1. Introduction
With the rapid development of industrial robot technology, many tasks which require traditional manual labor are gradually being replaced and completed by industrial robots. Packaging bags are widely used in various industries, and the transportation of packaging bags consumes large amounts of manpower and resources. It is particularly important to apply industrial robots to the automatic transportation systems of packaging bags [
1]. The automatic positioning of packaging bags requires the use of a 3D point cloud camera to extract the point cloud data of the packaging bags, identify the rotation and translation matrices of the targets in the point cloud relative to the template, and send the positioning results to the robot through coordinate transformation to achieve grasping. Therefore, point cloud registration technology is the key to automatic positioning of packaging bags.
PointNet is a widely used deep learning network model for processing point cloud data. It introduces symmetric functions to achieve permutation invariance for point clouds and uses T-Net to achieve rotation invariance for point clouds. There is a series of variant models based on PointNet, such as PointNet++ and PointCNN [
2,
3,
4,
5]. In 2018, Wang et al. proposed dynamic graph convolution (DGCNN), which enhances the representation ability of node features by considering the neighboring node features and edge features of nodes and rebuilding the graph structure in each iteration. In the same year, Wang et al. proposed deep closest point (DCP) [
6,
7,
8], which uses DGCNN to extract the local features of point clouds and iterates on point clouds according to the calculation process of the iterative closest point (ICP) algorithm. In the pose regression stage, DCP uses a probability function to estimate the rotation matrix. The disadvantage of DCP is that it cannot handle non-overlapping points. In 2019, Wang et al. proposed Partial-to-Partial Registration Net (PRNet) [
9], which added the Sinkhorn–Gumbel softmax algorithm to the DCP network and used self-supervised learning to directly extract geometric features from point clouds. PRNet uses a partial-to-partial approach to solve the problem of non-overlapping point clouds and successfully validates the rationality of applying deep learning to partial matching. In 2019, Sarode et al. proposed the Point Cloud Registration Network (PCRNet), which treats PointNet as a feature extractor and utilizes it to extract global features from source and target point clouds. After extracting the global features through PointNet, PCRNet directly fuses these features and generates a feature vector through a fully connected layer. The characteristic of PCRNet is that it achieves fast point cloud registration through this simple and efficient method, but it cannot handle non-overlapping point clouds [
10,
11]. In 2020, Yew et al. proposed the Robust Point Matching Network (RPMNet), which uses differentiable Sinkhorn normalization and annealing methods to enforce double random constraints. The model can effectively handle outliers [
12,
13]. In 2020, Yuan et al. proposed Deep Gaussian Mixture Registration (DeepGMR), based on the Gaussian mixture model. DeepGMR utilizes the pose-invariant correspondence between the original point cloud and the Gaussian mixture model (GMM) parameters to model point cloud registration as optimizing the KL divergence between two Gaussian mixture models [
14,
15,
16]. In 2021, Zeng et al. proposed CorrNet3D. CorrNet3D uses DGCNN to extract point clouds and then max pooling to obtain global features. By approximating a doubly random matrix, it reorders the points in the source point cloud and finds their corresponding points in the template point cloud to achieve registration of non-rigid point clouds [
17,
18,
19].
This study designs a point cloud registration network based on deep learning to solve the registration problem of packaging bag point clouds. The main contributions of this article are as follows:
- (1)
We improve the dynamic graph convolution module by introducing weight coefficients and enhancing global features such that the dynamic graph convolution module based on corresponding point matching can be applied in point cloud registration networks based on global features. We propose a point cloud feature interaction module to enable the network model to handle the registration problem of non-overlapping point clouds. A rotation translation separation structure is proposed which completely separates the calculation of rotation parameters and translation parameters which do not belong to the same vector space, making the point cloud registration network modular.
- (2)
In the feature fusion stage between the source point cloud and the template point cloud, the channel attention module is used to dynamically adjust the weights of different feature dimensions of the point cloud for the model to better utilize the most useful features among them. Spatial attention is used to help the model focus on the overlapping area between two clouds, improving the efficiency and registration accuracy of the model.
