1. Introduction
Three-dimensional (3D) printing is an additive manufacturing (AM) technique used to produce components with minimal material waste, reduced human intervention, and improved energy efficiency [
1]. Laser sintering (LS) is a widely used AM technique in which a high-powered laser selectively fuses powdered materials like polyamide (PA 12), polystyrene, thermoplastic elastomers, and polypropylene [
2]. This layer-by-layer fusion process creates solid objects based on a computer-aided design (CAD) model, enabling the production of complex geometries and intricate designs without the need for support structures. To meet industrial standards for large-scale production, effective quality management is essential to monitor and optimize the quality of the produced parts [
3].
The quality of the fabricated parts depends on the fusion bonding among consecutive powder layers and hatches, the stability of powder distribution, and the integrity of the powder bed [
4]. Powders with consistent particle size distribution and suitable material properties promote better fabrication. In order to manufacture a high-quality fabricated part, a uniform, clean powder bed with no irregularities is desirable [
3]. Powder bed defects like part edges, part accumulation, and powder trenches pose a threat to controlling the quality of the fabricated parts. Understanding these defects is crucial as they result in increased material wastage, additional cost, and lower efficiency [
4].
Table 1 shows some common powder bed defects, their causes, and potential mitigation strategies.
Figure 1a,b highlights examples of powder beds without and with irregularities, respectively.
The early detection of powder bed defects leads to immediate corrective measures, ensuring part quality while reducing costs and waste [
4]. Defect detection technology for AM must be affordable, capable of fast detection, adaptable to complex geometries, and able to detect multiple defects. Defect detection methods are typically categorized into two types: traditional non-destructive defect detection technology and machine learning-based defect detection processes [
