
An Adaptive Hybrid Prototypical Network for Interactive Few-Shot Relation Extraction

Abstract
1. Introduction
- (1)
- An adaptive hybrid prototypical network for interactive few-shot relation extraction is proposed. The relation labels and the relation explanations are integrated into the model as external data to assist in prototype representation. Furthermore, the model mitigates performance degradation due to data scarcity by leveraging the interactive knowledge between the query instances and the support instances;
- (2)
- An adaptive prototype fusion mechanism is proposed, which combines prototype networks with relational information adaptively to obtain more accurate prototypes;
- (3)
- The experimental results illustrate that the two mechanisms incorporated into our model play crucial roles in the proposed model, leading to significant improvements in performance.
2. Related Work
2.1. Optimization-Based Approaches for Few-Shot Relation Extraction
2.2. Metric-Based Approaches for Few-Shot Relation Extraction
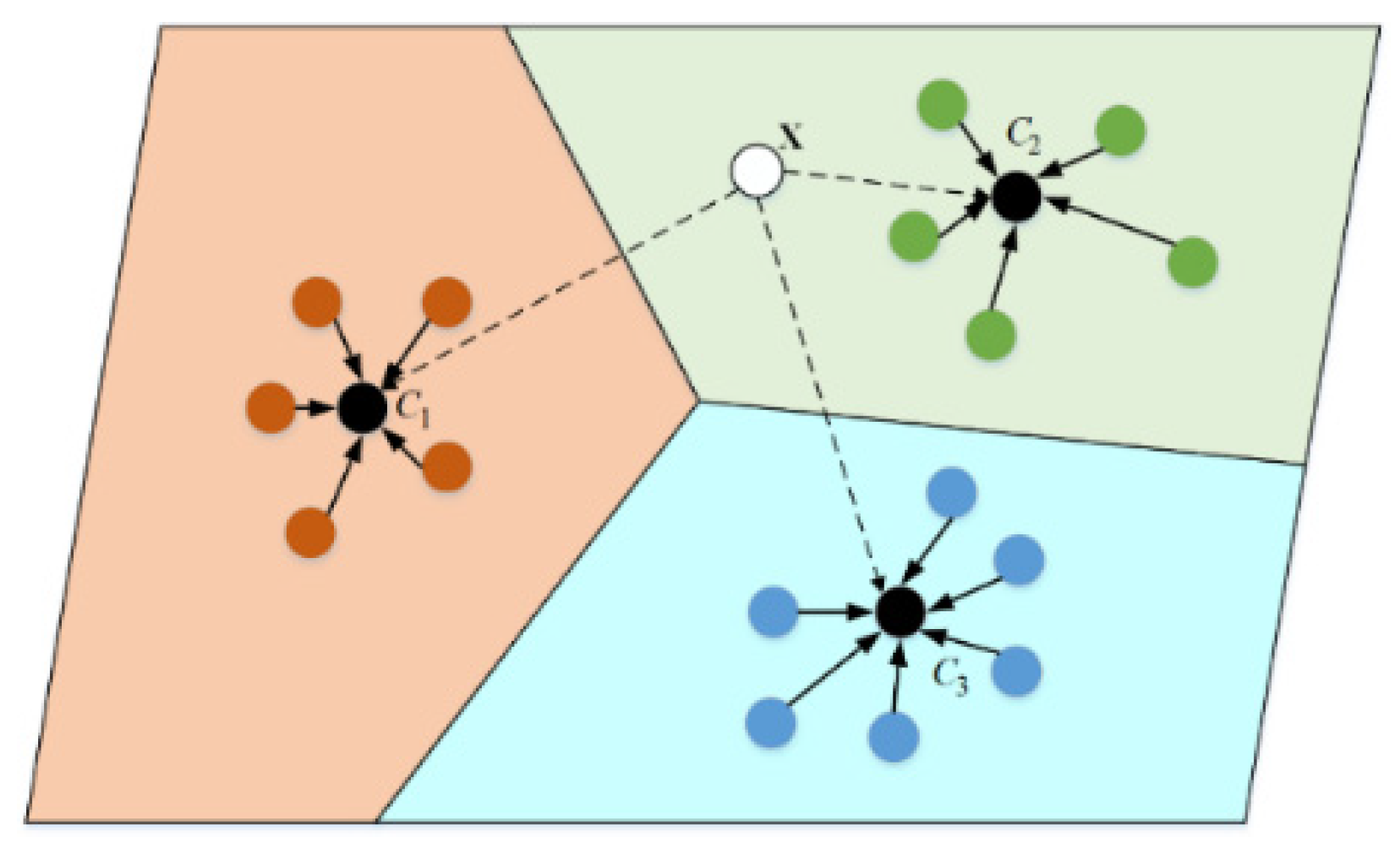
2.3. Prototypical Networks Approaches for Few-Shot Relation Extraction
3. Task Definition
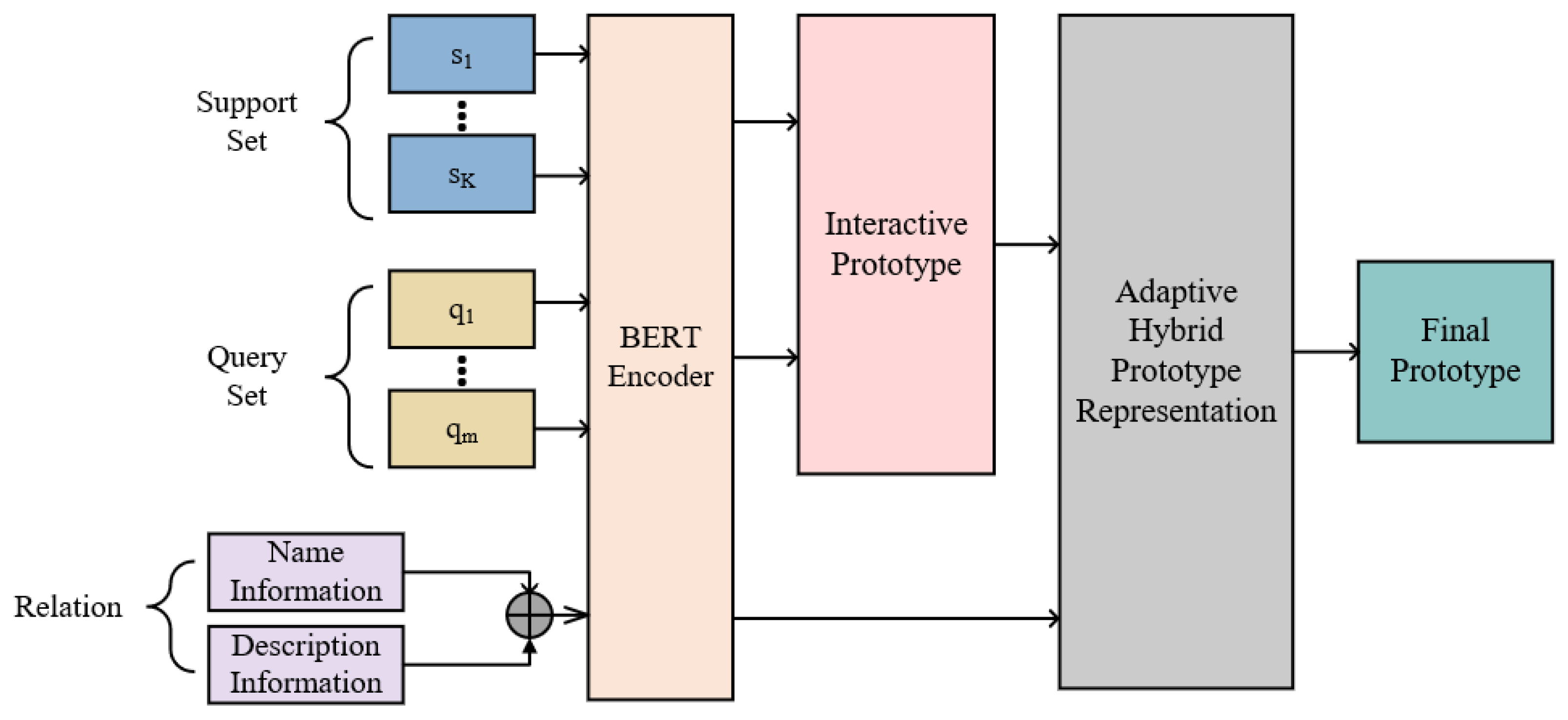
4. Methodology
| Algorithm 1 Architecture of AIRE at the training process |
| Input: Support Set Query Set relation set Output: T = {< (x, e1, e2, r) > | e1, e2 ∈ E, r ∈ } |
| 1: Obtain the context representation of each instance of S and Q by using the sentence encoder BERT |
| 2: Concatenate the entity name and relation description of relation information |
| 3: For each episode do |
