
IAACLIP: Image Aesthetics Assessment via CLIP


Abstract
1. Introduction
- 1.
- Unlike other multimodal methods, we utilize MLLMs to generate objective and consistent aesthetic descriptions for aesthetic images to assist in IAA tasks.
- 2.
- Based on the generated aesthetic image–description pairs, we propose the use of unified learning methods to complete the unified contrastive pre-training stage of our proposed method, facilitating CLIP’s transition from the general to the aesthetics.
- 3.
- We construct composite prompt templates based on the generated aesthetic descriptions to realize the perception training stage of our proposed method. This approach addresses the lack of comments in the real world, and according to experiments conducted on three IAA databases, our method exhibits a competitive performance compared to other state-of-the-art (SOTA) models.
2. Related Works
2.1. Image Aesthetics Assessment
2.2. Multimodal Learning in IAA
2.3. Multimodal Large Language Models
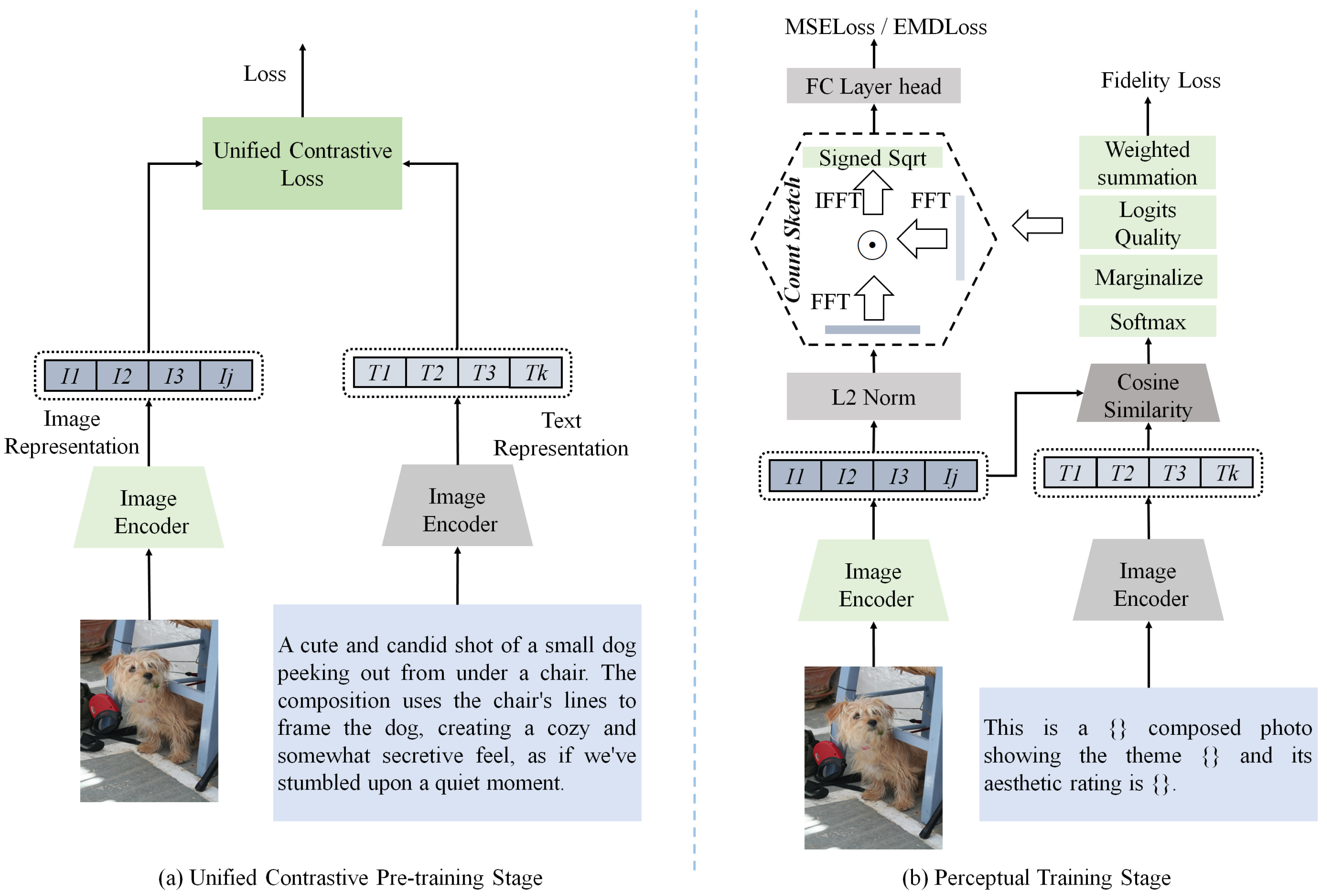
3. Methodology
3.1. Overview
3.2. The Construction of Aesthetic Descriptions
3.3. Unified Contrastive Pre-Training
3.4. Integration of Textual Prompts and Perceptual Training
4. Experimental Section
4.1. Experimental Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Performance Evaluation with Competing Model
4.5. Cross-Database Evaluation
4.6. Ablation Study
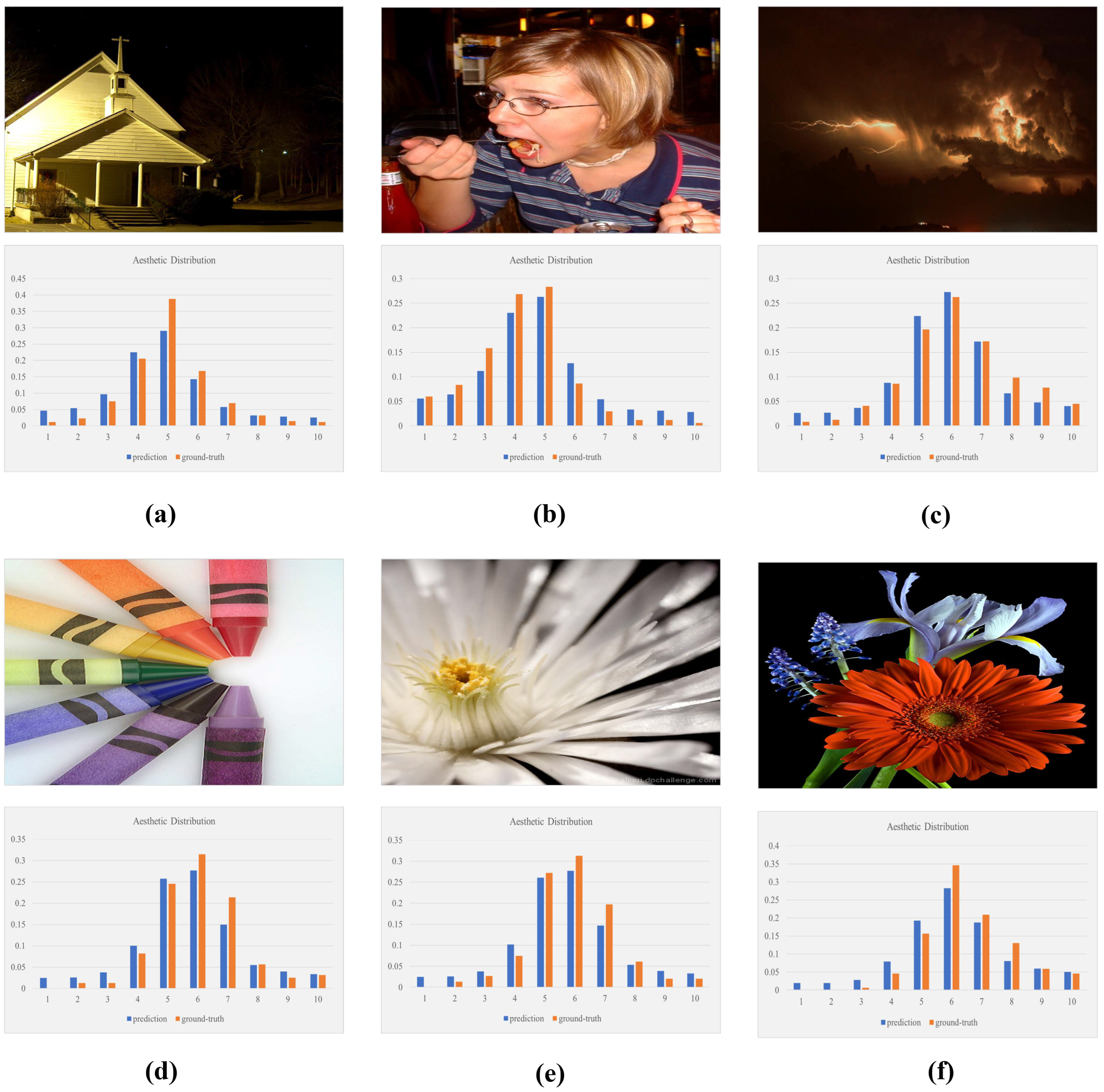
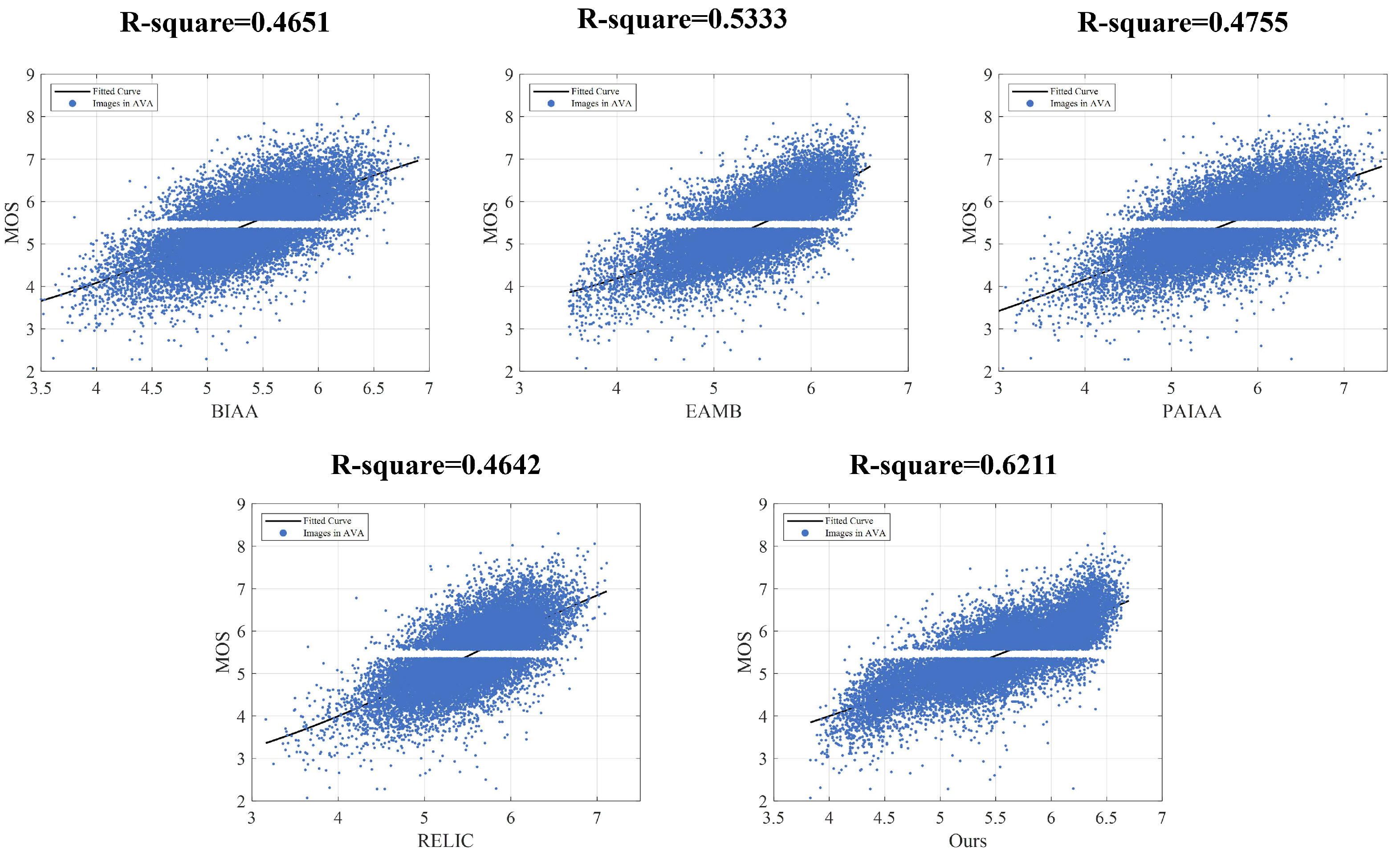
4.7. Visualization
4.8. Further Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zeng, H.; Cao, Z.; Zhang, L.; Bovik, A.C. A unified probabilistic formulation of image aesthetic assessment. IEEE Trans. Image Process. 2020, 29, 142–149. [Google Scholar] [CrossRef] [PubMed]
- He, S.; Zhang, Y.; Xie, R.; Jiang, D.; Ming, A. Rethinking image aesthetics assessment: Models, datasets and benchmarks. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 942–948. [Google Scholar]
- Chen, Q.; Zhang, W.; Zhou, N.; Lei, P.; Xu, Y.; Zheng, Y.; Fan, J. Adaptive fractional dilated convolution network for image aesthetics assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14114–14123. [Google Scholar]
