
DEC-YOLO: Surface Defect Detection Algorithm for Laser Nozzles


Abstract
1. Introduction
- (1)
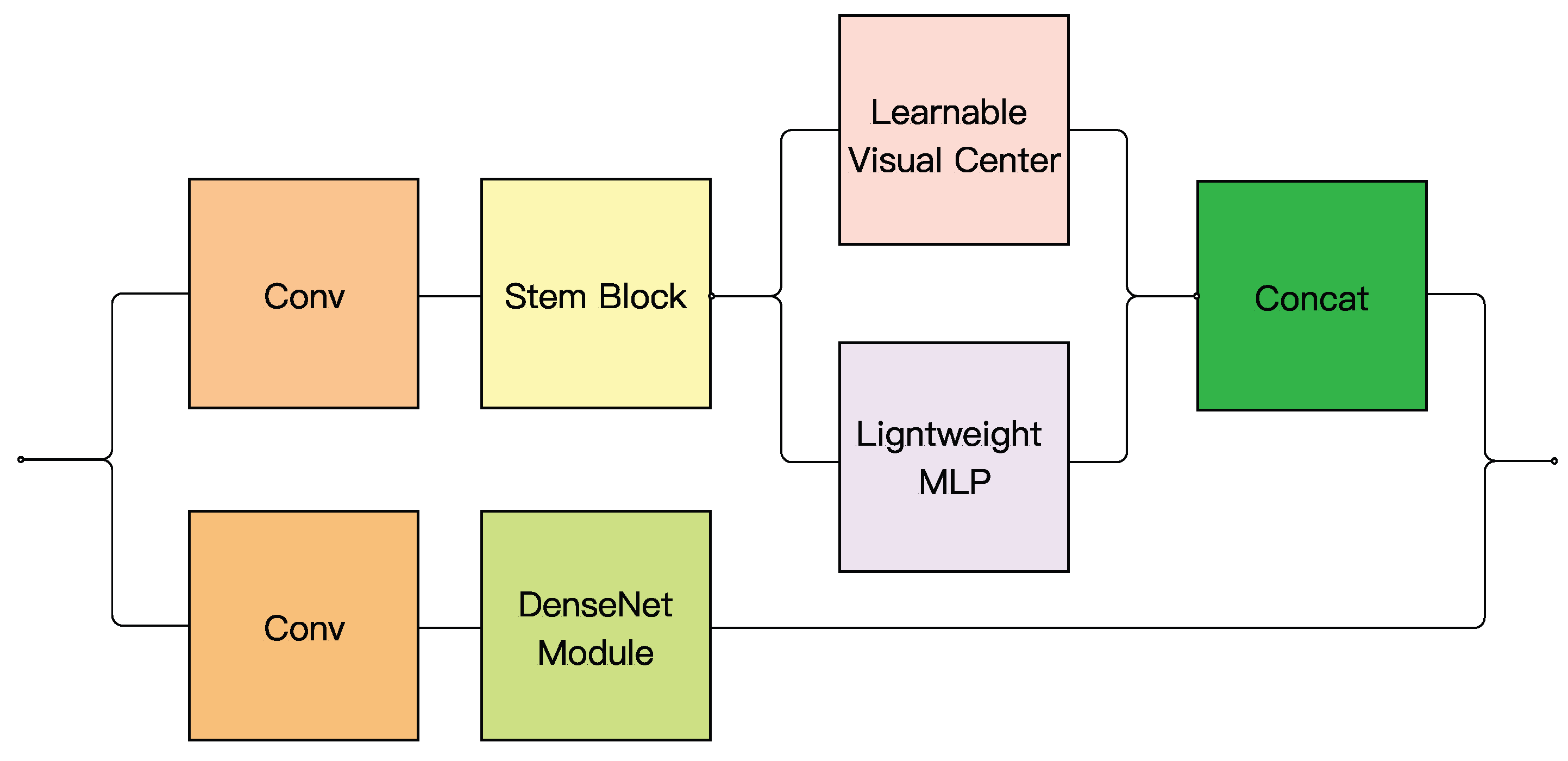
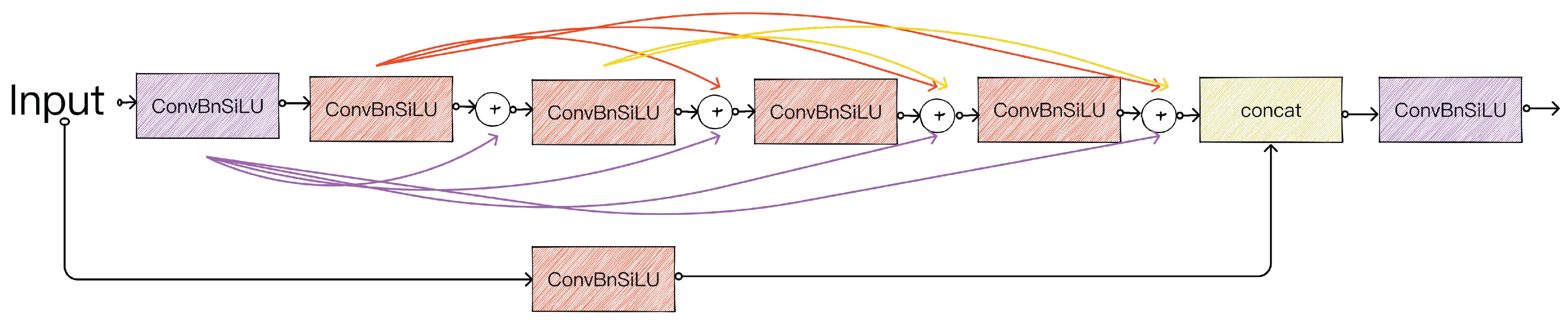
- The DEC module was constructed based on the ideas of DenseNet and the explicit vision center (EVC) to enhance the extraction of basic information.
- (2)
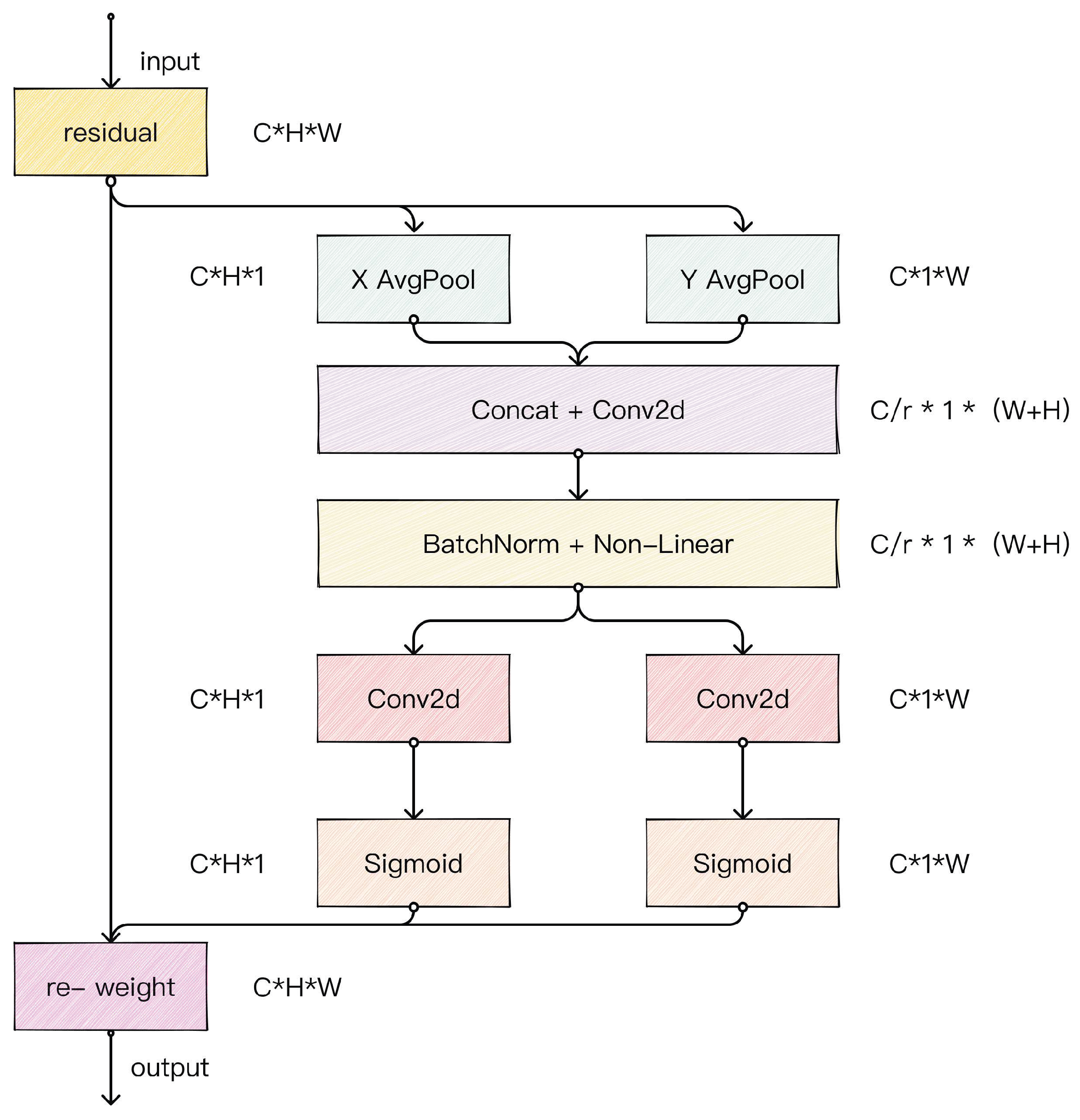
- Two effective measures are proposed to improve the performance of YOLOv7. Cross-layer connection is used to achieve the fusion of feature information between shallow and deep networks, and coordinate attention is used to reduce the interference of background information.
- (3)
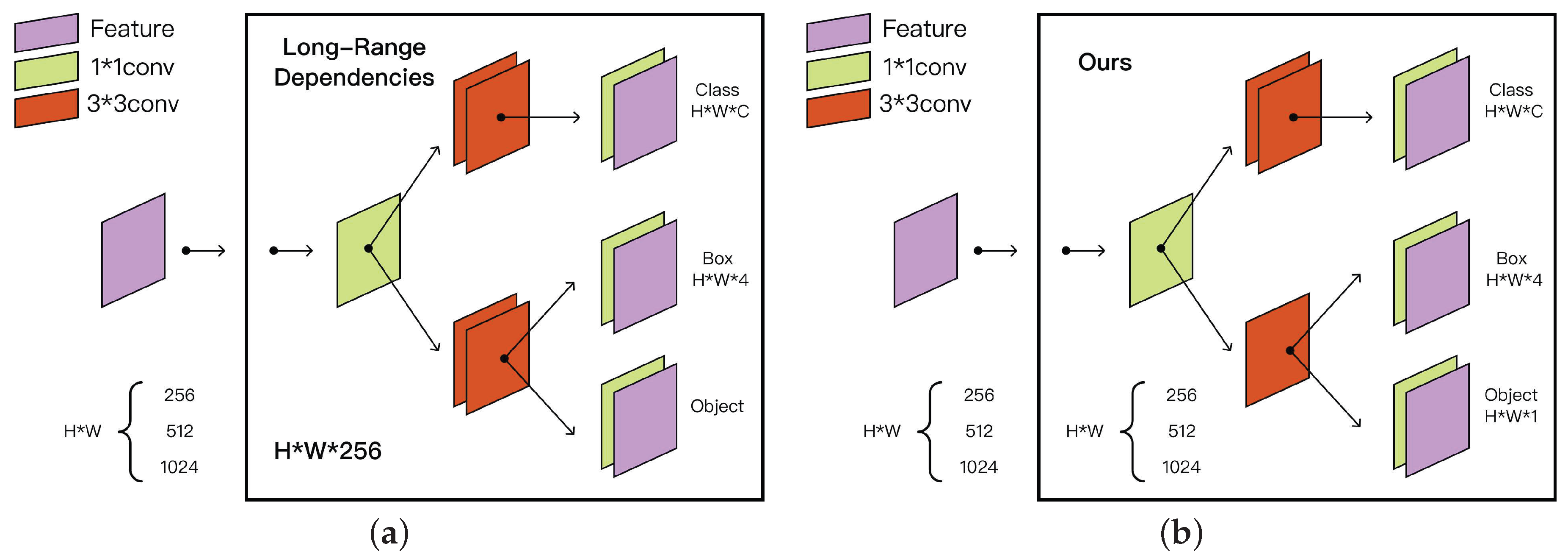
- The head decoupling strategy is devised to process the classification and regression tasks separately, which further improves the effectiveness of feature extraction.
- (4)
- By acquiring and processing images of different laser cutting heads in different scenarios, a dataset of surface defects on the laser nozzles containing three kinds of defects, namely, scratch, uneven surface, and contour damage, has been constructed to make up for the gap of commercially available data. This dataset is used to train and evaluate the DEC-YOLO algorithm.
