1. Introduction
Accurate indoor localization is essential for enabling intelligent context-aware services in human-centric environments. Applications such as asset tracking, indoor navigation, emergency response, healthcare monitoring, and smart automation [
1,
2,
3] critically depend on precise and reliable location information. For example, research indicates that reducing emergency response time by even one minute through improved localization accuracy could save over 10,000 lives annually in the United States [
4]. While GPS is the standard for outdoor localization, its signal fails to penetrate building structures effectively due to severe interference, multipath effects, and the lack of a direct line-of-sight to satellites [
5]. This limitation has spurred significant research efforts into developing GPS-independent indoor localization technologies [
6,
7,
8,
9]. A variety of wireless technologies have been researched for indoor localization, including Wi-Fi, Bluetooth, RFID, UWB, ZigBee, and inertial measurement units (IMUs) [
10,
11,
12,
13]. Among these, Wi-Fi has gained prominence due to its pervasive deployment in residential, commercial, and industrial environments, as well as native support in virtually all mobile devices [
8,
14,
15,
16,
17,
18,
19,
20,
21,
22]. The widespread availability of Wi-Fi infrastructure makes it an attractive choice for scalable indoor localization solutions.
Wi-Fi-based localization systems typically fall into two broad categories: fingerprinting and time-based ranging techniques [
23,
24]. Fingerprinting methods build a database of location-tagged signal characteristics, typically Received Signal Strength Indicator (RSSI) values, captured at known reference points. During runtime, incoming RSSI readings are matched against this fingerprint database to infer user location [
25,
26,
27]. These systems can use deterministic models [
3], probabilistic frameworks [
28], or machine learning models [
29]. Probabilistic models offer improved robustness to signal variability but often rely on simplifying assumptions such as independence between access points (APs), which is unrealistic and leads to the loss of inter-AP correlation [
24,
30]. In contrast, deep learning approaches can capture these correlations by learning joint signal distributions, achieving a superior performance. However, RSSI-based fingerprinting still suffers from significant limitations, including high sensitivity to multipath effects, noise, and hardware heterogeneity, which degrade the consistency and reliability of the signal signatures.
Time-based techniques focus on determining the distance between a mobile device and access points by analyzing the time it takes for signals to propagate. Common approaches include Time of Arrival (ToA) [
31,
32], Time Difference of Arrival (TDoA) [
33], and Round Trip Time (RTT) [
34], all of which have been extensively studied. While ToA and TDoA offer accurate measurements, they require tight time synchronization across devices, which is often impractical in distributed deployments. RTT overcomes this limitation by measuring the round trip signal delay using a single device’s clock, eliminating the need for synchronization. The IEEE 802.11 FTM protocol, introduced in the 2016 standard and refined in the 802.11az amendment (2023), has made RTT-based localization feasible on commodity hardware. This protocol enables accurate RTT measurements between smartphones and Wi-Fi APs, and its adoption is growing among commercial routers and Android devices, offering a practical path toward scalable, infrastructure-based localization. Compounding the above issues is the data bottleneck inherent to learning-based and fingerprinting-based localization systems. High-accuracy models require large volumes of labeled data—signal measurements that are manually collected and geo-annotated at fine-grained reference points across the target environment. This site-survey process is not only time-consuming and labor-intensive but also fragile in the face of environmental changes, such as moving furniture or relocating access points. Any such variation often mandates repeating the entire data collection pipeline, significantly limiting the practicality of supervised localization approaches.
To tackle these limitations, we introduce SelfLoc, a novel self-supervised localization framework designed to deliver high accuracy with minimal manual annotation. SelfLoc addresses both signal unreliability and data scarcity by jointly leveraging two complementary signal modalities, IEEE 802.11az compliant RTT and RSSI, and learning rich representations through a novel dual-contrastive learning framework. By fusing RTT’s temporal stability with RSSI’s spatial diversity, SelfLoc capitalizes on their complementary strengths to build robust and generalizable embeddings. The core of SelfLoc lies in its two-tiered contrastive learning mechanism. The temporal contrasting module learns to align signal representations across sequential observations taken at the same location, thus capturing the temporal consistency of wireless signals. Meanwhile, the contextual contrasting module is designed to enforce spatial discriminability, pushing apart the representations of measurements taken at different physical locations. This dual approach enables the model to form embeddings that are invariant to nuisance variations (e.g., signal jitter and device noise) while remaining sensitive to location-specific features. Additionally, SelfLoc incorporates signal-specific data augmentation strategies that reflect realistic signal distortions encountered in indoor settings. These include additive noise, signal dropout, and amplitude scaling, strengthening the model’s robustness to sensor imperfections and dynamic interference. Once pretrained on unlabeled signal data, the model is fine-tuned using only a small fraction of labeled samples, dramatically reducing the annotation cost without compromising accuracy. Through this combination of multimodal sensing, self-supervised representation learning, and contrastive regularization, SelfLoc achieves robust low-error localization even in the presence of hardware variability and environmental dynamics, thereby enabling scalable deployment in real-world smart indoor environments.
To validate the practical utility of SelfLoc, we conducted extensive experiments across two realistic indoor environments using off-the-shelf Wi-Fi infrastructure and commercially available Android smartphones. These testbeds—spanning diverse layouts and signal propagation conditions—reflect the types of dynamic, cluttered spaces found in homes, offices, and industrial settings. Our results show that SelfLoc consistently delivers high-precision localization, achieving a median error of just 0.55 m when trained with fully labeled data, and still maintains a reasonable performance with a median error of 2.1 m using only 1% of labeled data. Additionally, with just 50% of the training samples labeled, SelfLoc preserves sub-meter accuracy, outperforming state-of-the-art systems by at least 63.3%. These findings underscore SelfLoc’s effectiveness in real-world deployments and highlight its scalability and robustness—crucial characteristics for enabling intelligent automation and context-aware applications in next-generation smart environments.
2. Related Work
As smart building technologies continue to advance, indoor localization has emerged as a crucial research area. While GPS works efficiently outdoors, it performs poorly indoors because of signal attenuation and multipath effects. Alternative technologies such as Bluetooth, ultrasound, and RFID have been researched, but their practical deployment is often limited by cost, energy consumption, and bandwidth constraints. In contrast, Wi-Fi-based localization has attracted great attention due to the extensive availability of smartphones and existing wireless infrastructure, enabling cost-effective solutions without requiring additional hardware. Among Wi-Fi methods, those based on RSSI and time-based measurements are particularly prevalent. Recently, self-supervised learning has shown great promise in enhancing indoor localization by leveraging large volumes of unlabeled Wi-Fi data to learn rich, generalizable feature representations that capture the spatial characteristics of indoor environments. These pretrained models can then be fine-tuned with minimal labeled data to achieve high accuracy, even in complex and dynamic settings. This approach effectively reduces the dependence on labor-intensive data labeling—a significant bottleneck in traditional supervised localization systems. This section reviews key Wi-Fi localization techniques and examines how self-supervised learning can be integrated to improve both accuracy and scalability in smart building environments.
2.1. Wi-Fi-Based Techniques
Over the years, various technologies have been investigated for indoor positioning. Ultrasound-based systems [
35] provide accurate ranging capabilities but are sensitive to environmental noise and physical obstructions. Infrared tracking [
36], widely employed in motion capture applications, depends on a clear line-of-sight and is prone to interference from ambient lighting. Magnetic-field-based localization [
13,
37,
38] exploits spatial anomalies in magnetic fields; however, its performance often declines when infrastructure changes occur. Despite their promise, these approaches often face limitations such as hardware complexity, environmental sensitivity, and challenges in scalability.
In contrast, Wi-Fi-based localization has garnered increasing attention due to the ubiquitous presence of Wi-Fi infrastructure and its ability to support non-intrusive, device-free localization [
15,
18,
29]. Early solutions employed statistical methods such as Naïve Bayes classifiers [
39] on received signal strength (RSS) fingerprints, offering a basic localization performance but lacking robustness against signal variability and environmental dynamics [
40]. To enhance performance, researchers introduced Sparse Autoencoders (SAEs) [
41] that processed Channel State Information (CSI) as input features. Although SAEs improved modeling capacity, their fully connected architecture demanded extensive labeled datasets and incurred high computational overhead.
Recent advancements have increasingly utilized deep learning techniques, including Long Short-Term Memory (LSTM) networks [
38] and Convolutional Neural Networks (CNNs) [
42,
43], which have significantly enhanced localization accuracy and robustness. LSTMs excel at capturing temporal dependencies in sequential CSI data, whereas CNNs effectively extract spatial features from amplitude and phase information, helping to mitigate the effects of multipath fading and noise. Among these, CNN-1D architectures [
44] have demonstrated a superior performance by effectively modeling both temporal and spatial signal characteristics, achieving an optimal balance between accuracy and computational efficiency.
Despite this progress, several critical challenges persist. Scalability and generalization remain significant concerns, since models trained in one physical environment often struggle to generalize to new settings because of the inherent variability in Wi-Fi signal propagation. [
45]. Multi-user scenarios introduce additional complexity, including signal interference and overlapping CSI patterns, which demand more advanced and adaptive localization algorithms [
46]. Additionally, most existing systems rely on labor-intensive and time-consuming fingerprinting processes for model calibration, limiting their practicality in large-scale deployments.
To overcome these limitations, self-supervised learning (SSL) has emerged as a promising paradigm. SSL techniques eliminate the need for large labeled datasets by designing pretext tasks that exploit inherent structure in the data—such as predicting future CSI sequences, reconstructing missing signal components, or contrasting signals from nearby versus distant locations. These tasks enable models to learn generalized representations of spatial and temporal signal characteristics using only unlabeled data. Once pretrained, models can be fine-tuned on minimal labeled samples, significantly reducing manual effort while improving adaptability across diverse environments. SSL also opens avenues for continual learning, where models dynamically evolve with new data, making them highly suitable for deployment in changing indoor spaces.
In conclusion, Wi-Fi-based indoor localization has rapidly progressed from basic statistical models to advanced deep learning frameworks, and it is now entering a promising new phase driven by self-supervised and hybrid learning techniques. As research continues to address challenges related to scalability, multi-user inference, and deployment costs, the integration of SSL and multi-sensor fusion is poised to drive the development of next-generation, ubiquitous indoor localization systems [
47,
48] capable of operating reliably across a wide spectrum of real-world environments.
2.2. Time-Based Techniques
In addition to fingerprinting-based methods, time-based localization techniques have gained popularity for indoor positioning because of their reliance on signal propagation time and known transmission velocities. Prominent among these are Time of Arrival (ToA) [
31,
32], Time Difference of Arrival (TDoA) [
33], and Round Trip Time (RTT) [
34]. These techniques aim to estimate the location of a target by computing the signal’s time characteristics, but each presents trade-offs in terms of complexity, synchronization requirements, and robustness.
ToA estimates the time a signal takes to travel from transmitter to receiver and thus necessitates precise time synchronization between both ends [
31,
32]. TDoA alleviates some of these constraints by requiring synchronization only among transmitters; it measures the time differences of signals arriving at multiple receivers to compute the target’s position [
33]. Both techniques, however, are sensitive to clock drift, synchronization errors, and environmental dynamics such as multipath and NLOS (non-line-of-sight) propagation, which often degrade performance in practical scenarios.
RTT, by contrast, is a two-way ranging approach that estimates distance by computing the two-way propagation time of a signal sent from a transmitter, received by a target device, and returned to the origin. Its primary advantage is that it eliminates the need for synchronization between devices, relying instead on a single clock [
34]. Nonetheless, Wi-Fi-RTT-based localization is still vulnerable to NLOS conditions, multipath effects, and hardware-induced measurement errors.
To address these challenges, researchers have explored a range of calibration, filtering, and learning-based techniques. For instance, [
49] proposed a real-time RTT system with multipath error mitigation, while [
50] introduced a calibration model that compensates for static offset biases in range measurements. Other work has integrated auxiliary signals such as geomagnetic data, using algorithms like the Enhanced Mind Evolutionary Algorithm (EMEA) [
51] to optimize the positioning outcome. Additionally, machine learning models have been employed to classify LoS vs. NLoS paths, enhancing localization by filtering low-quality signals [
52]. Despite these efforts, traditional supervised learning approaches remain limited by their reliance on large labeled datasets, which are costly and impractical to collect across diverse environments. In response, self-supervised learning has emerged as a promising paradigm for indoor localization, especially for time-based systems [
53,
54]. SSL allows models to learn rich feature representations from unlabeled RTT or CSI sequences by leveraging pretext tasks such as signal reconstruction, temporal contrastive learning [
53,
55], or transformation prediction. These representations can then be fine-tuned with minimal labeled data to perform accurate localization across heterogeneous environments.
