domain statistical parameters (mean, variance) while neglecting frequency-domain signatures essential for periodic gait analysis [13]. Third, prevailing deep learning architectures exhibit architectural incompatibilities, CNNs [14], excel at local feature extraction but ignore temporal dependencies, while LSTMs [15] model sequential data at the expense of spatial resolution.
Our work addresses these limitations through three synergistic innovations:
- A multi-nodal MEMS network synchronizing data from wrist, chest, and ankle nodes using linear interpolation and frequency feature enhancement.
- A CNN–Transformer hybrid architecture combining dilated convolutional layers for multi-scale feature extraction with positional encoding-enhanced self-attention mechanisms.
- Comprehensive validation across seven ambulatory modes (including stair navigation and fall detection) demonstrating 99.8% recognition accuracy in real-world urban scenarios.
The structure of this paper follows the logical progression outlined below: Section 2 systematically reviews existing research achievements and analyzes their technical bottlenecks. Section 3 comprehensively elaborates the design principles and implementation workflow of the proposed algorithmic framework. Section 4 establishes a multi-dimensional evaluation framework to validate system performance. Section 5 synthesizes research findings and outlines future technical evolution pathways.
2. Related Work
Recent advances in wearable gait recognition primarily evolve along two axes: sensor configurations and model architectures.
Contemporary research predominantly adopts distributed deployment strategies to capture differentiated gait characteristics through body-positioned sensors. Wrist-worn devices demonstrate exceptional capabilities in fine-grained gesture detection: Fang et al. [16] achieved 89.59% static gesture recognition accuracy using gloves integrated with inertial and magnetic measurement units (IMMUs). Ramalingame et al.’s [17] forearm pressure sensors attaining 93% gesture discrimination precision. Trunk-mounted sensors (e.g., hip accelerometers) provide stable whole-body gait analysis, as demonstrated by Mantyjarvi’s [18] 83–90% gait recognition rates. Lower-limb sensors directly capture kinetic features, as evidenced by Zhao et al. [19] achieving 98.11% gait identification accuracy using foot-worn inertial sensors. Notably, existing systems predominantly focus on isolated body segments, lacking effective spatiotemporal fusion of heterogeneous sensor data.
Recognition algorithms have evolved through three phases: Initial Fourier transform-based signal processing methods achieved <80% accuracy in complex scenarios [20]. The machine learning era introduced multi-classification models (HMM [21], SVM [22]), elevating accuracy to 90% range. Deep learning breakthroughs via CNN [23] and RNN [24] architectures surpassed 91% recognition thresholds. Recent advancements highlight the Transformer’s superior temporal modeling in video action recognition, with the TRASEND model [25] improving the F1-score by 7% over conventional RNNs. In the study [26], Li et al. proposed GaitFormer, a hybrid architecture leveraging the Vision Transformer (ViT) model on RGB data, which achieved a recognition accuracy of 97%. However, the integration of local feature extraction and global dependency modeling in such hybrid architectures requires further refinement, while breakthroughs in multimodal spatiotemporal collaborative optimization remain to be explored.
3. Methodology
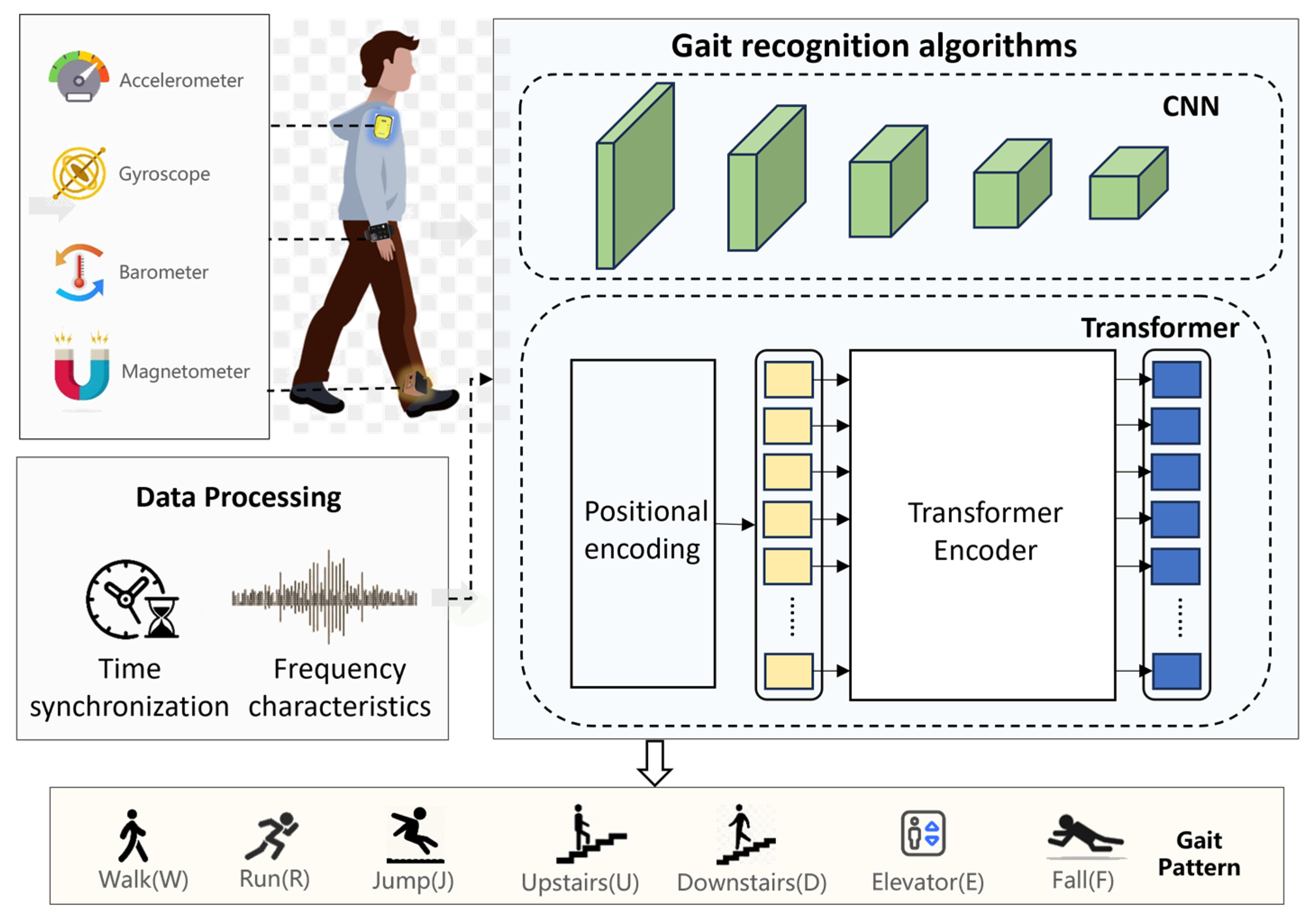
This study innovatively constructs a multi-source heterogeneous data fusion framework for gait recognition, achieving precise perception of human gait states via a distributed wearable sensor network. As shown in Figure 1, the system deploys three inertial measurement unit (IMU) nodes at critical kinematic regions—the wrist joint, sternum segment, and ankle joint—to synchronously capture multimodal gait parameters (e.g., acceleration, angular velocity), forming a spatiotemporally complementary limb gait characterization framework. Raw signals from each node undergo time-frequency domain preprocessing to enable cross-modal feature-level fusion. A cascaded CNN–Transformer architecture is then adopted: the CNN module extracts local spatiotemporal features through hierarchical convolutional operations, while the Transformer encoder leverages multi-head self-attention mechanisms to establish cross-modal global dependencies, enabling hierarchical parsing of gait patterns.
