
NGD-YOLO: An Improved Real-Time Steel Surface Defect Detection Algorithm
 ,
,  and
and
Abstract
1. Introduction
- (1)
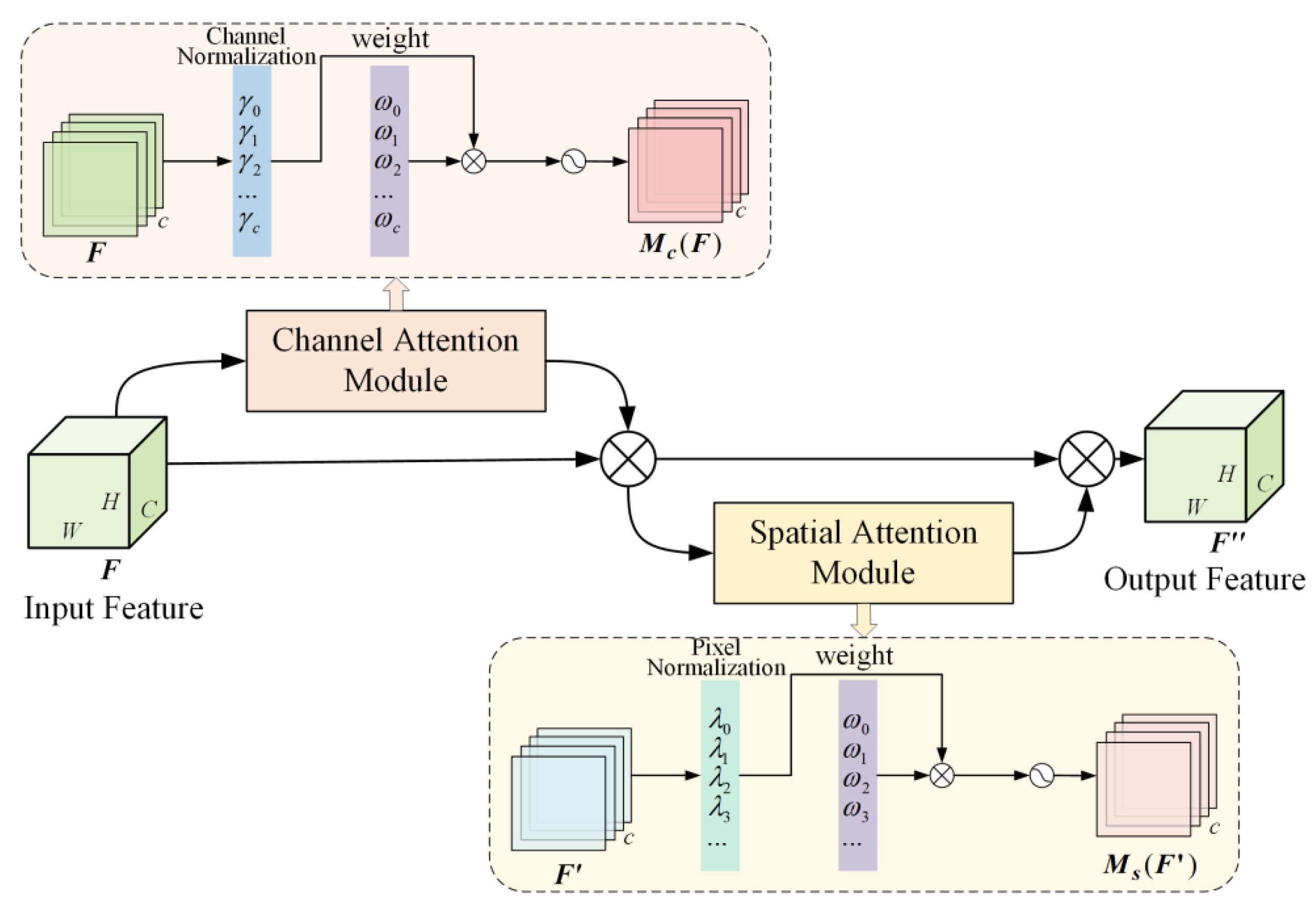
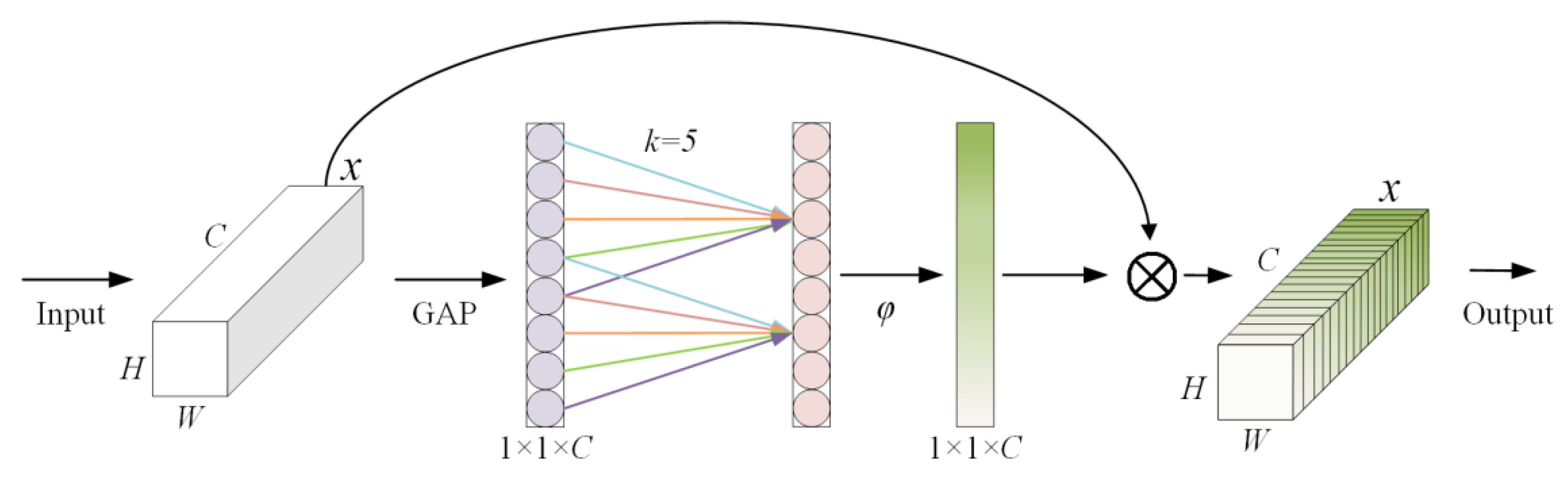
- Embedding the lightweight and efficient Normalization-based Attention Module (NAM) into the C3 module to construct a new C3NAM to enhance the multi-scale feature representation capability.
