1. Introduction
Facial action units (AUs) are part of the Facial Action Coding System (FACS) [
1], which defines facial motions based on their underlying muscles. AUs were originally developed to aid in tasks such as depression detection [
2] and expanded to other clinical settings [
3,
4], security [
5], entertainment [
6], robotics [
7], and others [
8]. These AUs represent human facial gestures in concrete and defined values to be used as the input to various systems.
AU recognition began the transition from using human experts to using computer programs with the release of the BP4D [
9,
10] and DISFA [
11,
12] datasets. AU recognition researchers quickly adopted the average F1 score across the different AUs as the standard metric for comparing solutions. This average F1 score was used to measure the performance of adding Convolutional Neural Networks (CNNs) [
13], Graph Neural Networks (GNNs) [
14], transformers [
15], and other contributions to AU recognition. This average F1 score has been used to measure general performance in AU recognition for over a decade.
While the average F1 score measures the general performance of AU recognition, it has its shortcomings. Throughout our years of AU recognition research, we observed that the average F1 score is biased by high-performing outliers. This pulls the average F1 score higher with good performance on recognizing one or a few AUs, while the performance on the remaining AUs decreases. As the average of the F1 score skews the reporting metric, it also influences the research performed across the field using this metric to compare solutions. Obtaining the highest average F1 score may not be sufficient for specific applications. Some models may have a lower average F1 score but have higher performance across more AUs. These models may be more suitable for applications requiring good performance on more than one or a few AUs. Two facial representations are presented in
Figure 1, which vary only by one AU. This figure demonstrates the necessity of high performance on more than a few AUs. The emphasis on the average F1 score has overlooked the importance of having high performance for multiple or a large number of AUs.
Our AU recognition solution introduces a mixture of experts (MoE) as the meta-learner for stacking ensembles. This proposed solution combines the benefits of both an MoE and a stacking ensemble as opposed to traditional methods that choose only one. For our ensemble, we use a heterogeneous, negative correlation, explicit stacking ensemble along with a unique method for identifying and selecting base learners. In addition, it involves the release of a synthetically generated AU dataset to be used in the training of the AU recognition task. This dataset is the first AU recognition dataset to be balanced across all AUs. Our solution achieves the highest performance across all AUs while also maintaining a comparable average F1 score to the state of the art (SOTA).
The contributions of the proposed method are summarized as follows:
We introduce an MoE as a meta-learner to combine the outputs of a stacking ensemble. This hybrid approach combines the advantages of both an ensemble and an MoE. To validate the performance of our proposed hybrid approach, we apply it to the task of AU recognition.
Our solution is centered on achieving high performance across all AUs, not just one or a few. Our proposed solution accomplishes this by applying a heterogeneous, negative correlation, explicit stacking ensemble for the first time to AU recognition.
A new synthetic dataset is created to be used for AU recognition training. This dataset is the first AU recognition dataset to be balanced across all AUs.
As indicated by the Borda rank, our proposed approach achieves the highest performance across all AUs on two publicly available datasets, BP4D [
9,
10] and DISFA [
11,
12]. Expanded on our previous approach, this solution achieves this while maintaining the highest average F1 scores achieved by our previous method.
The remaining portions of this paper are structured as follows. In
Section 2, we give an analysis of the relevant background, followed by an explanation of our approach in
Section 3. We report our experiments in
Section 4. Then, to validate and understand our approach, we performed an ablation study in
Section 5. Finally, we discuss our findings in
Section 6 and conclude with
Section 7.
2. Background
2.1. AU Recognition
AUs were originally defined in 1978 as part of the FACS [
1]. The BP4D [
9,
10] and DISFA [
11,
12] datasets became the standard for comparing methods within AU recognition when both were released in 2013. Example images of the datasets are given in
Figure 2 with label descriptions provided in
Table 1. AU recognition began with landmark tracking, then shifted to learning face representations [
16] and is normalized with cropping and face alignment [
17,
18]. The field moved to using CNNs [
13], GNNs [
14,
19,
20,
21,
22,
23,
24], and transformers [
15,
22,
24,
25]. Various approaches also use additional data as pre-training [
24,
26,
27,
28,
29] or incorporating text into their training pipeline [
26,
30].
Recent approaches, following the success seen in the large language model (LLM) community, use a mixture of experts (MoE) [
31] or an ensemble [
24]. While our solution incorporates an ensemble with an MoE meta-learner, our approach differs from previous methods. The previous use of an ensemble was a bagging method with only two base learners [
24], while our ensemble is a heterogeneous, negative correlation, stacking ensemble with multiple base learners. In addition, previous use of an MoE in AU recognition used the MoE in the traditional sense, with the MoE as the full model [
31]. Our approach combines an ensemble and MoE by proposing the use of the MoE as the meta-learner for the stacking ensemble.
2.2. Deep Network Ensembles
Our AU recognition method uses a heterogeneous, negative correlation, explicit stacking ensemble as defined by previous surveys [
32]. As opposed to the homogeneous ensembles that have the same architecture across base learners, our method uses heterogeneous ensembles that have different architectures for base learners. Negative correlation learning has base learners that, when one fails, another is more likely to succeed, leading to increased generalization. Explicit refers to having defined models as opposed to implicit models, where the weights are shared between models to approximate an ensemble. Stacking refers to training a meta-model on the ensemble to combine the base learners, as opposed to using a defined approach, such as averaging or voting.
2.3. Meta-Learner
To combine the predictions of a stacking ensemble, a meta-learner is required. There are many common approaches for meta-learners. Some of these common meta-learners for imbalanced datasets include logistic regression, AUC-maximizing, decision tree, naive Bayes, SVM with linear kernel, SVM with radial kernel, random forest, bagging, adaBoost, XGBoost, and lightGBM [
33]. In addition to these traditional meta-learners, there are neural network-based approaches, such as MLP layers or using a transformer.