2. Construction of Packaging Bag Point Cloud Dataset and Preprocessing
2.1. Point Cloud Collection
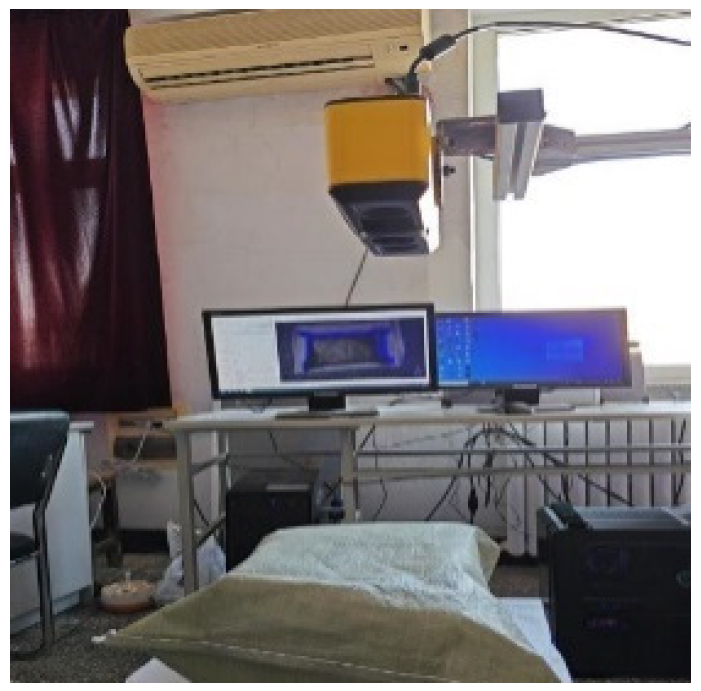
To construct a packaging bag point cloud dataset, a point cloud data acquisition platform for packaging bags based on the Cognex A5120 (Cognex Vision Inspection System (Shanghai) Co., Ltd, Shanghai, China) structured light camera was built, as shown in
Figure 1.
Packaging bags were placed in different positions and angles, and data were collected from the packaging bags in different poses. The collected data included left camera image data and right camera image data. Based on the left and right camera image data and camera parameters, point cloud data could be calculated.
Figure 2 shows the collected left and right camera images.
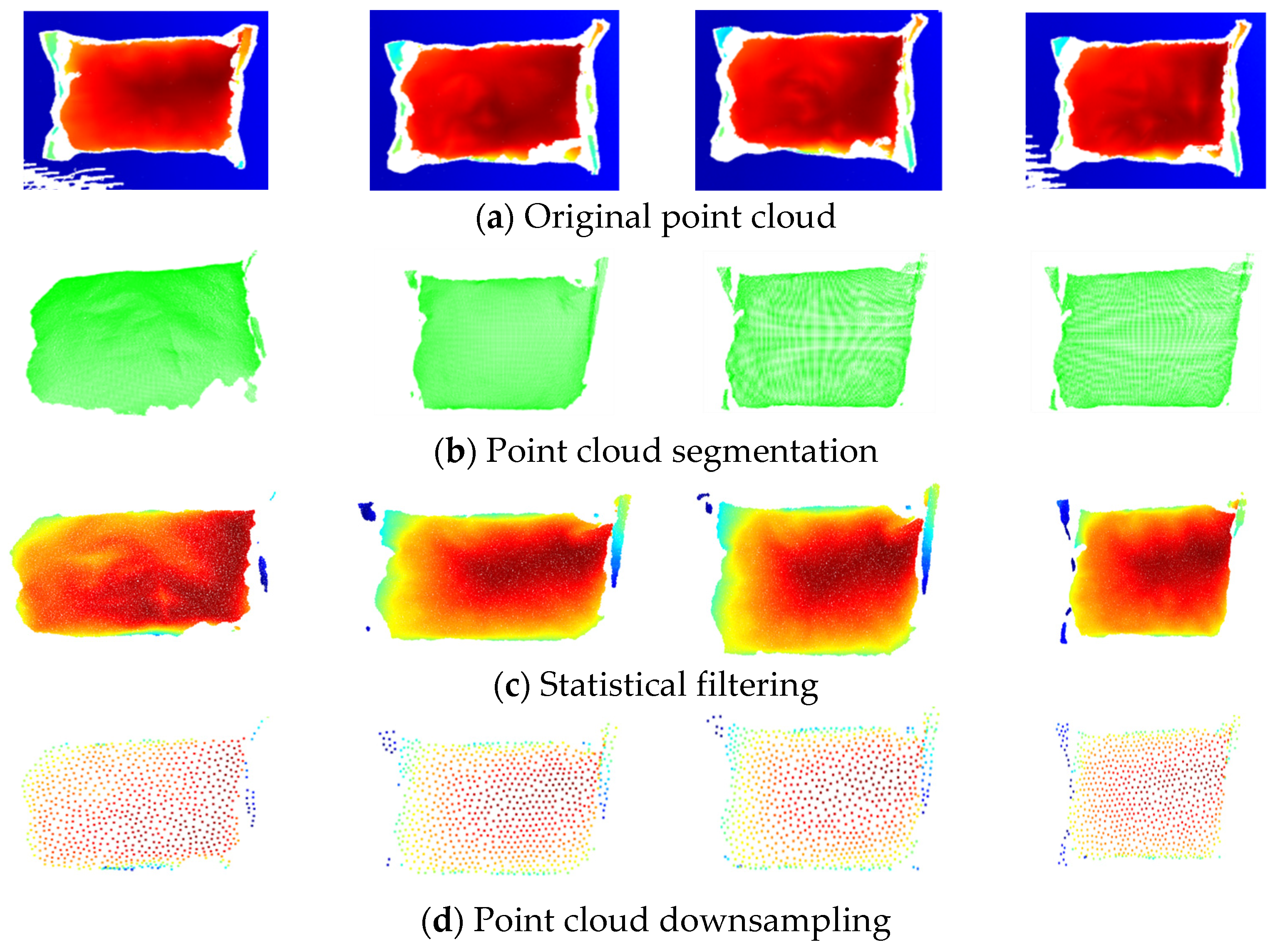
Figure 3 shows the obtained point cloud data, where blue is the reference plane of the point cloud plane. The distance between the point clouds was consistent with the spectral color arrangement order; that is, the point clouds farther away from the blue plane tended to be closer to red.
2.2. Point Cloud Segmentation Based on RANSAC Algorithm
The Random Sampling Consistency (RANSAC) algorithm [
20] is a classic point cloud processing algorithm widely used in the fields of point cloud segmentation and registration.
To remove the background, we used the RANSAC algorithm to segment the points from the background. The RANSAC algorithm estimates a mathematical model iteratively from a set of data containing a background. This algorithm divides point cloud data containing noise into inliers and outliers. Here, inliers are real points which exist in the target object, and outliers are the background.
2.3. Statistical Filtering to Remove Outliers
The statistical filter calculates the mean and standard deviation of the distance between each point in the point cloud and determines whether it is an outlier based on the standard deviation. Assuming that the point cloud data are , a point is randomly selected. Suppose that the set of neighboring points of is , where . We calculated the distance from to each point in the set and obtain the average distance .
Then, we calculated the distance mean
and distance standard deviation
of the entire point cloud using the following formula:
We then calculated the mean and standard deviation of the points within the point cloud and considered them outliers if they were not within the confidence interval .
