
Enhancing Quadruped Robot Walking on Unstructured Terrains: A Combination of Stable Blind Gait and Deep Reinforcement Learning

Abstract
1. Introduction
2. Related Works
3. Materials and Methods
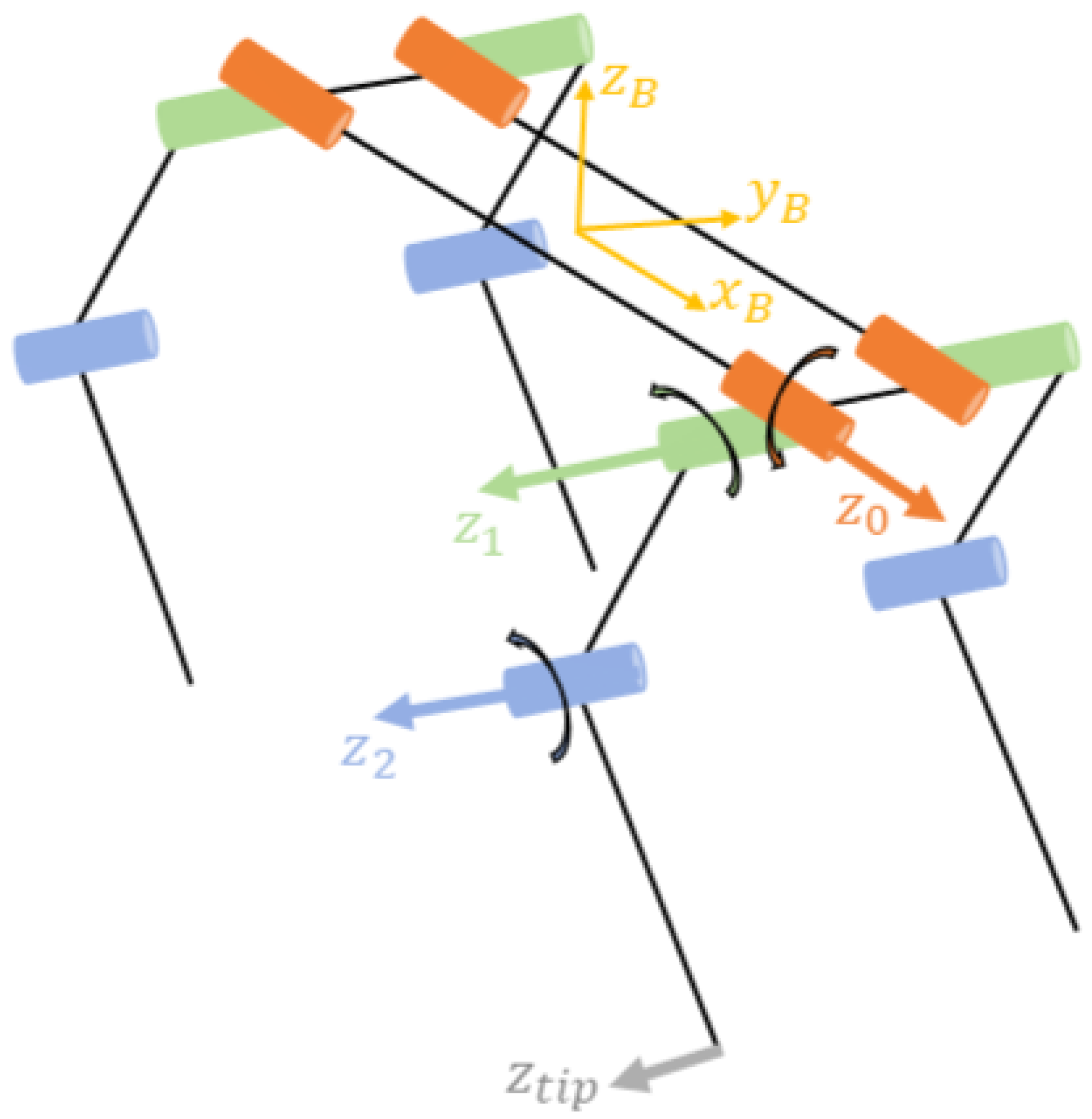
3.1. Kinematic Model
3.2. Stable Blind Gait
3.2.1. Theoretical Underpinnings of Quasi-Static Gait
