
Mexican Sign Language Recognition: Dataset Creation and Performance Evaluation Using MediaPipe and Machine Learning Techniques




Abstract
1. Introduction
- This study demonstrates the feasibility of real-time, low-cost computational algorithms for both static and continuous Mexican Sign Language (MSL) recognition. The approach includes full MSL dactylology [7] (covering letters such as “LL” and “RR”) and the recognition of the first ten numbers.
- To overcome the scarcity of resources, we developed and released an open-source MSL database. This database is now available to the research community, serving as a crucial resource for further innovation in SL recognition.
- Unlike previous studies that relied on cropped-hand images, controlled environments, or complex sensor data, our method utilizes full-frame video recordings—from the waist to the head—in real-world scenarios. This comprehensive capture enables the effective application of state-of-the-art algorithms for sign language recognition.
2. Literature Review
2.1. General Process of Sign Language Recognition
- Data Acquisition: receive image or video inputs and store them.
- Preprocessing: standardize, filter, or crop images.
- Segmentation: background or other parts removed.
- Feature Extraction: extract the features for classification.
- Classification: classify the predicted label or category with an algorithm.
2.2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Sign Language | Device | Created New Dataset | Full Frame/Image Scenario | # of Participants | # of Samples in the Dataset | MediaPipe | # of Landmarks Used (If MediaPipe) | # of Hands Considered for Detection at the Same Time | # of Classes from Dactylology | # of Classes from Numbers (From 1 to 10) | # of Classes from Words | Trained Models for Static SL | Trained Models for Continuous SL | Best Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Solís et al., 2015 [31] | Mexican | Digital Canon EOS rebel T3 EF-S 18–55 Camera | 1 | - | N.M. | N.M. | - | - | 1 | 24 | - | - | Jacobi-Fourier Moment + Multilayer Perceptron | - | 95% Jacobi–Fourier Moment + Multilayer Perceptron |