The comparison of meta-learners in this paper focuses on the neural network-based approaches. A common approach is to use MLP layers to combine the predictions. This is perhaps one of the most common meta-learners as it incorporates many benefits that come from linear layers. Most recently, transformers have been used as meta-learners in similar tasks [
34]. We are unable to find previous solutions that use our proposed solution of using an MoE as the meta-learner for a stacking ensemble.
2.4. Mixture of Experts
MoE was originally developed in 1991 [
35] but has recently resurfaced [
36]. Generally speaking, MoE has multiple experts and a gating network that calculates how much to weigh each expert’s prediction [
35]. Some recent solutions have the gating network not only select how much to weigh each network but also select which networks to run [
36]. This allows for MoEs to perform meta-learning by selecting which expert to use. Our use of an MoE as a meta-learner differs from the traditional use of an MoE. While an MoE performs meta-learning on its experts, we propose using an MoE to be the meta-learner for a stacking ensemble.
MoE is often used in the place of ensembles due to a variety of tradeoffs. However, recent studies conclude that ensembles and MoEs have complementary features that benefit from combination [
37]. These Google researchers find that by alternating a transformer and MoE blocks within an ensemble, they can combine the MoE and ensemble architectures. They argue that this approach allows for the benefits of both MoE and ensembles. As these researchers find one approach to combine the MoE and ensemble architectures, other solutions may remain. Our approach also argues that the MoE and ensemble architectures benefit from combining the two. Our approach proposes combining ensembles and MoEs by having the MoE be the meta-learner for the stacking ensemble.
2.5. Training on Synthetic Data
Training on synthetic data began with simple data augmentations as far back as the beginning of the deep learning revolution in the original AlexNet paper [
38]. Soon, synthetic data for training grew more sophisticated with new generation methods such as variational auto-encoders, generative adversarial networks (GANs), latent stable diffusion, and expanded to 3D generative methods such as neural radiance fields (NeRF) or Gaussian splatting.
The use of synthetic data during model training varies from solution to solution. Certain approaches use synthetic data as the only data with ground truth labels and use real images only in an unsupervised method. Other approaches use it as the exclusive training data or as a method to balance a skewed dataset during training by shuffling synthetic data in with real data in batches. Our solution uses synthetic data as additional data to aid in unbalanced datasets. We recognize that future research may look into using methods to refine our synthetic data [
39]. We acknowledge that significant work has been accomplished in the field of synthetic facial expression [
40,
41,
42,
43,
44], yet we find that our synthetic dataset is particularly beneficial due to its AU labels when applied as additional data during training.
2.6. Borda Rank
Borda rank is a ranking method that scores each method by the number of methods it outperforms [
45]. It is used in recent evaluation methods on other multi-label classification tasks [
46], general ranking of solutions [
45], and in classification approaches it is even used to make more robust predictions [
47]. Borda ranking leverages pairwise comparison, offering an advantage over traditional methods that limit comparisons to a fixed subset.
Pairwise comparison is at the core of the Borda count method. Pairwise comparison between two outputs to determine which is better is the foundation of the recent reinforcement learning with human feedback [
48]. Pairwise comparisons are continuing to grow throughout the LLM community [
49] and are beginning to be used more in image comparisons when standard metrics are insufficient [
50]. The incorporation of pairwise comparison through Borda ranking in the analysis of our solution applies these recent improvements to AU recognition.
3. Methods
Our approach for improving AU recognition performance across multiple AUs, not just the overall average F1 score, is the center of the reasoning behind our approach. To achieve this goal, we provide the description of our meta-learner in
Section 3.1; the information for our dataset in
Section 3.2; the details of our heterogeneous, negative correlation, explicit stacking ensemble in
Section 3.3; and training details in
Section 3.4.
Figure 3 visually represents the overall architecture.
3.1. Meta-Learner
The meta-learner for a stacking ensemble takes the predictions from each base learner as input and then outputs the final prediction. As each of our base learners is better in different circumstances, the meta-learner can choose when to use each base learner in the prediction. As the meta-learner learns how to combine the base learners’ predictions, it can also correct the errors of the base learners. In our implementation, each base learner is only trained on half of the available training data. Then, the meta-learner is trained on the full training data and the base learner’s predictions. As the meta-learner has more information, both from various base learners and from additional training data, it can improve results further than the base learners’ results. As each of the base learners is trained to perform well on one AU specifically, the meta-learner improves generalization by combining each of the predictions of the AU-specific base learners.
