Abstract
Private information retrieval (PIR) is a typical application scenario of encrypted computing, which allows users to retrieve data from a database by providing only an encrypted index. In an academic research scenario, multiple parties may entrust their data to a third party and require collaborative retrieval. However, due to competitive relationships and mutual distrust between these parties, they do not share public–private keys, making single-key mechanisms inadequate for meeting actual privacy requirements. In this case, based on the multi-key fully homomorphic encryption (MKFHE) algorithm, we construct an efficient PIR scheme with an access permission verification mechanism and dynamic database. Specifically, we design an MKFHE algorithm to protect multi-user privacy information. The vector–matrix multiplication optimization algorithm is adopted to improve computational efficiency, the expand algorithm is used to reduce user communication traffic, and homomorphic multiplication with ciphertext chunking is used to avoid excessive noise caused by direct ciphertext multiplication. Experiments based on the SEAL library show that by transferring part of the computational pressure to the offline stage, the online query response efficiency of our scheme is improved by about 7.69%, and the online computational efficiency of vector–matrix multiplication is improved by about 19.7%.
1. Introduction
In an open environment, researchers mainly rely on two cryptographic primitives, searchable encryption [1] and private information retrieval (PIR) [2], to meet the requirements for the private retrieval of encrypted data in a multi-source data framework. Searchable encryption technology supports users to perform flexible retrieval based on keywords by double encryption of the data and its keyword index. However, its core goal is to hide the search mode and data semantics, and it usually requires the data to be stored in ciphertext on the server side. In contrast, the design of a PIR protocol is more flexible. Users only need to encrypt the query index and send it to the server, the server data (which can be plaintext or ciphertext) are all involved in the encrypted calculation, and the ciphertext result is returned to the user, which prevents the server from inferring the specific location of the queried data and thus protects user data privacy. This feature endows PIR with distinct advantages for privacy preservation in multi-source data scenarios.
Fully homomorphic encryption (FHE) [3] enables arbitrary operation on ciphertext data without decryption, and the final result is also ciphertext, thus realizing data privacy protection in the process of calculating and using index and database data, which provides a more suitable idea for a PIR protocol. In 2009, Gentry [3] first constructed the PIR protocol based on the fully homomorphic encryption scheme in his doctoral dissertation, achieving sublinear communication complexity. Since then, PIR schemes based on fully homomorphic encryption have been developed rapidly. Each scheme weighs three indicators (request size, response size and server computing overhead) and develops a wide range of fast PIR methods. It is worth noting that for each user’s query, all the data in the database need to participate in the operation to generate the corresponding response. If any data does not participate in the operation in this process, it means that the user’s query target is not in it, and information leakage has occurred.
The PIR protocol based on fully homomorphic encryption can effectively protect the index information while preventing the server from obtaining the retrieval data and retrieval range. However, in real application scenarios, multi-source data often serves multiple independent users who do not trust each other, so the protocol should not only ensure the privacy and security of information retrieval but also meet the privacy requirements of data between participating users. Therefore, a PIR scheme using a multi-key fully homomorphic encryption (MKFHE) [4] algorithm is considered. This kind of scheme permits the collaborative computation of multiple data owners without disclosing the private information of each participant, which makes the scheme more suitable for real-world scenarios and has stronger practicability and broader application potential.
1.1. Related Work
Private information retrieval (PIR) technology has been evolving around two core goals of “preserving query privacy” and “reducing communication overhead” since it was proposed by Chor et al. [2] in 1995. Early schemes achieved privacy protection through information theoretic or computational complexity assumptions, but were limited by linear communication costs. With the breakthrough development of homomorphic encryption, PIR gradually evolved toward cryptography-based optimization approaches. In 2009, Gentry [3] proposed the first fully homomorphic encryption scheme, which brought a paradigm innovation for PIR. The PIR protocol based on the fully homomorphic encryption constructed by Gentry broke through the sublinear communication complexity for the first time, starting the practical exploration stage of the secret state retrieval. After that, fully homomorphic encryption and PIR schemes based on it began to develop rapidly.
In the research into PIR schemes based on fully homomorphic encryption, structural coding and ciphertext operation optimization are the key technical breakthroughs. In 2016, Melchor et al.’s XPIR [5] achieved a minute-level response on million-scale databases for the first time by using multidimensional vector encoding and ring learning with errors (RLWEs) [6] secret state operation. However, the size of the query increases linearly with the size of the database, which exposes the bottleneck of communication efficiency. SealPIR [7] proposed by Angel in 2018 introduced polynomial compression technology to compress the query size to 1/27 of XPIR, but at the cost of response size expansion and server computational complexity increase. To solve this problem, OnionPIR [8] by Mughees et al. in 2021 innovatively used RGSW [9] outer product operation to compress the response ciphertext expansion ratio from 100 times to 4.2 times; however, at the same time, it increases the client initialization time and the server memory bandwidth pressure, and the state dependence of the protocol also limits its dynamic update ability. Subsequent studies such as FastPIR [10] and SPIRAL [11] protocol families further try ciphertext rotation and hybrid encryption schemes, but it is always difficult to achieve the global optimum among request size, response size, and computational overhead, which highlights the inherent contradiction of efficiency balance in single-server architecture. There is still much room for the optimal design of PIR schemes based on fully homomorphic encryption.
At the same time, representing an important breakthrough in the field of cryptography, the multi-key homomorphic encryption (MKFHE) scheme aims to solve the problem of private computation with multi-party participation, and provides new possibilities for the design of PIR protocols for multi-user collaborative scenarios. The core goal of MKFHE is to allow multiple parties to directly perform joint operations on ciphertexts encrypted with independent keys, while ensuring that only the authorized party can decrypt the results. Since the LTV12 scheme [4] was proposed in 2012, MKFHE has formed four major technical routes of the NTRU type [4], GSW type [12], BGV type [13], and TFHE type [14], based on different mathematical assumptions and ciphertext operation mechanisms. Specifically, NTRU-type schemes rely on polynomial ring operations to achieve efficient key expansion, GSW schemes support low noise accumulation through approximate eigenvector methods, BGV schemes significantly reduce computational overhead while maintaining computational depth, and TFHE schemes focus on fast Boolean operation optimization. These characteristics theoretically enable it to support multi-user independent PIR scenarios. However, the complete scheme design of PIR based on MKFHE is still facing challenges, and there are some problems to be solved:
- Computational complexity and key management. The computational complexity of multi-key fully homomorphic encryption algorithm is high, especially in the process of encryption, decryption and homomorphic operation, resulting in large computational overhead and significant time consumption. Key management also becomes more complex because efficient key distribution, storage, and update mechanisms are required to prevent private key compromise or misuse with each party holding an independent key. In addition, improper key management may lead to degraded communication efficiency and increased system overhead.
- PIR protocol optimization and communication overhead. In the PIR protocol of MKFHE, balancing the request size, response size, and server computational overhead is an important challenge. Large response size will increase the burden of network transmission, while excessive computing overhead may affect the system efficiency. More importantly, the communication overhead and latency caused by frequent encrypted data exchange may put pressure on the real-time performance and scalability of the system.
- Privacy protection and user trust. Although MKFHE can effectively protect privacy, ensuring comprehensive protection of all participants’ data privacy in multi-party scenarios remains challenging. Since parties usually do not trust each other, how to enhance user trust and avoid man-in-the-middle attacks or data leakage through reasonable authentication and data sharing protocols has become a key issue in the design of the scheme.
1.2. Our Contributions
In this paper, an optimization scheme of PIR based on multi-key fully homomorphic encryption is proposed, which supports the dynamic update of the database. With the background of secure access to massive data in the environment of multiple data sources, the security architecture and attack protection method of private information retrieval are designed. The specific contributions are as follows:
- This paper provides theoretical methods and technical solutions for private information retrieval of multi-source data. An MKFHE method constructed by normalized public keys is used to reduce the amount of communication and simplify the calculation process. The distributed decryption technology is used to mitigate single-point-of-failure risks and effectively protect the private information of each participant.
