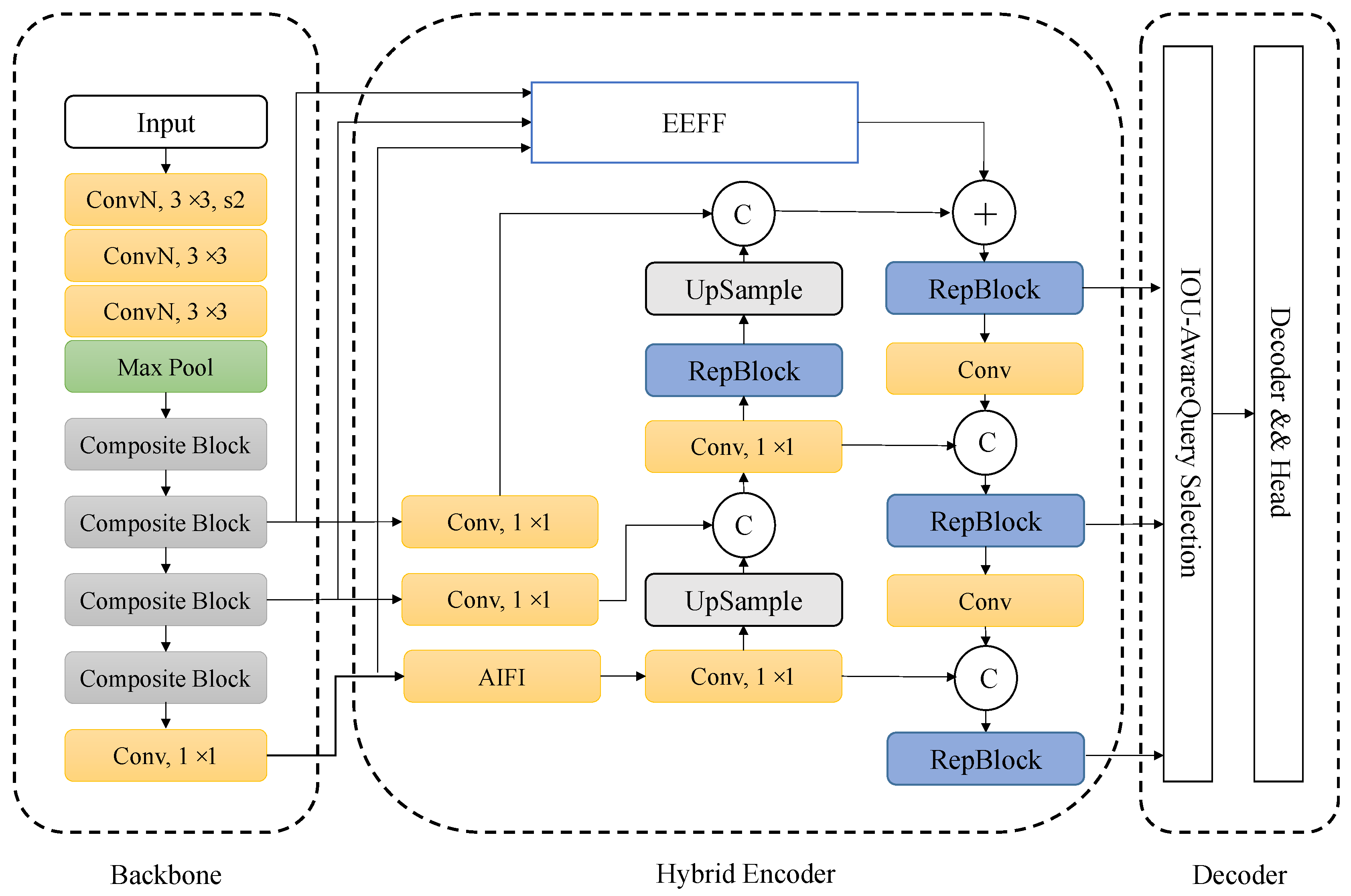
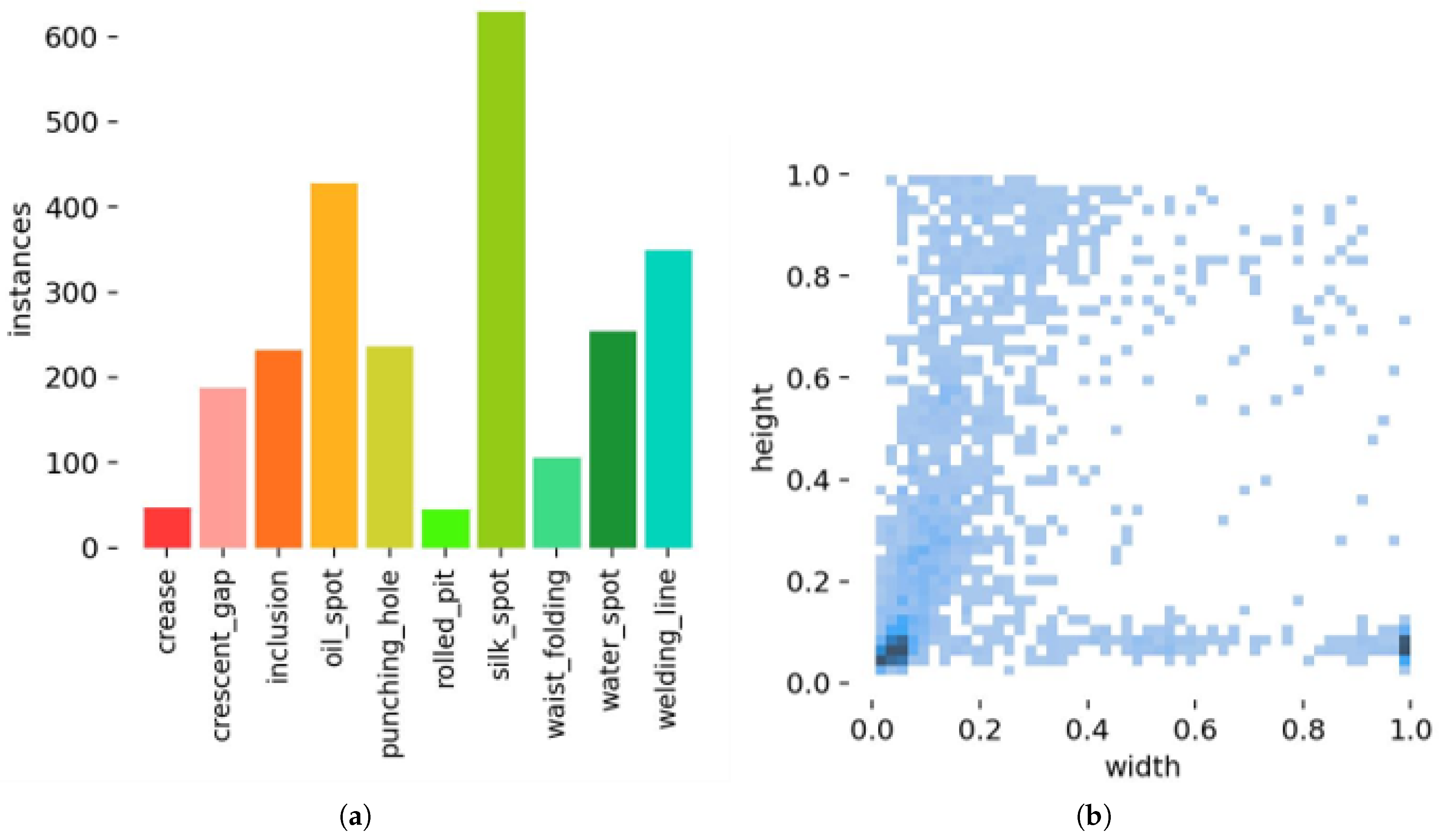
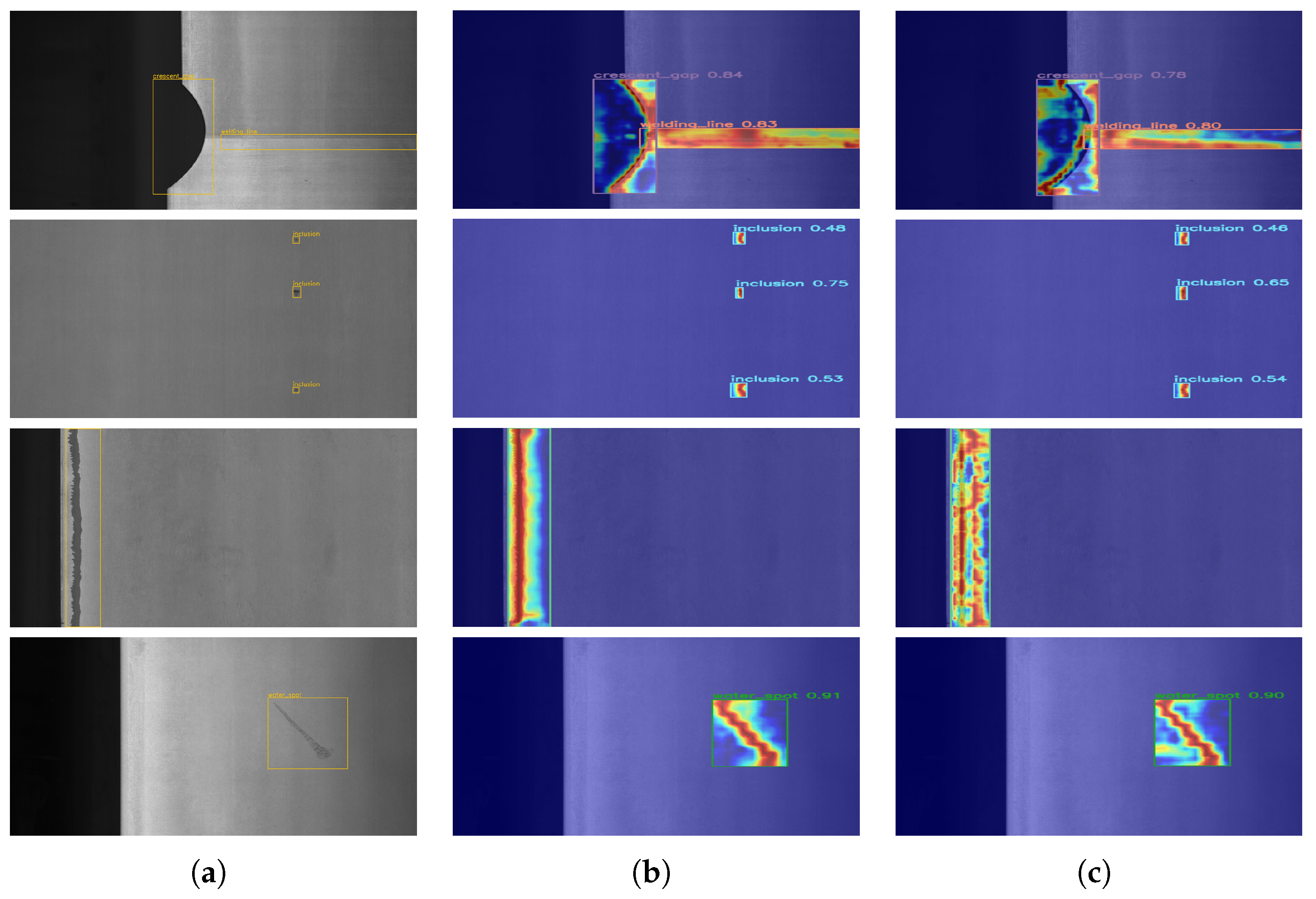
In this section, we provide a detailed introduction to our proposed MESC-DETR model and elaborate on the functional description of each module in the network. First, we present the RT-DETR model, which serves as the foundation of our algorithm. Subsequently, we offer comprehensive descriptions of key enhancements, including the composite backbone structure C-ConvNeXt, the edge-enhanced feature fusion (EEFF) structure, and the improved loss function Focal-MPDIoU loss.
3.3. C-ConvNeXt
The original RT-DETR algorithm employs two backbone variants, namely, the classical ResNet network and Baidu’s proprietary HGNetV2, with ResNet being the predominantly adopted version in current implementations. However, through empirical analysis, this study reveals that the baseline RT-DETR configuration demonstrates suboptimal performance in defect image feature learning. This limitation may stem from the significant domain gap between conventional detection datasets (e.g., COCO) and steel defect imagery, coupled with the inadequate transfer learning performance of ResNet-like architectures in industrial defect detection scenarios. Our experimental findings identify that the incorporation of ConvNeXtV2 networks effectively addresses this problem, substantially improving detection performance. Furthermore, by introducing the DHLC structure, we propose the novel Composite-ConvNeXtV2 (C-ConvNeXt) architecture, which significantly increases the backbone’s feature extraction capabilities beyond the baseline ConvNeXtV2.
