Abstract
Helmet-wearing detection for electric vehicle riders is essential for traffic safety, yet existing detection models often suffer from high target occlusion and low detection accuracy in complex road environments. To address these issues, this paper proposes YOLO-CBF, an improved YOLOv7-based detection network. The proposed model integrates coordinate convolution to enhance spatial information perception, optimizes the Focal EIOU loss function, and incorporates the BiFormer dynamic sparse attention mechanism to achieve more efficient computation and dynamic content perception. These enhancements enable the model to extract key features more effectively, improving detection precision. Experimental results show that YOLO-CBF achieves an average mAP of 95.6% for helmet-wearing detection in various scenarios, outperforming the original YOLOv7 by 4%. Additionally, YOLO-CBF demonstrates superior performance compared to other mainstream object detection models, achieving accurate and reliable helmet detection for electric vehicle riders.
1. Introduction
Electric vehicles offer a cost-effective solution for “last mile” travel but face higher crashes risks [1]. Helmets are the primary safety equipment for electric bike riders, providing crucial protection in the event of an crash [2,3]. Therefore, it is of great significance to study the detection of helmet wearing by electric vehicle drivers.
Numerous researchers have delved into the field of helmet detection, successfully achieving automatic helmet detection for electric vehicle drivers [4,5,6]. Paulchamy et al. [7] proposed an intelligent miner helmet that integrates air quality monitoring, utilizing Zigbee technology for data transmission to enhance miner safety. Bhagat et al. [8] employed OpenCV’s cascaded classifier for helmet detection, significantly improving the accuracy and efficiency of the detection model. Wonghabut et al. [9] introduced a law enforcement assistance model that leverages CCTV surveillance cameras to automatically detect helmet usage, thereby improving public safety supervision through deep learning technology to enhance the efficiency and accuracy of law enforcement. Dahiya et al. [10] developed an automatic detection system, HRDS, for identifying cyclists without helmets in real-time monitoring videos, achieving an accuracy of over 92%. Vishnu et al. [11] first subtracted video frames using adaptive backgrounds to identify moving objects, then used a CNN to determine whether motorcycle riders were wearing helmets among the moving objects. Wu et al. [12] achieved high accuracy and real-time helmet detection by optimizing the network structure and using transfer learning training, replacing the original Backbone network of YOLOv3.
At present, there are many helmet detection models based on deep learning [13,14], and the YOLO series detection models [15,16,17] have the characteristics of high accuracy and fast speed, which are very suitable for deployment in application scenarios. In addition, the speed and accuracy of current mainstream solutions still cannot meet the requirements of application scenarios. The YOLOv7 neural network algorithm is highly effective in object detection and is widely used for automatic helmet detection. However, detecting helmets in target images with limited pixels, small relative sizes, and complex road backgrounds poses challenges, often leading to missed or false detections. To address these issues, this paper adopts YOLOv7 as the base model and enhances it to achieve accurate helmet-wearing detection for electric vehicle riders, significantly improving detection accuracy
The main contributions and innovative points of this paper are as follows:
- Dataset Construction: To address the lack of a dataset for electric vehicle driver helmets in China, a comprehensive dataset was constructed. This dataset includes images under various lighting conditions, perspectives, congestion levels, and road environments on both urban and rural roads.
- Helmet Wearing Object Detection Network (YOLO-CBF): A new helmet-wearing object detection network, YOLO-CBF, was developed. Where, C represents coordinated revolution module, B represents Biformer dynamic spark attention module, and F represents fusion coordinated revolution module. This network enhances spatial information perception by incorporating coordinate information into the convolutional process through a specially designed coordinate convolution module. Additionally, by integrating dual-level routing attention into the Backbone of YOLOv7, the network’s ability to capture regional features is significantly improved, enhancing detection performance in occlusion scenarios.
- Improved Loss Function (Focal EIOU Loss): The Focal EIOU Loss function was adopted to address the slow convergence speed and inaccurate regressionce issues. This new loss function achieves quicker convergence and improved localization results, thereby improving overall detection accuracy.
2. Related Work
2.1. YOLOv7 Detection Model
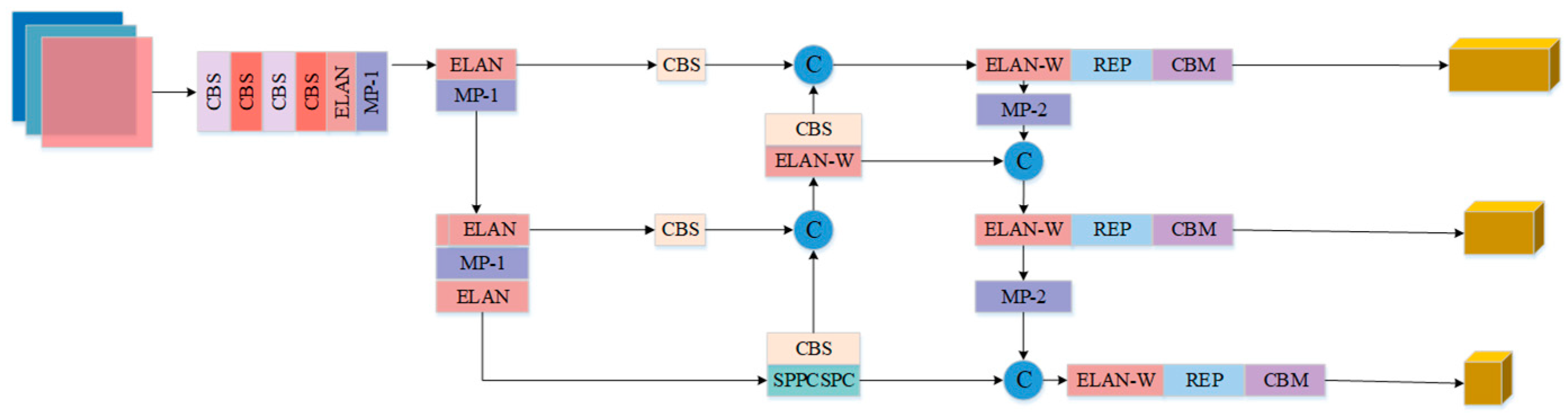
The input, the backbone network, and the head structure are the three main parts of the YOLOv7 detection model. As shown in Figure 1, the input consists of three-channel images at a resolution of 640 × 640 pixels. The backbone network includes convolutional layers, the ELAN module [18], and the MP module. The ELAN module is designed for feature extraction and channel control, enabling the network to learn a wider range of features. The head structure consists of the SPPC-SPC module, the PAFP structure, and the output layer. This configuration facilitates feature fusion by combining high-level and low-level feature maps, followed by further feature extraction and final prediction output of the processed feature maps.
