Abstract
With the rapid development of in-vehicle communication technology, the Internet of Vehicles (IoV) is gradually becoming a core component of next-generation transportation networks. However, ensuring the activity and reliability of IoV nodes remains a critical challenge. The emergence of blockchain technology offers new solutions to the problem of node selection in IoV. Nevertheless, traditional blockchain networks may suffer from malicious nodes, which pose security threats and disrupt normal blockchain operations. To address the issues of low participation and security risks among IoV nodes, this paper proposes a federated learning (FL) scheme based on blockchain and reputation value changes. This scheme encourages active involvement in blockchain consensus and facilitates the selection of trustworthy and reliable IoV nodes. First, we avoid conflicts between computing power for training and consensus by constructing state-channel transitions to move training tasks off-chain. Task rewards are then distributed to participating miner nodes based on their contributions to the FL model. Second, a reputation mechanism is designed to measure the reliability of participating nodes in FL, and a Proof of Contribution Consensus (PoCC) algorithm is proposed to allocate node incentives and package blockchain transactions. Finally, experimental results demonstrate that the proposed incentive mechanism enhances node participation in training and successfully identifies trustworthy nodes.
1. Introduction
As a key component of Internet of Things (IoT) applications, the Internet of Vehicles (IoV) technology enables seamless interconnectivity among vehicles, traffic infrastructure, and networks. This capability has positioned IoV as a focal point of interest for both industry and academia in recent years [1]. However, in the context of rapidly increasing data volumes in smart city transportation environments, IoV technology still faces numerous challenges that remain to be addressed. Meanwhile, the interaction between vehicles and communication-enabled network devices generates a vast amount of data flow, posing significant security challenges related to data sharing and transmission within vehicle networks [2]. On the one hand, the immense economic value of IoV data makes it increasingly vulnerable to threats such as data theft, attacks, and misuse [3]. On the other hand, the diversity of communication entities and the complexity of communication methods in IoV systems exacerbate the difficulty of managing and controlling these entities. While existing security solutions for IoV primarily focus on enhancing communication efficiency or protecting data privacy, there remains a significant gap in ensuring the trustworthiness of nodes and improving the overall security and reliability of the system.
In recent years, blockchain technology has garnered significant attention from scholars as a prominent research area [4,5,6,7]. Blockchain integrates various technologies, such as peer-to-peer (P2P) networks, smart contracts, consensus algorithms, and cryptography, to form a novel distributed ledger technology. Its decentralized nature, immutability, traceability, and transparency make it highly applicable in fields like the IoV, particularly in addressing centralization, data security, and privacy protection challenges. As an advanced distributed machine learning framework, FL plays a critical role in distributed environments and has made significant strides in safeguarding data privacy [8]. The combination of blockchain and FL offers a promising direction for tackling IoV-related challenges. FL allows various users to collaboratively process their data while aiming to build a unified and efficient global model [9]. Within this framework, each user retains exclusive local data ownership and actively participates in the network model training. Users serve as the sole holders of their local data and contribute parameters to the global model training process. Compared to traditional centralized machine learning methods, FL prevents the transmission of sensitive data between nodes, thus avoiding potential privacy breaches. Instead, users can retain their private data on local devices, ensuring data security and privacy.
However, the efficient and secure selection of nodes for participation in federated learning tasks remains a critical issue that needs to be addressed [10,11,12]. When selecting participant nodes, multiple factors, such as computational capabilities, communication bandwidth, and data quality, must be comprehensively considered. At the same time, effective security mechanisms are required to protect participants’ privacy and data security, preventing malicious attacks and data leakage [13,14,15].
To address these challenges, this paper proposes a solution that combines blockchain technology with FL, aiming to solve the security issues of FL in the context of IoV. Additionally, a reputation evaluation mechanism is introduced, which dynamically assesses the historical behavior of nodes to ensure the selection of high-quality and reliable nodes for model training, thereby enhancing the stability and effectiveness of the federated learning process. The main contributions of this paper can be summarized as follows:
- We propose a consensus mechanism that differentiates node incentives based on their contributions and introduces a reputation management system to monitor and regulate the reputation scores of nodes.
- We establish state channels and introduce a side-chain structure to alleviate the computational load on the main chain. Additionally, we calculate the C-Capacity value to assess the contribution of nodes participating in FL tasks, determining the rewards each node receives from the task issuer.
- We comprehensively evaluate nodes based on honesty, data accuracy, and interaction timeliness. Nodes with better performance will experience faster increases in their reputation scores. Experimental results demonstrate that the proposed algorithm offers advantages in terms of reduced latency and improved data packet arrival rates while incentivizing network nodes to participate in message forwarding.
The remainder of this paper is organized as follows: Section 2 discusses related work, Section 3 introduces our system model, Section 4 presents the state-channel-based node incentive mechanism, and Section 5 describes the PoCC consensus algorithm based on C-Capacity value proof. Section 6 provides experimental comparisons, and Section 7 concludes the paper.
2. Related Work
Research on blockchain-based IoV models is rapidly emerging [16,17,18,19,20]. With its decentralized structure, traceability, and immutability, blockchain enables the secure storage of vehicle privacy data and protects user data, making it widely adopted in IoV applications. The integration of blockchain and IoV holds excellent potential for future development. FL has already been successfully applied across various industries, and this paper explores its application within the IoV, proposing a FL system explicitly tailored for IoV environments.
At present, research on integrating blockchain with IoV in machine learning primarily focuses on FL [21,22,23,24,25]. FL enables distributed model development, allowing global users to collaborate without the centralized storage of local data, thus providing a certain degree of data privacy and security. Kim et al. [26] were the first to introduce blockchain into the FL infrastructure, proposing a local model update mechanism that garnered widespread attention. Li et al. [27] designed a privacy-preserving ride-sharing scheme, employing a private blockchain to encrypt ride-sharing data, ensuring secure communication between vehicles and users. Qu et al. [28] proposed the FL-Block fog computing model, combining blockchain with FL to achieve decentralized privacy protection, thereby preventing single-point failures and poisoning attacks. However, this model can still not entirely prevent malicious behavior from internal nodes. Tong et al. [29] proposed a blockchain-based hierarchical federated learning (HFL) framework to support UAV-enabled IoT networks. By integrating lightweight blockchain technology into federated learning, the framework addresses the trust deficit issues arising from decentralized global model aggregation. Wang et al. [30] developed a blockchain-based federated learning framework that enables fully decentralized learning while accounting for model and data heterogeneity. The framework incorporates a blockchain-based two-layer mining process designed to support secure and decentralized learning. Ghimire et al. [31] explored the issue of information propagation delay in blockchain-based federated learning for IoV through a blockchain-enabled federated learning architecture. Sui et al. [32] proposed an effective attack method targeting the signature algorithm in lightweight privacy-preserving blockchain federated learning (LPBFL) for IoT environments. They also designed a new signature method and a formal security model to provide robust protection against the identified security vulnerabilities. H. ur Rehman et al. [33] developed a hybrid blockchain architecture that combines consortium blockchain with locally Directed Acyclic Graphs (DAG), utilizing an asynchronous FL scheme based on deep reinforcement learning (DRL) to improve the effectiveness and reliability of data sharing. However, this architecture still relies on traditional consensus algorithms, leading to additional computational resource consumption, which limits performance improvements. Lu et al. [34] proposed a blockchain-enabled secure federated edge learning system that employs a layered blockchain framework, utilizing a main chain and sub-chains to achieve performance isolation and decentralized data management. However, this framework does not account for blockchain forks, which may cause interruptions in model updates. Xu et al. [35] designed a blockchain-based distributed privacy-preserving learning system that optimizes the FL framework, reduces centralization, enhances data security, and incorporates Byzantine fault tolerance to ensure the stability of model operation.
