

Emotional Analysis in a Morphologically Rich Language: Enhancing Machine Learning with Psychological Feature Lexicons

Abstract
1. Introduction
1.1. Research Background and Significance
1.2. The Main Problem: Challenges in Hebrew Natural Language Processing
1.3. Limitations of Existing Methods
1.4. Our Contribution: Research Goal, Method, and Innovation
2. Related Work
3. Methodology
3.1. The Data
3.2. Classification Methodology
3.3. Feature Lexicons Enrichment
3.4. Combined Feature Lexicons
4. Results
5. Discussion and Conclusions
5.1. The Role of Feature Lexicons in Depression Detection
5.2. Understanding Negative Feature Interactions
5.3. Contributions to Depression Detection
5.4. Limitations and Practical Implications
6. Summary and Future Research
6.1. Summary of the Research
6.2. Limitations of the Research
6.3. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
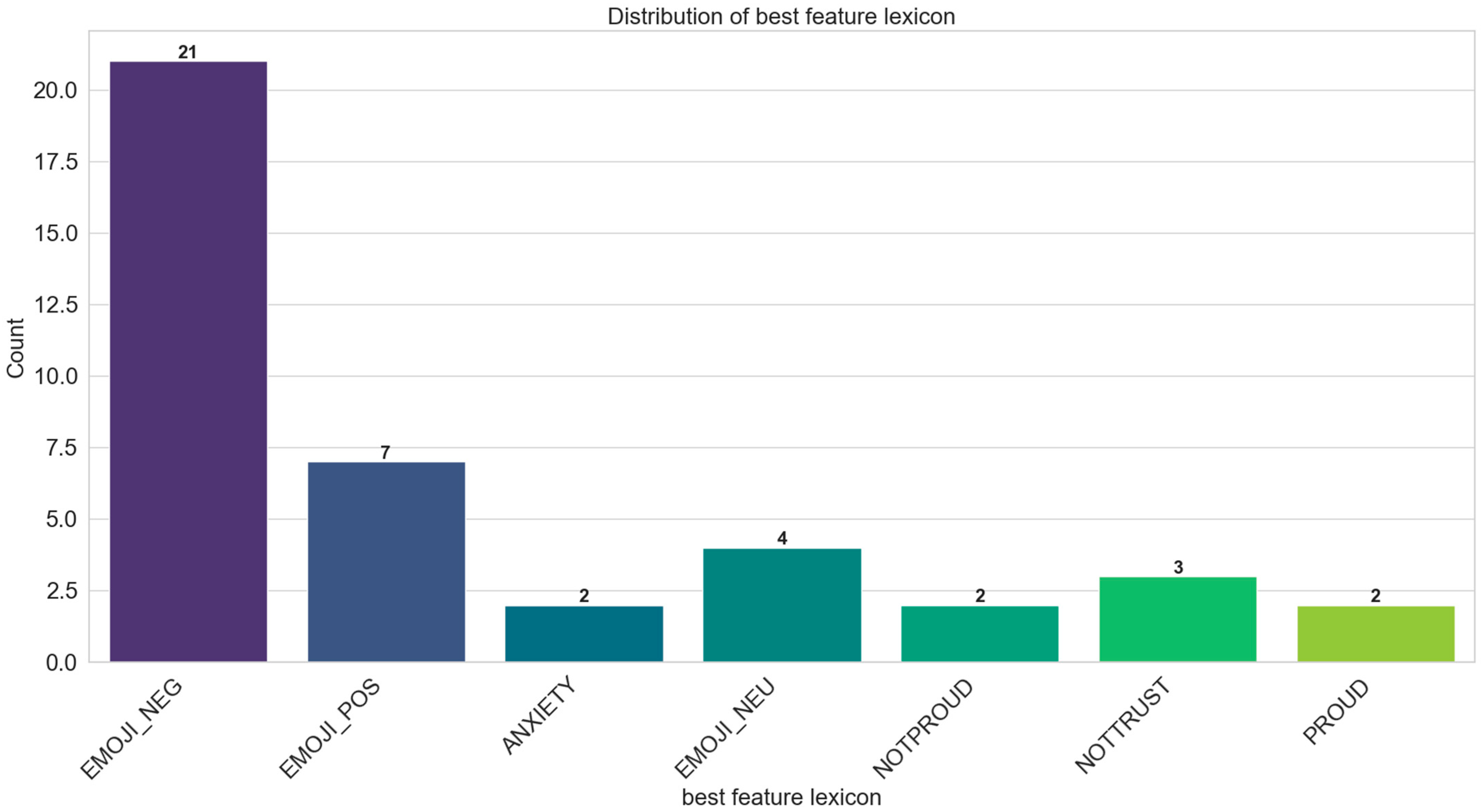
Appendix A. Feature Lexicons Enrichment Results
| Model | Feature | Max Features | Best Feature Lexicon | ACC |
| SVM | 3-c | 6000 | EMOJI_NEG | 0.839 |
| Stacking | 3-c | 6000 | EMOJI_NEG | 0.838 |
| SVM | 3-c | 6000 | EMOJI_NEG | 0.838 |
| SVM | 4-c | 9000 | EMOJI_NEG | 0.838 |
| Stacking | 3-c | 5000 | EMOJI_POS | 0.837 |
| Stacking | 3-c | 12,000 | EMOJI_POS | 0.837 |
| SVM | 4-c | 9000 | EMOJI_NEG | 0.837 |
| Voting | 3-c | 13,000 | EMOJI_POS | 0.837 |
| SVM | 3-c | 6000 | EMOJI_NEG | 0.836 |
| BG SVM | 4-c | 9000 | EMOJI_NEG | 0.836 |
| BG SVM | 4-c | 9000 | EMOJI_NEG | 0.836 |
| Stacking | 5-c | 15,000 | EMOJI_POS | 0.835 |
| SVM | 3-c | 6000 | EMOJI_NEG | 0.835 |
| Stacking | 4-c | 20,000 | ANXIETY | 0.835 |
| Stacking | 4-c | 20,000 | ANXIETY | 0.835 |
| SVM | 3-c | 5000 | EMOJI_NEG | 0.834 |
| SVM | 3-c | 5000 | EMOJI_NEG | 0.834 |
| SVM | 5-c | 9000 | EMOJI_NEG | 0.833 |
| Stacking | 5-c | 11,000 | EMOJI_NEU | 0.833 |
| Stacking | 5-c | 11,000 | NOTVIGOR | 0.833 |
| Stacking | 5-c | 11,000 | NOTPROUD | 0.832 |
| SVM | 5-c | 9000 | EMOJI_NEG | 0.832 |
| SVM | 5-c | 9000 | EMOJI_NEG | 0.832 |
| SVM | 3-c | 3000 | EMOJI_NEG | 0.831 |
| SVM | 4-c | 9000 | EMOJI_NEG | 0.831 |
