1. Introduction
The proliferation of location-based services (LBSs) and the rise of smart environments have fueled a significant demand for accurate and reliable indoor localization systems. Among various indoor positioning technologies, Wi-Fi-based localization has become a widely adopted solution due to its low deployment cost and ease of implementation by leveraging existing Wi-Fi infrastructure in wireless local area networks (WLANs). In particular, Wi-Fi fingerprinting, which utilizes standard signal measurements such as the received signal strength indicator (RSSI) from each Access Point (AP), has gained considerable popularity for its practicality, cost-effectiveness, and relatively straightforward implementation [
1].
Wi-Fi fingerprinting typically consists of two phases: an offline phase and an online phase. In the offline phase, RSSI measurements are collected from wireless access points (WAPs) at predefined reference locations, known as reference points (RPs). The collected RSSI values, in combination with the location information of the RPs, are utilized to construct a radio map that characterizes the signal environment of the target area. In the online phase, when a user attempts to estimate their location, their device measures current RSSI values from the surrounding WAPs. These measurements are then compared with the pre-constructed radio map to determine the user’s location.
Machine learning (ML) techniques have been extensively employed in the online phase for location determination. Support vector machine (SVM)-based localization methods [
2,
3,
4,
5] learn signal patterns from RSSI data and classify them using hyperplanes; however, they can suffer from slow training and inference times, particularly with large-scale or high-dimensional datasets. Random forest (RF) has been utilized in studies [
6,
7,
8,
9] due to its proficiency in handling large-scale fingerprint datasets by leveraging multiple decision trees, though it still requires significant computational resources during training. Weighted k-nearest neighbor (WKNN)-based methods [
10,
11,
12] offer advantages in terms of computational efficiency and implementation simplicity. However, they are sensitive to environmental changes and are often limited in their ability to capture the complex, non-linear relationship between RSSI values and physical locations [
13]. Recent advancements in computational capabilities, coupled with improvements in data availability, have paved the way for deep learning (DL)applications in Wi-Fi fingerprinting. Techniques employing autoencoders, convolutional neural networks (CNN), and recurrent neural networks (RNN) have been effectively applied to learn intricate and sequential patterns in RSSI data, thereby significantly enhancing localization accuracy and flexibility [
14,
15,
16,
17,
18].
Effective application of ML and DL techniques requires both sufficient quantity and high quality of training data. However, in real-world deployment scenarios, maintaining a sufficient volume of up-to-date fingerprint data is challenging, as the periodic recollection process is labor-intensive and time-consuming. This makes it difficult to sustain high-quality signal maps in dynamic environments, especially under real-time or batch processing constraints. To address this, prior research has primarily focused on two strategies. The first involves employing learning algorithms adept at handling data scarcity, such as semi-supervised [
19] and unsupervised learning techniques [
20]. The second strategy leverages data augmentation to synthetically expand the dataset by increasing the number of RPs. Common approaches include interpolation [
21], pathloss model calibration [
22], and generative models such as generative adversarial networks (GANs) [
23]. For example, Njima et al. [
23] proposed a GAN-based method that generates synthetic RSSI data under limited labeled scenarios by combining semi-supervised learning with a filtering mechanism to remove unrealistic samples. Sugasaki et al. [
24] introduced a Between-Location augmentation method—adapted from between-class learning—which linearly mixes two samples and applies normalization; to better suit Wi-Fi fingerprinting, they incorporated a neural network-based generative model reflecting the physical continuity of labels and RSSI characteristics. Tang et al. [
25] developed an RNN-based localization model enhanced with multi-output Gaussian process (MOGP)-based augmentation to improve interpretability and robustness in complex indoor environments, while these approaches contribute to dataset expansion and model generalization, they often assume relatively complete seed data and do not explicitly address the issue of missing data within individual fingerprint vectors.
A critical aspect of Wi-Fi fingerprint data quality is the pervasive problem of missing data. These missing entries can arise from numerous non-human factors, such as temporary sensor or communication module failures, signal interference, packet loss during transmission, and intermittent system outages [
26]. Furthermore, environmental dynamics, including unstable power supplies to WAPs, alterations in indoor structures or obstacles, and even user mobility patterns, can significantly compromise the stability of RSSI collection, frequently leading to incomplete fingerprint vectors where expected signals from certain WAPs are not recorded. Furthermore, missing RSSI readings can occur due to transient signal fluctuations, interference, or other unknown factors, leading to inconsistent sets of observed WAPs even at the same RP across different data collection instances. Such inconsistencies and incompleteness in the fingerprint vectors significantly impair a model’s ability to accurately learn the underlying mapping between RSSI patterns and physical locations. While some general data augmentation techniques might incidentally model or smooth over missingness (e.g., through learned representations in GANs), or rely on simple pre-imputation steps, they often fail to directly and probabilistically model the missing data mechanism itself. This can lead to the propagation of errors, introduction of bias, or failure to capture the true signal characteristics necessary for robust localization.
