
Class-Patch Similarity Weighted Embedding for Few-Shot Infrared Image Classification

Abstract
1. Introduction
2. Related Works
2.1. Few-Shot Learning
2.2. Few-Shot Classfication in Infrared Imaging
3. Method
3.1. Problem Definition
3.2. Class-Patch Similarity Weighted Embedding
3.3. Similarity Measure
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Experimental Results
4.3.1. Results on miniImageNet
4.3.2. Results on miniIRNet
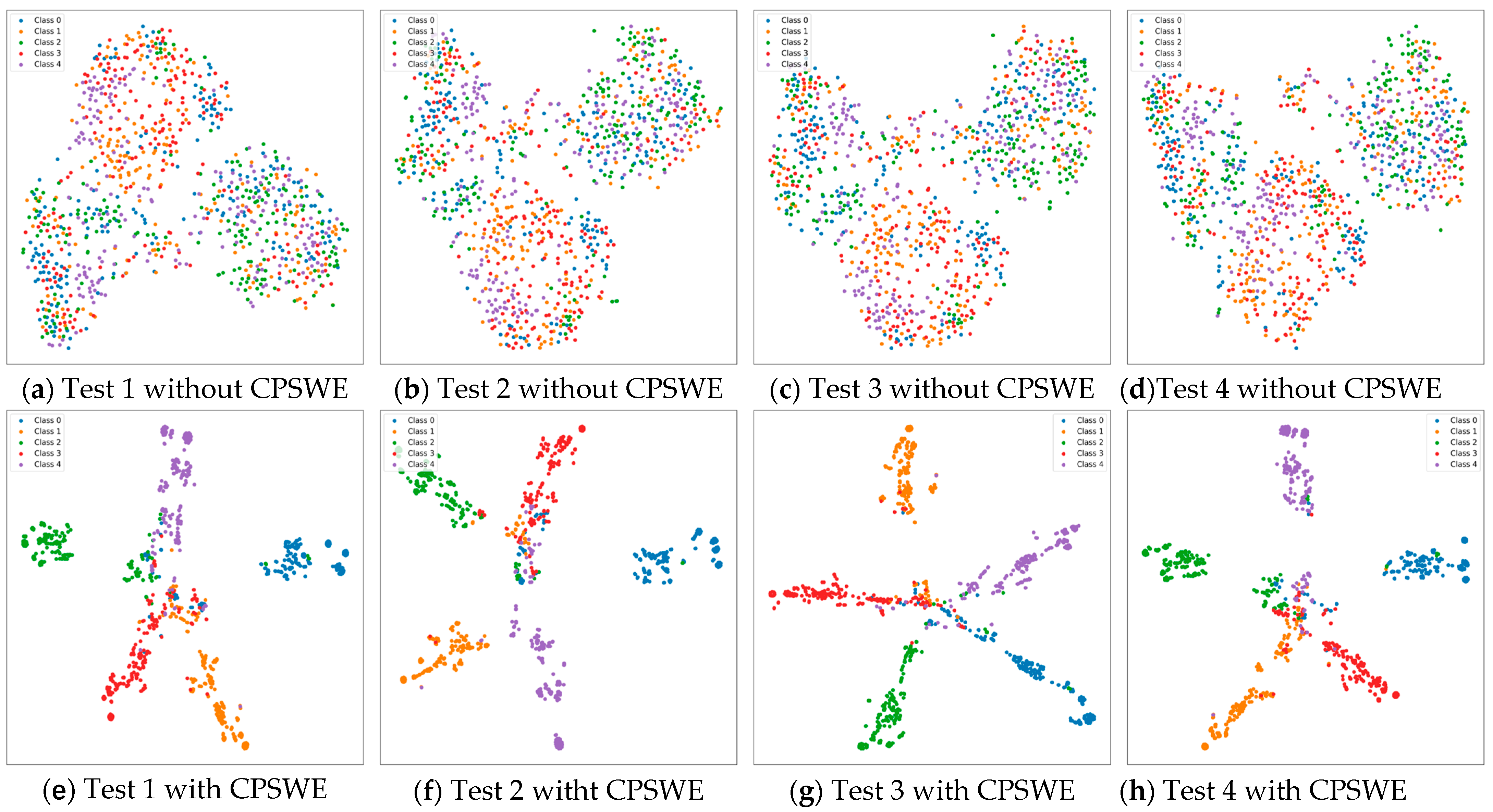
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hu, Y.; Wang, K.; Chen, L.; Li, N.; Lei, Y. Visualization of Invisible Near-Infrared Light. Innov. Mater. 2024, 2, 100067. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, X.; Cao, X.; Huang, C.; Liu, E.; Qian, S.; Liu, X.; Wu, Y.; Dong, F.; Qiu, C.-W.; et al. Artificial Intelligence: A Powerful Paradigm for Scientific Research. Innovation 2021, 2, 100179. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Yue, J.; Qin, Q. Global Prototypical Network for Few-Shot Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4748–4759. [Google Scholar] [CrossRef]
- Tan, J.; Zhang, R.; Zhang, Q.; Cao, Z.; Xu, L. Few-Shot Infrared Image Classification with Partial Concept Feature. In Proceedings of the 6th Pattern Recognition and Computer Vision, PRCV, Xiamen, China, 13–15 October 2023; Springer: Singapore, 2024; pp. 343–354. [Google Scholar]
- Zhang, H.; Luo, C.; Wang, Q.; Kitchin, M.; Parmley, A.; Monge-Alvarez, J.; Casaseca-de-la-Higuera, P. A Novel Infrared Video Surveillance System Using Deep Learning Based Techniques. Multimed. Tools Appl. 2018, 77, 26657–26676. [Google Scholar] [CrossRef]
- Berg, A.; Ahlberg, J.; Felsberg, M. A Thermal Object Tracking Benchmark. In Proceedings of the 2015 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015; pp. 1–6. [Google Scholar]
- Davis, J.; Keck, M. A two-stage approach to person detection in thermal imagery. In Proceedings of the 2005 Seventh IEEE Workshops on Applications of Computer Vision (WACV/MOTION’05), Breckenridge, CO, USA, 5–7 January 2005. [Google Scholar]
- Ariffin, S.M.Z.S.Z.; Jamil, N.; Rahman, P.N.M.A. DIAST Variability Illuminated Thermal and Visible Ear Images Datasets. In Proceedings of the 2016 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 21–23 September 2016; pp. 191–195. [Google Scholar]