| ERF | 3-c | 5000 | POS | 0.830 |
| ERF | 4-c | 9000 | EMOJI_POS | 0.830 |
| Voting | 5-c | 13,000 | EMOJI_NEG | 0.830 |
| Voting | 5-c | 9000 | EMOJI_POS | 0.830 |
| Stacking | 5-c | 16,000 | NOTPROUD | 0.830 |
| ERF | 3-c | 20,000 | NOTCALM | 0.830 |
| Stacking | 5-c | 11,000 | EMOJI_POS | 0.829 |
| Stacking | 5-c | 11,000 | EMOJI_NEU | 0.829 |
| Stacking | 5-c | 11,000 | EMOJI_NEU | 0.829 |
| Voting | 3-c | 13,000 | EMOJI_NEU | 0.829 |
| SVM | 5-c | 9000 | EMOJI_NEG | 0.829 |
| ERF | 4-c | 12,000 | PROUD | 0.829 |
| MLP | 5-c | 12,000 | CALM | 0.829 |
| Stacking | 5-c | 15,000 | DEPRESSIVE | 0.829 |
| SVM | 5-c | 9000 | EMOJI_NEG | 0.828 |
| Stacking | 5-c | 11,000 | NOTTRUST | 0.828 |
| ERF | 4-c | 19,000 | NOTANTICIPATION | 0.828 |
| SVM | 5-c | 9000 | EMOJI_NEG | 0.828 |
| ERF | 5-c | 14,000 | PROUD | 0.828 |
| GB | 3-c | 8000 | NOTTRUST | 0.828 |
| ERF | 3-c | 15,000 | NEG2 | 0.828 |
| Stacking | 5-c | 11,000 | HOSTILE | 0.828 |
| BG SVM | 5-c | 11,000 | HOSTILE | 0.828 |
| SVM | 5-c | 11,000 | EMOJI_NEG | 0.828 |
| Stacking | 5-c | 11,000 | NOTTRUST | 0.828 |
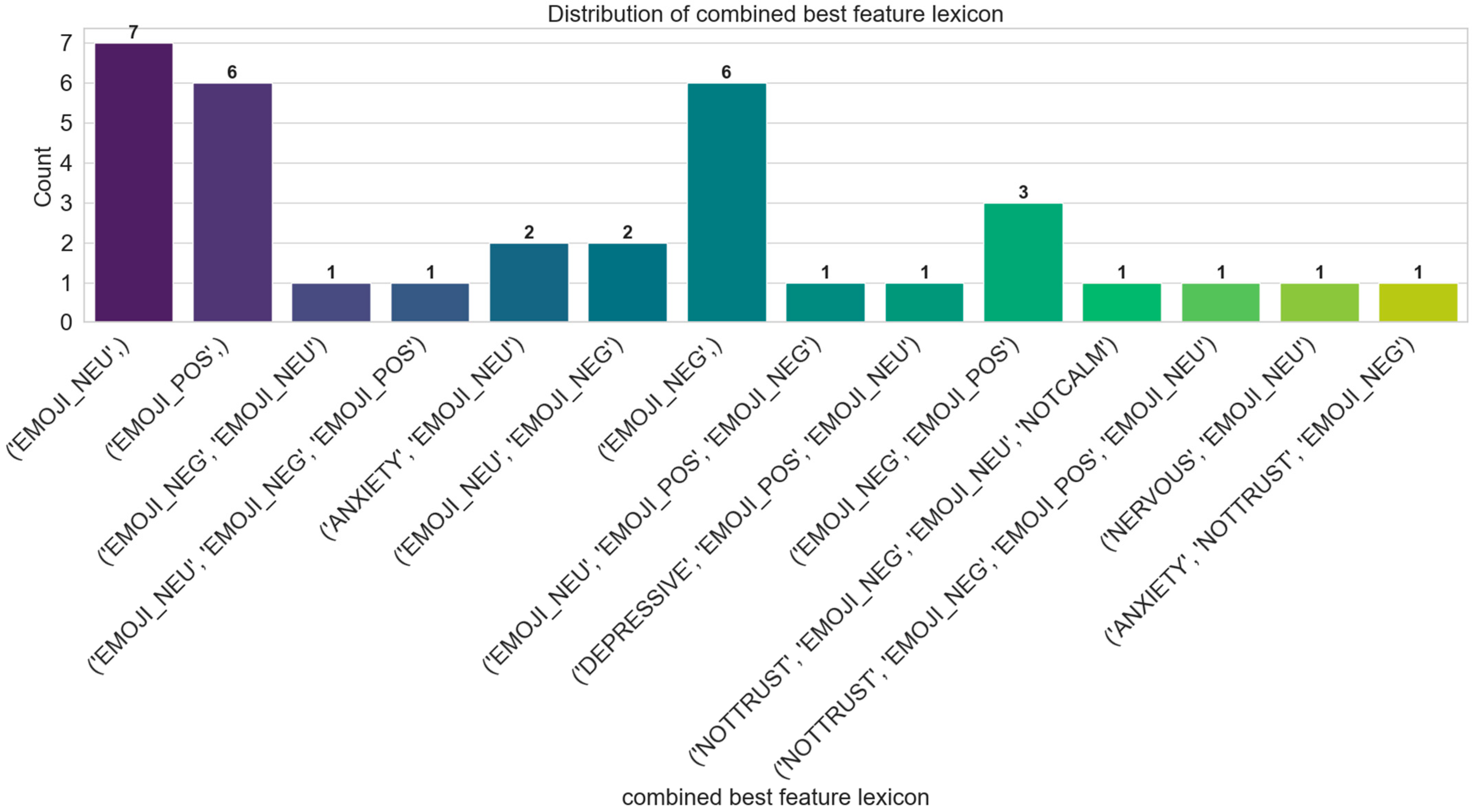
Appendix B. Combined Feature Lexicons Results
| Model | Feature | Best Lexicon | Combined Lexicon | Acc |
| Stacking | 3-c | EMOJI_NEG | (‘EMOJI_NEG’, ‘EMOJI_NEU’, ‘EMOJI_POS’) | 0.841 |
| SVM | 3-c | EMOJI_NEG | (‘EMOJI_NEU’,) | 0.839 |
| SVM | 3-c | EMOJI_NEG | (‘EMOJI_POS’,) | 0.838 |
| Voting | 3-c | EMOJI_POS | (‘EMOJI_NEG’, ‘EMOJI_NEU’) | 0.838 |
| Stacking | 3-c | EMOJI_POS | (‘EMOJI_NEU’, ‘EMOJI_NEG’, ‘EMOJI_POS’) | 0.838 |
| SVM | 4-c | EMOJI_NEG | (‘EMOJI_POS’,) | 0.838 |
| Stacking | 4-c | ANXIETY | (‘ANXIETY’, ‘EMOJI_NEU’) | 0.838 |
| SVM | 4-c | EMOJI_NEG | (‘EMOJI_NEU’, ‘EMOJI_NEG’) | 0.837 |
| Stacking | 5-c | EMOJI_POS | (‘EMOJI_NEU’, ‘EMOJI_POS’) | 0.837 |
| Stacking | 4-c | ANXIETY | (‘ANXIETY’, ‘EMOJI_NEG’, ‘EMOJI_POS’) | 0.836 |
| SVM | 3-c | EMOJI_NEG | (‘EMOJI_NEG’,) | 0.836 |
| Stacking | 3-c | EMOJI_POS | (‘EMOJI_NEU’, ‘EMOJI_POS’, ‘EMOJI_NEG’) | 0.836 |
| SVM | 3-c | EMOJI_NEG | (‘EMOJI_NEG’,) | 0.835 |
| SVM | 3-c | EMOJI_NEG | (‘EMOJI_NEU’,) | 0.834 |
