1. Introduction
In today’s digital age, the widespread adoption of cloud services, social media platforms, and mobile applications has extremely simplified data sharing and transmission. From enterprise-level databases hosted on a cloud to individual users uploading personal images on social media, there is a massive amount of data flowing continuously across various platforms. While this connectivity offers convenience and efficiency, it also raises significant security and privacy concerns. According to the 2024 IBM Cost of a Data Breach Report [
1], breaches disclosed by attackers cost an average of over 5 million US dollars, highlighting the heightened financial risks associated with delayed detection and disclosure.
Among various forms of data being exchanged, image-based content poses a particularly overlooked threat [
2]. Some users post personal identifiable information (PII), such as identification (ID) cards, driver’s licenses, passports, and financial statements, through snapshots or scanned documents on public platforms. Additionally, if enterprises store and exchange internal diagrams, design mockups, users’ sensitive data and confidential data within cloud collaboration tools, the risk of leakage may increase. This escalating concern over image-based data leakage underscores the urgency for more robust, proactive methods to detect and protect sensitive visual data online.
During a cybersecurity salon co-hosted by Google and the National Institute of Cyber Security in Taiwan [
3], we raised concerns about the risks of privacy-sensitive images being discovered through image-based search. In response, Heather Adkins, Google’s Vice President of Security, acknowledged that while Google has established policies and procedures for handling illegally posted or privacy-related content, automating the detection of such content remains highly challenging. She noted that one of the key difficulties lies in determining whether an image constitutes a genuine privacy violation or was intentionally shared, for example, as a mock document or illustrative sample. Although Google’s scope involves the entire Internet at a massive scale, this conversation highlights the broader complexity of automated leak detection. In contrast, our paper focuses on the problem of detecting images discovered through image-based search and analyzing textual features by artificial intelligence (AI), allowing for a more targeted approach to identifying and verifying potentially sensitive existing data leaks.
To address this gap, we propose an automatic sensitive image search system with generative AI (GenAI) to identify data leaks on the Internet. Our approach is based on four observations, as follows:
- (1)
Differences between image-based and text-based search. Text-based searches and image-based searches serve different purposes in information retrieval. Text-based searching relies on keyword-based queries. It typically returns images that include explicit textual labels. In contrast, image-based search utilizes visual feature matching, enabling the identification of sensitive images that lack textual labels.
- (2)
There is no proactive detection solution for sensitive images exposed online. Existing DLP tools primarily address internal data leakage through email monitoring, file transfer controls or rule-based text matching. However, they fail to proactively detect sensitive images already exposed online. Current practices generally rely on reactive approaches, resulting in delayed responses and higher damage.
- (3)
Directly using GenAI to generate sensitive documents may lead to failures. AI image generators may face content policy restrictions or produce images that look nothing like real-world documents (e.g., distorted text or unrealistic layouts) while lacking the structural consistency needed to resemble genuine forms of identification. As a result, such outputs may not accurately replicate real leak scenarios, reducing their usefulness in spotting potential risks.
- (4)
There is a need for actionable suggestions for sensitive image leaks on the Internet. Even if systems can detect leaks, organizations and individuals may not know what to do next. Without clear guidelines, such as ways to remove leaked images or notify those affected, people without cyber security or related knowledge may need actionable instructions for handling leaks and reducing their impact.
Building upon these insights, this paper proposes a system with GenAI that combines both visual and textual features for detecting sensitive images that were leaked online. This capability is critical for discovering images accidently shared due to misconfigured privacy settings or unintentional uploads without textual labels (e.g., metadata, descriptions).
The main contributions of this paper can be summarized as follows:
- (1)
We propose a novel post-leakage sensitive image search system that combines GenAI with image-based search to proactively identify sensitive content already available on the Internet.
- (2)
Our system employs both image-based and text-based matching, providing a more comprehensive search.
- (3)
Our system uses AI-driven methods to suppress meaningless matches, allowing for more effective identification of sensitive content.
- (4)
Our system can provide automated security suggestions following detection, offering actionable insights to individuals and organizations.
2. Related Works
DLP is an important branch of enterprise security that is tasked with identifying, monitoring and preventing the unauthorized leakage of sensitive data within organizational environments [
4]. Leaks can emerge from both external attackers and internal factors, ranging from malicious insiders to employees who unintentionally mishandle data. Such leaks not only cause severe reputational and financial damage but can also threaten an organization’s long-term stability. DLP solutions aim to detect and prevent sensitive data from leaving authorized boundaries. They deploy technologies such as content analysis or network monitoring to safeguard data from unauthorized transmission or copying [
5]. However, although existing DLP systems can prevent data leakage within enterprise environments, there are limited approaches to proactively detecting confidential or personal images that have already been leaked. Once such images become publicly accessible, whether through employee oversights or malicious acts, organizations often have no systematic way to discover them before adversaries exploit the leaked data.