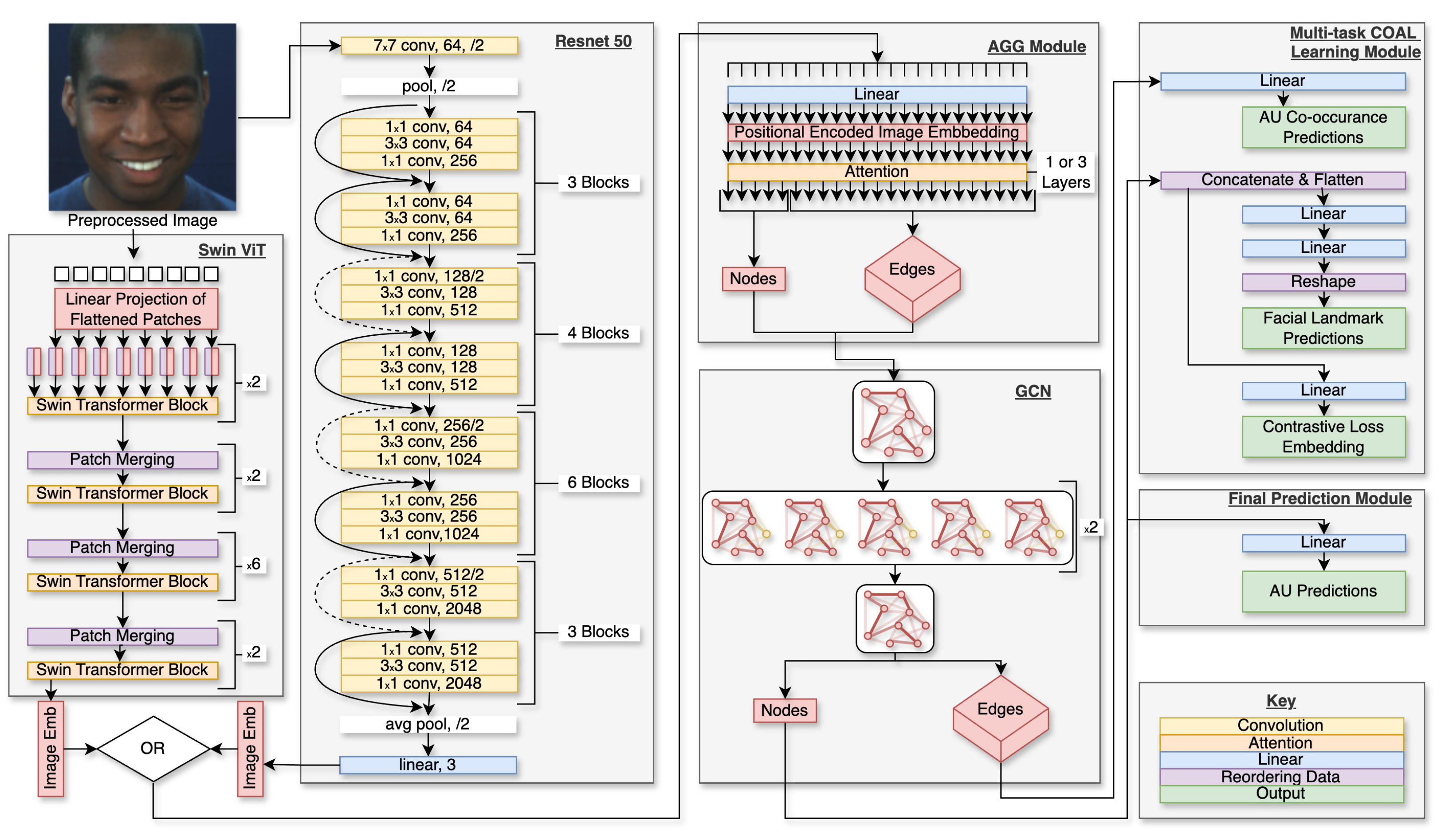
For our meta-learner, we use an MoE that takes the predictions from the stacking ensemble as input, and the gating network selects how much to weigh each expert. This allows for different experts to be trained for different circumstances, allowing the model to learn more fine-grained details than it would without the MoE. The MoE can also identify correlations between the model’s predictions.
Figure 4 displays some of the common types of base learners as well as our proposed selection of an MoE as the meta-learner. Our MoE uses one linear layer, followed by the gate network. The output of the first linear layer is also passed to the experts. In our implementation, each expert has two linear layers, and we use four times the number of classes for the number of experts.
We find that using an MoE is particularly useful due to the base learners having a large variation from one another. The large variation is due to each base learner only being trained on half of the training data, as well as each base learner focusing on high performance on one AU specifically. This greater variation in the base learners was selected because a more diverse ensemble will generally bring better results. The variation of the base learners is discussed more in-depth within
Section 3.3. The MoE’s ability to select which base learners to focus on complements this variation within the base learners.
3.2. Dataset
The unbalanced distribution of AUs in common datasets is a known problem in the AU recognition field [
20]. These unbalanced distributions are often addressed with loss function priors [
20], yet these challenges persist. We release the Synthetic AU (SynAU) dataset balanced across all AUs contained in the BP4D and DISFA datasets. The SynAU dataset is designed to be used in the training process alongside the images from the BP4D or the DISFA datasets. It is not intended to be used as an additional evaluation method. The released SynAU dataset includes 10 frames of each AU and 10 frames of every possible combination of 2 AUs. The balanced distribution across all AUs compared with the existing AU distributions is seen in
Figure 5. To avoid bias noticed in the related field of face recognition [
51,
52,
53,
54] the dataset is also balanced across race, age, and gender with distributions displayed in
Table 2. For greater variation, the released dataset also varies the individual’s weight, muscle, height, body proportions, face fat, shape of the face, and AU intensity. We acknowledge that race is more complicated than the simplification of the three races we provide. We point to the simplifications used in related fields as the basis for classifying race within our dataset [
54].
Although some may point to our SynAU datasets’ images being noticeably unrealistic, the network can learn general trends from these unrealistic images during training. This is similar to other vision-based tasks that use unrealistic synthetic data in training to evaluate real data [
55,
56]. Our dataset additionally allows for future research to increase the realism of the facial images, as performed in other approaches [
39]. To synthetically generate the dataset, we selected an open-source human graphical generation platform, Make Human [
57], as it allows explicit control of AUs with the tradeoff of a decrease in realism. Example images from SynAU are provided in
Figure 6.
