
Automatic Image Distillation with Wavelet Transform and Modified Principal Component Analysis



Abstract

1. Introduction
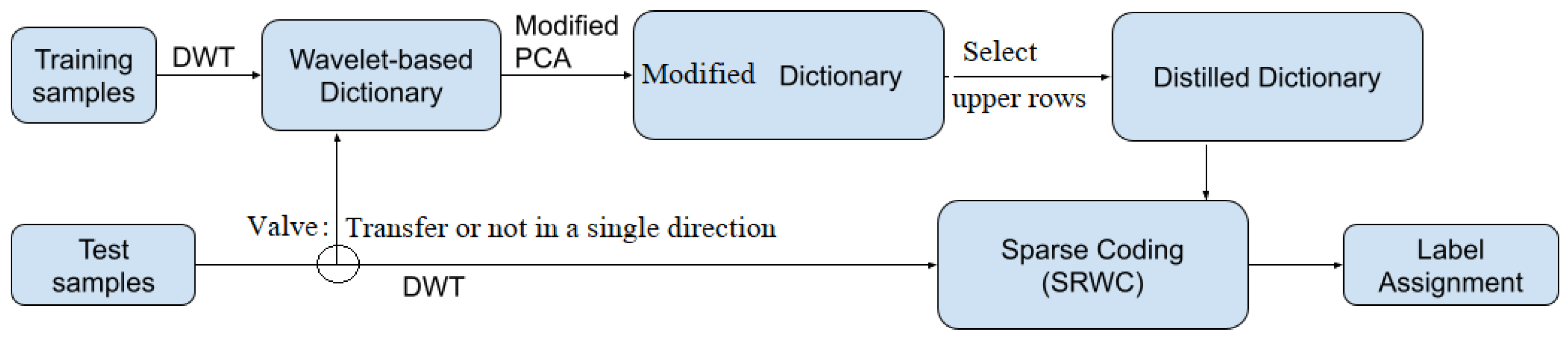
2. Wavelet-Based Training Dictionary Design
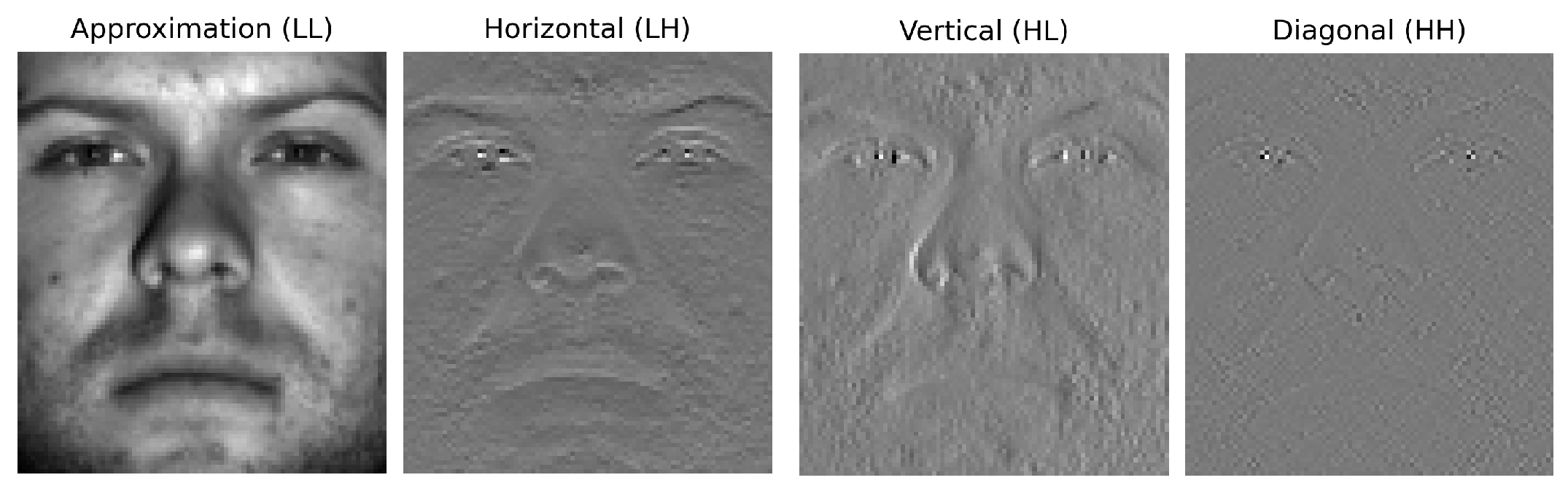
2.1. Image Decomposition to Wavelet Sub-Bands
2.2. Training Wavelet Dictionary Design
3. Distilling a Dictionary from the TWD
3.1. Modifying the Wavelet-Based Class Matrices
3.2. Creating a Distilled Wavelet Dictionary
4. Experimental Validation
4.1. Sparse Representation Wavelet-Based Classification
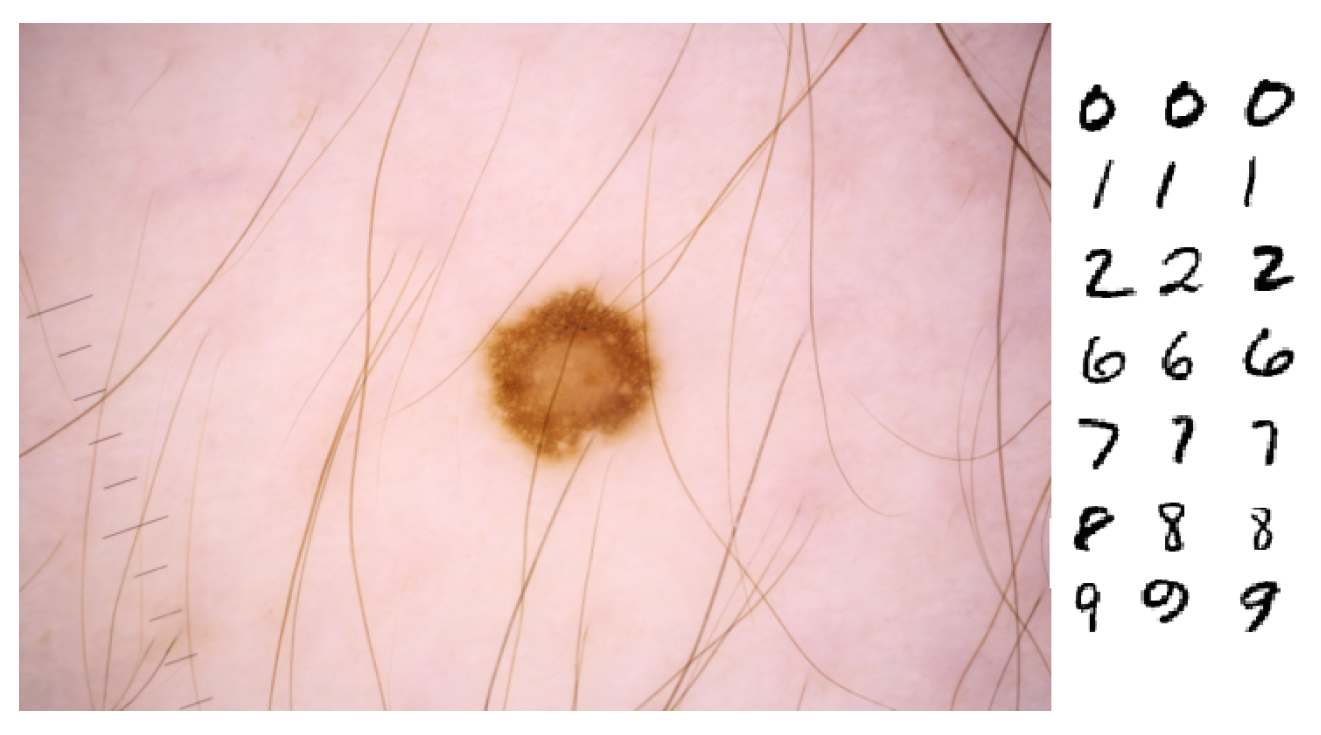
4.2. Original Datasets
4.3. Classification Metrics
- Accuracy (AC): measures the overall correctness of a model’s predictions:
4.4. Experimental Schemes
4.5. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ML | Machine learning |
| LL | Low-band wavelet coefficients |
| M-PCA | Modified principle component analysis |
| SRWC | Sparse representation wavelet-based classification |
| DWT | Discrete wavelet transform |
| TWD | Training wavelet dictionary |
| DWD | Distilled wavelet dictionary |
References
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar]
- Leevy, J.L.; Khoshgoftaar, T.M.; Bauder, R.A.; Naeem, S. A survey on addressing high-class imbalance in big data. J. Big Data 2018, 5, 1–30. [Google Scholar] [CrossRef]
- Nguyen, T.; Chen, Z.; Lee, J. Dataset meta-learning from kernel ridge-regression. In Proceedings of the International Conference on Learning Representations, ICLR, Vienna, Austria, 4 May 2024. [Google Scholar]
- Sachdeva, N.; McAuley, J. Data Distillation: A Survey. Trans. Mach. Learn. Res. 2023, 7, 1–21. [Google Scholar]
- Radosavovic, I.; Dollár, P.; Girshick, R.; Gkioxari, G.; He, K. Data Distillation: Towards Omni-Supervised Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4119–4128. [Google Scholar]
- Yang, Z.; Yang, H.; Majumder, S.; Cardoso, J.; Gallego, G. Data Pruning Can Do More: A Comprehensive Data Pruning Approach for Object Re-identification. Trans. Mach. Learn. Res. 2024, 2835–8856. Available online: https://openreview.net/forum?id=vxxi7xzzn7 (accessed on 27 December 2024).
