Abstract
With the rapid development of Multimodal Large Language Models (MLLMs) in education, their applications have mainly focused on content generation tasks such as text writing and courseware production. However, automated assessment of non-exam learning outcomes remains underexplored. This study shifts the application of MLLMs from content generation to content evaluation and designs a lightweight and extensible framework to enable automated assessment of students’ multimodal work. We constructed a multimodal dataset comprising student essays, slide decks, and presentation videos from university students, which were annotated by experts across five educational dimensions. Based on horizontal educational evaluation dimensions (Format Compliance, Content Quality, Slide Design, Verbal Expression, and Nonverbal Performance) and vertical model capability dimensions (consistency, stability, and interpretability), we systematically evaluated four leading multimodal large models (GPT-4o, Gemini 2.5, Doubao1.6, and Kimi 1.5) in assessing non-exam learning outcomes. The results indicate that MLLMs demonstrate good consistency with human evaluations across various assessment dimensions, with each model exhibiting its own strengths. Additionally, they possess high explainability and perform better in text-based tasks than in visual tasks, but their scoring stability still requires improvement. This study demonstrates the potential of MLLMs for non-exam learning assessment and provides a reference for advancing their applications in education.
1. Introduction
In recent years, Large Language Models (LLMs) have made groundbreaking progress in the field of natural language processing. These models not only possess powerful text generation capabilities but also demonstrate emerging abilities in reasoning, summarization, translation, and interaction [1,2]. Gradually, LLMs have been introduced into educational settings and applied to tasks such as intelligent question answering, essay grading, and lesson planning, significantly improving the efficiency of teaching and learning processes [3,4,5]. However, as LLMs are limited to processing textual modalities, they face clear limitations when dealing with the increasingly multimodal data in real educational contexts, such as slides, presentations, images, and videos. With technological advancements, Multimodal Large Language Models (MLLMs) have emerged, including OpenAI’s GPT-4o, Google’s Gemini, etc. These models are capable of understanding and generating multiple modalities, including text, images, audio, and video [6,7]. The application of such models in education has continued to expand, particularly excelling in content generation tasks such as producing class handouts and assisting in the creation of slides, providing new technical tools for teachers and learners [8,9,10]. Content-generation applications have gradually been commercialized and integrated into various educational platforms and tools, becoming a key focus of current educational AI development. Nonetheless, the use of MLLMs remains largely concentrated in the “generation” stage, while their potential in the critical phase of educational assessment has yet to be systematically explored [11,12,13,14].
Learning assessment is a core component of the educational process, directly influencing both feedback on student performance and the continuous improvement of instructional practices [15,16]. With the growing emphasis on core literacy, the focus of assessment has shifted from merely measuring knowledge acquisition to evaluating broader skill development. Assessment content has become increasingly diverse, moving beyond standardized test scores to emphasizing students’ abilities to express, create, and apply knowledge in authentic contexts [17,18,19]. As a result, non-test-based student outputs, such as project presentations, short essays, and oral reports, have become increasingly common in classroom settings. These tasks are typically multimodal in nature, involving not only Verbal Expression but also visual design and nonverbal behaviors, thus requiring evaluators to demonstrate a high level of integrative understanding and judgment. However, traditional assessment largely relies on manual grading and subjective judgments by teachers. When evaluating multimodal student work, inconsistencies often arise due to differences in individual teacher experience, leading to issues such as high subjectivity, low efficiency, and limited scalability [20,21]. In recent years, some studies have begun to explore the use of LLMs for automated scoring, but these efforts have mainly focused on structured textual tasks, such as essay grading or short-answer scoring [4,22]. For more complex, non-test-based outputs that integrate multiple modalities, the applicability and accuracy of existing models remain largely untested. Therefore, it is crucial to investigate the actual capabilities and potential value of MLLMs in the automated evaluation of such multimodal learning outcomes.
Against this background, this study focuses on the potential application of MLLMs in educational evaluation, aiming to extend their capabilities from content generation to the crucial area of learning assessment, with particular attention to the automated evaluation of non-exam, multimodal learning outcomes. We evaluate the capabilities of current mainstream MLLMs from two perspectives. The first focuses on educational dimensions, examining whether the models can understand and assess student work across key areas such as formatting, content, visual design, Verbal Expression, and nonverbal behavior. The second focuses on technical aspects, examining whether the models provide ratings similar to humans, maintain stable results across different contexts, and offer interpretability with clear explanations for their scoring decisions. To this end, we have developed a research framework that balances educational relevance and technical feasibility to systematically analyze MLLMs’ performance in multimodal assessment. At the same time, based on real university educational scenarios, we compiled and constructed an experimental dataset comprising various types of student work along with corresponding human-annotated scores to support quantitative evaluation of model capabilities. This study aims to expand the application boundaries of MLLMs in educational settings, help reduce teachers’ workload while improving efficiency, provide students with more targeted feedback, and promote the deep integration of intelligent technology and educational evaluation.
In summary, our research makes major contributions in three aspects:
- (1)
- We shift the application of MLLMs from content generation to competency-based assessment and design a lightweight, extensible framework for evaluating student outcomes in non-exam tasks. This framework provides structured support for applying MLLMs to automated assessment across five key educational dimensions.
- (2)
- We introduce a multimodal evaluation dataset comprising student essays, slide decks, and presentation videos, rated by human experts across five educational dimensions: Format Compliance, Content Quality, Slide Design, Verbal Expression, and Nonverbal Performance.
- (3)
- We conduct a comprehensive evaluation of leading MLLMs (GPT-4o, Gemini 2.5, Doubao1.6, and Kimi 1.5) across five educational dimensions and three technology dimensions. This study presents the performance of each model and provides an in-depth analysis of the strengths and limitations of MLLMs in learning assessment.
2. Literature Review
2.1. MLLMs in Education
Large Language Models (LLMs) are general-purpose language intelligence systems trained on extensive corpora, which have achieved remarkable breakthroughs in the field of natural language processing in recent years. Their core capabilities include text generation, semantic understanding, and linguistic reasoning [1,2]. These abilities make them a highly regarded artificial intelligence tool in educational technology. In educational settings, LLMs have been widely applied to various tasks, such as automated writing assistance, intelligent question answering, conversational teaching, and personalized learning recommendations, effectively enhancing teaching efficiency and learning flexibility for students [3,4]. Research has shown that LLMs demonstrate broad application potential across the entire teaching process, such as assisting teachers in setting learning objectives, designing course content, and enabling automated grading of assignments and intelligent essay revision [23,24,25]. However, their application remains relatively limited in complex educational scenarios, such as teaching interactions, task execution, and learning state feedback. Particularly in areas like understanding instructional goals, supporting teaching decisions, and adapting to specific learning contexts, LLMs’ reliance on unimodal (text-based) information processing struggles to meet the demands of multidimensional perception and efficient interaction in real classroom environments.
To overcome the limitations of LLMs in handling single-modality inputs, MLLMs have emerged, capable of understanding and generating various modalities such as text, images, video, and audio [7,9]. In recent years, the release of advanced models like GPT-4o, Gemini 2.5, and Claude 3.5 has significantly advanced general artificial intelligence, spurring the exploration of multimodal applications in education. In practice, educators have begun integrating MLLMs into diverse instructional tasks, expanding their functional boundaries in curriculum design and learning support. Teachers can leverage MLLMs to design courses, create multimodal learning tasks, experiment with innovative pedagogies, and conduct simulation-based training [26,27]. Learners benefit from multimedia effects to better understand complex concepts, use accessible interaction features to meet diverse needs, and receive real-time feedback in scenarios such as image generation and virtual experiments, thereby achieving personalized learning [28,29]. Education researchers can also rely on MLLMs for advanced data analysis, literature reviews, and the development of multimodal materials [30,31]. Compared with traditional AI tools, MLLMs demonstrate superior performance in handling complex inputs such as text-image combinations, speech, and video, enabling smoother human–computer interaction and enhancing classroom immersion. Their cross-modal understanding offers new means for instructional organization and assessment, with the potential to further evolve into intelligent assistants that support teaching decisions and personalized learning.