| SVM | 3-c | EMOJI_NEG | (‘EMOJI_NEU’,) | 0.834 |
| Stacking | 5-c | NOTVIGOR | (‘NOTVIGOR’, ‘EMOJI_POS’) | 0.834 |
| SVM | 5-c | EMOJI_NEG | (‘EMOJI_POS’,) | 0.833 |
| Stacking | 5-c | EMOJI_NEU | (‘EMOJI_POS’,) | 0.833 |
| Stacking | 5-c | NOTPROUD | (‘NOTPROUD’, ‘NOTTRUST’, ‘EMOJI_NEU’, ‘EMOJI_NEG’) | 0.833 |
| ERF | 4-c | EMOJI_POS | (‘NOTTRUST’,) | 0.832 |
| MLP | 4-c | EMOJI_NEG | (‘NERVOUS’, ‘ANXIETY’) | 0.832 |
| Stacking | 5-c | DEPRESSIVE | (‘DEPRESSIVE’, ‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.832 |
| SVM | 5-c | EMOJI_NEG | (‘EMOJI_POS’,) | 0.832 |
| SVM | 5-c | EMOJI_NEG | (‘EMOJI_NEU’,) | 0.832 |
| SVM | 4-c | EMOJI_NEG | (‘EMOJI_NEU’,) | 0.832 |
| Stacking | 5-c | NOTTRUST | (‘EMOJI_NEU’, ‘EMOJI_POS’, ‘NOTTRUST’) | 0.831 |
| SVM | 3-c | EMOJI_NEG | (‘EMOJI_NEG’,) | 0.831 |
| Stacking | 5-c | EMOJI_NEU | (‘NOTTRUST’, ‘EMOJI_NEG’, ‘HOSTILE’) | 0.831 |
| ERF | 5-c | PROUD | (‘ANXIETY’, ‘EMOJI_NEU’) | 0.831 |
| Stacking | 5-c | NOTTRUST | (‘EMOJI_NEU’, ‘NOTTRUST’) | 0.831 |
| Voting | 5-c | EMOJI_POS | (‘EMOJI_NEG’, ‘EMOJI_POS’) | 0.831 |
| Stacking | 5-c | NOTPROUD | (‘EMOJI_NEG’, ‘EMOJI_POS’) | 0.831 |
| ERF | 4-c | PROUD | (‘EMOJI_POS’, ‘NOTTRUST’, ‘ANXIETY’) | 0.831 |
| Voting | 5-c | EMOJI_NEG | (‘EMOJI_NEU’, ‘EMOJI_NEG’) | 0.830 |
| ERF | 3-c | NOTCALM | (‘NOTTRUST’, ‘EMOJI_NEG’, ‘EMOJI_NEU’, ‘NOTCALM’) | 0.830 |
| Stacking | 5-c | EMOJI_POS | (‘NOTTRUST’, ‘EMOJI_NEG’, ‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.830 |
| MLP | 5-c | CALM | (‘ANXIETY’, ‘EMOJI_NEG’, ‘EMOJI_POS’, ‘HOSTILE’) | 0.830 |
| ERF | 3-c | POS | (‘NERVOUS’, ‘EMOJI_NEU’) | 0.830 |
| Stacking | 5-c | EMOJI_NEU | (‘EMOJI_NEU’,) | 0.829 |
| Voting | 3-c | EMOJI_NEU | (‘EMOJI_NEG’,) | 0.829 |
| SVM | 5-c | EMOJI_NEG | (‘EMOJI_NEU’,) | 0.829 |
| Stacking | 5-c | HOSTILE | (‘EMOJI_NEU’, ‘NOTTRUST’, ‘EMOJI_POS’, ‘EMOJI_NEG’) | 0.829 |
| SVM | 5-c | EMOJI_NEG | (‘EMOJI_POS’,) | 0.828 |
| ERF | 3-c | NEG2 | (‘ANXIETY’, ‘NOTTRUST’, ‘EMOJI_NEG’) | 0.828 |
| SVM | 5-c | EMOJI_NEG | (‘EMOJI_NEG’,) | 0.828 |
| ERF | 4-c | NOTANTICIPATION | (‘ANXIETY’, ‘HOSTILE’, ‘EMOJI_NEU’, ‘NOTTRUST’) | 0.828 |
