
Development of Machine Learning-Based Indicators for Predicting Comeback Victories Using the Bounty Mechanism in MOBA Games



Abstract
1. Introduction
2. Background
2.1. League of Legends
2.1.1. Game Features
Resource
Combat
Objective Monster
Vision
2.1.2. Match Categories
2.2. Related Works
- Psychological Research and Player Behavior Analysis [36]: Studies in this field contribute to increased immersion and long-term engagement by understanding player motivations and behaviors.
3. Methodology
3.1. Data Collection
3.2. Data Preprocessing
3.3. Proposed Indicators and Definitions
3.3.1. Weighted Champion Mastery (WCM)
Calculation of Weighted Champion Mastery
Team-Level Relative Differences
3.3.2. Similarity Based on Key Champion Mastery
Calculation of Team Member Similarity
Team-Level Relative Differences
3.3.3. Top Mastery Selection Rate (CM Top10)
Calculation of Top Mastery Selection Rate
Team-Level Relative Differences
3.3.4. Jungle Pressure
3.4. Feature Selection
3.5. Prediction Model
3.5.1. Logistic Regression
3.5.2. Support Vector Machine (SVM)
3.5.3. Tree-Based Models
3.5.4. Multi-Layer Perceptron (MLP)
3.6. Evaluation Metrics
4. Results
4.1. Model Performance Evaluation
4.2. Feature Importance Analysis
4.3. Individual Case Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Experimental Environment

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Details |
|---|---|
| OS | Ubuntu Server 20.04.6 LTS |
| CPU | Intel i9-13900K |
| GPU | NVIDIA GeForce RTX 4090 |
| RAM | 128 GB (32 GB × 4) |
| Docker Image | Docker Hub: 3won/comeback-prediction:1.1 |
| Programming Language | Python 3.9 |
| Package | scikit-learn 1.5.1 XGBoost 2.1.1 CatBoost 1.2.5 LightGBM 4.5.0 optuna 3.6.1 shap 0.46.0 |
Appendix B. Hyperparameter Optimization
| Hyperparameter | Value |
|---|---|
| Regularization (C) | 8.7 |
| Kernel Function | rbf |
| Kernel Coefficient (gamma) | 3.0403 |
| Hyperparameter | Value |
|---|---|
| N Estimators | 571 |
| Max Depth | 19 |
| Min Child Weight | 2 |
| Subsample Ratio | 0.9993 |
| Colsample by Tree | 0.5886 |
| Grow Policy | Loss Guide |
| Max Leaves | 83 |
| Tree Method | Hist |
| Learning Rate (eta) | 0.0863 |
| Min Split Loss (gamma) | 0.0011 |
| L2 Regularization (lambda) | 1.8137 |
| L1 Regularization (alpha) | 0.0079 |
| Scale Positive Weight | 7.6183 |
| Hyperparameter | Value |
|---|---|
| Hidden Layer Sizes | (128, 64) |
| Activation | ReLU |
| Optimizer (Solver) | Adam |
| Initial Learning Rate | 0.0011 |
| Max Iterations | 419 |
| Batch Size | 200 |
References
- Funk, J. MOBA, DOTA, ARTS: A Brief Introduction to Gaming’s Biggest, Most Impenetrable Genre. Polygon, 3 September 2013. Available online: https://www.polygon.com/2013/9/2/4672920/moba-dota-arts-a-brief-introduction-to-gamings-biggest-most (accessed on 7 January 2025).
