1. Introduction
In the field of speech signal processing, adaptive filters can adjust the parameters in real time according to the changes in the input signal to better adapt to the non-stationary signals and unknown system environment [
1,
2,
3], so they have been more widely used in the fields of acoustic echo cancellation and active noise control [
4,
5,
6]. Adaptive filtering methods, including the least mean square (LMS) algorithm based on the minimum mean square error (MSE) criterion and the normalized least mean square (NLMS) algorithm, are widely used due to their relatively short data training time requirements [
7,
8,
9]. The affine projection (AP) algorithm, which uses recycled input signals to speed up convergence, was a significant advancement. Since then, AP-based algorithms have become the dominant choice in adaptive filtering [
10].
In order to optimize the robustness of AP class algorithms, researchers have proposed constrained optimization criterion algorithms such as the symbolic algorithm (SA) and maximum entropy criterion (MCC) algorithm [
11,
12,
13], combined them with AP algorithms in terms of the cost function, and proposed the APSA algorithm and APMCC algorithm with strong robustness [
14,
15]. Recently, the generalized maximum correlation entropy affine projection (APGMC) algorithm was introduced. It is based on the generalized correlation loss (GC-loss) function, which helps to lower the algorithm’s complexity [
16,
17]. Similarly, the recently discovered variable projection order (VPO) method is able to reduce the computational complexity associated with a fixed projection order and is widely used in AP algorithms [
18,
19,
20,
21].
However, the use of sound-absorbing materials in indoor environments, as well as directional microphone technology that captures sound only in a specific direction, has weakened the effects of multipath propagation of signals, resulting in a decreasing number of echo paths, which leads to an increasingly sparse echo channel. The upgrading of hardware technology has posed a comparative challenge to the development of system algorithms, and the traditional algorithms mentioned above may suffer from performance issues in certain applications. This is due to the challenge of precisely identifying a small set of critical parameters within the system [
22]. In this regard, some researchers found that the zero-attraction factor
l0-paradigm or
l1-paradigm constructed from the low-order paradigm of the weight vector can reduce the error of the algorithms in sparse systems [
23] and proposed the zero-attraction LMS (ZA-LMS) algorithm, the reweighted zero-attraction LMS (RZA-LMS) algorithm, the
l0-paradigm LMS (
l0-LMS) algorithm, polynomial ZA-LMS (PZA-LMS) algorithm, and so on [
24,
25,
26,
27].
However, there are not many applications of zero-attraction factor in AP algorithms, and the existing algorithms struggle to balance the steady-state error, convergence speed, and computational complexity [
28]. For example, the zero-attraction affine projection notation (APSAZA) algorithm has a simple structure but struggles to obtain a low steady-state error [
29]. The maximum correlation entropy affine projection with correlation entropy-induced metric (APMCCCIM) algorithm [
30] and the correntropy-based affine projection algorithm with compound inverse proportional function (APMCCCIPF) are more computationally complex due to the inclusion of the matrix inversion process [
31].
This paper proposes a variable-step generalized maximum correlation entropy affine projection algorithm (C-APGMC) with a sparse penalty term. In the short name of the algorithm, the first ‘C’ denotes the sparse regularization term added by the algorithm, i.e., the associated entropy-inducing metric. The algorithm uses the correlation entropy-induced metric (CIM), which approximates the l0-paradigm, as the paradigm penalty term. The overall algorithm can better exploit the sparse nature of echo paths while keeping the complexity low. The above advantages of the algorithm indicate that it is suitable for sparse channel identification for indoor online meetings and can solve the sparse channel echo cancellation problem in this scenario due to the environmental arrangement and hardware technology upgrades. In addition, the mean square deviation (MSD) of the algorithm can measure the average error between the output signal and the desired signal, thus establishing a link between the algorithmic step size and the current error and coordinating the algorithm’s performances. Thus, this approach will be applied in this paper to derive a formula for the variable step size in the proposed algorithm. This method solves the problem that current algorithms struggle to weigh the computational complexity and specific performance. As verified by simulation experiments, the proposed algorithm in this paper outperforms many existing algorithms in most aspects.
This paper consists of the following sections:
Section 2 discusses the application model of the algorithms as well as the existing base algorithms.
Section 3 discusses the algorithms proposed in this paper and their implementation process.
Section 4 provides a steady-state analysis of the algorithm.
Section 5 provides a complexity analysis of the algorithm. In
Section 6, several related algorithms are compared and simulated in terms of sparse system identification and echo cancellation.
Section 7 is the conclusion.
5. Complexity Analysis
This section compares the complexity of the proposed algorithm with several algorithms of the same type such as the APSAZA algorithm [
29], APMCCCIPF algorithm [
31], and MMCCCIM algorithm [
37]. In addition, to enhance the comparison, a fixed-step version of the algorithm proposed in this paper is added to the comparison.
Table 1 lists the comparison of the number of operations for multiplication and addition for several comparison algorithms, where
k is the number of taps and
P denotes the projection order.
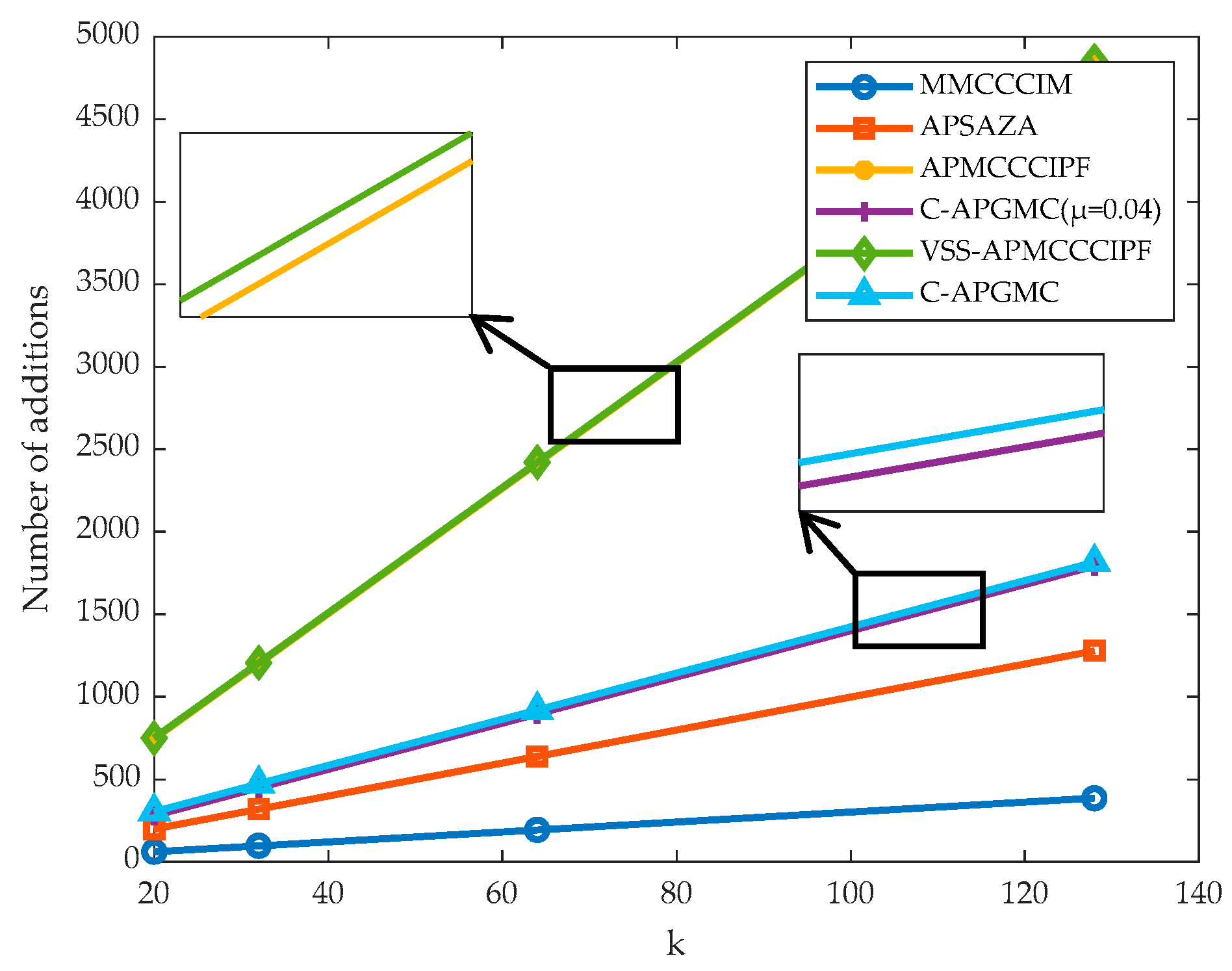