- In the design of the PIR scheme, the expand algorithm is used to further reduce the communication overhead, and the optimization method of vector–matrix multiplication is used to improve the online calculation efficiency of the scheme. The response generation efficiency is improved by 1.95–7.69%, and the online calculation efficiency of the vector–matrix multiplication is improved by 19.7%. In addition, the scheme also adopted homomorphic ciphertext multiplication with ciphertext chunking to avoid direct ciphertext multiplication, thereby reducing noise accumulation.
- The PIR scheme proposed in this paper can hide access and retrieval information well and has an access permission verification mechanism. It supports dynamic database and multi-user collaborative retrieval while protecting user data privacy, so as to enhance the practicability and flexibility of the method.
2. Preliminaries
2.1. Basic Notation
In this paper, a represents a vector, and represents the -th element of the vector . indicates that x is uniformly sampled from the probability distribution or set A. The polynomial ring is denoted as , with being the error distribution on R. Let λ be the security parameter, L be the circuit depth, and K is the upper limit on the number of parties. The integer is chosen as , the noise distribution over R is , and the is the ciphertext modulus. represents the asymptotic upper bound of the performance of the algorithm as the input size grows.
2.2. RLWE, Gadget Vector, and Smudging Lemma
RLWE, proposed by Lyubashevsky [6] as the ring-based variant of learning with errors (LWE) [15], constitutes a computationally hard lattice problem. Let security parameter define system parameters: prime modulus polynomial with being a power of 2; quotient ring and error probability distribution over . The RLWE problems are defined as follows:
Search Problem: Given pairs ( where , and , recover secret .
Decisional Problem: Distinguish between RLWE samples ( and uniform random pairs (.
The gadget vector and its associated decomposition function were proposed by Micciancio [16] in 2012. This function maps any element (where is a polynomial ring modulo ) to a vector , such that . The gadget vector is typically designed as a geometric sequence (e.g., for a base ).
Smudging lemma [17] is a key tool in cryptography for analyzing sensitive information masked by noise. If we add a “sufficiently wide” (magnitude much larger than ) independent noise to a random variable with bounded values (magnitude at most ), the distribution of will be statistically indistishable from the distribution of pure noise .
In other words, let be a bounded integer, and be uniformly sampled. If (where is a negligible function of the security parameter ), then the distribution of is statistically indistinguishable from that of .
2.3. Key Switching and Rotation
Key switching is a technique used to transform a ciphertext that is encrypted under one key to another key. This is particularly useful in homomorphic encryption schemes, where performing multiple operations on encrypted data may result in a ciphertext that becomes increasingly noisy and difficult to decrypt. Key switching helps mitigate this problem by allowing the ciphertext to be re-encrypted under a new key that is more suitable for further operations.
The specific algorithm for key switching is as follows:
- Calculate the length of the elements in , and select RLWE instances . Computing , and then output switch-key .
- A bit decomposition is performed on the ciphertext, get key switching result .where the and functions are defined as follows:
For a vector , define as the binary decomposition of each component of . Let , then , where and .
For a vector , define as: . This ensures the inner product invariance: .
Rotation refers to cyclically shifting the slots of a ciphertext in single instruction, multiple data (SIMD)-style homomorphic encryption. It allows permuting encrypted data for parallel processing.
For a ciphertext encoding a vector , a rotation by positions uses a Galois key . The rotated ciphertext satisfies . Implemented via automorphism in polynomial rings. ( is chosen because when , 5 is a primitive root of modulo , that is, can cover all odd numbers, thus generating different cyclic shift steps).
2.4. Private Information Retrieval
A typical single-server PIR scheme usually includes two entities, the user and the database server, as shown in Figure 1.
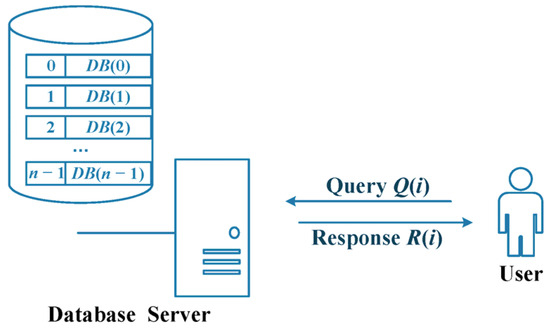
Figure 1.
Typical PIR model.
The database (DB) server is used to store and process the data, with a total of entries. To simplify the PIR protocol discussed later, we assume that the value of each item is a positive integer and not just a bit. In addition, after the query user makes a PIR query using unbounded computation, the server will provide the PIR response to the query user.
Users can directly make PIR queries to the DB server and obtain the desired results from the DB server. At the same time, the user does not want to reveal the query value to the DB server when requesting the corresponding data from the DB and hopes that the communication of the PIR is efficient.
Formally, the single-server PIR protocol consists of the following three phases:
- Query generation phase : Taking index as input, the user sends query to the server;
- Response generation phase : Using the query and the database DB, the server returns a response to the user;
- Response retrieval phase : After receiving the response , the user outputs the data corresponding to index .
A single-server PIR protocol is correct if for any database DB of size , any index is , holds, where .
In the security model, the DB server is honest but curious and has no collusion with any other third party. In other words, the DB server will faithfully follow the protocol; however, it is curious about the value of the user’s query. Note that if the DB server is compromised by some attacker, the compromised DB server may launch other active attacks and return a response with errors to unauthenticated users. However, since we focus on communication efficient PIR protocols for users in this paper, active attacks from compromised DB servers are beyond the main scope of this work, although it is not difficult to apply some verifiable techniques to address these attacks.
3. Building Blocks
In this paper, the PIR scheme involves the optimization technique of vector–matrix multiplication, which improves the online calculation efficiency by extracting the diagonal vector of the matrix and rotating the ciphertext in the offline stage of the server. The expand algorithm is used to reduce user communication traffic, while the ciphertext chunk algorithm is used to effectively reduce the noise accumulation in the calculation process. The MKFHE scheme is also optimized to meet the requirements of multi-user privacy protection in PIR scenarios. The purpose of this section is to explain these important components in detail.
3.1. Optimization Methods for Vector-Matrix Multiplication
Some HE schemes based on the RLWE assumption use the structure of the Galois group to implement the rotation operation of the plaintext slot, denoted by , which transforms the ciphertext of into the ciphertext of where denotes the step size of the rotation, which can be positive or negative, and the rotation is the same as .
Specifically, the optimized approach for vector–matrix multiplication [18] uses an algorithm for computing arbitrary linear transformations on encrypted vectors, which can be represented by combining rotation and constant multiplication operations. For some matrix , define its -th diagonal vector , where . The vector and matrix product can be expressed as the sum of component multiplications of the diagonal vector of the matrix and the rotated vector, i.e.,
where ⊙ denotes the component multiplication between vectors.
Given a matrix and a ciphertext of a vector m, the following homomorphic linear transformation algorithm (Algorithm 1) describes how to compute the ciphertext of the desired vector .
| Algorithm 1. Homomorphic linear transformation algorithm: |
| Input: plaintext matrix U, ciphertext vector . Output: ciphertext vector .
|
When vector matrix multiplication is directly calculated, each column of the matrix requires plaintext multiplications and additions, totaling multiplications and additions, that is, the complexity is asymptotically multiplications. As shown in the state linear transformation algorithm, the computational cost of vector and matrix multiplication mainly consists of constant multiplications and rotation operations. Note that rotation often requires a key transformation, which makes it more expensive to compute than addition or constant multiplication. Therefore, we can conclude that the operation complexity of the optimization method is asymptotically rotations.
3.2. Expand Algorithm
The expand algorithm (Algorithm 2) [7] requires a special homomorphic operation : Firstly, suppose we have a ciphertext pair , replace by , and transform into a new ciphertext , then the decryption key corresponding to the new ciphertext is changed to . For consistency, we use the key transformation algorithm to process the ciphertext , and obtain the ciphertext with decryption key . At this time, the ciphertext becomes the encryption of the message .
| Algorithm 2. Expand algorithm: |
| Input: , the size of the database n. Output: a set of ciphertexts .
|
The expand algorithm constructs a ciphertext vector from a single query index by performing lightweight homomorphic operations, including homomorphic addition, homomorphic substitution, and monomial multiplication. This generates a sparse encrypted vector where only the target position contains (others are ), ready for subsequent computations. (The details of the encryption algorithm MKFHE.Enc are given in the subsequent MKFHE scheme.)
