
A Named Entity Recognition Method for Chinese Vehicle Fault Repair Cases Based on a Combined Model

Abstract
1. Introduction
2. Data Sources and Analysis
2.1. Data Sources
2.2. Data Analysis
2.2.1. Text Feature Analysis
2.2.2. Text Processing Methods
3. Text Segmentation and Classification
3.1. Text Segmentation
3.2. Short-Text Classification
3.2.1. Text-CNN Model
3.2.2. Comparative Experiments of Models
4. Entity Recognition
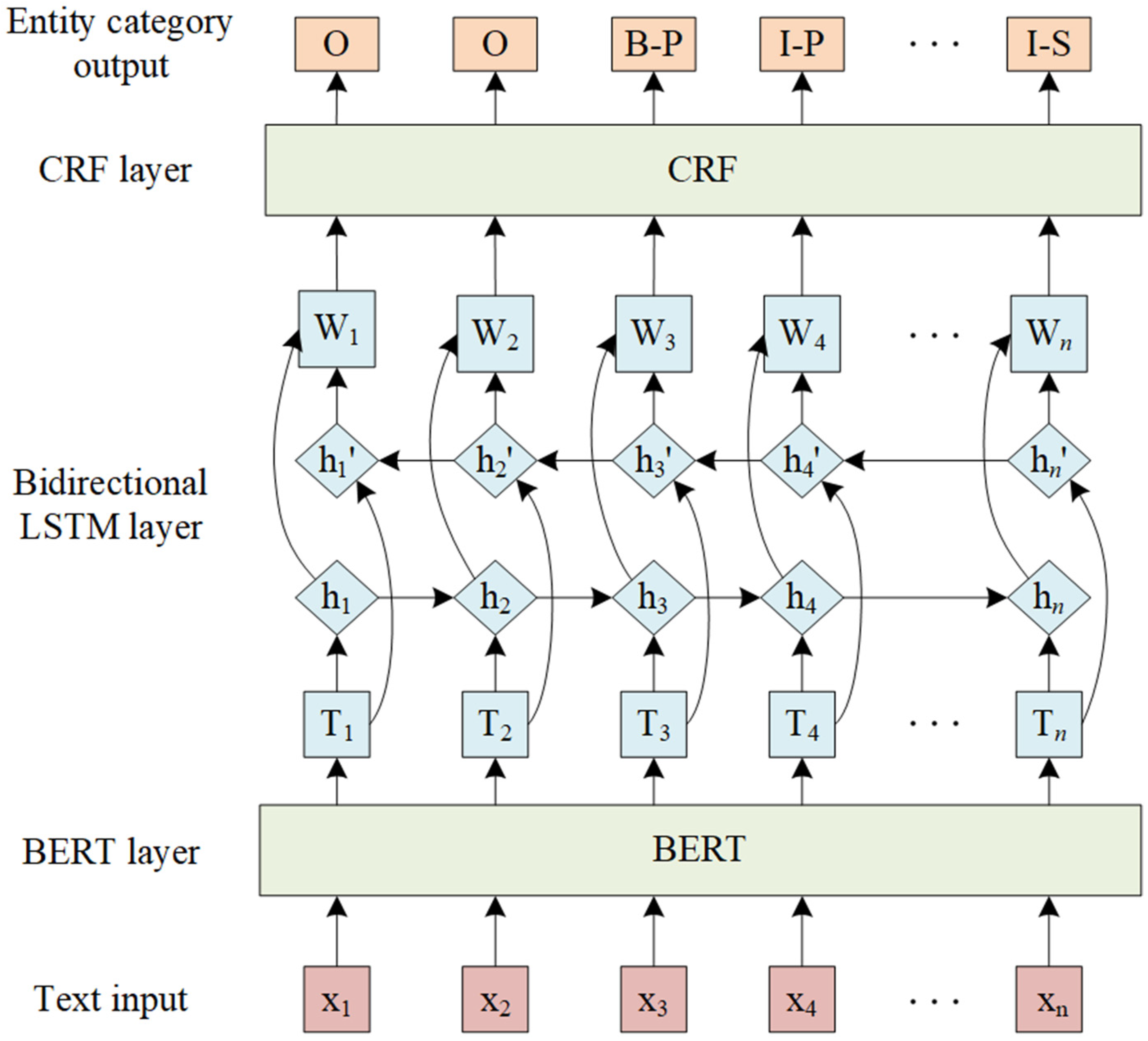
4.1. BERT-BiLSTM-CRF Model
4.2. Model Training
4.2.1. Text Sequence Pre-Labeling
4.2.2. Comparative Experiment
4.3. Entity Combination
4.3.1. Entity Relationship Matching Database
4.3.2. Non-Continuous Entity Combination
4.3.3. Entity Combination Algorithm
| Algorithm 1 Entity combination algorithm based on syntactic rules |
| Input:
Part entity list L1, failure mode entity list L2, all entity list L3, entity relationship matching dictionary Dict = {x1: ”y1, y2, …”, x2: “z1, z2, …”, …}, where x represents part, and y, z represent failure modes Output: Combined entity list L4 of “part entity + failure mode entity” form |
| 01: L4, stack ← ; part_ flag, sym_flag ← 0 //Initialize entity list, flags, and stack 02: for i1 in L1 do //Traverse the part entity list L1 03: for i2 in L3[L3.index(i1) + 1: n −1] do //Traverse all entities in list L3 starting from element i1 04: if i2 ∈ L2 then //Check if i2 is a failure mode entity 05: part_ flag ← 1 //Marks that a failure mode entity has been encountered 06: stack.push(i2) //Push the failure mode entity i2 onto the stack 07: if part_ flag == sym_flag then 08: break 09: end if 10: else 11: sym_flag ← 1 //Marks that the corresponding part entity has been found 12: if part_ flag == sym_flag then 13: break 14: end if 15: end if 16: end for 17: for j ∈ stack do 18: stack.pop(j) //Pop the top element j from the stack 19: if j ∈ Dict[i1] then //Check if failure mode j matches with part entity i1 20: L4 ← [i1 +j] //Combine the part entity and failure mode entity, and store in L4 21: end if 22: end for 23: stack ← ; part_ flag, sym_flag ← 0 //Reset stack and flags 24: end for 25: return L4 = [x1 + yi, x1 + zi,…] //Return the result 26: end |
4.4. Entity Recognition and Performance Analysis
4.4.1. Entity Recognition Experiment
4.4.2. Performance Analysis
5. Entity Alignment
5.1. Entity Feature Analysis
5.2. Text Similarity
5.3. Entity Alignment Methods
5.4. Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| NER | Named entity recognition |
| BERT | Bidirectional encoder representations from Transformers |
| BiLSTM | Bi-directional long short-term memory |
| CRF | Conditional random field |
| CNN | Convolutional neural network |
| ELMO | Embeddings from language models |
| Text-CNN | Convolutional neural network for sentence classification |
| Text-RNN | Recurrent neural network for sentence classification |
| RoBERTa | Robustly Optimized BERT Pretraining Approach |
| ELMO | Embeddings from Language Models |
| LELNER | Lightweight and effective low-resource named entity recognition |
| TF-IDF | Term frequency–inverse document frequency |
