1. Introduction
Many modern data-driven applications used in healthcare, financial services, e-commerce, and other sectors rely on streams of data to support real-time workflows and quick decision making, where meeting these often very complex operational demands is absolutely imperative [
1,
2]. However, this efficiency cannot be easily supported when distributed systems create an increasingly massive amount of data that require real-time processing [
3,
4,
5]. Runtime verification (RV) is a lightweight and cost-effective approach recently applied to software systems, with the aim of monitoring their runtime temporal properties in terms of correctness [
6,
7,
8,
9]. Among the domains where these issues are crucial, RV has been widely applied in aerospace, automotive safety, and industrial control systems.
Linear temporal logic (LTL) offers an effective method for specifying the temporal properties that systems must maintain, such as safety properties (“something bad never happens”), which can be violated within a finite time frame, and liveness properties (“something good eventually happens”), which can only be violated within an infinite time frame [
10,
11]. Despite LTL’s strengths, traditional LTL-based RV methods face significant challenges in keeping up with the high-speed, low-latency demands of distributed, large-scale streaming environments. These challenges arise due to the high computational resource demands for monitoring and evaluating temporal properties in real time, necessitating more efficient scalable solutions [
8,
12]. Despite the suitability of RVs for analyzing temporal properties, they are not designed to function seamlessly with stream processing applications, which prioritize efficient data handling and fault tolerance. This creates a gap in ensuring continuous compliance with system properties during data flow. This study investigates the following key research questions:
How can LTL-based monitoring be effectively integrated into a distributed streaming application such as Apache Spark to ensure compliance with safety and liveness properties?
What is the impact of LTL-based monitoring on system performance metrics such as latency and resource utilization?
How does the system scale with increasing data volume in a distributed stream processing context?
To address these challenges, a new LTL-based RV framework is proposed that integrates real-time monitoring of temporal properties in distributed stream processing. The framework is implemented in Apache Spark, a widely used engine for big data processing [
13,
14]. However, the proposed approach embeds LTL formulas directly into Spark’s stream processing pipeline, allowing for continuous verification of data streams to ensure compliance with predefined conditions. Specifically, in our case study, we monitor critical financial parameters such as transaction amount, frequency, and amount balance, verifying safety conditions (e.g., “the transaction amount should never exceed a certain threshold”) and liveness conditions (e.g., “the frequency must eventually exceed a critical threshold”). These temporal properties ensure that the system dynamically responds to changing conditions while maintaining operational correctness in real time.
The main contributions of this paper are as follows:
We present a new approach for integrating LTL-based RV with Apache Spark by embedding LTL formulas into the streaming pipeline for real-time compliance verification, eliminating the need for offline or batch analysis.
We introduce generalized LTL-based RV patterns for implementing LTL verification in Apache Spark, which can be extended to other stream processing frameworks.
We propose a scalable and systematic approach for embedding LTL monitoring into stream processing workflows, ensuring low-latency and real-time anomaly detection, while also being adaptable to other stream processing frameworks.
We validate the effectiveness of our method through a case study on financial data processing and experiments, demonstrating its impact on real-time reliability, correctness, and monitoring of temporal properties such as safety and liveness conditions.
The remainder of this paper is organized as follows: In
Section 2 reviews related work on RV and stream processing;
Section 3 presents the RV process, focusing on its theoretical foundations and the role of LTL;
Section 4 introduces LTL patterns and their integration with Apache Spark for real-time monitoring;
Section 5 presents the primary case study, showcasing our approach to real-time monitoring of financial data stream processing, while
Section 6 demonstrates its application to real-time monitoring of weather data stream processing;
Section 7 outlines the limitations of the current work;
Section 8 summarizes the paper, provides conclusions, and outlines future research directions.
2. Related Work
Runtime verification (RV) is used to validate the behavior of a system in real time to ensure that it meets its specifications. Unlike comprehensive functional methods such as model checking and theorem proving, which perform exhaustive verification before deployment, RV is less computationally demanding and suitable for dynamic systems that require real-time verification [
6,
9]. RV operates alongside the system, monitoring its behavior according to predefined rules and issuing alerts for any anomalies or violations. In particular, RV is suitable for real-time applications that cannot be fully verified prior to use. RV utilizes various logics and specifications, with linear temporal logic (LTL) being the most prominent due to its descriptive power over temporal properties. It has been applied to a wide range of domains, including traditional software systems, embedded systems, and cyber–physical systems, where it is effective in detecting timing errors during runtime. However, conventional RV methods often rely on batch processing techniques used in static analysis, which are not well suited for real-time applications that require low latency and continuous monitoring.
Recent works by Bauer et al. [
12] and Leucker [
15] provide a comprehensive overview of RV techniques for LTL. Bauer introduces three-valued semantics for LTL and timed LTL, enhancing the applicability of RV to temporal properties where uncertainty is involved. Leucker’s work focuses on applying LTL theorems to RVs, providing a solid theoretical foundation. These studies highlight RV’s ability to capture safety and liveness properties, but do not address the integration with real-time data streaming applications. Maggi et al. [
16] applied LTL-based declarative process models to RV, specifically for business processes, indicating that RV is suitable for monitoring compliance in workflows. Similarly, Guang-yuan and Zhi-song [
17] introduced linear temporal logic with clocks (LTLC), extending LTL to real-time system verification and demonstrating its effectiveness in ensuring system timeliness. These advancements enhance LTL’s expressiveness but still do not fully meet the demands of high-speed streaming environments. To address the challenges of distributed systems, previous research has focused on failure-aware and decentralized RV techniques. Basin et al. [
4] addressed challenges such as network failures and out-of-order message delivery that are typical of distributed systems in the real world. Mostafa and Bonakdarpour [
18] further explored these decentralized RV techniques to monitor LTL specifications in distributed systems, demonstrating their applicability through a simulated swarm of flying drones. Similarly, Danielsson and Sánchez [
19] proposed decentralized RV techniques for synchronized networks, improving the robustness of RV in environments without synchronized clocks. These approaches have highlighted the potential of RV in decentralized environments, but have not been integrated with modern stream processing frameworks.
Faymonville et al. [
20] contributed to the field with their work on parametric temporal logic, which allows dynamic monitoring of systems, particularly in the context of microservices and AI-based systems. This work emphasizes the need for scalability in RV, a key aspect that our proposed approach addresses by integrating with Apache Spark. The field of RV has seen substantial developments in recent years, particularly in addressing the high-speed, low-latency demands of modern stream processing systems. In addition, Zhang and Liu [
21] introduced scalable RV solutions for distributed edge computing, emphasizing improved real-time decision making capabilities in environments with limited resources. Similarly, Ganguly et al. [
22] addressed the challenges of RV in partially synchronous distributed systems, highlighting issues such as synchronization and fault tolerance. These studies underscore the need for efficient RV frameworks that can operate seamlessly with stream processing systems. Despite these advancements, existing approaches often rely on offline or batch analysis, limiting their utility in real-time applications. The proposed approach is built on these recent advances by integrating LTL-based monitoring directly into Apache Spark. Unlike previous methods that depend on batch processing, we propose a real-time, integrated LTL-based monitoring approach within streaming workflows, as detailed in
Section 1. A summary of the related work and how our approach builds on these advances is presented in
Table 1.
