
Interactive Holographic Display System Based on Emotional Adaptability and CCNN-PCG


Abstract
1. Introduction
1.1. Background
1.2. Related Studies
1.2.1. Research on Interactivity of Intelligent Digital Humans
1.2.2. Accelerating Computer-Generated Hologram Computation and Enhancing Quality
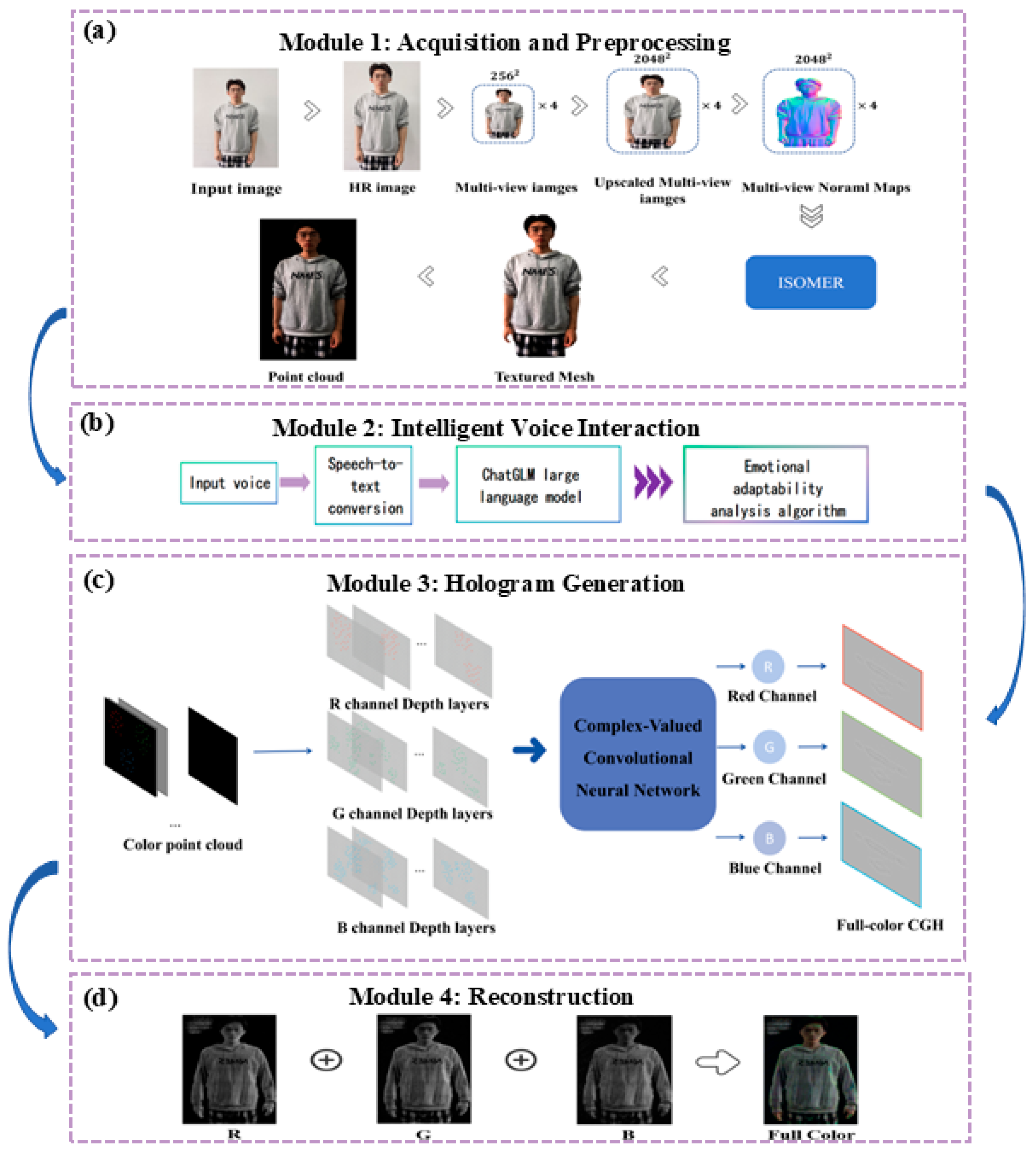
2. Full-Color Holographic System
2.1. System Architecture
- Acquisition and Preprocessing Module: This module utilizes the Unique3D framework and two-dimensional-to-three-dimensional technology to obtain depth multi-view images from single-view input, thereby generating 3D models. It performs point cloud sampling through Poisson sampling to improve the efficiency and accuracy of 3D model construction and point cloud data extraction, laying the foundation for subsequent holographic processing. Its main function is to efficiently build a digital human motion model library.
