Abstract
Federated Learning (FL) is revolutionizing Machine Learning (ML) by enabling devices in different locations to collaborate and learn from user-generated data without centralizing it. In dynamic and non-stationary environments like Internet of Things (IoT), Concept Drift (CD) is the phenomenon of data changing/evolving over time. Traditional FL frameworks struggle to maintain performance when local data distributions evolve, as they lack mechanisms for detecting and adapting to concept drift. However, the use of FL in such environments, where data changing/evolving continuously and Continual Learning (CL) is required to adapt to concept drift, remains a relatively unexplored area. This study specifically addresses this gap by examining strategies for continuous adaptation within federated systems when faced with non-stationary data. Following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, this study systematically reviews existing literature on FL adaptation to concept drift. To the best of our knowledge, this is the first systematic review that consolidates and reinterprets existing studies under the emerging framework of Federated Drift-Aware Learning (FDAL), bridging Federated and Continual Learning research toward adaptive and drift-resilient federated systems. We conducted an extensive systematic survey, including an analysis of state-of-the-art methods and the latest developments in this field. Our study highlights their strengths, weaknesses, and datasets used, identifies key challenges faced by FL systems in these scenarios, and explores potential future directions. Additionally, we categorize the limitations and future directions into major thematic areas that highlight core gaps and research opportunities. The results of this study will support researchers in overcoming the adaptation challenges that FL systems face when dealing with changing environments due to concept drift and serve as a critical resource for advancing adaptive federated intelligence.
1. Introduction
In recent years, technological advancements have led to a rapid increase in smart devices that have become integral to daily life. These include not only mobile phones but also wearable gadgets, service robots, and Internet of Things (IoT) devices. These devices are increasingly sophisticated, equipped with advanced sensors, and capable of interconnectivity, generating vast amounts of data. This data, collected from diverse real-world settings, offers new possibilities across various domains [1,2,3] such as education, healthcare, sports, travel, banking, and social interactions. A significant development is the application of machine learning across multiple devices, enabling them to learn, adapt, and improve autonomously, thereby enhancing user benefits. The primary objective of ML is to utilize collected data to build a model that leverages past experiences to make informed decisions in new situations. Devices like sensors and smartphones each gather specific data, such as sensor readings, photos, videos, or location information [4]. However, data from a single device may be insufficient for robust model development. Collaborative learning among devices, which share and learn from a larger, more diverse data set, results in a more effective model capable of making better decisions. This collective approach enhances the functionality and efficacy of smart devices.
The easiest way to perform ML across many devices is using a Central Client-Server method, where devices (clients) send their data to a main server, typically in the cloud. The server aggregates this data to build a robust model for intelligent decision-making. This model can either remain on the server, allowing devices to query it, or be distributed to devices for local use. However, this method raises significant privacy concerns as personal data, including IDs, phone numbers, addresses, photos, browsing history, and location, is collected. Governments have enacted laws to restrict the centralization of personal data to protect privacy [5]. Additionally, the Central Client-Server method struggles with scalability issues like storage capacity, communication costs, and speed. Transmitting large, continuous data from numerous devices is time-consuming and expensive, especially with complex data like videos [6,7]. Moreover, centralized processing can be slower than decentralized methods, causing delays problematic for real-time applications like self-driving cars [8].
A more effective approach to handling ML in scenarios where data is distributed across multiple devices is to employ a Decentralized Method. This approach involves retaining private data on each device and performing computations locally, rather than centrally aggregating data. Currently, the predominant method for achieving this decentralized approach is known as Federated Learning (FL) [9,10,11]. FL is an ML setting where the goal is to train a model across multiple decentralized edge devices or servers holding local data samples, without exchanging them. This approach is particularly useful in scenarios where data privacy, security, and access rights are of concern, or where the data itself is too large or sensitive to be centralized [12]. In other words, FL involves devices collaboratively training a model by sequentially updating it with local data. The process begins with the server initializing the model, which devices then refine using their data before returning updates. The server aggregates these updates, often by averaging. This approach preserves user privacy, reduces the server’s computational load, and enhances system scalability through distributed learning. FL is an emerging technological paradigm already being utilized for various applications. Examples include enhancing predictive text capabilities on smartphone keyboards [13], detecting malware [14,15], assisting in medical diagnoses [16,17], and enabling self-driving cars [18,19]. FL, though increasingly popular over the last decade, remains relatively new compared to traditional centralized data methods. Research in this field has surged since 2018, revealing its advantages and the challenges it faces, particularly in handling data with varying statistical properties over time; see Figure 1.
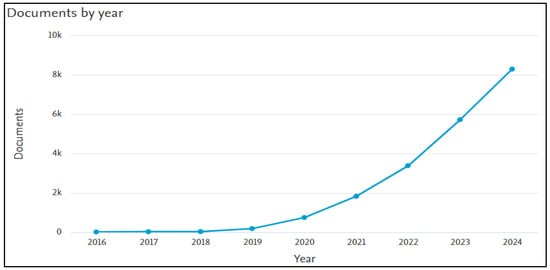
Figure 1.
Federated Learning Research (2016–2024)—Own analysis based on Scopus.
One of the primary challenges currently being addressed by researchers is optimizing FL for scenarios where data exhibits varying statistical properties or evolves over time [20,21,22,23,24]. Specifically, researchers explore innovative methods to handle data that is not consistent over time (e.g., non-stationary). Traditional ML methods, including FL approaches, typically assume that the data remains relatively stable (stationary). However, in real-world applications, this assumption often does not hold. Devices continuously collect data, which can change as the environment or conditions fluctuate. Consequently, it is crucial to develop adaptive learning systems that maintain effectiveness over time, even as the underlying data evolves. A notable situation highlighting the importance of adaptable learning systems is the COVID-19 pandemic. Over the past few years, significant changes in daily life, including shifts in consumer preferences and behaviors, have necessitated updates to many recommendation algorithms and models. These substantial alterations rendered existing models less effective, underscoring the critical need for learning systems capable of adapting to dynamic conditions and evolving data.
ML in the context of non-stationary data entails several challenges and constraints [25]:
- Continuous Data Arrival: Data does not arrive all at once but continuously over time. This requires an incremental learning approach, where the model must retain useful prior knowledge while incorporating new information. It is essential to avoid “catastrophic forgetting,” where learning new data results in the complete loss of previously acquired knowledge.
- Infinite Data Streams: The data flow can be infinite, making it impractical to store all data in memory. Consequently, each data point may only be reviewed a limited number of times. Even if storage capacity permits, data may need to be deleted for legal reasons or to protect individual privacy.
- Unpredictable Statistical Changes: The statistical properties of data unpredictably change, a phenomenon known as “concept drift.” This means that insights derived from older data may become obsolete, potentially degrading the model’s performance. Therefore, it is crucial to detect these changes and update the model accordingly to maintain its efficacy.
In multi-device applications, the challenge of non-stationarity becomes even more complex because each device processes a local and independent data stream. Therefore, learning a federated model in a non-stationary environment involves additional constraints [20,22]:
- Clients, such as smartphones or other devices, can join or leave the network at any time due to factors like battery life, internet connectivity, or the availability of data to share.
- Different clients may process data at varying speeds, depending on their computational power and environmental conditions.
- The nature of the data (data distribution) each client receives can change over time and may differ from one client to another.
- Concept drift, which refers to the emergence of new patterns or trends in the data, can occur or be detected at different times for each client.
A significant challenge in multi-device environments is the statistical heterogeneity of data, where traditional ML methods often assume data to be stationary meaning each data point is independent, and all data share the same probability distribution. While this assumption works well in centralized settings where data is pooled, it becomes problematic in FL contexts, where data is distributed across devices and can be highly variable. Although research in FL has expanded to address general frameworks and communication efficiency under privacy constraints, there remains a critical need for specific strategies to handle non-stationary data, ensuring robust drift detection and adaptive model management. This gap in the literature highlights an essential area for further study to enhance model resilience in dynamic federated environments, particularly as the field of continual adaptation in FL particularly in the context of concept drift is still relatively unexplored.
In Federated Learning, each client operates on a locally evolving data stream that may differ in distribution, feature space, or label frequency from others. When these local distributions shift over time, the individual models trained on each client gradually become biased toward their most recent data. During global aggregation, these accumulated local biases manifest as global concept drift, resulting in reduced convergence stability and generalization of the global model. Thus, the non-stationary nature of local data in FL environments inherently exposes the system to concept drift at both local and global levels [20,22,24].
This paper, therefore, makes a significant contribution by offering a comprehensive systematic review that consolidates and reinterprets existing studies on Federated Learning’s adaptability to dynamic data scenarios, particularly in the context of concept drift. The objective is to identify the scope, trends, and methods applied within FL and concept drift, thereby deepening our understanding of these domains and providing a detailed taxonomy of relevant methods. This paper aims to contribute to the following areas:
- It bridges the gap between FL and Concept Drift, an area that has been underexplored.
- It introduces and analyzes the relevant aspects motivating Federated Drift-Aware Learning (FDAL).
- It provides a structured taxonomy of FDAL approaches, elucidating the challenges and obstacles while identifying open research questions.
- It identifies and critically analyses the current state of FDAL approaches, highlighting both achievements and limitations.
- It proposes directions for future research, emphasizing the need for innovative solutions to improve the adaptability and effectiveness of federated learning in dynamic environments. Serving as a valuable resource, it guides researchers in navigating and addressing the adaptation challenges of federated learning, particularly in the context of concept drift.
Motivation and Contribution
Federated Learning (FL) has emerged as a transformative paradigm that enables distributed and privacy-preserving model training across decentralized devices. However, in real-world scenarios such as the Internet of Things (IoT), data is often non-stationary and evolves continuously over time a phenomenon known as concept drift (CD). Traditional FL frameworks assume data stability and global synchronization, which makes them ill-suited to handle dynamic, heterogeneous, and evolving data streams. This limitation creates a pressing need for drift-aware federated systems capable of adapting to temporal and spatial changes in client data.
Existing literature on FL primarily focuses on communication efficiency, model aggregation, and non-IID data handling. In contrast, studies addressing continual adaptation and drift management remain fragmented and largely explored within centralized or single-device settings. Few attempts explicitly integrate concept drift detection or adaptation within federated contexts. Moreover, existing reviews tend to treat Continual Learning (CL) and FL as separate paradigms rather than examining their intersection. Consequently, there is limited understanding of how federated models can continuously adapt to evolving data distributions while maintaining fairness and stability across clients.
This paper addresses the above gaps through the following key contributions:
- Comprehensive Synthesis: We present the first systematic survey that consolidates studies addressing Federated Learning under Concept Drift (FDAL), integrating findings across multiple domains and methodological frameworks.
- Theoretical Framing: We formally define the relationship between FL, CL, and CD, offering a unified theoretical foundation for understanding local and global drift phenomena in federated settings.
