Abstract
Reliable detection of X-ray tire defects is essential for safety and quality assurance in manufacturing. However, low contrast and high noise make traditional methods unreliable. This paper presents DyReCS-YOLO, a dynamic re-parameterized channel-shuffle network based on YOLOv8. The model introduces a C2f_DyRepFusion module combining dynamic convolution and a shuffle-and-routing mechanism, enabling adaptive kernel adjustment and efficient cross-channel interaction. Experiments on an industrial X-ray tire dataset containing 8326 images across 58 defect categories demonstrate that DyReCS-YOLO achieves an mAP@0.5 of 0.741 and mAP@0.5:0.95 of 0.505, representing improvements of 4.5 and 2.8 percentage points over YOLOv8-s, and 9.2 and 7.7 percentage points over YOLOv11-s, respectively. The precision increases from 0.698 (YOLOv8-s) and 0.668 (YOLOv11-s) to 0.739, while maintaining real-time inference at 189.5 FPS, meeting industrial online detection requirements. Ablation results confirm that the combination of dynamic convolution and channel shuffle improves small-defect perception and robustness. Moreover, DyReCS-YOLO achieves an mAP@0.5 of 0.975 on the public MT defect dataset, verifying its strong cross-domain generalization.
1. Introduction
Tire defects critically impact driving safety and must be detected reliably. As global vehicle numbers rise, tires, as core automotive safety components, must be of high quality to ensure performance. In high-speed scenarios, even tiny defects can cause catastrophic outcomes, thus imposing stringent requirements on defect detection accuracy in manufacturing. Conventional X-ray-based inspection is often conducted manually, but the low contrast and significant noise in tire X-ray images lead to poor accuracy and low efficiency under human judgment [1]. Meanwhile, the interior of a tire consists of rubber, metallic belts, and fabric layers, with over 50 possible defect types (such as foreign inclusions, ply misalignments, or wire bends), and repetitive textures and low-contrast features make some defects almost indistinguishable [2,3]. These factors pose a severe challenge for detection. Therefore, developing efficient and accurate automated detection techniques is critical for improving production efficiency and ensuring tire quality.
Currently, most tire defect detection methods use X-ray imaging, and identification is carried out by experts observing the images, which is slow and subjective. Deep learning-based object detection methods can automatically extract image features and retain more details, showing strong adaptability and portability. For instance, multi-scale feature fusion and attention modules have been introduced to enhance semantic and textural feature extraction, and improved networks and optimization strategies further boost performance. However, X-ray equipment is large and poses health hazards, making online inspection of tires difficult. Given the limitations of X-ray imaging, vision-based tire defect detection has emerged as a new research direction. Different parts of the tire and various defect types require specialized detection methods. Although some tailored methods achieve high accuracy under specific conditions, they often lack generality. Traditional image processing pipelines (preprocessing, threshold segmentation, morphological operations) can detect defects but still leave room for improvement in accuracy and speed.
Recent advances in deep learning, especially in object detection, provide new solutions for automatic tire defect recognition. Deep convolutional neural networks (CNNs) can automatically learn hierarchical features from X-ray tire images, significantly improving detection accuracy and speed [4,5]. The introduction of multi-layer feature fusion and attention mechanisms further enhances the detection model’s capability to identify defects in complex backgrounds and small targets [6].
The contributions of this work are summarized as follows:
- We propose a dual-branch architecture based on RCS-YOLO that combines DynamicConv and channel shuffle. Specifically, we design the RCS_Dynamic module to dynamically adjust convolutional kernel weights and enhance cross-channel interactions, significantly improving modeling capability for complex backgrounds in tire defect images.
- We introduce the SR_Dynamic module, which integrates channel shuffle with dynamic convolution. Channel shuffle breaks fixed channel dependencies to boost cross-channel information flow, while dynamic convolution generates optimal kernel weights conditioned on input features. This combination greatly enhances feature adaptability and diversity.
- We optimize data augmentation strategies for X-ray tire images and conduct comprehensive experiments on an industrial dataset of 8326 images. Our method achieves state-of-the-art performance and also demonstrates excellent results on the public MT surface defect dataset.