5].
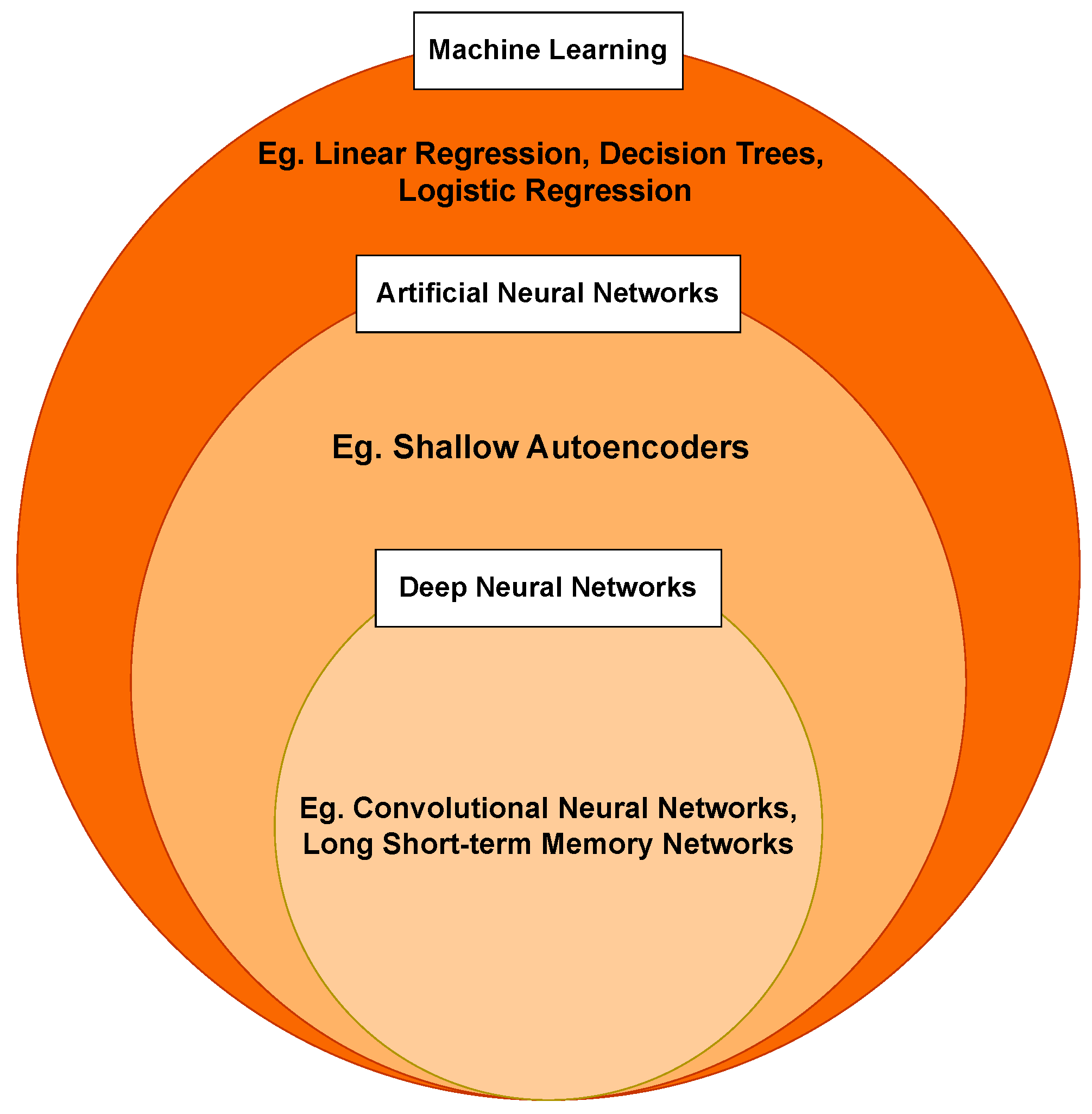
In recent years, machine learning (ML) has gained popularity in the AM domain [
6] and has proven effective in optimizing process parameters that affect part build quality. It is also being employed in in situ monitoring systems to establish an efficient defect detection process. By utilizing training datasets, ML algorithms can identify patterns and make inferences on test datasets. A hierarchical relationship among the ML algorithms is summarized in the diagram shown in
Figure 2.
Traditional ML algorithms rely on well-defined features, requiring extensive feature extraction and engineering [
8]. This limitation is addressed by advanced DL algorithms, which automatically extract relevant features. However, DL algorithms demand substantial computational resources for improved robustness and accuracy. This paper makes the following contributions to the field:
A lightweight VGG-based architecture with an integrated novel soft-attention mechanism, requiring 104 times fewer parameters than VGGNet, minimizing computational resources and enabling deployment on low-end devices.
The architecture outperforms state-of-the-art models in Accuracy, Precision, Recall, and F1 score on the same dataset, with nearly 10 times fewer MAC operations.
The paper is organized as follows:
Section 2 reviews the existing research related to the proposed study.
Section 3 details the proposed architecture and model intricacies.
Section 4 presents the experimental results, with analysis and discussion.
Section 5 summarizes the work, highlighting the advantages, limitations, and future potential of the proposed architecture.
2. Literature Survey
The application of deep convolutional neural networks (CNNs) in large-scale image classification has become widespread [
9]. The use of CNNs, transfer learning techniques, and ensemble methods has demonstrated promising outcomes in the field of additive manufacturing (AM) [
10,
11,
12,
13,
14].