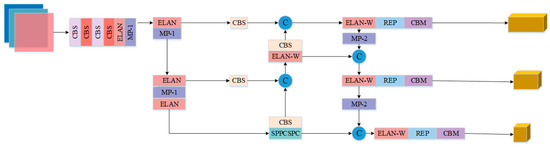
Figure 1.
The overall structure of YOLOv7.
2.2. Attention Mechanism
The attention mechanism enhances segmentation accuracy by adjusting feature weights during training to model long-range feature dependencies. Common attention mechanisms are classified into channel attention and spatial attention. The representative model of channel attention mechanism is Squeeze and Excitation Networks (SENet) [19], and the representative model of spatial attention mechanism is Spatial Transformer Networks (STN) [20]. Channel attention compresses features through global pooling operations, captures inter-channel dependencies, and selectively enhances or suppresses specific channels. Spatial attention incorporates contextual information by calculating the similarity between features, identifying key regions of the image for processing, and addressing the limitations of local receptive fields.
3. The Proposed YOLO-CBF
3.1. Motivation
The original YOLOv7 model has demonstrated strong performance in object detection, but it struggles with detecting small, distant targets and densely overlapping objects in complex driving scenarios, often resulting in missed or false detections. This is particularly problematic for helmet detection in electric vehicle riders, where accuracy is crucial. To overcome these limitations, we propose the YOLO-CBF network. By incorporating a BiFormer [21] dynamic sparse attention module, we reduce the computational and storage burden, while improving the model’s ability to focus on the most important features. Additionally, we replace the traditional convolutional layer with CoordConv [22], which enables the model to better capture spatial relationships between pixels, enhancing its ability to detect object shapes, structures, and layouts.