3.3. Ensemble Architecture
A heterogeneous ensemble is an ensemble that has varying architectures or different hyperparameters for the base models. It has not been used in the field of AU recognition previously. In our approach, each base model uses the Attention Graph Generator (AGG) module and has access to the Contrastive AU-co-prediction Landmark (COAL) module, both of which are part of our unique network architecture from our previous work [
24]. However, this paper contributes to the use or non-use of these and other modules within the heterogeneous ensemble. The AGG module creates the nodes and edges for the graph, while the COAL module allows for multi-task learning. This paper’s heterogeneous solution focuses on the variation in other elements within the architecture or the training process. Our approach varies the backbone (Swin Transformer [
58] or Resnet50 [
59]) and the number of layers (1 or 3) in the AGG module. In addition, the training variation includes the use or lack of use of the COAL module [
24], pre-training (FEC dataset [
60] or having no pre-training), and using our custom SynAU dataset as an augmentation in training or not. This results in having 5 variables (visual backbone, AGG layers, COAL module, pretraining, and synthetic dataset), each with two possible values, for a total of 32 possible combinations of models.
Section 3.4 explains the process of selecting base learners across these variables. Each of the 5 variables contains differing tradeoffs and allows different AUs to be optimized with different variations. Each of the five variables is displayed in
Figure 7.
We present negative correlation to the field of AU recognition to aid in increasing across multiple AUs, not just one or a few. Negative correlation in an ensemble is when one base model calculates an error; another model is more likely to make the correct prediction [
61], providing the ensemble with more diverse predictions. For this implementation of negative correlation, the base models are trained directly to perform well on one specific AU at a time. To incorporate this, we weight the loss function to be biased towards the specific AU on a scale from 2 to 12 while inversely weighting the AUs that are not the AU of current interest.
Section 3.4 explains the selection process for the weights.
Our previous ensemble method for AU recognition combines the solution with an averaging method [
24]. However, in related fields, training a network to combine the multiple base models, using explicit stacking, has proven to improve results [
62]. Taking these findings, we combine the models with a neural network approach using our meta-learner discussed in
Section 3.1. Each base model’s prediction is the input to the meta-learner, and the output is the final prediction for our solution. A visual representation of stacking the models before the meta-learner is given in
Figure 8.
3.4. Training Details
All training was performed on a P100 GPU, although multiple GPUs were used to train different base models simultaneously. For the base learners, we trained for five epochs with a learning rate of 1 × 10
−4, a learning rate weight decay of 5 × 10
−4, and used the AdamW optimizer [
63]. Our SynAU dataset was used for both datasets’ training when selected as one of the five heterogeneous variables. Our approach follows the standard three-fold cross-validation used throughout the literature.
Various AU recognition solutions using the BP4D and DISFA datasets use the same preprocessing and cross-fold validation. To compare our approach to these methods accurately, we maintain the preprocessing of using MTCNN for cropping and aligning the face and use the same split for the three-fold cross-validation. The FEC dataset [
60] was used for pretraining following previous solutions [
24,
29]. Our synthetic dataset was used only during the training process.
We used two base models for each AU, allowing both to be trained on half of the available training data and use the other half of the training data to select the best-performing model with inverted training and selection data splits for the two models. This split of the training data allows us to select from the multiple available models a model that has generalized to both the training dataset folds, not just the fold that it was explicitly trained on. The available models have 32 combinations from the heterogeneous aspects and 11 combinations from the negative correlation aspects of our ensemble architecture described in
Section 3.3. After the base models are selected for the ensemble, they are each frozen, and the final MoE head is trained on the concatenated prediction confidences from the base models. Each base model’s possible combinations are depicted in
Figure 7, and the stacking and selection of models are displayed in
Figure 8. Our selection of the models does not use the validation fold, only the training data to select the model. This approach avoids polluting the validation fold. We release each selected base learner’s final prediction to prevent others from having to perform as much computation.
4. Experiments
4.1. Comparison with Related Methods on the Average F1 Score
In the AU recognition field, the average F1 score is a widely adopted metric. As such, we report and compare average F1 scores against many top-performing methods on the BP4D dataset in
Table 3 and the DISFA dataset in
Table 4. We find that we outperform all other methods and achieve comparable results with our previous method on the average F1 score. On the BP4D dataset, we are 0.9 percentage points higher than the nearest approach. In a similar fashion, we are 1.0 percentage points higher than the next highest average F1 score on the DISFA dataset. Despite our innovative design to achieve higher results across all AUs, it is able to maintain the highest average F1 score presented in our previous work. We acknowledge that the average F1 score using this new method on the BP4D dataset is 0.1 lower than our original approach. However, we consider this an acceptable tradeoff for the increased performance across additional AU. The F1 score is the harmonic mean between precision and recall and is defined as
where F1 is the F1 score,
P is precision, and
R is recall.
4.2. Comparison with Related Methods Across All AUs
In many circumstances, comparing only the average F1 score is insufficient, as one or few high-performing AUs skew this reporting metric. To quantitatively compare across each AU, we use a pairwise comparison called the Borda rank, which provides the percentage of other methods it outperforms across each AU.
Incorporating pairwise comparison using Borda ranking into AU recognition follows recent trends in the literature of using pairwise comparison more abundantly in related fields [
46,
47,
48,
49,
50]. This incorporation brings about an approach for evaluating methods that emphasize performing well across multiple AUs, not just the overall average.
We first compute a Borda count for each AU, defined as the number of models outperformed by the model under consideration. In the Borda rank approach, we specify outperforming as being greater than or equal to the F1 score on the individual AU. Then we convert this Borda count to a percentage and compute the average across all AUs for a normalized averaged Borda ranking. Mathematically, this rank is:
with Borda Rank being the normalized average Borda rank,
M as the number of models to compare with,
N is the number of AUs in the dataset,
being the indicator function,
is the average F1 score of class
i on the model
f,
as the model being analyzed for the Borda ranking, and
being the
jth model being compared against.