2. Related Work
Early tire defect detection primarily relied on manual inspection and traditional image processing, especially during X-ray inspection. Classical methods used handcrafted filters, thresholding, edge detection, and morphological operations. For example, Liu et al. [7] applied Radon projection features for structural analysis of tire X-ray images to identify anomalies. Cui et al. [8] used principal component analysis (PCA) to reconstruct X-ray images and detect residual anomalies. Guo et al. [9] computed weighted texture dissimilarity among local regions to locate defects. These methods rely on grayscale and texture statistics, making them sensitive to noise and heavily parameter-dependent; they only perform well under stable lighting, background, and defect conditions. As tire structures became more complex and production lines faster, such methods exposed weaknesses like poor robustness, weak generalization, and difficulty detecting small defects.
Deep learning breakthroughs in industrial vision have offered new solutions. Convolutional neural networks (CNNs) learn features end-to-end and automatically extract multi-level information, significantly improving detection accuracy and generalization. Li et al. [4] proposed the TireNet model in 2021, using a two-branch network with a ResNet backbone for different defect types, achieving a miss rate of just 0.17%. Wang et al. [10] used a U-Net-style FCN for pixel-level segmentation of X-ray defects, which effectively improved localization of tiny defects. For object detection, Wu et al. [11] built a tire defect detection system based on Faster R-CNN, incorporating a feature pyramid to enhance small target perception, but its two-stage nature limited real-time applicability. To improve efficiency, researchers turned to single-stage detectors. Peng et al. [12] introduced TD-YOLOA (2023) with ELAN, SPPCSPC, and CBAM modules, achieving 91.3% mAP with 9.28 ms per image, balancing accuracy and speed. Zhao et al. [13] enhanced YOLOv4-tiny with a multi-scale attention module (MSAM+CBAM) to boost small-defect detection in complex backgrounds. In general, deep learning frameworks (YOLO, SSD, Faster R-CNN, etc.) have clearly outperformed traditional methods in detection accuracy and automation.
Current trends in tire defect detection emphasize lightweight models, intelligence, and self-supervision. For lightweight and real-time detection, industrial systems demand high inference speed, so researchers continuously optimize network structures. For instance, Zhao et al. replaced heavy convolutions with lightweight attention modules, and Xu and Pan [14] proposed DHS-YOLO using dynamic depthwise snake convolution, maintaining high accuracy with reduced computation. Data augmentation and self-supervised learning are important due to scarce defect samples. Lu [15] used a GAN-based approach to build a self-supervised detection model using only non-defect samples, achieving AUC of 0.873 by defect reconstruction error. Attention mechanisms and multi-scale feature fusion address complex textures and scales: Peng et al. introduced a channel–spatial attention module (CBAM) to enhance salient features, while Zhao et al. used a multi-scale attention network (MSANet) for context. Such structures significantly improve detection of slender or blurred defects.
Traditional algorithms, relying on handcrafted features and thresholds, are highly sensitive to noise, lighting, and deformation, and struggle with complex internal tire structures across different models. Deep learning models, driven by large-scale data and end-to-end learning, show superior accuracy, robustness, and generalization. For example, Xu and Pan reported that an improved YOLOv5 detector achieved over 90% mAP on a tire X-ray dataset, whereas a traditional Faster R-CNN reached only about 33.4%. Likewise, Peng et al. demonstrated real-time detection on an industrial line with TD-YOLOA. Although deep models significantly improve performance, they require extensive labeled data (high annotation cost) and often lack interpretability. In contrast, traditional methods are simple to implement but limited in complex and tiny-defect scenarios. Overall, deep learning is the mainstream for automatic tire defect detection and is evolving toward lightweight, adaptive feature extraction approaches.
In summary, traditional image processing methods played a role in early tire inspection due to their simplicity and interpretability, but their performance bottlenecks become evident as detection demands grow. Deep learning methods have made significant advances in accuracy, generalization, and automation through end-to-end feature learning. Current research is heading toward lightweight models, sensitivity to fine defects, few-shot learning, and cross-domain generalization. Our proposed DyReCS-YOLO model follows this trend, aiming to combine dynamic convolution with channel shuffle to improve X-ray tire defect detection performance while maintaining high inference speed.