ConvNeXt (the convolutional network), proposed by Liu et al. [
16] in 2020, demonstrated the untapped potential of CNNs by surpassing both Vision Transformers (ViT) and Swin Transformers using a pure CNN architecture. The key modifications include the following: (1) redesigning the block ratio distribution by adjusting the original ResNet-50 configuration from (3,4,6,3) blocks to an optimized (3,3,9,3) arrangement; and (2) revamping the initial convolutional layer with a 4 × 4 kernel and stride 4 to downsample 224 × 224 inputs to 56 × 56 resolution. Furthermore, ConvNeXt enhances network performance through grouped convolution operations and inverted bottleneck structures. ConvNeXtV2 was proposed by Woo et al. [
17] in 2023, and serves as the architectural foundation for our redesigned backbone in RT-DETR. The ConvNeXtV2 framework integrates a fully convolutional masked autoencoder (FCMAE) mechanism whose core principle involves randomly masking specific regions of input images and training the model to reconstruct these occluded areas. Compared to conventional masked autoencoder (MAE) architectures, FCMAE replaces fully-connected layers with fully convolutional operations, thereby enhancing feature extraction capabilities without computational overhead inflation. Additionally, FCMAE incorporates multi-scale masking strategies to enable hierarchical feature perception. ConvNeXtV2 further introduces global response normalization (GRN) layers to strengthen inter-channel feature competition through channel-wise excitation mechanisms. Given the specialized training paradigm of FCMAE, our implementation selectively adopts ConvNeXtV2’s backbone architecture while deliberately excluding its self-supervised training methodology. This redesigned backbone demonstrates significantly enhanced defect feature extraction capabilities compared to RT-DETR’s original ResNet and HGNetV2 implementations. The performance advantages of the ConvNeXtV2-based architecture will be empirically validated in subsequent experimental analyses.
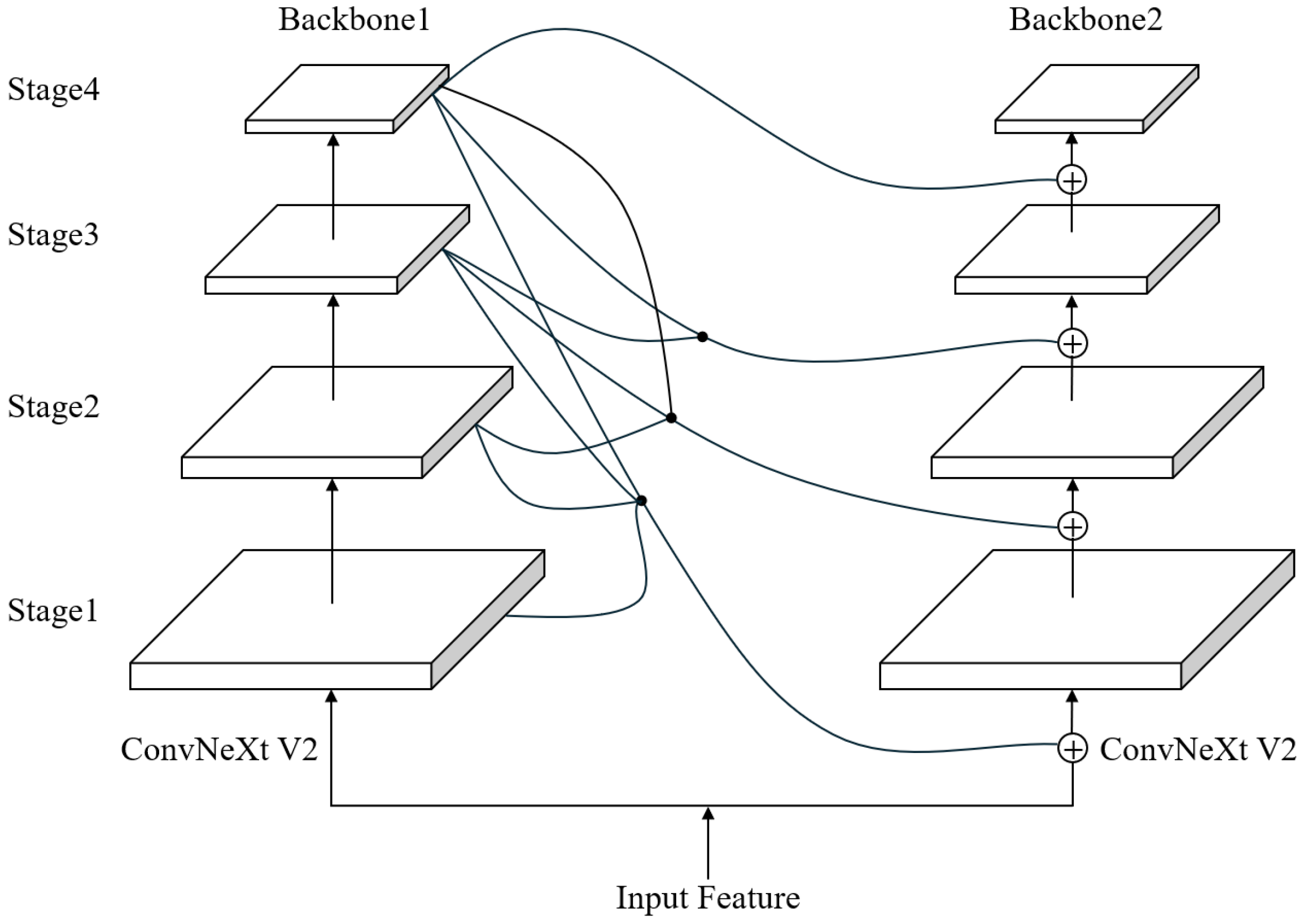
In object detection systems, the performance of detection algorithms is predominantly contingent upon the backbone network architecture, where more effective structural designs can yield substantial performance gains. To further enhance the network capabilities beyond ConvNeXtV2, this study introduces the dense higher-level composition (DHLC) methodology for interconnecting dual backbone networks. Originally proposed by Liang et al. [
18] in CBNet, the DHLC mechanism enables dense integration of multi-level features from multiple homogeneous backbones. Through progressively expanding receptive fields across cascaded networks, this architectural framework facilitates more effective detection via hierarchical feature integration.