Using the Borda rank to better evaluate the performance across all AUs, our proposed solution achieves the highest performance across all AUs on both datasets. We achieve the highest Borda rank of 87.5 on BP4D and the highest Borda rank of 75.6 on the DISFA dataset. Besides our methods, the highest performance on the BP4D dataset achieved a Borda rank of 76.5, and on the DISFA dataset, a Borda rank of 72.2. Our solution is 11.0 percentage points higher for the Borda rank on the BP4D dataset and 3.4 percentage points higher on the DISFA dataset. This demonstrates that our proposed solution achieves the highest performance across all AUs.
Table 3 demonstrates the Borda rank of each model on the BP4D dataset, and
Table 4 displays the Borda ranks across the DISFA dataset.
5. Ablation Study
To analyze the importance of our proposed meta-learner solution, we perform an ablation study on the BP4D dataset to determine our proposed solution’s contribution. The ablation study expands our high performance. It analyzes why certain decisions were made in the training process. In addition, we provide an ablation study on our SynAU additions, the ensemble components (heterogeneous, negative correlation, and explicit stacking), and our base model selection to demonstrate each of their impact on the overall performance.
5.1. Meta-Learner
To determine if our proposed solution of using our MoE as the meta-learner, we replace it with other possible meta-learners. As the meta-learner cannot simply be removed, we do not have a base to compare against. We find that if we use MLP layers, we achieve a 66.7 average F1 score and a Borda rank of 83.7. This is 0.5 percentage points lower on the F1 score and 3.8 percentage points lower on the Borda rank than our proposed solution. Also, replacing our proposed solution with a transformer resulted in a 66.4 average F1 score and a Borda rank of 81.1. These also decrease the performance. We also attempted using the AGG module from our prior work and found this also had lower results than this paper’s proposed solution. This comparison is seen in the first four rows of
Table 5, with the first row being our proposed solution. We conclude that using our proposed meta-learner increases the average F1 score by 0.5 to 0.9 percentage points and provides an additional 3.8 to 8.0 percentage points on the Borda rank.
5.2. Heterogeneous
To test the importance of the heterogeneous elements of our ensemble, we remove each method individually and demonstrate its decrease in results. The heterogeneous elements include the Swin transformer or the Resnet, the AGG module being one layer or three layers, using the COAL module or not, using the SynAU dataset or not, and finally, the use or forgoing of the pretraining. Each of these improves the overall average F1 score, as seen in
Table 5.
5.3. Negative Correlation
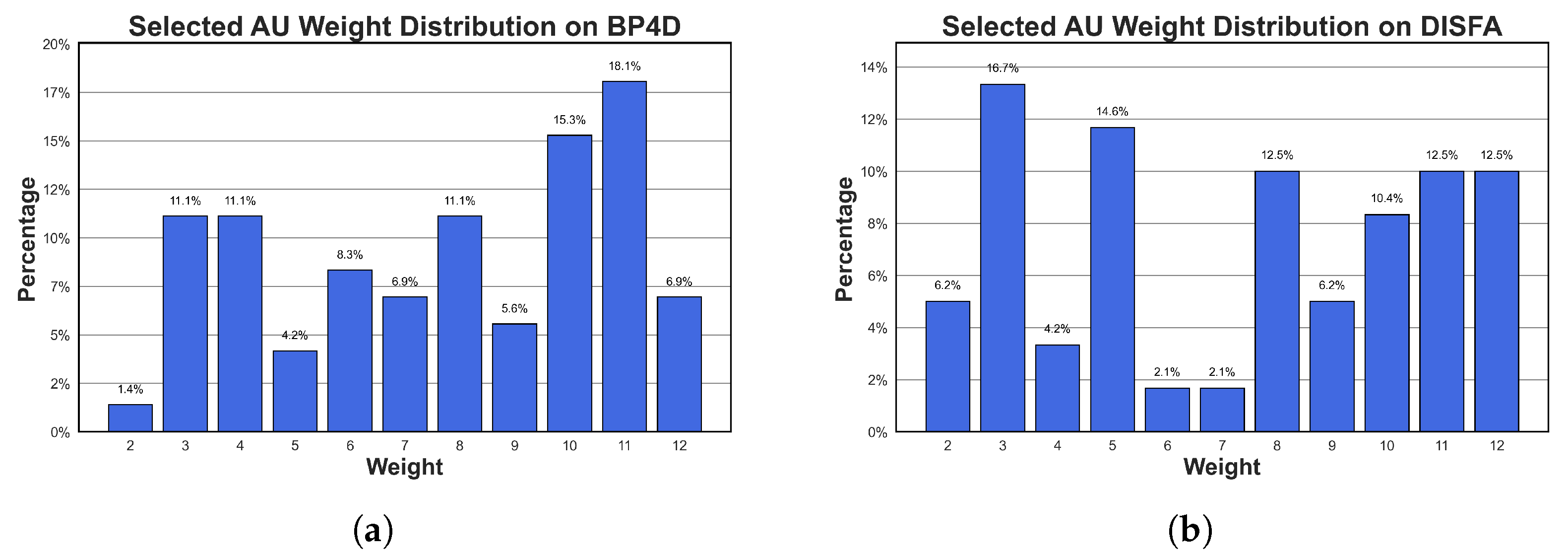
We analyze the varying weights within our negative correlation to demonstrate the need for each weight.
Figure 9 supports using varying weights as each weight is used throughout the training process. As each weight was selected for different AUs, our proposed solution selected the ideal weight for each specific AU.
5.4. Explicit Stacking
To identify the ideal model architecture for the stacking head, four different models were researched: An encoder transformer architecture [
68,
69], AGG architecture [
24], MoE [
31], and linear layers. The results are discussed in
Section 5.1.
5.5. Base Models Selection
The selection of which models were used is presented in
Table 6. The five different variables are each used for different AUs throughout our solution. This use of each variable supports our decision to use each variable in our proposed solution. Although each base learner is trained on only half the data, we enforce it to generalize to the other half, which enhances performance across all AUs.