To illustrate the prevalence of this missing data problem, we analyzed the UJIIndoorLoc dataset [
27], a widely used benchmark collected in a multi-building, multi-floor environment with multiple devices over an extended period. Let
denote the set of RPs within a 5 m radius of the
i-th RP, and let
and
represent the sets of WAPs observed at the
i-th and
j-th RPs, respectively. We denote each RP as
, where
j indicates the index of the
j-th reference point. In an ideal scenario with no missing data, one would expect
and
to be highly similar for
. To quantify the discrepancy, we define the missing rate
for each RP as follows:
Figure 1 demonstrates that a significant number of RPs exhibit non-zero missing
, indicating the prevalence of incomplete RSSI observations. Only approximately 18.2% of the dataset shows a low missing rate (below 0.2). The majority of RPs, accounting for 59.1% of the dataset, fall within the moderate missing rate range of 0.2 to 0.4. Although the proportion decreases in the higher missing rate range (0.4 to 0.8), it still constitutes a non-negligible 22.4%. In rare cases, RPs exhibit extremely high missing rates, with values reaching up to the 0.9–1.0 range.
These findings underscore that substantial discrepancies exist in the observed WAP sets even among spatially proximate RPs. This highlights a fundamental limitation in real-world fingerprint datasets, especially those collected over extended durations and under diverse conditions. The missing components might be naively ignored, poorly imputed, or their absence misinterpreted by a generative process that is not specifically designed for data completion. This can diminish the quality and realism of the augmented data, potentially reducing the generalization performance and robustness of the localization model, especially in environments characterized by high signal variability or sparse WAP coverage. Therefore, a significant gap exists for augmentation strategies that shift the primary focus from mere dataset expansion to the fundamental task of feature-level data completion and quality enhancement. Such strategies would explicitly recognize and address the missing data problem at its core, aiming to create more complete and veridical training samples as a prerequisite or integral part of any subsequent augmentation or model training.
To directly tackle this specific challenge of data incompleteness, we introduce FALoc, a novel framework designed to train robust localization models. Critically, FALoc re-envisions data augmentation for Wi-Fi fingerprinting not merely as a means of dataset expansion, but as a targeted process of feature-level data conditioning and completion. The core innovation of FALoc lies in its sophisticated mechanism for understanding and rectifying data incompleteness before or as an integral part of the augmentation process. It begins by constructing a bipartite graph representing the relationships between RPs and WAPs. A variational graph auto-encoder (VGAE) [
28] is then employed to model not only the RSSI values themselves but, crucially, the observation probabilities of these RSSIs. Based on these learned probabilities, FALoc intelligently decides whether to impute missing features with values generated by the VGAE or, in some cases, to remove features that are deemed unreliable or uninformative. This explicit modeling of missingness and the subsequent principled imputation or deletion at the feature level distinguishes FALoc from conventional augmentation methods that primarily generate new data points or transform existing ones without such focused handling of missing entries. These augmented data variants, which offer a more complete and consistent representation of the signal landscape, are then used to enrich the training data for the downstream localization model. We evaluated the performance of FALoc using the UJIIndoorLoc dataset [
27] and UTSIndoorLoc dataset [
16], a large-scale benchmark for Wi-Fi fingerprinting indoor localization. Our experimental results demonstrate that FALoc effectively handles missing data, leading to a significant improvement in localization accuracy.
The main contributions of this paper are as follows:
The identification and emphasis of missing data as a critical, yet often inadequately addressed, quality defect in Wi-Fi fingerprinting, distinct from general data scarcity.
The proposal of FALoc, a novel framework that leverages a bipartite graph representation and a VGAE to perform a distinct form of feature-level data augmentation, primarily focused on the principled imputation and handling of missing RSSI values, rather than solely on dataset expansion.
A comprehensive evaluation of a real-world dataset demonstrating the effectiveness of FALoc in enhancing localization performance specifically in the presence of prevalent missing data.
The remainder of this paper is organized as follows:
Section 2 details the proposed FALoc framework.
Section 3 presents the experimental setup and performance evaluation.
Section 4 discusses the findings and suggests future work. Finally,
Section 5 concludes the paper.