- Mantecón, T.; del-Blanco, C.R.; Jaureguizar, F.; García, N. Hand Gesture Recognition Using Infrared Imagery Provided by Leap Motion Controller. In Proceedings of the Advanced Concepts for Intelligent Vision Systems, 7th International Conference (ACVIS), Antwerp, Belgium, 20–23 September 2005; Springer: Cham, Switzerland, 2016; pp. 47–57. [Google Scholar]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A Visible-Infrared Paired Dataset for Low-Light Vision. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3496–3504. [Google Scholar]
- Liu, Q.; Li, X.; Yuan, D.; Yang, C.; Chang, X.; He, Z. LSOTB-TIR: A Large-Scale High-Diversity Thermal Infrared Single Object Tracking Benchmark. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 9844–9857. [Google Scholar] [CrossRef]
- Liu, Q.; He, Z.; Li, X.; Zheng, Y. PTB-TIR: A Thermal Infrared Pedestrian Tracking Benchmark. IEEE Trans. Multimed. 2020, 22, 666–675. [Google Scholar] [CrossRef]
- Dai, X.; Yuan, X.; Wei, X. TIRNet: Object Detection in Thermal Infrared Images for Autonomous Driving. Appl. Intell. 2021, 51, 1244–1261. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning (PMLR), Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Sun, Q.; Liu, Y.; Chua, T.-S.; Schiele, B. Meta-Transfer Learning for Few-Shot Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 403–412. [Google Scholar]
- Lee, K.; Maji, S.; Ravichandran, A.; Soatto, S. Meta-Learning with Differentiable Convex Optimization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10657–10665. [Google Scholar]
- Wang, R.; Demiris, Y.; Ciliberto, C. Structured Prediction for Conditional Meta-Learning. In Proceedings of the Advances in Neural Information Processing Systems 33, Northern Ireland, UK, 6–12 December 2020; Volume 33, pp. 2587–2598. [Google Scholar]
- Deleu, T.; Kanaa, D.; Feng, L.; Kerg, G.; Bengio, Y.; Lajoie, G.; Bacon, P.-L. Continuous-Time Meta-Learning with Forward Mode Differentiation. In Proceedings of the 9th International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical Networks for Few-Shot Learning. In Proceedings of the Advances in Neural Information Processing Systems 31, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. In Proceedings of the Advances in Neural Information Processing Systems 29, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–22 June 2018; pp. 3588–3597. [Google Scholar]
- Hou, R.; Chang, H.; MA, B.; Shan, S.; Chen, X. Cross Attention Network for Few-Shot Classification. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Xie, J.; Long, F.; Lv, J.; Wang, Q.; Li, P. Joint Distribution Matters: Deep Brownian Distance Covariance for Few-Shot Classification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7962–7971. [Google Scholar]