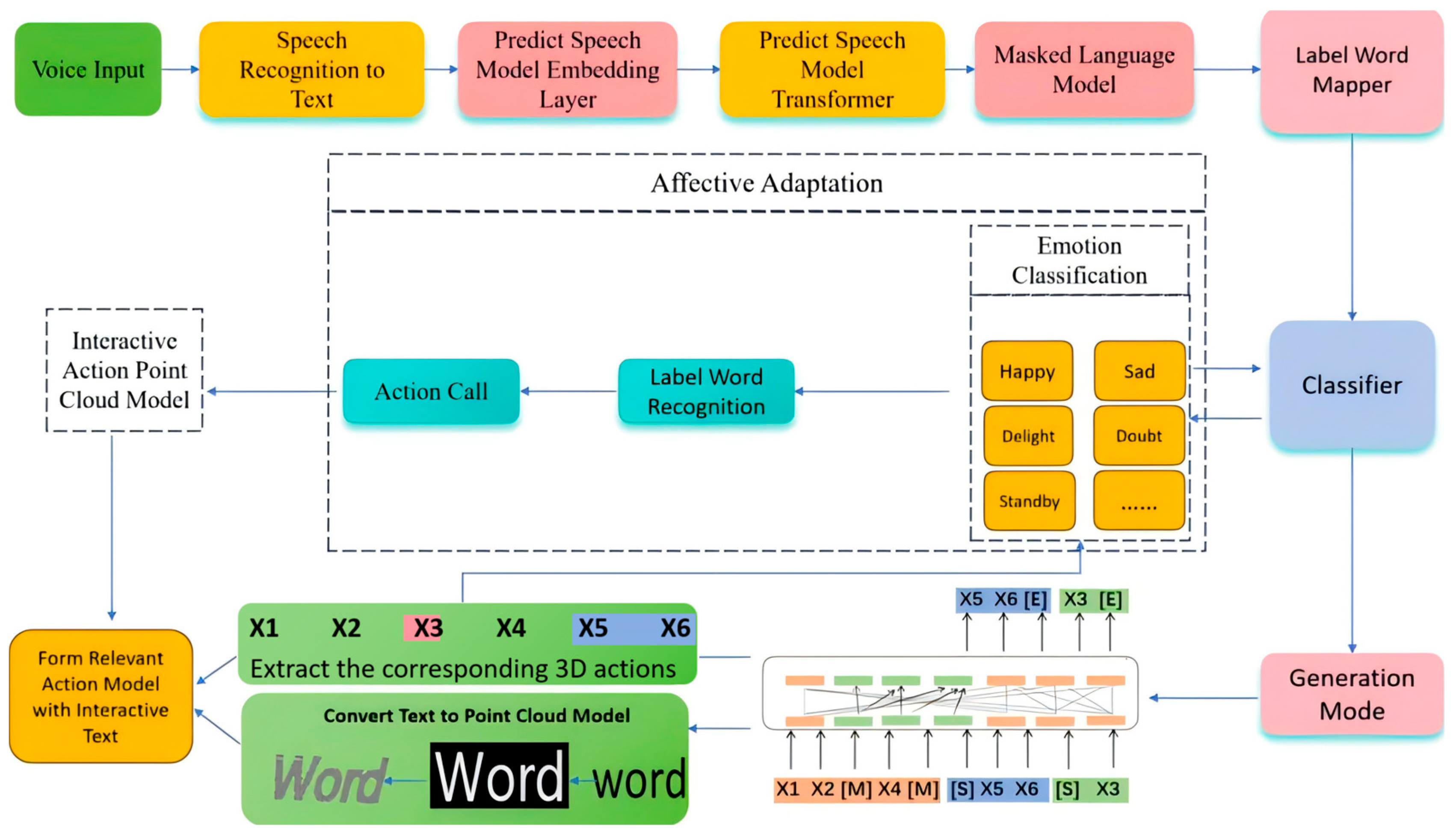
- Intelligent Voice Interaction Module: To enable real-time voice interaction in the holographic system, this module integrates the ChatGLM large language model and an emotional adaptability analysis algorithm to improve fluency and accuracy. Utilizing Microsoft’s Offline Speech Recognition API, it achieves speech-to-text conversion. The module constructs a point cloud model for digital humans that incorporates interactive textual information, enabling contextually appropriate responses through motion based on dialog content.