2. Proposed Framework
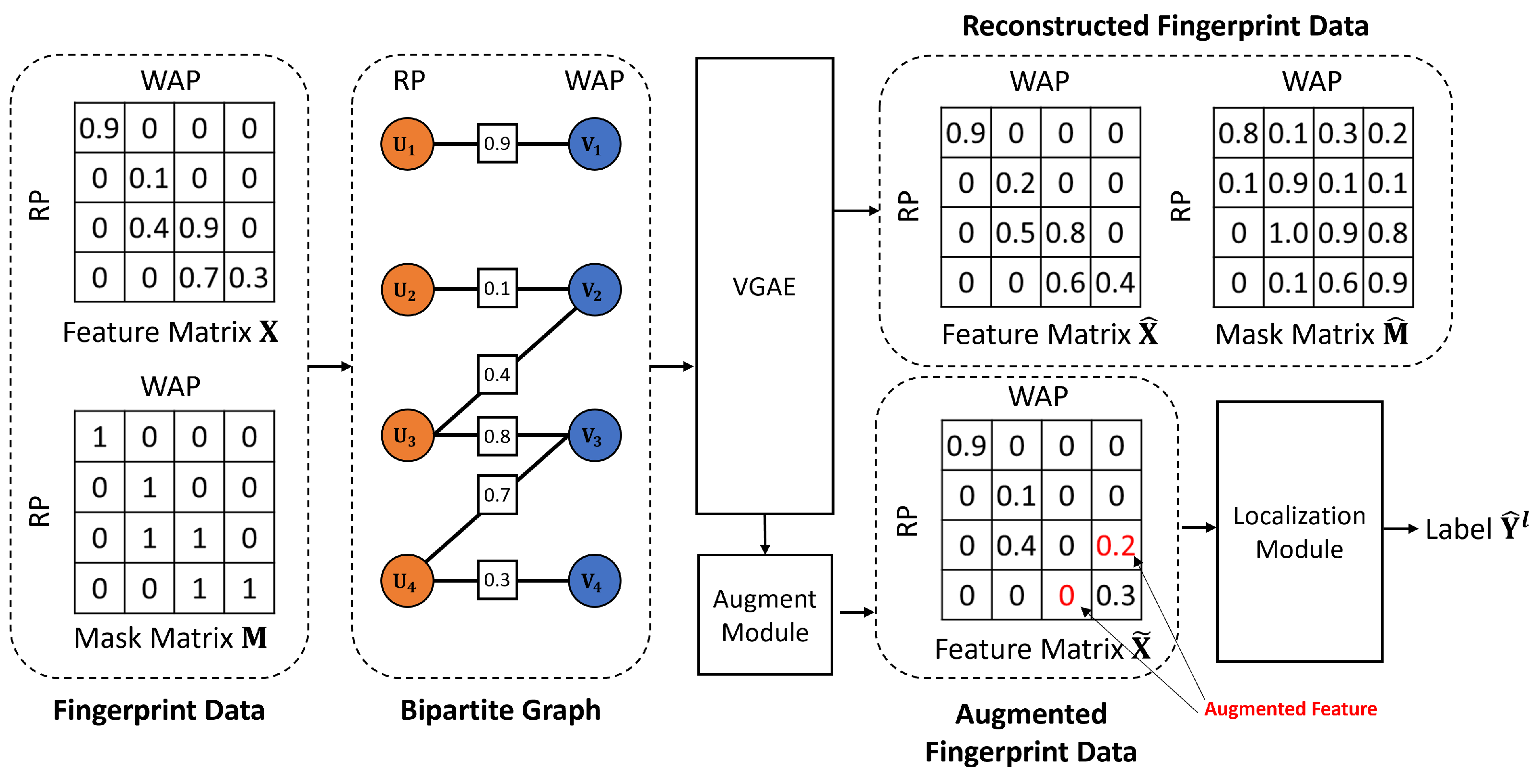
This section details the architecture and components of our proposed framework, FALoc (Feature-level Augmentation for Localization), specifically designed to address the challenge of missing RSSI values in Wi-Fi fingerprint data and thereby enhance indoor localization accuracy. FALoc leverages a graph-based representation of fingerprints, a VGAE to model RSSI observations and values, and a novel augmentation module to generate enriched training data for a neural network-based localization model. An overview of the FALoc framework is presented in
Figure 2.
The process begins with the input fingerprint data, consisting of a feature matrix (containing normalized RSSI values) and a corresponding binary mask matrix (indicating observed RSSI measurements). Due to the inherent sparsity and dynamic nature of real-world Wi-Fi environments, many entries in are typically missing, as reflected by zeros in . To capture the structural relationships within these data, a bipartite graph is constructed where RPs and WAPs form two distinct sets of nodes. An edge exists between an RP and a WAP if an RSSI measurement is observed (i.e., ), with the normalized RSSI value serving as an edge feature.
This graph is then processed by a VGAE, which learns latent embeddings for both RP and WAP nodes. The VGAE aims to reconstruct both the graph structure (i.e., the mask matrix , representing predicted RSSI observation probabilities) and the edge features (i.e., the RSSI values ). The encoder part of the VGAE utilizes graph attention mechanisms to aggregate neighborhood information effectively. The augmentation module subsequently leverages the outputs of the VGAE’s decoder ( and ) to stochastically generate augmented fingerprint data . This involves deciding whether to preserve an existing RSSI value, impute a missing one using if suggests a high likelihood of existence, or potentially remove an existing but seemingly unreliable observation. Finally, the augmented fingerprint data serves as input to a localization module, typically a neural network, which is trained to estimate the location labels . By training on these enriched and more complete fingerprints, the localization model is expected to achieve improved robustness and accuracy, particularly in scenarios with sparse or missing measurements.
