



Statistically Informed Multimodal (Domain Adaptation by Transfer) Learning Framework: A Domain Adaptation Use-Case for Industrial Human–Robot Communication


Abstract
1. Introduction
2. Background and Related Works
3. Methodology
3.1. Contributions
- SIMLea leverages publicly available, large datasets of multimodal data and high-accuracy models trained on them to provide feedback-driven labelling of shifted data. This feature leverages real user feedback to auto-label user data during operation, mimicking a key component of natural human communication, wherein feedback is used to continuously update the knowledge associated with the shared task and its status. This would reduce mislabelling. This allows the extension of the model’s learnt feature representations with those of new, covariate domain-shifted data and personalization of the model to the collaborating human, making communication more natural for the human.
- SIMLea is designed to allow feedback to be used from incommensurate modes of communication.
- Statistical measure of similarity is used to drive the adaptation framework to learn only relevant data and start and stop the computationally heavy learning process when required. Implementation of this aspect is presented in Section 5.2.
- SIMLea allows the amalgamation of empirical thresholds and standards and application-specific heuristics. It is an add-on to the ML model and does not require change in its architecture.
3.2. Assumptions of SIMLea
- As mentioned previously, the system only encounters covariate-shifted data. This means that all commands from the human are “correct” in the lexical sense and will fall into one of the pre-trained classes.
- The deployed base model (model trained on standard, publicly available dataset) is well-trained on the standard dataset, i.e., it performs well on the test set of that dataset. This assumption is extrapolated to the iteratively generated models as well since the shifted data are from the same application and are similar to the original data, ipso facto, the training parameters could be re-used for TL without change. By well-trained, one refers to the models possessing the required trade-off between bias and variance, determined based on tribal knowledge of the application.
- The ML classifier that understands (recognizes) feedback from the human has high variance and high accuracy.
3.3. Metric for an Informed Approach to Domain Adaptation
3.4. Covariate Domain Shift as a Measure of Similarity
3.5. Factor for Cessation of Domain Adaptation
3.6. Criterion for Feasibility of Transfer Learning
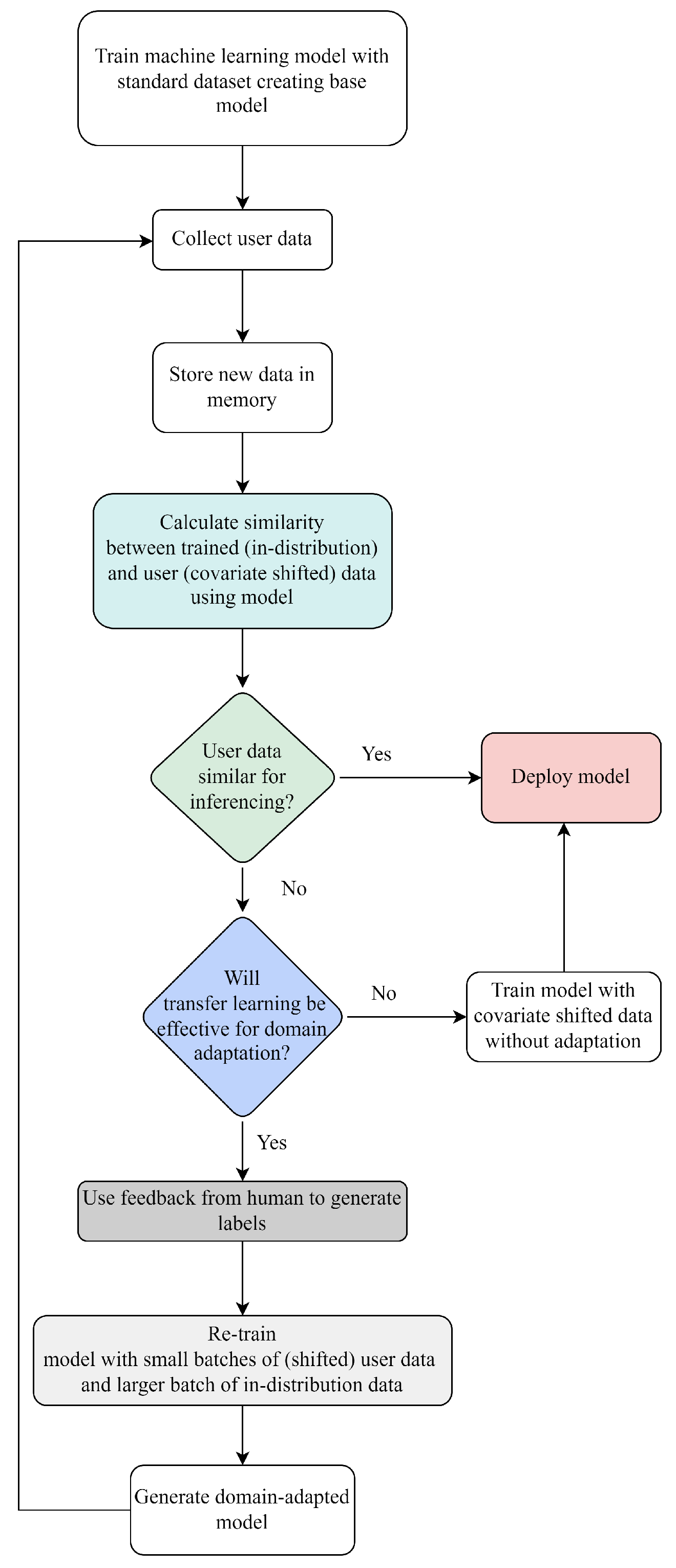
3.7. SIMLea Framework
- Train an ML model with a standard, publicly-available dataset such that it performs well on ID or source data: base model (model0).