3.3. Ciphertext Chunking Algorithm
The ciphertext chunking algorithm can effectively reduce the noise accumulation in the calculation process, which is divided into two parts: the homomorphic ciphertext multiplication with ciphertext chunking (Algorithm 3) and the homomorphic ciphertext decryption with ciphertext chunking (Algorithm 4).
In the process of using the ciphertext chunking algorithm, it is usually necessary to first perform homomorphic ciphertext multiplication with ciphertext chunking . It has two processes in turn, ciphertext chunking and plain-ciphertext multiplication, as shown in the following:
| Algorithm 3. Homomorphic ciphertext multiplication with ciphertext chunking: |
| Input: two homomorphic encrypted ciphertexts with block size F. Output: 2F ciphertexts .
|
The algorithm divides the ciphertext with large coefficient into F ciphertext chunks with small coefficient, and each ciphertext chunk is regarded as plaintext, so as to perform plaintext multiplication operation. Then in order to decrypt to get , it needs to be decrypted twice, that is, sequentially execute decryption, reconstruction, and decryption again. This process is called homomorphic ciphertext decryption with ciphertext chunking: , and the specific algorithm is as follows. (The details of the decryption algorithm MKFHE.Dec are given in the subsequent MKFHE scheme).
| Algorithm 4. Homomorphic ciphertext decryption with ciphertext chunking: |
| Input: a set of ciphertexts generated by the
algorithm. Output: decryption yields message .
|
Through this homomorphic ciphertext multiplication with ciphertext chunking, the ciphertext multiplication calculation in the PIR scheme is optimized, and the noise accumulation in the process is reduced. The decryption process is further recovered and reconstructed to ensure that the PIR scheme can obtain the correct output after complex calculations in the ciphertext state.
3.4. MKFHE Scheme
There are two types of multi-key schemes in the existing MKFHE algorithm. One is that each participant encrypts data with different public keys and then converts the ciphertext under the same key by key conversion method. The other is to convert each party’s key into a normalized public key and then encrypt and perform homomorphic operations. The latter is more convenient, efficient, and easy to calculate when solving the problem that the ciphertext encrypted with different keys cannot be directly homomorphic operation. At the same time, the MKFHE algorithm also has two different decryption methods. Sequential decryption starts from the first participant and sequentially transmits the decryption results to continue the decryption, which is simple but has great single-point-of-failure risks. Distributed decryption is that each participant calculates part of the decryption results independently, and then the final results are collected to complete the decryption together. It effectively safeguards the privacy of each participant’s private key, greatly mitigates single-point-of-failure risks, while demonstrating superior efficiency and strong scalability.
Our MKFHE scheme consists of five algorithms: initialization algorithm MKFHE.setup, key generation algorithm MKFHE.KeyGen, encryption algorithm MKFHE.enc, homomorphic operation algorithm MKFHE.Eval, and decryption algorithm MKFHE.dec. MKFHE.Setup sets the system parameters to construct the framework of multi-party homomorphic encryption. MKFHE.KeyGen generates public and private key pairs and computation keys for each party (i.e., the query user). These public keys are transformed into normalized public keys by performing specific operations (e.g., sum) on the public keys of all parties, so that the ciphertext size is reduced and independent of the number of parties. MKFHE.Eval provides homomorphic addition (EvalADD) and homomorphic multiplication (EvalMult) operations on ciphertexts. It performs specified homomorphic operations on two input ciphertexts to obtain the operation result ciphertext. MKFHE.Dec adopts a distributed decryption method.
The specific BFV-MKFHE scheme is given as follows:
- The security parameter is input, and the upper limit of the participant size , the plaintext domain , and the circuit depth are set. The integer is selected, the polynomial ring is denoted, the noise distribution is defined, and the ciphertext modulus and the special modulus satisfying are selected.
- The key is generated for the -th party, .
- (a)
- The private key generation: select uniformly from , the private key of the -th party is denoted as .
- (b)
- Public key generation: Select uniformly in , randomly sample noise from , the public key of the -th party is denoted as .
- (c)
- Normalized public key: Compute as the uniform public key used for encryption.
- (d)
- Computing key generation: select uniformly from , randomly sample noise from , computing , construct the computation key , where is the tool vector.
- The plaintext is encrypted using the normalized public key . is uniformly selected from , and the noise is randomly sampled. Generating ciphertext , where means approximate rounding.
- The computation key is input, and the ciphertext is performed via homomorphic operation, including homomorphic addition EvalADD and homomorphic multiplication EvalMult.
- (a)
- EvalADD: .
- (b)
- EvalMult: . Then, the modulus improved relinearization algorithm [19] MR-Relin is invoked to obtain the ciphertext .
The MR-Relin algorithm (Algorithm 5) is described in detail as follows:
| Algorithm 5. Relinearization algorithm for modulus improvement: MR-Relin |
| Input: a ciphertext after ⊗ operation, combination key
of the computing key and the public key. Output: ciphertext .
|
- Where is the bit decomposition function, which can transform an element into a vector , and satisfy the .
- Multi-party cooperation to achieve distributed decryption.
- (a)
- Each party randomly samples the noise (the noise selection satisfies the Smudging lemma) and uses its own private key to calculate the partial decryption result .
- (b)
- The partial decryption results are summed up to obtain the final decryption result .
Next, we prove the correctness and security of this MKFHE scheme.
3.4.1. Correctness
The correctness of this scheme is determined by the properties of the basic BFV [20] algorithm and the relinearization algorithm. A vector is obtained by encrypting the plaintext with multi-key BFV. Under the private key , the vector satisfies , so the decryption algorithm can correctly recover . If and are the encryption of and with respect to the private key , then their scaled tensor product such that , similar to the general BFV scheme, the relinearization algorithm can finally output , which satisfies . Therefore, it only needs to prove the correctness of the relinearization algorithm used in the scheme. The proof is as follows:
In the MR-Relin algorithm, by calculating , then adding and , we can obtain and . Notice that , .
According to the definition of , the following can be obtained:
The correctness of the relinearization algorithm can be proved by the above derivation. The MKFHE scheme meets the correctness requirements as a whole, and can correctly recover the corresponding plaintext after encryption, homomorphic operation, and distributed decryption, which is suitable for encrypted state computing scenarios that require multi-party cooperation.
3.4.2. Security
Based on the RLWE assumption and Smudging lemma, we strictly prove the security of the MKFHE scheme from three dimensions of encryption semantic security, multi-user scenario security, and distributed decryption privacy as follows.
- (1)
- IND-CPA security based on RLWE.
The indistinguishability under chosen plaintext attack (IND-CPA) security of the scheme directly reduces to the hardness of the RLWE problem. For individual players, the public key of the structure to meet , where is the uniform random polynomial is the small noise. According to the RLWE hypothesis, the attacker cannot distinguish the public key and uniform random sample , which . Furthermore, the ciphertext generated by the encryption process can be regarded as a linear combination of RLWE samples in in which and . Since the attacker cannot distinguish RLWE samples from random values, it cannot infer any information about the plaintext from the ciphertext, which satisfies IND-CPA security.
- (2)
- Key security in multi-user scenarios.
In a multi-user scenario, even if the attacker obtains the public keys of all parties , he cannot recover the private key of any party. In particular, the unified public key is a linear combination of the multiple independent RLWE samples. Due to the linearity of the RLWE problem, the attacker cannot separate the private key component or the noise of a single party from the unified public key. Even if the attacker obtains private keys through the side channel, the remaining private keys are still protected by RLWEs, because the decryption requires the joint operation of all participants. Therefore, the scheme still maintains the confidentiality of the key in the multi-user scenario.
- (3)
- Privacy protection for distributed decryption.
