1. Introduction
Computer technology has been extensively applied to various aspects of daily life, such as security surveillance, search engines, and autonomous driving. However, the inherent uncertainties and dual nature of these technologies have exposed the inadequacies of modern ethical standards, giving rise to a series of computer engineering ethics issues, including privacy leaks, algorithmic price discrimination, and algorithmic bias, which pose significant challenges to data privacy and confidentiality [
1,
2]. The emergence of these issues not only threatens individual rights but also undermines public trust in technological systems, highlighting the urgency of integrating ethical considerations into technological development. In computer engineering ethics research, case analysis serves as a crucial method for uncovering the essence of these problems and exploring potential solutions [
3,
4]. However, ethical cases often involve highly sensitive data, including personally identifiable information, behavioral motivations, and the complex factors underlying ethical decision-making. Traditional information extraction methods, which rely excessively on data, increase the risk of data exposure and hinder the sustainable development of technology. Therefore, it is of paramount importance to construct a framework capable of efficiently extracting data value while robustly protecting privacy.
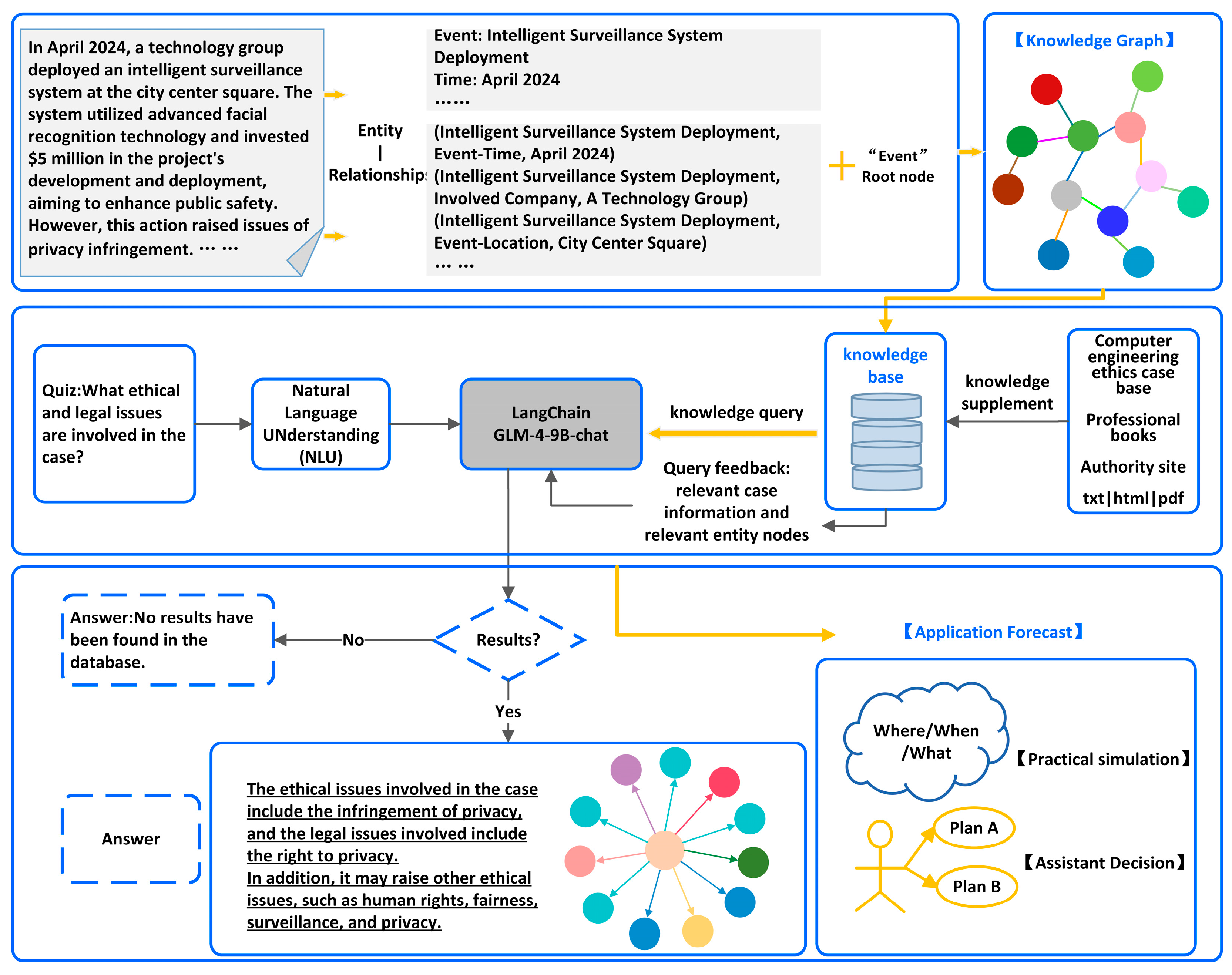
Using Large Language Models (LLMs) for information extraction represents an advanced application of machine learning techniques in natural language processing. Leveraging machine learning methodologies and frameworks, LLMs enable the understanding and generation of human language, thereby producing structured outputs without storing raw data, significantly reducing privacy risks. Moreover, LLMs exhibit robust Few-Shot and even Zero-Shot learning capabilities, allowing them to adapt to new tasks with minimal examples or prompts rapidly. This reduces reliance on large-scale annotated datasets and further enhances privacy protection. Additionally, through a series of prompt engineering techniques, the extraction performance of these models can be further improved, providing more refined technical support for information extraction tasks. The extracted results can be used to construct knowledge graphs, which organize and represent data graphically, making the information more intuitive and easier to comprehend. Furthermore, intelligent question answering systems can be implemented by integrating LLMs with knowledge graphs using the LangChain framework, offering users in-depth information support. This enables users to obtain instant answers anytime and anywhere, along with personalized responses and recommendations. Such integration brings significant benefits across multiple dimensions, including efficiency, cost-effectiveness, user experience, service quality, and data analysis.
Currently, research on applying LLMs to privacy-preserving information extraction in ethical cases is still in its infancy, and this article innovatively explores this topic. The main contributions of this article are as follows.