- Collect the new user data and store in memory. These data are unlabelled since they are generated in real-time by the user interacting with the robot. Calculate the similarity score (S) between the trained (in-distribution) data and the incoming user (covariate-shifted) data.
- If the similarity score is higher than a pre-set threshold (that is application and model specific), then the model can be effectively deployed and used for inferencing with the new data. If, on the other hand, the data are dissimilar, then transfer learning may be used if deemed feasible.
- The next step is a checkpoint to test if transfer learning would be effective for domain adaptation. The similarity score obtained in step 2 is used again. If the covariate-shifted dataset is similar to the in-distribution data, then iterative re-training can be used. If the datasets are very dissimilar, then instead of transfer learning the model should be trained from scratch and the new model deployed. Such a case may indicate a significant shift in the domain data, and either the new data needs to be rejected or the model needs to be changed.
- In the case of re-training, endeavouring to keep dataset size low, a small number of empirically determined instances per class of the covariate-shifted data are then auto-labelled by the robot asking for multimodal (in this case, verbal) feedback from the user, as per the work in [16].
- The model is iteratively re-trained with the new batch of covariate-shifted user images mixed with a larger batch of the source dataset or in-distribution data, as per the work in [16].
- Once the new model is generated, the representation space of this model is used to gauge the similarity of the two datasets, and the loop is re-traced. This ensures that a minimal amount of user data is required for effective learning of the model and is auto-labelled on a need-only basis.
- Case 1: either learnt the features of the target dataset well.
- Case 2: or it can no longer benefit from transfer learning because the datasets are too dissimilar.
4. Validation of SIMLea with Hand Gesture Recognition Data
4.1. Variance in HG Datasets
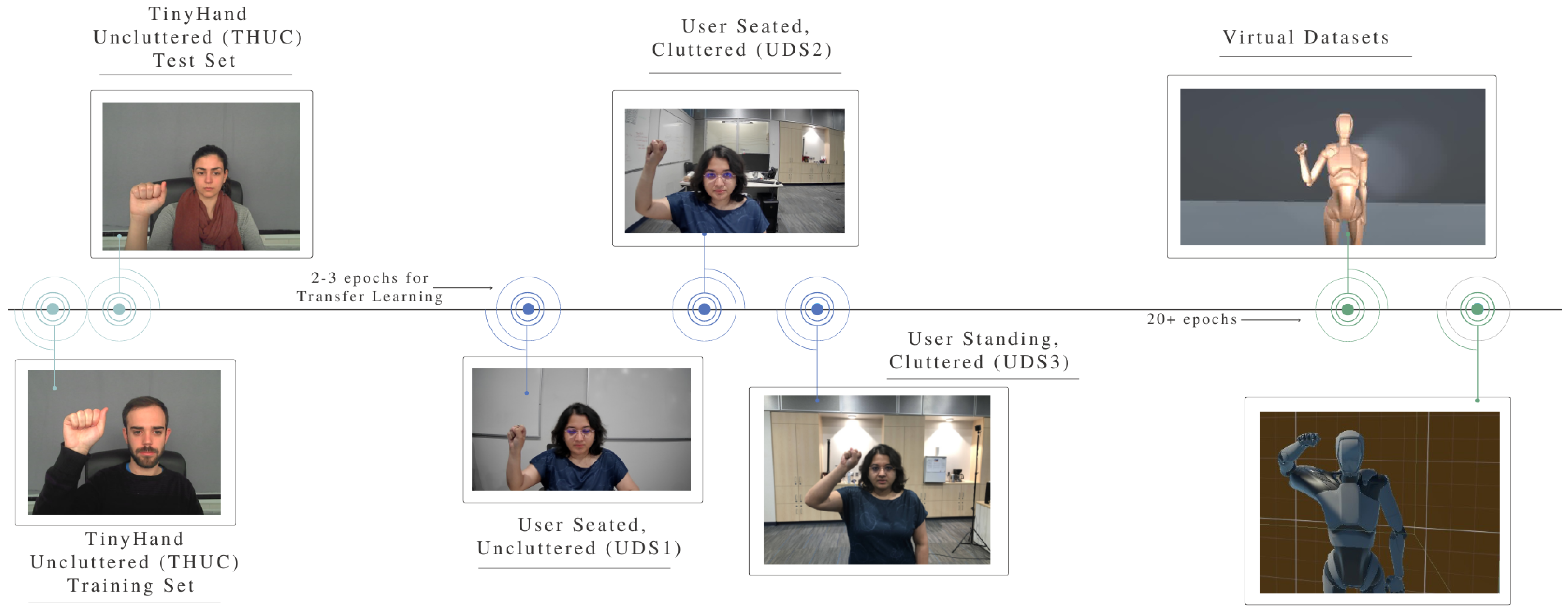
4.2. Covariate Domain Shifts in User Data
- model0 or base model is trained using standard dataset THUC in all tests, except in Section 5.3, where both THUC and THC are used.
- Iterative re-training of model0 on user-labelled data mixed with a portion of standard data generates modeln, where n refers to the number of iterations.
Shift Analysis with THUC Test Set as Source
- is the input data, where n is the sample size. A similar formulation can be done for a second dataset:
- generating , with m denoting the new sample size.
- Mean and standard deviations of the activations of each filter are obtained for all images in the dataset. These statistics will represent the central tendency and spread of the activations for each filter. Then, a normal distribution is fitted over the values using the mean and standard deviation values. These images are passed through the model unlabelled, and the outputs are obtained through the inference operation of model0. This is done for the source dataset (THUC) and the target datasets (UDS1, 2, and 3, and VDS).