| DP-CNN | Deep pyramid convolutional neural network |
| SimSCE | Simple contrastive learning of sentence embeddings |
| Word2vec | Word to vector |
References
- Priyankar, B.; Sriram, S.; Sleeman, W.C.; Palta, J.; Kapoor, R.; Ghosh, P. A Survey on Recent Named Entity Recognition and Relationship Extraction Techniques on Clinical Texts. Appl. Sci. 2021, 11, 8319. [Google Scholar] [CrossRef]
- Yeung, A.J.; Shek, A.; Searle, T.; Kraljevic, Z.; Dinu, V.; Ratas, M.; Al-Agil, M.; Foy, A.; Rafferty, B.; Oliynyk, V.; et al. Natural language processing data services for healthcare providers. BMC Med. Inform. Decis. Mak. 2024, 24, 356. [Google Scholar]
- Goyal, N.; Singh, N. Named entity recognition and relationship extraction for biomedical text: A comprehensive survey, recent advancements, and future research directions. Neurocomputing 2025, 618, 129171. [Google Scholar] [CrossRef]
- Pooja, H.; Jagadeesh, M.P. A Deep Learning Based Approach for Biomedical Named Entity Recognition Using Multitasking Transfer Learning with BiLSTM, BERT and CRF. SN Comput. Sci. 2024, 5, 482. [Google Scholar]
- Košprdić, M.; Prodanović, N.; Ljajić, A.; Bašaragin, B.; Milošević, N. From zero to hero: Harnessing transformers for biomedical named entity recognition in zero- and few-shot contexts. Artif. Intell. Med. 2024, 156, 102970. [Google Scholar]
- Tu, M. Named entity recognition and emotional viewpoint monitoring in online news using artificial intelligence. PeerJ Comput. Sci. 2024, 10, e1715. [Google Scholar] [CrossRef]
- Ren, Y.; Liu, Y. Recognition of News Named Entity Based on Multi-Level Semantic Features Fusion and Keyword Dictionary. Acad. J. Comput. Inf. Sci. 2024, 7, 32–40. [Google Scholar]
- Ding, J.; Xu, W.; Wang, A.; Zhao, S.; Zhang, Q. Joint multi-view character embedding model for named entity recognition of Chinese car reviews. Neural Comput. Appl. 2023, 35, 14947–14962. [Google Scholar]
- Park, C.; Jeong, S.; Kim, J. ADMit: Improving NER in automotive domain with domain adversarial training and multi-task learning. Expert Syst. Appl. 2023, 225, 120007. [Google Scholar]
- Affi, M.; Latiri, C. BE-BLC: BERT-ELMO-Based Deep Neural Network Architecture for English Named Entity Recognition Task. Procedia Comput. Sci. 2021, 192, 168–181. [Google Scholar]
- Gao, F.F.; Zhang, L.; Wang, W.; Zhang, B.; Liu, W.; Zhang, J.; Xie, L. Named Entity Recognition for Equipment Fault Diagnosis Based on RoBERTa-wwm-ext and Deep Learning Integration. Electronics 2024, 13, 3935. [Google Scholar] [CrossRef]
- Ni, J.; Wang, Y.; Wang, B. Named Entity Recognition for Automotive Production Equipment Fault Domain Fusing Radical Feature and BERT. J. Chin. Comput. Syst. 2024, 45, 1370–1375. [Google Scholar]
- Mao, T.; Xu, Y.; Liu, W.; Peng, J.; Chen, L.; Zhou, M. A simple but effective span-level tagging method for discontinuous named entity recognition. Neural Comput. Appl. 2024, 36, 7187–7201. [Google Scholar]
- Zhen, Y.; Li, Y.; Zhang, P.; Yang, Z.; Zhao, R. Frequent words and syntactic context integrated biomedical discontinuous named entity recognition method. J. Supercomput. 2023, 79, 13670–13695. [Google Scholar]
