
Traffic-Forecasting Model with Spatio-Temporal Kernel


Abstract
1. Introduction
- We introduce an innovative spatio-temporal kernel designed for graph learning, which explicitly disentangles spatial and temporal heterogeneity. To the best of our knowledge, this represents the first instance of employing a spatio-temporal kernel to concurrently generate both spatial and temporal graph matrices.
- We introduces the temporal graph convolution module to enhance temporal feature representation.
- The model was evaluated on two real-world datasets, demonstrating superior performance relative to a suite of state-of-the-art models.
2. Related Works
3. Method
3.1. Problem Definition
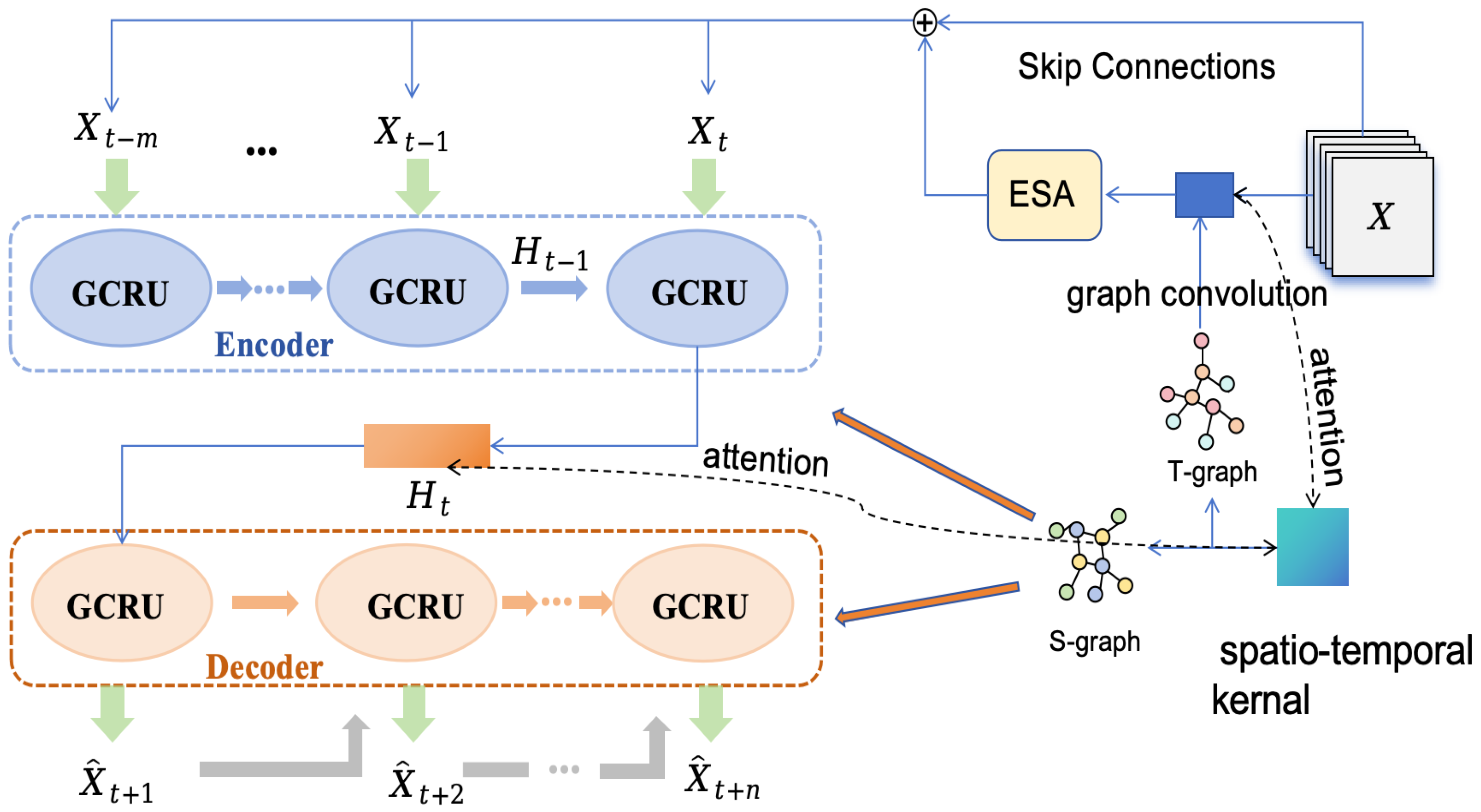
3.2. Model Architecture
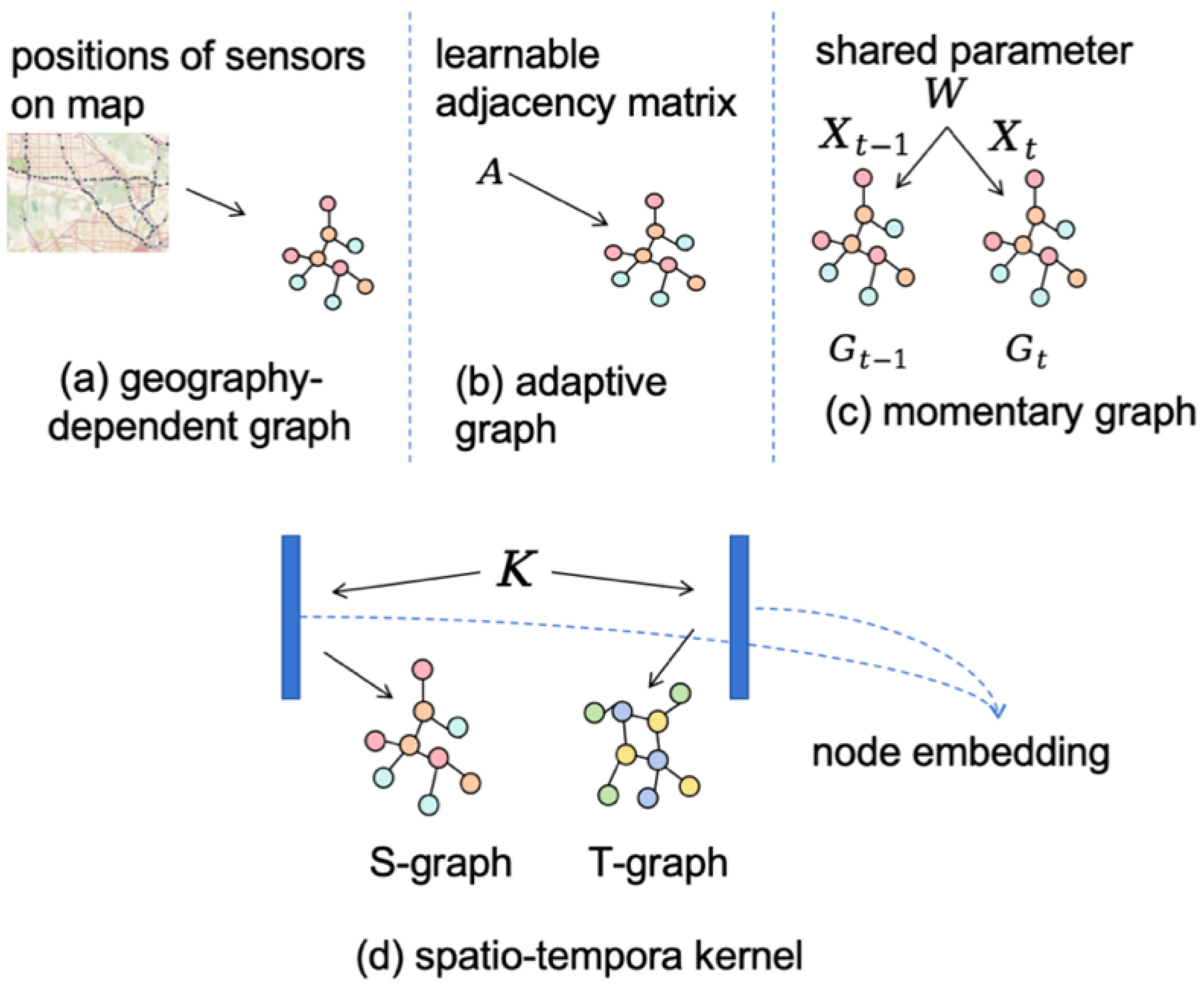
3.2.1. Spatio-Temporal Kernel
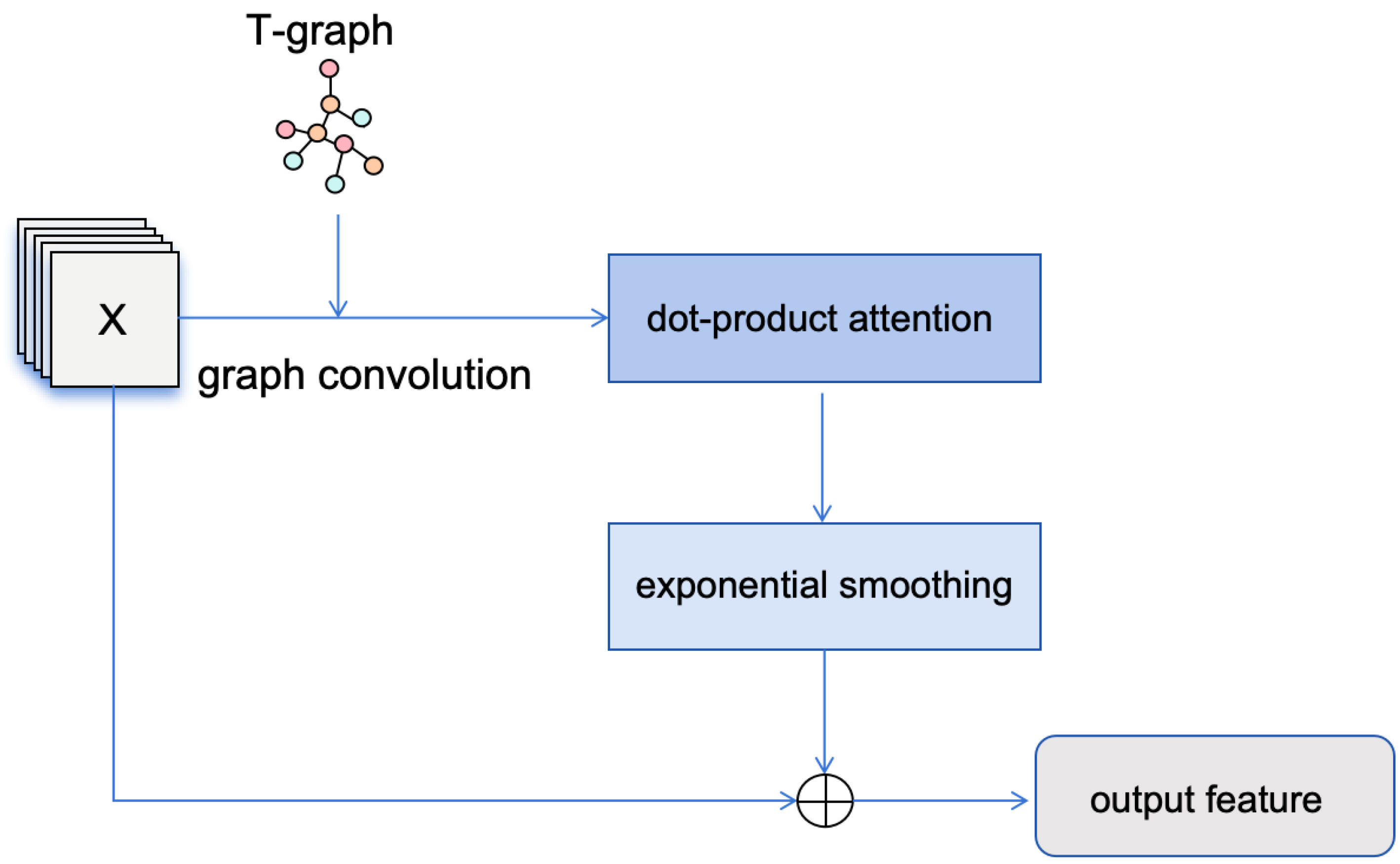
3.2.2. Temporal Graph Convolution Module
3.2.3. Graph Convolutional Recurrent Unit
3.2.4. Encoder Stacks and Decoder Stacks
4. Experiments
4.1. Datasets
4.2. Parameter Settings and Evaluation Metrics
4.3. Baselines
- Spatio-temporal graph convolutional networks (STGCN) [8]. A generic graph-based formulation for modeling dynamic skeletons, which is the first that applies graph-based neural networks for this task.
- Diffusion convolutional recurrent neural network (DCRNN) [7]. DCRNN employs an encoder–decoder framework for multi-step forecasting and substitutes the linear operations within the gated recurrent unit (GRU) with a diffusion graph convolution network.
- Graph WaveNet (GWNet) [13]. An advanced model derived from STGCN, which pioneers the use of an adaptive adjacency matrix to model spatial dependencies.