2.1. Bipartite Graph Representation of Wi-Fi Fingerprints
The foundation of FALoc is the representation of Wi-Fi fingerprint data as a bipartite graph, which naturally models the interactions between two distinct types of entities: RPs and WAPs. The bipartite graph structure is known to effectively capture the underlying relationships in highly sparse and irregular wireless signal environments, as it enables expressive graph-based latent representations [
29]. The dataset, comprising RSSI measurements from
WAPs at
RPs, is initially represented by a feature matrix
and an observation mask matrix
. Each element
in
indicates the presence (1) or absence (0) of an RSSI measurement from the
k-th WAP at the
i-th RP. The corresponding normalized RSSI value
is defined as follows:
In Equation (2),
is the raw RSSI value from the
k-th WAP at the
i-th RP, and
and
are the minimum and maximum RSSI values observed in the entire dataset, used for scaling. Each RP is associated with three types of location labels: its building identifier, floor level, and specific coordinates (longitude, latitude). These are encoded as one-hot vector
for building,
for floor, and min–max normalized coordinate pairs
for location.
The bipartite graph
is then constructed, where
represents the set of RP nodes and
represents the set of WAP nodes. An edge
exists if and only if
. The initial features for RP nodes,
, are derived from their location labels, aiming to provide the model with prior spatial information as follows:
In Equation (3),
,
, and
are trainable embedding matrices for building, floor, and location coordinates, respectively, and
D is the dimension of the initial node features. WAP nodes
are initialized with trainable feature vectors
, forming an embedding matrix
. Each edge
in
carries a feature vector
, where the scalar
is converted into a 1D vector, representing the normalized RSSI value connecting the RP and WAP.
2.2. Variational Graph Auto-Encoder
To learn meaningful representations from the potentially sparse and incomplete fingerprint graph, we employ a VGAE [
28]. The VGAE is well-suited for this task due to its ability to learn probabilistic latent embeddings for nodes and its generative nature, which allows for the reconstruction of graph structure (RSSI observation likelihoods) and features (RSSI values). VAE-based models have been shown to be effective in similar scenarios involving fluctuating communication data, demonstrating their suitability for such modeling tasks [
30]. It is trained using a self-supervised learning paradigm. The VGAE takes the bipartite graph
as input and outputs a reconstructed graph
, comprising reconstructed edge existence probabilities and edge features.
2.2.1. Node Embedding Modules and Modified GAT
The core of our VGAE’s encoder lies in its node embedding modules, which update RP and WAP node representations iteratively using a modified graph attention network (GAT) layer [
31]. This modified GAT layer is designed to incorporate information from both node features and edge features effectively. We describe the layer using the RP node embedding module as an example. For each layer
l, the modified GAT layer processes the node embeddings from the previous layer (
for RPs,
for WAPs) along with the edge features
for each connected pair
. This module produces the current layer’s RP embeddings (
). The attention mechanism utilizes trainable weight matrices (
,
,
) and attention vectors (
,
,
).
The attention coefficient
between the
i-th RP node
and its neighboring
k-th WAP node
in layer
l is computed as follows:
In Equations (4) and (5),
denotes the set of WAP neighbors of the
i-th RP node,
is the LeakyReLU activation function (with a negative slope of 0.2), and
represents a self-attention component (implicitly defined by the formulation, often involving only the RP node’s own features). The updated embedding
for the
i-th RP node is then computed as a weighted sum of transformations of its own features and its neighbors’ features as follows:
The WAP node embeddings
are updated through a symmetric process, attending to their neighboring RP nodes.
2.2.2. Encoder Architecture
The encoder of our VGAE consists of a two-layer Graph Neural Network (GNN) architecture. The first GNN layer comprises separate embedding modules (as described above) for RP and WAP nodes. These modules take the initial node features (, ) and the original set of edge features () as input, producing updated first-layer embeddings and .
The second GNN layer processes the activated embeddings from the first layer (e.g., after applying an ReLU activation function, ). Similarly to the first layer, it contains distinct embedding modules for RP and WAP nodes. These modules operate on , , and the set of edge features . This layer outputs parameters for the probabilistic latent embeddings: the means (, ) and the logarithms of the standard deviations (, ) for RP and WAP nodes, respectively.
Finally, the encoder utilizes the reparameterization trick to sample the latent node embeddings
and
from the learned distributions:
In Equation (7),
is a vector of random samples drawn from a standard normal distribution
, and ⊙ denotes element-wise multiplication. These latent embeddings capture the essential characteristics of RPs and WAPs in a lower-dimensional space.
2.2.3. Decoder
The decoder part of the VGAE uses the latent embeddings and to reconstruct the original graph properties: the mask matrix (predicting the likelihood of an RSSI observation between an RP-WAP pair) and the set of edge features (predicting the RSSI values themselves).
