

TSC-SIG: A Novel Method Based on the CPU Timestamp Counter with POSIX Signals for Efficient Memory Reclamation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
2.1. Unawareness of Reclamation
2.2. Awareness of Reclamation
3. Materials and Methods
3.1. System Model and Assumptions
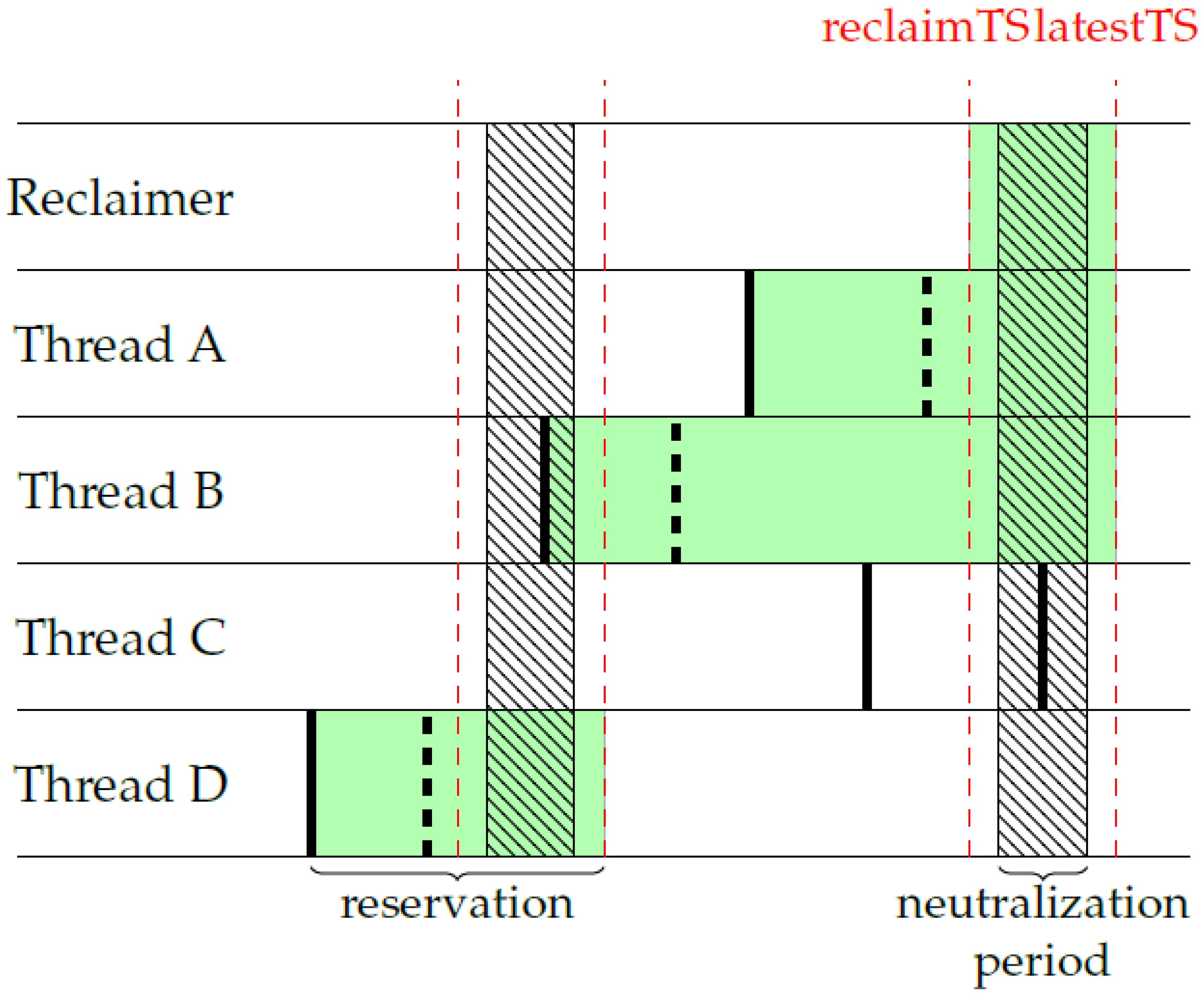
3.2. TSC-SIG
| Algorithm 1 Overview of pseudocode for TSC-SIG |
 |
| Algorithm 2 Applying TSC-SIG to Harris List [35] |
 |
3.3. Correctness
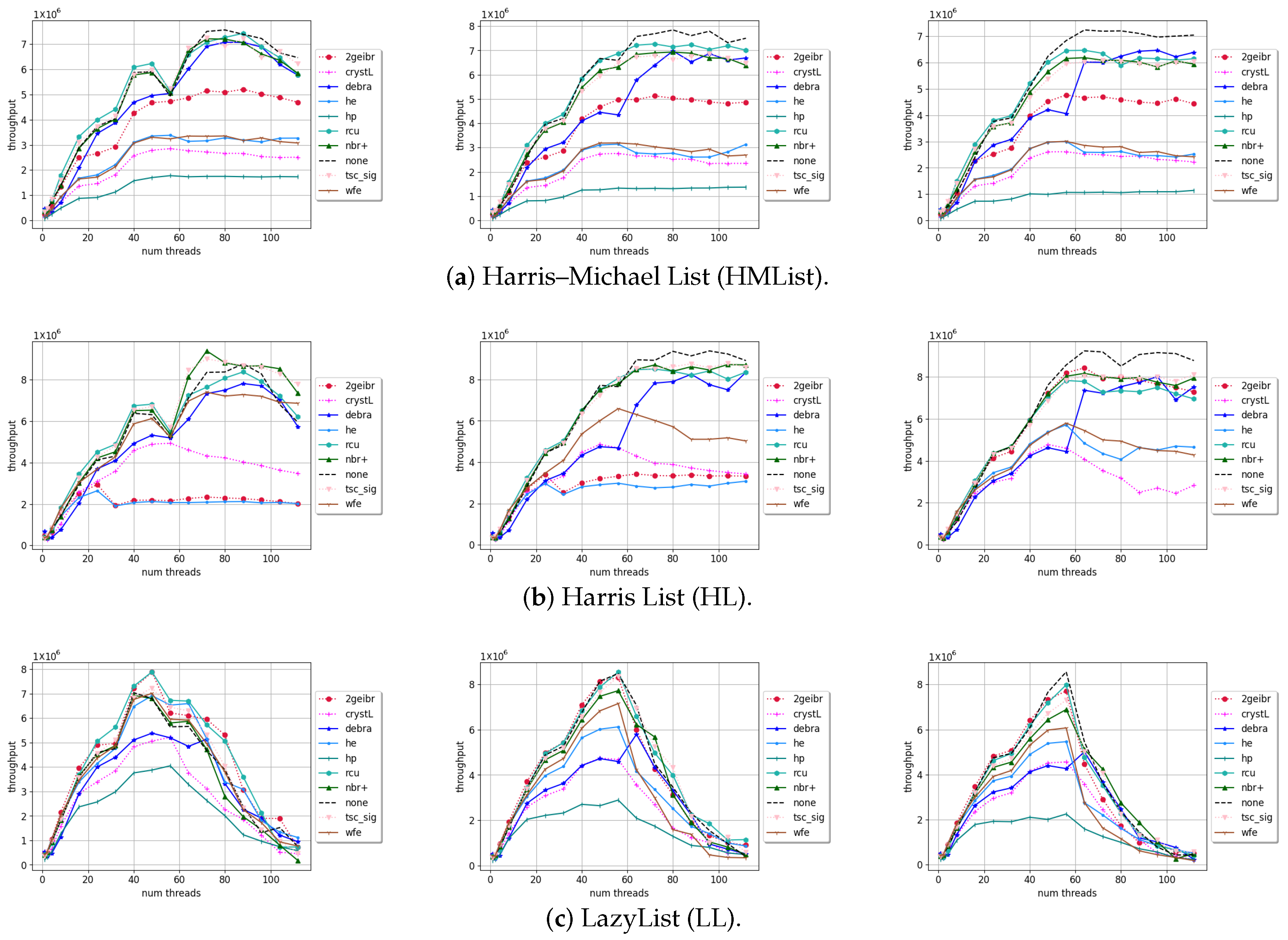
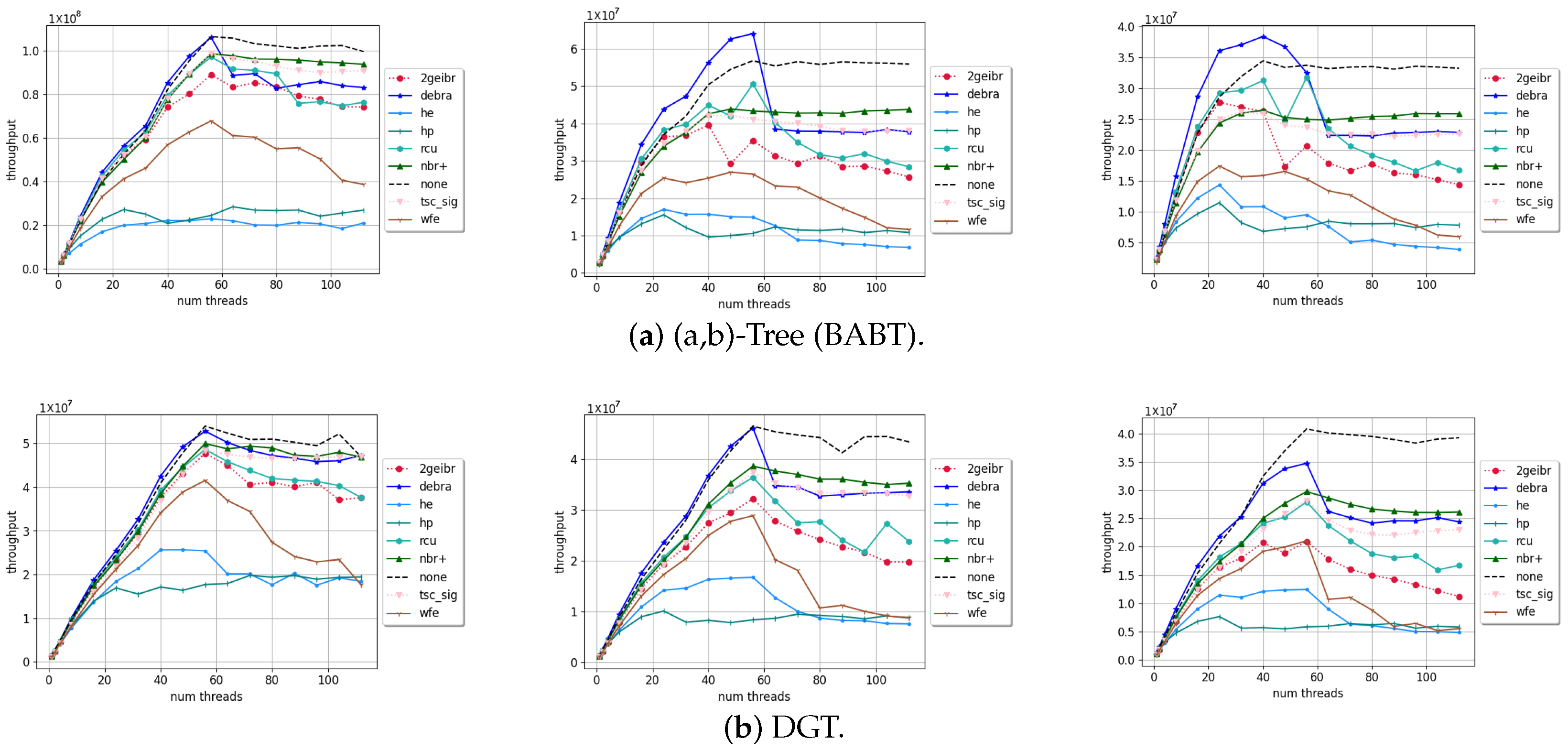
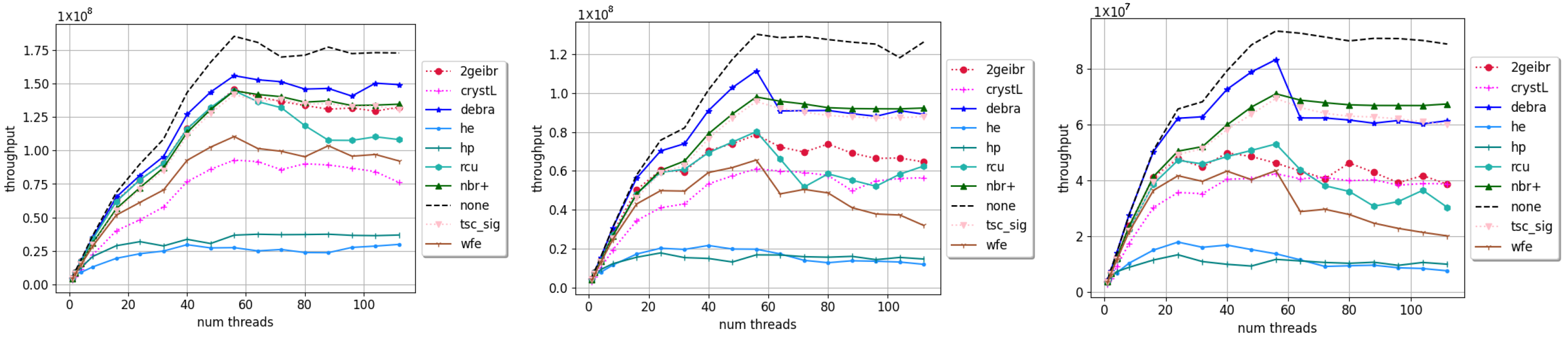
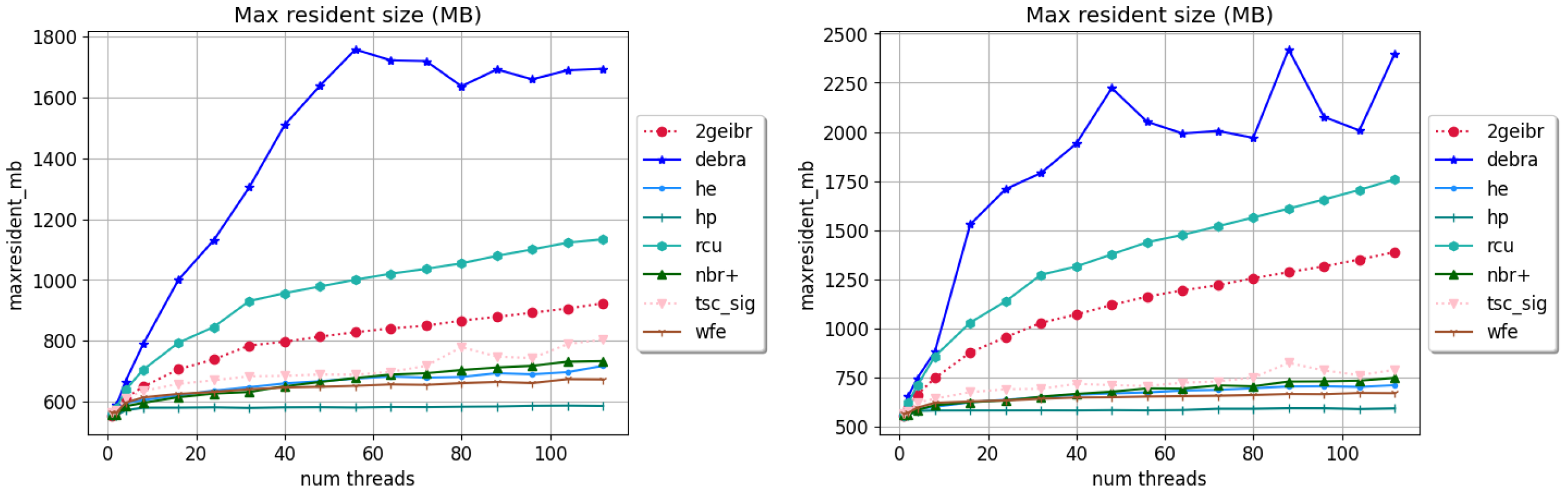
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Braginsky, A.; Kogan, A.; Petrank, E. Drop the Anchor: Lightweight Memory Management for