| 4: For i = 1→N do |
| 5: Build support prototypes by Equations (1) and (2) |
| 6: Build an interactive prototype based on the query instances by Equations (3) and (4) |
| 7: Fusion the interactive prototype and relation information by Equation (5) |
| 8: End for |
| 9: End for |
4.1. Sentence Encoder
4.2. Relation Representation
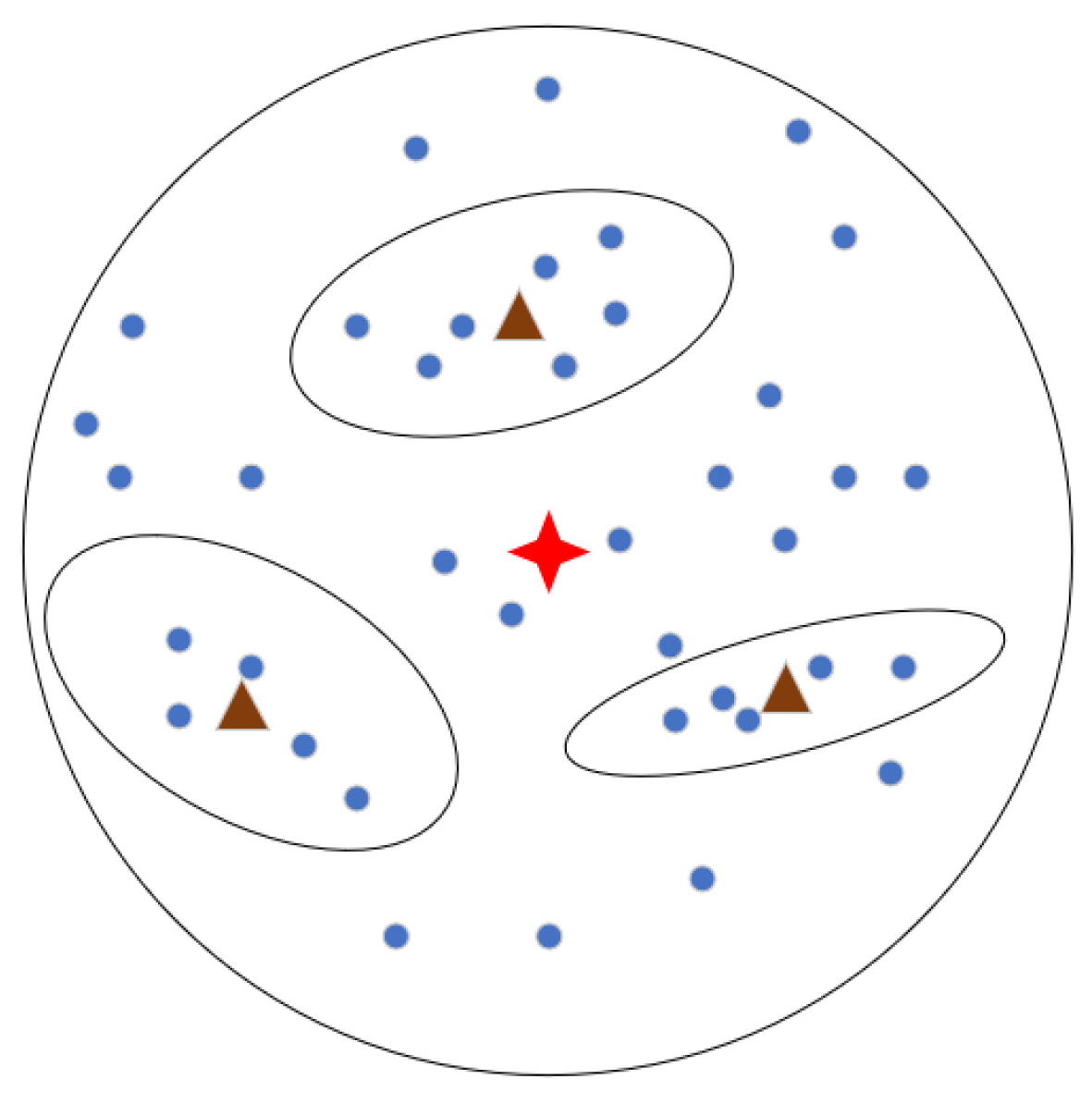
4.3. Interactive Prototypical Network
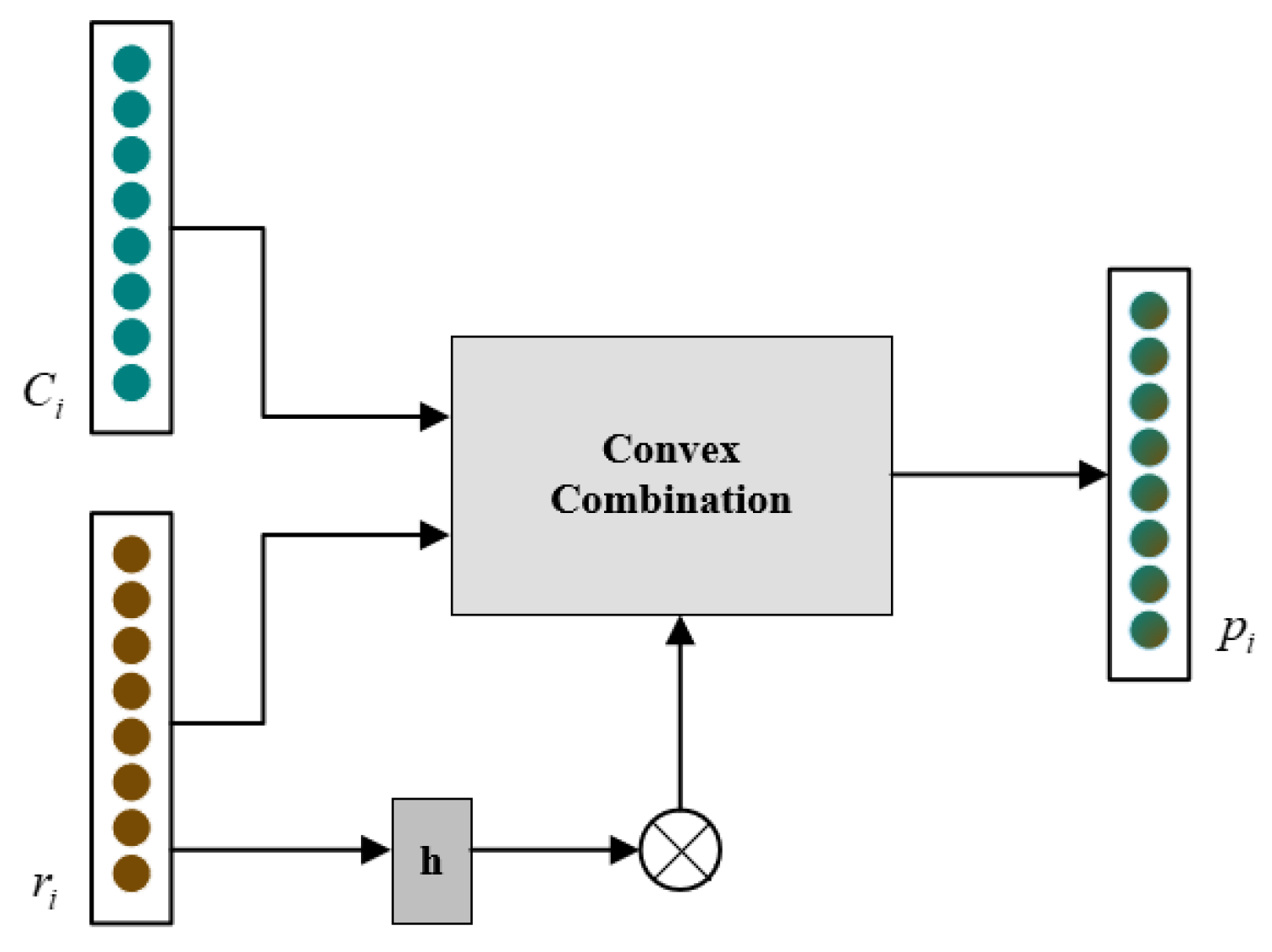
4.4. Adaptive Hybrid Prototype Representation
5. Experiments
5.1. Dataset and Evaluation
5.2. Baselines
5.3. Implementation Details
5.4. Overall Evaluation Results
- It is evident that the models utilizing BERT as the sentence encoder achieve generally higher performance compared to those using CNN. This suggests that BERT serves as a more effective sentence encoder;