- Kang, D.; Kwon, H.; Min, J.; Cho, M. Relational Embedding for Few-Shot Classification. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 8802–8813. [Google Scholar]
- Cheng, H.; Yang, S.; Zhou, J.T.; Guo, L.; Wen, B. Frequency Guidance Matters in Few-Shot Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2023, Paris, France, 2–6 October 2023; pp. 11814–11824. [Google Scholar]
- Sun, S.; Gao, H. Meta-AdaM: An Meta-Learned Adaptive Optimizer with Momentum for Few-Shot Learning. Adv. Neural Inf. Process. Syst. 2023, 36, 65441–65455. [Google Scholar]
- Zhang, B.; Luo, C.; Yu, D.; Li, X.; Lin, H.; Ye, Y.; Zhang, B. MetaDiff: Meta-Learning with Conditional Diffusion for Few-Shot Learning. Proc. AAAI Conf. Artif. Intell. 2024, 38, 16687–16695. [Google Scholar] [CrossRef]
- Zhu, H.; Koniusz, P. Transductive Few-Shot Learning With Prototype-Based Label Propagation by Iterative Graph Refinement. arXiv 2023, arXiv:2304.11598. [Google Scholar]
- Hiller, M.; Ma, R.; Harandi, M.; Drummond, T. Rethinking Generalization in Few-Shot Classification. Adv. Neural Inf. Process. Syst. 2022, 35, 3582–3595. [Google Scholar]
- He, Y.; Liang, W.; Zhao, D.; Zhou, H.-Y.; Ge, W.; Yu, Y.; Zhang, W. Attribute Surrogates Learning and Spectral Tokens Pooling in Transformers for Few-Shot Learning. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9109–9119. [Google Scholar]
- Hao, F.; He, F.; Liu, L.; Wu, F.; Tao, D.; Cheng, J. Class-Aware Patch Embedding Adaptation for Few-Shot Image Classification. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 18859–18869. [Google Scholar]
- Chen, R.; Liu, S.; Li, F. Infrared Aircraft Few-Shot Classification Method Based on Meta Learning. J. Infrared Millim. Waves 2021, 40, 554–560. [Google Scholar]
- LI, Y.-Z.; ZHANG, Y.; CHEN, Y.; YANG, C.-L. An Unsupervised Few-Shot Infrared Aerial Object Recognition Network Based on Deep-Shallow Learning Graph Model. J. Infrared Millim. Waves 2023, 42, 916–923. [Google Scholar] [CrossRef]
- Yang, B.; Zhang, R.; Liu, Y.; Liu, G.; Cao, Z.; Yang, Z.; Yu, H.; Xu, L. CTL-I: Infrared Few-Shot Learning via Omnidirectional Compatible Class-Incremental. In Proceedings of the 13th International Conference on Big Data Technologies and Applications, BDTA 2023, Edinburgh, UK, 23–24 August 2023; Springer: Cham, Switzerland, 2024; pp. 3–17. [Google Scholar]
