
An Evolutionary Game-Theoretic Approach to Triple-Strategy Coordination in RRT*-Based Path Planning

Abstract
1. Introduction
2. Related Research Background
2.1. Analysis of Classical RRT* Algorithm
| Algorithm 1 RRT* |
| Input: Start node , goal node , maximum iterations max_iter;
Output: Optimal path;
|
2.2. Analysis of Classical Dijkstra’s Algorithm
| Algorithm 2 Dijkstra |
| Input: Graph G, start node ;
Output: Shortest path distances from ;
|
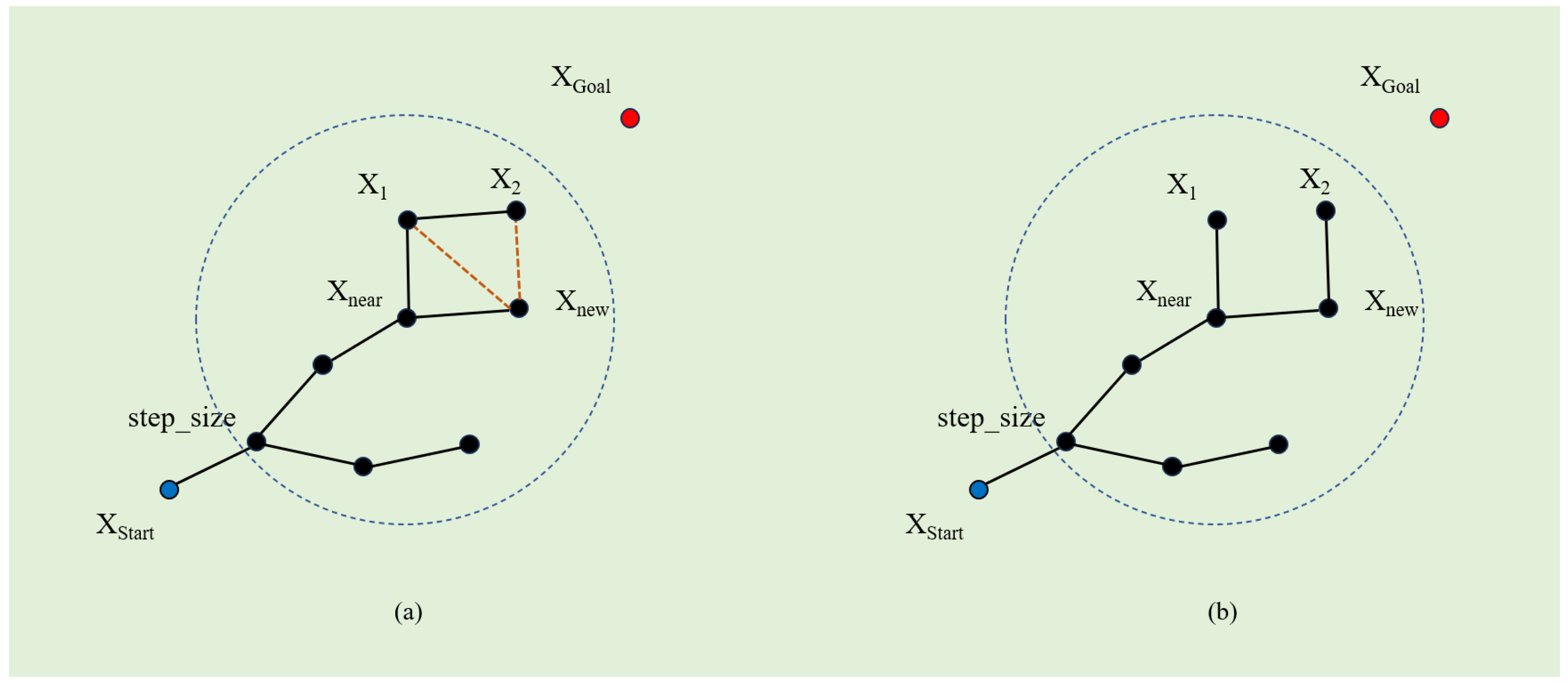
3. The Proposed Algorithm
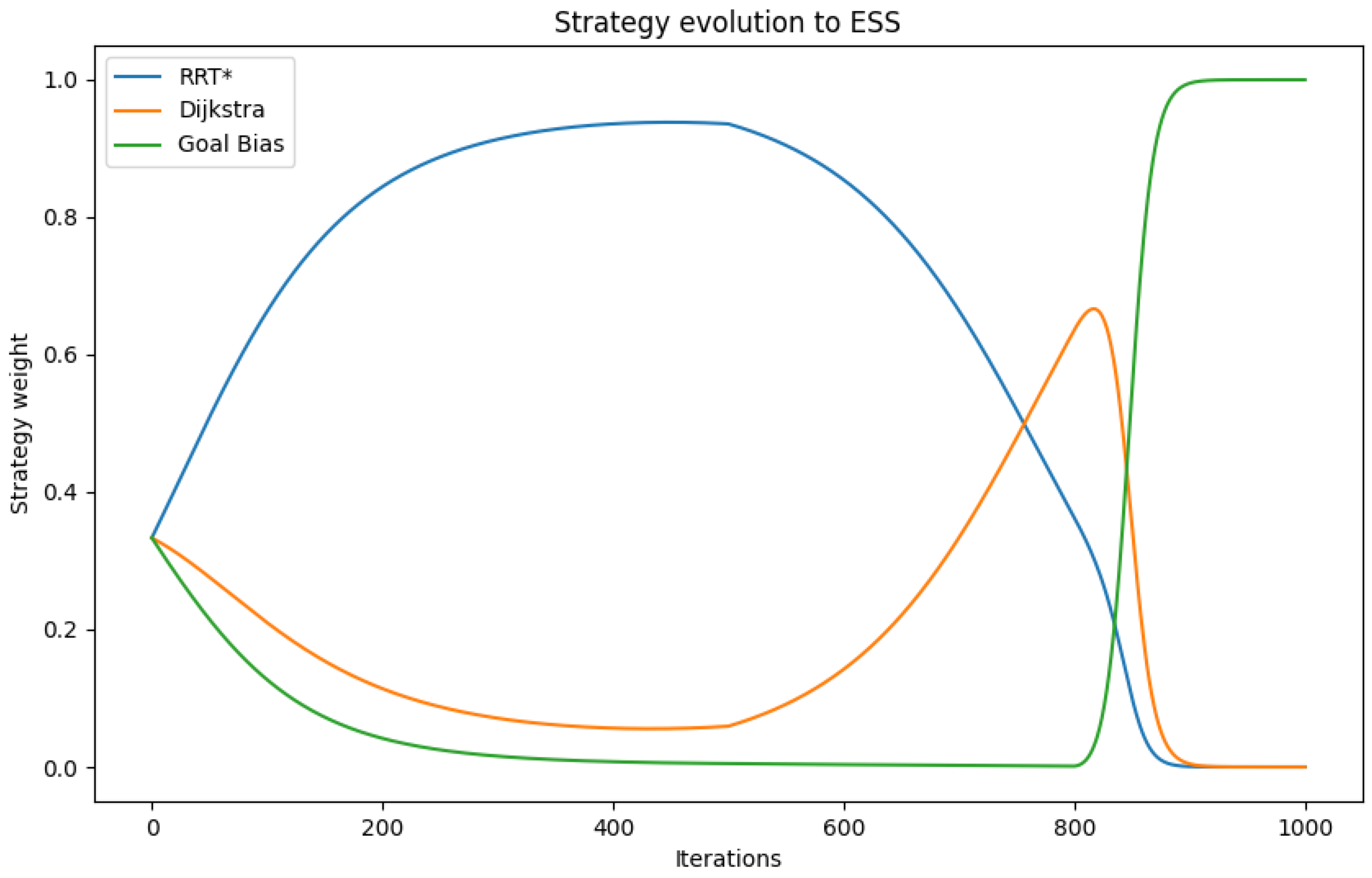
3.1. Mechanisms for Evolving Strategies
3.2. Strategy Implementation and Route Planning
4. Experimental Results and Discussion
4.1. Simple Environment
4.2. Complex Environment
4.3. Three-Dimensional Environment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| EG-DRRT* | Evolutionary Game-Theoretic Dynamic RRT* |
| RRT | Rapidly Exploring Random Tree |
| RRT* | Rapidly Exploring Random Tree Star |
| UAVs | Unmanned Aerial Vehicles |
| ESS | Evolutionarily Stable Strategy |
References
- Aggarwal, S.; Kumar, N. Path planning techniques for unmanned aerial vehicles: A review, solutions, and challenges. Comput. Commun. 2020, 149, 270–299. [Google Scholar] [CrossRef]
- Sanchez-Ibanez, J.R.; Pérez-del Pulgar, C.J.; García-Cerezo, A. Path planning for autonomous mobile robots: A review. Sensors 2021, 21, 7898. [Google Scholar] [CrossRef]
- Yin, C.; Xiao, Z.; Cao, X.; Xi, X.; Yang, P.; Wu, D. Offline and online search: UAV multiobjective path planning under dynamic urban environment. IEEE Internet Things J. 2017, 5, 546–558. [Google Scholar] [CrossRef]
- Lin, Y.; Saripalli, S. Sampling-based path planning for UAV collision avoidance. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3179–3192. [Google Scholar] [CrossRef]
- LaValle, S.M. Planning Algorithms; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Arslan, O.; Tsiotras, P. Use of relaxation methods in sampling-based algorithms for optimal motion planning. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 2421–2428. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Jones, M.; Djahel, S.; Welsh, K. Path-planning for unmanned aerial vehicles with environment complexity considerations: A survey. ACM Comput. Surv. 2023, 55, 1–39. [Google Scholar] [CrossRef]