Compared with the above works, DyReCS-YOLO differs in both motivation and design. TD-YOLOA mainly enhances local–global attention, and DHS-YOLO focuses on hybrid dynamic convolutions. Neither of them incorporates a re-parameterized channel-shuffle mechanism. In this work, we integrate DynamicConv and channel shuffle into a unified DyReCS module, allowing adaptive kernel aggregation and efficient feature interaction while maintaining real-time inference. This combination has not been explored in previous tire defect studies.
3. Proposed Method
3.1. Network Architecture
Inspired by the re-parameterized channel-shuffle (RCS) structure [16], we design a convolutional module (RCS_Dynamic) that fuses dynamic convolution (DynamicConv) with dynamic channel interaction (SR_Dynamic). In the YOLOv8 framework, we replace the original C2f module’s bottleneck layers with our C2f_DyRepFusion modules, achieving dynamic adaptive feature fusion with re-parameterized training. The C2f_DyRepFusion embeds the RCS_Dynamic module into the standard C2f block, forming a dynamic re-parameterized fusion structure. During training, a multi-branch structure (main branch and dynamic branch) enhances feature expression; during inference, branches are merged (via RepConv) into an equivalent single-path convolution, preserving lightweight inference.
The improved network structure is shown in Figure 1. It includes an input layer, backbone, neck, and head. In the backbone, we stack four C2f_DyRepFusion modules for multi-scale feature extraction. The neck adopts a feature pyramid network (FPN) for multi-layer feature fusion. The detection head retains the three-scale detection of YOLOv8. This design addresses challenges in X-ray tire images such as large scale variation, complex textures, and strong noise interference. By introducing dynamic convolution and channel shuffle, the model enhances feature adaptability and information flow, thus improving robustness and accuracy in complex industrial scenarios.
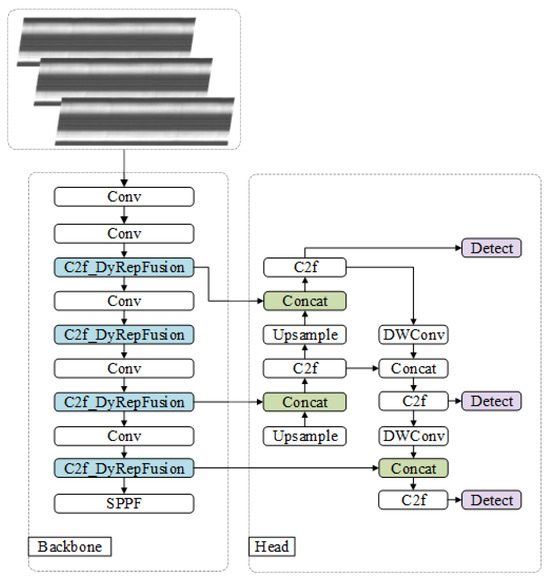
Figure 1.
Overall architecture of DyReCS-YOLO. The network consists of an input layer, a backbone, a neck, and a detection head. The backbone uses four C2f_DyRepFusion blocks (blue) to extract multi-scale features. The neck fuses features via a feature pyramid network, and the head performs three-scale object detection as in YOLOv8.
3.2. RCS_Dynamic Module
The RCS_Dynamic module (Figure 2) contains two paths: a backbone path with DynamicConv to extract local features, and a residual path (SR_Dynamic) for cross-channel information exchange and dynamic enhancement. The core is the dynamic convolution, which adapts its kernel weights based on input features. Specifically, given input feature map X, dynamic convolution computes a weighted sum of multiple expert kernels:
where are the expert convolution kernels, denotes convolution, and are adaptive weights satisfying . These weights are generated from the global context of X via a routing network:
where is global average pooling of X, W are learned parameters, and is the sigmoid activation. Equations (1) and (2) allow the convolutional response to dynamically adjust according to the input feature distribution, improving adaptability to various defect patterns.