Recent research shows that SSL-trained models are better at generalizing to unseen spaces and adapting to dynamic environmental changes without manual re-calibration. For instance, time-series encoders trained via contrastive or masked pretext tasks can learn invariant features that distinguish meaningful signal propagation patterns from noise and interference. These techniques are particularly beneficial in handling device heterogeneity, time drift, and signal distortion—common limitations of traditional time-based localization. In conclusion, integrating self-supervised learning with time-based approaches such as RTT provides a viable path toward scalable, accurate, and low-maintenance indoor localization. As research continues, hybrid frameworks that combine SSL, domain adaptation, and signal-domain calibration may pave the way for fully automated localization systems requiring minimal human intervention.
This paper presents a novel self-supervised approach to indoor localization that removes the dependency on large-scale labeled datasets. The proposed approach is capable of learning robust and discriminative features from unlabeled Wi-Fi RTT and RSSI signals.
Table 1 summarizes representative indoor localization methods and highlights the key differences with
SelfLoc. Unlike most prior work that relies on RSSI or CSI and fully supervised learning,
SelfLoc introduces a novel dual-contrastive self-supervised framework over RTT and RSSI, achieving high adaptability in dynamic environments with minimal labeled data.
3. Background on Wi-Fi FTM
RTT is a core technique in wireless localization, used to compute the distance between two devices by measuring the time it takes for a signal to travel from the transmitter to the receiver and return. The RTT technique gained formal support with the introduction of the Fine Time Measurement (FTM) protocol in the IEEE 802.11mc standard, which established the framework for time-of-flight-based distance estimation using commercial Wi-Fi hardware.
The RTT estimation process, as outlined in the IEEE 802.11mc standard, involves two key participants: the initiating station—commonly a mobile device aiming to determine its position—and the responding station, typically a Wi-Fi access point (AP) that acts as a fixed spatial reference. The process begins with the initiator sending a Fine Timing Measurement (FTM) request to the responder, specifying the number of bursts and the number of measurements per burst. Once the responder receives this request, it acknowledges it and proceeds to transmit FTM frames at the scheduled intervals, enabling the initiator to perform precise timing measurements based on the round trip delay of these exchanges.
Each FTM frame sent by the responder is timestamped at the time of departure (), and upon its reception, the initiating station records the arrival time (). To acknowledge the frame, the initiating station sends an ACK frame and logs the departure time (), which is then received by the responder at time . These four timestamps (, , , and ) are critical for calculating the RTT and are subsequently communicated back to the initiating station in the next FTM frame within the same burst.
The round trip time for each measurement can be calculated as
Since multiple measurements are typically taken in a single burst to reduce noise and improve robustness, an average RTT is computed over
N measurements:
This average RTT can then be converted to an estimated distance by accounting for the speed of signal propagation in space:
where
c is the speed of light in vacuum (approximately
m/s). Using distance estimates from multiple access points, localization algorithms such as multilateration or fingerprinting can be applied to estimate the two-dimensional or three-dimensional position of the initiating device.
Despite the simplicity and practicality of this approach, RTT-based localization faces several limitations under the 802.11mc framework. Notably, multipath propagation, non-line-of-sight (NLOS) conditions, and device-specific clocking inconsistencies introduce significant errors. Additionally, the sequential nature of ranging with multiple access points increases latency, while the active nature of the procedure raises privacy concerns, as users must transmit requests that can be intercepted or spoofed by adversaries [
64].
To address these limitations, the IEEE 802.11az standard—also known as Next Generation Positioning (NGP)—introduces a set of enhancements designed to significantly improve the accuracy, robustness, and efficiency of Wi-Fi-based localization systems. A key advancement is the refinement of the FTM protocol to support higher timestamp resolution and more precise time-of-flight estimation. Under optimal conditions, this enables ranging accuracy at the centimeter level, a significant improvement over the meter-level errors typical of 802.11mc.
Furthermore, IEEE 802.11az introduces optional support for Angle of Arrival (AoA) measurements, which rely on antenna arrays at access points to determine the incoming direction of the signal. By augmenting RTT with directional information, AoA greatly enhances geometric constraints, facilitating more accurate localization—especially in environments with poor anchor geometry or severe multipath interference. Another important feature is the capability for simultaneous multi-anchor ranging. Unlike IEEE 802.11mc, where devices must poll each AP sequentially, 802.11az allows devices to engage in concurrent ranging exchanges with multiple access points. This significantly reduces the time required for position updates and enables real-time tracking in high-density or dynamic environments. It also improves energy efficiency by minimizing the duration the device’s radio must remain active.
Taken together, these enhancements position IEEE 802.11az as a significant step forward in indoor localization, paving the way for more accurate and scalable positioning systems in applications ranging from asset tracking and navigation to smart buildings and emergency response.
4. SelfLoc System Details
4.1. SelfLoc System Overview
The architecture of
SelfLoc (depicted in
Figure 1) comprises two main stages: an offline training phase and an online localization phase. In the offline training phase, the environment is divided into a grid of reference locations where RTT and RSSI data are collected using a dedicated data acquisition module (e.g., a mobile Android application). This data collection is performed once during system deployment. The collected RTT/RSSI sequences are then passed through a preprocessing module that formats them into fixed-length feature vectors, removes outliers, and applies normalization to ensure consistency across devices and sessions. After preprocessing, the signal sequences are fed into a representation learning module. This module uses a self-supervised contrastive learning framework to train an encoder that extracts spatially informative embeddings from the RTT and RSSI signals without requiring location labels. The learned encoder is later fine-tuned with a small set of labeled data for the downstream localization task, resulting in a lightweight inference model. In the online localization phase, the user device captures current RTT and RSSI values relative to nearby access points. These raw inputs are preprocessed in the same way as in training, then passed through the trained encoder to extract embeddings. The resulting feature representation is input to a localization head that outputs a predicted location. This architecture allows
SelfLoc to work with minimal supervision and thus minimal data collection while maintaining accurate and low-latency localization.
4.2. The Preprocessor Module
The preprocessing module converts raw RTT and RSSI measurements into fixed-length feature vectors, where each entry corresponds to a predefined AP. As not all APs are detectable in every scan due to limited range, unheard APs are assigned placeholder values to maintain a consistent vector length. For missing RTT entries, a value of ms (equivalent to 60 m) is used, while unheard RSSI values are set to dBm. These values exceed the expected range for detectable APs, effectively encoding distance through signal absence. Occasionally, the Android API reports negative RTT values when the device is very close to an AP, likely due to chipset calibration or multipath compensation. RTT may also suffer latency when the device is in motion. While such anomalies hinder multilateration techniques, they are treated as discriminative features in our fingerprinting approach. Finally, both RTT and RSSI values are normalized to the range , which improves convergence during training.
4.3. Data Augmentation for RTT and RSSI-Based Localization
In self-supervised contrastive learning, data augmentation is not merely a regularization technique but is fundamental for generating positive pairs without labels. For scalar and context-sensitive measurements such as RTT and RSSI, which are influenced by propagation phenomena including multipath, attenuation, interference, and hardware variations, augmentation strategies must introduce diversity while maintaining location-discriminative patterns crucial for accurate localization.
To achieve this, we design two types of augmentations: weak augmentations, which introduce minor, natural signal variations, and strong augmentations, which apply more substantial perturbations to encourage robust feature learning.
4.3.1. Weak Augmentations
Weak augmentations introduce subtle, realistic variations in the input signals—such as slight noise, jitter, or scaling—to mimic natural fluctuations during data collection. These help the model learn stable and generalizable features, improving its robustness to minor changes in real-world signal conditions.
Additive noise (Jittering) simulates sensor noise and channel estimation errors by adding Gaussian noise to the measurements:
where
represents the RTT or RSSI measurement at time
t.
Scaling emulates variations in signal attenuation due to environmental dynamics by applying multiplicative perturbations:
where
is sampled from a uniform distribution.
Temporal shifting introduces small time shifts to simulate asynchrony or slight user movement variations:
Dropout masking randomly sets some values to zero to simulate missing data or temporary signal blockage:
4.3.2. Strong Augmentations
This type of augmentation imposes larger perturbations to encourage the model to learn more invariant and generalizable features while preserving location semantics.
MixUp generates synthetic training samples by interpolating between two independent signal sequences:
This encourages smoother decision boundaries and prevents overfitting.
Channel subset masking simulates partial observability of access points by randomly masking some AP readings:
where
is a randomly selected subset of access points. This is only applicable to RSSI, as RTT measurements are typically sparse and stable.
Interpolation and resampling alters the sampling rate slightly to mimic variability in collection rates or device behavior:
where
r is the resampling ratio.
4.4. Contrastive Learning with Augmented RTT/RSSI Data
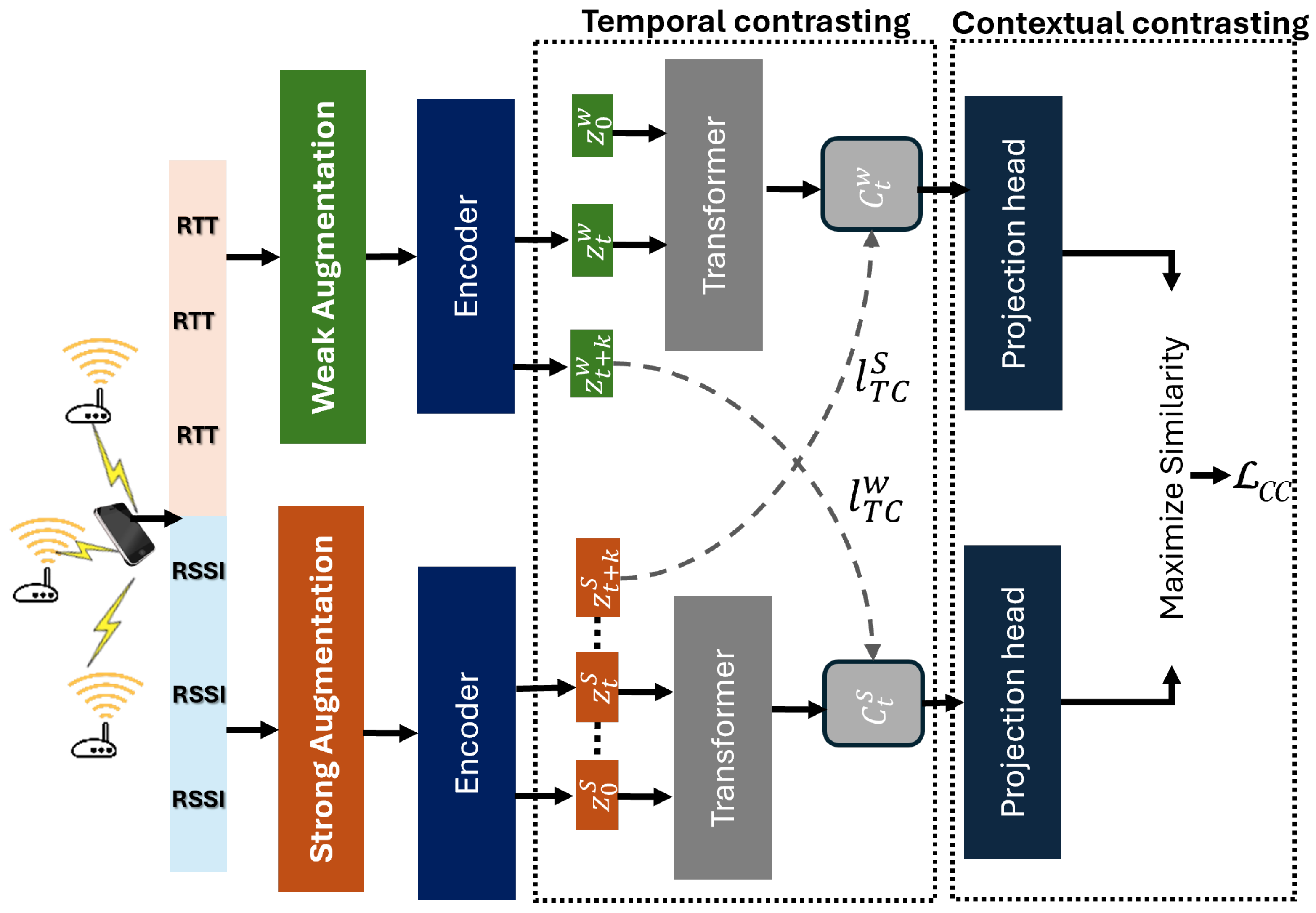
To enable robust localization without dense supervision, our framework leverages contrastive learning over augmented RTT and RSSI sequences. As illustrated in
Figure 2, the raw signals undergo weak and strong augmentations, denoted by
and
, to produce two semantically consistent yet distinct views of the same input:
These views are independently encoded and passed through temporal and contextual modules to extract spatially meaningful embeddings. A contrastive objective is then applied to bring representations of the same location closer while pushing those of different locations apart.