- Ren, J.; Shen, X.; Lin, Z.; Mech, R.; Foran, D.J. Personalized image aesthetics. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 638–647. [Google Scholar]
- Zhu, H.; Li, L.; Wu, J.; Zhao, S.; Ding, G.; Shi, G. Personalized image aesthetics assessment via meta-learning With bilevel gradient optimization. IEEE Trans. Cybern. 2022, 52, 1798–1811. [Google Scholar] [PubMed]
- Yan, X.; Shao, F.; Chen, H.; Jiang, Q. Hybrid CNN-transformer based meta-learning approach for personalized image aesthetics assessment. J. Vis. Commun. Image Represent. 2024, 98, 104044. [Google Scholar]
- Lv, P.; Fan, J.; Nie, X.; Dong, W.; Jiang, X.; Zhou, B.; Xu, M.; Xu, C. User-guided personalized image aesthetic assessment based on deep reinforcement learning. IEEE Trans. Multimed. 2023, 25, 736–749. [Google Scholar]
- Chen, H.; Shao, F.; Chai, X.; Gu, Y.; Jiang, Q.; Meng, X.; Ho, Y.-S. Quality evaluation of arbitrary style transfer: Subjective study and objective metric. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3055–3070. [Google Scholar]
- Luo, Y.; Tang, X. Photo and video quality evaluation: Focusing on the subject. In Proceedings of the European Conference on Computer Vision (ECCV), Marseille, France, 12–18 October 2008; pp. 386–399. [Google Scholar]
- Chai, X.; Shao, F.; Jiang, Q.; Ho, Y.-S. Roundness-preserving warping for aesthetic enhancement-based stereoscopic image editing. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1463–1477. [Google Scholar]
- Datta, R.; Joshi, D.; Li, J.; Wang, J.Z. Studying aesthetics in photographic images using a computational approach. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 288–301. [Google Scholar]
- Ke, Y.; Tang, X.; Jing, F. The design of high-level features for photo quality assessment. In Proceedings of the European Conference on Computer Vision (ECCV), New York, NY, USA, 17–22 June 2006; pp. 419–426. [Google Scholar]
- Tang, X.; Luo, W.; Wang, X. Content-based photo quality assessment. IEEE Trans. Multimed. 2013, 15, 1930–1943. [Google Scholar] [CrossRef]
- Wong, L.-K.; Low, K.-L. Saliency-enhanced image aesthetics class prediction. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 997–1000. [Google Scholar]