2. Related Work
2.1. Defect Detection
2.2. YOLOv7 Algorithm
3. Methods
3.1. DEC Module
3.2. Cross-Layer Connection
3.3. Efficient Decoupling Head
3.4. Coordinate Attention
4. Results and Discussion
4.1. Dataset
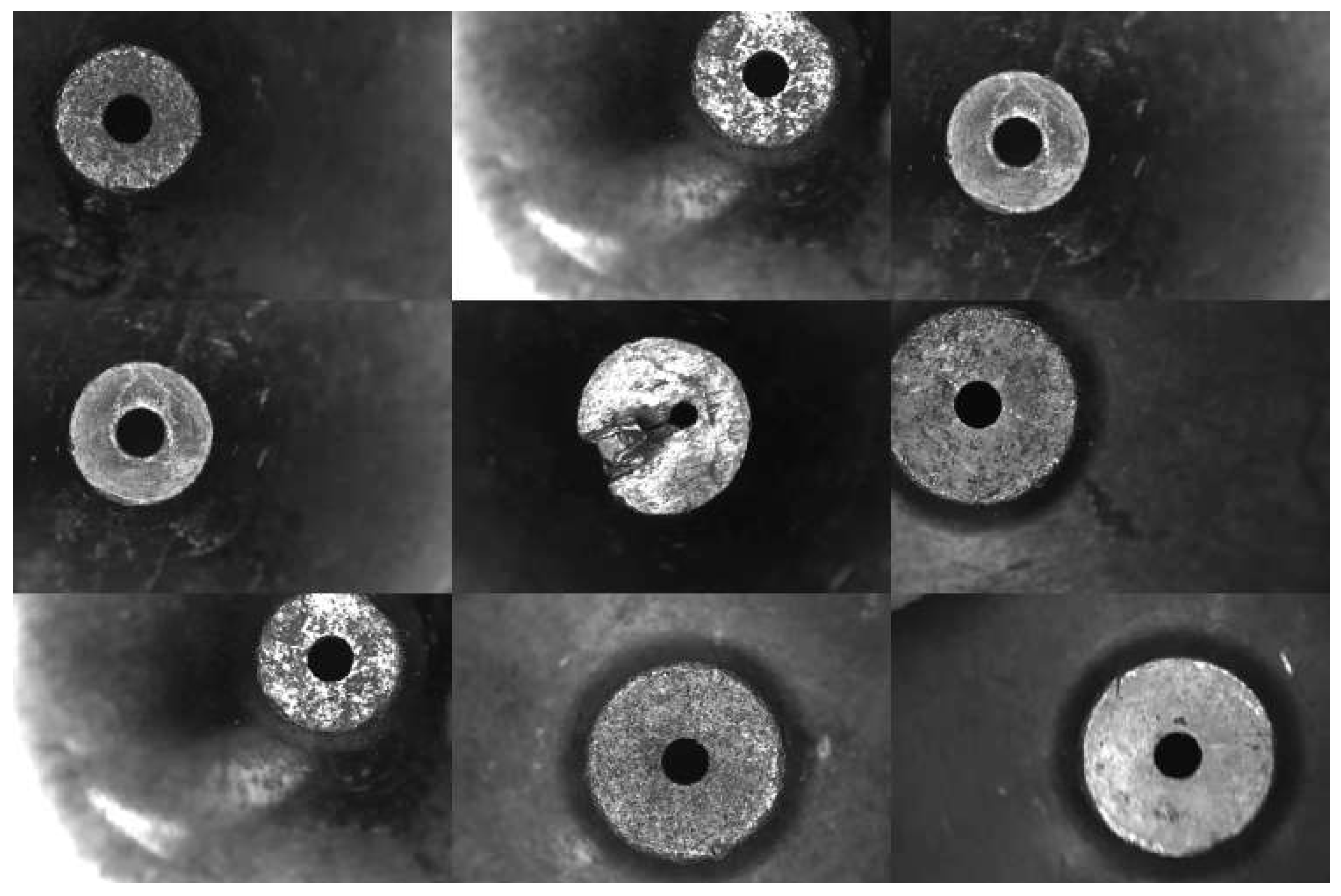
4.1.1. Data Collection
4.1.2. Data Augmentation
4.2. Experiments
4.2.1. Evaluation Index
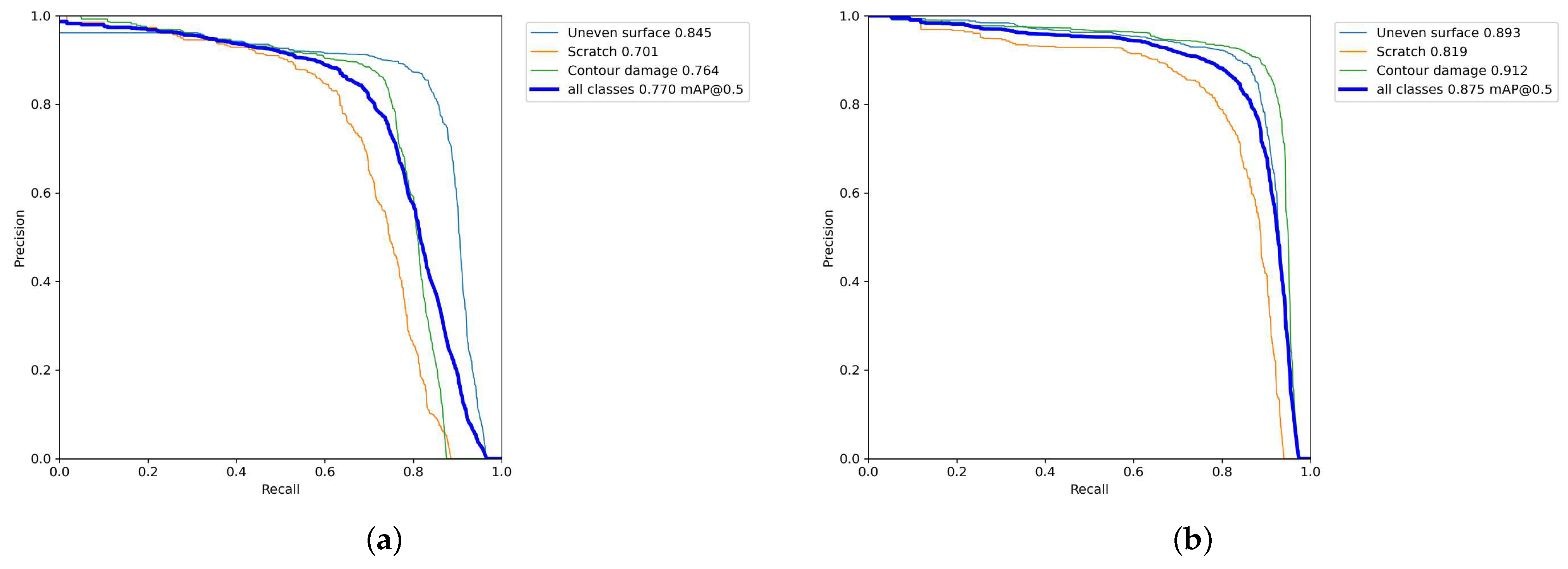
4.2.2. Ablation Experiments
4.2.3. Comparison Experiment of Different Models
4.3. Visualization and Analysis of Test Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Petring, D. Basic description of laser cutting. In LIA Handbook of Laser Materials Processing; Ready, J.F., Farson, D.F., Eds.; Laser Institute of America, Magnolia Publishing: Orlando, FL, USA, 2001; pp. 425–428. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLOv5: Ultralytics. GitHub Repository. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 June 2024).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 4 August 2024).