- Multivariate time-series graph neural network (MTGNN) [15]. An enhanced variant of GWNet, which eliminates the reliance on any prior knowledge for graph construction.
- Pattern-matching memory network (PM-MemNet) [35]. PM-MemNet utilizes memory networks for traffic-pattern matching.
- Graph for time series (GTS) [14]. GTS constructs a graph where the probability of each edge is determined by the long-term historical data associated with each node.
- Spectral temporal graph neural network (StemGNN) [10]. StemGNN integrates graph Fourier transform (GFT) to capture inter-series correlations and discrete Fourier transform (DFT) to model temporal dependencies within an end-to-end framework.
- Higher-order multi-graph neural network (HOMGNN) [29]. A methodology that integrates geographical dependency graphs with adaptive graphs, designed to address scenarios where higher-order neighbors exert a greater influence on the vertex.
- Multi-range attentive bicomponent graph convolutional network (MRA-BGCN) [36]. MRA-BGCN replaces the graph convolutional network (GCN) in DCRNN with the bicomponent graph convolution.
- Graph multi-attention network (GMAN) [37]. GMAN introduces a novel transform attention mechanism to eliminate the need for dynamic decoding, which is typically required in the standard transformer architecture.
- Traffic transformer [38]. A modified version of the transformer architecture, it employs a global encoder and a global-local decoder to capture and integrate spatial patterns.
4.4. Performance Comparison
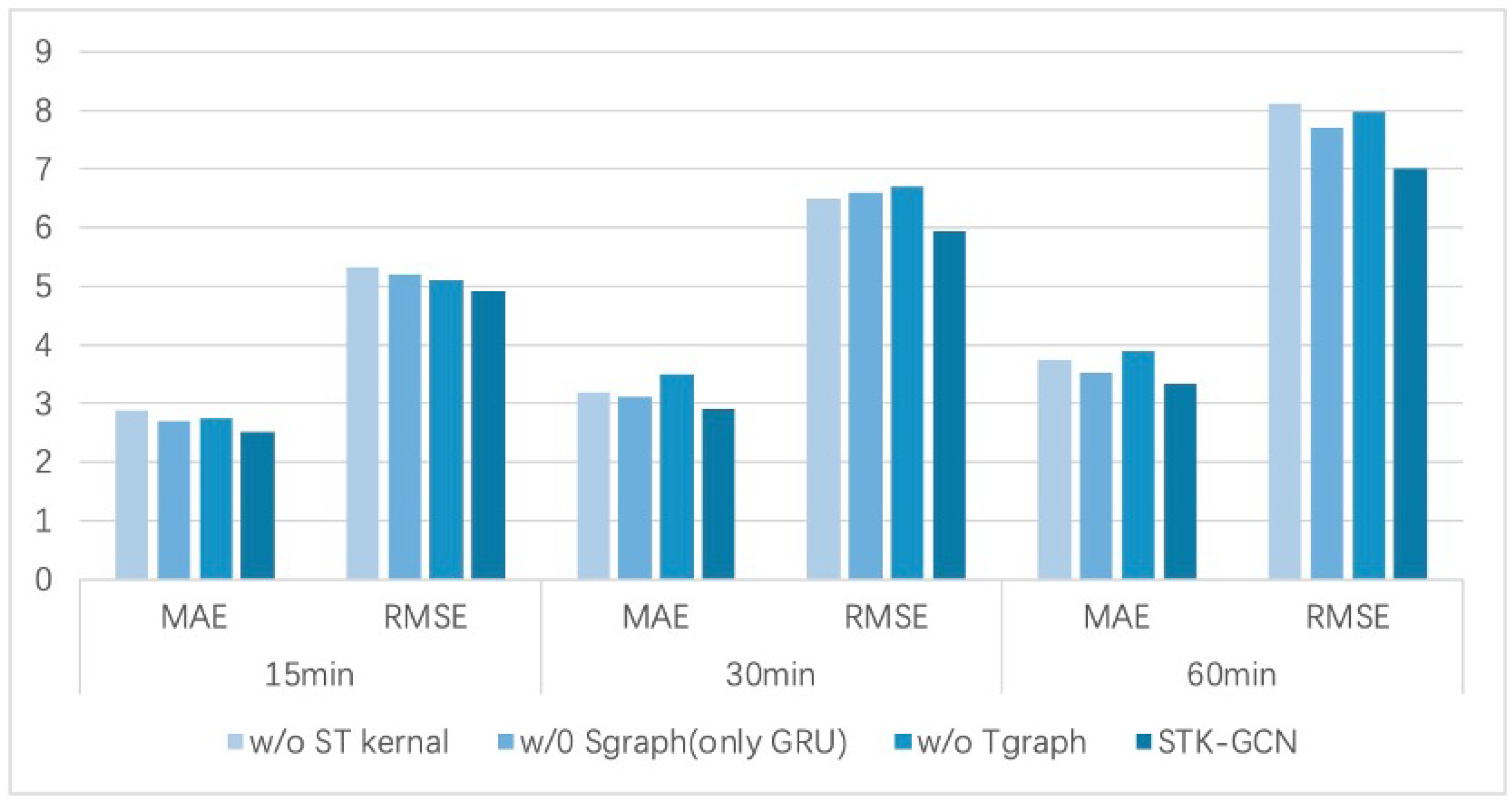
5. Ablation Study
- without spatio-temporal kernel. This model eliminates the spatio-temporal kernel and instead uses two adaptive graphs.
