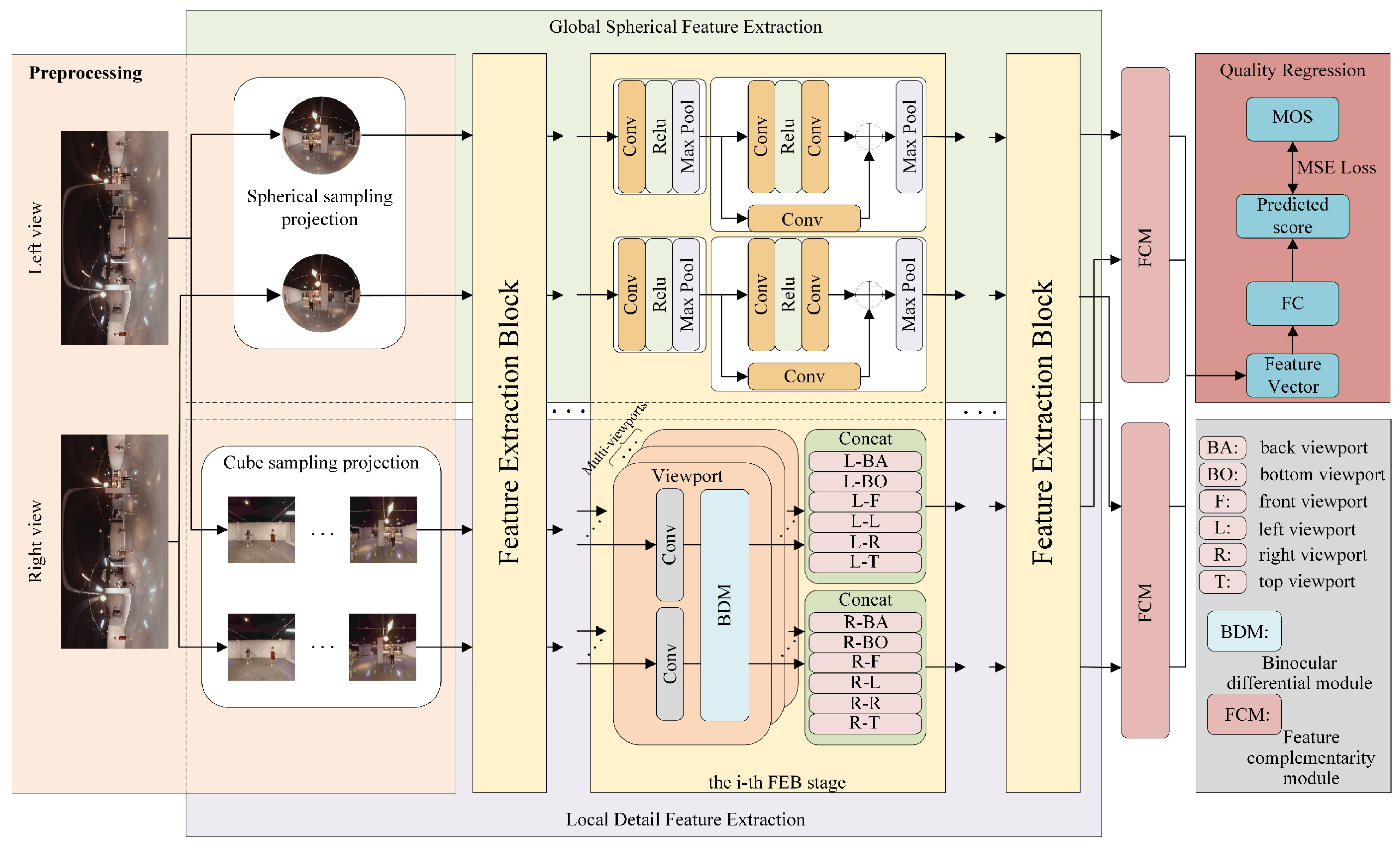
In this section, a detailed description of the proposed SOIQA method will be provided. The proposed method mainly consists of four components, namely, SOI preprocessing, global spherical feature extraction, local detail feature extraction, and overall quality regression. The overall architecture of the proposed framework is shown in
Figure 1. It comprises four main components: (1) an SOI preprocessing module to generate different projection samples; (2) a global feature extraction branch based on spherical convolutions that models the structural distortion characteristics over the sphere; (3) a local feature extraction branch that captures perceptual and binocular cues via a binocular difference module (BDM) enhanced with frequency-aware representations; and (4) a feature complementarity module (FCM) that adaptively fuses global and local features to perform final quality regression. These components are designed to jointly capture both the geometry-specific and perception-specific properties of SOI distortions. The following sections provide a detailed explanation of each component.