| Solís et al., 2016 [32] | Mexican | Digital Camera and four LED reflectors placed at the corners | 1 | - | N.M. | N.M. | - | - | 1 | 21 | - | - | Normalized moment + Multilayer Perceptron | - | 93% Normalized moment + Multilayer Perceptron |
| Jimenez et al., 2017 [24] | Mexican | Kinect | 1 | - | 100 | 1000 | - | - | 1 | 5 | 5 | - | HAAR 2D/HAAR 3D + AdaBoost | - | 95% HAAR 3D + AdaBoost |
| Shin et al., 2021 [33] | American | Camera | - | - | N.M. | ASL Alphabet 780,000 Finger Spelling A 65,774 Massey 1815 | 1 | 21 | 1 | 26 | - | - | Angle and/or Distance Features + SVM, GBL | Angle and/or Distance Features + SVM, GBL | With Angle and Distance Features + SVM: Massey dataset: 99.39% Finger Spelling A: 98.45% ASL alphabet: 87.60% |
| Indriani et al., 2021 [34] | American | Kinect | 1 | - | N.M. | 900 | 1 | 21 | 1 | - | 10 (From 0 to 9) | - | Hand condition detector | Hand condition detector | 95% Hand condition detector |
| Halder and Tayade, 2021 [35] | American Indian Italian Turkish | Camera | - | - | N.M. | N.M. | 1 | 21 | 1 | American 26 Indian 26 Italian 22 | American 10 Indian Turkish 10 | - | SVM, KNN, Random Forest, Decision Tree, Naive Bayes, ANN, MLP | - | 99% SVM in every SL |
| Espejel-Cabrera et al., 2021 [36] | Mexican | Camera with black clothes and background | 1 | 1 | 11 | 2480 | - | - | 2 | - | - | 249 | Decision Tree, SVM, Neural networks, Naive Bayes | - | +96% SVM |
| Sundar and Bagyammal, 2022 [37] | American | Camera | 1 | 1 | 4 | 93,600 | 1 | 21 | 1 | 26 | - | - | LSTM | LSTM | 99% LSTM |
| Chen et al., 2022 [38] | American | Camera | - | - | Dataset 1: 2062 Dataset 2: 5000 Dataset 3: 12,000 Dataset 4: 300 | N.M. | 1 | 21 | 1 | 21 | - | - | Recursive Feature Elimination (RFE) + proposed method, CNN | - | 96.3% RFE + proposed method |
| Samaan et al., 2022 [39] | American | Camera of OPPO Reno3 Pro mobile | 1 | 1 | 5 | 750 | 1 | 258 | 2 | - | - | 10 | - | GRU, LSTM, and BiLSTM | 99% GRU |
| Subramanian et al., 2022 [40] | Indian | Camera | 1 | 1 | N.M. | 900 | 1 | 540+ | 2 | - | - | 13 | - | Simple RNN, LSTM, Standard GRU, BiGRU, BiLSTM, MOPGRU (MediaPipe + GRU) | 99.92% MOPGRU (MediaPipe + GRU) |
| Mejía-Peréz et al., 2022 [27] | Mexican | Depth Camera (OAK-D) | 1 | 1 | 4 | 3000 | 1 | 67 | 2 | 8 | - | 22 | Gaussian Noise + RNN, LSTM, and GRU | Gaussian Noise + RNN, LSTM, and GRU | 97.11% Gaussian Noise + GRU |