In the process of distributed decryption, each participant outputs a partial decryption result , where is the Smudging noise added actively. According to the Smudging Lemma, when the magnitude of the Smudging noise is much larger than the magnitude of the noise in the private key of the participant or the noise generated during encryption, the distribution of will mask the statistical characteristics of these noises. In this case, the partial decryption result is statistically indistinguishable from the distribution containing only Smudging noise, hence ensuring that the information of the participant’s private key and the public key noise is not leaked.
In conclusion, the proposed MKFHE scheme meets the security requirements and is suitable for multi-party collaborative dense state computing scenarios.
4. PIR Scheme
Based on the building blocks presented before, this section presents an efficient PIR scheme with a dynamic database. The design of the scheme aims to improve the performance of the secret computing scheme, reduce the resource consumption in data processing process in the multi-source data environment by optimizing the calculation and communication mechanism, and ensure that the efficient query of private information can be completed without decryption.
4.1. System Model
In this model, a user requests data in the database by sending an encrypted query, the database server computes the response in secret state after receiving the query, and then the user jointly decrypts the final query result. The model achieves efficient information retrieval under the premise of protecting multi-user data privacy and prevents unauthorized access and leakage. The system model diagram is shown in Figure 2, and the detailed descriptions are as follows:
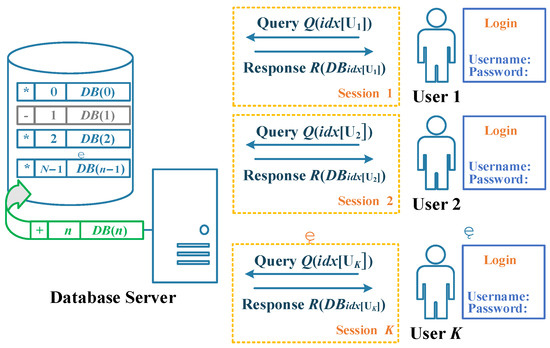
Figure 2.
System model.
- Database (DB) Server: A DB server is a computer or system dedicated to storing, managing, and providing database services. Its main responsibility is to handle database management system (DBMS) requests and provide services such as data storage, retrieval, and update for clients (such as applications, users). The database server has powerful functions in computing and storage. In this method, the database is denoted , and there are entries stored. After the query user makes a query using unbounded computation, the DB server will provide the response to the query user.
In addition, this method supports the dynamic update of the database. It only needs to mark the data stored in row and column of the original database matrix on the database side with the label of storage status “+, −, *”. Use (, +), (, −), (, *) to indicate that the status of the current database side element is newly appended, deprecated, or remains unchanged, respectively. Since the new label only presents the status information of the corresponding data of the location without specific data values, it can be disclosed to users who meet the access restrictions, so that they can conveniently store the status labels according to this group and issue queries.
- User: The client or entity that initiates a data query expects to retrieve specific information from the database without letting the database service provider know the data content of the query. The main goal of users is to ensure query privacy, that is, to obtain data while preserving their own privacy. In this method, multiple query users do not collude, and users who pass the access permission verification (that is, their username and password are correct when they login) can directly query the DB server and obtain the expected results from the DB server. At the same time, the user does not want to reveal the index value of the query to the DB server when requesting the corresponding data from the DB.
4.2. Security Model
The security model of the private information retrieval scheme in this paper is that the user and the database (DB) server are semi-honest, that is, the user and the DB server are honest-but-curious, and there is no collusion between the DB server and any other third party. Specifically, the user and the database server will faithfully follow the protocol and perform corresponding operations, performing encryption, decryption, calculation, and other tasks within the scope specified by the protocol to ensure the normal operation of the system. However, although they perform the operations in the protocol honestly, they may still try to obtain more information than the data they need by analyzing the ciphertext or query information during the execution out of curiosity.
Under this model, the database server cannot decrypt the ciphertext data and access its content, but it can observe the user’s query request and the response data returned by it. Nonetheless, the database server cannot infer a specific query target from it or leak sensitive information related to other users. This is crucial to protect user privacy, because the server’s “curiosity” will not lead to any leakage of private data. At the same time, users may also be curious about other users’ query results and hope to obtain other users’ query values by some means. However, according to the design of this scheme, users can only access the ciphertext data that they are authorized to use, and they will not expose or obtain the query content of other users during the query process. Therefore, under this security model, although the participants in the system may be curious about the behavior and data of other parties, data privacy is always guaranteed due to the strong privacy protection mechanism.
4.3. Specific PIR Scheme
According to the private information retrieval system model, the MKFHE scheme, and related algorithms and optimizations previously proposed on the basis of specific requirements, the following detailed description of the private information retrieval scheme based on multi-key fully homomorphic encryption is given. The PIR scheme ensures data privacy and security, improves computational efficiency, and supports efficient private information retrieval. The implementation of the scheme includes the following five stages, and the flow chart is shown in Figure 3.
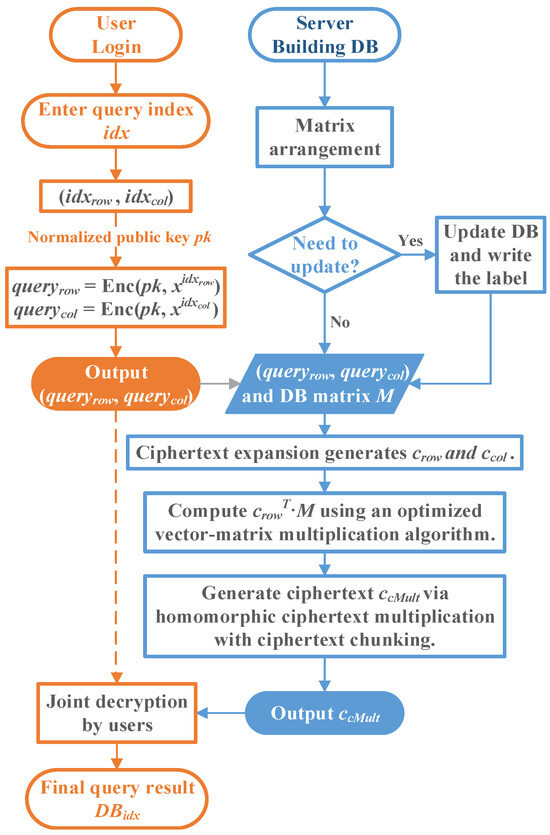
Figure 3.
Flowchart of the specific PIR scheme.
- (1)
- Database construction and access permission verification.
- (a)
- Database construction and matrix orchestrationConstruct a database of size . Let each record in the database be . Using the database matrix arrangement method, the database of elements is arranged into a matrix :
- (b)
- Verification of access permission
When users use the system for the first time, they should register by selecting a unique username and setting a strong password (such as containing upper and lower case letters, numbers, and special characters). The user password is processed by hash algorithms (such as bcrypt, SHA-256, etc.). The username and the processed user password are stored in the database.
When logging in, the user enters the username and password in the login screen. The system queries the database to find a record that matches the entered username and obtains the stored password hash value. Then, the password entered by the user is hashed using the same hash algorithm and compared with the hash value stored in the database. If the two match, authentication was successful. Otherwise, the login fails.
Once authentication is complete, the system will create a user session (e.g., generating a session ID) and provide access rights. In the system, user permissions are usually controlled by access control lists (ACL).
- (2)
- Dynamic database update.
- (a)
- Determine if the database needs to be updated dynamicallyDetermine whether it is necessary to support the dynamic update of the database. If necessary, add a set of storage status labels “+,−, *”, indicating the newly appended, deprecated, and remains unchanged of the corresponding location data, respectively. That is, for the element stored in column of row of the current database matrix, (, +), (, −), and (, *) are used to denote the status of this element as newly appended, deprecated, or remains unchanged data on the database side, respectively.
- (b)
- Update the databaseWhen the database needs to add new data, the server will put the new elements into the end of the original database in sequence, and mark the storage status label “+”, that is, (, +). When certain data in the database needs to be deleted, the database server will change the storage state label to “−”, marking the data as invalid, that is, (, −). The data in other database locations remain unchanged in (, *) state.