The advantage of the statistical removal method is that it can accurately identify outliers through statistical features and does not require excessive parameter adjustment. However, this method is sensitive to the distribution and statistical characteristics of point cloud data and may be affected by data noise and the sampling density. Therefore, in practical applications, it is necessary to carefully select and adjust relevant parameters to achieve better denoising results [
21].
2.4. Farthest Point Cloud Downsampling
Farthest point downsampling is based on the farthest point sampling method of point clouds, which is a commonly used sampling method for point clouds. Assuming that the point cloud data are , one can define an initial set . We selected points from the point cloud and then randomly selected a point from the point cloud as the initial point and put it into the set . We then chose the point which was farthest from for the set . At this time, the set was , and we calculated the distances between the remaining points and and separately. Suppose that the farthest point from is and the distance is . The farthest point from is , with the distance denoted by . We compared with . If , then would be placed in the set . Otherwise, would be placed in the set . We repeated this process until the required number of selected points was reached.
The advantage of farthest point downsampling is that it can preserve the main features of the point cloud without the need for pre-set parameters. In addition, this method performs relatively efficiently in processing large-scale point clouds [
22].
The preprocessing of the packaging bag point cloud is shown in
Figure 4.
3. Methodology
The DCDNet-Att model structure is shown in
Figure 5. The green, solid-lined blocks represent the rotate edgeConv block. The yellow, solid-lined blocks represent the translation edgeConv block. The gray cylinder represents the max pool function,
represents tensor concatenation, and
represents tensor multiplication. The green dashed box represents the rotate fully connected module. The yellow dashed box represents the translation fully connected module. The solid arrow represents the source path for point cloud data transfer. The dashed arrow represents the reference path for template point cloud data transfer,
represents the source point cloud, and
represents the template point cloud.
Both the and point clouds were simultaneously input into the variable weight dynamic graph convolution module which did not share parameters. Because the quaternion and the translation vector do not belong to the same vector space, the proposed network uses a point cloud feature extraction module which does not share parameters.