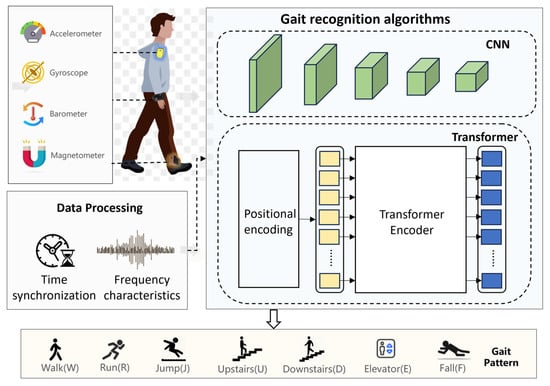
Figure 1.
The proposed human gait recognition system architecture based on CNN–Transformer multimodal information fusion.
3.1. Abbreviations and Acronyms
Deploying multiple sensors to capture gait information from various body parts effectively enhances action recognition accuracy compared to single-sensor solutions. Due to morphological differences across human body segments, heterogeneous sensor models are deployed at distinct positions, resulting in data heterogeneity in formats and feature dimensions. Consequently, standardized data preprocessing and fusion strategies become essential prerequisites for ensuring recognition reliability.
The disparity in sampling frequencies among sensors causes temporal inconsistency in data generation, while operational diversity leads to asynchronous data acquisition, creating non-uniform temporal sequences. In practical scenarios, multi-sensor wearable systems face increased susceptibility to electromagnetic interference with additional devices, coupled with environmental challenges like high temperature and humidity that induce noise contamination. Effective data processing thus plays a pivotal role in optimizing feature extraction and action classification.
This study implements spatiotemporal calibration based on raw sensor data and timestamps to achieve temporal alignment of multi-source data. Conventional synchronization and filtering techniques, such as extrapolation interpolation, predict new frame data by computing temporal differences and target positions. However, the nonlinear characteristics of human gait data may induce signal distortion through polynomial interpolation, generating significant errors. To address this, our framework establishes a master sensor to construct a unified temporal reference axis. By minimizing temporal intervals between interpolation points and adjacent data samples, we compute dynamic weights of preceding and subsequent temporal data to reconstruct missing node values, ultimately achieving precise multi-source synchronization and noise suppression.
The chest-mounted IMU, selected for its stable sampling rate and superior noise immunity, serves as the global temporal reference source. The unified timeline is defined as follows:
where represents the standardized sampling interval.
For discrete observations , rom subordinate sensor within , piecewise linear interpolation compensates missing data at
where denotes the local sampling interval of , with interpolation weights satisfying the convex combination constraint .
A sliding window consistency verification is implemented:
where and represent the mean and standard deviation within window, respectively. Invalid data trigger secondary interpolation compensation.
3.2. Time-Frequency Joint Feature Enhancement
Traditional gait pattern analysis predominantly relies on temporal statistical metrics (e.g., mean, variance), which inadequately capture periodic gait characteristics. This study innovatively introduces spectral analysis through Fast Fourier Transform (FFT) to achieve joint time-frequency signal representation. The computational complexity is reduced to O(N log N), offering a two-order-of-magnitude improvement over conventional DFT’s O(N2).
For a preprocessed discrete signal sequence , its Discrete Fourier Transform (DFT) is defined as follows:
where the twiddle factor satisfies periodicity .
Leveraging the Cooley–Tukey algorithm, a radix-2 FFT decomposition is implemented:
Split the sequence into even-indexed x [2r] and odd-indexed x [2r + 1] subsequences .
Then, recursive calculations are performed based on the following formula:
Finally, the frequency domain feature extraction is carried out. The Dominant Frequency Energy Ratio and Spectral Centroid are obtained by the following formula, respectively:
This framework significantly reduces time-frequency transformation latency while preserving spectral integrity, enabling real-time processing capabilities. The extracted features enhance gait discriminability by jointly encoding temporal dynamics and spectral signatures.
3.3. A Hybrid CNN–Transformer Architecture Forl Gait Recognition
The Convolutional Neural Network (CNN), a canonical feedforward deep learning architecture, has demonstrated exceptional performance in computer vision tasks such as image classification and object detection. Recently, its applications have expanded to sensor-based time-series data processing. Complementarily, the Transformer model, proposed by Google in 2017, employs a self-attention mechanism and has shown remarkable advantages in natural language processing and sequence modeling.
The two models exhibit complementary characteristics in feature extraction: CNNs utilize convolutional kernels to extract localized spatial features but struggle with global dependency modeling, while Transformers capture long-range dependencies through cascaded self-attention modules but lack sensitivity to local details. This study proposes a cascaded CNN–Transformer hybrid architecture, where the CNN module extracts spatial-localized features of body and limb movements, and the Transformer encoder captures long-term temporal dependencies in gait sequences.