- Luo, Y.; Shao, F.; Xie, Z.; Wang, H.; Chen, H.; Mu, B.; Jiang, Q. HFMDNet: Hierarchical fusion and multilevel decoder network for RGB-D salient object detection. IEEE Trans. Instrum. Meas. 2013, 15, 1930–1943. [Google Scholar]
- Lu, X.; Lin, Z.; Jin, H.; Yang, J.; Wang, J.Z. Rating image aesthetics using deep learning. IEEE Trans. Multimed. 2015, 17, 2021–2034. [Google Scholar]
- Talebi, H.; Milanfar, P. NIMA: Neural image assessment. IEEE Trans. Image Process. 2018, 27, 3998–4011. [Google Scholar]
- Li, L.; Zhu, H.; Zhao, S.; Ding, G.; Lin, W. Personality-assisted multi-task learning for generic and personalized image aesthetics assessment. IEEE Trans. Image Process. 2020, 29, 3898–3910. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Zhi, T.; Shi, G.; Yang, Y.; Xu, L.; Li, Y.; Guo, Y. Anchor-based knowledge embedding for image aesthetics assessment. Neurocomputing 2023, 539, 126197. [Google Scholar] [CrossRef]
- Celona, L.; Leonardi, M.; Napoletano, P.; Rozza, A. Composition and style attributes guided image aesthetic assessment. IEEE Trans. Image Process. 2022, 31, 5009–5024. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Zhu, T.; Chen, P.; Yang, Y.; Li, Y.; Lin, W. Image aesthetics assessment With attribute-assisted multimodal memory network. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7413–7424. [Google Scholar] [CrossRef]
- Nie, X.; Hu, B.; Gao, X.; Li, L.; Zhang, X.; Xiao, B. BMI-Net: A brain-inspired multimodal interaction network for image aesthetic assessment. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–November 2023; pp. 5514–5522. [Google Scholar]
- Sheng, X.; Li, L.; Chen, P.; Wu, J.; Dong, W.; Yang, Y.; Xu, L.; Li, Y.; Shi, G. AesCLIP: Multi-attribute contrastive learning for image aesthetics assessment. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 1117–1126. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Qu, B.; Li, H.; Gao, W. Bringing textual prompt to AI-generated image auality assessment. arXiv 2024, arXiv:2403.18714. [Google Scholar]
- Lu, X.; Lin, Z.; Jin, H.; Yang, J.; Wang, J.Z. RAPID: Rating pictorial aesthetics using deep learning. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 457–466. [Google Scholar]
- Lu, X.; Lin, Z.; Shen, X.; Mech, R.; Wang, J.Z. Deep multi-patch aggregation network for image style, aesthetics, and quality estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 990–998. [Google Scholar]