Furthermore, traditional bounding box loss functions like ln-norm or IoU often fail to deliver accurate results in bounding box regression, leading to slow convergence and imprecise predictions. To address this, we introduce the Efficient Intersection over Union (EIOU) loss function, which explicitly considers the overlapping area, center point, and edge length of bounding boxes. This allows for more accurate and faster convergence, especially in cases with anchor boxes that have low overlap with the target, ultimately improving detection performance in challenging real-world scenarios.
3.2. Overview
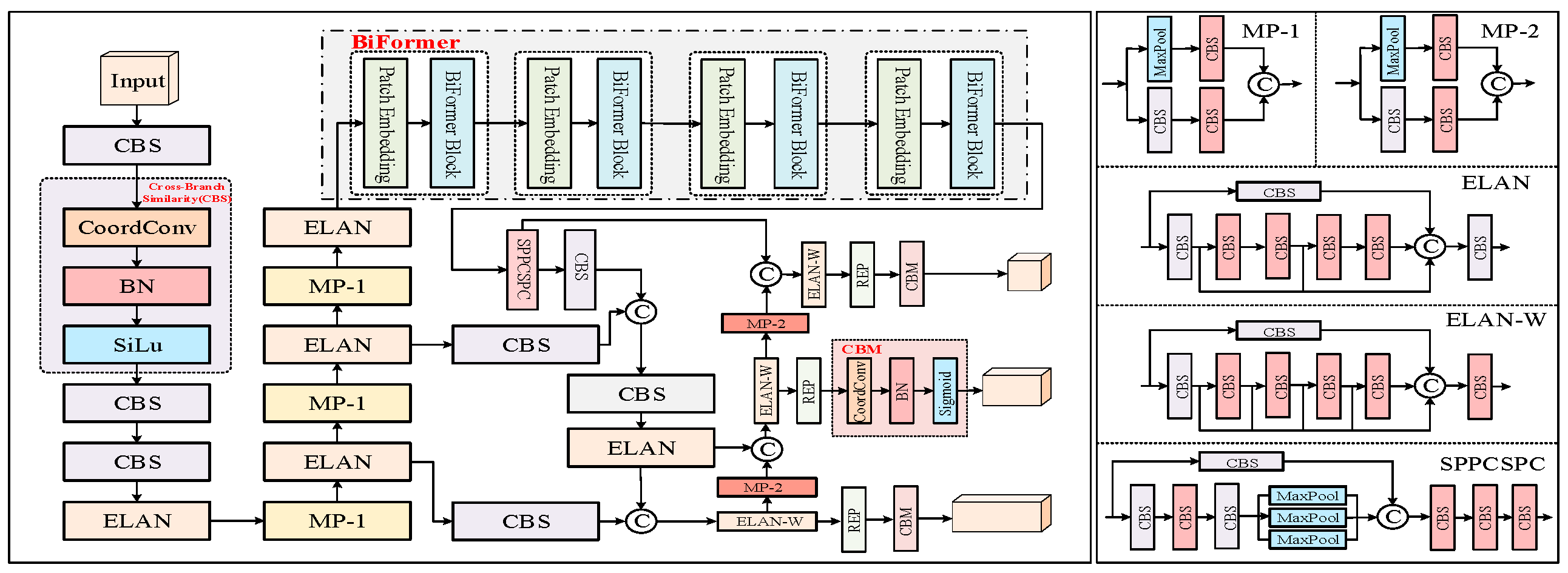
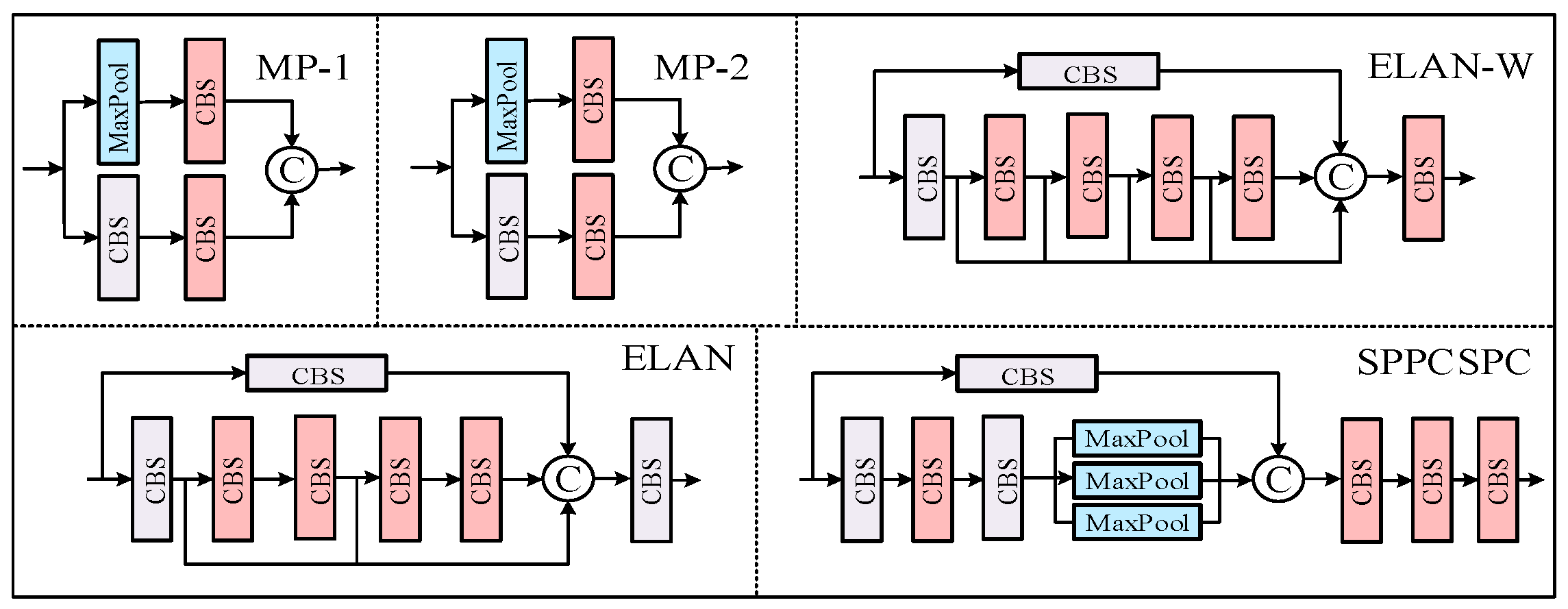
Figure 2 illustrates the overall structure of the YOLO-CBF model. The CBS module consists of three components: a convolutional layer, Batch Normalization, and the SiLU activation function, which collectively give the module its name (C for Conv, B for BatchNorm, and S for SiLU). The ELAN (Efficient Layer Aggregation Network) module enhances the accuracy and robustness of object detection by effectively aggregating feature information from multiple layers. The REP module is split into two parts: one for training and one for deployment. The training module includes three branches: the top branch uses a 3 × 3 convolution for feature extraction, the middle branch applies a 1 × 1 convolution for feature smoothing, and the final branch is an identity operation. The inference module consists of a 3 × 3 convolution with stride 1, which is reparameterized based on the training module (the structures of the CBS, ELAN, and ELAN-W modules are depicted in Figure 3).
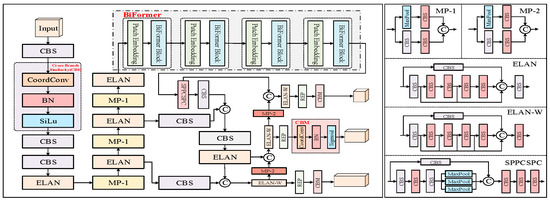
Figure 2.
An overview of the YOLO-CBF.
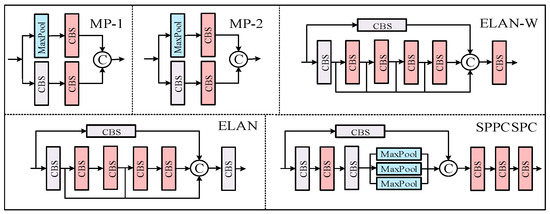
Figure 3.
Detailed module structure of YOLO-CBF.