- Choset, H.; Lynch, K.M.; Hutchinson, S.; Kantor, G.A.; Burgard, W. Principles of Robot Motion: Theory, Algorithms, and Implementations; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- LaValle, S. Rapidly-Exploring Random Trees: A New Tool for Path Planning; Research Report; TR 98-11; Computer Science Department, Iowa State University: Ames, IA, USA, 1998. [Google Scholar]
- Karaman, S.; Frazzoli, E. Sampling-based algorithms for optimal motion planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar] [CrossRef]
- Kuffner, J.J.; LaValle, S.M. RRT-connect: An efficient approach to single-query path planning. In Proceedings of the 2000 ICRA, Millennium Conference, IEEE International Conference on Robotics and Automation, San Francisco, CA, USA, 24–28 April 2000; Symposia Proceedings (Cat. No. 00CH37065). IEEE: Piscataway, NJ, USA, 2000; Volume 2, pp. 995–1001. [Google Scholar] [CrossRef]
- Marcucci, T.; Petersen, M.; von Wrangel, D.; Tedrake, R. Motion planning around obstacles with convex optimization. Sci. Robot. 2023, 8, eadf7843. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Liu, Z.; Li, Q.; Prorok, A. Mobile robot path planning in dynamic environments through globally guided reinforcement learning. IEEE Robot. Autom. Lett. 2020, 5, 6932–6939. [Google Scholar] [CrossRef]
- Choudhury, S.; Scherer, S.; Singh, S. RRT*-AR: Sampling-based alternate routes planning with applications to autonomous emergency landing of a helicopter. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 3947–3952. [Google Scholar] [CrossRef]
- Dang, X.; Edelkamp, S. SIL-RRT*: Learning Sampling Distribution through Self Imitation Learning. arXiv 2024. [Google Scholar] [CrossRef]
- He, Y.; Hou, T.; Wang, M. A new method for unmanned aerial vehicle path planning in complex environments. Sci. Rep. 2024, 14, 9257. [Google Scholar] [CrossRef] [PubMed]
- Elbanhawi, M.; Simic, M. Sampling-based robot motion planning: A review. IEEE Access 2014, 2, 56–77. [Google Scholar] [CrossRef]
- Dhulkefl, E.; Durdu, A.; Terzioğlu, H. Dijkstra algorithm using UAV path planning. Konya J. Eng. Sci. 2020, 8, 92–105. [Google Scholar] [CrossRef]