| Sosa-Jiménez et al., 2022 [26] | Mexican | Kinect | 1 | 1 | 22 | 18,040 | - | - | 2 | 29 | 10 (From 0 to 9) | 43 | Hidden Markov Model (HMM) | Hidden Markov Model (HMM) | 99% HMM |
| Rios-Figueroa et al., 2022 [25] | Mexican | Kinect | 1 | - | 15 | N.M. | - | - | - | 21 | - | - | Use of Spherical and/or Cartesian features classified by a Maximum A Posteriori (MAP) | - | 100% Spherical and Cartesian features classified by a Maximum A Posteriori (MAP) |
| Sánchez-Vicinaiz et al., 2024 [28] | Mexican | Camera | 1 | - | 1 internal DB | 3822 internal DB + 4347 external DB | 1 | 21 | 1 | 21 | - | - | MediaPipe + Customized CNN | - | 99.93% training 98.43% validation 83.63% testing |
| Current Study | Mexican | Camera | 1 | 1 | 11 | 3677 | 1 | 42 | 2 | 29 | 10 | - | SVM, GBL | LSTM, GRU | 92% SVM 85% GRU |
3. Materials and Methods
| Algorithm 1. Pseudocode for main pipeline of current work |
| BEGIN DataAcquisition INITIALIZE dataset FOR each participant IN participant_list DO FOR cycle FROM 1 TO 10 DO // Record using both hands for augmentation IF cycle < 6 THEN RECORD video WITH right hand for current cycle ELSE THEN RECORD video WITH left hand for current cycle STORE recorded videos IN dataset END FOR END FOR SAVE dataset END DataAcquisition BEGIN DataPreparation FOR each video IN dataset DO IF video IS a static sign THEN EXTRACT representative frame (screenshot) LABEL frame WITH corresponding sign label (using PASCAL VOC format) SAVE frame INTO prepared_dataset ELSE IF video IS a continuous sign THEN TRIM video TO appropriate start and end times LABEL video WITH corresponding sign label SAVE trimmed video INTO prepared_dataset END IF END FOR SAVE prepared_dataset END DataPreparation BEGIN FeatureExtraction FOR each sample (frame or video frame) IN prepared_dataset DO APPLY MediaPipe algorithm TO extract hand landmarks // Extract 21 landmarks per hand, thus 42 landmarks total FOR each landmark DO RETRIEVE 3D coordinates (X, Y, Z) END FOR COMPILE coordinates INTO feature vector (126 data points) ASSOCIATE feature vector WITH its label STORE feature vector in feature_dataset END FOR