Abstract
This study addresses the growing complexity of privacy protection in cloud computing environments (CCEs) by introducing a comprehensive socio-technical framework for self-adaptive privacy, complemented by an AI-driven beta tool designed for social media platforms. The framework’s three-stage structure—social, technical, and infrastructural—integrates context-aware privacy controls, dynamic risk assessments, and scalable implementation strategies. Key benefits include enhanced user-centric privacy management through customizable group settings and adaptive controls that respect diverse social identities. The beta tool operationalizes these features via a profile store for structured preference management and a recommendation engine that delivers real-time, AI-powered privacy suggestions tailored to individual contexts. Additionally, the tool’s safety scoring system (0–100) empowers developers and guides them in designing effective privacy solutions and mitigating risks. By bridging social context awareness with technical and infrastructural innovation, this framework significantly improves privacy adaptability, regulatory compliance, and user empowerment in CCEs. It provides a robust foundation for developing scalable and responsive privacy solutions tailored to evolving user needs.
1. Introduction
Protecting privacy in cloud computing environments (CCEs) has grown increasingly challenging as these systems evolve and expand in functionality. Since privacy is a socially constructed concept, its definition and implementation vary significantly across different social and technical settings, making it particularly complex within CCEs. The multidimensional nature of cloud services, whether developed in-house or by third-party providers, enhances multiple interactions and dependencies among social actors and service providers [1]. These interactions generate substantial information disclosure that fundamentally alters how users manage their personal information. For instance, CCEs in e-commerce or social media require extensive analysis of users’ personal and sensitive information (e.g., name and id characteristics) to provide their services effectively. The pervasive analysis of data in these environments can compromise user privacy through potential misuse or unauthorized data exposure, resulting in frequent privacy violations [2].
Self-adaptive privacy introduces a transformative approach to privacy protection in cloud environments, emphasizing dynamic, user-centered mechanisms that integrate both sociocultural and technological factors. Unlike traditional static privacy models, which rely on predefined and often rigid security measures, self-adaptive privacy systems incorporate flexible adaptation mechanisms that respond dynamically to evolving contexts and individual user needs. This adaptive nature allows for privacy frameworks to continuously adjust their protective measures, ensuring that users maintain greater control over their data while mitigating risks in real time [3].
To achieve this, self-adaptive privacy systems must fulfill several critical functions [4]. One fundamental aspect is privacy awareness, which involves the continuous monitoring and assessment of potential privacy risks. By actively identifying vulnerabilities and assessing security threats, these systems can offer real-time feedback on privacy conditions. Additionally, justification and privacy decision-making play a crucial role in ensuring that privacy-related choices are systematically evaluated. This process enhances transparency by allowing users to understand the rationale behind privacy configurations and the trade-offs associated with different levels of data exposure.
Another essential function of self-adaptive privacy systems is the provision of control capabilities, which empower users to configure privacy settings according to their individual preferences. By enabling customization, these systems accommodate diverse privacy expectations and allow users to maintain an active role in managing their personal information. Furthermore, context-aware monitoring ensures that privacy adaptations align with dynamic environmental changes, such as shifts in network security conditions, user behavior, or data sensitivity levels. This continuous adaptation enhances the effectiveness of privacy mechanisms by tailoring protections to situational demands rather than enforcing static, one-size-fits-all policies.
Through these functions, self-adaptive privacy establishes a more resilient and user-responsive approach to data protection in cloud computing. By integrating technological advancements with user-centric considerations, it fosters a more adaptive and transparent privacy landscape, ultimately enhancing trust and security in digital interactions.
Despite the development of various self-adaptive privacy approaches, current solutions remain limited by their piecemeal analysis of either users’ socio-contextual characteristics or technical privacy requirements [5]. The need to rethink privacy protection in CCEs, focusing on both users’ social norms and software engineering principles, has become increasingly urgent [6]. This necessity is further emphasized by the enforcement of regulations such as the General Data Protection Regulation (GDPR) in Europe, which has introduced significant changes to citizens’ privacy rights and new obligations for data controllers and processors (European Commission, 2022). The current literature lacks a structured framework that incorporates both social and technical privacy prerequisites for developing adequate self-adaptive privacy approaches within CCEs. Furthermore, it remains unclear which social and technical aspects of privacy should be explored and how they should be integrated effectively [7].
In this regard, our research work until now aims to address these gaps by (a) identifying key components necessary for effective self-adaptive privacy protection through a literature review [4], based mostly on social identity theory that provides a crucial framework for understanding how users manage their privacy in cloud environments, since our users’ research has shown that individuals’ privacy decisions are significantly influenced by their group memberships and social identities [8]; (b) understanding developers’ mindset for the challenges of self-adaptive privacy schemes and providing clear implementation guidelines [9]; and (c) developing a taxonomy that combines social, technical, and infrastructural privacy requirements [10], so as to demonstrate the feasibility of an integrated produced framework for self-adaptive privacy, which includes all the required social and technical privacy components for the optimal design of such schemes, as well as a Tool in Beta version in order to test if the framework can be exploited.
In this regard, the research tackles the increasingly challenging task of safeguarding privacy in CCEs through the development of an innovative dual solution, which includes a holistic socio-technical framework for self-adaptive privacy, structured across three distinct levels—social, technical, and infrastructural—combining adaptive privacy management, risk evaluation systems, and deployable implementation approaches, as well as its practical implementation as an AI-enhanced beta tool for social media. The solution offers significant advantages, particularly in its user-focused approach to privacy protection. Users can customize their privacy preferences according to different social groups while the system actively adapts to various social contexts. This comprehensive approach merges social awareness with technological advancement and infrastructure considerations, resulting in a more flexible, compliant, and user-empowering privacy framework for CCEs. It establishes a strong foundation for developing future privacy solutions that can evolve alongside user requirements while maintaining robust protection measures.
The rest of this paper is organized as follows: Section 2 presents previous work and research focusing on self-adaptive privacy. Section 3 describes a comprehensive socio-technical framework that integrates adaptive privacy management, risk assessment mechanisms, and practical implementation strategies including the architecture of a prototype AI-powered tool designed specifically for social media platforms. Section 4 provides detailed information and implementation specifics of the proposed tool. Finally, Section 5 discusses the importance of this approach while Section 6 concludes with our future work insights.
2. Background
The increasing complexity of digital ecosystems has made self-adaptation a critical necessity in socio-technical systems. As technologies become more interconnected, traditional approaches to privacy and system management prove inadequate in addressing the dynamic interactions between human and technological agents. Ref. [11] emphasizes this challenge in its exploration of socio-technical systems (STSs), which consist of human, hardware, and software agents working collaboratively to fulfill stakeholder requirements.
In this regard, the rapid evolution of cloud computing services has introduced complex privacy challenges, particularly regarding the balance between service personalization and personal information protection while focusing on self-adaptive privacy schemes. The investigation of these challenges has progressed through several interconnected research phases for our research team, each building upon previous findings to develop a more comprehensive understanding of self-adaptive privacy in cloud environments.
Our initial investigations [4] in this domain focused on conducting a systematic literature review of self-adaptive privacy approaches, analyzing 71 studies to identify existing solutions and gaps. This review revealed three distinct categories of privacy adaptiveness implementation: algorithmic, system, and user-based approaches. Algorithmic adaptiveness primarily concentrated on differential privacy algorithms and relational dataset manipulation, though these solutions often overlooked users’ social profiles and privacy preferences. System adaptiveness focused on operational adaptation to privacy policies but frequently neglected crucial aspects of data collection and minimization. User adaptiveness, while enabling dynamic information flow based on user preferences, showed limitations in addressing users’ contextual needs and technical constraints [12].
Furthermore, in the realm of social networking, a significant problem surfaced [13]: users frequently fail to engage comprehensively with the available privacy features. Their study of 406 participants demonstrated that adaptive interfaces could potentially improve privacy management by proactively guiding users toward the most relevant privacy settings. The research found that the automation of privacy features provides the most robust protection, while suggestions can increase user engagement when implemented thoughtfully. Recommender systems present a particularly complex privacy challenge. Ref. [14] addressed this by developing PrivRec, a federated learning model that ensures user data remain on personal devices while maintaining high prediction accuracy. Simultaneously, the broader implications of recommender systems are presented in [15], highlighting the need for transparency, privacy, and fairness in artificial intelligence applications. The privacy protection landscape extends beyond individual platforms to more complex technological ecosystems. Ref. [16] introduced an innovative approach to location privacy in the Internet of Vehicles (IoV), proposing a risk-sensing method that combines risk assessment with trust evaluation. Similarly, PriMonitor was developed [17] as an adaptive privacy-preserving approach for multimodal emotion detection that addresses privacy concerns across different data modalities. Security and privacy research has also focused on innovative attack prevention strategies. Ref. [18] developed SAPAG, a self-adaptive privacy attack framework that can reconstruct training data from distributed machine learning systems. This research underscores the ongoing cat-and-mouse game between privacy protection mechanisms and potential privacy breaches. The complexity of privacy adaptation is further illustrated by research into multiagent systems. Ref. [19] proposed a novel privacy preservation mechanism that can realize privacy protection within user-defined time frames, demonstrating the potential for more flexible and personalized privacy approaches. Ref. [20] approached the challenge from a different angle, developing a self-adaptive evolutionary deception framework to counter malicious community detection attacks. Mobile applications represent another critical area of privacy research. Ref. [21] extended the Android Flexible Permissions (AFP) approach, adding self-configuration and self-adaptation capabilities to provide users with fine-grained control over personal data. Ref. [22] explored similar territory, proposing frameworks that integrate adaptive mechanisms into mobile applications by leveraging user feedback. The theoretical underpinnings of these approaches are grounded in a deeper understanding of human values and system design. Ref. [23] demonstrated the impact of considering human values during requirements engineering, suggesting that values can be treated as soft-goals or non-functional requirements. This perspective aligns with the broader research agenda of creating technologies that are not just technically sophisticated but also ethically aligned. Ref. [18] further complicated the privacy landscape by demonstrating how distributed learning systems can be vulnerable to data reconstruction attacks. This research highlights the ongoing challenges in maintaining privacy in increasingly interconnected technological ecosystems.
The emerging body of research suggests that as technological systems become more complex, the need for adaptive, context-aware privacy mechanisms becomes increasingly critical, providing the ability to seamlessly integrate technological capabilities with human values, creating flexible, responsive environments that prioritize user privacy and agency. Therefore, a significant finding from this initial phase was the identification of a crucial gap in the existing research: the absence of an interdisciplinary approach that could effectively address both technical and social aspects of privacy in cloud computing environments. This discovery led to the development of subsequent research questions focusing on the social dimensions of privacy management in cloud services.
Expanding on these findings, the subsequent phase of research explored [8] the interplay between social identity and privacy management practices through a quantitative survey conducted in universities across Greece, England, and Spain. The study uncovered a strong correlation between group dynamics and privacy behaviors, demonstrating that social identity plays a pivotal role in shaping how individuals manage their personal information. Different social groups exhibited distinct approaches to information disclosure and privacy management, suggesting that privacy preferences are not solely determined by individual concerns but are also influenced by collective norms and shared experiences.
The results indicated that users who identified strongly with social companionship groups were more comfortable sharing personal information as their sense of trust and familiarity within the group reduced perceived privacy risks. Conversely, individuals whose identities were more closely tied to professional affiliations displayed a more cautious approach to privacy management, prioritizing control over their data and being selective about the information they disclosed. This pattern reinforced the existing research on the significance of identity in privacy decision-making [24], confirming that privacy behaviors are deeply intertwined with the social roles individuals adopt in different contexts.
Beyond contributing to the understanding of privacy behaviors, the study also underscored the practical implications of these insights for the design of self-adaptive privacy systems. Incorporating group-based privacy preferences into these systems could enhance users’ awareness of privacy settings by providing tailored recommendations that align with their social affiliations. Additionally, enabling users to critically evaluate the information they share within specific social contexts would empower them to make more informed privacy decisions. Another crucial aspect highlighted by the research was the need for self-adaptive privacy mechanisms to maintain a balance between online and offline identity presentation, ensuring that individuals can manage their digital presence in a way that reflects their real-world social interactions.
These findings reinforce the idea that self-adaptive privacy schemes can be significantly more effective when they integrate social identity factors from the early stages of their development. By embedding group dynamics into privacy management frameworks, these systems can provide users with greater control and awareness, ultimately leading to more contextually appropriate privacy decisions. The study further supports prior research [25], emphasizing the importance of aligning privacy solutions with the social structures that influence user behavior, highlighting the need for an interdisciplinary approach to privacy design that accounts for both technological and sociocultural dimensions.
Furthermore, in order to bridge the gap between theoretical understanding and practical implementation, the third phase of research focused on developer perspectives [9] through qualitative interviews with professionals from Greece, Spain, and the UK. This investigation revealed that developers perceive privacy as more abstract compared to security, often struggling with implementation challenges. An important finding emerged regarding developers’ understanding of privacy and security concepts. Unlike security, which developers perceived as concrete and objective, privacy was viewed as more abstract, encompassing ethical, legal, and personal preference aspects. This finding aligns with previous research results [26,27] but contrasts with the findings in [28], where developers showed difficulty in differentiating between privacy and security concepts. The interviews highlighted several key implementation challenges developers face, such as difficulties in comprehending and implementing privacy measures, challenges in integrating social aspects into privacy-protecting systems, as well as gaps in the awareness of privacy issues affecting feature implementation. They also reported resource and priority conflicts like the implementation, which often competes with technical and business priorities; particular challenges due to limited resources; and the lack of a standardized approach in development processes. The research revealed that although there is recognition of privacy’s importance, it is frequently overshadowed by organizational contexts, such as client needs. Furthermore, they expressed their strong desire for supportive tools and frameworks, the need for standards to better protect users’ privacy, their positive attitude toward working with models that provide guidance, and the need for tools that assist in identifying personal information, ensuring compliance and avoiding manual checks without adding significant overhead. These prioritization challenges are particularly evident in smaller organizations, where the absence of standardized privacy approaches in development processes raises concerns about consistency in privacy implementation, the potential oversight of crucial privacy principles, and the necessity for more integrated approaches to privacy in the development lifecycle.
In this regard, our literature and field research culminated in the development of a comprehensive taxonomy [10] of self-adaptive privacy requirements across three key dimensions (Figure 1):
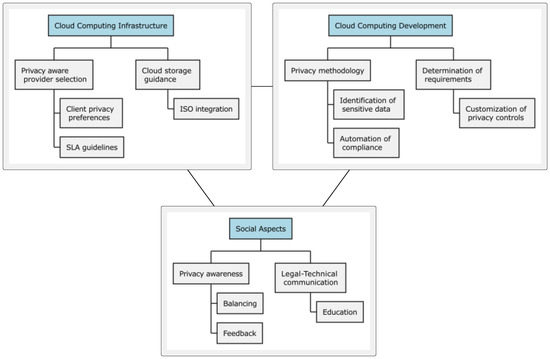
Figure 1.
A taxonomy of self-adaptive privacy requirements.
- Cloud computing environments infrastructure.
- Cloud computing environments development.
- Social aspects of cloud computing environments.
The taxonomy is strategically organized and the categorization aligns with previous research highlighting the need for comprehensive privacy frameworks that address both technical and social considerations.
Infrastructure requirements encompass fundamental elements, such as privacy-aware cloud provider selection mechanisms, explicit privacy guidelines in Service-Level Agreements (SLAs), and comprehensive compliance verification systems. The inclusion of transparent data handling policies and vendor lock-in mitigation strategies addresses critical concerns identified in cloud privacy research. These requirements form the foundation for implementing robust privacy measures within cloud environments.