3.1. SOI Preprocessing
Generally speaking, for omnidirectional images display, HMD devices first map the input ERP image into a sphere in three-dimensional spherical coordinates. Then, the device renders the visual content as a planar segment tangent to the sphere, determined by the viewing angle and field of view (FoV). By turning their heads, users can change their viewing angle, exploring the entire 360-degree image. Therefore, to comprehensively assess image quality, multiple viewpoints must be considered.
Inspired by this viewing procedure, we project the ERP image into both a spherical image and multiple viewport images. Specifically, six viewport images are rendered from a single omnidirectional image to ensure full coverage. Two views correspond to the poles, while the remaining four align with the horizon, rotating horizontally to encompass the equatorial region. The FoV is set to 90 degrees, consistent with most popular VR devices. Additionally, since users may begin viewing from different perspectives, our training samples include various viewpoints. The front view’s longitude is rotated from 0 to 360 degrees at intervals of ψ degrees, generating six viewport projections per ERP image. This approach not only expands the training set but also helps mitigate overfitting in deep learning models.
3.2. Global Spherical Feature Extraction
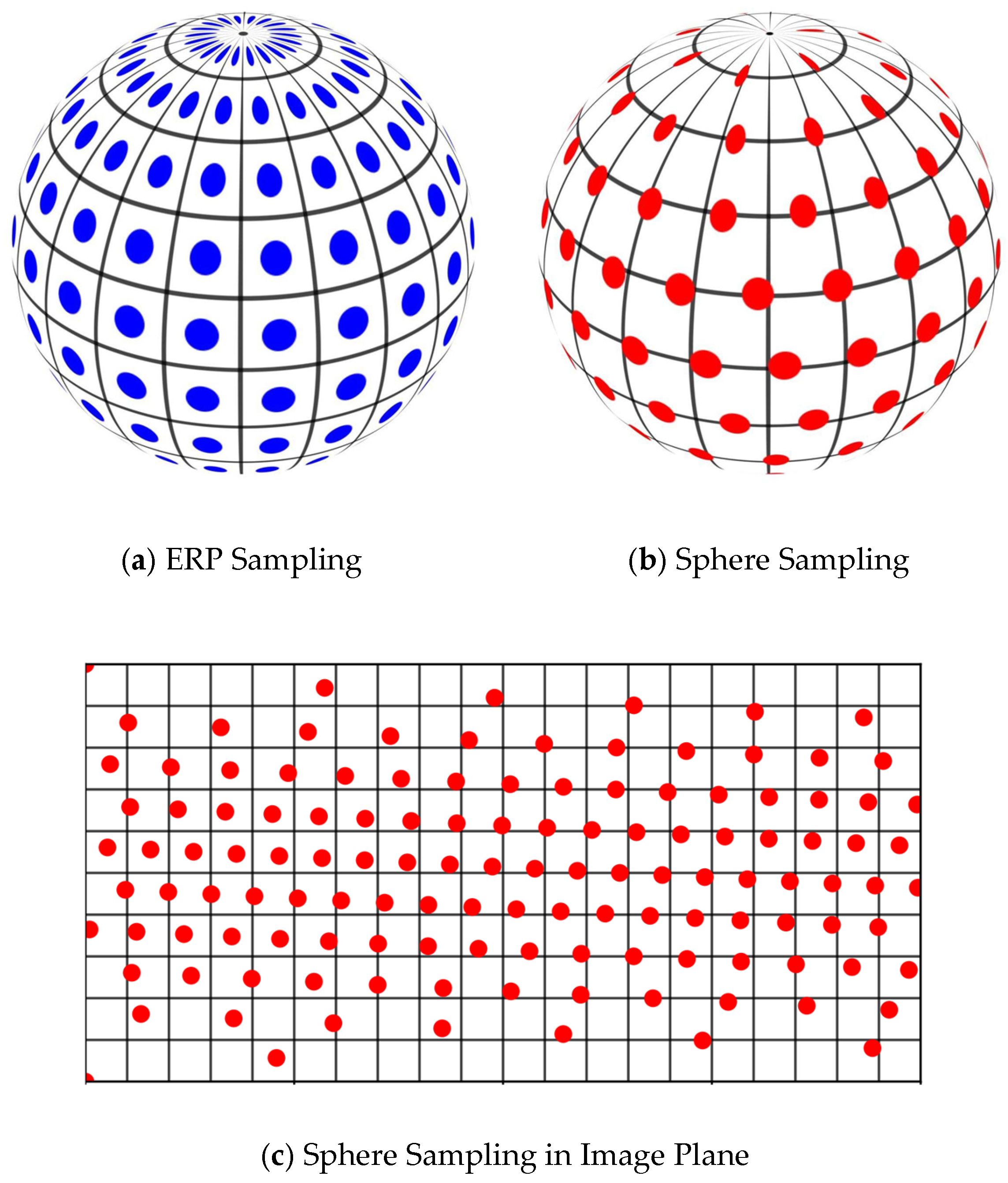
To comprehensively capture scene features and develop a global understanding of omnidirectional images, we utilize Sphere-CNN [
13] to learn spherical feature representations. Traditional CNN operations, such as convolution and pooling, are designed for regular 2D images and struggle with the geometric distortions present in equirectangular images. Sphere-CNN overcomes this limitation by adapting these operations to the spherical surface, enabling more accurate feature extraction that aligns with the characteristics of SOIs. The sampling in Sphere-CNN is illustrated in