SAVE feature_dataset END FeatureExtraction BEGIN ModelTrainingAndClassification // Process static sign samples LOAD static_signs FROM feature_dataset APPLY grid search to train SVM model using static_signs data APPLY grid search to train Gradient Boost Light (GBL) model using static_signs data SAVE trained static_sign_models // Process continuous sign samples LOAD continuous_signs FROM feature_dataset CONFIGURE LSTM model TRAIN LSTM model using continuous_signs data CONFIGURE GRU model TRAIN GRU model using continuous_signs data SAVE trained continuous_sign_models END ModelTrainingAndClassification BEGIN MainPipeline // Step 1: Data Acquisition CALL DataAcquisition() // Step 2: Data Preparation CALL DataPreparation() // Step 3: Feature Extraction CALL FeatureExtraction() // Step 4: Model Training and Classification CALL ModelTrainingAndClassification() // End of Pipeline END MainPipeline |
3.1. Data Acquisition
- Two native speakers who are deaf and learned MSL to communicate.
- Two bilingual speakers who learned MSL from their parents.
- Seven speakers who learned MSL in an educational program.
3.2. Data Preparation
3.3. Feature Extraction
3.4. Complemented Models for Classification
3.5. Evaluation Metrics
4. Results (Including Experimentation)
4.1. Dataset
4.2. Implementation Details
4.3. Quantitative Analysis
4.4. Comparative Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Labeled Dataset
| Static | ||
|---|---|---|
| Character/Number | Labeled | # of Samples |
| 1 | 0 | 92 |
| 2 | 1 | 92 |
| 3 | 2 | 92 |
| 4 | 3 | 92 |
| 5 | 4 | 92 |
| 6 | 5 | 92 |
| 7 | 6 | 92 |
| 8 | 7 | 92 |
| a | 8 | 94 |
| b | 9 | 94 |
| c | 10 | 94 |
| d | 11 | 94 |
| e | 12 | 94 |
| f | 13 | 94 |
| g | 14 | 94 |
| h | 15 | 94 |
| i | 16 | 93 |
| l | 17 | 93 |
| m | 18 | 93 |
| n | 19 | 93 |
| o | 20 | 93 |
| p | 21 | 93 |
| r | 22 | 93 |
| s | 23 | 93 |
| t | 24 | 73 |
| u | 25 | 92 |
| v | 26 | 93 |
| w | 27 | 93 |
| y | 28 | 93 |
| Total | - | 2696 |
| Continuous | ||
|---|---|---|
| Character/Number | Labeled | # of Samples |
| 9 | 0 | 100 |
| 10 | 1 | 100 |
| j | 2 | 102 |
| k | 3 | 102 |
| ll | 4 | 86 |
| ñ | 5 | 101 |
| q | 6 | 88 |
| rr | 7 | 101 |
| x | 8 | 101 |
| z | 9 | 100 |