- (2)
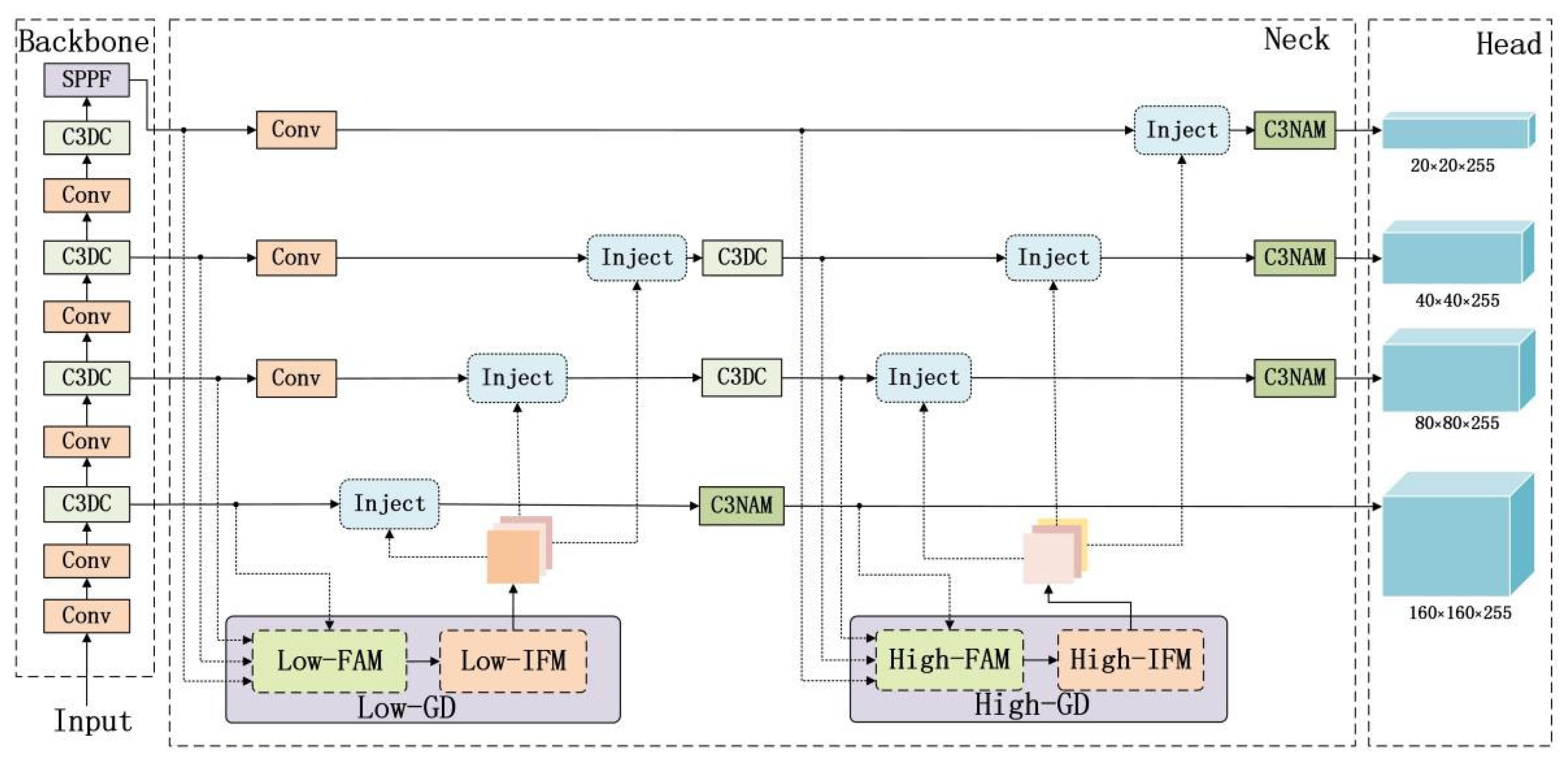
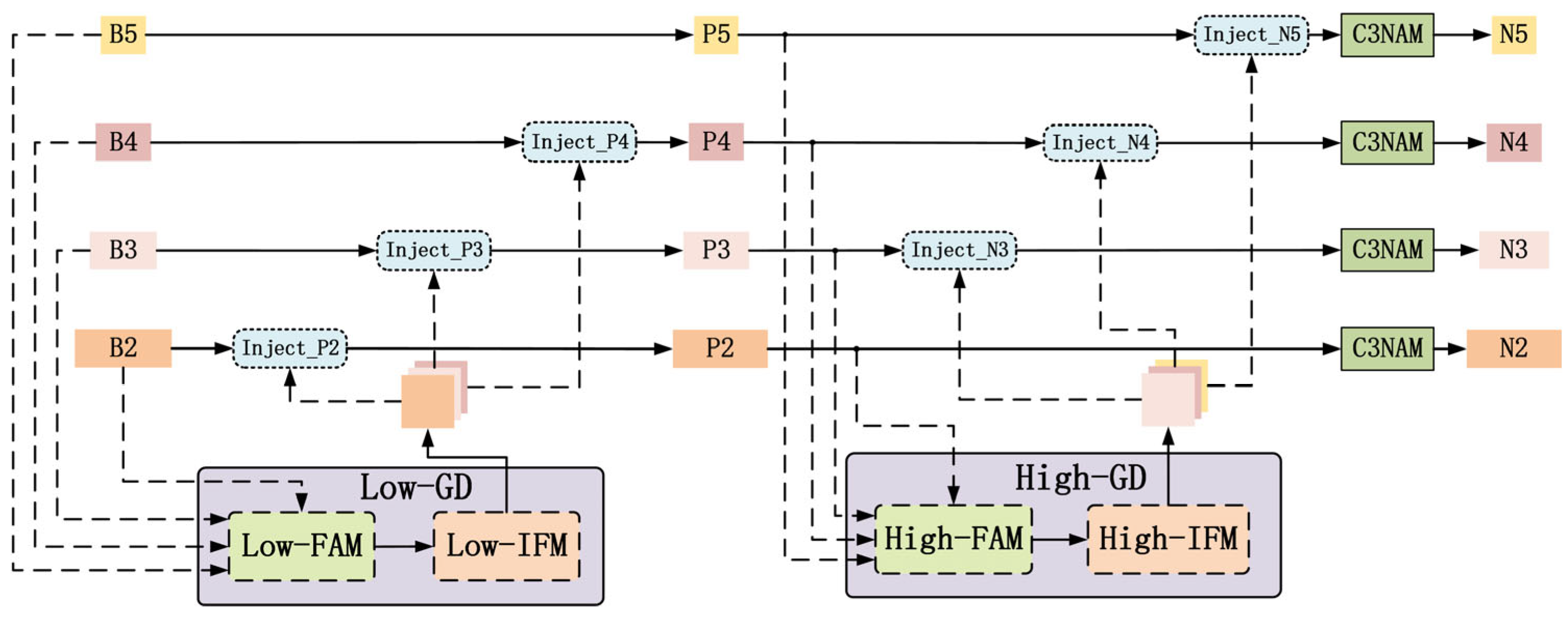
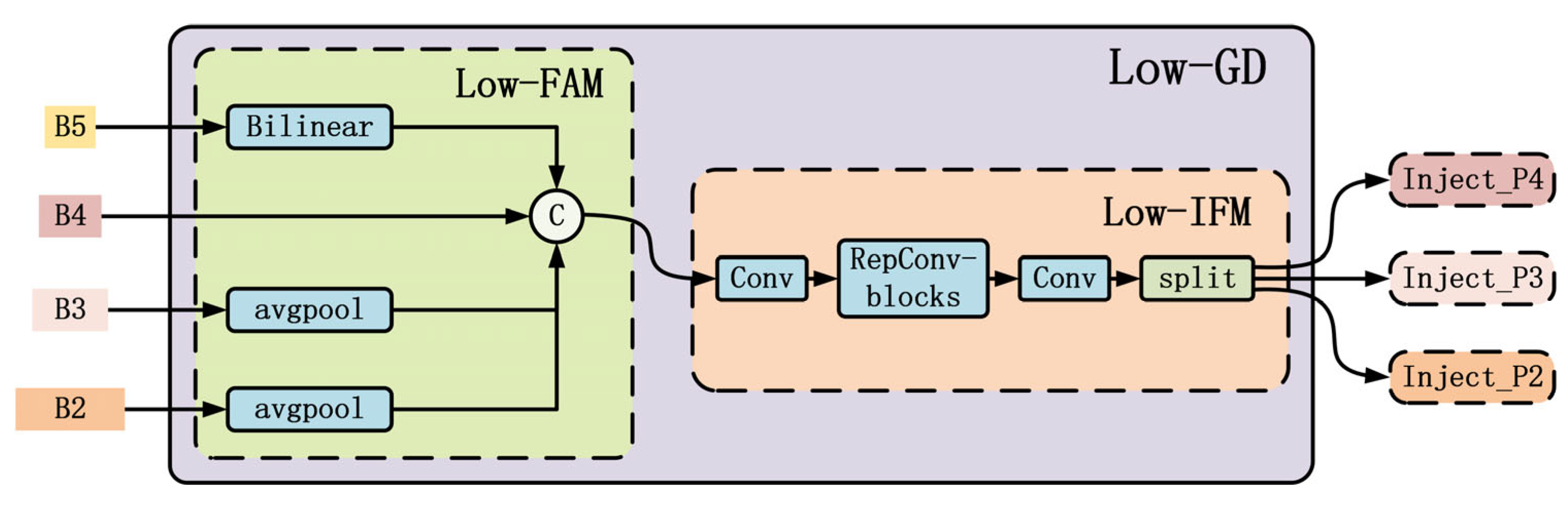
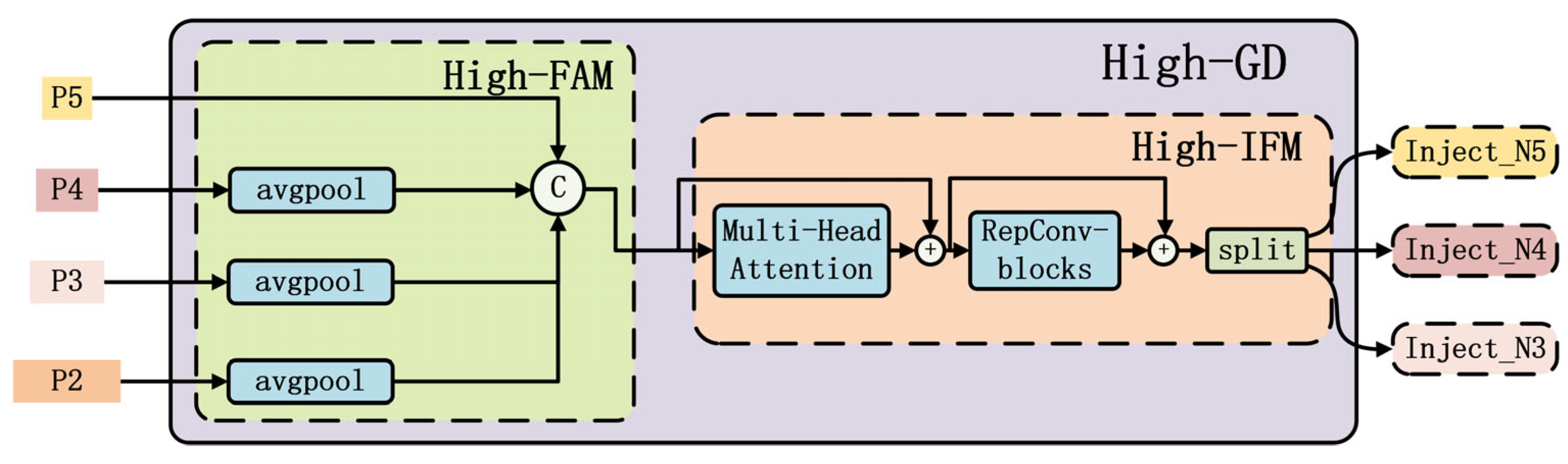
- Proposing the GD-NAM feature fusion mechanism with four detection heads, which fuses features using a Gather–Distribute (GD) approach and embeds the C3NAM to enhance representation capability, while adding a dedicated small target detection layer.