- (c)
- Store state labels publiclyA set of updated labels of the database is exposed to users who pass the access permission verification, and it is convenient for users to store state labels according to this group and issue queries.
- (3)
- Initialization and user query.
- (a)
- System initializationThe system calls the key generation algorithm MKFHE.Setup, sets the security parameters, the number of participating users and other parameters, generates different public and private key pairs for each user, generates the calculation key, and finally obtains the normalized public key and then makes it publicly available.
- (b)
- The user sends a query to the serverThe j-th user enters the query index , that is, user expects to query the -th record in the database. Then, user transforms the index into , which locates the position of the expected query element in the database orchestration matrix M in the form of row and column coordinates, where , . Finally, user uses to generate encryption , where , , which is sent to the DB server.
- (4)
- DB server calculation and response.
- (a)
- DB server computes the user queryThe DB server first receives the encrypted from user and runs the expand algorithm (Algorithm 2) to expand the encrypted query into two ciphertext vectors: , . Subsequently, the DB server calls the homomorphic addition MKFHE.EvalADD and the homomorphic multiplication MKFHE.EvalMult to compute the ciphertext row vector , where . This process can use the optimization method of vector–matrix multiplication to improve operation efficiency (Algorithm 1). Finally, the DB server uses homomorphic ciphertext multiplication based on ciphertext chunking (Algorithm 3) to calculate , and then uses homomorphic addition to sum , where contains 2F ciphertexts .
- (b)
- DB Server ResponseThe DB server responds to the user query by returning the ciphertext to the user.
- (5)
- The user obtains the final query result.
- (a)
- Multiple users jointly decrypt the response to obtain the final query resultThe user receives the query ciphertext result returned by the server, uses the homomorphic ciphertext decryption algorithm based on ciphertext chunking (Algorithm 4), jointly decrypts the response, and computes the final message output . That is, the final query result (database data corresponding to index ).
4.4. Correctness and Security Analysis of Our PIR Scheme
4.4.1. Correctness
The correctness of the proposed PIR scheme relies on the core features of the MKFHE algorithm and the scheme combined with the dynamic update mechanism of the database to ensure that users could accurately retrieve the target entries in the database. This is verified in stages:
- (1)
- Correctness of database matrix choreography
The database of size is arranged as a matrix , and each element corresponds to the database data . The user query index is transformed into the row and column coordinates , which satisfies , ensures that each is uniquely mapped to the matrix position , and traverses and covers all database elements.
- (2)
- Correctness of database dynamic update
When the database is dynamically updated, the system clearly identifies the validity of the data through the public status labels “+, -, *”. Before issuing a query, the client first accesses these tags to determine whether the target entry is valid or not and to avoid sending an invalid operation to the server. This mechanism not only reduces the computational burden of the server but also enables the client to sense the changes in the data state in real time, so that it can dynamically adjust the query strategy and only request the valid data. When the server updates the database, the index mapping of the original matrix structure is maintained by synchronously updating the data and labels, so that the user can still accurately locate the target position through the original index.
- (3)
- Correctness of encrypted query generation
User generates encrypted query . The row and column indexes are encoded in the form of polynomials and to ensure that the server can locate the target element through homomorphic operation. The correctness of homomorphic encryption depends on the correctness of MKFHE scheme.
- (4)
- Correctness of query expansion expand and matrix operations
After receiving the encrypted query, the database server expands the encrypted query into row vector and column vector , so that it is encrypted “1” only in the position of the target row and column , and the rest are encrypted “0”, which ensures that the homomorphic multiplication and addition operation only extracts the target element. Then perform matrix operations, through homomorphism by arithmetic ciphertext row vector , including . Since is only nonzero in row , the result corresponds to row of the matrix . Then use the homomorphic ciphertext multiplication based on ciphertext blocks to calculate and use homomorphic addition to sum . Since is nonzero only in the column, the final result corresponds to . The correctness of the procedure involving homomorphic addition and multiplication depends on the correctness of the MKFHE scheme.
- (5)
- Correctness of distributed decryption
After receiving the response ciphertext , the client decrypts the response jointly using a homomorphic ciphertext decryption algorithm chunksDec based on ciphertext chunking. The correctness of the decryption result depends on the correctness of the chunksDec decryption algorithm and reconstruction (the correctness of the ciphertext chunking algorithm is verified by the code in Section 5.3). The correctness of the involved homomorphic addition and multiplication and decryption depends on the correctness of the MKFHE scheme, and the MKFHE parameter ensures that the total noise amplitude is less than to avoid decryption errors.
In summary, depending on the correctness of the MKFHE scheme, the proposed scheme supports the dynamic update of the database while strictly guaranteeing the correctness of the query results. The client avoids invalid queries through tags and finally recovers the target data through distributed decryption, while the server responds to valid requests accurately through homomorphic operation. The design achieves efficient and scalable private information retrieval under the premise of protecting user privacy.
4.4.2. Security
We rigorously prove that the designed PIR scheme is secure against the attacker . A probabilistic polynomial-time simulator is constructed to play the role of DB server in interacting with the user, and it is proved that the user cannot distinguish between the real view and the ideal view computationally, thereby ensuring the security of the PIR scheme. Here are the detailed proof steps:
- (1)
- Define the true perspective and the ideal perspective
- Real perspective: The view of the user interacting with a real database server. The user sends an encrypted with index , and the DB server returns the query result ciphertext . After receiving , the user jointly decrypts it to obtain .
- Ideal perspective: The view of the user interacting with the simulator . The user sends an encrypted of index , and the simulator returns the ciphertext corresponding to to the user. After receiving the ciphertext , the user decrypts it to obtain .
- (2)
- Construct the simulator
- Receive the query: The simulator receives the sent by the user.
- Generate the ciphertext: The simulator generates an encrypted query which is computationally indistinguible with the real query , that is, , where is the index corresponding to . The simulator continues to perform the operations of the DB server Query and response phase on to obtain the ciphertext .
- Return the ciphertext: The simulator returns to the user.
- (3)
- Prove the indistinguishability
We need to show that the real and ideal views of the user are computationally indistinguishable. Specifically, we need to show that the following two distributions are computationally indistinguishable.
Real distribution: The distribution of user interactions with real DB servers, that is, .
Ideal distribution: The distribution of user interactions with the simulator , that is, .
- Indistinguishability of ciphertext: According to the security assumption of the MKFHE encryption scheme (the BFV-MKFHE scheme in this paper is IND-CPA secure), and are computationally indistinguishable, that is, c_cMult and Query^’ are also computationally indistinguishable by the same operation. That is, for any probabilistic polynomial-time distinguisher D, there exists a negligible function such that:
- Indistinguishability of viewpoints: Since ciphertexts and are computationally indistinguishable, the user’s true view and ideal view are also computationally indistinguishable.
- (4)
- Security conclusion
- On the side of user: The user can only obtain the from the database server, but not any other information in the database. Since and are indistinguishable, the user cannot infer other information about the database from the ciphertext. Then, we can assert that the user cannot learn anything about the data from the database server except , which means that the single-server PIR protocol is secure against the database server and leaks no other information.
- On the side of database server: The database server only receives the user’s query and cannot infer the user’s concrete query index . Therefore, the database server cannot obtain the user’s private information.
In summary, since the simulator is able to generate ciphertexts that are computationally indistinguishable from the ciphertexts returned by the real server, and the user cannot distinguish between the ideal and the real perspective, the following can be concluded: the PIR scheme designed in this paper is secure against the attacker , which can effectively protect the user’s access information and retrieval information, and prevent the database server from leaking other information.
4.5. Remark
Inspired by the new private information retrieval scheme proposed by Luo et al. in 2024 [21], this section further explores a transferable optimization method, which encodes a single column of the database matrix into a polynomial ring structure and utilizes the algebraic properties of the automorphism transformation to reduce computational complexity and enhance computational efficiency.
- (1)
- Technical implementation.