| Total | 981 | |
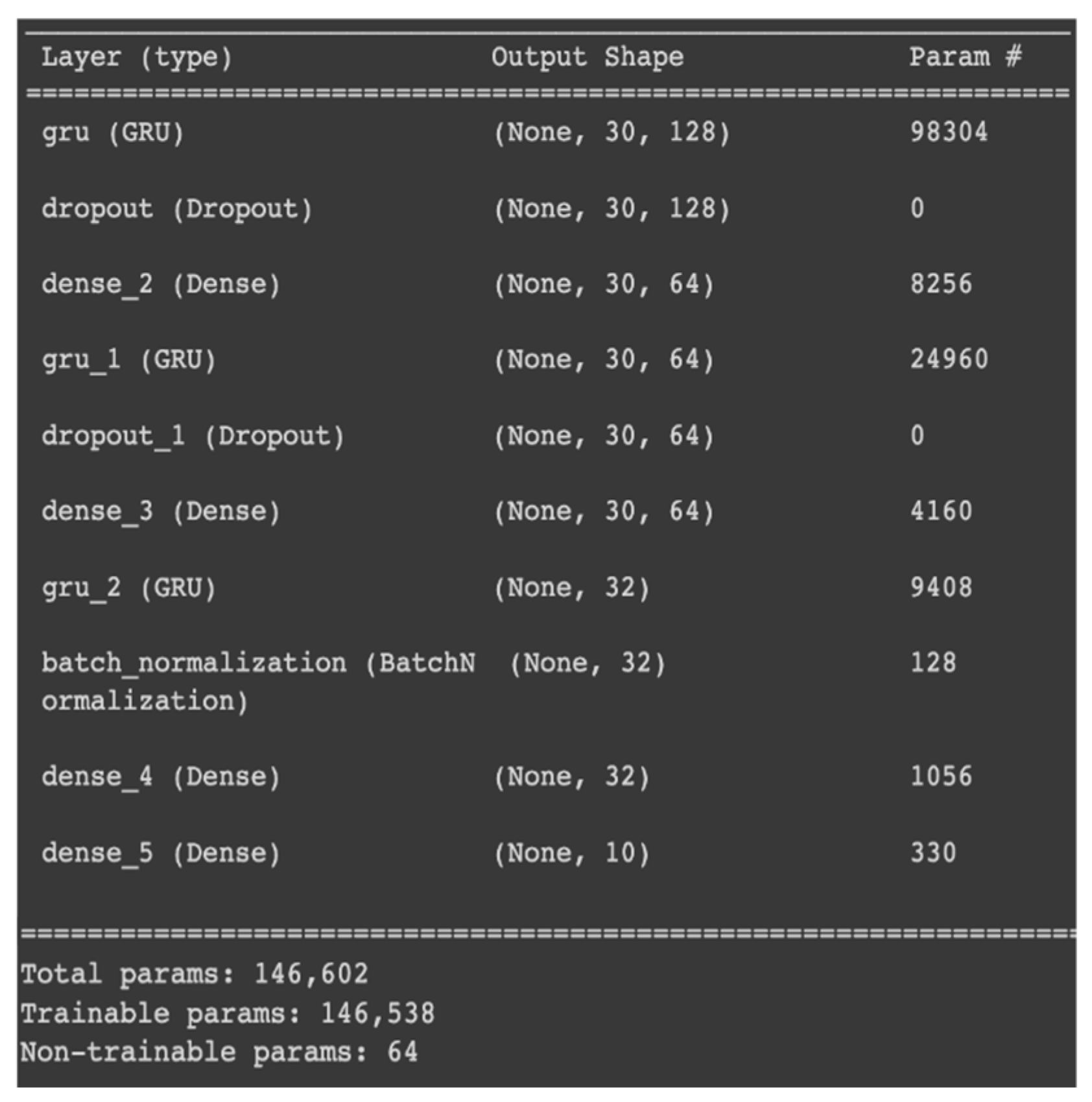
Appendix B. Detailed Architecture of the Models for Continuous Sign Language

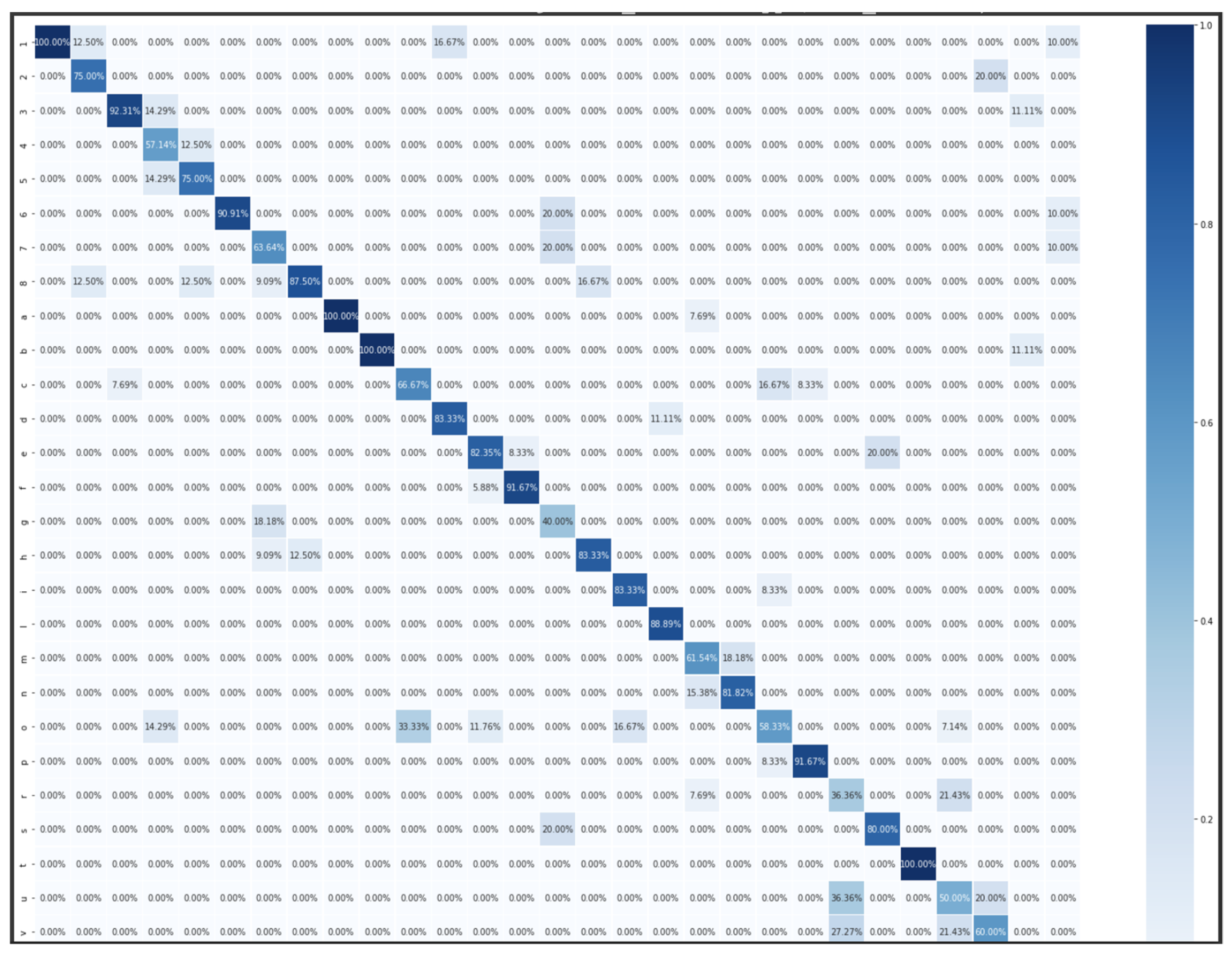
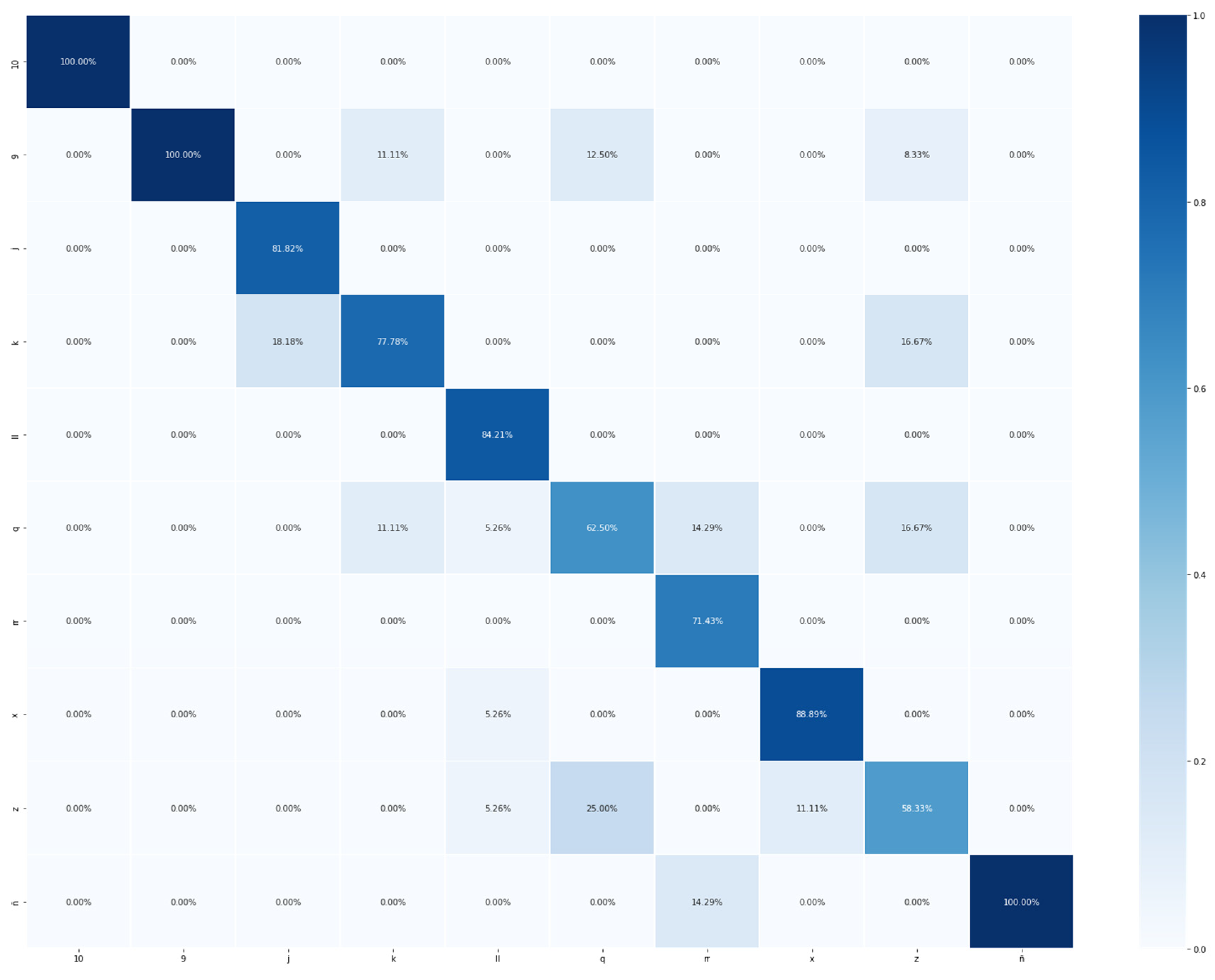
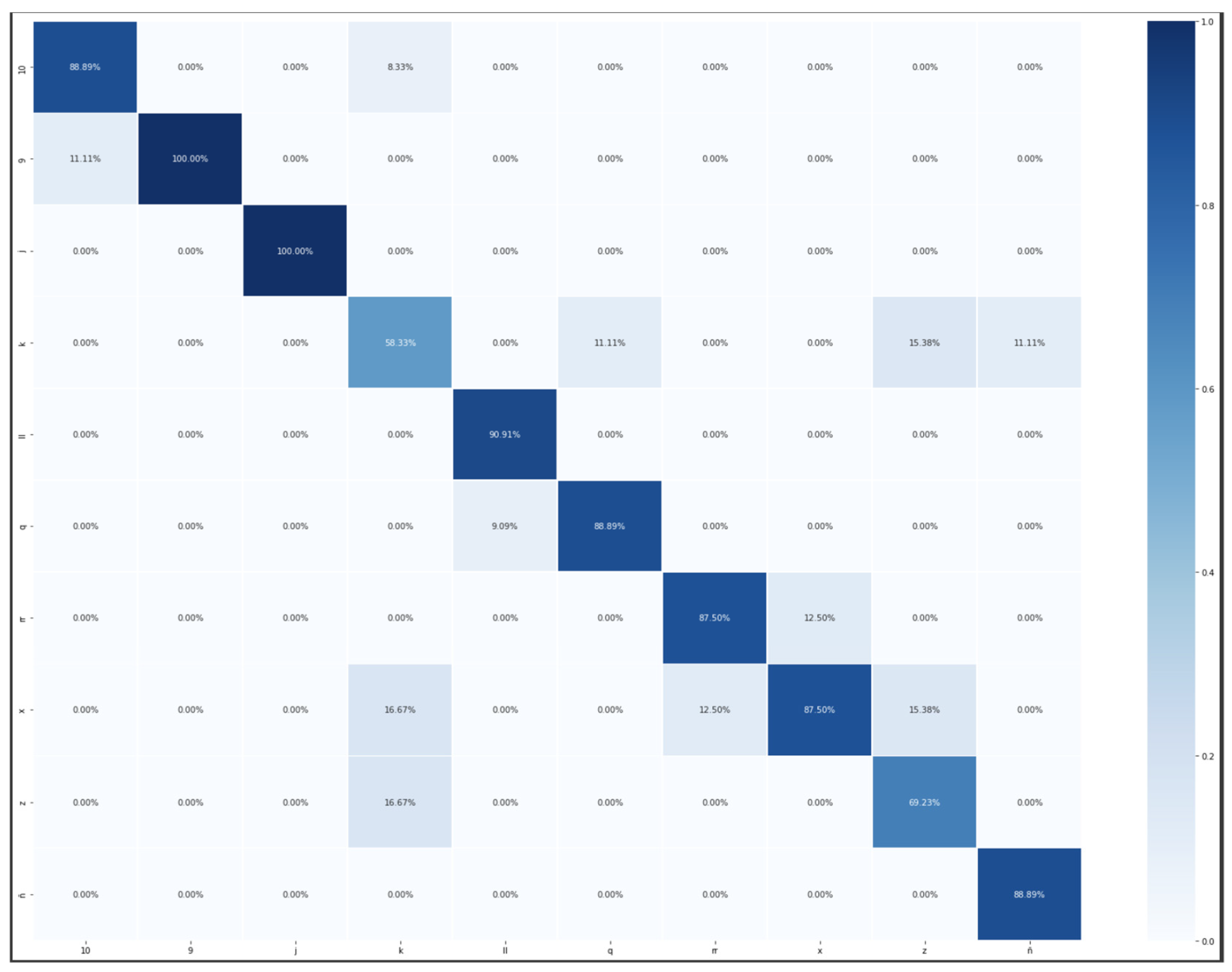
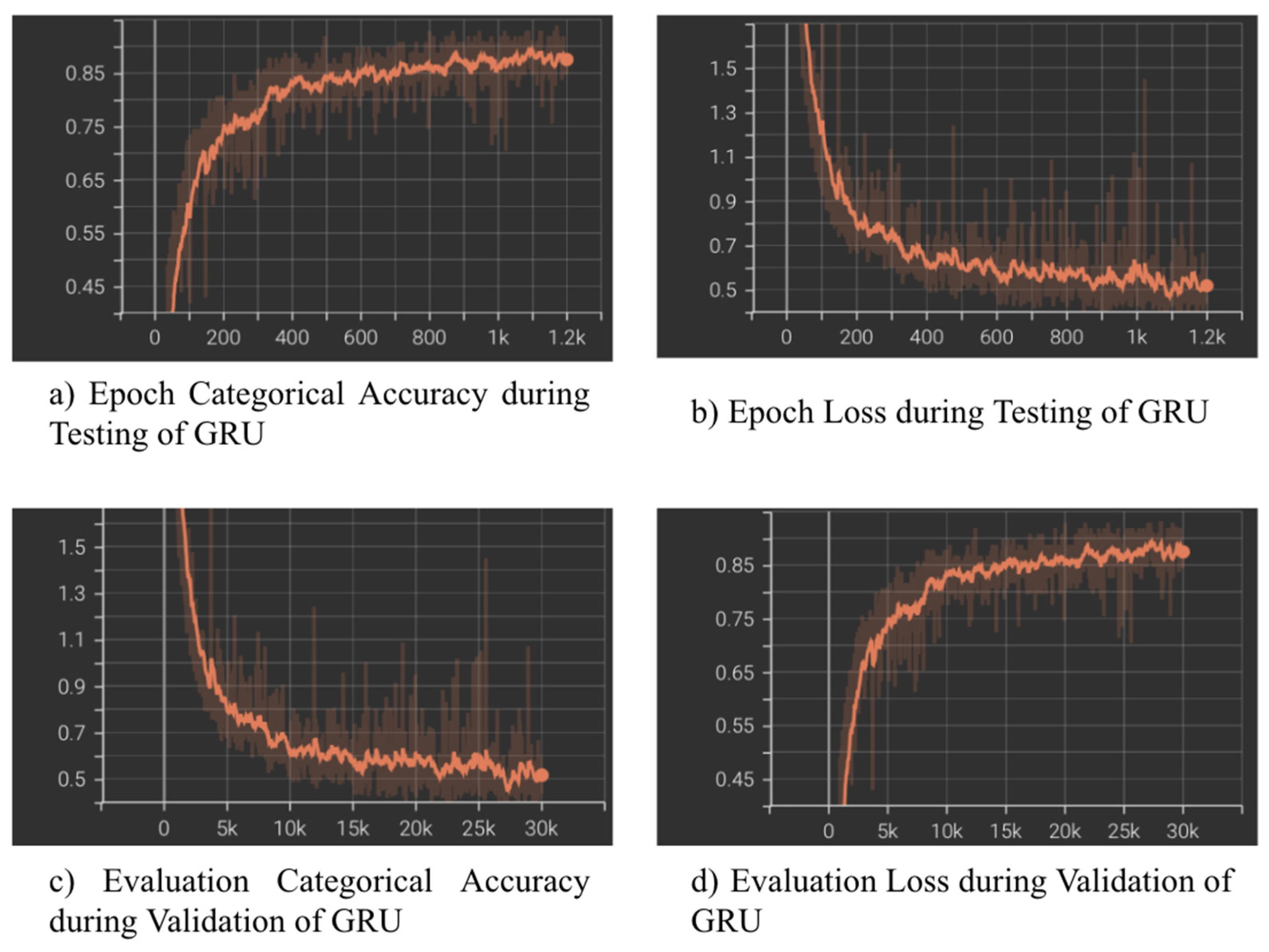
Appendix C. Confusion Matrixes and Categorical and Loss Curves

References
- World Health Organization. Deafness and Hearing Loss; World Health Organization: Geneva, Switzerland, 2023; Available online: https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss (accessed on 27 February 2023).
- Mariano, M. Enfrentan Personas con Discapacidad Auditiva retos en Escenario Actual. 2020. Available online: https://conecta.tec.mx/es/noticias/monterrey/educacion/enfrentan-personas-con-discapacidad-auditiva-retos-en-escenario-actual (accessed on 5 November 2021).
- Department of Economic Social Affairs of U.N. International Day of Sign Languages, 23 September 2019. 2019. Available online: https://www.un.org/development/desa/disabilities/news/news/sign-languages.html (accessed on 15 August 2021).
- United Nations. The 17 Goals. 2016. Available online: https://sdgs.un.org/goals (accessed on 19 November 2022).
- Consejo para Prevenir y Eliminar la Discriminación en la Ciudad de México. Lenguas de Señas son Fundamentales para el Desarrollo de las Personas Sordas y el Acceso a sus Derechos. 2019. Available online: https://copred.cdmx.gob.mx/comunicacion/nota/lenguas-de-senas-son-fundamentales-para-el-desarrollo-de-las-personas-sordas-y-el-acceso-sus-derechos (accessed on 7 August 2021).
- Cámara de Diputados del, H. Congreso de la Unión. Ley General de las Personas con Discapacidad. General Secretary; DOF 30-05-2011. 2008. Available online: https://www.diputados.gob.mx/LeyesBiblio/abro/lgpd/LGPD_abro.pdf (accessed on 20 October 2021).
- Serafín, M.E.; González, R. Manos con voz. Diccionario de la Lengua de Señas Mexicana; Consejo Nacional para Prevenir la Discriminación (CONAPRED) & Libre Acceso, A.C. Primera Edición, 2011; ISBN 978-607-7514-35-0. Available online: https://www.conapred.org.mx/publicaciones/manos-con-voz-diccionario-de-lengua-de-senas-mexicana/ (accessed on 18 January 2022).
