
Integrating Emotional Features for Stance Detection Aimed at Social Network Security: A Multi-Task Learning Approach


Abstract
1. Introduction
- To address the issue of data scarcity in stance detection, this study applied back-translation data augmentation based on the NLPCC2016-task4 Chinese Weibo stance detection dataset, expanding the original 3000 training samples to 12,000. Subsequently, a hybrid network model was constructed for the stance detection task, combining RoBERTa and BiLSTM networks. The stance detection task was reframed from a traditional three-class classification problem into three binary classification problems. The results indicate that this approach effectively extracts stance features.
- Building on the hybrid network, this study incorporated sentiment analysis as an auxiliary task to support the stance detection task. The experimental results show that the multi-task learning stance detection method, which integrates emotional features, significantly improves the model’s stance detection performance. This is particularly evident when training on multiple-topic datasets, where integrating emotional features offers a notable advantage.
2. Related Work
2.1. Stance Detection Method
2.2. Multi-Task Learning
3. Method
3.1. Definition of Multi-Task Learning
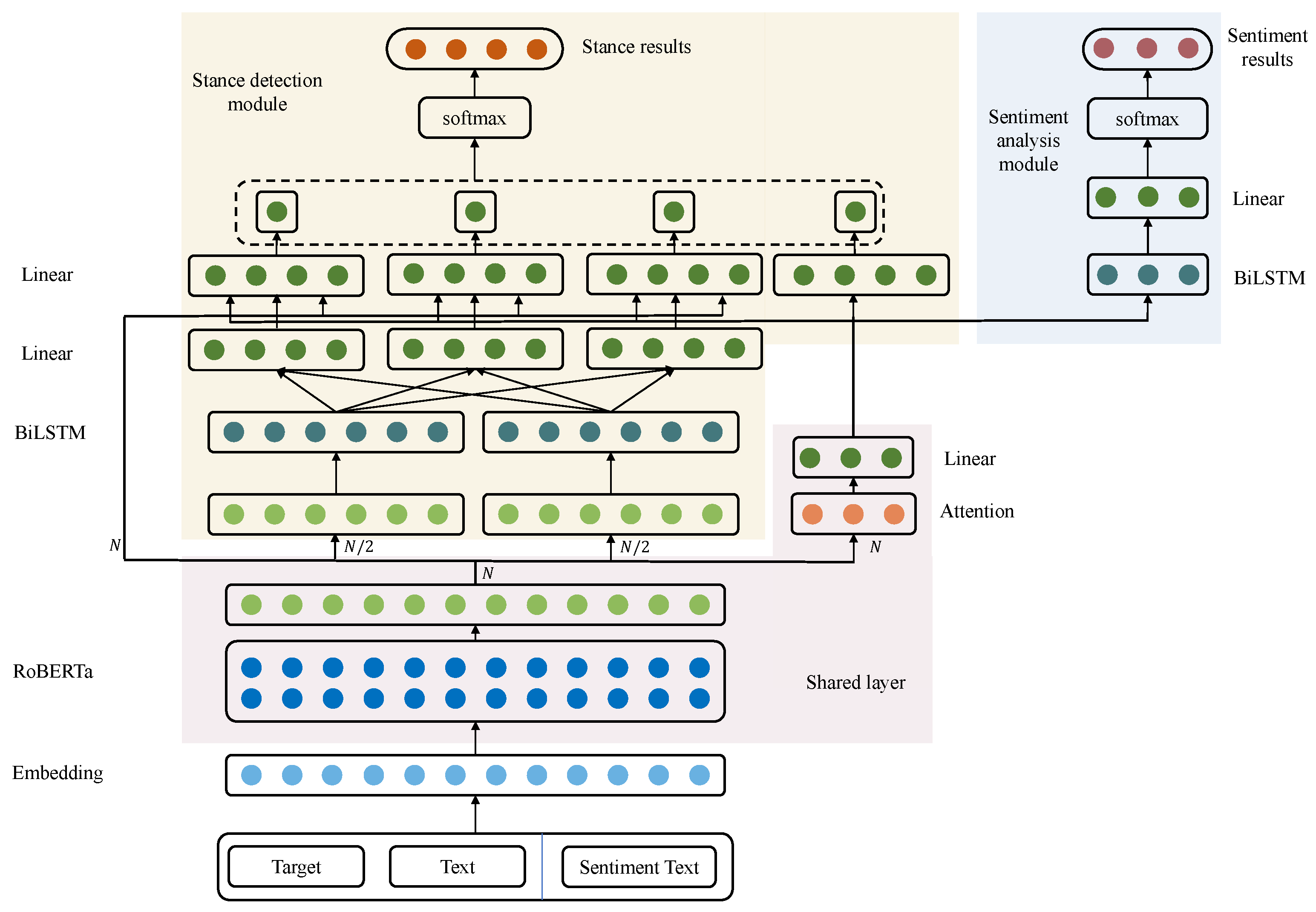
3.2. Overall Framework
3.3. Shared Layer
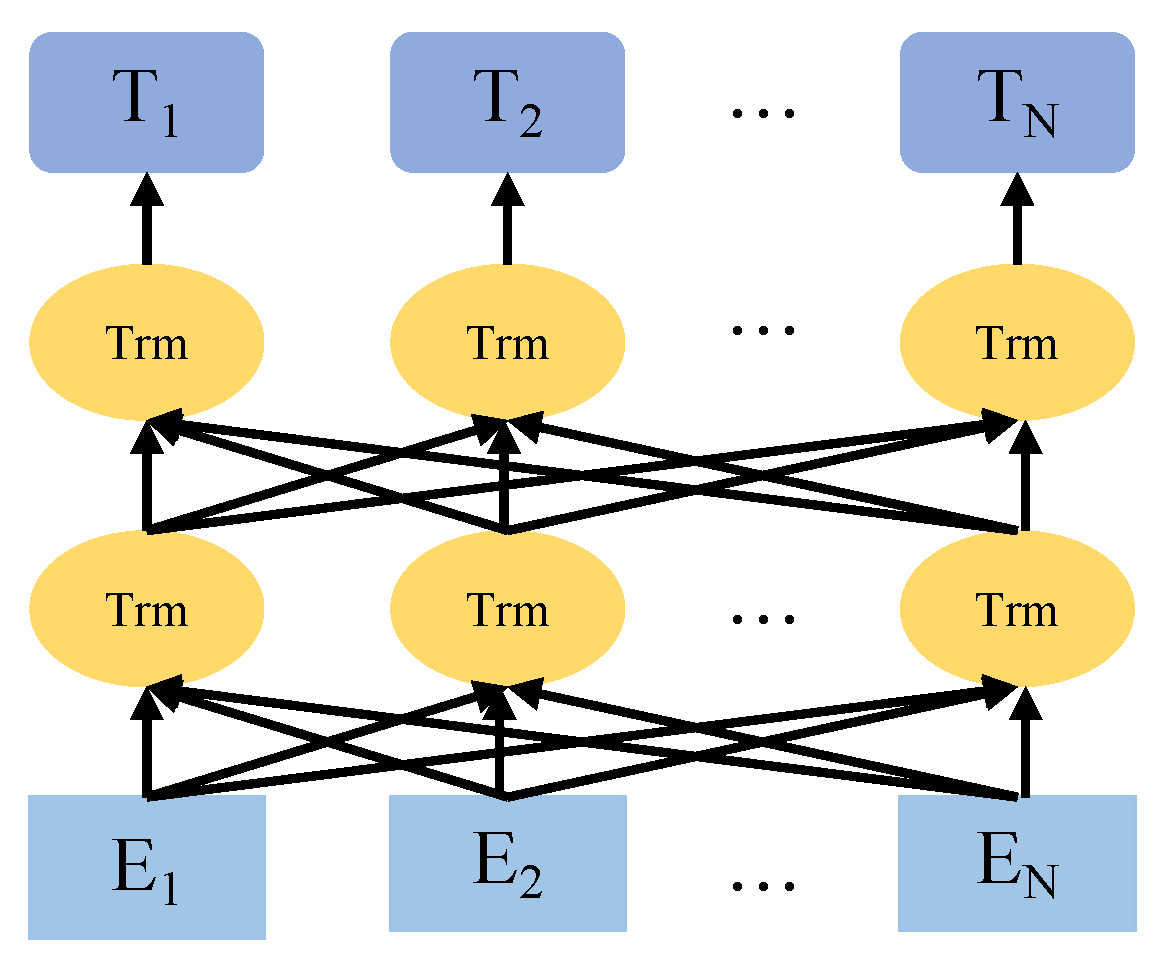
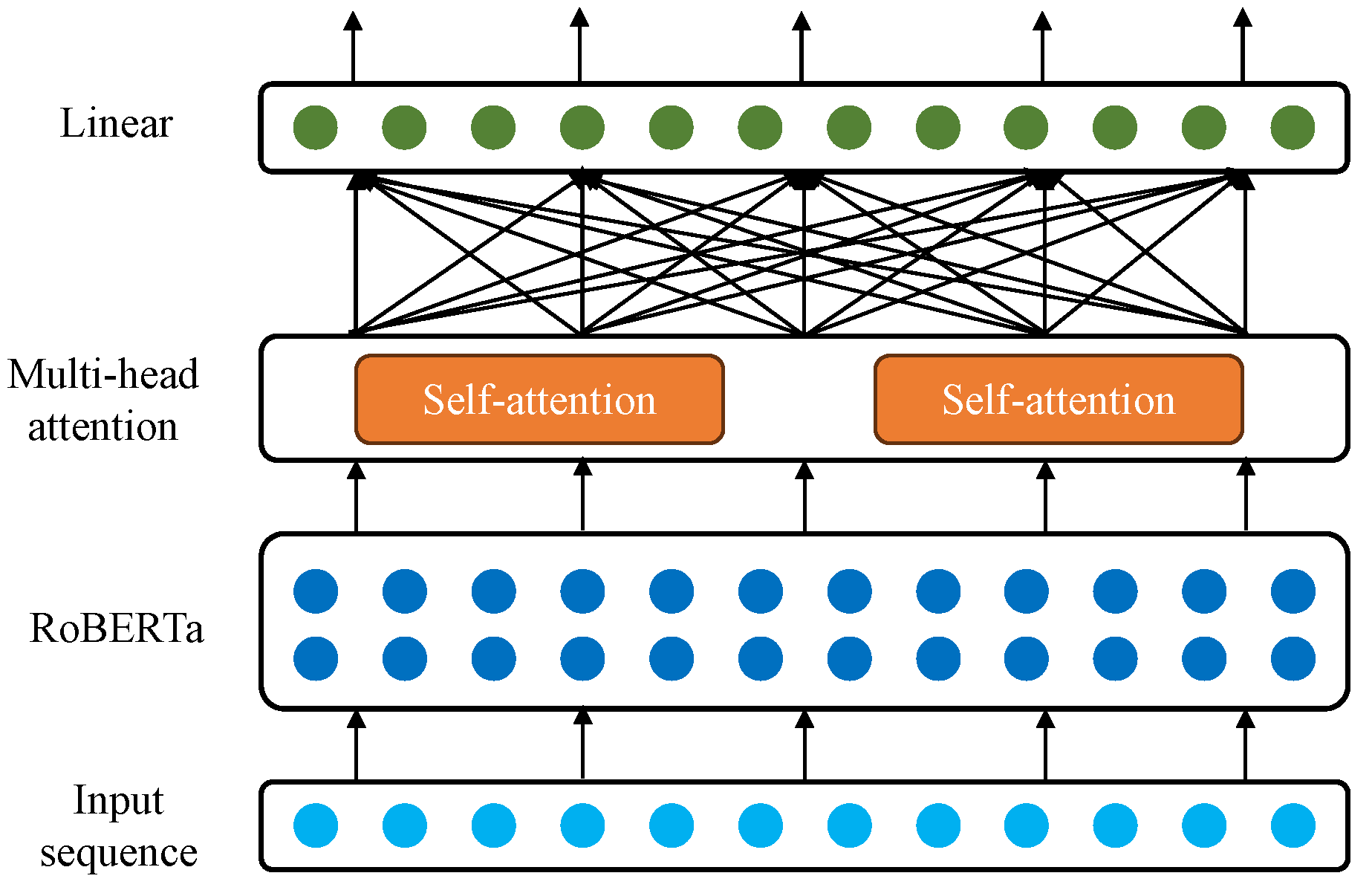
3.3.1. RoBERTa
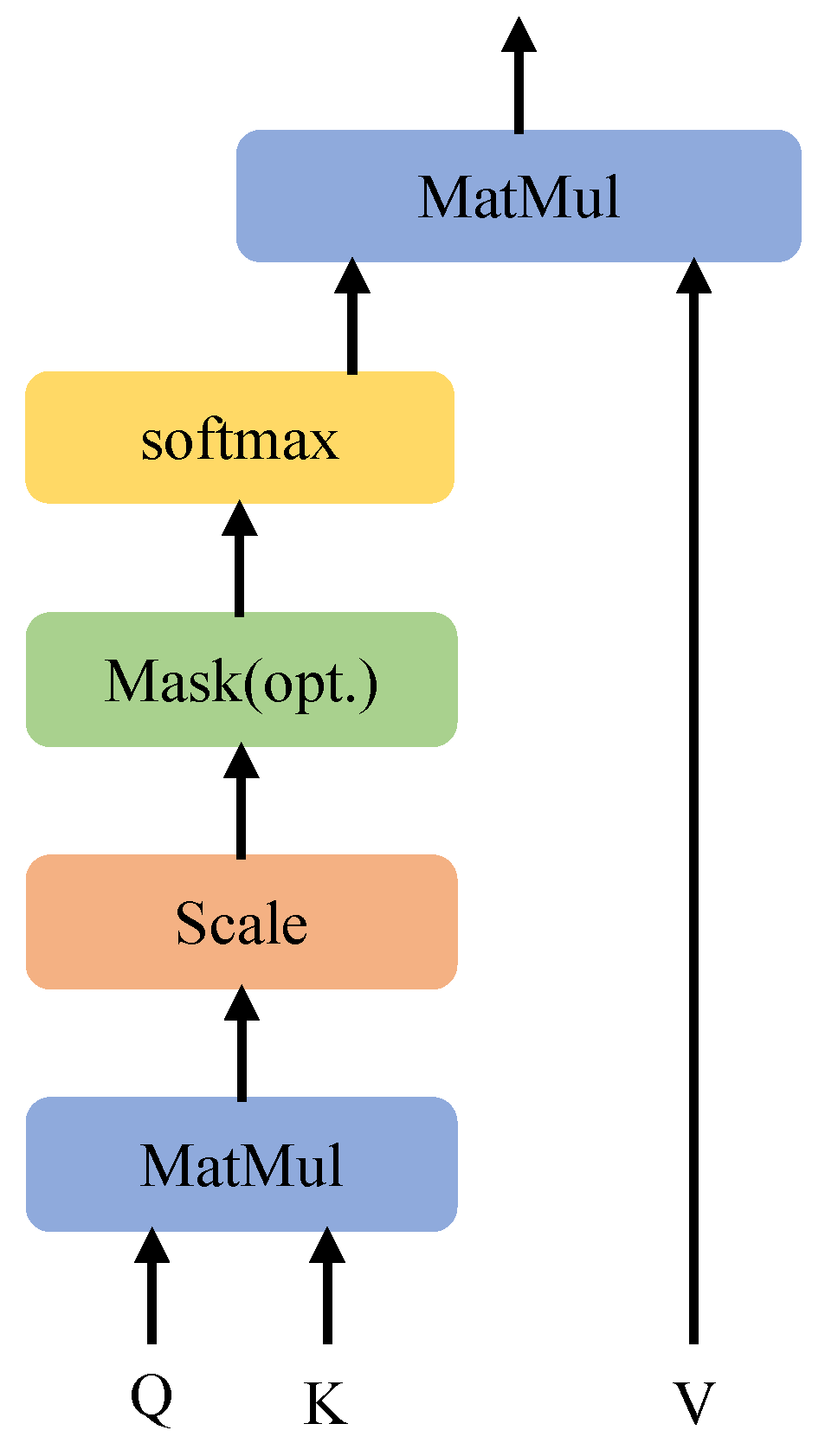
3.3.2. Attention Mechanism
3.3.3. Module Task Objective
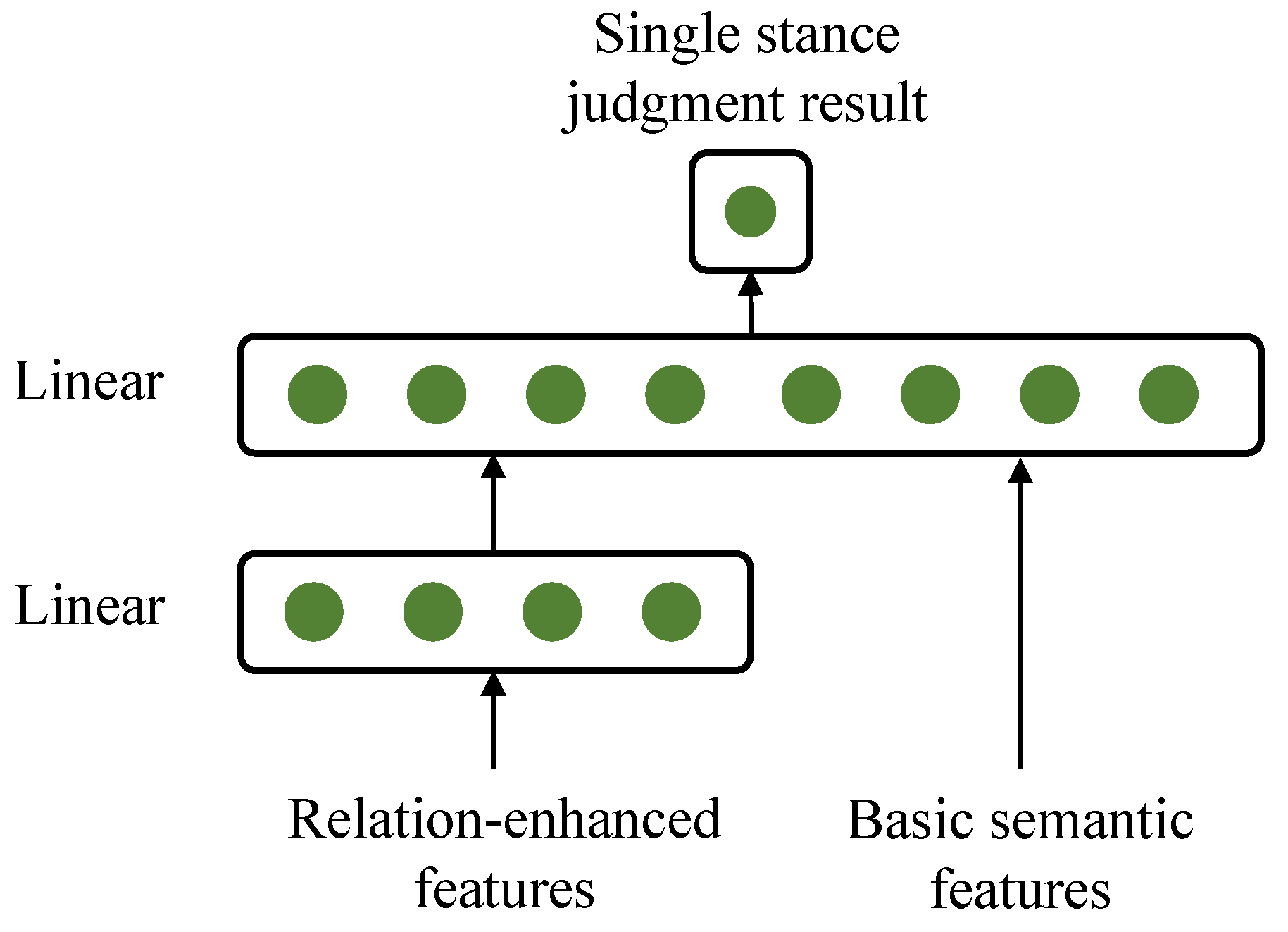
3.4. Stance Detection Module
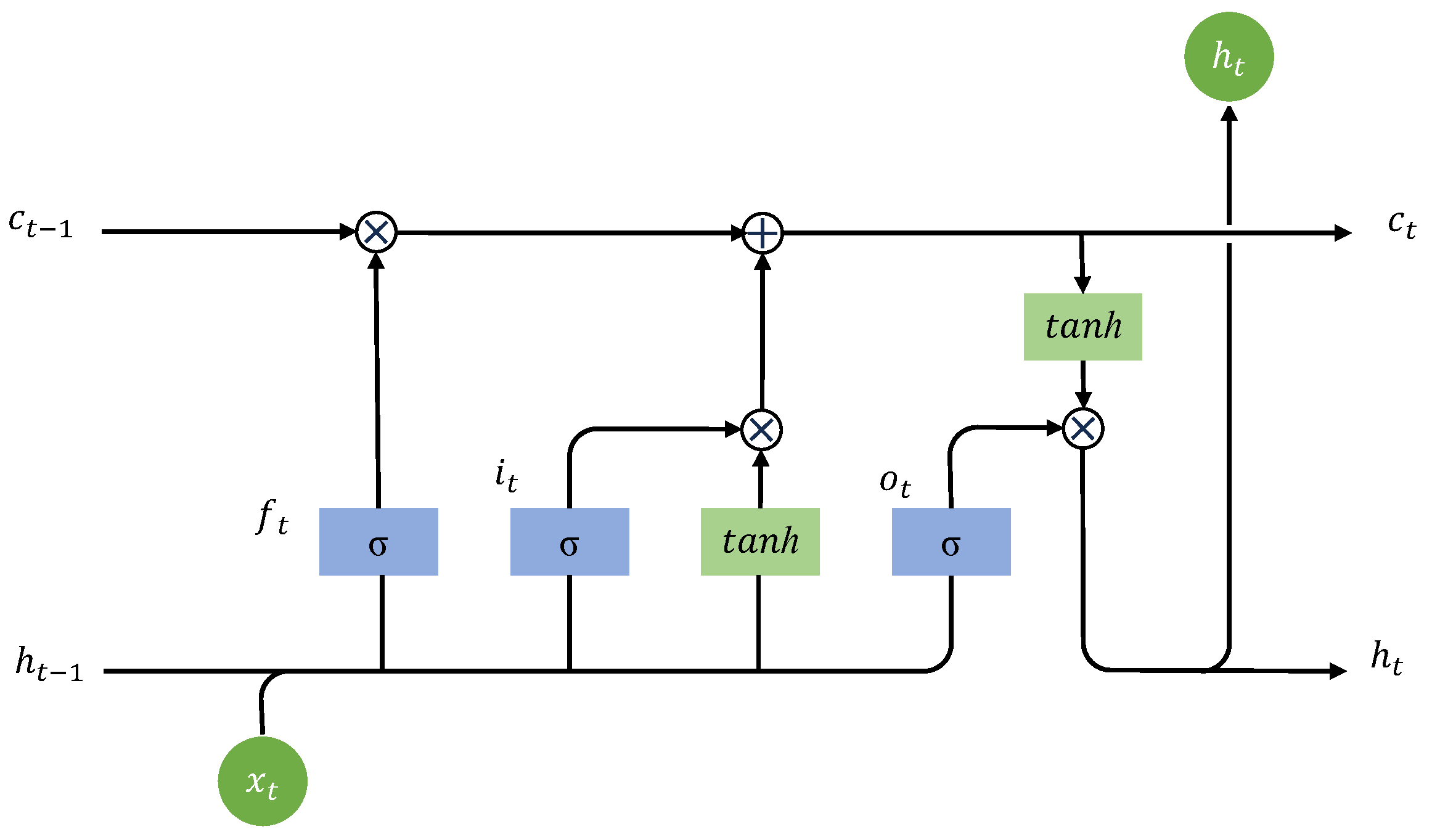
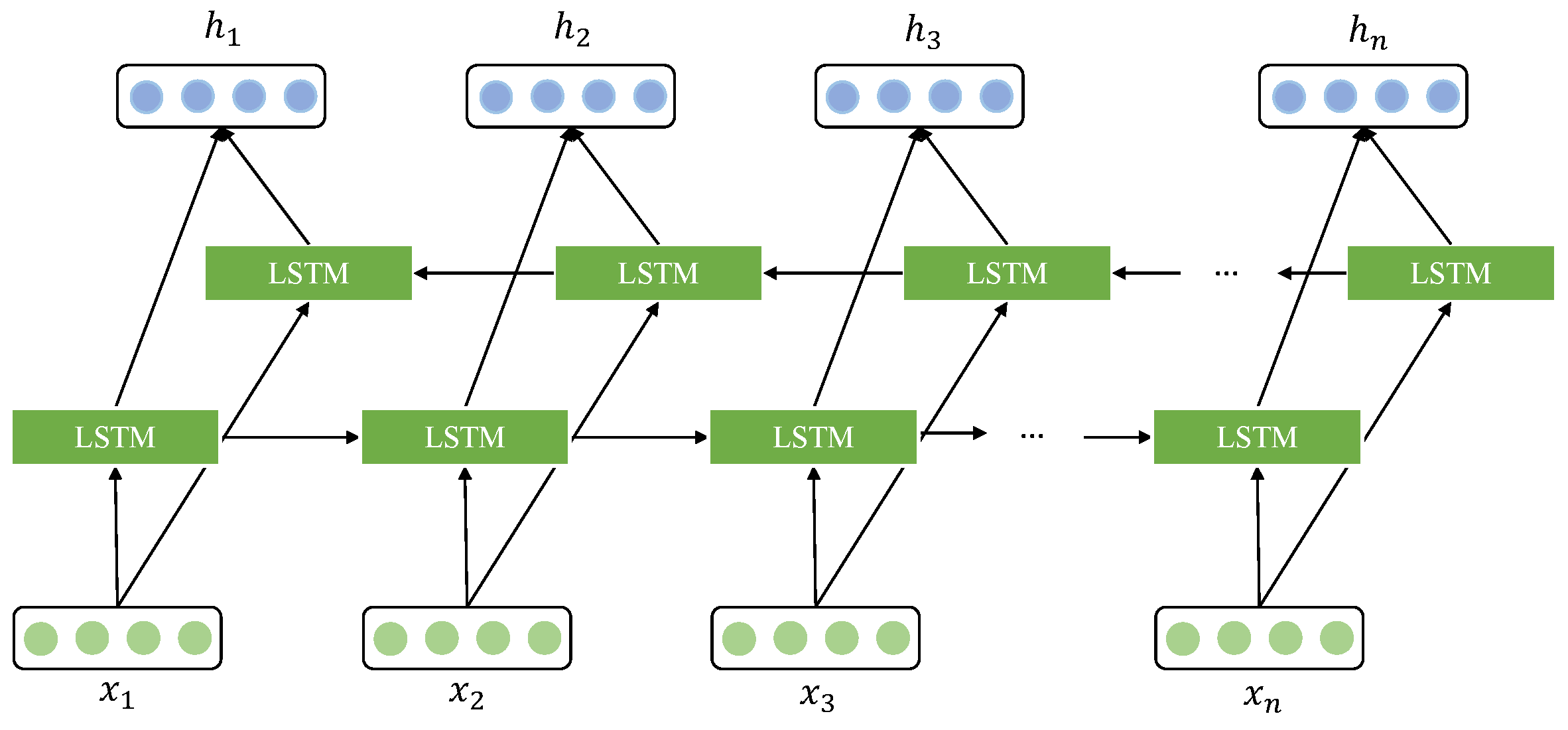