Inspired by this, this study proposes a backbone as Composite-ConvNeXt (C-ConvNeXt), which is formed by combining two ConvNeXtV2 networks through the DHLC connection method, with its architecture illustrated in
Figure 3. For the composite connection
, it takes
from the previous auxiliary backbone as input and outputs a feature of the same size as
. The specific operations of DHLC are detailed in (
1). Here, each backbone model consists of
L stages, where
denotes a
convolutional layer, and
represents a group normalization layer. For example, in the left backbone network, each layer is upsampled to the same resolution and summed with the input feature maps. These combined results then undergo convolution and group normalization (
) to form the first-layer output of the right backbone network. Finally, this processed output is fed into the subsequent EEFF architecture as part of its input features.
Composite-ConvNeXt combines higher-level features from the previous backbone network and incorporates them into lower-level layers of the subsequent backbone. this study employs Composite-ConvNeXt to replace the original feature extraction backbone in RT-DETR, thereby enhancing the global defect feature acquisition capability. In the experimental section that follows, we will analyze the rationality of backbone replacement and investigate the performance and speed characteristics of composite structures with varying numbers of backbone components.
3.4. EEFF Module
In defect detection tasks, defect images differ significantly from traditional object detection images. Metal defect images exhibit large variations in scale, including extremely small defect samples, and some defect categories have blurry edges, making accurate recognition and localization a major challenge. To address these issues, this study proposes an edge-enhanced feature fusion (EEFF) structure to solve the aforementioned two problems, with the overall module architecture shown in
Figure 4. The EEFF comprises the two following components: the SSFF feature fusion architecture and the EEM (edge enhancement module).
To address the challenge of capturing feature information from numerous small and medium-sized defects in the dataset, we introduce an SSFF module [
19] into the algorithm to capture multi-scale feature information. The SSFF module takes three-layer feature maps from the backbone as input. Among these three layers, two are derived from the intermediate backbone layers processed through the DHLC structure, whereas the third layer is obtained by applying dimensionality adjustment via a 1 × 1 convolution to the output of the entire backbone network. Specifically, the method adopts the central layer as a reference framework, leveraging 1 × 1 convolutional filters and nearest-neighbor interpolation to modify channel counts and feature map dimensions in neighboring upper/lower levels, synchronizing them with the central layer while maintaining cross-layer feature alignment consistency. Subsequently, an unsqueeze operation transforms the feature maps into a 4D format (dimensions: depth, height, width, channels), which concatenates them along the depth dimension to form a 3D feature map, preserving multi-scale information. This 3D feature map is further processed using 3D convolutions, 3D batch normalization, and Leaky ReLU activation to effectively capture multi-scale defect target information.