Recent research studies in visual privacy detection have explored object recognition and region classification techniques. AutoPri, proposed by Vishwamitra et al., introduced a multimodal variational autoencoder (MVAE) system that learns user-specific privacy preferences to classify personal photos as public or private. Their approach highlights the subjective nature of privacy; different users may perceive the same object (e.g., a bed, a pet, a drink) differently in terms of sensitivity. AutoPri also incorporates explainable AI to indicate which image regions trigger privacy concerns [
2]. DRAG (Dynamic Region-Aware GCN), developed by Yang et al., overcomes the limitations of prior models that rely solely on pretrained object detectors, which often fail to capture elements such as scene context or texture. DRAG dynamically identifies salient regions in images and models their correlations using a graph convolutional network informed by a self-attention mechanism. This flexibility allows the model to generalize across diverse privacy-leaking scenarios, outperforming both visual-only and multimodal baselines [
6]. Azizian and Bajić proposed a privacy-preserving autoencoder in a collaborative intelligence setting where inference is split between edge and cloud devices. Their method removes private information from intermediate feature representations using adversarial training. The goal is to prevent model inversion attacks while preserving object detection accuracy and optimizing feature compression for transmission [
7]. The Visual Censorship Study further contextualizes privacy in real-world news and social media imagery. It explores how visual redaction (e.g., blurring or masking) is applied inconsistently across contexts, often reflecting cultural or political biases. The study underscores the need for more standardized and automated methods for identifying sensitive visual content [
8]. While each of these works advances privacy-aware image analysis, they primarily focus on preventive mechanisms, either before an image is shared or during edge-cloud inference. However, none are designed to proactively detect personal or confidential images that have already been leaked and made publicly available online. Our work addresses this critical gap by using GenAI and computer vision techniques to discover sensitive images on the Internet after they have already been exposed, enabling a novel, post-leakage detection strategy not covered by current systems.
Image-based search is a content-based image retrieval (CBIR) technique that enables users to initiate online searches by providing an image, rather than text-based keywords. Instead of matching text strings, image-based search engines analyze the image’s visual features, such as color distributions, textures, and shapes, to locate similar or related content in large-scale databases [
9]. Traditional algorithms include Scale-Invariant Feature Transform (SIFT) and Maximally Stable Extremal Regions (MSER), both of which detect and describe stable regions or keypoints that remain robust under rotations and scaling [
10,
11,
12]. In recent years, deep learning has further enhanced image-based search capabilities by learning complex, high-dimensional feature representations that can recognize images even after modifications or partial occlusions. Popular search engines, such as Google Image Search or Google Lens, leverage these AI-driven methods to provide data about a photo’s origin, visually similar images and related webpages in near real time. In this paper, we leverage the capabilities of image-based search to proactively discover images containing private or sensitive data. By analyzing purely visual content, image-based search can locate sensitive images even if they lack textual indicators or are partially obscured, making it a crucial component for comprehensive leak detection strategies.
Feature extraction and matching are critical steps in many computer vision pipelines, especially those aimed at identifying relevant patterns or similarities. Feature extraction involves detecting keypoints within an image, such as corners, edges or other distinctive local regions, and describing these points in a way that makes them robust to common variations like scaling, rotation and illumination changes [
13]. Traditional approaches include SIFT [
14] and Speeded-Up Robust Features (SURF) [
15], both of which excel at generating rich, high-dimensional feature descriptors but at a relatively high computational cost. More recent methods, such as BRISK [
16] or Oriented FAST and Rotated BRIEF (ORB) [
17], utilize binary descriptors that are faster to compute and match, making them especially suitable for applications where real-time processing or resource efficiency is a priority.
Once these features are extracted, the next step is feature matching. This task tries to find correspondences between keypoints in two different images by comparing descriptors. The choice of matcher depends on the nature of the descriptors. For instance, descriptors that are real-valued (like those from SIFT or SURF) typically pair best with the Brute Force (BF) matcher using an L2 distance metric or Fast Library for Approximate Nearest Neighbors (FLANN) for faster lookups [
18]. Conversely, binary descriptors (from BRISK or ORB) are often matched using a Hamming distance metric in BF, ensuring quick comparisons well-suited to large-scale or real-time tasks.
According to Noble’s comparison [
19], the combination of BRISK and BF stands out. Although SIFT or SURF can detect a larger number of keypoints, they often incur higher computational overhead, both in extracting features and matching them. BRISK, on the other hand, achieves a balance by identifying a sufficient number of keypoints in significantly less time, and when paired with BF, yields reliable matches without extensive parameter tuning. By leveraging BRISK’s lightweight descriptors alongside the BF matcher’s robust but straightforward matching mechanism, our system efficiently identifies visual correspondence.
OCR is a technique that automatically converts text within images or scanned documents into machine-readable data by leveraging a combination of image processing, feature extraction, and pattern recognition. By transforming visual text into searchable and analyzable data, OCR greatly enhances workflows in document archiving, automated form processing and, crucially, security applications. In this paper, OCR plays a key role in detecting and confirming sensitive data within images already leaked online. Specifically, we employ deep-learning-based PaddleOCR to handle various languages and text orientations, enabling it to accurately recognize personal or confidential details (e.g., names, ID numbers) from images [
20].
3. Proposed Methods
The proposed system architecture is shown in
Figure 1, which integrates six modules: Input Module, Generation Module, Search and Filter Module, Recognition Module, Detection and Marking Module, and Report Generation Module. In the following paragraphs, we provide a detailed explanation of the six modules shown in
Figure 1, outlining their individual functions and how they interact within the pipeline.
Clarification: All face images shown in
Figure 1,
Figure 2,
Figure 3 and
Figure A1 were synthetically generated using GenAI and do not depict any real individuals. Therefore, no copyright permission is required.
