1. Introduction
Power consumption (PC) data play a crucial role in industrial operations and daily life, serving as the foundation for energy optimization and intelligent management. With the rapid development of Internet of Things (IoT) and smart grid technologies, the collection of PC data has become increasingly important, providing essential support for efficient energy management. High-quality data not only improve load forecasting accuracy [
1], optimize demand response strategies [
2], and facilitate in-depth analyses of user behavior patterns [
3] but also enhance building energy efficiency, directly influencing the sustainability and economic performance of energy systems. However, in practical applications, issues such as sensor or smart meter failures, network interruptions, and data transmission delays often result in missing PC data [
4]. Additionally, PC data typically exhibit high dimensionality and incompleteness (HDI) across temporal, spatial, and multi-parameter dimensions. These data gaps significantly affect the precision of load monitoring and energy analyses, posing significant challenges for data-dependent applications such as non-intrusive load monitoring (NILM), user behavior modeling, and energy forecasting [
5]. Therefore, effectively imputing missing portions of PC data to improve data integrity and quality has become a critical problem that needs to be addressed.
Current imputation methods face significant limitations when handling PC data, particularly in addressing high-dimensional sparsity and complex temporal dependencies [
6]. Traditional approaches, such as mean imputation, linear interpolation, and K-nearest neighbor (KNN), can provide preliminary imputations in simple scenarios but fail to effectively capture the periodic features and inter-device interactions inherent in PC data [
7]. While matrix completion methods can handle two-dimensional data, they are constrained by the dimensionality of the information that they can exploit [
8]. In contrast, high-dimensional tensors better capture underlying data characteristics; however, tensor decomposition models based on nuclear norm minimization (NNM) require the generation of complete tensors for training, resulting in high computational costs and limiting their application to large-scale sparse datasets [
9,
10]. Hidden Markov Models (HMMs) offer advantages in capturing changes in power load states and are suitable for identifying and predicting device usage patterns under varying conditions [
11]. However, HMMs rely on strong assumptions (e.g., stationarity) and require substantial historical data for training, restricting their practical applicability [
12]. Neural network-based imputation methods, such as Autoencoders [
13], Recurrent Neural Networks (RNNs) [
14], Long Short-Term Memory networks (LSTMs) [
15], and Generative Adversarial Networks (GANs) [
16], can model complex nonlinear relationships but are highly dependent on large datasets and prone to overfitting when dealing with sparse or high-dimensional data, leading to model instability [
17]. Additionally, metadata-based imputation methods improve accuracy and reliability by integrating auxiliary information, such as timestamps and geographic locations [
18,
19]. Probabilistic graphical models [
20] and Bayesian methods [
21] further enhance precision and robustness by modeling uncertainties and dependencies within the data. However, these methods typically require complex probabilistic inference, especially on high-dimensional datasets, resulting in significant computational overhead and time-consuming processes.
In recent years, tensor factorization models based on CANDECOMP/PARAFAC (CP) decomposition have gained significant attention for their efficiency in large-scale data imputation [
22,
23,
24]. These models utilize multiple low-dimensional matrices to represent latent features, enabling an accurate reconstruction of the original target tensor [
25]. Wu et al. proposed the Fused CP (FCP) decomposition model, which integrates priors such as low rank, sparsity, manifold information, and smoothness, and it was successfully applied to image restoration [
26]. Luo et al. enhanced non-negative tensor factorization models by introducing bias terms for QoS data imputation [
27]. Wu et al. further proposed a PID controlled tensor factorization model for imputing Dynamically Weighted Directed Networks [
28]. Ben Said et al. introduced the Spatiotemporal Tensor Completion Model, leveraging enhanced CP decomposition to repair missing values in urban traffic data by incorporating spatial and temporal features [
29]. Overall, tensor factorization models demonstrate promising potential and wide applicability in high-dimensional data completion. Zhu et al. developed the Multi-Task Neural Tensor Factorization (MTNTF) model, combining tensor factorization and neural networks to improve the accuracy and efficiency of traffic flow data imputation through multitask learning and attention mechanisms [
30]. Jin et al. proposed a Graph-Aware Tensor Factorization Convolutional Network that utilizes Graph Convolutional Networks (GCNs) as the encoder and tensor factorization as the decoder to more effectively represent and complete knowledge graphs [
31]. Deng et al. proposed a wireless network traffic prediction model that combines Bayesian Gaussian Tensor Factorization (BGCP) for imputing missing values and RNNs for traffic prediction [
32].