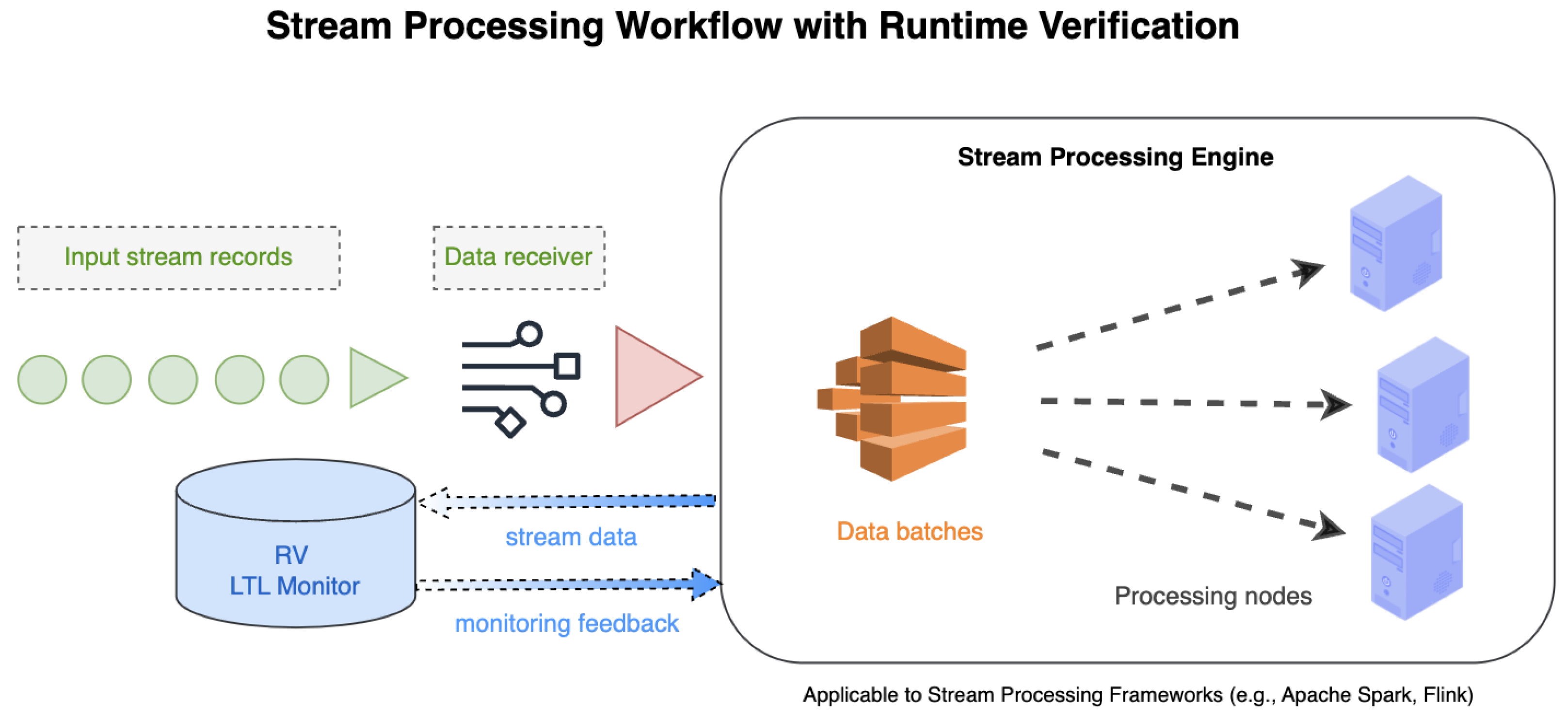
4. LTL-Based RV Patterns in Apache Spark
In this section, reusable patterns are presented for implementing LTL-based RV in Apache Spark’s stream processing. These patterns bridge the gap between LTL semantics and the real-time needs of distributed systems, enabling efficient RV and ensuring system compliance in large-scale applications. As defined in the Preliminaries section, RV relies on state machines that observe execution traces and verify compliance with specified properties. An RV monitor is formally defined in Equation (
1), where
M transitions between states based on incoming events and produces verdicts indicating whether the monitored system satisfies the given property. In this implementation, LTL operators are mapped to Spark-based monitoring patterns, ensuring efficient real-time verification in a distributed streaming environment.
4.1. Next Operator ()
The formula
checks whether a given condition
must hold in the next state (immediate next time step). The formal semantics of
is defined as:
In simple terms, means that for a condition to hold under , it must be satisfied in the next time step . The formula is highly relevant in real-time systems where immediate state transitions need to be monitored, such as detecting if performance metrics exceed thresholds in the next event. In real-time stream processing, the formula enables the detection of conditions that must hold in the next state in the event stream, as described in the reference monitor approach Algorithm 1
The monitoring process for the formula follows a stateless interpretation, where each event in the stream is treated independently to check whether the condition holds in the next event. Conceptually, the set of states, Q, is represented by the rows in the EventStream, with each row corresponding to a potential state at a specific timestamp. The initial state, , is implicitly the first row of the DataFrame, ordered by timestamp. The trace, , is defined by the sequence of events or rows in the DataFrame that are observed in the system over time, with each event in the stream representing a state at a particular time stamp. The alphabet of observed events, , refers to structured streaming events such as sensor readings, metrics, or other data points observed in the system. This alphabet represents the set of all possible events that could occur in the stream. The transition function, , defines the transition between states over time, tracked by the “lead” function, which retrieves the value of the next event in the time series. The verdict function, , filters events where the condition does not hold by checking the current and next events and determining whether the violation condition is met.
The following pseudocode (i.e., Algorithm 1) illustrates the core concept behind monitoring violations of the
condition in a stream of events.
| Algorithm 1 Next State Violation Monitoring for LTL Formula |
- 1:
Input: EventStream (DataFrame), , AdditionalParameters - 2:
Output: Violations (DataFrame) - 3:
Define a window ordered by timestamp to track the next event in time - 4:
Extract next event value: next_event = lead(event_value, 1) over window - 5:
for each event in EventStream (ordered by timestamp) do - 6:
Retrieve next event: next_event - 7:
if (next_event, AdditionalParameters) is False then - 8:
Add next_event to Violations - 9:
end if - 10:
end for - 11:
Return Violations
|
For example, in a factory setting, machines generate performance data streams (e.g., vibration levels). Detecting whether the vibration level exceeds a critical threshold in the next event helps prevent equipment failure. The LTL formula for this condition is as follows:
As defined in Equation (
7), the formula can be implemented in Apache Spark by first defining a condition function to check for vibration threshold violation in the next event. This function takes as input the vibration level of the next event (
next_event_value) and a predefined critical vibration threshold (
critical_vibration_threshold). If the vibration level exceeds the critical threshold, the function returns
True, indicating a violation. Otherwise, it returns
False.
Next, the condition is applied within a monitoring function that detects violations of the LTL property . This function processes a stream of vibration data (EventStream) and the critical vibration threshold (critical_vibration_threshold). It retrieves the next event relative to the current event using a function such as lead(current_event). The function then filters the events, selecting those in which the condition function vibration_violation_condition(next_event_value, critical_vibration_threshold) evaluates to True, indicating a violation. The function returns the set of detected violations.