- Li, Y.; Liao, N.; Yan, H.; Zhang, Y.; Wang, X. Bi-directional context-aware network for the nested named entity recognition. Sci. Rep. 2024, 14, 16106. [Google Scholar]
- Han, D.J.; Wang, Z.; Li, Y.; Ma, X.; Zhang, J. Segmentation-aware relational graph convolutional network with multi-layer CRF for nested named entity recognition. Complex Intell. Syst. 2024, 10, 7893–7905. [Google Scholar]
- Huang, Z.; Hu, J. Entity category enhanced nested named entity recognition in automotive domain. J. Comput. Appl. 2024, 44, 377–384. [Google Scholar]
- Chen, S.; Dou, Q.; Tang, H.; Jiang, P. Chinese nested named entity recognition based on vocabulary fusion and span detection. Appl. Res. Comput. 2023, 40, 2382–2386+2392. [Google Scholar]
- Liu, Y.D.; Zhang, K.; Tong, R.; Cai, C.; Chen, D.; Wu, X. A Two-Stage Boundary-Enhanced Contrastive Learning approach for nested named entity recognition. Expert Syst. Appl. 2025, 271, 126707. [Google Scholar]
- Chen, J.; Su, L.; Li, Y.; Lin, M.; Peng, Y.; Sun, C. A multimodal approach for few-shot biomedical named entity recognition in low-resource languages. J. Biomed. Inform. 2024, 161, 104754. [Google Scholar] [CrossRef]
- Hang, H.; Chao, M.; Shan, Y.; Tang, W.; Zhou, Y.; Yu, Z.; Yi, J.; Hou, L.; Hou, M. Low Resource Chinese Geological Text Named Entity Recognition Based on Prompt Learning. J. Earth Sci. 2024, 35, 1035–1043. [Google Scholar]
- Zhan, J.Z.; Hao, Y.Z.; Qian, W.; Liu, J. LELNER: A Lightweight and Effective Low-resource Named Entity Recognition model. Knowl.-Based Syst. 2022, 251, 109178. [Google Scholar] [CrossRef]
- Yang, J.; Yao, L.; Zhang, T.; Tsai, C.Y.; Lu, Y.; Shen, M. Integrating prompt techniques and multi-similarity matching for named entity recognition in low-resource settings. Eng. Appl. Artif. Intell. 2025, 144, 110149. [Google Scholar] [CrossRef]
- Zheng, C.; Xiao, S. Text Classification Method Combining Grammar Rules and Graph Neural Networks. J. Chin. Comput. Syst. 2023, 44, 1–12. [Google Scholar]
- Zhou, Y.; Li, J.; Chi, J.; Tang, W.; Zheng, Y. Set-CNN: A text convolutional neural network based on semantic extension for short text classification. Knowl.-Based Syst. 2022, 257, 109948. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, G.; Gao, H.; Dang, D. Multi-Scale Interaction Network for Multimodal Entity and Relation Extraction. Inf. Sci. 2024, 699, 121787. [Google Scholar] [CrossRef]
- Cai, B.; Tian, S.; Yu, L.; Long, J.; Zhou, T.; Wang, B. ATBBC: Named entity recognition in emergency domains based on joint BERT-BILSTM-CRF adversarial training. J. Intell. Fuzzy Syst. 2024, 46, 4063–4076. [Google Scholar] [CrossRef]
- Jiao, Y.; Zhao, L. Real-Time Extraction of News Events Based on BERT Model. Int. J. Adv. Netw. Monit. Control. 2024, 9, 24–31. [Google Scholar] [CrossRef]
- Yoo, J.; Cho, Y. ICSA: Intelligent chatbot security assistant using Text-CNN and multi-phase real-time defense against SNS phishing attacks. Expert Syst. Appl. 2022, 207, 117893. [Google Scholar] [CrossRef]