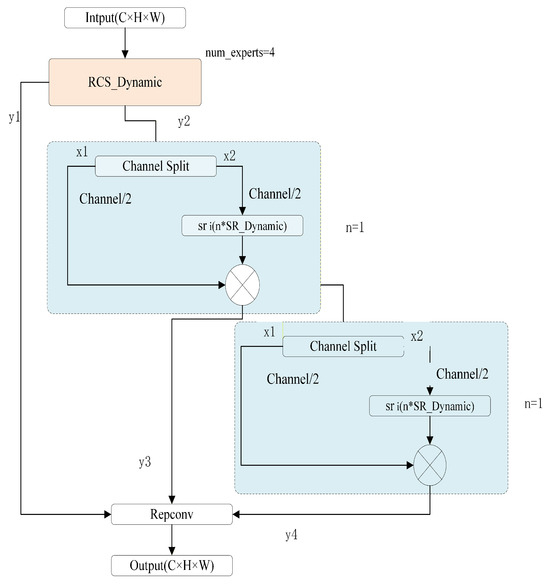
Figure 2.
Structure of the RCS_Dynamic module. The input feature map is split into two branches: the DynamicConv branch and the SR_Dynamic branch. The DynamicConv branch (top) applies multiple convolution kernels weighted by routing coefficients to extract local features; the SR_Dynamic branch (bottom) enables cross-channel information exchange and dynamic enhancement. The outputs are concatenated, channel-shuffled, and fused into a single output.
The dynamic convolution output Y is then split channel-wise into two parts: (residual part) and (dynamically enhanced part). The residual part is kept to preserve original features, while carries the enhanced features. These are concatenated and mixed via a channel-shuffle operation:
Channel shuffle rearranges channel information across groups, promoting feature fusion between groups and enhancing information flow without additional convolutions. Finally, the concatenated output Z passes through a convolution to fuse the channels. During training, RCS_Dynamic uses the split-branch structure; at inference, the branches can be merged (re-parameterized) into an equivalent single convolution, so the module adds no additional overhead in runtime.
3.3. SR_Dynamic Module
The SR_Dynamic module (Figure 3) further enriches feature interaction by combining channel shuffle with dynamic convolution. It begins by splitting the input feature map X into two groups of channels: . The first group bypasses dynamic processing (residual connection), while the second group undergoes a multi-expert dynamic convolution similar to Equations (1) and (2). Specifically, is enhanced by
with weights generated from the pooled features of . The outputs and are concatenated and then channel-shuffled:
mixing information across the two groups. This dynamic shuffle-and-routing mechanism breaks inter-group isolation: it allows cross-channel exchange after dynamic enhancement, increasing feature diversity and sensitivity to subtle differences. The SR_Dynamic module thus boosts the network’s ability to attend to both global and local cues in complex tire defect images, without significantly increasing computational cost.
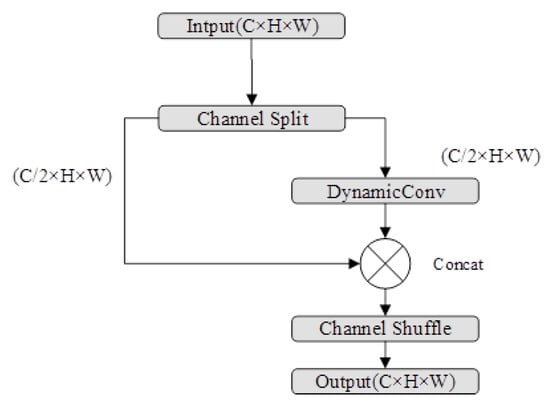
Figure 3.
Structure of the SR_Dynamic (Shuffle-and-Routing Dynamic) module. The input feature map is split into two channel groups. Group 1 (shown on the left) is passed through unchanged as a residual connection, while Group 2 (shown on the right) is processed by a multi-expert dynamic convolution branch (with multiple kernels weighted by routing coefficients). The outputs are concatenated and channel-shuffled to mix cross-group information.
4. Experimental Setup
4.1. Hardware and Training
All experiments were conducted on a high-performance platform with the following configuration: CPU—Intel Core i9-14900K; GPU—NVIDIA RTX 4090 (24 GB); RAM—64 GB; OS—Windows10; and framework—PyTorch 2.0.0 with CUDA 11.8. Training used a stochastic gradient descent (SGD) optimizer with an initial learning rate , momentum 0.9, and weight decay . Batch size was set to 4, and total training epochs to 200. We applied cosine annealing learning rate decay and early stopping to improve convergence.