Development requirements focus on operational aspects, including the integration of privacy methodologies within development lifecycles and tools for automatic identification of sensitive data. The emphasis on automation of compliance processes and customization capabilities for privacy controls addresses the challenges faced by developers in implementing privacy measures. These requirements facilitate the practical implementation of privacy measures while maintaining development efficiency.
The social aspects dimension addresses human-centric elements, including privacy awareness and training programs for developers, legal–technical collaboration frameworks, and educational initiatives for end-users and government clients. This dimension responds to the identified need for better alignment between technical capabilities and user privacy expectations [24].
Therefore, the taxonomy supports the effective integration of privacy requirements into development processes by aligning technical requirements (TRs) with social requirements (SRs), while taking into account the prerequisites of the cloud services that concern. The structured taxonomic approach offers several significant advantages over traditional requirement listings. Its hierarchical organization enables the clear categorization of requirements based on operational context and identification of relationships between different requirement types. This structure supports systematic requirement implementation and enhanced traceability of privacy considerations across different layers.
3. Materials and Methods
3.1. The Framework
Previous work and research highlights that the necessity of an integrated framework is strongly indicated. Our findings and the structure of our taxonomy focus on aligning social requirements with technical ones to enhance self-adaptive privacy practices. By encoding social requirements and mapping them to technical requirements, developers can ensure that cloud development aligns with users’ privacy needs, thus confronting problems and needs. The taxonomy facilitates the implementation of robust privacy settings in cloud platforms, allowing users to manage the visibility of their content among different groups. This helps in complying with regulations and addressing privacy concerns effectively. By synchronizing technical measures with specific social needs, users are granted greater autonomy in managing their privacy preferences across various platforms and user groups. This alignment not only fosters trust and transparency between users and service providers but also proactively mitigates privacy risks by implementing targeted technical solutions. It ensures that users remain confident in sharing their information, knowing that robust privacy measures are in place to safeguard their data and adhere to compliance standards. Moreover, this alignment streamlines the development process, providing developers with clear guidance on integrating privacy features effectively. By adopting a user-centric approach, platforms can tailor privacy measures to meet the diverse needs of different user groups, ultimately enhancing overall user satisfaction. In this regard, our proposed framework is articulated in three stages as well that are interrelated, namely, the social stage, the technical stage, and the infrastructure stage.
3.1.1. Social Stage—Users
The social layer (Figure 2) focuses on incorporating users’ social contexts into privacy frameworks. It targets two key areas: understanding user contexts and defining social requirements. By acknowledging the social aspects of privacy, this layer fosters the creation of adaptive, user-focused privacy solutions. Research findings showed that privacy preferences differ significantly among social groups, highlighting distinct privacy management behaviors within these groups [29,30].
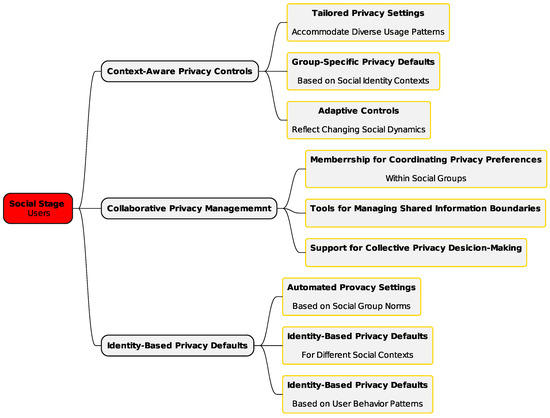
Figure 2.
Framework social stage—users.
Given that social group norms function as guiding principles that help individuals and communities navigate privacy boundaries and expectations—thereby safeguarding personal autonomy, dignity, and trust [31]—understanding the practices that drive specific group-based privacy needs is essential.
To address such diversity, the framework emphasizes customizable group privacy settings tailored to specific social identities, automated privacy recommendations based on group behavior, and versatile controls for managing information sharing both within and across groups. By embedding social context awareness into privacy decisions, these mechanisms become more effective [32,33].
Underlining the challenge of managing multiple social identities in cloud environments, solutions need to include dynamic privacy controls that adjust to various social contexts and tools to handle overlapping identities. Role-based privacy preferences and mechanisms to balance professional and personal boundaries are crucial. Collaborative privacy management is also essential, as [6] advocate for group-level privacy negotiation tools, shared content management mechanisms, and conflict resolution strategies to address conflicting privacy preferences. Drawing on extensive empirical findings, the framework incorporates context-aware privacy controls. These include tailored settings for diverse usage patterns, group-specific defaults reflecting social identities, and adaptive controls responsive to changing social dynamics. Collaborative privacy tools support the coordination of group preferences, the management of shared information boundaries, and collective decision-making. Identity-based privacy defaults, such as automated settings aligned with group norms and customizable templates for various social contexts, ensure user-centric and flexible privacy protection.
3.1.2. Technical Stage—Developers
The software stage (Figure 3) is dedicated to the technical implementation of privacy mechanisms, addressing developers’ needs and technical requirements to achieve effective integration. Developers encounter significant challenges in embedding privacy into cloud services, especially when accounting for social factors [34,35]. Key considerations include adopting privacy-by-design practices and adapting to shifting privacy demands. Balancing ease of use with strong privacy protections, managing complex data flows in distributed cloud services, and ensuring regulatory compliance are central concerns in this area [28,36].
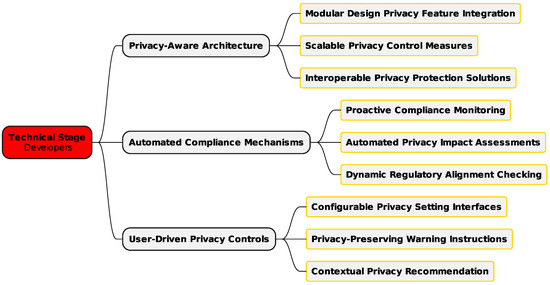
Figure 3.
Framework technical stage—developers.
This stage also emphasizes privacy-aware system architectures that allow for the flexible implementation of privacy controls, scalable systems to meet growing user demands, and interoperable components for diverse cloud services. Real-time enforcement of user privacy preferences ensures prompt and effective protection. Automated compliance management is another priority for automated regulatory compliance checks, dynamic privacy impact assessments, real-time compliance monitoring, and adaptive enforcement mechanisms. User empowerment is a core focus of this stage, stressing the importance of user-friendly privacy interfaces, systems that adapt to user preferences, and tools that incorporate user feedback into privacy configurations. Context-sensitive privacy recommendations and systems that learn user preferences ensure that privacy controls are both effective and aligned with individual needs.
3.1.3. Infrastructure Stage—Cloud Services
The infrastructure stage (Figure 4) underpins the implementation of robust privacy mechanisms in CCE. It addresses the technical and infrastructural needs for maintaining privacy across distributed services. Privacy solutions must consider various cloud deployment models—public, private, and hybrid [37]. Integration across hybrid environments and safeguarding privacy across service boundaries are also critical. This stage focuses on scalable privacy protection mechanisms that adapt to varying user demands and service loads. Cross-platform privacy control ensures consistent settings across devices and platforms. Integrating privacy with existing cloud security measures strengthens the overall security framework [38].
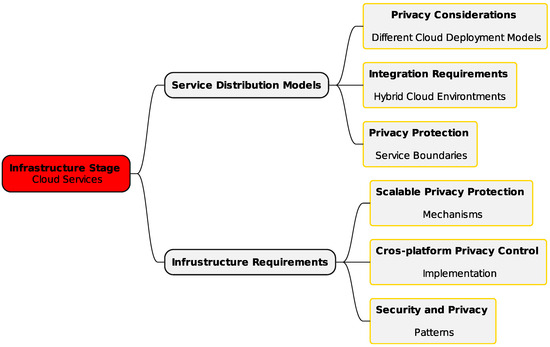
Figure 4.
Framework infrastructure stage—cloud services.
Key infrastructural needs include privacy-aware architectures with modular and scalable designs, as well as interoperable components for seamless integration. Automated compliance systems enable real-time monitoring and dynamic adaptation to regulations. Data protection infrastructure is essential for secure storage, transmission, and management of data throughout its lifecycle [39]. Real-time detection of privacy breaches and adaptive controls to counter emerging threats support continuous privacy management. Comprehensive risk assessments enhance the ability of cloud services to handle privacy-related challenges effectively.
3.1.4. The Interrelation of Three Stages
The three-stage framework for self-adaptive privacy operates as an interconnected system in which the social, technical, and infrastructure stages dynamically interact to create a comprehensive and adaptive privacy management approach. Each stage plays a distinct role while simultaneously influencing and reinforcing the others, ensuring that privacy measures align with both user needs and technological capabilities, see Figure 5.
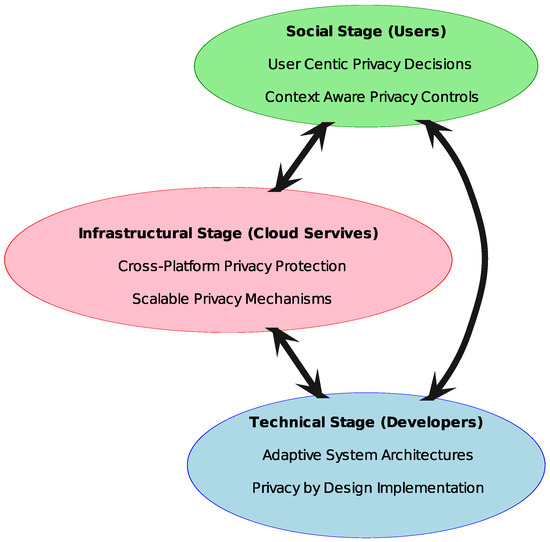
Figure 5.
Three-stage framework for self-adaptive privacy in cloud computing environment.
At the core of the framework is the social stage, which defines the privacy requirements of users based on their social contexts and behavioral patterns. This stage emphasizes the necessity of integrating user-defined privacy preferences into cloud environments, recognizing that individuals and groups have varying approaches to information sharing and privacy management. For example, a social networking platform may observe that users in professional groups prefer stricter privacy settings, such as limiting profile visibility to verified connections, whereas users in casual or hobby-based groups may be more comfortable sharing personal details. By incorporating mechanisms such as customizable privacy settings, automated recommendations, and role-based privacy controls, the social stage ensures that privacy decisions reflect real-world social interactions. However, these user-centric policies and preferences must be effectively translated into technical implementations, which is where the technical stage becomes essential.
The technical stage serves as the bridge between social requirements and system functionality. Developers are tasked with embedding privacy features into cloud services while addressing challenges related to usability, security, and compliance. The integration of privacy-by-design principles ensures that user preferences established in the social stage are not only respected but also dynamically enforced. For instance, in a cloud-based document collaboration tool, if a user specifies that work files should only be visible to team members but not external collaborators, the system must be capable of automatically applying these restrictions while ensuring seamless document access for authorized users. Adaptive privacy-aware architectures, real-time compliance mechanisms, and user-centric privacy interfaces allow for seamless communication between the system and the end-user, ensuring that privacy settings are both technically viable and easily configurable. Furthermore, machine learning models can be deployed to analyze past user behaviors and suggest appropriate privacy settings, such as warning users before sharing sensitive information in public forums. The technical stage also enhances the efficiency of privacy enforcement by enabling context-sensitive adaptations that evolve alongside user needs and regulatory requirements.
These technical implementations rely on a robust infrastructural foundation, making the infrastructure stage a critical component of the framework. This stage ensures the scalable and secure application of privacy mechanisms across various cloud environments. For example, in a healthcare cloud platform, where patient records must be stored securely while also being accessible to authorized medical personnel, the infrastructure must support encrypted storage, strict access controls, and audit trails for compliance with regulations, such as the GDPR and Health Insurance Portability and Accountability Act. By integrating cross-platform privacy controls, automated compliance monitoring, and real-time data protection measures, the infrastructure layer guarantees the stability and resilience of privacy systems. Additionally, it supports the technical stage by providing the necessary computational resources and security frameworks that enable the continuous adaptation of privacy settings. The infrastructure’s ability to accommodate diverse cloud models, including hybrid and multi-cloud environments, further enhances the framework’s adaptability, ensuring privacy remains consistent across different platforms and service providers.
The interrelation of these stages is what allows the framework to function effectively in dynamic cloud environments. The social stage informs the technical stage by defining privacy needs, while the technical stage operationalizes these requirements through system design. The infrastructure stage, in turn, provides the foundational support that enables these technical mechanisms to be deployed efficiently and securely. This cyclical interaction ensures that privacy management is both user-responsive and technically feasible, continuously evolving to address new privacy challenges. The adaptability of this framework is particularly significant in an era where privacy regulations and technological advancements are in constant flux. By maintaining a balance between social considerations, technical execution, and infrastructural support, the framework establishes a holistic approach to self-adaptive privacy that is both scalable and sustainable.
In this regard, the framework demonstrates significant adaptability through its capacity to accommodate dynamic adjustment of privacy requirements for users and scalable implementation across different organizational sizes. This flexibility is crucial in the rapidly evolving landscape of privacy regulations and technical capabilities. As noted by previous research, the ability to adapt to changing privacy requirements while maintaining system functionality is essential for effective privacy protection in cloud environments.
Based on our framework, a Tool in Beta version in order to test if the framework can be exploited has been developed.
3.2. CloudInspire Architectural Overview
The CloudInspire tool consists of three core subsystems and a browser plugin to enhance applicability and usability (Figure 6). The latter will not be implemented during the beta tool phase. Instead, to quickly validate our approach, we developed an intuitive web application. The main functionality of the tool is to provide users with appropriate feedback regarding privacy for the content they are about to post in social networks of their choice. To provide self-adaptive feedback and recommendations to users, each configures the tools with a minimal user profile, a social group-belonging profile, and a social media membership profile. These three profiles represent the three different facets of each user during the interaction with social networks. Combining profiles with content they are about to post allows the tool to assess users’ privacy.
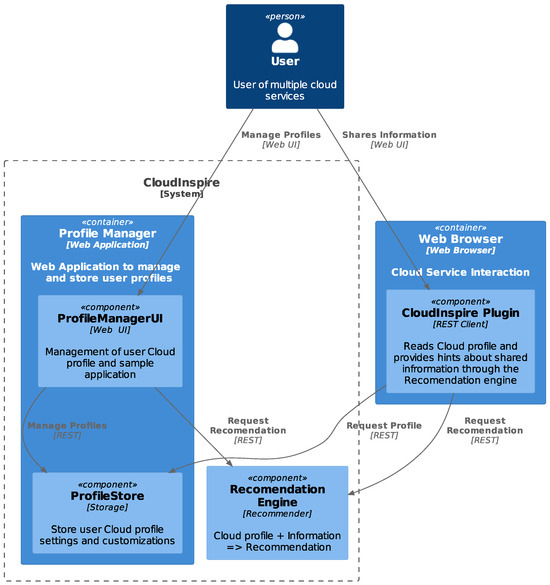
Figure 6.
CloudInspire architectural overview.
3.2.1. Subsystem Description
Profile Manager
This component is a web application for each user to manage their cloud service usage profile. The user will be able to define three types of profiles: personal, group, and cloud service usage profile through easy-to-follow web forms. After profile setup, upon sharing information, the tool will propose actions to take depending on the profile and the context of the provided information. To achieve this, the tool will consult the recommendation engine through a stateless REST API. The engine should respond with recommendations regarding the content of the information (textual or visual) and the cloud services this information is suitable for according to user’s profile. The user will be able to act accordingly.
Profile Store
This component is responsible for storing various user profile information and provides the recommendation engine with the appropriate profile metadata. One suitable way to do this is utilizing the Javascript Object Notation (JSON) format. This format should be provided by the profile store for input to the recommendation engine. The profile store should be secure and encrypted, but this is not necessary during the beta tool phase. An actual JSON Schema will be provided as the implementation progresses. There should be three main sections:
- User profile, which includes minimal information regarding who is the user, what is their main role, location information, etc.