- (3)
- Proposing an efficient lightweight convolution module, DCConv, and combining it with the C3 module to construct the C3DC module, addressing the problem of ignoring channel information interaction in Depthwise Convolution (DWConv) by introducing the Efficient Channel Attention (ECA) mechanism, improving detection speed and accuracy while reducing model parameters.
2. Related Work
2.1. Deep Learning-Based Defect Detection
2.2. Synergistic Optimization Strategy of Dynamic Attention Mechanisms and Lightweight Design
2.3. Design Cross-Layer Multi-Scale Feature Fusion Networks
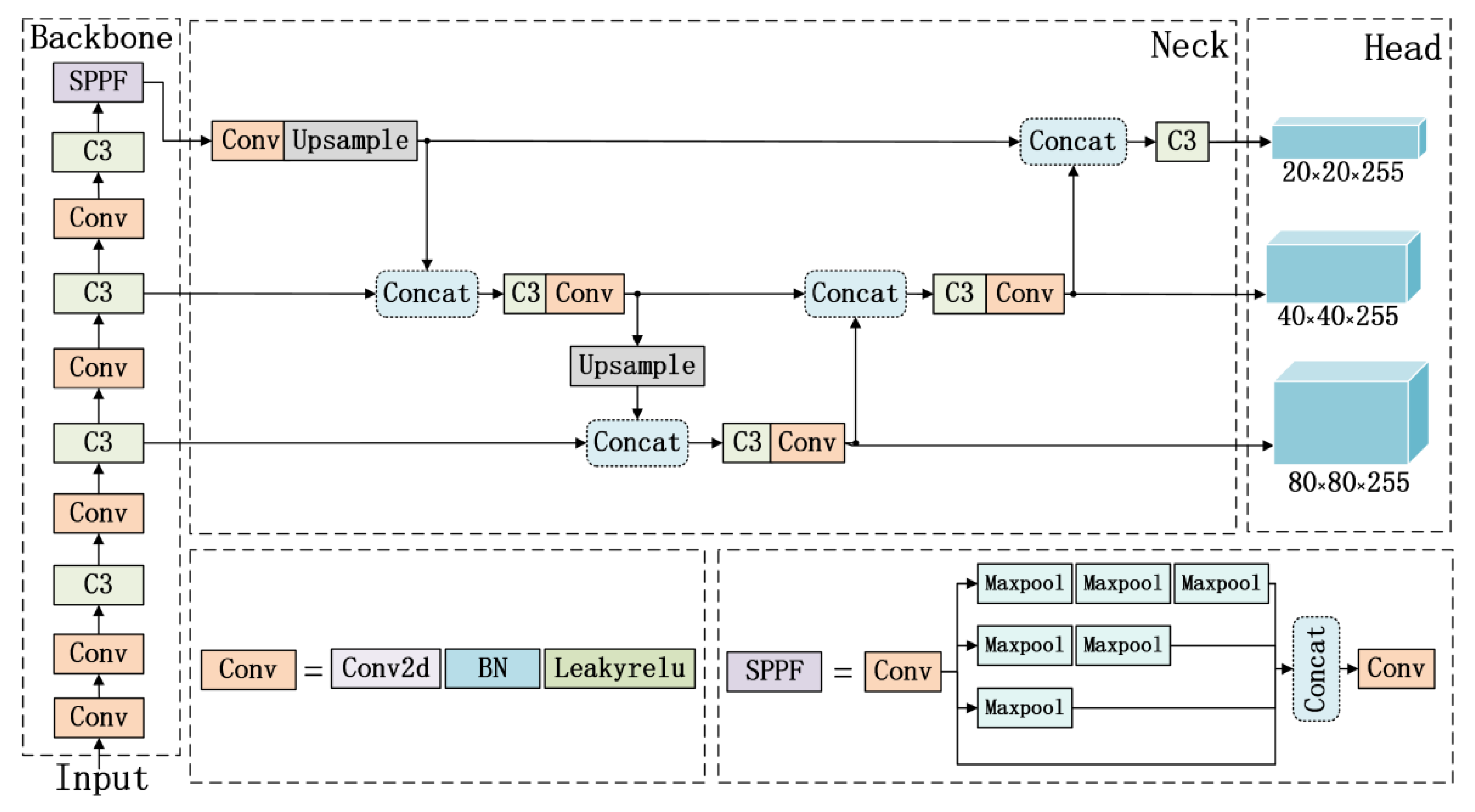
2.4. YOLOv5 Model and Its Limitations
3. NGD-YOLO Model
3.1. Convolutional Attention Module Based on C3NAM
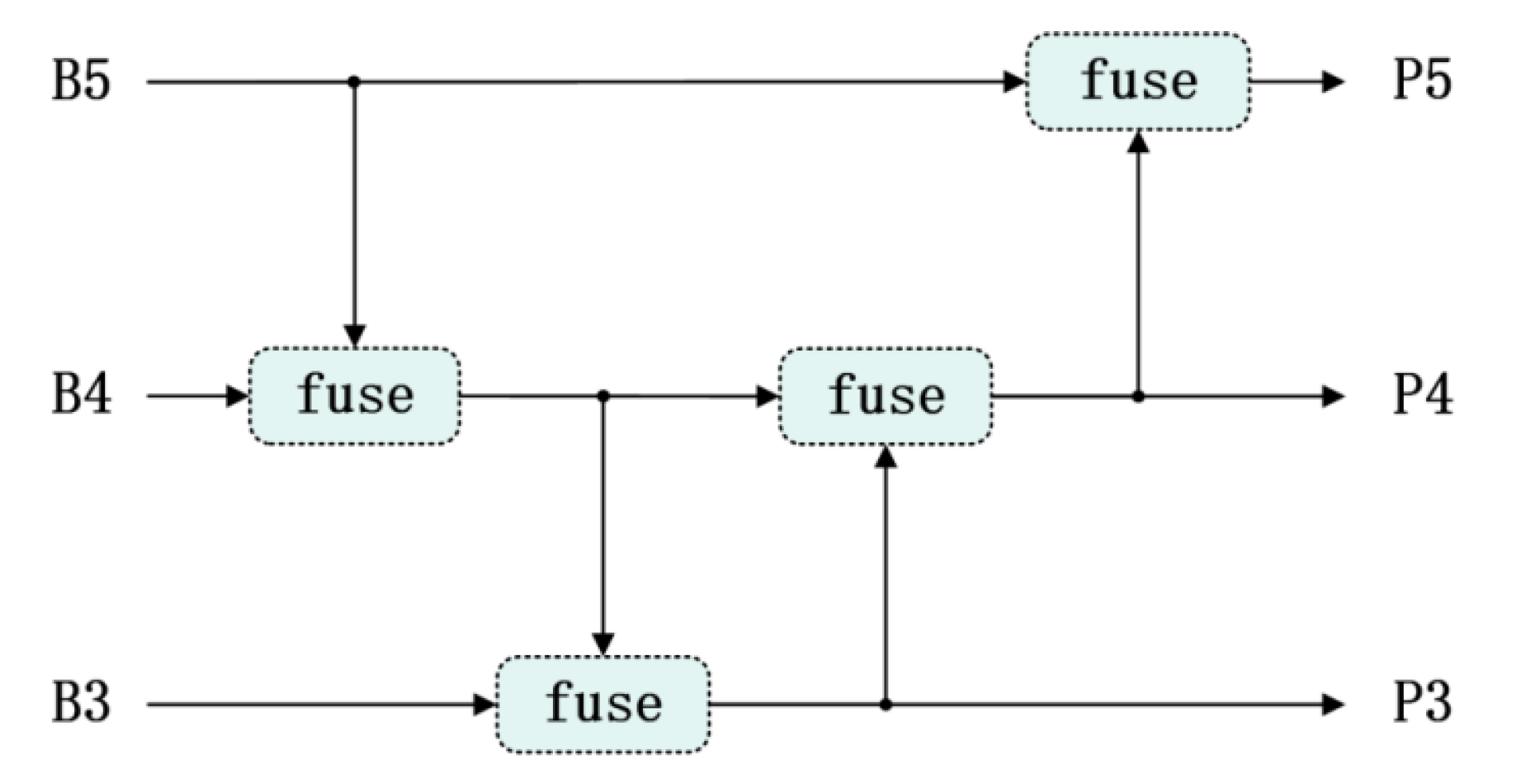
3.2. Cross-Layer Multi-Scale Feature Fusion Module Based on GD-NAM
3.3. Lightweight Convolutional Attention Module Based on C3DC
4. Experiments and Results
4.1. Experimental Set
4.2. Evaluation Indicators
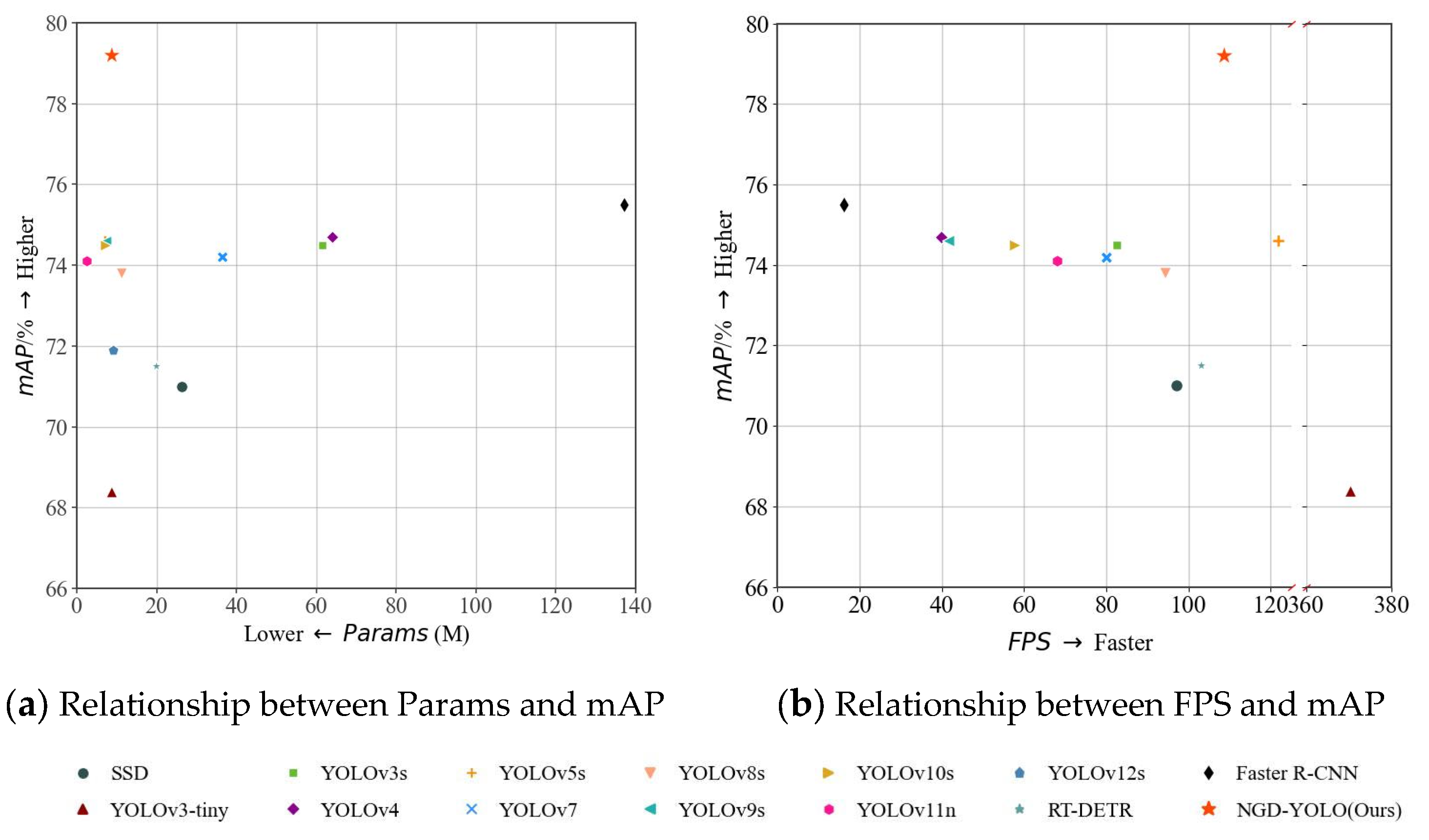
4.3. Comparative Experiment
4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, Q.; Fang, X.; Liu, L.; Yang, C.; Sun, Y. Automated Visual Defect Detection for Flat Steel Surface: A Survey. IEEE Trans. Instrum. Meas. 2020, 69, 626–644. [Google Scholar] [CrossRef]
- Saberironaghi, A.; Ren, J.; El-Gindy, M. Defect Detection Methods for Industrial Products Using Deep Learning Techniques: A Review. Algorithms 2023, 16, 95. [Google Scholar] [CrossRef]
- Nick, H.; Ashrafpoor, A.; Aziminejad, A. Damage Identification in Steel Frames Using Dual-Criteria Vibration-Based Damage Detection Method and Artificial Neural Network. Structures 2023, 51, 1833–1851. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, J.; Yu, H.; Li, F.; Yu, L.; Zhang, C. Surface Defect Detection of Steel Products Based on Improved YOLOv5. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022; School of Electrical and Information Engineering: Singapore; Tianjin University: Tianjin, China; Hebei Jinxi Iron and Steel Group: Tangshan, China, 2022; pp. 5794–5799. [Google Scholar]
- Su, Y.; Deng, Y.; Zhou, N.; Si, H.; Peng, J. Steel Surface Defect Detection Algorithm Based on Improved YOLOv5s. In Proceedings of the 2024 IEEE 6th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 24–26 May 2024; Volume 6, pp. 865–869. [Google Scholar]