Figure 2. As shown in
Figure 2, compared with standard 2D convolution on ERP images, spherical convolution preserves the spatial continuity and geometric consistency of omnidirectional content. This sampling scheme enables the network to more accurately model structural distortions distributed across the sphere, which is crucial for SOI quality assessment.
In this work, let
S represent the unit sphere, and its surface can be expressed as
S2. Each point on the sphere, denoted as
, is uniquely determined by its latitude
and longitude
. Next, let
represent the tangent plane at the point
. Points on this plane
are represented using coordinates
. The 3 × 3 kernel sampling locations are denoted as
, where
. The shape of these kernels corresponds to the step sizes
and
of the equirectangular image at the equator. Then, the location of the filters on
can be determined by projection as
Meanwhile, when applying convolution kernels at different locations on the sphere, the inverse projection needs to be used to determine the location of these kernels on the tangent plane. The inverse projection maps points on the sphere to the tangent plane centered at
The specific inverse projection can be expressed as
where
,
.
By establishing the projection framework and inverse projection of convolution kernels on the sphere, the global feature extraction can be implemented. To be specific, the sphere quality feature extraction branch consists of four-stage sphere convolution blocks for feature encoding. Each sphere convolution block begins with a 3 × 3 spherical convolution layer for feature extraction, followed by batch normalization and ReLU activation. A maxpooling layer is then applied to aggregate the features, and a residual connection is introduced to preserve the original feature information. After four stages of feature extraction and aggregation, the encoded features are passed to the feature interaction module. The overall network structure is illustrated in
Figure 1.