We have collected and organized different types of ethical case datasets, which are stored in their respective local systems. Under the framework of federated learning, models are trained using local data, and only model parameter updates are uploaded to a central server for aggregation, achieving a balance between data privacy protection and shared data analysis. The construction of these datasets provides a solid data foundation for model training and application, supporting subsequent intelligent analysis and decision-making;
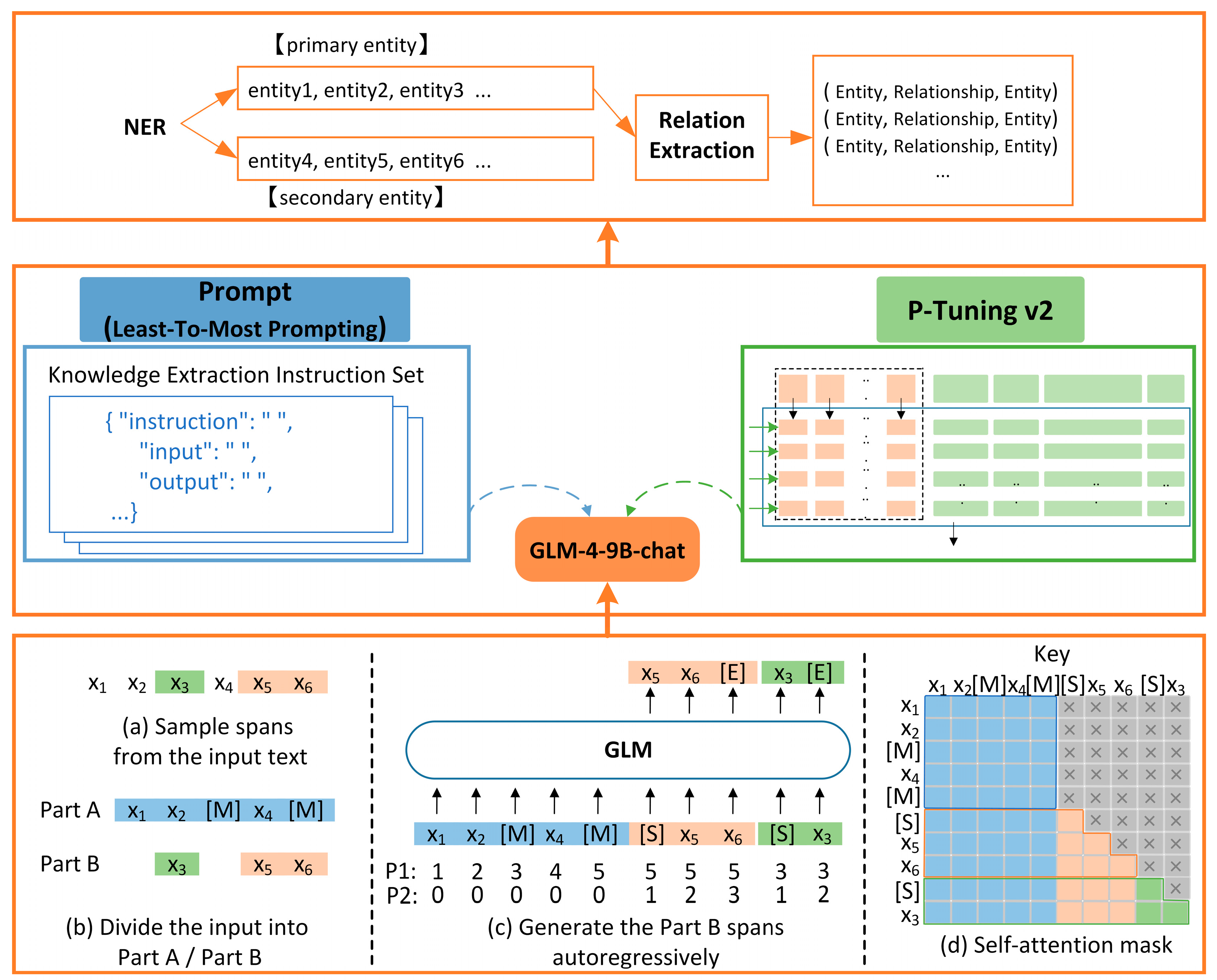
We propose an information extraction model for computer engineering ethical cases based on ChatGLM-LtMP. This model is capable of efficiently completing extraction tasks through Few-Shot Prompting, reducing data dependency and minimizing the risk of privacy leakage;
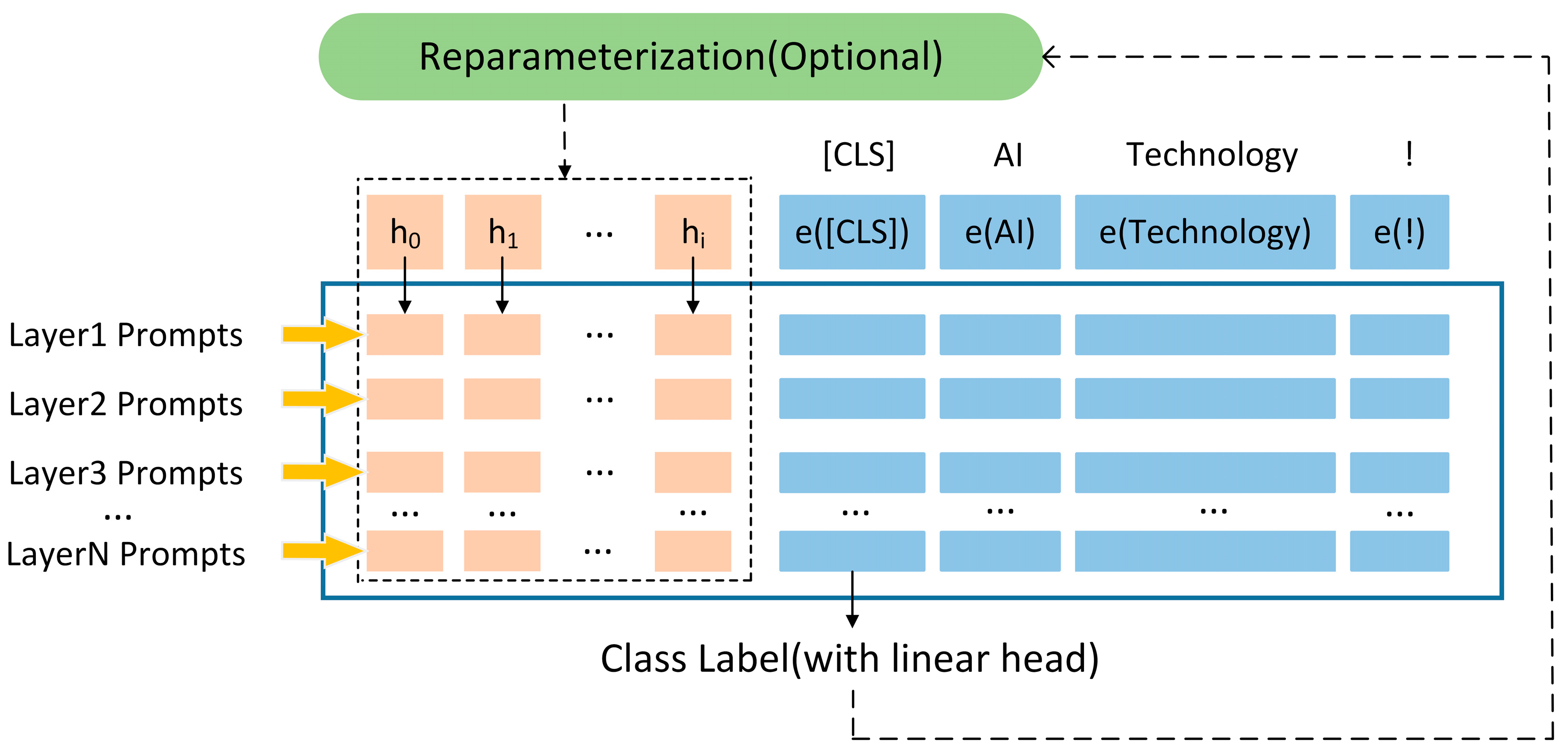
We employed the Least-to-Most (LtM) Prompting method to construct the prompt templates, guiding the model to extract only a portion of the case information at each step, thereby reducing the risk of exposure to sensitive data. Moreover, we optimized the model parameters with the P-Tuning v2 technique to further enhance the model’s performance. Extensive information extraction experiments were conducted on both general and ethics case datasets constructed in this paper, with a comparative analysis against current mainstream models. The results indicate that the ChatGLM-LtMP model outperforms existing methods across multiple metrics;
Additionally, we integrated the Neo4j graph database to construct a knowledge graph that stores only structured information, thus avoiding the storage of raw text from ethics cases and enhancing data security. Furthermore, by leveraging the LangChain framework, we implemented intelligent question answering for cases, setting dynamic prompt restrictions to limit the data accessible, which simultaneously protects privacy and improves the real-time performance and accuracy of the question and answer service. This provides intelligent support for research in the field of computer engineering ethics.
The rest of the paper is organized as follows.
Section 2 discusses related work.
Section 3 describes constructing the computer engineering ethics case dataset.
Section 4 proposes the ChatGLM-LtMP model.
Section 5 completes the information extraction experiments.
Section 6 constructs the intelligent question answering system.
Section 7 concludes the paper.
3. Constructing Datasets
The scope of ethical cases is broad, and with the advancement of computer and artificial intelligence technologies, the rate of updates is accelerating. To enhance the efficiency of dataset construction and updates, the authors of this paper have taken targeted measures by conducting independent data collection for specific categories of ethical cases. Furthermore, federated learning technology has been employed to ensure data security and privacy protection, enabling secure data sharing among multiple parties. This approach has improved the quality and diversity of the dataset without exposing the original data.
In the data acquisition stage, we use the vast amount of resource data on the Internet to crawl case information from several authoritative official websites. In addition, we obtain cases from open academic journals and relevant industry reports to supplement the dataset. The dataset not only includes the main text information of the cases but also provides a wealth of contextual information, such as case background, outcome analysis, and social impact, which facilitates in-depth research. At the same time, a wide range of case types, such as privacy protection, data security, intellectual property rights, etc., are covered to ensure the diversity and representativeness of the data. The data used aligns with the requirements for use in academic research and does not involve commercial use or infringement. The workflow for web data crawling is outlined as follows. Firstly, the URL list of the target page is obtained, and each page URL is extracted one by one; then, the list of case URLs is parsed, extracted, and stored; finally, the case text is extracted from the case URLs, and the text is written to a local file until all URLs are processed.