| SVM | 5-c | EMOJI_NEG | (‘EMOJI_NEG’,) | 0.828 |
| Voting | 5-c | EMOJI_NEG | (‘EMOJI_NEG’, ‘EMOJI_POS’) | 0.827 |
| GB | 3-c | NOTTRUST | (‘EMOJI_NEG’, ‘EMOJI_POS’, ‘ANXIETY’) | 0.825 |
Appendix C. Combined Lexicon Results for First Model
| Lexicon Combination | Value |
| (‘EMOJI_NEU’,) | 0.839 |
| (‘EMOJI_POS’,) | 0.839 |
| (‘ANXIETY’,) | 0.818 |
| (‘HOSTILE’,) | 0.822 |
| (‘NOTTRUST’,) | 0.815 |
| (‘EMOJI_NEG’,) | 0.839 |
| (‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.839 |
| (‘ANXIETY’, ‘EMOJI_NEU’) | 0.818 |
| (‘HOSTILE’, ‘EMOJI_NEU’) | 0.822 |
| (‘NOTTRUST’, ‘EMOJI_NEU’) | 0.815 |
| (‘EMOJI_NEG’, ‘EMOJI_NEU’) | 0.839 |
| (‘ANXIETY’, ‘EMOJI_POS’) | 0.818 |
| (‘HOSTILE’, ‘EMOJI_POS’) | 0.822 |
| (‘NOTTRUST’, ‘EMOJI_POS’) | 0.815 |
| (‘EMOJI_NEG’, ‘EMOJI_POS’) | 0.839 |
| (‘ANXIETY’, ‘HOSTILE’) | 0.818 |
| (‘ANXIETY’, ‘NOTTRUST’) | 0.813 |
| (‘ANXIETY’, ‘EMOJI_NEG’) | 0.818 |
| (‘HOSTILE’, ‘NOTTRUST’) | 0.811 |
| (‘HOSTILE’, ‘EMOJI_NEG’) | 0.822 |
| (‘NOTTRUST’, ‘EMOJI_NEG’) | 0.815 |
| (‘ANXIETY’, ‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.818 |
| (‘HOSTILE’, ‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.822 |
| (‘NOTTRUST’, ‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.815 |
| (‘EMOJI_NEG’, ‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.839 |
| (‘ANXIETY’, ‘HOSTILE’, ‘EMOJI_NEU’) | 0.818 |
| (‘ANXIETY’, ‘NOTTRUST’, ‘EMOJI_NEU’) | 0.813 |
| (‘ANXIETY’, ‘EMOJI_NEG’, ‘EMOJI_NEU’) | 0.818 |
| (‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_NEU’) | 0.811 |
| (‘HOSTILE’, ‘EMOJI_NEG’, ‘EMOJI_NEU’) | 0.822 |
| (‘EMOJI_NEG’, ‘NOTTRUST’, ‘EMOJI_NEU’) | 0.815 |
| (‘ANXIETY’, ‘HOSTILE’, ‘EMOJI_POS’) | 0.818 |
| (‘ANXIETY’, ‘NOTTRUST’, ‘EMOJI_POS’) | 0.813 |
| (‘ANXIETY’, ‘EMOJI_NEG’, ‘EMOJI_POS’) | 0.818 |
| (‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_POS’) | 0.811 |
| (‘HOSTILE’, ‘EMOJI_NEG’, ‘EMOJI_POS’) | 0.822 |
| (‘EMOJI_NEG’, ‘NOTTRUST’, ‘EMOJI_POS’) | 0.815 |
| (‘ANXIETY’, ‘HOSTILE’, ‘NOTTRUST’) | 0.814 |
| (‘ANXIETY’, ‘HOSTILE’, ‘EMOJI_NEG’) | 0.818 |