Notably, Westphal et al. [
3] proposed a novel approach using VGG16 and Xception networks for defect detection in powder bed images obtained during the laser sintering (LS) manufacturing process. Random oversampling and undersampling were employed to address the class imbalance problem. The VGG16 architecture achieved the highest performance, with a classification accuracy of 97.10% on non-augmented data. Abhilash et al. [
15] proposed a Residual Neural Network (ResNet50)-based model that achieved 96% accuracy in predicting the surface condition in a selective laser melting (SLM) process, followed by wire electric discharge polishing (WEDP) to polish the surfaces of the manufactured components. Kim et al. [
16] employed a failure detection model using the VGG19 CNN to detect the filament tangling phenomenon, known as the “spaghetti-shape-error”, in metal extrusion processes, achieving 97% accuracy. Pandiyan et al. [
17] demonstrated the technique of transfer learning using two networks, VGG16 and ResNet18, trained on spectrograms of acoustic emissions from the laser powder bed fusion (LPBF) process of stainless steel. These networks were retrained using transfer learning on the spectrograms of LPBF processes involving bronze for a similar classification problem. Jin et al. [
18] proposed an autonomous correction system for Fused Deposition Modeling (FDM), incorporating a pre-trained ResNet50, which achieved over 98% accuracy in defect detection and used a feedback loop to adjust 3D printing parameters, ensuring a defect-free design by self-correcting issues like over-extrusion or under-extrusion.
Among the contemporary studies, Westphal et al. [
3] stands out for achieving the highest reported performance, with a classification accuracy of 97.10%. Their use of a publicly available dataset is particularly useful for this research, as it facilitates a direct comparison with the approach presented here. Ansari et al. [
19] also used a dataset labeled with CAD design data and post-build X-ray computed tomography (XCT) scans. Data augmentation techniques, including vertical and horizontal flips, were applied to address the class imbalance. A novel CNN architecture, tuned using a hyper-band optimization algorithm, achieved 90% accuracy on CAD design-labeled images and 97% accuracy on XCT-assisted labeled images. Cue et al. [
20] conducted extensive experiments to assess the impact of various CNN hyperparameters, such as L2 regularization, dropout rates, and the number of convolution layers, on the performance of a network trained on a laser metal deposition dataset. The final architecture achieved an accuracy of 92.1% with a latency of 8.01 milliseconds during image classification. Caggiano et al. [
21] devised a bi-stream deep CNN architecture with skip connections for online defect detection in SLM processes due to improper process conditions. This algorithm implemented a feature fusion technique while analyzing both SLM powder layers and part slices images, achieving a high accuracy of 99.4%.
Bimrose et al. [
22] trained an ML model based on the ResNet-34 architecture to automatically detect hidden defects in AM parts using their X-ray CT images, achieving an accuracy of over 98% in fewer than 50 epochs with approximately 1000 images. Ruan et al. [
23] proposed EPSC-YOLOv9 to improve defect detection in industrial surfaces by detecting small and complex-shaped defects. The algorithm, which incorporated efficient multi-scale attention mechanisms and pyramid convolutions in the backbone network, achieved superior performance compared to YOLOv9c, YOLOv10, and MSFT-YOLO. The methodology also incorporated Soft-NMS and a new convolution attention module called the CISBA module, which improved the detection of small targets in complex backgrounds. Notably, this method demonstrated excellent performance on the NEU-DET and GC10-DET datasets. Abdalla et al. [
24] introduced an ensemble of deep neural networks trained on various features representing drugs and polymeric materials to predict the printability of drug formulations using LS. The model achieved over 90% accuracy when trained on Morgan fingerprint (MFP) features. Xiang et al. [
25] proposed a novel defect detection network named BMA-YOLO, incorporating three modules: Block-wise Feature Fusion Convolution (BFFConv) to reduce model complexity, Multidimensional Convolutional Depooling Attention (MCDA) to improve contextual understanding, and an Auxiliary Training Head (AuxHead) to enhance model stability and generalization. The proposed model achieved impressive results with a mean Average Precision (mAP@0.5) of 77.7% on the NEU-DET dataset, 99.4% on the DAGM2007 dataset, and 95.4% on the PCB-DET dataset, making the model robust and scalable for industrial surface defect detection.