However, despite the promising application prospects of MLLMs, their exploration in the education field has so far mainly focused on generative tasks such as text creation, image description, and slide production. In more challenging tasks involving the evaluation of learning outcomes, MLLMs have yet to demonstrate sufficient stability and reliability. When faced with students’ submissions of PowerPoint (PPT) presentations, speech videos, essays, and other unstructured, multimodal assignments, the models still show deficiencies in integrating information, identifying key content, understanding modes of expression, and mapping to evaluation criteria. On one hand, existing models lack deep modeling of educational assessment standards, making it difficult to accurately reflect the multidimensional performance valued by teachers; on the other hand, the subjectivity and contextual dependence of educational evaluation further increase the challenges of consistency and interpretability in model outputs. Therefore, it is essential to address the practical needs of educational assessment by focusing on the multiple challenges teachers face in the evaluation process, such as conducting multidimensional assessments of student work, providing reliable and interpretable feedback, and managing a large volume of assignments [32,33,34]. In this context, it is necessary to further enhance the expressive understanding, standard adaptation, and interpretability of multimodal large models to support their effective application in real-world educational assessment scenarios.
2.2. Learning Assessment
Learning assessment refers to the measurement, interpretation, and value judgment of students’ learning processes and outcomes based on certain educational objectives, and it is an indispensable part of the teaching system. It not only concerns the confirmation of students’ academic achievement but also aims to promote learning, provide feedback to teaching, and support educational decision-making [15,35]. Under the influence of modern educational concepts, the goal of learning assessment is gradually shifting from summative evaluation focusing on “correctness of results” to formative evaluation emphasizing “process engagement” and “competency development” [36,37,38]. This type of assessment concerns not only what students have learned but also how they learn, whether they can apply knowledge, and whether they possess potential for further development. This shift has led to increasing diversity in both the objects and forms of learning assessment. Students’ learning outcomes are no longer limited to standardized test scores but have expanded to multiple forms of performance that are closer to authentic tasks, such as written texts, oral presentations, project demonstrations, and multimodal creations [39,40]. These multimodal outcomes better reflect students’ comprehensive literacy and practical abilities, aligning with the current curriculum reform aimed at core literacy. However, they also bring new challenges to the assessment system, such as difficulty in standard setting, challenges in quantitative evaluation, and increased subjectivity. Especially in unstructured tasks and open-ended outcomes, understanding how to scientifically, fairly, and efficiently identify student performance remains a key issue that urgently needs to be addressed in learning assessment reform.
As student learning outcomes become increasingly diverse, traditional manual assessment methods are gradually revealing their limitations. Although teachers have unique strengths in understanding context, identifying individual student differences, and capturing expressive nuances, which enable them to make personalized judgments aligned with actual teaching practices, manual grading struggles to keep pace with the growing scale and variety of student work. It is often inefficient, highly subjective, and difficult to replicate [41,42,43]. In response, educational technology researchers have been exploring automated assessment methods and advancing systems based on natural language processing, image recognition, and other techniques. These systems have shown initial success in standardized testing contexts, such as automated essay scoring, short-text comprehension, and image-assisted grading [3,4,5]. As the forms of student work continue to evolve, assessment targets have gradually expanded beyond textual tasks to include non-text modalities such as spoken expression, presentation videos, and interactive behaviors. Recent studies have attempted to integrate speech recognition with oral assessment and computer vision with video-based interview evaluation, achieving some early progress in multimodal automated assessment [44,45,46]. However, these approaches are often limited to single modalities or narrowly defined tasks, lacking generalizability and scalability. When applied to more complex outputs such as mixed-media reports or classroom videos involving nonverbal interactions, existing methods often struggle to integrate multisource information and to provide contextually appropriate interpretations. As a result, they are unable to meet the dual demands of real-world teaching for both understanding and feedback.
In recent years, the development of MLLMs has opened up new possibilities for the intelligent assessment of student learning outcomes. Compared with earlier technical approaches that relied on single-modality features, MLLMs possess the ability to understand and generate across modalities, enabling them to process various input forms such as images, text, and speech simultaneously [1,2,3]. This offers a more promising path for the automated evaluation of diverse learning artifacts and opens new avenues for developing intelligent assessment systems aimed at comprehensive competencies. However, the actual capabilities of MLLMs in educational assessment contexts have yet to be systematically validated. On the one hand, the interpretability and expressive capacity of different input modalities (such as presentation videos, slide decks, and written reports) in evaluation tasks require further investigation. On the other hand, the stability and accuracy of different types of MLLMs (such as GPT-4o and Gemini) in specific educational tasks lack empirical comparison [6,7]. Although MLLMs are equipped with general multimodal understanding abilities, understanding how to effectively align their outputs with specific dimensions of educational assessment—such as Content Quality, mode of expression, and performance characteristics—still lacks a clear practical framework. Especially for frontline teachers, understanding how to appropriately use MLLMs for evaluating student outcomes in real teaching settings remains in need of more tool support and case-based guidance. Overall, MLLMs provide a technological opportunity for multimodal learning assessment, but their effectiveness, applicability, and usability in educational practice still require further exploration and validation.
3. Methodology
3.1. Research Design
This study aims to explore the feasibility and performance of MLLMs in the automated evaluation of non-exam-based student learning outcomes, as illustrated in Figure 1. The research design consists of three main steps. First, drawing on educational theory, we developed a lightweight and extensible automated scoring framework that supports the integration of multimodal inputs, enabling multidimensional evaluation of diverse student outputs such as essays, slides, and presentation videos. Second, we constructed a multimodal assessment dataset from real classroom settings, including various forms of student work manually scored by experts based on five educational dimensions: Format Compliance, Content Quality, Slide Design, Verbal Expression, and Nonverbal Performance. These human scores serve as a benchmark for evaluating model performance. Finally, we selected four representative advanced MLLMs—GPT-4o, Gemini 2.5, Doubao1.6, and Kimi 1.5—to automatically score the collected student outputs, and systematically analyzed their performance and limitations across different tasks and dimensions using five educational criteria and three technical evaluation metrics: consistency, stability, and interpretability. The rationale behind this selection is as follows: first, all models support multimodal input and can process multiple data types such as text and images; second, they are all accessible via web interfaces, with GPT-4o and Gemini 2.5 representing leading international models, while Doubao1.6 and Kimi 1.5 are commonly used domestic multimodal models, particularly suitable for Chinese-language tasks. Therefore, these four models meet this study’s requirements in terms of accessibility, representativeness, and task suitability. This study seeks to bridge the gap between the practical demands of educational assessment and the capabilities of multimodal AI, highlighting the potential and challenges of applying MLLMs to support diverse learning outcome evaluations in authentic educational contexts.
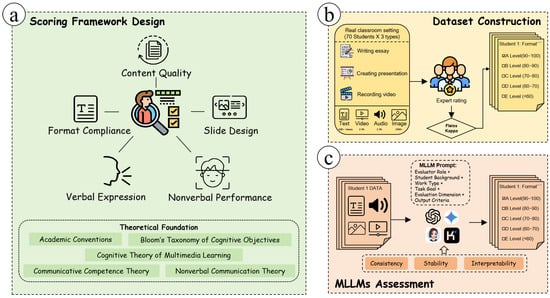
Figure 1.