- Ma, S.; Liu, J.; Chen, C.W. A-Lamp: Adaptive layout-aware multi-patch deep convolutional neural network for photo aesthetic assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 722–731. [Google Scholar]
- Huang, Y.; Li, L.; Chen, P.; Wu, J.; Yang, Y.; Li, Y.; Shi, G. Coarse-to-fine image aesthetics assessment with dynamic attribute selection. IEEE Trans. Multimed. 2024, 26, 9316–9329. [Google Scholar] [CrossRef]
- Li, L.; Huang, Y.; Wu, J.; Yang, Y.; Li, Y.; Guo, Y.; Shi, G. Theme-aware visual attribute reasoning for image aesthetics assessment. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4798–4811. [Google Scholar] [CrossRef]
- Chen, H.; Shao, F.; Mu, B.; Jiang, Q. Image aesthetics assessment with emotion-aware multibranch network. IEEE Trans. Instrum. Meas. 2024, 73, 1–15. [Google Scholar] [CrossRef]
- Zhang, X.; Xiao, Y.; Peng, J.; Gao, X.; Hu, B. Confidence-based dynamic cross-modal memory network for image aesthetic assessment. Pattern Recognit. 2024, 149, 110227. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.; Lacroix, T.; Roziére, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Zhu, D.; Chen, J.; Shen, X.; Li, X.; Elhoseiny, M. MiniGPT-4: Enhancing vision-language understanding with advanced large language models. arXiv 2023, arXiv:2304.105921. [Google Scholar]
- Li, B.; Zhang, Y.; Chen, L.; Wang, J.; Yang, J.; Liu, Z. Otter: A multi-modal model with in-context instruction tuning. arXiv 2023, arXiv:2305.03726. [Google Scholar]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y. Visual instruction tuningg. arXiv 2023, arXiv:2304.08485. [Google Scholar]
- Huang, Y.; Yuan, Q.; Sheng, X.; Yang, Z.; Wu, H.; Chen, P.; Yang, Y.; Li, L.; Lin, W. AesBench: An expert benchmark for multimodal large language models on amage aesthetics perception. arXiv 2024, arXiv:2401.08276. [Google Scholar]
- Yang, Y.; Xu, L.; Li, L.; Qie, N.; Li, Y.; Zhang, P.; Guo, Y. Personalized image aesthetics assessment with rich attributes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 19829–19837. [Google Scholar]