Non-Blocking Data Structures. In Proceedings of the Twenty-Fifth Annual ACM Symposium on Parallelism in Algorithms and Architectures, Montréal, QC, Canada, 23–25 July 2013; pp. 33–42. [Google Scholar] [CrossRef]
- Brown, T.A. Reclaiming Memory for Lock-Free Data Structures: There has to be a Better Way. In Proceedings of the 2015 ACM Symposium on Principles of Distributed Computing, Donostia-San Sebastián, Spain, 21–23 July 2015; PODC’15. pp. 261–270. [Google Scholar] [CrossRef]
- Kang, J.; Jung, J. A Marriage of Pointer- and Epoch-Based Reclamation. In Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation, London, UK, 15–20 June 2020; pp. 314–328. [Google Scholar] [CrossRef]
- Michael, M. Hazard Pointers: Safe Memory Reclamation for Lock-Free Objects. IEEE Trans. Parallel Distrib. Syst. 2004, 15, 491–504. [Google Scholar] [CrossRef]
- Herlihy, M.; Luchangco, V.; Martin, P.; Moir, M. Nonblocking Memory Management Support for Dynamic-Sized Data Structures. ACM Trans. Comput. Syst. 2005, 23, 146–196. [Google Scholar] [CrossRef]
- Dice, D.; Herlihy, M.; Kogan, A. Fast Non-Intrusive Memory Reclamation for Highly-Concurrent Data Structures. In Proceedings of the 2016 ACM SIGPLAN International Symposium on Memory Management, Santa Barbara, CA, USA, 14 June 2016; pp. 36–45. [Google Scholar] [CrossRef]
- Singh, A.; Brown, T.A.; Mashtizadeh, A.J. Simple, Fast and Widely Applicable Concurrent Memory Reclamation via Neutralization. IEEE Trans. Parallel Distrib. Syst. 2024, 35, 203–220. [Google Scholar] [CrossRef]