Research Design.
3.2. Scoring Framework Design
This study adopts academic essays, presentation slides, and oral reports as assessment artifacts, aligning with common practices in formative assessment within higher education that emphasize the evaluation of students’ comprehensive abilities [36,37,38]. These types of outputs are widely used in university teaching and can systematically reflect students’ competencies in knowledge construction, information integration, and communication. Compared to traditional standardized tests, such multimodal assessment approaches are better suited to the current educational emphasis on the multidimensional development of core literacy [17,18,19].
In terms of dimension design, the scoring framework is based on core concepts from various educational theories. It defines five evaluation dimensions: Format Compliance, Content Quality, Slide Design, Verbal Expression, and Nonverbal Performance. Specifically, Format Compliance emphasizes the accuracy and standardization of academic expression, reflecting the scholarly community’s expectations for consistent presentation of research work. Content Quality focuses on students’ depth of subject knowledge and critical analysis skills, corresponding to the cultivation of higher-order thinking in Bloom’s cognitive taxonomy [47]. Slide Design is informed by cognitive research in multimedia learning and examines students’ abilities in visual presentation of information [48]. The Verbal Expression dimension draws on theories of language communication and evaluates students’ ability to organize and articulate ideas within a professional context [49]. Nonverbal Performance assessment is based on research in nonverbal communication, capturing indicators such as eye contact and facial movements to reflect the speaker’s level of engagement and expressiveness [50]. In addition, to enhance the scoring focus and consistency of the models in multimodal tasks, we integrated the characteristics of each modality with the evaluation dimensions and designed corresponding prompts through in-depth communication with course instructors. As shown in Table 1, this scoring framework systematically presents evaluation dimensions, task modalities, prompt designs, and examples, which not only provide an operational foundation for model-driven automatic assessment but also offer guidance for teachers conducting multimodal teaching evaluations.

Table 1.
Overview of the evaluation framework and prompt design.
In practical applications, this scoring framework does not rely on complex multimodal preprocessing procedures or customized system interfaces. Instead, it leverages structured prompt design to guide MLLMs in evaluating and providing feedback on student work across various dimensions. The method can directly receive original learning outputs and, driven by prompts, generate multidimensional scoring results along with explanatory texts. To enhance standardization and interpretability, the framework includes clearly defined scoring prompt templates for each dimension, specifying the dimension’s definition, scoring criteria, key points, and operational instructions. For example, in the “content quality” dimension, the prompt guides the model to examine the clarity of the main argument, the adequacy of supporting evidence, and the coherence of logical structure, and to provide corresponding evaluations based on the student work. The scoring results are expressed using a five-level scale from A to E, with each level accompanied by detailed behavioral descriptors to improve consistency and reproducibility in model scoring. In addition, to ensure transparency, the model is required not only to produce a final score but also to provide justifications. This design enhances the reliability and validity of automated scoring in educational contexts and increases its pedagogical value in instructional diagnosis and learning improvement.
Overall, this scoring framework is grounded in educational theory and leverages the multimodal understanding and generation capabilities of large models. Through structured task modeling and prompt-based guidance, it enables multidimensional and interpretable automated assessment of complex student work. While maintaining implementation simplicity, the framework demonstrates strong scalability and reproducibility. It offers a clear pathway for exploring the application boundaries of large models in educational assessment and serves as a paradigm reference for future research and practical evaluation in teaching.
3.3. Dataset Construction
The multimodal assessment dataset constructed in this study was sourced from the final practical project of the “Introduction to Computer Science” course offered to undergraduate students majoring in Computer Science and Technology at a university, reflecting authentic learning scenarios in a real classroom setting. The dataset includes the complete learning outputs of 70 students from the fall semester of the 2024–2025 academic year. Each student independently selected a course-related topic (such as computer network architecture or algorithm complexity analysis) and completed three related tasks: composing an academic paper exceeding 4000 words, creating an approximately 15-slide presentation (PPT), and recording an approximately 3 min oral presentation video.
The data annotation was carried out by a team of three teaching assistants with extensive instructional experience, using a five-dimensional evaluation framework. Each dimension was aligned with a specific modality: format accuracy and Content Quality focused on the academic essay, Slide Design on the PPT, and Verbal Expression and Nonverbal Performance on the presentation video. The ratings were determined strictly according to the detailed scoring standards defined in Table 1, which specify the evaluation criteria for each dimension and the descriptors for the five-level grading scale (A to E). Specifically, the table provides clear guidance on the expected performance for each grade level across all dimensions, ensuring that both human annotators and models have a standardized reference for assessment. All assessments use a five-level grading scale (A to E), where A represents excellent (90–100 points) and E represents failing (below 60 points). After receiving standardized instructions and preliminary training, the teaching assistants independently scored the work of 70 students across five dimensions. The Fleiss Kappa consistency coefficients for each dimension were 0.744, 0.817, 0.786, 0.717, and 0.704, all indicating a high level of agreement. For cases with inconsistent scores, the teaching assistants reached consensus through group discussion.
The dataset consists of 210 multimodal samples (70 students × 3 types of work), including approximately 300,000 Chinese characters of academic essays, about 1050 pages of PPT presentations, and oral presentation videos totaling around 210 min. Figure 2 shows examples of the data from each modality. For privacy protection, the content in the images has been blurred. The three modalities form 70 matched sets, supporting cross-modal correlation research and analysis. In terms of the distribution of score levels, the formatting dimension had the highest proportion of A grades, exceeding 90%, indicating that most students were able to complete their work in accordance with academic paper requirements and adhere to academic norms. In the Content Quality dimension, B grades dominated, accounting for over 70%, suggesting that while students generally met basic standards in content depth and logical structure, there is still room for improvement. In the Slide Design dimension (PPT), B grades accounted for over 60%, reflecting an overall moderate performance and indicating that students possess a certain foundation in visual communication but require further enhancement. For video-based modalities, the Verbal Expression and Nonverbal Performance dimensions had B grade proportions of over 50% and 70%, respectively, a pattern that typically reflects the mild nervousness often observed in beginners during public speaking.

Figure 2.
Examples of multimodal data. (a) Essay—showing students’ written arguments. (b) Slide—illustrating key points and organization. (c) Presentation—demonstrating oral communication and visual explanation skills.
The dataset offers several notable advantages: First, all samples were collected from real classroom settings, ensuring ecological validity. Second, the three types of student outputs are based on different topics within the same course subject, providing thematic consistency while allowing content diversity for comprehensive multimodal evaluation. Third, the fine-grained, multidimensional expert ratings provide a high-quality annotation benchmark for subsequent automatic scoring tasks using multimodal large models.
3.4. MLLM Setting and Evaluation
To explore the feasibility and performance of current mainstream MLLMs in assessing non-standardized educational outcomes, this study selected four representative systems: OpenAI’s GPT-4o, Google’s Gemini 2.5, Kimi 1.5 from Moonshot AI, and Doubao1.6 from ByteDance [51,52]. These models possess capabilities to process multimodal inputs such as images and text, demonstrating strong performance in cross-modal understanding and generation tasks. They have been widely applied in education, research, content creation, and other fields, representing the forefront of multimodal technology development [53,54,55]. Since this study focuses on evaluating the models’ potential in real educational scenarios rather than deployment or engineering aspects, the assessment was conducted via official web interfaces using freely available access rather than API subscriptions. This approach not only eliminates technical barriers and usage costs but also provides practical guidance for educators, enabling them to adopt the proposed evaluation framework without requiring programming skills.