In summary, current research on blockchain-driven machine learning primarily focuses on enhancing the efficiency of federated learning, including improvements in training accuracy, convergence speed, and data reliability. However, in most cases, traditional blockchain consensus mechanisms are not suitable and present challenges such as resource inefficiency, potential centralization, forced consensus leading to timeouts, and limited scalability, making it difficult to meet dynamic user demands. To address these challenges, this paper proposes a solution that integrates blockchain and FL. By introducing a state-channel transfer mechanism, training tasks are offloaded from the main blockchain to the off-chain, mitigating computational conflicts inherent in traditional consensus mechanisms. Furthermore, we design a PoCC consensus algorithm based on contribution value, which effectively incentivizes node participation and dynamically adjusts rewards and engagement based on node contributions. Additionally, a novel reputation mechanism is introduced to filter reliable nodes by evaluating their contributions in federated learning, ensuring the trustworthiness of nodes within the IoV system.
3. System Model
The system model of the proposed FL framework is illustrated in Figure 1, consisting of three main layers: the blockchain layer, the application layer, and the edge layer. The blockchain layer is responsible for storing network transaction information and the historical reputation scores of nodes. The data interaction process for FL occurs in the application layer, including task publishing and submission tasks. This layer comprises roadside units (RSUs), which manage communication between vehicles within a designated region and other participating vehicles. The edge layer encompasses cloud servers with powerful computational capabilities, which handle local model training tasks that the primary chain nodes cannot process efficiently.
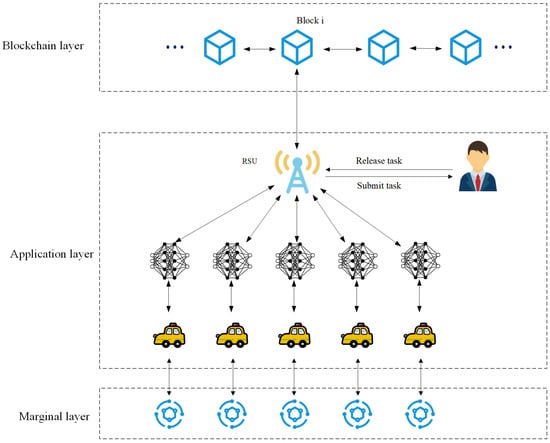
Figure 1.
Federated learning system model.
In this paper, computationally intensive training tasks are delegated to the side chain, while tasks requiring data privacy protection are executed on the main chain. The blockchain system employs a dual-chain architecture, where the main chain consists of a central server and working nodes, while the side chain is composed of authorized nodes dedicated to alleviating computational load. For security purposes, both the main chain and side chain are designed as consortium blockchains, enhancing reliability and ensuring efficient block generation. The consensus process between blocks is completed using a Contribution-Capacity consensus mechanism. In the proposed FL framework, participants are categorized into three primary roles:
- Task Publisher: Responsible for announcing the detailed requirements of the FL tasks on the blockchain and providing corresponding incentives.
- Central Server: Acts as the manager of FL tasks. Upon receiving the task from the publisher, it selects working nodes to perform the local training process. The central server typically operates as one of the nodes on the main chain and is also responsible for managing incentives and task distribution.
- Working Nodes: Participants in the FL tasks, utilizing their local data to update model parameters. They receive varying incentives based on their training results.
The composition of participants in existing FL systems closely mirrors that of blockchain architectures. The central server assumes the role of a leader node, while the working nodes share similarities with the mining nodes in blockchain systems, facilitating deeper integration between the two. The task flow for each participant in the FL process is illustrated in Figure 2.
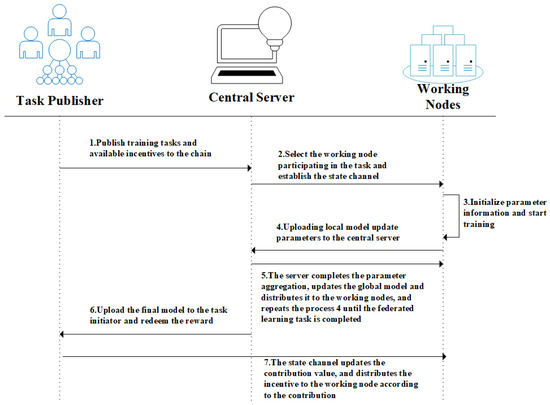
Figure 2.
Task publication and incentive process.
In the task process, the task publisher first announces the specific FL task and the corresponding reward details on the central server. Upon receiving this information, the central server temporarily holds the task rewards to ensure fairness and security. Additionally, the central server deploys key information, such as the task’s initialization parameters, on the main chain, allowing the working nodes to smoothly access this information for subsequent tasks.
Once authorized to participate in the FL task, the working nodes begin executing the task after completing their initialization configuration. Each working node operates with its independent dataset and computational resources. During the training process, these nodes continuously update their local models and generate corresponding gradient parameters, accurately reflecting their contribution to optimizing the global model.
To ensure fairness and efficiency in the training process, the central server leverages side-chain technology to evaluate each working node’s contribution during every training round. By assessing the impact of each working node on the global aggregation process, the central server determines the corresponding reward for each node based on its contribution in that round and updates the cumulative incentive status. This contribution-based incentive mechanism encourages active participation and engagement from the working nodes, facilitating the smooth execution of the FL tasks.
Once the model gradually converges and meets the task’s predefined requirements, the central server uploads the final model to the task publisher. Upon receiving the model, the task publisher conducts validation and testing to ensure that its performance and accuracy align with the expected standards. Once the validation is successful, the task publisher will download the model and mark the task as complete. At this point, the participating working nodes can redeem their earned incentives from the central server.
4. State-Channel-Based Node Incentive Mechanism
4.1. State-Channel Parameters
State channels [36], as an efficient off-chain transaction method, enable transactions to be transferred to side chains, reducing the burden on the main blockchain and increasing the system’s transaction throughput. By using state channels, transaction delays are deferred until on-chain processing, allowing nodes to perform complex computations off-chain, thereby reducing the computational load on the main chain. The results of off-chain computations are stored locally but eventually must be recorded on-chain. The core concept is to accumulate off-chain states, delaying changes in node incentives and easing on-chain pressure. Since the blockchain verification of each transaction and periodic consensus mechanisms significantly reduce the efficiency of FL while also increasing storage and computational costs, this paper integrates state-channel mechanisms with FL to accelerate the learning process and alleviate the computational burden on main-chain nodes. The state-channel process can be summarized in three stages:
- Channel Initialization: Before FL begins, the task publisher sets up the training task on the blockchain, and a state channel is established between each participating worker node and the task publisher. This channel remains locked until the completion of each round of the learning task. After every consensus round, the state of each worker node is updated through the state channel.