3.4.1. BiLSTM
3.4.2. Module Task Objective
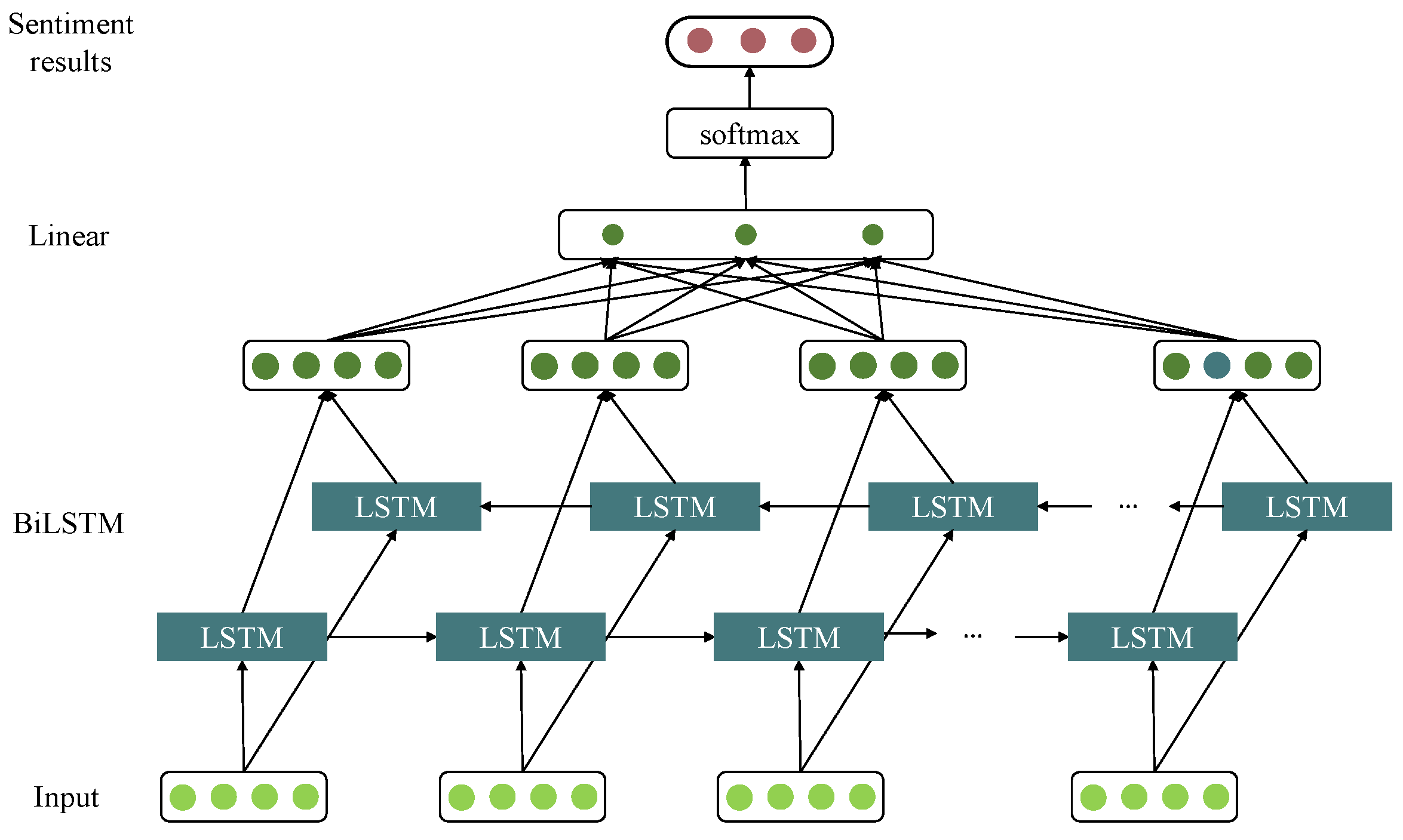
3.5. Sentiment Analysis Module
4. Experiment
4.1. Datasets
4.2. Experimental Settings
4.3. Evaluation Metrics
4.4. Results
4.4.1. Effect of Different Emotional Data Volumes
4.4.2. Comparison with Different Network Models
- Dian [11]. This model explores multiple text features and uses supervised learning methods like SVM for stance classification.