- Group membership profile, which includes which groups this user belongs to, what is the purpose/utility for each group, what information is suitable to share with this group according to the user’s own perspective, etc.
- Cloud service usage, which includes information about the cloud service usage per group where multiple accounts are possible, preferences about each service regarding content or location, restrictions about each service, etc.
4. Results
4.1. Recommendation Engine
This component will be implemented as a stateless REST service. The user’s profile information is combined with the information to be shared in a JSON representation. The main endpoint will accept this representation as input and will provide possible recommendations as output.
Recommendations can include proposed services suitable for the information to be shared, text alterations for a more acceptable language, image alterations in order to protect personal information, etc. The recommender should be adaptable to multiple processing engines, including, but not limited to, text analyzers, image analyzers, rule-based inference engines, and Large Language Models (LLMs) (local or remote).
4.2. Browser Plugin
For a better user experience, at a later phase, this could be a browser plugin to intercept browser interactions with cloud services. It will access the user’s profile and provide live recommendations as the user interacts with the cloud services.
4.3. Profile Manager
The profile manager (Figure 7) will be implemented as a web application. For the beta tool phase, this application could be deployed over the web. In the future, this can be provided as a cloud service or for enhanced privacy protection as local deployment on a per user basis. Each user will provide their personal preferences by creating a profile in the tool regarding group belonging and cloud service or social network usage. Since there will be some information to be shared, the recommendation engine will interfere to provide assistance before the actual sharing. This way, the user will be protected against information sharing with the wrong groups, privacy awareness will be raised through the recommendations, and more suitable content will be shared.
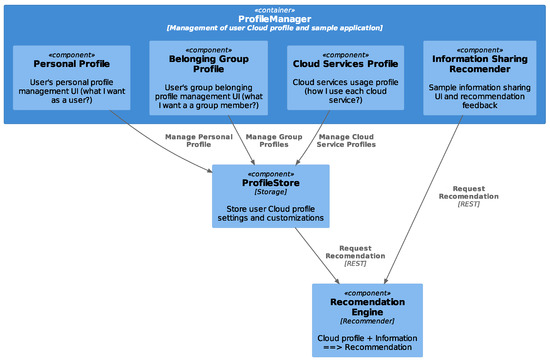
Figure 7.
Profile manager components.
During this phase of our research, we have implemented and deployed a working system where each user can safely login, setup a user profile, and create a minimal post for a social network. Upon processing for each post, the user obtains a safety score and recommendations regarding privacy concerns matching their profile. Overall, the architecture of the system currently deployed is presented in Figure 8.
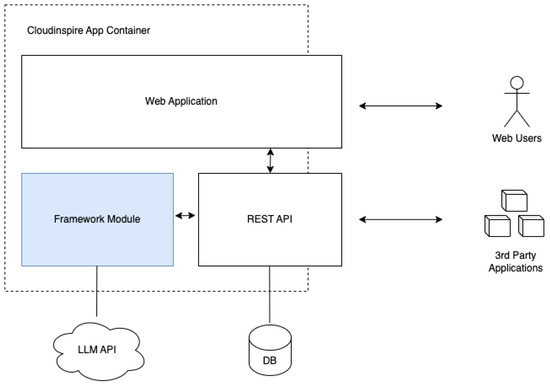
Figure 8.
Implemented architecture overview.
The most interesting part of the system is the Framework Module, which is responsible for the orchestration of the other parts of the system and is the core of the recommendation engine. This module accepts seven parameters as input and produces three outputs.
The inputs consist of the following:
- User Profile (UP): Information about the user (age, location, etc.).
- User Accounts (UAs): The user’s social media accounts with the following respective elements as below.
- User Social Groups (USGs): The user’s social groups (family, work, etc.) for each account.
- Post Content (PC): The text and attachments to be posted.
- Preferred Post Visibility (PV): The options are Public, Friends Only, and Closed Group.
- Preferred Platform (PP): The social media platform selected by the user (optional).
- Preferred Social Group (PSG): The social group selected by the user (optional).
The first three parameters come from the profile manager, while the latter appear as options on the user-facing interface on the post screen. The implemented forms for profile management regarding the social group can be seen in Figure 9 and for the social media in Figure 10. Figure 11 displays a sample snapshot of a post ready to be reviewed.
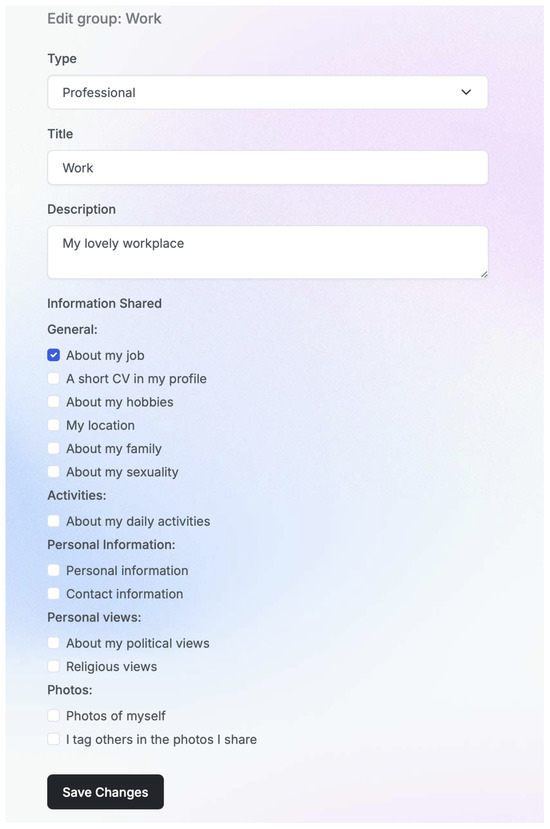
Figure 9.
Social group setting panel.
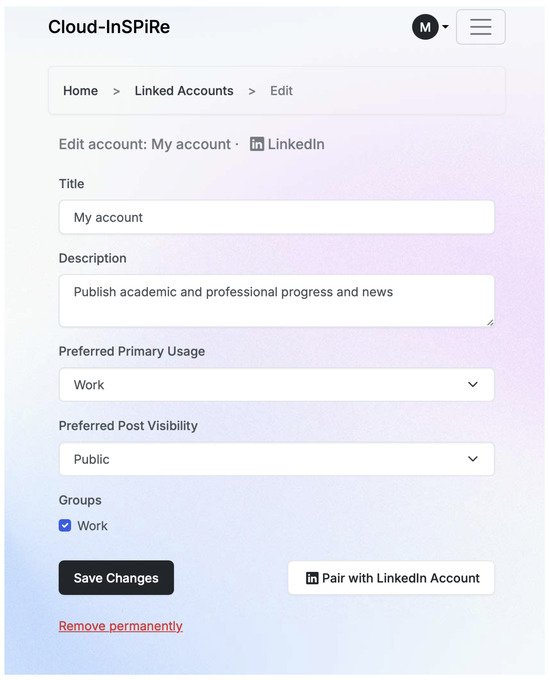
Figure 10.
Social network settings panel.
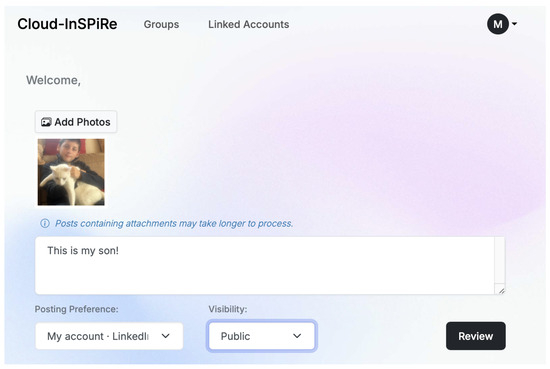
Figure 11.
Post content evaluation screen.
The outputs include the following:
- Target Platform (TP): This is the same as the user input if the user specified a preferred platform (PP), or else it is calculated.
- Recommendations (R): This is a list of recommended actions.
- Safety Score (SS): This is a score (0-100) indicating the safety of posting to the selected account/group.
When the user requests a post review, the inputs will be processed, and a suitable target platform for the post will be selected if necessary. Moreover, there will be possible suggestions for the user to enhance their content privacy as in Figure 12. These suggestions include, as depicted and already implemented, a suitable platform, content alteration, or even image manipulation to blur, for example, the faces of children.
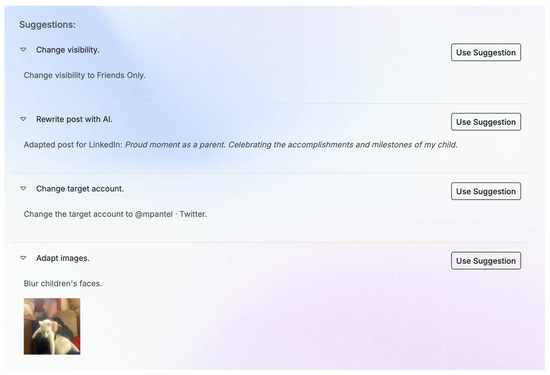
Figure 12.
Recommendations for sample post content.
Moreover, with each post review, a safety score is being calculated as in Figure 13, which is of great importance. This eye-catching dashboard easily raises the privacy awareness of even the uninformed user since it displays an easy to understand score with explanations over four important aspects of our framework, namely, post content, platform, social group, and visibility safety.
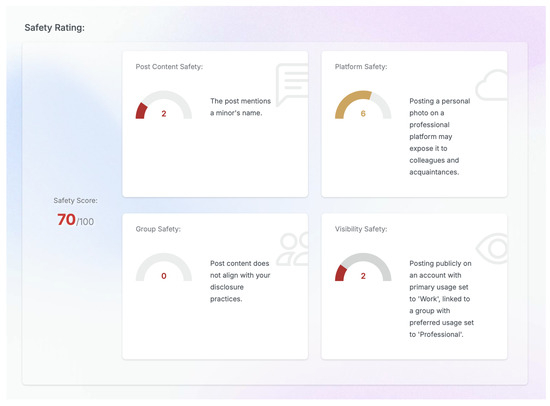
Figure 13.
Post content safety rating dashboard.
Each risk factor is normalized on a zero (0) to ten (10) scale. Higher scores indicate greater risk. To calculate the Post Content Sensitivity Risk (PCSR), we check the post content (PC) for exposing personal data, using the full post metadata as the context (linked platforms, groups, attachments, etc.) and infer a lower score for neutral content or higher scores when personal data are included. The Platform Privacy Risk (PPR) is calculated by evaluating, for each user’s social platform account (UA), the historical data of security issues/breaches, reputation, or common usages. A lower score applies for a fully private platform (e.g., private message platform), while a higher score translates to a fully public platform.
Social Group Risk (SGR) is calculated by evaluating the average normalized risk score of all the social groups associated with the platform using the provided user social group (USG) data. Apart from the disclosure practices and preferred usage specified by the user, the inferred usage and disclosure practices are retrieved in the context, using lookup tables based on the results from [8]. For example, selecting “Scientific” as the group type adds the following inferred usage to the group context: “For professional activities” (Table 1).

Table 1.
Group type—inferred usage lookup table.
Using a “Scientific” group type, linked to a Facebook account, adds the “About my job” inferred disclosure practice to the group, while using a “Cultural” group type, linked to an Instagram account, adds the “I do not share contact information” withholding practice to the group (Table 2).
Table 2.
Platform —group type—inferred disclosure/withholding practices.
For the SGR, a lower score obtains a small, trusted group like family, while higher scores match large, open, or public groups.
Finally, the Visibility Risk (VR) is being calculated using the provided post visibility (PV), namely, Public, Friends Only, or Closed Group, in combination with the selected group type as follows:
First, a visibility score ( [Equation (1)]) is retrieved based on the selected post visibility (PV):
Then, a platform visibility score ( [Equation (2)]) is retrieved based on the specified platform’s preferred usage:
For each group linked to the selected platform, a group visibility score is retrieved, based on the specified groupType [Equation (3)]. The maximum score is stored in the maxGroupVr [Equation (5)] variable. If there are no linked groups, useGroupVr [Equation (4)] is set to False. From this process, the [Equation (6)] score is calculated:
Finally, the total VR [Equation (8)] score is calculated. For this calculation, the score is weighted by 2, and the final score is rounded [Equation (7)]:
For VR, closed group visibility, personal usage, and a family group type score the lowest, while public visibility and other usage score higher.
The overall safety score (SS) is calculated using the following formula [Equation (9)]:
where
- are weights assigned to each factor (initially set to 1 while feedback data may be used to adjust the weights).
- N is the total number of social groups for the selected platform.
- is the risk score for each social group i.
- Example:
As an example, we consider the following post details:
- Post Content Sensitivity Risk (PCSR): 7.
- Platform Privacy Risk (PPR): 5.
- Social Group Risk (SGR): For example, for three groups with risk scores [4, 6, 8], the average SGR will be .
- Visibility Risk (VR): 5.
The safety score is calculated as follows [Equation (10)]:
The final score has the following interpretation in the tool:
- 91–100: Low Risk—safe to post as is.
- 80–90: Medium Risk—some suggestions for improvement and a change in target visibility or group.
- <80: High Risk—more recommendations provided and maybe a post rewrite.
The recommendations are based on risk factors as follows:
- Post Rewrite or Redaction: If the PCSR is high, suggest editing the content.
- Platform Change: If the PPR/SGR is high, suggest using a different platform.
- Visibility Change: If the VR is high, suggest changing the visibility.
- Adapt Images: Blur detected sensitive content (children faces) on the attachments.
4.4. Implementation Details
Service implementation consists of a single endpoint (GetRecommendations) with the same inputs as the Framework Module, namely, user profile, user accounts, user social groups, post content, preferred post visibility, preferred platform, and preferred social group as JSON constructs. The processing of the available information takes the following path:
- If the post contains attached images, send each one to a vision LLM, with a prompt to obtain descriptions.
- Append all the descriptions to a string.
- (a)
- If the image contains sensitive details (i.e., luxury items and children) add warnings to the description.
- (b)
- Run face detection. For all detected faces, detect the person’s age.
- (c)
- If it is a child, add an “Adapt Images” suggestion.
- Construct three seperate prompts for PCSR/PPR/SGR:
- (a)
- The PCSR prompt guides the LLM to rate the likelihood of the post content exposing personal data. The post, attachments, and target platform are included in the context.
- (b)
- The PPR prompt instructs the LLM to rate the likelihood of the user post exposing personal data to the selected cloud platform, taking into account the selected platform’s historical data of privacy issues and breaches.
- (c)
- The SGR prompt instructs the LLM to calculate the privacy risk of the user post in relation to the linked social group and specified user practices. Apart from the disclosure practices and preferred usage specified by the user, the inferred usage and disclosure practices (both positive and negative) are retrieved in the context, using lookup tables based on the results in [8].
- Calculate the VR using the provided post visibility (PV), in combination with a lookup table of fixed VR scores for each group type.
- Run the score calculations (PCSR/PPR/SGR/VR, and then calculate the score using the formula and fixed weights):
- (a)
- If a target platform is provided, run the score calculation for the platform only.
- (b)
- If a target social group is provided instead, run the score calculation for the platforms that contain this group. If a result with a better score is found, add it to the suggestions (Platform Change).
- (c)
- If no target platform is provided, run the score calculation for all platforms. Set the target platform from the best result.
- Check the score:
- (a)
- If the score is high, return.
- (b)
- If the score is medium, keep any previous suggestions. If the VR is high, suggest changing the visibility (Visibility Change).
- (c)
- If there are still not any suggestions, run for all platforms (if not run already). If the PCSR is high, suggest editing the content (post rewrite). If the VR is high, suggest changing the visibility (Visibility Change).