- Berger, J.; Pope, D. Can Losing Lead to Winning? Manag. Sci. 2011, 57, 817–827. [Google Scholar] [CrossRef]
- Gomez, M.A.; Reus, M.; Parmar, N.; Travassos, B. Exploring Elite Soccer Teams’ Performances during Different Match-Status Periods of Close Matches’ Comebacks. Chaos Solitons Fractals 2020, 132, 109566. [Google Scholar] [CrossRef]
- Goldschmied, N.; Mauldin, K.; Thompson, B.; Raphaeli, M. NBA Game Progression of Extreme Score Shifts and Comeback Analysis: A Team Resilience Perspective. Asian J. Sport Exerc. Psychol. 2024, 4, 75–81. [Google Scholar] [CrossRef]
- Kou, Y.; Gui, X. Playing with Strangers: Understanding Temporary Teams in League of Legends. In Proceedings of the First ACM SIGCHI Annual Symposium on Computer-Human Interaction in Play, Toronto, ON, Canada, 19–21 October 2014; pp. 161–169. [Google Scholar] [CrossRef]
- Tang, W. Understanding Esports from the Perspective of Team Dynamics. Sport J. 2018, 21, 1–14. [Google Scholar]
- Kou, Y.; Gui, X. Emotion Regulation in Esports Gaming: A Qualitative Study of League of Legends. Proc. ACM Hum. Comput. Interact. 2020, 4, 158. [Google Scholar] [CrossRef]
- Kwon, S.H. Analyzing the Impact of Team-Building Interventions on Team Cohesion in Sports Teams: A Meta-Analysis Study. Front. Psychol. 2024, 15, 1353944. [Google Scholar] [CrossRef]
- Mateo-Orcajada, A.; Vaquero-Cristóbal, R.; Gallardo-Guerrero, A.M.; Abenza-Cano, L. The Impact of Videogames on the Mood of Amateur Youth Players During Consecutive Games. Front. Sports Act. Living 2023, 5, 1309918. [Google Scholar] [CrossRef]
- Li, Q.; Xu, P.; Chan, Y.Y.; Wang, Y.; Wang, Z.; Qu, H.; Ma, X. A Visual Analytics Approach for Understanding Reasons Behind Snowballing and Comeback in MOBA Games. IEEE Trans. Vis. Comput. Graph. 2017, 23, 211–220. [Google Scholar] [CrossRef]
- Tahri, O.; Usman, M.; Demonceaux, C.; Fofi, D.; Hittawe, M.M. Fast Earth Mover’s Distance Computation for Catadioptric Image Sequences. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2485–2489. [Google Scholar] [CrossRef]
- Lee, J.-N.; Lee, J.-Y. A Study on the Factors Influencing Rank Prediction in PlayerUnknown’s Battlegrounds. Electronics 2025, 14, 626. [Google Scholar] [CrossRef]
- Lee, C.M.; Ahn, C.W. Feature Extraction for StarCraft II League Prediction. Electronics 2021, 10, 909. [Google Scholar] [CrossRef]
- Mohan, S.; Thirumalai, C.; Srivastava, G. Effective Heart Disease Prediction Using Hybrid Machine Learning Techniques. IEEE Access 2019, 7, 81542–81554. [Google Scholar] [CrossRef]
- Randhawa, K.; Loo, C.K.; Seera, M.; Lim, C.P.; Nandi, A.K. Credit Card Fraud Detection Using AdaBoost and Majority Voting. IEEE Access 2018, 6, 14277–14284. [Google Scholar] [CrossRef]
- Moreira, D.O.; Reis, L.P.; Cortez, P. Using Machine Learning to Predict Wine Quality and Prices: A Demonstrative Case Using a Large Tabular Database. IEEE Access 2024, 12, 182296–182309. [Google Scholar] [CrossRef]
- Al-Asadi, M.A.; Tasdemir, S. Predict the Value of Football Players Using FIFA Video Game Data and Machine Learning Techniques. IEEE Access 2022, 10, 22631–22645. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Kumar, R.; Srirama, V.; Chadaga, K.; Muralikrishna, H.; Sampathila, N.; Prabhu, S.; Chadaga, R. Using Explainable Machine Learning Methods to Predict the Survivability Rate of Pediatric Respiratory Diseases. IEEE Access 2024, 12, 189515–189534. [Google Scholar] [CrossRef]
- El-Sofany, H.F. Predicting Heart Diseases Using Machine Learning and Different Data Classification Techniques. IEEE Access 2024, 12, 106146–106160. [Google Scholar] [CrossRef]
- Gu, W.; Foster, K.; Shang, J.; Wei, L. A Game-Predicting Expert System Using Big Data and Machine Learning. Expert Syst. Appl. 2019, 130, 293–305. [Google Scholar] [CrossRef]
