1. Introduction
The rapid growth of wireless communication systems and the ever-increasing demand for spectrum efficiency present significant challenges in managing and optimizing wireless frequency resources [
1]. Effective wireless signal classification (WSC) is a key enabler in addressing these challenges [
2,
3]. In this context, advanced techniques such as deep learning (DL) have emerged as promising solutions for WSC, particularly in scenarios with limited labeled data. Effective WSC is vital in various real-world applications, including specific emitter identification (SEI), which distinguishes individual transmitters by extracting wireless frequency fingerprinting (RFF) features. SEI is essential for military radar communication, interference detection, and cognitive wireless systems, leveraging hardware-specific discrepancies to provide tamper-resistant and counterfeit-resilient identification. Similarly, accurate modulation type classification is critical for optimizing spectrum utilization and ensuring reliable communication in increasingly complex electromagnetic environments. However, traditional WSC methods often rely on prior information and feature extraction, which may fail to fully capture the dynamic and intricate characteristics of wireless signals. Consequently, there is a growing need for effective WSC methods to extract and utilize wireless resources more efficiently [
4].
With the rapid progression of deep learning (DL) technologies, a growing number of DL-based wireless signal classification (WSC) methodologies have been developed. Unlike traditional machine learning (ML) approaches, DL-based methods excel in automatically extracting high-dimensional features from radio signals through neural networks, which enhances their capability to manage non-cooperative signals within dynamic spectrum environments [
5]. Nonetheless, conventional supervised learning (SL) frameworks necessitate a substantial amount of labeled data for training neural networks—a requirement that is often challenging to meet and prohibitively expensive in real-world scenarios [
6]. This limitation significantly impedes the practical deployment of SL-based WSC techniques in engineering applications. Consequently, the ability to effectively leverage unlabeled radio signals in data-constrained environments has become increasingly critical.
To address the challenge of limited labeled samples, self-supervised learning (SSL) has emerged as a promising solution that extracts features from unlabeled data. SSL leverages pretext tasks during pre-training to capture high-dimensional representations through encoders, which are then transferred to downstream tasks. By designing various loss functions in pretext tasks, models can learn comprehensive representations that encapsulate the intrinsic information of the original input. Consequently, in downstream tasks, a simple classifier can achieve effective wireless signal classification (WSC) even with limited labeled samples. Recent studies [
7,
8] have employed contrastive SSL, primarily relying on the MoCo [
9] framework. Additionally, the research [
10] has demonstrated remarkable results in WSC by employing contrastive clustering of radio signals at both the instance and emitter levels. Traditional methods construct positive and negative samples through data augmentation and perform contrastive learning on high-dimensional representations. However, they have overlooked feature-level augmentation strategies, which may limit their ability to capture the complex characteristics of radio signals.
In this study, we introduce feature-level augmented contrastive learning (FLA-CL). FLA-CL is primarily composed of two parts: (i) a self-supervised pretraining encoder incorporating feature-level augmentation and (ii) a classifier for downstream tasks. Throughout the self-supervised pretraining phase, we apply both data and feature-level augmentations to generate improved positive and negative sample pairs within a high-dimensional space. This method, regulated by contrastive loss, allows the network to acquire stronger and more discriminative feature representations. The pretrained encoder’s weights are then utilized for downstream tasks, where WSC is achieved using a classification head. Our contributions are as follows:
To address the challenges of feature representation, robustness, and discriminability in complex wireless signal classification tasks, we propose a feature-level augmented self-supervised pretraining strategy. This strategy constructs positive and negative sample pairs in high-dimensional space.
The proposed FLA-CL is evaluated on two datasets. The experimental results demonstrate that even with only 10% of the data used for training in the downstream task, our method outperforms other SL and SSL methods in terms of classification accuracy and robustness.
This paper is structured as follows: An overview of the proposed framework is depicted in
Figure 1.
Section 2 introduces the signal model and formulates the problem.