- Off-Chain Trusted Computation: During the model training process, the data generated can be transferred to trusted off-chain nodes for computation through the state channel. The task publisher and multiple worker nodes update the states by creating transactions that can be submitted to the main chain. Each state change updates the “Status” parameter in the transaction block, and the transaction value represents the reward for each worker node’s contribution, calculated based on the Contribution-Capacity value vector. This ensures that the incentives earned by each node for its contributions continuously exceed the computational costs incurred, promoting steady growth in rewards.
- Channel Closure: Once FL has converged and reached its final stage, the state channel between each node and the task publisher is closed. Before the channel closure, each worker node uploads its final transaction block, which includes the total redeemable incentive amount earned by the node during the FL task.
When miners receive a FL task, they select data criteria that match the target training based on the service requester’s needs, such as data content, timeliness, and the identity of data holders, and specify this information within the task. Willing participants can join the channel according to these criteria, either running locally as main-chain nodes or submitting the task to trusted third-party blockchain nodes (miners) for completion. Once the minimum number of participants required for the task is reached, the task’s basic configuration information is deployed to the blockchain for all participants to download and synchronize. Simultaneously, the task publisher must deposit the incentive amount and task collateral into the miner node to prevent resource waste in the event of task cancellation. The basic configuration information of the task includes:
- Channel Construction Parameters: Key parameters for each participating miner node account, including the amount of valid data contributed, the addresses of the channel participants, and the signature threshold required for channel updates.
- FL Parameters: For all FL tasks, certain fundamental training parameters must be pre-configured, such as the choice of the initial model, common hyperparameters, and parameters related to model iteration. Once the task is initiated, the central server and participating nodes will first complete the initialization phase of FL, which includes model initialization and preprocessing of training data. After the model is successfully initialized, the clients will begin the initial training of the model using local data.
- Model Accuracy: The accuracy of the local model in relation to the global model is a critical factor influencing the reputation score of the working node. This score reflects the contribution of the local model’s training results to the parameter aggregation process. The higher the local model’s training accuracy, the higher the corresponding reputation score of the working node. Conversely, nodes with lower training accuracy will have lower reputation scores. The calculation of model accuracy will be discussed in detail later.
4.2. Data Interaction Process
The off-chain data interaction process is achieved by establishing the same transaction model as the current blockchain and continuously adjusting its process state values. Once a working node begins training its local model, the interaction between the central server, which manages the task, and any client during the nth round of training is illustrated in Figure 3.
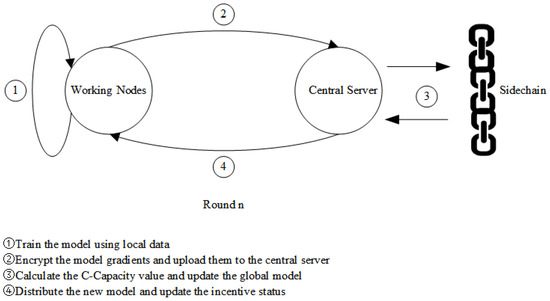
Figure 3.
Federated learning process in the n-th round.
The detailed workflow is as follows:
- During the initialization phase, the client collects data from each vehicle participating in the training within the IoV and performs multiple model iterations using these local datasets to obtain the latest local model gradient values.
- The working node then encrypts the model gradient values from this update and transmits them to the central server. Once the server receives gradient values from a number of clients exceeding the predefined threshold, it aggregates the local gradients of each participating client using an aggregation function, producing a global model. Simultaneously, the server also publishes a task on the side chain to calculate the Contribution-Capacity (C-Capacity) values based on the accuracy of each node’s model in this training round.
- Nodes in the side chain use the aggregation function to calculate the C-Capacity value vector for all participating clients in the current round. The central server then updates the global model using the aggregated parameters.
- The aggregation nodes calculate each working node’s contribution value for this round based on the blocks received from the side chain and update the nodes’ incentives. They construct incentive messages and sign the message block using their private keys. Subsequently, they encrypt the model parameters obtained from the previous round’s aggregation with a specific encryption algorithm and package the model together with the incentive messages. This package is then sent to all working nodes as the starting point for the next round of training. Upon receiving the package, the working nodes verify its contents and, once confirmed, proceed to the th round of FL tasks.
In each round of FL, clients contribute to the global model by uploading local model gradients, while the central server updates their individual incentives based on contribution using side-chain technology. Transactions within the side chain accumulate without the need for immediate submission to the main chain, reducing the burden on the main chain, but preventing immediate incentive redemption. To safeguard their interests, worker nodes must monitor the status of their incentive updates. At the conclusion of the state channel, worker nodes rigorously verify the correctness of the messages. After multiple rounds of parameter aggregation, the global model maintained by the central server gradually converges. Once the task requirements are nearly met, the process enters the state channel closing phase.
Once the task publisher’s criteria are met, the central server announces the closure of the transmission channel and initiates the incentive redemption period. Worker nodes must submit transactions before the deadline using the latest incentive data and signatures, ensuring the signatures align with the highest reward amounts. Nodes are required to include incentive status update details. In the parameters section of the FL parameter field, sign it with their private key to ensure the correct identity for redeeming all rewards. After the redemption period ends, the central server will check for any unused incentives, allocate the earned rewards, return any remaining incentives to the task publisher, and close the state channel. If malicious behavior is detected, the central server will disqualify the node from the task and revoke its rewards.
The structure of the main-chain transaction block is illustrated in Figure 4, omitting some basic components of the blockchain transaction block process for simplicity.
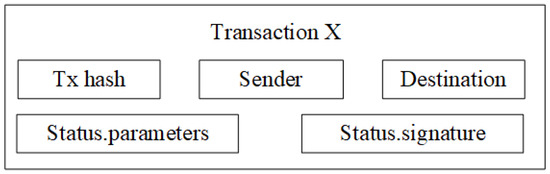
Figure 4.
The structure of the transaction block.
4.3. Behavioral Detection and Reputation Management Mechanism
In general, the central server is reluctant to accept local model updates from working nodes that consistently propagate false information. Before model aggregation, various classic attack detection methods are employed to evaluate the quality of local model updates [37]. If a client engages in positive sharing behavior with its server, the accuracy of the global model improves, and the client’s reputation score increases. Conversely, negative sharing behavior results in a decline in the client’s reputation. Nodes with reputation scores that fall below a certain threshold will be disqualified from participating in further training.
This paper focuses solely on the impact of the interaction between a single client and the central server on the client’s reputation score. For simplicity, we use i and j to represent the vehicle and its leader, respectively. Leader j calculates the reputation of vehicle i based on the following factors:
- Honesty Scores: A higher honesty score between the vehicle and its leader indicates more positive interactions. Based on the two types of model sharing in the interaction—positive sharing and negative sharing—the honesty score can be categorized into the following two types, with the respective calculation formulas:where represents the total number of interactions between vehicle i and leader j, and denotes the number of positive or negative sharing interactions, respectively.