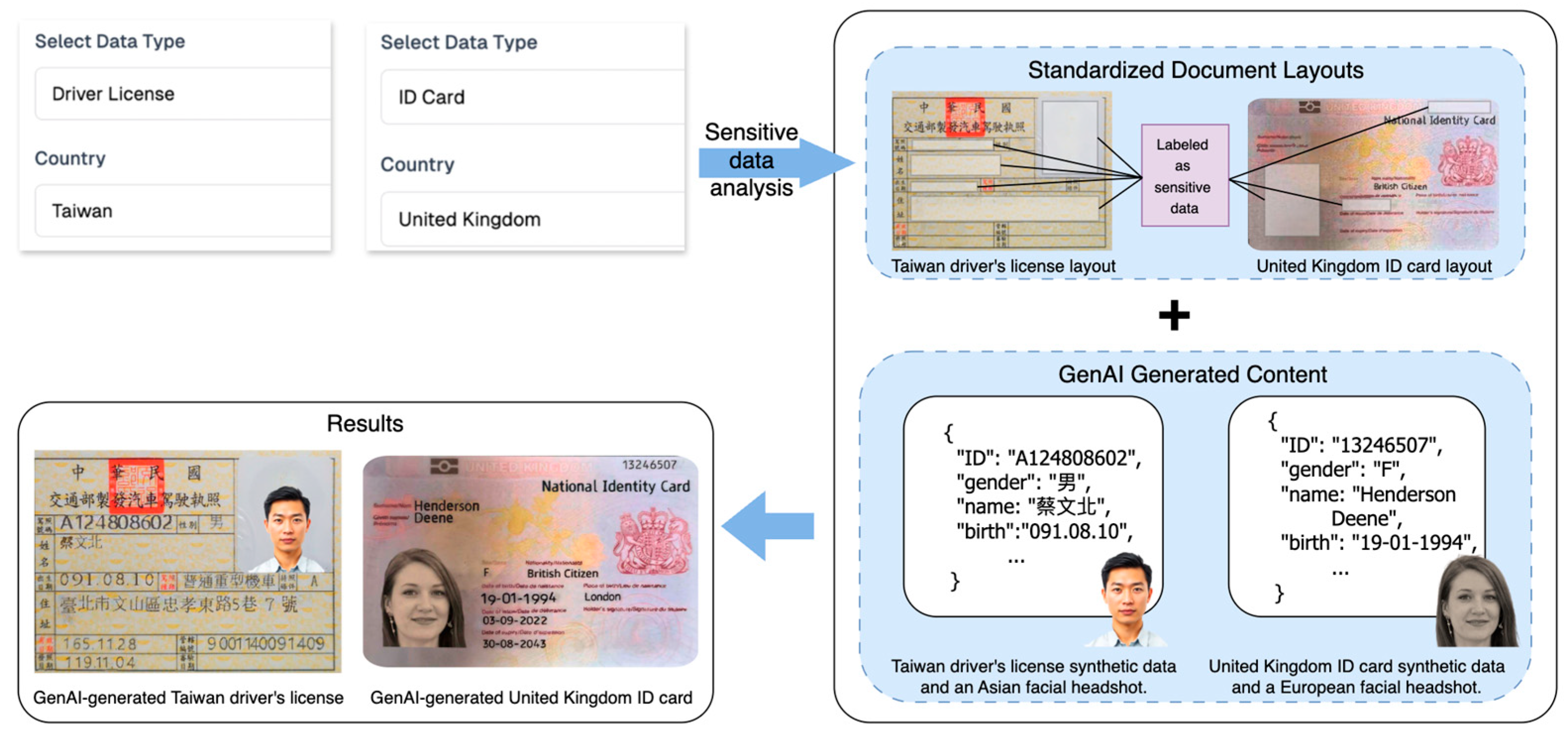
As shown in
Figure 2, in the Input Module, users specify the type of sensitive data they want to detect, such as Taiwan driver’s licenses and United Kingdom ID cards. Once selected, the system automatically generates a corresponding prompt for GenAI, ensuring that both the image and text outputs align with the selected document type. In the Generation Module, these prompts are used to create synthetic sensitive images by combining GenAI-generated content with standardized document layouts. This layered generation strategy enables the system to produce outputs that closely resemble real-world sensitive documents, which, in turn, improves the accuracy of visual feature matching during retrieval. Our system utilized GenAI in this module based on two practical advantages: extensibility and data diversity. First, the system is designed to support a broad range of document types, each with distinct formats. GenAI allows us to generate realistic examples for new types efficiently using prompt-based control, thereby avoiding the need for manually reconstructing document templates. Second, even for the same document category, GenAI produces natural variations in layout and content. This diversity improves the generalizability of visual features and enhances the coverage of the downstream image-based search, allowing the system to detect a broader range of potential leaks.