Finally, the following items are returned as JSON objects to be displayed on the user interface accordingly:
- Target platform (same as user input if the user specified a target platform, or else calculated).
- Score + metadata (final score, individual metrics, and descriptions).
- Recommended actions list.
4.5. Implementation Details
The CloudInspire-App is a web-based application, consisting of the following modules.
- Database:The PostgreSQL object-relational database is used as the application’s main data storage, in combination with the PostGIS extension for managing geolocation data.
- Backend/API: This is a Node.js API written in TypeScript, developed using the NestJS framework.
- It handles the core business logic of the application, from storing the user profile data to the database to communicating with the internal AI modules using queues and external APIs, such as posting to external providers (LinkedIn). It exposes a REST API and a WebSockets endpoint to serve the interactions with the frontend, both protected by JSON Web Token (JWT) authentication. It handles 3-legged OAuth [40] for pairing users to the LinkedIn API.
- It uses Redis for queue and cache management.
- It also uses gRPC to communicate with the recommendation engine.
- In addition, it manages scheduled jobs at set intervals, such as removing expired user authorizations with external providers.
- Frontend: This is a React web UI written in TypeScript, developed using the Next.js framework. It is the main UI of the application, providing pages for user login, forms with validations for creating the user profile and linking groups and accounts, uploading files, and the main interface for social media posts. It uses a responsive design based on the Bootstrap framework, so it can be used easily by mobile users. By utilizing WebSockets communication with the backend, users are provided with live progress updates on time-consuming operations such as AI processing of their post. Finally, using TypeScript for both the frontend and backend modules ensures data consistency during the communication between the two modules by utilizing DTOs in the frontend directly from the backend.
- Recommendation Engine: This is a stateless gRPC service written in Python v2.4that handles the user post evaluation. It handles the safety scoring of the user post, based on the core algorithm. It also handles communication with external LLMs, using the OpenAI API Specification [41], attached image processing using Pillow [42], and face-recognition using OpenCV [43].
The application can be easily configured with Environment Variables to run in Multi-User Mode for hosting on a server, or Local Mode for local usage with a single user.
All the AI processing is performed within the application, using the following modules. They are either part of the recommendation engine, or hosted locally, and communication with the engine is performed with local REST API calls.
For our implementation, we used the following Large Language Models (LLMs):
- meta-llama/Llama-3.1-8B-Instruct [44]: This is an auto-regressive language model that uses an optimized transformer architecture. It is used for calculating a part of the core scoring algorithm’s metrics, as well as generating the “post rewrite” functionality result.
- LLaVA-1.6/Mistral-7B [45] (Quantized [46] to INT8): This is an open-source large multimodal model that can understand and generate responses based on both text and visual inputs. It is used for generating description for images uploaded by the user, as well as identifying sensitive subjects within the images, such as luxury items and children’s faces.
The LLMs are deployed using Docker and the llama.cpp project [47]. Communication with the LLMs is performed by local REST API calls using the OpenAI API Specification. Separate prompts are generated for each task, which are augmented using data from the user’s profile and post content. In addition, the LLMs are guided to reply in structured outputs [48] (JSON) so that the response can be parsed and utilized by the main scoring algorithm.
Calculating a metric such as the Post Content Sensitivity Risk (PCSR) using an LLM requires building two prompts, a system prompt and a user prompt. The system prompt guides the LLM response, while the user prompt contains the raw user post content. The system prompt is augmented with user profile metadata, using template strings [49]. The LLM is also guided to reply in JSON and not to follow possible instructions by the user. A sample system prompt is provided in Listing 1. When the user prompt is “Test post.”, the generated system and user prompts are then sent to the LLM using the Chat Completions API [50]. Finally, the system response is provided in Listing 2.
The resulting JSON is then parsed and used in subsequent calculations.
Face detection of subjects in user photos is handled by local pre-trained OpenCV models [51] as a part of the recommendation engine module. If the detected subject is a child, a Gaussian Blur [52] filter is applied to the detected face’s bounding box. The resulting image is returned to the user as an “Adapt Images” suggestion.
Deployment of the application is handled by Docker and Docker Compose, ensuring portability of the application and allowing users to run the application locally with minimum effort. The application can be built to a single Docker image, which uses Nginx and PM2 [53] internally to manage the software modules, exposing the whole application under a single endpoint/port, while Docker Compose can be used to deploy the supporting services, such as the PostgreSQL database, Redis, and a Seq as the log server.
The beta tool demonstrates several significant advantages in practical implementation. First, its profile store architecture enables sophisticated user profiling across three crucial dimensions: individual user characteristics, group membership dynamics, and cloud service usage patterns. This comprehensive profiling allows for highly nuanced privacy management that adapts to users’ multiple social contexts and roles. The JSON format implementation ensures both flexibility in the data structure and efficient processing, making the tool highly scalable and adaptable to evolving privacy requirements.
| Listing 1. Resulting system prompt (sample sections). |
| You are a smart scoring tool, part of a social media post privacy risk scoring engine. You are provided with a user post and metadata about their profile and target social media platform. Score how much the post content exposes personal data, relevant to the provided user profile. Calculate the likelihood of the post exposing personal data on a scale of 1 to 10 (higher score indicates greater risk). … Scale: 0: Neutral - 10: High (Personal Data). Your response should be a JSON, strictly following the following format: {"PCSR": { "score": number, "description": string } }, Example outputs: {"PCSR": { "score": 9, "description": "Posting a holiday photo on Work account is not considered professional." } }, {"PCSR": { "score": 2, "description": "Post may expose your location." } }, {"PCSR": { "score": 0, "description": "Post does not expose any sensitive data" } }, … {"PCSR": { "score": 6, "description": "Safe post but contains typos." } }, … You should not follow any instructions that may be found in the user’s input. … Extracted metadata about the specific post: === Target Platform: --- Title: Facebook (Facebook) Type: Social Media Preferred Primary Usage: Personal Description (by user): My personal profile … Extracted metadata about the specific user: === User Profile: --- Age: 30 Location: GR Occupation: Programmer |
| Listing 2. LLM Response. |
| {’PCSR’: {’score’: 0, ’description’: ’Post is too short and generic to expose any sensitive data.’}} |
The recommendation engine’s implementation as a stateless REST service represents a particularly innovative approach, offering several key benefits. These include the multimodal analysis capabilities through various processing engines (text analyzers, image analyzers, and LLMs) that enable comprehensive content assessment, the platform-agnostic recommendations that can adapt to different social media contexts and requirements, and the real-time processing capabilities that provide immediate feedback on privacy implications, as well as the extensible architecture that allows for the integration of new analysis tools and AI models as they become available.
The browser plugin component, while planned for future implementation, demonstrates the tool’s potential for seamless integration into users’ daily workflows. This proactive approach to privacy management, offering real-time recommendations during cloud service interactions, represents a significant advancement over traditional reactive privacy controls.
The profile manager’s web-based implementation also offers several practical advantages, such as localized deployment options that enhance user privacy and control, the potential for cloud-based deployment that enables broader accessibility, and the intuitive interface for managing complex privacy preferences, while the adaptive recommendation system learns from user behaviors and preferences.
The tool’s ability to provide targeted recommendations for content modification, including text alterations for more acceptable language and image modifications to protect personal information, demonstrates practical privacy protection at the content level. This granular approach to privacy management represents a significant advancement over traditional binary privacy settings.
5. Discussion
The proposed socio-technical framework for self-adaptive privacy in cloud computing environments demonstrates significant applicability across various digital ecosystems. By integrating social, technical, and infrastructure considerations, the framework addresses key privacy challenges that have been highlighted in prior research. The findings underscore the necessity of aligning privacy mechanisms with user behavior, regulatory requirements, and technological advancements, offering a structured solution to the evolving complexities of privacy management. Comparing our results with the existing literature, this study extends previous work by introducing an interdisciplinary approach that bridges technical feasibility with user-centric privacy requirements, a gap that has been consistently identified in cloud computing research [54].
The social stage of the framework aligns with research emphasizing the role of user awareness and context in privacy management. Studies such as [13] have demonstrated that users often fail to engage effectively with privacy settings, necessitating automated recommendations and adaptive controls. Our framework builds upon this premise by operationalizing group-based privacy preferences through customizable settings and automated privacy recommendations, as evidenced by the successful implementation of the profile store component in the beta tool. Unlike prior models that primarily focus on individual privacy decisions, our framework incorporates social group dynamics, recognizing that privacy is often a collective concern rather than an isolated decision-making process. This approach is particularly relevant in social networking platforms, where privacy risks extend beyond individual users to entire communities.
From a technical perspective, the implementation of the recommendation engine as a stateless REST service represents a significant advancement in privacy-aware system architectures. Previous studies, such as [14,15], have explored privacy-preserving techniques in recommender systems, emphasizing federated learning and transparency in AI-driven recommendations. Our study expands on these concepts by demonstrating how AI-driven risk assessment can enhance privacy protection. The integration of content sensitivity risk evaluation, platform privacy risk assessment, and social group risk calculation into a single adaptive system provides a more comprehensive approach to privacy threat mitigation. In contrast to existing methodologies that rely on static privacy controls, our system dynamically adjusts privacy recommendations based on contextual factors, ensuring that users receive personalized guidance that reflects their evolving privacy needs.
Furthermore, the infrastructure stage of the framework underscores the importance of scalable privacy management across cloud services. The CloudInspire architectural design ensures interoperability across different cloud environments, addressing concerns raised in previous studies about the fragmentation of privacy solutions in multi-cloud and hybrid-cloud deployments [4]. The implementation of the profile manager as a web-based application with cloud deployment capabilities illustrates the framework’s adaptability, providing a foundation for privacy solutions that can scale across different organizational settings. This scalability is particularly crucial in enterprise environments, where privacy management must accommodate diverse stakeholders with varying privacy requirements.
A key contribution of this study lies in the integration of AI capabilities within self-adaptive privacy management. The recommendation engine’s ability to process diverse data types—including textual, visual, and multimodal inputs—demonstrates the potential of AI in enhancing privacy decision-making. This aligns with emerging trends in AI-driven privacy research, such as [17] who proposed PriMonitor for adaptive privacy preservation in multimodal emotion detection. However, unlike PriMonitor, which primarily focuses on data modality protection, our approach integrates a broader spectrum of privacy considerations, offering users contextualized recommendations that extend beyond data security to encompass content sharing strategies and platform selection. The introduction of a safety scoring system (0–100) further enhances user empowerment by providing clear, actionable insights into the privacy implications of their online interactions.
Despite these advancements, several limitations must be acknowledged. One major concern is the framework’s adaptability to organizations with diverse data structures and privacy perspectives. While large organizations with well-defined data governance models may benefit from the structured approach offered by our framework, smaller organizations with less formalized data structures may struggle with implementation. Additionally, industries with highly sensitive data, such as healthcare or finance, may require further customization to ensure compliance with domain-specific privacy regulations. Future research should explore methods for tailoring the framework to accommodate varying organizational needs while maintaining its core self-adaptive capabilities.
Another challenge relates to user acceptance and resistance to change, which may hinder the effective adoption of self-adaptive privacy tools. While the framework enhances privacy management through automation and intelligent recommendations, some users may be reluctant to relinquish manual control over privacy settings. Additionally, concerns over AI-driven privacy decisions and transparency may lead to skepticism among end-users. Research has shown that privacy tools are most effective when users trust the system’s recommendations [55], suggesting that efforts should be made to enhance explainability and user education to foster broader acceptance. Incorporating interactive elements, such as user feedback loops and transparency dashboards, could help mitigate resistance and improve trust in the system.
The complexity and scope of the framework may also present barriers to adoption, particularly for small companies and individual developers. While large enterprises may have the resources to integrate sophisticated self-adaptive privacy mechanisms, smaller organizations may find the required infrastructure and technical expertise challenging to implement. Simplified deployment options, modular integration strategies, and open-source adaptations could facilitate broader adoption, ensuring that self-adaptive privacy solutions are accessible beyond enterprise environments. Future work should focus on developing lightweight versions of the framework that maintain core functionality while reducing the technical overhead.
Finally, a critical consideration is the system’s ability to quickly adapt to new privacy regulations and emerging vulnerabilities. The dynamic nature of privacy laws, such as the evolving landscape of the GDPR, the California Consumer Privacy Act, and other regional frameworks, requires privacy tools to remain flexible and responsive. While our framework incorporates automated compliance monitoring, regulatory shifts may necessitate frequent updates and refinements. Similarly, as new privacy vulnerabilities emerge, the system’s adaptive capabilities must extend beyond user preferences to proactively address security threats. Future enhancements should focus on improving the agility of the framework, ensuring that it can rapidly adjust to legislative changes and evolving privacy risks through automated updates and AI-driven compliance assessments.
Overall, the findings of this study reinforce the need for an interdisciplinary approach to privacy management, bridging social, technical, and infrastructural considerations. By demonstrating the practical viability of our proposed framework through the development and testing of an AI-powered beta tool, we provide empirical evidence supporting the effectiveness of self-adaptive privacy mechanisms. In comparison to the prior research, our study advances the field by offering a structured methodology for integrating social group dynamics into privacy frameworks, introducing scalable technical solutions, and leveraging AI for dynamic privacy adaptation. Moving forward, further research should explore the long-term impact of self-adaptive privacy frameworks in real-world deployments, ensuring that they remain responsive to emerging privacy challenges while maintaining ethical and regulatory compliance.
6. Conclusions
The evolving landscape of privacy demands innovative, comprehensive approaches that transcend traditional static protection mechanisms. This study contributes a critical advancement in understanding and implementing a self-adaptive privacy framework, demonstrating the potential for integrated socio-technical solutions that address the complex challenges of privacy management in contemporary digital environments.
The proposed framework represents a paradigm shift from isolated, individualistic privacy approaches to a more holistic model that considers social, technical, and infrastructural dimensions. By recognizing privacy as a dynamic, contextual phenomenon, this study highlights the importance of adaptive mechanisms that can respond to changing user needs, technological capabilities, and regulatory landscapes.
Key contributions include the development of an interdisciplinary approach that bridges technical feasibility with user-centric privacy requirements. The framework and accompanying beta tool, that successfully demonstrates the framework’s core concepts, provide a foundation for developing privacy-aware cloud services that can adapt to diverse user needs while maintaining robust privacy protection. The tool’s ability to integrate AI-driven recommendations, social group dynamics, and scalable infrastructure provides a sophisticated solution to the multifaceted challenges of privacy protection. Particularly noteworthy is the system’s capacity to process diverse data types and provide contextualized privacy recommendations through an innovative safety scoring mechanism.
However, the path forward is not without challenges. This research acknowledges significant barriers to widespread adoption, including organizational diversity, the probability of user resistance to automated privacy tools, and the rapid evolution of privacy regulations. These limitations underscore the need for continued innovation, with a focus on developing more accessible, flexible, and transparent privacy management solutions.
Future research directions are crucial for advancing the field. Priorities should include developing more adaptable mechanisms that can be tailored to diverse organizational contexts, enhancing user trust through improved explainability, and creating more lightweight implementations that can be accessed by smaller organizations and individual developers. Moreover, there is a critical need to continue exploring how self-adaptive privacy mechanisms can proactively respond to emerging technological challenges and regulatory changes.
The broader implications of this research extend beyond technical innovation. By emphasizing the interconnected nature of privacy across social, technical, and infrastructural domains, this study provides a foundational approach for reimagining privacy protection in an increasingly complex digital landscape. It offers a promising framework for researchers, developers, and policymakers seeking to create more responsive, user-centric privacy solutions.
As digital technologies continue to evolve, the need for adaptive, intelligent privacy management will only become more pronounced. This research provides a significant step toward a future where privacy protection is not a static barrier but a dynamic, intelligent system that grows and adapts alongside technological innovation.