- Model Accuracy (Ac): The degree to which a vehicle improves model accuracy is another factor influencing its reputation. Let the global model loss before and after the t-th interaction between vehicle i and its leader j be represented as and , respectively. The model accuracy for vehicle i during the t-th interaction is calculated as follows:When the global model’s loss decreases after the t-th interaction, i.e., , it indicates that the updated model has had a positive impact on the global model, resulting in . The greater the reduction in loss, the higher the value of . Conversely, if the loss increases, . If the uploaded parameters have no effect on the global model, . Contributions are classified into positive and negative contributions.where represents positive contributions, and represents negative contributions.
- Interaction Timeliness: The sharing of local models by vehicles is not always consistent, meaning that more recent events have a greater impact on accurate and reliable reputation calculations. Therefore, the interaction timeliness between leader j and vehicle i is defined as:where represents the current time, and is the time when vehicle i shared its local model during the t-th interaction. This is a weighted function that uses model contribution as a weighting factor, taking into account the importance of both model contribution and timeliness. The interaction timeliness function can also be divided into positive and negative values:
The reputation score is used to evaluate the interaction behavior between working node i and server node j. Taking the aforementioned factors into account, the reputation score for working node i is defined as follows:
where and represent the weights assigned to honest and malicious behaviors, respectively. The honest behavior of working node i increases the values of and , both of which are always non-negative. Conversely, the product of and is always negative, and its absolute value increases with the frequency of malicious behavior. By combining these two parts, the final reputation score for working node i is calculated.
The reputation scores for all clients receiving tasks from the central server j are calculated, and the highest reputation score is defined as , . The threshold for the reputation score is represented as , . The system selects vehicles with reputation scores exceeding this threshold to proceed to the subsequent iteration stage. The value of is adaptive based on the model training requirements; as increases, the reliability demands of the model also increase, requiring more iterations to meet specific global model loss criteria. Using this trust mechanism, the task publisher can select higher-quality vehicle nodes as participants in the FL process and set specialized training objectives. These requirements can be sent to the working nodes as part of the transaction details.
5. PoCC Consensus Algorithm Based on C-Capacity Proof
5.1. Consensus Algorithm Process
In the PoCC consensus algorithm, to promptly reflect the quality of node behavior and ensure the trustworthiness of the selected nodes, the task publisher node dynamically updates the reputation score of each miner in the blockchain. The workflow of the PoCC consensus algorithm is shown in Figure 5.
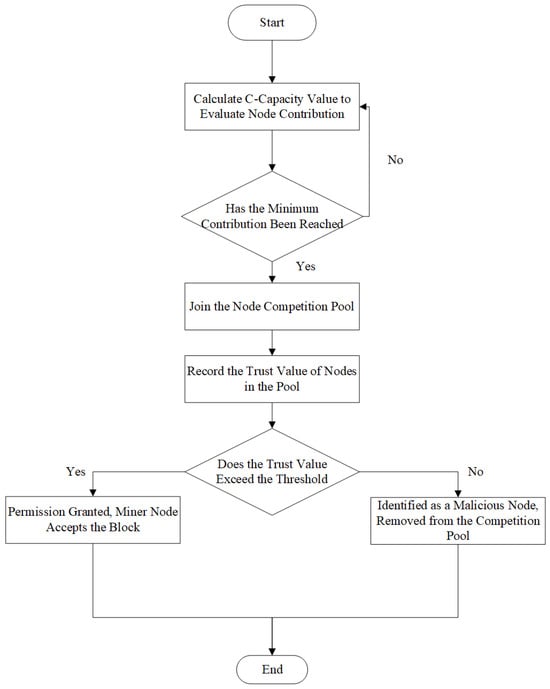
Figure 5.
Consensus algorithm workflow diagram.
The specific steps are as follows:
Step 1: Establish the interaction between the central server and the working nodes: In the network, when a miner node connects with the task publisher node, it is considered an interaction, establishing a relationship between the two. During the process of information transmission and behavior interaction, nodes will receive a dynamically updated reputation score. Conversely, if a node fails to connect with the task publisher node, no interaction occurs, and the node is considered to have exited the current consensus.
Step 2: Calculate node contribution: The accuracy of the model parameters generated by the miner node’s local model training is evaluated. Contributions are assigned based on the accuracy of different models among nodes, and rewards are distributed accordingly. This contribution is also used to dynamically adjust the difficulty of subsequent proofs.
Step 3: Selecting reliable nodes to generate blocks: First, the predefined reputation threshold is checked to assess whether each working node’s real-time reputation meets the required standard. Nodes that meet the threshold are permitted to continue participating in the federated learning task. The nodes that pass this filtering process are considered more reliable and secure.
Step 4: Block creation and confirmation: Given that all working nodes have equal status, each has an opportunity to submit blocks to the blockchain. The algorithm ensures that blocks are generated in sequence based on each node’s contribution. During the block verification process, when a working node passes the reputation check and is granted permission to create and submit a block, the other nodes confirm the legitimacy of that block.
Step 5: Status update: After each consensus process is completed, participating nodes update their reputation scores by querying prior interactions with the central server. The updated reputation values will serve as the basis for the next round of consensus. Additionally, the contribution and reputation values of each working node are packaged and stored on the main chain, recording the behavior of the nodes in this round and initiating the next consensus round.
Within the PoCC consensus algorithm framework, each working node is eligible to generate a block. When a working node actively contributes to the global model, its reputation score is enhanced. Conversely, nodes that engage in harmful behavior are downgraded to a lower reputation level. If their reputation drops below a predefined threshold, they will no longer be considered trustworthy or active participants. As a result, it becomes very difficult for nodes to negatively impact the global model using heterogeneous data.
5.2. Proof of Contribution
In game theory, the distribution of participants’ benefits based on the Shapley value [38] reflects each coalition member’s contribution to the overall objective. This approach allows participants to receive a proportional share of the benefits according to their individual contributions, making it fairer than traditional average-based distribution methods. It also offers a more balanced and reasonable allocation compared to methods solely based on resource investment, resource allocation efficiency, or any combination of the two, as it captures the collaborative efforts of all members.
The formula for calculating the Shapley value is as follows:
where represents the total value increment of the coalition when node i joins the subset s. This is the core of the Shapley value, quantifying the actual contribution of node i; represents the set of all subsets containing member i, and denotes the weighting factor for each scenario, which is calculated as follows:
where the weight coefficient is used to calculate the Shapley value and represents the probability of subset sss occurring, determined by the size of subset s and the permutations of the remaining nodes, normalized by the total number of permutations .