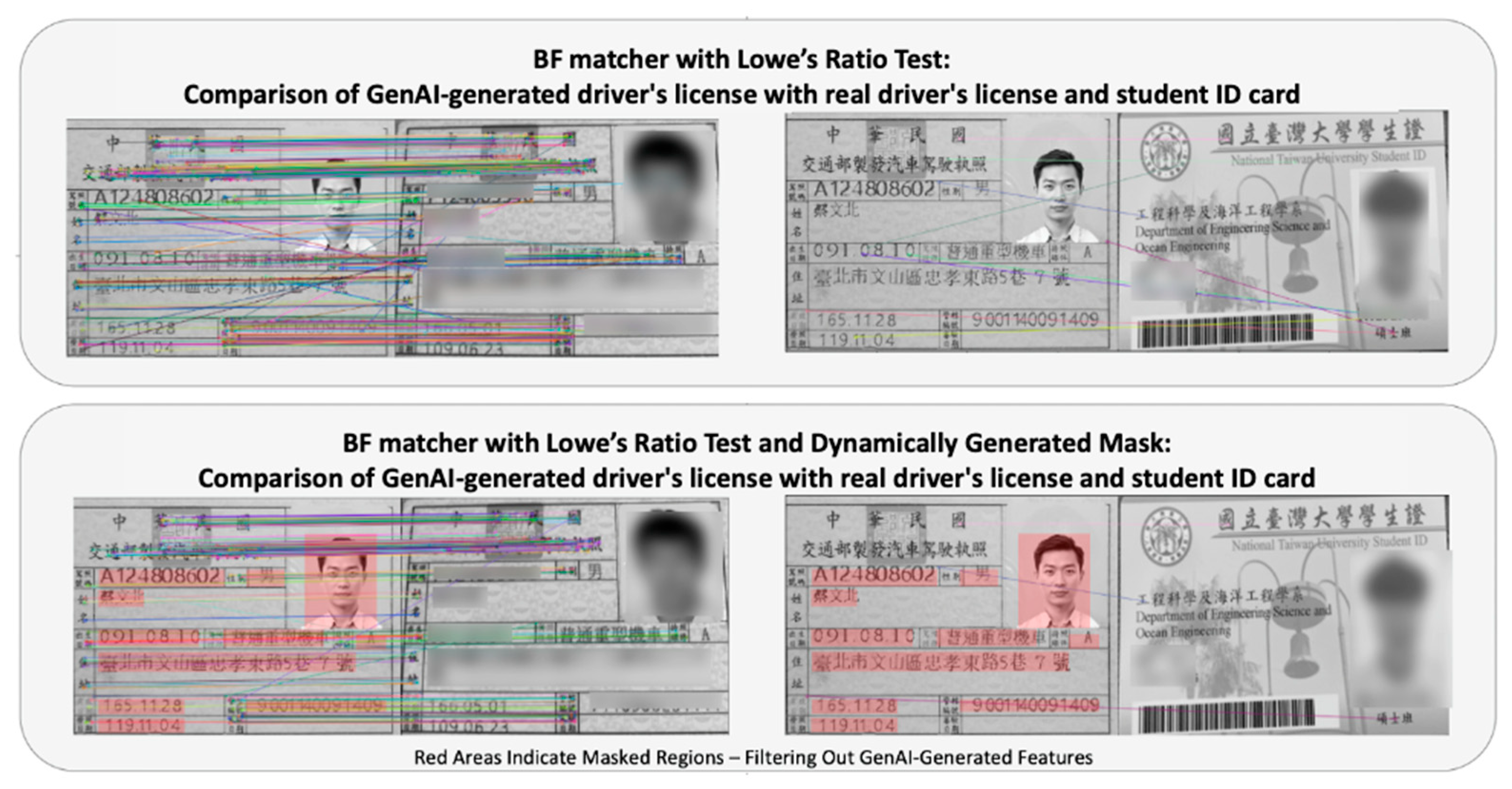
Next, the Search and Filter Module receives the synthetic reference document generated by the Generation Module as input. The module employs Selenium to conduct image-based searches across various online platforms and downloads the resulting candidate images. After candidate images are retrieved, our system performs feature matching using BRISK descriptors with a BF matcher. To enhance precision, we apply Lowe’s ratio test with a threshold of 0.75 [
12] and additionally introduce a dynamically generated region mask based on the GenAI-generated reference layout. This masking ensures that only structurally relevant regions contribute to the feature matching process, suppressing noise from irrelevant keypoints. The overall effect of this approach is a tighter match distribution in true-positive cases and near-zero false matches for unrelated images (evaluated in
Section 4.2).
Figure 3 compares the output of different feature matching configurations, illustrating how our proposed method reduces irrelevant matches while preserving meaningful correspondences, and implementation details are provided in Algorithm 1.
| Algorithm 1: BF matcher with Lowe’s Ratio Test and Dynamically Generated Mask |
| Input: Reference image img1, Comparison image img2, Mask image masked_img, Ratio threshold r (default = 0.75) |
| Output: Filtered good matches G, Keypoints kp1, kp2 |
| 1: | Step 1: Masking. |
| 2: | Convert mask_img to grayscale and binarize it. |
| 3: | Apply the binary mask to img1 to limit feature detection to valid regions. |
| 4: | Step 2: Detecting. |
| 5: | Detect BRISK keypoints and descriptors kp1, des1 from img1 using mask. |
| 6: | Detect BRISK keypoints and descriptors kp2, des2 from img2 (without mask). |
| 7: | if descriptors are invalid: |
| 8: | return 0 |
| 9: | end if |
| 10: | Step 3: Matching. |
| 11: | Use BFMatcher with k-NN (k = 2) to match des1 and des2 |
| 12: | m: best match (nearest neighbor) |
| 13: | n: second-best match |
| 14: | : |
| 15: | retain
m |
| 16: | end if |
| 17: | Step 4: Output. |
| 18: | Return filtered matches G, and keypoints kp1, kp2 |
| 19: | return G, kp1, kp2 |
The Recognition Module extracts sensitive data from filtered images using a deep learning-based OCR tool (Paddle OCR, v.2.6.2) [
20]. The system identifies and recognizes text, numbers (e.g., ID numbers, driver’s license data), and other relevant content from the images. The recognized content is verified against predefined sensitive data patterns using regular expressions (regex) to ensure accuracy. This module assigns a confidence score (ranging from 0 to 1) to each recognized result for further risk assessment. Once sensitive data is detected, the Detection and Marking Module categorizes the image as either “High Risk” or “Potential Risk” based on the completeness and format of the data. High-risk labels are applied to images containing fully identifiable sensitive data (e.g., complete ID numbers), while Potential Risk labels are applied to images containing data that conforms to the designated privacy data format. Further details of the OCR results can be found in
Appendix A.