The upcoming subsections elaborate on the full learning pipeline. First, we introduce the temporal and contextual contrasting modules that operate at different abstraction levels to capture time-series consistency and spatial separability. Finally, we describe how these modules are integrated into a four-phase training framework that transitions from self-supervised pretraining to semi-supervised fine-tuning.
4.4.1. Temporal Contrasting for RTT and RSSI Sequences
The temporal contrasting module is designed to capture time-dependent features from sequences of RTT and RSSI measurements, which inherently reflect variations in wireless propagation due to device motion, environmental transitions, and spatial displacement. Rather than relying on handcrafted temporal filters, we leverage contrastive learning with an autoregressive model to extract meaningful latent dynamics from raw signal sequences.
Let
denote the RTT/RSSI signal at time step
t and
represent its corresponding latent embedding extracted by an encoder. The encoder processes a sequence
to produce a series of embeddings
. An autoregressive model
is then used to summarize these embeddings up to time
t into a context vector
, where
h is the hidden size:
The context vector
is used to predict the embeddings of future signal steps
for
, using a log-bilinear model to preserve mutual information between the temporal context and future signal embeddings:
where
is a learnable projection that aligns the context vector with the dimensionality
d of the latent representation.
To enhance representation learning through view diversity, we use two augmentations of the same sequence: a weakly augmented view and a strongly augmented view. The weak view produces context vectors and the strong view produces . We then introduce a cross-view prediction task where the strong context vector is used to predict the future steps of the weak view and vice versa. This strategy strengthens temporal alignment while enforcing robustness to augmentation-induced perturbations.
The contrastive loss for the strong-to-weak prediction (
) is defined as
Similarly, the weak-to-strong loss
is defined as
where
is a temperature hyperparameter and
denotes the set of negative samples drawn from the mini-batch. This formulation encourages the model to accurately predict temporal progression across views while minimizing reliance on superficial signal distortions.
To effectively model long-range dependencies in signal evolution, we implement as a Transformer encoder. Unlike recurrent models, Transformers use self-attention to process all elements in the sequence simultaneously, making them particularly suitable for capturing non-local patterns in wireless signals.
The Transformer encoder is composed of
L stacked layers, where each layer includes two primary components: a multi-head self-attention (MHA) mechanism and a position-wise feedforward neural network (MLP). Both components are wrapped with residual connections and followed by layer normalization:
To enable sequence-level summarization, we prepend a learnable context token
to the input sequence of projected features
, where
After the input sequence passes through
L Transformer encoder layers, the final temporal context vector is obtained by selecting the first token from the output of the last layer:
This context vector captures the evolution of RTT/RSSI features over time and is passed to downstream modules such as contextual contrasting or localization-specific heads. By learning such temporally aware signal embeddings through contrastive objectives, the model becomes highly sensitive to spatial transitions and motion patterns, enabling more accurate localization in dynamic indoor environments.
4.4.2. Contextual Contrasting for RTT and RSSI Sequences
To boost the spatial discriminability of learned representations, we present a contextual contrasting module tailored for RTT and RSSI sequences. While temporal contrasting focuses on the signal dynamics across time, this module targets the embedding separability across spatial locations. It ensures that signals originating from distinct regions are embedded further apart, while different augmentations of the same spatial region remain close in the latent space.
Each input signal sequence is augmented twice, yielding two structurally different but semantically similar views. These are encoded into latent context vectors, forming pairs and , representing the two augmentations of the same sample. For a batch of N samples, this produces context embeddings. The pair forms a positive match, while the remaining samples serve as negative examples for .
The similarity between any two context vectors is computed using cosine similarity over
-normalized embeddings, defined as
The contextual contrastive loss for a sample
i and its positive pair
is formulated as
where
is the temperature parameter controlling the sharpness of the distribution, and
is an indicator that filters out the self-comparison. To obtain the total contextual contrasting loss over the batch, we average across all symmetric pairs:
This loss aligns semantically similar views while promoting global separability in the latent space.
The final self-supervised training objective combines the contextual contrasting loss with the temporal contrasting losses introduced in the previous section. This unified loss is defined as
where
and
are scalar weights used to balance temporal and contextual contrastive learning. This formulation enables the model to learn embeddings that are both temporally stable and spatially discriminative, preparing them for effective downstream localization.
Algorithm 1 summarizes the self-supervised training process of
SelfLoc, which jointly optimizes temporal and contextual contrastive objectives using signal-specific augmentations over RTT and RSSI sequences.
| Algorithm 1: SelfLoc: Dual Contrastive Self-Supervised Training |
Input: Unlabeled wireless signal dataset
Output: Trained encoder for localization embeddings
![Electronics 14 02675 i001]() |
4.5. Self-Supervised Localization Framework
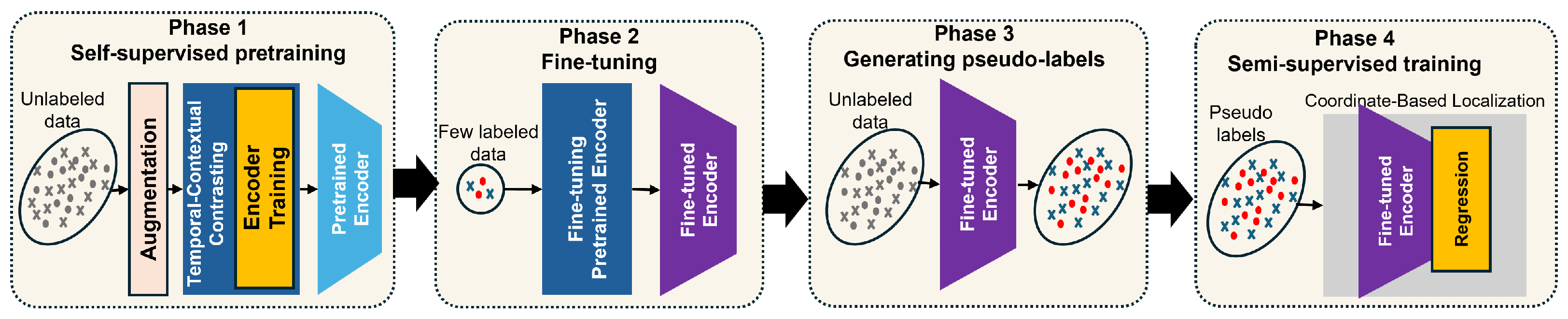
To enable high-accuracy localization with minimal labeled data, we employ a structured four-phase training pipeline as illustrated in
Figure 3. This framework combines self-supervised representation learning with semi-supervised fine-tuning and classification to yield robust and spatially discriminative embeddings from RTT and RSSI signals.
Phase 1: self-supervised pretraining. In the first stage, the model is trained on unlabeled RTT/RSSI sequences using dual contrastive objectives. Each input sequence is augmented twice—once using weak and once using strong signal transformations. The resulting views are passed through a shared encoder, followed by temporal and contextual contrasting modules that encourage the model to learn embeddings that are consistent across augmentations while being sensitive to location-specific features. This phase establishes a foundation of meaningful spatial representation without requiring any ground truth positions.
Phase 2: supervised fine-tuning. Next, the pretrained encoder is fine-tuned using a small labeled dataset , where denotes the 2D coordinates of the known user position. A regression head is trained on top of the encoder to predict physical locations. This step aligns the learned embedding space with real-world coordinates and enables precise spatial inference.
Phase 3: pseudo-label generation. To extend supervision, the fine-tuned model is used to generate pseudo-location labels for previously unlabeled inputs in . These predictions serve as approximate ground truth, allowing the model to exploit a larger training set without manual annotation. Only pseudo-labeled samples with low prediction uncertainty are retained to ensure training quality.
Phase 4: semi-supervised training. In the final stage, the model is retrained on a combination of labeled and pseudo-labeled samples. This involves two main objectives: (i) a supervised localization loss using mean squared error (MSE) for the 2D coordinates and (ii) a supervised contrastive loss that enhances feature separation between distinct spatial locations.
To incorporate positional supervision into the contrastive loss, we define for each sample
i a set of positive matches as
where
and
are the predicted locations for samples
i and
p and
is a small distance threshold for defining locality. The supervised contrastive loss is then computed as
where
denotes the contrastive loss function, which brings embeddings of spatially similar locations closer while pushing those from dissimilar locations further apart. It is defined as
where
represents the cosine similarity between the
-normalized embeddings
and
and
is a temperature scaling factor.
Total objective. The full training loss integrates the MSE localization loss and the supervised contrastive loss:
where
and
are weighting coefficients. This combined objective ensures that the encoder produces signal representations that are both geometrically faithful and structurally robust across different environments.
Overall, this training strategy allows SelfLoc to scale to new deployment areas with limited labeled data while preserving high localization accuracy by learning discriminative, position-aware embeddings from raw wireless signals.
4.6. Deployment Architecture and Maintenance Considerations
SelfLoc supports a versatile deployment architecture that spans local (on-device) inference, centralized processing, and efficient model maintenance strategies. This adaptability makes the system suitable for real-world applications ranging from personal indoor navigation to enterprise-level infrastructure monitoring.
In edge inference scenarios, the
SelfLoc encoder can be deployed directly onto devices such as smartphones, embedded gateways, or low-cost computers like the Raspberry Pi 4. Given the computational demands of Transformer-based architectures, the Raspberry Pi 4 (ARM Cortex-A72 quad-core, 4 GB RAM) exhibits inference latencies in the range of 250–350 ms per sample when running the full encoder in float precision using optimized PyTorch 2.6.0 or ONNX v1.18.0 runtimes. With quantization (INT8) or model distillation as in [
65], latency can be reduced to approximately 120–180 ms, which is suitable for applications requiring 1–2 Hz localization updates. The estimated runtime memory footprint on such edge devices is around 40–60 MB, including model weights, temporary tensors, and signal preprocessing buffers. These figures make it feasible for responsive, privacy-preserving deployment, especially in personal or assistive indoor positioning use cases.
In a centralized inference setup, SelfLoc can be deployed on high-performance servers equipped with GPUs such as the NVIDIA RTX A6000, which features 48 GB of GDDR6 memory and 10,752 CUDA cores. This hardware enables efficient inference for Transformer-based models at scale. Based on profiling results, SelfLoc achieves a single-sample inference latency of approximately 96 ms on the RTX A6000, including signal preprocessing and forward pass. When batched (e.g., 128 samples), the total processing time remains under 10 ms, enabling real-time parallel inference across multiple users. The large memory capacity also allows concurrent model serving, monitoring, and visualization tasks without significant resource contention. The estimated peak memory usage remains modest (~1.2 GB), leaving headroom for additional services such as data logging, map fusion, or user management.
For long-term deployments, SelfLoc offers a highly practical and low-overhead model maintenance strategy thanks to its self-supervised learning design. Instead of requiring frequent manual labeling, the system can be periodically fine-tuned using newly collected, unlabeled RTT and RSSI data. This enables it to adapt to environmental changes such as access point relocations, indoor layout modifications, or gradual signal drift. In edge deployments, such updates are lightweight (e.g., encoder weights only, ~4 MB) and can be delivered seamlessly via over-the-air (OTA) updates. In centralized deployments, continuous data logging enables automatic retraining, ensuring that the model remains up to date without human intervention.