As the number of worker nodes increases, the computational complexity of Shapley value calculations escalates rapidly, turning it into an NP (Nondeterministic Polynomial) problem, which is one of the limitations of traditional Shapley values. Although blockchain consensus algorithms create blocks through hash computations, this high computational cost is unacceptable in many applications due to the waste of computational power. In existing research, the use of Shapley values for allocating federated learning incentives is limited, and typically, only the incremental impact of clients on the global model is considered, overlooking imbalances between participants. Traditional Shapley value assumes equal risk distribution among coalition members. Still, in federated learning, each participant contributes only local model parameters rather than raw data, which can result in suboptimal global model updates and affect research outcomes. To address these issues, this paper proposes a novel Contribution-Capacity value (C-Capacity) to replace the Shapley value by dynamically optimizing the contribution levels of different training nodes. Under a diversified training node algorithm, the C-Capacity value is transferred to side-chain computations, utilizing its complexity as a consensus difficulty value to prevent resource waste on the main chain and ensure fair contribution allocation. This paper also adjusts the C-Capacity value calculation formula and optimizes two key parameters:
- Weight Optimization: Considering the impact of node interaction behavior on the system model, this paper introduces an additional set of data reliability weights for the proof value:where represents the reliability weight of the data held by the i-th working node in the federated learning task. This value does not fully reflect the quality of the node’s local dataset within the C-Capacity score, as it is influenced by multiple factors. The formula for calculating is as follows:where , it can be observed that the sum of the weights for all participants in a given task equals 1. represents the honesty score of working node i during training round h, based on its interactions with central server j. The honesty score of the working node will be recorded on the main chain and associated with the node’s identity.The improved weight can be expressed as follows:Compared to traditional weight allocation methods, the PoCC algorithm incorporates the role of node reputation. The reputation score is continuously updated based on each node’s actions within the federated learning process, enabling dynamic adjustments to the weight values. Nodes that make more positive contributions are assigned higher weights, incentivizing greater participation and performance.
- Contribution Optimization: In the proposed federated learning model, the task publisher can either provide a dataset for the central server to verify the accuracy of the working nodes’ trained models or allow the working nodes to evaluate model performance using a portion of their own local datasets. During the optimization of the training process, this paper not only focuses on the small impact of local model parameters on the overall loss function but also emphasizes model evaluation metrics. A reduction in the loss function does not always directly indicate the superiority of the final model. The contribution optimization function can be expressed as follows:where , is a system-defined constant used to control the weight proportion of the parameters; represents the time spent by the central server to verify the training results, and indicates the average time taken by all nodes to complete the training task. The function f is the loss function of the federated learning model, which is specifically defined as:where A is the predefined local model update function for different tasks, represents the set of local model updates from the working nodes, denotes the loss function of the local model, and c represents the input from the working nodes.
In summary, the C-Capacity value can be calculated using the following formula:
The C-Capacity value reflects each node’s contribution to the federated learning process. A higher C-Capacity value indicates that a node has provided more resources, making it eligible for greater rewards from the task publisher. Introducing this value encourages competition among nodes, as those contributing more can earn higher returns. This motivates nodes to maximize their contribution to the system, enhancing overall node participation and engagement.
After the main node completes the calculation of each node’s C-Capacity and reputation values in the network, it determines whether the node’s contribution to the federated learning task meets the system’s minimum requirements. If the requirements are met, the node is added to the competition pool. The behavior of nodes in the competition pool is continuously monitored, and if the central server detects malicious activity, the reputation of those nodes will be reduced. Conversely, the reputation of nodes making positive contributions to the system will be increased. In addition, the PoCC algorithm considers the accuracy of model training and the interaction between miner nodes and working nodes as key factors in determining the overall reliability of a node. The system evaluates reputation based on predefined benchmarks and selects appropriate clients for task training, creating a reliable global model. A reputation threshold N is used to filter the set of working nodes. If a miner node’s reputation is below N, it will not be allowed to participate in federated learning task training. However, if the reputation is greater than or equal to N, the node can continue to participate until its reputation drops below the acceptable level in a subsequent round.
6. Simulation Results and Analysis
6.1. Parameter Settings
The experimental setup for this section is as follows: the operating system is 64-bit Windows 11, with an i5-12500 CPU running at a base frequency of 3.0 GHz and 16 GB of DDR4 memory. The development languages used are C++ and Python, and the federated learning experimental environment is built on the PyTorch framework. We evaluate the effectiveness of the reputation mechanism in limiting malicious nodes in the FL model using the HighD dataset, and assess the performance of the filtered vehicle nodes across various aspects of the FL process. A list of the parameters used in the experiment is provided in Table 1.

Table 1.
Initial parameters for simulation.
6.2. Results Analysis
To validate the effectiveness and advantages of the proposed POCC algorithm, comparative experiments were conducted using the TBMS algorithm from [39], the BRM algorithm from [40], and the ADOV algorithm from [41]. The algorithms selected for comparison share similar objectives with the proposed algorithm, as they leverage blockchain technology and incorporate reputation-related mechanisms to improve the stability and reliability of system communication while reducing the impact of malicious nodes within a certain number of participating nodes. However, the compared algorithms do not explicitly consider the incentive effects on nodes or the impact of specific or historical node behaviors on the system. Therefore, the comparison highlights the effectiveness of the proposed algorithm in addressing these aspects.
Figure 6 illustrates the change in message delivery rates under low vehicle density conditions in the network, comparing the PoCC algorithm with the TBMS algorithm, the BRM algorithm, and the ADOV algorithm. As the proportion of malicious vehicle nodes in the network gradually increases from 10% to 45%, a steady decline in transmission success rates can be observed across all four algorithms. This trend indicates that the overall performance and reliability of the network face increasing challenges as the number of malicious nodes grows. Notably, when the proportion of malicious nodes remains constant, the PoCC algorithm proposed in this paper effectively tracks and evaluates node performance through localized training processes. This mechanism not only enhances the network’s ability to identify malicious nodes but also improves its defense and resilience against harmful nodes. This advantage allows the PoCC algorithm to maintain higher stability and reliability in the face of malicious attacks compared to the TBMS algorithms and the BRM algorithm.
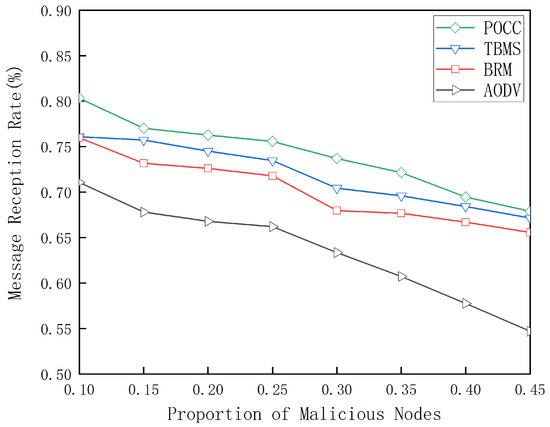
Figure 6.
Transmission rate under different proportions of malicious nodes.