- FDAL Taxonomy: We introduce a structured taxonomy that categorizes drift-aware learning approaches based on temporal and spatial dimensions, providing a clear framework for analyzing adaptability in federated environments.
- Critical Analysis: We evaluate 22 state-of-the-art FDAL algorithms, highlighting their mechanisms, limitations, and future research opportunities related to scalability, fairness, and resource efficiency.
- Future Directions: We identify emerging challenges—such as catastrophic forgetting, communication overhead, and fairness under drift—and outline potential research pathways toward robust, adaptive, and privacy-preserving federated systems.
This paper is organized as follows: In Section 2, we outline the research methodology used throughout this study. Section 3 provides background and motivational insights into FL, focusing on its advantages and the challenges it faces, especially in dynamic data environments. In Section 4, we explore the phenomenon of concept drift in non-stationary environments and emphasize the importance of integrating drift awareness into FL. Section 5 delves into the advancement towards Federated Drift-Aware Learning (FDAL), where we define the problem of learning in a federated setting with drift awareness, present a taxonomy, and review the state of the art in FDAL, with particular attention to the temporal and spatial features of concept drift within FL. In Section 6, we address the research questions raised in this work, providing detailed insights into key areas of FDAL that require further exploration. Finally, Section 7 presents conclusion and future work. The key abbreviations and their full forms are provided in Table 1.

Table 1.
Abbreviations.
2. Research Methodology
This paper aims to provide a comprehensive systematic overview of studies that examine FL’s adaptability to dynamic data scenarios, particularly in the context of concept drift. Our literature search was conducted across established academic databases, guided by keywords such as “Federated Drift-Aware Learning,” “Federated Learning” in the presence of “Concept Drift,” “Federated Learning,” and “Concept Drift.” Relevant papers were selected and analyzed through this process, enabling us to trace the evolution of methodologies and techniques, and to establish a framework for FL under concept drift. To ensure a thorough and relevant review, the selection of research papers was conducted in four phases, following the PRISMA [26]. Our systematic approach involved an extensive search across multiple databases, including Google Scholar, Science Direct, ACM Digital Library, IEEE Xplore, SpringerLink, and SCOPUS, chosen for their comprehensive coverage of scientific and technological fields. This search strategy aimed to provide valuable insights from a wide range of sources. Figure 2 presents the PRISMA flowchart, outlining the four phases used to rigorously screen the collected papers.
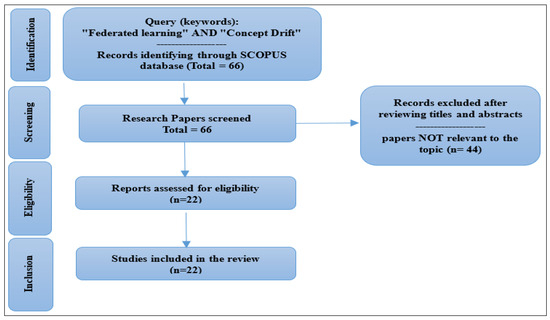
Figure 2.
PRISMA Flow Chart.
- The first phase, Identification, involves accessing various repositories to search for studies in the identified research area. A total of 66 records were identified through the SCOPUS database.
- In the second phase, Screening, a transparent process is applied to select papers by evaluating recommendations from each stage of the systematic review. Records were excluded after reviewing titles and abstracts, with 44 papers found to be irrelevant to the topic.
- Next, Eligibility is determined by evaluating the full-length articles.
- In the Inclusion phase, the selected articles for the review are finalized, with a total of 22 articles included.
In systematic literature reviews, inclusion and exclusion criteria play a crucial role by providing clear guidelines for selecting research based on specified parameters. These criteria ensure that the studies included align with the aims and scope of the review, thereby enhancing the rigor and relevance of the findings. This study applied the following criteria:
- The article is written in English and published in either an academic journal or as a conference paper.
- The selected research must strongly relate to both federated learning and concept drift.
- The article should contribute to the application of federated learning in environments with dynamic data, ensuring adaptation to concept drift.
This approach enables a thorough and focused review of relevant literature. The present work is situated within the relatively unexplored context of continual and federated learning for multi-device applications. Although existing studies have examined the adoption of FL in Continual Learning, no comprehensive reviews have focused on FL in environments with dynamic data and the need for adaptation to concept drift. This review covers techniques, identifies existing gaps, and suggests future research directions.
Investigations
To explore key insights into the adaptability of FL in evolving data scenarios, we have formulated a set of fundamental research questions, each aimed at uncovering distinct aspects of the field. These investigations will deepen our understanding and contribute meaningfully to ongoing research on enhancing federated learning models’ adaptability and performance in managing concept drift. The following research questions will be investigated in our study:
- (1)
- How can concept drift be formally defined within FL environments, and what unique challenges arise in detecting and managing it across decentralized data sources?
- (2)
- How can FL models be effectively adapted to handle diverse types of concept drift (e.g., sudden, gradual, incremental) in dynamic multi-device environments without compromising model accuracy or client privacy?
- (3)
- What role do local versus global concept drifts play in influencing the performance and fairness of federated models across diverse client environments, and how can these be managed to prevent model degradation?
- (4)
- How can FDAL frameworks minimize computational and communication overhead while maintaining model adaptability in non-stationary environments?
- (5)
- How can FL models utilize both temporal and spatial dimensions in client data to enhance the accuracy and timeliness of drift detection?
- (6)
- What challenges can we infer that researchers face in constructing FL models in the presence of concept drift?
3. Federated Learning: Background and Motivational Insights
In 1959, Arthur Samuel from IBM introduced the term ‘machine learning’ when he demonstrated that computers could be programmed to learn to play checkers [27]. In 1957, Frank Rosenblatt implemented the first neural network, known as the perceptron [28], based on concepts proposed by Warren McCulloch and Walter Pitts [29]. The field of machine learning continued to grow throughout the following decades, laying the foundation for many modern advancements. ML, now a core subset of Artificial Intelligence (AI), focuses on creating systems that can learn from data and improve their performance on tasks without needing explicit programming for each task. Through a process called “training” these systems adjust themselves based on data collected from their surroundings, producing models that make predictions or decisions in both familiar and unseen situations. Formally:
Definition 1.
Let the tuple (xi, yi) be a data sample, where xi∈ X is an input vector, also known as features, and yi∈ Y is the desired outcome, possibly unknown. Let
be a training dataset, where M is the number of samples. An ML model is a mapping function defined over X that establishes an output for every possible input.
Recent advancements in electronics and communication technology, such as the move from 4G to 5G and soon 6G, have spurred an increase in the use of smart devices, including smartphones, tablets, smartwatches, and home assistants. These devices generate vast amounts of data, creating opportunities to build ML models that are more powerful, accurate, and personalized to individual needs. This phenomenon has given rise to what is called “Multi-Device Learning”.
However, most traditional ML approaches assume that data is stationary and centralized, meaning that data does not change over time and is collected in one location for processing. This centralized assumption becomes problematic in multi-device environments, where data is continuously generated on individual devices and is often privacy-sensitive. A more decentralized approach is required to handle these challenges.
Centralized ML faces key limitations in multi-device environments, especially due to the burden of data transfer, the need for strict privacy measures, and limited adaptability to evolving data. These limitations led to the development of Distributed Machine Learning (DML) [30,31], which spreads the training process across multiple machines or devices. In DML (Figure 3), each device performs local training on its data, contributing to a final model that aggregates the learning from all devices without centralizing data storage. DML can be set up in two main ways:
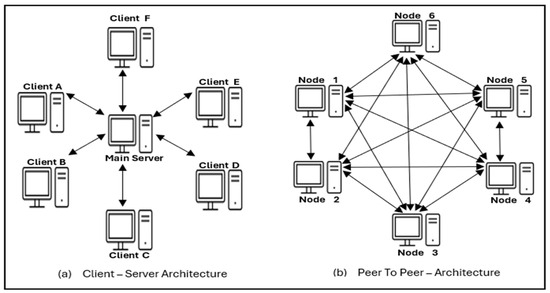
Figure 3.
DML Communication.
- Peer-to-Peer (P2P) Architecture: In P2P setups, each device (or “node”) operates independently, communicating directly with other nearby nodes, allowing for a decentralized structure without a central server.
- Client-Server Architecture: Here, a central server coordinates the learning among devices, but rather than centralizing data, it facilitates the aggregation of insights from each device’s learning.
DML began taking shape in the 1990s as researchers saw that dividing the training process across devices allowed for handling of larger datasets efficiently, making it more practical than relying on a single, powerful server [30]. Two primary DML methods emerged:
- Parallel Optimization: In this method, the training of a single model is divided among several devices, each handling a portion of the data. This approach accelerates training by allowing each device to work on a subset of the task.
- Distributed Ensemble Methods: In contrast to parallel optimization, each device in an ensemble method trains its own independent model. These models are then combined or aggregated to improve decision-making, a technique known as ensemble learning, which leverages the strengths of multiple models to enhance overall accuracy.
FL builds upon DML concepts [31,32,33] but is specifically designed to protect data privacy while accommodating the scale of devices in a decentralized structure. FL enables devices to collaboratively train a model without transferring raw data; instead, only model updates or parameter adjustments are exchanged, preserving each device’s data privacy.
In FL (Figure 4), the typical process involves two main steps: local updates and global aggregation. Local updates occur on each device, where it trains the model using its own data, such as a smartphone learning from a user’s interactions. After local training, the device sends updates to a central server that performs global aggregation—combining these updates to refine the model without collecting actual user data. Only necessary information for model improvement is exchanged, keeping individual data private while enabling collaborative learning.
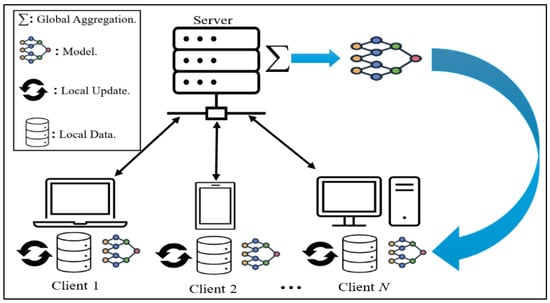
Figure 4.
Typical Federated Learning Setup.
Introduced by Google researchers around 2015 [34], FL focuses on scenarios where numerous devices, often millions, hold unique, nonuniform data and have limited network connectivity. This approach enables collaborative model improvement across distributed data sources while ensuring data privacy and security. FL differs from earlier DML methods in significant ways:
- Statistical Heterogeneity: In FL, each device’s data reflects unique interactions with users and its environment, leading to significant variability in data across devices. This variability means that data from one device may not represent the broader population, posing challenges for model performance and consistency.
- Massive Distribution and Limited Communication: FL must operate efficiently across a network with a much larger number of data samples per client than average, with many devices having sporadic network connectivity. This setup necessitates models that can be updated with minimal communication, accommodating devices with limited data exchange capabilities.