During the data processing phase, we implemented a three-stage progressive cleaning strategy to systematically enhance data quality and compliance. First Stage: Manual Review. Manual screening was performed to remove blank texts, case-irrelevant information (e.g., off-topic comments, duplicate paragraphs, and malformatted content). Second Stage: Automated Cleaning via Canopy-K-means Clustering [
29]. The Canopy-K-means algorithm, a hybrid method combining coarse-grained pre-clustering (Canopy) and fine-grained precise clustering (K-means), was adopted for noise reduction and anomaly detection in large-scale, high-dimensional data. The workflow proceeded as follows: Firstly, unstructured ethics case texts were encoded into dense vectors using a pre-trained model to generate numerical features suitable for clustering. Secondly, data was partitioned using loose threshold T1 (identifying potentially similar texts) and tight threshold T2 (excluding highly overlapping candidate cluster centers). For instance, texts related to “autonomous vehicle liability determination” were grouped into Canopy clusters encompassing technical and legal dimensions. Then, the number of cluster centers K was determined proportionally to the square root of the dataset size to avoid overfitting (K too large) or cluster impurity (K too small). K-means++ initialized centroids, followed by iterative objective function optimization. Small clusters and edge points were removed as anomalies. Finally, texts with identical MD5 hashes or semantic similarity exceeding thresholds were deduplicated (retaining the earliest occurrence). Outliers (e.g., semantically irrelevant or malformatted texts) were flagged for manual verification. This stage reduced duplicate texts by 7%, achieved a 23% anomaly removal rate, and improved efficiency by 40% compared to single-round manual cleaning. Third Stage: Expert Validation. Domain experts reviewed the cleaned data to verify privacy compliance and ensure alignment with research objectives. The final corpus comprised 2632 validated text entries.
Building on insights from domain experts and requirements of specific application scenarios, we conducted an in-depth analysis of privacy-related information in case studies. Based on this analysis, 11 entity types and 10 relationship types between entities were defined. These entity types specifically include: the core content of the event (Event); the specific time at which the event occurred (Time); the geographical location of the event, encompassing privacy information of individuals or organizations, such as residence, workplace, or movement paths (Address); the full names or titles of the individuals involved (Name); the organizations involved (Organization); the commercial companies involved (Company); the government agencies involved (Government); technological factors (Technology); information related to the legal obligations and rights of individuals or organizations (Legal); ethical judgments and codes of conduct related to individuals or organizations (Ethical); monetary amounts associated with personal financial situations or business transaction payments (Amount). On this foundation, we defined the types of relationships between entities, which include Event-Time, Event-Location, Involved-Person, Involved-Organization, Involved-Company, Involved-Government, Technology-Factor, Legal-Aspect, Ethical-Aspect, and Involved-Amount. To ensure annotation quality, three annotators independently labeled 2632 text entries using the Label Studio tool. The inter-annotator agreement was validated through Cohen’s Kappa consistency test. A random subset (10%) of annotated samples was reviewed by domain experts to correct mislabeled instances (e.g., “data collection protocol” erroneously labeled as Technology instead of Legal). Subsequently, the Isolation Forest algorithm was employed to detect anomalous annotations (e.g., relationship types conflicting with contextual semantics), resulting in the removal of 1.2% low-quality samples. Ultimately, 10,604 high-confidence entity-relationship pairs were retained for analysis, as summarized in
Table 1.