- without Sgraph. The spatial graph convolution was removed, that is, the graph convolution part in GCRU was eliminated and GRU was used alone.
- without Tgraph. This variant eliminates the temporal graph convolution module, encompassing both the temporal graph convolution and the exponential smoothing components.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MAE | RMSE | MAPE |
|---|---|---|---|
| without ST kernal | 3.50 | 7.16 | 9.92% |
| without Sgraph | 2.90 | 6.05 | 7.93% |
| without Tgraph | 2.89 | 5.96 | 7.86% |
| STK-GCN | 2.86 | 5.90 | 7.76% |
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviations | Full Form |
| STK-GCN | Spatio-temporal kernel graph convolutional network |
| GCRU | Graph convolutional recurrent unit |
| MAE | Mean absolute error |
| RMSE | Root mean squared error |
| MAPE | Mean absolute percentage error |
References
- Li, Z.; Sergin, N.D.; Yan, H.; Zhang, C.; Tsung, F. Tensor Completion for Weakly-Dependent Data on Graph for Metro Passenger Flow Prediction; Association for the Advancement of Artificial Intelligence: Washington, DC, USA, 2020; Volume 34, pp. 4804–4810. [Google Scholar]
- Hu, J.; Yang, B.; Guo, C.; Jensen, C.S. Risk-aware path selection with time-varying, uncertain travel costs: A time series approach. Int. Conf. Very Large Data Bases 2018, 27, 179–200. [Google Scholar]
- Figueiredo, L.; Jesus, I.; Machado, J.T.; Ferreira, J.R.; De Carvalho, J.M. Towards the development of intelligent transportation systems. In Proceedings of the ITSC 2001. 2001 IEEE Intelligent Transportation Systems. Proceedings (Cat. No.01TH8585), Oakland, CA, USA, 25–29 August 2001; pp. 1206–1211. [Google Scholar]
- Jiang, W.; Luo, J. Graph neural network for traffic forecasting: A survey. Expert. Syst. Appl. 2022, 207, 117921. [Google Scholar]
- Williams, B.M.; Hoel, L.A. Modeling and forecasting vehicular traffic flow as a seasonal ARIMA process: Theoretical basis and empirical results. J. Transp. Eng. 2003, 129, 664–672. [Google Scholar] [CrossRef]
- Wu, C.H.; Ho, J.M.; Lee, D.T. Travel-time prediction with support vector regression. IEEE Trans. Intell. Transp. Syst. 2004, 5, 276–281. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv 2017, arXiv:1707.01926. [Google Scholar]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. arXiv 2017, arXiv:1709.04875. [Google Scholar]
- Seo, Y.; Defferrard, M.; Vandergheynst, P.; Bresson, X. Structured sequence modeling with graph convolutional recurrent networks. In Proceedings of the Neural Information Processing: 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, 13–16 December 2018; Proceedings Part I 25. Springer: Cham, Switzerland, 2018; pp. 362–373. [Google Scholar]
- Cao, D.; Wang, Y.; Duan, J.; Zhang, C.; Zhu, X.; Huang, C.; Tong, Y.; Xu, B.; Bai, J.; Tong, J.; et al. Spectral temporal graph neural network for multivariate time-series forecasting. Adv. Neural. Inf Process. Syst. 2020, 33, 17766–17778. [Google Scholar]
- Chen, C.; Li, K.; Teo, S.G.; Zou, X.; Wang, K.; Wang, J.; Zeng, Z. Gated residual recurrent graph neural networks for traffic prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 485–492. [Google Scholar]