- KL divergence is calculated between pairs of source and target datasets for each filter of a layer.
- The mean of KL divergence values over all filters per layer is obtained, thereby generating one value per source-target pair per layer.
5. Results
5.1. Application of SIMLea to User Datasets
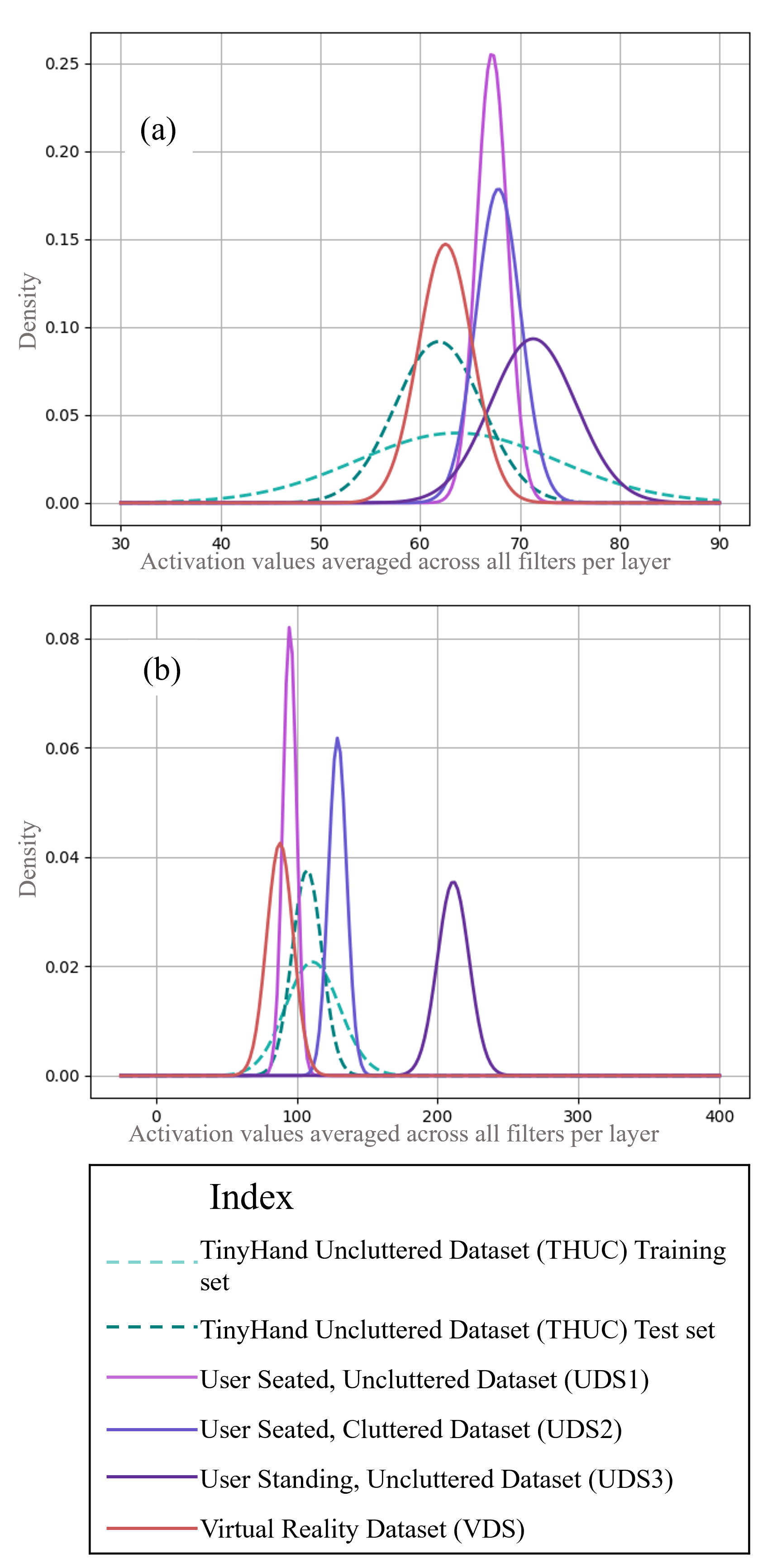
5.2. Application of SIMLea to Virtual Reality Datasets
5.3. Application of SIMLea to a Simulated Long-Serving Model
- There is a distribution shift between the training sets of the model itself, i.e., between THUC and THC (indicated by R shift values of 46.29, 30.18, 11.02 of layers 1–3, respectively). The shift is the smallest among the pairs due to the model being trained on both data, although in terms of visible similarity, THUC and UDS1 would be the most similar. Apart from that, the image sizes of the two training dataset were also different (THUC: 640 × 480 pixels, THC 1920 × 10,180 pixels), indicating a change in sensors capturing the data.
- The covariate shift R values for UDS1_R, indicating right-handed gestures are lesser than UDS1_L, indicating left-handed ones for layers 1 and 2 (134.27 versus 201.43 for layer 1, 53.63 vs. 68.53 for layer 2 for right-handed and left-handed, respectively). This is logical since the original training set contains only right-handed gestures and thus may be biased toward them.