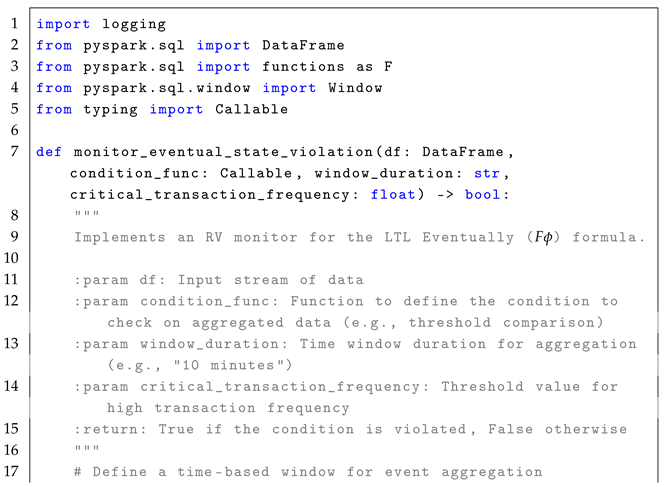
4.2. Eventually Operator ()
The formula
checks whether a given condition
will hold at some point in the future, which means that there exists a time
where
is true. The formal semantics of
is defined as:
In simple terms, means that for a condition to hold at the current time step i, it must be satisfied at some future time step j, where . The formula is highly relevant in real-time systems where conditions are expected to be met eventually, rather than immediately. For example, it can be used to monitor whether a critical threshold for performance metrics, such as machine vibration levels, will be exceeded within a defined time frame. In real-time stream processing, the formula enables the detection of conditions that must eventually hold within a specific time window in the event stream, as described in the reference monitor approach Algorithm 2.
The monitoring process for the formula follows a stateless interpretation, where each event in the stream is treated independently to check whether a condition is met at some point in the future. Conceptually, the set of states, Q, is represented by the rows in the EventStream, and each event is observed in relation to the events that follow it, using windows-based time to define the future context for evaluation. The initial state, , is implicitly the first row of the DataFrame, ordered by timestamp. The trace, , is defined by the sequence of events or rows in the DataFrame that are observed in the system over time, with each event in the stream representing a state at a particular time stamp. The alphabet of observed events, , refers to structured streaming events such as sensor readings, metrics, or other data points observed in the system. This alphabet represents the set of all possible events that could occur in the stream. The transition function, , defines how states evolve over time using windowing to capture future conditions. The verdict function, , filters out windows where is not satisfied.
The following pseudocode (i.e., Algorithm 2) illustrates the core concept behind monitoring violations of the
condition in a stream of events.
| Algorithm 2 Eventual State Violation Monitoring For LTL Formula |
- 1:
Input: EventStream (DataFrame), , WindowDuration, AdditionalParameters - 2:
Output: Violations (Boolean) - 3:
Define time-based window to aggregate events into fixed windows based on “timestamp” using WindowDuration. - 4:
Aggregate values to compute max(event_value) in each window. - 5:
for each window in EventStream (ordered by timestamp) do - 6:
Evaluate aggregated condition and apply (aggregated_value, AdditionalParameters) - 7:
if is False then - 8:
Mark window as a violation - 9:
end if - 10:
end for - 11:
if any window is marked as a violation then - 12:
Return True - 13:
else - 14:
Return False - 15:
end if
|
For example, in a cloud system, services generate real-time availability status updates. It is crucial to detect whether a service will eventually become available within a defined time window (e.g., 10 min) to ensure system reliability. The LTL formula for this condition is as follows:
As defined in Equation (
9), the formula can be implemented in Spark by first defining the condition function to check the availability of the service within a time window. This function takes as input the aggregated service availability status (
aggregated_value). If the aggregated value is
False, indicating a violation, the function returns
True. Otherwise, it returns
False.
Next, the condition is applied within a monitoring function that detects violations of the LTL property . This function processes a stream of service availability data (EventStream) and the duration of the time window (WindowDuration). It groups the events into time-based windows of duration WindowDuration. For each window, the condition function service_availability_condition(aggregated_value) is evaluated. If the condition is evaluated to False, the current window is added to the violations. The function returns the set of detected violations.
4.3. Globally Operator ()
The formula
enforces that a given condition
must remain true for all future time steps, ensuring continuous compliance. The formal semantics of
is defined as:
In simple terms, means that for a condition to hold at the current time step i, it must remain satisfied for all future time steps . The formula is highly relevant in real-time systems, where continuous compliance with operational rules must be ensured. For example, in a factory monitoring system, can check whether machine vibrations remain within a safe range throughout the operation period. In real-time stream processing, the formula allows event-driven monitoring of conditions that must remain valid for all observed data points within a defined time window, as described in the reference monitor approach Algorithm 3.
The monitoring process for the formula follows a stateless interpretation, where each event in the stream is independently verified to ensure that the condition remains valid for all future data points. Conceptually, the set of states is represented by the rows in the EventStream, each corresponding to a potential state at a specific timestamp. The initial state, , is implicitly the first row of the DataFrame, ordered by timestamp. The trace, , is defined by the sequence of events or rows in the DataFrame that are observed in the system over time, with each event in the stream representing a state at a particular time stamp. The alphabet of observed events, , refers to structured streaming events such as sensor readings, metrics, or other data points observed in the system. This alphabet represents the set of all possible events that could occur in the stream. The transition function, , defines how states evolve by verifying whether the monitored condition holds in each state. The verdict function, , determines compliance by filtering out rows where condition is violated.
The following pseudocode (i.e., Algorithm 3) illustrates the core concept behind monitoring violations of the
condition in a stream of events.
| Algorithm 3 Global State Violation Monitoring for LTL Formula |
- 1:
Input: EventStream (DataFrame), , AdditionalParameters - 2:
Output: Violations (Boolean) - 3:
Filter events to identify events where (event_value, AdditionalParameters) evaluates to False. - 4:
if any event violates then - 5:
Return True - 6:
else - 7:
Return False - 8:
end if
|
For example, in a manufacturing setting where machines generate real-time vibration data streams, ensuring that the vibration level stays below a critical threshold is vital for operational safety. The LTL formula for this condition is as follows:
As defined in Equation (
11), the formula can be implemented in Spark first by defining the condition function to check the vibration level at each event. This function takes as input the observed vibration level (
value) and a predefined critical vibration threshold (
critical_vibration_threshold). If the vibration level is below the critical threshold, the function returns
True, indicating a violation. Otherwise, it returns
False.
Next, the condition is applied within a monitoring function that detects violations of the LTL property . This function processes a stream of vibration data (EventStream) and the critical vibration threshold (critical_vibration_threshold). It filters the events in the stream by applying the condition function vibration_violation_condition(value, critical_vibration_threshold). If any violations are detected, a warning message is logged. The function returns the set of detected violations.