- Zhang, J.; Wang, H.; Tian, Y.; Liu, K. An Accurate Fuzzy Measure-Based Detection Method for Various Types of Defects on Strip Steel Surfaces. Comput. Ind. 2020, 122, 103231. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhou, Q.; Wang, H. CABF-YOLO: A Precise and Efficient Deep Learning Method for Defect Detection on Strip Steel Surface. Pattern Anal. Appl. 2024, 27, 36. [Google Scholar] [CrossRef]
- Song, X.; Cao, S.; Zhang, J.; Hou, Z. Steel Surface Defect Detection Algorithm Based on YOLOv8. Electronics 2024, 13, 988. [Google Scholar] [CrossRef]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An End-to-End Steel Surface Defect Detection Approach via Fusing Multiple Hierarchical Features. IEEE Trans. Instrum. Meas. 2020, 69, 1493–1504. [Google Scholar] [CrossRef]
- Ye, Q.; Dong, Y.; Zhang, X.; Zhang, D.; Wang, S. Robustness Defect Detection: Improving the Performance of Surface Defect Detection in Interference Environment. Opt. Lasers Eng. 2024, 175, 108035. [Google Scholar] [CrossRef]
- Zhang, C.; Yu, J.; Zhao, Y.; Wu, H.; Wu, G. Cracks Segmentation of Engineering Structures in Complex Backgrounds Using a Concatenation of Transformer and CNN Models Driven by Scene Understanding Information. Structures 2024, 65, 106685. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Chen, J.; Liu, M.; Fu, Q.; Yao, Z. Hot Rolled Steel Strip Surface Defect Detection Method Based on Deep Learning. Autom. Inf. Eng. 2019, 40, 11–16, 19. [Google Scholar] [CrossRef]
- Xia, Y.; Lu, Y.; Jiang, X.; Xu, M. Enhanced Multiscale Attentional Feature Fusion Model for Defect Detection on Steel Surfaces. Pattern Recognit. Lett. 2025, 188, 15–21. [Google Scholar] [CrossRef]
- Cheng, X.; Yu, J. RetinaNet with Difference Channel Attention and Adaptively Spatial Feature Fusion for Steel Surface Defect Detection. IEEE Trans. Instrum. Meas. 2021, 70, 2503911. [Google Scholar] [CrossRef]
- Sun, G.; Wang, S.; Xie, J. An Image Object Detection Model Based on Mixed Attention Mechanism Optimized YOLOv5. Electronics 2023, 12, 1515. [Google Scholar] [CrossRef]
- Shi, J.; Yang, J.; Zhang, Y. Research on Steel Surface Defect Detection Based on YOLOv5 with Attention Mechanism. Electronics 2022, 11, 3735. [Google Scholar] [CrossRef]
- Tang, J.; Liu, S.; Zhao, D.; Tang, L.; Zou, W.; Zheng, B. PCB-YOLO: An Improved Detection Algorithm of PCB Surface Defects Based on YOLOv5. Sustainability 2023, 15, 5963. [Google Scholar] [CrossRef]
- Luo, T.; Wang, X.; Li, Z.; Zeng, T.; Chen, W. Steel Surface Defect Detection Based on Multi-Scale Feature Fusion. Intell. Comput. Appl. 2024, 14, 197–200. [Google Scholar]