3.3. Local Detail Feature Extraction
In SOIQA, binocular interaction is a crucial factor that has attracted significant research attention. Several Full-Reference (FR) SIQA methods have incorporated this aspect to simulate the human brain’s visual mechanisms [
36,
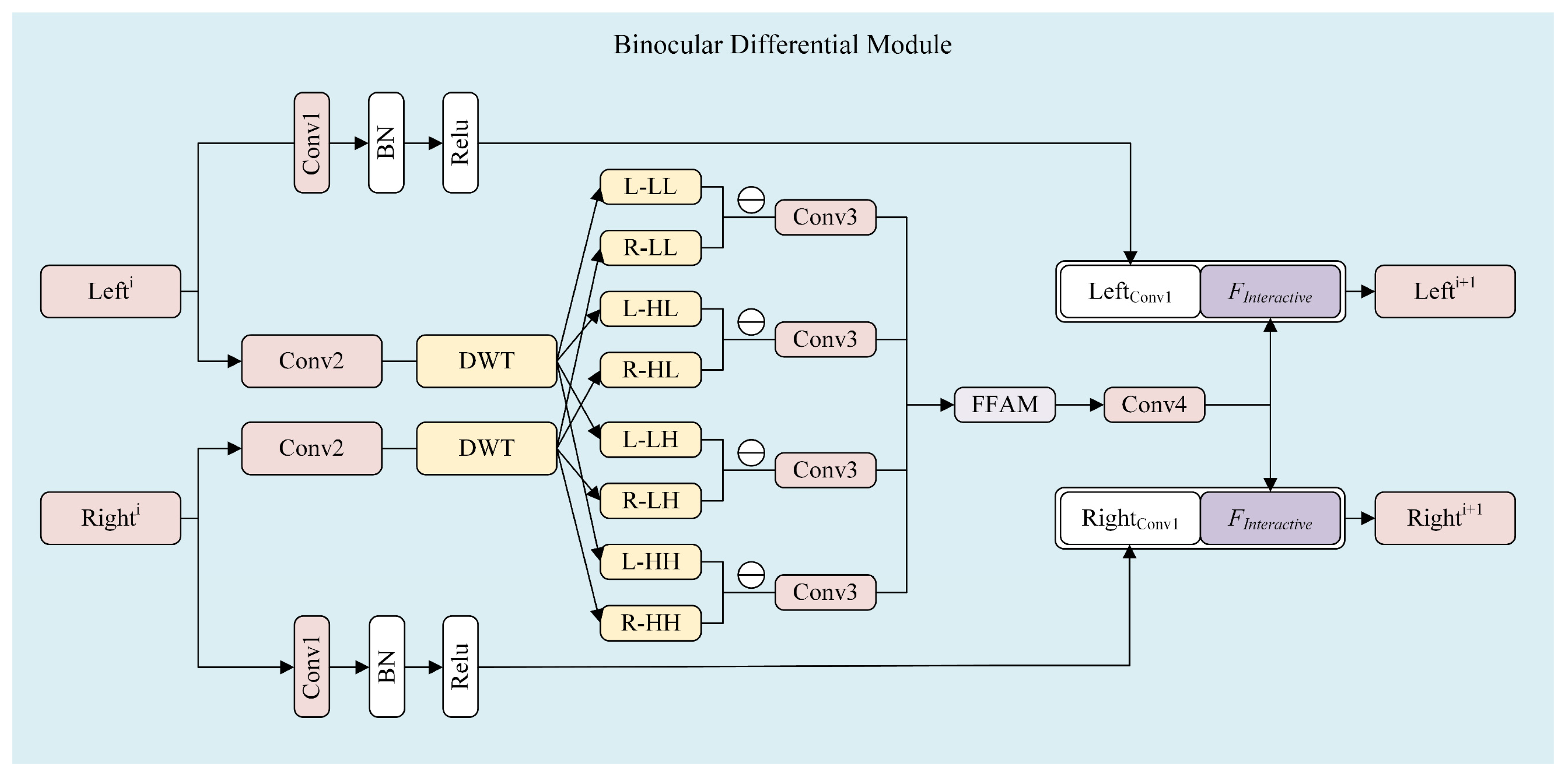
37]. However, the fusion strategies employed in these studies primarily rely on averaging or manually assigned weights to combine binocular visual content. Such approaches are not only time-consuming but also prone to inaccuracies, potentially compromising the effectiveness of the fusion process. To overcome these limitations, we propose a Binocular Differential Module (BDM) that leverages convolution and Discrete Wavelet Transform (DWT) to replicate the complex interactive transmission of stereoscopic visual signals in the human eye, as illustrated in
Figure 3. By integrating these operations, BDM enhances the accuracy and efficiency of binocular fusion, leading to a more biologically plausible and robust quality assessment framework.
The BDM mainly consists of convolution, frequency decomposition, left–right feature differencing, and feature concatenation. Here, the inputs to the BDM are denoted as Lefti and Righti, where i represents the index of the BDM, indicating the stage of feature extraction. To preserve the original visual information during the transmission of visual signals across HVS, the feature inputs are first processed through the branch started with Conv1. In this branch, the inputs undergo filtering and normalization without any additional complex processing. The number of convolution kernels in Conv1 varies across the four stages of the BDM. This initial convolution step yields the outputs LeftConv1 and RightConv1, which are then aggregated for further processing.