3.2.2. Advantages in Unstructured Terrains
3.2.3. Static Stability Analysis
3.2.4. Swing Leg Trajectory
| Algorithm 1 Stable Step Algorithm | |
| Require: | |
| ▹ Target leg identifier ▹ Position adjustment ▹ Target foot height ▹ Ground force threshold |
Ensure:
| |
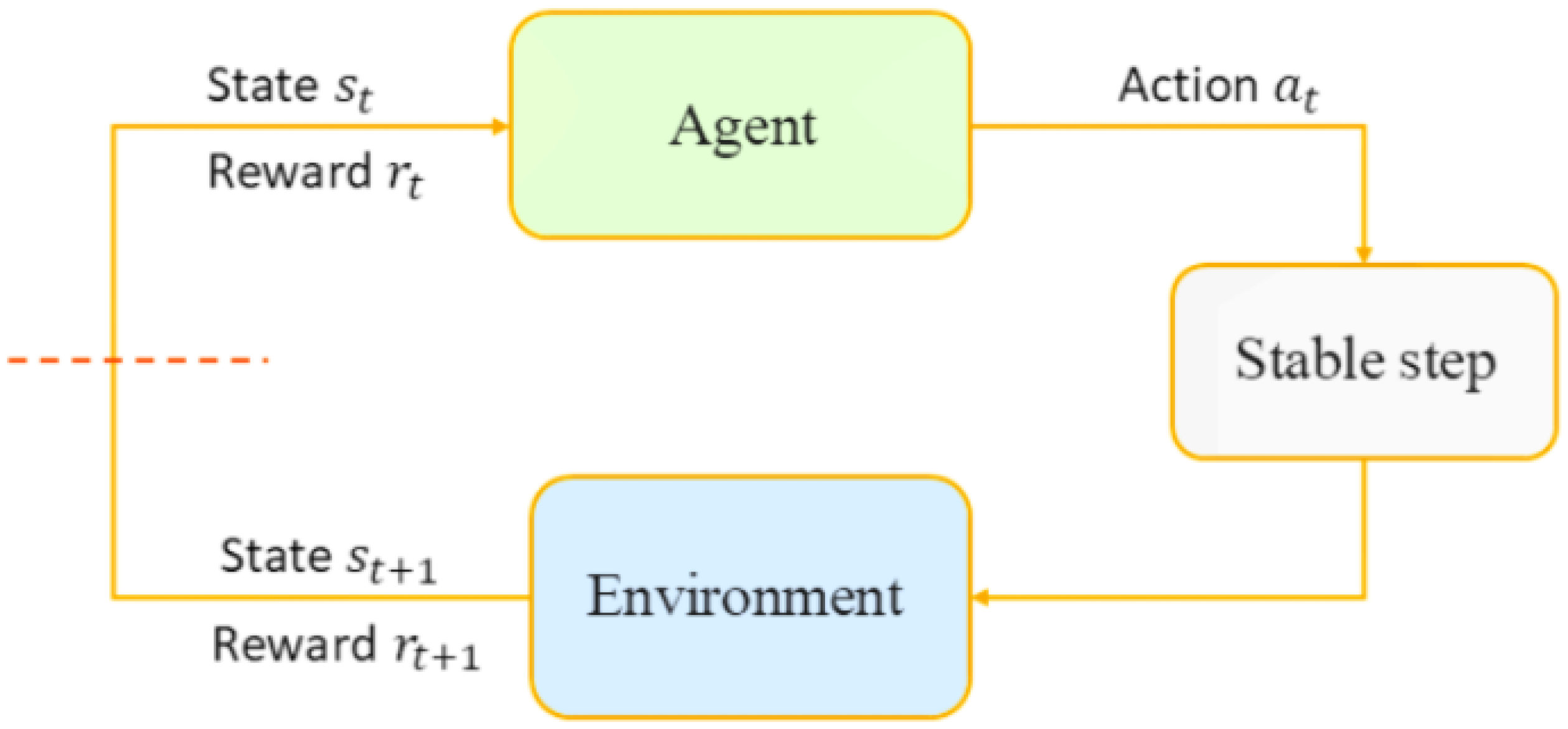
3.3. Reinforcement Learning and Stable Blind Gait Combined Algorithm