- Chu, Y.; Yu, X.; Rong, X. A Lightweight Strip Steel Surface Defect Detection Network Based on Improved YOLOv8. Sensors 2024, 24, 6495. [Google Scholar] [CrossRef]
- Zhang, L.; Cai, J. Target Detection System Based on Lightweight Yolov5 Algorithm. Comput. Technol. Dev. 2022, 32, 134–139. [Google Scholar] [CrossRef]
- Liang, L.; Long, P.; Lu, B.; Li, R. Improvement of GBS-YOLOv7t for Steel Surfacedefect Detection. Opto-Electron. Eng. 2024, 51, 61–73. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, D. Lightweight Steel Surface Defect Detection Model Based on Machine Vision. Comput. Technol. Autom. 2024, 43, 43–49. [Google Scholar] [CrossRef]
- Ma, S.; Zhao, X.; Wan, L.; Zhang, Y.; Gao, H. A Lightweight Algorithm for Steel Surface Defect Detection Using Improved YOLOv8. Sci. Rep. 2025, 15, 8966. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Fang, H.; Liu, Z.; Zheng, B.; Sun, Y.; Zhang, J.; Yan, C. Dense Attention-Guided Cascaded Network for Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Instrum. Meas. 2022, 71, 5004914. [Google Scholar] [CrossRef]
- Shen, K.; Zhou, X.; Liu, Z. MINet: Multiscale Interactive Network for Real-Time Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Ind. Inform. 2024, 20, 7842–7852. [Google Scholar] [CrossRef]
- Han, B.; He, L.; Ke, J.; Tang, C.; Gao, X. Weighted Parallel Decoupled Feature Pyramid Network for Object Detection. Neurocomputing 2024, 593, 127809. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Han, L.; Li, N.; Li, J.; Gao, B.; Niu, D. SA-FPN: Scale-Aware Attention-Guided Feature Pyramid Network for Small Object Detection on Surface Defect Detection of Steel Strips. Measurement 2025, 249, 117019. [Google Scholar] [CrossRef]
- Ni, Y.; Zi, D.; Chen, W.; Wang, S.; Xue, X. Egc-Yolo: Strip Steel Surface Defect Detection Method Based on Edge Detail Enhancement and Multiscale Feature Fusion. J. Real-Time Image Process. 2025, 22, 65. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, W.; Li, Z.; Shu, S.; Lang, X.; Zhang, T.; Dong, J. Development of a Cross-Scale Weighted Feature Fusion Network for Hot-Rolled Steel Surface Defect Detection. Eng. Appl. Artif. Intell. 2023, 117, 105628. [Google Scholar] [CrossRef]
- Yu, X.; Lyu, W.; Wang, C.; Guo, Q.; Zhou, D.; Xu, W. Progressive Refined Redistribution Pyramid Network for Defect Detection in Complex Scenarios. Knowl.-Based Syst. 2023, 260, 110176. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Jia, L.; Zhou, Y. An Improved You Only Look Once Model for the Multi-Scale Steel Surface Defect Detection with Multi-Level Alignment and Cross-Layer Redistribution Features. Eng. Appl. Artif. Intell. 2025, 145, 110214. [Google Scholar] [CrossRef]