For reconstructing the mask matrix, indicating the probability of an edge (RSSI observation), a bilinear decoder is employed. This choice is common for link prediction tasks as it efficiently models pairwise interactions. The reconstructed mask matrix
is as follows:
In Equation (8),
is a trainable weight matrix. Each entry
represents the predicted probability that an RSSI value is observed between the
i-th RP and the
k-th WAP.
For edge feature reconstruction (predicting RSSI values), a Multi-Layer Perceptron (MLP) decoder is used, offering flexibility to model complex relationships. The reconstructed edge feature (RSSI value)
for a potential or existing edge
is computed as follows:
In Equation (9),
and
are the trainable weight and bias parameters for this edge feature reconstruction network. The output
is the predicted normalized RSSI vector.
2.3. Augmentation Module
A key innovation of FALoc is its augmentation module, which leverages the VGAE’s outputs ( and ) to generate augmented versions of the fingerprint data. This module aims to create more complete and robust training samples by stochastically imputing likely missing RSSI values or removing potentially spurious ones. The decoder’s output serves as the predicted probability of an RSSI observation between the i-th RP and k-th WAP.
The augmentation logic is based on comparing the original observation mask with the VGAE’s predicted probability :
If (observed) and is high (e.g., , where is a predefined threshold), the original RSSI is likely valid and should be preserved with high probability.
If (missing) and is low (e.g., ), the absence of RSSI is likely genuine, and it should remain missing with high probability.
If (observed) but is low (e.g., ), the observed RSSI might be an outlier or unreliable. This suggests potential feature deletion.
If (missing) but is high (e.g., ), the original RSSI was likely missing, not genuinely absent. This suggests potential feature imputation using .
To implement this stochastic imputation and deletion, we first define a probability
for the existence of an augmented link
as follows:
The augmented mask entry
is then sampled from a Bernoulli distribution with probability
. To enable end-to-end training through this discrete sampling process, we use the Gumbel–softmax reparameterization trick [
32] as follows:
In Equation (11),
G is a sample drawn from the
distribution, and
is the temperature parameter of the Gumbel–softmax, controlling the smoothness of the approximation.
indicates the presence of an RSSI value in the augmented fingerprint, and
indicates its absence.
Finally, the augmented feature matrix
is constructed based on the original features
, the VGAE-reconstructed features
, and the sampled augmented mask
as follows:
This process generates augmented fingerprints where missing values are probabilistically imputed and unreliable existing values are potentially removed, leading to a richer and more robust training set.
2.4. Localization Module
The localization module is responsible for predicting the user’s location based on the (augmented) Wi-Fi fingerprints. We employ a standard neural network architecture for this task, formulated as follows.
In Equation (13),
is the
i-th row of the augmented feature matrix (the fingerprint for the
i-th RP),
denotes the localization neural network with trainable parameters
, and
represents the estimated location labels (e.g., coordinates) for the
i-th RP. The network
is typically an MLP, chosen for its ability to model complex non-linear mappings. The model is trained to minimize an estimation loss (e.g., Mean Absolute Error or Mean Squared Error) between the true labels
and the predicted labels
. By training this module with the augmented data
, we aim to improve its generalization capability, especially its robustness to missing RSSI values encountered during online localization.
2.5. Model Training and Inference
The training of the FALoc framework is performed in two main stages to ensure stability and effective learning. The procedure for training and inference is shown in Algorithm 1.
| Algorithm 1 FALoc Training and Inference Procedure |
Require: Training data , learning rates , , balance weight Ensure: Trained localization model Pretraining (VGAE only): for each epoch do Apply edge dropout to graph E Reconstruct via VGAE Compute loss Update VGAE with learning rate end for Main Training (End-to-End): for each epoch do Generate augmented data using Gumbel-softmax Predict Compute loss Update all modules with learning rate Apply early stopping if validation degrades end for Inference: Given query , return
|
Pretraining Phase: Initially, only the VGAE component is pretrained. The objective during this phase is to enable the VGAE to accurately learn to reconstruct the graph structure (mask matrix
) and the edge features (RSSI values
). The loss function for pretraining is as follows.
In Equation (14),
is the binary cross-entropy reconstruction loss for the mask matrix, encouraging
to predict true observation likelihoods.
is the reconstruction loss for the feature matrix, typically the Mean Absolute Error (MAE) calculated only over observed entries (where
), penalizing deviations between original and reconstructed RSSI values. To enhance generalization during VGAE training and prevent the model from simply memorizing the input graph, edge dropout is applied: a certain percentage of edges from
are randomly removed before being fed into the VGAE at each training epoch.
Main Training Phase (End-to-End): After pretraining the VGAE, the entire FALoc framework, including the VGAE, the augmentation module, and the localization module, is trained end-to-end. The overall loss function in this phase incorporates the VGAE reconstruction losses and the localization task loss as follows:
In Equation (15),
is the loss for the location label prediction (e.g., MAE for coordinates), and
is a hyperparameter balancing the reconstruction tasks with the primary localization task. During this phase, the gradients from the localization loss
flow back through the augmentation module (enabled by the Gumbel–softmax trick) and into the VGAE, allowing the VGAE to learn representations that are not only good for reconstruction but also beneficial for the downstream localization task. Early stopping is employed based on the localization performance on a validation set to prevent overfitting.