More importantly, SelfLoc supports the potential for continual self-supervised learning, where the model incrementally updates its internal representations over time using streaming input data. This is particularly useful in dynamic environments where signal conditions may shift due to factors like human movement, asset rearrangement, or network reconfiguration. Continual learning can be implemented using efficient strategies such as online contrastive learning or memory-efficient replay buffers, enabling SelfLoc to maintain its localization performance while avoiding catastrophic forgetting. These updates can be scheduled periodically (e.g., nightly) or triggered adaptively when model confidence degrades.
Altogether, this combination of lightweight periodic updates and adaptive continual learning makes SelfLoc a robust and sustainable solution for real-world indoor localization, with minimal maintenance cost and high resilience to change.
5. Evaluation
This section outlines the experimental setup designed to evaluate the performance of the SelfLoc system, detailing the test environments, hardware configurations, and data collection procedures. We begin by describing the data collection environment and tools. Then, we analyze how system behavior changes with key parameter variations. Finally, we benchmark SelfLoc against existing state-of-the-art localization methods.
5.1. Setup and Tools
To evaluate
SelfLoc, we conducted experiments in two representative indoor test environments.
Table 2 outlines their key characteristics. The first environment, referred to as “Lab,” occupies an entire floor within our university building, covering an area of 629 m
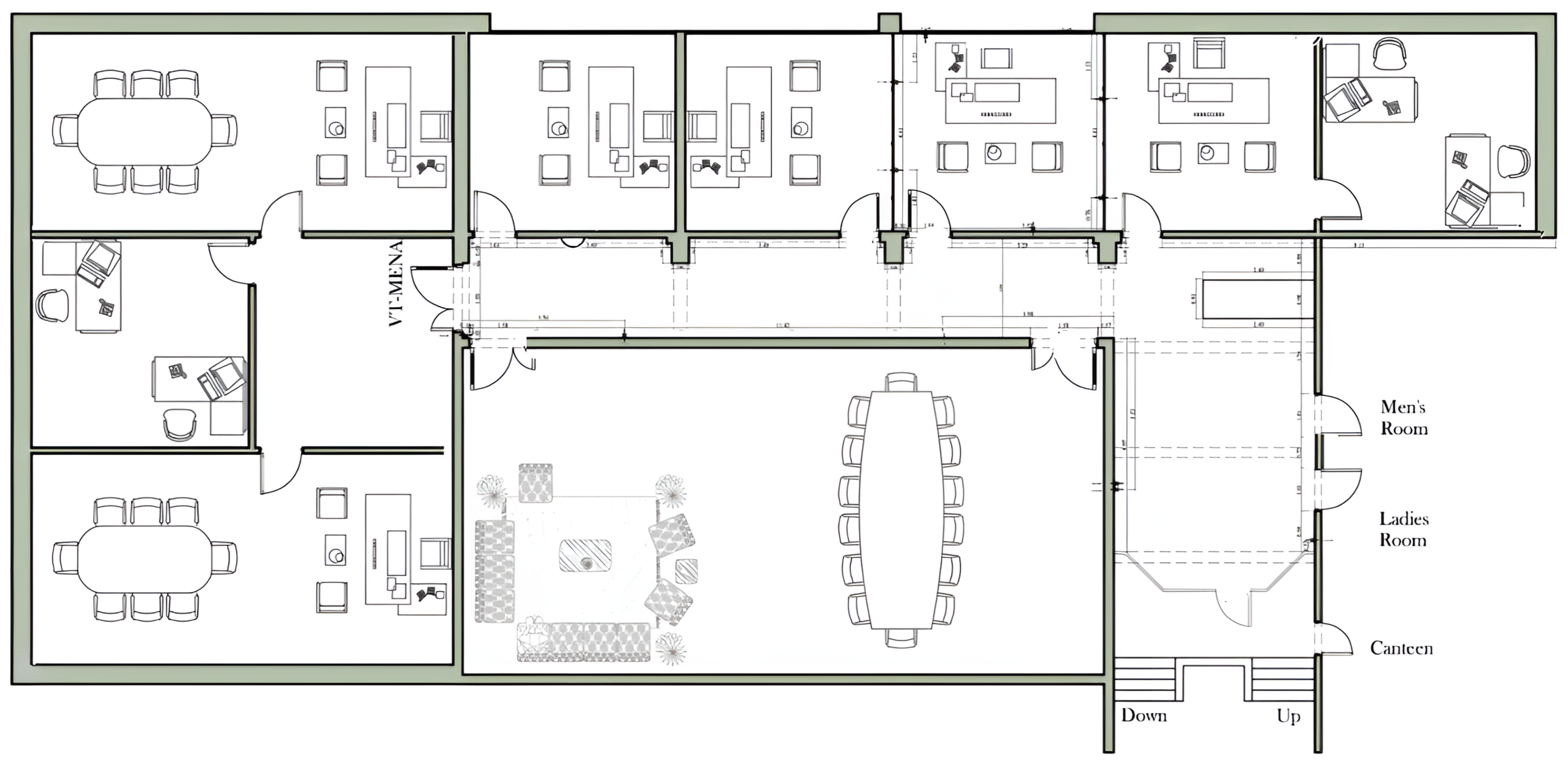
2. It includes nine rooms of different sizes and a long corridor, as shown in
Figure 4. The second environment, called “Office,” is an administrative space measuring 141 m
2 with a layout that features five rooms, a spacious meeting area, and a connecting corridor, shown in
Figure 5. Both environments were equipped with seven IEEE 802.11mc-compliant Google Wi-Fi access points, strategically deployed to provide full coverage. The area of interest in each testbed was divided into a uniform grid of reference points spaced 1 m apart. This granularity allows for detailed spatial resolution. In total, the lab testbed includes 143 reference locations, while the office testbed comprises 76. Each reference point was verified to be within the signal coverage of at least one access point, ensuring reliable data collection across the entire environment.
The data collection process utilized an Android application deployed on multiple smartphones, including Google Pixel XL and Pixel 2XL devices. This application continuously recorded RSSI and RTT measurements by scanning surrounding access points. To guarantee accurate ground truth labeling, measurements across all devices were carefully synchronized during the data collection phase. One phone was designated for manually entering the current location, which triggered synchronized scans across all devices.
At every reference location, at least 100 signal samples were collected over a 3 min interval (a scan rate of approximately 0.6 scans per second) to support model training. Independent hold-out test sets were then gathered separately, comprising 21 locations in the office testbed and 30 in the lab testbed. These test locations were entirely disjoint from the training set and were recorded on different days during regular working hours to reflect temporal variations and realistic indoor dynamics.
To support replication, we explicitly report all relevant parameters—including the sampling rate, number of scans per point, device placement, and preprocessing defaults—in
Table 2 and
Table 3.
5.2. Impact of Different Parameters and Modules
5.2.1. Semi-Supervised Localization with SelfLoc
To assess the effectiveness of
SelfLoc in low-supervision scenarios, we evaluate its performance under varying proportions of labeled training data: 1%, 5%, 10%, 50%, 75%, and 100%.
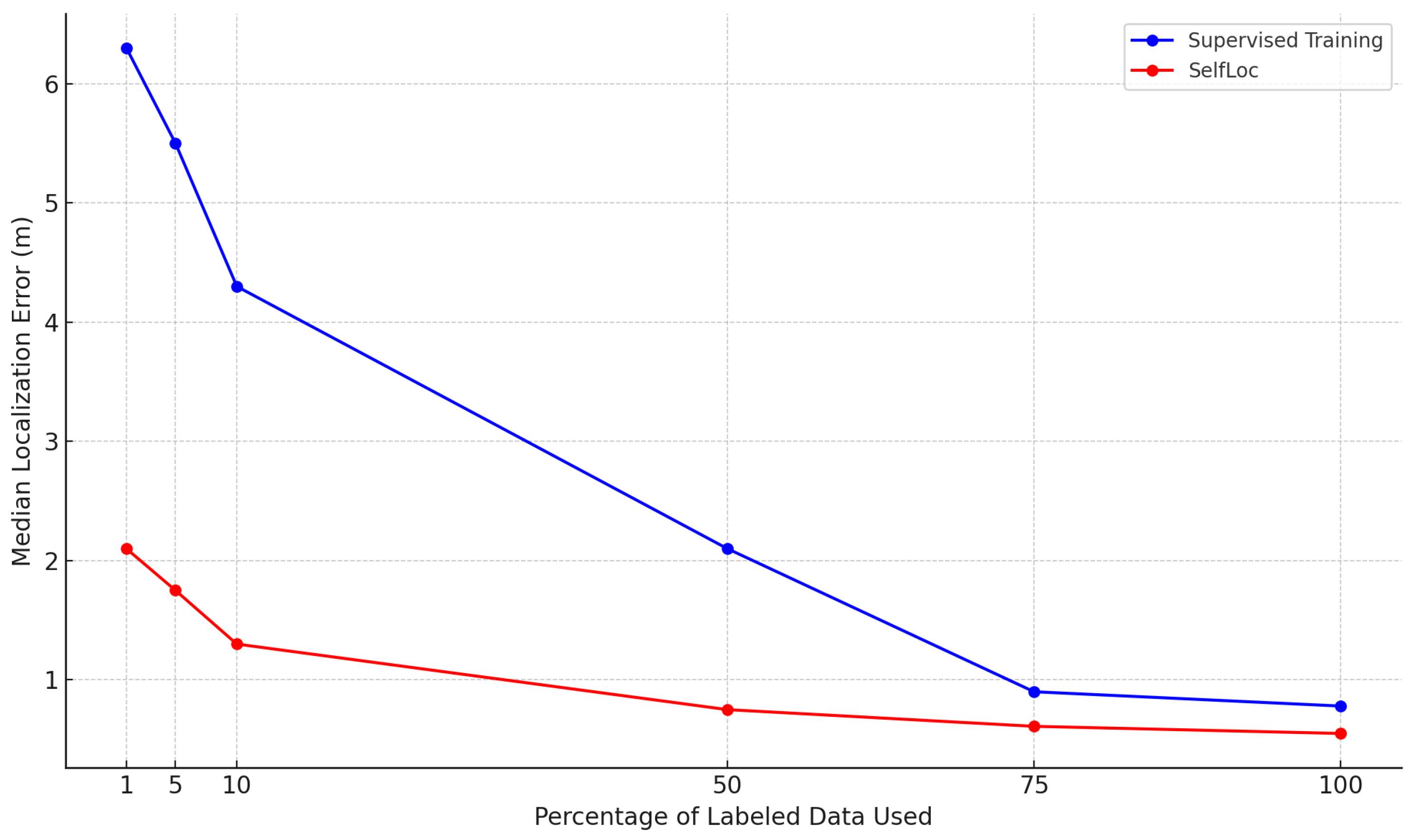
Figure 6 compares the median localization error of
SelfLoc against a fully supervised baseline across these label ratios.
The results demonstrate the advantage of our contrastive self-supervised framework. With just 1% of labeled data, SelfLoc achieves a median localization error of 2.1 m, whereas the supervised baseline exceeds 6 m under the same conditions. At 10% supervision, SelfLoc reduces the error to 1.3 m—equivalent to the performance of the supervised model trained with five times the amount of labeled data. At 50% labeled data, SelfLoc maintains sub-meter accuracy with an error of 0.75 m and continues to improve as supervision increases, reaching 0.61 m at 75% and 0.52 m at 100%. In contrast, the supervised baseline remains consistently worse, achieving only 0.78 m even with full supervision. These results validate the effectiveness of our dual contrastive strategy in learning spatially discriminative and temporally coherent embeddings from RTT and RSSI signals. By leveraging self-supervised pretraining, SelfLoc generalizes better in data-scarce settings, making it highly suitable for practical deployments where labeled data collection is costly or infeasible.