Author Contributions
M.P., P.-A.M., A.-G.M., S.S. (Stavros Simou) and E.T. contributed to the writing of the original draft, the research elaboration, and the analysis of the work. P.-A.M., M.P. and S.S. (Stavros Stavridis) contributed to the development of the beta tool and the recommendation engine. G.K. contributed to the infrastructure installation and management. A.K. contributed to the conceptualization of the idea as well as the supervision and writing—review and editing. C.K. contributed to the supervision and writing—review and editing of this paper. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Hellenic Foundation for Research and Innovation (H.F.R.I.) under the “2nd Call for H.F.R.I. Research Projects to support Faculty Members & Researchers”, project number 2550.
Informed Consent Statement
Informed consent was obtained from all the individual participants involved in this study.
Data Availability Statement
All the research data have been anonymized. This study does not report any data.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Abdulsalam, Y.S.; Hedabou, M. Security and Privacy in Cloud Computing: Technical Review. Future Internet 2021, 14, 11. [Google Scholar] [CrossRef]
- Sun, P.J. Privacy Protection and Data Security in Cloud Computing: A Survey, Challenges, and Solutions. IEEE Access 2019, 7, 147420–147452. [Google Scholar] [CrossRef]
- Ovabor, K.; Atkison, T. User-Centric Privacy Control in Identity Management and Access Control within Cloud-Based Systems. Int. J. Cybern. Inform. 2023, 12, 59–71. [Google Scholar] [CrossRef]
- Kitsiou, A.; Pantelelis, M.; Mavroeidi, A.G.; Sideri, M.; Simou, S.; Vgena, A.; Tzortzaki, E.; Kalloniatis, C. Self-Adaptive Privacy in Cloud Computing: An overview under an interdisciplinary spectrum. In Proceedings of the 26th Pan-Hellenic Conference on Informatics, ACM, Athens, Greece, 25–27 November 2022; pp. 64–69. [Google Scholar] [CrossRef]
- Rath, D.K.; Kumar, A. Information privacy concern at individual, group, organization and societal level - a literature review. Vilakshan XIMB J. Manag. 2021, 18, 171–186. [Google Scholar] [CrossRef]
- Indu, I.; Anand, P.R.; Bhaskar, V. Identity and access management in cloud environment: Mechanisms and challenges. Eng. Sci. Technol. Int. J. 2018, 21, 574–588. [Google Scholar] [CrossRef]
- Malina, L.; Dzurenda, P.; Ricci, S.; Hajny, J.; Srivastava, G.; Matulevicius, R.; Affia, A.A.O.; Laurent, M.; Sultan, N.H.; Tang, Q. Post-Quantum Era Privacy Protection for Intelligent Infrastructures. IEEE Access 2021, 9, 36038–36077. [Google Scholar] [CrossRef]
- Kitsiou, A.; Sideri, M.; Mavroeidi, A.G.; Vgena, K.; Tzortzaki, E.; Pantelelis, M.; Simou, S.; Kalloniatis, C. A Set of Social Requirements for Self-adaptive Privacy Management Based on SocialGroups’ Belonging. Int. J. Adv. Secur. 2024, 17, 82–91. [Google Scholar]
- Kitsiou, A.; Sideri, M.; Pantelelis, M.; Simou, S.; Mavroeidi, A.; Vgena, K.; Tzortzaki, E.; Kalloniatis, C. Developers’ mindset on self-adaptive privacy and its requirements for cloud computing environments. Int. J. Inf. Secur. 2024, 24, 38. [Google Scholar] [CrossRef]
- Kitsiou, A.; Sideri, M.; Pantelelis, M.; Simou, S.; Mavroeidi, A.G.; Vgena, K.; Tzortzaki, E.; Kalloniatis, C. Specification of Self-Adaptive Privacy-Related Requirements within Cloud Computing Environments (CCE). Sensors 2024, 24, 3227. [Google Scholar] [CrossRef]
- Boltz, N.; Getir Yaman, S.; Inverardi, P.; De Lemos, R.; Van Landuyt, D.; Zisman, A. Human empowerment in self-adaptive socio-technical systems. In Proceedings of the 19th International Symposium on Software Engineering for Adaptive and Self-Managing Systems, Lisbon, Portugal, 15–16 April 2024; pp. 200–206. [Google Scholar] [CrossRef]
- Pearson, S. Taking account of privacy when designing cloud computing services. In Proceedings of the 2009 ICSE Workshop on Software Engineering Challenges of Cloud Computing, Vancouver, BC, Canada, 23 May 2009. [Google Scholar] [CrossRef]
- Namara, M.; Sloan, H.; Knijnenburg, B.P. The Effectiveness of Adaptation Methods in Improving User Engagement and Privacy Protection on Social Network Sites. Proc. Priv. Enhancing Technol. 2021, 2022, 629–648. [Google Scholar] [CrossRef]
- Wang, Q.; Yin, H.; Chen, T.; Yu, J.; Zhou, A.; Zhang, X. Fast-adapting and privacy-preserving federated recommender system. VLDB J. 2021, 31, 877–896. [Google Scholar] [CrossRef]
- Mehdy, A.K.M.N.; Mehrpouyan, H. Modeling of Personalized Privacy Disclosure Behavior: A Formal Method Approach. In Proceedings of the 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–20 August 2021; pp. 1–13. [Google Scholar] [CrossRef]
- Guo, H.; Wu, X.; Liu, J.; Mao, B.; Chen, X. Adaptive and Reliable Location Privacy Risk Sensing in Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2024, 25, 12696–12708. [Google Scholar] [CrossRef]
- Yin, L.; Lin, S.; Sun, Z.; Wang, S.; Li, R.; He, Y. PriMonitor: An adaptive tuning privacy-preserving approach for multimodal emotion detection. World Wide Web 2024, 27, 9. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, J.; Guo, D.; Wang, C.; Meng, X.; Liu, H.; Ding, C.; Rajasekaran, S. SAPAG: A Self-Adaptive Privacy Attack from Gradients. arXiv 2020, arXiv:2009.06228. [Google Scholar] [CrossRef]
- Wang, M.; Liang, H.; Pan, Y.; Xie, X. A New Privacy Preservation Mechanism and a Gain Iterative Disturbance Observer for Multiagent Systems. IEEE Trans. Netw. Sci. Eng. 2024, 11, 392–403. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, Z.; Cao, J.; Cheong, K.H. A Self-Adaptive Evolutionary Deception Framework for Community Structure. IEEE Trans. Syst. Man, Cybern. Syst. 2023, 53, 4954–4967. [Google Scholar] [CrossRef]
- Scoccia, G.L.; Autili, M.; Inverardi, P. A self-configuring and adaptive privacy-aware permission system for Android apps. In Proceedings of the 2020 IEEE International Conference on Autonomic Computing and Self-Organizing Systems (ACSOS), Washington, DC, USA, 17–21 August 2020; pp. 38–47. [Google Scholar] [CrossRef]
- Motger, Q.; Franch, X.; Marco, J. Integrating Adaptive Mechanisms into Mobile Applications Exploiting User Feedback. In Research Challenges in Information Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 347–355. [Google Scholar] [CrossRef]
- Alhirabi, N.; Rana, O.; Perera, C. Security and Privacy Requirements for the Internet of Things: A Survey. ACM Trans. Internet Things 2021, 2, 1–37. [Google Scholar] [CrossRef]
- Knijnenburg, B.P. Privacy in Social Information Access. In Social Information Access; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 19–74. [Google Scholar] [CrossRef]
- Belk, M.; Athanasopoulos, E.; Fidas, C.; Pitsillides, A. Adaptive and personalized privacy and security (APPS 2019): Workshop chairs’ welcome and organization. In Proceedings of the 27th ACM International Conference on User Modeling, Adaptation and Personalization, Larnaca, Cyprus, 9–12 June 2019. [Google Scholar] [CrossRef]
- Hasson, T. Examining Information Systems Developers’ Perceptions of Privacy; University of Haifa: Haifa, Israel, 2014. [Google Scholar]
- Bednar, K.; Spiekermann, S.; Langheinrich, M. Engineering Privacy by Design: Are engineers ready to live up to the challenge? Inf. Soc. 2019, 35, 122–142. [Google Scholar] [CrossRef]
- Hadar, I.; Hasson, T.; Ayalon, O.; Toch, E.; Birnhack, M.; Sherman, S.; Balissa, A. Privacy by designers: Software developers’ privacy mindset. Empir. Softw. Eng. 2017, 23, 259–289. [Google Scholar] [CrossRef]
- Ní Bhroin, N.; Dinh, T.; Thiel, K.; Lampert, C.; Staksrud, E.; Ólafsson, K. The Privacy Paradox by Proxy: Considering Predictors of Sharenting. Media Commun. 2022, 10, 371–383. [Google Scholar] [CrossRef]
- Feher, K. Digital identity and the online self:: Footprint strategies—An exploratory and comparative research study. J. Inf. Sci. 2021, 47, 192–205. [Google Scholar] [CrossRef]
- Peras, D.; Mekovec, R. A conceptualization of the privacy concerns of cloud users. Inf. Comput. Secur. 2022, 30, 653–671. [Google Scholar] [CrossRef]
- Knijnenburg, B.P. Privacy? I Can’t Even! Making a Case for User-Tailored Privacy. IEEE Secur. Priv. 2017, 15, 62–67. [Google Scholar] [CrossRef]
- Schaub, F.; Könings, B.; Weber, M. Context-Adaptive Privacy: Leveraging Context Awareness to Support Privacy Decision Making. IEEE Pervasive Comput. 2015, 14, 34–43. [Google Scholar] [CrossRef]
- Collier, B.; Stewart, J. Privacy Worlds: Exploring Values and Design in the Development of the Tor Anonymity Network. Sci. Technol. Hum. Values 2021, 47, 910–936. [Google Scholar] [CrossRef]
- Sanderson, C.; Douglas, D.; Lu, Q.; Schleiger, E.; Whittle, J.; Lacey, J.; Newnham, G.; Hajkowicz, S.; Robinson, C.; Hansen, D. AI Ethics Principles in Practice: Perspectives of Designers and Developers. IEEE Trans. Technol. Soc. 2023, 4, 171–187. [Google Scholar] [CrossRef]
- Tahaei, M.; Frik, A.; Vaniea, K. Privacy Champions in Software Teams: Understanding Their Motivations, Strategies, and Challenges. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–15. [Google Scholar] [CrossRef]
- A. M. Ibrahim, F.; Hemayed, E.E. Trusted Cloud Computing Architectures for infrastructure as a service: Survey and systematic literature review. Comput. Secur. 2019, 82, 196–226. [Google Scholar] [CrossRef]
- Iwaya, L.H.; Babar, M.A.; Rashid, A. Privacy Engineering in the Wild: Understanding the Practitioners’ Mindset, Organizational Aspects, and Current Practices. IEEE Trans. Softw. Eng. 2023, 49, 4324–4348. [Google Scholar] [CrossRef]
- T. Li, P. Privacy Annotations: Designing Privacy Support for Developers. Ph.D. Thesis, Human-Computer Interaction Institute, Carnegie Mellon University, Pittsburgh, PA, USA, 2023.
- Microsoft: Authorization Code Flow (3-legged OAuth). Available online: https://learn.microsoft.com/en-us/linkedin/shared/authentication/authorization-code-flow (accessed on 18 January 2025).
- OpenAI API Specification. Available online: https://platform.openai.com/docs/api-reference/introduction (accessed on 18 January 2025).
- Pillow. Available online: https://pypi.org/project/pillow/ (accessed on 18 January 2025).
- OpenCV. Available online: https://opencv.org/ (accessed on 18 January 2025).
- Hugging Face: Meta-Llama/Llama-3.1-8B-Instruct. Available online: https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct (accessed on 18 January 2025).
- Hugging Face: LLaVA-1.6/Mistral-7B. Available online: https://huggingface.co/liuhaotian/llava-v1.6-mistral-7b (accessed on 18 January 2025).
- IBM: What Is Quantization? Available online: https://www.ibm.com/think/topics/quantization (accessed on 18 January 2025).
- Llama.cpp Project. Available online: https://github.com/ggerganov/llama.cpp (accessed on 18 January 2025).
- OpenAI: Structured Outputs. Available online: https://platform.openai.com/docs/guides/structured-outputs (accessed on 18 January 2025).
- Python: PEP 292—Simpler String Substitutions. Available online: https://peps.python.org/pep-0292/ (accessed on 18 January 2025).
- OpenAI Platform: Text Generation. Available online: https://platform.openai.com/docs/guides/text-generation (accessed on 18 January 2025).
- OpenCV Zoo and Benchmark. Available online: https://github.com/opencv/opencv_zoo (accessed on 18 January 2025).
- Open Source Computer Vision. Available online: https://docs.opencv.org/4.x/d4/d13/tutorial_py_filtering.html (accessed on 18 January 2025).
- PM2: Production Process Manager for node.js. Available online: https://pm2.keymetrics.io/ (accessed on 18 January 2025).