Zhao et al. [
26] proposed a real-time defect detection system for Laser Powder Bed Fusion using 3D point cloud data and deep learning. They compared PointNet, PointNet++, and Point Cloud Transformer (PCT), with PCT achieving the best performance (mean Intersection over Union (mIoU): 82.83%, overall segmentation accuracy (OA): 98.34%). However, these models struggled to detect small and complex defects due to feature loss during downsampling. To overcome this issue, the authors introduced a 2D projection-based approach using DeepLabV3+, which improved accuracy and reduced inference time to 11 ms per layer. The system was deployed in a closed-loop control setup, achieving 100% defect correction with zero false detections in real-world printing tests. Ero et al. [
27] proposed a novel methodology consisting of a self-organizing map, a fuzzy logic scheme, and a tailored U-Net architecture for in situ defect detection during the LPBF process using optical tomography (OT) data. The proposed model demonstrated high performance, with defect probability scores ranging from 0.375 to 0.819 for lack of fusion defects and from 0.391 to 0.616 for intentional keyhole defects. This framework also allowed the integration of expert knowledge through customizable fuzzy rules, enhancing its adaptability and interpretability, making it a practical tool for real-time quality assurance in additive manufacturing. Nevertheless, the dataset provided by Westphal et al. [
3] remains particularly well-aligned with the focus of this paper, making it an ideal choice for comparison with the approach proposed here.
3. Materials and Methods
This section provides a detailed description of the proposed model, focusing on the architecture and its key components. It introduces a lightweight, soft-attention-based CNN framework for classifying powder bed images, which uses fewer parameters than state-of-the-art models like VGG19 and ResNet50, making it more computationally efficient.
3.1. Soft-Attention
In classification tasks, only a small portion of a powder bed image is relevant, while the rest of the image can be considered unimportant. Therefore, the model must focus on the relevant regions. This is achieved through the proposed soft-attention mechanism. Building upon the work of Tomita et al. [
28] in detecting cancerous and precancerous esophagus tissues, and Xu et al. [
29] in image caption generation, this paper uses 3D-convolution-based soft attention [
30] to highlight the pertinent regions of the image required for classification.
The soft-attention module takes a feature tensor
as input [
28,
31]. As shown in
Figure 3, this tensor
is convolved with a 3D convolution layer containing weights
, where
K is the number of 3D weights. The resulting feature maps are passed through a softmax activation layer to generate
attention or context-aware maps. These maps are then aggregated to form a unified feature map, denoted by
, which is multiplied by the original feature tensor
to produce the final tensor
.
In this work, we apply a 3D-convolution-based soft-attention mechanism in the context of 2D image analysis to effectively capture inter-channel and spatial feature dependencies, which are critical for identifying fine-grained powder bed defects such as cracks and ditches. While traditional 2D attention mechanisms operate primarily along spatial dimensions, the 3D convolutional structure allows the model to jointly encode information across the channel and spatial dimensions, thus enabling more expressive feature learning without a significant increase in computational complexity. The 3D convolution operates over the intermediate feature maps rather than the raw 3D data, effectively modeling context across adjacent layers in a compact form. This design choice was found to offer improved defect localization and representation capacity during our experiments.
Gradient-weighted Class Activation Maps (GradCAM) [
32] is a visualization technique used in deep learning that highlights the relevant features of an image used to predict the target class. It produces a localization map by computing the gradients of the error for the particular target class with respect to the feature maps for a particular convolutional layer.
Figure 4 demonstrates the credibility of the Soft-Attention block with the help of GradCAM applied on the max-pooling layer after the Soft-Attention block. Areas with higher activation are denoted in red. The Soft-Attention block helps the model to focus on relevant parts of the powder bed required for classification and also plays an important role in making the architecture lightweight yet powerful, surpassing all state-of-the-art models in terms of performance, as demonstrated in the ablation study in
Section 4.5.
3.2. VGG
Simonyan et al. [
33] introduced a very deep convolutional neural network called VGG19 that achieved state-of-the-art results on the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [
34]. In comparison to VGG16, the VGG19 network has nineteen weight layers in total. The feature extractor of the architecture consists of sixteen convolutional layers organized into five blocks, each followed by a max-pooling layer of size
and a stride of two. The convolutional layers have a filter size of
with a stride of one and a padding of one in order to preserve the spatial features. ReLU [
35] serves as the activation function in the network. Block one includes two convolutional layers with sixty-four filters, while block two consists of two convolutional layers with 128 filters. Block three comprises four convolutional layers with 256 filters, and Blocks four and five each contain four convolutional layers with 512 filters.