5.6. SynAU Additions
Table 6 demonstrates which base learners used the SynAU dataset. When we do not include the SynAU dataset in our ensemble approach, we obtain an average F1 score of 66.9, as seen in
Table 5. The improvement from 66.9 to 67.2 demonstrates that the SynAU dataset improves results, despite any imperfections.
6. Discussion
For certain downstream tasks, AU recognition works better when it achieves high performance across all AUs. In contrast, many current solutions perform well on one or few AUs, due in part to the focus on the average F1 score for evaluation. Various facial representations differ by one or a few AUs. For such facial representations, a high average F1 score might not indicate the ideal network, as it could underperform on the differing AUs.
To address this issue, we propose using an MoE as the meta-learner for a stacking ensemble. We argue that the combination of an ensemble and an MoE will result in a hybrid of the benefits of both. Our results in
Section 4 demonstrate that our solution achieves the highest performance across all AUs for both the BP4D and DISFA datasets according to the Borda rank. In addition, our solution maintains the same top average F1 score as our previous work. Then, in
Section 5.1, we demonstrate that using our proposed meta-learner provides an additional 0.9 percentage points on the average F1 score and improves the Borda rank by 8.0 percentage points.
In addition, we use our heterogeneous, negative correlation, explicit stacking ensemble, and our new synthetic AU dataset, SynAU. Our solution allows each base learner to be trained to perform well on one AU. In our heterogeneous solution, we find that each AU selects a different combination of the five variants: visual backbone, the number of layers in the AGG module, use of pretraining, use of the SynAU dataset, and the COAL learning module. By allowing each base learner to select a unique combination of these five variants, our solution improves each AU unit directly. We created the SynAU dataset with AU labels to be used as additional data during training. Unlike previous studies that benefited from using additional data from related tasks [
24,
26,
27,
28,
29], our method’s synthetic data has labels specifically for AU recognition. This allows the SynAU dataset to directly provide a further understanding of AUs, while previous methods were forced to revolve around the understanding of human faces.
We find that using an MoE as our meta-learner in AU recognition achieves higher performance on both the average F1 score and across all AUs as given by the Borda rank. We hypothesize this is due to the conjunction of MoE having various experts to choose between and the large variation between the base learners. Because of the large variation in the base learners, each base learner will perform well in different circumstances. This means that, depending on the circumstances, the meta-learner must also perform differently. The MoE provides this with its gate model that selects how much to weigh each expert. Then, the specific experts can be trained directly on the varying circumstances. Ultimately, we see that the MoE complements a stacking ensemble when used as the meta-learner.
We hypothesize that future work will benefit from applying an MoE as the meta-learner for additional tasks beyond AU recognition. We particularly anticipate that the MoE meta-learner will excel at tasks where the base learners greatly vary within the stacking ensemble. Our findings in this paper support this hypothesis as base learners with large variations were found to complement the MoE meta-learner in AU recognition.
Despite the model’s high performance across all AUs while maintaining the highest average F1 score, it does contain its limitations. One notable limitation is the size of the model. It is generally accepted that using an ensemble results in increased computational load. However, this limitation may be outweighed in high-risk scenarios such as security systems, clinical settings, or robotics. These scenarios generally require high performance across all AUs, as the price of a false positive or false negative is higher. Even in scenarios of lower risk, such as animation, the cost of computation may be outweighed as it is only used at creation rather than each time an animation is shown, potentially outweighing the cost of computation. In addition, future research may focus on using our solution as the teacher model in model distillation to overcome this limitation.
7. Conclusions
Each AU plays a critical role in applications such as animation, clinical settings, and robotics. Yet, previous solutions generally focus on the average F1 score, leading to a potential skew in performance across each of the AUs. To address this issue, we propose using an MoE as the meta-learner in a stacking ensemble. This connection of ensembles and MoEs allows for benefits from both methods to be applied to the same solution. In addition, we release a heterogeneous, negative correlation, explicit stacking ensemble, the first for AU recognition. The ensemble allows for each base learner to be fine-tuned to focus on one AU, leading to better performance across all AUs. In addition, we create the SynAU dataset that provides AU labels on synthetic images and is the first AU recognition dataset that has balanced AU labels.
When compared with existing models, our previous solution achieved the highest average F1 score. This work maintains the highest average F1 score while also focusing on achieving high performance across all AU. To evaluate performance across all AU, we use the Borda rank measurement. As indicated by this additional metric, our proposed solution achieves the highest performance across all AUs. Along with our solution, we release the SynAU dataset, a synthetic AU dataset for training augmentations. We provide an ablation study demonstrating the importance of each of this article’s contributions. We anticipate future research applying our proposed meta-learner to other tasks, going beyond AU recognition. To aid in this or other future research, we release our code, each base learner’s predictions, and our model’s final predictions at
https://github.com/byu-rvl/Ensemble_AU_release (accessed on 1 June 2025).