After two rounds of rotation, for the
point cloud and
point cloud, rotated point cloud features
and
were obtained. The rotated point cloud features were transmitted to the point cloud feature interaction (PCFI) module for feature interaction. The point cloud features from the first feature interaction step were processed by feature extraction, feature interaction, and feature extraction. The point cloud features obtained are named
and
. One can find
by performing tensor addition on five sets—
,
,
,
, and
—and obtain
by performing tensor addition on five sets:
,
,
,
, and
. The translation vector extracts point cloud features from
and
through the rotation variable weight dynamic graph convolution module to obtain
and
, respectively. It then combines
and
into a pair of datasets and uses the point cloud feature rise (PCFR) module. After processing by the PCFR module,
and
are obtained. By incorporating a channel attention mechanism and spatial attention mechanism,
and
are obtained. Tensor addition of
and
is performed to obtain the fusion features
of point clouds
and
. Finally,
is subjected to pose regression through a fully connected module to obtain the quaternion.
Figure 5 shows the point cloud pose regression (PPR) module. After multiplying the quaternion
by point cloud
, the
and
point clouds are input again into the translation feature extraction module, and all of the above operations are repeated to obtain the translation vector. At this point, the point cloud alignment process ends. The translation vector obtained in the previous round is added to the point cloud, and all of the above processes are repeated until the iteration ends.
The calculation process of DCDNet-Att can be expressed as follows:
where
represents the tensor concatenation,
represents the rotation feature extraction module,
represents the translation feature extraction module,
represents the point cloud feature interaction module,
represents the rotation bottleneck module,
represents the rotation bottleneck module,
represents the rotation feature regression function,
represents the translation feature regression function, which is a fully connected neural network,
represents quaternions,
represents the translation vector obtained in this round of the registration process,
represents the translation vector obtained in the previous round of the registration process,
is zero,
represents the spatial attention mechanism, and
represents the channel attention mechanism.
The attention mechanism enables the model to dynamically focus its attention on different parts of the input data, thereby improving the performance and performance of the model.
3.1. PCFI, PCFR, and PPR Modules
The PCFI module encourages the model to focus on the same geometric features between the and point clouds by interacting with their global and local features. These features include the overall shape of the packaging bag point cloud and the outer surface, which has not undergone deformation.
The PCFR module consists of three conventional convolutional layers, with the convolutional layer dimensions being 1024, 2048, and 1024. The green and yellow parts in
Figure 5 represent one-dimensional convolution modules, which are combined into a bottleneck module. The bottleneck module is the post-processing process of point clouds. After the point cloud is processed through the variable weight dynamic graph convolution module and feature interaction module, the model has a preliminary ability to focus on the overlapping areas of the point cloud. Through the bottleneck module, the point cloud is processed to enhance the overlapping point cloud features and weaken the non-overlapping point cloud features.
The network first calculates the rotation features of the point cloud and regresses the rotation features to obtain quaternions. The quaternions are multiplied by the source point cloud to obtain a preliminary transformed source point cloud. The transformed source and target point clouds are then input back into the neural network to extract translation features. Finally, the translation vector is obtained by regressing the translation features.
3.2. Channel Attention
The role of the channel attention mechanism is to fully integrate the source point cloud features with the template point cloud features. A channel attention mechanism is an attention mechanism used to handle the relationships between data channels. In deep learning, each channel of tensor data represents specific features or information, but not all channels are equally important to the final task. A channel attention mechanism aims to dynamically adjust the weights of these channels such that the model can better utilize the most useful information, and by learning the weights of each channel, the model can automatically focus on the channels which are more meaningful to the task [
23,
24]:
- (1)
Calculating weights: Unlike spatial attention mechanisms, channel attention mechanisms do not require convolution processing of point cloud features; rather, they directly use channel attention functions to process point cloud features to obtain channel attention weights.
- (2)
Channel weighted summary: Based on the calculated channel attention weights, the point cloud features are weighted and summarized to obtain the final point cloud features.
The channel attention mechanism can be expressed as follows:
where
presents the point cloud features of dimensions
. Suppose that
is greater than
. Then,
is the channel attention coefficient between position
and
. Meanwhile,
is the feature of the point cloud at position
. The initial value of
is zero, and
will be updated in the training process of the attention mechanism.