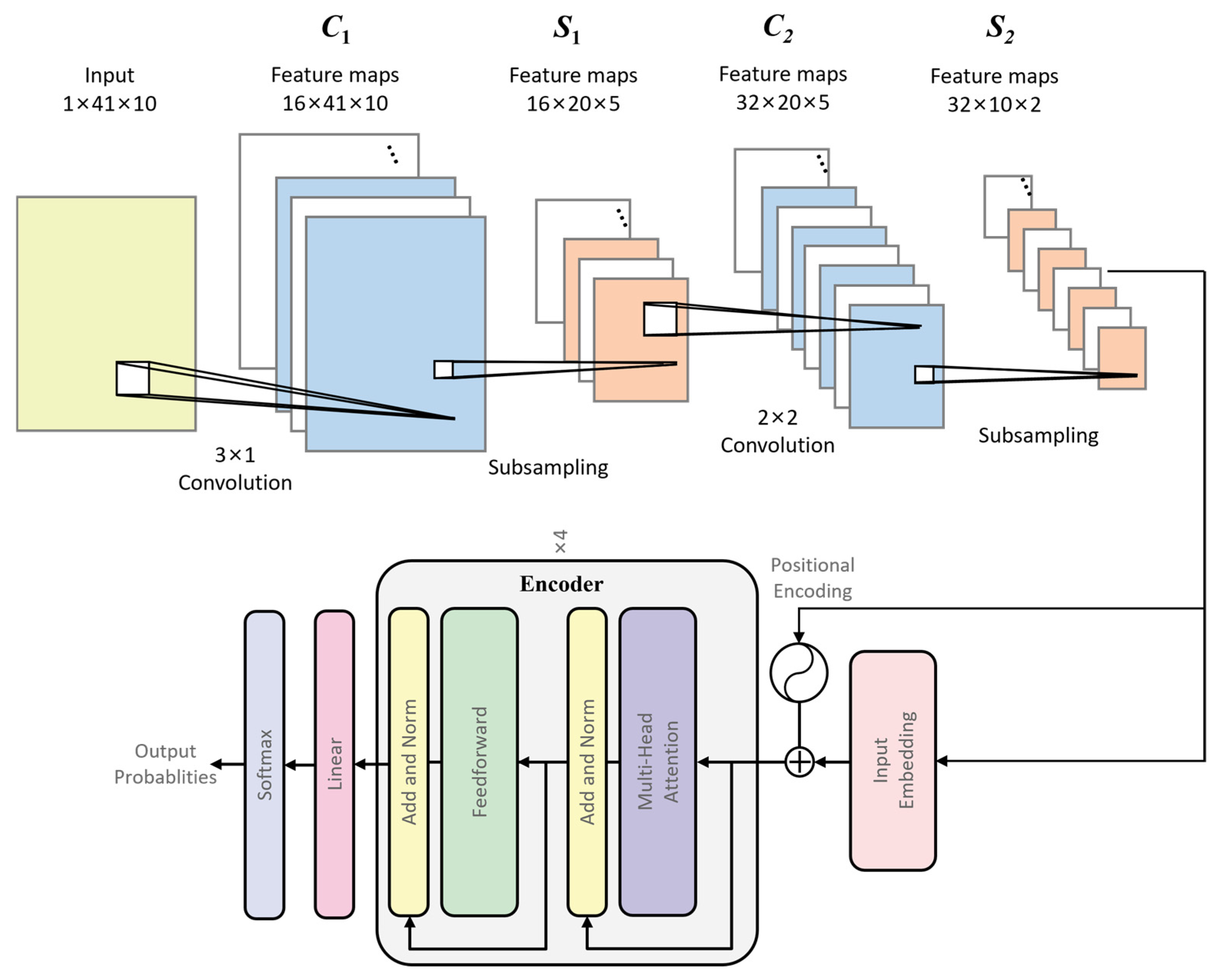
As illustrated in Figure 2, the system comprises four processing stages: raw data are first processed by the CNN module, followed by a positional encoding layer to inject temporal information. The encoded features are then fed into a Transformer encoder for enhancement, and finally classified via a linear layer and softmax classifier. The CNN module adopts a dual-layer convolutional structure, each followed by ReLU activation and max-pooling. The CNN module accepts an input dimension of 41 × 10 and incorporates a dual-layer convolutional architecture. The first convolutional layer employs a 3 × 1 kernel, while the second utilizes a 2 × 2 kernel. Each convolutional layer is sequentially followed by a ReLU activation function and a max-pooling operation. The Transformer network comprises four encoder layers, each containing a multi-head attention layer and a feedforward layer, both succeeded by layer normalization. The multi-head attention mechanism integrates four parallel single-head attention units, with each head operating in an 8-dimensional feature space.
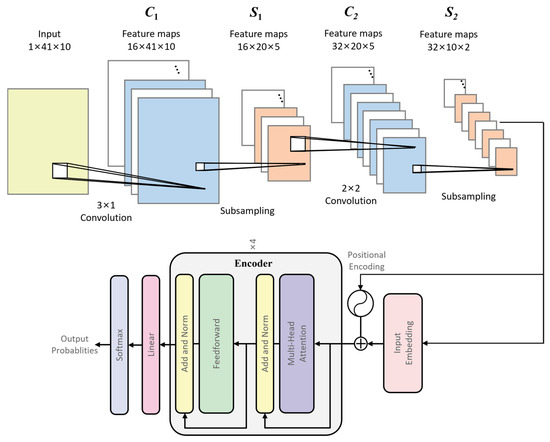
Figure 2.
A CNN–Transformer network tailored for gait recognition.
The convolution operation is formulated as follows:
where , , and denote the kernel, stride, and padding parameters of the layer. After activation, pooling reduces feature dimensionality via sliding-window sampling:
The temporal encoding layer employs trigonometric positional embeddings:
Ensuring derivability between adjacent time steps to preserve sequential correlations. The encoder core integrates multi-head self-attention and feedforward neural networks (FFNNs). The attention head computation is defined as follows:
Multi-head mechanisms concatenate subspace attention matrices and fuse features via a weight matrix :
To mitigate gradient vanishing, residual connections and modified layer normalization are applied:
The deepens feature representation through dual linear transformations:
Given the gait recognition task requires no sequence generation, the decoder is omitted to reduce complexity. Final outputs are projected to class space via softmax for probability estimation.
Training employs gradient backpropagation. The residual function for the CNN module is defined as follows:
With parameter updates governed by an error-sensitive mechanism, larger classification errors trigger more significant weight adjustments.
The cross-entropy loss is adopted:
where gradient calculations reveal a positive correlation between weight update rates and prediction errors, enhancing convergence efficiency.
4. Experiments and Evaluation
This study systematically validates the proposed method in Section 3 using experimental data collected from a multi-source wearable sensing system with three-node deployments (wrist, foot, and chest). Section 4.1 details the configuration parameters of the experimental setup, including the design of a multi-scenario gait testing platform, hardware specifications of the sensors, and data acquisition protocols. Section 4.2 analyzes the time-frequency domain feature evolution patterns of sensor signals from different anatomical locations (wrist, foot, chest), elucidating the mapping relationships between gait patterns and multimodal sensing data. Section 4.3 focuses on validating the performance advantages of the multimodal fusion system in gait feature extraction and recognition tasks. Through comparative experiments, the improvements in recognition accuracy are quantified by contrasting multi-source information versus single-sensor data, as well as the proposed model architecture against conventional models.
4.1. Experimental Setup
This study establishes a multimodal spatiotemporal feature fusion-based gait recognition validation framework, conducting multi-pattern gait analysis experiments in mixed indoor–outdoor scenarios within a typical urban environment. As shown in Figure 3, the experimental system comprises a heterogeneous sensor node network and an urban scenario simulation platform, with sensor deployment covering three critical anatomical locations:

Figure 3.
Multi-gait pattern experiment.
Wrist Sensor Unit: Designed as a smart wristband, it integrates a nine-axis IMU (triaxial accelerometer, triaxial gyroscope, triaxial magnetometer) and a PPG biosensor, capturing hand gait trajectories and physiological signals at a 100 Hz sampling rate.