5.2.2. Impact of Temporal and Contextual Contrasting Modules
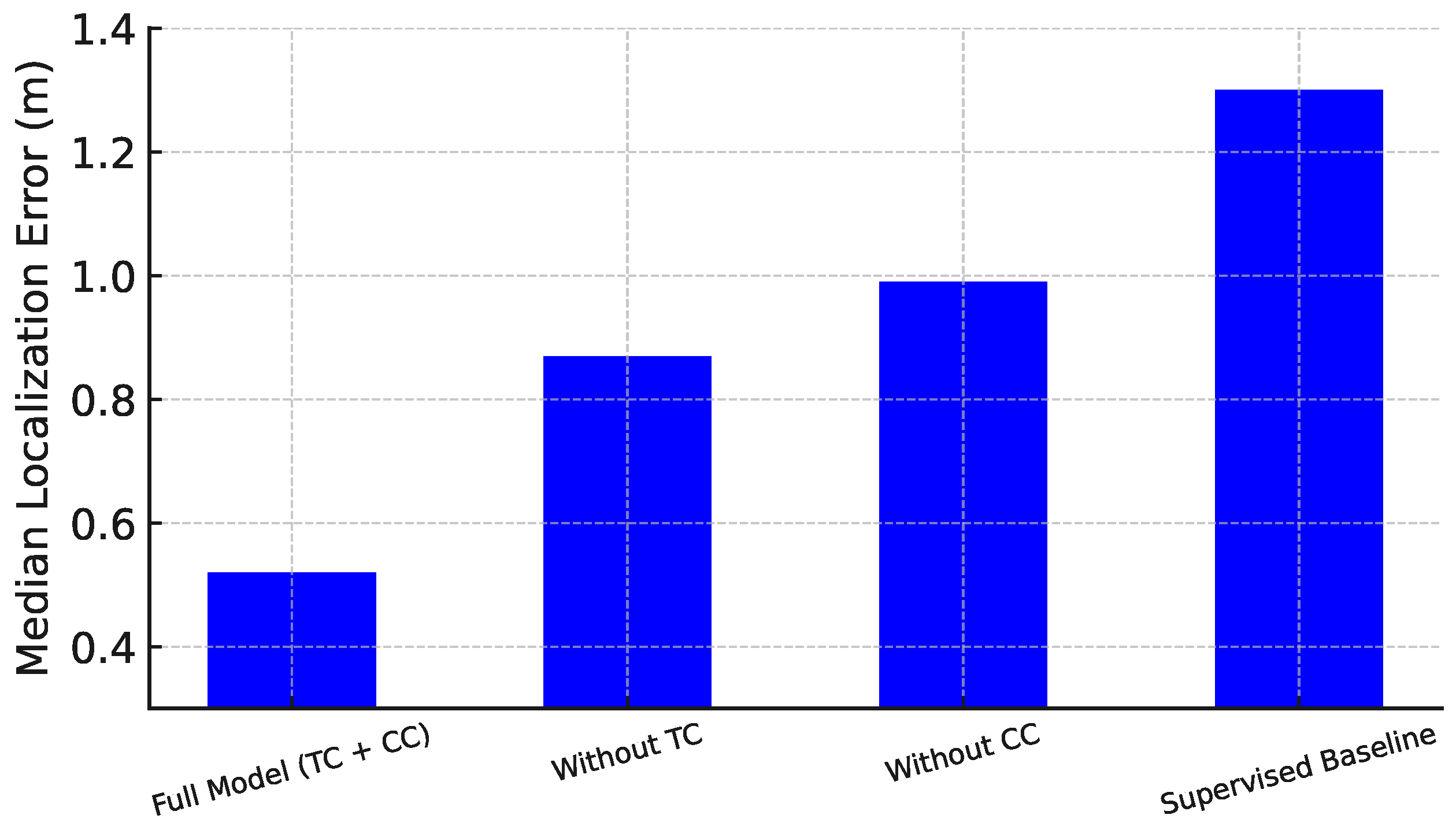
We further analyze the effectiveness of the temporal contrasting (TC) and contextual contrasting (CC) modules through controlled ablation studies. Models with and without these modules are compared to assess their contribution to localization accuracy.
Figure 7 shows the median localization error when each module is removed. Removing temporal contrasting notably increases error, demonstrating its importance in capturing consistent motion patterns across time. Without TC, the error rises from 0.52 m to 0.87 m. This highlights the role of temporal consistency in learning location-discriminative features.
Similarly, eliminating contextual contrasting degrades performance, increasing the error to 0.99 m. This confirms that CC helps the model better separate identity and spatial context during representation learning. In contrast, the supervised baseline suffers the highest error at 1.3 m, showing limited generalization without contrastive pretraining.
Together, TC and CC significantly reduce localization error, especially with limited labeled data. This validates that enforcing both temporal coherence and contextual separation is essential for robust and accurate localization using RTT and RSSI signals.
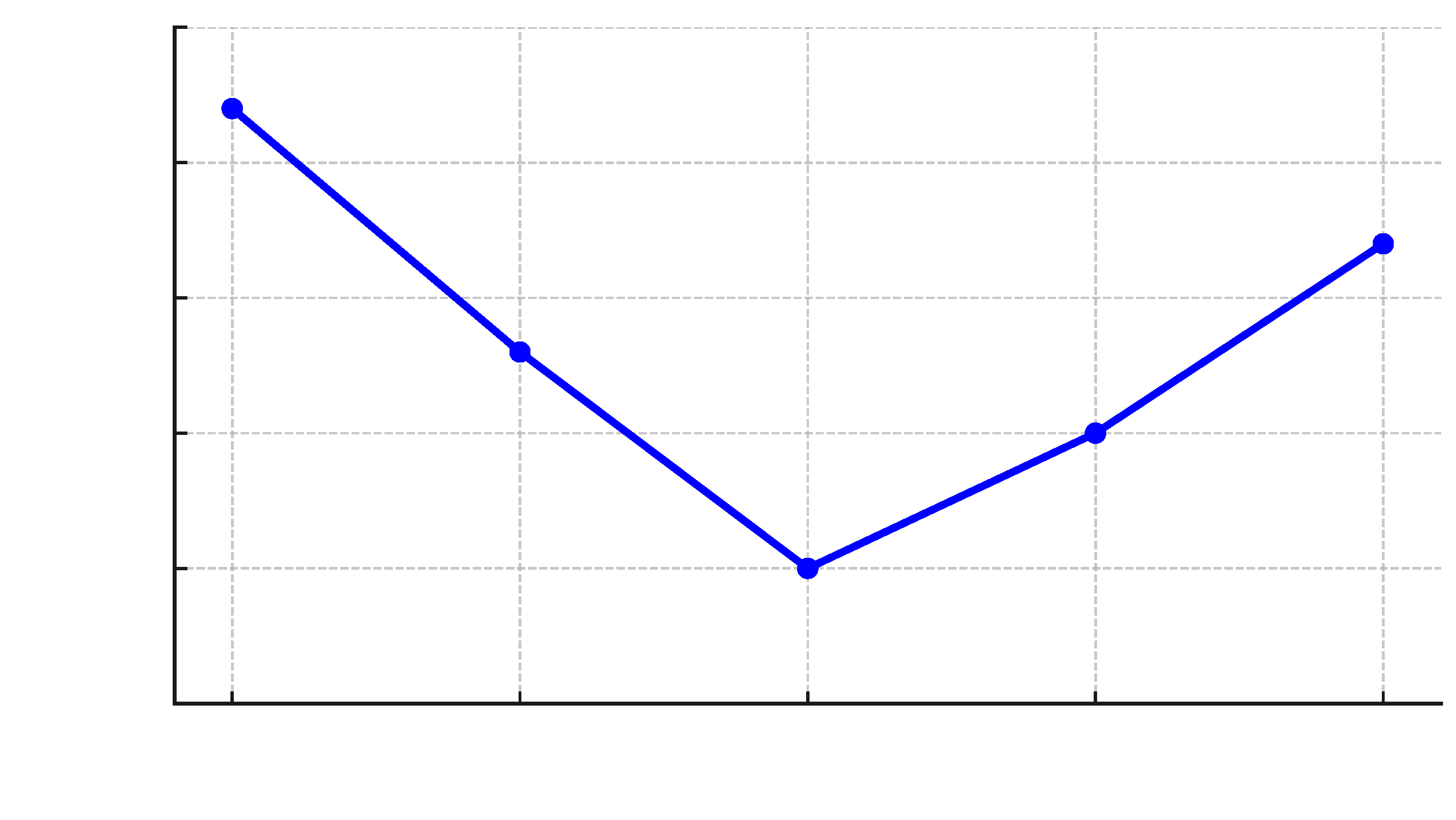
5.2.3. Sensitivity to Temporal Context Window (K)
To evaluate the robustness of
SelfLoc to the size of the temporal context window
K, we conduct a sensitivity analysis by varying
K from two to six and measuring the resulting median localization error. As shown in
Figure 8,
SelfLoc achieves the best performance at
, with a median error of 0.55 m. This setting balances the trade-off between temporal richness and overfitting to specific signal patterns. Performance remains stable across a broad range, with only modest degradation observed when
K is reduced to two or increased to six. This robustness demonstrates that
SelfLoc does not rely on a carefully tuned
K, making it well-suited for deployment in environments with varying signal dynamics. Overall, the evaluation confirms that
SelfLoc can effectively leverage temporal structure in RTT and RSSI sequences while maintaining a stable performance across different context sizes—a desirable property for real-world applications with diverse signal conditions.
5.2.4. Impact of Data Augmentation on Localization Accuracy
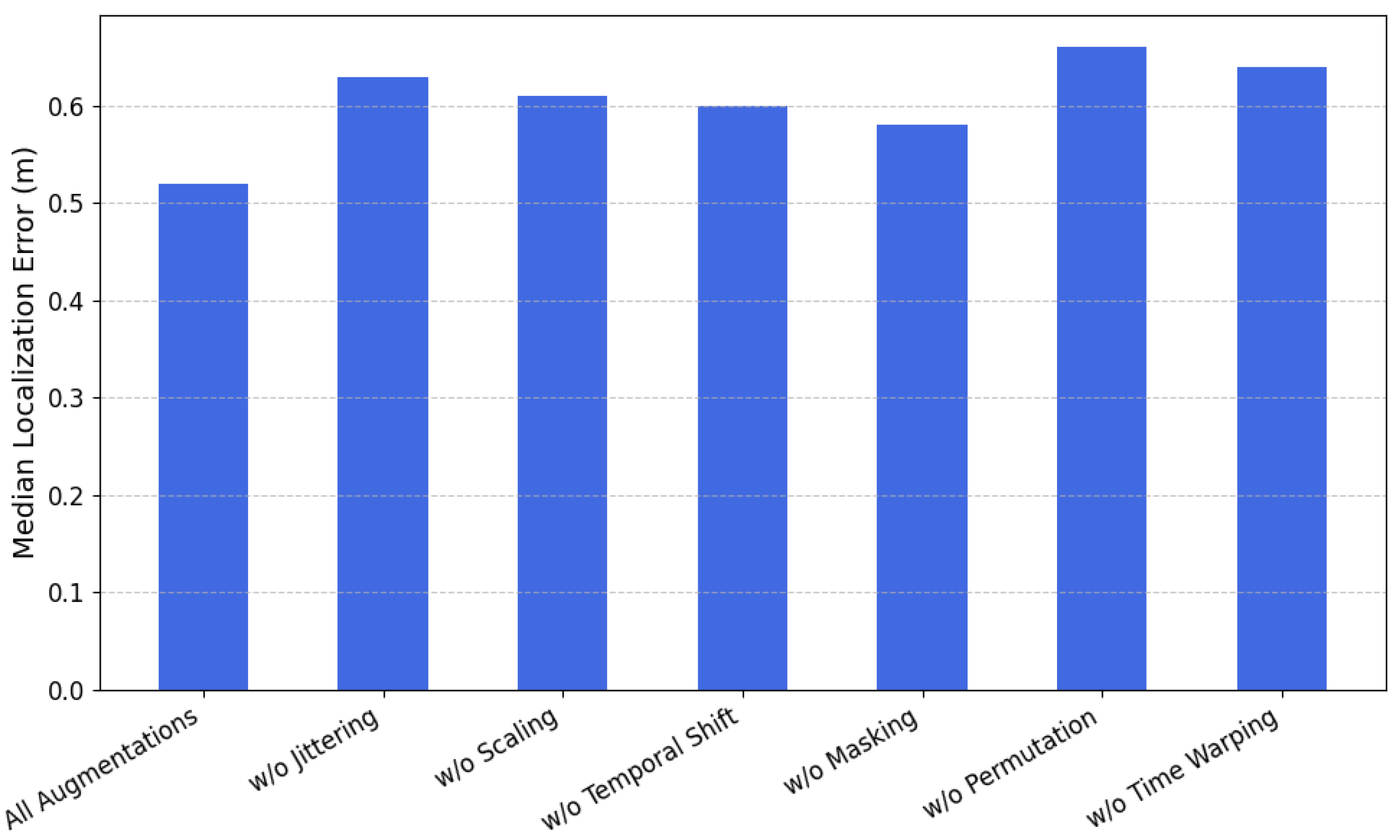
To better understand the contribution of each data augmentation strategy within our contrastive learning framework, we conduct an ablation study by selectively removing one augmentation method at a time during pretraining. The goal is to evaluate how critical each augmentation technique is in enabling robust feature learning from RTT and RSSI signals.