- Yang, J.; Li, C.; Zhang, P.; Xiao, B.; Liu, C.; Yuan, L.; Gao, J. Unified contrastive learning in image-text-label space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 19141–19151. [Google Scholar]
- Zhang, W.; Zhai, G.; Wei, Y.; Yang, X.; Ma, K. Blind image quality assessment via vision-language correspondence: A multitask learning perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 14071–14081. [Google Scholar]
- Tsai, M.; Liu, T.; Qin, T.; Chen, H.; Ma, W. FRank: A ranking method with fidelity loss. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 383–390. [Google Scholar]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal compact bilinear pooling for visual question answering and visual grounding. arXiv 2016, arXiv:1606.01847. [Google Scholar]
- Murray, N.; Marchesotti, L.; Perronnin, F. AVA: A large-scale database for aesthetic visual analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2408–2415. [Google Scholar]
- Kong, S.; Shen, X.; Lin, Z.; Mech, R.; Fowlkes, C. Photo aesthetics ranking network with attributes and content adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 662–679. [Google Scholar]
- Wang, Y.; Cui, Y.; Lin, J.; Jiang, G.; Yu, M.; Fang, C.; Zhang, S. Blind quality evaluator for enhanced colonoscopy images by integrating local and global statistical features. IEEE Trans. Instrum. Meas. 2024, 73, 1–15. [Google Scholar]
- Murray, N.; Gordo, A. A deep architecture for unified aesthetic prediction. arXiv 2017, arXiv:1708.04890. [Google Scholar]
- Zhang, X.; Gao, X.; Lu, W.; He, L. A gated peripheral-foveal convolutional neural network for unified image aesthetic prediction. IEEE Trans. Multimed. 2019, 21, 2815–2826. [Google Scholar]
- Hosu, V.; Goldlucke, B.; Saupe, D. Effective aesthetics prediction with multi-level spatially pooled features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9367–9375. [Google Scholar]
- Ke, J.; Wang, Q.; Wang, Y.; Milanfar, P.; Yang, F. MUSIQ: Multi-Scale image quality transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 5128–5137. [Google Scholar]
- Niu, Y.; Chen, S.; Song, B.; Chen, Z.; Liu, W. Comment-guided semantics-aware image aesthetics assessment. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 1487–1492. [Google Scholar]