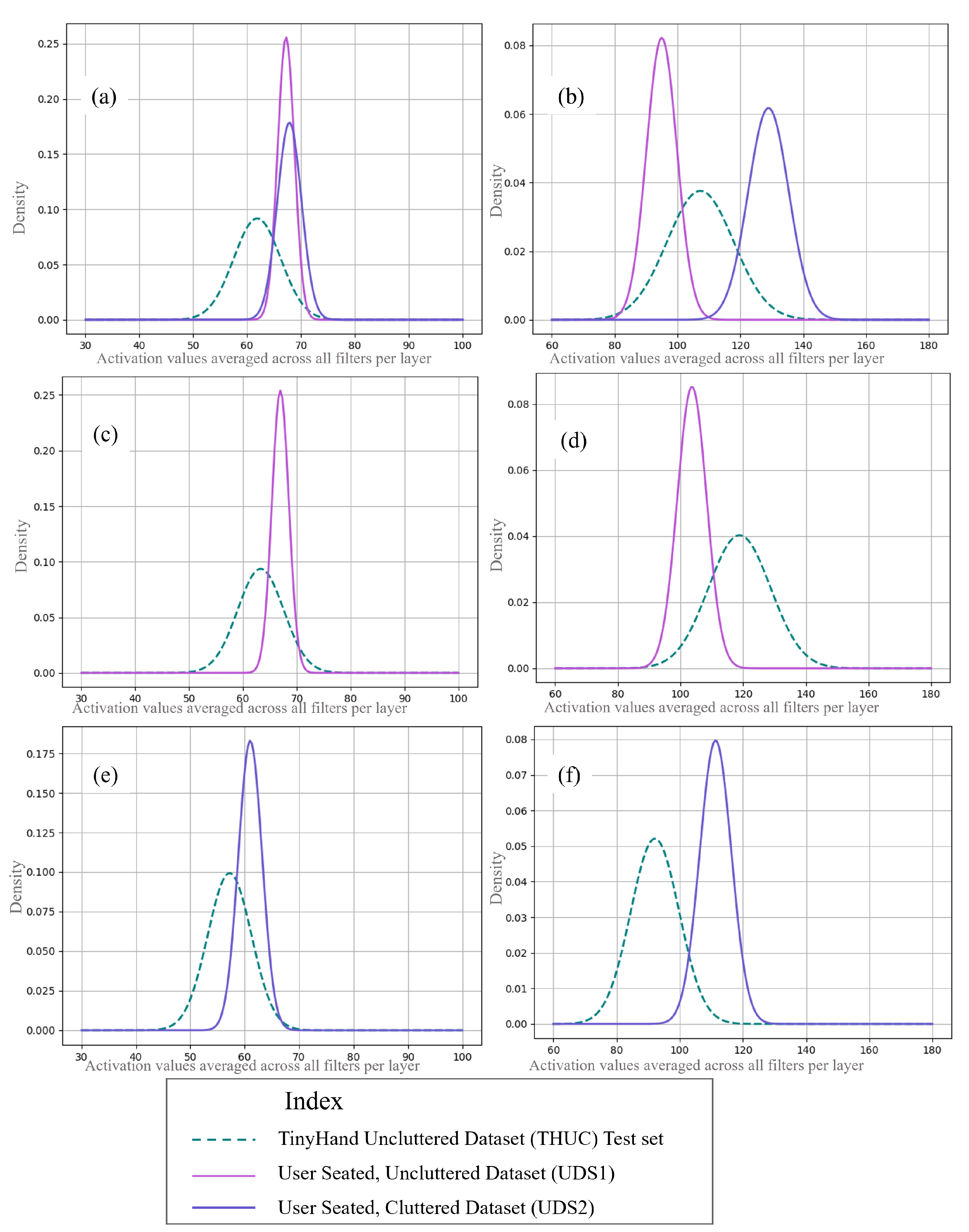
- UDS1 is more similar to the training sets of THUC than UDS2 or UDS3, and the level of similarity decreases in that order. This behaviour is attributed to the similar, uncluttered, clean backgrounds of THUC and UDS1. This is inferred from the shift values: for layer 1: UDS1_R is 134.27, for UDS2 329.49, and for UDS3 610.39, and this trend also holds for layer 2.
- THC with the cluttered backgrounds and standing humans are interpreted to be more similar to UDS3 followed by UDS2 and finally UDS1, which shows a large domain shift. This trend is also followed by the deeper layers. This is expected since UDS3 contains the user standing in front of a cluttered background and gesturing and is thus structurally most similar to THC. Shift values of 62.79, 178.75, 1897.07 for layer 1 for UDS3, UDS2, and UDS1_R, respectively, indicate this for example.
- VDS is the least similar to THC or THUC and reflects results from the previous studies. Shift values for VDS are the largest in both tables for all three layers as compared to other datasets.
- Accuracy scores for the user datasets are higher than in the previous study. This is also expected since the model contains higher variance. With that said, the metric is still able to detect a shift in distribution of incoming data. UDS2 and 3 may be used for DA, while UDS1 could be allowed to be classified with the current model. For DA, a mix of THUC, THC, and UDS1 can be used as the “old” data and the data from UDS2 or UDS3, respectively, as the “new” data.