Figure 9 summarizes the median localization error when individual augmentations are omitted. The baseline result, achieved with all augmentations applied, yields the lowest error at 0.52 m, demonstrating the effectiveness of the complete augmentation pipeline. However, when specific augmentations are removed, the performance degrades noticeably. Removing
Permutation leads to the largest increase in error, reaching 0.66 m. This highlights its important role in enforcing temporal pattern invariance and preventing the model from overfitting to signal order. Similarly, excluding
Time Warping and
Jittering results in errors of 0.64 and 0.63 m, respectively, reflecting their relevance for learning robust representations under dynamic and noisy conditions.
Other augmentations, such as scaling, temporal shifting, and masking, also contribute to performance, though their removal causes smaller increases in localization error. This indicates that while these techniques help diversify the data and improve generalization, they are slightly less critical compared to permutation-based and warping augmentations.
Overall, this analysis confirms that each augmentation contributes to learning location-discriminative and generalizable embeddings. In particular, strong augmentations that alter the temporal structure are especially beneficial. The results emphasize the importance of a carefully designed augmentation pipeline to fully exploit contrastive learning for accurate and label-efficient localization.
5.2.5. Impact of Spatial Discretization on Localization Performance
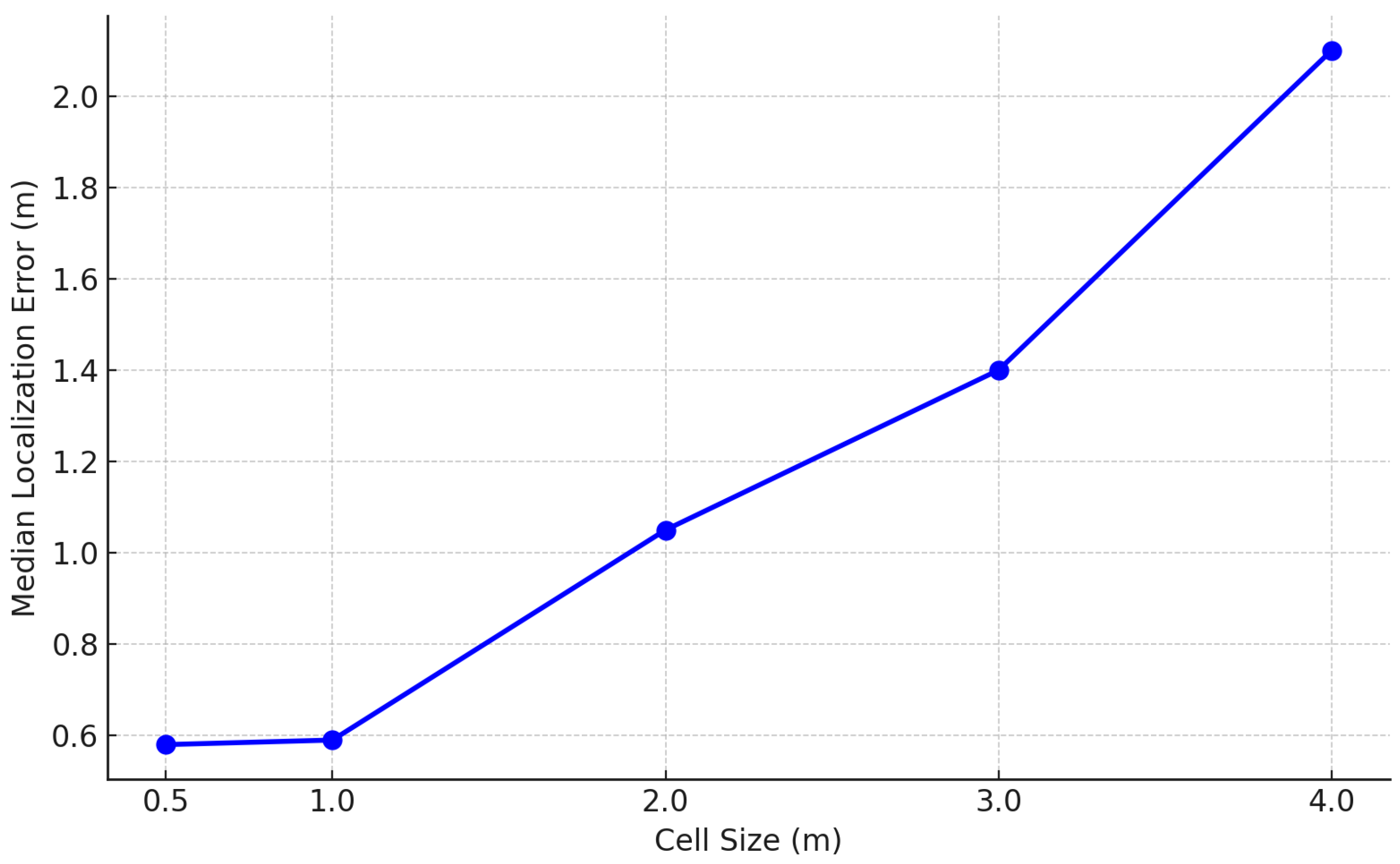
In this section, we assess the impact of spatial discretization on the
SelfLoc system’s localization performance. Spatial discretization refers to partitioning the area of interest into fixed-size grid cells, each treated as a unique class label during training. This granularity directly influences how RTT and RSSI signal sequences are mapped to physical space and thus impacts the model’s ability to distinguish between nearby locations. As shown in
Figure 10, varying the grid cell size reveals a consistent trend: localization accuracy degrades as spatial resolution decreases. With small cell sizes of 0.5 m and 1.0 m, the system achieves median localization errors of 0.58 m and 0.59 m, respectively. These results demonstrate that fine-grained discretization enables the model to capture subtle signal variations, leading to highly precise location estimation. However, as the cell size increases to 2.0 m, 3.0 m, and 4.0 m, the localization error rises significantly, reaching 1.05 m, 1.40 m, and 2.10 m, respectively. This degradation occurs because larger cells encompass greater spatial variability, merging semantically distinct positions into a single label. Consequently, intra-class variance increases while inter-class separability decreases, making it more difficult for the model to learn discriminative spatial features. In the context of contrastive learning, this also weakens the integrity of positive pairs, as signals within the same large cell may originate from physically distant and structurally diverse locations.
These findings highlight a key design trade-off in grid-based fingerprinting systems. While fine spatial discretization improves localization precision, it increases the number of training classes and requires denser data collection. Coarser grids reduce system complexity but sacrifice spatial fidelity. Therefore, selecting an appropriate cell size should balance the competing goals of localization accuracy, computational cost, and data annotation effort, depending on the specific deployment constraints.
5.2.6. Impact of Input Modalities on Localization Performance
To evaluate the individual contribution of each signal modality, we compare the localization performance of
SelfLoc when using only RSSI, only RTT, and their combination.
Figure 11 reports the median localization error achieved in each configuration. RTT only significantly outperforms RSSI only, achieving a median error of 0.85 m compared to 1.50 m. This is expected, as RTT provides more stable and geometry-aware measurements, whereas RSSI is more susceptible to multipath and environmental noise. Combining both modalities leads to a further improvement, with the hybrid RTT+RSSI configuration achieving a median error of 0.55 m. This represents a relative improvement of approximately 63% over RSSI only and 35% over RTT only. The performance gain can be attributed to the complementary strengths of the two modalities: RTT contributes robustness in stable line-of-sight conditions, while RSSI enhances localization in NLoS scenarios where RTT measurements may be sparse or noisy. These results highlight the benefit of multimodal learning in enhancing spatial resolution, especially under variable environmental conditions. Incorporating both RTT and RSSI enables
SelfLoc to learn richer, more generalizable representations that improve accuracy across diverse deployment settings.
5.2.7. Effect of Access Point Density on Localization Accuracy
We analyze the influence of access point (AP) density on the localization accuracy of the SelfLoc system. This is performed by progressively reducing the number of RTT and RSSI measurements used during inference, simulating scenarios with fewer observable APs. At each density level, AP entries are randomly removed from the input feature vectors to assess system performance under realistic deployment constraints.
Figure 12 shows that increasing the number of APs significantly improves the median localization accuracy. With only one AP, the system relies entirely on RSSI values and yields a median error of 1.50 m. Introducing just one additional AP (two total) improves accuracy by 13.3%, reducing the error to 1.30 m. As the AP count grows, the benefits become more pronounced: with three APs, the error drops to 1.05 m—a 30% reduction relative to the one-AP case. With four and five APs, the error decreases further to 0.85 m and 0.70 m, representing 43.3% and 53.3% reductions, respectively. When seven APs are available,
SelfLoc achieves its lowest median localization error of 0.55 m, which is a substantial 63.3% improvement over the single-AP scenario. These improvements stem from the increased spatial diversity and geometric constraints provided by additional APs. A higher AP density enriches the feature space, making it easier for the model to resolve location ambiguities caused by multipath effects or signal fading. These findings confirm that access point density plays a critical role in enabling accurate and robust localization. While
SelfLoc remains functional under low-density conditions, significant accuracy gains can be realized with moderate increases in AP availability, supporting the case for strategic AP deployment in real-world environments.
5.3. Comparative Evaluation
In this section, we compare the performance of
SelfLoc against four representative Wi-Fi-based localization systems: WiNar [
14], WiDeep [
29], the multilateration-based system in [
17], and RRLoc [
62]. WiNar uses deterministic RTT fingerprinting, matching online scans to a pre-recorded database. RSSI values are used to weigh candidate positions. While simple and fast, WiNar struggles in dynamic environments due to its non-learning nature. WiDeep is a deep learning model that leverages denoising autoencoders to clean and embed RSSI data. Though it generalizes better than deterministic methods, its reliance on RSSI limits robustness in multipath-heavy conditions. The ranging-based system applies geometric multilateration using RTT and filters NLOS readings. It performs well in line-of-sight conditions but is highly sensitive to RTT noise and AP placement. RRLoc fuses RTT and RSSI using Deep Canonical Correlation Analysis (DCCA) with dual-branch networks, learning a shared latent space via supervised regression. While accurate, it requires significant computation and lacks explicit spatio-temporal modeling. All systems are evaluated on the same testbeds using identical data and configuration for a fair comparison. Performance is assessed in terms of localization error and inference latency.
5.3.1. Localization Performance Across Systems and Testbeds
We evaluate the median localization accuracy of
SelfLoc against four representative systems—RRLoc, WiNar, WiDeep, and a ranging-based multilateration technique—across two realistic indoor environments.