- He, S.; Ming, A.; Zheng, S.; Zhong, H.; Ma, H. EAT: An enhancer for aesthetics-oriented transformers. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 1023–1032. [Google Scholar]
- Ke, J.; Ye, K.; Yu, J.; Wu, Y.; Milanfar, P.; Yang, F. Vila: Learning image aesthetics from user comments with vision-language pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10041–10051. [Google Scholar]
- Zhou, H.; Yang, R.; Tang, L.; Qin, G.; Zhang, Y.; Hu, R.; Li, X. Gamma: Toward Generic Image Assessment with Mixture of Assessment Experts. arXiv 2025, arXiv:2503.06678. [Google Scholar]
- Malu, G.; Bapi, R.; Indurkhya, B. Learning photography aesthetics with deep CNNs. arXiv 2017, arXiv:1707.03981. [Google Scholar]
- Liu, D.; Puri, R.; Kamath, N.; Bhattacharya, S. Composition-aware image aesthetics assessment. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020; pp. 3558–3567. [Google Scholar]
- Li, L.; Duan, J.; Yang, Y.; Xu, L.; Li, Y.; Guo, Y. Psychology inspired model for hierarchical image aesthetic attribute prediction. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- She, D.; Lai, Y.-K.; Yi, G.; Xu, K. Hierarchical layout-aware graph convolutional network for unified aesthetics assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8471–8480. [Google Scholar]
- Yi, R.; Tian, H.; Gu, Z.; Lai, Y.-K.; Rosin, P.L. Towards artistic image aesthetics assessment: A large-scale dataset and a new method. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 22388–22397. [Google Scholar]
- Sheng, K.; Dong, W.; Ma, C.; Mei, X.; Huang, F.; Hu, B.-G. Attention-based multi-patch aggregation for image aesthetic assessment. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 879–886. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | ImageSize | ACC (%)↑ | PLCC↑ | SRCC↑ | MSE↓ | RMSE↓ | MAE↓ | EMD↓ |
|---|---|---|---|---|---|---|---|---|---|
| DMA-Net [27] | AlexNet | (227) | 75.40 | / | / | / | / | / | / |
| Kong et al. [44] | AlexNet | (227) | 77.30 | / | 0.558 | / | / | / | / |
| APM [46] | ResNet-101 | (500) | 80.30 | / | 0.709 | 0.279 | / | / | / |
| NIMA [17] | VGG16 | (224) | 80.60 | 0.610 | 0.592 | / | / | / | 0.05 |
| A-Lamp [28] | ResNet-101 | (224) | 82.50 | / | / | / | / | / | / |
| Zeng et al. [1] | ResNet-101 | (384) | 80.80 | 0.720 | 0.719 | 0.275 | / | / | / |