The Report Generation Module is responsible for integrating all data processed by the preceding modules and generating reports to assist in understanding the specifics of data leakage and risk assessment. First, the module consolidates the data generated by various components, collecting results from each module. These data include filtered images, identified sensitive data, and the risk level for each image. The report will detail each image flagged as a potential leakage risk, including the image source and the specific sensitive data exposed. These details will also be highlighted with bounding boxes for quick identification of the leaked content.
Since the data involves sensitive and private data, the module employs a local model for computation and analysis, ensuring that all sensitive data is processed within a local environment. Currently, the system runs the LLAMA 3.2 model locally on the OLLAMA platform. By inputting the data generated by previous modules into this model, the system generates reports in a predefined format, enabling a secure and efficient data processing and analysis workflow.
As shown in
Figure 4, it provided recommendations for addressing a data leakage incident involving the unauthorized sharing of PII on Threads.net. The root cause analysis suggests that the leak resulted from an individual’s intentional or accidental disclosure rather than a website misconfiguration or third-party breach. To mitigate the issue, the recommendations include requesting content removal by reporting the violation through Threads.net’s support system, filing a complaint with Taiwan’s Personal Data Protection Commission (PDPC) to address legal and regulatory concerns and seeking legal counsel to explore potential actions under Taiwan’s Personal Data Protection Act (PDPA).
4. Experimental Results
In this section, we present a comprehensive evaluation of our proposed system, including real-world case analysis, synthetic dataset validation, and performance benchmarks. We begin by assessing system precision and recall based on real-world web image retrieval results, including a case study on Taiwan driver’s license leaks. We then evaluate the fidelity of our GenAI-generated images using pHash-based similarity analysis. To validate the effectiveness of our feature matching strategy, we further compare performance with and without the dynamically generated region mask. We also evaluate the Recognition Module using the IDNet dataset covering multiple document types. Finally, we assess system efficiency under different hardware configurations and conclude with a discussion on system robustness and future directions.
4.1. Real-World Image Evaluation
In our experimental evaluation, we deployed the system to perform image-based searches and retrieved 610 real-world web images for analysis. After processing these images through our proposed system, we identified 27 images as containing sensitive data. To validate the effectiveness and accuracy of our system, we conducted a detailed manual review, confirming that the dataset actually contained 29 sensitive images.
The resulting system performance metrics are as follows:
True Positives (TP): 27 images correctly identified.
False Positives (FP): 0 images incorrectly identified.
False Negatives (FN): 2 images containing sensitive data missed by the system.
Based on these metrics, the precision and the recall of our system are calculated as follows:
Through further error analysis, we identified that both FN cases resulted from OCR misclassifications, specifically the OCR algorithm mistaking the English letter “O” for the number “0”. To address this issue, we implemented a post-processing mechanism that automatically generates both “O” and “0” variants whenever either character is detected during OCR. This ensures that both interpretations are considered in downstream pattern matching, regardless of the OCR output. After introducing this correction strategy, no further O/0 misclassification errors were observed in subsequent evaluations, indicating a reliable improvement in the system’s robustness. Overall, the results indicate that our system accurately identifies sensitive images leaked online, with a high precision rate demonstrating excellent reliability in filtering irrelevant results.
To detail our experiments, we focused on detecting driver’s license leaks in Taiwan. Using image-based search, our system gathered 80 publicly accessible images from the Internet. A filtering process based on feature matching was then applied, which took 9.78 s and excluded 12 images. Upon inspection, these 12 images contained no private data. Many of these excluded images contained obscured text (e.g., blurred, pixelated, or blacked-out sections) or had low resolution and poor image quality. Next, we performed OCR on 68 images and discovered 2 images that contained complete personal data, confirming actual privacy leaks. Among the 68 images, the system detected 2 images that posed any risk of sensitive data exposure.
Among the detected cases, two involved severe access control vulnerabilities that allowed unauthorized access to other individuals’ driver’s license data simply by modifying the URL. In the first image (
Figure 5), we found that a company’s website permitted direct access to driver’s license data by altering the URL without requiring authentication or additional permissions. By systematically modifying specific parts of the URL, an attacker could retrieve other individuals’ driver’s licenses, exposing sensitive data such as names, ID numbers and addresses. This indicates that the website lacks adequate access control mechanisms, making it vulnerable to unauthorized data retrieval.
In another image (
Figure 6), we observed a similar issue where a 128-bit hexadecimal value in the URL could be altered to access driver’s license data, again without authentication. This suggests that the website relies on URL-based identifiers rather than proper authentication mechanisms, potentially allowing an attacker to modify the URL parameters and retrieve sensitive customer data. Although these values have not yet been confirmed as MD5 hash results, they match the MD5 hash format and lack additional protective measures.