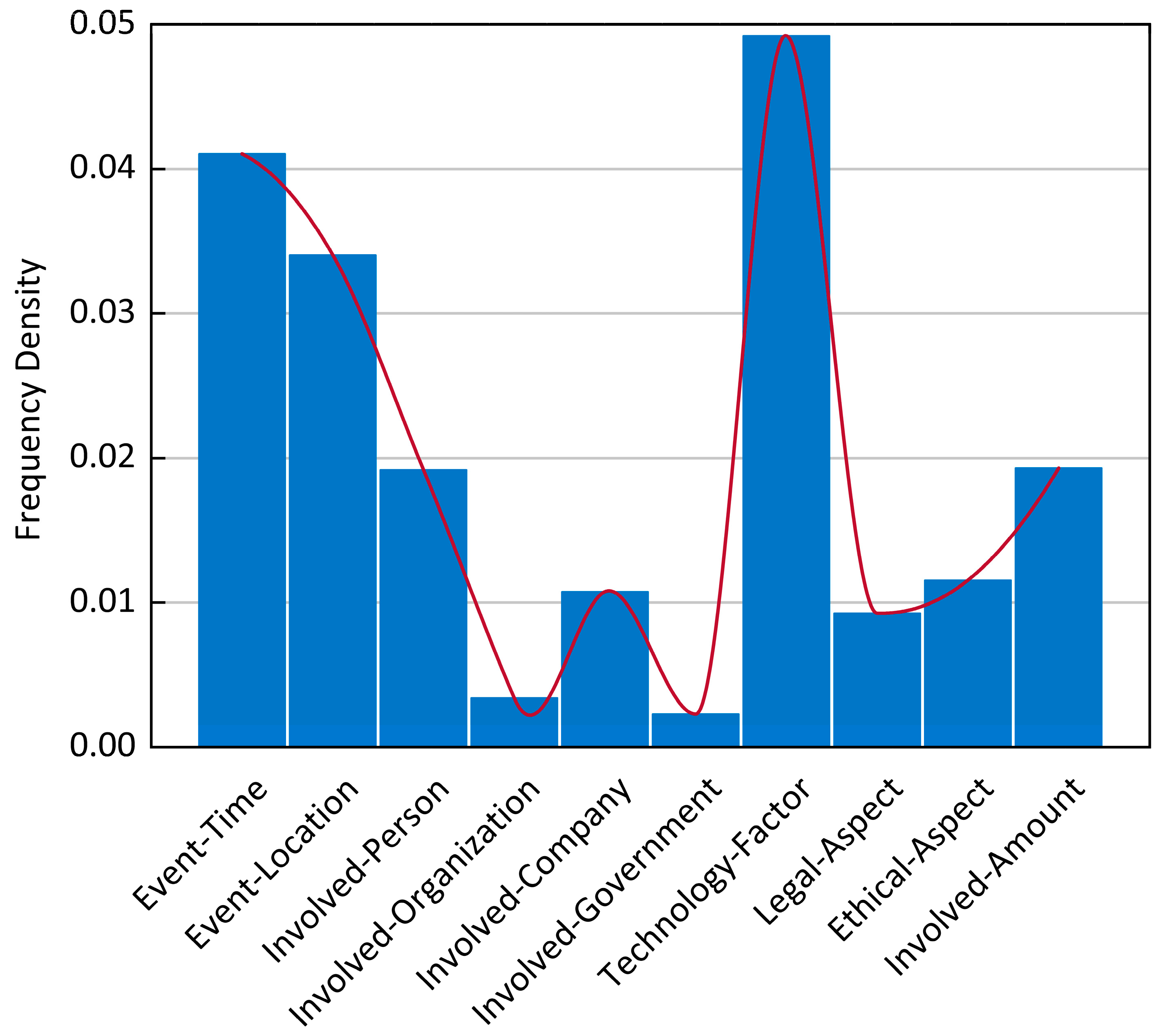
To analyze the frequency distribution of entity-relationship types, a histogram was generated with a bin width of 5, as illustrated in
Figure 1.
Analysis of the data in
Table 1 and
Figure 1 reveals a significant distribution bias in entity-relationship types within the dataset. The entity-relationship pairs, Technology-Factor and Event-Time, exhibit the highest frequencies, indicating that technical factors and temporal information dominate the dataset. This reflects the domain-specific characteristics of computer engineering ethics cases, which are typically driven by computer-related technologies and associated with fixed occurrence times. In contrast, Involved-Government and Involved-Organization appear least frequently, suggesting that events involving government or organizational participation are rare in the dataset. Such imbalance may lead to model bias toward high-frequency categories, insufficient generalization for low-frequency categories, and distortion of evaluation metrics.
To enhance the model’s understanding of low-frequency domain knowledge, we introduce a specialized corpus related to computer engineering ethics for knowledge augmentation. The newly added corpus consists of 12 authoritative documents (totaling 21,247 words), covering The ACM Code of Ethics, GDPR provisions, and other professional literature. The specific processing workflow is as follows: Initially, the raw documents are manually reviewed to eliminate irrelevant expressions. Subsequently, regular expressions are employed to remove extraneous content (such as headers, footers, etc.) from the files, and OCR recognition is performed on the PDF documents to ensure text integrity. Following this, the data annotation process described earlier is utilized to annotate 106 entity-relationships. Finally, the preprocessed corpus knowledge is integrated with the existing dataset for subsequent model training.
5. Experimental Results and Discussion of Information Extraction
5.1. Experimental Setup
The experiments were conducted using the Windows 11 × 64 operating system with an Intel Core i9 CPU at a central frequency of 3.91 GHz. The GPU was an NVIDIA RTX 4090 with 80 GB of video memory. The programming language used was Python 3.11.5. During model training, key parameters such as pre_seq_len and learning_rate were adaptively adjusted, and the experimental parameter settings are shown in
Table 2.