| GPF-CNN [47] | InceptionNet | (224) | 81.81 | 0.704 | 0.690 | / | 0.524 | 0.407 | 0.045 |
| Hosu et al. [48] | Inception-ResNet | Full | 81.70 | 0.757 | 0.756 | / | / | / | / |
| MUSIQ [49] | ViT | Full | 81.50 | 0.738 | 0.726 | 0.242 | 0.490 | / | / |
| Celona et al. [20] | EfficientNet-B4 | Full | 81.80 | 0.732 | 0.733 | / | 0.512 | 0.401 | 0.044 |
| Niu et al. [50] | ResNet-50 | (224) | 81.90 | 0.740 | 0.734 | 0.242 | / | / | / |
| TANet [2] | MobileNetV2 | (224) | 80.60 | 0.765 | 0.758 | / | / | / | 0.047 |
| EAT [51] | Swin Transformer | (224) | / | 0.770 | 0.759 | / | / | / | / |
| EAMB-Net [31] | EfficientNet-B4 | (512) | 81.36 | 0.740 | 0.743 | 0.258 | 0.508 | 0.394 | 0.043 |
| AesCLIP [23] | ViT | (224) | 83.10 | 0.779 | 0.771 | 0.218 | / | / | 0.041 |
| CADAS [29] | EfficientNet-B4 | (224) | 82.40 | 0.751 | 0.753 | / | / | / | 0.043 |
| VILA-R [52] | CLIP-B/16 | (224) | / | 0.774 | 0.774 | / | / | / | / |
| Gamma [53] | CLIP-B/16 | (224) | / | 0.749 | 0.750 | / | / | / | / |
| Ours | CLIP-B/16 | (224) | 82.40 | 0.788 | 0.791 | 0.218 | 0.467 | 0.361 | 0.040 |
| Method | RegNet | DCNN | NIMA | RGNet | Zeng et al. | HIAA | Celona et al. | CADAS | TAVAR | AesCLIP | Ours |
|---|---|---|---|---|---|---|---|---|---|---|---|
| [44] | [54] | [17] | [55] | [1] | [56] | [20] | [29] | [30] | [23] | ||
| SRCC↑ | 0.678 | 0.689 | 0.737 | 0.710 | 0.719 | 0.739 | 0.757 | 0.768 | 0.761 | 0.790 | 0.795 |
| Metric | RAPID | AADB | PAM | NIMA | A-Lamp | HGCN | MLSP | MUSIQ | TANet | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| [26] | [44] | [4] | [17] | [28] | [57] | [48] | [49] | [2] | ||
| SRCC↑ | 0.314 | 0.379 | 0.422 | 0.390 | 0.411 | 0.486 | 0.490 | 0.517 | 0.513 | 0.508 |
| PLCC↑ | 0.332 | 0.400 | 0.440 | 0.405 | 0.422 | 0.493 | 0.508 | 0.489 | 0.531 | 0.537 |
| MSE↓ | 0.022 | 0.021 | 0.020 | 0.021 | 0.019 | 0.020 | 0.019 | 0.018 | 0.016 | 0.015 |
| Method | Train on TAD66K and Test on AADB | Train on AADB and Test on TAD66k | Train on AVA and Test on AADB | Train on AADB and Test on AVA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | PLCC | SRCC | ACC | PLCC | SRCC | ACC | PLCC | SRCC | ACC | PLCC | SRCC | |