Author Contributions
Conceptualization, A.S. and D.-J.L.; methodology, A.S.; software, A.S.; validation, A.S.; formal analysis, A.S.; investigation, A.S.; resources, D.-J.L.; data curation, D.-J.L.; writing—original draft preparation, A.S.; writing—review and editing, A.S. and D.-J.L.; visualization, A.S.; supervision, D.-J.L.; project administration, D.-J.L.; funding acquisition, D.-J.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Acknowledgments
This work is made possible by researchers at the University of Denver and Binghamton University who created and provided the DISFA and BP4D datasets. During the preparation of this manuscript/study, the authors used ChatGPT-3.5 for the purpose of rephrasing specific key sentences for clarity and grammar. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
| AdaBoost | Adaptive boosting |
| AGG | Attention graph generator |
| AU | Action unit |
| AUC | Area under the curve |
| BP4D Dataset | Binghamton–Pittsburgh 4-dimensional dataset |
| CNN | Convolutional neural network |
| COAL | Contrastive action-unit-co-prediction landmark |
| DISFA Dataset | Denver intensity of spontaneous facial action dataset |
| F1 | Harmonic mean between precision and recall |
| FACS | Facial action coding system |
| FEC dataset | Facial expression comparison dataset |
| GANS | Generative adversarial networks |
| GCN | Graph convolutional network |
| GNN | Graph neural network |
| GPU | Graphics processing unit |
| LightGBM | Light gradient boosting machine |
| LLM | Large language model |
| MoE | Mixture of experts |
| MTCNN | Multi-task cascaded convolutional networks |
| NeRF | Neural radiance fields |
| Resnet | Residual network |
| SOTA | State of the art |
| SVM | Support vector machine |
| Swin Transformer | Shifted window transformer |
| SynAU dataset | Synthetic action unit dataset |
| ViT | Vision transformer |
| XGBoost | Extreme gradient boosting |
References
- Ekman, P.; Friesen, W.V. Facial action coding system. In Environmental Psychology & Nonverbal Behavior; American Psychological Association: Washington, DC, USA, 1978. [Google Scholar]
- Fu, C.; Qian, F.; Su, Y.; Su, K.; Song, S.; Niu, M.; Shi, J.; Liu, Z.; Liu, C.; Ishi, C.T.; et al. Facial action units guided graph representation learning for multimodal depression detection. Neurocomputing 2025, 619, 129106. [Google Scholar] [CrossRef]
- Okunishi, T.; Zheng, C.; Bouazizi, M.; Ohtsuki, T.; Kitazawa, M.; Horigome, T.; Kishimoto, T. Dementia and MCI Detection Based on Comprehensive Facial Expression Analysis From Videos During Conversation. IEEE J. Biomed. Health Inform. 2025, 29, 3537–3548. [Google Scholar] [CrossRef] [PubMed]
- Ji, Y.; Wang, S.; Xu, R.; Chen, J.; Quan, Y.; Jiang, X.; Deng, Z.; Liu, J. Hugging Rain Man: A Novel Facial Action Units Dataset for Analyzing Atypical Facial Expressions in Children with Autism Spectrum Disorder. IEEE Trans. Affect. Comput. 2025, 1–17. [Google Scholar] [CrossRef]
- Bai, W.; Liu, Y.; Zhang, Z.; Li, B.; Hu, W. Aunet: Learning relations between action units for face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 24709–24719. [Google Scholar]
- Della Greca, A.; Ilaria, A.; Tucci, C.; Frugieri, N.; Tortora, G. A user study on the relationship between empathy and facial-based emotion simulation in Virtual Reality. In Proceedings of the 2024 International Conference on Advanced Visual Interfaces, Genoa, Italy, 3–7 June 2024; pp. 1–9. [Google Scholar]
- Liu, X.; Ni, R.; Yang, B.; Song, S.; Cangelosi, A. Unlocking Human-Like Facial Expressions in Humanoid Robots: A Novel Approach for Action Unit Driven Facial Expression Disentangled Synthesis. IEEE Trans. Robot. 2024, 40, 3850–3865. [Google Scholar] [CrossRef]
- Zhi, R.; Liu, M.; Zhang, D. A comprehensive survey on automatic facial action unit analysis. Vis. Comput. 2020, 36, 1067–1093. [Google Scholar] [CrossRef]
- Zhang, X.; Yin, L.; Cohn, J.F.; Canavan, S.; Reale, M.; Horowitz, A.; Liu, P.; Girard, J.M. Bp4d-spontaneous: A high-resolution spontaneous 3d dynamic facial expression database. Image Vis. Comput. 2014, 32, 692–706. [Google Scholar] [CrossRef]
- Zhang, X.; Yin, L.; Cohn, J.F.; Canavan, S.; Reale, M.; Horowitz, A.; Liu, P. A high-resolution spontaneous 3d dynamic facial expression database. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–6. [Google Scholar]
- Mavadati, S.M.; Mahoor, M.H.; Bartlett, K.; Trinh, P.; Cohn, J.F. Disfa: A spontaneous facial action intensity database. IEEE Trans. Affect. Comput. 2013, 4, 151–160. [Google Scholar] [CrossRef]
- Mavadati, S.M.; Mahoor, M.H.; Bartlett, K.; Trinh, P. Automatic detection of non-posed facial action units. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1817–1820. [Google Scholar]
- Corneanu, C.; Madadi, M.; Escalera, S. Deep structure inference network for facial action unit recognition. In Proceedings of the European Conference on Computer Vision (ECCV), 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 298–313. [Google Scholar]
- Li, G.; Zhu, X.; Zeng, Y.; Wang, Q.; Lin, L. Semantic relationships guided representation learning for facial action unit recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8594–8601. [Google Scholar]
- Shao, Z.; Liu, Z.; Cai, J.; Wu, Y.; Ma, L. Facial action unit detection using attention and relation learning. IEEE Trans. Affect. Comput. 2019, 13, 1274–1289. [Google Scholar] [CrossRef]
- Zhao, K.; Chu, W.S.; Zhang, H. Deep region and multi-label learning for facial action unit detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3391–3399. [Google Scholar]
- Li, W.; Abtahi, F.; Zhu, Z.; Yin, L. Eac-net: Deep nets with enhancing and cropping for facial action unit detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2583–2596. [Google Scholar] [CrossRef]