3.3. BiFormer Dynamic Sparse Attention Module
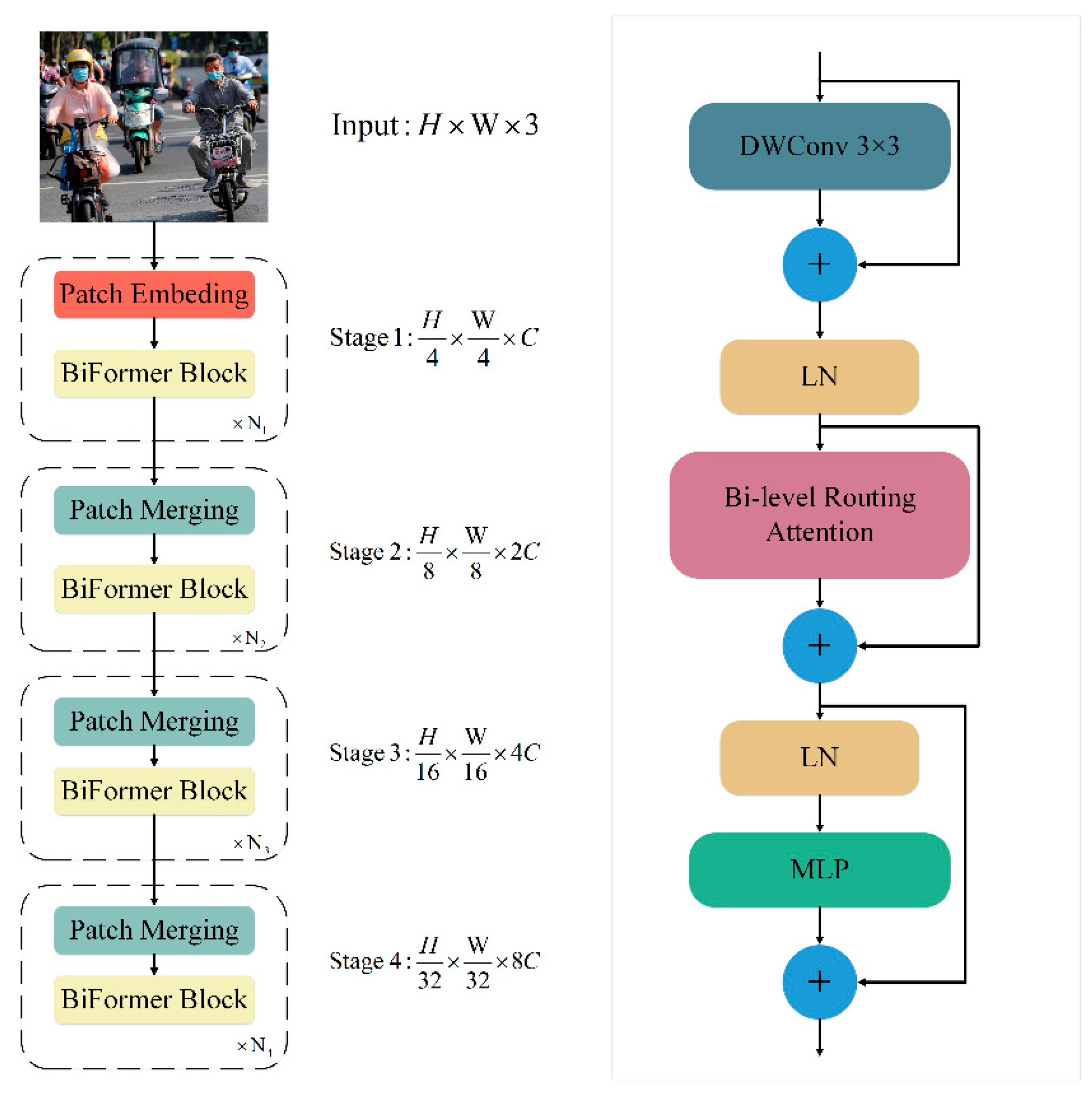
To overcome the scalability limitations of the traditional multi-head self-attention mechanism, which becomes increasingly inefficient with larger input sizes, this paper introduces the BiFormer dynamic sparse attention mechanism into the YOLOv7 model. While the standard multi-head attention excels in capturing global semantic information, its computational complexity grows significantly as input dimensions increase. By contrast, BiFormer addresses these challenges by dynamically selecting important features for attention, thereby enhancing both model efficiency and performance. The structure of the BiFormer module, along with the design of the BiFormer block, is shown in Figure 4.
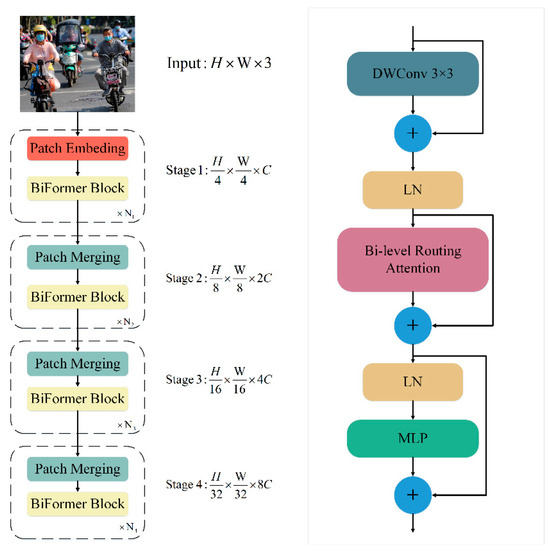
Figure 4.
Left: The overall structure of BiFormer Right: Details of BiFormer Block.
Built upon the Bi-level Routing Attention (BRA) module, the model integrates the innovative BiFormer universal visual converter. The BiFormer dynamic sparse attention mechanism leverages the BRA module to finely segment the input feature map and selectively compute attention weights based on feature correlations. Specifically, the BRA module derives query (Q), key (K), and value (V) vectors via linear mapping and uses an adjacency matrix to build a directed graph, which identifies the participation relationships among various key-value pairs. This approach ensures that each region establishes connections only with others deemed relevant, facilitating dynamic sparse connections. Such sparse connections efficiently allocate computational resources, reduce complexity, and enhance scalability and efficiency by focusing computational efforts on highly correlated regions.