- Yang, S.; Xie, Z.; Peng, H.; Xu, M.; Sun, M.; Li, P. Dataset Pruning: Reducing Training Data by Examining Generalization Influence. In Proceedings of the 2023 International Conference on Learning Representations, ICLR, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Sirakov, N.M.; Shahnewaz, T.; Nakhmani, A. Training Data Augmentation with Data Distilled by the Principal Component Analysis. Electronics 2024, 13, 282. [Google Scholar] [CrossRef]
- Yu, X.; Teng, L.; Zhang, D.; Zheng, J.; Chen, H. Attention correction feature and boundary constraint knowledge distillation for efficient 3D medical image segmentation. Expert Syst. Appl. 2025, 262, 125670. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Y.; Huang, F.; Qi, X.; Wang, L.; Liu, X. Negative-Core Sample Knowledge Distillation for Oriented Object Detection in Remote Sensing Image. IEEE Trans. Geosci. Remote Sens. 2024, 62, 56486182. [Google Scholar] [CrossRef]
- Li, X.; Huang, G.; Cheng, L.; Zhong, G.; Liu, W.; Chen, X.; Cai, M. Cross-domain visual prompting with spatial proximity knowledge distillation for histological image classification. J. Biomed. Inform. 2024, 158, 104728. [Google Scholar] [CrossRef]
- Zhao, B.; Mopuri, K.R.; Bilen, H. Dataset Condensation with Gradient Matching. In Proceedings of the International Conference on Learning Representations-ICLR, Vienna, Austria, 4 May 2021. [Google Scholar]
- Wang, T.; Zhu, J.-Y.; Torralba, A.; Efros, A. Dataset Distillation. arXiv 2020, arXiv:1811.10959v3. [Google Scholar]
- Vinaroz, M.; Park, M. Differentially private kernel inducing points using features from scatternets (DP-KIP-scatternet) for privacy preserving data distillation. arXiv 2024, arXiv:2301.13389. Available online: https://arxiv.org/pdf/2301.13389v2 (accessed on 15 January 2025).
- Cazenavette, G.; Wang, T.; Torralba, A.; Efros, A.A.; Zhu, J.Y. Dataset distillation by matching training trajectories. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4750–4759. [Google Scholar]
- Hotelling, H. Analysis of a complex of statistical variables into principa. J. Educ. Psychol. 1933, 24, 417. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. Wires Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Ngo, L.H.; Luong, M.; Sirakov, N.M.; Viennet, E.; Le-Tien, T. Skin lesion image classification using sparse representation in quaternion wavelet domain. Signal Image Video Process. 2022, 16, 1721–1729. [Google Scholar]
- Ngo, L.H.; Luong, M.; Sirakov, N.M.; Le-Tien, T.; Guerif, S.; Viennet, E. Sparse Representation Wavelet Based Classification. In Proceedings of the International Conference in Image Processing, ICIP2018, Athens, Greece, 7–10 October 2018; IEEE XPlore: Piscataway, NJ, USA, 2018; pp. 2974–2978. [Google Scholar] [CrossRef]
- Mallat, S. Wavelet Tour of Signal Processing: The Sparse Way; Academic Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Zou, W.; Li, Y. Image classification using wavelet coefficients in low-pass bands. In Proceedings of the International Joint Conference on Neural Networks, IJCNN, Orlando, FL, USA, 12–17 August 2007; IEEE Xplore: Piscataway, NJ, USA, 2007; pp. 114–118. [Google Scholar]
- Georghiades, A.S.; Belhumeur, P.N.; Kriegman, D. From few tomany: Illumination cone models for face recognition under variable lighting and pose. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 643–660. [Google Scholar] [CrossRef]
- Kadam, S.S.; Adamuthe, A.C.; Patil, A.B. CNN model for image classification on MNIST and fashion-MNIST dataset. J. Sci. Res. 2020, 64, 374–384. [Google Scholar] [CrossRef]
- General Site for the MNIST Database. Available online: http://yann.lecun.com/exdb/mnist (accessed on 12 September 2024).