- Wang, D.; Tan, J.; Wang, H.; Kong, L.; Zhang, C.; Pan, D.; Li, T.; Liu, J. SDS-YOLO: An Improved Vibratory Position Detection Algorithm Based on YOLOv11. Measurement 2025, 244, 116518. [Google Scholar] [CrossRef]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations 2021, Vienna, Austria, 4 May 2021. [Google Scholar]
- Akhyar, F.; Liu, Y.; Hsu, C.-Y.; Shih, T.K.; Lin, C.-Y. FDD: A deep learning-based steel defect detectors. Int. J. Adv. Manuf. Technol. 2023, 126, 1093–1107. [Google Scholar] [CrossRef] [PubMed]
- Zhao, W.; Chen, F.; Huang, H.; Li, D.; Cheng, W. A new steel defect detection algorithm based on deep learning. Comput. Intell. Neurosci. 2021, 1–13. [Google Scholar] [CrossRef]
- Chen, K.; Zeng, Z.; Yang, J. A deep region-based pyramid neural network for automatic detection and multi-classification of various surface defects of aluminum alloys. J. Build. Eng. 2021, 43, 102523. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhang, C.; Chang, C.C.; Jamshidi, M. Concrete bridge surface damage detection using a single-stage detector. Comput. Civ. Infrastruct. Eng. 2020, 35, 389–409. [Google Scholar] [CrossRef]