This model can capture picture features of various levels and scales, using a four-level pyramid structure and a 32-times down-sampling rate. BiFormer uses overlapping block embedding in the first stage. A block merging module is used in the second through fourth stages to increase the number of channels while decreasing the input spatial resolution. For feature transformation, continuous BiFormer blocks are then used. After introducing the BiFormer dynamic sparse attention mechanism, YOLOv7 better utilizes the self-attention mechanism in object detection tasks, improving its perception ability and detection accuracy towards targets.
Compared to traditional attention mechanisms, BiFormer dynamic sparse attention offers two distinct advantages:
- Dynamic Region Selection: It dynamically selects regions for attention calculation based on input image characteristics, avoiding the computational complexity of fully connected operations.
- Connections: By introducing sparse connections, the model focuses only on feature regions with high correlation, enhancing performance and efficiency. This approach enables more effective computation allocation and allows the model to adapt seamlessly to input data of varying scales and resolutions.
To address the scalability challenges of multi-head self-attention, this paper integrates BiFormer dynamic sparse attention into YOLOv7. This improvement allows for more adaptable computation distribution and enhances content awareness, enabling dynamic sparsity that is responsive of queries within the model.
3.4. Fusion Coordinate Convolution Module
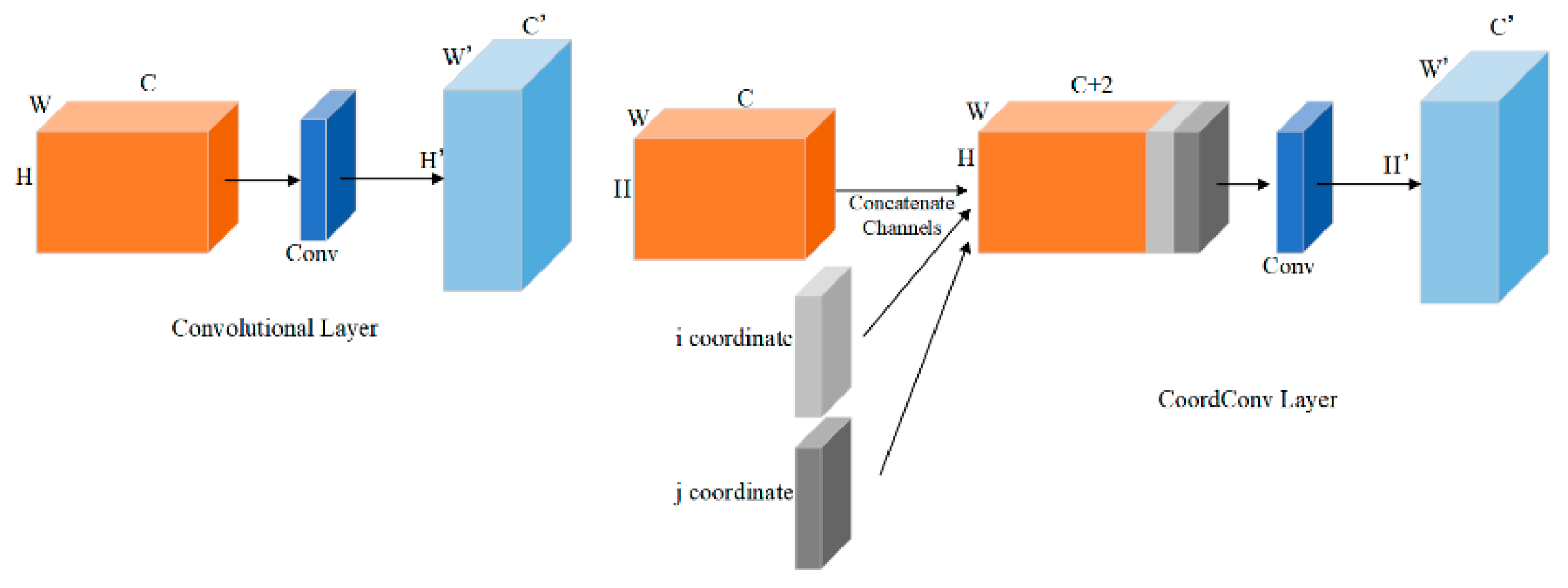
Traditional convolutional methods often lack sensitivity to spatial position information, which is essential for tasks involving positional awareness, such as helmet-wearing detection. Therefore, this paper introduces CoordConv to improve the perception and utilization of spatial information from input data.
CoordConv extends convolutional neural networks by appending two channels to the input feature map to encode i and j coordinates. This modification allows the network to flexibly learn translation invariance or dependencies, improving its ability to understand and utilize object positions within images. As depicted in Figure 5, CoordConv enables the network in helmet detection tasks to predict object positions more accurately by providing richer spatial information, thereby enhancing the network’s understanding of the spatial layout of objects.
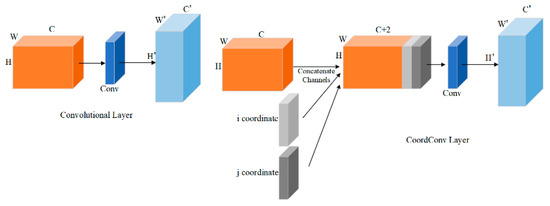
Figure 5.
Traditional convolution and coordinate convolution, where the left side is the traditional convolution layer and the right side represents the coordinate convolution layer.