MD5 was once widely used for data integrity checks and cryptographic hashing, but its security has been widely questioned. Multiple studies [
21,
22,
23,
24,
25] have highlighted MD5’s vulnerability to collision attacks, where different input values can produce the same hash result, significantly weakening its security. As a result, MD5 is now considered unsuitable for any high-security applications. In this case, if the URL indeed uses MD5 hashing, attackers could leverage collision attacks to generate valid MD5 hash values and inject them into the system URL or other applications containing sensitive data. This could bypass security mechanisms, allowing unauthorized access to personal sensitive data and leading to a major data leak.
4.2. pHash-Based Similarity Analysis
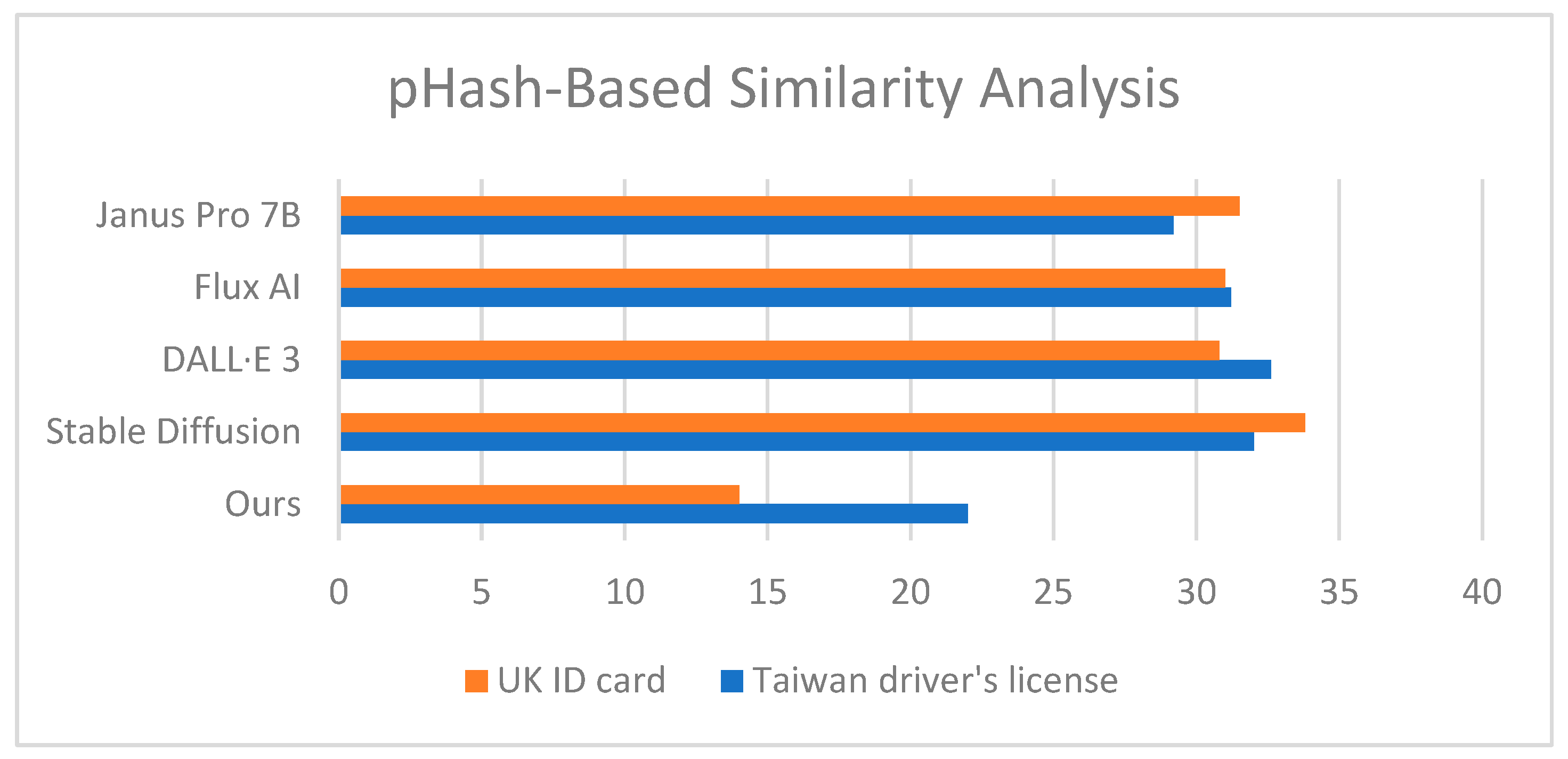
To evaluate the fidelity of our Generation Module, we adopted pHash to measure the visual similarity between generated images and real document samples. pHash encodes images into hash values such that perceptually similar images yield smaller hash distances since lower scores indicate higher visual similarity. For each evaluation prompt, we generated 10 synthetic images using both our method and four widely used text-to-image models, Stable Diffusion 2.1, DALL·E 3, Flux1.AI and Janus Pro 7B. We then calculated the average pHash distance between the generated images and the official reference sample for each document type. In our experiments, we used two identity document types, the UK ID card and the Taiwan driver’s license. The results are summarized in
Figure 7, showing that our method consistently achieved the lowest pHash distances, reflecting the highest structural and perceptual fidelity. For the UK ID card, baseline models yielded average pHash distances ranging from 30.80 to 33.80, whereas our method achieved a significantly lower score of 14.00. Similarly, for the Taiwan driver’s license, other models scored between 29.20 and 32.60, while our method produced an average distance of 22.00. These findings demonstrate that our Generation Module produces synthetic outputs with superior structural alignment to authentic identity documents. This enhanced fidelity supports more effective feature extraction and visual matching in downstream detection tasks, improving the system’s overall capability to identify real-world sensitive image leaks.