- Deforche, M.; De Vos, I.; Bronselaer, A.; De Tré, G. A Hierarchical Orthographic Similarity Measure for Interconnected Texts Represented by Graphs. Appl. Sci. 2024, 14, 1529. [Google Scholar] [CrossRef]
- Chang, D.; Lin, E.; Brandt, C.; Taylor, R.A. Incorporating domain knowledge into language models by using graph convolutional networks for assessing semantic textual similarity: Model development and performance comparison. JMIR Med. Inform. 2021, 9, e23101. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Vehicle Model | Fault Description | Handling Results | Workstation No. | Replaced Part Name |
|---|---|---|---|---|---|
| 1 | E… | Source text: “客户反映倒挡总是挂不上。” Translation: “The customer reported that the reverse gear is always difficult to engage.” | Source text: “经检查发现是由于换挡开关故障导致。” Translation: “Upon inspection, it was found that the issue was caused by a faulty gear shift switch.” | 259F2410 | Source text: “驾驶模式选择开关” Translation: “The driving mode selection switch” |
| 2 | E… | Source text: “按动车辆喇叭有杂音” Translation: “Pressing the vehicle horn produces a buzzing sound.” | Source text: “电喇叭击穿故障,更换电喇叭” Translation: “The electric horn has a short circuit fault, and the electric horn needs to be replaced.” | 102G0200 | Source text: “电喇叭总成(高音)” Translation: “Electric horn assembly (high tone)” |
| 3 | E… | Source text: “检查行驶中底盘后面异响。” Translation: “Inspect abnormal noise from the rear chassis while driving.” | Source text: “电驱动桥内部异响,更换电驱动桥处理。” Translation: “Internal noise in the electric drive axle, replace the electric drive axle.” | 402S3067 | Source text: “电驱动桥” Translation: “Electric drive axle” |
| … | … | … | … | … | … |
| Original Long Text | Short Texts | |||
|---|---|---|---|---|
| Source text: “经技师检查,车内顶灯内部虚接导致顶灯时亮时不亮,更换前顶灯进行修复处理” Translation: “Upon inspection by the technician, the internal loose connection of the interior roof light caused intermittent lighting. The front roof light was replaced for repair.” | Source text: “经技师检查” Translation: “Upon inspection by the technician” | Source text: “车内顶灯内部虚接” Translation: “the internal loose connection of the interior roof light” | Source text: “导致顶灯时亮时不亮” Translation: “caused intermittent lighting” | Source text: “更换前顶灯进行修复处理” Translation: “The front roof light was replaced for repair” |
| Source text: “该车辆报修方向盘偏左,路试确实偏左.上定位仪测量总前束0.53度偏大,重新做四轮定位调整前束修复.” Translation: “The vehicle was reported for the steering wheel being slightly tilted to the left. Road testing confirmed the tilt. The alignment tool measured a total toe of 0.53 degrees, which was too large. The four-wheel alignment was redone, adjusting the toe for repair.” | Source text: “该车辆报修方向盘偏左” Translation: “The vehicle was reported for the steering wheel being slightly tilted to the left” | Source text: “路试确实偏左” Translation: “Road testing confirmed the tilt” | Source text: “上定位仪测量总前束0.53度偏大” Translation: “the alignment tool measured a total toe of 0.53 degrees, which was too large” | Source text: “重新做四轮定位调整前束修复” Translation: “The four-wheel alignment was redone, adjusting the toe for repair” |