- Diao, Z.; Wang, X.; Zhang, D.; Liu, Y.; Xie, K.; He, S. Dynamic spatial-temporal graph convolutional neural networks for traffic forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 890–897. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph wavenet for deep spatial-temporal graph modeling. arXiv 2019, arXiv:1906.00121. [Google Scholar]
- Shang, C.; Chen, J.; Bi, J. Discrete graph structure learning for forecasting multiple time series. arXiv 2021, arXiv:2101.06861. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Connecting the dots: Multivariate time series forecasting with graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 753–763. [Google Scholar]
- Stock, J.H.; Watson, M.W. Vector autoregressions. J. Econ. Perspect. 2001, 15, 101–115. [Google Scholar]
- Van Lint, J.; Van Hinsbergen, C. Short-term traffic and travel time prediction models. Artif. Intell. Appl. Crit. Transp. Issues. 2012, 22, 22–41. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [PubMed]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural. Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Fang, Y.; Zhao, F.; Qin, Y.; Luo, H.; Wang, C. Learning all dynamics: Traffic forecasting via locality-aware spatio-temporal joint transformer. IEEE Trans. Intell. Transp. Syst. 2022, 23, 23433–23446. [Google Scholar]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.X.; Yan, X. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. Adv. Neural. Inf. Process. Syst. 2019, 32, 5243–5253. [Google Scholar]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 922–929. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Zhang, Z.; Cui, P.; Zhu, W. Deep learning on graphs: A survey. IEEE Trans. Knowl. Data Eng. 2020, 34, 249–270. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar]
- Jiang, R.; Wang, Z.; Yong, J.; Jeph, P.; Chen, Q.; Kobayashi, Y.; Song, X.; Fukushima, S.; Suzumura, T. Spatio-temporal meta-graph learning for traffic forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 8078–8086. [Google Scholar]
- Yuan, K.; Liu, J.; Lou, J. Higher-order masked graph neural networks for traffic flow prediction. In Proceedings of the 2022 IEEE International Conference on Data Mining (ICDM), Orlando, FL, USA, 28 November–1 December 2022; pp. 1305–1310. [Google Scholar]
- Abduljabbar, R.; Dia, H.; Liyanage, S. Machine learning models for traffic prediction on arterial roads using traffic features and weather information. Appl. Sci. 2024, 14, 11047. [Google Scholar] [CrossRef]
- Alonso-Solorzano, Á.; Pérez-Acebo, H.; Findley, D.J.; Gonzalo-Orden, H. Transition probability matrices for pavement deterioration modelling with variable duty cycle times. Int. J. Pave. Eng. 2024, 24, 2278694. [Google Scholar]
- Wu, Y.; Pang, Y.; Zhu, X. Evolution of prediction models for road surface irregularity: Trends, methods and future. Constr. Build. Mater. 2024, 449, 138316. [Google Scholar]
- Hyndman, R.; Koehler, A.B.; Ord, J.K.; Snyder, R.D. Forecasting with Exponential Smoothing: The State Space Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural. Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Lee, H.; Jin, S.; Chu, H.; Lim, H.; Ko, S. Learning to remember patterns: Pattern matching memory networks for traffic forecasting. arXiv 2021, arXiv:2110.10380. [Google Scholar]