- Brown, J.A.; Cuzzocrea, A.; Kresta, M.; Kristjanson, K.D.L.; Leung, C.K.; Tebinka, T.W. A Machine Learning Tool for Supporting Advanced Knowledge Discovery from Chess Game Data. In Proceedings of the 16th International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 649–654. [Google Scholar] [CrossRef]
- Hitar-García, J.A.; Morán-Fernández, L.; Bolón-Canedo, V. Machine Learning Methods for Predicting League of Legends Game Outcome. IEEE Trans. Games 2022, 15, 171–181. [Google Scholar] [CrossRef]
- Costa, L.M.; Mantovani, R.G.; Souza, F.C.M.; Xexeo, G. Feature Analysis to League of Legends Victory Prediction on the Picks and Bans Phase. In Proceedings of the 2021 IEEE Conference on Games (CoG), Copenhagen, Denmark, 17–20 August 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, N.; Li, L.; Xiao, L.; Yang, G.; Zhou, Y. Outcome Prediction of Dota2 Using Machine Learning Methods. In Proceedings of the 2018 International Conference on Mathematics and Artificial Intelligence (ICMAI), Chengdu, China, 20–22 April 2018; pp. 61–67. [Google Scholar] [CrossRef]
- Hodge, V.J.; Devlin, S.; Sephton, N.; Block, F.; Cowling, P.I.; Drachen, A. Win Prediction in Multiplayer Esports: Live Professional Match Prediction. IEEE Trans. Games 2019, 13, 368–379. [Google Scholar] [CrossRef]
- Ani, R.; Harikumar, V.; Devan, A.K.; Deepa, O.S. Victory Prediction in League of Legends Using Feature Selection and Ensemble Methods. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 74–77. [Google Scholar] [CrossRef]
- Do, T.D.; Wang, S.I.; Yu, D.S.; McMillian, M.G.; McMahan, R.P. Using Machine Learning to Predict Game Outcomes Based on Player-Champion Experience in League of Legends. In Proceedings of the 16th International Conference on the Foundations of Digital Games, Montreal, QC, Canada, 3–6 August 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Omar, H.I.; Prayogo, M.; Muliawan, V.; Gunawan, A.A.S.; Setiawan, K.E. Finding Feature Importance in Optimized Classification Model: League of Legends Ranked Matches. In Proceedings of the 2024 IEEE International Conference on Artificial Intelligence and Mechatronics Systems (AIMS), Bandung, Indonesia, 21–23 February 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Shen, Q. A Machine Learning Approach to Predict the Result of League of Legends. In Proceedings of the 2022 International Conference on Machine Learning and Knowledge Engineering (MLKE), Guilin, China, 25–27 February 2022; pp. 38–45. [Google Scholar] [CrossRef]
- Lee, S.K.; Hong, S.J.; Yang, S.I. Predicting Game Outcome in Multiplayer Online Battle Arena Games. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 21–23 October 2020; pp. 1261–1263. [Google Scholar] [CrossRef]
- Do, T.D.; Dylan, S.Y.; Anwer, S.; Wang, S.I. Using Collaborative Filtering to Recommend Champions in League of Legends. In Proceedings of the 2020 IEEE Conference on Games (CoG), Osaka, Japan, 24–27 August 2020; pp. 650–653. [Google Scholar] [CrossRef]
- Chen, S.; Zhu, M.; Ye, D.; Zhang, W.; Fu, Q.; Yang, W. Which Heroes to Pick? Learning to Draft in MOBA Games with Neural Networks and Tree Search. IEEE Trans. Games 2021, 13, 410–421. [Google Scholar] [CrossRef]
- Bao, Z.; Sun, X.; Zhang, W. A Pre-Game Item Recommendation Method Based on Self-Supervised Learning. In Proceedings of the 2023 IEEE 6th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Haikou, China, 18–20 August 2023; pp. 961–966. [Google Scholar] [CrossRef]
- Hong, S.-J.; Lee, S.-K.; Yang, S.-I. Champion Recommendation System of League of Legends. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 21–23 October 2020; pp. 1252–1254. [Google Scholar] [CrossRef]
- Smerdov, A.; Somov, A.; Burnaev, E.; Zhou, B.; Lukowicz, P. Detecting Video Game Player Burnout with the Use of Sensor Data and Machine Learning. IEEE Internet Things J. 2021, 8, 16680–16691. [Google Scholar] [CrossRef]
- Riot Games. Riot Games API. Available online: https://developer.riotgames.com/ (accessed on 16 December 2024).