- McKenney, P.E.; Slingwine, J.D. Read-copy update: Using execution history to solve concurrency problems. In Parallel and Distributed Computing and Systems; Citeseer: Princeton, NJ, USA, 1998; Volume 509518, pp. 509–518. [Google Scholar]
- Fraser, K. Practical Lock-Freedom; Technical Report UCAM-CL-TR-579; University of Cambridge, Computer Laboratory: Cambridge, UK, 2004. [Google Scholar] [CrossRef]
- Hart, T.E.; McKenney, P.E.; Brown, A.D.; Walpole, J. Performance of Memory Reclamation for Lockless Synchronization. J. Parallel Distrib. Comput. 2007, 67, 1270–1285. [Google Scholar] [CrossRef]
- Ramalhete, P.; Correia, A. Brief Announcement: Hazard Eras—Non-Blocking Memory Reclamation. In Proceedings of the 29th ACM Symposium on Parallelism in Algorithms and Architectures, Washington, DC, USA, 24–26 July 2017; pp. 367–369. [Google Scholar] [CrossRef]
- Wen, H.; Izraelevitz, J.; Cai, W.; Beadle, H.A.; Scott, M.L. Interval-Based Memory Reclamation. In Proceedings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Vienna, Austria, 24–28 February 2018; pp. 1–13. [Google Scholar] [CrossRef]
- Alistarh, D.; Leiserson, W.M.; Matveev, A.; Shavit, N. ThreadScan: Automatic and Scalable Memory Reclamation. In Proceedings of the 27th ACM Symposium on Parallelism in Algorithms and Architectures, Portland, OR, USA, 13–15 June 2015; pp. 123–132. [Google Scholar] [CrossRef]
- Intel. Intel 64 and IA-32 Architectures Software Developer’s Manual. 2024. Available online: https://www.intel.com/content/www/us/en/developer/articles/technical/intelsdm.html (accessed on 12 November 2024).