Furthermore, CoordConv enhances the network’s robustness when dealing with occlusion, rotation, scale variations, and other scenarios. By incorporating coordinate information, the network can better distinguish features from different locations, thereby improving its ability to adapt to complex transformations within images. This approach provides flexible and powerful tools for handling various tasks, enabling the network to better understand and process spatial relationships within images.
3.5. Optimized Focal and Efficient IOU Loss
Precise BBR is vital for accurately pinpointing objects in object detection. However, many current BBR loss functions have two primary limitations:
- Both ln-norm and IoU-based loss functions often struggle to fully capture the objectives of BBR, resulting in slower convergence and less accurate regression outcomes.
- Several loss functions neglect the imbalance issue in BBR, where anchor boxes with little overlap with the target box can significantly influence BBR optimization.
To address these issues, the EIOU loss function is introduced. EIOU specifically evaluates variations in three geometric factors essential for BBR. Extending from EIOU, a novel loss function called Focal EIOU [23] is proposed, defined by Equation (1):
where Cw and Ch are the width and height of the minimum enclosing box that covers two boxes. The loss function is divided into three parts in this paper: IoU loss LIoU, aspect loss Lasp, and distance loss Ldis. This division allows the paper to retain the beneficial characteristics of CIoU losses. Additionally, EIoU loss focuses on minimizing differences in width and height between the target and anchor boxes directly, resulting in quicker convergence and improved localization accuracy.
However, when LEIoU approaches zero, the overall gradient diminishes, reducing the impact of reweighting boxes with small LEIoU. This paper introduces a reweighting mechanism for the EIoU loss based on the value of IoU to overcome this problem, resulting in the Focal EIoU loss as shown in Equation (2):
Among them, and are parameters that adjust the extent of outlier suppression.
4. Experiments and Analysis
4.1. Dataset Construction
To address the current lack of a dataset for electric vehicle driver helmets and the need for diverse scenario representation, real-life images of electric vehicle helmets were collected and compiled into a custom dataset for helmet-wearing detection. This dataset serves as the foundation for comparative and ablation experiments in training and testing. The images were gathered from various traffic scenarios in Changsha, Hunan Province, covering non-peak and peak commuting times, as well as urban and suburban road sections. This diversity ensures the model’s robustness and applicability in real-world settings. The images were captured using a phone with an original pixel size of 3120 × 3120, resized to 640 × 640 for consistency. A subset of experimental dataset samples is illustrated in Figure 6.

Figure 6.
Partial samples in the dataset.
Post-acquisition, images were annotated using Labelimg software (version 1.8.6). Following the format of PASCAL VOC 2012, the dataset consists of 962 images showing electric vehicle helmet-wearing in natural road environments. During annotation, images feature electric vehicle drivers with helmets labeled as “helmets”, and those without helmets labeled as “no helmets”. Electric vehicles without drivers and pedestrians are not labeled. Upon input to the model, images are automatically adjusted to 512 × 512 dimensions. The dataset was split into training, validation, and testing sets using random seeding, with a distribution ratio of 7:1.5:1.5.
4.2. Implementation Details
All experiments in this study used the same environmental configuration and hyperparameter settings. Table 1 shows the hyperparameter settings. The model underwent training and testing on the Windows 11 system. Developed based on the Pytorch (version 3.9) framework. The CPU model is the Intel i7-11800h processor, with a running memory of 16GB and a GPU of the Nvidia 3050 4GB mobile graphics card.

Table 1.
Hyperparameter settings.
Four metrics—Recall, Precision, AP (Average Precision), and mAP (mean Average Precision) were used in this research to thoroughly and impartially assess the detection ability of the upgraded YOLOv7 model. The specific calculation formulas for each indicator are shown in Equations (3)–(6):
Precision (P) represents the percentage of true positive samples among all samples predicted as positive by the model. Recall (R) measures the percentage of true positive samples among all actual positive samples. True Positives (TP) are the samples correctly predicted as positive, while False Positives (FP) are the samples predicted as positive but are actually negative. False Negatives (FN) are the samples predicted as negative, though the actual value is positive. The total number of categories is denoted by S. Average Precision (AP) is the mean of precision values across different recall levels, and the mean Average Precision (mAP) represents the average of AP values across all categories. Specifically, mAP (IoU = 0.5) refers to the average precision computed when the Intersection over Union (IoU) between predicted and actual bounding boxes is 0.5.
4.3. Comparison Results
AP, Precision, Recall, and mAP are the key evaluation metrics used to assess the model’s performance. To evaluate the effectiveness of the proposed YOLO-CBF model, we compared it with several other models, including YOLOX [24], YOLOv5 [25], YOLOv7 [26], YOLOv8 [27], YOLOv9 [28], YOLOv10 [29], Tsai’s model [30], and the improved YOLOv7 model presented in this paper. The comparative experimental results, shown in Table 2, reveal that the YOLO-CBF model outperforms the other models in helmet detection tasks, achieving an average accuracy of 92.4%, which exceeds the performance of other widely-used detection models. The enhanced model consistently outperforms the original YOLOv7 across all metrics.
Table 2.
Comparison results on private datasets.
Experiments were conducted on a public safety helmet dataset to validate the generalization and robustness of the YOLO-CBF model. Additionally, more images were collected using web crawlers and video capture to augment the dataset, enriching the scenarios and balancing the categories. As shown in Figure 7, the dataset includes images of sunny and cloudy days, as well as urban and rural roadways. The selected experimental dataset contains 3056 images, of which 2501 were used for training and 555 for testing. The results of model comparisons are presented in Table 3.

Figure 7.
Public dataset samples.
Table 3.
Comparison results on public datasets.