Foot and Chest Positioning Modules: Based on MEMS-IMU technology, these modules incorporate six-axis inertial measurement units (±8 g acceleration range, ±2000°/s angular velocity range), barometric altimeters, and Bluetooth 5.0 low-energy transmission. A customized embedded system enables synchronized acquisition and preprocessing of gait parameters. The specific parameters of the device are shown in Table 1.

Table 1.
The specific parameters of the MEMS-IMU sensors mounted on the wrist, shoulder, and foot used in the experiments.
The experiment was conducted in the New Main Building area of Beihang University, simulating typical urban gait sequences. Participants performed predefined gait sequences while wearing multi-node sensor devices, with the system synchronously recording kinematic parameters (acceleration, angular velocity, orientation angles) and environmental features (barometric pressure, geomagnetism) from each anatomical location. A heterogeneous dataset containing seven fundamental gait patterns (walking, running, upstairs, downstairs, elevator ascending, falling, jumping) was constructed to rigorously validate the scene adaptability of the proposed multi-source spatiotemporal feature joint modeling approach.
4.2. Multi-Node Biomechanical Signal Analysis
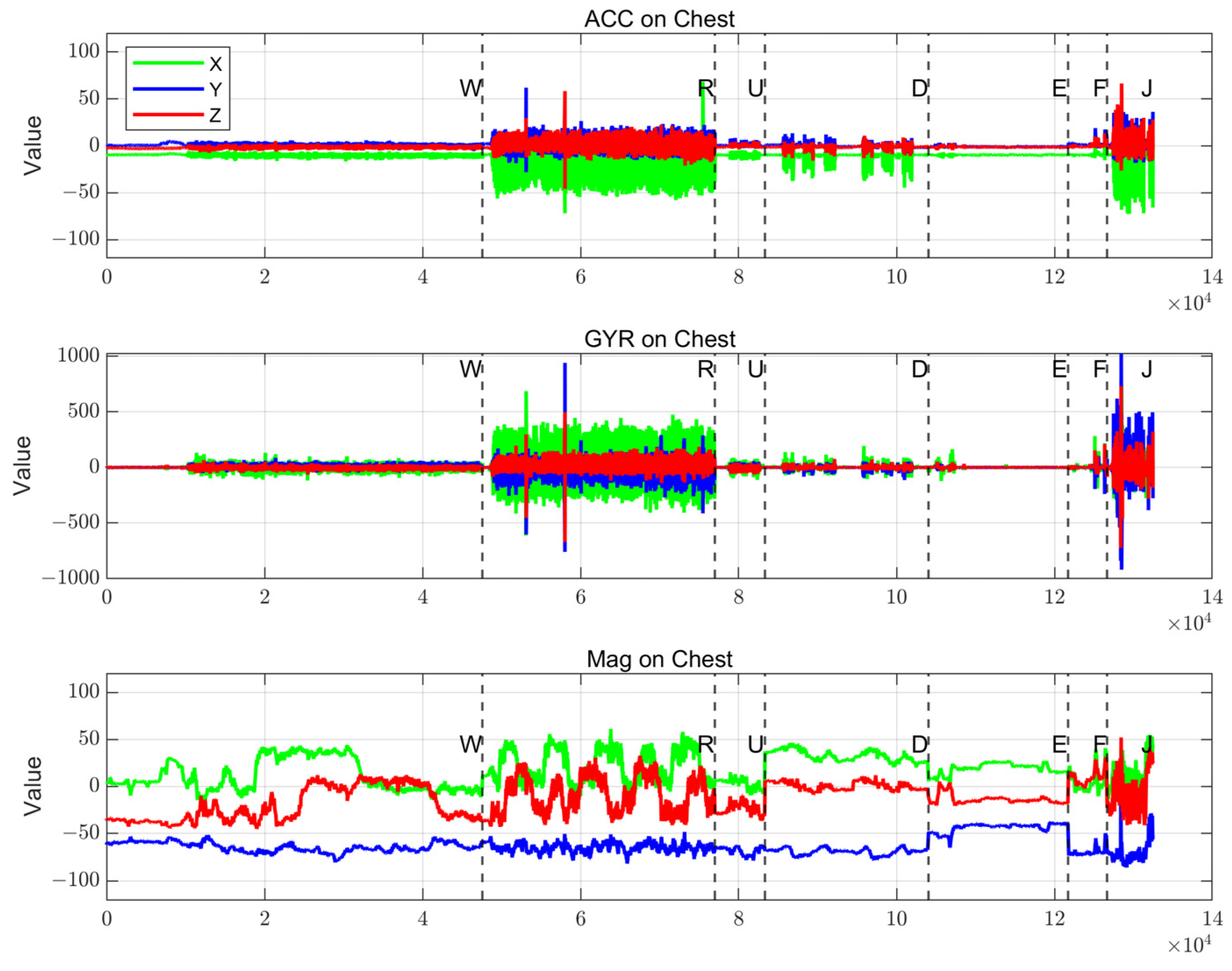
This study reveals characteristic patterns of human gait through multi-source sensor data analysis. As shown in Figure 4 and Figure 5, seven gait patterns (Walking—W; Running—R; Jumping—J; Upstairs—U; Downstairs—D; Elevator—E; Falling—F) are visually distinguished via color-coded visualization. Data from three sensor types in the chest inertial measurement unit (IMU) exhibit significant variations in Figure 4:
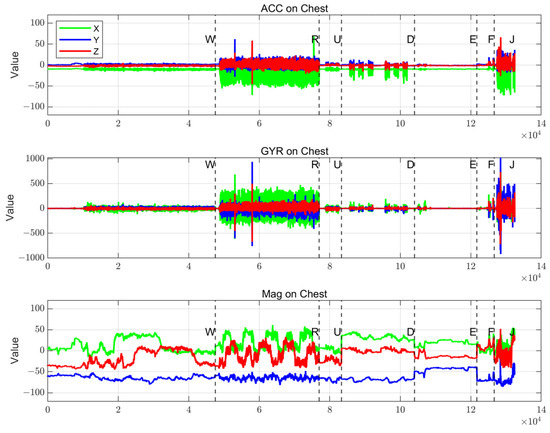
Figure 4.
Chest-mounted accelerometer, gyroscope, and magnetometer output data.