Section 3 provides a detailed explanation of the proposed FLA-CL. In
Section 4, we evaluate the effectiveness of the proposed framework using several experiments conducted on two datasets. Lastly,
Section 5 offers concluding remarks.
3. The Proposed Framework
The overall framework of the proposed FLA-CL is illustrated in
Figure 1. Given a wireless signal, it is first transformed into two augmentations,
and
, through strong or weak augmentation. Next, these two augmentations are fed into a Transformer encoder to obtain feature representations
and
. Then, to extract more comprehensive representations,
is passed through the enhanced prediction head (EPH) to generate the feature
. Finally,
and
are learned in the high-dimensional feature space through contrastive loss to acquire discriminative features.
3.1. Contrastive SSL Framework
3.1.1. Transformer-Based Encoder
At the beginning of the encoder, an input encoding layer, comprising residual convolutional blocks and positional encoding layers, is introduced to extract high-frequency information from the radio signal data. This module provides a broader and richer feature space for the subsequent Transformer-based encoder, thereby enhancing the overall performance of the model. In the TCN module, the ReLU function enhances the model’s capacity to handle nonlinear functions, forcing the model to learn and extract high-frequency information. The structure of the residual convolutional block within the TCN module is as follows:
where
denotes the convolutional layer,
represents the BatchNorm layer, and
stands for the ReLU function.
Although the input encoding layer excels at capturing local spatiotemporal features, they are limited in its ability to integrate global contextual information. To address this, the Informer module is introduced to extract relevant features from long-term sequences across multiple time steps [
12]. Compared to traditional Transformer models, the Informer employed in the encoder streamlines the computational process within the Multi-Head Self-Attention (MHSA) framework. MHSA is an effective approach for modeling long-range dependencies between different segments. It operates in parallel across multiple attention heads, with each head focusing on different subspaces of the input sequence representation. This approach allows for more accurate modeling of dependencies between distant elements within the input sequence. The feed-forward network (FFN) structure between MHSA layers comprises two consecutive linear transformation layers. These layers include nonlinear activation functions, which enhance the interaction and transformation of information between MHSA modules, thereby improving the overall representation of the model. The existing studies have demonstrated the effectiveness of the Informer architecture on wireless signal classification tasks [
13].
The alternating stacks of multi-layer MHSA and FFN constitute the primary architectural framework of Informer. This layered design facilitates the gradual refinement and comprehensive understanding of deep modulation information. The process can be expressed as (
4) and (
5):
where
represents layer normalization,
k denotes the index of the layers, and
and
denote the output of the TCN and Informer, respectively. For ease of representation,
is abbreviated as
x.
3.1.2. Enhanced Prediction Head
As shown in
Figure 1C, the encoder maps the features
extracted from the strongly augmented input into an enhanced feature space via the EPH, resulting in the enhanced feature
. This feature-level augmentation significantly increases the diversity of positive and negative samples in the feature space, compelling the network to learn more comprehensive feature representations. The structure of the EPH is as follows:
where
denotes the fully connected layer, and
denotes the DropOut layer.
By enhancing , the distribution range and diversity of positive and negative samples in the feature space are expanded, which strengthens the consistency of sample features belonging to the same class in the feature space. This promotes greater intra-class aggregation and facilitates the model’s learning of more robust and comprehensive features.
3.1.3. Contrastive Loss
In contrastive learning, the InfoNCE loss is a critical component. It helps the model learn practical and highly discriminative feature representations in SSL tasks by pulling similar sample pairs closer and pushing dissimilar pairs apart. These learned representations typically lead to improved performance in downstream tasks. The mathematical formula for the InfoNCE loss is as follows:
where
is the query vector,
is the positive key vector from the same sample,
denotes the negative key vectors from different samples, and
T is the temperature scaling factor that adjusts the sharpness of the similarity distribution.
3.2. Downstream Tasks
In the downstream classification task, the features extracted by the FLA-CL pretrained encoder are fed into a randomly initialized classification head
, which is updated using a small number of labeled samples. The structure of the classification head is identical to that of the EPH, except that the output dimension of the final fully connected layer corresponds to the number of classes. The network is updated using the cross-entropy loss as follows:
where
is the ground truth label.