Also, FL is distinct from traditional DML approaches due to the specific challenges it addresses:
- Unbalanced and Non-stationary Data: User interaction with devices varies widely, so the volume and type of data collected on each device are often unbalanced. Some users interact with a service frequently, generating a lot of data, while others use it less, leading to varying data contributions. Additionally, the data is non-stationary, it changes over time as users’ behavior and the environment evolve, which requires models to adapt to ongoing shifts.
- Limited Communication Resources: Devices participating in FL often operate under constraints, such as sporadic internet connectivity, limited battery power, and bandwidth. To be effective, FL systems must perform well even when communication with the central server is restricted, making efficient model updates essential.
FL provides a decentralized approach that not only protects data privacy but also enables ML systems to operate with diverse and evolving data sources. However, FL faces distinct challenges, particularly due to statistical heterogeneity [35,36,37,38]. Differences in data among devices can hinder model convergence, accuracy, and consistency across the network. As data patterns shift with changes in user behavior and environmental factors, FL systems must support continuous learning and adaptation to stay effective. Although FL research has expanded, there is a growing focus on developing strategies that enable continuous learning within federated environments. The need for FL systems to handle non-stationary data across large networks of devices remains underexplored, making it a vital area for future research. Meeting the challenge of creating adaptive, privacy-preserving federated models that work in dynamic, decentralized settings requires innovative approaches beyond traditional machine learning assumptions.
In contrast, centralized ML research on Continual Learning (CL) and concept drift has largely focused on single learners, limiting its applicability to multi-device FL scenarios [39,40,41]. Traditional ML methods often assume that data is stationary and independently and identically distributed (IID). While this assumption may hold in centralized environments, it does not align with federated settings, where data is inherently heterogeneous and constantly changing. Given the novelty of FL, particularly in relation to CL and concept drift, there is an urgent need for research that addresses the unique challenges of learning from non-stationary data in multi-device, federated contexts.
4. Concept Drift Phenomenon: Background and Motivational Insights
Constant change is a critical issue in dynamic fields like aviation, self-driving cars, nuclear reactors, healthcare, military, smart cities, and aerospace. In these areas, evolving environments mean that if systems do not adapt properly, it could lead to significant risks, even endangering lives [25,42]. Therefore, it is essential that systems in these domains can adjust to ongoing changes to remain safe and effective. In predictive modeling, historical data is used to create a model that makes predictions about new data. This process can be thought of as a function (f) that takes an input (x) and predicts an outcome (y), represented as . However, in non-stationary environments where relationships between input (x) and output (y) change over time, predictive models face unique challenges. Models built on past data may become less accurate as the environment shifts. Adapting to these changes requires advanced learning methods, such as CL. In CL, models update as they encounter new data distributions and tasks while retaining previous knowledge. This approach mirrors human learning, where new skills are developed without forgetting past knowledge. CL is particularly valuable in settings where data arrives continuously, known as data streams
Learning from data streams poses specific challenges [43,44,45]. First, there are constraints related to memory and processing, as models must handle incoming data quickly without storing everything indefinitely. More critically, the data itself is variable patterns or “concepts” in the data shift over time. This changing nature of data is known as Concept Drift [39], a term introduced in early academic studies [46]. Concept drift occurs when the statistical characteristics of the target variable (the outcome the model predicts) change, making previous patterns unreliable and reducing model accuracy [47]. Concept drift has real-world implications. For example, during the COVID-19 pandemic, behavioral changes led to shifts in various metrics. In Melbourne City, patterns in shopping habits, electricity consumption, and motor vehicle accidents have altered significantly. Predicting motor vehicle collisions based on pre-pandemic data would have been difficult during the lockdown, as accident rates dropped due to reduced traffic. Similarly, electricity usage patterns shifted as restrictions eased and people returned to workplaces. Models trained on pre-pandemic data would struggle to remain accurate because the underlying patterns had changed. Therefore, concept drift is a shift in data patterns over time, impacting the effectiveness of predictive models. Addressing this phenomenon is crucial, especially in fields that rely on accurate, up-to-date predictions [48]. CL offers a promising solution by enabling models to evolve with changing data, helping maintain relevance and accuracy in non-stationary environments. Formally, we can define concept drift as follows:
Taking this into account, modifications in incoming data can be identified as alterations in the constituents of Bayesian decision theory [39,48,49]:
Definition 2.
For a specified data stream S, if there is a change in concept between the time points t and t + Δ, it happens if and only if there is some x such that pt(x, y) is not equal to pt+Δ(x, y). Here pt denotes the joint distribution at time t linking the collection of input attributes to the class label, where the symbol Δ represents the time difference between t and t + Δ, indicating the interval length for detecting concept drift.
- Prior probabilities p(y) are susceptible to alterations.
- Probabilities p(x|y) of class conditional are likewise susceptible to alterations.
- As a result, posterior probabilities p(y|x) might either change or remain the same.
In machine learning, we can break down the joint probability of inputs (x) and outputs (y) into two parts: P(x, y) = P(x) · P(y|x). Considering this, concept drift is typically divided into two types, based on which part of this equation changes [39,49], as depicted in Figure 5.
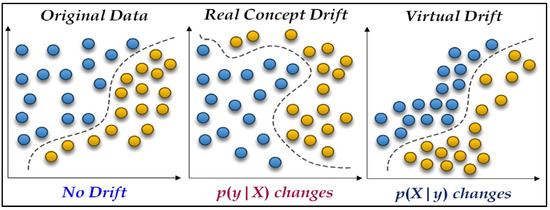
Figure 5.
Illustrates two concept drift scenarios in a binary classification problem within a two-dimensional input space.
Virtual Concept Drift: This happens when there is a change in the input data’s probability (how often different types of input data occur), but the way inputs relate to outputs stays the same. Formally, it means .
Real Concept Drift: This type occurs when the relationship between the inputs and the outputs changes. Even if the input data’s probability stays the same, the way these inputs predict the outputs is different. In formal terms,
When real concept drift occurs, it means the model’s decision-making process (its decision boundary) is outdated because the relationship between the input data and the predicted outcome has shifted. To address this, the model needs to be adjusted to accommodate the new data. This involves updating the model, particularly the part responsible for classifying or categorizing the data, to maintain accuracy despite changing data patterns. Concept drift can also be categorized based on how the joint distribution of new data differs from previous data. These categories help us understand the nature of data changes, including their speed and extent, which is essential for updating and maintaining model accuracy. The three common types of concept drift are Sudden Drift, Recurring Drift, and Gradual Drift [25,39,50,51], as depicted in Figure 6.
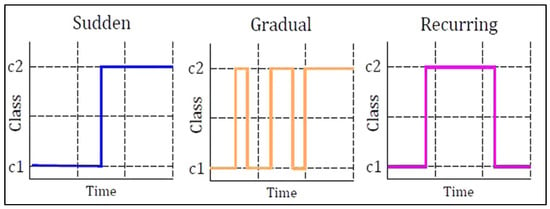
Figure 6.
Concept Drift Types.
- Sudden Drift: This is when there is a clear moment in time where the old way of understanding the data changes to a new way. It is like flipping a switch from one concept to another.
- Recurring Drift: Here, the concept drift happens more than once and might even return to the original concept. It is like a pattern that repeats or comes back after some time.
- Gradual Drift: In this type, the new concept slowly starts to mix in with the old one. It is not a sudden change, but a blend where the old and new concepts exist together for a while.
Other types of drifts include incremental drift, where data values gradually evolve over time. Blip drift refers to a rare occurrence that, within a static distribution, may be classified as an outlier. Noise drift involves random fluctuations in data instances (noise) that need to be filtered out.
Data streams that have concept drift are generally handled using either Trigger/Active approaches [52,53,54,55,56] or Evolving/Passive approaches [57,58,59,60,61].
- Trigger/Active Approaches: These methods update the model only when a drift is detected. They monitor the algorithm’s error rate, as a stable data environment typically results in a decreasing error rate. However, if the data changes (drifts), the error rate rises. These approaches use two thresholds: a warning level and a drift level. When the error rate reaches the warning level, it suggests a potential drift. If the error rate continues to rise and reaches the drift level, it confirms that a drift has indeed occurred.
- Evolving/Passive Approaches: Unlike trigger/active approaches, these methods continuously update the model with each new data point, regardless of whether a drift is detected. They do not specifically monitor for changes or drifts in the data. Instead, they aim to maintain a model that consistently reflects the most recent data.
Both approaches aim to keep the model up to date with the latest trends or patterns in incoming data, but they differ in how they determine when to update the model. Trigger/active approaches wait for signs of change before updating, whereas evolving/passive approaches continuously adjust the model, regardless of whether a change in the data is detected [62].
Concept drift is crucial in non-stationary environments, as it reflects changes in data patterns over time, which can significantly impact model accuracy. Continuous learning plays an essential role in addressing concept drift, enabling models to adapt in real-time to evolving data trends. The next section will focus on Advancing Towards Federated Learning with Concept Drift Awareness: Federated Drift-Aware Learning.
5. Advancing Towards Federated Drift-Aware Learning (FDAL)
In the previous sections, we have covered the fundamentals of FL, explaining why it has become a popular method for multi-device learning. We highlighted its benefits, particularly in terms of digital privacy and scalability. We also introduced the phenomenon of concept drift, providing background and motivational insights into its significance in non-stationary data streams. This section will move forward by focusing on learning in a federated setting while being aware of concept drift.
5.1. Learning in a Federated Setting with Drift Awareness: Problem Formulations
Previously, we presented formal definitions of the concept drift problem and FL separately. However, in FL settings, where the environment is non-stationary and involves multiple devices, the situation becomes more complex. Each device has its own stream of data. When training a global model in a federated way, it is important to consider that each of these local data streams (from each device) might change in its own unique way over time [9,11]. This adds an extra layer of complexity to the problem.
The objective in FL is to collaboratively train a global model using data distributed across multiple devices, without sharing the data centrally [11]. The global model aggregation process in Federated Learning can be formally defined as shown in Equation (1).
where
- ω: Global model parameters.
- m: Number of devices.
- : Proportion of total data from the device.
- : Loss function for the device’s data.
The central server updates the global model by aggregating parameter updates from all devices. In a typical FL setup, training progresses through multiple rounds, each involving local updates on client devices and a global aggregation on a central server. Initially, the model parameters are set on the server. At the beginning of each round r, a random subset of clients , is selected. The server sends the current global model parameters to each client in this subset. Each client then applies Stochastic Gradient Descent (SGD) on its local data to update its model parameters, resulting in an updated parameter set . After completing local updates, clients send their updated parameters back to the server. The server then aggregates these parameters, typically by averaging, into a new global set . The original method for this aggregation, Federated Averaging (FedAvg), proposed by Google [63,64], uses a weighted average to merge parameters from each client. This concept can be formally expressed as shown in Equation (2), which represents the occurrence of concept drift when the joint distribution of input and output variables changes over time:
where denotes the joint probability distribution at time t, and represents the updated distribution after drift occurs. The goal is to adapt the model to maintain accuracy as the data distribution evolves.