| (‘ANXIETY’, ‘NOTTRUST’, ‘EMOJI_NEG’) | 0.813 |
| (‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_NEG’) | 0.811 |
| (‘ANXIETY’, ‘HOSTILE’, ‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.818 |
| (‘ANXIETY’, ‘NOTTRUST’, ‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.813 |
| (‘ANXIETY’, ‘EMOJI_NEG’, ‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.818 |
| (‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.811 |
| (‘HOSTILE’, ‘EMOJI_NEG’, ‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.822 |
| (‘EMOJI_NEG’, ‘NOTTRUST’, ‘EMOJI_POS’, ‘EMOJI_NEU’) | 0.815 |
| (‘ANXIETY’, ‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_NEU’) | 0.814 |
| (‘ANXIETY’, ‘HOSTILE’, ‘EMOJI_NEG’, ‘EMOJI_NEU’) | 0.818 |
| (‘EMOJI_NEG’, ‘ANXIETY’, ‘NOTTRUST’, ‘EMOJI_NEU’) | 0.813 |
| (‘EMOJI_NEG’, ‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_NEU’) | 0.811 |
| (‘ANXIETY’, ‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_POS’) | 0.814 |
| (‘ANXIETY’, ‘HOSTILE’, ‘EMOJI_NEG’, ‘EMOJI_POS’) | 0.818 |
| (‘EMOJI_NEG’, ‘ANXIETY’, ‘NOTTRUST’, ‘EMOJI_POS’) | 0.813 |
| (‘EMOJI_NEG’, ‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_POS’) | 0.811 |
| (‘ANXIETY’, ‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_NEG’) | 0.814 |
| (‘EMOJI_POS’, ‘ANXIETY’, ‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_NEU’) | 0.814 |
| (‘EMOJI_NEU’, ‘EMOJI_POS’, ‘ANXIETY’, ‘HOSTILE’, ‘EMOJI_NEG’) | 0.818 |
| (‘EMOJI_NEU’, ‘EMOJI_POS’, ‘ANXIETY’, ‘NOTTRUST’, ‘EMOJI_NEG’) | 0.813 |
| (‘EMOJI_NEU’, ‘EMOJI_POS’, ‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_NEG’) | 0.811 |
| (‘EMOJI_NEU’, ‘ANXIETY’, ‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_NEG’) | 0.813 |
| (‘EMOJI_POS’, ‘ANXIETY’, ‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_NEG’): | 0.813 |
| (‘EMOJI_NEG’, ‘EMOJI_POS’, ‘ANXIETY’, ‘HOSTILE’, ‘NOTTRUST’, ‘EMOJI_NEU’): | 0.813 |
Appendix D. Experimental Setup
- k-Nearest Neighbors (KNN).
- Logistic Regression (LR).
- Multinomial Naive Bayes (MNB).
- Support Vector Machine (SVM).
- Decision Tree (DT).
- A simple Multilayer Perceptron (MLP).