- Kutner, M.H.; Nachtsheim, C.J.; Neter, J. Applied Linear Regression Models, 4th ed.; McGraw-Hill Education: New York, NY, USA, 2004. [Google Scholar]
- Yu, H.F.; Huang, F.L.; Lin, C.J. Dual Coordinate Descent Methods for Logistic Regression and Maximum Entropy Models. Mach. Learn. 2011, 85, 41–75. [Google Scholar] [CrossRef]
- Burges, C.J. A Tutorial on Support Vector Machines for Pattern Recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient Boosting with Categorical Features Support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 3149–3157. [Google Scholar]
- Hinton, G.E. Connectionist Learning Procedures. In Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 1990; pp. 555–610. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Zhang, C.; Ma, Y. Ensemble Machine Learning; Springer: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Watanabe, S. Tree-Structured Parzen Estimator: Understanding Its Algorithm Components and Their Roles for Better Empirical Performance. arXiv 2023, arXiv:2304.11127. [Google Scholar] [CrossRef]

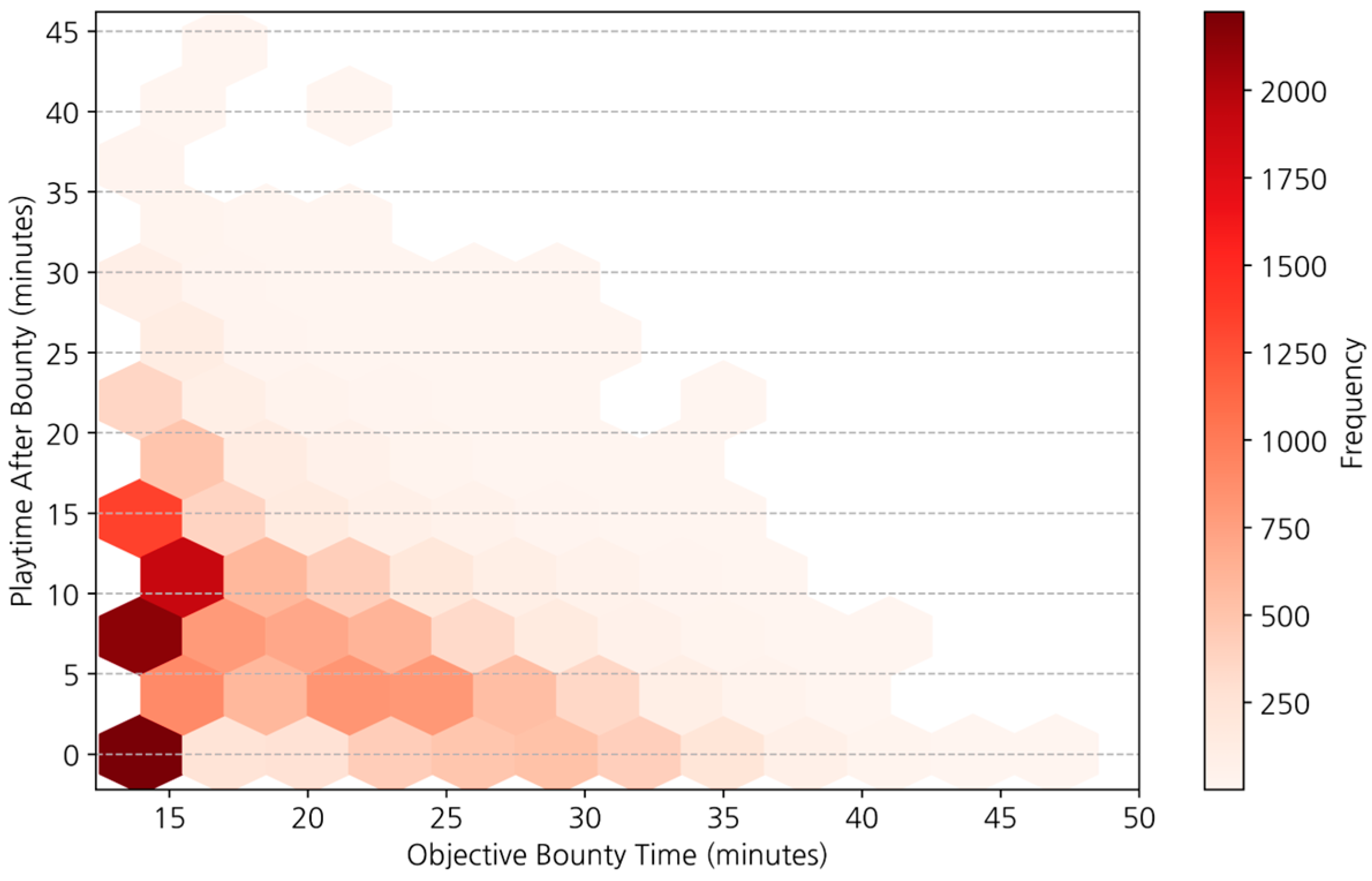
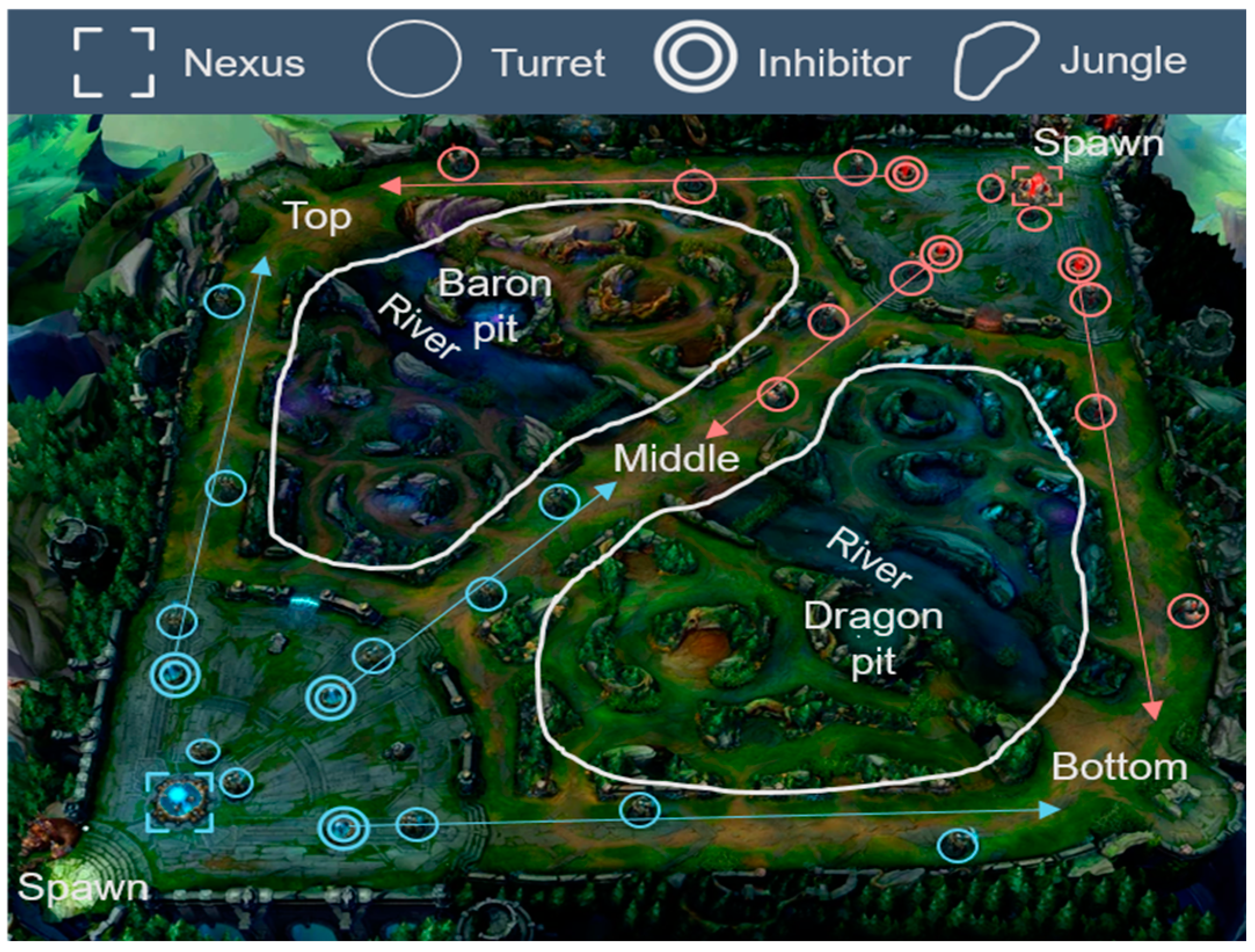

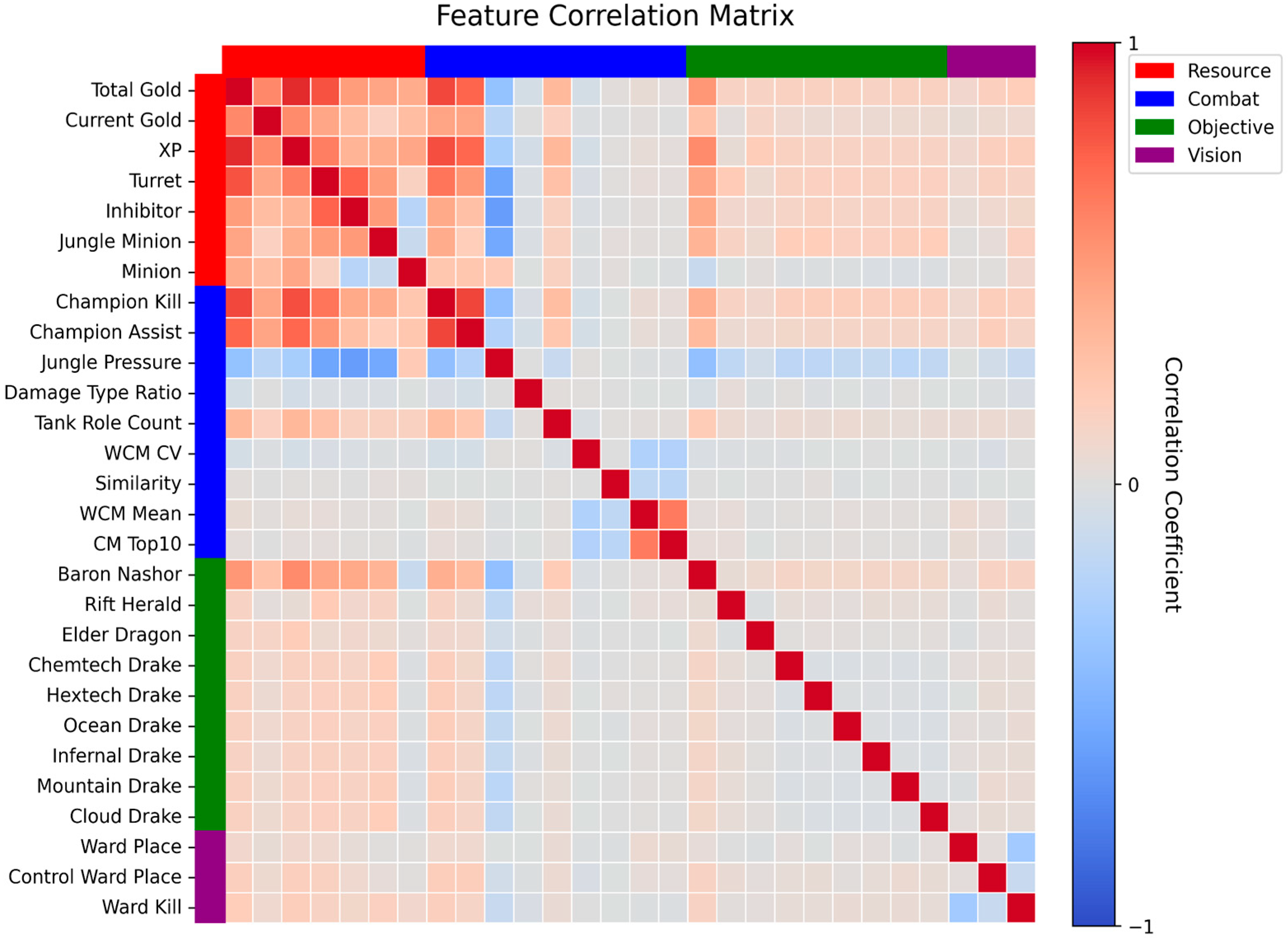
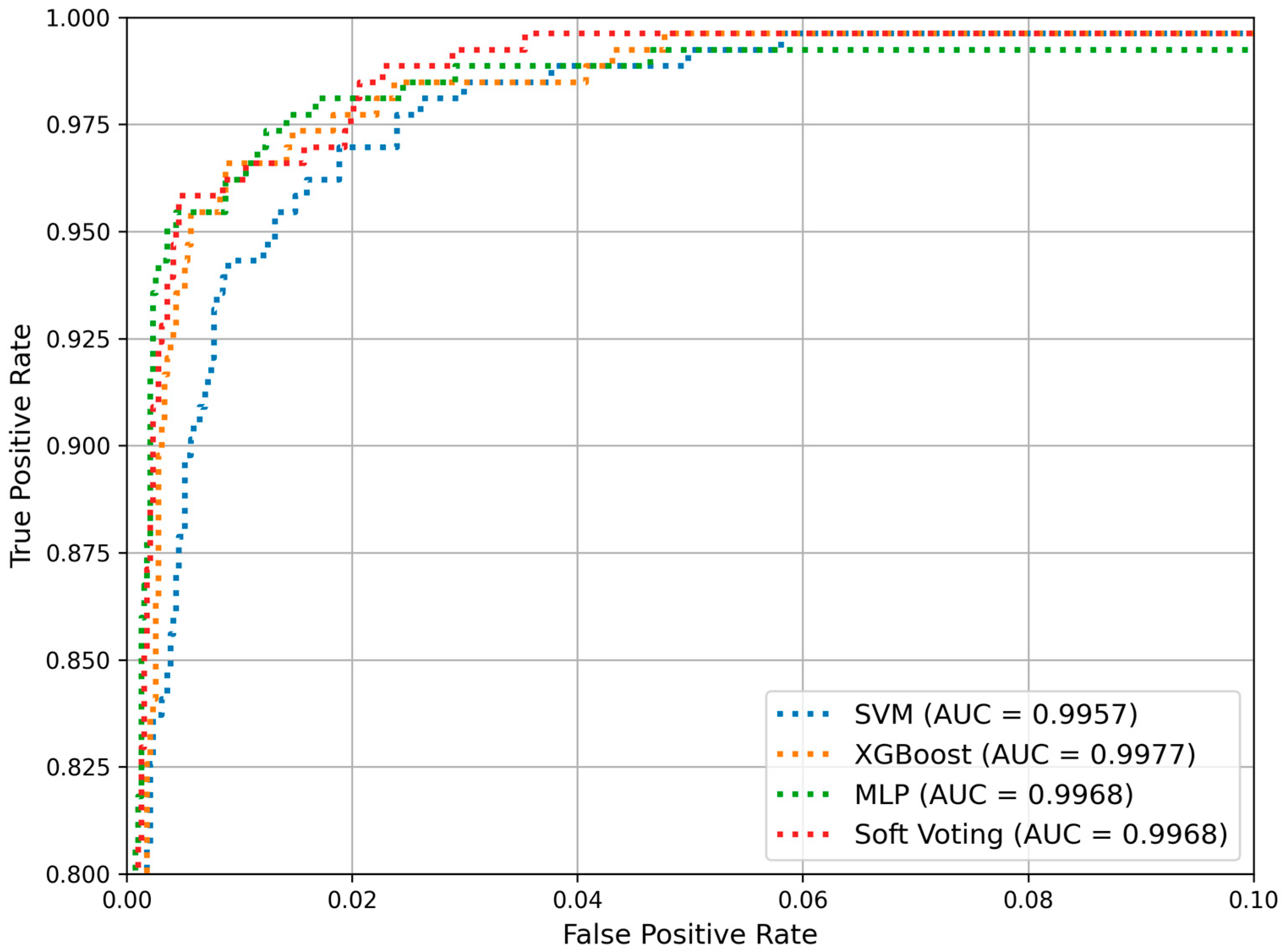



| Research Type | Data Scope | Main Focus | Model | Game Title |
|---|---|---|---|---|
| Professional Match Analysis | Pre-game | Player–champion combinations and team synergy | LR, SVM, NB, KNN, XGBoost, MLP, Stacking | LoL [23] |