Now, let us define and develop the concept of FDAL by extending the idea of concept drift to an FL environment, which includes multiple clients and a central server. The objective is to collaboratively train a global model using data from the C available clients, each working independently and concurrently. Each client’s data will be uniquely influenced by its local environment, leading to potential changes over time. These changes, known as concept drifts, may affect all, some, or only one of the clients. Accordingly, we can formally define the challenge of Federated Drift-Aware Learning in two forms as follows:
Definition 3
(Local Concept Drift in FL). Consider a time period [0, t]. We have a set of clients, labelled as C = {c1, c2 ..., cc}, and each client cj in C has a dataset of size
. This dataset is made up of pairs () where
represents the features of the data and
is the outcome or label associated with those features. Each dataset
follows a specific probability distribution
, which is estimated by the joint probability density function
We say a local concept drift has occurred at time
for client j if there is a significant change in the probability distribution from
to
. In formal terms, this can be expressed as:
There exists a time t and client j such that the probability distribution at time t,
is not equal to the distribution at time t + 1,, denoted by:
It is important to point out, however, that each and every local concept drift, meaning the change in the data pattern of one single client, does not necessarily affect the global model; hence, it gets trained across all clients. In other words, there could be a distribution shift in the data of a certain client, but it does not change the overall pattern across the board among the totality of the clients. The global model, therefore, is unaffected and such a singular variation can safely be ignored. The condition here resembles what is called virtual concept drift in data streams. Hence, Global Concept Drift in Federated Learning can be defined as a distribution change at time t as follows:
In simpler terms, a Global Drift can be viewed as a correlated or system-wide change in data distributions occurring across multiple clients, whereas Local Drift refers to isolated distributional changes within individual clients.
It is also worth pointing out that a global concept drift can only occur when there is at least one local concept drift present across participating clients. In this regard, a global drift embodies some consequence for the performance of the federated model. On the other hand, a local drift does not necessarily have such a model performance consequence on the overall.
Definition 4
(Global Concept Drift in FL). Consider a set period of time [0, t] and a set of clients C = {c1,c2 ..., cc}. Each client cj in C holds a local dataset consisting of pairs
, with
being the feature vector and
its corresponding output, and the dataset is of size
. This local dataset follows a specific probability distribution
. Let the sum of all data points across clients at time t be
, making
the global data distribution, which comes with an associated probability density function
. We say that a global concept drift occurs at timestamp t + 1 if:
There exists a time t such that the global data distribution at time t,
is significantly different from the distribution at time t + 1,
which we denote as:
Accordingly, a global drift is considered actionable only when it substantially degrades the performance of the global model, thereby necessitating model updates; minor or transient local drifts that do not affect overall performance are disregarded.
5.2. Federated Drift-Aware Learning (FDAL): Taxonomy and State of the Art Approaches
In this section, we provide a comprehensive assessment and taxonomy of the state-of-the-art approaches in FDAL. Research on Continual Learning (CL) and concept drift has received considerable attention recently. However, most of this research has been conducted in a centralized setting. There is limited work that combines Concept Drift and Federated Learning, especially within multi-device contexts. A primary challenge in these multi-device settings is the statistical heterogeneity of the data. Traditional Machine Learning methods often assume that data is stationary, meaning they treat each data sample as an independent occurrence, all drawn from a single probability distribution. This assumption works well in centralized settings where all training data is in one place. However, research into continual adaptation strategies for federated settings remains limited, partly due to the relatively recent emergence of the FL paradigm. As a result, there is a growing need for studies that address the unique challenges posed by non-stationary data in federated environments.
To address these challenges, a taxonomy has been developed to categorize and describe concept drift in FL, covering both temporal and spatial dimensions. As shown in Figure 7, this taxonomy is crucial for understanding and developing effective FL strategies in non-stationary environments.
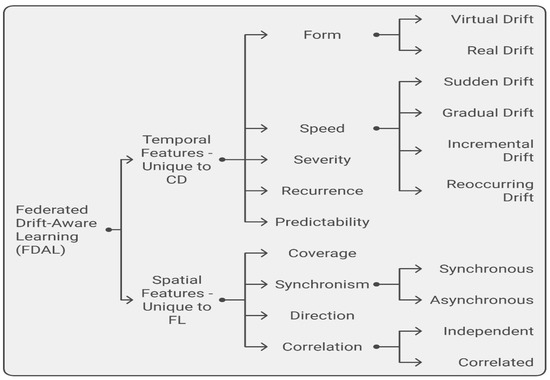
Figure 7.
Taxonomy of Federated Drift-Aware Learning Features.
Both features temporal and spatial are crucial for understanding and addressing concept drift in the context of Federated Learning [65,66]. They guide the development of advanced FL models that can adapt to the dynamically changing data environments across distributed clients.
- Temporal Features—Unique to CD
The temporal dimension of the taxonomy deals with changes in data over time within a single data stream. This includes:
- ○
- Form: This refers to the nature of changes in the data concept. For example, in a health monitoring FL system, a gradual drift might be observed as a slow evolution of patient health metrics over months, whereas a sudden drift could be seen with the rapid onset of an illness. This distinction emphasizes the importance of handling different forms of drift, including Virtual Drift and Real Drift.
- ○
- Speed: The rate at which the concept changes is vital. In financial market predictions using FL, a rapid drift might occur during market crashes, requiring immediate model adjustments, whereas slower drifts could be associated with gradual economic trends. These changes can manifest as Sudden Drift, Gradual Drift, Incremental Drift, and Reoccurring Drift, each posing unique challenges to the learning process.
- ○
- Severity: It measures the extent of the change. In a recommendation system, a minor change in user preferences might only need minor model updates, whereas a major shift, like a new technology trend, would necessitate significant alterations.
- ○
- Recurrence: This deals with how often previous concepts reappear. For instance, in retail, purchasing patterns might recur annually, demonstrating a cyclic nature in the data stream.
- ○
- Predictability: This concerns the ability to anticipate future concept changes. In a traffic management system using FL, predictable drifts might occur due to recurring events like holidays, while unpredictable drifts could arise from unexpected road closures.
- Spatial Features—Unique to FL
The spatial dimension of the taxonomy is unique to FL and addresses how concept drift occurs across the network of multiple clients. It includes:
- ○
- Coverage: This describes the extent of drift across clients. For example, in an FL application for social media analysis, a new trending topic might affect only certain demographics (partial coverage) or become universally popular (full coverage).
- ○
- Synchronism: Indicates the timing of drifts across clients. In environmental monitoring, certain changes like seasonal shifts might occur synchronously across all sensors, while others, like local pollution events, happen asynchronously. This highlights the need to consider both Synchronous and Asynchronous drifts.
- ○
- Direction: This refers to the alignment of concept drifts among clients. For instance, in a network of autonomous vehicles, some might experience similar drifts in sensor readings due to weather conditions (aligned drift), while others in different regions might not (divergent drift).
- ○
- Correlation: This examines interdependencies among drifts in various clients. In a distributed energy grid, fluctuations in one part of the grid might be correlated with changes in another, indicating a dependent network of drifts. It is crucial to distinguish between Independent and Correlated drifts in such scenarios.
In centralized learning, all data are jointly optimized, allowing correlations among samples to be naturally captured within a single loss function. In contrast, spatial correlations in Federated Learning occur across distributed clients, each maintaining its own local dataset. Aggregation methods such as [64] implicitly assume that local model updates are independent and resemble unbiased estimates of the global gradient. When data across clients are correlated—such as similar behavioral patterns or overlapping feature spaces—this assumption no longer holds. The resulting correlated updates introduce systematic bias into the global averaging process, leading to slower convergence or oscillations in the aggregated model. This violation of the independence assumption makes spatial correlations a fundamental challenge unique to FL, one that does not arise in centralized training where all correlations are globally optimized together.
Federated Drift-Aware Learning: State of the Art Approach
In this section, a thorough evaluation of current methods for Federated Drift-Aware Learning is presented.
In this work [67], authors address the challenges of federated and continual learning under concept-drift conditions, particularly when data is non-IID and nonstationary. In this context, they present an extension to the FedAvg algorithm that adapts to concept drift by employing a distribution-based detection algorithm along with rehearsal methods to prevent catastrophic forgetting of previously learned information. This approach enhances the learning capabilities of models in distributed settings, such as smartphones, by efficiently managing limitations in storage, communication, and computational resources. Experimental results indicate that the proposed method outperforms standard FedAvg in tasks like human activity recognition, demonstrating its effectiveness in real-world applications where data distribution evolves over time.
In [68], the work proposes a novel Federated Learning algorithm, Adaptive-FedAVG, designed to tackle nonstationary data-generating processes caused by concept drift. Through extensive experiments on image classification benchmarks like MNIST and CIFAR-10, the algorithm demonstrates excellent performance in nonstationary conditions and remains competitive with traditional methods in stationary settings. The key innovation is its adaptive learning rate, which effectively balances stability and plasticity to handle concept drift. While the results are promising, the paper notes that a theoretical analysis of the algorithm’s convergence properties is still needed, identifying this as a direction for future research. This contribution is important, addressing a critical gap in Federated Learning’s ability to manage concept drift.
In [69], the work proposes FedDrift and FedDrift-Eager, the first algorithms to address federated learning in the presence of distributed concept drift, where drifts occur in a staggered manner across time and clients. These methods use clustering techniques to adapt to such drifts, achieving significantly higher accuracy than current baselines and even approaching the performance of an idealized oracle algorithm. The empirical results demonstrate these algorithms’ effectiveness across various datasets and drift scenarios, highlighting their potential to enhance federated learning systems. The study also emphasizes the need for further research in this emerging area, particularly regarding the privacy implications of clustering clients. This work establishes a foundation for future exploration and development in federated learning under distributed concept drift.
Flash: Concept Drift Adaptation in Federated Learning [70], this work introduces FLASH, a new adaptive optimizer for federated learning that addresses both statistical heterogeneity and concept drift. FLASH relies on client-side early-stopping training to detect and identify concept drifts, while the server side uses drift-aware adaptive optimization to adjust learning rates effectively in real time. The authors provide theoretical convergence rates for FLASH and empirically demonstrate its ability to improve both generalized and personalized accuracy while minimizing accuracy drops during concept drift. This approach notably reduces the number of federated rounds needed to recover from concept drift, highlighting its potential to enhance the robustness and efficiency of federated learning systems.