- Bagging: BaggingClassifier with SVM, LR, and DT as base estimators.
- Random Forest: ExtraTreesClassifier.
- Boosting: GradientBoostingClassifier, XGBoost, and AdaBoost (with DT and LR as base estimators).
- Hybrid Ensembles:
- ○
- A VotingClassifier combining predictions from LR, SVC, DT, and MNB.
- ○
- A StackingClassifier using LR, SVC, DT, and MNB as base learners and a meta-classifier to combine their outputs.
- Removal of HTML tags and URLs.
- Removal of punctuation.
- Removal of Hebrew stopwords.
- Reduction of repeated characters (e.g., “!!!!” to “!”).
- Removal of non-Hebrew characters.
- Removal of numbers.
- Normalization of whitespace.
- Lemmatization: Hebrew words were reduced to their root form using the YAP (Yet Another Parser) library.
| Parameter | Tuning Range/Values | Description |
| min_df | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] | Tested integer values from 1 to 10 to filter out very rare terms. |
| max_df | [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] | Tested 10 levels to filter out very common terms. |
| ngram_range | Word and Character n-grams | Explored various word (1–3) and character (3–10) n-gram ranges. |
References
- Feldman, R. Techniques and applications for sentiment analysis. Commun. ACM 2013, 56, 82–89. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis and Opinion Mining; Springer Nature: London, UK, 2022. [Google Scholar]
- Shapira, N.; Atzil-Slonim, D.; Juravski, D.; Baruch, M.; Stolowicz-Melman, D.; Paz, A.; Alfi-Yogev, T.; Azoulay, R.; Singer, A.; Revivo, M.; et al. Hebrew psychological lexicons. In Proceedings of the Seventh Workshop on Computational Linguistics and Clinical Psychology: Improving Access, Online, 11 June 2021; pp. 55–69. [Google Scholar]
- Keinan, R.; Margalit, E.; Bouhnik, D. Analysis of user trends in digital health communities using big data mining. PLoS ONE 2024, 19, e0290803. [Google Scholar] [CrossRef] [PubMed]
- Keinan, R.; Margalit, E.A.; Bouhnik, D. Impacts of a Public Health Crisis on Health-Centered Online Social Networks. Informing Sci. Int. J. Emerg. Transdiscipl. 2025, 28, 022. [Google Scholar] [CrossRef] [PubMed]
- Tsarfaty, R.; Seker, A.; Sadde, S.; Klein, S. What’s wrong with Hebrew NLP? And how to make it right. arXiv 2019, arXiv:1908.05453. [Google Scholar]
- Itai, A.; Wintner, S. Language resources for Hebrew. Lang. Resour. Eval. 2008, 42, 75–98. [Google Scholar] [CrossRef]
- Keinan, R. Sexism Identification in Social Networks Using TF-IDF Embeddings, PreProccessing, Feature Selection, Word/Char n-grams and Various Machine Learning Models in Spanish and English. In Proceedings of the CLEF 2024: Conference and Labs of the Evaluation Forum, Grenoble, France, 9–12 September 2024. [Google Scholar]
- Keinan, R. Text Mining at SemEval-2024 Task 1: Evaluating Semantic Textual Relatedness in Low-Resource Languages using Various Embedding Methods and Machine Learning Regression Models. In Proceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024), Mexico City, Mexico, 20–21 June 2024; pp. 420–431. [Google Scholar]
- Keinan, R.; HaCohen-Kerner, Y. JCT at SemEval-2023 Tasks 12 A and 12B: Sentiment Analysis for Tweets Written in Low-resource African Languages using Various Machine Learning and Deep Learning Methods, Resampling, and HyperParameter Tuning. In Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023), Toronto, ON, Canada, 13–14 July 2023; pp. 365–378. [Google Scholar]
- Amram, A.; David, A.B.; Tsarfaty, R. Representations and architectures in neural sentiment analysis for morphologically rich languages: A case study from Modern Hebrew. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 2242–2252. [Google Scholar]
- Aisopos, F.; Tzannetos, D.; Violos, J.; Varvarigou, T. Using n-gram graphs for sentiment analysis: An extended study on Twitter. In Proceedings of the 2016 IEEE Second International Conference on Big Data Computing Service and Applications (BigDataService), Qxford, UK, 29 March–1 April 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 44–51. [Google Scholar]
- HaCohen-Kerner, Y.; Miller, D.; Yigal, Y.; Shayovitz, E. Cross-domain Authorship Attribution: Author Identification using Char Sequences, Word Uni-grams, and POS-tags Features: Notebook for PAN at CLEF 2018. In Proceedings of the 19th Working Notes of CLEF Conference and Labs of the Evaluation Forum, CLEF 2018, Avignon, France, 10–14 September 2018. [Google Scholar]