To further enhance the neural network’s ability to extract refined visual features, a secondary branch, initiated by Conv2, is introduced and applied to the input data. Specifically, to simulate the interaction between left and right visual content, we propose a novel differential cross-convolution approach. Following the application of Conv2, the extracted features are decomposed by DWT, which is integrated for its capability to perform multi-resolution analysis and localized feature extraction. This transformation decomposes the features into four distinct sub-bands: LL (low-low), HL (high-low), LH (low-high), and HH (high-high). For each sub-band, differential feature extraction is conducted to capture additional interaction information, thereby enriching the representation of binocular interactions. The differences in each sub-band can be obtained as Equation (5). Then,
Dt is obtained through a set of 1 × 1 convolution kernels, referred to as Conv3. This step further refines the extracted differential features, enhancing their discriminability for subsequent processing.
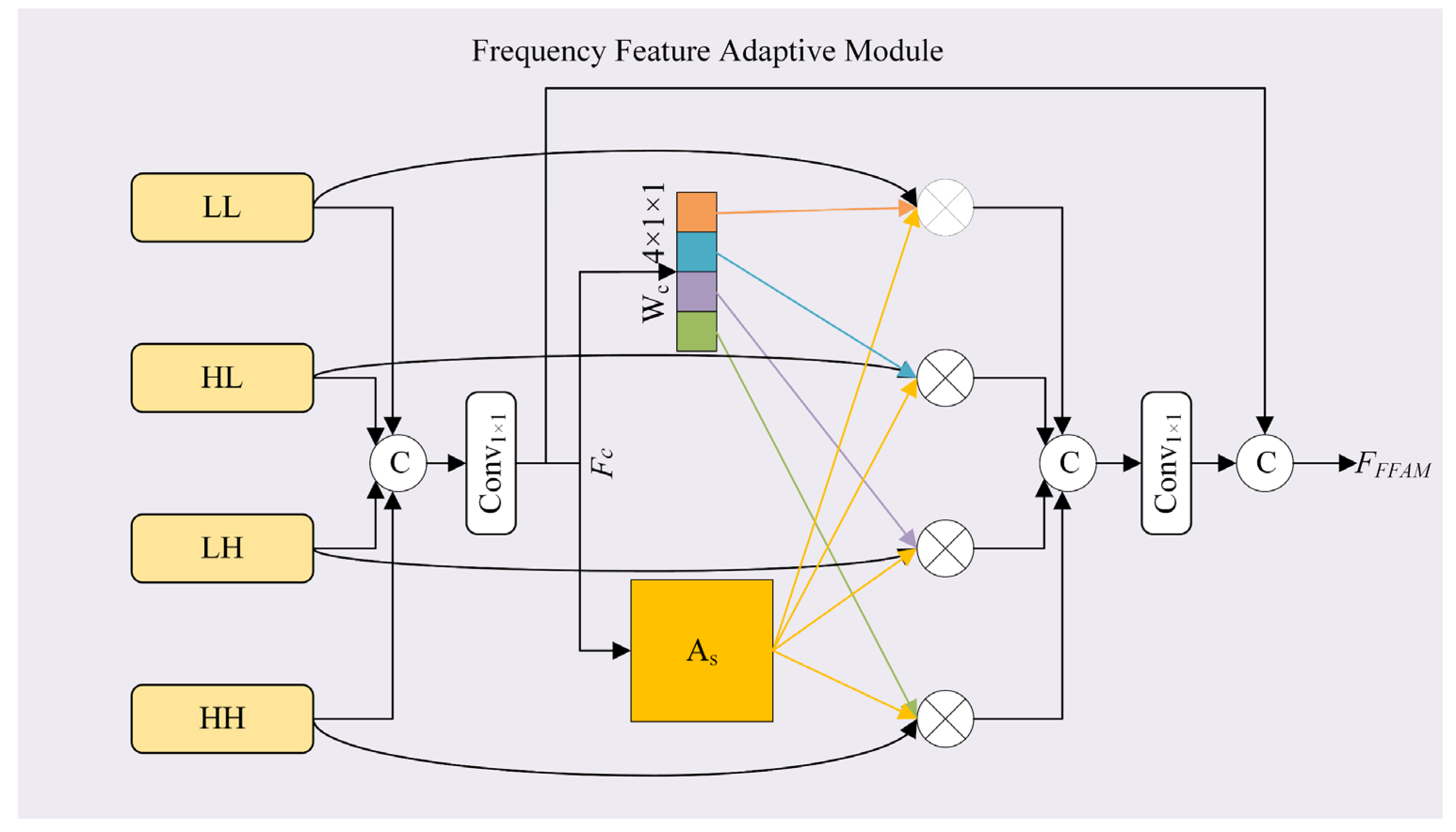
To selectively combine the four groups of features at different frequency levels, we introduce a multi-level Frequency Feature Adaptive Module (FFAM). This module assigns adaptive weights to each feature group and integrates them through a spatial attention mechanism, enabling dynamic feature fusion. By leveraging this approach, the FFAM enhances the representation of binocular interactions and generates the final interaction feature. The architecture of the proposed FFAM is illustrated in
Figure 4.