- Ahmed, M.A.; Zaidan, B.B.; Zaidan, A.A.; Salih, M.M.; bin Lakulu, M.M. A Review on Systems-Based Sensory Gloves for Sign Language Recognition State of the Art between 2007 and 2017. Sensors 2018, 18, 2208. [Google Scholar] [CrossRef] [PubMed]
- Guzsvinecz, T.; Szucs, V.; Sik-Lanyi, C. Suitability of the Kinect Sensor and Leap Motion Controller—A Literature Review. Sensors 2019, 19, 1072. [Google Scholar] [CrossRef]
- Kim, E.J.; Byrne, B.; Parish, S.L. Deaf people and economic well-being: Findings from the Life Opportunities Survey. Disabil. Soc. 2018, 33, 374–391. [Google Scholar] [CrossRef]
- Adeyanju, I.A.; Bello, O.O.; Adegboye, M.A. Machine learning methods for sign language recognition: A critical review and analysis. Intell. Syst. Appl. 2021, 12, 200056. [Google Scholar] [CrossRef]
- Alam Md, S.; Kwon, K.-C.; Md Imtiaz, S.; Hossain, M.B.; Kang, B.-G.; Kim, N. TARNet: An Efficient and Lightweight Trajectory-Based Air-Writing Recognition Model Using a CNN and LSTM Network. In Human Behavior and Emerging Technologies; Yan, Z., Ed.; Wiley: Hoboken, NJ, USA, 2022; Volume 2022, pp. 1–13. [Google Scholar] [CrossRef]
- Mohammedali, A.H.; Abbas, H.H.; Shahadi, H.I. Real-time sign language recognition system. Int. J. Health Sci. 2022, 6, 10384–10407. [Google Scholar] [CrossRef]
- Mujahid, A.; Awan, M.J.; Yasin, A.; Mohammed, M.A.; Damaševičius, R.; Maskeliūnas, R.; Abdulkareem, K.H. Real-Time Hand Gesture Recognition Based on Deep Learning YOLOv3 Model. Appl. Sci. 2021, 11, 4164. [Google Scholar] [CrossRef]
- Liu, P.; Li, X.; Cui, H.; Li, S.; Yuan, Y. Hand Gesture Recognition Based on Single-Shot Multibox Detector Deep Learning. Mob. Inf. Syst. 2019, 2019, 3410348. [Google Scholar] [CrossRef]
- Bilgin, M.; Mutludogan, K. American Sign Language Character Recognition with Capsule Networks. In Proceedings of the 2019 3rd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 11–13 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Lum, K.Y.; Goh, Y.H.; Lee, Y.B. American Sign Language Recognition Based on MobileNetV2. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 481–488. [Google Scholar] [CrossRef]
- Rathi, D. Optimization of Transfer Learning for Sign Language Recognition Targeting Mobile Platform. arXiv 2018, arXiv:1805.06618. [Google Scholar] [CrossRef]
- Bantupalli, K.; Xie, Y. American Sign Language Recognition Using Machine Learning and Computer Vision. Master’s Thesis, Kennesaw State University, Kennesaw, GA, USA, 2019. Available online: https://digitalcommons.kennesaw.edu/cs_etd/21 (accessed on 22 October 2021).
- Elhagry, A.; Elrayes, R.G. Egyptian Sign Language Recognition Using CNN and LSTM. arXiv 2021, arXiv:2107.13647. [Google Scholar] [CrossRef]
- Li, D.; Opazo, C.R.; Yu, X.; Li, H. Word-level Deep Sign Language Recognition from Video: A New Large-scale Dataset and Methods Comparison. arXiv 2020, arXiv:1910.11006. [Google Scholar] [CrossRef]
- Güler, R.A.; Neverova, N.; Kokkinos, I. DensePose: Dense Human Pose Estimation In The Wild. arXiv 2018, arXiv:1802.00434. [Google Scholar] [CrossRef]
- Zhang, F.; Bazarevsky, V.; Vakunov, A.; Tkachenka, A.; Sung, G.; Chang, C.-L.; Grundmann, M. MediaPipe Hands: On-device Real-time Hand Tracking. arXiv 2020, arXiv:2006.10214. [Google Scholar] [CrossRef]
- Jimenez, J.; Martin, A.; Uc, V.; Espinosa, A. Mexican Sign Language Alphanumerical Gestures Recognition using 3D Haar-like Features. IEEE Lat. Am. Trans. 2017, 15, 2000–2005. [Google Scholar] [CrossRef]
- Rios-Figueroa, H.V.; Sánchez-García, A.J.; Sosa-Jiménez, C.O.; Solís-González-Cosío, A.L. Use of Spherical and Cartesian Features for Learning and Recognition of the Static Mexican Sign Language Alphabet. Mathematics 2022, 10, 2904. [Google Scholar] [CrossRef]
- Sosa-Jiménez, C.O.; Rios-Figueroa, H.V.; Solís-González-Cosio, A.L. A Prototype for Mexican Sign Language Recognition and Synthesis in Support of a Primary Care Physician. IEEE Access 2022, 10, 127620–127635. [Google Scholar] [CrossRef]
- Mejía-Peréz, K.; Córdova-Esparza, D.-M.; Terven, J.; Herrera-Navarro, A.-M.; García-Ramírez, T.; Ramírez-Pedraza, A. Automatic Recognition of Mexican Sign Language Using a Depth Camera and Recurrent Neural Networks. Appl. Sci. 2022, 12, 5523. [Google Scholar] [CrossRef]
- Sánchez-Vicinaiz, T.J.; Camacho-Pérez, E.; Castillo-Atoche, A.A.; Cruz-Fernandez, M.; García-Martínez, J.R.; Rodríguez-Reséndiz, J. MediaPipe Frame and Convolutional Neural Networks-Based Fingerspelling Detection in Mexican Sign Language. Technologies 2024, 12, 124. [Google Scholar] [CrossRef]
- Koishybay, K.; Mukushev, M.; Sandygulova, A. Continuous Sign Language Recognition with Iterative Spatiotemporal Fine-tuning. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 10211–10218. [Google Scholar] [CrossRef]
- Geng, J.; Huang, D.; De la Torre, F. DensePose From WiFi. arXiv 2023, arXiv:2301.00250. [Google Scholar] [CrossRef]