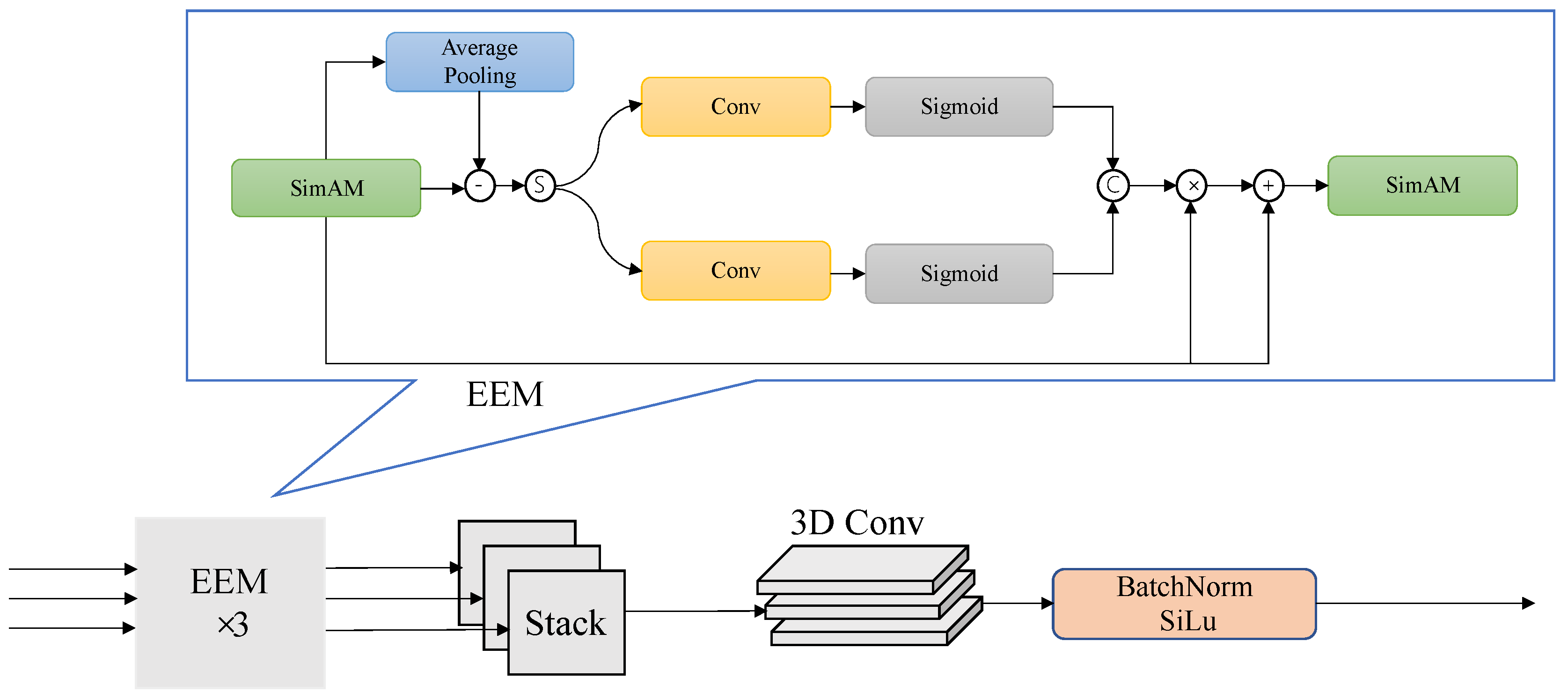
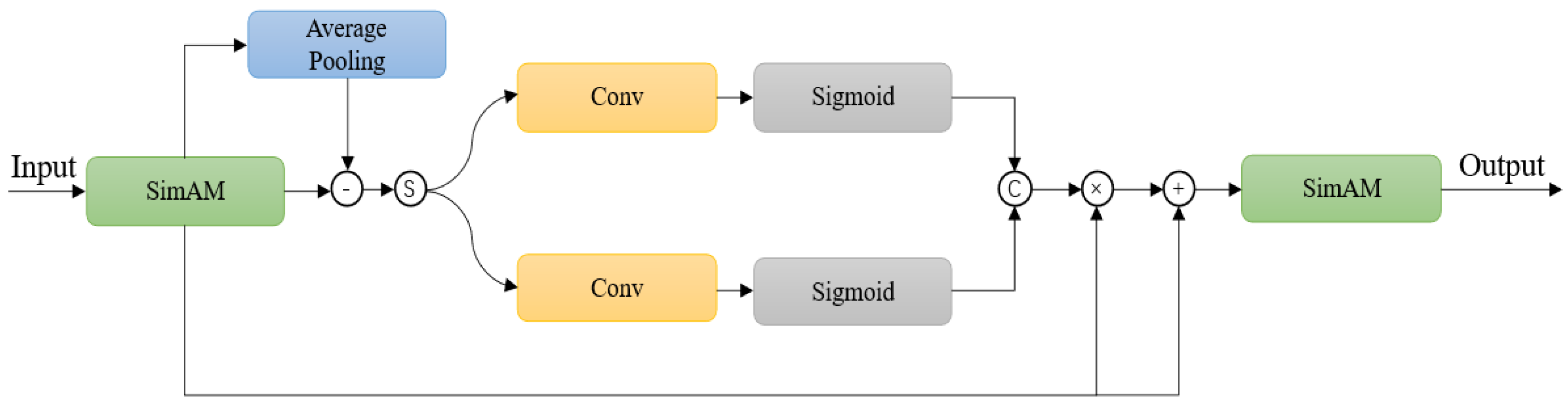
To address the issue of blurred defect edges, we propose an Edge Enhancement Module (EEM) to extract and enhance edge information in features. The overall workflow of the module is illustrated in
Figure 5. In the EEM, the first-level input features are initially preprocessed using SimAM attention to identify regions of interest. After SimAM processing, the EEM employs pooling, subtraction, and convolution to extract edge features. Edge features typically manifest as high gradient values. By applying average pooling, the features are smoothed, and then a subtraction operation is performed to subtract the averaged features, thereby highlighting the edge regions. The workflow transitions into a dual-branch structure, employing a 1 × 1 convolutional layer fused with a sigmoid activator to amplify edge feature clarity and prominence. Subsequent refinement occurs via element-wise product and summation mechanisms to intensify these processed signals. Finally, the SimAM attention mechanism is reapplied to focus on critical regions, yielding the refined output feature
. The overall workflow of the EEM module is as follows:
where
stands for the 1 × 1 convolution;
for the average pool;
for the activation function of the sigmoid. Unlike other edge feature extraction methods (e.g., TAFFNet), our method explicitly extracts edge gradients through SimAM-guided pooling-subtraction operations and dual-branch amplification, enabling precise localization of blurred defect contours.
3.5. Focal-MPDIoU Loss
To enhance the model’s training accuracy and convergence speed, this section proposes a novel regression loss. The overall loss function is defined in Equation (
5). Where
represents the proposed bounding box regression loss, and
retains the original uncertainty-minimization selection algorithm from RT-DETR. Here,
and
y denote the predicted and ground truth values, respectively, while
and
correspond to the predicted and ground truth bounding box coordinates and class labels.
The cross-entropy loss (CEL) is widely used in classification tasks, and its formulation is defined in Equation (
6), where
p denotes the predicted probabilities and
Y represents the ground truth labels. Since the ground truth values
are binary (either 0 or 1), Equation (
6) can be simplified to Equation (
7).
During model training, if there is an imbalance between positive and negative samples, the model tends to focus excessively on negative samples. Since negative samples (typically background images) belong to easy-to-classify categories, the training process can become dominated by these easily classifiable negative samples, adversely affecting the model’s convergence performance. To address this issue, Lin et al. [