5.4. Examination of Batch Size for Shift Calculation
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Alternate Shift Analysis with THUC Training Set as Source

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tested On | THUC | UDS1 | UDS2 | UDS3 | VDS |
|---|---|---|---|---|---|
| Accuracy | 0.96 | 0.58 | 0.48 | 0.16 | 0.09 |
| R, Layer 1 | 146.08 | 417.86 | 3863.28 | 4689.43 | 8211.66 |
| R, Layer 2 | 183.72 | 241.45 | 3037.89 | 8296.30 | 4,701,616.77 |
| R, Layer 3 | 1.63 | 45.87 | 93.03 | 72.51 | 409.55 |
| R, Layer 4 | 3.98 | 10.94 | 10.65 | 25.16 | 12.11 |
| R, Layer 5 | 0.18 | 1.72 | 3.29 | 4.94 | 5.83 |
References
- Ullah, I.; Adhikari, D.; Khan, H.; Anwar, M.S.; Ahmad, S.; Bai, X. Mobile robot localization: Current challenges and future prospective. Comput. Sci. Rev. 2024, 53, 100651. [Google Scholar] [CrossRef]
- Mukherjee, D.; Gupta, K.; Chang, L.H.; Najjaran, H. A Survey of Robot Learning Strategies for Human-Robot Collaboration in Industrial Settings. Robot. Comput. Integr. Manuf. 2022, 73, 102231. [Google Scholar] [CrossRef]
- Mukherjee, D. Statistically-Informed Multimodal Domain Adaptation in Industrial hUman-Robot Collaboration Environments. Ph.D. Thesis, University of British Columbia, Vancouver, BC, Canada, 2023. [Google Scholar] [CrossRef]
- Mukherjee, D.; Gupta, K.; Najjaran, H. A Critical Analysis of Industrial Human-Robot Communication and Its Quest for Naturalness Through the Lens of Complexity Theory. Front. Robot. AI 2022, 9, 477. [Google Scholar] [CrossRef] [PubMed]
- Drummond, N.; Shearer, R. The Open World Assumption; Technical report; University of Manchester: Manchester, UK, 2006. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Motiian, S.; Piccirilli, M.; Adjeroh, D.A.; Doretto, G. Unified Deep Supervised Domain Adaptation and Generalization. arXiv 2017, arXiv:1709.10190. [Google Scholar] [CrossRef]
- Kothandaraman, D.; Nambiar, A.; Mittal, A. Domain Adaptive Knowledge Distillation for Driving Scene Semantic Segmentation. arXiv 2020, arXiv:2011.08007. [Google Scholar] [CrossRef]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Unsupervised Domain Adaptation with Residual Transfer Networks. arXiv 2016, arXiv:1602.04433. [Google Scholar] [CrossRef]
- Chen, M.; Weinberger, K.Q.; Blitzer, J. Co-training for domain adaptation. Adv. Neural Inf. Process. Syst. 2011, 24. Available online: https://papers.nips.cc/paper_files/paper/2011/hash/93fb9d4b16aa750c7475b6d601c35c2c-Abstract.html (accessed on 1 March 2025).
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Schwaiger, A.; Sinhamahapatra, P.; Gansloser, J.; Roscher, K. Is uncertainty quantification in deep learning sufficient for out-of-distribution detection? AISafety@ IJCAI 2020, 54, 1–8. [Google Scholar]
- Hendrycks, D.; Gimpel, K. A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks. arXiv 2016, arXiv:1610.02136. [Google Scholar] [CrossRef]
- Chi, S.; Tian, Y.; Wang, F.; Zhou, T.; Jin, S.; Li, J. A novel lifelong machine learning-based method to eliminate calibration drift in clinical prediction models. Artif. Intell. Med. 2022, 125, 102256. [Google Scholar] [CrossRef]
- Mukherjee, D.; Hong, J.; Vats, H.; Bae, S.; Najjaran, H. Personalization of industrial human—Robot communication through domain adaptation based on user feedback. User Model. User Adapt. Interact. 2024, 34, 1327–1367. [Google Scholar] [CrossRef]
- Sotirios Panagou, W.P.N.; Fruggiero, F. A scoping review of human robot interaction research towards Industry 5.0 human-centric workplaces. Int. J. Prod. Res. 2024, 62, 974–990. [Google Scholar] [CrossRef]
- Mukherjee, D.; Gupta, K.; Najjaran, H. An AI-powered Hierarchical Communication Framework for Robust Human-Robot Collaboration in Industrial Settings. In Proceedings of the 2022 31st IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Naples, Italy, 29 August–2 September 2022; pp. 1321–1326. [Google Scholar]
- Stacke, K.; Eilertsen, G.; Unger, J.; Lundström, C. Measuring Domain Shift for Deep Learning in Histopathology. IEEE J. Biomed. Health Inform. 2021, 25, 325–336. [Google Scholar] [CrossRef]
- Stacke, K.; Eilertsen, G.; Unger, J.; Lundström, C. A Closer Look at Domain Shift for Deep Learning in Histopathology. arXiv 2019, arXiv:1909.11575. [Google Scholar] [CrossRef]
- Nisar, Z.; Vasiljevic, J.; Gancarski, P.; Lampert, T. Towards Measuring Domain Shift in Histopathological Stain Translation in an Unsupervised Manner. In Proceedings of the 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI), Kolkata, India, 28–31 March 2022. [Google Scholar] [CrossRef]
- Ketykó, I.; Kovács, F. On the Metrics and Adaptation Methods for Domain Divergences of sEMG-based Gesture Recognition. arXiv 2019, arXiv:1912.08914. [Google Scholar] [CrossRef]
- Vangipuram, S.K.; Appusamy, R. A Survey on Similarity Measures and Machine Learning Algorithms for Classification and Prediction. In Proceedings of the International Conference on Data Science, E-Learning and Information Systems 2021, New York, NY, USA, 5–7 April 2021; pp. 198–204. [Google Scholar] [CrossRef]
- Li, X.; Yang, X.; Ma, Z.; Xue, J.H. Deep metric learning for few-shot image classification: A Review of recent developments. Pattern Recognit. 2023, 138, 109381. [Google Scholar] [CrossRef]
- Chechik, G.; Sharma, V.; Shalit, U.; Bengio, S. Large scale online learning of image similarity through ranking. J. Mach. Learn. Res. 2010, 11, 1–27. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Pereira, F. Analysis of representations for domain adaptation. Adv. Neural Inf. Process. Syst. 2006, 19. Available online: https://dl.acm.org/doi/10.5555/2976456.2976474 (accessed on 18 March 2025).