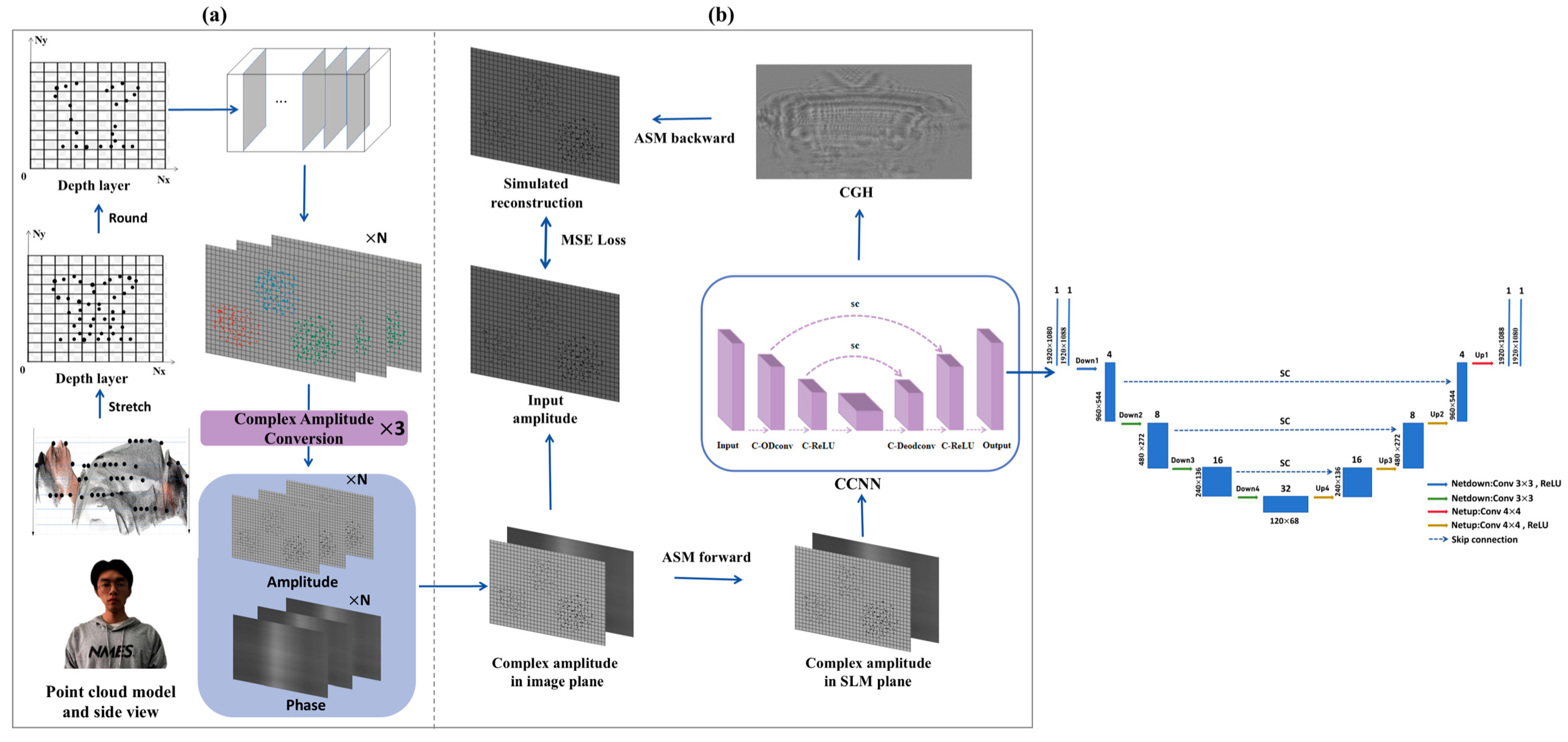
- Hologram Generation Module: This module optimizes computational architecture to achieve high-quality hologram generation with significantly improved computational efficiency by using our proposed CCNN-PCG method. The point cloud data undergoes operations such as point removal, layering, and compression into an image. Subsequently, it is divided into three channels and input into the CCNN to obtain a three-channel output of the CGH. This advancement enables dynamic holographic display capabilities.