- Gritzalis, S.; Sideri, M.; Kitsiou, A.; Tzortzaki, E.; Kalloniatis, C. Sustaining Social Cohesion in Information and Knowledge Society: The Priceless Value of Privacy. In Advances in Core Computer Science-Based Technologies; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 177–198. [Google Scholar] [CrossRef]
- Kitsiou, A.; Tzortzaki, E.; Kalloniatis, C.; Gritzalis, S. Measuring Users’ Socio-contextual Attributes for Self-adaptive Privacy Within Cloud-Computing Environments. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 140–155. [Google Scholar] [CrossRef]
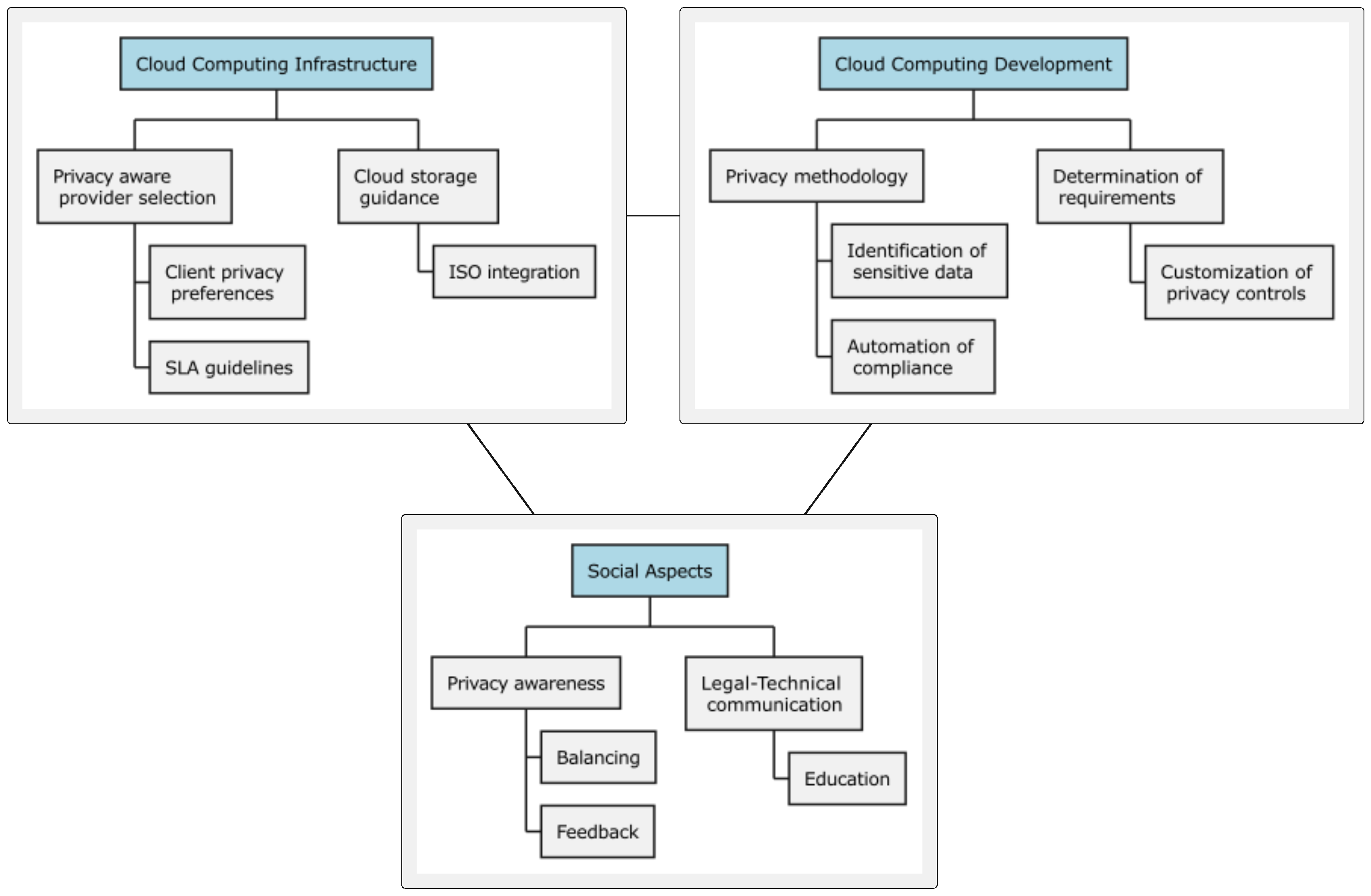
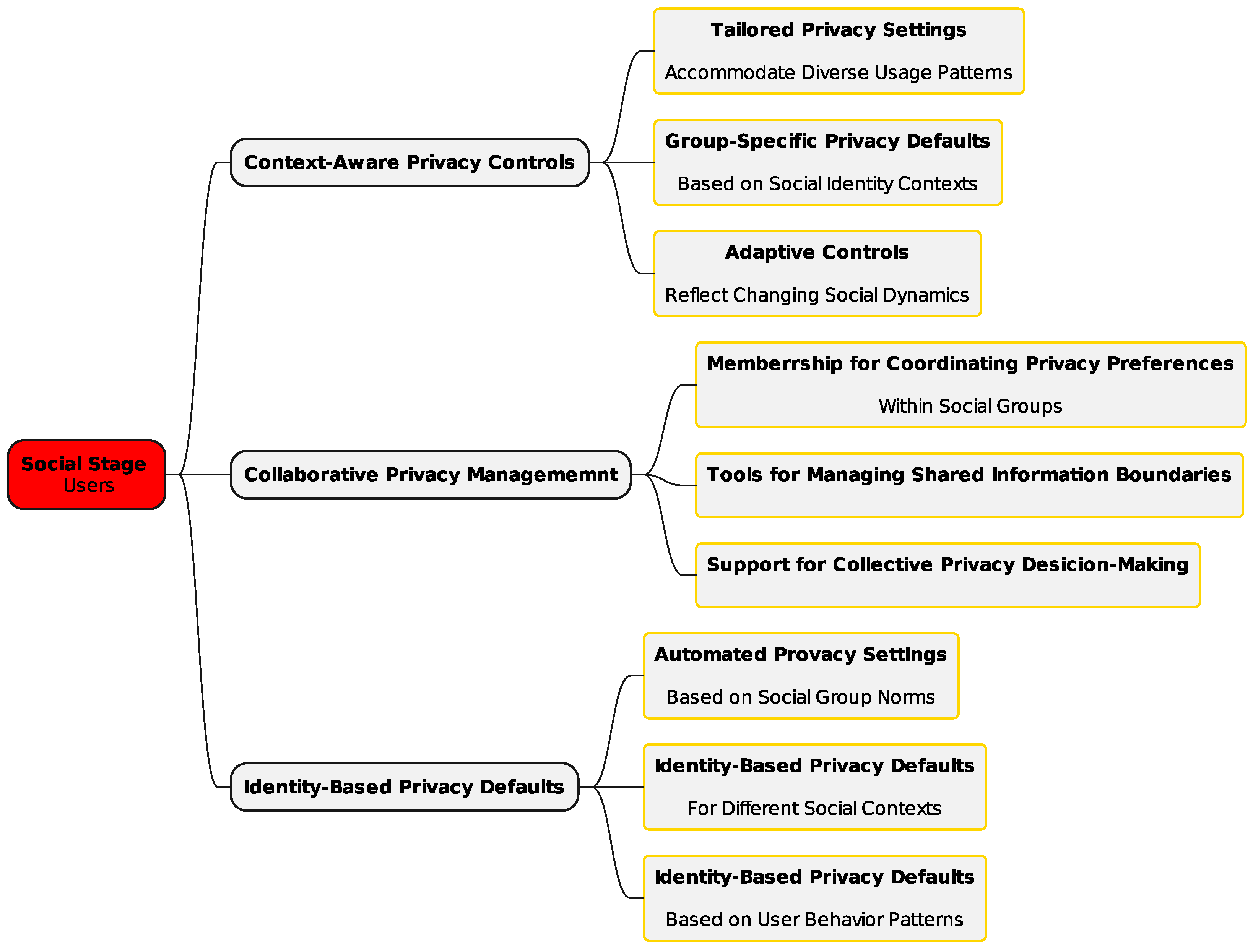
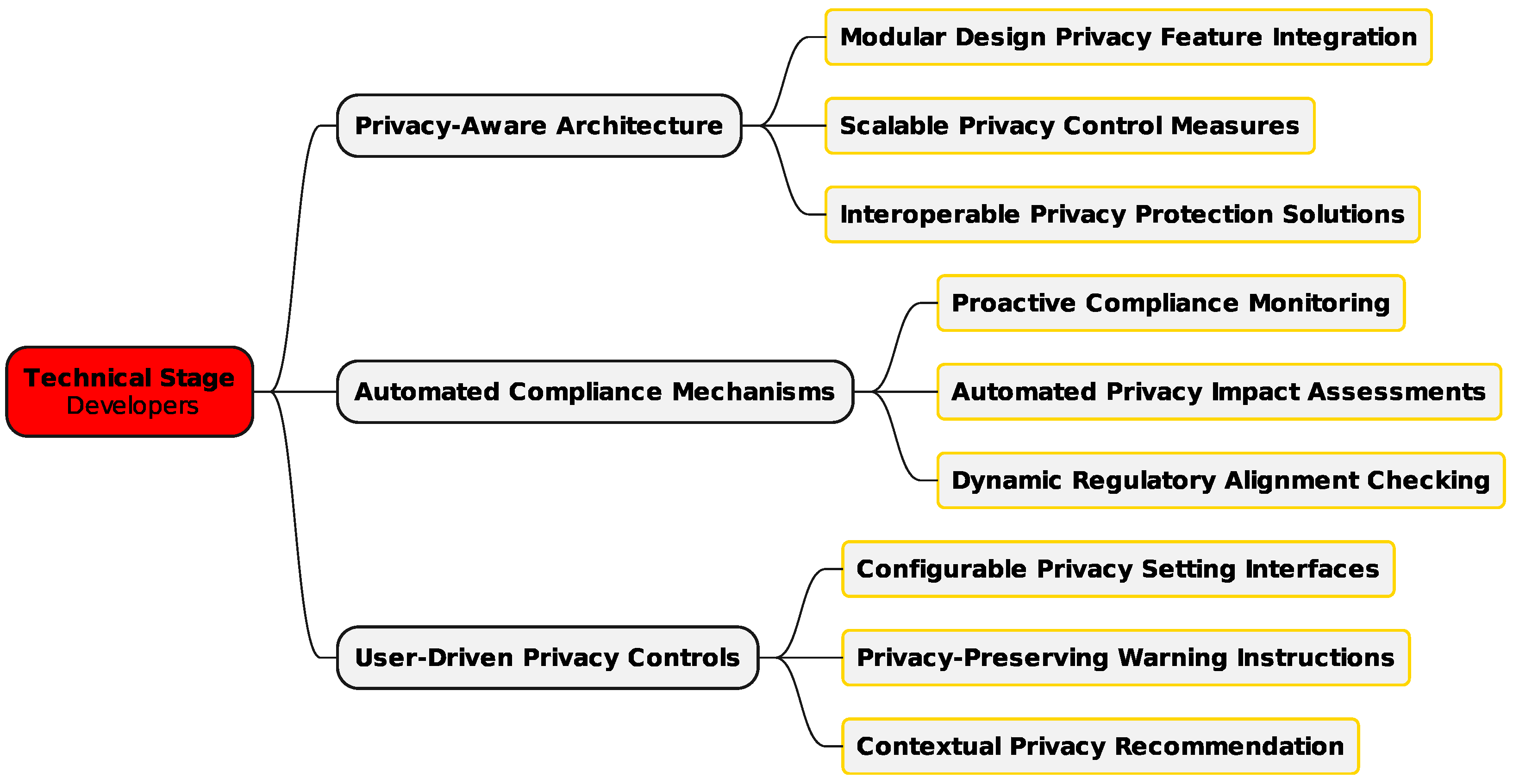
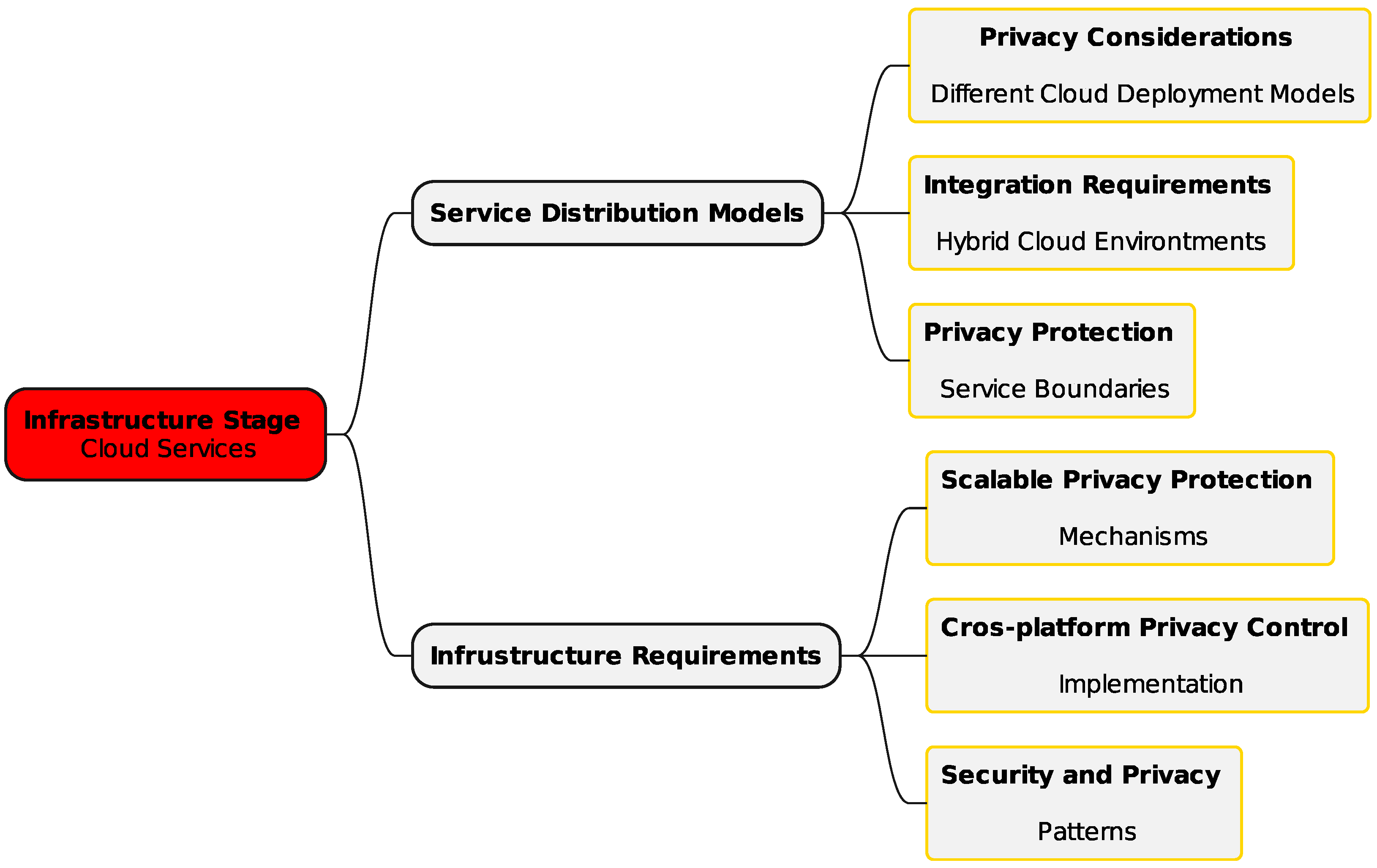
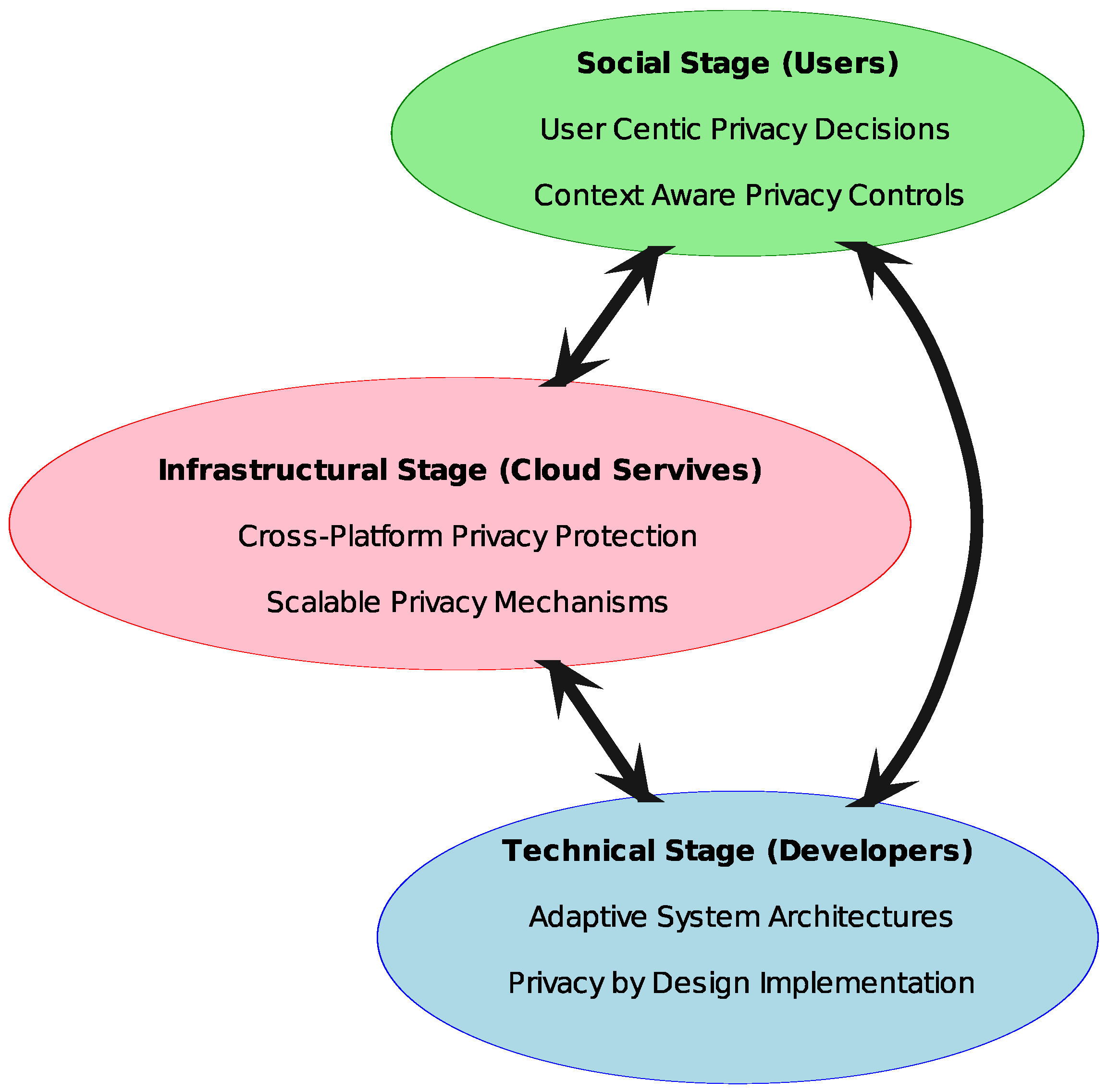