- Huang, X.; Choi, S.H. SAPENet: Self-Attention Based Prototype Enhancement Network for Few-Shot Learning. Pattern Recognit. 2023, 135, 109170. [Google Scholar] [CrossRef]
- Sim, C.; Kim, G. Cross-Attention Based Dual-Similarity Network for Few-Shot Learning. Pattern Recognit. Lett. 2024, 186, 1–6. [Google Scholar] [CrossRef]
- Huang, Y.; Hao, H.; Ge, W.; Cao, Y.; Wu, M.; Zhang, C.; Guo, J. Relation Fusion Propagation Network for Transductive Few-Shot Learning. Pattern Recognit. 2024, 151, 110367. [Google Scholar] [CrossRef]
- Ye, H.-J.; Hu, H.; Zhan, D.-C.; Sha, F. Few-Shot Learning via Embedding Adaptation With Set-to-Set Functions. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8805–8814. [Google Scholar]
- Chen, Z.; Ge, J.; Zhan, H.; Huang, S.; Wang, D. Pareto Self-Supervised Training for Few-Shot Learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13658–13667. [Google Scholar]
- Zhang, X.; Meng, D.; Gouk, H.; Hospedales, T. Shallow Bayesian Meta Learning for Real-World Few-Shot Recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 631–640. [Google Scholar]
- Chen, W.-Y.; Liu, Y.-C.; Kira, Z.; Wang, Y.-C.F.; Huang, J.-B. A Closer Look at Few-Shot Classification. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019; p. 3. [Google Scholar]
- Chen, Y.; Liu, Z.; Xu, H.; Darrell, T.; Wang, X. Meta-Baseline: Exploring Simple Meta-Learning for Few-Shot Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 9062–9071. [Google Scholar]
- Liu, Y.; Zhang, W.; Xiang, C.; Zheng, T.; Cai, D.; He, X. Learning to Affiliate: Mutual Centralized Learning for Few-Shot Classification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14391–14400. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | ≈Params | miniImageNet | |
|---|---|---|---|---|
| 1-Shot | 5-Shot | |||
| ProtoNet [19] | ResNet-12 | 12.4 M | 60.76 ± 0.47 | 78.51 ± 0.34 |
| CAN [22] | ResNet-12 | 12.4 M | 63.85 ± 0.48 | 79.44 ± 0.34 |
| SAPENet [35] | ResNet-12 | 12.4 M | 66.41 ± 0.20 | 82.76 ± 0.14 |
| DeepBDC [23] | ResNet-12 | 12.4 M | 67.34 ± 0.43 | 84.46 ± 0.28 |
| ReNet [24] | ResNet-12 | 12.4 M | 67.60 ± 0.44 | 82.58 ± 0.30 |
| DSN [36] | ResNet-12 | 12.4 M | 70.37 ± 0.41 | 85.25 ± 0.30 |
| RFPN [37] | ResNet-12 | 12.4 M | 67.43 ± 0.51 | 83.69 ± 0.43 |
| FEAT [38] | WRN-28-10 | 36.5 M | 65.10 ± 0.20 | 81.11 ± 0.14 |
| PSST [39] | WRN-28-10 | 36.5 M | 64.16 ± 0.44 | 80.64 ± 0.32 |
| MetaQDA [40] | WRN-28-10 | 36.5 M | 67.83 ± 0.64 | 84.28 ± 0.69 |
| FewTURE [29] | ViT-Small | 22 M | 68.02 ± 0.88 | 84.51 ± 0.53 |