- Reconstruction Module: This module innovatively adopts a double-layer verification mechanism. First, through high-precision numerical simulation, optical wave diffraction theory is used to simulate the hologram encoding data, and algorithms such as Fourier transform are used to verify the imaging effect in advance. Second, the module enters the optical reconstruction stage, relying on core devices such as spatial light modulators and lasers to convert digital signals into actual optical wave interference patterns. Through real-time monitoring and dynamic calibration, it ensures the spatial resolution and depth perception of color holographic images.
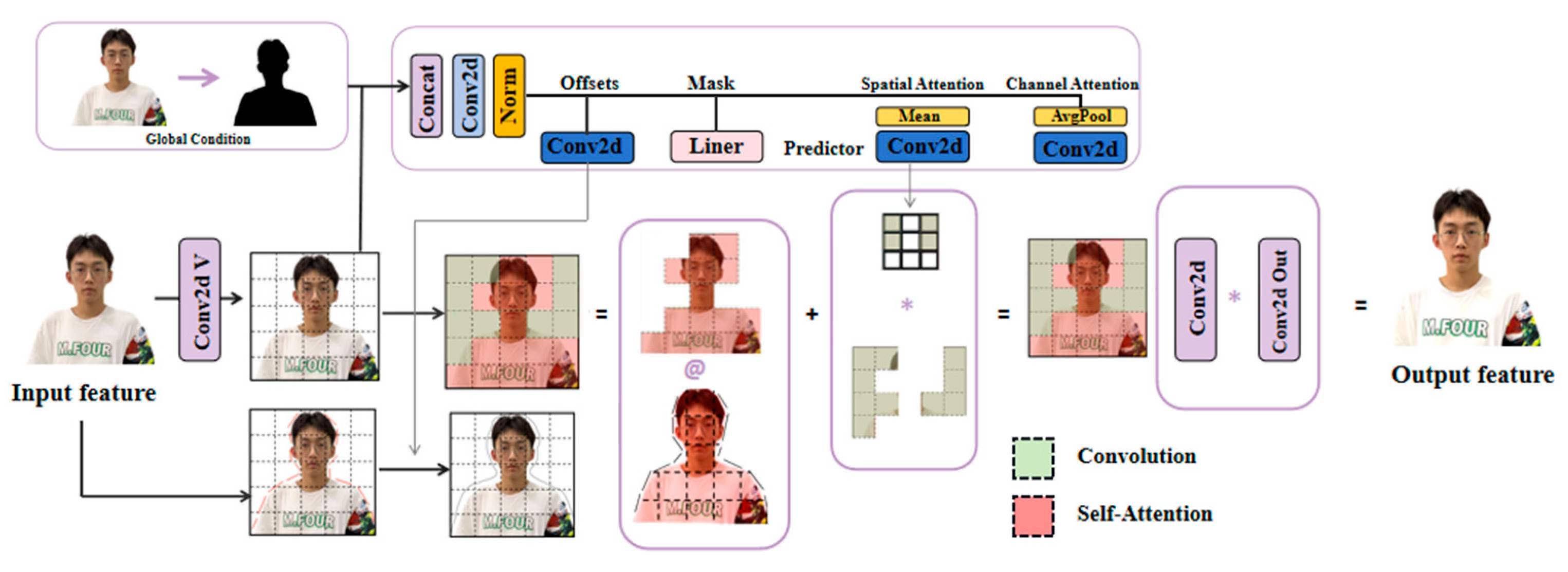
2.2. High-Quality Digital Human Model Generation and Processing
2.3. Emotional Adaptability Analysis
2.4. Complex-Valued Convolutional Neural Network Point Cloud Gridding Algorithm
3. Experiment and Results
3.1. Interactive Voice Experiment Verification
3.2. Generation Speed and Reconstructed Image Quality Enhancement
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cao, L.C.; He, Z.H.; Liu, K.X.; Sui, X.M. Progress and challenges in dynamic holographic 3D display for the metaverse. Infrared Laser Eng. 2022, 51, 267–281. [Google Scholar]
- Chen, C.P.; Ma, X.; Zou, S.P.; Liu, T.; Chu, Q.; Hu, H.; Cui, Y. Quad-channel waveguide-based near-eye display for metaverse. Displays 2023, 81, 102582. [Google Scholar] [CrossRef]
- Tang, Y.; Yi, J.; Tan, F. Facial micro-expression recognition method based on CNN and transformer mixed model. Int. J. Biom. 2024, 16, 463–477. [Google Scholar] [CrossRef]
- Tan, F.; Zhai, M.; Zhai, C. Foreign object detection in urban rail transit based on deep differentiation segmentation neural network. Heliyon 2024, 10, e37072. [Google Scholar] [CrossRef]
- Nagahama, Y. Interactive zoom display in a smartphone-based digital holographic microscope for 3D imaging. Appl. Opt. 2024, 63, 6623–6627. [Google Scholar] [CrossRef]
- Li, J.; Lai, Y.; Li, W.; Ren, J.Y.; Zhang, M.; Kang, X.H.; Wang, S.Y.; Li, P.; Zhang, Y.Q.; Ma, W.Z.; et al. Agent Hospital: A simulacrum of hospital with evolvable medical agents. arXiv 2024, arXiv:2405.02957. [Google Scholar] [CrossRef]
- Durante, Z.; Huang, Q.; Wake, N.; Gong, R.; Park, J.S.; Sarkar, B.; Taori, R.; Noda, Y.; Terzopoulos, D.; Choi, Y.; et al. Agent AI: Surveying the horizons of multimodal interaction. arXiv 2024, arXiv:2401.03568. [Google Scholar] [CrossRef]
- Prabhavalkar, R.; Hori, T.; Sainath, T.N.; Schlüter, R.; Watanabe, S. End-to-end speech recognition: A survey. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 325–351. [Google Scholar] [CrossRef]