Specifically, the features from the four sub-bands (LL, HL, LH, HH) are first concatenated. The concatenated features are then processed by an upsampling operation, denoted as
U(⋅), followed by a 1 × 1 convolution that reduces the channel dimension from 512 to 128, obtaining the feature
Fc. To effectively capture both the overall feature distribution and the salient activations within the sub-bands, we employ a combination of average pooling (Avg-Pool) and maximum pooling (Max-Pool) to learn the independent weights
Wc. Avg-Pool provides a smooth representation of the feature distribution, while Max-Pool emphasizes significant activations, leveraging their complementary properties. The combined pooling results are then normalized using the sigmoid function
σ(⋅), ensuring that the weights are bounded between 0 and 1. The detailed calculation of
Wc can be expressed as
where 0 ≤
Wc ≤ 1 and
.
To capture the spatial dependencies within the feature maps, a spatial attention map As is learned through a convolution operation on Fc, enhancing the model’s ability to focus on important spatial information. The weights Wc and the spatial attention map As are then multiplied with the corresponding features with different frequency components, ensuring that both spatial and channel-wise dependencies are incorporated into the final feature representation. Subsequently, the features are concatenated and processed through a 1 × 1 convolution to reduce the channel dimension from 512 to 128, retaining the most salient information while reducing computational complexity. As a result, multi-level adaptive features are generated, effectively capturing both spatial and channel-wise dependencies and improving the model’s ability to represent complex interactions within the input data.
Finally, as depicted in
Figure 3, the features extracted through binocular interaction are aggregated with those from the Conv1 branch. The resulting aggregated features serve as the input for the subsequent stage of multi-stage feature extraction.
3.4. Feature Interaction and Quality Regression
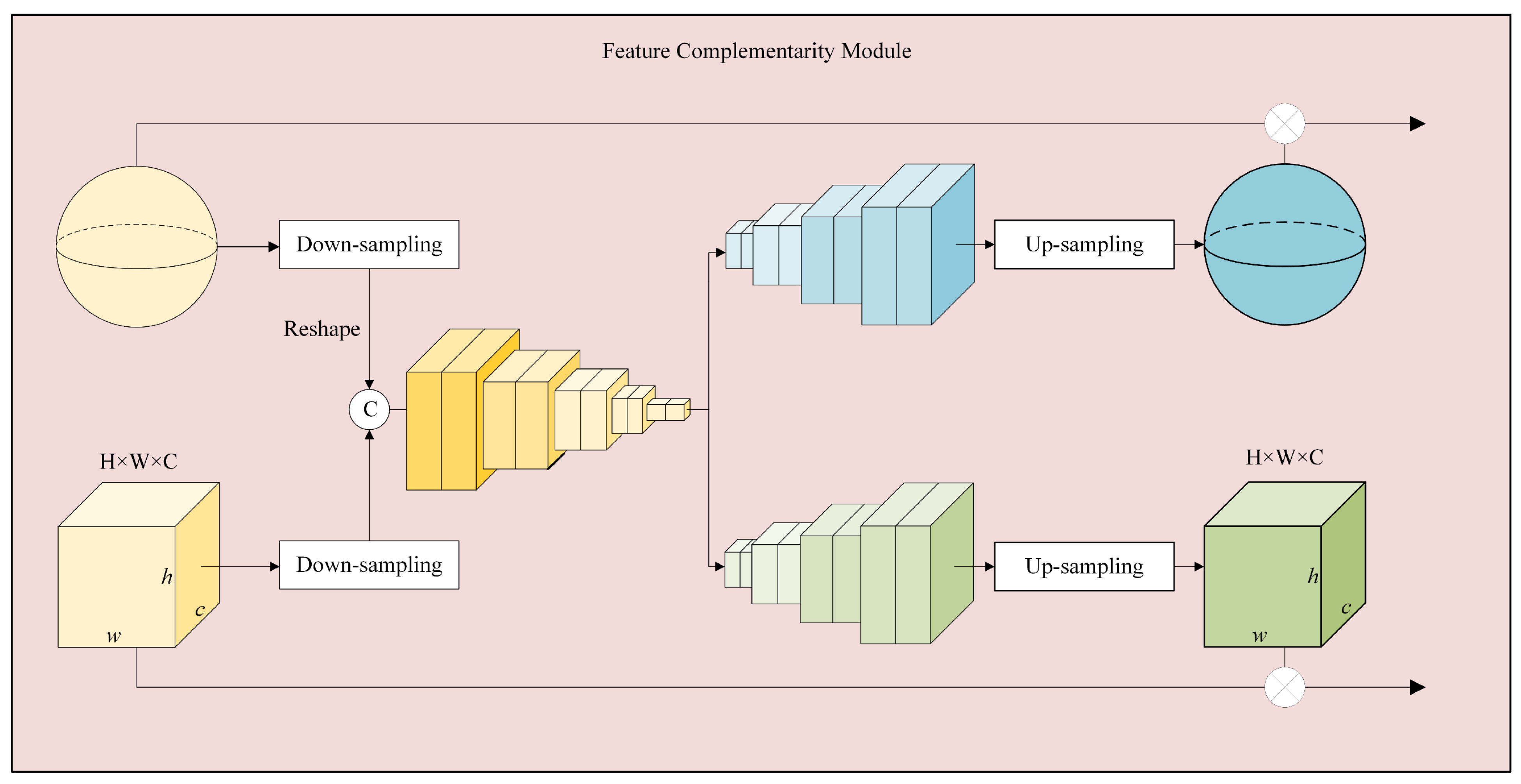
In quality assessment, integrating local and global features is crucial for capturing both fine-grained details and contextual information. To achieve this, we propose a Feature Complementarity Module (FCM) that enhances feature representation while maintaining computational efficiency. The functionality of the Feature Complementarity Module (FCM), as illustrated in
Figure 5, is to effectively integrate global and local feature streams. Specifically, features from both branches are first aligned in spatial resolution using transpose convolution operations. Then, channel- and spatial-wise interactions are enabled through a gated fusion mechanism implemented with sigmoid activations. This allows the model to adaptively emphasize perceptually salient features from both the spherical and binocular perspectives. Finally, the fused representation is fed into a fully connected regression head to predict the final quality score.