| Player–champion statistics | LR, SVM, NB, KNN, DT, RF | LoL [24] | ||
| Past champion statistics and champion bans/picks | LR, SVM, RF | Dota 2 [25] | ||
| Entire game (5 min intervals) | Real-time prediction based on in-game indicators | LR, RF, LGBM, CfsSubsetEval | Dota 2 [26] | |
| Combination of pre-game and in-game data | Champion bans/picks and in-game indicators | RF, GBoost, XGBoost | LoL [27] | |
| Solo Ranked Match Analysis | Pre-game (Iron through Diamond tiers) | Player–champion mastery | SVM, KNN, RF GBOOST, MLP | LoL [28] |
| Early game (Diamond tier) | In-game indicators | LR, SVM, NB, KNN, RF | LoL [29] | |
| LR, SVM, LB, KNN, DT, ET, RF, GBoost, Adaboost, Voting | LoL [30] | |||
| Post-game (Top tier) | RF | LoL [31] |
| Abbreviation | Meaning |
|---|---|
| LR | Logistic Regression |
| SVM | Support Vector Machine |
| NB | Naive Bayes |
| KNN | K-Nearest Neighbors |
| DT | Decision Tree |
| ET | Extra Trees |
| RF | Random Forest |
| GBoost | Gradient Boosting |
| Adaboost | Adaptive Boosting |
| XGBoost | Extreme Gradient Boosting |
| LGBM | Light Gradient Boosting Machine |
| MLP | Multi-Layer Perceptron |
| CfsSubsetEval | Correlation-based Feature Subset Evaluation |
| Dataset | Total | No Comeback | Comeback Victory |
|---|---|---|---|
| # Train | 16,548 | 15,491 | 1057 |