- Yang, F.; Yang, M.; Li, X.; Wu, Y.; Zhao, Z.; Raj, B. A closer look at reinforcement learning-based automatic speech recognition. Comput. Speech Lang. 2024, 87, 101641. [Google Scholar] [CrossRef]
- Boisseau, É. Imitation and large language models. Minds Mach. 2024, 34, 42. [Google Scholar] [CrossRef]
- Wu, K.; Liu, F.; Cai, Z.; Yan, R.J.; Wang, H.Y.; Hu, Y.T.; Duan, Y.Q.; Ma, K.S. Unique3D: High-quality and efficient 3D mesh generation from a single image. arXiv 2024, arXiv:2405.20343. [Google Scholar]
- Wang, Y.; Zhao, S.J.; Liu, Y.; Li, J.L.; Zhang, L. CAMixerSR: Only Details Need More Attention. arXiv 2024, arXiv:2402.19289. [Google Scholar] [CrossRef]
- Zhao, Y.; Huang, Z.; Ji, J.; Xie, M.; Liu, W.; Chen, C.P. Holographic voice-interactive system with Taylor Rayleigh-Sommerfeld based point cloud gridding. Opt. Lasers Eng. 2024, 179, 108270. [Google Scholar] [CrossRef]
- Pan, Y.; Xu, X.; Liang, X. Fast distributed large-pixel count hologram computation using a GPU cluster. Appl. Opt. 2023, 52, 6562–6571. [Google Scholar] [CrossRef]
- Kwon, M.W.; Kim, S.C.; Kim, E.S. Three-directional motion-compensation mask-based novel look-up table on graphics processing units for video-rate generation of digital holographic videos of three-dimensional scenes. Appl. Opt. 2016, 55, A22–A31. [Google Scholar] [CrossRef]
- Pi, D.; Liu, J.; Han, Y.; Khalid, A.; Yu, S. Simple and effective calculation method for computer-generated hologram based on non-uniform sampling using ook-up-table. Opt. Express 2019, 27, 37337–37348. [Google Scholar] [CrossRef]
- Cao, H.K.; Jin, X.; Ai, L.Y.; Kim, E.S. Faster generation of holographic video of 3-D scenes with a Fourier spectrum-based NLUT method. Opt. Express 2021, 29, 39738–39754. [Google Scholar] [CrossRef]
- Shimobaba, T.; Masuda, N.; Ito, T. Simple and fast calculation algorithm for computer- generated hologram with wavefront recording plane. Opt. Lett. 2009, 34, 3133–3135. [Google Scholar] [CrossRef]
- Wang, Y.; Sang, X.; Chen, Z.; Li, H.; Zhao, L. Real-time photorealistic computer-generated holograms based on backward ray tracing and wavefront recording planes. Opt. Commun. 2018, 429, 12–17. [Google Scholar] [CrossRef]
- Shi, L.; Li, B.; Kim, C.; Kellnhofer, P.; Matusik, W. Towards real-time photorealistic 3D holography with deep neural networks. Nature 2021, 591, 234–239. [Google Scholar] [CrossRef]
- Peng, Y.; Choi, S.; Padmanaban, N.; Wetzstein, G. Neural holography with camera-in-the- loop training. ACM Trans. Graph. 2020, 39, 185. [Google Scholar] [CrossRef]