- Chen, J.; Jin, W.; Liu, Y.; Huang, X.; Zhang, Y. Multi-Scale and Dynamic Snake Convolution-Based YOLOv9 for Steel Surface Defect Detection. J. Supercomput. 2025, 81, 541. [Google Scholar] [CrossRef]
- Zhang, H.; Li, S.; Miao, Q.; Fang, R.; Xue, S.; Hu, Q.; Hu, J.; Chan, S. Surface Defect Detection of Hot Rolled Steel Based on Multi-Scale Feature Fusion and Attention Mechanism Residual Block. Sci. Rep. 2024, 14, 7671. [Google Scholar] [CrossRef]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Han, K.; Wang, Y. Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism. arXiv 2023, arXiv:2309.11331. [Google Scholar] [CrossRef]
- Yan, R.; Zhang, R.; Bai, J.; Hao, H.; Guo, W.; Gu, X.; Liu, Q. STMS-YOLOv5: A Lightweight Algorithm for Gear Surface Defect Detection. Sensors 2023, 23, 5992. [Google Scholar] [CrossRef]
- Yang, J.; Liu, Z. A Novel Real-Time Steel Surface Defect Detection Method with Enhanced Feature Extraction and Adaptive Fusion. Eng. Appl. Artif. Intell. 2024, 138, 109289. [Google Scholar] [CrossRef]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-Based Attention Module. arXiv 2021, arXiv:2111.124190. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | AP/% | mAP/% | Params/M | GFLOPs | FPS | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Cr | In | Pa | Ps | Rs | Sc | |||||
| SSD | 38.5 | 76.3 | 86.1 | 76.2 | 65.0 | 83.9 | 71.0 | 26.285 | 62.7 | 97.0 |
| YOLOv3-tiny | 43.4 | 80.8 | 91.3 | 57.6 | 71.4 | 66.0 | 68.4 | 8.678 | 12.9 | 370.3 |
| YOLOv3s | 43.5 | 78.2 | 90.9 | 79.5 | 62.3 | 92.4 | 74.5 | 61.524 | 154.6 | 82.6 |
| YOLOv4 | 41.1 | 78.3 | 90.1 | 81.3 | 66.1 | 91.0 | 74.7 | 63.965 | 60.0 | 39.8 |
| YOLOv5s | 43.4 | 78.4 | 90.9 | 78.5 | 67.9 | 88.7 | 74.6 | 7.026 | 15.8 | 121.9 |
| YOLOv7 | 41.3 | 79.5 | 93.7 | 74.8 | 64.0 | 91.9 | 74.2 | 36.508 | 103.2 | 80.0 |
| YOLOv8s | 47.8 | 77.6 | 91.6 | 79.8 | 54.0 | 92.2 | 73.8 | 11.128 | 28.4 | 94.3 |
| YOLOv9s | 49.0 | 79.8 | 92.8 | 81.1 | 53.6 | 91.5 | 74.6 | 7.169 | 26.7 | 41.5 |
| YOLOv10s | 49.8 | 76.8 | 92.5 | 84.2 | 51.2 | 92.7 | 74.5 | 7.220 | 21.4 | 57.8 |
| YOLOv11n | 49.7 | 75.9 | 87.9 | 83.5 | 56.4 | 91.5 | 74.1 | 2.583 | 6.3 | 68.0 |
| YOLOv12s | 36.4 | 75.0 | 92.2 | 75.6 | 59.3 | 92.6 | 71.9 | 9.077 | 19.3 | 196.1 |
| RT-DETR | 43.4 | 76.5 | 87.5 | 76.6 | 51.8 | 93.1 | 71.5 | 19.879 | 57.0 | 103.1 |
| Faster R-CNN | 46.0 | 81.2 | 88.4 | 80.6 | 64.5 | 92.5 | 75.5 | 137.099 | 370.2 | 16.1 |