4.3. Feature Matching Evaluation with and Without Dynamically Generated Mask
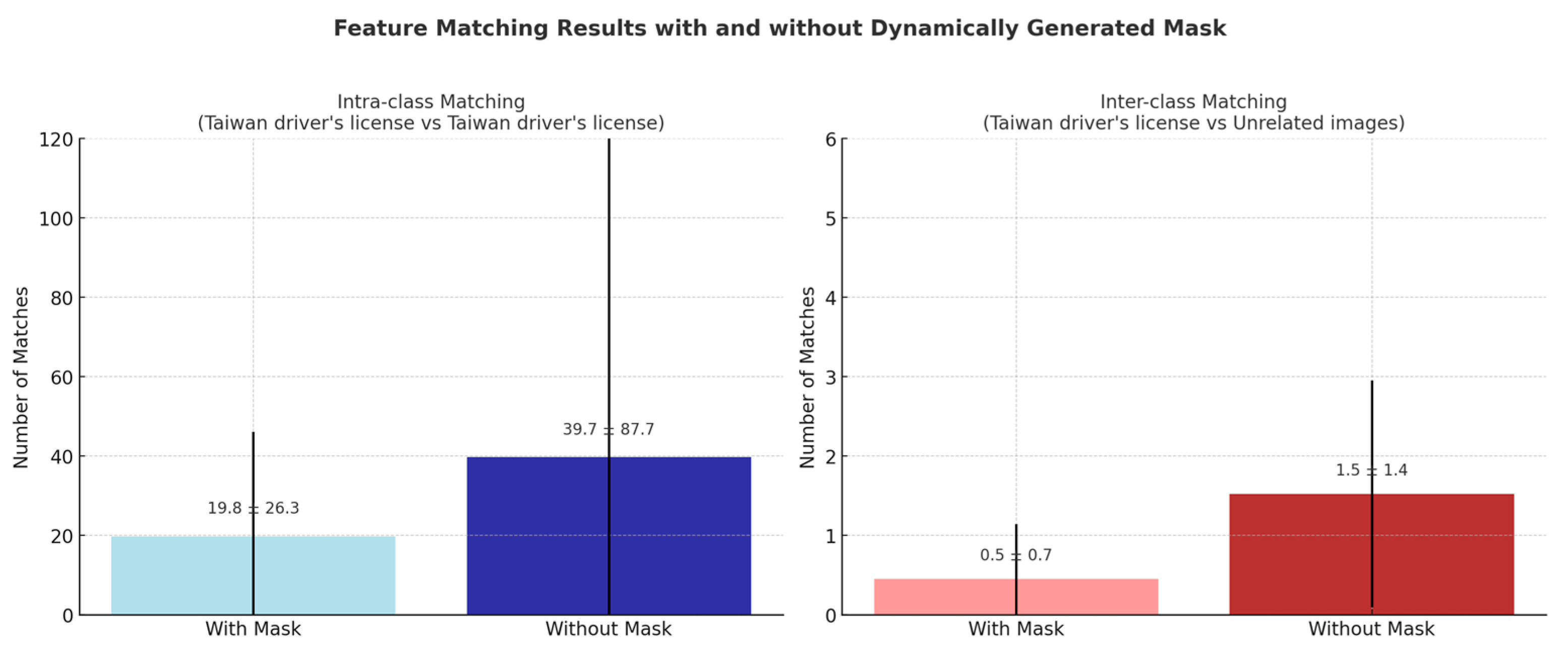
To quantitatively evaluate the effectiveness of our feature matching with the dynamically generated mask approach, we conducted a comparison experiment consisting of 12,720 matching operations. We selected 80 images of Taiwan driver’s licenses and 80 unrelated images. Each Taiwan driver’s license was used as a query image, matched against the remaining 159 target images under two configurations, with and without the dynamically generated mask. The results are shown in
Figure 8 and summarized below:
- (1)
For Taiwan driver’s license vs. Taiwan driver’s license (true positives), the mean number of valid keypoint matches was reduced by 50.1% (from 39.7 to 19.8). Additionally, the standard deviation dropped by 70.0% (from 87.7 to 26.3), indicating that matching became more consistent and focused on meaningful document regions.
- (2)
For Taiwan driver’s license vs. unrelated images (true negatives), the mean number of matches decreased by 70.4% (from 1.52 to 0.45), significantly reducing false match potential and improving overall discriminative performance.
This experiment further supports the novelty of our feature matching methods with a dynamically generated mask, which improves discriminative power and reduces noise.