4. Experiment Results and Analysis
4.1. Datasets and Implementation Details
To substantiate the efficacy of the proposed method, comprehensive experiments were conducted on four public datasets: RadioML2016.10a [
14] and the ADS-B short dataset [
15], both acquired in real-world scenes. For brevity, these datasets are hereafter referred to as RMLa and ADS-B, respectively.
4.1.1. RMLa
The RMLa dataset serves as a benchmark for WSC, comprising synthetic signals across 11 modulation schemes, including both digital (e.g., BPSK, QPSK) and analog (e.g., AM-SSB, WBFM) types. It provides 2000 samples per modulation type in various signal-to-noise ratios (SNRs) (−20 dB to 18 dB), with each sample comprising 128 I/Q components. This dataset is crucial for evaluating machine learning models in tasks such as modulation recognition under various noise conditions.
4.1.2. ADS-B
The ADS-B dataset consists of automatic dependent surveillance-broadcast signals used for aircraft tracking and identification. It captures real-world aviation data encompassing 198 classes.
The experiments were implemented in the PyTorch v1.13.1 framework and conducted on an Ubuntu server equipped with an NVIDIA RTX 3090 GPU platform (NVIDIA Corporation, Santa Clara, CA, USA). The unlabeled experimental data were split into training, validation, and test sets in an 8:1:1 ratio. During the SSL pre-training phase, the unlabeled data were further divided into training and validation sets in a 7:3 ratio. The SSL stage was fixed at 100 epochs, and the network model was updated using the AdamW optimizer. In the fine-tuning phase, various data augmentation techniques were applied, including time warping, rotation, inversion, and time-domain signal dropout [
8]. A portion of the unlabeled data was manually labeled for training during the 50-epoch fine-tuning phase. The model with the best performance on the validation set was selected for testing on the test set, and the learning rate followed a cosine annealing schedule. The initial learning rate for both SSL and SL was set to 0.001. The validation and test sets were strictly excluded from participation in any training stage.