In [65], the study examines the impact of concept drift in federated learning (FL) across both temporal and spatial dimensions, analyzing features such as form, speed, severity, coverage, and synchronism. The findings indicate that these features negatively affect both global and local model accuracy; the global model often shows bias toward majority data concepts, leading to poor performance on minority concepts. These results underscore the critical need to address concept drift in FL, suggesting that each drift type requires specific handling. Future research will explore additional features not covered here and develop metrics to measure their impact on real-world datasets, with considerations for vertical FL. In [66], the paper proposes Concept-Drift-Aware Federated Averaging (CDA-FedAvg), an innovative approach designed to improve federated learning by addressing concept drift in multi-device environments. CDA-FedAvg demonstrates notable performance improvements over traditional FedAvg, especially in non-IID data settings common to IoT applications like smartphone-based human activity recognition. Although promising, the study acknowledges limitations in simulating real-world conditions, indicating a need for further research into actual concept drift and client heterogeneity. Future work aims to enhance the framework’s adaptability across temporal and spatial dimensions, extending its applicability beyond smartphones to create more robust federated learning systems.
The work in [71] proposes a new method for detecting concept drift in federated networked systems, with a specific application to Intelligent Transportation Systems (ITS). Utilizing federated learning updates, the approach combines PCA for dimensionality reduction with K-means clustering to identify drifted nodes. Experimental results show that this framework effectively detects drifted nodes across various non-iid scenarios, making it applicable to any federated networked system. While the study successfully identifies drifted nodes, it notes the need for further exploration in areas such as scalability, thresholding schemes, and deeper network architectures. Future research will expand this framework to different machine learning tasks and assess its performance in larger network environments.
FedConD proposed in [72], an innovative framework for managing concept drift in asynchronous federated learning environments, particularly with sensor data. FedConD adapts to sudden and gradual drifts by using a drift detection mechanism and adjusting regularization parameters for effective drift adaptation. Additionally, it employs a communication strategy that optimizes local updates, reducing communication costs and improving model convergence. Experimental results show that FedConD maintains balanced and fair model performance across devices, even under varying drift conditions. This study represents a significant advancement in federated learning, addressing the challenges of heterogeneous device data and dynamic data distributions to enable more robust and adaptive learning systems in IoT applications.
FACFed is a pioneering approach [73] in federated stream learning, excelling in both reducing discrimination in client data and improving predictive performance. This framework achieves low discrimination scores and high balanced accuracy across various datasets, even in non-IID conditions with significant class imbalances. By applying fairness measures such as statistical parity and equal opportunity, FACFed ensures fairness for each client and shows promise for centralized fairness-aware learning applications. Experimental results demonstrate its superiority over existing methods in both discrimination mitigation and predictive accuracy. This work opens avenues for further advancements in optimizing federated learning frameworks to address concept drift and fairness in diverse real-time applications.
FedStream [74] introduces a new federated learning framework tailored to handle concept-drifting data streams in a distributed, privacy-preserving way. It effectively integrates each client’s local model with a global model, achieving substantial performance improvements, with an average gain of over 18% compared to existing methods. The framework is particularly efficient in low-bandwidth environments, requiring far less communication data than traditional approaches. However, FedStream currently applies only to fully supervised data streams. Future work aims to expand its capabilities to semi-supervised settings, addressing cases where client data streams have few or delayed labels, thus enhancing its applicability and effectiveness in real-world distributed learning scenarios.
A new study introduces a new multiscale algorithmic framework for federated learning that addresses concept drift challenges in non-stationary environments [75]. By combining FedAvg and FedOMD algorithms with techniques for detecting and adapting to non-stationarity, the framework enhances the generalization performance of federated learning on evolving data distributions. The researchers derive dynamic regret bounds for these algorithms, demonstrating their effectiveness in near-stationary settings with bounded drift, without needing prior knowledge of drift magnitude. The results show improved performance in terms of instantaneous FL loss and classification accuracy compared to existing methods. Future research could expand these techniques to other federated learning algorithms and explore broader applications to increase adaptability to complex concept drifts.
FLARE [76] addresses the challenge of concept drift in federated learning-based IoT deployments through a dual-scheduler mechanism that minimizes data communication while preserving model accuracy. By utilizing confidence scores and the Kolmogorov–Smirnov test, FLARE detects changes in data distribution with reduced latency compared to traditional fixed-interval methods. The framework achieves significant improvements, including a 5× reduction in data exchange and a 16× reduction in detection latency. However, further research is needed to adapt FLARE for gradual or incremental drifts and to develop adaptive thresholding schemes for broader applicability across different datasets and environments.
SFLEDS [77], an innovative semi-supervised federated learning framework designed to tackle challenges in evolving data streams, such as label scarcity, concept drift, and privacy concerns. SFLEDS enhances prediction performance while preserving client privacy by using prototype-based learning and inter-client consistency checks. Extensive experiments show its superiority over existing semi-supervised and supervised methods. However, the approach incurs high computational costs due to its privacy-preserving measures. Future research will focus on improving efficiency with advanced synchronization mechanisms for faster training convergence. Overall, SFLEDS marks a significant step forward in federated learning, providing a robust solution for dynamic environments like IoT, where data generation is continuous and privacy is crucial.
The work in [78] proposes a new architecture for ensemble and continual federated learning, designed to handle non-stationary data streams and address concept drift in classification tasks. The approach combines local training, semi-supervised labeling, drift detection, and global model aggregation, providing a flexible and adaptive solution. The ensemble-based global model demonstrates robust performance, often surpassing individual local models, opening up new research opportunities in federated learning. Future directions include exploring model combination strategies, distributed feature selection, and improving explainability through local learners. Additionally, personalization and privacy enhancements remain open areas for development, promising to expand the architecture’s applicability across diverse real-world scenarios.
HarmoFL [79] is proposed, a novel federated learning framework designed to manage local and global drifts in heterogeneous medical image datasets. By applying amplitude normalization and weight perturbation, HarmoFL effectively harmonizes non-iid features across clients, leading to better model convergence and improved performance. Extensive experiments demonstrate its superiority over existing methods, showing higher accuracy and enhanced segmentation results. Theoretical analysis further supports these empirical findings, indicating that the overall non-iid drift is bounded. This work advances federated learning in medical applications and inspires future research to explore harmonizing strategies for diverse non-iid challenges. Future directions include expanding HarmoFL to other domains and validating its effectiveness across a broader range of datasets.
The work in [80] addresses the use of concept drift detection in continuous federated learning (CFL) platforms, with a focus on dynamic client participation. It examines the adverse impact of concept drift on model performance, assessed by Mean Absolute Error (MAE), and compares error-based and data-based detection methods. Error-based detection identifies the optimal performance point, while data-based detection is more effective for early drift detection. The study is limited by reliance on a single dataset and a narrow set of detection approaches. Future research will expand evaluations across a broader range of models and data types to develop a comprehensive drift detection framework. This work emphasizes the importance of choosing suitable drift detection methods tailored to specific CFL tasks.
The work in [81] introduces FedNN, a novel federated learning approach that addresses concept drift challenges in heterogeneous client data through Weight Normalization (WN) and Adaptive Group Normalization (AGN). These techniques help stabilize and accelerate model convergence by maintaining consistent activations during global model updates. While the approach shows improved accuracy and faster convergence across seven datasets, it does not enhance model performance in concept drift scenarios, highlighting an area for further research. The study encourages continued exploration of federated learning methods to manage diverse data heterogeneity, aiming to inspire practical solutions for real-world non-IID FL problems and improve the practicality of future FL applications.
The work in [82] introduces an innovative unsupervised approach for detecting sudden data drift in federated learning environments. Using Federated Fuzzy c-means clustering and a federated version of the fuzzy Davies-Bouldin index, this method preserves data privacy while effectively identifying shifts in data distribution. The approach demonstrates strong performance, achieving high true positive rates with minimal false positives. However, it shows sensitivity to parameter selection and has low detection rates when only a few data points are affected by drift. Future research will address these limitations, explore real-world applications, and extend the method to detect concept drift in supervised systems. This work advances federated learning by providing a foundation for continued refinement of drift detection techniques.
Ref. [83] is an innovative federated learning approach designed to address concept drift in distributed environments. By maintaining a dynamic repository of tailored models, FedRepo effectively detects and mitigates concept drift during inference. Tested in the context of electricity consumption forecasting, the methodology shows improved performance when concept drift is identified. FedRepo’s privacy-by-design approach ensures models are continuously adapted to clusters of similar clients, responding seamlessly to data shifts. Future research will apply this methodology to other distributed scenarios, benchmarking its customization and adaptability against existing strategies. This work highlights federated learning’s potential to manage concept drift without compromising performance or privacy.
Ref. [84] introduces an on-device federated learning approach that enables edge devices to collaboratively update their models by sharing intermediate training results. By using the Online Sequential Extreme Learning Machine (OS-ELM) alongside an autoencoder, this method effectively addresses concept drift, particularly for anomaly detection in IoT environments. The approach achieves accuracy comparable to traditional methods while significantly reducing computation and communication costs. Despite the challenge of limited training data per device, the one-shot cooperative model update shows promise. Future research will focus on optimizing client selection strategies to further improve accuracy and efficiency.
Table 2 summarizes and highlights the state of the art in terms of research questions (RQ)/aims, approaches used, applications/domains, performance, types of concept drift, and the limitations of each work in the literature so far. Meanwhile, Table 3 describes dataset features/characteristics and the metrics used/performance.
Table 2.
Detailed Findings and Analysis of Federated Drift-Aware Learning (FDAL) Methods/Algorithms.
Table 3.
Datasets and Metric Used/Performance in each of our Literature Review.
- Summary of Key Limitations and Research Priorities
The studies reviewed in Table 2 consistently highlight several recurring limitations that define the current state of Federated Drift-Aware Learning (FDAL). The most frequently reported issue concerns computational overhead and scalability, as many methods incur high communication or processing costs and are difficult to deploy efficiently in large-scale or resource-constrained environments. A second major limitation is the lack of theoretical convergence analysis, with multiple studies noting that existing algorithms perform well empirically but lack formal validation or stability proofs under non-stationary data. Third, many papers emphasize limited adaptability and robustness to diverse drift types, since most approaches focus on specific forms of drift—such as sudden, gradual, or incremental while handling mixed or asynchronous drifts across clients remains unresolved. Finally, the literature repeatedly mentions experimental constraints, including simplified or unrealistic datasets and evaluation settings that do not fully reflect real-world data heterogeneity. Together, these limitations outline clear priorities for future research: improving computational efficiency, developing theoretically grounded algorithms, enhancing robustness across heterogeneous drift scenarios, and validating FDAL approaches under realistic experimental conditions.
6. Federated Drift-Aware Learning (FDAL): Addressing Research Questions
“How can concept drift be formally defined within Federated Learning environments, and what unique challenges arise in detecting and managing it across decentralized data sources?”