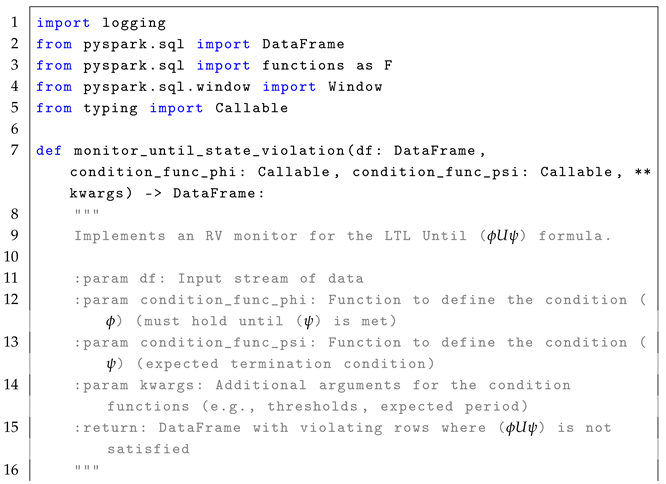
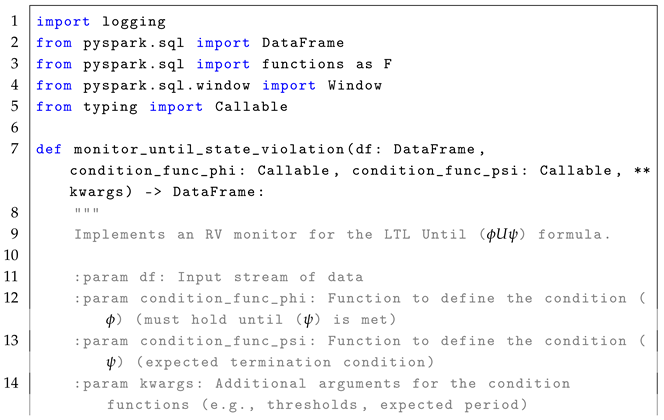
4.4. Until Operator ()
The formula
checks whether a given condition
must hold until condition
becomes true at some future time. The formal semantics of
is defined as:
In simple terms, means that condition must remain true from the current time step i until a future time step j, where is satisfied. The formula is highly relevant in real-time systems where a condition must be maintained until a terminating event occurs. For example, in a manufacturing system, the production process must continue operating within acceptable parameters until a maintenance signal is triggered. In real-time stream processing, enables the monitoring of whether a condition is continuously maintained until another condition is satisfied within a defined period, as described in the reference monitor approach Algorithm 4.
The monitoring process for the formula follows a stateless interpretation, where each event in the stream is treated independently to check whether condition persists until condition occurs. Each event is observed in relation to subsequent events, using time-based evaluation to determine whether is met within an expected period. Conceptually, the set of states is represented by the rows in the EventStream, where each row corresponds to an observation at a given time stamp, without explicitly maintaining past states. The initial state, , is implicitly the first row in the DataFrame when ordered by timestamp. The trace, , is defined by the sequence of events or rows in the DataFrame that are observed in the system over time, with each event in the stream representing a state at a particular time stamp. The alphabet of observed events, , consists of structured streaming events such as sensor readings or log entries, representing the possible types of event in the system. The transition function, , determines how events progress over time using timestamp-based tracking. The verdict function, , identifies violations when condition is not upheld until is satisfied within the expected period.
The following pseudocode (i.e., Algorithm 4) illustrates the core monitoring mechanism for detecting violations of the
condition in a streaming environment.
| Algorithm 4 Until State Violation Monitoring for LTL Formula |
- 1:
Input: EventStream (DataFrame), , , AdditionalParameters - 2:
Output: Violations (DataFrame) - 3:
Define window: Order events by timestamp to process them in chronological order - 4:
for each event in EventStream (excluding the first event) do - 5:
Compute time gap: - 6:
if is True then - 7:
Track until is met: Look ahead and check if holds within the AdditionalParameters (e.g., expected_period) - 8:
if fails within the expected period then - 9:
Add to violations if holds but fails within the expected time - 10:
end if - 11:
end if - 12:
end for - 13:
Return Violations
|
For example, in a manufacturing setting, machines generate real-time vibration data streams. Ensuring that vibration levels remain below a critical threshold is vital for operational safety. The LTL formula for this condition is as follows:
As defined in Equation (
13), the formula can be implemented in Spark by first defining the condition functions to check the production quality and maintenance signals. The first condition function checks whether the observed output quality (
value) exceeds the predefined quality threshold (
quality_threshold). If the value is greater than the threshold, the function returns
True, indicating a violation. Otherwise, it returns
False. The second condition function checks whether the time gap (
gap) since the last maintenance signal is within the expected period (
expected_period). If the gap is less than or equal to the expected period, the function returns
True, indicating that the maintenance signal was in good condition. Otherwise, it returns
False.
Next, conditions are applied within the monitoring function that detects violations of the LTL property . This function processes a stream of production quality data (EventStream), the quality threshold (quality_threshold), and the expected maintenance period (expected_period). The events are first ordered by timestamp, and the time gap between each event is computed as the difference between the current event timestamp and the previous event timestamp. The function then filters out rows where there is no previous timestamp (that is, the first row). It applies the output quality condition by filtering events where the observed quality is below the threshold. The maintenance signal condition is applied next, filtering events where the time gap exceeds the expected maintenance period. The function identifies violations by joining the filtered quality events with the maintenance signal condition, highlighting cases where the quality threshold was violated but no maintenance signal was received on time. The function returns the set of detected violations.
5. Case Study 1: Real-Time Monitoring of Financial Transaction Data Streams
To validate the generalized patterns, we applied them to a real-time financial transaction data processing scenario aimed at monitoring LTL properties, including thresholds for critical financial conditions such as transaction amount, transaction frequency, and account balance. This study addressed three key research questions related to the integration of LTL-based monitoring into Apache Spark, evaluating its impact on system performance, and assessing its scalability.
5.1. System Setup
The system is configured to support the integration of Apache Spark Streaming with a custom RV monitor. This setup is streamlined for high performance and scalability with supporting infrastructure for data ingestion and deployment. The Apache Spark pipeline processes financial transaction data streams in real time using the RV monitor to evaluate LTL properties. Detected violations are recorded and reported for immediate action. The system utilizes Kafka for high-throughput data ingestion, Airflow for workflow orchestration, and InfluxDB for time series data storage. Together, these components collectively enable efficient data flow, scheduling, and performance tracking. The system is implemented in Python and is deployed using Docker Compose, enabling scalability and simplified maintenance across distributed environments. The system setup provides the foundation for the proposed integration, demonstrating the potential of combining Spark’s distributed processing capabilities with the rigor of monitoring.
Table 2 summarizes the key configuration details for the Apache Spark and Kafka broker components used in the system setup.
5.2. Specification of LTL Property
The monitor is designed to enforce the safety and liveness properties within the financial transaction pipeline. These properties are critical to ensuring the reliability and correctness of the system. The safety properties define thresholds to prevent fraudulent or suspicious financial activity. Violations are detected when the following limits are exceeded. A safety violation occurs if a single transaction exceeds USD 10,000 or falls below USD 1.00, potentially indicating test transactions or fraudulent micro-based transactions. High-risk behavior is flagged if an account performs more than 10 transactions within a 5 min window, which may indicate money laundering or bot activity. Account balances are monitored to ensure they remain above USD 50 to prevent overdrafts or account misuse. The liveness properties verify that the transaction updates are received consistently and that there are no data gaps, ensuring that the system maintains real-time monitoring. Transaction streams are expected to update at least every 10 min (600 s) without significant delays. The system also ensures that all transactions contain the expected attributes, preventing incomplete or corrupted records.