3.3. Spatial Attention Mechanism
In the process of point cloud processing, the spatial attention mechanism focuses not only on the geometric features of the input point cloud but also on the positional relationship of the point cloud in space. A spatial attention mechanism can make the model no longer simply extract features from point cloud data but help the model focus on information in certain specific areas, namely the overlapping areas between two point clouds, which can improve the efficiency and registration accuracy of the model [
25].
The calculation process of the spatial attention mechanism used in this article is as follows:
- (1)
Extracting point cloud features: It extracts point cloud features through two-dimensional convolution and performs average pooling or global pooling on the point cloud features,
- (2)
Encoding point cloud spatial position information: It encodes the spatial position information of the pooled point cloud features so that the model can consider the positional relationships between features,
- (3)
Calculate weight: It calculates the attention weight of each spatial position to reflect its importance.
- (4)
Weighted summary: Based on the calculated spatial attention weights, the point cloud features are weighted and summarized to obtain the final point cloud features.
The spatial attention mechanism can be expressed as follows:
where
,
,
, and
present the point cloud features of dimensions
,
,
, and
present a two-dimensional convolution group,
is the spatial attention coefficient between positions
and
,
is the feature of the point cloud at position
, and
is a feature scaling factor. The initial value of
is zero, and
will be updated as the training process of attention mechanism is carried out.
5. Discussion
The training and optimization of DCDNet-Att were carried out on the AutoDL cloud GPU platform, with the deep learning model running on Ubuntu 22.04 and the deep learning framework being PyTorch 1.13.0+cu113. The CPU used for training the model was a 15 vCPU Intel (R) Xeon (R) Platinum 8358P CPU @ 2.60 GHz, and the GPU was an NVDIA A100-SXM4-80GB (80 GB). For the network model parameter settings, the initial learning rate was 0.0001, and the learning rate was multiplied by 0.1 every 50 epochs. The total number of iterations for the entire dataset was 300 epochs, the batch size was 64, and the random seed size was 1234. The training set had 7500 samples, the validation set had 1000 samples, and the test set had 1000 samples.