Figure 7 shows how the average latency of the PoCC algorithm, as well as the TBMS algorithm, the BRM algorithm, and the ADOV algorithm, changes with the increasing number of malicious vehicle nodes. The figure indicates that as the number of malicious nodes in the network increases, the average latency for all four algorithms also rises. This suggests that more malicious nodes negatively impact network performance, leading to higher data transmission delays. Under the same proportion of malicious nodes, the latency of the PoCC algorithm is slightly higher than that of the other algorithms. This is because the PoCC algorithm emphasizes security in its design, which may require additional time and resources when dealing with malicious nodes, thus resulting in increased latency. However, this increase remains within an acceptable range, as the PoCC algorithm provides a higher level of security. Compared to TBMS algorithm and the BRM algorithm, the consensus mechanism proposed in this paper performs better regarding latency. This indicates that the proposed consensus mechanism enhances network security and effectively controls latency, ensuring that the network maintains good performance even in the presence of malicious node attacks.
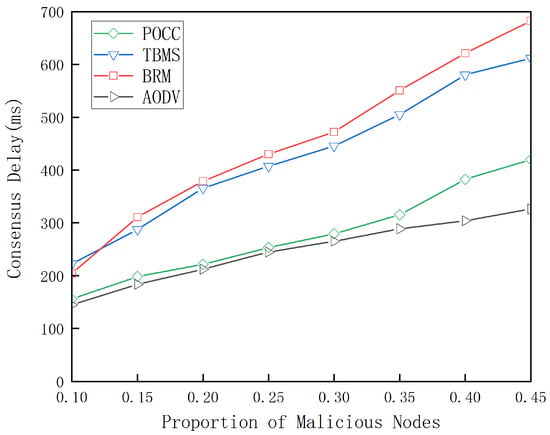
Figure 7.
Latency under different proportions of malicious nodes.
Figure 8 illustrates the overall trend of node reputation changes as the proportion of malicious message packets in the total number of messages varies. When the proportion of malicious messages is = 0, this indicates that the node is honest, meaning it does not send malicious messages or discard packets received from other vehicles. In this case, the node’s behavior is entirely trustworthy and reliable. Due to the accumulation of positive behavior, the node’s performance parameters increase rapidly, directly influencing a swift rise in its reputation score. Under this reputation management system, honest nodes can quickly accumulate enough reputation value with relatively few communications, ensuring their continuous participation in node selection. However, when false messages are present in the messages sent by the node, its reputation score decreases in proportion to the number of such messages, eventually stabilizing after approximately 100 communications. When reaches or exceeds 0.5, meaning more than half of the node’s messages are malicious, the node’s reputation score declines at a faster rate. This rate increases as the proportion of malicious messages grows, helping the network more quickly identify and eliminate malicious nodes, thereby maintaining network stability. These results demonstrate that the proposed reputation management mechanism effectively manages node reputation dynamically, allowing the IoV system to rapidly and accurately identify nodes exhibiting malicious behavior and preserve the overall stability of the network.
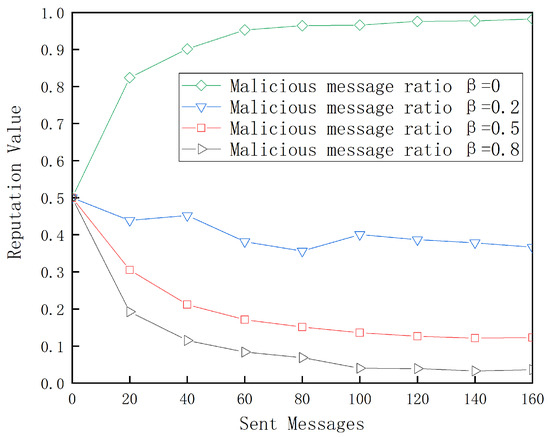
Figure 8.
Reputation changes affected by malicious messages.
To evaluate the incentive efficiency of the proposed PoCC algorithm, the following simulation experiments were conducted. In an IoV scenario consisting of varying numbers of mobile nodes, the enthusiasm of nodes to participate in message forwarding was tested under the conditions of being incentivized by the algorithm versus without any algorithmic incentive. This was measured by comparing the number of forwarded versus dropped data packets as an indicator of node activity.
Figure 9 and Figure 10 present the average experimental results after multiple rounds of testing. As the number of vehicle nodes in the network increases, each node receives more data packets from other nodes, leading to an increase in total communication events. Within certain vehicle density limits, this enhances the network’s dynamism while avoiding congestion caused by excessive data traffic. Nodes have two options when handling messages from other nodes: either receive and forward the message packet or choose to drop it. The figures show that as the number of nodes increases, the total number of forwarded messages rises in both the incentivized and non-incentivized systems. However, when there is no incentive mechanism in place, nodes lack the motivation to participate in the federated learning competition. This results in a higher probability of nodes discarding received data packets to conserve local device resources, thereby becoming malicious nodes within the network.
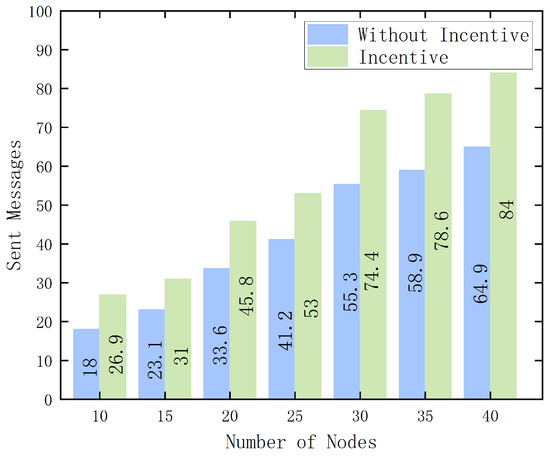
Figure 9.
Changes in the number of sent message packets under the incentive algorithm.
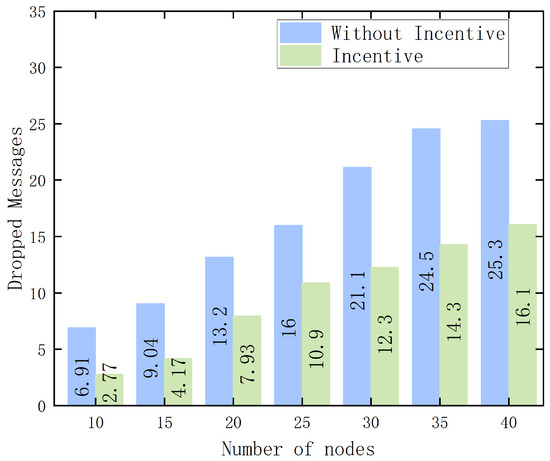
Figure 10.
Changes in the number of dropped message packets under the incentive algorithm.
In contrast, when the incentive mechanism is present, vehicle nodes actively engage in competition to earn rewards. They are more inclined to forward received message packets, as the incentive encourages long-term gains. This behavior improves the overall message delivery rate across the network. Similarly, with the incentive mechanism, the number of dropped message packets decreases, and this effect becomes more pronounced as the number of vehicle nodes increases. Nodes tend to forward messages rather than drop them, maximizing their chances of earning rewards. The comparison demonstrates that the proposed incentive mechanism is both reasonable and effective. It provides reliable rewards for vehicles and enhances their enthusiasm to participate in node selection, compared to a non-incentivized environment.