- TAN (Target-specific Attention Neural Network) [34]. This model combines RNN, LSTM, and a target-specific attention mechanism to perform stance detection by extracting information related to the target, considering the role of target topics in stance analysis.
- ATA (Attention-Target-Attention) [35]. An improved version of the TAN model, it proposes a two-stage attention mechanism for stance classification, effectively integrating target topics with Weibo texts.
- BCC (BERT-Condition-CNN) [36]. This model uses BERT to obtain vector representations of target topics and Weibo texts, processes the relationship features between the target and text through a Condition layer, and finally uses CNN for feature extraction and stance detection.
- CBL (CNN-BiLSTM) [37]. This model adopts CNN and BiLSTM to extract local features and global semantics from text to perform stance detection on Weibo posts.
- BGA (GCN and BiLSTM) [38]. This model uses BiLSTM to obtain text features and constructs a Graph Convolution Network (GCN) to capture syntactic relations and word dependencies. It calculates attention scores for target topics to analyze the stance tendencies of Weibo texts.
- BERT-SECA [39]. A sentiment-enhanced stance detection model based on convolutional attention, it focuses on the relevant features between text and target topics and integrates emotional features to enhance text representation.
- KE-BERT (Multi-type Knowledge-Enhanced and BERT) [40]. This model combines multiple types of commonsense knowledge to enhance semantic information, using improved BERT and convolutional attention mechanisms to encode and integrate commonsense knowledge for determining stance.
- Hybrid Network. This is the RoBERTa-BiLSTM hybrid model proposed in this paper. It first extracts basic semantic information between comment texts and target topics using RoBERTa, and then uses BiLSTM to enhance the relational features between comment texts and topics. The model’s three independent stance judgment modules evaluate support, opposition, and neutrality stances separately.
- MTL (Multi-task Learning). This is the multi-task learning model proposed in this paper, which builds upon the RoBERTa-BiLSTM hybrid network model by adding a sentiment analysis module. It integrates stance detection with sentiment analysis, performing multi-task learning with stance detection as the primary task and sentiment analysis as the auxiliary task.
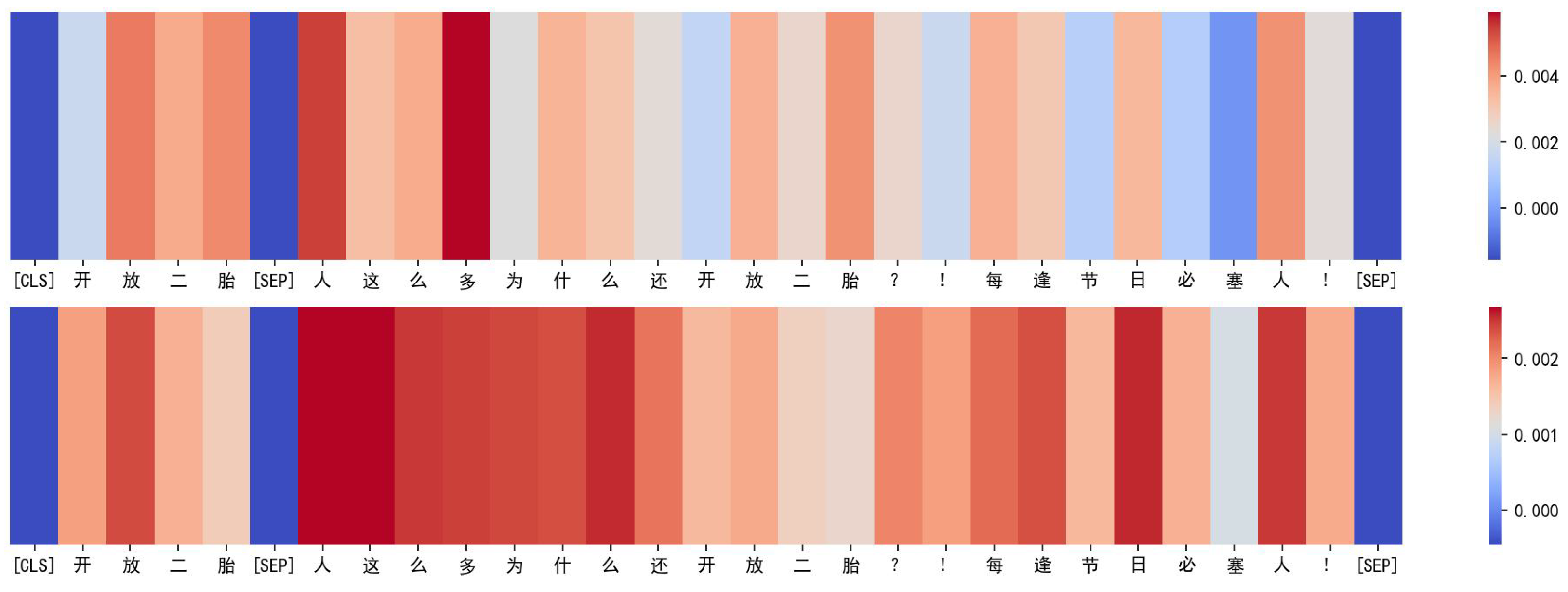
4.4.3. Quantitative Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alturayeif, N.; Luqman, H.; Ahmed, M. A systematic review of machine learning techniques for stance detection and its applications. Neural Comput. Appl. 2023, 35, 5113–5144. [Google Scholar] [CrossRef]
- Küçük, D.; Can, F. A tutorial on stance detection. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 1626–1628. [Google Scholar]
- AlDayel, A.; Magdy, W. Stance detection on social media: State of the art and trends. Inf. Process. Manag. 2021, 58, 102597. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, J.; Zuo, X. Survey of multi-task learning. Chin. J. Comput. 2020, 43, 1340–1378. [Google Scholar] [CrossRef]
- Cao, R.; Luo, X.; Xi, Y.; Qiao, Y. Stance detection for online public opinion awareness: An overview. Int. J. Intell. Syst. 2022, 37, 11944–11965. [Google Scholar] [CrossRef]
- Ghosh, S.; Singhania, P.; Singh, S.; Rudra, K. Stance Detection in Web and Social Media: A Comparative Study. In Proceedings of the tenth International Conference of the CLEF Association (CLEF2019), Lugano, Switzerland, 9–12 September 2019; pp. 75–87. [Google Scholar]
- Li, Y.; Sun, Y.; Jing, W. Survey of text stance detection. J. Comput. Res. Dev. 2021, 58, 2538–2557. [Google Scholar]
- Gómez-Suta, M.; Echeverry-Correa, J.; Soto-Mejía, J.A. Stance detection in tweets: A topic modeling approach supporting explainability. Expert Syst. Appl. 2023, 214, 119046. [Google Scholar] [CrossRef]
- Nababan, A.H.; Mahendra, R.; Budi, I. Survey of multi-task learning. Procedia Comput. Sci. 2022, 197, 76–81. [Google Scholar] [CrossRef]
- Al-Ghadir, A.I.; Azmi, A.M.; Hussain, A. A novel approach to stance detection in social media tweets by fusing ranked lists and sentiments. Inf. Fusion 2021, 67, 29–40. [Google Scholar] [CrossRef]
- Dian, Y.; Jin, Q.; Wu, H. Stance detection in Chinese microblogs via fusing multiple text features. Comput. Eng. Appl. 2017, 53, 77–84. [Google Scholar]