From the above table, it can be concluded that enhancing the adaptability of the algorithm to the environment may come at the cost of increased computational complexity. For example, the algorithm proposed in this paper increases the number of multiplications by 5
P + 6 times and the number of additions by
P + 20 times after adding the variable-step-size strategy. And after one parameter is determined, a small change in another parameter may also bring a relatively large impact on the complexity of the algorithm, so it is necessary to coordinate the relationship between the projection order of the algorithm and the filter length. In addition, the following figure visualizes the complexity comparison of the algorithms. Since all the affine projection class algorithms used in this paper have a projection order of 4 in the simulation experiments,
P = 4 is set to make the length of the unknown system weight vectors
k increase sequentially according to the trend of 20, 32, 64, and 128. The
Figure 1 and
Figure 2 of the change in the number of multiplication and addition operations of several algorithms are obtained, respectively.
From the above charts, it can be seen that the proposed algorithm in this paper has slightly more computation than the MMCCCIM algorithm after adding the CIM paradigm constraints, but the complexity is much lower than that of the same type of APMCCCIPF algorithm because the proposed algorithm does not need to perform matrix inversion. After adding the variable step factor, the complexity of the algorithm increases slightly, since the algorithms in this paper all use diagonal matrices, which actually involve only vector operations, but the computational complexity of the C-APGMC algorithm is still lower than that of the VSS-APMCCCIPF algorithm. In conclusion, all of the above algorithms add sparse regular terms in order to enhance the adaptability to the application scenarios, which increases some computational costs, but the proposed algorithm in this paper has the highest computational efficiency due to the use of the GC-loss scheme instead of the matrix inverse scheme to ensure the accuracy and real-time performance of the signal processing.
6. Simulation Results
In this section, the optimal values of several fixed parameters of the proposed algorithm will be determined and compared with several algorithms of the same type for system identification, and finally, echo cancellation simulation tests will be performed with reference to the above experiments.
The normalized mean square deviation (NMSD) will be employed as a performance metric to evaluate the filtering effectiveness of each algorithm, as defined in Equation (40).
In the simulation experiments, the steady-state error represents the minimum level of error that the system can achieve after a period of time. Ideally the steady-state error should be close to zero. The lower the value obtained in Equation (40), the closer the steady-state error is to zero. In addition, the speed of convergence of the algorithm can be assessed by observing whether the curve representing the algorithm reaches a steady state of convergence quickly; the steady-state error of the algorithm can be assessed by the lowest value when the curve reaches the steady state; the robustness of the algorithm can be assessed by the degree of fluctuation of the curve under different noise disturbances and whether the curve can converge normally and quickly. The tracking performance of the algorithm can be evaluated by whether the algorithm curve can recover quickly when there is a sudden change in the system impulse response and reach the next steady state, and the steady-state error when each algorithm reaches the fastest convergence will be compared in the experiments as a performance evaluation criterion. The data obtained from the experiments were calculated by averaging the results of 200 independent simulations.
6.1. Algorithm Parameter Selection
The following figure shows the comparison and selection of parameters such as
α and kernel width
σ in the
B(
n) matrix of the proposed algorithm. In order to ensure environmental adaptability, we draw on the exhaustive method and grid search method in determining the important parameters. Firstly, we draw on [
17,
31] to initialize the parameters, and after obtaining the optimal value of the first parameter, we will set it as the initial value to continue to determine the second parameter and so on to obtain the optimal combination of parameters. The simulation experiment environment is the same as the system identification experiment environment. Gaussian white noise has a flat spectral property that can cover all frequency components of the system, and Gaussian noise can be adjusted for its autocorrelation by the autoregressive (AR) model, which enables the input signal to better simulate the statistical properties of the actual signal. Therefore, the input signal used in this system identification experiment is the AR signal, which is obtained from the Gaussian white noise signal trained by the AR training model:
where
z is a complex variable that characterizes the signal in the frequency domain. G(
z) represents the transfer function of the autoregressive model, describing the relationship between the input and output signals. The model is trained with a Gaussian white noise signal, which serves as the input. This approach enhances the adaptive filter’s recognition accuracy and improves convergence speed.
The algorithms in the experiments are projected with order P = 4. The unknown system is randomly generated from numbers between −1 and 1 according to the set sparsity with a length of 120. The total number of iterations for the algorithm in the non-smooth environment is 2 × 104, where the system impulse response changes from w0 to −w0 at 1 × 104 iterations. The Gaussian noise signal-to-noise ratio is 20 dB throughout the system identification simulation experiments. In the experiment each parameter will be taken from small to large within a reasonable range. Based on the experimental outcomes, the point with the lowest steady-state error, while maintaining the same convergence rate, is selected as the optimal value for use in subsequent experiments.