- Chen, W.; Chen, L.; Xie, Y.; Cao, W.; Gao, Y.; Feng, X. Multi-range attentive bicomponent graph convolutional network for traffic forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3529–3536. [Google Scholar]
- Zheng, C.; Fan, X.; Wang, C. GMAN: A Graph Multi-Attention Network for Traffic Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1234–1241. [Google Scholar]
- Yan, H.; Ma, X. Learning dynamic and hierarchical traffic spatiotemporal features with transformer. IEEE trans. Intell. Transp. Syst. 2020, 23, 22386–22399. [Google Scholar]



| Dateset | Nodes | Start Time | Timesteps |
|---|---|---|---|
| METR-LA | 207 | 1 March 2012 | 34,272 |
| PEMS-BAY | 325 | 1 January 2017 | 52,116 |
| Dataset | Model | 15 min | 30 min | 60 min | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | ||
| METR-LA | STGCN | 2.88 | 5.74 | 7.62% | 3.47 | 7.24 | 9.57% | 4.59 | 9.40 | 12.70% |
| DCRNN | 2.77 | 5.38 | 7.30% | 3.15 | 6.45 | 8.80% | 3.60 | 7.60 | 10.50% | |
| GWNet | 2.69 | 5.15 | 6.90% | 3.07 | 6.22 | 8.37% | 3.53 | 7.37 | 10.01% | |
| MTGNN | 2.69 | 5.18 | 6.86% | 3.05 | 6.17 | 8.19% | 3.49 | 7.23 | 9.87% | |
| PM-MemNet | 2.65 | 5.29 | 7.01% | 3.03 | 6.29 | 8.42% | 3.46 | 7.29 | 9.97% | |
| StemGNN | 2.56 | 5.06 | 6.46% | 3.01 | 6.03 | 8.23% | 3.43 | 7.23 | 9.85% | |
| HOMGNN | 2.65 | 5.06 | 6.83% | 3.02 | 6.10 | 8.22% | 3.48 | 7.18 | 9.94% | |
| MRA-BGCN | 2.67 | 5.12 | 6.80% | 3.06 | 6.17 | 8.30% | 3.49 | 7.30 | 10.00% | |
| GMAN | 2.77 | 5.48 | 7.25% | 3.07 | 6.34 | 8.35% | 3.40 | 7.21 | 9.72% | |
| Traffic transformer | 2.66 | 5.11 | 6.75% | 3.00 | 6.06 | 8.00% | 3.39 | 7.04 | 9.37% | |
| STK-GCN | 2.52 | 4.91 | 6.33% | 2.91 | 5.95 | 7.71% | 3.33 | 7.01 | 9.28% | |
| PEMSBAY | STGCN | 1.36 | 2.96 | 2.90% | 1.81 | 4.27 | 4.17% | 2.49 | 5.69 | 5.79% |
| DCRNN | 1.38 | 2.95 | 2.90% | 1.74 | 3.97 | 3.90% | 2.07 | 4.74 | 4.90% | |
| GWNet | 1.34 | 2.83 | 2.79% | 1.69 | 3.80 | 3.79% | 2.00 | 4.54 | 4.73% | |
| MTGNN | 1.33 | 2.80 | 2.81% | 1.65 | 3.75 | 3.73% | 1.93 | 4.45 | 4.58% | |
| GTS | 1.34 | 2.84 | 2.83% | 1.67 | 3.83 | 3.79% | 1.98 | 4.56 | 4.59% | |
| PM-MemNet | 1.34 | 2.82 | 2.81% | 1.65 | 3.76 | 3.71% | 1.95 | 4.49 | 4.54% | |
| HOMGNN | 1.32 | 2.75 | 2.79% | 1.63 | 3.68 | 3.71% | 1.93 | 4.42 | 4.62% | |
| MRA-BGCN | 1.29 | 2.72 | 2.90% | 1.61 | 3.67 | 3.80% | 1.91 | 4.46 | 4.60% | |
| GMAN | 1.36 | 2.93 | 2.88% | 1.64 | 3.78 | 3.71% | 1.90 | 4.40 | 4.45% | |
| Traffic Transformer | 1.35 | 2.82 | 2.84% | 1.66 | 3.72 | 3.75% | 1.95 | 4.49 | 4.65% | |
| STK-GCN | 1.29 | 2.72 | 2.70% | 1.60 | 3.67 | 3.62% | 1.89 | 4.42 | 4.48% | |
| Model | STGCN | DCRNN | GWNet | GMAN | STK-GCN |
|---|---|---|---|---|---|
| 0.7351 | 0.7897 | 0.8044 | 0.7968 | 0.8235 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, H. Traffic-Forecasting Model with Spatio-Temporal Kernel. Electronics 2025, 14, 1410. https://doi.org/10.3390/electronics14071410
Deng H. Traffic-Forecasting Model with Spatio-Temporal Kernel. Electronics. 2025; 14(7):1410. https://doi.org/10.3390/electronics14071410
Chicago/Turabian StyleDeng, Han. 2025. "Traffic-Forecasting Model with Spatio-Temporal Kernel" Electronics 14, no. 7: 1410. https://doi.org/10.3390/electronics14071410
APA StyleDeng, H. (2025). Traffic-Forecasting Model with Spatio-Temporal Kernel. Electronics, 14(7), 1410. https://doi.org/10.3390/electronics14071410