- Harmouch, M. 17 Types of Similarity and Dissimilarity Measures Used in Data Science. 2021. Available online: https://towardsdatascience.com/17-types-of-similarity-and-dissimilarity-measures-used-in-data-science-3eb914d2681/ (accessed on 1 March 2025).
- Jiang, L.; Guo, Z.; Wu, W.; Liu, Z.; Liu, Z.; Loy, C.C.; Yang, S.; Xiong, Y.; Xia, W.; Chen, B.; et al. DeeperForensics Challenge 2020 on Real-World Face Forgery Detection: Methods and Results. arXiv 2021, arXiv:2102.09471. [Google Scholar] [CrossRef]
- Perera, P.; Nallapati, R.; Xiang, B. OCGAN: One-class Novelty Detection Using GANs with Constrained Latent Representations. arXiv 2019, arXiv:1903.08550. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Yu, P.S. Outlier detection for high dimensional data. In Proceedings of the 2001 ACM SIGMOD International Conference on Management of Data, Santa Barbara, CA, USA, 21–24 May 2001; pp. 37–46. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Bao, P.; Maqueda, A.I.; del Blanco, C.R.; García, N. Tiny hand gesture recognition without localization via a deep convolutional network. IEEE Trans. Consum. Electron. 2017, 63, 251–257. [Google Scholar] [CrossRef]
- Warden, P. Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar] [CrossRef]
- Mukherjee, D.; Singhai, R.; Najjaran, H. Systematic Adaptation of Communication-focused Machine Learning Models from Real to Virtual Environments for Human-Robot Collaboration. arXiv 2023, arXiv:2307.11327. [Google Scholar]


| Domain Adaptation Technique | Methodology | Assumption |
|---|---|---|
| Unsupervised Domain Adaptation (UDA) [9] | Based on paired RGB images in both source as well as target domains | Assumes existence of paired data in same format in both source and target domains |
| Residual Transfer Network [10] | Based on simultaneously learning adaptive classifiers and transferrable features | Assumes that the source and target classifiers only differ by a small residual function |
| Co-Training for Domain Adaptation [11,12] | Based on slowly adapting the training set from the source to the target domain by inclusion of target instances with the highest confidence scores | Assumes the existence of two separate views of a single object and two trained classifiers respectively |
| Personalization through feedback-enabled human–robot communication (PF-HRCom) [16] | Based on iterative transfer learning and feedback generated labels, verification of learning conducted in a supervised manner using labelled test data Can be used for incommensurables modes | Assumes existence of labelled test data and trained model for generating feedback |
| Proposed work: Statistically Informed Multimodal (Domain Adaptation by Transfer) Learning (SIMLea) | Based on iterative transfer learning, feedback enabled labelling of unlabelled data, statistical similarity measure to start and stop learning process | Assumes trained model for generating feedback |
| Tested On | THUC | UDS1 | UDS2 | UDS3 | VDS |
|---|---|---|---|---|---|
| Accuracy | 0.96 | 0.58 | 0.48 | 0.16 | 0.09 |
| R, Layer 1 | 0.87 | 125.04 | 529.88 | 407.37 | 662.69 |
| R, Layer 2 | 0.77 | 87.26 | 486.05 | 943.40 | 10,571.15 |
| R, Layer 3 | 0.38 | 33.86 | 70.78 | 67.34 | 116.28 |
| R, Layer 4 | 0.18 | 8.58 | 9.78 | 26.56 | 6.26 |
| R, Layer 5 | 0.12 | 2.08 | 5.08 | 6.54 | 6.12 |
| Subsection | Datasets Used | Aim |
|---|---|---|
| 5.1. Application of SIMLea to User Datasets | TinyHand Uncluttered Dataset (THUC), User Seated, Uncluttered (UDS1), User Seated, Cluttered (UDS2), User Standing, Cluttered (UDS3) | Application of SIMLea and tracking of covariate shifts and accuracy of models generated through iterative training |