- International Skin Imaging Collaboration. SIIM-ISIC 2020 Challenge Dataset. Internat. Skin Imaging Collaboration. Available online: https://challenge2020.isic-archive.com/ (accessed on 17 May 2023).
- Guo, T.; Mousavi, H.S.; Vu, T.H.; Monga, V. Deep wavelet prediction for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dubitzky, D.; Granzow, M.; Berrar, D.P. Fundamentals Data Mining Genomics Proteomics; Springer: Boston, MA, USA, 2007. [Google Scholar]
- Sirakov, N.M.; Bowden, A.; Chen, M.; Ngo, L.H.; Luong, M. Embedding vector field into image features to enhance classification. J. Comput. Appl. Math. 2024, 44, 115685. [Google Scholar]
- Nguyen, T.; Novak, R.; Xiao, L.; Lee, J. Dataset distillation with infinitely wide convolutional networks. In Proceedings of the NeurIPS 2021, 35 Annual Conference on Neural Information Processing Systems, Virtual Conference, 7–10 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P.S., Vaughan, J.W., Eds.; Curran Associates Inc.: Red Hook, NY, USA; Volume 34, pp. 5186–5198. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training per Class | Total for 38 Classes | Train/Test per Class | Ac% | |
|---|---|---|---|---|
| Original images YaleB-38 classes | 64 | 2432 | 30/34 | 98.06% [28] |
| Case 1 setup for YaleB-38 classes | ||||
| Distilled images 1st experiment | 57 | 2166 | 30/27 | 98.9% |
| Distilled images 2nd experiment | 44 | 1672 | 30/14 | 98.72% |
| Distilled images 3rd experiment | 38 | 1444 | 30/8 | |
| Distilled images 3rd experiment | 32 | 1216 | 30/2 | 98.7% |
| Case 2 setup for YaleB-38 classes | ||||
| Distilled images | 18 | 684 | 18/26 | 91.5% |
| Training per Class | Total for 38 Classes | Train/Test per Class | Ac % | |
|---|---|---|---|---|
| Original images digit-MNIST-10 classes | 600 | 6000 | 600/1000 | 11% |
| Original images digit-MNIST-10 classes | 1000 | 10,000 | 1000/1000 | 14.19% |
| Case 3 setup for digit-MNIST-10 classes | ||||
| Distilled images 1st experiment | 157 | 1570 | 157/1000 | 95.25% |
| Distilled images 2nd experiment | 94 | 940 | 94/1000 |
| Training Samples (Malignant/Benign) | Original Images | Sharpened with Laplacian | Distilled Under Case 3 Setup |
|---|---|---|---|
| 292/584 | score = 0.7734 [28] | score = 0.7804 [28] | score = 0.7336 |
| 523/7704 | - | - | score = 0.8115 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sirakov, N.M.; Ngo, L.H. Automatic Image Distillation with Wavelet Transform and Modified Principal Component Analysis. Electronics 2025, 14, 1357. https://doi.org/10.3390/electronics14071357
Sirakov NM, Ngo LH. Automatic Image Distillation with Wavelet Transform and Modified Principal Component Analysis. Electronics. 2025; 14(7):1357. https://doi.org/10.3390/electronics14071357
Chicago/Turabian StyleSirakov, Nikolay Metodiev, and Long H. Ngo. 2025. "Automatic Image Distillation with Wavelet Transform and Modified Principal Component Analysis" Electronics 14, no. 7: 1357. https://doi.org/10.3390/electronics14071357
APA StyleSirakov, N. M., & Ngo, L. H. (2025). Automatic Image Distillation with Wavelet Transform and Modified Principal Component Analysis. Electronics, 14(7), 1357. https://doi.org/10.3390/electronics14071357