This study adopts a modality-based scoring strategy to automatically evaluate students’ submitted non-standardized work. Each student’s submission includes three types of materials: a short paper, a PPT file, and a classroom presentation video, corresponding to three separate scoring tasks. The text portion focuses on the overall performance in formatting and Content Quality; the PPT portion emphasizes the overall quality of the slides; the video portion concentrates on the student’s Verbal Expression and Nonverbal Performance during the presentation. Additionally, it should be noted that although mainstream multimodal large models possess video understanding capabilities, some models do not support direct video file input due to limitations of the web interface, and there are also restrictions on the number of files that can be uploaded. Therefore, in this study, the classroom presentation videos were preprocessed by first transcribing the audio into a textual transcript to enable the model to analyze the verbal content, and then extracting video frames at five-second intervals. This frame extraction strategy follows the uniform-time segmentation commonly used in educational video and classroom analysis research (typically 5–10 s intervals), which allows meaningful nonverbal gestures and verbal progression to be captured without generating redundant data [56,57]. Considering that current web-based multimodal LLM interfaces generally allow a maximum of 10 files per interaction and that the transcript occupies one file, only nine video frames could be included. Based on this limitation, we selected nine key frames evenly spaced throughout the video timeline to maximize coverage of students’ nonverbal behaviors. Finally, the model takes the text materials and nine images as input to comprehensively evaluate Verbal Expression and Nonverbal Performance, providing corresponding scoring rationales. It is worth noting that the evaluations were not conducted in independent sessions; instead, assignments were input sequentially within the same session. This design simulates the effect of teachers’ memory on grading, allowing the model to reference previous work when assessing assignments in the same class, thereby supporting more reasonable relative grading and better reflecting real classroom conditions. The entire scoring process closely mimics human scoring methods to enable direct comparison and in-depth analysis between model and human results.
To comprehensively assess the capabilities of MLLMs in such tasks, our analysis focused on three aspects: the similarity between model and human ratings, the stability of model ratings, and the explainability of the scores. Similarity was measured by analyzing the consistency and deviation between each model’s ratings and human scores across different evaluation dimensions. Stability was assessed by fully restarting independent sessions and re-evaluating the same assignments at different time points using the same dataset, evaluation dimensions, and prompt settings, with weighted agreement coefficients used to compare results and check consistency. Explainability was assessed by human raters using a five-point Likert scale to score the models’ scoring rationales, and the mean score was calculated to reflect the rationality of their scoring. By integrating these three dimensions, the aim was to gain a deeper understanding of the performance and potential of MLLMs in educational assessment tasks.
4. Results Analysis
4.1. Model Performance Across Educational Dimensions
In this study, we evaluated the automatic scoring performance of four MLLMs across five educational assessment dimensions and compared their results with human ratings. Table 2 presents the exact agreement rates between each model and human ratings on the five dimensions, that is, the absolute agreement rate with no deviation in rating levels. Overall, the different models demonstrated their respective strengths and differences across the dimensions. Gemini and GPT showed relatively stable performance, while Doubao and Kimi exhibited significant deviations in certain dimensions. Figure 3 further illustrates the rating distributions of different models on the A–E scale across each dimension.
Table 2.
Exact agreement rates between MLLMs and human ratings on educational dimensions.
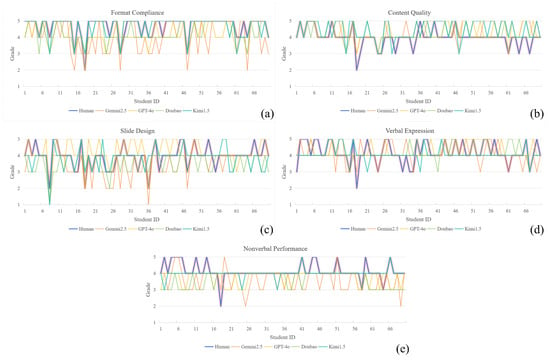
Figure 3.
Rating Level Distribution of MMLMs Across Five Educational Dimensions. A = 5, B = 4, C = 3, D = 2, E = 1. (a) Format Compliance, (b) Content Quality, (c) Slide Design, (d) Verbal Expression, (e) Nonverbal Performance.
Specifically, in the Format Compliance dimension, all models generally rated lower than humans, with more dispersed distributions; Gemini showed a stricter rating tendency. For Content Quality, the models’ ratings were overall higher, mainly concentrated in A and B levels, while human ratings included some D levels, indicating that the models failed to effectively distinguish low-quality texts. In the Slide Design dimension, human ratings were primarily concentrated between A and C, with only one D rating, showing a relatively balanced distribution. In contrast, all four MLLMs gave some E ratings, representing extreme cases. Specifically, GPT’s ratings were relatively stable, focused on A and B levels, slightly higher overall than human ratings; Gemini’s ratings fluctuated widely and were generally lower; Doubao’s ratings concentrated on B and C, slightly lower than humans; Kimi’s rating trend was closer to humans, mainly distributed in A–C. For the Verbal Expression dimension, the rating distributions of the MLLMs were overall similar to those of humans. GPT’s ratings focused on A and B levels, showing a clear high-score trend; Kimi and Doubao mainly rated at the B level with concentrated distributions; Gemini’s ratings were more dispersed, covering A–C levels. In the Nonverbal Performance dimension, MLLMs’ ratings were generally lower than humans’, mainly concentrated in the B and C levels, whereas human ratings were mostly in A and B. Kimi’s ratings were the most concentrated, with the vast majority of samples rated at B; Doubao and GPT had similar rating ranges, both not covering A; Gemini’s ratings were widely distributed, spanning the A to D levels.
When exploring the potential and practical value of MLLMs in evaluating student work, the significance reflected by the degree of deviation between rating levels differs substantially in educational assessment. Solely relying on exact agreement rates as an evaluation metric fails to adequately reflect the potential and practical value of MLLMs in student work assessment. Based on this, we calculated the proportion of rating differences between model scores and human ratings across five dimensions (differences of 0 levels, 1 level, and 2 levels) to more comprehensively reveal the deviation between the two. As shown in Figure 4, nearly all models are primarily concentrated at differences of 0 and 1 level across all dimensions, with very few instances of a 2-level difference and none at 3 levels or above. Especially in the Content Quality dimension, each of the four models shows a combined proportion of “exact agreement” and “one-level difference” exceeding 98%, demonstrating very high consistency. This result indicates that although the models differ in scoring details and dimensional characteristics, from the perspective of overall deviation, they still closely approximate human ratings in most cases, providing a practical and feasible foundation for the automatic evaluation of multimodal student work.
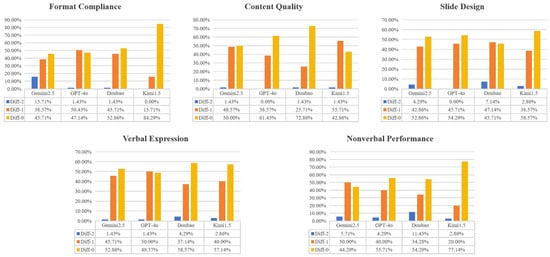
Figure 4.
Distribution of absolute differences in rating levels between MLLMs and humans. Diff-0 indicates complete agreement, Diff-1 indicates a one-level difference, and Diff-2 indicates a two-level difference.