| 5.2. Application of SIMLea to Virtual Reality Dataset | TinyHand Uncluttered Dataset (THUC), Virtual Dataset (VDS) | Application of SIMLea and tracking of covariate shifts and accuracy of models generated through iterative training Qualitative representation of covariate domain shifts encountered in hand gesture classification showing the relative shifts and corresponding similarity in the standard and used shifted datasets |
| 5.3. Application of SIMLea to a simulated Long- Serving Model | TinyHand Uncluttered Dataset (THUC), TinyHand Cluttered Dataset (THC), User Seated, Uncluttered (UDS1), User Seated, Cluttered (UDS2), User Standing, Cluttered (UDS3) Virtual Dataset (VDS) | Study of application of SIMLea to a continuously adaption scenario of a model deployed for a simulated long time usage |
| 5.4. Examination of Batch Size for Shift Calculation | TinyHand Uncluttered Dataset (THUC), TinyHand Cluttered Dataset (THC), Uncluttered Datasets with Left-Handed Gestures (UDS1_L) | Study of application of SIMLea on large and small sized covariate shifted datasets |
| Tested On | New Accuracy | New R on MaxPool Layer | ||||
|---|---|---|---|---|---|---|
| Layer1 | Layer2 | Layer3 | Layer4 | Layer5 | ||
| UDS1 | 0.73 | 119.49 | 81.06 | 28.86 | 9.10 | 2.04 |
| Tested On | New Accuracy | New R on MaxPool Layer | ||||
|---|---|---|---|---|---|---|
| Layer1 | Layer2 | Layer3 | Layer4 | Layer5 | ||
| UDS2 | 0.59 | 393.80 | 171.09 | 53.07 | 16.99 | 5.58 |
| Tested On | THUC | UDS1_L | UDS1_R | UDS2 | UDS3 | VDS |
|---|---|---|---|---|---|---|
| Accuracy | 0.97 | 0.84 | 0.78 | 0.59 | 0.52 | 0.09 |
| R, Layer 1 | - | 201.43 | 134.27 | 329.49 | 610.39 | 39,025 |
| R, Layer 2 | - | 68.53 | 53.63 | 68.74 | 61.04 | 386.46 |
| R, Layer 3 | - | 27.13 | 32.46 | 53.34 | 10.73 | 15.58 |
| Tested On | THC | UDS1_L | UDS1_R | UDS2 | UDS3 | VDS |
|---|---|---|---|---|---|---|
| Accuracy | 0.72 | 0.84 | 0.78 | 0.59 | 0.52 | 0.09 |
| R, Layer 1 | 46.29 | 2207.42 | 1897.07 | 178.75 | 62.79 | 2439 |
| R, Layer 2 | 30.18 | 264.05 | 256.69 | 157.53 | 24.67 | 459.35 |
| R, Layer 3 | 11.02 | 47.40 | 62.81 | 36.60 | 11.75 | 79.57 |
| Tested On | UDS1_L (Large Set) | UDS1_L (Small Set) | UDS1_L (Large Set) | UDS1_L (Small Set) |
|---|---|---|---|---|
| Source | THUC | THUC | THC | THC |
| R, Layer1 | 190.88 | 201.43 | 2360.98 | 2207.42 |
| R, Layer2 | 53.60 | 68.53 | 223.89 | 264.05 |
| R, Layer3 | 23.44 | 27.13 | 45.48 | 47.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mukherjee, D.; Najjaran, H. Statistically Informed Multimodal (Domain Adaptation by Transfer) Learning Framework: A Domain Adaptation Use-Case for Industrial Human–Robot Communication. Electronics 2025, 14, 1419. https://doi.org/10.3390/electronics14071419
Mukherjee D, Najjaran H. Statistically Informed Multimodal (Domain Adaptation by Transfer) Learning Framework: A Domain Adaptation Use-Case for Industrial Human–Robot Communication. Electronics. 2025; 14(7):1419. https://doi.org/10.3390/electronics14071419
Chicago/Turabian StyleMukherjee, Debasmita, and Homayoun Najjaran. 2025. "Statistically Informed Multimodal (Domain Adaptation by Transfer) Learning Framework: A Domain Adaptation Use-Case for Industrial Human–Robot Communication" Electronics 14, no. 7: 1419. https://doi.org/10.3390/electronics14071419
APA StyleMukherjee, D., & Najjaran, H. (2025). Statistically Informed Multimodal (Domain Adaptation by Transfer) Learning Framework: A Domain Adaptation Use-Case for Industrial Human–Robot Communication. Electronics, 14(7), 1419. https://doi.org/10.3390/electronics14071419