4.2. Dataset and Augmentation
Our dataset consists of X-ray tire images collected from an industrial production line. After manual filtering to remove severely blurred or damaged samples, and applying data augmentation (random rotations, flips, translations, noise addition, contrast adjustment, and filtering) to under-represented defect categories, we obtained a balanced dataset of 8326 images across 58 defect classes. The dataset is split 8:1:1 into training (6662 images), validation (832 images), and testing (832 images). During training, high-resolution images were scaled or cropped proportionally to to fit the network input. At inference, we used full-resolution images to ensure consistency with deployment conditions.
4.3. Evaluation Metrics
We evaluate performance using standard object detection metrics: precision P, recall R, mean Average Precision (mAP), detection speed (FPS), and model size (Params). The mean Average Precision (mAP) averaged over all classes is defined as
where n is the total number of defect classes and is the area under the precision–recall curve for class j. Precision and recall are computed as
where is true positives, false positives, and false negatives.
5. Results and Discussion
5.1. Comparison with Baseline Models
As shown in Table 1, our proposed DyReCS-YOLO achieves the best performance among all comparison models. Specifically, DyReCS-YOLO obtains a precision of 0.739, recall of 0.685, mAP@0.5 of 0.741, and mAP@0.5:0.95 of 0.505. Compared with the baseline YOLOv8-s, the improvements are +4.5 percentage points in mAP@0.5 and +2.8 percentage points in mAP@0.5:0.95, demonstrating enhanced feature representation and detection robustness. Although the number of parameters increases from 11.2 M to 12.2 M, the model still maintains real-time inference at 189.5 FPS, which satisfies industrial deployment requirements. These results confirm that the proposed dynamic re-parameterized C2f fusion strategy effectively improves detection accuracy while preserving high efficiency.

Table 1.
Performance comparison of different detectors on the test dataset.
5.2. Ablation and Visualization
To analyze the contributions of each component, we conducted ablation experiments by gradually adding dynamic convolution and channel shuffle to the baseline (see Table 2). We observed that adding dynamic convolution alone slightly reduced precision at 0.5 but significantly improved mAP@0.5:0.95, indicating better small-defect recall. Introducing channel shuffle further increased precision and mAP. The full model (including both DynamicConv and SR_Dynamic) achieved the highest detection accuracy, demonstrating the positive effect of our modules.
Table 2.
Ablation study of the proposed modules on the X-ray tire defect dataset.
For qualitative analysis, we applied Grad-CAM visualization on four representative defect samples (Figure 4). Subfigures (a)–(d) correspond to (a) a foreign object in the tire carcass, (b) a bent steel belt, (c) a serpentine (curved) belt ply defect, and (d) a ply fabric split. The heatmaps show that our model activates most strongly at the true defect locations, indicating accurate focus and localization of defects even in complex textured regions. This confirms that DyReCS-YOLO effectively captures defect cues.
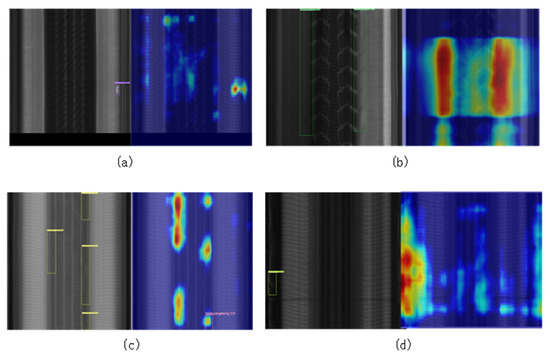
Figure 4.
Grad-CAM heatmaps of the DyReCS-YOLO model on four representative tire defect samples. (a) Foreign object in tire carcass. (b) Steel belt bending. (c) Serpentine belt-layer defect. (d) Ply (fabric) split. The model’s activations (hotter colors) align with the true defect regions (indicated by bounding boxes), indicating accurate localization.