5.1. Ablation Experiment
In order to verify the effectiveness of the attention mechanism, this section conducted ablation experiments on DCDNet-Att and calculated the registration error between not adding an attention mechanism, adding a certain attention mechanism separately, and adding different attention mechanisms in different orders. The results are shown in
Table 1.
In
Table 1, 🗵 represents the basic network without adding an attention mechanism, S represents adding only a spatial attention mechanism in the feature fusion stage, C represents adding only a channel attention mechanism in the feature fusion stage, and S + C represents adding both a spatial attention mechanism and channel attention mechanism in the feature fusion stage, with the spatial attention mechanism at the front and the channel attention mechanism at the back. Similarly, C + S represents a channel attention mechanism at the front and a spatial attention mechanism at the back. From the table, it can be seen that compared with not adding an attention mechanism, any attention mechanism among S, C, S + C, and C + S can reduce the registration error of the model, proving that attention mechanisms significantly improved the network. The combination of channel attention and spatial attention mechanisms had the greatest improvement effect on the model.
5.2. Generalization Experiment
In order to test the generalization ability of DCDNet-Att, this section compares DCDNet-Att with other algorithm models using a dataset with unseen categories.
Table 2 shows a comparison of the generalization experimental results based on the data in this article.
5.3. Comparison Experiment with Different Iteration Times
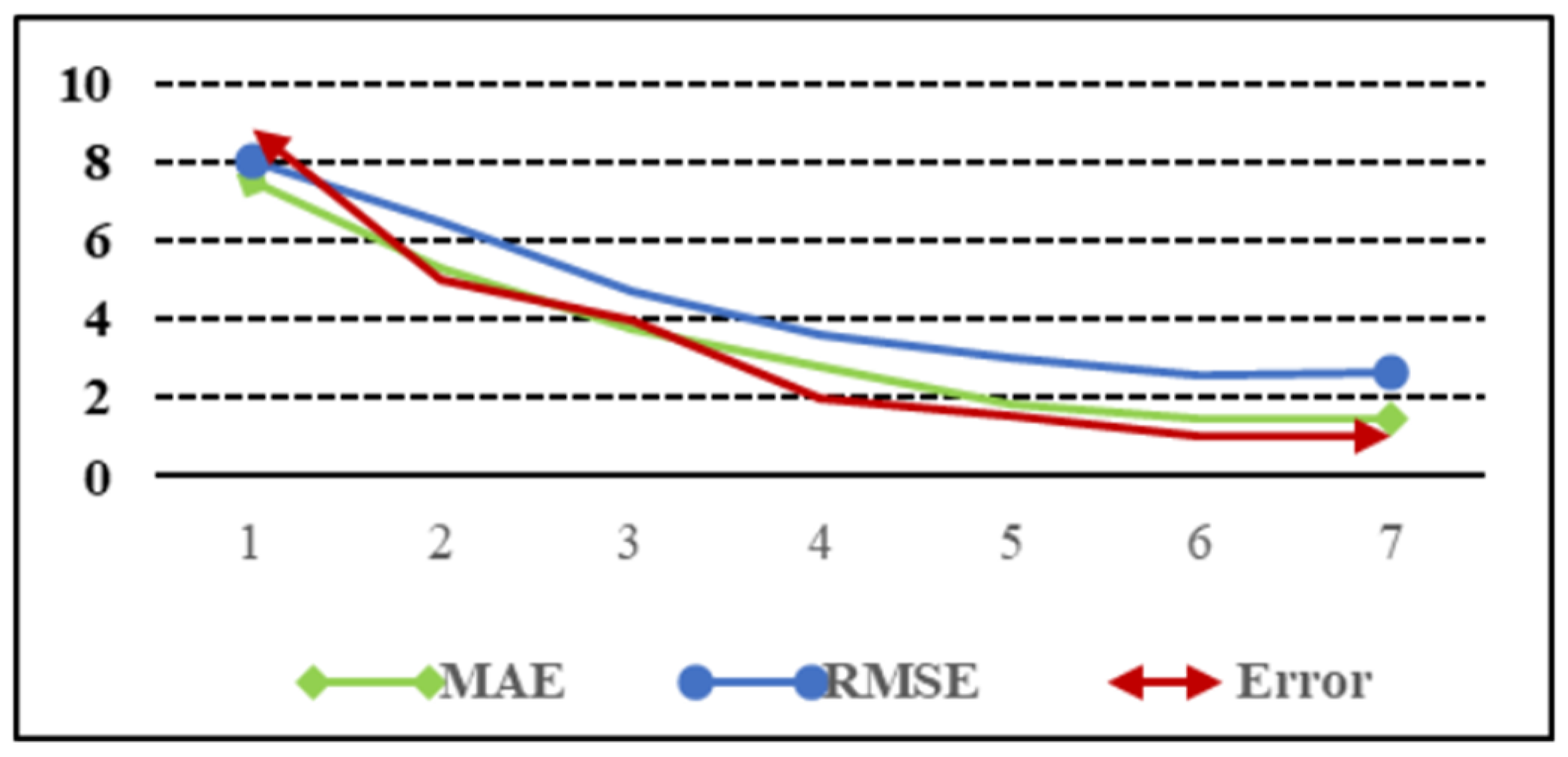
The impact of different iterations on the registration error of DCDNet-Att is shown in
Table 3 and
Figure 6, which show the rotation MAE, RMSE, and Error data and a line graph for seven iterations, respectively.
The X axis represents the number of iterations. From the chart, it can be seen that for DCDNet-Att, after six iterations, the rotation MAE, RMSE, and Error values for point cloud registration were 1.458, 2.541, and 1.024, respectively, which were small and tended to stabilize.
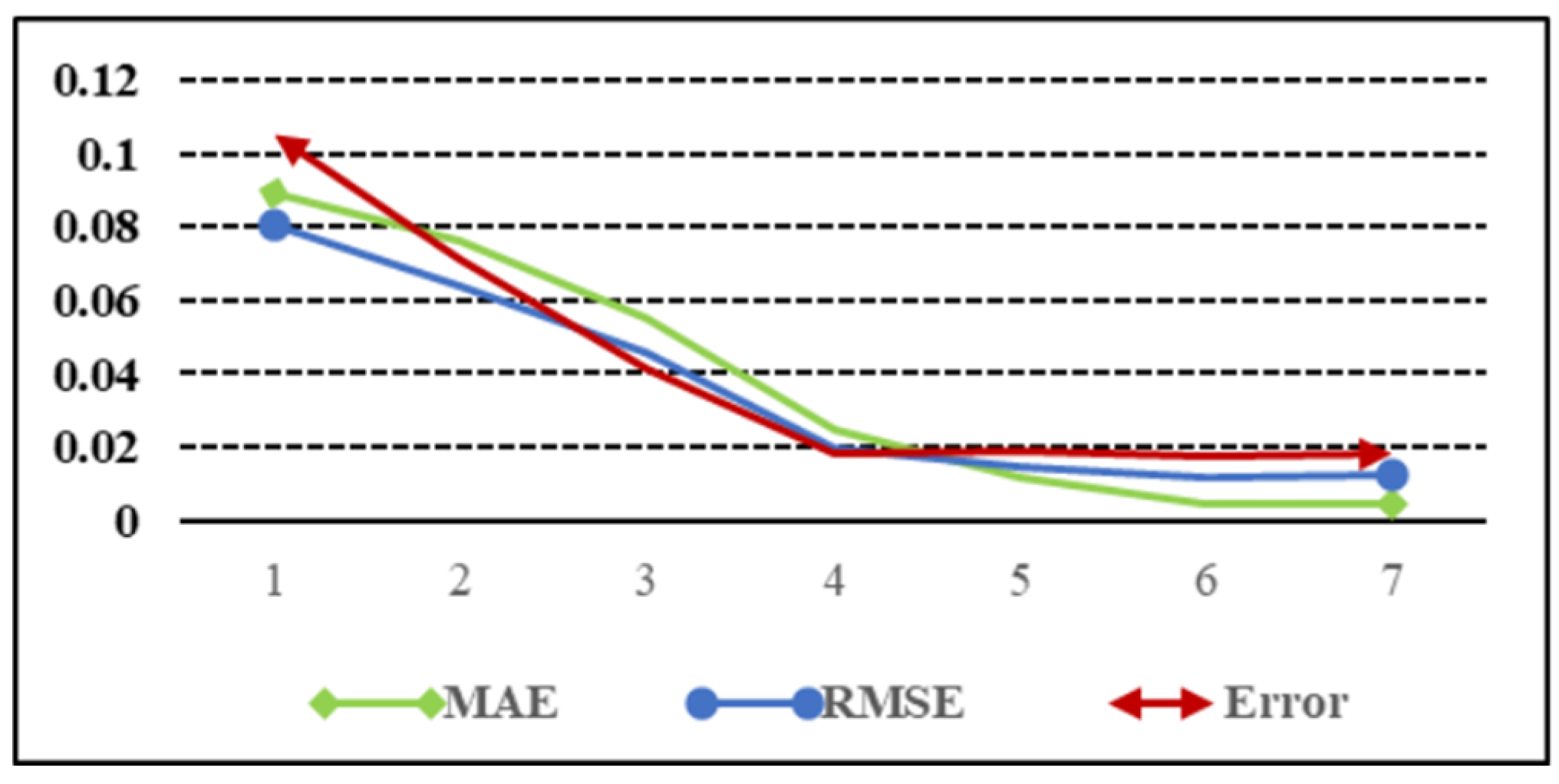