- The table demonstrates that AIRE significantly outperforms the strong baseline models. Specifically, AIRE attains an average accuracy of 90.19% on the test set, surpassing all other BERTBASE models. Notably, AIRE reaches accuracies of 91.53% and 86.36% on the 5-way 1-shot and 10-way 1-shot tasks, respectively. Furthermore, it exceeds the second-best model by 0.64% and 2.27% in these respective tasks;
- Both TD-Proto and ConceptFERE model leverage external data as auxiliary information to improve the performance of their respective models. However, our proposed AIRE model does not rely on external data. Instead, it effectively extracts valuable information from the query set within the task, thereby achieving superior results compared to them;
- AIRE model is built upon the prototype network. It exhibits superior performance compared to models leveraging graph neural networks, such as DualGraph and REGRAB, thereby validating the efficacy of the prototype network. Additionally, since our model does not employ an attention mechanism, it achieves greater advantages in terms of reduced model complexity and computational cost when compared to Proto-HATT and CTEG;
- Compared to the CBPM model, both methods harness latent category information within the query set to produce more precise relation prototypes. Nevertheless, our proposed model shows superior performance with average accuracy. Notably, it achieves a substantial improvement in the 10-way 1-shot task, with an accuracy gain of 3.82%. These results provide additional evidence of the efficacy of our AIRE model.