- (a)
- Database matrix encodingFirst, each column of the database matrix is encoded as a polynomial in the polynomial ring , that is, for the database matrix , its -th column is encoded as . When the database server generates the response, can be directly multiplied with the RLWE ciphertext in the user’s query.
- (b)
- Shift optimization for rotationIn the polynomial ring , given a polynomial , the rotation operation can be cyclically shifted by the automorphism transformation , i.e., . In fact, an automorphism transformation on its coefficient form is equivalent to a permutation on its corresponding number theoretic transform (NTT) form [22]. That is, two NTT representations with different rotation steps and have the same elements, and they are just a permutation of each other. Therefore, can be obtained by performing NTT only once for all rotation steps , instead of multiple times. This feature enables ciphertext rotation operation to be completed directly by the shift instruction in memory without complex multiplication. Combined with basis decomposition commutativity , rotation operation can be decomposed into two phases: preprocessing and online replacement. In the preprocessing phase, all forms of automorphism of are computed and stored; in the online phase, the preprocessed NTT representation is called directly to complete the cyclic shift by memory replacement.
- (2)
- Application in the PIR Scheme.
- (a)
- Query generation phaseWhen the user generates a query, it needs to specify the target index . When constructing the RLWE ciphertext, the RLWE ciphertext encrypting the one-hot vector is generated, where is the vector whose -th bit is 1. When constructing RGSW ciphertext, the RGSW ciphertext encrypting is generated. The polynomial encoding enables query construction with only one polynomial encryption and does not need to deal with complex two-dimensional index logic.
- (b)
- Response generation phaseThe server utilizes the preprocessed matrix and the query ciphertext for efficient computation. Firstly, is calculated by the baby-step giant-step strategy, and the matrix–vector multiplication is decomposed into multiple lightweight shifts and point multiplications. In the baby-step, all displacement copies of are precomputed, and the preprocessed basis decomposition results are multiplexed. The giant-step combines the displacement results and generates the final response by key switching. Then the outer product of the RGSW ciphertext and RLWE ciphertext is used to extract the target element . The frequency domain point multiplication and automorphism permutation reduce the response generation complexity from to .
- (c)
- Response retrieval phaseWhen the client decrypts the final LWE ciphertext, it obtains through the standard LWE decryption process without additional inverse polynomial transformation. The preprocessing and frequency domain computation are completely completed by the server, and the decryption complexity of the client is the same as that of plaintext retrieval.
- (3)
- Performance improvement analysis.
As shown in Table 1.

Table 1.
Performance improvement analysis.
5. Performance Analysis
In this section, we mainly analyze the performance of the PIR scheme designed in this paper, focusing on the evaluation of computational efficiency, communication overhead, scalability, and other aspects, and compare it with the existing SealPIR [7], as shown in Table 2. Through sufficient theoretical analysis and experimental verification, the PIR scheme proposed in this paper shows significant advantages in many aspects.
Table 2.
Comparison of PIR schemes.
5.1. Optimized MKFHE and Dynamic Database
In our PIR scheme, based on the multi-user scenario, considering that each query user is independent of each other, a BGV-type [13] multi-key fully homomorphic encryption scheme is used to ensure the private information security of users and improve the overall security of the system. The optimized MKFHE scheme used in the PIR scheme in this paper effectively reduces the noise, and by using the same public key, reduces the calculation key size and ciphertext size while saving the homomorphic multiplication time. The comparative analysis between the proposed MKFHE scheme and other BGV-type multi-key homomorphic encryption schemes is shown in Table 3.
Table 3.
Comparison of BGV-type MKFHE schemes.
Compared with the existing SealPIR scheme [7] which only uses a single BFV scheme, the proposed PIR scheme is obviously more suitable for real-world scenarios with multi-party participation and has significant application advantages. Our scheme also supports the dynamic updating of the database, allowing the database to dynamically add or delete data during the operation of the scheme to adapt to the requirements of frequent data changes in real scenarios. It has strong flexibility and applicability and is of great significance in practical applications.
5.2. Vector-Matrix Multiplication Optimization
Compared with SealPIR, this paper introduces an optimization algorithm of vector–matrix multiplication, which significantly improves the computational efficiency. The detailed analysis is as follows:
Computational complexity: The optimization method mainly consists of additions, multiplications (corresponding to CMult operations), and rotations (corresponding to Rot operations). Since the rotation operation involves key conversion, the computational cost is high, and the total complexity is asymptotically rotations.
Optimization effect:
In order to test the performance of the optimization method, our experimental platform uses a computer with normal performance, Intel Core i5-8250U CPU 1.60 GHz, running Ubuntu 20.04 64-bit Linux operating system through a virtual machine environment, and equipped with 24 GB memory and 8-core processor. In the experiment, we use the open source encryption library SEAL 4.0.0 to simulate the PIR scheme with the optimized algorithm of vector–matrix multiplication designed in this paper and compare it with the existing SealPIR scheme. The experiment uses the BFV encryption algorithm in the SEAL library to encrypt the user’s query index and decrypt the final result. To ensure classical security of 128 bits, we set the polynomial modulus to 4096, the size of the coefficient modulus to 109, and the plaintext modulus to 20 bits. The database sizes selected in the experiment are and , that is, the size of a single database data item is set to 256 B, and the dimension of the database matrix is set to 2.
It should be mentioned that our experimental results are based on the mean of 50 runs of the program. (Some of the values are shown in Table 4). At the same time, in order to compare and study the efficiency improvement of the PIR scheme after the optimization method of embedding vector–matrix multiplication, the following “Our scheme” does not implement multi-key encryption, database dynamic update, and other functions.
Table 4.
Partial running results of the PIR scheme.
Our experimental results show that the time of query generation, query serialization and deserialization, and response decryption are all between 1 and 7 ms, which is short, and there is no difference between the schemes, that is, the addition of the optimization method of vector matrix multiplication has no effect on these times, and the unified analysis is as follows.
The generation time of the client query is about 3 ms, which is short because the query operation only needs to encrypt the index once. Its computational complexity is limited by lightweight polynomial multiplication and a small choice of plaintext modulus, which indicates that the client resource consumption is low and suitable for edge device deployment. The difference between the query serialization time of 6–7 ms and the deserialization time of 1–2 ms reflects the overhead characteristics of data format conversion, that is, the client needs to convert the ciphertext structure into the network transmission format, which involves the modulo number aligned byte stream encapsulation of the polynomial coefficients, while the server can quickly restore the ciphertext pair in microseconds with the efficient memory mapping mechanism. The decryption of the client takes about 4 ms, and the low time consumption highlights the advantage of asymmetric computing, that is, the decryption only needs to restore the polynomial coefficients of a single ciphertext and does not need to consider the complex noise constraints, so that the terminal device can quickly obtain the plaintext results.
However, the addition of the optimization method of vector–matrix multiplication undoubtedly has a certain impact on the preprocessing time of PIR scheme. The comparison diagram of the preprocessing time of PIR scheme drawn from the data is shown in Figure 4.
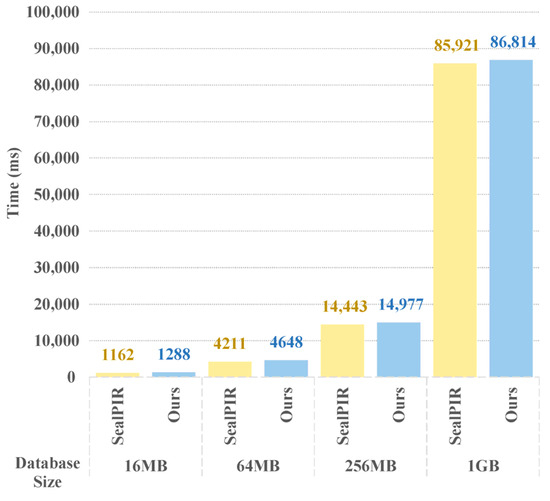
Figure 4.
Comparison of preprocessing time of PIR scheme.