It should be noted that the parameter sensitivity analysis range of this experiment is determined based on a large number of simulation experiments, and parameter selection outside the range is likely to cause the algorithm to fail to converge properly. Therefore, in order to ensure that the algorithm can operate efficiently and stably in the real environment, the impact of parameter selection on the performance of the algorithm will be analyzed in depth within the current range. For parameter
α, too large a value can lead to too much influence of the error on the algorithm, and too small a value can weaken the adaptive performance of the algorithm. For parameter
β, too large a value will result in the algorithm relying too much on the sparsity of the system, and too small a value will weaken the algorithm’s ability to adapt to sparse systems. For the parameter
σ, a value that is too large may hinder the algorithm’s ability to adapt to complex signal dynamics, while a value that is too small could lead to overfitting. Regarding the parameter
t, an excessively large value causes the algorithm to overly depend on past data, slowing down convergence. Conversely, a value that is too small results in rapid changes in the step size, reducing the algorithm’s stability. As shown in
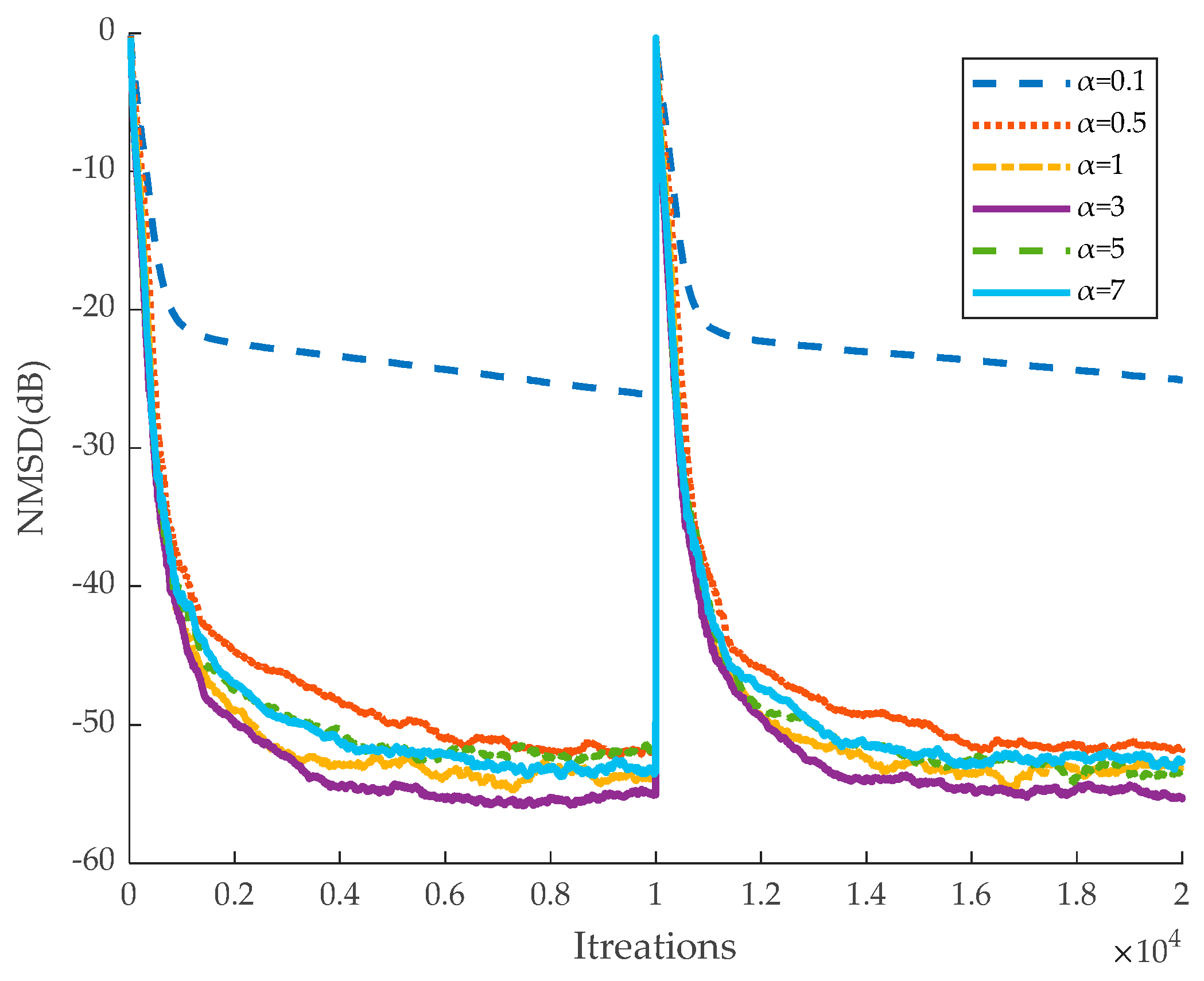
Figure 3, when the parameter
α in the matrix
B(
n) is within the range of (0.5, 7), the algorithm achieves faster convergence and a lower steady-state error. When
α is less than 0.5, the algorithm exhibits a high steady-state error and fails to converge after 1 × 10⁴ iterations. Furthermore, when
α exceeds 3, the steady-state error increases as
α rises. Based on these observations, the optimal value of
α for the algorithm is determined to be 3. Similarly, as shown in