Concept drift has recently emerged as a fundamental challenge in Federated Learning (FL), where models must continuously adapt to evolving data distributions across decentralized client devices [75,78,85]. Due to the non-stationary nature of FL environments, concept drift can be categorized into local drift, which affects individual clients, and global drift, which impacts the entire FL network [79]. Local drift occurs when a single client’s data distribution changes independently, whereas global drift represents broader shifts that necessitate system-wide model updates [70]. Distinguishing between these types of drift is crucial to ensuring efficient adaptation without unnecessary computational overhead.
Detecting and managing concept drift in FL is uniquely complex due to the decentralized nature of data, where clients operate independently with privacy constraints limiting direct access to raw data [65]. This makes drift detection highly reliant on indirect indicators, such as model performance or local updates, which can delay responses and increase communication overhead. Additionally, different types of drift sudden, gradual, and incremental require distinct handling approaches to maintain model accuracy while preserving client privacy [72].
To address these challenges, FL systems leverage selective adaptation strategies that balance localized and global model updates. Techniques like FedDrift-Eager [69] prioritize clients experiencing major shifts, ensuring that only essential updates are propagated. Hybrid approaches further optimize drift management by combining continuous passive monitoring with selective active updates, reducing computational and communication overhead [72]. Additionally, spatiotemporal modelling can enhance drift detection by integrating time-based monitoring with spatial clustering, allowing models to adapt where both temporal and spatial signals indicate significant changes [65].
Without effective drift management mechanisms, FL models risk performance degradation, biased predictions, and increased computational demands. However, by implementing drift-aware learning frameworks, FL systems can maintain adaptability, fairness, and efficiency in decentralized, dynamic environments. Future research should focus on developing fairness-aware FL models that dynamically adjust update weightings based on drift severity, ensuring equitable learning outcomes across all clients.
“How can Federated Learning models be effectively adapted to handle diverse types of concept drift (e.g., sudden, gradual, incremental) in dynamic multi-device environments without compromising model accuracy or client privacy?”
Concept drift poses a significant challenge in Federated Learning (FL), where decentralized models must adapt to evolving data patterns while preserving client privacy [35]. Different types of drift, such as sudden, gradual, and incremental shifts, require distinct adaptation strategies to maintain model accuracy without excessive computational overhead [73]. Achieving this balance is essential in dynamic, multi-device environments where data distributions continuously evolve [75]. As discussed in Section 5 on Federated Drift-Aware Learning (FDAL), concept drift in FL can be categorized as local drift, which affects individual devices, and global drift, which impacts the overall model [78]. A sudden drift on a single client may not require global model adjustments, whereas incremental drift across multiple clients can accumulate into a significant distribution shift, demanding broader updates. Distinguishing between these drift types allows FL systems to apply selective adaptation strategies, ensuring that only necessary updates are performed.
To efficiently manage these drifts, FL models utilize specialized techniques. Adaptive-FedAvg [68] dynamically adjusts model parameters based on real-time drift detection, enabling responses to both sudden and incremental shifts without centralizing data. Meanwhile, FLASH [70] incorporates client-side early-stopping mechanisms to detect drift, ensuring that updates occur only when necessary, thereby reducing unnecessary communication and preserving privacy. These approaches demonstrate the growing capability of FL frameworks to manage various drift types while maintaining decentralized learning.
Failure to implement adaptive mechanisms can lead to inefficient updates, increased computational overhead, and loss of model generalization. However, by integrating drift-aware learning techniques, FL systems can maintain performance, optimize resource allocation, and uphold client privacy, ensuring robust adaptation in evolving environments.
“What role do local versus global concept drifts play in influencing the performance and fairness of federated models across diverse client environments, and how can these be managed to prevent model degradation?”
Concept drift is a critical challenge in Federated Learning (FL), affecting both model performance and fairness across diverse client environments [74]. The distinction between local and global concept drift is essential, as their impact on the model varies significantly [73,79]. Local drift occurs at the client level and does not always necessitate global model updates, as it primarily affects specific clients. In contrast, global drift alters the overall data distribution across multiple clients, posing a higher risk of model degradation if not promptly addressed [79].
To mitigate these challenges, FL frameworks implement specialized techniques to manage drift effectively. FedDrift-Eager [69], for instance, employs staggered updates that prioritize clients experiencing major shifts, ensuring that the model remains relevant while minimizing disruptions for unaffected devices. Additionally, incorporating fairness-aware mechanisms can help balance majority and minority concept representations in updates, reducing bias and promoting equitable model performance across all clients.
Managing concept drift requires a strategic balance between localized adaptations and broader system-wide updates. If left unaddressed, local drift can lead to inconsistencies in individual client predictions, while unmitigated global drift can cause significant declines in model accuracy. Future research should explore Federated Drift-Aware Learning (FDAL) frameworks that dynamically adjust update weightings based on drift severity, ensuring that FL models maintain both adaptability and fairness across evolving data distributions.
“How can Federated Drift-Aware Learning (FDAL) frameworks minimize computational and communication overhead while maintaining model adaptability in non-stationary environments?”
Federated Learning (FL) operates in dynamic, resource-constrained environments where minimizing computational and communication overhead is crucial for efficient model deployment [73]. In non-stationary settings, models must adapt to evolving data distributions without overwhelming client devices, particularly in environments like IoT networks where bandwidth and battery life are limited.
To address this challenge, FedConD [72] and similar approaches selectively transmit model updates based on the significance of detected drift, reducing unnecessary communication while preserving model accuracy. By prioritizing updates only when substantial changes occur, these techniques help mitigate computational burden. However, while such methods enhance efficiency, they risk overlooking subtle, cumulative drifts that can degrade long-term model performance.
A potential solution lies in hybrid adaptation strategies that combine continuous passive monitoring with selective active updates. This approach enables FDAL frameworks to dynamically adjust update frequencies based on drift severity, striking an optimal balance between adaptability and efficiency. By leveraging intelligent update mechanisms, FL systems can ensure sustained model performance while minimizing the resource demands imposed on client devices.
Failure to incorporate adaptive drift management mechanisms may lead to excessive communication overhead or delayed model responses to evolving data patterns. However, by refining drift-aware update techniques, FL models can maintain responsiveness, computational efficiency, and long-term stability in decentralized, non-stationary environments.
“How can federated learning models utilize both temporal and spatial dimensions in client data to enhance the accuracy and timeliness of drift detection?”
Detecting concept drift in Federated Learning (FL) requires leveraging both temporal and spatial dimensions to improve accuracy and responsiveness. Temporal drift captures how data evolves over time, while spatial drift identifies localized changes across different client environments [83]. Integrating these two dimensions enables a more adaptive drift detection mechanism that prioritizes updates where significant changes occur. By combining time-based monitoring with spatial clustering, FL models can distinguish between local and widespread drift. For instance, if multiple geographically clustered clients experience concurrent drift, a global model adaptation may be necessary. In contrast, isolated drifts with limited temporal impact can be addressed at the local level, preventing unnecessary global updates. This hybrid strategy ensures that FL models remain responsive to evolving data patterns while maintaining computational efficiency.
Balancing temporal and spatial signals is also critical for preventing catastrophic forgetting, where frequent updates risk overwriting previously learned patterns. A well-designed FL framework selectively adapts to meaningful changes while preserving stability in less affected areas. By dynamically adjusting updates based on drift severity, FL models can achieve higher accuracy, faster adaptation, and improved fairness across decentralized environments.
“What challenges can we infer that researchers face in constructing Federated Learning models in the presence of concept drift?”
A comprehensive analysis of 22 studies highlights a broad spectrum of challenges and future directions in federated and continual learning. This research underscores the complexities involved in deploying federated learning (FL) models in dynamic, heterogeneous, and evolving data environments. A key concern is the significant limitations that hinder FL models, particularly in contexts where data is non-IID (non-independent and identically distributed). These challenges, along with existing gaps, emphasize the need for innovative solutions to enhance the robustness, efficiency, and adaptability of FL frameworks. In this section, we present an in-depth discussion of these challenges and explore potential future directions for addressing them. The limitations have been categorized into several key areas, each encompassing specific topics that highlight core issues and research needs. These areas and their associated topics, which are discussed in detail below.
One of the most pressing issues is non-IID data handling and adaptation. Federated learning struggles to accommodate data that varies significantly across clients, limiting its ability to adapt to evolving data distributions over time. Existing adaptive optimization approaches often fail to respond effectively to concept drift, resulting in significant drops in accuracy. Methods such as FedAvg also face difficulties in generalizing within dynamic settings due to their inability to manage time-varying data shifts effectively [65,77].
Another major challenge is catastrophic forgetting and memory retention. Without continual learning strategies, models tend to forget previously learned tasks, particularly in environments with closely related classes [68]. This issue highlights the necessity for mechanisms that can maintain knowledge retention over time in federated environments, ensuring that past knowledge is not lost as new data is introduced [86].
Algorithms and framework limitations further hinder the deployment of FL models. Issues such as FIL-VER’s unexplored real-world applicability, Adaptive-FedAVG’s convergence challenges under non-stationary conditions, and the scalability limitations of frameworks like CDA-FedAvg restrict their broader adoption. Addressing these limitations is crucial for improving the stability and efficiency of FL frameworks [68,72,75].
Concept drift detection and adaptation present additional challenges. Approaches such as FedDrift struggle to recognize multiple new concepts simultaneously, while traditional methods like PCA and K-Means may not effectively handle complex drifts, particularly in large networks. Further difficulties arise in asynchronous environments and when using fixed thresholds for drift detection, which can lead to inaccurate adaptation and suboptimal model performance [70,73,74,77,78].
Another critical issue is model bias and data heterogeneity. Federated learning models often exhibit bias toward majority concepts, leading to decreased performance on minority-class data. This issue is particularly problematic in applications such as medical data classification, where ensuring balanced model performance is essential for reliable decision-making. The presence of heterogeneous data further complicates model convergence and consistency across decentralized nodes [66,71].
Optimization challenges in FL also pose significant hurdles. Accurately approximating previous local objective functions is difficult, often resulting in information loss. Additional challenges stem from class imbalances and unreliable drift correction techniques, both of which require more robust and adaptive optimization strategies [81,84]. A related issue is handling non-stationary and dynamic data. Federated learning models often struggle to process continuous data streams and adapt to dynamic changes, particularly when dealing with partially labeled datasets. These limitations highlight gaps in existing methodologies and the need for more flexible and adaptive learning frameworks [77,83].
Finally, class imbalance and drift correction further impact model performance. Variations in class representation and challenges in accurately correcting drift contribute to inconsistencies in model learning. Developing more reliable approaches to mitigate these issues is essential for ensuring stable and accurate model performance across diverse applications [84].