5.5. Ablation Analysis
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, X.; Deng, Y.; Yang, M.; Wang, L.; Zhang, R.; Cheng, H.; Lam, W.; Shen, Y.; Xu, R. A Comprehensive Survey on Relation Extraction: Recent Advances and New Frontiers. ACM Comput. Surv. 2024, 56, 293:1–293:39. [Google Scholar] [CrossRef]
- Zhong, L.; Wu, J.; Li, Q.; Peng, H.; Wu, X. A Comprehensive Survey on Automatic Knowledge Graph Construction. ACM Comput. Surv. 2024, 56, 1–62. [Google Scholar] [CrossRef]
- Bertinetto, L.; Henriques, J.F.; Valmadre, J.; Torr, P.H.S.; Vedaldi, A. Learning Feed-Forward One-Shot Learners; NIPS Foundation: La Jolla, CA, USA, 2016; pp. 523–531. [Google Scholar]
- Han, X.; Zhu, H.; Yu, P.; Wang, Z.; Yao, Y.; Liu, Z.; Sun, M. FewRel: A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4803–4809. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for Few-Shot Learning; NIPS Foundation: La Jolla, CA, USA, 2017; pp. 4077–4087. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation Classification via Convolutional Deep Neural Network; Dublin City University and Association for Computational Linguistics: Dublin, Ireland, 2014; pp. 2335–2344. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Relation Extraction: Perspective from Convolutional Neural Networks. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, CO, USA, 5 June 2015; pp. 39–48. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1105–1116. [Google Scholar]
- Lin, C.; Miller, T.; Dligach, D.; Amiri, H.; Bethard, S.; Savova, G. Self-training improves Recurrent Neural Networks performance for Temporal Relation Extraction. In Proceedings of the Ninth International Workshop on Health Text Mining and Information Analysis, Brussels, Belgium, 31 October 2018; pp. 165–176. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant Supervision for Relation Extraction Without Labeled Data; Association for Computational Linguistics: Suntec, France; Singapore, 2009; pp. 1003–1011. [Google Scholar]
- Yin, W. Meta-learning for Few-shot Natural Language Processing: A Survey. arXiv 2020, arXiv:2007.09604. [Google Scholar]
- Han, X.; Gao, T.; Lin, Y.; Peng, H.; Yang, Y.; Xiao, C.; Liu, Z.; Li, P.; Zhou, J.; Sun, M. More Data, More Relations, More Context and More Openness: A Review and Outlook for Relation Extraction. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, Suzhou, China, 4–7 December 2020; pp. 745–758. [Google Scholar]
- Munkhdalai, T.; Yu, H. Meta Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2554–2563. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Yuan, J.; Guo, H.; Jin, Z.; Jin, H.; Zhang, X.; Luo, J. One-shot learning for fine-grained relation extraction via convolutional siamese neural network. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 2194–2199. [Google Scholar]
- Xie, Y.; Xu, H.; Li, J.; Yang, C.; Gao, K. Heterogeneous graph neural networks for noisy few-shot relation classification. Knowl. Based Syst. 2020, 194, 105548. [Google Scholar] [CrossRef]
- Gao, T.; Han, X.; Liu, Z.; Sun, M. Hybrid Attention-Based Prototypical Networks for Noisy Few-Shot Relation Classification. Proc. AAAI Conf. Artif. Intell. 2019, 33, 6407–6414. [Google Scholar]
- Ye, Z.-X.; Ling, Z.-H. Multi-Level Matching and Aggregation Network for Few-Shot Relation Classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2872–2881. [Google Scholar]
- Yang, K.; Zheng, N.; Dai, X.; He, L.; Huang, S.; Chen, J. Enhance Prototypical Network with Text Descriptions for Few-shot Relation Classification. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management; Association for Computing Machinery: New York, NY, USA, 2020; pp. 2273–2276. [Google Scholar]
- Yang, S.; Zhang, Y.; Niu, G.; Zhao, Q.; Pu, S. Entity Concept-enhanced Few-shot Relation Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Online, 1–6 August 2021; pp. 987–991. [Google Scholar]