- Ruan, W.; Liu, Y.; Spear, M. Boosting Timestamp-Based Transactional Memory by Exploiting Hardware Cycle Counters. ACM Trans. Archit. Code Optim. 2013, 10, 1–21. [Google Scholar] [CrossRef]
- Grimes, O.; Nelson-Slivon, J.; Hassan, A.; Palmieri, R. Opportunities and Limitations of Hardware Timestamps in Concurrent Data Structures. In Proceedings of the 2023 IEEE International Parallel and Distributed Processing Symposium (IPDPS), St. Petersburg, FL, USA, 15–19 May 2023; pp. 624–634. [Google Scholar] [CrossRef]
- Clements, A.T.; Kaashoek, M.F.; Zeldovich, N. Scalable address spaces using RCU balanced trees. In Proceedings of the Seventeenth International Conference on Architectural Support for Programming Languages and Operating Systems, London, UK, 3–7 March 2012; ASPLOS XVII. pp. 199–210. [Google Scholar] [CrossRef]
- Heller, S.; Herlihy, M.; Luchangco, V.; Moir, M.; Scherer, W.N.; Shavit, N. A Lazy Concurrent List-Based Set Algorithm. In Principles of Distributed Systems; Anderson, J.H., Prencipe, G., Wattenhofer, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 3–16. [Google Scholar]
- Michael, M.M. High performance dynamic lock-free hash tables and list-based sets. In Proceedings of the Fourteenth Annual ACM Symposium on Parallel Algorithms and Architectures, Winnipeg, MB, Canada, 11–13 August 2002; SPAA’02. pp. 73–82. [Google Scholar] [CrossRef]
- Brown, T.; Ellen, F.; Ruppert, E. A general technique for non-blocking trees. In Proceedings of the 19th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Orlando, FL, USA, 15–19 February 2014; pp. 329–342. [Google Scholar]
- Drachsler, D.; Vechev, M.; Yahav, E. Practical concurrent binary search trees via logical ordering. In Proceedings of the 19th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Orlando, FL, USA, 15–19 February 2014; pp. 343–356. [Google Scholar]
- Jung, J.; Lee, J.; Kim, J.; Kang, J. Applying Hazard Pointers to More Concurrent Data Structures. In Proceedings of the 35th ACM Symposium on Parallelism in Algorithms and Architectures, Orlando, FL, USA, 17–19 June 2023; pp. 213–226. [Google Scholar] [CrossRef]
- Nikolaev, R.; Ravindran, B. Universal Wait-Free Memory Reclamation. In Proceedings of the 25th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, San Diego, CA, USA, 22–26 February 2020; pp. 130–143. [Google Scholar] [CrossRef]
- Anderson, D.; Blelloch, G.E.; Wei, Y. Concurrent Deferred Reference Counting with Constant-Time Overhead. In Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, Virtual Event, Canada, 20–25 June 2021; pp. 526–541. [Google Scholar] [CrossRef]
- Nikolaev, R.; Ravindran, B. Hyaline: Fast and Transparent Lock-Free Memory Reclamation. In Proceedings of the 2019 ACM Symposium on Principles of Distributed Computing, Toronto, ON, Canada, 29 July–2 August 2019; pp. 419–421. [Google Scholar] [CrossRef]
- Nikolaev, R.; Ravindran, B. Crystalline: Fast and memory efficient wait-free reclamation. arXiv 2021, arXiv:2108.02763. [Google Scholar]
- Cohen, N.; Petrank, E. Efficient Memory Management for Lock-Free Data Structures with Optimistic Access. In Proceedings of the 27th ACM Symposium on Parallelism in Algorithms and Architectures, Portland, OR, USA, 13–15 June 2015; SPAA’15. pp. 254–263. [Google Scholar] [CrossRef]