Inference Phase: During the online location inference phase, the system processes a new Wi-Fi fingerprint observed by the user’s device to estimate their current location. Unlike the training phase where data augmentation is crucial, the inference phase in FALoc is straightforward. The raw fingerprint vector
, as collected from the environment (which may contain missing RSSI values), is directly fed as input to the trained localization module
. The localization network then outputs the predicted location labels
as follows:
The rationale behind this direct approach is that the localization module
has already been trained on a diverse set of augmented fingerprints generated by the VGAE and augmentation module. This comprehensive training is intended to equip
with the robustness to effectively handle incomplete or varied fingerprint data encountered during real-world inference, without requiring explicit data augmentation or completion steps at inference time.
3. Performance Evaluation
To assess the effectiveness of the proposed FALoc framework, we conducted comprehensive experiments using a well-established public benchmark dataset. This section details the dataset, evaluation metrics, experimental setup, and a comparative analysis of the results.
3.1. Dataset Description
We utilized the UJIIndoorLoc dataset [
27] and the UTSIndoorLoc dataset [
16], which are large-scale benchmarks for Wi-Fi fingerprinting-based indoor localization. The UJIIndoorLoc dataset was collected from three multi-floor buildings at Jaume I University, covering approximately 108,703 m
2. It includes RSSI measurements from 520 distinct WAPs and provides additional metadata such as
FLOOR,
BUILDINGID,
SPACEID,
RELATIVEPOSITION,
USERID,
PHONEID,
TIMESTAMP,
LONGITUDE, and
LATITUDE. The UTSIndoorLoc dataset was collected in a multi-floor building at the University of Technology Sydney. Each sample consists of a 589-dimensional RSSI vector along with metadata including
Pos_x,
Pos_y,
Floor_ID,
Building_ID,
User_ID,
Phone_type, and
Time.
The distribution of observed RSSI values spans from −104 dBm to 0 dBm in the UJIIndoorLoc dataset, and from −96 dBm to −37 dBm in the UTSIndoorLoc dataset. In UJIIndoorLoc and UTSIndoorLoc dataset, RSSI values that were not observed at a given location are marked with +100 dBm. We used these +100 dBm entries to identify unobserved signals, setting the corresponding elements in our mask matrix
to 0 (i.e.,
). Subsequently, for the feature matrix
used as model input, these unobserved signals were represented by a normalized value of 0, following Equation (
2) in
Section 2.1. This process results in fingerprint vectors that are often incomplete. The UJIIndoorLoc and UTSIndoorLoc datasets exhibit considerable variation in observed WAPs and RSSI values, making it a suitable testbed for evaluating FALoc, which is designed to handle such incomplete data.
3.2. Evaluation Metrics and Baselines
The primary performance metric used for evaluating localization accuracy is the mean Euclidean distance error, calculated between the predicted 2D coordinates (longitude and latitude) and the ground truth coordinates of the test samples. In addition to the mean error, we report several other statistical metrics to provide a comprehensive understanding of the error distribution: MAE, Mean Squared Error (MSE), Root Mean Square Error (RMSE), and the coefficient of determination (). Lower values for mean error, MAE, MSE, and RMSE indicate better performance, while a higher value signifies a better fit of the model to the data.
Our proposed method, MLP with FALoc, involves training an MLP-based localization module using the augmented fingerprints generated by FALoc as described in
Section 3. As a baseline for comparison, we implemented a standard MLP without FALoc. For this baseline, the MLP was trained directly on the original fingerprint data, where missing RSSI values (identified from the +100 dBm markers and subsequently masked in
) were represented as 0 after the same normalization process applied to FALoc’s input. This zero-filling approach is a common practice for handling missing data when no specialized mechanism is employed. This ensures a fair comparison, isolating the impact of the FALoc feature augmentation and imputation strategy. In addition to the zero-filled baseline, we also implemented a variant of FALoc using a traditional variational autoencoder (VAE) instead of the proposed VGAE, in order to assess the benefits of graph-based modeling. This VAE-based model was trained under the same augmentation and MLP pipeline, but without exploiting the graph structure of the fingerprints. While our framework also processes building and floor labels as part of the RP node features in the VGAE, the quantitative evaluation presented in this section focuses on the accuracy of 2D coordinate prediction, which is the most common primary metric for these dataset.
3.3. Experimental Setup
The UJIIndoorLoc and UTSIndoorLoc datasets was divided into a training set and a testing set. The training samples were further partitioned, with 80% used for actual model training and 20% reserved as a validation set. This validation set was used for hyperparameter tuning and to implement an early stopping mechanism to prevent overfitting. Early stopping was triggered if the localization error on the validation set did not show improvement for a patience period.