5.3. Mapping of LTL Formulas
In this section, we focus on the mapping of linear temporal logic (LTL) formulas to their respective safety or liveness properties, demonstrating their application in real-time data streams in Apache Spark. The goal is to provide a high-level understanding of how each formula relates to monitoring temporal properties in distributed stream processing environments. Each LTL formula is explained conceptually, showcasing its relevance and practical implications in monitoring critical system behaviors.
The formula
X specifies that the condition
must hold in the immediate next state. It is particularly relevant in predictive scenarios, where the system monitors critical financial transitions in real time. The formula enforces safety by triggering alerts when a future violation is anticipated. In this context, the linear temporal logic (LTL) formula for transaction amount monitoring is
, which ensures that the transaction amount exceeds or falls below predefined thresholds in the next time step. Violations of this property trigger immediate alerts, enabling rapid interventions. Similarly, formula
F ensures that condition
will hold at some point in the future, as a liveness property guarantees that desirable or critical events will eventually be detected. The LTL formula for transaction frequency monitoring is
, ensuring that the system eventually detects if the transaction frequency exceeds a critical threshold. The formula
G enforces that the condition
holds throughout the entire runtime of the system, which is essential to ensure continuous safety in financial monitoring. The corresponding LTL formula for account balance monitoring is
, ensuring that the account balance does not drop below critical levels at any time during the monitoring period, protecting against prolonged exposure risks. Lastly, the formula
specifies that a condition
must remain constant until another condition
is met. This ensures the continuity of a condition until a triggering event occurs. The LTL formula for transaction monitoring is
, ensuring that the transaction amount persists until a data update is received, allowing continuous account tracking during system updates. Detailed implementation code snippets for these formulas are provided in
Appendix A for reference.
5.4. Performance Analysis and Evaluation
The performance of the real-time financial transaction data processing system was evaluated on three key metrics: latency, resource utilization (CPU and memory), and processing time. In addition, scalability was analyzed to assess how well the system maintained performance under increasing data loads. Each metric was tested with varying batch sizes (100, 1000, 10,000, and 100,000 messages) to evaluate the system’s ability to meet real-time processing requirements while handling large volumes of streaming data.
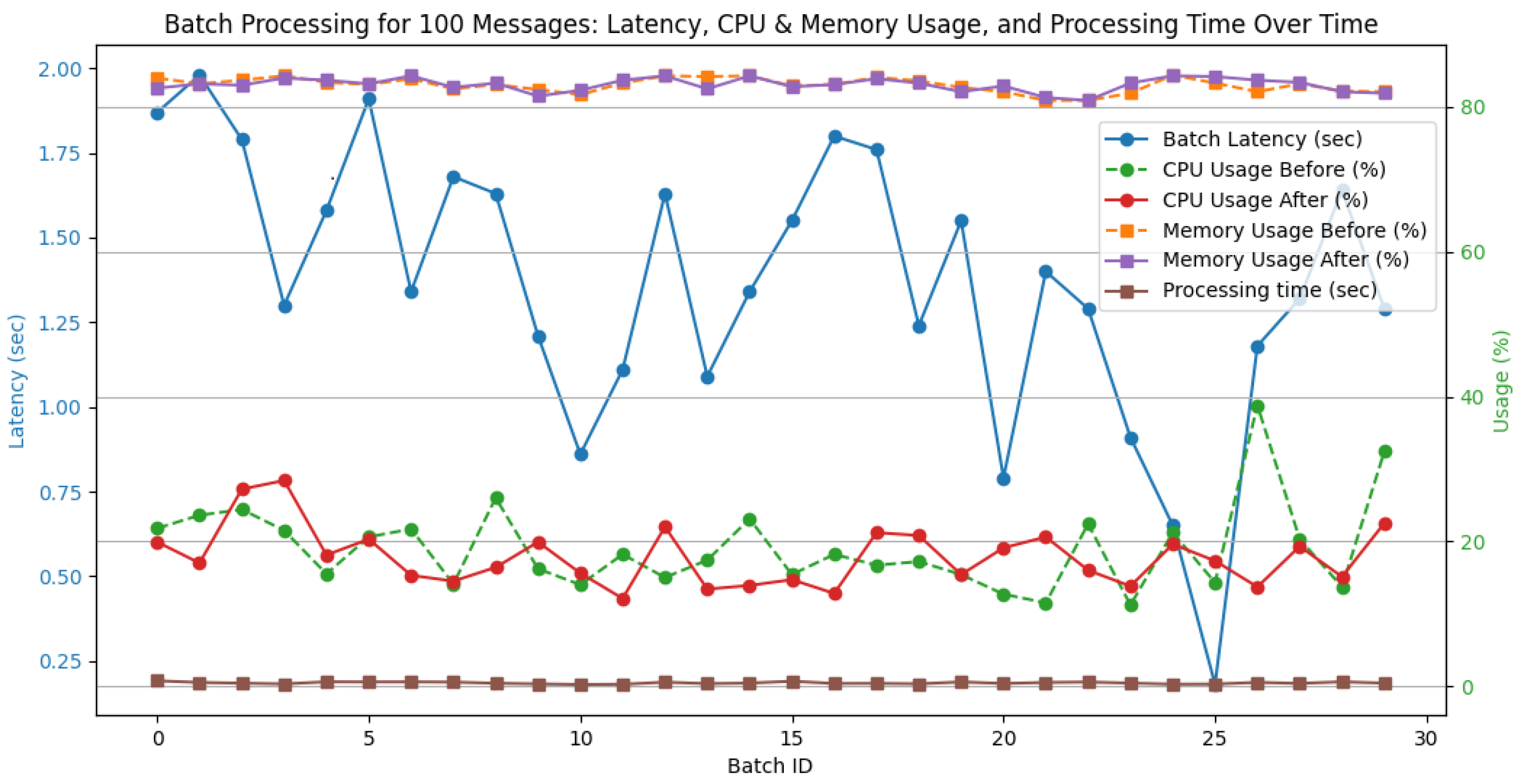
For a batch size of 100 messages, Apache Spark exhibited low and stable latency, with an average batch latency of 1.36 s, as shown in
Figure 4. CPU and memory usage showed minimal fluctuations before and after processing, indicating efficient resource management. The processing time remained within an acceptable range, further reinforcing the system’s ability to handle small batch sizes with consistent performance and low overhead.