- Sun, L.; Wei, J.; Zhu, D.; Shi, M. Surface Defect Detection Algorithm of Aluminum Profile Based on AM-YOLOv3 Model. Laser Optoelectron. Prog. 2021, 58, 2415007. [Google Scholar]
- Li, J.; Su, Z.; Geng, J.; Yin, Y. Real-time Detection of Steel Strip Surface Defects Based on Improved YOLO Detection Network. IFAC-PapersOnLine 2018, 51, 76–81. [Google Scholar] [CrossRef]
- Wan, G.; Fang, H.; Wang, D.; Yan, J.; Xie, B. Ceramic tile surface defect detection based on deep learning. Ceram. Int. 2022, 48, 11085–11093. [Google Scholar] [CrossRef]
- Li, Y.; Xu, S.; Zhu, Z.; Wang, P.; Li, K.; He, Q.; Zheng, Q. EFC-YOLO: An Efficient Surface-Defect-Detection Algorithm for Steel Strips. Sensors 2023, 23, 7619. [Google Scholar] [CrossRef]
- Wang, H.; Xu, X.; Liu, Y.; Lu, D.; Liang, B.; Tang, Y. Real-Time Defect Detection for Metal Components: A Fusion of Enhanced Canny–Devernay and YOLOv6 Algorithms. Appl. Sci. 2023, 13, 6898. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Xin, Z. Efficient Detection Model of Steel Strip Surface Defects Based on YOLO-v7. IEEE Access 2022, 10, 133936–133944. [Google Scholar] [CrossRef]