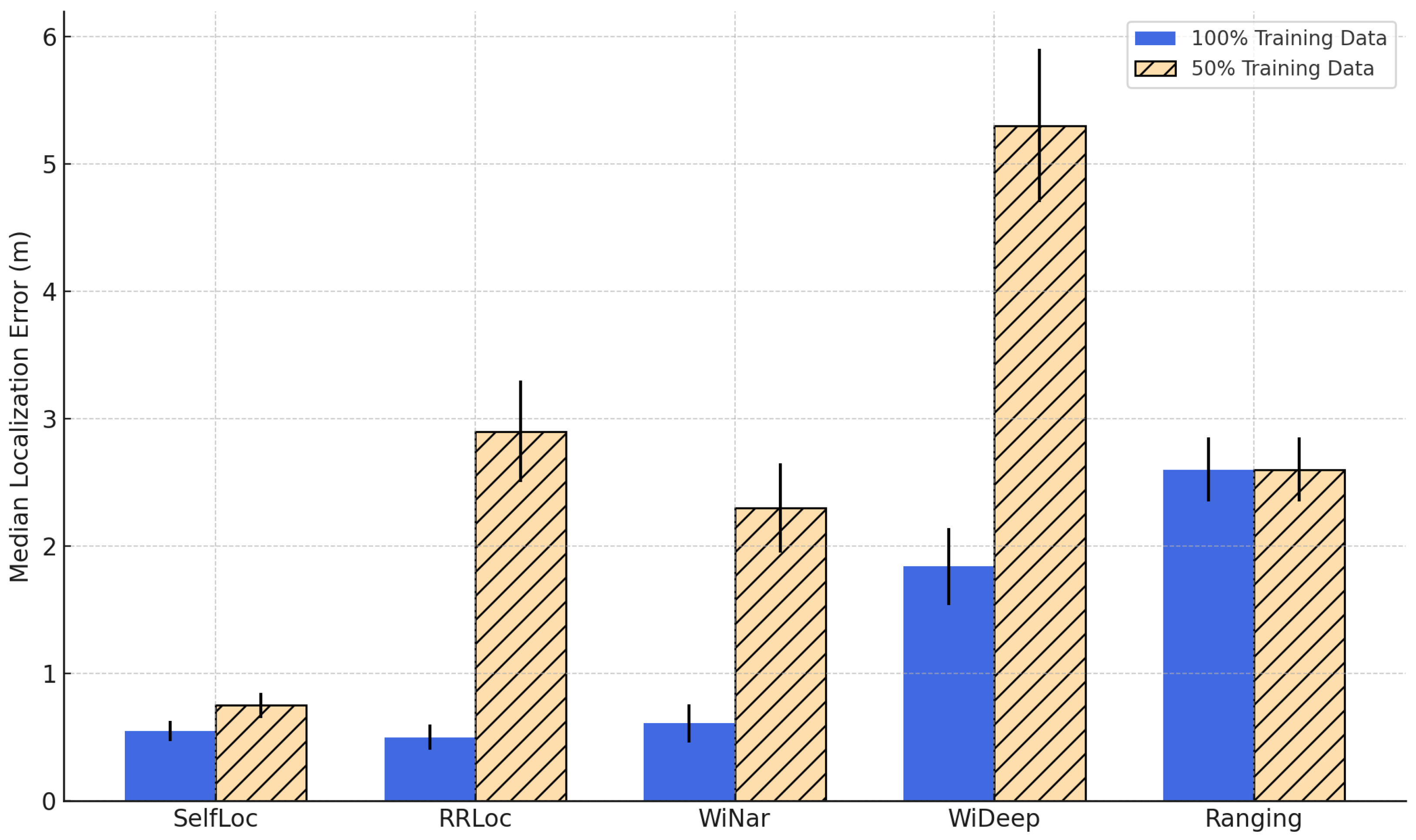
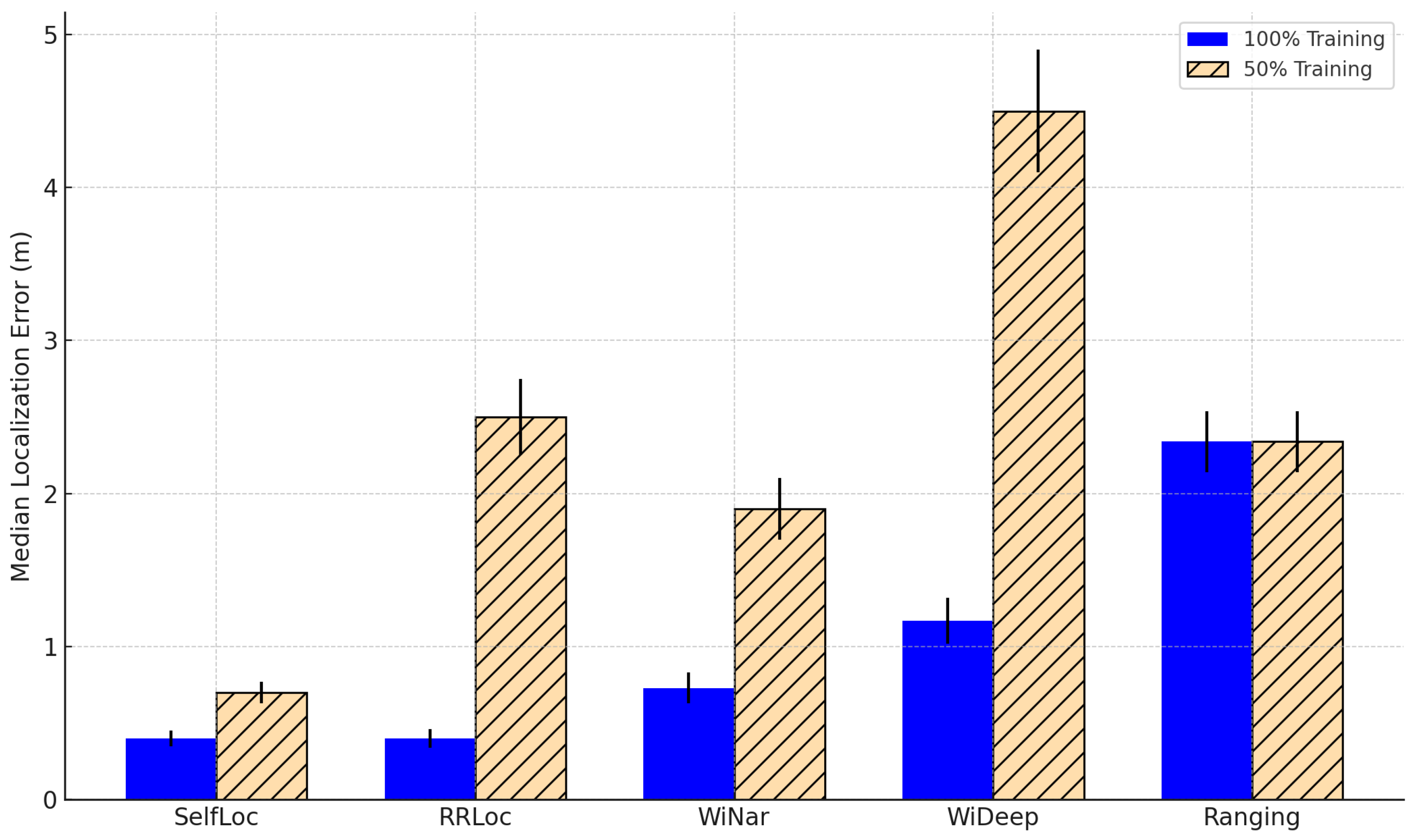
Figure 13 and
Figure 14 show the results for both 100% and 50% training data scenarios in the lab and office testbeds, respectively.
SelfLoc consistently achieves the best localization performance in both testbeds, regardless of training data availability. When trained on the full dataset, SelfLoc maintains sub-meter accuracy (0.4 m and 0.55 m in lab and office), and even with only 50% of the labeled data, its error remains below 0.75 m. This highlights its data efficiency and ability to generalize from limited supervision, primarily attributed to the contrastive learning framework that captures invariant spatial signal structures through dual augmentation views. RRLoc performs closely to SelfLoc when trained on the full dataset in the lab testbed, benefiting from its joint DCCA-based feature fusion of RTT and RSSI. However, its performance deteriorates significantly when trained with 50% of the data—resulting in median errors of 2.5 m in the lab and 2.9 m in the office. This is due to the over-reliance on modality-specific representations without strong pretraining, making it prone to overfitting under low supervision. WiNar, based on deterministic fingerprinting and weighted matching using RSSI and RTT, performs moderately well with 100% labeled data (0.73 m in lab, 0.61 m in office) but degrades under reduced supervision. The degradation stems from its non-learning-based nature: the system lacks a learned generalization model, relying solely on nearest-neighbor searches over raw measurements, which becomes unreliable as the fingerprint density drops. WiDeep, a deep learning system based on a denoising autoencoder trained solely on RSSI, shows high localization error even with full training (1.17 m in lab, 1.84 m in office), and degrades sharply to over 4.5–5.3 m with 50% labels. This is expected given RSSI’s high temporal variance, sensitivity to device placement, and its lack of absolute spatial semantics. Furthermore, WiDeep defines a full neural network per reference point, leading to high model complexity and inefficiency during inference, as discussed in the previous subsection. The ranging-based system exhibits the worst performance across all conditions, with a consistent error of 2.34–2.6 m. This method directly applies multilateration using RTT values and relies heavily on clear line-of-sight (LOS) measurements and precise synchronization, both of which are often violated in complex indoor environments. Its inability to learn spatial features or mitigate RTT bias under NLOS results in its high localization error and poor generalizability.
Impact of Testbed Characteristics. The lab testbed spans a large area of 629 m2, with nine rooms and long corridors, allowing a wider signal variation and richer spatial diversity. In contrast, the office testbed is more compact (141 m2), with closer spatial proximity between reference points and stronger multipath interference due to wall reflections. This makes fine-grained spatial resolution more challenging. Despite these differences, SelfLoc demonstrates strong generalization across both layouts. Its learned embeddings capture both temporal consistency and contextual spatial cues, making it more robust to layout-induced noise. The performance drop between environments is minimal for SelfLoc, whereas traditional systems exhibit more pronounced degradation in the office due to the increased ambiguity in RSSI/RTT readings.
These results confirm that SelfLoc offers state-of-the-art localization accuracy, even under limited supervision and challenging environments. Its fusion of RTT and RSSI, enhanced with contrastive self-supervised pretraining and signal-specific augmentations, enables it to outperform all baselines. This makes it a highly scalable and reliable solution for next-generation indoor localization in smart industrial and collaborative automation scenarios.
A comprehensive summary of localization error statistics across different systems is provided in
Table 4 and
Table 5, showing
SelfLoc’s consistent performance across both lab and office testbeds under 50% training data.