- Liu, C.; Li, W.; Demarest, B.; Chen, Y.; Couture, S.; Dakota, D.; Haduong, N.; Kaufman, N.; Lamont, A.; Pancholi, M.; et al. Iucl at semeval-2016 task 6: An ensemble model for stance detection in twitter (SemEval-2016). In Proceedings of the Tenth International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016; pp. 394–400. [Google Scholar]
- Sobhani, P.; Mohammad, S.; Kiritchenko, S. Detecting stance in tweets and analyzing its interaction with sentiment. In Proceedings of the Fifth Joint Conference on Lexical and Computational Semantics, Berlin, Germany, 11–12 August 2016; pp. 159–169. [Google Scholar]
- Fu, Y.; Li, X.; Li, Y.; Wang, S.; Li, D.; Liao, J.; Zheng, J. Incorporate opinion-towards for stance detection. Knowl.-Based Syst. 2022, 246, 108657. [Google Scholar] [CrossRef]
- Baly, R.; Mohtarami, M.; Glass, J.; Màrquez, L.; Moschitti, A.; Nakov, P. Integrating stance detection and fact checking in a unified corpus. arXiv 2018, arXiv:1804.08012. [Google Scholar]
- Zhang, H.; Li, Y.; Zhu, T.; Li, C. Commonsense-based adversarial learning framework for zero-shot stance detection. Neurocomputing 2024, 563, 126943. [Google Scholar] [CrossRef]
- Umer, M.; Imtiaz, Z.; Ullah, S.; Mehmood, A.; Choi, G.S.; On, B. Fake news stance detection using deep learning architecture (CNN-LSTM). IEEE Access 2020, 8, 156695–156706. [Google Scholar] [CrossRef]
- Karande, H.; Walambe, R.; Benjamin, V.; Kotecha, K.; Raghu, T. Stance detection with BERT embeddings for credibility analysis of information on social media. PeerJ Comput. Sci. 2021, 7, e467. [Google Scholar] [CrossRef] [PubMed]
- Ng, L.H.X.; Carley, K.M. Is my stance the same as your stance? A cross validation study of stance detection datasets. Inf. Process. Manag. 2022, 59, 103070. [Google Scholar] [CrossRef]
- Sun, Y.; Li, Y. Stance detection with knowledge enhanced bert. In Proceedings of the first CAAI International Conference on Artificial Intelligence, Hangzhou, China, 5–6 June 2021; pp. 239–250. [Google Scholar]
- Li, Y.; Sun, Y.; Zhu, N. BERTtoCNN: Similarity-preserving enhanced knowledge distillation for stance detection. PLoS ONE 2021, 16, e0257130. [Google Scholar] [CrossRef] [PubMed]
- Pham, H.T.; Han, S. Natural language processing with multitask classification for semantic prediction of risk-handling actions in construction contracts. J. Comput. Civ. Eng. 2023, 37, 04023027. [Google Scholar] [CrossRef]
- Alturayeif, N.; Luqman, H.; Ahmed, M. Enhancing stance detection through sequential weighted multi-task learning. Soc. Netw. Anal. Min. 2023, 14, 7. [Google Scholar] [CrossRef]
- Upadhyaya, A.; Fisichella, M.; Nejdl, W. A multi-task model for sentiment aided stance detection of climate change tweets. In Proceedings of the Seventeenth International AAAI Conference on Web and Social Media, Limassol, Cyprus, 5–8 June 2023; pp. 854–865. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Thirty-First International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Swets, J.A. Information retrieval systems. Science 1963, 141, 245–250. [Google Scholar] [CrossRef]
- van Rijsbergen, C.J. Information Retrieval, 2nd ed.; Butterworths: London, UK, 1979. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2019, arXiv:1607.01759. [Google Scholar]
- Du, J.; Xu, R.; He, Y.; Gui, L. Stance classification with target-specific neural attention networks. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI 2017), Melbourne, Australia, 19–25 August 2017; pp. 3988–3994. [Google Scholar]
- Yue, T.; Zhang, S.; Yang, L.; Lin, H.; Yu, K. Stance Detection Method Based on Two-Stage Attention Mechanism. J. Guangxi Norm. Univ. (Nat. Sci. Ed.) 2019, 37, 42–49. [Google Scholar]
- Wang, A.; Huang, K.; Lu, L. Stance detection in Chinese microblogs via Bert-Condition-CNN model. Comput. Syst. Appl. 2019, 28, 45–53. [Google Scholar]
- Zhang, C.; Hao, J.; Liu, X.; Sun, Y. Research on stance detection in Chinese micro-blog based on CNN-BiLSTM. Comput. Technol. Dev. 2020, 30, 154–159. [Google Scholar]
- Yang, S.; Li, Y.; Zhao, Q. Stance detection method of Chinese micro-blog based on GCN and BiLSTM. J. Chongqing Univ. Technol. (Nat. Sci.) 2020, 34, 167–173. [Google Scholar]
- Geng, Y.; Zhang, S.; Zhang, Y.; Lin, H.; Yang, L. Sentiment-enhanced weibo stance detection based on convolutional attention. J. Shanxi Univ. (Nat. Sci. Ed.) 2022, 45, 302–312. [Google Scholar]