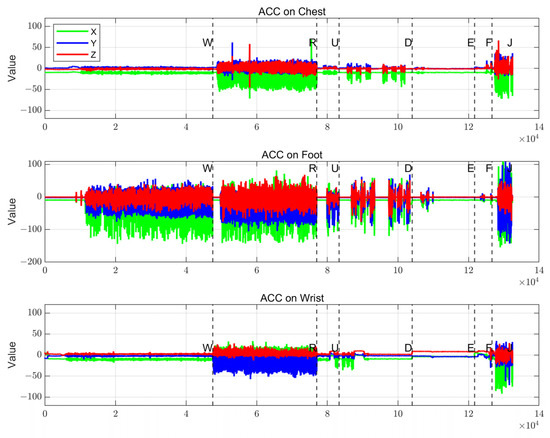
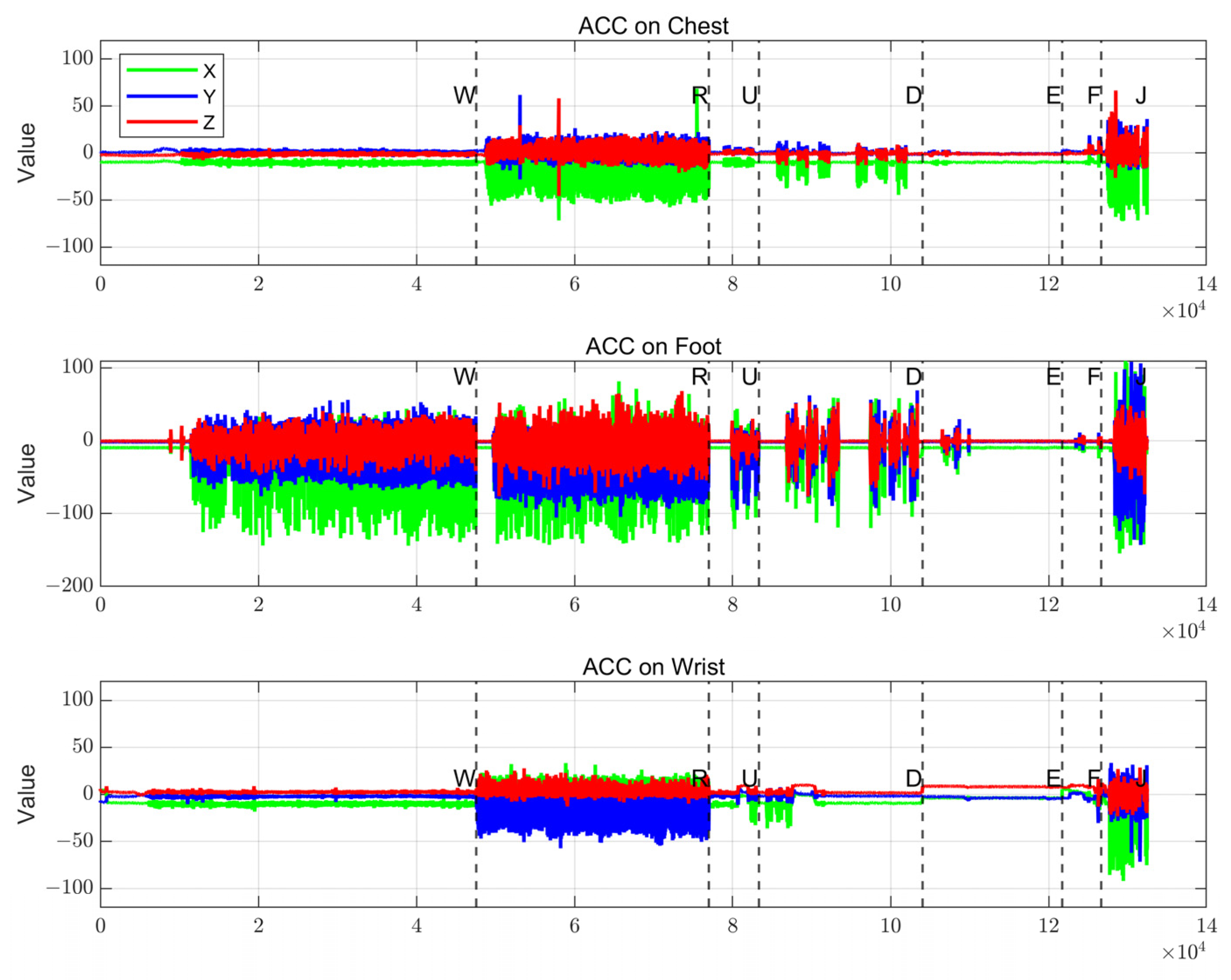
Figure 5.
Wrist-mounted, foot-mounted, and chest-mounted accelerometer output data in a wearable human body sensor system.
- The triaxial accelerometer shows comparable amplitude across all three axes during high-intensity gaits (R, J).
- The gyroscope reveals X-axis angular velocity dominance during running and Y-axis prominence during jumping.
- The foot sensor records maximum acceleration responses during weight-bearing gaits (R, J), with jumping impact peaks being most pronounced, while low-dynamic gaits (e.g., E) yield minimal values, consistent with the foot’s role as the primary load-bearing region.
- The wrist sensor exhibits large-amplitude data only during intense gaits, with smooth fluctuations in regular gaits, reflecting correlations between upper limb swing amplitude and gait intensity.
- The chest sensor demonstrates intermediate variation magnitudes, where multi-axis data combinations characterize the trajectory of the body’s center of mass.
Sensor data discrepancies across anatomical regions originate from biomechanical mechanisms. The foot directly transmits ground reaction forces; the wrist reflects limb coordination during swinging; and the chest synthesizes torso posture adjustments. These spatial distribution characteristics provide complementary information foundations for multi-source data fusion.
4.3. Performance Evaluation of CNN–Transformer Hybrid Architectures for Multi-Node Wearable Sensor Networks
4.3.1. Effectiveness Analysis of Multi-Source Sensor Wearable System
This study enhances human gait pattern recognition performance through a multi-sensor data fusion strategy, with experimental designs comparing four training modes: single-node (chest, foot, wrist) sensing and multi-source fusion models. Data acquisition covers seven typical gait patterns (Walking—W; Running—R; Jumping—J; Upstairs—U; Downstairs—D; Elevator—E; Falling—F), with synchronized gait parameter recordings from sensors at each anatomical location.