4.2. Comparison Experiment Results
This study compares the proposed FLA-CL with various SSL methods, such as SemiAMC [
7] and TCSSAMR [
8], as well as SL methods like HCGDNN [
10], PETCGDNN [
16], MCLDNN [
17], ICAMCNet [
18], AWN [
19], CVCNN [
20], SFS-SEI [
21], and the supervised FLA-CL.
Table 1 presents the means and standard deviations of the OA and kappa scores across the two experiments for all the evaluated methods. Notably, the proposed FLA-CL method achieved the highest OA across both two datasets.
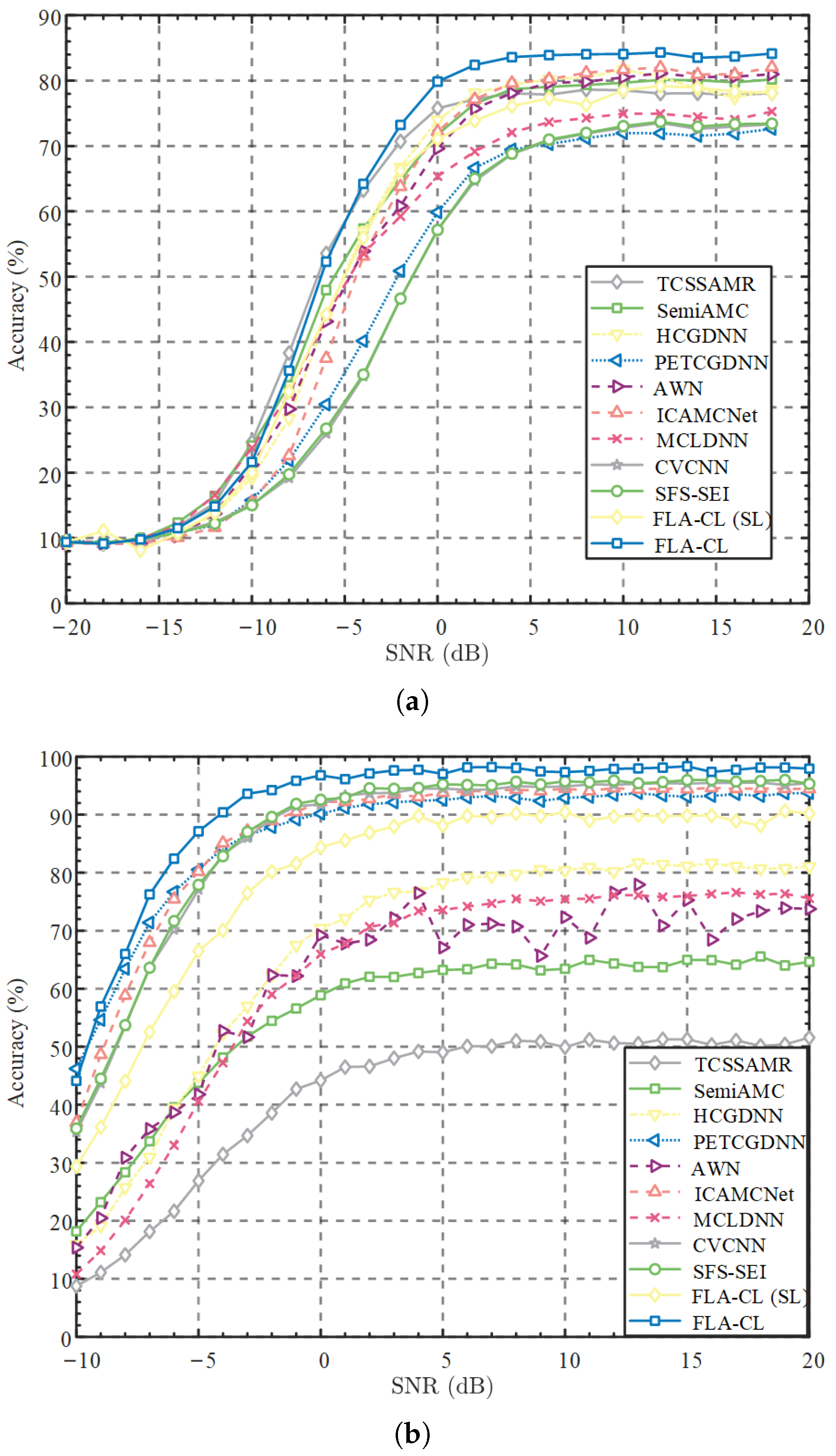
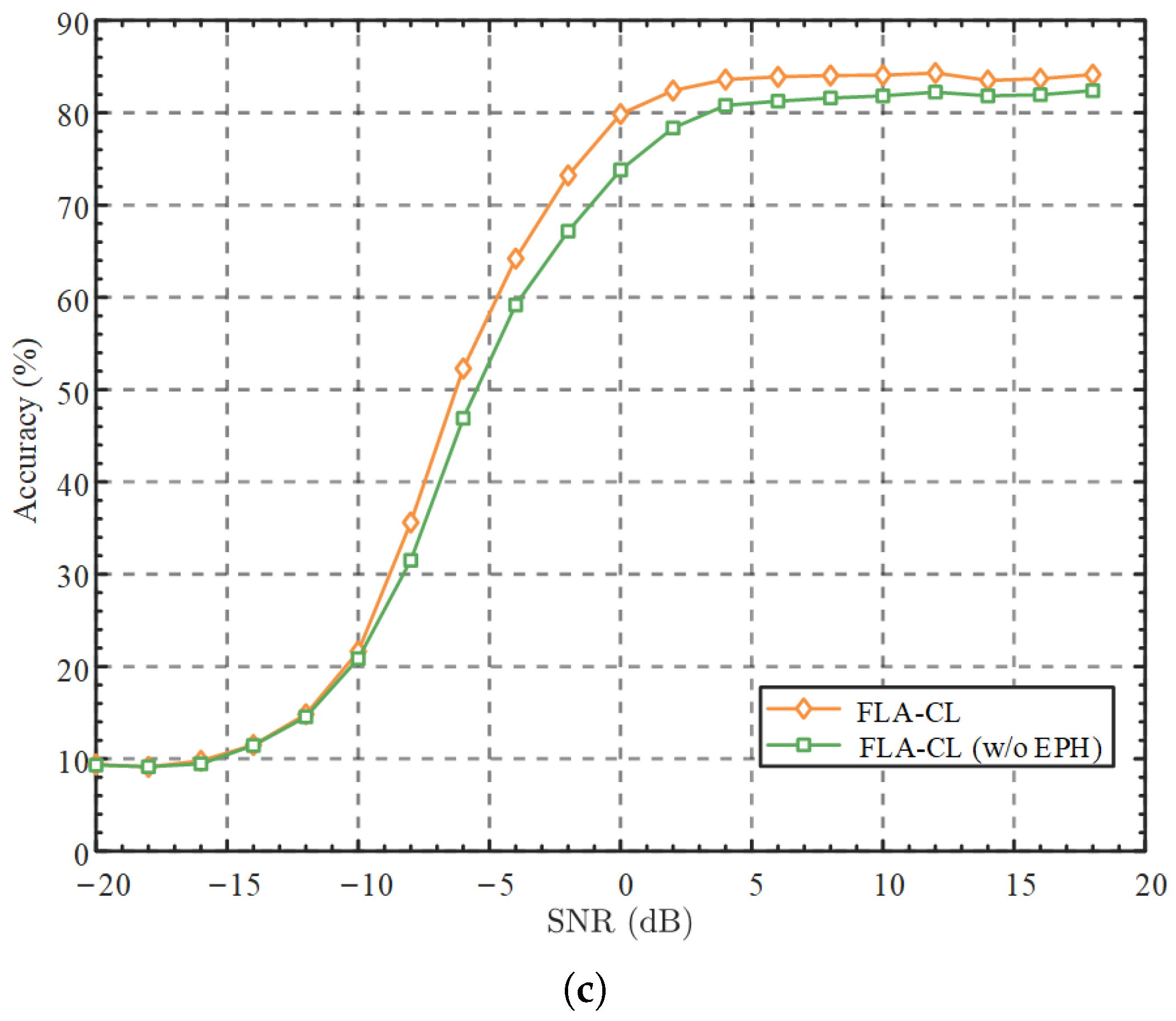
The visualization of our experimental results is shown in
Figure 2. Specifically,
Figure 2a presents the accuracy curves of different methods on the RML2016a dataset under varying SNRs.
Figure 2b shows the corresponding accuracy curves on the ADS-B dataset.
Figure 2c illustrates the ablation study of the EPH module on the RML2016a dataset.