This study employs Precision (P), Recall (R), and F1 Score as evaluation metrics for the information extraction experiments. A higher F1 Score indicates better model performance [
31].
5.2. Comparative Experiments Under Different Fine-Tuning Methods
To investigate the impact of Zero-Shot-LtM and Few-Shot-LtM on the performance of the ChatGLM-LtMP model, we conducted evaluation experiments on the same ethics case dataset using Zero-Shot-LtM, One-Shot-LtM, Three-Shot-LtM, Five-Shot-LtM, and Few-Shot-LtM (with sample sizes ranging from 6 to 9) [
32]. For the Few-Shot-LtM setting, we recorded the highest F1 Score achieved by the model during testing. The experimental results are presented in
Table 3.
By analyzing the data, we observe that the model’s F1 Score exhibits an overall increasing trend from Zero-Shot-LtM to Few-Shot-LtM. For instance, the F1 Score for “Involved-Person” increases from 87.09% to 95.33%, representing an improvement of 8.24%, and the F1 Score for “Involved-Government” rises from 82.36% to 91.61%, marking an increase of 9.25%. However, it is noteworthy that as the number of samples increases, the rate of improvement in the F1 Score begins to slow. This phenomenon suggests that, under the current model architecture and dataset conditions, the model can effectively learn and extract most entity-relationships by providing a limited number of annotated samples.
Furthermore, we observe that the F1 Scores for the entity types “Legal-Aspect” and “Ethical-Aspect” under Few-Shot-LtM are relatively low. This phenomenon can be attributed to two main reasons: First, the tail entities associated with these categories are highly abstract and complex. Second, accurately identifying these entity-relationships requires the model to possess specialized knowledge in legal and ethical domains and strong language comprehension and reasoning capabilities, which significantly increase the task’s difficulty. However, it is worth noting that the Few-Shot-LtM model improves 8.26% and 8.04% in F1 Score on these two types of entity-relationships, respectively, and this improvement is significant. This finding demonstrates that the characteristics of Few-Shot-LtM hold significant reference value for entity-relationship extraction tasks in resource-constrained or emerging domains. With rapid computer tech progress and evolving engineering ethics cases, this model offers an effective way to learn complex entity-relationships. Its advantage is capturing and recognizing new, complex relationships with limited data, opening new AI applications in the field.
Furthermore, understanding the relationship between sample size and performance saturation is critical for evaluating the model’s learning capabilities. To this end, we extended our experiments to explore performance variations across different sample sizes, ranging from Few-Shot-LtM (6–9 samples) to Few-Shot-LtM (10–30 samples), and analyzed the saturation points. The experimental results revealed that for most entity-relationship types, performance saturated at approximately 17 samples, with marginal performance gains (<0.05%) observed beyond this point. For instance, the F1 Score for Involved-Person increased by an average of 0.21% between 10–17 samples but only by 0.03% between 18–30 samples. Low-frequency entities exhibited slightly higher saturation points, around 21 samples. For example, the F1 Score for Involved-Government improved by 0.15% between 10–21 samples and by 0.04% between 22–30 samples. These findings suggest that, under the current model architecture and task settings, 17–21 samples represent a reasonable stopping point, balancing near-optimal performance and minimized annotation costs. This insight provides valuable guidance for sample selection in practical applications and lays the groundwork for future research, such as sample optimization in low-resource scenarios.
5.3. Comparative Experiments on Generic Datasets
To validate the effectiveness of the improved ChatGLM-LtMP model in entity-relationship extraction tasks, this study selected three widely used datasets for comparative experiments: ACE2005, DuIE2.0, and Chinese Literature Text [
33,
34]. The ACE2005 dataset, released by the Linguistic Data Consortium, is a benchmark dataset in the field of entity-relationship extraction. It contains a large volume of English and Chinese data, providing a robust foundation for model evaluation. The construction corpus of DuIE2.0 dataset comes from Baidu Encyclopedia, Baidu Information Stream, and Baidu Posting, which covers both written and spoken expressions, and is able to comprehensively examine the model’s ability to extract relationships in real scenarios. This is similar to the ethical case dataset constructed in this study in terms of expression characteristics. The Chinese Literature Text dataset annotates entities such as characters, time, and locations, along with their interrelationships, sharing consistency with the ethics case dataset in certain entity-relationship categories. These datasets exhibit similarities to the dataset constructed in this study across multiple dimensions, making them suitable as benchmarks for comparative experiments.
In this study, five entity-relationship recognition models, which have been applied in many studies and are highly representative and universal, are selected for comparison experiments. The experimental results are detailed in
Table 4.
BERT + Multi-head [
35]: A joint entity-relationship extraction model that integrates the multi-head attention mechanism of Transformer with the pre-trained capabilities of BERT. It employs a single linear layer classifier and dropout techniques to evaluate the performance of multi-task learning, making it suitable for addressing multi-relationship problems.
CasRel
BERT [
36]: An entity-relationship extraction model based on BERT. It models relationships as functions that map subjects to objects while identifying all possible relationships for a given subject and their corresponding objects. This approach significantly enhances the model’s ability to extract relationships in complex scenarios.
RIFRE [
34]: A representation iterative fusion method based on heterogeneous graph neural networks. It models entities and relationships within a graph structure and iteratively fuses these two types of semantic information using a message-passing mechanism. This results in node representations better suited for relationship extraction tasks, improving model performance.
OneRel [
37]: A model that treats joint extraction as a fine-grained triplet classification problem. It consists of a score-based classifier and a relation-specific tagging strategy, providing consistent performance gains in complex scenarios involving overlapping patterns and multiple triplets.
PI-Marker
BERT [
38]: A model designed explicitly for Chinese natural language processing tasks. It enhances the model’s understanding of Chinese text by introducing word boundary markers into the BERT architecture.
By analyzing the data in
Table 4, we observe that the ChatGLM-LtMP model demonstrates outstanding performance across all three datasets: ACE2005, DuIE2.0, and Chinese Literature Text. It achieves the highest scores in Precision, Recall, and F1 Score among all models, indicating its strong generalization capability and practical value in entity-relationship extraction tasks. Furthermore, we note that all models perform best on the Chinese Literature Text dataset, which has the simplest text structure. At the same time, their performance is relatively weaker on the DuIE2.0 dataset, which features the most complex text structure. This phenomenon reveals the challenges and room for improvement of the model in processing complex text, and highlights the importance of model optimization for specific tasks and dataset characteristics. It also provides a direction for further optimization of the model in this paper: more real-world complex samples can be added to the training data, and the generalization ability and robustness of the model can be further improved through targeted optimization of the model so that it can play a more significant role in a broader range of application scenarios.