7. Conclusions
This paper focuses on a reputation management mechanism for the IoV based on federated learning and introduces a PoCC algorithm with incentives to complete the consensus process between vehicle nodes. This approach not only enhances the network’s ability to filter out malicious nodes but also increases the motivation of honest nodes, encouraging more active participation in node competition. First, this solution employs channel construction to reduce the computational burden on main-chain nodes while using the C-Capacity value to represent the contribution of different nodes in federated learning. This value serves as the basis for determining the final rewards each node receives from the task publisher. Next, a reputation evaluation mechanism is introduced to the network, dynamically updating each node’s reputation based on its behavior toward data packets. This reputation score directly affects whether a vehicle can participate in subsequent rounds of federated learning. Finally, the algorithm’s performance in terms of latency, packet arrival rate, and reputation score changes was tested, with the experimental results demonstrating the feasibility and effectiveness of this mechanism. However, the reputation framework outlined in this document is only applicable to a limited number of nodes, and maintaining the proper functioning of the consensus mechanism becomes challenging as the number of nodes increases significantly. Therefore, future research will focus on enhancing the scalability of the model to meet the demands of large-scale node networks. Additionally, efforts will be made to design more flexible and efficient incentive mechanisms to further improve network efficiency and fairness. Moreover, the performance of the model will be validated in complex IoV scenarios, particularly those characterized by a high proportion of malicious nodes or significant data heterogeneity. These endeavors aim to provide more optimized solutions for reputation management and consensus mechanisms in IoV systems.
Author Contributions
Conceptualization, Z.S. and R.C.; Data curation, R.C., J.Z. and Y.L.; Formal analysis, R.C. and Z.S.; Funding acquisition, Z.S., C.L.; Investigation, R.C., J.Z., M.C., Z.S., Y.L. and C.L.; Methodology, R.C.; Project administration, Z.S., C.L. and M.C.; Resources, R.C. and C.L.; Software, R.C.; Supervision, Z.S., C.L. and M.C.; Validation, R.C., C.L. and Z.S.; Visualization, R.C.; Writing—original draft, R.C.; Writing—review and editing, R.C., Z.S. and C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 62362013, and in part by the Guangxi Natural Science Foundation under Grant 2023GXNSFAA026294.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Surapaneni, P.; Bojjagani, S.; Bharathi, V.C.; Morampudi, M.K.; Maurya, A.K.; Khan, M.K. A Systematic Review on Blockchain-Enabled Internet of Vehicles (BIoV): Challenges, Defenses, and Future Research Directions. IEEE Access 2024, 12, 123529–123560. [Google Scholar] [CrossRef]
- Stoyanova, M.; Nikoloudakis, Y.; Panagiotakis, S.; Pallis, E.; Markakis, E.K. A Survey on the Internet of Things (IoT) Forensics: Challenges, Approaches, and Open Issues. IEEE Commun. Surv. Tutor. 2020, 22, 1191–1221. [Google Scholar] [CrossRef]
- Xing, L.; Zhao, P.; Gao, J.; Wu, H.; Ma, H. A Survey of the Social Internet of Vehicles: Secure Data Issues, Solutions, and Federated Learning. IEEE Intell. Transp. Syst. Mag. 2023, 15, 70–84. [Google Scholar] [CrossRef]
- Bellaj, B.; Ouaddah, A.; Bertin, E.; Crespi, N.; Mezrioui, A. Drawing the Boundaries Between Blockchain and Blockchain-like Systems: A Comprehensive Survey on Distributed Ledger Technologies. Proc. IEEE 2024, 112, 247–299. [Google Scholar] [CrossRef]
- Zhou, Y.; Manea, A.N.; Hua, W.; Wu, J.; Zhou, W.; Yu, J.; Rahman, S. Application of Distributed Ledger Technology in Distribution Networks. Proc. IEEE 2022, 110, 1963–1975. [Google Scholar] [CrossRef]
- Yadav, A.S.; Agrawal, S.; Kushwaha, D.S. Distributed Ledger Technology-Based Land Transaction System with Trusted Nodes Consensus Mechanism. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 6414–6424. [Google Scholar] [CrossRef]
- Serena, L.; D’Angelo, G.; Ferretti, S. Security Analysis of Distributed Ledgers and Blockchains through Agent-Based Simulation. Simul. Model. Pract. Theory 2022, 114, 102413. [Google Scholar] [CrossRef]
- Xie, Q.; Ding, Z.; Tang, W.; He, D.; Tan, X. Provable Secure and Lightweight Blockchain-Based V2I Handover Authentication and V2V Broadcast Protocol for VANETs. IEEE Trans. Veh. Technol. 2023, 72, 15200–15212. [Google Scholar] [CrossRef]
- Chai, H.; Leng, S.; Chen, Y.; Zhang, K. A Hierarchical Blockchain-Enabled Federated Learning Algorithm for Knowledge Sharing in Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3975–3986. [Google Scholar] [CrossRef]
- Passerat-Palmbach, J.; Farnan, T.; McCoy, M.; Harris, J.D.; Manion, S.T.; Flannery, H.L.; Gleim, B. Blockchain-Orchestrated Machine Learning for Privacy Preserving Federated Learning in Electronic Health Data. In Proceedings of the 2020 IEEE International Conference on Blockchain (Blockchain), Rhodes, Greece, 2–6 November 2020; pp. 550–555. [Google Scholar] [CrossRef]
- Yan, R.; Zheng, Y.; Yu, N.; Liang, C. Multi-Smart Meter Data Encryption Scheme Based on Distributed Differential Privacy. Big Data Min. Anal. 2024, 7, 131–141. [Google Scholar] [CrossRef]
- Qashlan, A.; Nanda, P.; Mohanty, M. Differential Privacy Model for Blockchain-Based Smart Home Architecture. Future Gener. Comput. Syst. 2024, 150, 49–63. [Google Scholar] [CrossRef]
- Basak, S.; Chatterjee, K.; Singh, A. DPPT: A Differential Privacy Preservation Technique for Cyber-Physical Systems. Comput. Electr. Eng. 2023, 109, 108661. [Google Scholar] [CrossRef]
- Kumar, G.S.; Premalatha, K.; Maheshwari, G.U.; Kanna, P.R.; Vijaya, G.; Nivaashini, M. Differential Privacy Scheme Using Laplace Mechanism and Statistical Method Computation in Deep Neural Network for Privacy Preservation. Eng. Appl. Artif. Intell. 2024, 128, 107399. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, Y.; Qin, X.; Xu, X.; Zhang, P. Adaptive Resource Allocation for Blockchain-Based Federated Learning in Internet of Things. IEEE Internet Things J. 2023, 10, 10621–10635. [Google Scholar] [CrossRef]