- Solís, F.; Toxqui, C.; Martínez, D. Mexican Sign Language Recognition Using Jacobi-Fourier Moments. Engineering 2015, 7, 700–705. [Google Scholar] [CrossRef]
- Solís, F.; Martínez, D.; Espinoza, O. Automatic Mexican Sign Language Recognition Using Normalized Moments and Artificial Neural Networks. Engineering 2016, 08, 733–740. [Google Scholar] [CrossRef]
- Shin, J.; Matsuoka, A.; Hasan Md, A.M.; Srizon, A.Y. American Sign Language Alphabet Recognition by Extracting Feature from Hand Pose Estimation. Sensors 2021, 21, 5856. [Google Scholar] [CrossRef] [PubMed]
- Indriani Harris, M.; Agoes, A.S. Applying Hand Gesture Recognition for User Guide Application Using MediaPipe. In Proceedings of the 2nd International Seminar of Science and Applied Technology (ISSAT 2021), Bandung, Indonesia, 12 October 2021. [Google Scholar] [CrossRef]
- Halder, A.; Tayade, A. Real-time Vernacular Sign Language Recognition using MediaPipe and Machine Learning. Int. J. Res. Publ. Rev. 2021, 2, 9–17. [Google Scholar]
- Espejel-Cabrera, J.; Cervantes, J.; García-Lamont, F.; Ruiz Castilla, J.S.; D Jalili, L. Mexican sign language segmentation using color based neuronal networks to detect the individual skin color. Expert Syst. Appl. 2021, 183, 115295. [Google Scholar] [CrossRef]
- Sundar, B.; Bagyammal, T. American Sign Language Recognition for Alphabets Using MediaPipe and LSTM. Procedia Comput. Sci. 2022, 215, 642–651. [Google Scholar] [CrossRef]
- Chen, R.-C.; Manongga, W.E.; Dewi, C. Recursive Feature Elimination for Improving Learning Points on Hand-Sign Recognition. Future Internet 2022, 14, 352. [Google Scholar] [CrossRef]
- Samaan, G.H.; Wadie, A.R.; Attia, A.K.; Asaad, A.M.; Kamel, A.E.; Slim, S.O.; Abdallah, M.S.; Cho, Y.-I. MediaPipe’s Landmarks with RNN for Dynamic Sign Language Recognition. Electronics 2022, 11, 3228. [Google Scholar] [CrossRef]
- Subramanian, B.; Olimov, B.; Naik, S.M.; Kim, S.; Park, K.-H.; Kim, J. An integrated mediapipe-optimized GRU model for Indian sign language recognition. Sci. Rep. 2022, 12, 11964. [Google Scholar] [CrossRef]
- Rodriguez, M.; Outmane, O.; Bassam, A.; Noureddine, L. Mexican Sign Language’s Dactylology and Ten First Numbers—Raw Videos. From Person #1 to #3 [Data Set]. Mendeley. V1. 2023. Available online: https://data.mendeley.com/datasets/48xybsmvpv/1 (accessed on 30 May 2023). [CrossRef]
- Rodriguez, M.; Outmane, O.; Bassam, A.; Noureddine, L. Mexican Sign Language’s Dactylology and Ten First Numbers—Raw Videos. From Person #4 to #7 [Data Set]. Mendeley. V1. 2023. Available online: https://data.mendeley.com/datasets/jp4ymf2vjw/1 (accessed on 30 May 2023). [CrossRef]
- Rodriguez, M.; Outmane, O.; Bassam, A.; Noureddine, L. Mexican Sign Language’s Dactylology and Ten First Numbers—Raw Videos. From Person #8 to #10 [Data Set]. Mendeley. V1. 2023. Available online: https://data.mendeley.com/datasets/69fmdb25xm/1 (accessed on 1 June 2023). [CrossRef]
- Rodriguez, M.; Outmane, O.; Bassam, A.; Noureddine, L. Mexican Sign Language’s Dactylology and Ten First Numbers—Raw Videos. Person #11 [Data Set]. Mendeley. V1. 2023. Available online: https://data.mendeley.com/datasets/3dzn5rstwx/1 (accessed on 1 June 2023). [CrossRef]
- Rodriguez, M.; Outmane, O.; Bassam, A.; Noureddine, L. Mexican Sign Language’s Dactylology and Ten First Numbers—Labeled Images and Videos. From Person #1 to #5 [Data Set]. Mendeley. V1. 2023. Available online: https://data.mendeley.com/datasets/5s4mt7xrd9/1 (accessed on 30 May 2023). [CrossRef]
- Rodriguez, M.; Outmane, O.; Bassam, A.; Noureddine, L. Mexican Sign Language’s Dactylology and Ten First Numbers—Labeled Images and Videos. From Person #6 to #11 [Data Set]. Mendeley. V1. 2023. Available online: https://data.mendeley.com/datasets/67htnzmwbb/1 (accessed on 30 May 2023). [CrossRef]
- Rodriguez, M.; Outmane, O.; Bassam, A.; Noureddine, L. Mexican Sign Language’s Dactylology and Ten First Numbers—Extracted Features and Models [Data Set]. Mendeley. V1. 2023. Available online: https://data.mendeley.com/datasets/hmsc33hmkz/1 (accessed on 30 May 2023). [CrossRef]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar] [CrossRef]
- Rodriguez, M.; Outmane, O.; Bassam, A.; Noureddine, L. TrainingAndExtractionForMSLRecognition. Github. 2023. Available online: https://github.com/EmmanuelRTM/TrainingAndExtractionForMSLRecognition (accessed on 13 July 2023).
- Renotte, N. ActionDetectionforSignLanguage. GitHub. 2020. Available online: https://github.com/nicknochnack/ActionDetectionforSignLanguage (accessed on 11 May 2022).
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, 2nd ed.; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2019; pp. 335–338. [Google Scholar]
- TheAIGuysCode. Colab-webcam. GitHub. 2020. Available online: https://github.com/theAIGuysCode/colab-webcam (accessed on 5 December 2022).
- Google. Hand Landmarks Detection Guide. 2024. Available online: https://ai.google.dev/edge/mediapipe/solutions/vision/hand_landmarker (accessed on 26 December 2024).