- Xiangming, Q.; Xu, D. Improved Yolov7-tiny Algorithm for Steel Surface Defect Detection. Comput. Eng. Appl. 2023, 59, 176–183. [Google Scholar]
- Xu, X.; Zhang, G.; Zheng, W.; Zhao, A.; Zhong, Y.; Wang, H. High-Precision Detection Algorithm for Metal Workpiece Defects Based on Deep Learning. Machines 2023, 11, 834. [Google Scholar] [CrossRef]
- Xie, Y.; Yin, B.; Han, X.; Hao, Y. Improved YOLOv7-based steel surface defect detection algorithm. Math. Biosci. Eng. 2024, 21, 346–368. [Google Scholar] [CrossRef]
- Li, Z.; Jia, D.; He, Z.; Wu, N. MSG-YOLO: A Multi-Scale Dynamically Enhanced Network for the Real-Time Detection of Small Impurities in Large-Volume Parenterals. Electronics 2025, 14, 1149. [Google Scholar] [CrossRef]
- Wang, Y.; Yun, W.; Xie, G.; Zhao, Z. YOLO-WAD for Small-Defect Detection Boost in Photovoltaic Modules. Sensors 2025, 25, 1755. [Google Scholar] [CrossRef]
- He, L.; Zheng, L.; Xiong, J. FMV-YOLO: A Steel Surface Defect Detection Algorithm for Real-World Scenarios. Electronics 2025, 14, 1143. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized feature pyramid for object detection. IEEE Trans. Image Process. 2023, 32, 4341–4354. [Google Scholar] [PubMed]