| NGD-YOLO | 54.6 | 79.6 | 94.3 | 80.8 | 72.6 | 93.4 | 79.2 | 8.752 | 18.3 | 108.6 |
| Model | AP/% | mAP/% | GFLOPs | |||||
|---|---|---|---|---|---|---|---|---|
| Cr | In | Pa | Ps | Rs | Sc | |||
| Liu’s [24] | 38.9 | 81.9 | 97.2 | 88.6 | 71.4 | 90.7 | 78.1 | 10.1 |
| Ma’s [25] | 47.5 | 82.9 | 94.7 | 79.1 | 70.2 | 97.3 | 78.6 | 5.1 |
| Huang’s [35] | 54.5 | 80.2 | 93.1 | 87.4 | 79.7 | 97.0 | 80.7 | 52.0 |
| Zhang’s [37] | 51.2 | 83.1 | 91.0 | 82.2 | 71.5 | 91.8 | 78.5 | 20.1 |
| NGD-YOLO (Ours) | 54.6 | 79.6 | 94.3. | 80.8 | 72.6 | 93.4 | 79.2 | 18.3 |
| GD | NAM | Small Target | P/% | R/% | mAP/% | Params/M | GFLOPs |
|---|---|---|---|---|---|---|---|
| - | - | - | 71.3 | 72.1 | 74.6 | 7.027 | 15.8 |
| √ | 71.4 | 74.0 | 75.9 | 9.129 | 19.8 | ||
| √ | √ | 72.7 | 75.6 | 76.2 | 9.128 | 19.8 | |
| √ | √ | √ | 76.1 | 71.3 | 76.8 | 9.212 | 21.0 |
| DWConv | ECA | P/% | R/% | mAP/% | Params/M | GFLOPs |
|---|---|---|---|---|---|---|
| - | - | 75.8 | 74.4 | 78.2 | 9.212 | 21.0 |
| √ | 74.3 | 71.2 | 77.3 | 8.596 | 17.5 | |
| √ | √ | 76.4 | 73.5 | 79.2 | 8.752 | 18.3 |
| C3NAM | GD-NAM | C3DC | P/% | R/% | mAP/% | Params/M | GFLOPs |
|---|---|---|---|---|---|---|---|
| - | - | - | 71.3 | 72.1 | 74.6 | 7.027 | 15.8 |
| √ | 70.4 | 75.0 | 75.6 | 7.027 | 15.8 | ||
| √ | 76.1 | 71.3 | 76.8 | 9.212 | 21.0 | ||
| √ | 74.6 | 72.4 | 77.0 | 6.607 | 13.6 | ||
| √ | √ | 75.8 | 74.4 | 78.2 | 9.212 | 21.0 | |
| √ | √ | 70.4 | 77.6 | 77.4 | 8.751 | 18.3 | |
| √ | √ | 75.7 | 71.8 | 77.8 | 6.609 | 13.6 | |
| √ | √ | √ | 76.4 | 73.5 | 79.2 | 8.752 | 18.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Xiao, A.; Hu, X.; Zhu, S.; Wan, G.; Qi, K.; Shi, P. NGD-YOLO: An Improved Real-Time Steel Surface Defect Detection Algorithm. Electronics 2025, 14, 2859. https://doi.org/10.3390/electronics14142859
Li B, Xiao A, Hu X, Zhu S, Wan G, Qi K, Shi P. NGD-YOLO: An Improved Real-Time Steel Surface Defect Detection Algorithm. Electronics. 2025; 14(14):2859. https://doi.org/10.3390/electronics14142859
Chicago/Turabian StyleLi, Bingyi, Andong Xiao, Xing Hu, Sisi Zhu, Gang Wan, Kunlun Qi, and Pengfei Shi. 2025. "NGD-YOLO: An Improved Real-Time Steel Surface Defect Detection Algorithm" Electronics 14, no. 14: 2859. https://doi.org/10.3390/electronics14142859
APA StyleLi, B., Xiao, A., Hu, X., Zhu, S., Wan, G., Qi, K., & Shi, P. (2025). NGD-YOLO: An Improved Real-Time Steel Surface Defect Detection Algorithm. Electronics, 14(14), 2859. https://doi.org/10.3390/electronics14142859