5.4. Comprehensive Performance Assessment Experiment
5.4.1. Comprehensive Performance Comparison Between ChatGLM-LtMP and Baseline Models
To further validate the performance of the improved ChatGLM-LtMP model in the task of entity-relationship extraction for computer engineering ethics cases, this paper conducts comparative experiments on the same ethics case dataset. The OneRel and PL-Marker
BERT models, which exhibited the best performance in
Section 5.3, are selected as the benchmark models. Additionally, two large language models, Qwen-7B-Chat [
39] and Baichuan-7B [
40], are introduced. Qwen-7B-Chat is a 7-billion-parameter-scale model based on Alibaba Cloud’s Qianyi Qiwang large model series, which has undergone extensive pre-training to understand and generate natural language. Baichuan-7B is an open-source large-scale pre-trained model developed by Baichuan Intelligent, achieving state-of-the-art results in multiple authoritative Chinese, English, and multilingual general domains for models of the same size. The experimental results are presented in
Table 5.
By analyzing the data in
Table 5, we observe that the ChatGLM-LtMP model achieves a precision of 94.38%, a recall of 93.06%, and an F1 Score of 93.71%, all of which are the highest among the compared models. Specifically, it outperforms the Baichuan-7B model by 4.04%, 3.78%, and 3.9% in precision, recall, and F1 Score, respectively, and surpasses the Qwen-7B-Chat model by 6.3%, 5.94%, and 5.59% in the same metrics. Compared to the OneRel model, the ChatGLM-LtMP model shows even more substantial gains, with improvements of 14.03%, 13.88%, and 13.95% in precision, recall, and F1 Score, respectively, marking the most notable optimization over baseline models. Furthermore, by comparing the data in
Table 4 and
Table 5, we find that the performance of our model on the ethics case dataset is significantly better than on the general datasets, with noticeable increases in precision, recall, and F1 Score. To evaluate the generalization capability of the ChatGLM-LtMP model, we conducted a 5-fold cross-validation experiment. In this process, the model was trained on 80% of the data in each fold and validated on the remaining 20%. We rigorously monitored the validation loss trajectory and implemented an early stopping strategy, halting training when no significant decrease in validation loss was observed for five consecutive epochs, thereby mitigating overfitting risks. The average cross-validated F1-score reached 92.86%, in close proximity to the test set F1-score of 93.71%, providing robust evidence against overfitting. Furthermore, the smooth convergence characteristics of the training loss curve demonstrate that the model effectively learned data features during iterations without observable oscillations or divergence, ensuring reliable prediction accuracy and robustness. A cross-lingual performance analysis revealed an 11% discrepancy between Chinese and English validation results. Given that the dataset predominantly comprises Chinese texts with limited English content, this performance level satisfies current research requirements. Future extensions to broader multilingual scenarios will necessitate targeted optimizations. Collectively, these experimental findings demonstrate that the ChatGLM-LtMP model achieves state-of-the-art effectiveness in entity-relationship extraction tasks for computer engineering ethics cases, significantly outperforming existing mainstream methods. This framework holds substantial promise as a critical tool for advancing ethical case studies and practical applications.
5.4.2. Performance Comparison of the Model Across Different Entity Relation Categories
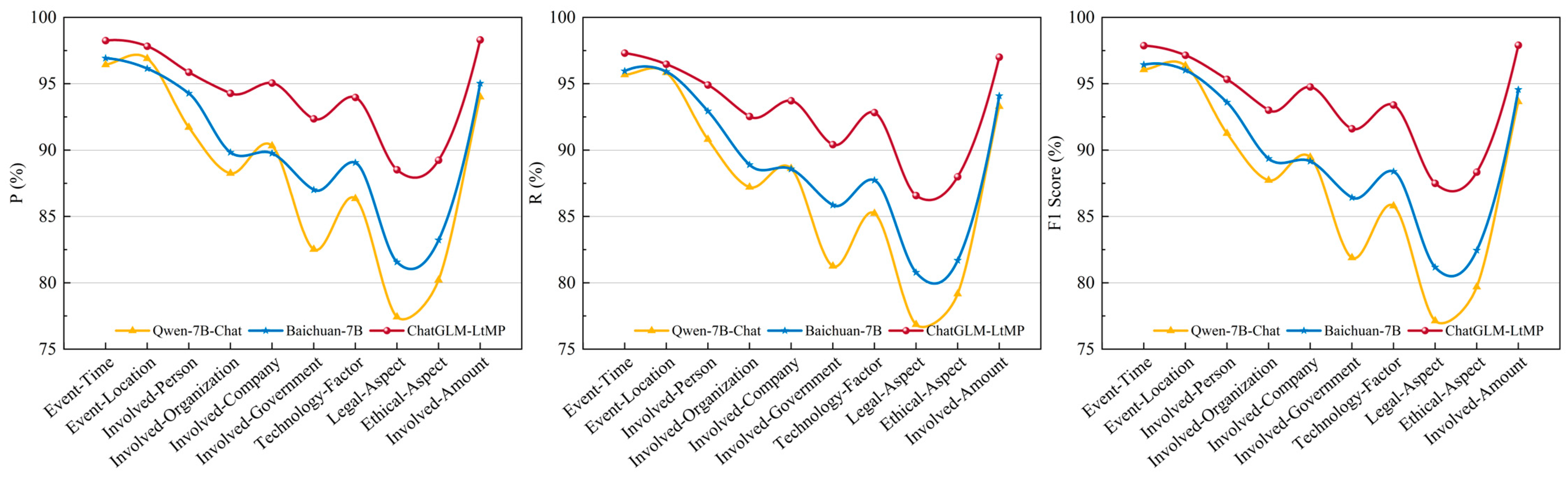
To further analyze the performance of different models in extracting ten types of entity-relationships, this study compares the results of the Qwen-7B-Chat, Baichuan-7B, and ChatGLM-LtMP models, as illustrated in
Figure 5.