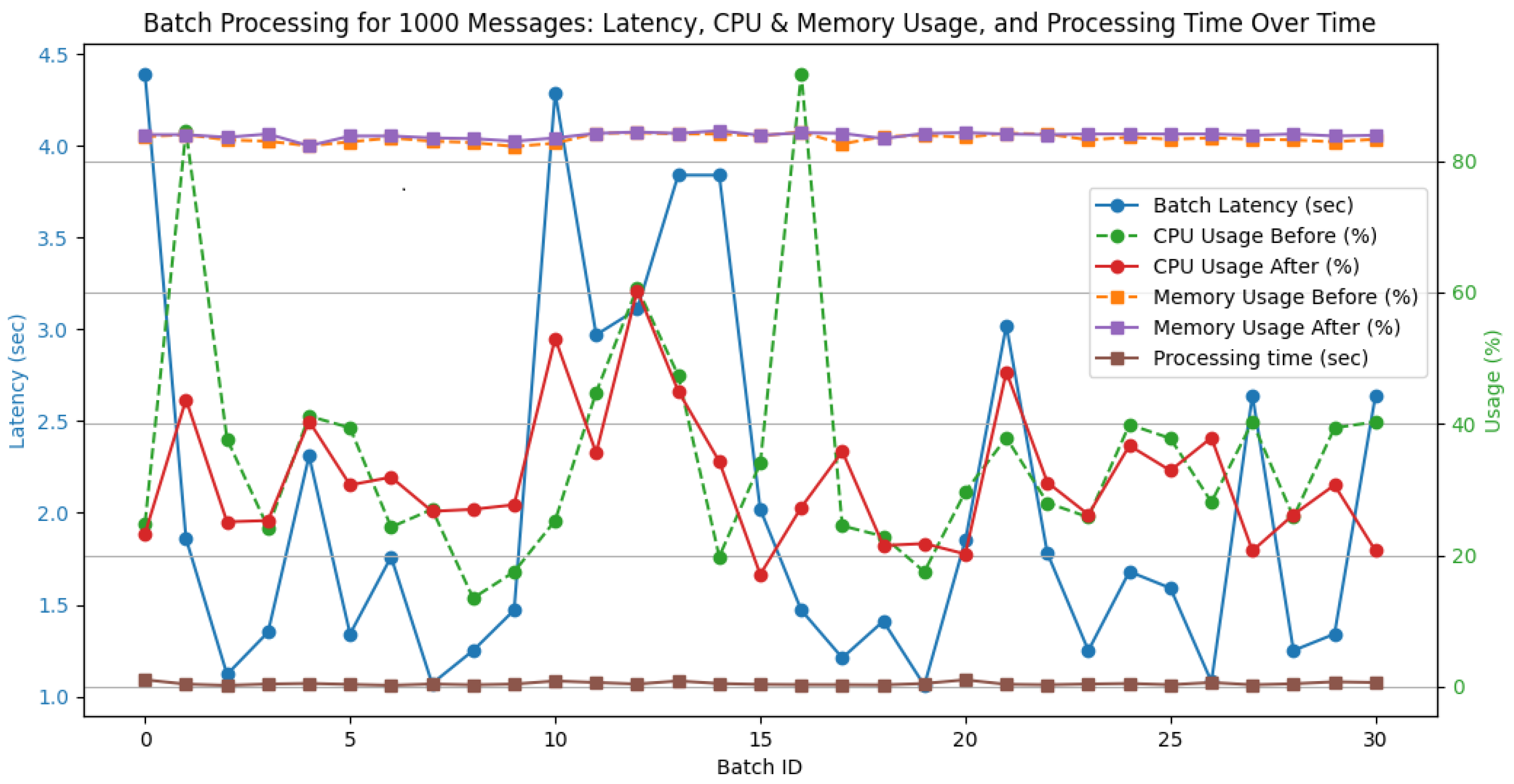
For a batch size of 1000 messages, Apache Spark exhibited low latency, with an average latency of 2.04 s, which occasionally peaked at 5.54 s, as shown in
Figure 5. CPU usage fluctuated during batch processing between 10.90% and 73.40%, stabilizing to a range of 9.50% to 46.00% after processing. Memory usage remained between 81.90% and 84.60%, showing minor variations throughout the process. The processing time per batch remained relatively low, with an average of 0.63 s, which confirms the efficiency on this scale. These results indicate that the system scales effectively to 1000 messages, with only a moderate increase in processing demands.
For a batch size of 10,000 messages, Apache Spark experienced increased latency and CPU usage, reflecting the heavier computational workload, as shown in
Figure 6. The average batch latency increased to 2.94 s, with peaks reaching up to 3.99 s during periods of high load. The CPU usage fluctuated significantly, ranging from 8.90% to 85.90% before processing and 10.20% to 77.20% after processing. Despite these fluctuations, the system maintained a stable memory footprint, with usage fluctuating between 81.70% and 84.80%. The average processing time per batch increased to 0.75 s, with some batches requiring up to 1.17 s.
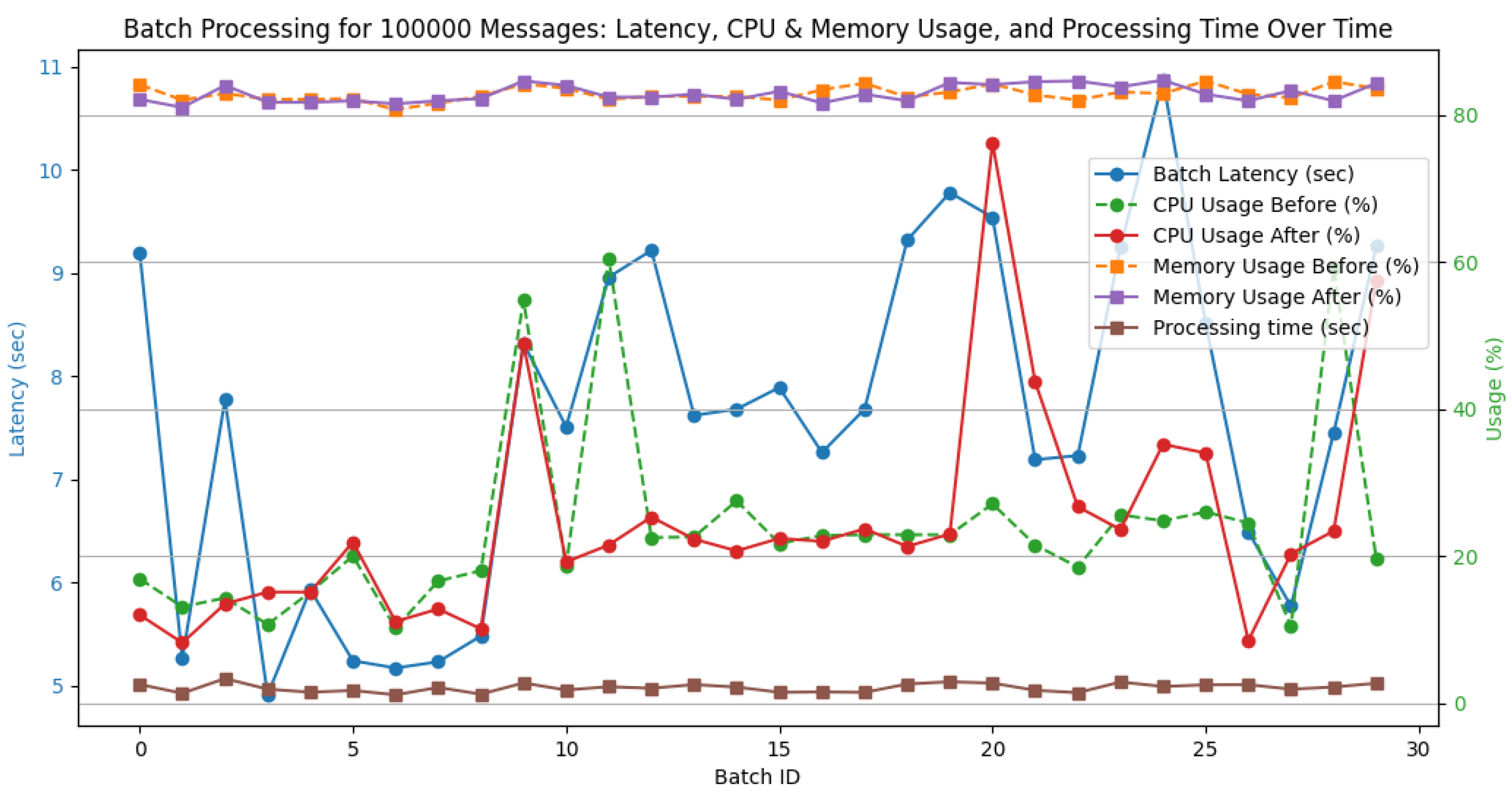
For a batch size of 100,000 messages, Apache Spark experienced increased latency and CPU usage, reflecting the heavier computational workload, as shown in
Figure 7. The average batch latency increased to 7.57 s, with peaks reaching up to 10.74 s during periods of high load. The CPU usage fluctuated significantly, ranging from 10.20% to 60.50% before processing and from 8.20% to 57.50% after processing. Despite these fluctuations, the system maintained a stable memory footprint, with usage fluctuating between 80.70% and 84.70%. The average processing time per batch increased to 2.1 s, with some batches requiring up to 3.34 s.