| Source text: “转向器总成异响,左、右转向拉杆总成松旷,更换转向器总成、左右拉杆总成。” Translation: “The steering assembly made abnormal noise, and the left and right steering rods were loose. The steering assembly and both steering rods were replaced.” | Source text: “转向器总成异响” Translation: “The steering assembly made abnormal noise” | Source text: “左、右转向拉杆总成松旷” Translation: “and the left and right steering rods were loose” | Source text: “更换转向器总成、左右拉杆总成” Translation: “The steering assembly and both steering rods were replaced” | —— |
| Field Category | Fault Description Text | Handling Result Text |
|---|---|---|
| Fault phenomenon field | Source text: “车里顶灯开门时候时亮时不亮” Translation: “Interior roof light intermittently lights up when the door is opened” | Source text: “导致顶灯时亮时不亮” Translation: “Caused roof light to intermittently light up” |
| Fault cause field | —— | Source text: “车内顶灯内部虚接” Translation: “Loose internal connection in the interior roof light” |
| Maintenance method field | —— | Source text: “更换前顶灯进行修复处理” Translation: “Replaced the front roof light for repair” |
| Other fields | Source text: “车里顶灯开门时候时亮时不亮” Translation: “Customer reported to the shop” | Source text: “经技师检查” Translation: “Upon inspection by the technician” |
| Model | Precision/% | Recall/% | F1-Score/% |
|---|---|---|---|
| BERT | 86.49 | 83.27 | 84.85 |
| RoBERTa | 87.35 | 85.19 | 86.26 |
| Text-RNN | 89.22 | 90.61 | 89.91 |
| DP-CNN | 90.35 | 91.37 | 90.86 |
| Fast-Text | 91.24 | 90.88 | 91.06 |
| Text-CNN | 91.82 | 90.36 | 91.08 |
| Text Sequence | BIOS Labels |
|---|---|
| Source text: “客户到店反映,” Translation: “ The customer reported to the shop that” | O|O|O|O|O|O|O |
| Source text: “车里胎压灯亮。” Translation: “the tire pressure light was on.” | O|O|B-P|I-P|I-P|S|O |
| Source text: “经技师检查,” Translation: “Upon inspection by the technician,” | O|O|O|O|O|O |
| Source text: “轮胎压力传感器短路,” Translation: “it was found that a short circuit in the tire pressure sensor” | B-P|I-P|I-P|I-P|I-P|I-P|I-P|B-S|I-S|O |
| Source text: “导致胎压灯亮,” Translation: “caused the tire pressure light to illuminate.” | O|O|B-P|I-P|I-P|S|O |
| Source text: “更换轮胎压力传感器。” Translation: “The tire pressure sensor was replaced.” | O|O|B-P|I-P|I-P|I-P|I-P|I-P|I-P|O |
| Model | Precision/% | Recall/% | F1-Score/% |
|---|---|---|---|
| BERT-CRF | 81.56 | 83.41 | 82.47 |
| BiLSTM-CRF | 84.03 | 86.27 | 85.14 |
| Word2v-BiLSTM-CRF | 88.61 | 89.09 | 88.85 |
| FLAT | 89.62 | 89.24 | 89.43 |
| roBERTa-wwm-ext | 90.57 | 90.06 | 90.31 |
| BERT-BiLSTM-CRF | 91.06 | 89.53 | 90.29 |
| Phenomenon Part Entity | Phenomenon Entity | Fault Part Entity | Cause Entity |
|---|---|---|---|
| Source text: “倒挡” Translation: “reverse gear” | Source text: “挂不上、异响、…” Translation: “difficult to engage, abnormal noise, …” | Source text: “换挡开关” Translation: “shift switch” | Source text: “短路、损坏、…” Translation: “short circuit, damage, …” |
| Source text: “胎压故障灯” Translation: “tire pressure fault light” | Source text: “亮、报警、…” Translation: “illuminates, alarm, …” | Source text: “右前轮发射器” Translation: “right front wheel transmitter” | Source text: “信号丢失、信号失效、…” Translation: “signal loss, signal failure, …” |