- Wen, M.; Xia, T.; Liao, B.; Tian, Y. Few-shot relation classification using clustering-based prototype modification. Knowl-Based Syst 2023, 268, 110477. [Google Scholar] [CrossRef]
- Gao, T.; Han, X.; Zhu, H.; Liu, Z.; Li, P.; Sun, M.; Zhou, J. FewRel 2.0: Towards More Challenging Few-Shot Relation Classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6249–6254. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding; Association for Computational Linguistics: Dublin, Ireland, 2019; pp. 4171–4186. [Google Scholar]
- Qu, M.; Gao, T.; Xhonneux, L.-P.A.C.; Tang, J. Few-shot Relation Extraction via Bayesian Meta-learning on Relation Graphs. In Proceedings of the ICML2020, Virtual, 13–18 July 2020; pp. 7867–7876. [Google Scholar]
- Liu, Y.; Hu, J.; Wan, X.; Chang, T.-H. A Simple yet Effective Relation Information Guided Approach for Few-Shot Relation Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 757–763. [Google Scholar]
- Ma, R.; Ma, B.; Wang, L.; Zhou, X.; Wang, Z.; Yang, Y. Relational concept enhanced prototypical network for incremental few-shot relation classification. Knowl. Based Syst. 2024, 284, 111282. [Google Scholar] [CrossRef]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning; NIPS Foundation: La Jolla, CA, USA, 2016; pp. 3630–3638. [Google Scholar]
- Huisman, M.; Rijn, J.N.v.; Plaat, A. A Survey of Deep Meta-Learning. Artif. Intell. Rev. 2021, 54, 4483–4541. [Google Scholar]
- Hospedales, T.M.; Antoniou, A.; Micaelli, P.; Storkey, A.J. Meta-Learning in Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5149–5169. [Google Scholar] [CrossRef] [PubMed]
- Baldini Soares, L.; FitzGerald, N.; Ling, J.; Kwiatkowski, T. Matching the Blanks: Distributional Similarity for Relation Learning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2895–2905. [Google Scholar]
- Xing, C.; Rostamzadeh, N.; Oreshkin, B.N.; Pinheiro, P.O. Adaptive Cross-Modal Few-Shot Learning; NIPS Foundation: La Jolla, CA, USA, 2019; pp. 4848–4858. [Google Scholar]
- Satorras, V.G.; Estrach, J.B. Few-Shot Learning with Graph Neural Networks. In Proceedings of the ICLR 2018 Conference, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Mishra, N.; Rohaninejad, M.; Chen, X.; Abbeel, P. A Simple Neural Attentive Meta-Learner. arXiv 2018, arXiv:1707.03141. [Google Scholar]
- Wang, Y.; Bao, J.; Liu, G.; Wu, Y.; He, X.; Zhou, B.; Zhao, T. Learning to Decouple Relations: Few-Shot Relation Classification with Entity-Guided Attention and Confusion-Aware Training. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 5799–5809. [Google Scholar]
- Yu, T.; Yang, M.; Zhao, X. Dependency-Aware Prototype Learning for Few-Shot Relation Classification; International Committee on Computational Linguistics: Gyeongju, Republic of Korea, 2022; pp. 2339–2345. [Google Scholar]
- Li, J.; Feng, S.; Chiu, B. Few-Shot Relation Extraction With Dual Graph Neural Network Interaction. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 14396–14408. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Relation | Support Set |
|---|---|
| R1: role occupied (indicating that the individual currently or previously occupied the designated public office or position) | (1) Ceremony was held at Vigyan Bhavan in Mumbai on 15 March 1992, where the awards were presented by Dr. Rajendra Prasad, who was the President of India at that time. (2) In his role as a superdelegate, Watson remained an advocate for New York Senator Hillary Clinton. (3) On 13 September 2017, Swedish defense minister Peter Hultqvist stated that this exercise conveys a significant message regarding our security policy. |