- Petrank, E. A Practical Wait-Free Simulation for Lock-Free Data Structures. ACM SIGPLAN Not. 2014, 49, 357–368. [Google Scholar]
- Cohen, N.; Petrank, E. Automatic Memory Reclamation for Lock-Free Data Structures. In Proceedings of the 2015 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications, Pittsburgh, PA, USA, 25–30 October 2015; pp. 260–279. [Google Scholar] [CrossRef]
- Cohen, N. Every Data Structure Deserves Lock-Free Memory Reclamation. Proc. ACM Program. Lang. 2018, 2, 1–24. [Google Scholar] [CrossRef]
- Sheffi, G.; Herlihy, M.; Petrank, E. VBR: Version Based Reclamation. In Proceedings of the 33rd ACM Symposium on Parallelism in Algorithms and Architectures, Virtual, 6–8 July 2021; SPAA’21. pp. 443–445. [Google Scholar] [CrossRef]
- Herlihy, M. A Methodology for Implementing Highly Concurrent Data Objects. ACM Trans. Program. Lang. Syst. 1993, 15, 745–770. [Google Scholar] [CrossRef]
- Treiber, R.K. Systems Programming: Coping with Parallelism; International Business Machines Incorporated, Thomas J. Watson Research Center: New York, NY, USA, 1986. [Google Scholar]
- Singh, A.; Brown, T.; Mashtizadeh, A. NBR: Neutralization Based Reclamation. In Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Virtual Event, Republic of Korea, 27 February 2021; pp. 175–190. [Google Scholar] [CrossRef]
- Harris, T.L. A Pragmatic Implementation of Non-blocking Linked-lists. In Distributed Computing; Welch, J., Ed.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 300–314. [Google Scholar]
- Brown, T.; Prokopec, A.; Alistarh, D. Non-Blocking Interpolation Search Trees with Doubly-Logarithmic Running Time. In Proceedings of the 25th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, San Diego, CA, USA, 22–26 February 2020; pp. 276–291. [Google Scholar] [CrossRef]
- Evans, J A Scalable Concurrent Malloc(3) Implementation for FreeBSD. 2006. Available online: https://papers.freebsd.org/2006/bsdcan/evans-jemalloc/ (accessed on 12 November 2024).
- David, T.; Guerraoui, R.; Trigonakis, V. Asynchronized Concurrency: The Secret to Scaling Concurrent Search Data Structures. ACM SIGARCH Comput. Archit. News 2015, 43, 631–644. [Google Scholar] [CrossRef]
- Brown, T. Techniques for Constructing Efficient Lock-free Data Structures. arXiv 2017, arXiv:1712.05406. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Yi, Z.; Zhu, X. TSC-SIG: A Novel Method Based on the CPU Timestamp Counter with POSIX Signals for Efficient Memory Reclamation. Electronics 2025, 14, 1371. https://doi.org/10.3390/electronics14071371
Zhang C, Yi Z, Zhu X. TSC-SIG: A Novel Method Based on the CPU Timestamp Counter with POSIX Signals for Efficient Memory Reclamation. Electronics. 2025; 14(7):1371. https://doi.org/10.3390/electronics14071371
Chicago/Turabian StyleZhang, Chen, Zhengming Yi, and Xinghui Zhu. 2025. "TSC-SIG: A Novel Method Based on the CPU Timestamp Counter with POSIX Signals for Efficient Memory Reclamation" Electronics 14, no. 7: 1371. https://doi.org/10.3390/electronics14071371
APA StyleZhang, C., Yi, Z., & Zhu, X. (2025). TSC-SIG: A Novel Method Based on the CPU Timestamp Counter with POSIX Signals for Efficient Memory Reclamation. Electronics, 14(7), 1371. https://doi.org/10.3390/electronics14071371