Specifically, in FCM, the process begins with a series of downsampling operations, including convolution, batch normalization, Dropout, and ReLU activation. These operations progressively refine feature representations, enhancing their nonlinearity and robustness. To restore the feature map size for improved interaction and fusion with subsequent layers, a transpose convolution layer (trans-Conv) is introduced. The upsampling process further adjusts and reconstructs the features, ensuring their compatibility with local viewport processing requirements. By integrating transpose convolution, batch normalization, Dropout, and activation functions, local features are precisely processed and fused with the previously processed global features. In the later stage, an additional specialized transpose convolution layer further refines the upsampled features, ultimately generating the final output features optimized for quality assessment. This approach effectively captures and integrates both local and global features, significantly enhancing the model’s overall performance.
To further strengthen the interaction between local and global features, the FCM employs the Sigmoid activation function for feature normalization and probabilistic weighting. For local viewport features, the Sigmoid function is applied to each segmented part and multiplied with the corresponding local features, enabling targeted weighting and modulation. This mechanism allows the model to selectively highlight or suppress specific local feature information based on task requirements. Similarly, the Sigmoid-processed results are multiplied with global features to refine their representation, facilitating deep interaction and collaborative optimization between local and global features. The overall architecture of the FCM is depicted in
Figure 5. By incorporating key elements of the U-Net architecture, the FCM ensures comprehensive and effective interaction between global features and local viewport features, addressing complex feature processing challenges in image quality assessment.
As described above, the viewport and global features are assigned weights using FC (which may refer to a specific operation or module, to be determined based on context), and the final prediction score is computed. For end-to-end training, the loss function is defined as
where
Qpredict represents the predicted score calculated by proposed network, and
Qlabel is the mean opinion score (MOS) acquired by subjective scoring.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}