Therefore, to address the issue of missing PC data, this study makes the following main contributions:
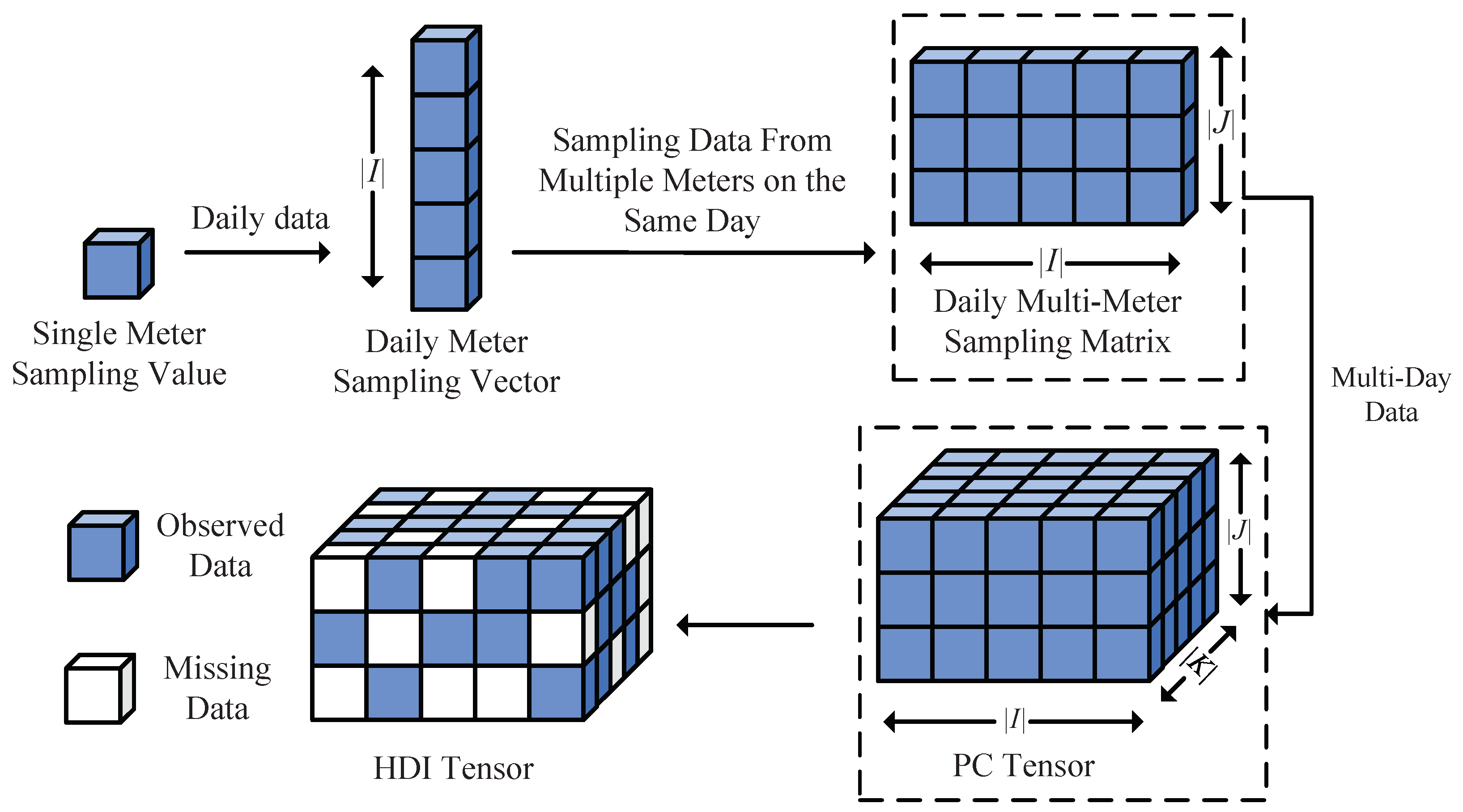
Third-Order PC Tensor Construction: This study develops a third-order tensor structure that preserves temporal patterns and effectively models inter-appliance relationships. For example, monitoring the PC of 10 devices in a building at a sampling rate of 1 Hz over a 24 h period results in a tensor with dimensions of , representing the number of devices, time steps (86,400 s per day), and 7 consecutive days.