| Source text: “底盘” Translation: “chassis” | Source text: “异响、漏油、…” Translation: “abnormal noise, oil leakage, …” | Source text: “右半轴球笼” Translation: “right half shaft ball joint” | Source text: “松旷、漏油、…” Translation: “loose, oil leakage, …” |
| Source text: “雨刮” Translation: “wiper” | Source text: “不工作、刮不干净、…” Translation: “not working, does not clean properly, …” | Source text: “洗涤泵” Translation: “wash pump” | Source text: “漏水、开裂、…” Translation: “leaking, cracked, …” |
| Source text: “电喇叭” Translation: “electric horn” | Source text: “不响、杂音、…” Translation: “no sound, noise, …” | Source text: “电喇叭” Translation: “electric horn” | Source text: “短路、接触不良、…” Translation: “short circuit, poor contact, …” |
| … | … | … | … |
| Text Type | Processing Method | Nested Text | Non-Continuous Entities and Nested Text | ||||
|---|---|---|---|---|---|---|---|
| Precision/% | Recall/% | F1-Score/% | Precision/% | Recall/% | F1-Score/% | ||
| Fault description | Entity recognition | 84.00 | 72.22 | 77.67 | 59.33 | 64.61 | 61.86 |
| Text classification + entity recognition | 96.33 | 85.81 | 90.77 | 70.67 | 72.17 | 71.41 | |
| Text classification + entity recognition + entity matching database | 96.33 | 85.81 | 90.77 | 75.67 | 74.01 | 74.83 | |
| Processing results | Entity recognition | 70.33 | 66.82 | 68.53 | 61.67 | 66.49 | 63.99 |
| Text classification + entity recognition | 85.67 | 83.66 | 84.65 | 74.00 | 76.13 | 75.05 | |
| Text classification + entity recognition + entity matching database | 85.67 | 83.66 | 84.65 | 78.33 | 82.55 | 80.38 | |
| sim1 | sim2 | Number of Entities | Aligned Entities Accuracy Rate (%) | Number of Entity Categories | Sample Entity Alignment Rate (%) | ||
|---|---|---|---|---|---|---|---|
| Aligned | Pending Review | Before Alignment | After Alignment | ||||
| 0.9 | 0.8 | 973 | 27 | 93.2 | 345 | 286 | 17.1 |
| 0.8 | 0.7 | 989 | 11 | 90.8 | 345 | 225 | 34.8 |
| 0.7 | 0.6 | 986 | 14 | 83.8 | 345 | 197 | 42.9 |
| 0.6 | 0.5 | 986 | 14 | 72.4 | 345 | 154 | 55.4 |
| Similarity Method | Cosine | Jaccard | Edit Distance | Synonyms | Average | Max |
|---|---|---|---|---|---|---|
| Accuracy/% | 88 | 85 | 87 | 80 | 90.8 | 78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geng, H.; Qing, H.; Hu, J.; Huang, W.; Kang, H. A Named Entity Recognition Method for Chinese Vehicle Fault Repair Cases Based on a Combined Model. Electronics 2025, 14, 1361. https://doi.org/10.3390/electronics14071361
Geng H, Qing H, Hu J, Huang W, Kang H. A Named Entity Recognition Method for Chinese Vehicle Fault Repair Cases Based on a Combined Model. Electronics. 2025; 14(7):1361. https://doi.org/10.3390/electronics14071361
Chicago/Turabian StyleGeng, Huangzheng, Haihua Qing, Jie Hu, Wentao Huang, and Hanrui Kang. 2025. "A Named Entity Recognition Method for Chinese Vehicle Fault Repair Cases Based on a Combined Model" Electronics 14, no. 7: 1361. https://doi.org/10.3390/electronics14071361
APA StyleGeng, H., Qing, H., Hu, J., Huang, W., & Kang, H. (2025). A Named Entity Recognition Method for Chinese Vehicle Fault Repair Cases Based on a Combined Model. Electronics, 14(7), 1361. https://doi.org/10.3390/electronics14071361