Recent research has highlighted how modern Transformer-based architectures can advance adaptive and explainable learning in distributed environments. For example, ref. [87] proposed an Encoder-only Attention-Guided Transformer Framework that combines multi-head self-attention with probabilistic hyperparameter tuning using the Tree-structured Parzen Estimator (TPE) to improve model stability, efficiency, and interpretability. Such techniques are directly relevant to FDAL, where edge clients often face imbalanced and noisy data distributions. Incorporating attention-guided optimization and explainability mechanisms could enhance FDAL algorithms’ ability to handle heterogeneous IoT data while maintaining transparency in global aggregation decisions.
Addressing these challenges is critical for advancing federated and continual learning, making them more robust, scalable, and adaptable to real-world applications. Ongoing research and innovation in these areas will be instrumental in overcoming existing limitations and driving the future development of FL models.
7. Conclusions and Future Work
This study presented a systematic review of Federated Learning under Concept Drift (FDAL), addressing the growing need for adaptive and privacy-preserving learning in dynamic environments. By analyzing the intersection of Federated Learning (FL), Continual Learning (CL), and Concept Drift (CD), the review clarified how data distribution shifts challenge both local and global model stability in distributed networks such as IoT ecosystems.
The paper provided a unified framework that differentiates between local and global drifts, illustrating how localized model updates may collectively induce global performance degradation. Through a taxonomy organized along temporal and spatial dimensions, we categorized existing FDAL methods based on their adaptability mechanisms, learning objectives, and communication strategies. This synthesis revealed that most current approaches emphasize short-term adaptation while long-term knowledge retention and fairness across clients remain under-explored.
The review further identified three critical research gaps: (i) the need for scalable drift detection compatible with limited-resource edge devices, (ii) the lack of theoretical convergence guarantees in distributed adaptive systems, and (iii) insufficient exploration of heterogeneous drift scenarios, where drifts occur asynchronously across clients. Addressing these issues will require hybrid solutions that combine Continual Learning strategies with efficient communication and personalized aggregation in FL frameworks.
Overall, this review offers a coherent theoretical perspective and an organized taxonomy that unify ongoing research on Federated Learning and Continual Learning under the emerging framework of Federated Drift-Aware Learning (FDAL). Future studies should focus on developing drift-resilient aggregation mechanisms, lightweight monitoring modules for resource-constrained clients, and evaluation benchmarks that better reflect realistic, evolving environments. By bridging the gap between drift detection and federated optimization, this integrative framework can advance toward adaptive, fair, and trustworthy federated intelligence capable of sustaining long-term performance in dynamic real-world applications.
Author Contributions
Conceptualization, O.A.M., E.P. and N.A.; methodology, O.A.M., E.P. and S.B.; software, O.A.M.; validation, E.P. and N.A.; formal analysis, O.A.M.; investigation, O.A.M., E.P., N.A. and S.B.; data curation, O.A.M.; writing—original draft preparation, O.A.M.; writing—review and editing, E.P., S.B. and N.A.; visualization, O.A.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, S.; Xu, L.D.; Zhao, S. 5G Internet of Things: A survey. J. Ind. Inf. Integr. 2018, 10, 1–9. [Google Scholar] [CrossRef]
- Chettri, L.; Bera, R. A Comprehensive Survey on Internet of Things (IoT) Toward 5G Wireless Systems. IEEE Internet Things J. 2020, 7, 16–32. [Google Scholar] [CrossRef]
- Ahmed, S.F.; Bin Alam, S.; Afrin, S.; Rafa, S.J.; Taher, S.B.; Kabir, M.; Muyeen, S.M.; Gandomi, A.H. Towards a secure 5G-enabled Internet of Things: A survey on requirements, privacy, security, challenges, and opportunities. IEEE Access 2024, 12, 13125–13145. [Google Scholar] [CrossRef]
- Vemuri, V.K. The Hundred-Page Machine Learning Book. J. Inf. Technol. Case Appl. Res. 2020, 22, 136–138. [Google Scholar] [CrossRef]
- Custers, B.; Sears, A.M.; Dechesne, F.; Georgieva, I.; Tani, T.; van der Hof, S. EU Personal Data Protection in Policy and Practice; Springer Nature: Durham, NC, USA, 2019; p. 29. [Google Scholar] [CrossRef]
- Ananthanarayanan, G.; Bahl, P.; Bodik, P.; Chintalapudi, K.; Philipose, M.; Ravindranath, L.; Sinha, S. Real-Time Video Analytics: The Killer App for Edge Computing. Computer 2017, 50, 58–67. [Google Scholar] [CrossRef]
- Wang, J.; Amos, B.; Das, A.; Pillai, P.; Sadeh, N.; Satyanarayanan, M. A scalable and privacy-aware IoT service for live video analytics. In Proceedings of the 8th ACM Multimedia Systems Conference, Taipei, Taiwan, 20–23 June 2017; MMSy: New York, NY, USA, 2017; pp. 38–49. [Google Scholar] [CrossRef]
- Yaqoob, I.; Khan, L.U.; Kazmi, S.M.A.; Imran, M.; Guizani, N.; Hong, C.S. Autonomous Driving Cars in Smart Cities: Recent Advances, Requirements, and Challenges. IEEE Netw. 2020, 34, 174–181. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl. Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. arXiv 2021, arXiv:1912.04977. [Google Scholar] [CrossRef]
- Banabilah, S.; Aloqaily, M.; Alsayed, E.; Malik, N.; Jararweh, Y. Federated learning review: Fundamentals, enabling technologies, and future applications. Inf. Process Manag. 2022, 59, 103061. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Wu, X.; Liang, Z.; Wang, J. FedMed: A Federated Learning Framework for Language Modeling. Sensors 2020, 20, 4048. [Google Scholar] [CrossRef]
- Rey, V.; Sánchez Sánchez, P.M.; Huertas Celdrán, A.; Bovet, G. Federated learning for malware detection in IoT devices. Comput. Netw. 2022, 204, 108693. [Google Scholar] [CrossRef]
- Fang, W.; He, J.; Li, W.; Lan, X.; Chen, Y.; Li, T.; Huang, J.; Zhang, L. Comprehensive Android Malware Detection Based on Federated Learning Architecture. IEEE Trans. Inf. Forensics Secur. 2023, 18, 3977–3990. [Google Scholar] [CrossRef]
- Qayyum, A.; Ahmad, K.; Ahsan, M.A.; Al-Fuqaha, A.; Qadir, J. Collaborative federated learning for healthcare: Multi-modal COVID-19 diagnosis at the edge. IEEE Open J. Comput. Soc. 2022, 3, 172–184. [Google Scholar] [CrossRef]
- Antunes, R.S.; Da Costa, C.A.; Küderle, A.; Yari, I.A.; Eskofier, B. Federated Learning for Healthcare: Systematic Review and Architecture Proposal. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–23. [Google Scholar] [CrossRef]
- Zhang, H.; Bosch, J.; Olsson, H.H. End-to-End Federated Learning for Autonomous Driving Vehicles. In Proceedings of the International Joint Conference on Neural Networks, Online, 18–22 July 2021. [Google Scholar] [CrossRef]
- Nguyen, A.; Do, T.; Tran, M.; Nguyen, B.X.; Duong, C.; Phan, T.; Tjiputra, E.; Tran, Q.D. Deep Federated Learning for Autonomous Driving. In Proceedings of the IEEE Intelligent Vehicles Symposium, Aachen, Germany, 4–9 June 2022; pp. 1824–1830. [Google Scholar] [CrossRef]
- Lu, Z.; Pan, H.; Dai, Y.; Si, X.; Zhang, Y. Federated Learning with Non-IID Data: A Survey. IEEE Internet Things J. 2024, 11, 19188–19209. [Google Scholar] [CrossRef]
- Zeng, Y.; Mu, Y.; Yuan, J.; Teng, S.; Zhang, J.; Wan, J.; Ren, Y.; Zhang, Y. Adaptive Federated Learning with Non-IID Data. Comput. J. 2023, 66, 2758–2772. [Google Scholar] [CrossRef]
- Ma, X.; Zhu, J.; Lin, Z.; Chen, S.; Qin, Y. A state-of-the-art survey on solving non-IID data in Federated Learning. Future Gener. Comput. Syst. 2022, 135, 244–258. [Google Scholar] [CrossRef]
- Chen, Y.; Ning, Y.; Slawski, M.; Rangwala, H. Asynchronous Online Federated Learning for Edge Devices with Non-IID Data. In Proceedings of the 2020 IEEE International Conference on Big Data, Big Data 2020, Atlanta, GA, USA, 10–13 December 2020; pp. 15–24. [Google Scholar] [CrossRef]
- Zeng, Y.; Mu, Y.; Yuan, J.; Teng, S.; Zhang, J.; Wan, J.; Ren, Y.; Zhang, Y. Federated Learning with Non-IID Data. Comput. J. 2018. [Google Scholar] [CrossRef]
- Mahdi, O.A.; Ali, N.; Pardede, E.; Alazab, A.; Al-Quraishi, T.; Das, B. Roadmap of Concept Drift Adaptation in Data Stream Mining, Years Later. IEEE Access 2024, 12, 21129–21146. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. Int. J. Surg. 2010, 8, 336–341. [Google Scholar] [CrossRef]
- Samuel, A. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Liu, J.; Huang, J.; Zhou, Y.; Li, X.; Ji, S.; Xiong, H.; Dou, D. From distributed machine learning to federated learning: A survey. Knowl. Inf. Syst. 2022, 64, 885–917. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection. IEEE Trans. Knowl. Data Eng. 2023, 35, 3347–3366. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated Learning in Mobile Edge Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- Chamikara, M.A.P.; Bertok, P.; Khalil, I.; Liu, D.; Camtepe, S. Privacy preserving distributed machine learning with federated learning. Comput. Commun. 2021, 171, 112–125. [Google Scholar] [CrossRef]
- Konečný, J.; McMahan, B.; Ramage, D. Federated Optimization: Distributed Optimization Beyond the Datacenter. arXiv 2015, arXiv:1511.03575. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Ghosh, A.; Hong, J.; Yin, D.; Ramchandran, K. Robust Federated Learning in a Heterogeneous Environment. arXiv 2019, arXiv:1906.06629. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, W.; Wang, H.; Mi, H.; Hospedales, T.M. FedH2L: Federated Learning with Model and Statistical Heterogeneity. arXiv 2021, arXiv:1906.06629. [Google Scholar]
- Ye, M.; Fang, X.; Du, B.; Yuen, P.C.; Tao, D. Heterogeneous Federated Learning: State-of-the-art and Research Challenges. ACM Comput. Surv. 2023, 56, 1–44. [Google Scholar] [CrossRef]