- Ai, S.; Liu, F.; Zhang, D. Pill Defect Detection Based on Improved YOLOv5s Network. Instrumentation 2022, 9, 27–36. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Quantity |
|---|---|
| Scratch | 223 |
| Uneven surface | 619 |
| Contour damage | 477 |
| Data Type | Quantity |
|---|---|
| Scratch | 2007 |
| Uneven surface | 5571 |
| Contour damage | 4293 |
| Baseline | A | B | C | D | mAP@0.5 | mAP@0.5:0.95 | Scratch (AP@0.5) | Uneven Surface (AP@0.5) | Contour Damage (AP@0.5) |
|---|---|---|---|---|---|---|---|---|---|
| ✓ | 77.0% | 52.9% | 70.1% | 84.5% | 76.4% | ||||
| ✓ | ✓ | 85.3% | 60.4% | 81.3% | 87.2% | 87.4% | |||
| ✓ | ✓ | 79.4% | 54.4% | 71.6% | 85.7% | 80.9% | |||
| ✓ | ✓ | 80.1% | 55.1% | 72.2% | 84.9% | 83.2% | |||
| ✓ | ✓ | 77.5% | 53.1% | 70.0% | 85.1% | 77.4% | |||
| ✓ | ✓ | ✓ | 86.5% | 62.0% | 81.6% | 87.8% | 90.2% | ||
| ✓ | ✓ | ✓ | ✓ | 87.2% | 62.1% | 81.7% | 89.0% | 90.8% | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 87.5% | 62.4% | 81.9% | 89.3% | 91.2% |
| Model | mAP@0.5 | FPS |
|---|---|---|
| Yolov7 | 77.0% | 175.4 |