- Camgoz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation. arXiv 2020, arXiv:2003.13830. [Google Scholar] [CrossRef]
- Min, Y.; Hao, A.; Chai, X.; Chen, X. Visual Alignment Constraint for Continuous Sign Language Recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 11522–11531. [Google Scholar] [CrossRef]



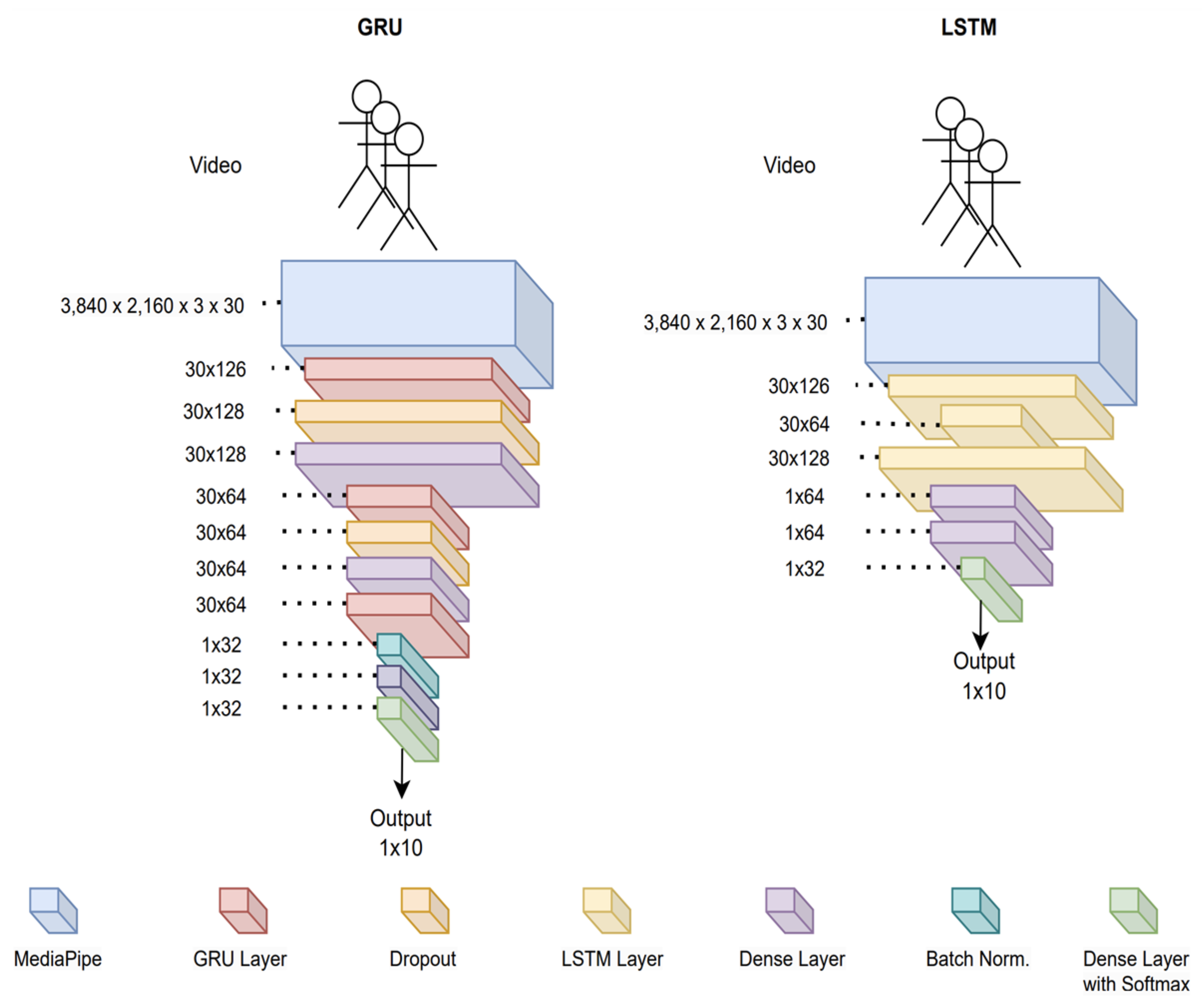


| Model | Sign | Authors |
|---|---|---|
| VGG16 | Static | Mujahid et al., 2021 [14] |
| YOLOv3 and Darknet53 | Static | Mujahid et al., 2021 [14] |
| Single Shot Detector (SSD) | Static | Liu et al., 2019 [15]; Mujahid et al., 2021 [14] |
| Capsule Networks | Static | Bilgin and Mutludogan, 2019 [16] |
| MobileNetV2 | Static | Lum et al., 2020 [17]; Rathi, 2018 [18] |
| Inception v4 + LSTM | Continuous | Bantupalli and Xie, 2019 [19] |
| Inception v3 + LSTM | Continuous | Elhagry and Elrayes, 2021 [20] |
| 3D CNN | Continuous | Li et al., 2020 [21] |
| VGG16 + GRU | Continuous | Li et al., 2020 [21] |
| Model | Grid Search Parameter | Parameters | Best Parameter |
|---|---|---|---|
| SVM | C | 0.1, 1, 10, 100, 800, 1000, 1200 | 1200 |
| Gamma | 1, 0.1, 0.01, 0.001, 0.0001 | 0.1 | |
| Kernel | rbf, linear, poly, sigmoid | poly | |
| Cross Validation | 5 | 5 | |
| GBL | Loss | Categorical Cross-entropy | Categorical Cross-entropy |
| Learning Rate | 0.09, 0.1, 0.11, 0.125, 0.15 | 0.11 | |
| Max Iter | 100, 150, 200, 250, 300, 350 | 250 | |
| Cross Validation | 3 | 3 |
| Model | Type of Sign | # of Classes | Phase | Accuracy | Precision (Macro) | Recall (Macro) | F1 Score (Macro) |
|---|---|---|---|---|---|---|---|
| GBL | Static | 29 | Testing | 77.04% | 76.85% | 76.82% | 76.19% |
| SVM † | 94.07% | 93.73% | 94.25% | 93.56% | |||
| LSTM | Continuous | 10 | 79.59% | 80.31% | 80.93% | 80.28% | |
| GRU ‡ | 84.69% | 86.01% | 86.00% | 85.57% | |||
| GBL | Static | 29 | Validation | 77.04% | 77.28% | 76.83% | 76.15% |
| SVM † | 91.48% | 90.93% | 89.96% | 89.90% | |||
| LSTM | Continuous | 10 | 76.77% | 75.87% | 77.46% | 76.00% | |
| GRU ‡ | 81.82% | 82.50% | 82.19% | 81.47% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodriguez, M.; Oubram, O.; Bassam, A.; Lakouari, N.; Tariq, R. Mexican Sign Language Recognition: Dataset Creation and Performance Evaluation Using MediaPipe and Machine Learning Techniques. Electronics 2025, 14, 1423. https://doi.org/10.3390/electronics14071423
Rodriguez M, Oubram O, Bassam A, Lakouari N, Tariq R. Mexican Sign Language Recognition: Dataset Creation and Performance Evaluation Using MediaPipe and Machine Learning Techniques. Electronics. 2025; 14(7):1423. https://doi.org/10.3390/electronics14071423
Chicago/Turabian StyleRodriguez, Mario, Outmane Oubram, A. Bassam, Noureddine Lakouari, and Rasikh Tariq. 2025. "Mexican Sign Language Recognition: Dataset Creation and Performance Evaluation Using MediaPipe and Machine Learning Techniques" Electronics 14, no. 7: 1423. https://doi.org/10.3390/electronics14071423
APA StyleRodriguez, M., Oubram, O., Bassam, A., Lakouari, N., & Tariq, R. (2025). Mexican Sign Language Recognition: Dataset Creation and Performance Evaluation Using MediaPipe and Machine Learning Techniques. Electronics, 14(7), 1423. https://doi.org/10.3390/electronics14071423