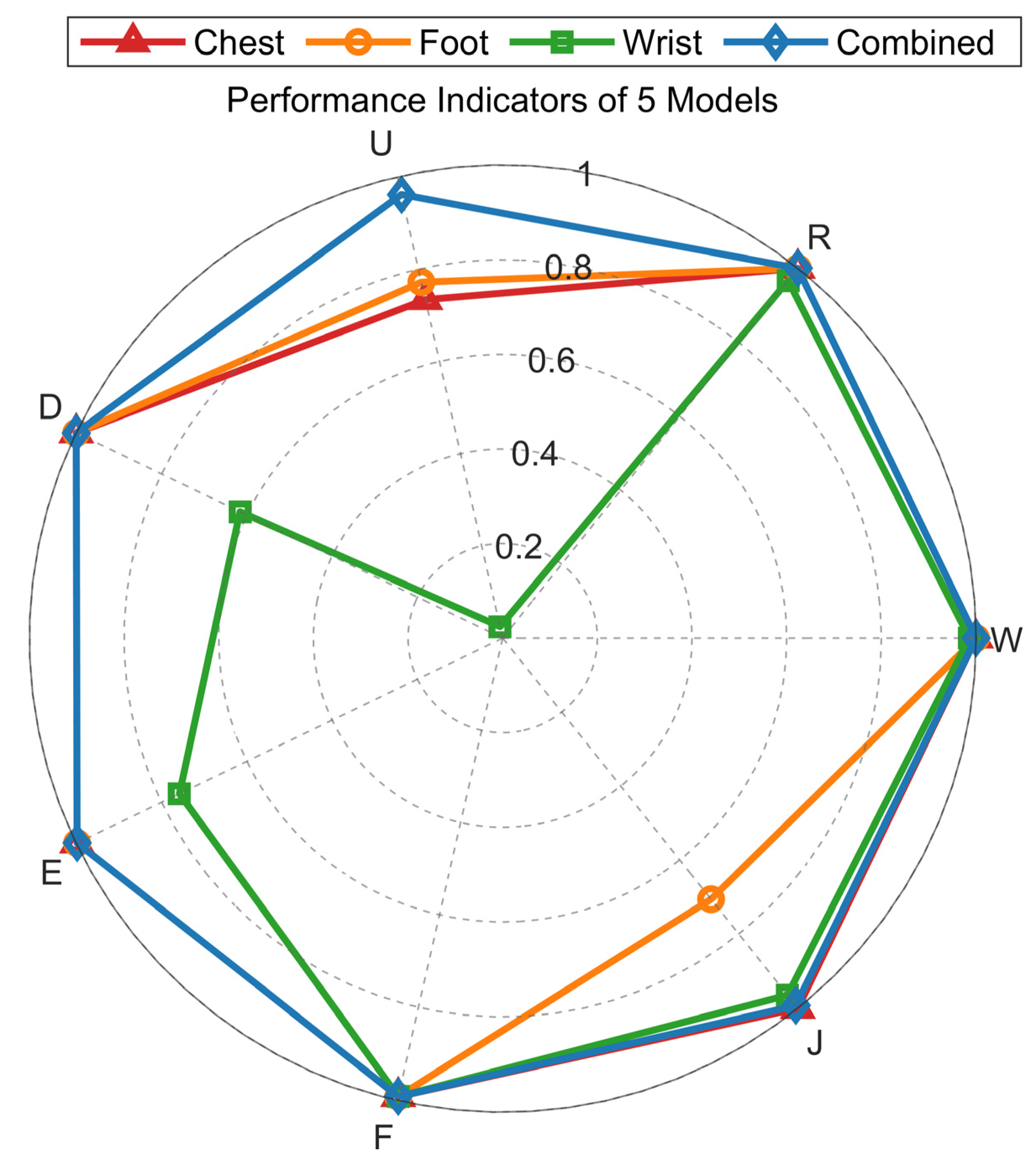
As shown in Figure 6, the multi-source fusion model achieves optimal accuracy across all gait categories, validating the effectiveness of the fusion strategy. Walking, running, and falling exhibit high recognition accuracy: single-node models (chest/foot) and the fusion model achieve 100% accuracy, while the wrist-only model exceeds 95%. Stair-climbing recognition faces significant challenges: the wrist-only model achieves <10% accuracy, and chest/foot single-node models remain below 80%, likely due to multi-joint coordination complexity and feature overlap with jumping patterns.
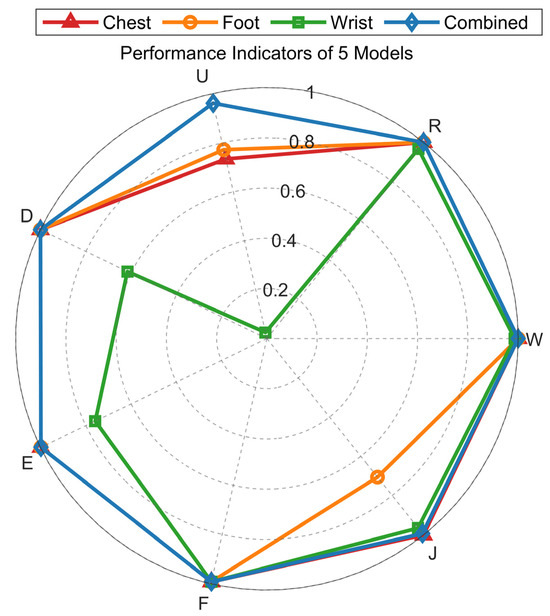
Figure 6.
Recognition accuracy of models trained on heterogeneous datasets for seven gait categories.
The multi-source fusion model maintains >95% accuracy in stair-climbing recognition, surpassing the best single-node model by over 15 percentage points, highlighting the value of multimodal feature complementarity. Experimental results demonstrate that single-sensor nodes exhibit perceptual blind spots for specific gait patterns, while multi-source data fusion effectively compensates for localized feature deficiencies, enhancing system capability in complex action discrimination. This performance improvement validates the necessity of cross-anatomical sensor network design.
4.3.2. Performance Analysis of Human Gait Recognition Algorithms
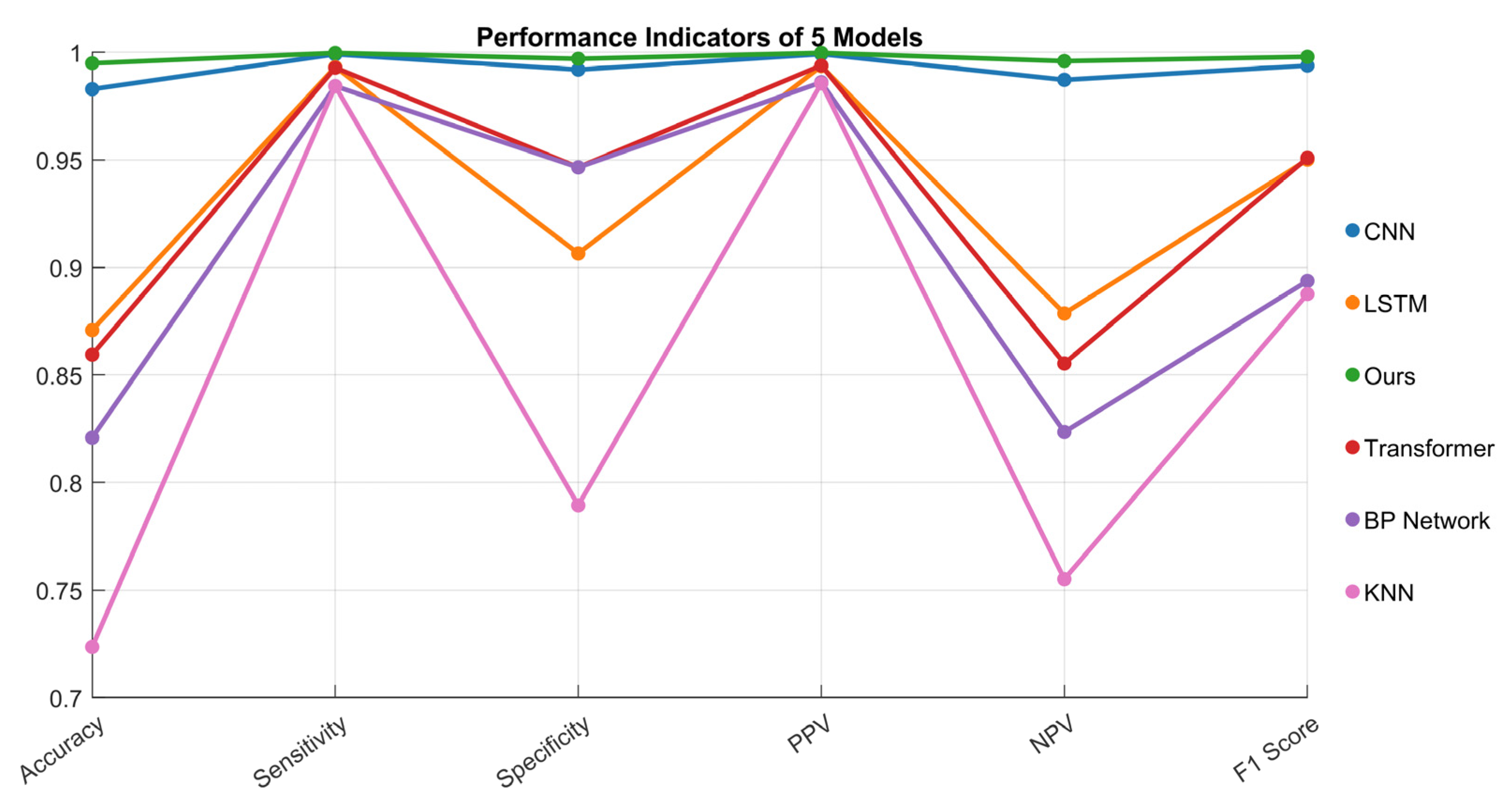
This study validates the superiority of the CNN–Transformer–Attention hybrid architecture for gait recognition through comparative experiments with multiple models. Based on seven categories of human gait data (walking, running, stair climbing, etc.), the proposed hybrid model is compared against BP neural networks, CNN, LSTM, and standard Transformer models. Experimental results, as shown in Figure 7, demonstrate that the innovative model achieves a test accuracy of 99.8%, significantly outperforming all counterparts. The CNN model, leveraging its local feature extraction capability, attains the second-best performance (98.2%), while LSTM, Transformer, and BP networks all fall below 96%.
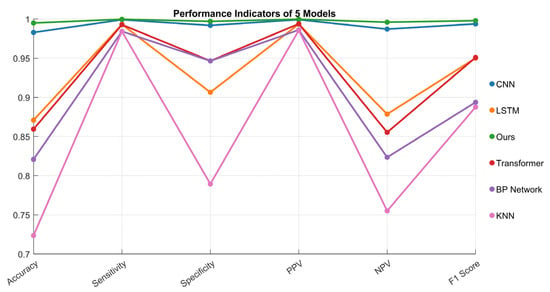
Figure 7.
Recognition accuracy rates of five distinct models for gait classification.
In terms of additional performance metrics, the hybrid architecture exhibits core advantages:
- Highest Sensitivity: The proposed model achieves the highest coverage in recognizing all gait types, with no missed detections in transient actions (e.g., falling).
- Optimal Specificity: The model demonstrates the highest classification reliability, reducing misjudgment rates by 60% compared to the second-best model.