| Yolov7 + Decoupled Head | 79.8% | 136.6 |
| Yolov7 + Efficient Decoupled Head | 80.1% | 143.8 |
| Algorithm | mAP@0.5 | Scratch (AP@0.5) | Uneven Surface (AP@0.5) | Contour Damage (AP@0.5) |
|---|---|---|---|---|
| YOLO *+CA | 87.5% | 81.9% | 89.3% | 91.2% |
| +CBAM | 83.5% | 80.7% | 81.4% | 88.3% |
| +SE | 85.7% | 80.1% | 87.8% | 89.1% |
| +NAM | 85.9% | 80.6% | 87.4% | 89.8% |
| +ECA | 86.0% | 80.4% | 87.3% | 90.2% |
| Methods | mAP@0.5 | Params (M) | FPS | F1-Score | Scratch (AP@0.5) | Uneven Surface (AP@0.5) | Contour Damage (AP@0.5) |
|---|---|---|---|---|---|---|---|
| Faster-RCNN | 70.0% | 137.2 | 12.3 | 0.72 | 64.3% | 69.4% | 76.4% |
| SSD | 55.8% | 26.5 | 45.6 | 0.60 | 47.1% | 51.2% | 69.2% |
| YOLOv5s | 73.2% | 7.2 | 203 | 0.75 | 61.5% | 83.5% | 74.7% |
| YOLOv6s | 73.1% | 15 | 211 | 0.74 | 61.2% | 83.3% | 74.8% |
| YOLOv7-tiny | 75.7% | 38.9 | 187.2 | 0.77 | 65.1% | 84.4% | 77.5% |
| YOLOv7 | 77.0% | 71.5 | 175.4 | 0.78 | 70.1% | 84.5% | 76.4% |
| YOLOv8l | 79.2% | 44.6 | 184.4 | 0.79 | 73.7% | 81.4% | 82.6% |
| YOLOv9t | 80.2% | 6.3 | 163.5 | 0.81 | 75.6% | 84.9% | 80.1% |
| YOLOv10n | 78.7% | 2.7 | 159.9 | 0.79 | 72.6% | 80.6% | 82.9% |