| R2: director (individual or individuals responsible for directing films, TV series, stage plays, video games, or similar productions) | (1) In 2016, the work was adapted into a motion picture featuring Helen Mirren and Donald Sutherland, with Italian filmmaker Paolo Virzi at the helm. (2) Examples of this type of analysis include the examination of Laura Mulvey and Peter Wollen’s 1977 work, Riddles of the Sphinx, as well as the question What Does It Mean to Say Feminism Is Back? (3) She served as the Acting Director for Films Nominated for the Oscars for “Birdman”, which was directed by Alejandro Gonzlez Inarritu. |
| R3: nominated for (denotes an award nomination received by an individual, organization, or creative project) | (1) Norma Rae received multiple Academy Award nominations, including a nod for Best Picture. (2) He received a nomination for the Academy Award for Best Directing for the film 1917 at the 92nd Academy Awards in 2020, along with fellow producers Michael Lerman and Callum McDougall. (3) Cate Blanchett earned nominations for Best Actress in a Leading Role at the Academy Awards for her performance in TÁR. |
| Query Instance | |
| R1, R2, OR R3 | In 2023, under the name Margot Elise Robbie, she received a nomination for the Academy Award for Best Costume Design for her film Babylon. |
| Model | NEK | ISQ | AH |
|---|---|---|---|
| TD-Proto [19] | √ | ||
| ConceptFERE [20] | √ | ||
| Proto-HATT [17] | √ | √ | |
| MLMAN [18] | √ | √ | |
| CBPM [21] | √ | √ | |
| Ours (AIRE) | √ | √ | √ |
| Hyperparameters | Values |
|---|---|
| BERT parameter | BERTBASE (uncased) |
| Learning rate | 2 × 10−5 |
| Max length | 128 |
| Train iteration number | 30,000 |
| Batch size | 4 |
| Optimizer | AdamW |
| Model | Encoder | 5-Way 1-Shot | 5-Way 5-Shot | 10-Way 1-Shot | 10-Way 5-Shot | Average Accuracy |
|---|---|---|---|---|---|---|
| Proto-CNN [8] | CNN | 74.29 | 85.18 | 61.15 | 74.41 | 73.76 |
| Proto-BERT [8] | BERT | 80.68 | 94.13 | 83.41 | 90.25 | 89.28 |
| REGRAB [17] | BERT | 90.30 | 94.25 | 84.09 | 89.93 | 89.64 |
| SNAIL [33] | CNN | 71.13 | 80.04 | 50.61 | 66.68 | 67.12 |
| Proto-HATT [17] | CNN | 74.84 | 85.81 | 62.05 | 75.25 | 74.49 |
| TD-Proto [19] | BERT | 84.76 | 92.38 | 74.32 | 85.92 | 84.35 |
| MLMAN [18] | CNN | 78.21 | 88.01 | 65.70 | 78.35 | 77.57 |
| BERT-PAIR [22] | BERT | 88.32 | 93.22 | 80.63 | 87.02 | 87.30 |
| ConceptFERE [20] | BERT | 89.21 | 90.34 | 75.72 | 81.82 | 84.27 |
| CTEG [34] | BERT | 88.11 | 95.25 | 81.29 | 91.33 | 89 |
| CBPM [21] | BERT | 90.89 | 94.68 | 82.54 | 89.67 | 89.45 |
| DAPL [35] | BERT | 85.94 | 94.28 | 77.59 | 89.26 | 86.77 |
| DualGraph [36] | BERT | 88.71 | 93.92 | 81.79 | 88.05 | 88.12 |
| AIRE (ours) | BERT | 91.53 | 93.76 | 86.36 | 89.10 | 90.19 |
| Model | 5-Way 1-Shot | 10-Way 1-Shot |
|---|---|---|
| AIRE | 91.53 | 86.36 |
| w/o interactive model | 91.21 | 86.10 |
| w/o adaptive hybrid model | 90.89 | 85.43 |
| w/o interactive and adaptive hybrid model | 89.35 | 82.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Liu, S.; Huang, S.; Zheng, L. An Adaptive Hybrid Prototypical Network for Interactive Few-Shot Relation Extraction. Electronics 2025, 14, 1344. https://doi.org/10.3390/electronics14071344
Liu B, Liu S, Huang S, Zheng L. An Adaptive Hybrid Prototypical Network for Interactive Few-Shot Relation Extraction. Electronics. 2025; 14(7):1344. https://doi.org/10.3390/electronics14071344
Chicago/Turabian StyleLiu, Bei, Sanmin Liu, Subin Huang, and Lei Zheng. 2025. "An Adaptive Hybrid Prototypical Network for Interactive Few-Shot Relation Extraction" Electronics 14, no. 7: 1344. https://doi.org/10.3390/electronics14071344
APA StyleLiu, B., Liu, S., Huang, S., & Zheng, L. (2025). An Adaptive Hybrid Prototypical Network for Interactive Few-Shot Relation Extraction. Electronics, 14(7), 1344. https://doi.org/10.3390/electronics14071344