For qualitative analysis, we visualize the detection results of four representative defect samples in Figure 5. Subfigures (a)–(d) correspond to (a) a folded steel belt, (b) overlapping steel belts, (c) an air bubble, and (d) overlapping carcass plies. The results indicate certain limitations in detection performance: samples (a), (c), and (d) were completely missed by the model, while in (b), the defect was only partially detected. The corresponding heatmaps reveal that the model either failed to activate in relevant regions or generated insufficiently salient responses, particularly in complex structural areas. This suggests that further improvements are required to enhance the model’s sensitivity to subtle or structurally complex defects.
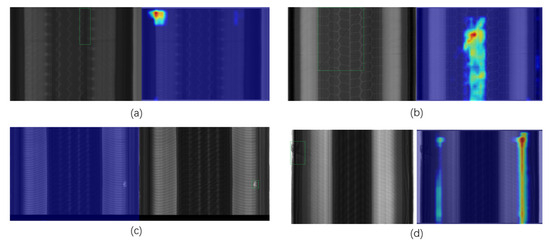
Figure 5.
Detection results and corresponding Grad-CAM heatmaps of the DyReCS-YOLO model on four representative tire defect samples. (a) Folded steel belt. (b) Overlapping steel belts. (c) Air bubble. (d) Overlapping carcass plies. The model fails to detect the defects in (a,c,d), and only partially detects the defect in (b), with the heatmaps revealing weak or absent activations in the corresponding regions.
5.3. Generalization and Robustness
To further evaluate the generalization capability of the proposed DyReCS-YOLO, we test the model on the public MT tile surface defect dataset, which contains 1344 images covering six classes of surface defects. As shown in Table 3, DyReCS-YOLO achieves a precision of 0.902, recall of 0.945, mAP@0.5 of 0.975, and mAP@0.5:0.95 of 0.648. Compared to YOLOv8-s and YOLOv11-s, our model improves mAP@0.5 by 1.9 percentage points and 1.9 percentage points, respectively, and increases mAP@0.5:0.95 by 4.7 and 2.5 percentage points. These results demonstrate that the proposed dynamic feature fusion strategy not only enhances performance on the training domain (X-ray tire defects), but also exhibits strong cross-domain generalization when applied to other industrial defect types with different visual characteristics.
Table 3.
Model performance on the MT tile defect dataset.
6. Conclusions and Future Work
In this paper, we presented DyReCS-YOLO, a dynamic re-parameterized detection model built on the YOLOv8 framework, to improve X-ray tire defect inspection. Our approach integrates DynamicConv and SR_Dynamic modules into the RCS-style C2f blocks, enabling input-adaptive feature extraction and cross-channel interaction. On our industrial X-ray tire dataset, the improved model achieved about a 4.7-percentage-point increase in mAP@0.5 compared to the baseline YOLOv8-s. It also demonstrated excellent transfer performance on the public MT defect dataset, indicating strong detection capability in scenarios with complex textures and multi-scale defects. These results validate that the proposed method significantly enhances detection ability under challenging conditions.
Despite the increase in parameters, DyReCS-YOLO still maintains real-time inference at 189.5 FPS under TensorRT FP16 deployment, which meets industrial online detection requirements. Future work will focus on further reducing computational cost through model pruning, quantization, and knowledge distillation to improve hardware adaptability and embedded deployment efficiency.
Although DyReCS-YOLO does not introduce a fundamentally new architecture, its contribution lies in the industrial adaptation and systematic integration of dynamic convolution and channel shuffle specifically for X-ray tire defect detection, where low contrast and complex textures pose unique challenges. Our redesign of the fusion ratios, expert numbers, and re-parameterization strategy provides a task-specific performance improvement suitable for real-time deployment in manufacturing lines.
Future work will address current limitations and industrial needs:
- Lightweight strategies:Incorporate network pruning, channel pruning, quantization, and knowledge distillation to reduce inference latency and computational overhead, aiming to achieve real-time rates without significant accuracy loss.
- Rare-defect detection: Introduce methods like Focal Loss, class-balanced sampling, synthetic defect generation (GAN), or few-shot learning to improve recall for under-represented defect classes.
- Multi-modal and multi-view fusion: Explore fusion of X-ray data with visible-light or thermal images, or employ multi-view projections to compensate for occlusions in complex tire structures.
- Online and active learning: Develop semi-automated labeling and online learning pipelines so that the model can continuously learn newly observed defect types during production, reducing manual annotation and improving long-term adaptability.