20] proposed a novel loss function called focal loss, as shown in Equation (
8).
By examining Equations (
8), it can be observed that focal loss introduces a penalty term
compared to the traditional cross-entropy loss, where the factor
ensures the penalty term
is always positive. Consequently,
. However, the difference of
becomes larger when
is higher and smaller when
is lower. This indicates that focal loss prioritizes predictions with higher
values more than the original cross-entropy loss (CEL), enabling the model to achieve better performance on harder-to-classify samples. Currently, in classification tasks, focal loss has demonstrated exceptional capability in handling imbalanced datasets.
When using the traditional Intersection over Union (IoU) as a loss function, it suffers from several limitations. For instance, the loss becomes zero when bounding boxes do not overlap, which halts training progress; moreover, it fails to distinguish between different overlap scenarios when IoU values are identical. To address these issues, researchers have proposed improved variants such as GIoU [
21], DIoU [
22], and CIoU [
23]. However, these methods still exhibit significant limitations when handling cases where bounding boxes partially overlap and have aspect ratios similar to the ground truth boxes. To optimize performance in such scenarios, this work adopts the MPDIoU method proposed by Ma et al. [
24]. In essence, MPDIoU enhances IoU by introducing an optimization term that reduces the IoU value through the incorporation of distances between the top-left and bottom-right corners of the predicted and ground truth bounding boxes. A detailed formulation is provided in Equation (
9). By leveraging
, the method effectively mitigates the occurrence of overlapping regression boxes with similar characteristics. Here, (
), (
) denote the top-left and bottom-right point coordinates of
A and (
), (
) denote the similar point coordinates of
B.
To achieve higher training precision, this study draws inspiration from the loss function design of Zhang et al. [
25], integrating
with focal loss to propose the Focal-MPDIoU loss (F-MPDIoU loss). During model training, the number of negative samples (background regions) in predictions significantly outweighs positive samples (target objects), resulting in a large proportion of low-quality, low-IoU regression outcomes. These suboptimal predictions hinder the effective minimization of the loss function. To address this issue, we enhance the original MPDIoU by incorporating insights from focal loss. As illustrated in Equation (
8), focal loss introduces an adaptive scaling factor
to balance the contribution of positive and negative samples during loss computation. Building on this principle, we augment
with a penalty term
. The complete formulation of Focal-MPDIoU loss is provided in Equation (
10).