A MLP served as the core architecture for the localization module (
) in both the FALoc-enhanced setup and the baseline. We implemented FALoc and the baseline MLP model using PyTorch 2.6.0 and PyTorch Geometric hl2.4.0 libraries. To ensure optimal performance for both configurations, an extensive grid search was conducted to find the best hyperparameters for the MLP models and for the FALoc-specific components (e.g., VGAE architecture,
,
). The optimized hyperparameters used for the final evaluation are detailed in
Table 1.
In
Table 1,
D represents the dimensionality of the initial RP and WAP node features. The VGAE Encoder Architecture indicates the number of units in successive GAT layers leading to the parameters of the latent distributions; for instance, ’First, Layer(256 → 128), Mean&Log Std.(128 → 64)’ means the initial 256-dimensional features are processed by a GAT layer outputting 128 features, followed by another GAT layer outputting 64 features for both mean and standard deviation vectors, resulting in a latent dimension 64 per node type. The VGAE Decoder for the mask is bilinear, and for RSSI values, it is an MLP. The Localization MLP Architecture ’520 → 500 → 500 → 500 → 500 → 2’ describes an MLP with an input layer (size corresponding to the number of WAPs, 520), four hidden layers each with 500 neurons, and an output layer predicting 2D coordinates.
3.4. Results
Table 2 summarizes the positioning error statistics for both the baseline MLP and the MLP enhanced with our FALoc framework. The corresponding cumulative distribution function (CDF) of positioning errors is illustrated in
Figure 3, providing a visual representation of the error distributions across all test samples.
The results clearly demonstrate that integrating FALoc significantly improves the localization performance of the MLP model across both datasets. On the UJIIndoorLoc dataset, the mean positioning error decreased from 8.191 m for the baseline MLP to 7.135 m with FALoc (VGAE), representing a relative improvement of approximately 12.9%. Similarly, the MAE dropped from 5.214 to 4.561 m, while the MSE was reduced from 66.294 to 49.603 . The RMSE also improved from 8.142 to 7.043 m, a reduction of about 13.5%. These improvements in squared error metrics suggest that FALoc effectively mitigates large outliers in positioning error, likely by generating more reliable fingerprint representations in place of missing or noisy signals. The value also increased slightly from 0.991 to 0.993, indicating that the model with FALoc better explains the variance in true locations.
On the UTSIndoorLoc dataset, which features a different environment and Wi-Fi topology, a similar trend is observed. The mean positioning error improved from 7.808 m (baseline) to 7.138 m (FALoc-VGAE), and the MAE dropped from 4.819 to 4.232 m. The MSE decreased from 43.435 to 39.121 , and RMSE was reduced from 6.591 to 6.255 m. Although the absolute errors on UTSIndoorLoc are lower than those on UJIIndoorLoc, the relative improvements remain consistent, confirming that FALoc generalizes well across different deployment settings. The increase in from 0.605 to 0.722 further supports that FALoc enhances the model’s ability to predict accurate positions even in more challenging or diverse environments.
In addition to outperforming the baseline MLP, the proposed FALoc framework based on VGAE also demonstrates superiority over the prior VAE-based variant across both datasets. On the UJIIndoorLoc dataset, the VGAE model achieved a lower mean error (7.135 m vs. 7.808 m) and MAE (4.561 m vs. 4.934 m) compared to the VAE model. Furthermore, VGAE showed substantial improvements in MSE (49.603 vs. 61.878 ) and RMSE (7.043 m vs. 7.866 m), indicating its effectiveness in reducing both average and large deviations in localization. Even the score, already high with VAE (0.9978), was slightly better with VGAE (0.993), highlighting consistent model generalization. On the UTSIndoorLoc dataset, which presents a more diverse environment, similar patterns are observed. VGAE outperformed VAE across all metrics: mean error (7.138 m vs. 7.382 m), MAE (4.232 m vs. 4.413 m), MSE (39.121 vs. 40.074 ), RMSE (6.255 m vs. 6.330 m), and (0.722 vs. 0.694). These results confirm that VGAE-based FALoc not only advances beyond the traditional zero-filled baseline, but also improves upon earlier augmentation techniques, offering more robust and generalizable localization performance across heterogeneous indoor environments.
Figure 3 further corroborates these findings. The CDF curve for the FALoc-enhanced MLP consistently lies above that of the baseline MLP across nearly all error ranges. This is especially pronounced in the lower error region (e.g., 0–10 m), where a notably larger fraction of test samples achieve lower positioning errors when FALoc is employed. For instance, with FALoc, over 75% of the predictions fall within a 10 meter error margin, compared to approximately 65% for the baseline. This upward shift in the CDF curve highlights not only a reduction in average error but also an improvement in the overall reliability and robustness of the localization model.