3.3. Proposed Method
In our experiments, a custom-made lightweight architecture based on soft attention was utilized to classify LS powder bed images. Similar to the VGG19 architecture, the proposed design comprises sixteen convolutional neural network layers divided into five blocks. Each convolutional neural network layer has a filter size of
with a stride of one and padding of one. This is followed by a batch normalization layer to (a) address the problem of internal covariate shift [
36], (b) inject slight regularization, and (c) ensure stable gradient flow for improved neural network training. Subsequently, a Parametric Rectified Linear Unit (PReLU) activation layer [
37] is implemented to facilitate enhanced model training while minimizing the risk of over-fitting.
In the feature extractor part of the architecture, every block except the last one is followed by a max-pooling layer of size . Block one comprises two convolutional layers with 16 filters, while block two has two convolutional layers with 32 filters. Block three contains four convolutional layers with 64 filters, and blocks four and five each consist of four convolutional layers with 128 filters.
The features from the last convolutional layer are passed into the soft-attention layer, which gives
as the output. Subsequently, a max-pooling layer with a size of
and a stride of one was applied on
, resulting in an output tensor
. A residual connection from the last convolutional layer is passed to a max-pooling layer with a size of
and a stride of one, which is then concatenated with the tensor
. The resulting feature map is followed by a PReLU activation layer that is followed by a global average pooling and a batch-normalization layer. A linear layer with 256 units was applied next, followed by a PReLU layer and a batch normalization layer. A linear layer with two units was finally applied to classify the images.
Figure 5 illustrates the system architecture and data flow.
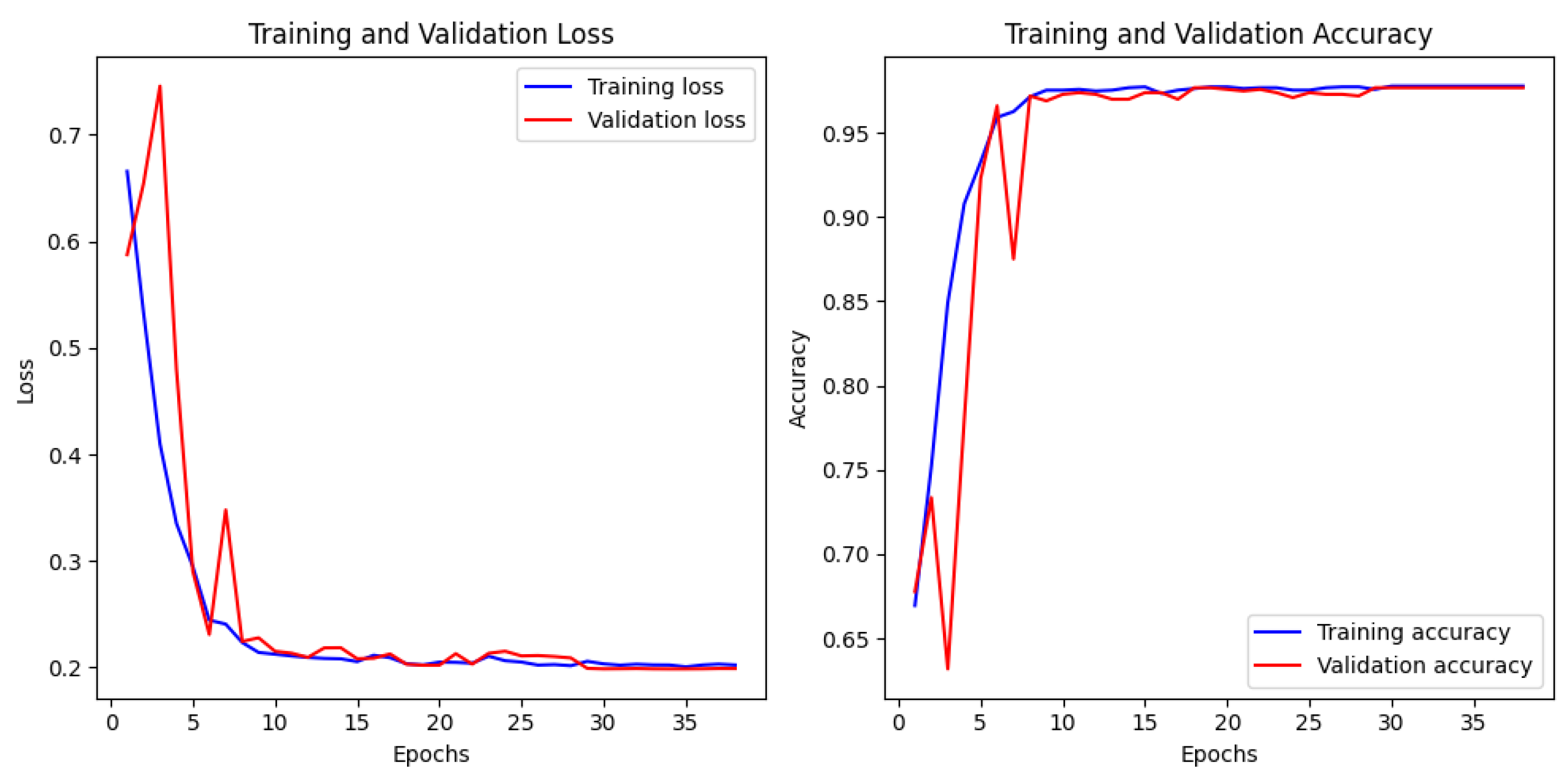
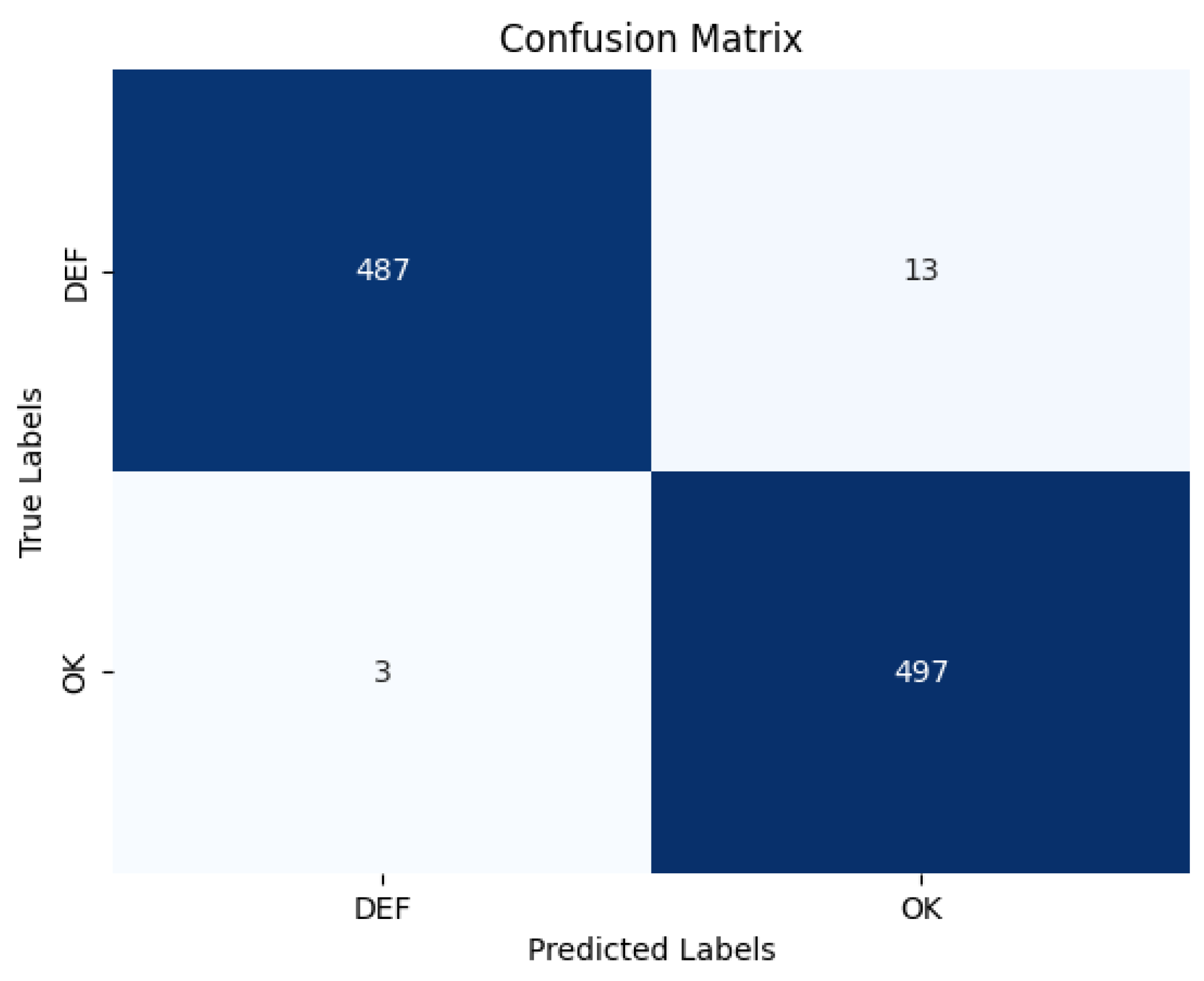
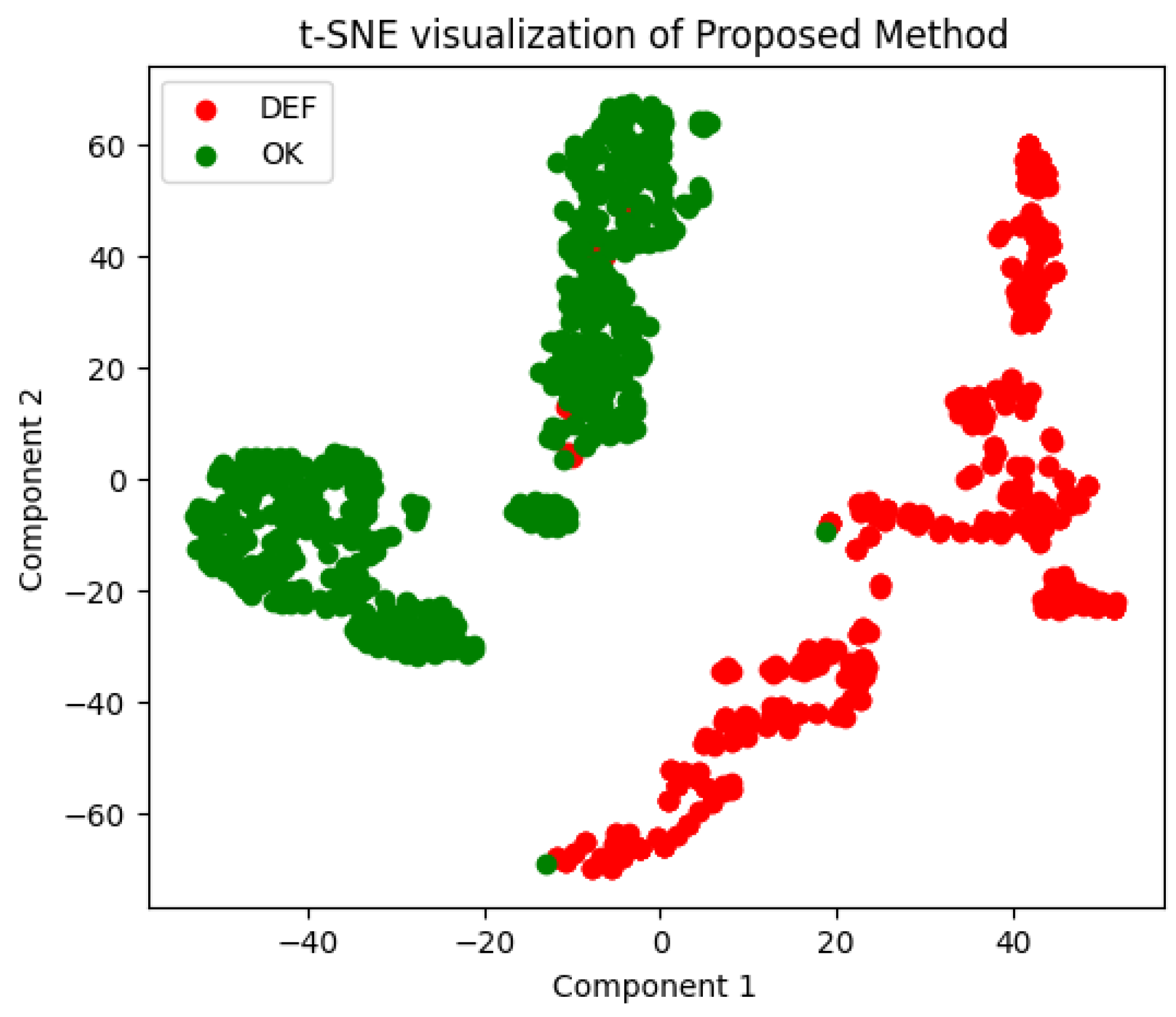
5. Conclusions
The process of in situ defect detection in the field of AM is growing in importance. This work introduces a lightweight CNN architecture paired with a Soft-Attention mechanism for classifying powder bed images. Extensive experimentation and detailed analysis demonstrates that the model not only achieves better performance compared to previous work but also has fewer parameters, thereby facilitating deployment on lighter devices. The proposed model achieved an accuracy of 98.40% and AUC score of 98.40%, as shown in