- Gama, J.; Zliobaite, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. 2014, 46, 1–37. [Google Scholar] [CrossRef]
- Wang, S.; Schlobach, S.; Klein, M. Concept drift and how to identify it. J. Web Semant. 2011, 9, 247–265. [Google Scholar] [CrossRef]
- Lesort, T.; Caccia, M.; Rish, I. Understanding Continual Learning Settings with Data Distribution Drift Analysis. arXiv 2021, arXiv:2104.01678. [Google Scholar]
- Gama, J. Knowledge Discovery from Data Streams; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Krempl, G.; Žliobaite, I.; Brzeziński, D.; Hüllermeier, E.; Last, M.; Lemaire, V.; Noack, T.; Shaker, A.; Sievi, S.; Spiliopoulou, M.; et al. Open challenges for data stream mining research. ACM SIGKDD Explor. Newsl. 2014, 16, 1–10. [Google Scholar] [CrossRef]
- Prasad, B.R.; Agarwal, S. Stream data mining: Platforms, algorithms, performance evaluators and research trends. Int. J. Database Theory Appl. 2016, 9, 201–218. [Google Scholar] [CrossRef]
- Gama, J.; Sebastiao, R.; Rodrigues, P.P. Issues in evaluation of stream learning algorithms. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 329–338. [Google Scholar]
- Schlimmer, J.C.; Granger, R.H. Beyond incremental processing: Tracking concept drift. In Proceedings of the Fifth AAAI National Conference on Artificial Intelligence, Philadelphia, Pennsylvania, 11–15 August 1986. [Google Scholar]
- Li, J.; Yu, H.; Zhang, Z.; Luo, X.; Xie, S. Concept drift adaptation by exploiting drift type. ACM Trans. Knowl. Discov. Data 2024, 18, 1–22. [Google Scholar] [CrossRef]
- Kelly, M.G.; Hand, D.J.; Adams, N.M. The impact of changing populations on classifier performance. In Proceedings of the fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 367–371. [Google Scholar]
- Žliobaitė, I. Learning under concept drift: An overview. arXiv 2010, arXiv:1010.4784. [Google Scholar] [CrossRef]
- Tsymbal, A. The Problem of Concept Drift: Definitions and Related Work; Computer Science Department, Trinity College: Dublin, Ireland, 2004; Volume 106, p. 58. [Google Scholar]
- Gama, J.; Sebastiao, R.; Rodrigues, P.P. On evaluating stream learning algorithms. Mach. Learn. 2013, 90, 317–346. [Google Scholar] [CrossRef]
- Mahdi, O.A.; Pardede, E.; Ali, N.; Cao, J. Fast reaction to sudden concept drift in the absence of class labels. Appl. Sci. 2020, 10, 606. [Google Scholar] [CrossRef]
- Mahdi, O.A.; Pardede, E.; Ali, N.; Cao, J. Diversity measure as a new drift detection method in data streaming. Knowl. Based Syst. 2020, 191, 105227. [Google Scholar] [CrossRef]
- Mahdi, O.A.; Pardede, E.; Ali, N. KAPPA as drift detector in data stream mining. Procedia Comput. Sci. 2021, 184, 314–321. [Google Scholar] [CrossRef]
- Gama, J.; Medas, P.; Castillo, G.; Rodrigues, P. Learning with drift detection. In Proceedings of the Advances in Artificial Intelligence–SBIA 2004: 17th Brazilian Symposium on Artificial Intelligence, Sao Luis, Maranhao, Brazil, 29 September–1 October 2004; pp. 286–295. [Google Scholar]
- Baena-Garca, M.; del Campo-Ávila, J.; Fidalgo, R.; Bifet, A.; Gavalda, R.; Morales-Bueno, R. Early drift detection method. In Fourth International Workshop on Knowledge Discovery from Data Streams; ACM Press: New York, NY, USA, 2006; pp. 77–86. [Google Scholar]
- Street, W.N.; Kim, Y. A streaming ensemble algorithm (SEA) for large-scale classification. In Proceedings of the seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 377–382. [Google Scholar]
- Nishida, K.; Yamauchi, K.; Omori, T. ACE: Adaptive classifiers-ensemble system for concept-drifting environments. In Proceedings of the Multiple Classifier Systems: 6th International Workshop, MCS 2005, Seaside, CA, USA, 13–15 June 2005; pp. 176–185. [Google Scholar]
- Elwell, R.; Polikar, R. Incremental learning of concept drift in nonstationary environments. IEEE Trans. Neural Netw. 2011, 22, 1517–1531. [Google Scholar] [CrossRef]
- Krawczyk, B.; Woźniak, M. Reacting to different types of concept drift with adaptive and incremental one-class classifiers. In Proceedings of the 2015 IEEE 2nd International Conference on Cybernetics (CYBCONF), Gdynia, Poland, 24–26 June 2015; pp. 30–35. [Google Scholar]
- Kotler, J.; Maloof, M. Dynamic weighted majority: A new ensemble method for tracking concept drift. In IEEE International Conference on Data Mining; IEEE Computer Society: Washington, DC, USA, 2003; pp. 123–130. [Google Scholar]
- Mahdi, O.A. Diversity Measures as New Concept Drift Detection Methods in Data Stream Mining. Ph.D. Thesis, La Trobe University, Melbourne, Australia, 2020. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Arcas, B.A.Y. Federated Learning of Deep Networks using Model Averaging. arXiv 2016. [Google Scholar] [CrossRef]
- Brendan McMahan, H.; Moore, E.; Ramage, D.; Hampson, S.; Agüera y Arcas, B. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Yang, G.; Chen, X.; Zhang, T.; Wang, S.; Yang, Y. An Impact Study of Concept Drift in Federated Learning. In Proceedings of the 2023 IEEE International Conference on Data Mining (ICDM), Shanghai, China, 1–4 December 2023. [Google Scholar]
- Casado, F.E.; Lema, D.; Criado, M.F.; Iglesias, R.; Regueiro, C.V.; Barro, S. Concept drift detection and adaptation for federated and continual learning. Multimed. Tools Appl. 2022, 81, 3397–3419. [Google Scholar] [CrossRef]
- Casado, F.E.; Lema, D.; Iglesias, R.; Regueiro, C.V.; Barro, S. Concept Drift Detection and Adaptation for Robotics and Mobile Devices in Federated and Continual Settings. Adv. Intell. Syst. Comput. 2021, 1285, 79–93. [Google Scholar] [CrossRef]
- Canonaco, G.; Bergamasco, A.; Mongelluzzo, A.; Roveri, M. Adaptive Federated Learning in Presence of Concept Drift. In Proceedings of the International Joint Conference on Neural Networks, Shenzhen, China, 18–22 July 2021. [Google Scholar] [CrossRef]
- Jothimurugesan, E.; Hsieh, K.; Wang, J.; Joshi, G.; Gibbons, P.B. Federated learning under distributed concept drift. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Valencia, Spain, 25–27 April 2023. [Google Scholar]
- Panchal, K.; Choudhary, S.; Mitra, S.; Mukherjee, K.; Sarkhel, S.; Mitra, S.; Guan, H. Flash: Concept drift adaptation in federated learning. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Manias, D.M.; Shaer, I.; Yang, L.; Shami, A. Concept drift detection in federated networked systems. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021. [Google Scholar]
- Chen, Y.; Chai, Z.; Cheng, Y.; Rangwala, H. Asynchronous federated learning for sensor data with concept drift. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021. [Google Scholar]
- Badar, M.; Nejdl, W.; Fisichella, M. FAC-fed: Federated adaptation for fairness and concept drift aware stream classification. Mach. Learn. 2023, 112, 2761–2786. [Google Scholar] [CrossRef]
- Mawuli, C.B.; Che, L.; Kumar, J.; Din, S.U.; Qin, Z.; Yang, Q.; Shao, J. FedStream: Prototype-Based Federated Learning on Distributed Concept-Drifting Data Streams. In Proceedings of the IEEE Transactions on Systems, Man, and Cybernetics: Systems, Maui, HI, USA, 1–4 October 2023. [Google Scholar]
- Ganguly, B.; Aggarwal, V. Online Federated Learning via Non-Stationary Detection and Adaptation Amidst Concept Drift. In IEEE/ACM Transactions on Networking; IEEE: Washington, DC, USA, 2023. [Google Scholar]
- Chow, T.; Raza, U.; Mavromatis, I.; Khan, A. Flare: Detection and mitigation of concept drift for federated learning based IoT deployments. In Proceedings of the 2023 International Wireless Communications and Mobile Computing, Marrakesh, Morocco, 19–23 June 2023. [Google Scholar]
- Mawuli, C.B.; Kumar, J.; Nanor, E.; Fu, S.; Pan, L.; Yang, Q.; Zhang, W.; Shao, J. Semi-supervised federated learning on evolving data streams. Inf. Sci. 2023, 643, 119235. [Google Scholar] [CrossRef]
- Casado, F.E.; Lema, D.; Iglesias, R.; Regueiro, C.V.; Barro, S. Ensemble and continual federated learning for classification tasks. Mach. Learn. 2023, 112, 3413–3453. [Google Scholar] [CrossRef]
- Jiang, M.; Wang, Z.; Dou, Q. Harmofl: Harmonizing local and global drifts in federated learning on heterogeneous medical images. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 28 February–1 March 2022. [Google Scholar]
- Düsing, C.; Cimiano, P. Monitoring Concept Drift in Continuous Federated Learning Platforms. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2024; pp. 83–94. [Google Scholar] [CrossRef]
- Kang, M.; Kim, S.; Jin, K.H.; Adeli, E.; Pohl, K.M.; Park, S.H. FedNN: Federated learning on concept drift data using weight and adaptive group normalizations. Pattern Recognit. 2024, 149, 110230. [Google Scholar] [CrossRef]
- Stallmann, M.; Wilbik, A.; Weiss, G. Towards unsupervised sudden data drift detection in federated learning with fuzzy clustering. In Proceedings of the 2024 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Yokohama, Japan, 30 June–5 July 2024. [Google Scholar]
- Tsiporkova, E.; De Vis, M.; Klein, S.; Hristoskova, A.; Boeva, V. Mitigating Concept Drift in Distributed Contexts with Dynamic Repository of Federated Models. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023. [Google Scholar]
- Ito, R.; Tsukada, M.; Matsutani, H. An on-device federated learning approach for cooperative model update between edge devices. IEEE Access 2021, 9, 92986–92998. [Google Scholar] [CrossRef]
- Guo, Y.; Lin, T.; Tang, X. Towards federated learning on time-evolving heterogeneous data. arXiv 2021, arXiv:2112.13246. [Google Scholar]
- Yoon, J.; Jeong, W.; Lee, G.; Yang, E.; Hwang, S.J. Federated continual learning with weighted inter-client transfer. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021. [Google Scholar]
- Shukla, P.K.; Veerasamy, B.D.; Alduaiji, N.; Addula, S.R.; Sharma, S.; Shukla, P.K. Encoder only attention-guided transformer framework for accurate and explainable social media fake profile detection. Peer-Peer Netw. Appl. 2025, 18, 232. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).