The preprocessing time of the PIR scheme is relatively long, mainly because the server needs to complete the core operations such as homomorphic encryption coding and key generation of the database in the startup phase. The initialization process of the database involves dividing the original data into blocks and encoding them into polynomial structures. This step needs to optimize the computational efficiency by number theoretic transformation (NTT), and its complexity is positively related to the scale of the data. At the same time, the generation of the Galois key needs to construct multiple rotation keys according to the degree of the polynomial ring to support the replacement operation of the ciphertext slot. The computational overhead of such key generation increases significantly with the increase in the degree of the polynomial ring. Figure 4 shows that the average time of the proposed scheme in this operation is about 126–893 ms more than SealPIR, which is mainly used for the diagonal extraction of the database matrix. However, this operation takes very little time in the whole preprocessing stage, and can be implemented offline, so it has little impact on the overall performance of the scheme.
The response generation time on the server side is the main performance bottleneck of the scheme, and the core load of the scheme comes from the homomorphic multiplication and addition operation and the noise management mechanism. In SealPIR, the server needs to perform slot-by-slot multiplication and accumulation of the encoded database polynomials and query ciphertext. Although the NTT acceleration of polynomial multiplication reduces the complexity to , the calculation still requires high computing power support.
As shown in Figure 5, the optimization algorithm of vector–matrix multiplication introduced in the proposed scheme may increase the total average time of this operation to a certain extent, mainly because the additional ciphertext rotation operation is introduced to support a more flexible slot access pattern. Ciphertext rotation realizes slot cyclic shift through Galois key, and its computational complexity is related to polynomial degree and rotation step size. A single rotation can take several milliseconds, and the overall time may be prolonged after accumulation. However, the ciphertext rotation operation can be completely processed offline by the server, and the tree reduction (butterfly network) optimization method can be used, so that only Galois rotation operations are needed to generate rotated ciphertexts, which reduces the online computation time by about 15–1784 ms and improves the efficiency by about 1.95% to 7.69%. This trade-off strategy not only shifts the pressure of real-time computing to offline processing but also imposes higher demands for server storage resources.
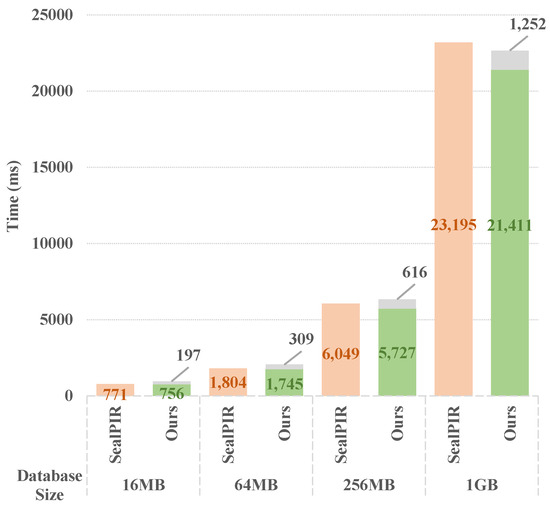
Figure 5.
Comparison of server response generation time in PIR scheme.
Among them, the core idea of using a butterfly network (similar to tree reduction) optimization method to further reduce the ciphertext rotation time is as follows: First, all rotation steps can be expressed in binary form (such as ), the server can precalculate the Galois key corresponding to these rotation steps, that is, the rotation key with step is stored through GaloisKeys. When performing the rotation operation, the server does not need to calculate the ciphertext rotation independently for each rotation step but unrolls the rotation operation layer by layer by way of hierarchical expansion. Starting from the lowest layer (step size ), the rotation of larger steps is applied layer by layer, and each layer operation reuses the result of the previous layer to generate a new copy of the ciphertext by strided combination. In this way, the number of rotations required is significantly reduced, thus further improving the efficiency of rotation operations.
In order to further explore the vector–matrix multiplication optimization module, we selected a database size of integers, and performed 50 tests without optimizing the ciphertext rotation operation (i.e., directly multiplying the vector and the matrix), taking the average and obtaining the following results, as shown in Figure 6. The direct method takes 1.03256 s and the online calculation time of the optimized method is 0.82915 s (the total time is 5.36311 s, including 0.12583 s for diagonal extraction and encoding and 4.40813 s for ciphertext rotation), which is 0.20341 s shorter and the performance is improved by about 19.7%.
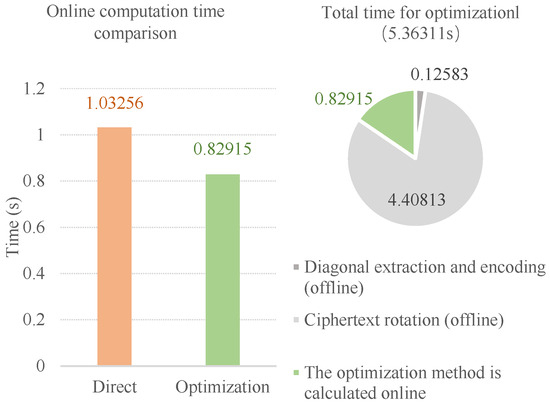
Figure 6.
Test results of vector–matrix multiplication optimization.
5.3. Program Verification of Ciphertext Chunking Algorithm
In the design of the PIR scheme, the matrix of the database leads to the operation of ciphertext multiplied by ciphertext. In order to ensure the correctness of the whole protocol, the parameter of the homomorphic encryption scheme needs to be set large, which reduces the computational efficiency. In order to solve this problem, the scheme adopted the homomorphic ciphertext multiplication based on ciphertext block, and the ciphertext generated by this special homomorphic ciphertext multiplication must also go through a special homomorphic decryption to recover the final result. In this paper, the specific operation steps of the ciphertext blocking algorithm (Section 3.3) are given in detail, and its correctness is verified by code implementation. The detailed analysis is as follows:
The experimental platform of Intel Core i5-8250U 1.60 GHz CPU, 8 GB memory, Windows 10 operating system, Python 3.12.6 implementation on VScode platform is used to verify the correctness. The parameters are set as polynomial modulus degree , coefficient modulus , plaintext modulus , and special modulus , the average , noise , chunk size , weight .
The experimental results show that the direct method directly multiplies the two ciphertexts in 5.81 s, and the decryption time is 0.07 s. In the ciphertext chunking algorithm, the ciphertext chunking time is 0.02 s, the plaintext multiplication time is 70.90 s, and the decryption time is 0.66 s. The correctness verification results show that the corresponding plaintext of the recovered data can be decrypted correctly after the homomorphic ciphertext multiplication and decryption operation based on the ciphertext chunking algorithm.
This part of the code uses the most basic BFV scheme and does not use any other encryption libraries or optimizations, so it takes a long time to build, but it can still be used for qualitative analysis and algorithm correctness verification. Therefore, the above results can verify well the correctness of the ciphertext chunking algorithm given in this paper. At the same time, it can also be seen that running the homomorphic ciphertext multiplication and decryption based on ciphertext chunking requires more time (about ten times) than the direct multiplication and decryption of two ciphertexts, and there is significant room for improvement in computational efficiency.
Through the performance analysis of four parts of the optimized BFV-MKFHE scheme, supporting database dynamic update, vector–matrix multiplication optimization algorithm, and program verification of ciphertext chunking algorithm, it can be seen that the PIR scheme designed in this paper demonstrates significant advantages in terms of computational efficiency, communication overhead, and scalability. In particular, the introduction of the vector–matrix multiplication optimization algorithm improves the online calculation efficiency of server vector–matrix multiplication by about 19.7%. The performance analysis results show that the proposed scheme can effectively support the requirements of private information retrieval, optimize the design scheme, improve computational efficiency, and be more suitable for practical application scenarios.
6. Conclusions
In this paper, an efficient private information retrieval scheme with dynamic database is proposed, which aims to study the design of a private information retrieval scheme under a multi-data source framework based on multi-key fully homomorphic encryption algorithm. The scheme focuses on improving the computational efficiency and scalability of private information retrieval. The improved MKFHE algorithm is used to generate encrypted queries with a lower length from different clients, the vector–matrix multiplication optimization method is embedded to improve the computational efficiency of response phase, and the expand algorithm and ciphertext chunking algorithm are used to further reduce communication traffic and noise, respectively. The scheme also adds a user access permission verification mechanism to avoid unauthorized users from accessing the system. At the same time, it supports the dynamic update of the database, which enhances the flexibility and practicability of the scheme. In the future, the scheme can further integrate technical points such as NTT preprocessing and automorphism shift optimization, and deeply explore the potential of hardware acceleration, so as to promote the evolution of privacy information retrieval to lower latency and higher throughput.