4.2. Model Performance Across Stability and Interpretability
To evaluate the stability of MLLMs’ scoring, we conducted a second round of scoring on the same dataset of multimodal student assignments. Each model independently re-evaluated all submissions under identical scoring dimensions and prompt settings. To quantify the consistency between the two rounds of results, we employed the “Weighted Cohen’s Kappa” coefficient. This metric not only measures the proportion of agreement but also accounts for the severity of rating differences, assigning greater penalties to larger discrepancies across levels (e.g., between A and E). As shown in Table 3, all models achieved overall consistency coefficients below 0.5, indicating limited stability in evaluating non-exam student work. Each model showed relatively higher stability in the Format Compliance dimension, while performance in the Nonverbal Performance dimension was the weakest, with all consistency coefficients falling below 0.4. Specifically, GPT-4o showed higher consistency than the other models in most of the five dimensions. In contrast, Gemini and Doubao showed particularly low consistency in the Slide Design and Nonverbal Performance dimensions, with coefficients falling below 0.2, reflecting substantial score variability. It is evident that the stability of MLLMs in automatically scoring students’ non-exam-based work remains limited.
Table 3.
Consistency of MLLMs in two-round scoring experiments (weighted kappa).
In terms of explainability, we focused on whether the models could clearly articulate the basis for their scores while providing the evaluation results. Specifically, for each model’s five evaluation dimensions, we randomly sampled 20 scoring records, resulting in a total of 20 × 5 × 4 = 400 records. Using a five-point Likert scale, two dataset creators independently rated the reasonableness of the scoring justifications. The explainability score for each record was calculated as the average of the two raters’ scores, and the mean score of the 20 records in each dimension was taken as the model’s explainability score for that dimension. The results (Table 4) show that all models achieved relatively high explainability in the Format Compliance and Content Quality dimensions, with average scores above 4; Slide Design ranked next, with an average score of around 4; while in the Verbal Expression and Nonverbal Performance dimensions, the models’ average scores were mostly below 4, indicating that the models still perform better on text-based tasks than on image or multimodal understanding tasks. In addition, we present examples of model outputs across various evaluation dimensions in Table 5. These outputs are generated by the multimodal LLMs under the standardized prompt templates provided in Table 1, which, for each dimension, explicitly define the evaluation objective, the criteria, and the unified output format (grade + justification). Guided by these criteria, the models produce justifications that point to modality-appropriate evidence (e.g., argumentation and evidence for papers, layout and information organization for slides, and visual/voice cues for presentation videos). It can be seen that the models not only provide rating levels but also offer reasonable scoring justifications, including summaries of the work and identification of issues. For example, in the formatting dimension, the models can meticulously identify specific problems, a level of detail often beyond what human teachers can achieve under time constraints, thus providing more reliable support for teaching assessment. This not only demonstrates the models’ strong understanding and analytical abilities but also enhances the transparency and explainability of the scoring, offering valuable references for teachers and increasing the trustworthiness and practicality of automated evaluation results.
Table 4.
Interpretability scores of MLLMs across different educational assessment dimensions.
Table 5.
Examples of model outputs for scoring across different evaluation dimensions.
5. Discussion
5.1. Potential and Performance Variations of MLLMs in Educational Assessment
This study reveals significant dimensional differences in the automatic scoring of student work by MLLMs, reflecting both their potential and existing challenges. In the formatting dimension, the scores given by MLLMs were generally lower than those given by human raters. This is mainly because human teachers, often constrained by time, tend to overlook fine-grained details such as punctuation, paragraph indentation, numbering, and consistency in reference formatting, whereas MLLMs are able to accurately capture these subtle differences [58,59]. By analyzing the rationales provided by the models, we found that they can identify and point out specific formatting issues in assignments, guiding students to improve the formatting of their work. In the Content Quality dimension, MLLMs tend to assign higher scores than humans. This arises from their reliance on large-scale pre-trained knowledge bases and contextual reasoning abilities, enabling them to identify and semantically complete topic-related information [60,61]. However, MLLMs show limited sensitivity to academic misconduct, struggling to recognize plagiarism or copied formatting marks (e.g., “##”, “∗∗”), whereas human raters typically penalize such cases heavily, leading to notable score discrepancies in this dimension. Differences observed in the PPT design dimension highlight variations in visual understanding capabilities. For instance, Gemini places greater emphasis on visual details and design consistency, resulting in lower and more fluctuating scores, whereas GPT-4o demonstrates higher tolerance for overall visual presentation, yielding more stable evaluations [62,63]. Regarding expression, MLLMs evaluate primarily based on the logic and fluency of the textual transcript, lacking the ability to capture speech intonation and emotional cues, which results in more concentrated and somewhat optimistic score distributions [64,65]. In contrast, human raters consider voice, tone, and emotional factors, producing broader and more subjective scoring patterns [66]. Lastly, in Nonverbal Performance, models generally give lower and more uniform scores, largely due to current limitations in recognizing subtle facial expressions and contextual emotional nuances. The small size and peripheral positioning of student faces in videos reduce the visual modules’ ability to extract critical facial features effectively [67]. In addition, Doubao and Kimi performed better overall on the Chinese dataset used in this study, which may be attributed to their status as leading Chinese MLLMs with advantages in processing Chinese text and multimodal content.
Overall, although MLLMs show varying performance across different dimensions, they generally maintain good consistency with human ratings, demonstrating potential for assessing non-exam student work, especially excelling in textual detail control and semantic understanding. At the same time, this study also found that MLLMs can identify specific issues and provide targeted feedback in certain dimensions (such as formatting review), demonstrating their unique strengths in detailed evaluation and improvement suggestions. As a powerful assistant tool for teachers, MLLMs can not only improve the efficiency and objectivity of educational evaluation, but with the continuous enhancement of multimodal integration and emotional understanding capabilities, their practical application prospects in the education field will become even broader.
5.2. Discussion and Insights on Scoring Stability and Interpretability of MLLMs
The findings of this study indicate that the stability of Multimodal Large Language Models (MLLMs) in grading non-exam-type student work is generally suboptimal. Such tasks are characterized by a high degree of subjectivity and multimodal integration, with evaluation criteria across different dimensions often exhibiting a certain level of ambiguity. Even among human evaluators, discrepancies may occur, which can exacerbate fluctuations in the model’s scoring results across different reasoning paths. Moreover, multimodal inputs such as text, PPT slides, and oral presentation segments must undergo multi-stage feature extraction and fusion, during which subtle variations in feature weighting may be amplified in the final scoring stage [68,69]. Consequently, even when the input content and prompts are completely identical, the model’s outputs will still vary at different points in time. This also underscores the importance of enhancing scoring stability through strategies such as optimizing multimodal feature fusion, introducing deterministic reasoning mechanisms, and aggregating results from multiple scoring runs. Regarding interpretability, MLLMs demonstrate relatively strong explanatory capabilities in text-based scoring dimensions, which stems from their powerful natural language understanding and generation abilities, as well as the role of attention mechanisms in capturing and associating key information [70,71]. However, in dimensions involving visual and multimodal information, the models exhibit relatively reduced explainability, reflecting current technical bottlenecks in fusing visual features with linguistic descriptions in multimodal models [72,73]. These suggest that improving scoring stability and multimodal explainability remains a key direction for the future development of MLLMs.