| ReLIC | 63.2 | 0.453 | 0.414 | 61.3 | 0.220 | 0.215 | 60.9 | 0.514 | 0.547 | 60.6 | 0.513 | 0.522 |
| TANet | 57.5 | 0.396 | 0.392 | 61.1 | 0.219 | 0.211 | 60.3 | 0.520 | 0.599 | 59.8 | 0.567 | 0.564 |
| EMBT | 58.9 | 0.510 | 0.500 | 57.0 | 0.235 | 0.226 | 59.9 | 0.521 | 0.574 | 60.7 | 0.567 | 0.568 |
| SAAN | 59.3 | 0.313 | 0.289 | 60.5 | 0.193 | 0.181 | 61.3 | 0.556 | 0.599 | 61.1 | 0.583 | 0.594 |
| Ours | 66.8 | 0.512 | 0.519 | 62.9 | 0.286 | 0.286 | 61.4 | 0.622 | 0.566 | 61.3 | 0.593 | 0.602 |
| Unified Contrastive Pre-Training | Prompt for Perceptual Training | PLCC | SRCC | ACC |
|---|---|---|---|---|
| 0.761 | 0.757 | 81.51 | ||
| ✓ | 0.780 | 0.778 | 82.13 | |
| ✓ | 0.784 | 0.783 | 81.67 | |
| ✓ | ✓ | 0.788 | 0.791 | 82.40 |
| Method | AVA [43] | AADB [44] | TAD66K [2] | |||
|---|---|---|---|---|---|---|
| PLCC | SRCC | PLCC | SRCC | PLCC | SRCC | |
| Concat | 0.783 | 0.783 | 0.778 | 0.781 | 0.529 | 0.498 |
| Element-wise product | 0.781 | 0.783 | 0.768 | 0.783 | 0.520 | 0.493 |
| Element-wise addition | 0.785 | 0.784 | 0.778 | 0.778 | 0.523 | 0.498 |
| MCBP | 0.788 | 0.791 | 0.782 | 0.795 | 0.538 | 0.508 |
| Method | PLCC↑ | SRCC↑ | ACC↑ | Params (M)↓ |
|---|---|---|---|---|
| NIMA [17] | 0.382 | 0.393 | 71.01 | 23.51 |
| MPada [59] | 0.425 | 0.437 | 74.33 | 27.56 |
| MLSP [48] | 0.430 | 0.441 | 74.92 | 73.97 |
| BIAA [5] | 0.376 | 0.389 | 71.61 | 97.49 |
| TANet [2] | 0.437 | 0.453 | 75.45 | 13.88 |
| SAAN [58] | 0.467 | 0.473 | 76.80 | 30.81 |
| EAMB [31] | 0.487 | 0.496 | 77.31 | 69.03 |
| Ours | 0.523 | 0.505 | 76.86 | 82.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Yan, X.; Wei, X.; Shao, F. IAACLIP: Image Aesthetics Assessment via CLIP. Electronics 2025, 14, 1425. https://doi.org/10.3390/electronics14071425
Li Z, Yan X, Wei X, Shao F. IAACLIP: Image Aesthetics Assessment via CLIP. Electronics. 2025; 14(7):1425. https://doi.org/10.3390/electronics14071425
Chicago/Turabian StyleLi, Zhuo, Xingao Yan, Xuebin Wei, and Feng Shao. 2025. "IAACLIP: Image Aesthetics Assessment via CLIP" Electronics 14, no. 7: 1425. https://doi.org/10.3390/electronics14071425
APA StyleLi, Z., Yan, X., Wei, X., & Shao, F. (2025). IAACLIP: Image Aesthetics Assessment via CLIP. Electronics, 14(7), 1425. https://doi.org/10.3390/electronics14071425