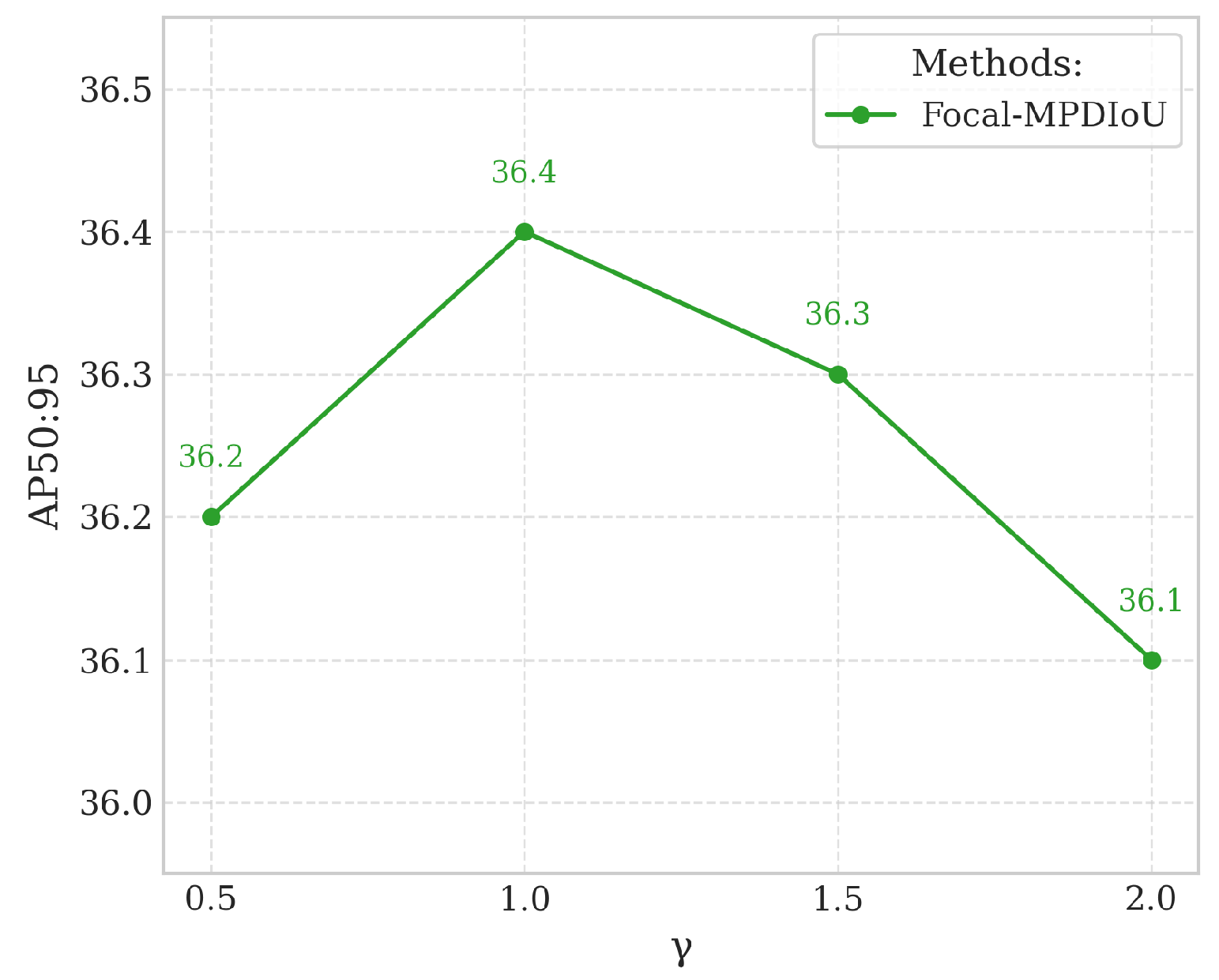
Here, serves as the penalty term control factor, set to 0.5 in experiments. When the predicted bounding box has a very small IoU value (indicating low confidence in the sample, which is likely a negative instance), the term approaches zero. This mechanism effectively reduces training oscillations caused by low-quality samples and achieves balanced weighting between positive and negative samples. Here, low-quality samples refer to anchor boxes or predicted boxes that exhibit minimal overlap with ground truth target boxes (e.g., very low IoU values) and contribute little meaningful information to model training.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}