As shown in Table 3, the YOLO-CBF model proposed in this paper demonstrates excellent performance on public datasets, surpassing other models in both helmet-wearing and non-helmet-wearing accuracy. Its mAP is 0.4% higher than the best-performing YOLOX and 14.6% higher than the worst-performing YOLOv5, highlighting the model’s strong generalization and robustness.
4.4. Ablation Study
Ablation experiments were conducted on the upgraded YOLOv7 modules using the same experimental setup to assess the efficacy of the model’s improvements. The results, shown in Table 4, demonstrate that the enhanced model improves helmet-wearing detection accuracy. The introduction of the CoordConv module increased the model’s mAP by 2%, highlighting its significant impact on detection performance. The BiFormer module further boosted recall, markedly improving helmet detection compared to the original YOLOv7. Additionally, the inclusion of Focal EIOU refined the model’s accuracy, making it more precise and comprehensive. These improvements collectively enhance the overall performance of helmet detection, confirming the effectiveness of the proposed method in detecting helmet-wearing for electric vehicle riders in complex scenarios.
Table 4.
Effectiveness of YOLOv7, CoordConv, BiFormer and Focal-EIoU on private datasets.
The optimal model weight parameter file obtained during training was tested on actual urban roads, featuring various challenges such as blurred images, occlusions, and small detection targets, which are typical of everyday road conditions. Figure 8 illustrates the detection results. It is evident that the original YOLOv7 model struggles with issues like misidentifying worn helmets as not worn, mistakenly classifying non-worn helmets as worn, and failing to detect whether electric bike riders are wearing helmets. Additionally, the model incorrectly labels pedestrians as not wearing helmets, leading to false positives and reduced detection accuracy. In contrast, the proposed object detection model demonstrates accurate results without errors or omissions. These findings confirm that the improvements introduced in this paper are effective for real-world road environment detection.

Figure 8.
Visual comparison: (a) the original image, (b) the detection result of YOLOv7, and (c) the detection result of the YOLO-CBF model.
To further validate the model’s universality and practicality, ablation experiments were conducted on the public dataset mentioned in Section 4.3. The results are presented in Table 5. The initial model achieved an accuracy of 91.6%. After replacing the traditional convolution with CoordConv, the mAP increased by 1.6%, demonstrating that CoordConv significantly enhances detection performance. Subsequently, the addition of a BiFormer attention module with double-layer path attention, which captures dependency relationships between different positions in the sequence, further boosted the mAP by 2.2%. To address the slow convergence and inaccuracies associated with traditional box regression methods, Focal EIOU was adopted as the model’s loss function, resulting in an additional 0.2% improvement in mAP.
Table 5.
Effectiveness of YOLOv7, CoordConv, BiFormer and Focal-EIoU on public datasets.
Overall, integrating CoordConv, the Focal EIOU loss function, and the BiFormer attention mechanism into the original YOLOv7 model significantly enhances its detection capabilities, resulting in a 4.0% increase in mAP compared to the baseline model. The improved model is lightweight, offers superior detection performance, is easy to deploy, and meets the requirements for electric vehicle helmet detection in real-world scenarios.
5. Conclusions
The YOLO-CBF model proposed in this article significantly improves the accuracy and robustness of helmet wearing detection for electric vehicle drivers through a series of innovative improvements. On the basis of YOLOv7, this model introduces CoordConv to enhance spatial information perception ability, optimizes Focal EIOU loss function to improve the accuracy of bounding box regression, and combines BiFormer dynamic sparse attention mechanism to improve the detection performance of the model in complex scenes. These improvements have enabled YOLO-CBF to perform well in various complex road environments, with an average accuracy (mAP) of 95.6%, which is a 4% improvement compared to the original YOLOv7. In addition, YOLO-CBF has demonstrated excellent detection performance in comparative experiments with multiple mainstream object detection models, especially in dealing with small targets, high occlusion, and complex backgrounds.
However, despite significant progress in detection accuracy, YOLO-CBF still faces some challenges in practical applications. Firstly, the training and inference process of the model requires high computational resources, especially when dealing with large-scale datasets, which significantly increases the computational and time costs. Secondly, although the model performs well on public datasets, its generalization ability still needs further validation and optimization when facing data from different regions and traffic rules. In addition, in extreme scenarios such as low light and high occlusion, the detection accuracy of the model may decrease, especially when the target pixels are limited and the relative size is small, the performance of the model still has certain limitations.
The future research direction will focus on improving the efficiency and generalization ability of the model. On the one hand, by further expanding the dataset and covering more diverse scenes and lighting conditions, the adaptability and robustness of the model can be enhanced. On the other hand, exploring more efficient network architectures and optimization algorithms to reduce the computational complexity and storage requirements of models while maintaining or further improving detection performance is key to achieving model lightweighting and real-time deployment. In addition, by combining multitask learning and jointly optimizing helmet detection with other related tasks such as traffic violation detection and vehicle type recognition, it is expected to further improve the overall performance of the model. Finally, studying the performance of the model under adversarial attacks and exploring methods to enhance its robustness is of great significance for addressing potential security threats.
Through these improvements, the YOLO-CBF model is expected to play a greater role in future traffic monitoring and safety management, providing more reliable guarantees for the safety of electric vehicle drivers.
Author Contributions
Conceptualization, Z.W. and J.Q.; methodology, Z.W., X.X. and Y.T.; software, Z.W.; validation, Z.W. and J.Q.; formal analysis, Z.W. and Y.T.; investigation, J.Q.; data curation, Z.W.; writing—original draft preparation, Z.W.; writing—review and editing, J.Q., X.X. and Y.T.; supervision, J.Q. and X.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding, and the APC was also not funded.