| # Test | 4138 | 3874 | 264 |
| Task | Binary Classification | ||
| Evaluation | Accuracy, Precision, Recall, F1 Score | ||
| Variable | VIF |
|---|---|
| Total Gold | 15.9175 |
| XP | 13.6273 |
| Champion Kill | 7.0370 |
| Turret | 6.1828 |
| Champion Assist | 4.2609 |
| Inhibitor | 3.2327 |
| Minion | 2.6836 |
| Baron Nashor | 2.6138 |
| Jungle Pressure | 2.1851 |
| Jungle Minion | 2.0661 |
| Variable | VIF |
|---|---|
| Champion Kill | 5.2940 |
| Champion Assist | 3.9325 |
| Jungle Pressure | 2.0319 |
| Inhibitor | 1.8965 |
| Jungle Minion | 1.8272 |
| CM Top10 | 1.7576 |
| WCM Mean | 1.7567 |
| Baron Nashor | 1.4128 |
| Minion | 1.3323 |
| Ward Kill | 1.2353 |
| Variable | Description |
|---|---|
| Comeback Victory | Whether a comeback victory occurred (1, 0) |
| Inhibitor | Number of inhibitors destroyed |
| Jungle Minion | Number of jungle monsters killed |
| Minion | Number of minions killed |
| Mountain Drake | Number of Mountain Drakes killed |
| Chemtech Drake | Number of Chemtech Drakes killed |
| Cloud Drake | Number of Cloud Drakes killed |
| Infernal Drake | Number of Infernal Drakes killed |
| Ocean Drake | Number of Ocean Drakes killed |
| Hextech Drake | Number of Hextech Drakes killed |
| Elder Dragon | Number of Elder Dragons killed |
| Rift Herald | Number of Rift Heralds killed |
| Baron Nashor | Number of Baron Nashors killed |
| Champion Kill | Number of champion kills |