3.3.1. Integration of SAC and Stable Step
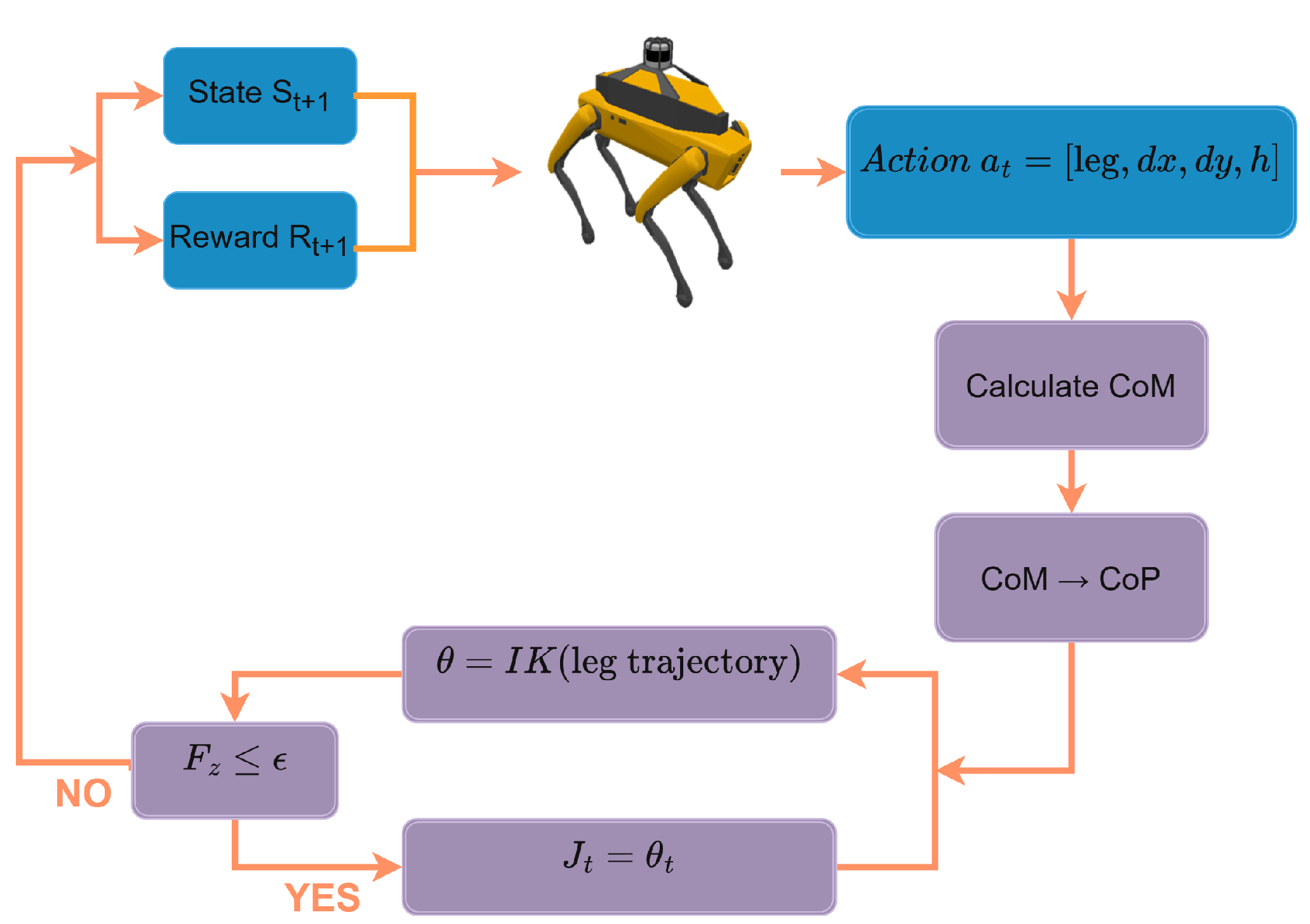
3.3.2. Algorithm Structure
3.3.3. Algorithm Pseudocode
| Algorithm 2 Reinforcement Learning with Stable Step |
|
3.4. Implementation
Simulator Environment and API Connection
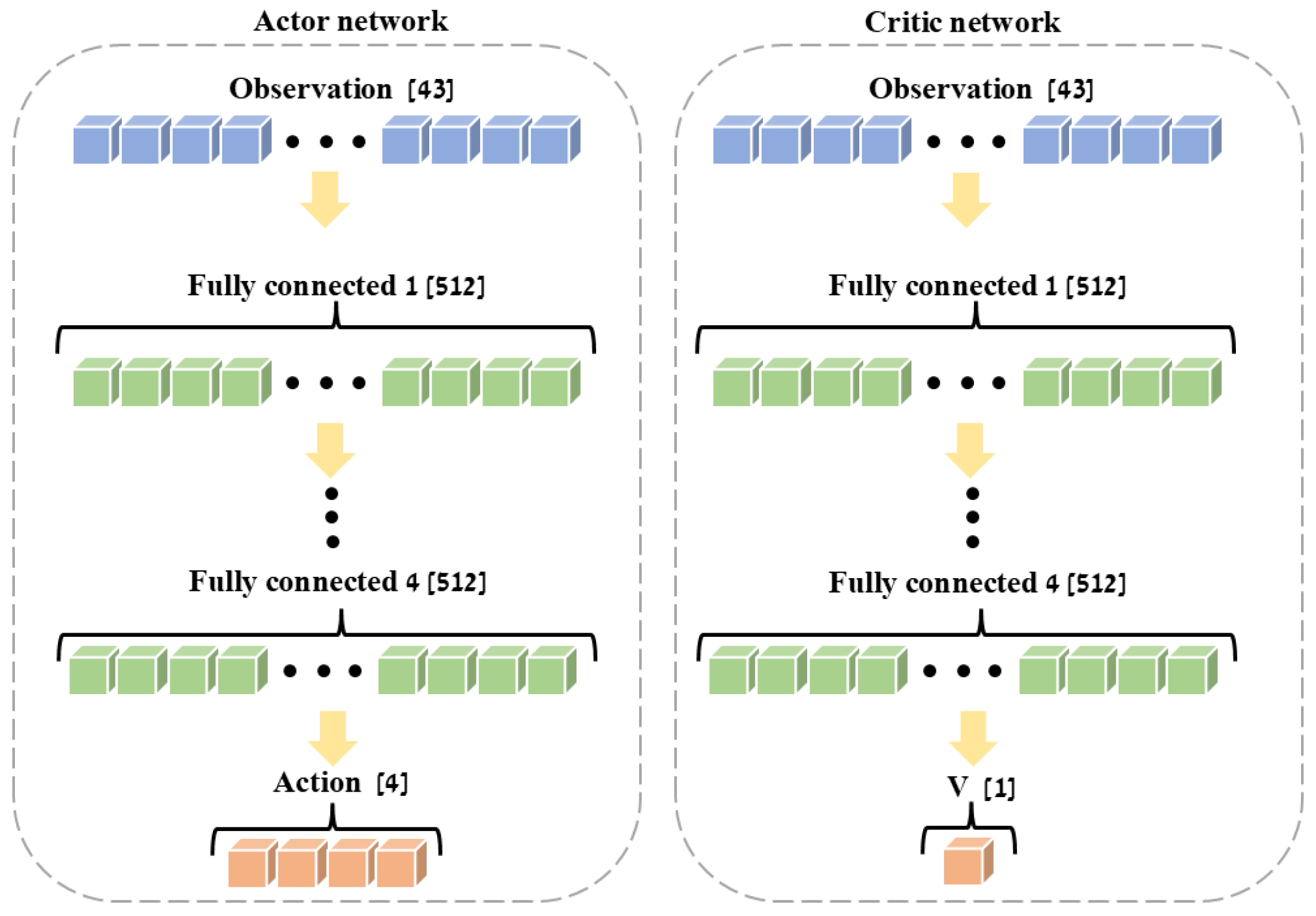
3.5. Network Architecture and Hyperparameters
3.6. Observation and Action Space
3.7. Reward Shaping
3.8. Simulation Setup and Parameters
- Stair Climbing Success Rate: The percentage of simulation episodes in which the robot successfully ascended the stair obstacle and reached the target position without falling. Reported as a percentage (%) for each stair height (7 cm, 10 cm, 13 cm) in Table 4.