As shown in
Table 1, after SSL pre-training, the proposed FLA-CL demonstrates a 4.76% improvement in OA compared to fine-tuning with random initialization. This confirms that FLA-CL effectively leverages large amounts of unlabeled data to learn broadly applicable features. Compared to other SL and SSL methods, FLA-CL achieves at least a 2.56% improvement in OA. Additionally, as depicted in
Figure 2a, FLA-CL outperforms TCSSAMR in high SNR regions above 0 dB, with an overall OA improvement of 5.55%. This is primarily due to FLA-CL’s use of the Transformer-based Informer architecture, which enhances the relationships between key global attention points, thereby boosting network performance. As illustrated in
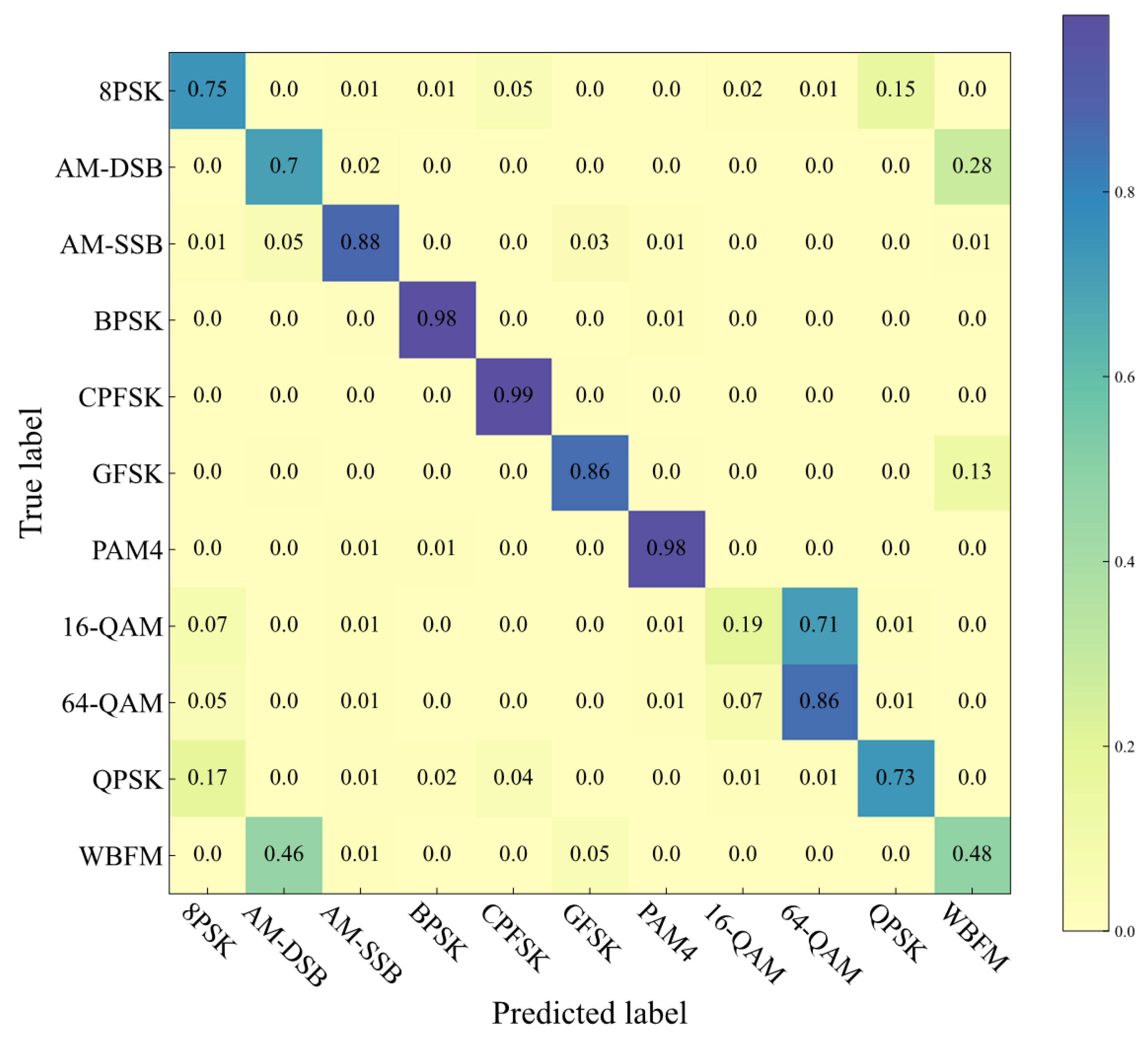
Figure 3, at 0 dB, the proposed method achieves nearly 90% recognition accuracy for most modulation signals. However, due to the high similarity between 16-QAM and 64-QAM in the time domain, the network tends to confuse these two categories.