From the perspective of educational applications, enhancing the scoring stability and explainability of MLLMs not only helps increase teachers’ trust in automated scoring results but also provides students with clearer and more constructive feedback, thereby promoting improved teaching outcomes [74,75]. Especially in the assessment of non-exam assignments, a stable and transparent scoring mechanism is fundamental for effective teaching assistance. Regarding the issue of low-scoring stability, future research could explore various strategies, including using ensemble scoring across multiple models or different instances to reduce uncertainty, aggregating multiple outputs from the same model to mitigate output fluctuations, and optimizing prompt design to guide the model to focus on key evaluation criteria, thereby improving scoring consistency. At the same time, advancing multimodal explanation techniques can help enhance the interpretability and reliability of scores. Through these approaches, it is expected that MLLMs can achieve more robust and widely applicable use in educational settings. Therefore, future research should focus on developing stability calibration methods and model ensemble strategies while also advancing innovations in multimodal explanation techniques to achieve reliable and widespread application of MLLMs in education.
5.3. Ethical Considerations and Risk Mitigation in MLLM Use
Although Multimodal Large Language Models (MLLMs) have demonstrated strong performance in educational assessment and show considerable application potential, their use in educational settings must be accompanied by careful consideration of ethical issues. The European Union has designated education as one of the eight high-risk application areas for AI systems, indicating that MLLMs in automated grading or learning assessment could have a significant impact on students’ grades and educational outcomes, raising critical ethical concerns such as fairness, transparency, and accountability [76,77]. For example, students from different backgrounds may be subject to biased scoring, lack of transparency in scoring criteria may reduce teachers’ and students’ trust in the results, and model errors or misuse could lead to unclear responsibility in educational decision-making. To mitigate these risks, multiple safeguards should be implemented: incorporating human-in-the-loop mechanisms at key decision points to allow teachers to supervise and correct model scoring; providing interpretable feedback to help teachers and students understand the scoring rationale; regularly calibrating models and evaluating performance to ensure fairness and stability; and clearly defining accountability to enable traceability and correction if issues arise [33,78]. Future research should also explore additional approaches focused on educational ethics, such as fairness constraints, multimodal explanation methods, and human–AI collaborative intelligent assessment systems, to achieve responsible and sustainable application of MLLMs in education.
6. Conclusions
This study explores the potential of MLLMs for automatic assessment of non-exam learning outcomes and develops a lightweight and scalable multimodal outcome evaluation model. We constructed a multimodal dataset encompassing student papers, slides, and presentation videos and designed a cross-evaluation mechanism combining educational assessment dimensions with technical capability dimensions to systematically evaluate the performance of four mainstream MLLMs. The results show that these models maintain a relatively high level of consistency with human ratings across multiple educational assessment dimensions, despite some variation among different models. The models can not only provide rating levels but also generate well-structured and logically sound scoring rationales, offering valuable reference for teachers. However, overall scoring stability still requires improvement. Additionally, this study completes the entire scoring process through a web-based interactive interface built on multimodal models, avoiding high costs and technical barriers, significantly reducing usage difficulty, and enhancing operational convenience in real teaching scenarios. Overall, this study provides theoretical and methodological support for the practical application of intelligent-assisted educational assessment and promotes the further development of generative artificial intelligence in the field of educational evaluation.
6.1. Limitations
Although this study provides new perspectives on the application of MLLMs in educational assessment and verifies their preliminary feasibility across multiple educational dimensions, certain limitations remain and require further improvement in future work. First, the data samples in this study are primarily drawn from a single discipline, so the model’s stability and generalization across different subject areas remain to be further explored. Second, the analysis of video content is based on static image frames due to the limited support for video formats in current mainstream multimodal large model web interfaces, while deploying models that support native video understanding involves higher technical barriers. Therefore, the model may not fully capture students’ dynamic expressions and emotional features in video understanding. Third, the dataset is in Chinese, which may limit the applicability of the results to other languages and cultural contexts, potentially affecting the performance and interpretation of MLLMs in non-Chinese educational scenarios. Additionally, the limited size of expert annotations may affect the representativeness and generalizability of the evaluation results.
6.2. Future Work
In future research, we will further explore and improve the application of MLLMs in educational assessment. First, we will introduce multimodal student works from more diverse disciplines and grade levels to systematically examine the models’ adaptability in cross-domain learning outcome evaluation. Second, we will explore processing short micro-clips to better capture nonverbal cues such as gestures, facial expressions, and intonation and compare the results both with human ratings and with the ASR (Automatic Speech Recognition) + uniform-frame baseline. As model capabilities and interfaces improve, we look forward to directly inputting full-length videos for more comprehensive multimodal evaluation. Third, we will optimize prompt design and evaluation processes based on teachers’ needs, strengthen model interaction guidance, and explore human–machine collaborative scoring to leverage the advantages of MLLMs in assisting feedback, thereby improving the interpretability and practicality of feedback and providing more valuable support for teachers. Fourth, we plan to extend the evaluation framework to incorporate additional dimensions, including fairness, bias, efficiency, and other aspects of trustworthy AI, to enable a more comprehensive assessment of MLLMs in educational settings. On comparable single-modal tasks, consideration may also be given to comparing model performance with traditional automated scoring systems to provide a more intuitive reference. By continuously advancing these directions, we aim to further enhance the usability, fairness, and educational value of MLLMs in real teaching environments.
Author Contributions
Conceptualization, Y.C. and Y.M.; methodology, Y.C.; formal analysis, Y.C., Y.L. (Yixin Li), Y.R. and Y.L. (Yixin Liu); data curation, Y.C., Y.L. (Yixin Li), Y.R. and Y.L. (Yixin Liu); writing—original draft preparation, Y.C., Y.L. (Yixin Li) and Y.R.; writing—review and editing, Y.M.; visualization, Y.C.; supervision, Y.M.; project administration, Y.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Natural Science Foundation of Shanghai Municipality (No.24ZR1418500), and the Education and Scientific Research Project of Shanghai (No.C2025017).
Institutional Review Board Statement
This study was performed in line with the principles of the Declaration of Helsinki. Approval was granted by the Ethics Committee of East China Normal University (Date 2022-12-09/No. HR 786-2022).
Informed Consent Statement
Verbal informed consent was obtained from the participants. Verbal consent was obtained rather than written because the data used in this article are anonymized and do not include identifiable images of individuals.
Data Availability Statement
Data are available from the first author upon reasonable request.