Figure 9, which is only 0.9% lower than existing work, with nearly 10 times less computational complexity than the state-of-the-art. However, there are some limitations. The model was tested on a small dataset due to the lack of available datasets in this domain. This limitation affects the generalizability of the results, and further testing on larger datasets is required to validate its robustness.
As part of future work, we aim to develop a larger and more diverse dataset to evaluate the model’s performance across a broader range of scenarios. Additionally, we plan to address the limitations of the proposed architecture by optimizing its computational efficiency, thereby further reducing the carbon footprint during both training and inference. We also intend to explore various data augmentation techniques to enhance the model’s robustness and improve its generalization capabilities. Furthermore, we aim to extend the applicability of our model to metallic powder materials in future studies by evaluating its adaptability across diverse material domains. Given the image-based nature of the task, the model can be efficiently retrained using datasets that consist of metallic powder bed images. Although the proposed approach demonstrates strong performance on the current dataset, its ability to handle real-world industrial challenges, such as variations in illumination and sensor noise, remains a limitation. Addressing these issues will be a key focus of our future research.
Moreover, a real-time, in situ process monitoring system could be developed to observe the powder bed during the build process. This system would employ a camera mounted within the build chamber to capture layer-wise images of the powder bed during printing. These images would then be processed in real time using the proposed model deployed on platforms such as an Intel Xeon 2.20 GHz CPU, an NVIDIA Tesla P100 GPU, or any edge device. By quantizing the model to FP16, significant speedups could be achieved on edge devices. Upon completion of the build, a comprehensive diagnostic report could be generated based on the layer-by-layer analysis. Additionally, a closed-loop feedback control system could be designed to dynamically adjust process parameters in response to the in situ diagnostic results for each layer, leading to significant improvements in part quality and process stability within powder bed fusion (PBF) additive manufacturing.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}