- Robustness: Addressing imbalanced gait durations, the proposed method achieves an F1-score of 0.997, surpassing traditional models by 0.05–0.12, proving its robustness in complex real-world scenarios.
The results confirm that the hybrid model effectively addresses the limitations of traditional methods in joint spatiotemporal feature modeling by integrating the CNN’s local feature perception and Transformer’s global dependency modeling capabilities, providing an enhanced solution for multimodal gait recognition.
5. Conclusions
This study addresses the core challenge of human gait pattern recognition in intelligent sensing by proposing a multimodal spatiotemporal feature-enhanced CNN–Transformer hybrid architecture. Current research faces two critical technical bottlenecks: limited representation capability of single-modal sensing data and inadequate analytical capacity of traditional algorithms for complex spatiotemporal features. To overcome these, innovations are made in both sensing systems and algorithmic models:
- Multi-source Sensor Network Construction: A distributed wearable node network is designed to synchronously capture gait parameters from wrist, chest, and ankle regions. Temporal calibration and frequency-domain feature fusion are employed to construct a spatiotemporally correlated feature matrix.
- Cross-modal Feature Enhancement: Compared to single-node sensing solutions (wristband/chest strap/foot device), the multi-source fusion system significantly improves recognition accuracy, achieving 7.98%, 0.43%, and 5.59% enhancements over wrist-, chest-, and foot-only systems, respectively.
- Hybrid Model Architecture Optimization: The CNN–Transformer–Attention hybrid architecture integrates the CNN’s local feature extraction strengths with the Transformer’s global dependency modeling. It achieves >99% recognition accuracy across seven fundamental gait patterns, outperforming traditional CNN, LSTM, and other models by 3–8 percentage points.
This technical solution provides reliable gait pattern analysis capabilities for intelligent health monitoring systems through multi-node spatiotemporal feature collaboration, effectively supporting applications such as exercise rehabilitation training guidance and abnormal gait alerts. Future research will focus on investigating a broader spectrum of gait variations to expand the recognition scope and better capture the diversity inherent in real-world scenarios. While the current study focuses on lower limb-dominant basic gait recognition, future work will also prioritize extending recognition capabilities to complex actions (e.g., trunk rotation, upper limb lifting/holding) to enhance system applicability in daily activity monitoring.