Table 4 and
Figure 7 show the MAE, RMSE, and Error data and a line graph of the translation errors corresponding to the first seven iterations, respectively.
The X axis represents the number of iterations. From the chart, it can be seen that for DCDNet-Att, after six iterations, the translation MAE, RMSE, and Error values of the point cloud registration were 0.0048, 0.0114, and 0.0174, respectively, and tended to stabilize. Therefore, for DCDNet-Att, six iterations could obtain the optimal results. Fewer iterations resulted in low network registration accuracy, while more iterations increased the computational complexity of the network and could not better improve the model’s registration accuracy.
5.4. Registration Results for Noise-Free Point Clouds
The ModelNet40 [
26] dataset was registered using the DCDNet-Att network, and some of the registration results are shown in
Figure 8.
The red point cloud in
Figure 8 is the template point cloud, the green point cloud is the source point cloud, and the blue point cloud is the registered template point cloud. It can be seen from the figure that DCDNet-Att had a good registration effect on the noise-free, partially overlapping point clouds.
We compared the registration performance of DCDNet-Att based on the data in this article with eight methods, including ICP, GO-ICP, and FGR. The results are shown in
Table 5.
From the chart, it can be seen that compared with other methods, DCDNet-Att had significant advantages in both rotation accuracy and translation accuracy. DCDNet-Att performed well in the noise-free point cloud registration tasks.
5.5. Registration Results for Point Clouds with Gaussian Noise
To verify whether DCDNet-Att still had good robustness to noise during point cloud registration, Gaussian noise with a mean of 0.5 and a standard deviation of 0.01 was added to the ModelNet40 dataset for registration using this network. The partial registration results are shown in
Figure 9.
In
Figure 9, the red point cloud represents the number of template point clouds, the green point cloud represents the source point cloud, and the blue point cloud represents the registered template point cloud data. From the registration result graph, it can be seen that DCDNet-Att had good registration results for the Gaussian noise point clouds, with a mean of 0.5 and a standard deviation of 0.01.