Author Contributions
Conceptualization, X.L. and W.X.; methodology, X.L. and W.X.; software, X.L.; validation, X.L.; formal analysis, X.L.; writing—original draft preparation, X.L.; writing—review and editing, X.L., W.X., and J.Z.; visualization, X.L.; supervision, Y.C. and W.Z.; project administration, D.T., Y.C., and W.Z.; funding acquisition, D.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China, grant number 2023YFB3106200 and the APC was funded by The 30th Research Institute of China Electronics Technology Group Corporation.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| PIR | Private Information Retrieval |
| FHE | Fully Homomorphic Encryption |
| MKFHE | Multi-key Fully Homomorphic Encryption |
| LWE | Learning With Errors |
| RLWE | Ring Learning With Errors |
| DB | Database |
| SIMD | Single Instruction, Multiple Data |
| ACL | Access Control List |
| IND-CPA | Indistinguishability under Chosen Plaintext Attack |
| NTT | Number Theoretic Transform |
References
- Song, D.X.; Wagner, D.; Perrig, A. Practical techniques for searches on encrypted data. In Proceedings of the 2000 IEEE Symposium on Security and Privacy (S&P 2000), Berkeley, CA, USA, 14–17 May 2000; pp. 44–55. [Google Scholar]
- Chor, B.; Goldreich, O.; Kushilevitz, E.; Sudan, M. Private information retrieval. In Proceedings of the IEEE Symposium on Foundations of Computer Science (FOCS), Milwaukee, WI, USA, 22–25 October 1995. [Google Scholar]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the 41st Annual ACM Symposium on Theory of Computing (STOC 2009), Bethesda, MD, USA, 31 May–2 June 2009; pp. 169–178. [Google Scholar]
- López-Alt, A.; Tromer, E.; Vaikuntanathan, V. On-the-fly multiparty computation on the cloud via multikey fully homomorphic encryption. In Proceedings of the 44th Annual ACM Symposium on Theory of Computing (STOC 2012), New York, NY, USA, 19–22 May 2012; pp. 1219–1234. [Google Scholar]
- Aguilar-Melchor, C.; Barrier, J.; Fousse, L.; Killijian, M.O. XPIR: Private information retrieval for everyone. In Proceedings of the Privacy Enhancing Technologies Symposium (PETS), Darmstadt, Germany, 19–22 July 2016. [Google Scholar]
- Lyubashevsky, V.; Peikert, C.; Regev, O. On ideal lattices and learning with errors over rings. In Advances in Cryptology—EUROCRYPT 2010, Proceedings of the 29th Annual International Conference on the Theory and Applications of Cryptographic Techniques, French Riviera, France, 30 May–3 June 2010; Springer: Berlin/Heidelberg, Germany, 2010; Volume 29, pp. 1–23. [Google Scholar]
- Angel, S.; Chen, H.; Laine, K.; Setty, S. PIR with compressed queries and amortized query processing. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–23 May 2018; pp. 962–979. [Google Scholar]
- Mughees, M.H.; Chen, H.; Ren, L. OnionPIR: Response efficient single-server PIR. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Seoul, Republic of Korea, 15–19 November 2021; pp. 2292–2306. [Google Scholar]
- Gentry, C.; Sahai, A.; Waters, B. Homomorphic encryption from learning with errors: Conceptually-simpler, asymptotically-faster, attribute-based. In Advances in Cryptology—CRYPTO 2013, Proceedings of the 33rd Annual Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2013; Proceedings, Part I; Springer: Berlin/Heidelberg, Germany, 2013; pp. 75–92. [Google Scholar]
- Ahmad, I.; Yang, Y.; Agrawal, D.; El Abbadi, A.; Gupta, T. Addra: Metadata-private voice communication over fully untrusted infrastructure. In Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation (OSDI 21), Virtual Event, 14–16 July 2021; USENIX Association: Berkeley, CA, USA, 2021. [Google Scholar]
- Menon, S.J.; Wu, D.J. Spiral: Fast, high-rate single-server PIR via FHE composition. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 23–26 May 2022; pp. 930–947. [Google Scholar]
- Mukherjee, P.; Wichs, D. Two round multiparty computation via multi-key FHE. In Advances in Cryptology—EUROCRYPT 2016, Proceedings of the 35th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Vienna, Austria, 8–12 May 2016; Proceedings, Part II; Springer: Berlin/Heidelberg, Germany, 2016; Volume 35, pp. 735–763. [Google Scholar]
- Chen, L.; Zhang, Z.; Wang, X. Batched multi-hop multi-key FHE from ring-LWE with compact ciphertext extension. In Theory of Cryptography, Proceedings of the 15th International Conference, TCC 2017, Baltimore, MD, USA, 12–15 November 2017; Proceedings, Part II; Springer: Cham, Switzerland, 2017; Volume 15, pp. 597–627. [Google Scholar]
- Chen, H.; Chillotti, I.; Song, Y. Multi-key homomorphic encryption from TFHE. In Advances in Cryptology—ASIACRYPT 2019, Proceedings of the 25th International Conference on the Theory and Application of Cryptology and Information Security, Kobe, Japan, 8–12 December 2019; Proceedings, Part II; Springer: Cham, Switzerland, 2019; Volume 25, pp. 446–472. [Google Scholar]
- Regev, O. On lattices, learning with errors, random linear codes, and cryptography. J. ACM 2009, 56, 34. [Google Scholar] [CrossRef]
- Micciancio, D.; Peikert, C. Trapdoors for lattices: Simpler, tighter, faster, smaller. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques—EUROCRYPT 2012, Cambridge, UK, 15–19 April 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 700–718. [Google Scholar]
- Asharov, G.; Jain, A.; López-Alt, A.; Tromer, E.; Vaikuntanathan, V.; Wichs, D. Multiparty computation with low communication, computation and interaction via threshold FHE. In Advances in Cryptology—EUROCRYPT 2012, Proceedings of the 31st Annual International Conference on the Theory and Applications of Cryptographic Techniques, Cambridge, UK, 15–19 April 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 31, pp. 483–501. [Google Scholar]
- Jiang, X.; Kim, M.; Lauter, K.; Song, Y. Secure outsourced matrix computation and application to neural networks. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 1209–1222. [Google Scholar]
- Yang, Y.; Zhao, D.; Li, Z.; Liu, Y. BFV-MKFHE: Design of multi-key fully homomorphic encryption scheme based on BFV. J. Cryptologic Res. 2023, 10, 1151–1164. [Google Scholar]
- Fan, J.; Vercauteren, F. Somewhat practical fully homomorphic encryption. IACR Cryptology ePrint Archive 2012, Report No. 2012/144. Available online: https://eprint.iacr.org/2012/144.pdf (accessed on 3 July 2025).
- Luo, M.; Liu, F.-H.; Wang, H. Faster FHE-Based Single-Server Private Information Retrieval. In Proceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security, Salt Lake City, UT, USA, 9–13 December 2024; pp. 1405–1419. [Google Scholar]
- Gentry, C.; Halevi, S.; Smart, N.P. Fully homomorphic encryption with polylog overhead. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques—EUROCRYPT 2012, Cambridge, UK, 15–19 April 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 465–482. [Google Scholar]
- Li, N.; Zhou, T.; Yang, X.; Han, Y.; Liu, W.; Tu, G. Efficient multi-key FHE with short extended ciphertexts and directed decryption protocol. IEEE Access 2019, 7, 56724–56732. [Google Scholar] [CrossRef]
- Chen, H.; Dai, W.; Kim, M.; Song, Y. Efficient multi-key homomorphic encryption with packed ciphertexts with application to oblivious neural network inference. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 395–412. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).