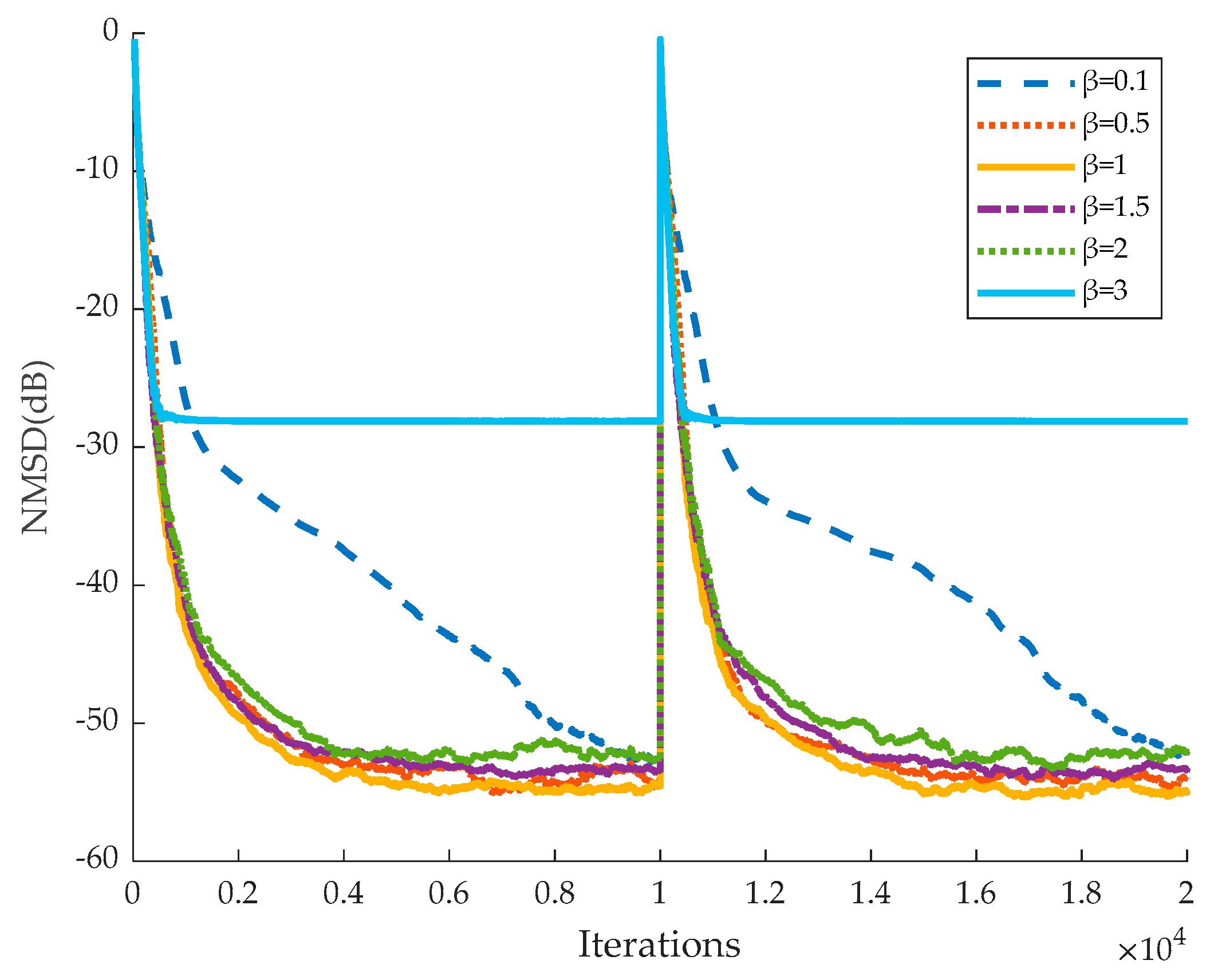
Figure 4,
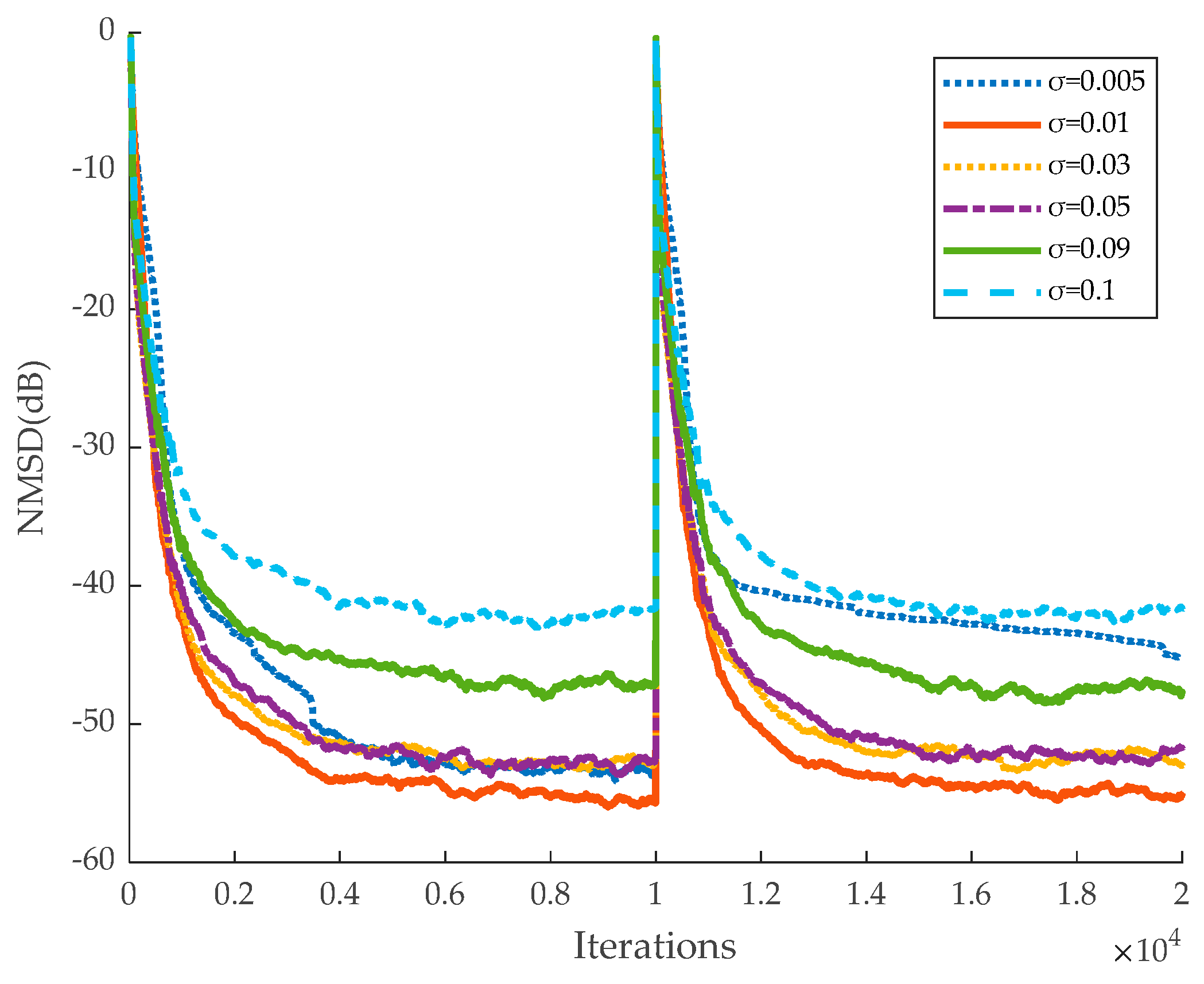
Figure 5 and
Figure 6 the best parameters are identified as
β = 1,
σ = 0.01, and
t = 0.997.
6.2. Sparse System Identification
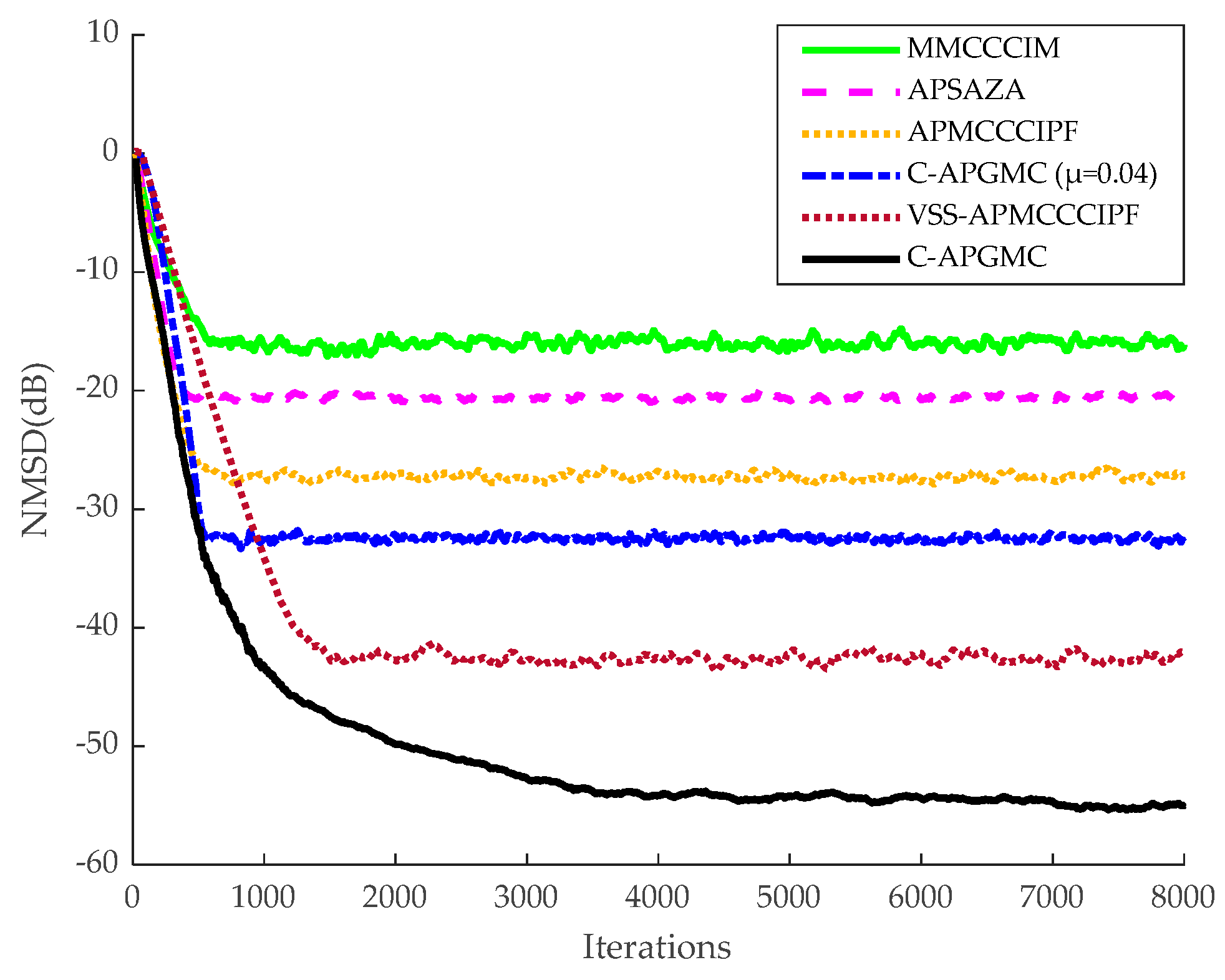
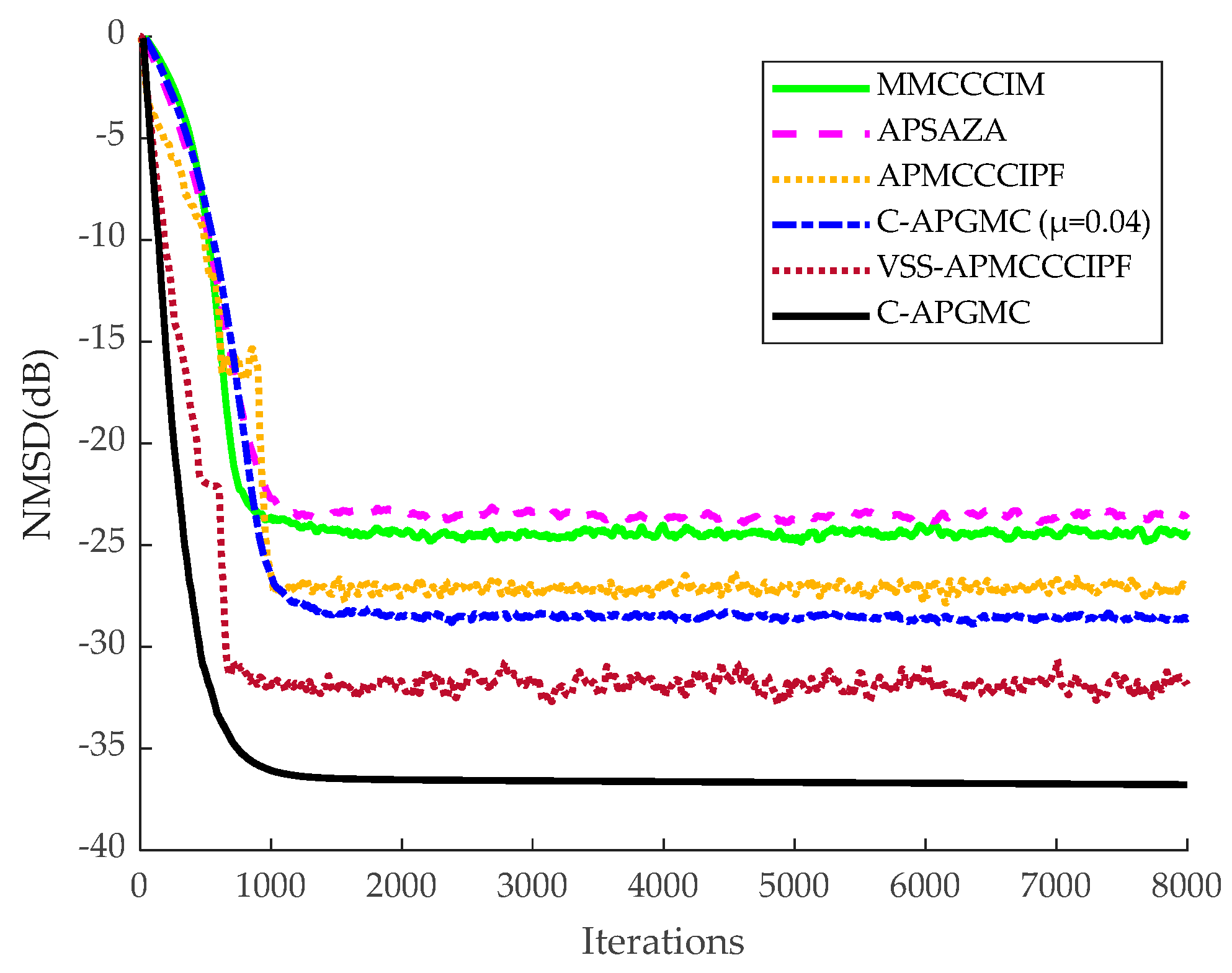
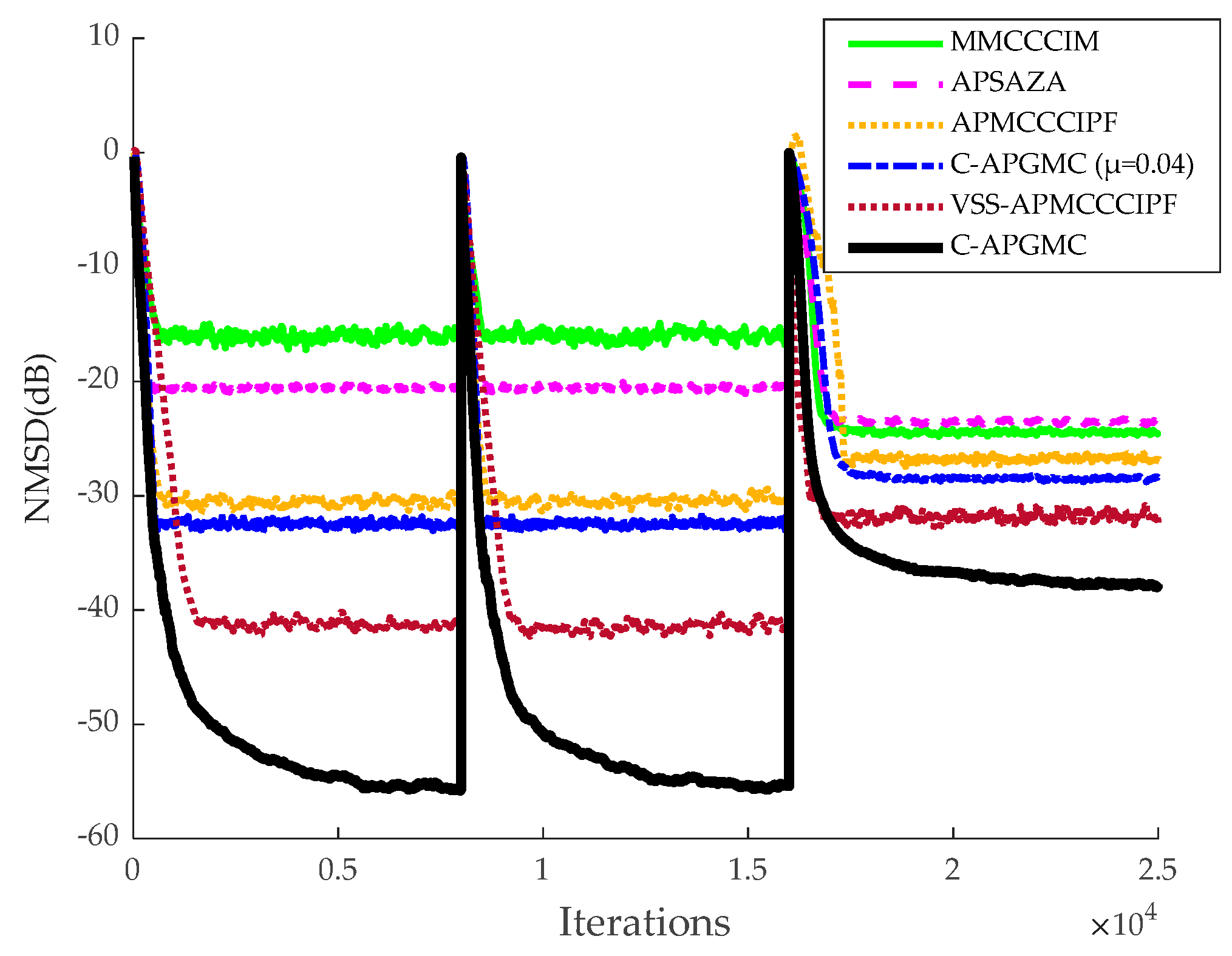
Before the echo cancellation simulation, a system identification simulation experiment needs to be set up in order to provide reasonable initial parameter settings for the adaptive filters so that the individual filter algorithms can achieve the fastest convergence rate. In this section, the algorithm proposed in this paper is compared with the same type of MMCCCIM, APSAZA, APMCCCIPF, and VSS-APMCCCIPF algorithms, and in order to enhance the comparison of the effects, the fixed-step version of the algorithm proposed in this paper is also included in the comparison.