Robust Momentum-Enhanced Non-Negative Tensor Factorization (RMNTF) Model: This study introduces the RMNTF model, enhancing robustness through the integration of adversarial loss and regularization. The sigmoid activation function ensures non-negativity constraints, thereby improving the interpretability of the imputation results. Additionally, momentum-based optimization methods accelerate the optimization process, significantly reducing convergence time.
Implementation and Performance Evaluation: This study completes detailed implementation and performance evaluations of the RMNTF algorithm on two publicly available PC datasets. The results demonstrate the model’s ability to provide high-accuracy imputation for missing PC data, outperforming existing methods in handling high-sparsity scenarios.
The structure of this paper is as follows:
Section 2 outlines the theoretical foundations;
Section 3 describes the proposed model in detail;
Section 4 presents the experimental results and evaluates the model’s performance; and, finally,
Section 5 summarizes the advantages of the RMNTF model in PC data imputation, discusses its key findings and model limitations, and suggests potential directions for future research.
3. RMNTF Model
3.1. Decoupling Non-Negativity Constraints in Tensor Factorization
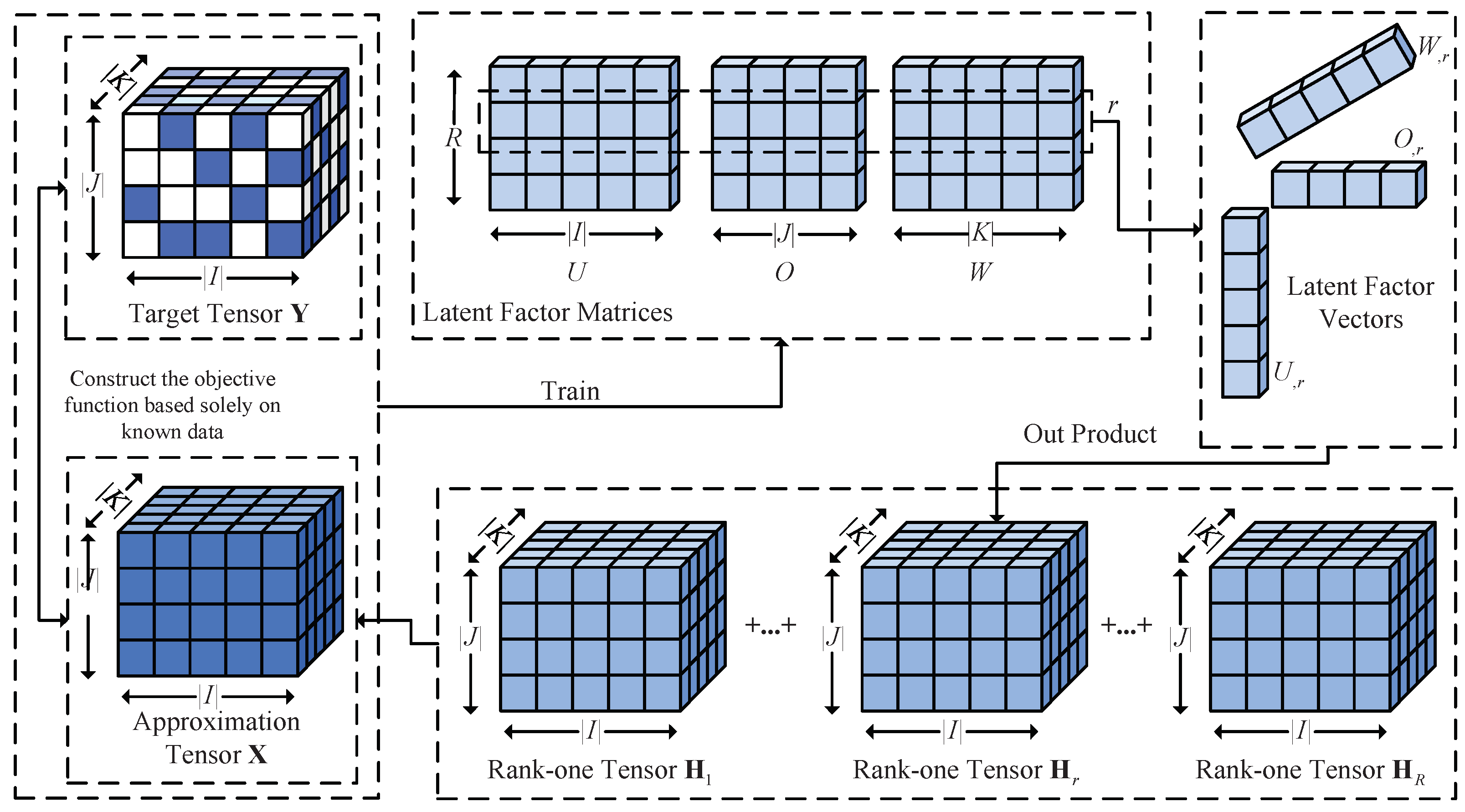
In this paper, three decision parameter matrices (DPs) are introduced for the LFs U, O, and W, denoted as , , and , respectively. By incorporating DPs, the model decouples the optimization process from the non-negativity constraints, enabling more efficient learning while maintaining flexibility in the optimization of the LFs.
The LFs are generated through a mapping function
f applied to the elements of the DPs, defined as
where
,
, and
are elements of the DPs
,
, and
, respectively. Element-wise mapping ensures that the generated LFs automatically satisfy the non-negativity constraints.
To ensure non-negativity, the mapping function
f, based on [
41], must satisfy the following conditions:
Based on these conditions, the sigmoid function is selected as the mapping function, defined as
The derivative approaches zero as but never equals zero, thus satisfying all necessary conditions.
The flexibility of the sigmoid function allows the DPs , , and to take values freely in the real number domain while ensuring that the LFs are non-negative. This characteristic guarantees that the reconstructed tensor remains non-negative, consistent with the physical significance of PC data. Furthermore, nonlinear mapping enhances the model’s ability to capture complex relationships and patterns, thereby improving overall representation performance.
As a result, the objective function
, which appears in (
8), is reformulated as
3.2. Adversarial Loss Regularization for Enhanced Robustness
To enhance the robustness and generalization ability of the model, an adversarial loss regularization term is introduced into the objective function. By adding carefully designed perturbations to the true values, the model simulates worst-case input variations, forcing it to learn features that are robust to these disturbances. This approach improves the model’s performance in diverse and noisy environments [
42,
43].
The first step is to generate adversarial samples by maximizing the following objective function, which aims to create perturbations by maximizing the error between the observed and reconstructed samples:
Maximizing this objective function generates perturbations that increase the error between the perturbed samples and the model’s predictions.
For each observed value
, perturbations are generated using the Fast Gradient Sign Method (FGSM) [
42]. The FGSM computes the gradient of the objective function with respect to the observed value to determine the direction and magnitude of the perturbation. Specifically, the perturbed value
is given by
where
is a hyperparameter controlling the magnitude of the perturbation, and
is the error between the observed value and the reconstructed value, indicating deviation from the model’s reconstruction.