| YOLOv11n | 79.3% | 2.6 | 162.7 | 0.79 | 73.7% | 83.6% | 80.6% |
| DEC-YOLO | 87.5% | 91.4 | 103.4 | 0.86 | 81.9% | 89.3% | 91.2% |
| Method | False Positive Rate (FPR) | False Negative Rate (FNR) |
|---|---|---|
| YOLOv5s | 18.2% | 3.5% |
| YOLOv7 | 15.7% | 2.7% |
| YOLOv8l | 12.4% | 2.5% |
| DEC-YOLO | 6.3% | 2.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Deng, H.; Zhou, F.; Zheng, Y. DEC-YOLO: Surface Defect Detection Algorithm for Laser Nozzles. Electronics 2025, 14, 1279. https://doi.org/10.3390/electronics14071279
Li S, Deng H, Zhou F, Zheng Y. DEC-YOLO: Surface Defect Detection Algorithm for Laser Nozzles. Electronics. 2025; 14(7):1279. https://doi.org/10.3390/electronics14071279
Chicago/Turabian StyleLi, Shaoxu, Honggui Deng, Fengyun Zhou, and Yitao Zheng. 2025. "DEC-YOLO: Surface Defect Detection Algorithm for Laser Nozzles" Electronics 14, no. 7: 1279. https://doi.org/10.3390/electronics14071279
APA StyleLi, S., Deng, H., Zhou, F., & Zheng, Y. (2025). DEC-YOLO: Surface Defect Detection Algorithm for Laser Nozzles. Electronics, 14(7), 1279. https://doi.org/10.3390/electronics14071279