- Yang, L.; Li, Y.; Wang, J.; Sherratt, R.S. Sentiment analysis for E-commerce product reviews in Chinese based on sentiment lexicon and deep learning. IEEE Access 2020, 8, 23522–23530. [Google Scholar] [CrossRef]
- De Choudhury, M.; Counts, S.; Horvitz, E. Predicting postpartum changes in emotion and behavior via social media. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 3267–3276. [Google Scholar]
- O’Dea, B.; Wan, S.; Batterham, P.J.; Calear, A.L.; Paris, C.; Christensen, H. Detecting suicidality on Twitter. Internet Interv. 2015, 2, 183–188. [Google Scholar] [CrossRef]
- Aldarwish, M.M.; Ahmad, H.F. Predicting depression levels using social media posts. In Proceedings of the 2017 IEEE 13th International Symposium on Autonomous Decentralized System (ISADS), Bangkok, Thailand, 22–24 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 277–280. [Google Scholar]
- Tadesse, M.M.; Lin, H.; Xu, B.; Yang, L. Detection of depression-related posts in reddit social media forum. IEEE Access 2019, 7, 44883–44893. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends® Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Milintsevich, K.; Dias, G.; Sirts, K. Evaluating Lexicon Incorporation for Depression Symptom Estimation. arXiv 2024, arXiv:2404.19359. [Google Scholar] [CrossRef]
- Ogunleye, B.; Sharma, H.; Shobayo, O. Sentiment Informed Sentence BERT-Ensemble Algorithm for Depression Detection. Big Data Cogn. Comput. 2024, 8, 112. [Google Scholar] [CrossRef]
- Chiong, R.; Budhi, G.S.; Dhakal, S. Combining sentiment lexicons and content-based features for depression detection. IEEE Intell. Syst. 2021, 36, 99–105. [Google Scholar] [CrossRef]
- Shalumov, V.; Haskey, H. Hero: Roberta and Longformer Hebrew Language Models. arXiv 2023, arXiv:2304.11077. [Google Scholar]
- Liu, C.; Sheng, Y.; Wei, Z.; Yang, Y.-Q. Research of text classification based on improved TF-IDF algorithm. In Proceedings of the 2018 IEEE International Conference of Intelligent Robotic and Control Engineering (IRCE), Lanzhou, China, 24–27 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 218–222. [Google Scholar]
- Zhang, W.; Yoshida, T.; Tang, X. A comparative study of TF* IDF, LSI and multi-words for text classification. Expert Syst. Appl. 2011, 38, 2758–2765. [Google Scholar] [CrossRef]
- Wieting, J.; Bansal, M.; Gimpel, K.; Livescu, K. Charagram: Embedding words and sentences via character n-grams. arXiv 2016, arXiv:1607.02789. [Google Scholar] [CrossRef]
- Tatman, R. Sentiment Lexicons for 81 Languages, Kaggle. Available online: https://www.kaggle.com/datasets/rtatman/sentiment-lexicons-for-81-languages/data (accessed on 30 July 2025).
- Hakami, S.A.A.; Hendley, R.J.; Smith, P. Arabic emoji sentiment lexicon (Arab-ESL): A comparison between Arabic and European emoji sentiment lexicons. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Online, 19 April 2021; pp. 60–71. [Google Scholar]
- Li, M.; Ch’ng, E.; Chong, A.Y.L.; See, S. Multi-class Twitter sentiment classification with emojis. Ind. Manag. Data Syst. 2018, 118, 1804–1820. [Google Scholar] [CrossRef]
- Liebeskind, C.; Liebeskind, S. Emoji prediction for hebrew political domain. In Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 468–477. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Name | Description | Number |
|---|---|---|
| ANGER | Words related to expressing anger or irritation | 230 |
| ANXIETY | Words associated with feelings of anxiety and nervousness | 241 |
| ASHAMED | Words reflecting a sense of shame or embarrassment | 175 |
| CALM | Words indicative of a calm and composed emotional state | 160 |
| CONFUSION | Words representing a state of confusion or bewilderment | 175 |
| DEPRESSIVE | Words associated with feelings of depression | 162 |
| DISGUST | Words expressing a sense of strong dislike or revulsion | 191 |
| EMOJI_NEG | Emojis conveying negative emotions | 297 |
| EMOJI_NEU | Emojis conveying neutral emotions | 226 |
| EMOJI_POS | Emojis conveying positive emotions | 511 |
| FATIGUE | Words related to feelings of tiredness or exhaustion | 212 |