The sign function plays a crucial role in perturbation generation, determining the direction and magnitude of the perturbation. Specifically, the sign function operates as follows:
If , i.e., , then , meaning that the perturbation is added to (i.e., is increased).
If , i.e., , then , meaning that the perturbation is subtracted from (i.e., is decreased).
If , then no perturbation is applied.
This method ensures that the perturbation is applied in the direction of the model’s prediction error, maximizing the model’s ability to adapt to worst-case input scenarios.
Based on the perturbed reconstructed value
, the adversarial regularization term
is defined to incorporate the perturbation’s effect into the model’s training. This regularization term measures the difference between the perturbed sample and the reconstructed data, and it is given by
The purpose of this regularization term is to dynamically adjust the instance error through perturbations, thereby enhancing the model’s sensitivity to disturbances.
By adding the regularization term (
15) into the objective function (
12), the adversarially regularized objective function
becomes
where
is a hyperparameter controlling the weight of the adversarial regularization term, balancing the influence of the original error and the adversarial loss. By minimizing
, the model not only reduces the prediction error on the original data but also strengthens its robustness to perturbed data.
Figure 3 presents the procedure for perturbing the
tensor to generate the perturbed tensor
.
3.3. Stochastic Gradient Descent (SGD)-Based Tensor Factorization Model
According to [
27,
28,
44], SGD reduces computational complexity by iteratively optimizing the gradient of individual samples (or mini-batches), making it particularly suitable for high-dimensional and large-scale tensor factorization. Additionally, its simplicity and ease of implementation further enhance its applicability. Therefore, this study employs SGD to minimize the objective function in (
16), with the update rules specified as follows:
where
is the element-wise error term in the objective function
, representing the contribution of the error at position
to the entire objective function.
The detailed computation of the gradients of
with respect to the DPs
,
, and
in (
17) is as follows:
3.4. Incorporating Momentum in TF
The Momentum Method is a technique used to accelerate the optimization of gradient descent [
45,
46]. By introducing the concept of “momentum” in parameter updates, it reduces oscillations during training and speeds up convergence. The core idea of the Momentum Method is to apply an exponentially weighted moving average of past gradients to the current gradient update. This means that, when updating parameters, it not only considers the current gradient but also accumulates information from previous gradients, thus accelerating in steep directions and reducing oscillations in winding paths.
The update formulas of the Momentum Method are as follows:
where
represents the parameter value at the
t-th iteration, and
represents the updated “momentum”, which is the weighted sum of the current gradient and the historical gradients.
To accelerate convergence in solving the tensor factorization model, the SGD algorithm is improved. By combining (
17) and (
19), the update rule for the decision parameter matrix
based on the Momentum Method is given as
Since the momentum-based update rules of
and
are similar to those of
, they are not presented here. In this paper, three auxiliary matrices,
,
, and
, are used to record the historical momenta of the DPs
,
, and
. Based on (
17) and (
20), the detailed update rules of the DPs are as follows:
The RMNTF model is fully presented as described above.
3.5. Algorithm Design and Analysis
Building on the above, this paper presents Algorithm 1, which aims to optimize model performance by updating the DPs. This process involves calculating historical momentum and applying dynamic error perturbations. The computational complexity is
| Algorithm 1 RMNTF |
| Input:
|
| output: |
| Operation | Cost |
| 1: | Initialize with random numbers | |
| 2: | Initialize with zeros | |
| 3: | Initialize | |
| 4: | while converge | |
| 5: | for do | |
| 6: | | |
| 7: | Compute using (14) | |
| 8: | for to R do | |
| 9: | | |
| 10: | | |
| 11: | | |
| 12: | | |
| 13: | | |
| 14: | | |
| 15: | end for | − |
| 16: | end for | − |
| 17: | end while | − |
In practical scenarios (as shown in
Table 2),
. Thus, lower-order terms and coefficients are omitted to derive (
22). Furthermore, given that
n and
R are both positive, the computational complexity of RMNTF can be inferred to be linear with respect to the number of known elements
.