By analyzing
Figure 5, we observe that the “Event-Time” category achieves high-performance metrics across all models, with F1 Scores of 96.06%, 96.44%, and 97.87%, respectively. Similarly, the “Involved-Amount” category also demonstrates strong performance, with F1 Scores reaching 93.65%, 94.56%, and 97.91%, respectively. Further analysis of the dataset samples reveals that these two entity types possess clear and objective textual features, whereas the tail entities are often numerical. This characteristic enables the models to perform extraction tasks more accurately. In contrast, the extraction performance for the “Legal-Aspect” category is relatively lower, with F1 Scores of 77.14%, 81.17%, and 87.5%, respectively. Similarly, the performance for the “Ethical-Aspect” category is also suboptimal, with corresponding metrics of 79.69%, 82.45%, and 88.34%, respectively. Despite this, the ChatGLM-LtMP model proposed in this study shows significant improvements in F1 Score for both “Ethical-Aspect” and “Legal-Aspect”, with increases of more than 5% compared to the Qwen-7B-Chat and Baichuan-7B models. This result further validates the proposed model’s relative advantages and practical value in extraction tasks for computer ethics cases.
To determine whether the performance difference between ChatGLM-LtMP and Baichuan-7B is statistically significant, we conducted a paired-sample McNemar test. During the test, we ensured the consistency and integrity of the data. The null hypothesis was defined as follows: There is no statistically significant difference in performance between ChatGLM-LtMP and Baichuan-7B, meaning the two models perform comparably. As shown in
Table 6, the McNemar test yielded a
p-value of 0.042, which is below the significance level of 0.05, leading to the rejection of the null hypothesis. This indicates a statistically significant performance difference between the two models. Thus, the experimental results support the conclusion that ChatGLM-LtMP outperforms Baichuan-7B. Additionally, to further evaluate the models’ generalization capabilities, we designed a Zero-Shot experiment to test their performance on unseen ethics cases. The results demonstrated that ChatGLM-LtMP achieved an F1 Score of 81.32% in the Zero-Shot scenario, significantly higher than Baichuan-7B’s 78.65%. This suggests that ChatGLM-LtMP not only excels on known data but also exhibits strong generalization capabilities on unseen ethics cases.
The aforementioned analysis elucidates the model’s superior performance in conventional data scenarios; however, practical deployment necessitates addressing challenges posed by noise contamination and unseen terminologies. To establish a holistic performance evaluation framework, this study subsequently investigates the model’s robustness under aberrant data environments.
5.4.3. Anomaly Detection and Analysis
To gain deeper insights into the weaknesses of the ChatGLM-LtMP model on specific data types or tasks and evaluate its sensitivity to anomalous and privacy-related information, we conducted targeted anomaly detection and analysis. In the test set, 15% of annotation errors (e.g., mislabeled “Technology” entities as “Legal” entities) and 15% of domain-specific unknown terms (e.g., “Algorithmic Accountability”) were randomly introduced. The error-correction and adaptation capabilities of ChatGLM-LtMP were systematically observed and compared with baseline models, including Qwen-7B-Chat and Baichuan-7B. As summarized in
Table 7, this experiment provides critical insights for optimizing the model to ensure robustness and reliability in real-world applications.
The results demonstrate that these models exhibit a certain level of sensitivity to anomalous information. Among the three models, ChatGLM-LtMP showed the smallest performance degradation (8.89%) when handling anomalous data, indicating superior robustness. This was followed by Qwen-7B-Chat, which experienced a performance drop of 10.56%. In contrast, Baichuan-7B exhibited the largest decline (11.12%), performing the worst in processing anomalous data. These findings highlight the advantages of our proposed model and underscore the importance of optimizing models to address their weaknesses. To further investigate these weaknesses, we conducted a manual analysis of 200 error samples and categorized them into six types based on their common characteristics, as summarized in
Table 8.
Analyzing the above results, we can identify the following key observations: Firstly, the bias in pre-trained data is a major weakness of the model. Due to insufficient coverage of domain-specific knowledge in the pre-trained data, the model exhibits limited understanding of rare terminologies, with the most prominent errors occurring in the recognition of “Ethical-Aspect” and “Legal-Aspect”. These two categories involve highly specialized domain knowledge, and the imbalanced distribution of texts in the dataset fails to cover all relevant content, leading to a higher probability of model errors. Additionally, the recognition errors for “Involved-Government” are also notable. Further analysis of the dataset samples reveals that the limited volume of data for this entity-relationship results in insufficient model generalization. To address these issues, our preliminary work has already incorporated domain-specific corpora to enhance the representation of domain-specific terminologies. However, experiments indicate that manually constructed domain knowledge bases still face limitations, such as insufficient timeliness due to their dynamic update nature and high costs associated with manual annotation and maintenance. Therefore, we propose a three-phase optimization strategy: (1) constructing a real-time update framework based on dynamic crawling and semantic parsing, focusing on authoritative texts such as EU digital acts and IEEE ethical standards to enable incremental updates to the knowledge base; (2) introducing differential privacy techniques during the data collection phase, adding Laplace noise to sensitive information to ensure anonymized processing of personal data in compliance with the “privacy by design” principle; and (3) designing a dual-channel review mechanism of “machine pre-screening and domain expert verification”, employing an attention-weight-based credibility scoring system to filter out low-quality or conflicting entries.
Secondarily, data ambiguity and insufficient contextual information have also impacted model performance. Although our prior work optimized model behavior through a two-stage disambiguation framework, integrating semantic representation and contextual reasoning, further improvements remain achievable. The entity-relationships with the highest error rates include Event-Time, Involved-Person and Involved-Company, which is attributed to two main factors: (1) non-standardized temporal expressions (e.g., ambiguous date formats like “02/03” that cannot disambiguate between 3 February and 2 March), and (2) naming conflicts where corporate and personal names exhibit high similarity (e.g., Ford, Dell, and Tesla), leading to recognition confusion.
Finally, annotation errors significantly degraded model performance. Limited domain expertise among annotators resulted in annotation inconsistencies, particularly for specialized terminologies. We have rectified erroneous labels and developed detailed annotation guidelines to ensure consistency. Notably, errors attributable to intrinsic model limitations accounted for a minimal proportion of total errors. Consequently, our optimization efforts focus on the aforementioned three aspects, with plans to implement targeted test sets designed to systematically monitor model improvement across these dimensions.
5.5. Ablation Experiment
To validate the impact of Least-to-Most Prompting and P-Tuning v2 on the overall performance of the model, this study conducted ablation experiments on the ChatGLM-LtMP model using the same dataset [
41]. The experiments involved removing LtM and P-Tuning v2 individually to observe their effects on model performance. The results of these experiments are presented in
Table 9.