The number of iterations in this experiment was 8000 in the smooth environment and 2.5 × 10
4 in the non-smooth environment. To ensure that the performance of each algorithm is optimal, the step size is set to
μ = 0.08 for the MMCCCIM algorithm,
μ = 0.02 for the APSAZA algorithm,
μ = 0.04 for the APMCCCIPF algorithm, the kernel width
σ = 0.01, and the zero-attraction factor
β = 0.0001. For the VSS-APMCCCIPF algorithm, the step size of the variable parameter in the convex combination factor
t = 0.98. For the C-APGMC algorithm,
α = 3,
β = 1, kernel width
σ = 0.01, the convex combination factor
t = 0.997. The results are shown in the
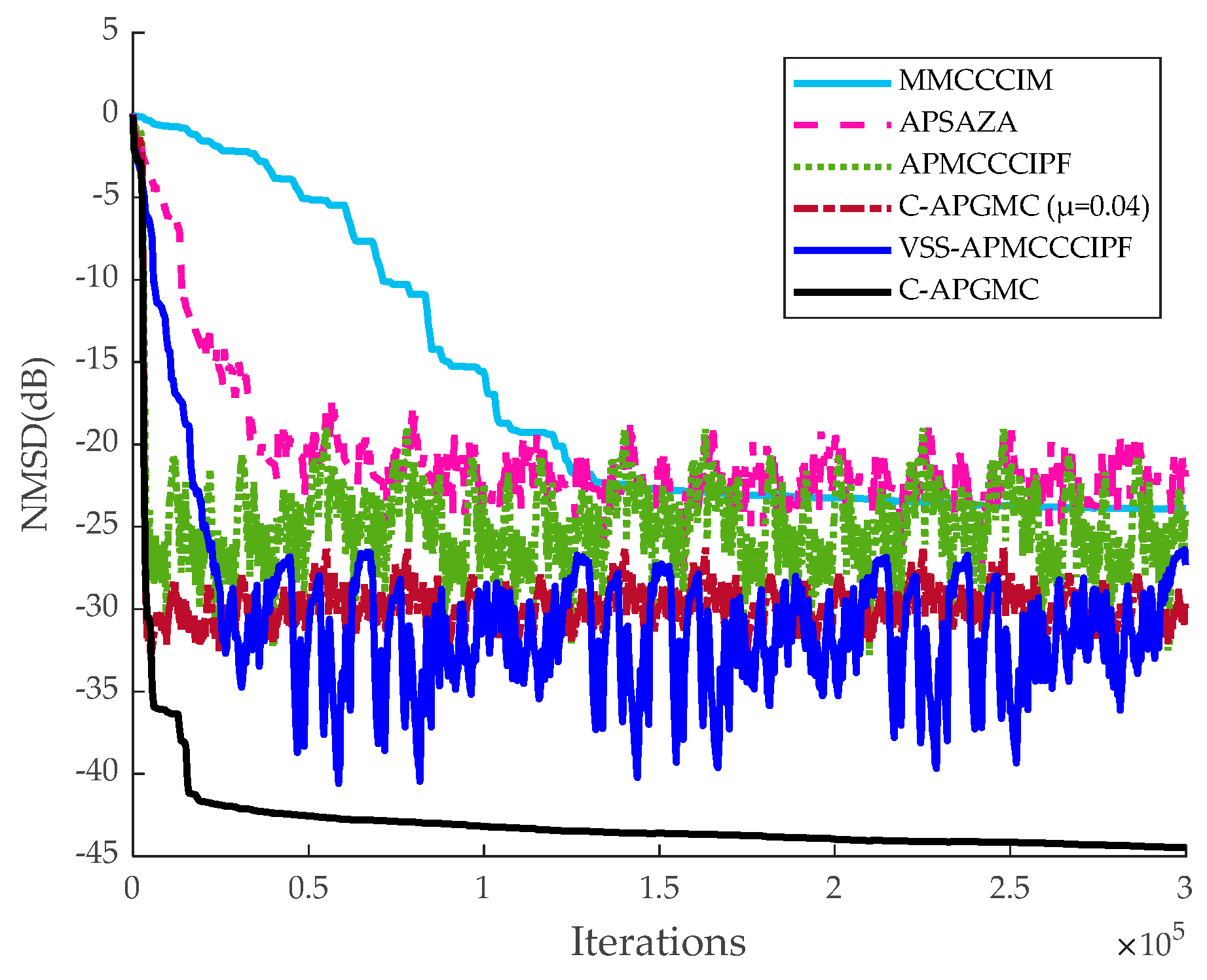
Figure 7,
Figure 8 and
Figure 9.
As can be seen from the above figures, in the sparse system, the MMCCCIM algorithm has the worst effect because it does not reuse the input signal. In addition, compared with CIM, which approximates
l0-paradigm, the APSAZA algorithm performs poorly due to the fact that it employs
l1-paradigm as a sparse penalty term, and its zero-attraction ability is weaker than that of CIM [
24]. The APMCCCIPF algorithm and the proposed algorithm have better performance due to the combination of faster convergence of the AP algorithm and advanced sparse constraints, and the APMCCCIPF algorithm has simpler structure due to sparse constraints on the CIPF function in order to reduce the complexity and its steady-state error is slightly higher than the fixed-step version of the algorithm proposed in this paper. The VSS-APMCCCIPF algorithm adopts a variable-step strategy and its steady-state error is further reduced compared with the fixed-step version of the algorithm proposed in this paper. In comparison, the C-APGMC algorithm presented in this study, which employs the MSD method to derive a variable-step-size formula and incorporates historical input signals, demonstrates superior performance in both convergence speed and steady-state error. In non-sparse systems, the algorithm proposed in this paper still has the smallest steady-state error, and in this experiment, it can be seen that the algorithm proposed in this paper can also perform well if there are multipath echo channels in the echo cancellation scenario of the algorithm, which results in a decrease in the sparsity of the echo paths. The above experiment confirms the effectiveness of the C-APGMC algorithm and its variable-step-size strategy proposed in this paper in the application of system identification scenarios.