Acknowledgments
We thank the teachers and students who participated in this research.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A Survey on Evaluation of Large Language Models. ACM Trans. Intell. Syst. Technol. 2024, 15, 39. [Google Scholar] [CrossRef]
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Akhtar, N.; Barnes, N.; Mian, A. A Comprehensive Overview of Large Language Models. ACM Trans. Intell. Syst. Technol. 2025, 16, 106. [Google Scholar] [CrossRef]
- Gan, W.; Qi, Z.; Wu, J.; Lin, J.C.W. Large Language Models in Education: Vision and Opportunities. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; pp. 4776–4785. [Google Scholar] [CrossRef]
- Kasneci, E.; Sessler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Milano, S.; McGrane, J.A.; Leonelli, S. Large language models challenge the future of higher education. Nat. Mach. Intell. 2023, 5, 333–334. [Google Scholar] [CrossRef]
- Yin, S.; Fu, C.; Zhao, S.; Li, K.; Sun, X.; Xu, T.; Chen, E. A survey on multimodal large language models. Natl. Sci. Rev. 2024, 11, nwae403. [Google Scholar] [CrossRef]
- Zhang, D.; Yu, Y.; Dong, J.; Li, C.; Su, D.; Chu, C.; Yu, D. MM-LLMs: Recent Advances in MultiModal Large Language Models. arXiv 2024, arXiv:2401.13601. [Google Scholar]
- Imran, M.; Almusharraf, N. Google Gemini as a Next Generation AI Educational Tool: A Review of Emerging Educational Technology. Smart Learn. Environ. 2024, 11, 22. [Google Scholar] [CrossRef]
- Küchemann, S.; Avila, K.E.; Dinc, Y.; Hortmann, C.; Revenga, N.; Ruf, V.; Stausberg, N.; Steinert, S.; Fischer, F.; Fischer, M.; et al. On opportunities and challenges of large multimodal foundation models in education. npj Sci. Learn. 2025, 10, 11. [Google Scholar] [CrossRef]
- Magnusson, P.; Godhe, A.L. Multimodality in Language Education: Implications for Teaching. Des. Learn. 2019, 11, 127–137. [Google Scholar] [CrossRef]
- Monib, W.K.; Qazi, A.; Apong, R.A.; Azizan, M.T.; De Silva, L.; Yassin, H. Generative AI and future education: A review, theoretical validation, and authors’ perspective on challenges and solutions. PeerJ Comput. Sci. 2024, 10, e2105. [Google Scholar] [CrossRef]
- Munaye, Y.Y.; Admass, W.; Belayneh, Y.; Molla, A.; Asmare, M. ChatGPT in Education: A Systematic Review on Opportunities, Challenges, and Future Directions. Algorithms 2025, 18, 352. [Google Scholar] [CrossRef]
- Albadarin, Y.; Saqr, M.; Pope, N.; Tukiainen, M. A systematic literature review of empirical research on ChatGPT in education. Discov. Educ. 2024, 3, 60. [Google Scholar] [CrossRef]
- Emirtekin, E. Large Language Model-Powered Automated Assessment: A Systematic Review. Appl. Sci. 2025, 15, 5683. [Google Scholar] [CrossRef]
- Wiliam, D. What is assessment for learning? Stud. Educ. Eval. 2011, 37, 3–14. [Google Scholar] [CrossRef]
- Berry, R. Assessment for Learning; Hong Kong University Press: Hong Kong, 2008; Volume 1. [Google Scholar]
- OECD. The Definition and Selection of Key Competencies: Executive Summary; OECD: Paris, France, 2005. [Google Scholar]
- Trilling, B.; Fadel, C. 21st Century Skills: Learning for Life in Our Times; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Van Roekel, D. Global Competence is a 21st Century Imperative; NEA Policy and Practice Department: Washington, DC, USA, 2010; pp. 1–4. [Google Scholar]
- Bloxham, S.; Boyd, P. Developing Effective Assessment in Higher Education: A Practical Guide: A Practical Guide; McGraw-Hill Education (UK): Maidenhead, UK, 2007. [Google Scholar]
- Fagbohun, O.; Iduwe, N.P.; Abdullahi, M.; Ifaturoti, A.; Nwanna, O. Beyond traditional assessment: Exploring the impact of large language models on grading practices. J. Artif. Intell. Mach. Learn. Data Sci. 2024, 2, 1–8. [Google Scholar] [CrossRef]
- Yan, L.; Sha, L.; Zhao, L.; Li, Y.; Martinez-Maldonado, R.; Chen, G.; Li, X.; Jin, Y.; Gašević, D. Practical and ethical challenges of large language models in education: A systematic scoping review. Br. J. Educ. Technol. 2024, 55, 90–112. [Google Scholar] [CrossRef]
- Luckin, R.; Cukurova, M.; Kent, C.; Du Boulay, B. Empowering educators to be AI-ready. Comput. Educ. Artif. Intell. 2022, 3, 100076. [Google Scholar] [CrossRef]
- Kasneci, E.; Gao, H.; Ozdel, S.; Maquiling, V.; Thaqi, E.; Lau, C.; Rong, Y.; Kasneci, G.; Bozkir, E. Introduction to Eye Tracking: A Hands-On Tutorial for Students and Practitioners. arXiv 2024, arXiv:2404.15435. [Google Scholar] [CrossRef]
- Pankiewicz, M.; Baker, R.S. Large Language Models (GPT) for automating feedback on programming assignments. arXiv 2023, arXiv:2307.00150. [Google Scholar] [CrossRef]
- Kohnke, L.; Moorhouse, B.L.; Zou, D. ChatGPT for language teaching and learning. Relc J. 2023, 54, 537–550. [Google Scholar] [CrossRef]
- Shanahan, M.; McDonell, K.; Reynolds, L. Role play with large language models. Nature 2023, 623, 493–498. [Google Scholar] [CrossRef] [PubMed]
- Mayer, R.E. Cognitive theory of multimedia learning. Camb. Handb. Multimed. Learn. 2005, 41, 31–48. [Google Scholar]
- Hutson, J.; Robertson, B. Exploring the educational potential of AI generative art in 3D design fundamentals: A case study on prompt engineering and creative workflows. Glob. J. Hum.-Soc. Sci. A Arts Humanit.-Psychol. 2023, 23, 485. [Google Scholar]
- Waghmare, C. Introduction to chatgpt. In Unleashing The Power of ChatGPT: A Real World Business Applications; Springer: Berkeley, CA, USA, 2023; pp. 1–26. [Google Scholar]
- Kooli, C. Chatbots in education and research: A critical examination of ethical implications and solutions. Sustainability 2023, 15, 5614. [Google Scholar] [CrossRef]
- Gupta, M.S.; Nitu Kumar, D.V.R. AI and Teacher Productivity: A Quantitative Analysis of Time-Saving and Workload Reduction in Education. In Proceedings of the International Conference on Advancing Synergies in Science, Engineering, and Management (ASEM-2024), Virginia Beach, VA, USA, 6–9 November 2024. [Google Scholar]
- Weegar, R.; Idestam-Almquist, P. Reducing workload in short answer grading using machine learning. Int. J. Artif. Intell. Educ. 2024, 34, 247–273. [Google Scholar] [CrossRef]
- Yusuf, H.; Money, A.; Daylamani-Zad, D. Towards reducing teacher burden in Performance-Based assessments using aivaluate: An emotionally intelligent LLM-Augmented pedagogical AI conversational agent. Educ. Inf. Technol. 2025, 30, 1–45. [Google Scholar] [CrossRef]
- Taras, M. Assessment for learning: Assessing the theory and evidence. Procedia-Soc. Behav. Sci. 2010, 2, 3015–3022. [Google Scholar] [CrossRef]
- Taras, M. Assessment–summative and formative–some theoretical reflections. Br. J. Educ. Stud. 2005, 53, 466–478. [Google Scholar] [CrossRef]
- Black, P.; Wiliam, D. Developing the theory of formative assessment. Educ. Assess. Eval. Account. (Former. J. Pers. Eval. Educ.) 2009, 21, 5–31. [Google Scholar] [CrossRef]
- Dixson, D.D.; Worrell, F.C. Formative and summative assessment in the classroom. Theory Pract. 2016, 55, 153–159. [Google Scholar] [CrossRef]
- Pearson, P.D.; Hiebert, E.H. Based Practices for Teaching Common Core Literacy; Teachers College Press: New York, NY, USA, 2015. [Google Scholar]