Although latency increased with larger batch sizes, Apache Spark maintained consistent performance trends, with latency scaling predictably in relation to the increasing batch sizes. The average batch latency increased predictably from 1.36 s for (100 messages) to 2.04 s for (1000 messages) to 2.94 s for (10,000 messages) and to 7.57 s for (100,000 messages), with peaks reaching up to 10.74 s at higher loads. These results align with reported benchmarks for distributed stream processing systems [
28], demonstrating that Spark’s performance is competitive with state-of-the-art systems under similar workloads.
During the case study evaluation, CPU and memory usage were closely monitored, particularly under peak load conditions. For 100-message batches, CPU utilization remained stable with minimal fluctuations. For 1000-message batches, CPU usage varied between 10.90% and 73.40% before processing and stabilized at 8.9% to 85.9% after processing. For 10,000-message batches, CPU utilization showed more significant fluctuations, ranging from 10.20% to 77.20% before processing and 9.80% to 90.30% after processing. For 100,000-message batches, CPU utilization showed more significant fluctuations, ranging from 8.20% to 57.50% before processing and 80.70% to 84.70% after processing. Memory usage remained stable across all batch sizes, fluctuating between 82.80% and 85.30%, indicating efficient resource management [
28].
The scalability of the system was assessed by gradually increasing the data ingestion rate and scaling the Spark worker nodes. Apache Spark effectively maintained sub-5 s latencies for large batch sizes, ensuring timely anomaly detection and responsiveness under load [
28]. Even with 100,000-message batches, the system maintained an average latency of 7.57 s, with a peak reaching 10.74 s, which remains within an acceptable range for real-time analytics. Across different configurations, Spark consistently achieved sub-2 s latencies for smaller batch sizes, reinforcing its ability to handle varying workloads without significant performance degradation.
6. Case Study 2: Real-Time Monitoring of Weather Data Streams
To validate the generalized patterns, we applied them to a real-time weather data processing scenario aimed at monitoring LTL properties, including thresholds for critical weather conditions such as temperature and wind speed. This study addressed three key research questions related to the integration of LTL-based monitoring into Apache Spark, evaluating its impact on system performance, and assessing its scalability.
6.1. System Setup
The system setup follows the same configuration detailed in the first case study, integrating Apache Spark Streaming with a custom RV monitor to evaluate LTL properties in real time. The setup ensures efficient data ingestion via Kafka, workflow orchestration through Airflow, and time series data storage using InfluxDB. The deployment utilizes Docker Compose for scalability and simplified maintenance.
Table 2 in the first case study provides the full configuration details for Apache Spark and Kafka brokers.
6.2. Specification of LTL Property
The monitor is designed to enforce the safety and liveness properties within the weather data pipeline. These properties are critical to ensure the reliability and correctness of the system. The safety properties define thresholds to prevent undesirable situations, such as severe weather conditions. Violations are detected when the following limits are exceeded. A safety violation occurs if the temperature rises above 35 °C or drops below 10 °C. Hazardous conditions are highlighted if wind speeds exceed 50 km/h. UV exposure levels are monitored to ensure that they remain below 8. The liveness properties verify that the system consistently delivers updates and avoids data gaps, ensuring eventual data availability. Data streams are verified to provide updates every 10 min (600 s) without interruptions. The system also ensures that precipitation data are always accessible, maintaining a complete and expected attribute set.
6.3. Mapping of LTL Formulas
This section focuses on the mapping of linear temporal logic (LTL) formulas to their respective safety or liveness properties, demonstrating their application in real-time data streams in Apache Spark. The goal is to provide a high-level understanding of how each formula relates to monitoring temporal properties in distributed stream processing environments. Each LTL formula is explained conceptually, showcasing its relevance and practical implications in monitoring critical system behaviors.
The formula
X specifies that the condition
must hold in the immediate next state. It is particularly relevant in predictive scenarios, where the system monitors critical financial transitions in real time. The formula enforces safety by triggering alerts when a future violation is anticipated. In this context, the linear temporal logic (LTL) formula for temperature monitoring is
, which ensures that the temperature exceeds or falls below predefined thresholds in the next time step. Violations of this property trigger immediate alerts, enabling rapid interventions. Similarly, formula
F ensures that condition
will hold at some point in the future, as a liveness property, guarantees that desirable or critical events will eventually be detected. The LTL formula for transaction frequency monitoring is
, ensuring that the system eventually detects if the wind speed exceeds a critical threshold. The formula
G enforces that the condition
holds throughout the entire runtime of the system, which is essential to ensure continuous safety in financial monitoring. The corresponding LTL formula for the monitoring of the UV index is
, ensuring that the account balance does not drop below critical levels at any time during the monitoring period, protecting against prolonged exposure risks. Lastly, the formula
specifies that a condition
must remain constant until another condition
is met. This ensures the continuity of a condition until a triggering event occurs. The LTL formula for transaction monitoring is
, ensuring that precipitation persists until a data update is received, allowing continuous account tracking during system updates. Detailed implementation code snippets for these formulas are provided in
Appendix B for reference.
6.4. Performance Analysis and Evaluation
The performance of the real-time weather data processing system was evaluated on three key metrics: latency, resource utilization (CPU and memory), and processing time. In addition, scalability was analyzed to assess how well the system maintained performance under increasing data loads. Each metric was tested with varying batch sizes (100, 1000, 10,000, and 100,000 messages) to evaluate the system’s ability to meet real-time processing requirements while handling large volumes of streaming data.
For a batch size of 100 messages, Apache Spark exhibited low and stable latency, with an average batch latency of 1.14 s, as shown in
Figure 8. CPU and memory usage showed minimal fluctuations before and after processing, indicating efficient resource management. Processing time remained within an acceptable range, further reinforcing the system’s ability to handle small batch sizes with consistent performance and low overhead.
For a batch size of 1000 messages, Apache Spark exhibited low latency, with an average latency of 2.28 s, which occasionally peaked at 4.39 s, as shown in
Figure 9. CPU usage fluctuated during batch processing between 24.90% and 93.20%, stabilizing to a range of 17.10% to 53.00% after processing. Memory usage remained between 82.00% and 84.40%, showing minor variations throughout the process. The processing time per batch remained relatively low, with an average of 0.49 s, which confirms the efficiency on this scale. These results indicate that the system scales effectively to 1000 messages, with only a moderate increase in processing demands.