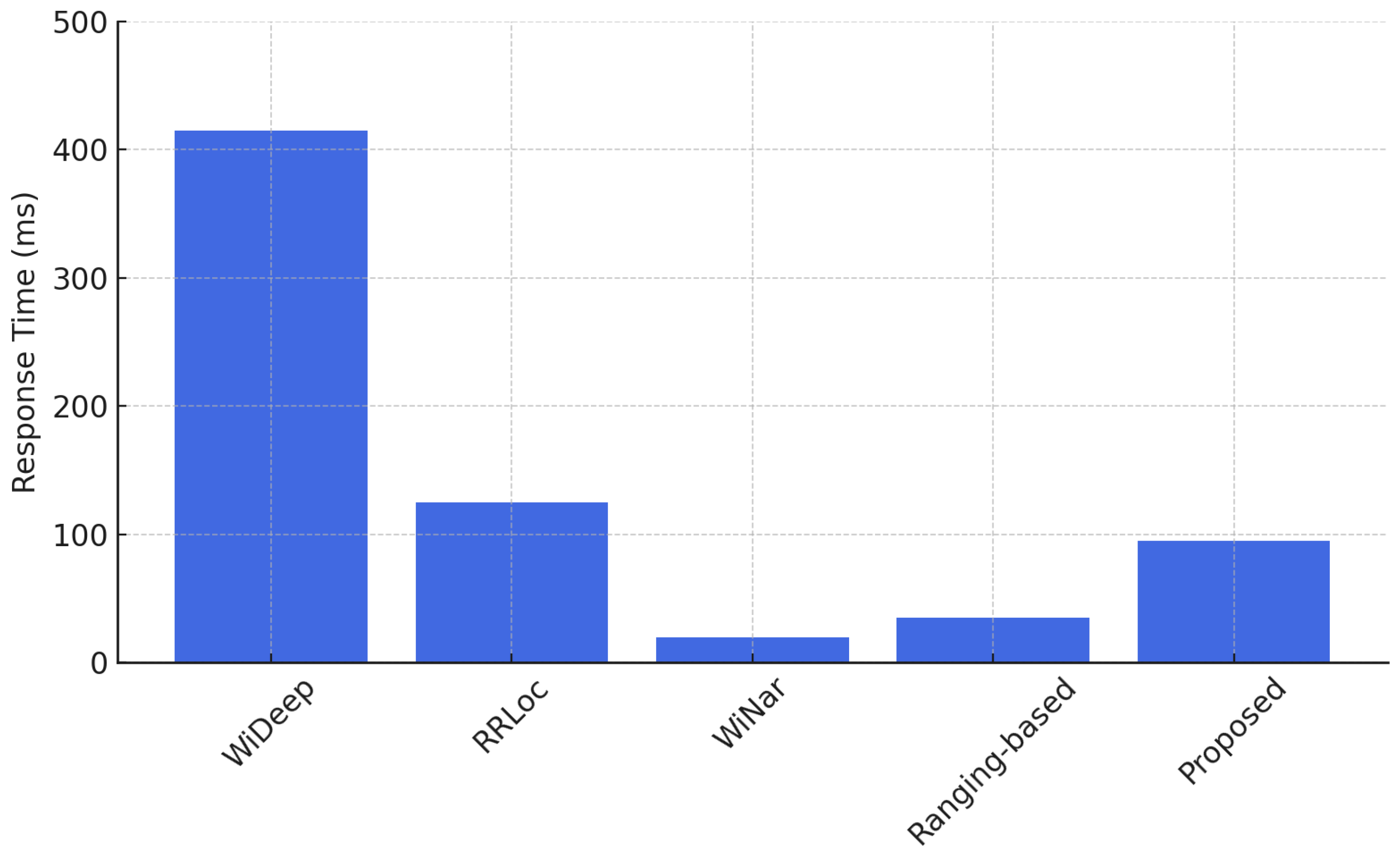
5.3.2. Time per Location Estimate
In this section, we also evaluate the computational efficiency of each system in terms of the average inference time per location estimate. This was measured on a Lenovo ThinkPad X1 laptop equipped with an Intel i7-8750H CPU (2.2 GHz), 64 GB RAM, and GTX1050Ti GPU. As illustrated in
Figure 15,
SelfLoc achieves an average inference time of 95 ms, supporting real-time localization. This latency is significantly lower than that of WiDeep, which requires 415 ms per estimate. WiDeep’s high overhead stems from its architecture—each reference point is associated with a dedicated network, meaning every inference requires passing the input through all networks. In contrast,
SelfLoc uses a streamlined, contrastive encoder with a single shared model, drastically reducing computational load while preserving accuracy. Compared to RRLoc, which reports a 125 ms response time,
SelfLoc still demonstrates a 24% improvement in latency. This stems from the fact that RRLoc’s dual-branch DCCA encoder introduces overhead in both training and inference due to its modality-specific deep pipelines and joint optimization loss. WiNar and the ranging-based method are faster due to their deterministic nature, but they fail to match
SelfLoc in terms of accuracy or resilience to environmental changes.
These results highlight the strength of SelfLoc in achieving a favorable trade-off between accuracy and responsiveness—two critical factors for enabling real-time localization in intelligent environments. By leveraging self-supervised contrastive learning, SelfLoc not only eliminates the need for dense labeling but also learns spatially meaningful signal embeddings that are robust to hardware variability as validated next.
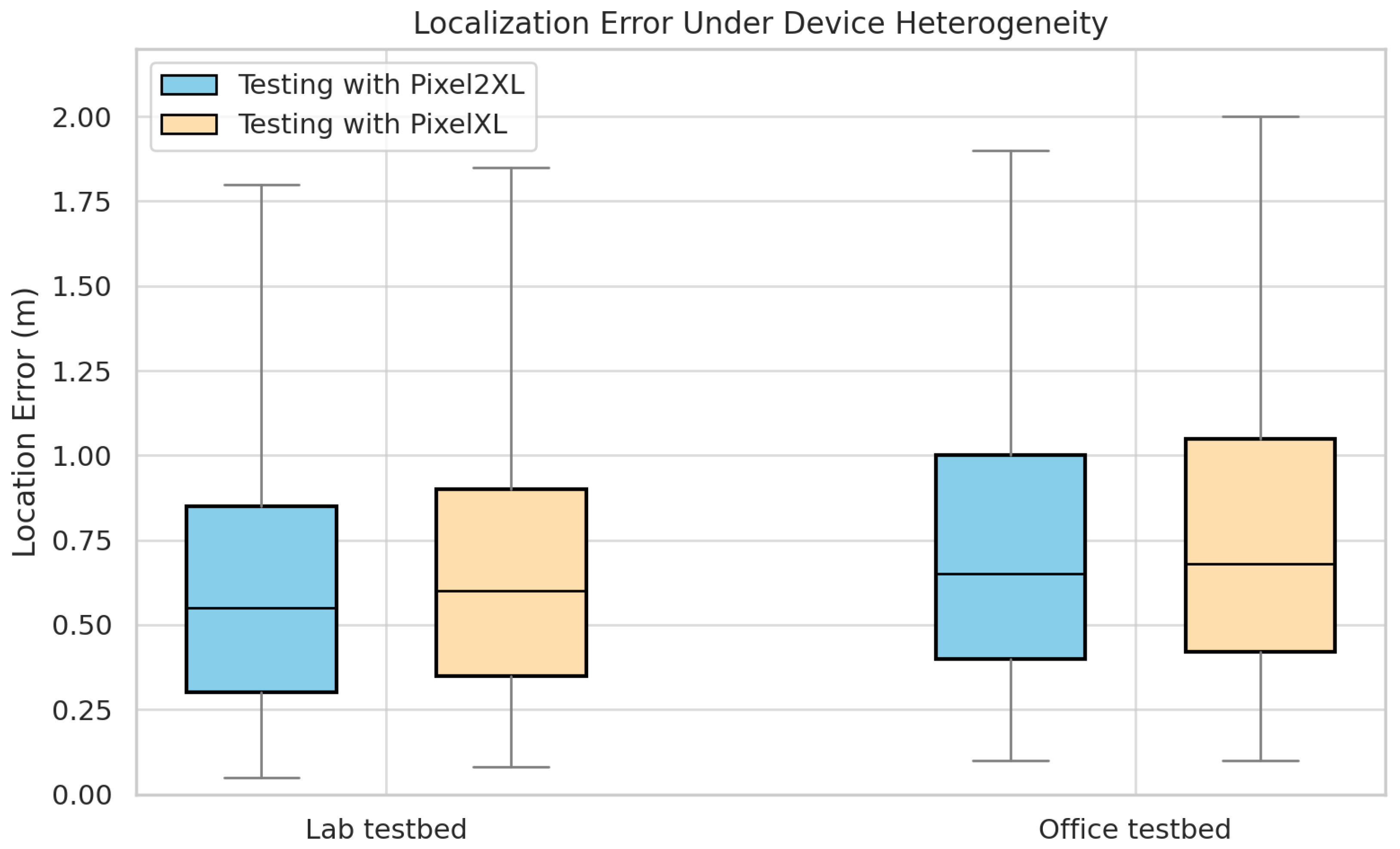
5.3.3. Robustness to Device Heterogeneity
In this section, we examine the robustness of the
SelfLoc system to device heterogeneity, where training and testing are conducted on different smartphone models. Specifically, we train the localization model using RTT and RSSI data collected from one device (e.g., Pixel 2XL) and evaluate it on another (e.g., Pixel XL), and vice versa.
Figure 16 shows the resulting localization errors for both lab and office testbeds.
The results confirm that
SelfLoc delivers a stable localization performance despite cross-device deployment. In the lab testbed, median errors are 0.54 m and 0.61 m when tested with Pixel 2XL and Pixel XL, respectively. In the office testbed, the errors are 0.59 m and 0.62 m for the same respective testing devices. This limited deviation reflects the system’s resilience to hardware variability. The underlying cause of such differences primarily stems from hardware-induced variability in RSSI measurements. Smartphone models differ in antenna placement, receiver sensitivity, internal shielding, and chipset signal processing—all of which influence received signal strength. For instance, the Pixel 2XL may offer more stable or less noisy RSSI readings due to better antenna gain or more recent radio firmware. These variations introduce systematic offsets in the RSSI values between devices, leading to minor shifts in signal profiles for the same location. RTT, on the other hand, is less affected by such hardware discrepancies. Since RTT measures physical signal propagation delays rather than amplitude, it is more robust to device-specific distortions. Prior work has demonstrated that RTT readings show far less variability across phones compared to RSSI [
34].
By combining both modalities,
SelfLoc benefits from the complementary properties of RSSI (sensitive to signal quality) and RTT (resilient to device differences). This fusion enables the system to generalize well even when the device used during deployment differs from the one used during training. As more Android devices continue to support IEEE 802.11mc/az RTT, the applicability of such systems in heterogeneous device environments will continue to improve [
66].
5.4. Discussion and Limitations
While SelfLoc achieves high accuracy and strong generalization across realistic indoor environments, several practical limitations remain:
Low AP density: Sparse access point deployments reduce geometric diversity, weakening the spatial separability learned by contrastive training. As shown in our experiments (
Figure 12), localization error increases in such cases. This can be mitigated through strategic AP placement or by fusing additional sensor modalities such as inertial or magnetic data.
Multipath-rich environments: Highly reflective materials (e.g., metal or glass) introduce multipath effects that distort both RTT and RSSI measurements. While RTT is more stable, severe multipath conditions may still degrade accuracy. Incorporating adaptive filtering or training with multipath-aware augmentations is a promising mitigation strategy.
Dynamic environments and real-world generalization: Our dataset was collected in active office and lab spaces with moving people and periodic furniture rearrangement, simulating realistic deployment scenarios. These conditions introduce signal occlusions and environmental drift.
SelfLoc addresses these challenges through contrastive learning with robust signal-specific augmentations, which promote invariance to temporal and spatial perturbations. While our current evaluation does not include large-scale public venues (e.g., malls and transit hubs), we consider this a promising future direction. We provide a real-world deployment demo highlighting system stability under such dynamics:
https://youtu.be/BTWH0JrJumQ accessed on 24 June 2025).
Continual adaptation: While SelfLoc supports periodic retraining on unlabeled data, its architecture also lends itself to continual self-supervised learning, enabling incremental updates using streaming signal data. This is especially beneficial in dynamic settings, where indoor layouts and propagation conditions evolve over time. Future extensions may employ online contrastive learning or lightweight replay buffers to enable efficient, adaptive model updates without full retraining.
Dependence on partial labels: Although
SelfLoc minimizes supervision, a small amount of labeled data is still needed for fine-tuning and pseudo-label bootstrapping. Future work can explore transfer learning across buildings to reduce this dependency and achieve near-zero-label deployment similar to [
67].
Hardware compatibility: RTT support requires both the client and access points to be IEEE 802.11mc/az compliant, which may limit immediate applicability. As industry adoption grows, broader compatibility is expected. Meanwhile, fallback to RSSI only operation offers a viable alternative.
Three-dimensional multi-floor localization: SelfLoc currently focuses on 2D localization and has not been evaluated in multi-floor buildings. Differentiating floors is challenging due to the limited vertical resolution of RTT and the ambiguity of RSSI across floors. This can lead to floor misclassification. A promising direction is to integrate altimetry (e.g., barometric sensors) for coarse floor estimation, followed by floor-specific 2D localization [
68]. Alternatively, learning floor-discriminative features [
69] or using AoA where available can improve 3D localization robustness.
These limitations highlight realistic deployment challenges, yet they also point to promising future directions to enhance the scalability, robustness, and adaptability of SelfLoc in diverse indoor settings.
6. Conclusions
This paper presents a SelfLoc system that demonstrates how self-supervised contrastive learning can be effectively applied to indoor localization by addressing the critical challenge of reducing dependence on large-scale labeled datasets. Through its dual-contrastive strategy, SelfLoc captures both temporal dynamics and spatial distinctiveness in Wi-Fi RTT and RSSI signals, enabling it to robustly track user movement and distinguish between nearby locations, even in environments with high signal similarity or multipath effects. The incorporation of signal-specific augmentations further enhances generalization across different deployment settings. SelfLoc offers a scalable, accurate, and adaptable localization framework well-suited for dynamic smart environments, paving the way for widespread adoption in industrial and societal applications.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}