| GUILTY | Words indicating a sense of guilt or remorse | 183 |
| HOSTILE | Words reflecting a hostile or aggressive attitude | 179 |
| JOY | Words associated with feelings of joy and happiness | 207 |
| NEG | Negative sentiment words | 1626 |
| NEG2 | Additional negative sentiment words | 115 |
| NERVOUS | Words expressing nervousness or apprehension | 214 |
| NOTAMUSED | Words conveying a lack of amusement or boredom | 111 |
| NOTANTICIPATION | Words indicating a lack of anticipation | 106 |
| NOTCALM | Words suggesting a lack of calmness or tranquility | 187 |
| NOTCONTENTMENT | Words indicating a lack of contentment | 201 |
| NOTINTERESTED | Words conveying a lack of interest or enthusiasm | 151 |
| NOTJOY | Words indicating a lack of joy | 365 |
| NOTNERVOUS | Words reflecting a lack of nervousness | 158 |
| NOTPROUD | Words indicating a lack of pride | 117 |
| NOTTRUST | Words suggesting a lack of trust | 141 |
| NOTVIGOR | Words indicating a lack of vigor or energy | 172 |
| PARALINGUISTIC | Words related to paralinguistic features, such as intonation | 150 |
| POS | Positive-sentiment words | 906 |
| POS2 | Additional positive-sentiment words | 82 |
| PROUD | Words expressing a sense of pride | 153 |
| SAD | Words associated with feelings of sadness | 203 |
| SURPRISE | Words reflecting a sense of surprise | 138 |
| TRUST | Words associated with feelings of trust and confidence | 156 |
| Model | Feature | Max Features | Best Feature Lexicon | ACC |
|---|---|---|---|---|
| SVM | 3-c | 6000 | EMOJI_NEG | 0.839 |
| Stacking | 3-c | 6000 | EMOJI_NEG | 0.838 |
| SVM | 3-c | 6000 | EMOJI_NEG | 0.838 |
| SVM | 4-c | 9000 | EMOJI_NEG | 0.838 |
| Stacking | 3-c | 5000 | EMOJI_POS | 0.837 |
| Stacking | 3-c | 12,000 | EMOJI_POS | 0.837 |
| Lexicon | Acc |
|---|---|
| ANGER | 0.820 |
| ANXIETY | 0.818 |
| ASHAMED | 0.817 |
| CALM | 0.822 |
| CONFUSION | 0.810 |
| DEPRESSIVE | 0.822 |
| DISGUST | 0.819 |
| EMOJI_NEG | 0.839 |
| EMOJI_NEU | 0.839 |
| EMOJI_POS | 0.839 |
| FATIGUE | 0.803 |
| GUILTY | 0.818 |
| HOSTILE | 0.822 |
| JOY | 0.811 |
| NEG | 0.817 |
| NEG2 | 0.808 |
| NERVOUS | 0.812 |
| NOTAMUSED | 0.818 |
| NOTANTICIPATION | 0.809 |
| NOTCALM | 0.813 |
| NOTCONTENTMENT | 0.816 |
| NOTINTERESTED | 0.813 |
| NOTJOY | 0.817 |
| NOTNERVOUS | 0.820 |
| NOTPROUD | 0.829 |
| NOTTRUST | 0.815 |
| NOTVIGOR | 0.823 |
| PARALINGUISTIC | 0.828 |
| POS | 0.802 |
| POS2 | 0.813 |
| PROUD | 0.820 |
| SAD | 0.820 |
| SURPRISE | 0.823 |
| TRUST | 0.808 |
| Model | Feature | Best Lexicon | Combined Lexicon | Acc |
|---|---|---|---|---|
| Stacking | 3-c | EMOJI_NEG | (‘EMOJI_NEG’, ‘EMOJI_NEU’, ‘EMOJI_POS’) | 0.841 |
| SVM | 3-c | EMOJI_NEG | (‘EMOJI_NEU’,) | 0.839 |
| SVM | 3-c | EMOJI_NEG | (‘EMOJI_POS’,) | 0.838 |
| Voting | 3-c | EMOJI_POS | (‘EMOJI_NEG’, ‘EMOJI_NEU’) | 0.838 |
| Stacking | 3-c | EMOJI_POS | (‘EMOJI_NEU’, ‘EMOJI_NEG’, ‘EMOJI_POS’) | 0.838 |
| SVM | 4-c | EMOJI_NEG | (‘EMOJI_POS’,) | 0.838 |
| Stacking | 4-c | ANXIETY | (‘ANXIETY’, ‘EMOJI_NEU’) | 0.838 |
| SVM | 4-c | EMOJI_NEG | (‘EMOJI_NEU’, ‘EMOJI_NEG’) | 0.837 |
| Stacking | 5-c | EMOJI_POS | (‘EMOJI_NEU’, ‘EMOJI_POS’) | 0.837 |
| Stacking | 4-c | ANXIETY | (‘ANXIETY’, ‘EMOJI_NEG’, ‘EMOJI_POS’) | 0.836 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Keinan, R.; Margalit, E.; Bouhnik, D. Emotional Analysis in a Morphologically Rich Language: Enhancing Machine Learning with Psychological Feature Lexicons. Electronics 2025, 14, 3067. https://doi.org/10.3390/electronics14153067
Keinan R, Margalit E, Bouhnik D. Emotional Analysis in a Morphologically Rich Language: Enhancing Machine Learning with Psychological Feature Lexicons. Electronics. 2025; 14(15):3067. https://doi.org/10.3390/electronics14153067
Chicago/Turabian StyleKeinan, Ron, Efraim Margalit, and Dan Bouhnik. 2025. "Emotional Analysis in a Morphologically Rich Language: Enhancing Machine Learning with Psychological Feature Lexicons" Electronics 14, no. 15: 3067. https://doi.org/10.3390/electronics14153067
APA StyleKeinan, R., Margalit, E., & Bouhnik, D. (2025). Emotional Analysis in a Morphologically Rich Language: Enhancing Machine Learning with Psychological Feature Lexicons. Electronics, 14(15), 3067. https://doi.org/10.3390/electronics14153067