- Zhong, C.L.; Sang, X.Z.; Yan, B.B.; Li, H.; Chen, D.; Qin, X.J. Real-Time High-Quality Computer-Generated Hologram Using Complex-Valued Convolutional Neural Network. IEEE Trans. Vis. Comput. Graph. 2024, 30, 3709–3718. [Google Scholar] [CrossRef]
- Dong, Z.X.; Jia, J.D.; Li, Y.; Ling, Y.Y. Divide-Conquer-and-Merge: Memory-and Time-Efficient Holographic Displays. In Proceedings of the 2024 IEEE Conference Virtual Reality and 3D User Interfaces (VR), Orlando, FL, USA, 16–21 March 2024. [Google Scholar]
- Li, Z.S.; Liu, C.; Li, X.W.; Zheng, Y.; Huang, Q.; Zheng, Y.W.; Hou, Y.H.; Chang, C.L.; Zhang, D.W.; Zhuang, S.L.; et al. Real-time holographic camera for obtaining real 3D scene hologram. Light Sci. Appl. 2025, 14, 74. [Google Scholar] [CrossRef]
- Chen, S.; Yu, J.; Xu, X.; Chen, Z.; Lu, L.; Hu, X.; Yang, Y. Split-guidance network for salient object detection. Vis. Comput. 2023, 39, 1437–1451. [Google Scholar] [CrossRef]
- Chen, S.; Tang, H.; Huang, Y.; Zhang, L.; Hu, X. S2dinet: Towards lightweight and fast high-resolution dichotomous image segmentation. Pattern Recognit. 2025, 164, 111506. [Google Scholar] [CrossRef]
- Zhao, Y.; Bu, J.W.; Liu, W.; Ji, J.H.; Yang, Q.H.; Lin, S.F. Implementation of a full-color holographic system using RGB-D salient object detection and divided point cloud gridding. Opt. Express 2023, 31, 1641–1655. [Google Scholar] [CrossRef]
- Bu, J.W.; Zhao, Y.; Ji, J.H. Full-color holographic system featuring three-dimensional salient object detection based on a U2-RAS network. J. Opt. Soc. Am. A 2023, 40, B1–B7. [Google Scholar] [CrossRef]
- Yang, Q.H.; Zhao, Y.; Liu, W.; Bu, J.W.; Ji, J.H. A full-color holographic system based on Taylor Rayleigh-Sommerfeld diffraction point cloud grid algorithm. Appl. Sci. 2023, 13, 4466. [Google Scholar] [CrossRef]
- Sun, X.H.; Mu, X.Y.; Xu, C.; Pang, H.; Deng, Q.L.; Zhang, K.; Jiang, H.B.; Du, J.L.; Yin, S.Y.; Du, C.L. Dual-task convolutional neural network based on the combination of the U-Net and a diffraction propagation model for phase hologram design with suppressed speckle noise. Opt. Express 2022, 30, 2646–2658. [Google Scholar] [CrossRef]
- Chang, C.L.; Ding, X.; Wang, D.; Ren, Z.Z.; Dai, B.; Wang, Q.; Zhuang, S.L.; Zhang, D.W. Split Lohmann computer holography: Fast generation of 3D hologram in single-step diffraction calculation. Adv. Photonics Nexus 2024, 3, 036001. [Google Scholar] [CrossRef]
- Chao, B.; Gopakumar, M.; Choi, S.; Kim, J.; Shi, L.; Wetzstein, G. Large Étendue 3D holographic display with content-adaptive dynamic fourier modulation. In Proceedings of the SIGGRAPH Asia 2024 Conference Paper, Tokyo, Japan, 3–6 December 2024; pp. 1–12. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Points | Viewing Angle | Point Cloud Distribution | |