| Champion Assist | Number of champion assists |
| Ward Place | Number of wards placed |
| Control Ward Place | Number of control wards placed |
| Ward Kill | Number of wards killed |
| Damage Type Ratio | Ratio of physical damage (AD) to magic damage (AP) within the team |
| Tank Role Count | Number of tanks within the team |
| Jungle Pressure | Frequency of jungle invades by the jungle player (per minute) |
| WCM Mean | Weighted average champion mastery of the team’s five players, based on recent match records and performance |
| WCM CV | Weighted coefficient of variation of champion mastery for the team’s five players, based on recent match records and performance |
| CM Top10 | A rate quantifying the contribution of skilled players within the team, calculated based on the frequency of selecting the top 10 highest-mastery champions played by team members |
| Similarity | A metric representing the similarity among team members based on the top 10 highest-mastery champions for each player |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| LR | 0.9843 | 0.8284 | 0.9508 | 0.8854 |
| SVM | 0.9872 | 0.8552 | 0.9621 | 0.9055 |
| Random Forest | 0.9899 | 0.9563 | 0.8813 | 0.9173 |
| XGBoost | 0.9903 | 0.9118 | 0.9394 | 0.9254 |
| CatBoost | 0.9884 | 0.8740 | 0.9567 | 0.9134 |
| LightGBM | 0.9891 | 0.8897 | 0.9470 | 0.9174 |
| MLP (32) | 0.9917 | 0.9663 | 0.9008 | 0.9323 |