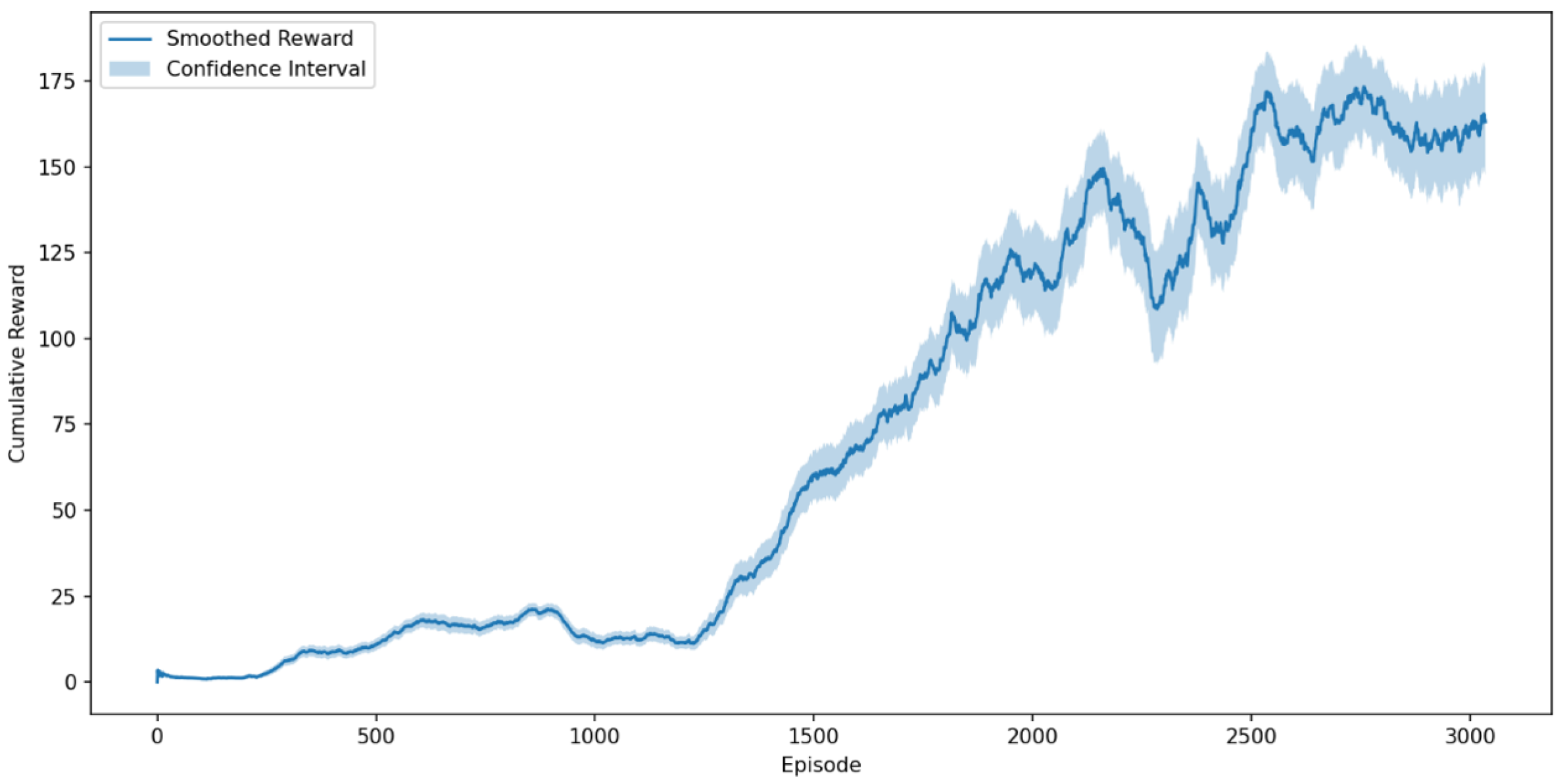
- Cumulative Reward per Episode: The total reward accumulated by the reinforcement learning agent during a single simulation episode. The rolling average of this parameter over training episodes, along with the 95% confidence interval, is presented in Figure 9.