Data Availability Statement
Restrictions apply to the availability of these data. Data was obtained from ZhiQiang Wu and are available 1796949274@qq.com with the permission of Confidentiality principle of school laboratory data.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, K.; Zhao, X.; Bian, J.; Tan, M. Automatic safety helmet wearing detection. arXiv 2018, arXiv:1802.00264. [Google Scholar]
- Xu, H.; Wu, Z. MCX-YOLOv5: Efficient helmet detection in complex power warehouse scenarios. J. Real-Time Image Process. 2024, 21, 27. [Google Scholar]
- Liu, J.; Xian, X.; Hou, Z.; Liang, J.; Liu, H. Safety helmet wearing correctly detection based on capsule network. Multimedia Tools Appl. 2024, 83, 6351–6372. [Google Scholar]
- e Silva, R.R.V.; Aires, K.R.T.; Veras, R.D.M.S. Helmet detection on motorcyclists using image descriptors and classifiers. In Proceedings of the 2014 27th SIBGRAPI Conference on Graphics, Patterns and Images, Rio de Janeiro, Brazil, 26–30 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 141–148. [Google Scholar]
- Benyang, D.; Xiaochun, L.; Miao, Y. Safety helmet detection method based on YOLO v4. In Proceedings of the 2020 16th International Conference on Computational Intelligence and Security (CIS), Liuzhou, China, 27–30 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 155–158. [Google Scholar]
- Shine, L.; CV, J. Automated detection of helmet on motorcyclists from traffic surveillance videos: A comparative analysis using hand-crafted features and CNN. Multimed. Tools Appl. 2020, 79, 14179–14199. [Google Scholar] [CrossRef]
- Paulchamy, B.; Natarajan, C.; Wahith, A.A.; Sharan, P.M.; Vignesh, R.H. An intelligent helmet for miners with air quality and destructive event detection using zigbee. Glob. Res. Dev. J. Eng. 2018, 3, 41–46. [Google Scholar]
- Bhagat, S.; Contractor, D.; Sharma, S.; Sharma, T. Cascade classifier based helmet detection using OpenCV in image processing. In Proceedings of the National Conference on Recent Trends in Computer and Communication Technology (RTCCT), Surat, India, 10–11 May 2016; p. 10. [Google Scholar]
- Wonghabut, P.; Kumphong, J.; Satiennam, T.; Ung-Arunyawee, R.; Leelapatra, W. Automatic helmet-wearing detection for law enforcement using CCTV cameras. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Ho Chi Minh City, Vietnam, 17–19 April 2018; IOP Publishing: Bristol, UK, 2018; Volume 143, p. 012063. [Google Scholar]
- Dahiya, K.; Singh, D.; Mohan, C.K. Automatic detection of bike-riders without helmet using surveillance videos in real-time. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3046–3051. [Google Scholar]
- Vishnu, C.; Singh, D.; Mohan, C.K.; Babu, S. Detection of motorcyclists without helmet in videos using convolutional neural network. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3036–3041. [Google Scholar]
- Wu, F.; Jin, G.; Gao, M.; He, Z.; Yang, Y. Helmet detection based on improved YOLO V3 deep model. In Proceedings of the 2019 IEEE 16th International Conference on Networking, Sensing and Control (ICNSC), Banff, AB, Canada, 9–11 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 363–368. [Google Scholar]
- Gu, Y.; Wang, Y.; Shi, L.; Li, N.; Zhuang, L.; Xu, S. Automatic detection of safety helmet wearing based on head region location. IET Image Process. 2021, 15, 2441–2453. [Google Scholar]
- Otgonbold, M.-E.; Gochoo, M.; Alnajjar, F.; Ali, L.; Tan, T.-H.; Hsieh, J.-W.; Chen, P.-Y. SHEL5K: An extended dataset and benchmarking for safety helmet detection. Sensors 2022, 22, 2315. [Google Scholar] [CrossRef] [PubMed]
- Cheng, R.; He, X.; Zheng, Z.; Wang, Z. Multi-scale safety helmet detection based on SAS-YOLOv3-tiny. Appl. Sci. 2021, 11, 3652. [Google Scholar] [CrossRef]
- Deng, L.; Li, H.; Liu, H.; Gu, J. A lightweight YOLOv3 algorithm used for safety helmet detection. Sci. Rep. 2022, 12, 10981. [Google Scholar]
- Zhou, Q.; Qin, J.; Xiang, X.; Tan, Y.; Xiong, N.N. Algorithm of Helmet Wearing Detection Based on AT-YOLO Deep Mode. Comput. Mater. Contin. 2021, 69, 159–174. [Google Scholar]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient long-range attention network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 649–667. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the 29th International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; series NIPS’15. MIT Press: Cambridge, MA, USA, 2015; Volume 2, pp. 2017–2025. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W. Biformer: Vision transformer with bi-level routing attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Liu, R.; Lehman, J.; Molino, P.; Such, F.P.; Frank, E.; Sergeev, A.; Yosinski, J. An intriguing failing of convolutional neural networks and the CoordConv solution. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; series NIPS’18. Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 9628–9639. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wu, W.; Liu, H.; Li, L.; Long, Y.; Wang, X.; Wang, Z.; Li, J.; Chang, Y. Application of local fully Convolutional Neural Network combined with YOLO v5 algorithm in small target detection of remote sensing image. PLoS ONE 2021, 16, e0259283. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Lou, H.; Duan, X.; Guo, J.; Liu, H.; Gu, J.; Bi, L.; Chen, H. DC-YOLOv8: Small-size object detection algorithm based on camera sensor. Electronics 2023, 12, 2323. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Tsai, C.M.; Hsieh, J.W.; Chang, M.C.; He, G.L.; Chen, P.Y.; Chang, W.T.; Hsieh, Y.K. Video analytics for detecting motorcyclist helmet rule violations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5366–5374. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).