- Soltani, A.R.; Tawfik, H.; Goulermas, J.Y.; Fernando, T. Path planning in construction sites: Performance evaluation of the Dijkstra, A*, and GA search algorithms. Adv. Eng. Inform. 2002, 16, 291–303. [Google Scholar] [CrossRef]
- Zeng, W.; Church, R.L. Finding shortest paths on real road networks: The case for A. Int. J. Geogr. Inf. Sci. 2009, 23, 531–543. [Google Scholar] [CrossRef]
- Smith, J.M.; Price, G.R. The logic of animal conflict. Nature 1973, 246, 15–18. [Google Scholar] [CrossRef]
- Sandholm, W.H. Population Games and Evolutionary Dynamics; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm Category | Time/s | Length/m | Iterations |
|---|---|---|---|
| EG-DRRT* | 0.12 | 155.81 | 745.3 |
| RRT | 0.29 | 172.76 | 1212.0 |
| RRT* | 1.53 | 150.83 | 1369.5 |
| RRT-Connect | 0.63 | 166.53 | 1246.7 |
| Algorithm Category | Time/s | Length/m | Iterations |
|---|---|---|---|
| EG-DRRT* | 19.38 | 596.13 | 17,764.8 |
| RRT | 19.86 | 611.09 | 17,742.7 |
| RRT* | 74.82 | 598.59 | 18,450.3 |
| RRT-Connect | 35.79 | 603.33 | 18,896.2 |
| Algorithm Category | Time/s | Length/m | Iterations |
|---|---|---|---|
| EG-DRRT* | 6.42 | 157.78 | 4217.6 |
| RRT | 8.35 | 169.52 | 3727.7 |
| RRT* | 15.63 | 163.06 | 5317.8 |
| RRT-Connect | 9.33 | 160.25 | 5236.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, L.; Hao, Y.; Yang, L.; Li, M. An Evolutionary Game-Theoretic Approach to Triple-Strategy Coordination in RRT*-Based Path Planning. Electronics 2025, 14, 1453. https://doi.org/10.3390/electronics14071453
Qi L, Hao Y, Yang L, Li M. An Evolutionary Game-Theoretic Approach to Triple-Strategy Coordination in RRT*-Based Path Planning. Electronics. 2025; 14(7):1453. https://doi.org/10.3390/electronics14071453
Chicago/Turabian StyleQi, Lin, Yongping Hao, Liyuan Yang, and Meixuan Li. 2025. "An Evolutionary Game-Theoretic Approach to Triple-Strategy Coordination in RRT*-Based Path Planning" Electronics 14, no. 7: 1453. https://doi.org/10.3390/electronics14071453
APA StyleQi, L., Hao, Y., Yang, L., & Li, M. (2025). An Evolutionary Game-Theoretic Approach to Triple-Strategy Coordination in RRT*-Based Path Planning. Electronics, 14(7), 1453. https://doi.org/10.3390/electronics14071453