- Steps to Climb (Successful Episodes): The average number of stable steps taken by the robot to successfully ascend the stair obstacle in episodes where the stair climb was completed without falling. This metric, while not explicitly presented as a separate figure or table, is implicitly reflected in the stair-climbing reward function (Equation (6)).
4. Results
4.1. Learning Progression
4.2. Cumulative Reward Analysis
4.3. Model Generalization
4.4. Discussion
4.4.1. Limitations
4.4.2. Future Work
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, S.; Liu, M.; Yin, Y.; Rong, X.; Li, Y.; Hua, Z. Static gait planning method for quadruped robot walking on unknown rough terrain. IEEE Access 2019, 7, 177651–177660. [Google Scholar] [CrossRef]
- Fankhauser, P.; Bjelonic, M.; Bellicoso, C.D.; Miki, T.; Hutter, M. Robust rough-terrain locomotion with a quadrupedal robot. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 5761–5768. [Google Scholar]
- Lee, J.; Hwangbo, J.; Wellhausen, L.; Koltun, V.; Hutter, M. Learning quadrupedal locomotion over challenging terrain. Sci. Robot. 2020, 5, eabc5986. [Google Scholar] [CrossRef] [PubMed]
- Kolter, J.Z.; Ng, A.Y. The Stanford LittleDog: A learning and rapid replanning approach to quadruped locomotion. Int. J. Robot. Res. 2011, 30, 150–174. [Google Scholar] [CrossRef]
- Dai, H.; Tedrake, R. Planning robust walking motion on uneven terrain via convex optimization. In Proceedings of the 2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), Cancun, Mexico, 15–17 November 2016; pp. 579–586. [Google Scholar]
- Rudin, N.; Hoeller, D.; Reist, P.; Hutter, M. Learning to walk in minutes using massively parallel deep reinforcement learning. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 91–100. [Google Scholar]
- Liu, Z.; Acero, F.; Li, Z. Learning vision-guided dynamic locomotion over challenging terrains. arXiv 2021, arXiv:2109.04322. [Google Scholar]
- Oßwald, S.; Gutmann, J.S.; Hornung, A.; Bennewitz, M. From 3D point clouds to climbing stairs: A comparison of plane segmentation approaches for humanoids. In Proceedings of the 2011 11th IEEE-RAS International Conference on Humanoid Robots, Bled, Slovenia, 26–28 October 2011; pp. 93–98. [Google Scholar]
- Peng, X.B.; Berseth, G.; Yin, K.; Van De Panne, M. DeepLoco: Dynamic locomotion skills using hierarchical deep reinforcement learning. ACM Trans. Graph. (TOG) 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Tsounis, V.; Alge, M.; Lee, J.; Farshidian, F.; Hutter, M. DeepGait: Planning and control of quadrupedal gaits using deep reinforcement learning. IEEE Robot. Autom. Lett. 2020, 5, 3699–3706. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar]
- Hao, Q.; Wang, Z.; Wang, J.; Chen, G. Stability-guaranteed and high terrain adaptability static gait for quadruped robots. Sensors 2020, 20, 4911. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.M.O.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Kang, D.; Zimmermann, S.; Coros, S. Animal gaits on quadrupedal robots using motion matching and model-based control. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 8500–8507. [Google Scholar]
- Margolis, G.B.; Yang, G.; Paigwar, K.; Chen, T.; Agrawal, P. Rapid locomotion via reinforcement learning. arXiv 2022, arXiv:2205.02824. [Google Scholar]
- McGhee, R.B.; Frank, A.A. On the stability properties of quadruped creeping gaits. Math. Biosci. 1968, 3, 331–351. [Google Scholar] [CrossRef]
- Zhang, G.; Liu, H.; Qin, Z.; Moiseev, G.V.; Huo, J. Research on self-recovery control algorithm of quadruped robot fall based on reinforcement learning. Actuators 2023, 12, 110. [Google Scholar] [CrossRef]