The results show that when Least-to-Most Prompting is added individually, the F1 Score increases from 87.33% to 90.65%, a gain of 3.32%. When P-Tuning v2 is applied individually, the F1 Score rises from 87.33% to 88.81%, an improvement of 1.48%. When both methods are combined, the F1 Score increases by 6.38%, achieving optimal model performance. This finding indicates that LtMP has a more significant optimization effect compared to P-Tuning v2, while the combination of LtMP and P-Tuning v2 delivers the best performance.
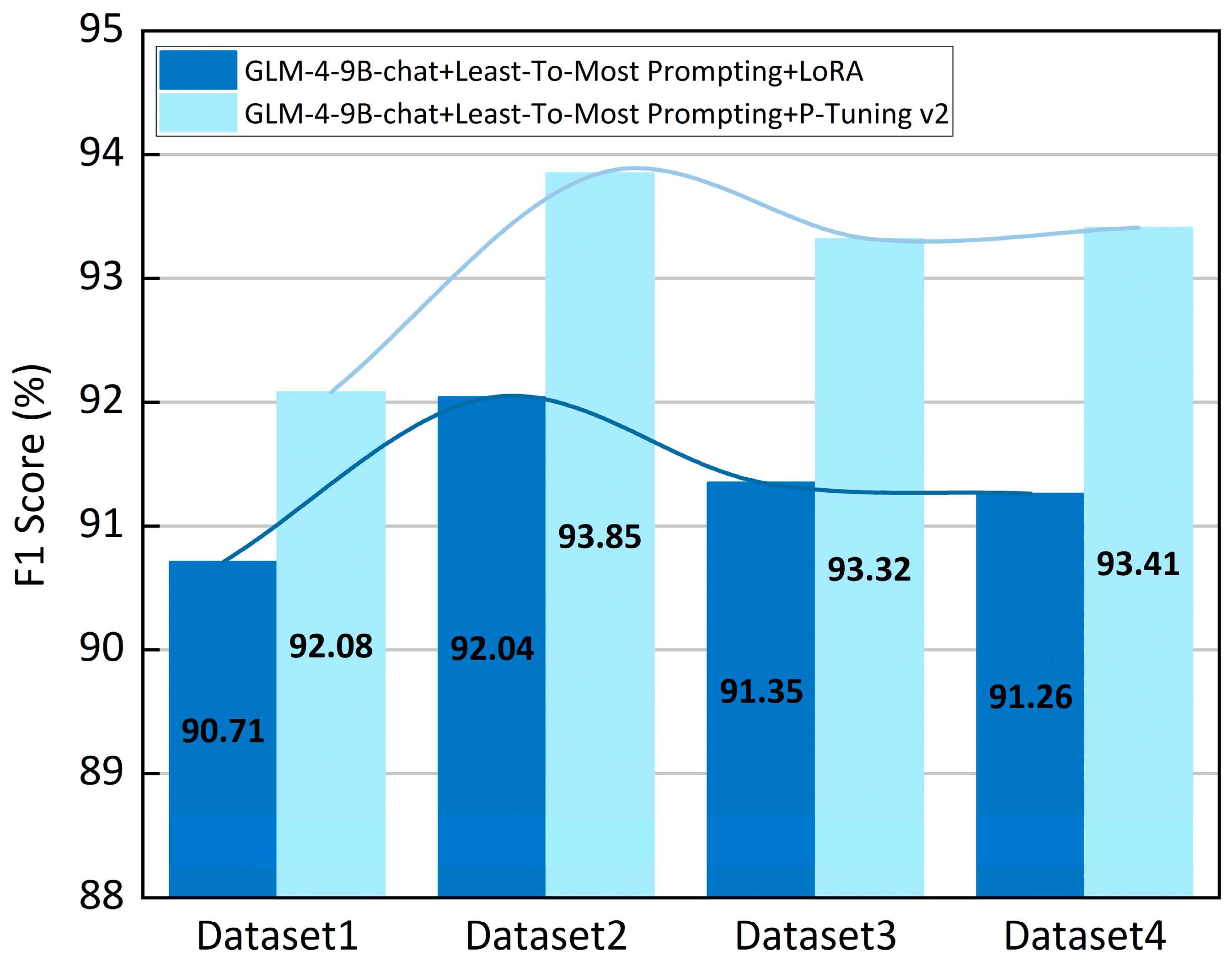
Given that the performance improvement from P-Tuning v2 alone is not substantial, this study employs another widely used strategy, LoRA [
42], for a comparative experiment to further validate the impact of different parameter fine-tuning strategies on the model. In the experiment, four distinct ethics case test sets were selected and constructed from the dataset. While keeping the LtM strategy unchanged, the model was fine-tuned using both LoRA and P-Tuning v2 methods. The experimental results are shown in
Figure 6. The results reveal that across all four ethics case test sets, the F1 Score achieved with the LoRA method is consistently lower than that with P-Tuning v2. P-Tuning v2 enhances task adaptability by introducing continuous trainable prompt vectors, which directly adjust the semantic representation of the input space without modifying the model weights. This characteristic enables greater flexibility in tasks requiring multi-level reasoning and domain knowledge integration, making it particularly suitable for extracting ethical and legal relationships in the ethics case studies discussed in this paper. In contrast, LoRA updates weight matrices through low-rank decomposition. While parameter-efficient, LoRA exhibits insufficient sensitivity to local semantics, especially when handling low-frequency entities (e.g., Involved-Government), as it struggles to capture domain-specific contextual dependencies. The results of this paper confirm that, for entity-relationship extraction tasks in computer engineering ethics cases, P-Tuning v2 is a more suitable fine-tuning approach.
7. Conclusions
In this study, an innovative computer engineering ethics case dataset was constructed, enabling cross-institutional data sharing through federated learning while ensuring privacy preservation during machine learning processes involving sensitive information. We propose ChatGLM-LtMP, that integrates Least-to-Most Prompting and P-Tuning v2 techniques. This framework achieves efficient Zero-Shot and Few-Shot information extraction tasks, delivering superior performance that significantly outperforms baseline models. Furthermore, a knowledge graph was implemented using the Neo4j graph database, coupled with the LangChain framework to enable intelligent question-answering functionality. These advancements provide robust technical support for ethical case analysis and application development.
However, the current dataset exhibits scenario coverage bias, with insufficient representation of rapidly evolving domains such as metaverse ethics and quantum computing ethics. Additionally, the model lacks multimodal data processing capabilities for images, audio, and video. Future work will focus on expanding and refining the dataset while prioritizing the development of multimodal interaction technologies. By integrating diverse data sources, we aim to achieve more natural and efficient human-computer interaction experiences, thereby addressing the demands of increasingly heterogeneous application scenarios.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}