- Rigorous statistical evaluation: Future experiments will use cross-validation, multiple runs, and confidence intervals to strengthen statistical significance and reproducibility of results.
Author Contributions
Conceptualization, Q.D.; writing—review and editing, validation, X.B.; supervision, J.H., Y.Z. and X.Q.; formal analysis, X.B. and L.T.; visualization, X.B. All authors have read and agreed to the published version of the manuscript.
Funding
This work was financially supported by Key R&D project of Shandong Province (2024CXGC010212) fund.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Qin, F.; Yuan, H.; Zhu, D.; Liu, X.; Li, M.; Ji, X. Automatic Weld Defect Detection in Steel Plates Based on Ultrasonic Total Focusing Method and Multi-layer Feature Fusion Target Detection Network. J. Mech. Eng. 2025, 61, 55–66. (In Chinese) [Google Scholar]
- Saleh, R.A.A.; Ertunç, H.M. Attention-based deep learning for tire defect detection: Fusing local and global features in an industrial case study. Expert Syst. Appl. 2025, 269, 126473. [Google Scholar] [CrossRef]
- Wu, Z.; Jiao, C.; Chen, L. Tire defect detection method based on improved Faster R-CNN. Comput. Appl. 2021, 41, 1939–1946. [Google Scholar] [CrossRef]
- Li, Y.; Fan, B.; Zhang, W.; Jiang, Z. TireNet: A high recall rate method for practical application of tire defect type classification. Future Gener. Comput. Syst. 2021, 125, 1–9. [Google Scholar] [CrossRef]
- Wang, G.; Cui, X.; Wang, X.; Gong, Y.; Ding, Z. Tire defect detection based on encoder and multi-scale feature fusion. Electron. Meas. Technol. 2024, 47, 25–32. [Google Scholar]
- Zhang, H.; Wu, Y. Research progress on vision-based automobile component defect detection. Chin. J. Sci. Instrum. 2023, 44, 1–20. [Google Scholar]
- Liu, H.; Yang, X.; Latecki, L.J.; Yan, S. Dense neighborhoods on affinity graph. Int. J. Comput. Vis. 2012, 98, 65–82. [Google Scholar] [CrossRef]
- Cui, X.; Liu, Y.; Wang, C. Defect automatic detection for tire X-ray images using inverse transformation of principal component residual. In Proceedings of the IEEE Conference on Artificial Intelligence and Pattern Recognition, Lodz, Poland, 19–21 September 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Guo, Q.; Zhang, C.; Li, H.; Zhang, X. Defect detection in tire X-ray images using weighted texture dissimilarity. J. Sens. 2016, 2016, 4140175. [Google Scholar] [CrossRef]
- Wang, R.; Guo, Q.; Lu, S.; Zhang, C. Tire defect detection using fully convolutional network. IEEE Access 2019, 7, 43502–43510. [Google Scholar] [CrossRef]
- Wu, Z.; Jiao, C.; Sun, J.; Chen, L. Tire defect detection based on Faster R-CNN. In Proceedings of the International Conference on Machine Vision Applications, Yangon, Myanmar, 26–28 February 2020. [Google Scholar] [CrossRef]
- Peng, C.; Li, X.; Wang, Y. TD-YOLOA: An efficient YOLO network with attention mechanism for tire defect detection. IEEE Trans. Instrum. Meas. 2023, 72, 3529111. [Google Scholar] [CrossRef]
- Zhao, M.; Tian, Q.; Zhang, Y. MSANet: Efficient detection of tire defects in radiographic images. Meas. Sci. Technol. 2023, 33, 125401. [Google Scholar] [CrossRef]
- Xu, D.; Pan, J. DHS-YOLO: Enhanced detection of slender wheat seedlings under dynamic illumination conditions. Agriculture 2025, 15, 510. [Google Scholar] [CrossRef]
- Lu, J. Unsupervised learning with generative adversarial network for automatic tire defect detection from X-ray images. Sensors 2021, 21, 6773. [Google Scholar] [CrossRef] [PubMed]
- Kang, M.; Ting, C.M.; Ting, F.F.; Phan, R.C.-W. RCS-YOLO: A fast and high-accuracy object detector for brain tumor detection. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).