- Li, X.; Gao, H.; Li, J.; Wang, Y.; Guo, Y. Hierarchically planning static gait for quadruped robot walking on rough terrain. J. Robot. 2019, 2019, 3153195. [Google Scholar] [CrossRef]
- Chen, X.; Gao, F.; Qi, C.; Tian, X.; Wei, L. Kinematic analysis and motion planning of a quadruped robot with partially faulty actuators. Mech. Mach. Theory 2015, 94, 64–79. [Google Scholar] [CrossRef]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Reinf. Learn. 1992, 8, 229–256. [Google Scholar]
- Ye, L.; Wang, Y.; Wang, X.; Liu, H.; Liang, B. Optimized static gait for quadruped robots walking on stairs. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 921–927. [Google Scholar] [CrossRef]
- Coros, S.; Karpathy, A.; Jones, B.; Reveret, L.; Van De Panne, M. Locomotion skills for simulated quadrupeds. ACM Trans. Graph. (TOG) 2011, 30, 1–12. [Google Scholar] [CrossRef]
- Focchi, M.; Orsolino, R.; Camurri, M.; Barasuol, V.; Mastalli, C.; Caldwell, D.G.; Semini, C. Heuristic planning for rough terrain locomotion in presence of external disturbances and variable perception quality. In Advances in Robotics Research: From Lab to Market; Grau, A., Morel, Y., Puig-Pey, A., Cecchi, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 165–209. [Google Scholar]
- Prayogo, R.C.; Triwiyatno, A. Quadruped robot with stabilization algorithm on uneven floor using 6 DOF IMU based inverse kinematic. In Proceedings of the 2018 5th International Conference on Information Technology, Computer, and Electrical Engineering (ICITACEE), Semarang, Indonesia, 27–28 September 2018; pp. 39–44. [Google Scholar]
- Cheng, Y.; Liu, H.; Pan, G.; Ye, L.; Liu, H.; Liang, B. Quadruped robot traversing 3D complex environments with limited perception. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024. [Google Scholar] [CrossRef]
- Chen, S.; Wan, Z.; Yan, S.; Zhang, C.; Zhang, W.; Liu, Q.; Zhang, D.; Farrukh, F.D. SLR: Learning Quadruped Locomotion without Privileged Information. arXiv 2024, arXiv:2406.04835. [Google Scholar]
- DeFazio, D.; Hirota, E.; Zhang, S. Seeing-Eye Quadruped Navigation with Force Responsive Locomotion Control. arXiv 2023, arXiv:2309.04370. [Google Scholar]
- Zhuang, Z.; Fu, Z.; Wang, J.; Atkeson, C. Robot Parkour Learning. arXiv 2023, arXiv:2309.05665. [Google Scholar] [CrossRef]
- Li, H.; Yu, W.; Zhang, T.; Wensing, P.M. Zero-shot retargeting of learned quadruped locomotion policies using hybrid kinodynamic model predictive control. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 11971–11977. [Google Scholar]
- Shao, Y.; Jin, Y.; Liu, X.; He, W.; Wang, H.; Yang, W. Learning free gait transition for quadruped robots via phase-guided controller. IEEE Robot. Autom. Lett. 2021, 7, 1230–1237. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Sun, J.; Yao, M.; Xiao, X.; Xie, Z.; Zheng, B. Co-optimization of Morphology and Behavior of Modular Robots via Hierarchical Deep Reinforcement Learning. In Proceedings of the Robotics: Science and Systems, Daegu, Republic of Korea, 10–14 July 2023. [Google Scholar]
- Xie, Z.; Shang, H.; Xiao, X.; Yao, M. Mapless navigation of modular mobile robots using deep reinforcement learning. In Proceedings of the 2022 IEEE International Conference on Industrial Technology (ICIT), Shanghai, China, 22–25 August 2022; pp. 1–6. [Google Scholar]
- Pongas, D.; Mistry, M.; Schaal, S. A robust quadruped walking gait for traversing rough terrain. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 1474–1479. [Google Scholar] [CrossRef]