Table 6 shows a comparison of the results for the registration errors between DCDNet-Att and seven algorithms, including ICP in the ModelNet40 point cloud dataset with Gaussian noise.
From the chart, it can be seen that compared with the other seven algorithms, DCDNet-Att had rotation MAE, RMSE, and Error values of 2.028, 3.437, and 2.478, respectively, and translation values of 0.0107, 0.0327, and 0.0285, respectively, all of which were superior to the other algorithms. It can be seen that DCDNet-Att has robust anti-noise performance, and the registration rotation accuracy and translation accuracy were the best.
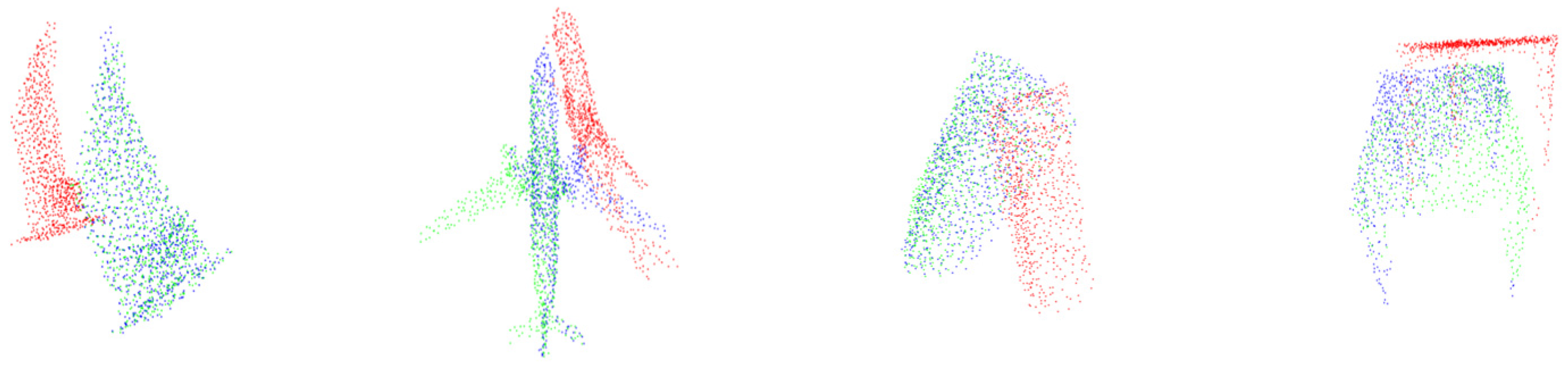
5.6. Registration Results of Packaging Bags
To verify the registration effect of DCDNet-Att on packaging bags, eight different packaging bag templates were used for the packaging bag point cloud registration experiments. The registration results are shown in
Figure 10.
The red point cloud is the template point cloud, the blue point cloud is the point cloud to be registered, and the green point cloud is the registered point cloud data. From the registration results, it can be seen that although there was deformation in the point cloud of the packaging bags, which resulted in incomplete overlap between the target point cloud and the template point cloud, the network fully utilized the global and local features of the packaging bag for registration, and the registration results were good. Using registration data to express the position of the target can help accurately locate the packaging bag.
6. Conclusions
This article proposed a dual branch point cloud registration network (DCDNet-Att) based on variable weight dynamic graph convolution with a dual attention mechanism to solve the problem of packaging bag point cloud registration. The network uses a variable weight dynamic graph convolution module to extract point cloud features, a feature interaction module to extract common features between the source point cloud and the template point cloud, and a bottleneck module to further emphasize the same geometric features between the two point clouds. It uses a channel attention function to process point cloud features and obtain the channel attention weights, weighs and summarizes point cloud features, and then encodes the spatial position information of the point cloud features so that the model can consider the positional relationship between features, calculate the attention weight of each spatial position, and use a rotation translation separation structure to sequentially obtain quaternions and translation vectors. It uses a feature-fitting loss function to constrain the parameters of the neural network model to make the model have a larger receptive field. Experimental verification was conducted on the registration of packaging bag point clouds with publicly available dataset point clouds, and the results demonstrated the effectiveness of DCDNet-Att.
The packaging bag point cloud dataset need further enrichment. Due to experimental limitations, the collected packaging bag sizes, shapes, and quantities were limited, and the validation results of the model were limited. Increasing the data volume of the packaging bag point cloud dataset can better verify the generalization ability and registration effect of deep learning models on packaging bag point clouds.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}