The storage complexity is primarily determined by three factors: (1) the DPs
and
and their corresponding LFs
O, and
W; (2) the auxiliary matrices
used to store the historical momentum information of the DPs; and (3) the entries in the set
, along with their corresponding reconstructed values. Therefore, the storage complexity of the model is given by
In (
23), the storage complexity of the RMNTF model primarily depends on the number of known tensor entries and the dimensionality of latent factors, both of which exhibit a linear relationship.
5. Discussion
The findings of this study provide valuable insights into PC data analyses, particularly in the context of high-dimensional and incomplete data. Our proposed RMNTF model demonstrates significant improvements in both accuracy and computational efficiency over existing methods. This section discusses the results in relation to those of previous studies, the working hypotheses, and their broader implications, and it suggests potential directions for future research.
Our results support the working hypothesis that integrating adversarial loss regularization and
regularization enhances the robustness of tensor factorization models in the presence of incomplete data. RMNTF’s superior performance, evidenced by lower RMSE and MAE values across all datasets, highlights the effectiveness of these regularization techniques. This is consistent with prior studies, which emphasize the benefits of regularization in improving generalization and stability in machine learning models [
53,
54]. Another key contribution of our model is the enforcement of non-negativity constraints via the sigmoid function, ensuring that imputed values are physically meaningful and interpretable. This aligns with the inherent characteristics of PC data, which cannot be negative, and represents a significant advancement over models that do not incorporate such constraints. The momentum-based optimization approach in RMNTF has proven to be an effective tool for accelerating convergence, reducing the computational burden compared to that of traditional tensor factorization methods. This is especially relevant for large-scale applications, where time and resource efficiency are critical.
The implications of our findings go beyond PC data analyses. RMNTF’s ability to accurately handle high-dimensional and incomplete data makes it applicable across various domains, including finance, healthcare, and social network analyses [
55,
56,
57], where such data characteristics are common. The model’s robustness and interpretability make it a valuable tool for decision-making in these fields.
Despite the promising results demonstrated by RMNTF, several limitations must be addressed in future work:
Computational Resource Requirements: While RMNTF performs well in terms of computational efficiency, its resource demands remain high when processing large-scale datasets. In resource-constrained environments, such as embedded systems or mobile devices, scalability and parallelization are crucial. Future research should focus on adapting RMNTF for distributed computing and parallel frameworks to improve efficiency in large-scale applications [
58,
59].
Complexity of Parameter Selection: The model’s performance is highly sensitive to hyperparameters (e.g., regularization and momentum coefficients). Selecting appropriate parameters often requires extensive experimentation and tuning, which adds complexity. Future work should explore smarter hyperparameter optimization methods, such as Bayesian optimization or metaheuristic algorithms, to automate the selection of optimal parameters and enhance both usability and efficiency [
60,
61].
Real-World Validation: Although RMNTF has been tested on public datasets, these may not fully capture the complexities of real industrial environments. Validating the model in real-world settings is essential to assess its effectiveness, robustness, and stability, especially in environments with higher noise and data uncertainty. Future research should focus on applying the model to industrial applications and conducting field validation to evaluate its performance in real-time data processing [
62,
63].
Limitations of Data Sources: The datasets used in this study are primarily sourced from publicly available PC datasets, which may introduce biases and limit the model’s generalizability. Future research should consider more diverse data sources, including different building types, regions, and devices, to improve the model’s adaptability and generalization capability [
64].
Data Quality Limitations: Although the datasets have been cleaned and preprocessed, noise and outliers may still persist, affecting model accuracy. Future work should adopt more advanced noise filtering and outlier detection methods to enhance data quality and ensure stable model training and prediction [
65,
66].
In conclusion, the RMNTF model represents a significant advancement in tensor factorization for handling missing PC data. Its effectiveness, robustness, and efficiency position it as a leading solution for data imputation tasks. Future research will further refine and expand the model’s capabilities, ensuring its continued relevance and impact in the era of big data.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}