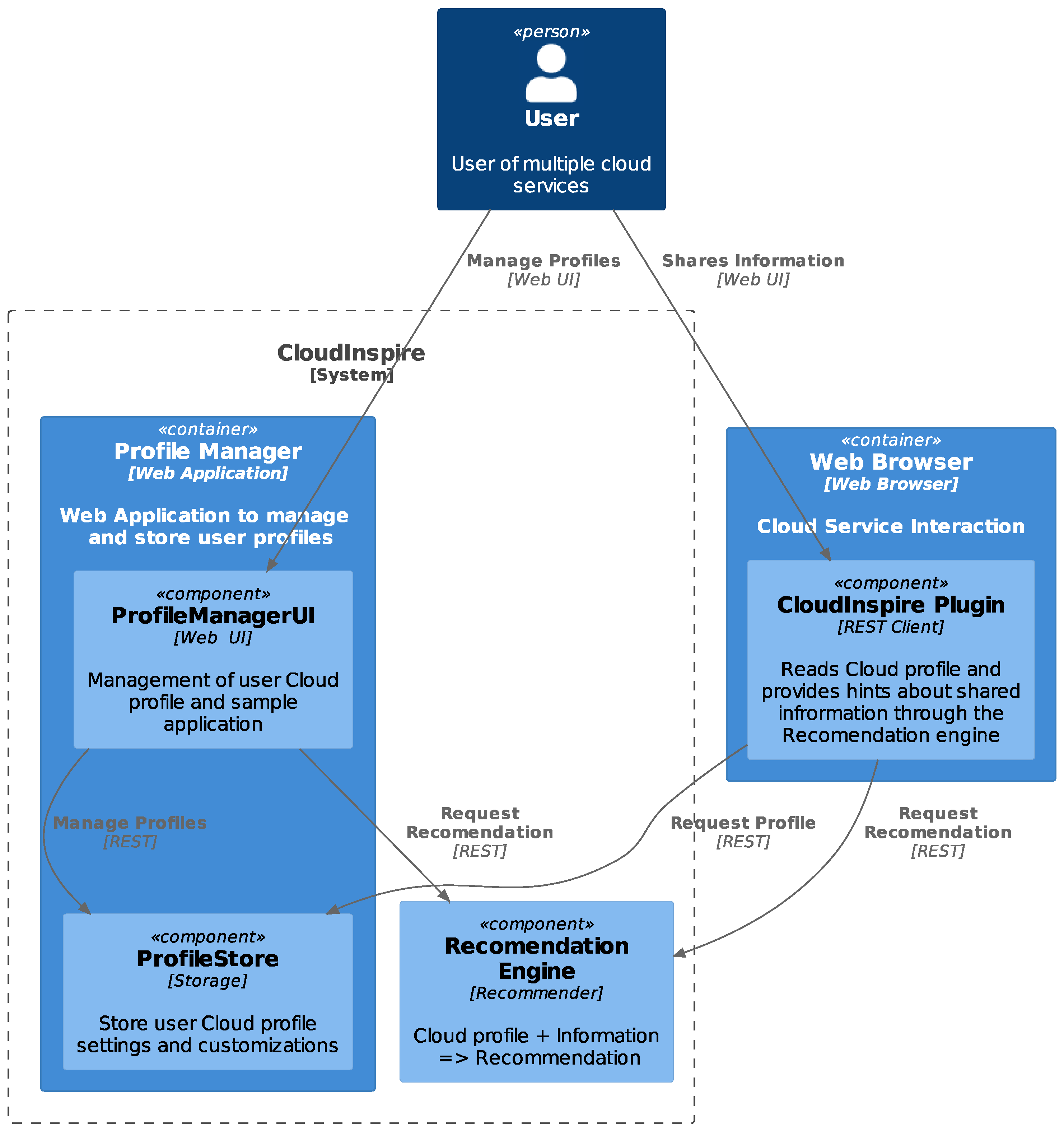
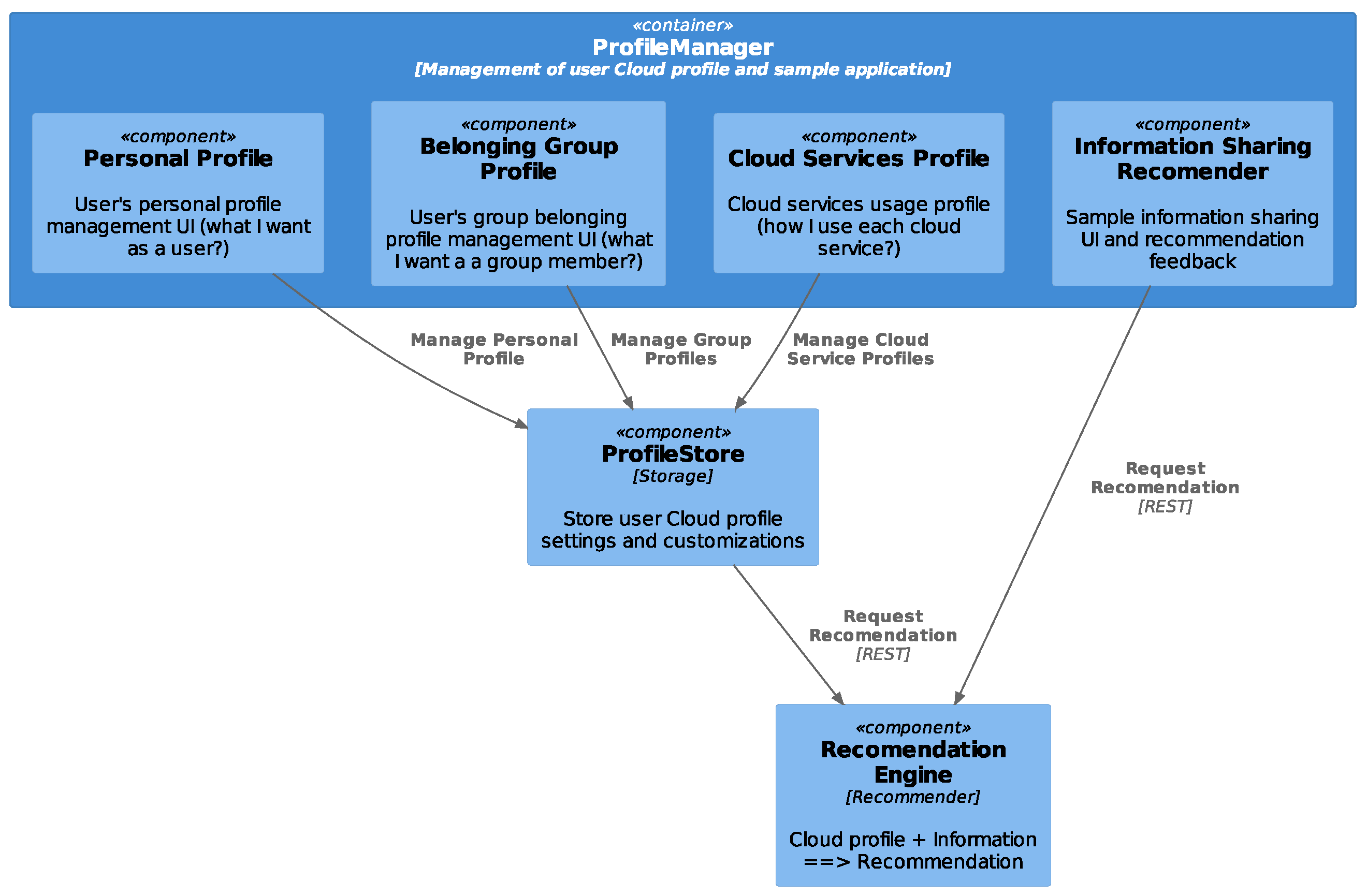
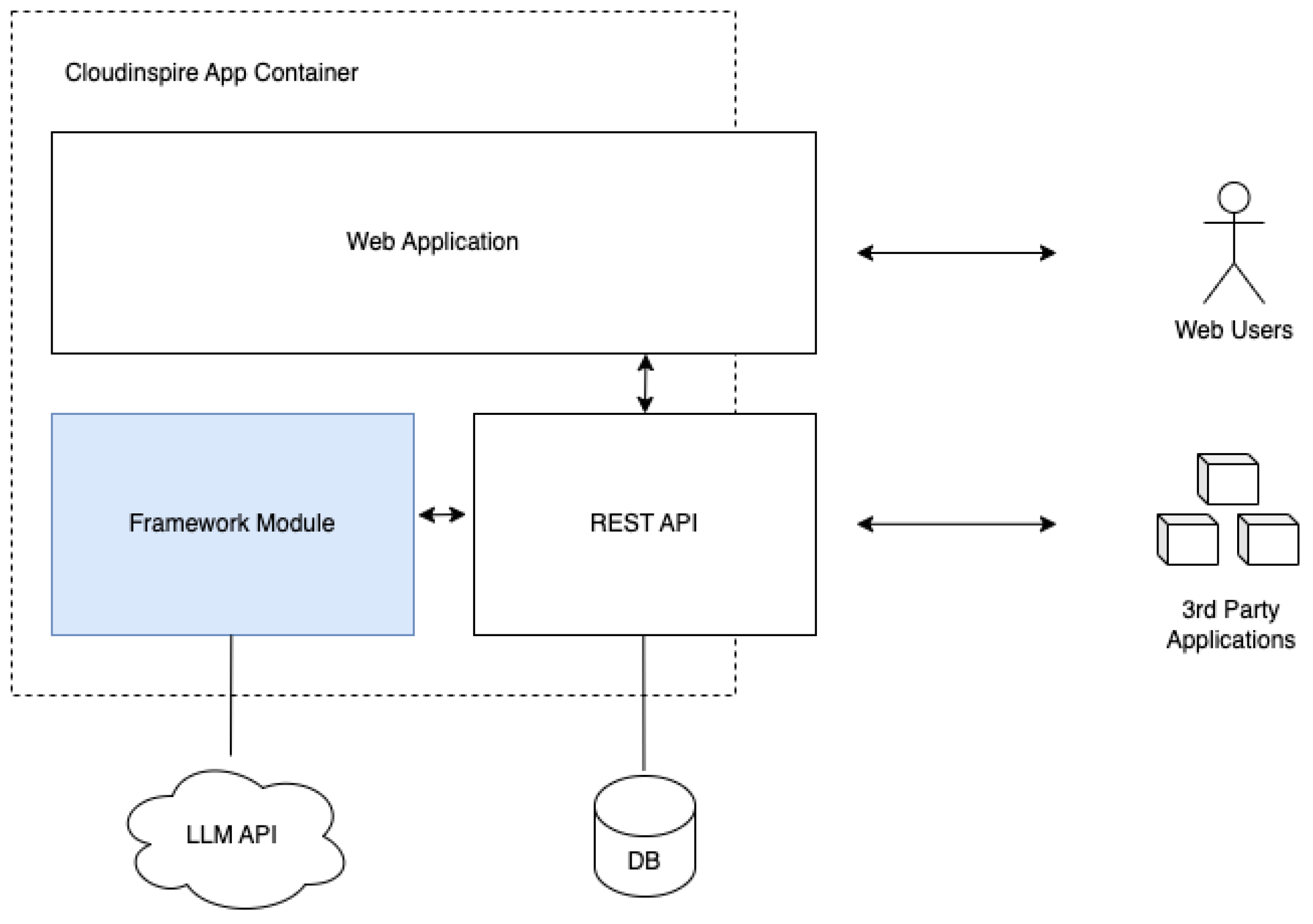
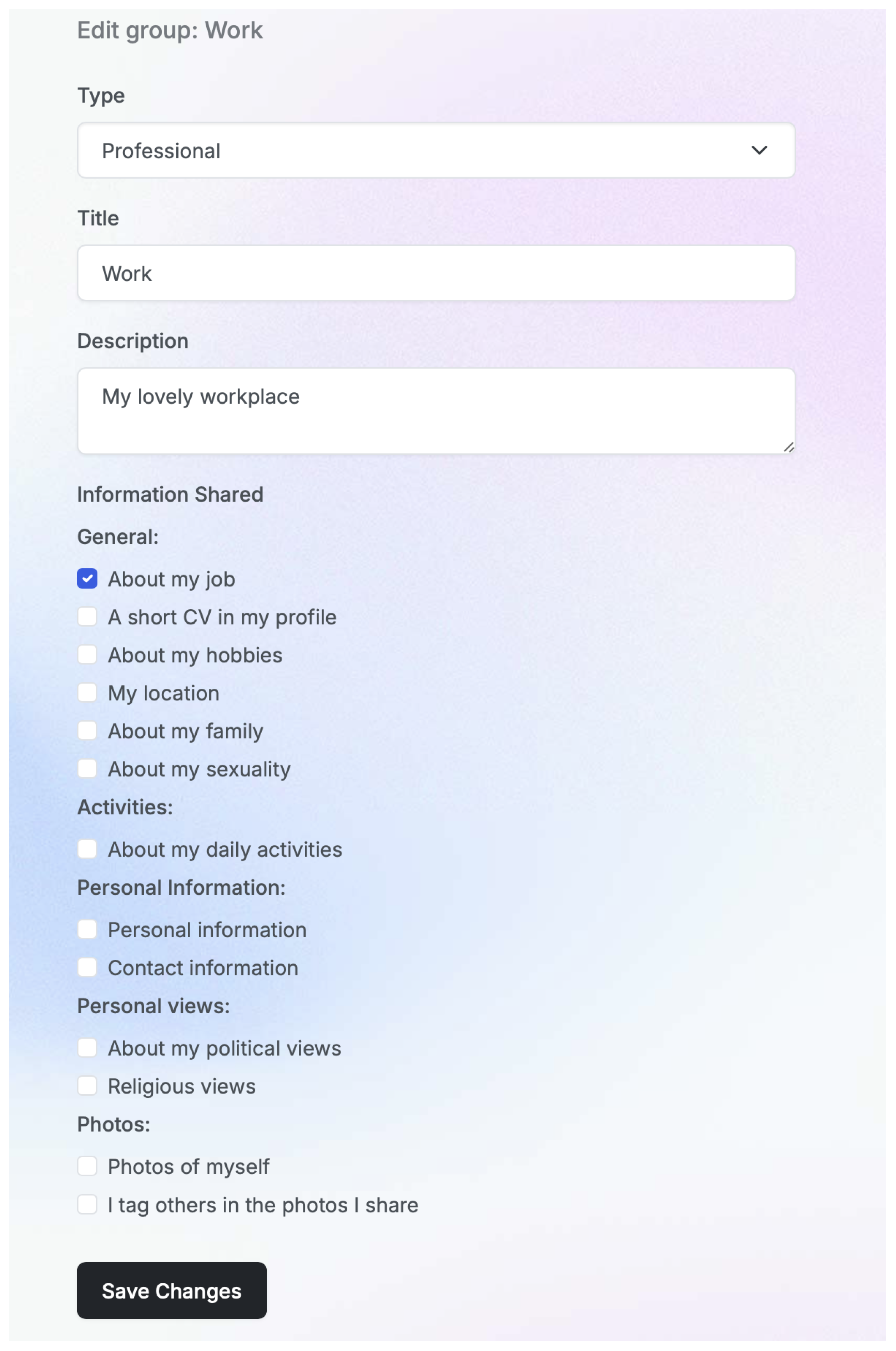
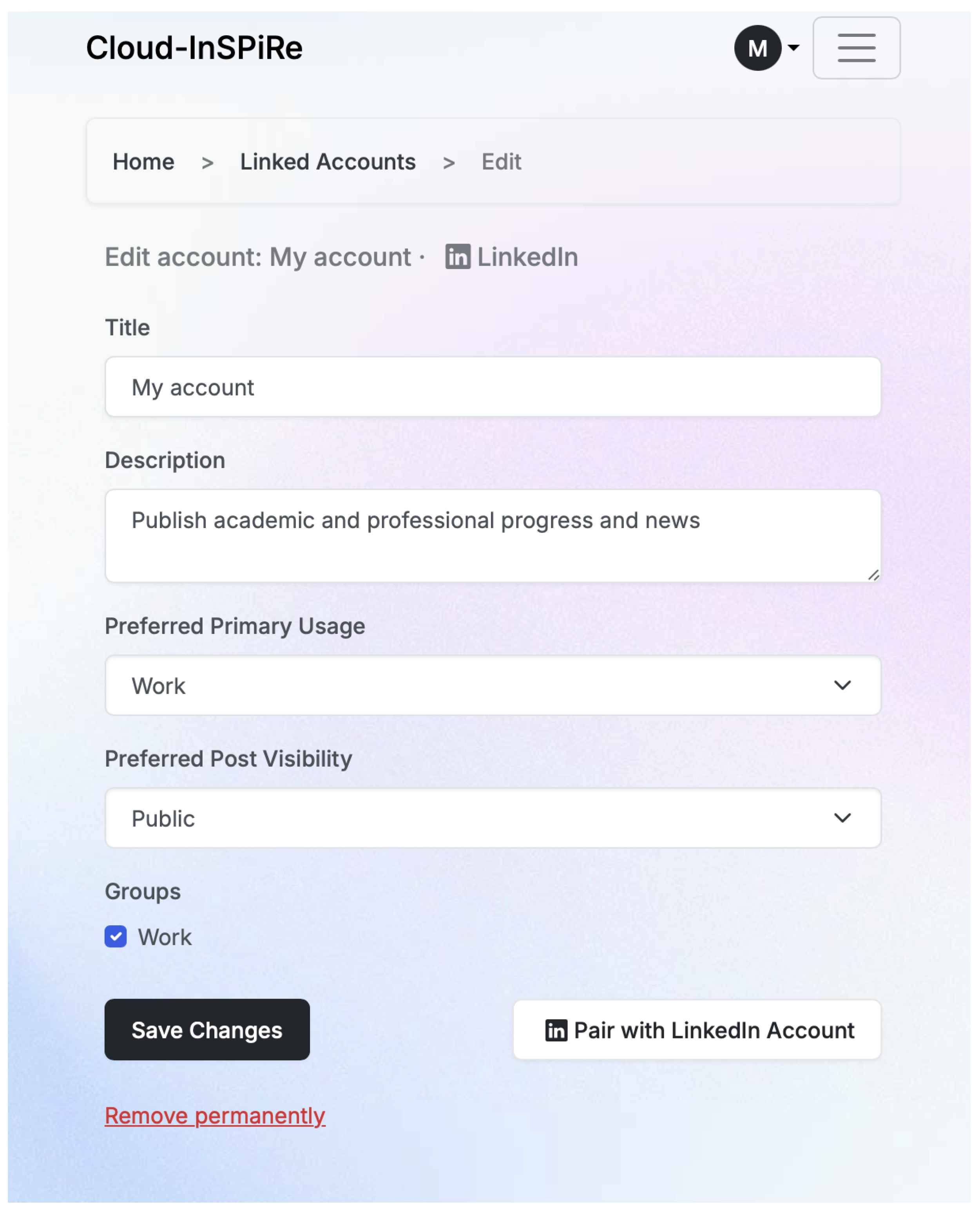
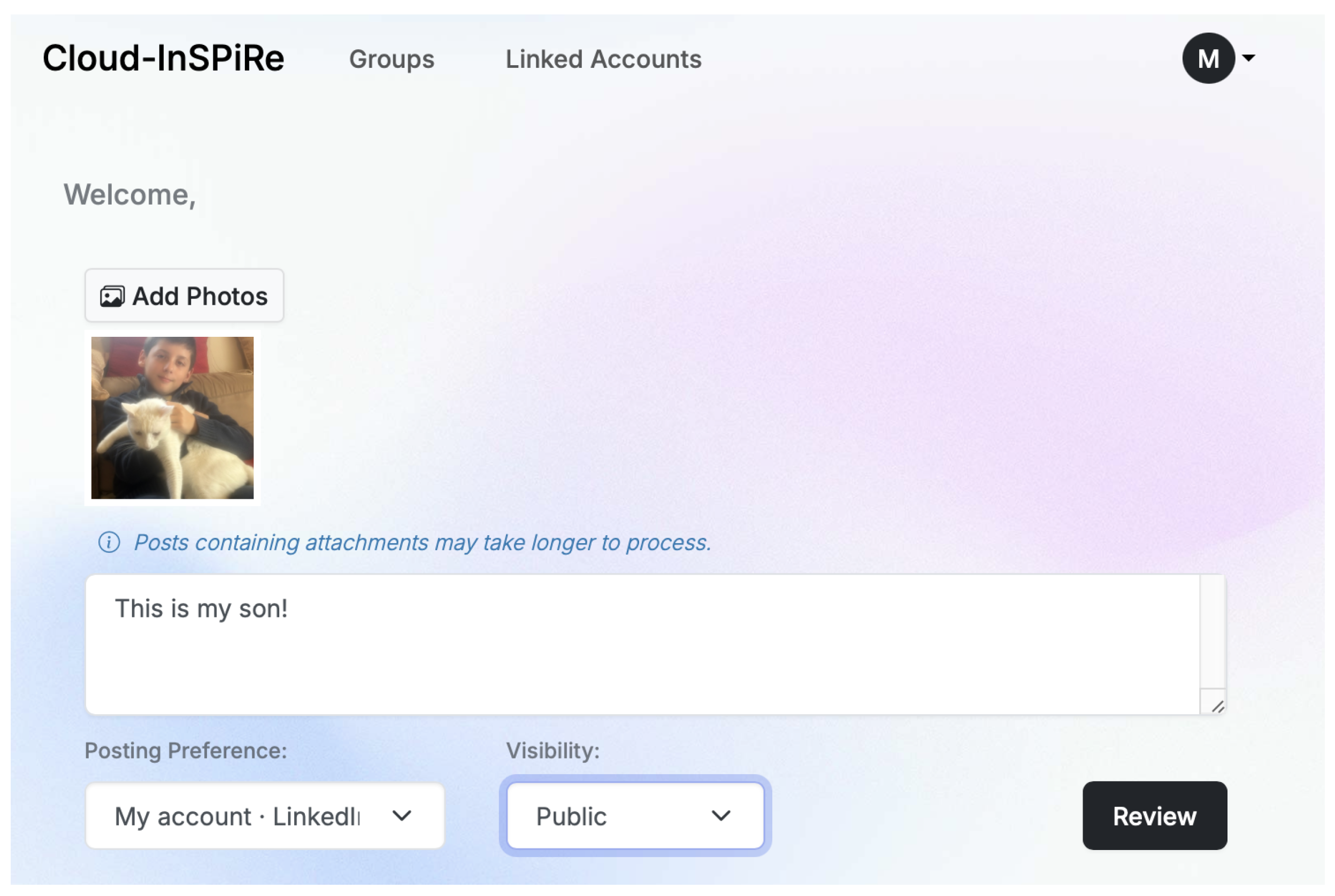
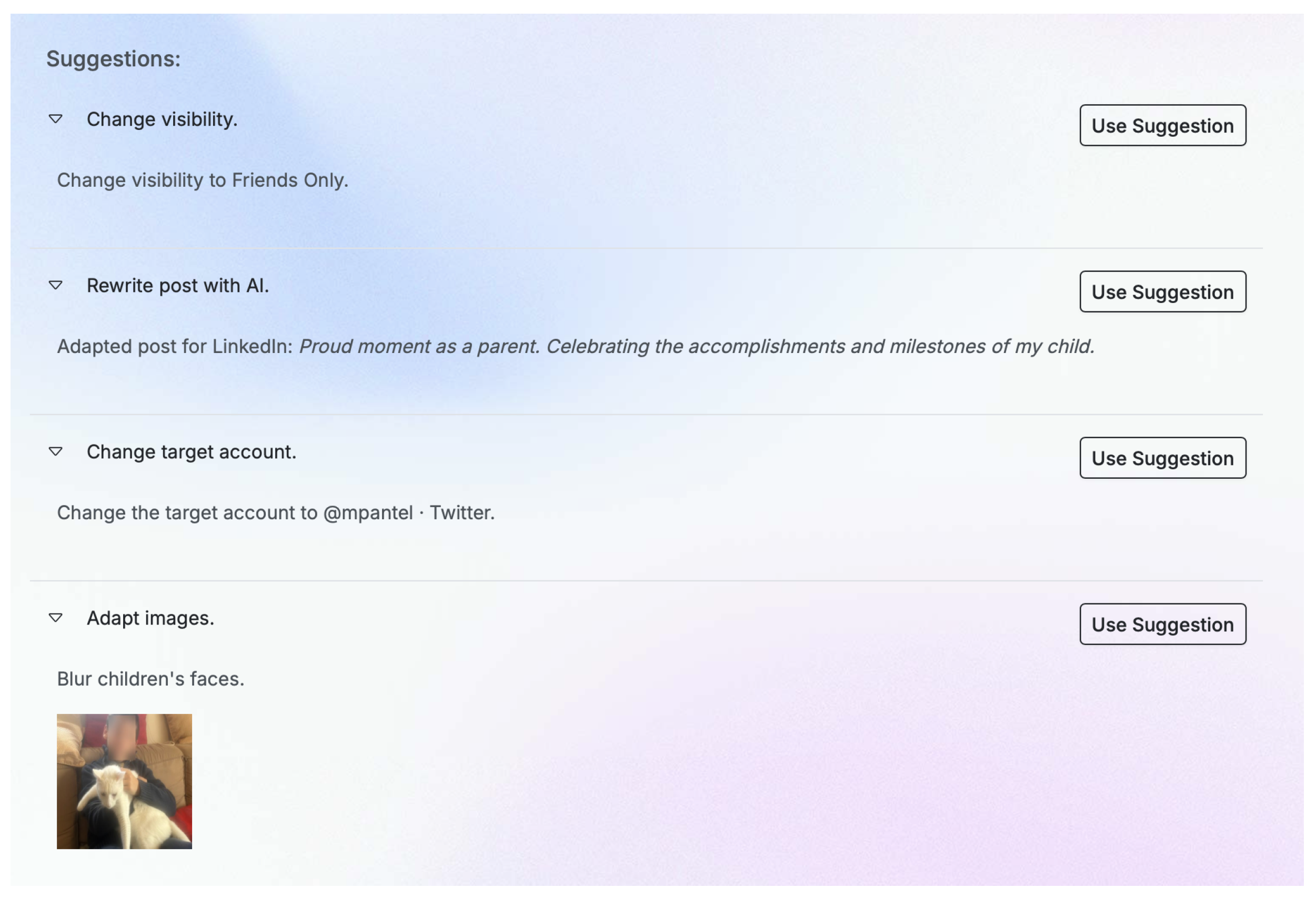
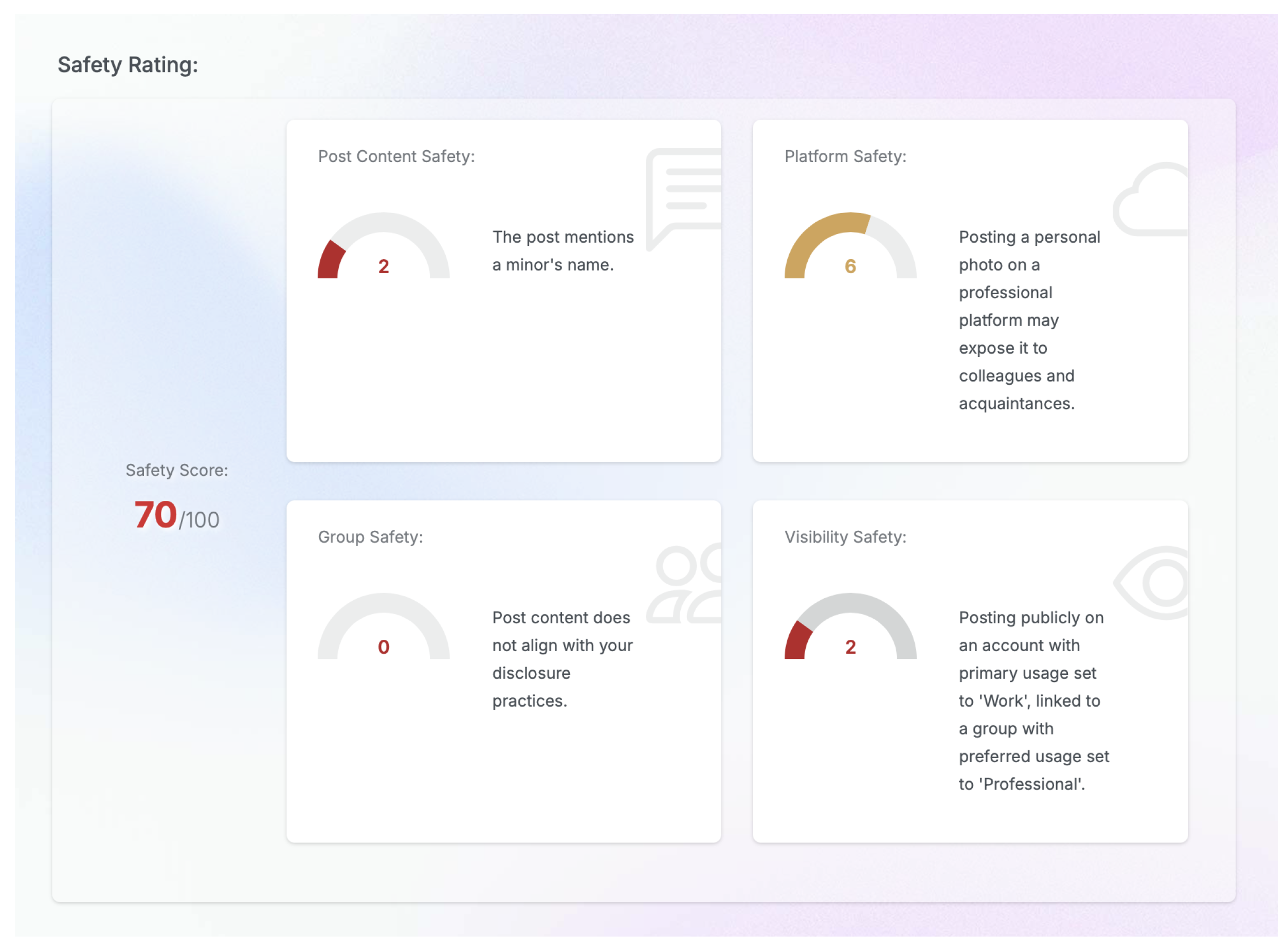
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).