6.3. Echo Cancellation
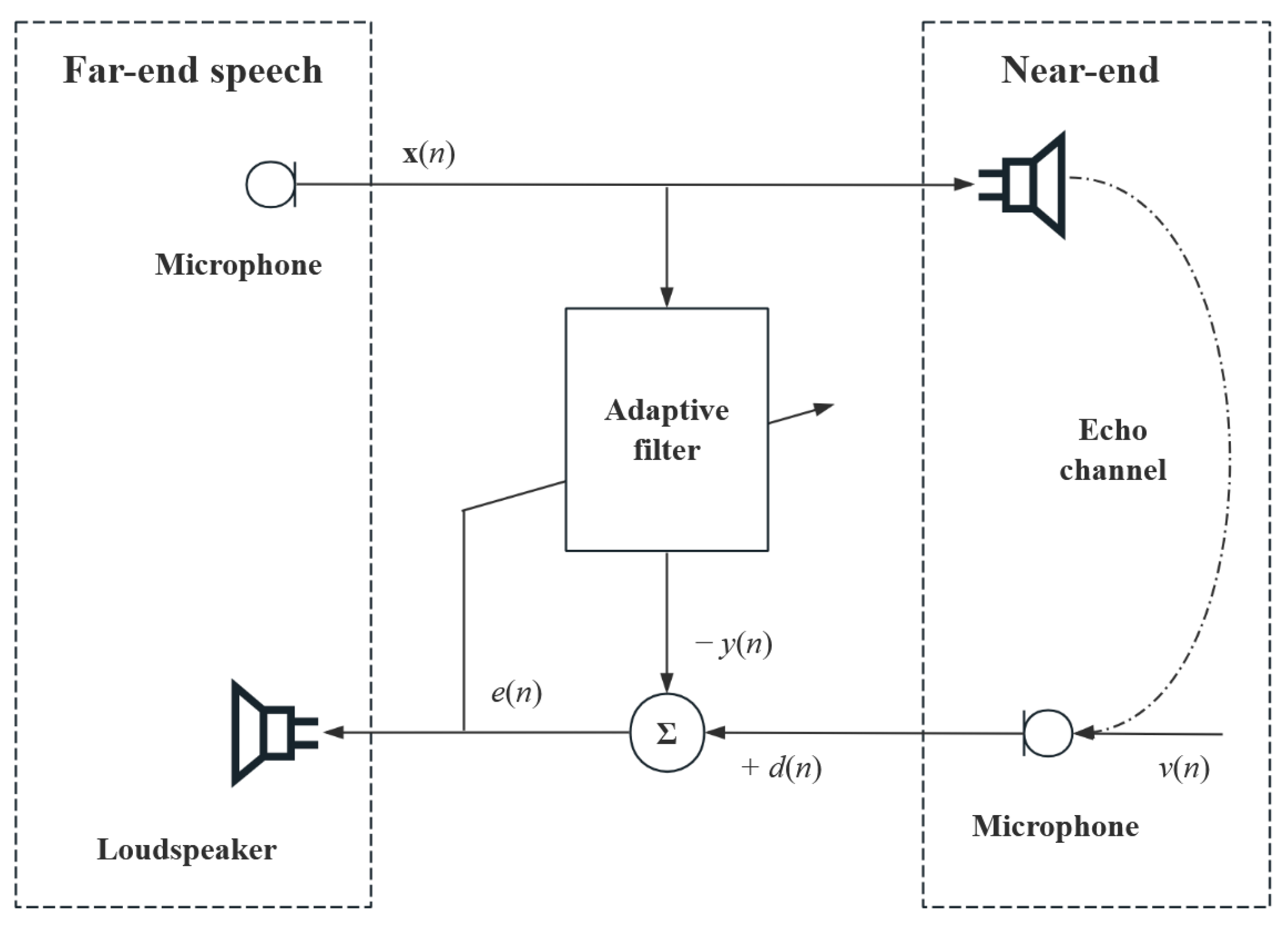
This section continues to validate the performance of the proposed algorithm in echo cancellation scenarios. As shown in the
Figure 10, the speech signal
x(
n) from the far end is transmitted to the near end, undergoes various reflections, is interspersed with noise
v(
n) to form an echo signal
d(
n) that is collected by the directional microphone, and is finally re-transmitted back to the far end. It should be noted that the movement of the near-end microphone position will cause an abrupt change in the impulse response of the echo system. The adaptive algorithm will simulate the echo path through known conditions to obtain a more accurate echo signal, thus eliminating the echo.
By analyzing the results of the sparse system identification experiments, setting the system impulse response length to 128 better reflects the indoor characteristics of the echo cancellation scenario, and the algorithm can exert its maximum performance under the echo path of this length. The echo cancellation simulation experiments in this paper are all performed with the same system impulse response and this sparse path setting is shown in the
Figure 11:
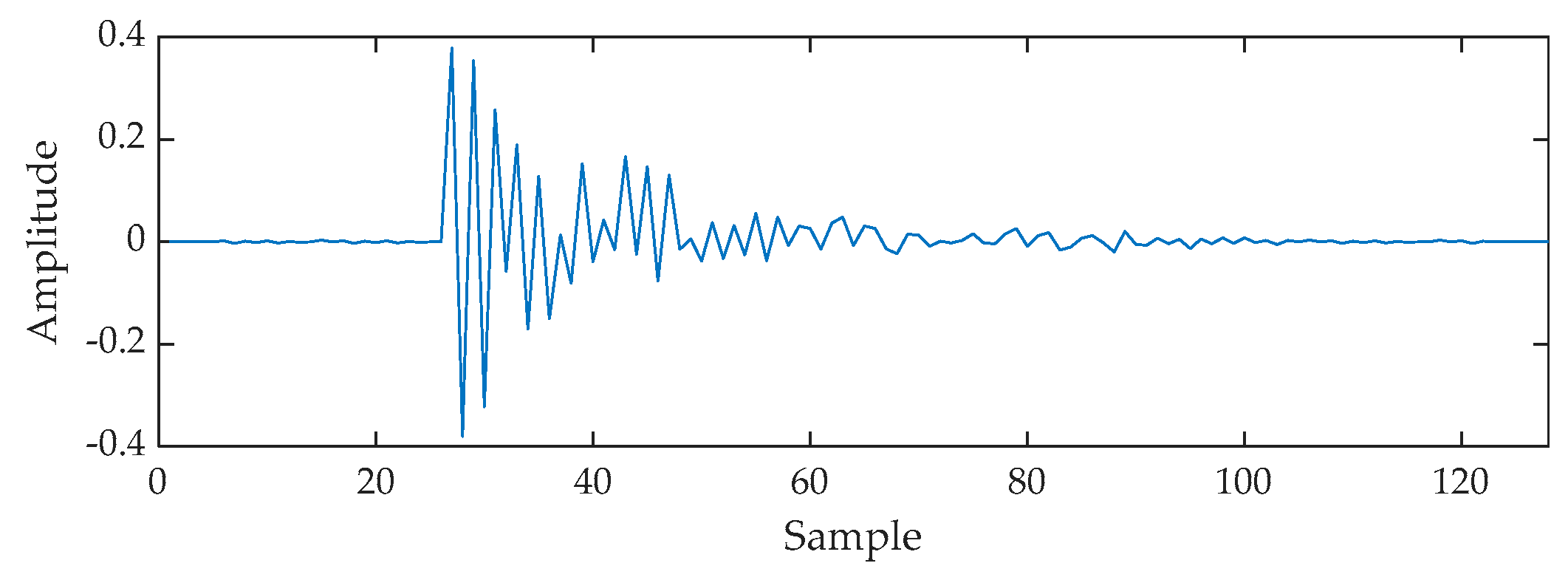
In the above figure, most of the impulse response values are zero or very small, with a peak only at a sample length of 27, which decays with time, which is consistent with the characteristics of non-multipath echo channels and delayed propagation in indoor teleconferencing and is suitable for modeling this scenario. The input signal is a real speech signal with a sampling frequency of 8 kHz and its waveform is shown in the
Figure 12.