| MLP (64, 32) | 0.9921 | 0.9578 | 0.9173 | 0.9367 |
| MLP (128, 64, 32) | 0.9911 | 0.9399 | 0.9218 | 0.9300 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| SVM | 0.9884 | 0.8885 | 0.9356 | 0.9114 |
| XGBoost | 0.9915 | 0.9225 | 0.9470 | 0.9346 |
| MLP (128, 64) | 0.9937 | 0.9612 | 0.9394 | 0.9502 |
| Soft Voting | 0.9928 | 0.9466 | 0.9394 | 0.9430 |
| Hard Voting | 0.9932 | 0.9470 | 0.9470 | 0.9470 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Kim, N. Development of Machine Learning-Based Indicators for Predicting Comeback Victories Using the Bounty Mechanism in MOBA Games. Electronics 2025, 14, 1445. https://doi.org/10.3390/electronics14071445
Lee J, Kim N. Development of Machine Learning-Based Indicators for Predicting Comeback Victories Using the Bounty Mechanism in MOBA Games. Electronics. 2025; 14(7):1445. https://doi.org/10.3390/electronics14071445
Chicago/Turabian StyleLee, Junhyuk, and Namhyoung Kim. 2025. "Development of Machine Learning-Based Indicators for Predicting Comeback Victories Using the Bounty Mechanism in MOBA Games" Electronics 14, no. 7: 1445. https://doi.org/10.3390/electronics14071445
APA StyleLee, J., & Kim, N. (2025). Development of Machine Learning-Based Indicators for Predicting Comeback Victories Using the Bounty Mechanism in MOBA Games. Electronics, 14(7), 1445. https://doi.org/10.3390/electronics14071445