As shown in
Figure 2b and
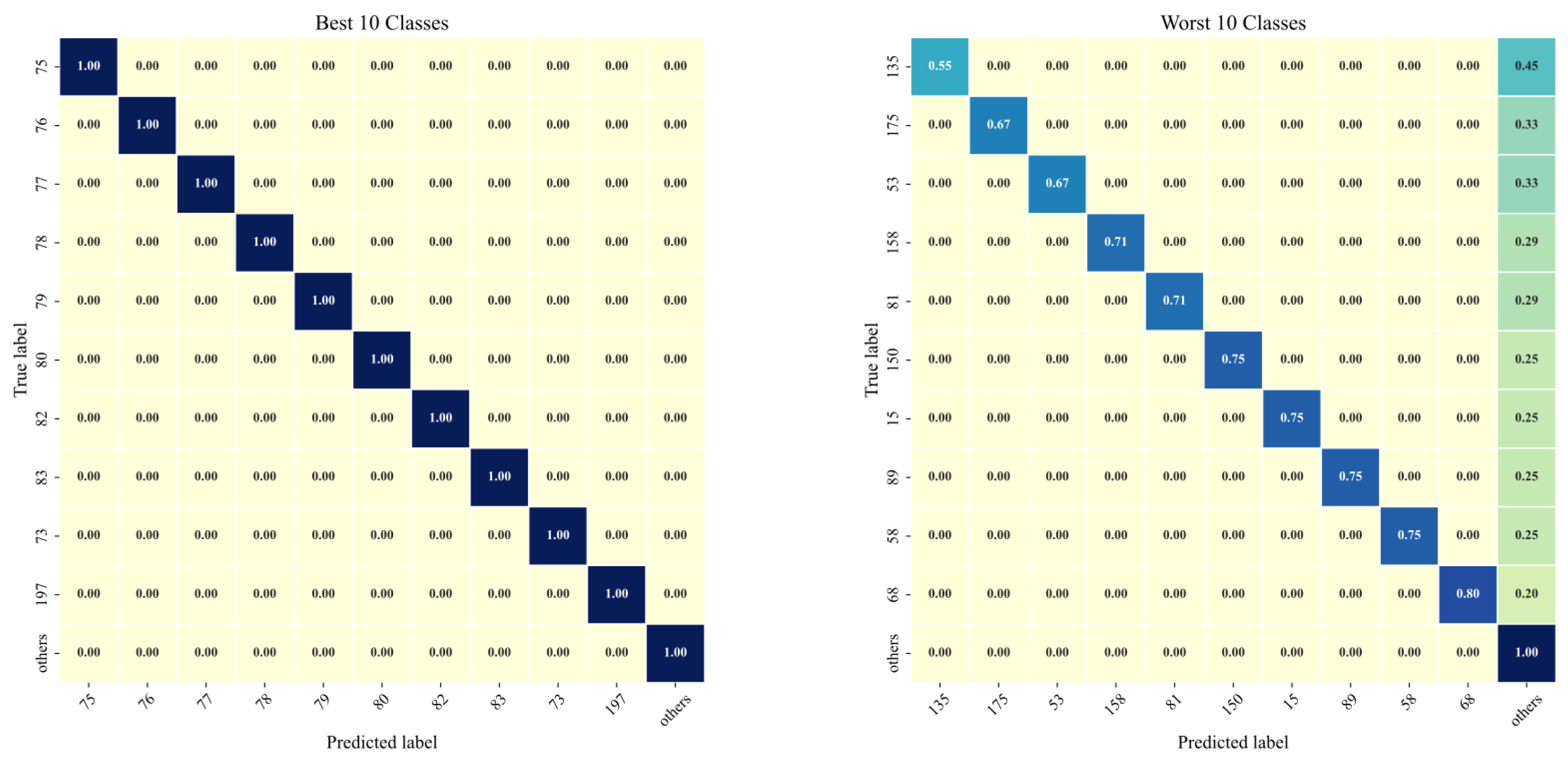
Table 1, the proposed FLA-CL outperforms the CVCNN and SFS-SEI methods, which are specifically designed for emitter recognition, on the ADS-B dataset, with a 3.62% improvement in OA. This demonstrates the excellent generalization ability of our approach across different radio signal datasets. Compared to FLA-CL (SL), our method achieves a 10.26% improvement in OA after self-supervised pre-training, further validating the effectiveness of SSL. Due to the large number of classes in the ADS-B dataset, the overall confusion matrix visualization is less effective. Therefore, we selected the top 10 best-performing and bottom 10 worst-performing classes for confusion matrix visualization. As shown in
Figure 4, our proposed method achieves perfect classification performance on the best-performing classes, and even for the worst-performing classes, it still demonstrates reasonable effectiveness.