For a batch size of 10,000 messages, Apache Spark experienced increased latency and CPU usage, reflecting the heavier computational workload, as shown in
Figure 10. The average batch latency increased to 3.35 s, with peaks reaching up to 7.55 s during periods of high load. The CPU usage fluctuated significantly, ranging from 10.60% to 85.80% before processing and 9.80% to 90.30% after processing. Despite these fluctuations, the system maintained a stable memory footprint, with usage fluctuating between 83.20% and 84.70%. The average processing time per batch increased to 0.94 s, with some batches requiring up to 1.81 s.
For a batch size of 100,000 messages, Apache Spark experienced increased latency and CPU usage, reflecting the heavier computational workload, as shown in
Figure 11. The average batch latency increased to 8.85 s, with peaks reaching up to 10.74 s during periods of high load. The CPU usage fluctuated significantly, ranging from 14.2% to 84.5% before processing and from 9.9% to 91.5% after processing. Despite these fluctuations, the system maintained a stable memory footprint, with usage fluctuating between 82.8% and 85.3%. The average processing time per batch increased to 2.28 s, with some batches requiring up to 3.70 s.
Although latency increased with larger batch sizes, Apache Spark maintained consistent performance trends, with latency scaling predictably in relation to the increasing batch sizes. The average batch latency increased predictably from 1.14 s (100 messages) to 2.28 s (1000 messages) to 3.35 s (10,000 messages) and to 8.85 s (100,000 messages), with peaks reaching 10.74 s at higher loads. These results align with reported benchmarks for distributed stream processing systems [
28], demonstrating that Spark’s performance is competitive with state-of-the-art systems under similar workloads.
During the case study evaluation, CPU and memory usage were closely monitored, particularly under peak load conditions. For 100-message batches, CPU utilization remained stable with minimal fluctuations. For 1000-message batches, CPU usage varied between 24.90% and 93.20% before processing and stabilized at 17.10% to 53.00% after processing. For 10,000-message batches, CPU utilization showed more significant fluctuations, ranging from 10.60% to 85.80% before processing and 9.80% to 90.30% after processing. For 100,000-message batches, CPU utilization showed more significant fluctuations, ranging from 14.20% to 84.50% before processing and 9.90% to 91.50% after processing. Memory usage remained stable across all batch sizes, fluctuating between 82.80% and 85.30%, indicating efficient resource management [
28]. The scalability of the system was assessed by gradually increasing the data ingestion rate and scaling the Spark worker nodes. Apache Spark effectively maintained sub-5-second latencies for large batch sizes, ensuring timely anomaly detection and responsiveness under load [
28]. Even with 100,000-message batches, the system maintained an average 8.52 s latency, with peak delays of 10.74 s, which remains within an acceptable range for real-time analytics. Across different configurations, Spark consistently achieved sub-2 s latencies for smaller batch sizes, reinforcing its ability to handle varying workloads without significant performance degradation.
7. Limitations
The proposed framework for real-time monitoring of LTL properties in distributed stream processing applications offers several advantages; however, it also presents certain limitations. First, scalability may become a concern as the volume of data grows and real-time monitoring could incur resource overhead that affects system performance, particularly in large-scale environments. In addition, the complexity of LTL formulas could impact verification performance, especially for more complex temporal properties, leading to potential bottlenecks in resource-constrained settings. Another limitation is the fault tolerance aspect of the approach. Although the system benefits from the robustness of distributed systems, ensuring accurate LTL monitoring during node failures or network disruptions may require further investigation.
The framework’s focus on Apache Spark limits its immediate applicability to other stream processing frameworks. Adapting it to platforms such as Apache Flink or Kafka Streams would require additional validation due to architectural differences in API design, state management, and check-pointing mechanisms. For example, Apache Flink’s stateful stream processing and fault tolerance model introduce challenges in integrating real-time LTL monitoring, while Kafka Streams’ close integration with Kafka’s messaging system may necessitate modifications to the monitoring logic. Addressing these differences will be a crucial aspect of future work to ensure cross-platform compatibility.
A key limitation of this study is the absence of direct experimental comparisons with existing research. Unlike traditional stream processing benchmarks, real-time verification of LTL properties lacks well-established performance baselines, making it difficult to objectively evaluate improvements. Future research should focus on defining standardized benchmarks and conducting comparative experiments across multiple frameworks, particularly Apache Flink and Kafka Streams, to assess trade-offs in latency, throughput, and resource utilization.
Furthermore, while the proposed method ensures low latency, the trade-offs between latency and throughput need to be considered, particularly in large-scale or production environments. The case study used for validation is based on financial transaction data, and additional research is required to evaluate the generalization of the framework to other domains, such as financial systems, sensor networks, or social media applications. The dependency on the Spark configuration also introduces variability in performance, and the real-time performance of the framework in a fully deployed production environment remains an open question. In terms of temporal property specification, while the framework supports a range of LTL properties, the complexity of formulating and specifying intricate temporal relationships remains a challenge. Future work will focus on expanding the evaluation to diverse use cases and exploring further optimizations for handling complex LTL formulas, improving fault tolerance, and achieving cross-platform compatibility through benchmarking against alternative frameworks.
8. Conclusions
The case study emphasizes the rationale for selecting Apache Spark as the primary framework, exploring the implications of implementing LTL monitoring in distributed stream processing, and discussing the constraints of generalizing the findings. Spark was chosen for its robustness in stream processing, its compatibility with distributed computing environments, and its mature ecosystem [
13,
28]. Although its microbatch processing model does not achieve true real-time processing, it provides stable latency, which is crucial for detecting time-sensitive violations specified by LTL properties. Furthermore, integration of Spark with tools such as Kafka and InfluxDB facilitates efficient data ingestion, processing, and storage, meeting the specific requirements of our study. The integration of LTL-based monitoring through a custom runtime verification (RV) monitor demonstrated how safety and liveness properties could be applied in real-time stream processing. The system successfully monitored financial transaction metrics, such as amount, frequency, and account balance, as well as monitored weather data metrics, such as temperature, wind speed, UV index, in real time, embedding LTL formulas directly into Spark’s processing pipeline. This setup ensured continuous compliance verification for time-sensitive properties, which is essential for safety-critical applications like disaster management.
The implemented framework showed good scalability when processing larger data volumes. Despite the additional processing required by LTL monitoring, Apache Spark was able to handle larger batches (up to 100,000 messages) without significant performance degradation. The latency increased proportionally with batch size but remained within acceptable limits for real-time processing. Furthermore, Spark’s ability to scale horizontally with additional worker nodes allowed the system to maintain performance even under high-load conditions, making it a suitable choice for real-time monitoring in high-throughput applications. However, a significant aspect that requires further research is the comparative evaluation of this approach with other stream processing frameworks. Future work will focus on benchmarking the proposed framework against Apache Flink, Kafka Streams, and other streaming engines to assess factors such as latency, throughput, and resource utilization. Establishing standardized testing methodologies for LTL monitoring will improve the generalization of this approach in different real-time applications. Furthermore, future enhancements will explore optimizations to improve responsiveness to dynamic data conditions and extend the framework to support diverse domains beyond financial transactions and weather data. In general, this study demonstrates the feasibility of integrating LTL-based runtime verification into distributed stream processing and highlights the need for further research to refine its performance, scalability, and cross-platform applicability.






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}