In summary, the empirical evidence strongly supports the efficacy of FALoc. By explicitly modeling RSSI observation probabilities and performing feature-level data augmentation to handle missing values, FALoc enables the localization model to learn more effectively from incomplete real-world data. This results in statistically and practically significant improvements across all standard performance metrics, leading to more accurate and consistent indoor localization outcomes. The enhanced performance, particularly the reduction in larger errors, can be attributed to FALoc’s ability to provide the localization model with intelligently imputed and more complete feature vectors, mitigating the adverse effects of naively handled (e.g., zero-filled) missing data that the baseline model contends with.
4. Discussion and Future Work
4.1. Feasibility of Real-World Deployment
One important consideration for real-world deployment is the sensitivity of the threshold parameter , which determines the confidence margin used in the neighbor filtering step. As directly influences the trade-off between recall and precision, its optimal value is not universal but must be adjusted according to the characteristics of the deployment environment, such as signal fluctuation, density of reference points, and physical obstructions. Practitioners should conduct environment-specific calibration to fully leverage the benefits of our framework. Future work could explore adaptive thresholding strategies that dynamically adjust based on signal statistics based on the feature of datasets.
Another important consideration is the computational complexity. The proposed method utilizes deep learning only during the offline training phase, which is typically conducted on server-side infrastructure, where resource constraints are less critical. In contrast, the online inference phase, which runs on the user device, requires a computational load comparable to that of conventional fingerprinting-based inference methods. Therefore, the proposed framework is sufficiently feasible even on resource-constrained devices and does not impose significant computational overhead during real-time inference. In addition, while the use of graph-based modeling may raise concerns regarding scalability, particularly in large-scale graphs, it is important to note that such operations are confined to the offline training phase. Moreover, in our current datasets, the number of WAPs is around 500, which reflects realistic deployment scenarios and remains well within the capacity of standard training infrastructure. Thus, scalability does not pose a practical limitation in the context of our framework.
To evaluate the real-world feasibility of real-time deployment, we measured the computation time during the online inference phase.
Table 3 presents the computation times of both baseline methods and the proposed approach. As shown in
Table 3, the inference time of our method is significantly lower than that of conventional WKNN-based techniques [
13], which typically operate in the tens of milliseconds, thereby demonstrating strong potential for real-time application even under strict latency constraints.
4.2. Future Work
While FALoc demonstrates promising results, we acknowledge certain areas for future exploration. For instance, the current VGAE architecture and augmentation policy, though effective, might benefit from further optimization for even greater efficiency or adaptability to different types of missingness.
Building upon this work, our future research will focus on several key directions. We plan to investigate more advanced graph neural network architectures. For instance, recent work has applied self-attention mechanisms to graph learning to improve representational capacity [
33]. Following such examples, we intend to explore architectures incorporating temporal dynamics or attention mechanisms tailored for heterogeneous graph structures, to further refine the modeling of RP-WAP interactions.
Additionally, we aim to develop adaptive augmentation policies that can dynamically adjust the imputation and deletion strategy based on data characteristics or even feedback from the localization model during training. In particular, since WiFi signals are highly sensitive to environmental changes, recent studies have explored models that adapt to variations across different data collection domains. For example, some works have focused on improving feature extractors to alleviate domain imbalance [
34], while others have enhanced the mapping between signal variations and target locations to achieve robust localization [
35]. Exploring the framework’s scalability and performance across a wider range of diverse indoor environments, including those with extremely high levels of data sparsity, also remains a priority.
In the current study, all experiments were conducted using a single benchmark dataset, while this allowed us to verify the effectiveness of the proposed method under controlled conditions, we acknowledge that further evaluation of additional datasets is necessary to validate its generalizability across different domains. However, due to differences in label definitions, feature spaces, and data collection protocols, applying the same experimental setting across multiple datasets was considered out of the current study’s scope. As part of our future work, we plan to expand our evaluation to include multiple datasets collected under varying conditions, which will allow a more comprehensive assessment of domain robustness and practical applicability.
Another important direction for future research is to conduct a detailed ablation study to isolate and quantify the contribution of each component in the proposed framework. The current design was developed as an integrated pipeline, where all components are intended to operate synergistically rather than independently. Therefore, we focused on validating the effectiveness of the full system rather than optimizing individual parts in isolation, while we acknowledge that such synergy may not be fully captured through ablation analysis, we recognize the importance of understanding the internal contribution of each module. A comprehensive ablation study will be considered in future work to further clarify the role of each component in enhancing overall localization performance.
While our proposed method demonstrates promising performance compared to the MLP baseline, it has not yet been benchmarked against other state-of-the-art models such as GAN-based, CNN-based, or RNN-based approaches. This limitation stems from practical constraints in the current study, such as time and scope. Nonetheless, we acknowledge that such comparisons are essential to more rigorously assess the generalizability and competitiveness of the proposed framework. As part of our future work, we plan to conduct extensive comparisons with a broader range of advanced models, including GANs, CNNs, and RNNs, which have shown strong performance in data augmentation and localization tasks. Such benchmarking will provide deeper insights into the strengths and limitations of our method in comparison to alternative architectures and strategies.







{kind=link}
{kind=link}
{kind=link}