To ensure the optimal performance of each algorithm, for the APMCCCIPF algorithm, the step size is set to
μ = 0.04, the kernel width
σ = 0.1, the zero-attraction factor
β = 1 × 10
−6, and the rest of the algorithmic parameter settings are the same as those used in the above-mentioned system identification applications. To assess the performance of each algorithm under varying noise conditions, the final set of simulation experiments includes Gaussian noise with a signal-to-noise ratio of 20 dB, as well as impulsive noise following an
α-stable distribution [
38]. The
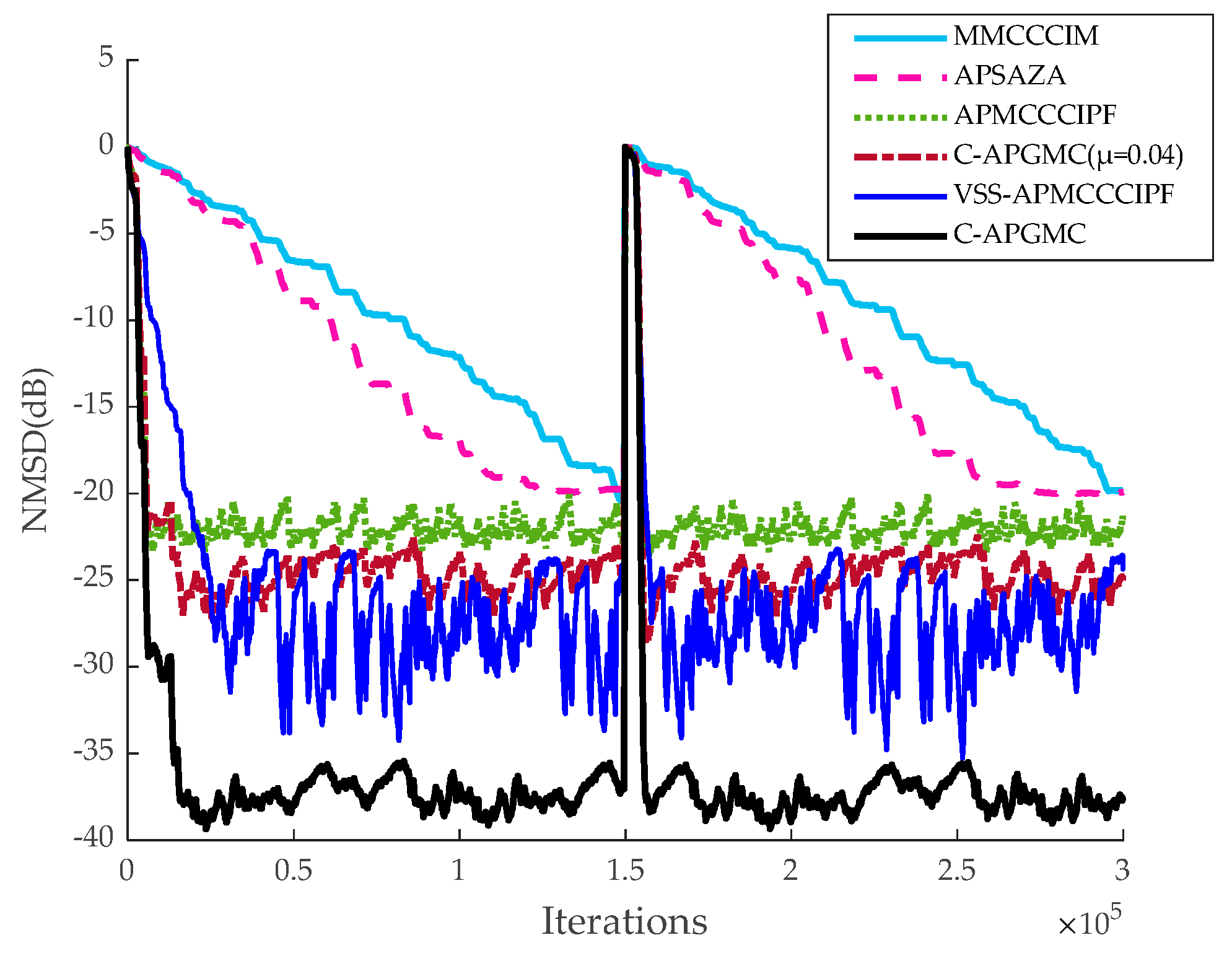
Figure 13,
Figure 14 and
Figure 15 present the simulation outcomes for all six algorithms across different echo cancellation scenarios.
The above comparison shows that with approximately the same convergence rate for all types of algorithms, the steady-state error of the C-APGMC algorithm with fixed step size is between those of the APMCCCIPF algorithm and the VSS-APMCCCIPF algorithm, and C-APGMC has the smoothest performance in reaching the steady state with the smallest steady-state error due to the availability of convex combination factors. Upon introducing mixed noise, the performance of all algorithms is impacted to some degree. However, the algorithm presented in this study maintains low steady-state error and high stability, thanks to the aforementioned advantages. The above results demonstrate the strong performance of the algorithm proposed in this paper in the simulation of indoor sparse echo channels compared to other algorithms of the same type, proving that the algorithm possesses a relatively strong echo cancellation effect in indoor teleconferencing scenarios.
7. Conclusions
This paper proposes the C-APGMC algorithm, which is based on the generalized maximum correlation entropy affine projection (APGMC) algorithm. The algorithm uses the CIM method as a sparse penalty term, making it more suitable for application scenarios such as echo cancellation. In addition, a variable-step-size formulation of the algorithm is derived by means of the MSD method and the introduction of a convex combinatorial factor. The performance analysis and simulation results show that, although the introduction of a variable step factor slightly increases complexity, the algorithm achieves faster convergence, reduced steady-state error, and improved tracking capability in sparse systems. Additionally, the proposed algorithm outperforms recent methods, such as the APMCCCIPF algorithm, which are also designed for sparse systems. Finally, from the comparative simulation experiments of echo cancellation with different noise inputs, it can be concluded that the interference of strong impulse noise is not conducive to the performance of the proposed algorithm in sparse echo path recognition, and the present algorithm is more suitable for indoor echo cancellation environments. Future research could try to incorporate active noise control (ANC) techniques to reduce the effect of strong impulse noise on echo cancellation algorithms.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}