| CPEA [31] | ViT-Small | 22 M | 71.97 ± 0.65 | 87.06 ± 0.38 |
| CPSWE | ViT-Small | 22 M | 73.31 ± 0.65 | 88.55 ± 0.35 |
| Model | Backbone | ≈Params | miniIRNet | |
|---|---|---|---|---|
| 1-Shot | 5-Shot | |||
| ProtoNet [19] | ResNet-12 | 12.4 M | 70.81 ± 0.41 | 83.03 ± 0.30 |
| Baseline [41] | ResNet-12 | 12.4 M | 71.20 ± 0.42 | 89.74 ± 0.58 |
| MetaBaseline [42] | ResNet-12 | 12.4 M | 76.10 ± 0.72 | 89.26 ± 0.72 |
| MCL [43] | ResNet-12 | 12.4 M | 71.15 ± 0.74 | 81.95 ± 0.59 |
| DeepBDC [23] | ResNet-12 | 12.4 M | 75.42 ± 0.86 | 91.17 ± 0.30 |
| ReNet [24] | ResNet-12 | 12.4 M | 71.19 ± 0.99 | 85.85 ± 0.71 |
| FewTURE [29] | ViT-Small | 22 M | 75.84 ± 0.92 | 91.23 ± 0.34 |
| CPEA [31] | ViT-Small | 22 M | 74.93 ± 0.73 | 90.00 ± 0.43 |
| CPSWE | ViT-Small | 22 M | 77.71 ± 0.67 | 92.06 ± 0.39 |
| Weighted Embedding | 1-Shot | 5-Shot |
|---|---|---|
| × | 75.22 ± 0.68 | 89.94 ± 0.46 |
| √ | 77.71 ± 0.67 | 92.06 ± 0.39 |
| Scaling Factor | 1-Shot | 5-Shot |
|---|---|---|
| 73.50 ± 0.73 | 90.45 ± 0.42 | |
| 5 | 77.20 ± 0.68 | 91.69 ± 0.40 |
| 77.25 ± 0.70 | 91.03 ± 0.39 | |
| 77.71 ± 0.67 | 92.06 ± 0.39 | |
| 77.23 ± 0.69 | 91.63 ± 0.37 | |
| 77.12 ± 0.69 | 90.86 ± 0.41 | |
| 77.04 ± 0.64 | 90.64 ± 0.44 |
| Similarity Measures | 1-Shot | 5-Shot |
|---|---|---|
| 76.79 ± 0.67 | 90.82 ± 0.43 | |
| 76.68 ± 0.68 | 91.40 ± 0.40 | |
| 76.59 ± 0.71 | 91.48 ± 0.42 | |
| 77.71 ± 0.67 | 92.06 ± 0.39 |
| Distance Function | 1-Shot | 5-Shot |
|---|---|---|
| Euclidean distance | 75.55 ± 0.75 | 90.60 ± 0.42 |
| Cosine similarity | 77.71 ± 0.67 | 92.06 ± 0.39 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Gong, J.; Wang, X.; Wu, D.; Zhang, Y. Class-Patch Similarity Weighted Embedding for Few-Shot Infrared Image Classification. Electronics 2025, 14, 290. https://doi.org/10.3390/electronics14020290
Huang Z, Gong J, Wang X, Wu D, Zhang Y. Class-Patch Similarity Weighted Embedding for Few-Shot Infrared Image Classification. Electronics. 2025; 14(2):290. https://doi.org/10.3390/electronics14020290
Chicago/Turabian StyleHuang, Zhen, Jinfu Gong, Xiaoyu Wang, Dongjie Wu, and Yong Zhang. 2025. "Class-Patch Similarity Weighted Embedding for Few-Shot Infrared Image Classification" Electronics 14, no. 2: 290. https://doi.org/10.3390/electronics14020290
APA StyleHuang, Z., Gong, J., Wang, X., Wu, D., & Zhang, Y. (2025). Class-Patch Similarity Weighted Embedding for Few-Shot Infrared Image Classification. Electronics, 14(2), 290. https://doi.org/10.3390/electronics14020290