4.3. Ablation Experiment Results
To evaluate the impact of the EPH component in the proposed FLA-CL method, an ablation study was conducted by removing the EPH from the module, denoted as FLA-CL (w/o EPH). The accuracy curves across different SNRs on the RMLa dataset are shown in
Figure 2c. We observe that in the −20 to −10 dB range, the performance difference between the two is minimal, as it is difficult for the network to learn effective feature information amid significant noise at extremely low SNRs. However, in the −6 to 0 dB range, FLA-CL achieves an average 5.63% improvement in overall accuracy (OA) compared to FLA-CL (w/o EPH). This improvement is due to the enhanced feature representation in the high-dimensional space provided by the EPH during SSL pre-training, allowing the model to learn more generalized and robust features. Moreover, although feature-level and data-level augmentations are beneficial for generating samples required by contrastive learning, they inevitably introduce noise that may not be present in real-world environments. Therefore, EPH applies dropout to linear layers, which allows the model to better capture subtle differences while dynamically ignoring noise. This architectural innovation contributes significantly to the overall performance gain, especially under high-SNR conditions where background noise is minimal. In such cases, the impact of noise introduced by data augmentation becomes more pronounced, and reducing its influence on the model is particularly important, thereby improving performance under low SNR conditions.
4.4. Limitations and Future Works
Although the proposed method shows promising results in wireless signal representation, several limitations need to be addressed. First, all experiments were conducted with simulated signals and did not include real-world data from actual communication systems. Consequently, real-life impairments such as channel noise, interference, and hardware-induced distortions were overlooked, which may have impacted the model’s generalization performance in practical settings. Second, the current framework has limited ability to distinguish between 16-QAM and 64-QAM modulated signals, which share a similar constellation structure and can often result in misclassification. Third, this study primarily focused on classification accuracy, neglecting essential factors such as computational complexity, model size, and inference efficiency, which are crucial for deployment on edge or embedded devices during model design.
To tackle the limitations mentioned, we propose several avenues for future research. First, we aim to gather real-world signal data using universal software radio peripheral (USRP) transceiver platforms to enhance the dataset with realistic channel conditions and hardware influences, facilitating a more thorough evaluation under practical scenarios. Second, to boost the ability to discriminate between similar modulation types, we plan to investigate advanced feature learning strategies, such as attention-based modules or metric learning approaches, which can more effectively capture subtle differences in signal characteristics. Lastly, to enable deployment on resource-constrained edge devices, we will examine model compression techniques, such as network pruning, quantization, and knowledge distillation, with the goal of creating a lightweight yet efficient model version.
5. Conclusions
This paper presents FLA-CL, an innovative self-supervised learning framework that enhances wireless signal recognition by employing feature-level augmentation combined with contrastive learning. This method enables the model to acquire strong and distinct feature representations by creating improved positive and negative sample pairs within a high-dimensional environment, thereby allowing the model to develop robust and distinct feature representations. Comprehensive experiments with both simulated and real-world data demonstrate the effectiveness of FLA-CL, resulting in significant improvements in classification accuracy and resilience compared to the existing methodologies. Remarkably, even when utilizing only 10% of labeled data for downstream tasks, our approach consistently surpasses other supervised learning (SL) and self-supervised learning (SSL) techniques, underlining the efficacy of feature-level augmentation for wireless communication applications.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}