4.4. Sensitive Data Recognition Evaluation on IDNet
To further validate the robustness of our Recognition Module, we evaluated it using the synthetic IDNet dataset, which is publicly available on Zenodo (DOI: 10.5281/zenodo.13854897, 10.5281/zenodo.13852734). IDNet provides synthetically generated identity documents from different countries and regions. For more rigorous evaluation, we selected three countries from the dataset with identity documents that include publicly available checksum validation mechanisms. This subset includes a total of 17,937 images, which allows us to objectively verify whether the recognized fields conform to known validity rules, providing a more grounded assessment of our module’s accuracy. Ground truth labels were not directly provided by the dataset and were manually annotated by using IDNet’s JSON metadata and official document format specifications. Specifically, labels were assigned by verifying structural elements according to the known layouts of each country’s identity card.
The resulting system performance metrics are as follows:
True Positives (TP): 477 images correctly identified.
False Positives (FP): 0 images incorrectly identified.
False Negatives (FN): 1 image containing sensitive data missed by the system.
True Negatives (TN): 17,459 images identified as images without sensitive data by the system.
This corresponds to a positive/negative sample ratio of approximately 1:36.5 (478 positive samples vs. 17,459 negative samples), reflecting a highly imbalanced real-world scenario where sensitive document exposures are rare. Evaluating under such conditions provides a more realistic test of system robustness and its ability to avoid false positives despite skewed class distributions.
The recognition evaluation results are presented in
Table 1. As shown, our system performs consistently well across ID cards from various countries. Overall, it achieves a precision of 100% and a recall of 99.7%, demonstrating the system’s effectiveness in accurately identifying sensitive information across diverse identity document formats. These results suggest that the Recognition Module is robust and adaptable to variations in document layouts and field structures.
4.5. System Time Cost Evaluation
To evaluate our system’s processing efficiency, we conducted tests on two hardware setups. System A used an Apple M1 Pro with 16 GB unified memory (Apple Inc., Cupertino, CA, USA). System B consisted of an Intel i5-12400 (6-core, 2.50 GHz) (Intel Corporation, Santa Clara, CA, USA) with an ASUS TUF Gaming GeForce NVIDIA RTX 3070 GPU and 32 GB RAM (ASUSTeK Computer Inc., Taipei, Taiwan). We report the average processing time per image in seconds for each module in the pipeline. Based on the results summarized in
Table 2, System B demonstrates significantly faster per-image performance across all modules, particularly in computation-heavy stages such as image and report generation phases. This efficiency gain is attributed to the use of a discrete GPU and higher memory bandwidth. Notably, the Generation and Report modules are the most time-consuming, indicating potential optimization targets for deployment at scale.
As part of the system evaluation, it is crucial to assess the feasibility of deploying our system within an enterprise environment. This includes considering the system’s hardware requirements, scalability, and its ability to handle real-time processing in an organizational setting. For enterprises, deploying a robust and scalable system requires careful consideration of several factors:
Hardware Infrastructure: The system can be deployed on both powerful workstations and cloud environments, depending on the scale of operations. For internal deployment, based on our evaluation, high-performance hardware with a strong GPU is recommended.
Scalability: The system is designed to be scalable. By integrating efficient algorithms and leveraging cloud infrastructure, the system can scale to process large volumes of data. For high-scale deployment, such as monitoring millions of images, cloud services with GPU acceleration (e.g., AWS, Azure) are recommended for processing efficiency.
Security and Privacy: Since the system handles sensitive data, it must be deployed with strong security measures. This includes using on-premise servers or a private cloud for data processing, ensuring that sensitive images never leave the internal network unless explicitly authorized.
4.6. Discussion
Our experimental results highlight several areas for future improvement, offering a clear roadmap for addressing the core research challenge. The Generation Module, despite demonstrating high-fidelity outputs (as validated by low pHash distances in
Figure 7), remains computationally intensive. Future research could investigate lighter-weight generative approaches, such as latent diffusion models or quantized generative models, to significantly reduce computational overhead without sacrificing visual fidelity [
26,
27].
The Report Generation Module currently incurs considerable latency due to local inference using LLMs. To enhance efficiency, future iterations could incorporate retrieval-augmented generation (RAG), leveraging external knowledge databases to rapidly generate accurate responses [
28].
From a deployment perspective, large-scale applications would benefit significantly from GPU-based parallel processing, asynchronous data pipelines, and containerized orchestration (e.g., Kubernetes clusters). By distributing tasks across multiple nodes, the system can process large volumes of images concurrently, reducing end-to-end latency and improving throughput. These technologies would allow efficient handling of substantial image volumes while maintaining robust system performance and facilitating easier integration into existing enterprise infrastructures [
29,
30].
Additionally, while recognition accuracy is already high across tested document types, broader and more diverse evaluations, particularly involving low-quality or noisy inputs, could further enhance system robustness and generalizability. Employing robust OCR algorithms specifically optimized for degraded images and integrating noise-resistant feature extraction methods would likely improve accuracy under challenging real-world conditions.
Moreover, we recognize that BRISK may be less effective under significant image rotations or scale changes. Although most real-world leaked images we encountered were front-facing and normally oriented, future work will include robustness testing using synthetic transformations, such as rotation, zoom, and skew, to better understand the system’s limitations and explore alternative descriptors with improved invariance.
Finally, addressing the human factors associated with data leakage remains crucial. Ongoing security awareness training and clear procedural guidelines for employees are essential complementary measures. Combined with proactive automated detection mechanisms, such human-centered strategies provide a comprehensive, layered defense-in-depth approach, significantly strengthening organizational resilience against data leaks.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}