Author Contributions
Methodology, Y.X.; Formal analysis, S.Q.; Writing—original draft, N.L.; Writing—review & editing, J.W.; Supervision, M.X. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Key Research and Development Program of China under Grant 2022YFB3904604.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Dataset available on request from the authors.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cai, J.-Y.; Luo, Y.-Y.; Cheng, C.-H. A Smart Space Focus Enhancement System Based on Grey Wolf Algorithm Positioning and Generative Adversarial Networks for Database Augmentation. Electronics 2025, 14, 865. [Google Scholar] [CrossRef]
- Zhu, Y.; Fang, X.; Li, C. Multi-Sensor Information Fusion for Mobile Robot Indoor-Outdoor Localization: A Zonotopic Set-Membership Estimation Approach. Electronics 2025, 14, 867. [Google Scholar] [CrossRef]
- Guan, D.; Hua, C.; Zhao, X. Two-Path Spatial-Temporal Feature Fusion and View Embedding for Gait Recognition. Appl. Sci. 2023, 13, 12808. [Google Scholar] [CrossRef]
- Khare, S.; Sarkar, S.; Totaro, M. Comparison of Sensor-Based Datasets for Human Activity Recognition in Wearable IoT. In Proceedings of the 2020 IEEE 6th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 2–16 June 2020; pp. 1–6. [Google Scholar]
- Shi, Y.; Du, L.; Chen, X.; Liao, X.; Yu, Z.; Li, Z.; Wang, C.; Xue, S. Robust Gait Recognition Based on Deep CNNs With Camera and Radar Sensor Fusion. IEEE Internet Things J. 2023, 10, 10817–10832. [Google Scholar] [CrossRef]
- Wang, J.; Xia, M.; Zhang, D.; Wen, W.; Chen, W.; Shi, C. Urban GNSS Positioning for Consumer Electronics: 3D Mapping and Advanced Signal Processing. IEEE Trans. Consum. Electron. 2025. [Google Scholar] [CrossRef]
- Luo, M.; Yin, M.; Li, J.; Li, Y.; Kobsiriphat, W.; Yu, H.; Xu, T.; Wu, X.; Cao, W. Lateral Walking Gait Recognition and Hip Angle Prediction using a Dual-Task Learning Framework. Cyborg Bionic Syst. 1960, 1–28. [Google Scholar] [CrossRef]
- Yu, F.; Liu, Y.; Wu, Z.; Tan, M.; Yu, J. Adaptive gait training of a lower limb rehabilitation robot based on human–robot interaction force measurement. Cyborg Bionic Syst. 2024, 5, 0115. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, X.; He, D.; Wang, R.; Guo, Y. sEMG signals characterization and identification of hand movements by machine learning considering sex differences. Appl. Sci. 2022, 12, 2962. [Google Scholar] [CrossRef]
- Song, J.; Zhu, A.; Tu, Y.; Huang, H.; Arif, M.A.; Shen, Z.; Zhang, X.; Cao, G. Effects of different feature parameters of sEMG on human motion pattern recognition using multilayer perceptrons and LSTM neural networks. Appl. Sci. 2020, 10, 3358. [Google Scholar] [CrossRef]
- Muhammad, Z.U.R.; Syed, G.; Asim, W.; Imran, N.; Gregory, S.; Dario, F.; Ernest, K. Stacked Sparse Autoencoders for EMG-Based Classification of Hand Motions: A Comparative Multi Day Analyses between Surface and Intramuscular EMG. Appl. Sci. 2018, 8, 1126. [Google Scholar] [CrossRef]
- Qiu, S.; Zhao, H.; Jiang, N.; Wang, Z.; Liu, L.; An, Y.; Zhao, H.; Miao, X.; Liu, R.; Fortino, G. Multi-sensor information fusion based on machine learning for real applications in human activity recognition: State-of-the-art and research challenges. Inf. Fusion 2022, 80, 241–265. [Google Scholar] [CrossRef]
- Chen, P.; Jian, Q.; Wu, P.; Guo, S.; Cui, G.; Jiang, C.; Kong, L. A Multi-Domain Fusion Human Motion Recognition Method Based on Lightweight Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4019605. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, Y.; Wang, L.; Wang, X.; Tan, T. A Comprehensive Study on Cross-View Gait Based Human Identification with Deep CNNs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 209–226. [Google Scholar] [CrossRef] [PubMed]
- Liao, R.; Cao, C.; Garcia, E.B.; Yu, S.; Huang, Y. Pose-Based Temporal-Spatial Network (PTSN) for Gait Recognition with Carrying and Clothing Variations. In Biometric Recognition: 12th Chinese Conference, CCBR 2017, Shenzhen, China, 28–29 October 2017; Springer: Cham, Switzerland, 2017; pp. 474–483. [Google Scholar]
- Fang, B.; Sun, F.; Liu, H.; Liu, C. 3D human gesture capturing and recognition by the IMMU-based data glove. Neurocomputing 2018, 277, 198–207. [Google Scholar] [CrossRef]
- Ramalingame, R.; Barioul, R.; Li, X.; Sanseverino, G.; Krumm, D.; Odenwald, S.; Kanoun, O. Wearable Smart Band for American Sign Language Recognition With Polymer Carbon Nanocomposite-Based Pressure Sensors. IEEE Sens. Lett. 2021, 5, 6001204. [Google Scholar] [CrossRef]
- Mantyjarvi, J.; Himberg, J.; Seppanen, T. Recognizing human motion with multiple acceleration sensors. In Proceedings of the 2001 IEEE International Conference on Systems, Man and Cybernetics. e-Systems and e-Man for Cybernetics in Cyberspace (Cat.No.01CH37236), Tucson, AZ, USA, 7–10 October 2001; Volume 2, pp. 747–752. [Google Scholar]
- Zhao, H.; Wang, Z.; Qiu, S.; Wang, J.; Xu, F.; Wang, Z.; Shen, Y. Adaptive gait detection based on foot-mounted inertial sensors and multi-sensor fusion. Inf. Fusion 2019, 52, 157–166. [Google Scholar] [CrossRef]
- Cunado, D.; Nixon, M.S.; Carter, J.N. Using gait as a biometric, via phase-weighted magnitude spectra. In Audio-and Video-Based Biometric Person Authentication: First International Conference, AVBPA’97 Crans-Montana, Switzerland, 12–14 March 1997; Proceedings 1; Springer: Berlin/Heidelberg, Germany, 1997; pp. 93–102. [Google Scholar]
- Wang, W.; Xi, J.; Zhao, D. Learning and Inferring a Driver’s Braking Action in Car-Following Scenarios. IEEE Trans. Veh. Technol. 2018, 67, 3887–3899. [Google Scholar] [CrossRef]
- Wang, J.; Shi, C.; Xia, M.; Zheng, F.; Li, T.; Shan, Y.; Jing, G.; Chen, W.; Hsia, T.C. Seamless Indoor–Outdoor Foot-Mounted Inertial Pedestrian Positioning System Enhanced by Smartphone PPP/3-D Map/Barometer. IEEE Internet Things J. 2024, 11, 13051–13069. [Google Scholar] [CrossRef]
- Bianchi, V.; Bassoli, M.; Lombardo, G.; Fornacciari, P.; Mordonini, M.; Munari, I.D. IoT Wearable Sensor and Deep Learning: An Integrated Approach for Personalized Human Activity Recognition in a Smart Home Environment. IEEE Internet Things J. 2019, 6, 8553–8562. [Google Scholar] [CrossRef]
- Wang, J.; Shi, C.; Zheng, F.; Yang, C.; Liu, X.; Liu, S.; Xia, M.; Jing, G.; Li, T.; Chen, W.; et al. Multi-frequency smartphone positioning performance evaluation: Insights into A-GNSS PPP-B2b services and beyond. Satell. Navig. 2024, 5, 25. [Google Scholar] [CrossRef]
- Buffelli, D.; Vandin, F. Attention-Based Deep Learning Framework for Human Activity Recognition With User Adaptation. IEEE Sens. J. 2021, 21, 13474–13483. [Google Scholar] [CrossRef]
- Li, J.; Wang, Z.; Wang, C.; Su, W. GaitFormer: Leveraging dual-stream spatial–temporal Vision Transformer via a single low-cost RGB camera for clinical gait analysis. Knowl.-Based Syst. 2024, 295, 111810. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).