- Islam, M.R.; Rashid, M.M. A Survey on Blockchain Security and Its Impact Analysis. In Proceedings of the 023 9th International Conference on Computer and Communication Engineering (ICCCE), Kuala Lumpur, Malaysia, 15–16 August 2023; pp. 317–321. [Google Scholar] [CrossRef]
- Tu, S.; Yu, H.; Badshah, A.; Waqas, M.; Halim, Z.; Ahmad, I. Secure Internet of Vehicles (IoV) With Decentralized Consensus Blockchain Mechanism. IEEE Trans. Veh. Technol. 2023, 72, 11227–11236. [Google Scholar] [CrossRef]
- Vishwakarma, L.; Nahar, A.; Das, D. LBSV: Lightweight Blockchain Security Protocol for Secure Storage and Communication in SDN-Enabled IoV. IEEE Trans. Veh. Technol. 2022, 71, 5983–5994. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, L.; Wu, Q.; Mu, Y. Blockchain-Enabled Efficient Distributed Attribute-Based Access Control Framework with Privacy-Preserving in IoV. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 9216–9227. [Google Scholar] [CrossRef]
- Li, D.; Chen, R.; Wan, Q.; Guan, Z.; Li, S.; Xie, M.; Su, J.; Liu, J. Intelligent and Fair IoV Charging Service Based on Blockchain with Cross-Area Consensus. IEEE Trans. Intell. Transp. Syst. 2023, 24, 15984–15994. [Google Scholar] [CrossRef]
- Tyagi, S.; Rajput, I.S.; Pandey, R. Federated Learning: Applications, Security Hazards and Defense Measures. In Proceedings of the 2023 International Conference on Device Intelligence, Computing and Communication Technologies (DICCT), Dehradun, India, 17–18 March 2023; pp. 477–482. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, X.; Wu, D.; Wang, R.; Zhang, P.; Wu, Y. Efficient Asynchronous Federated Learning Research in the Internet of Vehicles. IEEE Internet Things J. 2023, 10, 7737–7748. [Google Scholar] [CrossRef]
- Li, Z.; Wu, H.; Lu, Y.; Ai, B.; Zhong, Z.; Zhang, Y. Matching Game for Multi-Task Federated Learning in Internet of Vehicles. IEEE Trans. Veh. Technol. 2024, 73, 1623–1636. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Z.; Li, Z.; Xu, Y.; Yang, X.; Qi, F.; Jia, H. FRNet: An MCS Framework for Efficient and Secure Data Sensing and Privacy Protection in IoVs. IEEE Internet Things J. 2023, 10, 16343–16357. [Google Scholar] [CrossRef]
- Zhou, H.; Zheng, Y.; Huang, H.; Shu, J.; Jia, X. Toward Robust Hierarchical Federated Learning in Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5600–5614. [Google Scholar] [CrossRef]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.-L. Blockchained On-Device Federated Learning. IEEE Commun. Lett. 2020, 24, 1279–1283. [Google Scholar] [CrossRef]
- Li, M.; Zhu, L.; Lin, X. Efficient and Privacy-Preserving Carpooling Using Blockchain-Assisted Vehicular Fog Computing. IEEE Internet Things J. 2019, 6, 4573–4584. [Google Scholar] [CrossRef]
- Qu, Y.; Gao, L.; Luan, T.H.; Xiang, Y.; Yu, S.; Li, B.; Zheng, G. Decentralized Privacy Using Blockchain-Enabled Federated Learning in Fog Computing. IEEE Internet Things J. 2020, 7, 5171–5183. [Google Scholar] [CrossRef]
- Tong, Z.; Wang, J.; Hou, X.; Chen, J.; Jiao, Z.; Liu, J. Blockchain-Based Trustworthy and Efficient Hierarchical Federated Learning for UAV-Enabled IoT Networks. IEEE Internet Things J. 2024, 11, 34270–34282. [Google Scholar] [CrossRef]
- Wang, Q.; Liao, W.; Guo, Y.; McGuire, M.; Yu, W. Blockchain-Empowered Federated Learning Through Model and Feature Calibration. IEEE Internet Things J. 2024, 11, 5770–5780. [Google Scholar] [CrossRef]
- Ghimire, B.; Rawat, D.B.; Rahman, A. Efficient Information Dissemination in Blockchain-Enabled Federated Learning for IoV. IEEE Internet Things J. 2024, 11, 15310–15319. [Google Scholar] [CrossRef]
- Sui, Z.; Sun, Y.; Zhu, J.; Chen, F. Comments on “Lightweight Privacy and Security Computing for Blockchained Federated Learning in IoT”. IEEE Internet Things J. 2024, 11, 15043–15046. [Google Scholar] [CrossRef]
- ur Rehman, M.H.; Salah, K.; Damiani, E.; Svetinovic, D. Towards Blockchain-Based Reputation-Aware Federated Learning. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 183–188. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain Empowered Asynchronous Federated Learning for Secure Data Sharing in Internet of Vehicles. IEEE Trans. Veh. Technol. 2020, 69, 4298–4311. [Google Scholar] [CrossRef]
- Xu, M.; Zou, Z.; Cheng, Y.; Hu, Q.; Yu, D.; Cheng, X. SPDL: A Blockchain-Enabled Secure and Privacy-Preserving Decentralized Learning System. IEEE Trans. Comput. 2023, 72, 548–558. [Google Scholar] [CrossRef]
- Cortes-Goicoechea, M.; Franceschini, L.; Bautista-Gomez, L. Resource Analysis of Ethereum 2.0 Clients. In Proceedings of the 2021 3rd Conference on Blockchain Research & Applications for Innovative Networks and Services (BRAINS), Paris, France, 27–30 September 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Evdakov, A.E.; Kutumov, Y.D.; Shadrikova, T.Y.; Shuin, V.A. A Research of Digital Directional Current Protection Devices Operation Stability in Transient Modes During Single Phase to Earth Faults in 6-10 KV Networks with Isolated Neutral Point. In Proceedings of the 2020 3rd International Youth Scientific and Technical Conference on Relay Protection and Automation (RPA), Moscow, Russia, 22–23 October 2020; pp. 1–16. [Google Scholar] [CrossRef]
- Shah, S.A.A.; Ahmed, E.; Rodrigues, J.J.P.C.; Ali, I.; Md Noor, R. Shapely Value Perspective on Adapting Transmit Power for Periodic Vehicular Communications. IEEE Trans. Intell. Transp. Syst. 2018, 19, 977–986. [Google Scholar] [CrossRef]
- Abbes, S.; Rekhis, S. A Blockchain-Based Solution for Reputation Management in IoV. In Proceedings of the Wireless Communications and Mobile Computing (IWCMC), Harbin, China, 28 June–2 July 2021; pp. 1129–1134. [Google Scholar] [CrossRef]
- Li, S.; Liu, X.; Ma, W.; Yu, K.; Liu, Y. Blockchain-Based Reputation Management Scheme for the Internet of Vehicles. In Proceedings of the 2023 IEEE International Conference on Data Mining Workshops (ICDMW), Shanghai, China, 1–4 December 2023; pp. 1040–1049. [Google Scholar] [CrossRef]
- Kurkina, N.; Papaj, J. Performance Analysis of AODV Routing Protocol and Its Modifications for MANET. In Proceedings of the 2023 World Symposium on Digital Intelligence for Systems and Machines (DISA), Košice, Slovakia, 21–22 September 2023; pp. 140–144. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).