- Or, Y.; Rimon, E. Analytic characterization of a class of 3-contact frictional equilibrium postures in 3D gravitational environments. Int. J. Robot. Res. 2010, 29, 3–22. [Google Scholar] [CrossRef]
- Ding, L.; Wang, G.; Gao, H.; Liu, G.; Yang, H.; Deng, Z. Footstep planning for hexapod robots based on 3D quasi-static equilibrium support region. J. Intell. Robot. Syst. 2021, 103, 25. [Google Scholar] [CrossRef]
- Inkol, K.A.; Vallis, L.A. Modelling the dynamic margins of stability for use in evaluations of balance following a support-surface perturbation. J. Biomech. 2019, 95, 109302. [Google Scholar] [CrossRef] [PubMed]
- Focchi, M.; Del Prete, A.; Havoutis, I.; Featherstone, R.; Caldwell, D.G.; Semini, C. High-slope terrain locomotion for torque-controlled quadruped robots. Auton. Robot. 2017, 41, 259–272. [Google Scholar] [CrossRef]
- Kajita, S.; Kanehiro, F.; Kaneko, K.; Fujiwara, K.; Harada, K.; Yokoi, K.; Hirukawa, H. Biped walking pattern generation by using preview control of zero-moment point. In Proceedings of the 2003 IEEE International Conference on Robotics and Automation, Taipei, Taiwan, 14–19 September 2003; Volume 2, pp. 1620–1626. [Google Scholar] [CrossRef]
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-Baselines3: Reliable reinforcement learning implementations. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Explanation |
|---|---|
| The displacement in the x-direction in the world frame | |
| The displacement in the y-direction in the world frame | |
| h | The height of the leg movement |
| Symbol | Definition |
|---|---|
| Identifier of the leg to be moved (1–4) | |
| Desired displacement in the x-direction (world frame) | |
| Desired displacement in the y-direction (world frame) | |
| h | Height of the leg movement during the swing phase |
| Center of Polygon, the ideal CoM position for stability | |
| Center of mass of the robot | |
| Vertical force sensor reading at the leg tip | |
| Force threshold for ground contact detection | |
| Vector of joint angles calculated by inverse kinematics | |
| Joint angle for joint i (after IK calculation) |
| Symbol | Definition |
|---|---|
| One complete training iteration | |
| s | Current state observed by the agent |
| a | Action selected by the agent’s policy |
| Policy function, probability of actions given state s | |
| r | Reward received after taking action a |
| Next state observed after taking action a | |
| Components of action a, parameters for stable step (Algorithm 1) |
| Stair Height [cm] | Success Rate [%] |
|---|---|
| 10 | 93 |
| 7 | 98 |
| 13 | 65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marcus, S.D.; Shapiro, A.; Giladi, C. Enhancing Quadruped Robot Walking on Unstructured Terrains: A Combination of Stable Blind Gait and Deep Reinforcement Learning. Electronics 2025, 14, 1431. https://doi.org/10.3390/electronics14071431
Marcus SD, Shapiro A, Giladi C. Enhancing Quadruped Robot Walking on Unstructured Terrains: A Combination of Stable Blind Gait and Deep Reinforcement Learning. Electronics. 2025; 14(7):1431. https://doi.org/10.3390/electronics14071431
Chicago/Turabian StyleMarcus, Shirelle Drori, Amir Shapiro, and Chen Giladi. 2025. "Enhancing Quadruped Robot Walking on Unstructured Terrains: A Combination of Stable Blind Gait and Deep Reinforcement Learning" Electronics 14, no. 7: 1431. https://doi.org/10.3390/electronics14071431
APA StyleMarcus, S. D., Shapiro, A., & Giladi, C. (2025). Enhancing Quadruped Robot Walking on Unstructured Terrains: A Combination of Stable Blind Gait and Deep Reinforcement Learning. Electronics, 14(7), 1431. https://doi.org/10.3390/electronics14071431