|---|---|---|---|
| Ours | 200,000–900,000 | 360° | Uniform distribution |
| Depth Camera | 50,000–300,000 | 180° | Concentrated distribution |
| Number | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Models | Standby1 | Standby2 | Affirmation | Negation | Instructions | Fear | Surprise |
| Number | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| Models | Ponder | Uneasiness | Confidence | Anxiety | Fatigue | Laugh | Cry |
| Network Layers | Arity | Convolution Type | Normalization Module | Activation Function | |
|---|---|---|---|---|---|
| CCNN-PCG | 3 | 938 | C-conv | Used | C-Relu |
| Holo-encoder | 8 | Million-level | Conv | Batch Normalization | Relu |
| Object | Generation Time | ||||
|---|---|---|---|---|---|
| Name | Points | Layers | PCG | Holo-Encoder | CCNN-PCG |
| Figure 7a—1 | 450,429 | 30 | 0.154 | 0.227 | 0.063 |
| Figure 7a—6 | 423,568 | 30 | 0.157 | 0.214 | 0.068 |
| Figure 7b—1 | 414,298 | 30 | 0.152 | 0.221 | 0.064 |
| Figure 7b—6 | 470,651 | 30 | 0.152 | 0.208 | 0.067 |
| Figure 7c—1 | 438,386 | 30 | 0.153 | 0.231 | 0.064 |
| Figure 7d—1 | 435,582 | 30 | 0.153 | 0.223 | 0.066 |
| Object | PSNR | ||||
|---|---|---|---|---|---|
| Name | Points | Layers | PCG | Holo-Encoder | CCNN-PCG |
| Figure 7a—1 | 450,429 | 30 | 25.41 | 20.47 | 29.34 |
| Figure 7a—6 | 423,568 | 30 | 24.18 | 20.63 | 29.32 |
| Figure 7b—1 | 414,298 | 30 | 24.22 | 19.98 | 28.95 |
| Figure 7b—6 | 470,651 | 30 | 23.46 | 20.33 | 29.01 |
| Figure 7c—1 | 438,386 | 30 | 23.33 | 21.07 | 28.87 |
| Figure 7d—1 | 435,582 | 30 | 23.74 | 19.54 | 28.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Xu, Z.; Zhang, T.-Y.; Xie, M.; Han, B.; Liu, Y. Interactive Holographic Display System Based on Emotional Adaptability and CCNN-PCG. Electronics 2025, 14, 2981. https://doi.org/10.3390/electronics14152981
Zhao Y, Xu Z, Zhang T-Y, Xie M, Han B, Liu Y. Interactive Holographic Display System Based on Emotional Adaptability and CCNN-PCG. Electronics. 2025; 14(15):2981. https://doi.org/10.3390/electronics14152981
Chicago/Turabian StyleZhao, Yu, Zhong Xu, Ting-Yu Zhang, Meng Xie, Bing Han, and Ye Liu. 2025. "Interactive Holographic Display System Based on Emotional Adaptability and CCNN-PCG" Electronics 14, no. 15: 2981. https://doi.org/10.3390/electronics14152981
APA StyleZhao, Y., Xu, Z., Zhang, T.-Y., Xie, M., Han, B., & Liu, Y. (2025). Interactive Holographic Display System Based on Emotional Adaptability and CCNN-PCG. Electronics, 14(15), 2981. https://doi.org/10.3390/electronics14152981