- Wang, T.; Yuan, J.; Qi, R.; Li, Y. Multi-type knowledge-enhanced microblog stance detection model. J. Guangxi Norm. Univ. (Nat. Sci. Ed.) 2024, 42, 79–90. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Numbers | Topics |
|---|---|
| Topic 1 | iPhone SE (iPhone SE) |
| Topic 2 | 春节放鞭炮 (Setting off firecrackers in Spring Festival) |
| Topic 3 | 俄罗斯叙利亚反恐行动 (Russia’s anti-terrorism operation in Syria) |
| Topic 4 | 开放二胎 (Having a second child) |
| Topic 5 | 深圳禁摩限电 (Motor ban and power restriction in Shenzhen) |
| Before Data Enhancement | After Data Enhancement | |
|---|---|---|
| Training set | 600 | 2400 |
| Testing set | 200 | 200 |
| Total | 800 | 2600 |
| Environment | Setting Values | |
|---|---|---|
| Hardware environment | OS | Ubuntu 20.04.6 LTS |
| CPU | Intel(R) Xeon(R) CPU E5-2680 | |
| GPU | NVIDIA GeForce RTX 3090 | |
| Software environment | torch | 2.1.0 (CUDA 12.0) |
| python | 3.10.12 | |
| transformers | 4.36.2 | |
| pandas | 2.1.4 | |
| Hyperparameter values | batch_size | 16 |
| criterion | CrossEntropyLoss | |
| learning_rate | 1 × 10−5 | |
| epochs | 30 |
| Number | |||||
|---|---|---|---|---|---|
| 0 | 77.58 | 79.96 | 78.77 | 78.40 | 79.30 |
| 1000 | 76.77 | 80.21 | 78.49 | 79.77 | 77.55 |
| 2000 | 78.16 | 80.55 | 79.35 | 78.46 | 80.35 |
| 3000 | 78.60 | 80.85 | 79.72 | 79.15 | 80.42 |
| 4000 | 78.84 | 78.50 | 78.67 | 78.64 | 79.54 |
| 5000 | 76.06 | 79.66 | 77.86 | 76.21 | 79.60 |
| Models | |||||
|---|---|---|---|---|---|
| TextCNN [32] | 59.84 | 64.75 | 62.30 | 63.24 | 61.43 |
| FastText [33] | 60.97 | 63.35 | 62.16 | 62.08 | 62.39 |
| BERT [26] | 75.84 | 78.93 | 77.39 | 76.75 | 78.26 |
| RoBERTa [27] | 75.90 | 80.20 | 78.05 | 78.18 | 77.94 |
| MTL (ours) | 78.60 | 80.85 | 79.72 | 79.15 | 80.42 |
| Models | Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 | |
|---|---|---|---|---|---|---|
| Dian [11] | 61.49 | 77.61 | 61.96 | 84.69 | 78.16 | 72.78 |
| TAN [34] | 59.33 | 77.50 | 59.19 | 65.00 | 72.38 | 66.68 |
| ATA [35] | 59.95 | 80.08 | 56.34 | 81.80 | 80.70 | 71.77 |
| BCC [36] | 63.10 | 80.30 | 63.60 | 84.90 | 80.00 | 74.40 |
| CBL [37] | 49.36 | 76.15 | 50.65 | 72.22 | 70.12 | 63.70 |
| BGA [38] | 63.20 | 80.50 | 64.10 | 84.50 | 81.40 | 74.70 |
| BERT-SECA [39] | 71.00 | 86.10 | 68.90 | 86.20 | 85.20 | 79.50 |
| KE-BERT [40] | 72.20 | 86.50 | 69.00 | 88.10 | 85.50 | 80.30 |
| Hybrid Network | 68.29 | 86.40 | 75.43 | 89.94 | 84.98 | 81.01 |
| MTL (ours) | 71.76 | 88.39 | 72.11 | 88.06 | 86.25 | 81.31 |
| Topics | Comment Text | Labeled Stance | Hybrid Network | MTL (Ours) |
|---|---|---|---|---|
| topic 3 | 国家大事岂是你这一介草民能理解的 (National affairs are beyond your understanding as a commoner.) | NONE | NONE | OPPOSE |
| 俄罗斯早就把资料公布出来美国才马后炮之前干嘛去了(Russia has already released the information, but what did the United States do before it was released?) | SUPPORT | SUPPORT | OPPOSE | |
| 俄罗斯卫星网,专业造谣第一网(Russian Satellite Network, the first professional rumor website.) | OPPOSE | OPPOSE | SUPPORT | |
| topic 4 | #开放二胎# 看完我就呵呵了!尤其最后一段话,媒体为了迎合政策也真是煞费苦心了(#Having a second child# After reading it, I chuckled! Especially in the last paragraph, the media went to great lengths to comply with the policy.) | OPPOSE | OPPOSE | NONE |
| 想当初那些因为生二胎各种罚款撤职的真是唏嘘不已。违背自然规律终究还是要回归到尊重自然的道路上。(It is unfortunate to think about those dismissed from their positions due to various fines for having a second child. Going against the laws of nature ultimately requires returning to the path of respecting nature.) | SUPPORT | SUPPORT | OPPOSE |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, Q.; Huang, F.; Li, F.; Wei, J.; Jiang, S. Integrating Emotional Features for Stance Detection Aimed at Social Network Security: A Multi-Task Learning Approach. Electronics 2025, 14, 186. https://doi.org/10.3390/electronics14010186
Pu Q, Huang F, Li F, Wei J, Jiang S. Integrating Emotional Features for Stance Detection Aimed at Social Network Security: A Multi-Task Learning Approach. Electronics. 2025; 14(1):186. https://doi.org/10.3390/electronics14010186
Chicago/Turabian StylePu, Qiumei, Fangli Huang, Fude Li, Jieyao Wei, and Shan Jiang. 2025. "Integrating Emotional Features for Stance Detection Aimed at Social Network Security: A Multi-Task Learning Approach" Electronics 14, no. 1: 186. https://doi.org/10.3390/electronics14010186
APA StylePu, Q., Huang, F., Li, F., Wei, J., & Jiang, S. (2025). Integrating Emotional Features for Stance Detection Aimed at Social Network Security: A Multi-Task Learning Approach. Electronics, 14(1), 186. https://doi.org/10.3390/electronics14010186