- Calfee, R.; Wilson, K.M.; Flannery, B.; Kapinus, B. Formative assessment for the common core literacy standards. Teach. Coll. Rec. 2014, 116, 1–32. [Google Scholar] [CrossRef]
- Darvishi, A.; Khosravi, H.; Sadiq, S.; Gašević, D.; Siemens, G. Impact of AI assistance on student agency. Comput. Educ. 2024, 210, 104967. [Google Scholar] [CrossRef]
- Song, C.; Song, Y. Enhancing academic writing skills and motivation: Assessing the efficacy of ChatGPT in AI-assisted language learning for EFL students. Front. Psychol. 2023, 14, 1260843. [Google Scholar] [CrossRef]
- Urban, M.; Děchtěrenko, F.; Lukavskỳ, J.; Hrabalová, V.; Svacha, F.; Brom, C.; Urban, K. ChatGPT improves creative problem-solving performance in university students: An experimental study. Comput. Educ. 2024, 215, 105031. [Google Scholar] [CrossRef]
- Park, J.Y.; Ko, C.B. Proposal for AI video interview using image data analysis. Int. J. Internet Broadcast. Commun. 2022, 14, 212–218. [Google Scholar]
- Su, Y.S.; Suen, H.Y.; Hung, K.E. Predicting behavioral competencies automatically from facial expressions in real-time video-recorded interviews. J. Real-Time Image Process. 2021, 18, 1011–1021. [Google Scholar] [CrossRef]
- Wu, J. Real-time Interactive Assessment in English Oral Teaching Using Speech Recognition Technology. In Proceedings of the 2024 International Conference on Machine Intelligence and Digital Applications, Ningbo, China, 30–31 May 2024; pp. 200–204. [Google Scholar]
- Krathwohl, D.R. A revision of Bloom’s taxonomy: An overview. Theory Pract. 2002, 41, 212–218. [Google Scholar] [CrossRef]
- Mayer, R.E. Multimedia learning. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 2002; Volume 41, pp. 85–139. [Google Scholar]
- Richards, J.C.; Schmidt, R.W. Language and Communication; Routledge: New York, NY, USA, 2014. [Google Scholar]
- Mehrabian, A. Nonverbal Communication; Routledge: New York, NY, USA, 2017. [Google Scholar]
- Team, G.; Georgiev, P.; Lei, V.I.; Burnell, R.; Bai, L.; Gulati, A.; Tanzer, G.; Vincent, D.; Pan, Z.; Wang, S.; et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv 2024, arXiv:2403.05530. [Google Scholar] [CrossRef]
- Hurst, A.; Lerer, A.; Goucher, A.P.; Perelman, A.; Ramesh, A.; Clark, A.; Ostrow, A.; Welihinda, A.; Hayes, A.; Radford, A.; et al. Gpt-4o system card. arXiv 2024, arXiv:2410.21276. [Google Scholar] [CrossRef]
- Gandolfi, A. GPT-4 in education: Evaluating aptness, reliability, and loss of coherence in solving calculus problems and grading submissions. Int. J. Artif. Intell. Educ. 2025, 35, 367–397. [Google Scholar] [CrossRef]
- Koçak, M.; Oğuz, A.K.; Akçalı, Z. The role of artificial intelligence in medical education: An evaluation of Large Language Models (LLMs) on the Turkish Medical Specialty Training Entrance Exam. BMC Med. Educ. 2025, 25, 609. [Google Scholar] [CrossRef]
- Lee, S.; Jung, S.; Park, J.H.; Cho, H.; Moon, S.; Ahn, S. Performance of ChatGPT, Gemini and DeepSeek for non-critical triage support using real-world conversations in emergency department. BMC Emerg. Med. 2025, 25, 176. [Google Scholar] [CrossRef]
- Dai, Z.; McReynolds, A.; Whitehill, J. In Search of Negative Moments: Multi-Modal Analysis of Teacher Negativity in Classroom Observation Videos. In Proceedings of the 16th International Conference on Educational Data Mining, Bengaluru, India, 11–14 July 2023; pp. 278–285. [Google Scholar] [CrossRef]
- Lu, W.; Yang, Y.; Song, R.; Chen, Y.; Wang, T.; Bian, C. A Video Dataset for Classroom Group Engagement Recognition. Sci. Data 2025, 12, 644. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (long and short papers), pp. 4171–4186. [Google Scholar]
- Hua, H.; Shi, J.; Kafle, K.; Jenni, S.; Zhang, D.; Collomosse, J.; Cohen, S.; Luo, J. Finematch: Aspect-based fine-grained image and text mismatch detection and correction. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Cham, Switzerland, 2024; pp. 474–491. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Lee, S.; Sim, W.; Shin, D.; Seo, W.; Park, J.; Lee, S.; Hwang, S.; Kim, S.; Kim, S. Reasoning abilities of large language models: In-depth analysis on the abstraction and reasoning corpus. ACM Trans. Intell. Syst. Technol. 2025, Accepted. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PmLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Ahmed, J.; Nadeem, G.; Majeed, M.K.; Ghaffar, R.; Baig, A.K.K.; Shah, S.R.; Razzaq, R.A.; Irfan, T. THE RISE OF MULTIMODAL AI: A QUICK REVIEW OF GPT-4V AND GEMINI. Spectr. Eng. Sci. 2025, 3, 778–786. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Mustaqeem, M.; Kwon, S. Speech emotion recognition based on deep networks: A review. In Proceedings of the Annual Conference of KIPS, Jeju, Republic of Korea, 22–24 April 2021; Korea Information Processing Society: Seoul, Republic of Korea, 2021; pp. 331–334. [Google Scholar]
- Ekman, P. Facial expressions of emotion: New findings, new questions. Psychol. Sci. 1992, 3, 34–38. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Xie, J.; Yang, J.; Luo, Z.; Cao, Y.; Gao, Q.; Zhang, M.; Hu, W. AdaDARE-gamma: Balancing Stability and Plasticity in Multi-modal LLMs through Efficient Adaptation. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 11–15 June 2025; pp. 19758–19768. [Google Scholar]
- Zhou, L.; Schellaert, W.; Martínez-Plumed, F.; Moros-Daval, Y.; Ferri, C.; Hernández-Orallo, J. Larger and more instructable language models become less reliable. Nature 2024, 634, 61–68. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Singh, C.; Inala, J.P.; Galley, M.; Caruana, R.; Gao, J. Rethinking interpretability in the era of large language models. arXiv 2024, arXiv:2402.01761. [Google Scholar] [CrossRef]
- Nagrani, A.; Yang, S.; Arnab, A.; Jansen, A.; Schmid, C.; Sun, C. Attention bottlenecks for multimodal fusion. Adv. Neural Inf. Process. Syst. 2021, 34, 14200–14213. [Google Scholar]
- Dang, Y.; Huang, K.; Huo, J.; Yan, Y.; Huang, S.; Liu, D.; Gao, M.; Zhang, J.; Qian, C.; Wang, K.; et al. Explainable and interpretable multimodal large language models: A comprehensive survey. arXiv 2024, arXiv:2412.02104. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar] [CrossRef]
- Singh, A. Evaluating the Transparency and Explainability of llm-Based Educational Systems. SSRN. Available online: https://ssrn.com/abstract=5198565 (accessed on 3 March 2025).
- Saarela, M.; Gunasekara, S.; Karimov, A. The EU AI Act: Implications for Ethical AI in Education. In Proceedings of the International Conference on Design Science Research in Information Systems and Technology, Montego Bay, Jamaica, 2–4 June 2025; Springer: Cham, Switzerland, 2025; pp. 36–50. [Google Scholar]
- Schiff, D. Education for AI, not AI for education: The role of education and ethics in national AI policy strategies. Int. J. Artif. Intell. Educ. 2022, 32, 527–563. [Google Scholar] [CrossRef]
- Pedro, F.; Subosa, M.; Rivas, A.; Valverde, P. Artificial Intelligence in Education: Challenges and Opportunities for Sustainable Development; UNESCO: Paris, France, 2019. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).