- Shao, Z.; Liu, Z.; Cai, J.; Ma, L. Deep adaptive attention for joint facial action unit detection and face alignment. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 705–720. [Google Scholar]
- Liu, Z.; Dong, J.; Zhang, C.; Wang, L.; Dang, J. Relation modeling with graph convolutional networks for facial action unit detection. In Proceedings of the MultiMedia Modeling: 26th International Conference, MMM 2020, Daejeon, Republic of Korea, 5–8 January 2020; Proceedings, Part II 26. Springer: Cham, Switzerland, 2020; pp. 489–501. [Google Scholar]
- Song, T.; Chen, L.; Zheng, W.; Ji, Q. Uncertain graph neural networks for facial action unit detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 5993–6001. [Google Scholar]
- Song, T.; Cui, Z.; Zheng, W.; Ji, Q. Hybrid message passing with performance-driven structures for facial action unit detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6267–6276. [Google Scholar]
- Luo, C.; Song, S.; Xie, W.; Shen, L.; Gunes, H. Learning Multi-dimensional Edge Feature-based AU Relation Graph for Facial Action Unit Recognition. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-22, Vienna, Austria, 23–29 July 2022; pp. 1239–1246. [Google Scholar]
- Liu, X.; Yuan, K.; Niu, X.; Shi, J.; Yu, Z.; Yue, H.; Yang, J. Multi-scale promoted self-adjusting correlation learning for facial action unit detection. IEEE Trans. Affect. Comput. 2024, 16, 697–711. [Google Scholar] [CrossRef]
- Sumsion, A.; Lee, D.J. ELEGANT: An Ensemble with Attention Mechanism in a Multi-Task Graph Neural Network for Facial Action Unit Detection. 2025; under review. [Google Scholar]
- Jacob, G.M.; Stenger, B. Facial action unit detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7680–7689. [Google Scholar]
- Yang, H.; Yin, L.; Zhou, Y.; Gu, J. Exploiting semantic embedding and visual feature for facial action unit detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10482–10491. [Google Scholar]
- Chang, Y.; Wang, S. Knowledge-driven self-supervised representation learning for facial action unit recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20417–20426. [Google Scholar]
- Cui, Z.; Kuang, C.; Gao, T.; Talamadupula, K.; Ji, Q. Biomechanics-guided Facial Action Unit Detection through Force Modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8694–8703. [Google Scholar]
- An, R.; Jin, A.; Chen, W.; Zhang, W.; Zeng, H.; Deng, Z.; Ding, Y. Learning facial expression-aware global-to-local representation for robust action unit detection. Appl. Intell. 2024, 54, 1405–1425. [Google Scholar] [CrossRef]
- Chang, Y.; Zhang, C.; Wu, Y.; Wang, S. Facial Action Unit Recognition Enhanced by Text Descriptions of FACS. IEEE Trans. Affect. Comput. 2024, 16, 814–826. [Google Scholar] [CrossRef]
- Yuan, K.; Yu, Z.; Liu, X.; Xie, W.; Yue, H.; Yang, J. Auformer: Vision transformers are parameter-efficient facial action unit detectors. arXiv 2024, arXiv:2403.04697. [Google Scholar]
- Ganaie, M.A.; Hu, M.; Malik, A.K.; Tanveer, M.; Suganthan, P.N. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Zian, S.; Kareem, S.A.; Varathan, K.D. An empirical evaluation of stacked ensembles with different meta-learners in imbalanced classification. IEEE Access 2021, 9, 87434–87452. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, X. Transformers as meta-learners for implicit neural representations. In Proceedings of the European Conference on Computer Vision, 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 170–187. [Google Scholar]
- Jacobs, R.A.; Jordan, M.I.; Nowlan, S.J.; Hinton, G.E. Adaptive mixtures of local experts. Neural Comput. 1991, 3, 79–87. [Google Scholar] [CrossRef] [PubMed]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res. 2022, 23, 1–39. [Google Scholar]
- Allingham, J.U.; Wenzel, F.; Mariet, Z.E.; Mustafa, B.; Puigcerver, J.; Houlsby, N.; Jerfel, G.; Fortuin, V.; Lakshminarayanan, B.; Snoek, J.; et al. Sparse MoEs meet Efficient Ensembles. Trans. Mach. Learn. Res. 2022. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1106. [Google Scholar] [CrossRef]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from simulated and unsupervised images through adversarial training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2107–2116. [Google Scholar]
- Abbasnejad, I.; Sridharan, S.; Nguyen, D.; Denman, S.; Fookes, C.; Lucey, S. Using Synthetic Data to Improve Facial Expression Analysis with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Pumarola, A.; Agudo, A.; Martinez, A.M.; Sanfeliu, A.; Moreno-Noguer, F. Ganimation: One-shot anatomically consistent facial animation. Int. J. Comput. Vis. 2020, 128, 698–713. [Google Scholar] [CrossRef]
- Ding, H.; Sricharan, K.; Chellappa, R. Exprgan: Facial expression editing with controllable expression intensity. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Tripathy, S.; Kannala, J.; Rahtu, E. ICface: Interpretable and Controllable Face Reenactment Using GANs. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020. [Google Scholar]
- Shah, N.B.; Wainwright, M.J. Simple, robust and optimal ranking from pairwise comparisons. J. Mach. Learn. Res. 2018, 18, 1–38. [Google Scholar]
- Miri, M.; Dowlatshahi, M.B.; Hashemi, A. Evaluation multi label feature selection for text classification using weighted borda count approach. In Proceedings of the 2022 9th Iranian Joint Congress on Fuzzy and Intelligent Systems (CFIS), Bam, Iran, 2–4 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Tiwari, L.; Madan, A.; Anand, S.; Banerjee, S. REGroup: Rank-aggregating Ensemble of Generative Classifiers for Robust Predictions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2595–2604. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Park, C.; Choi, M.; Lee, D.; Choo, J. PairEval: Open-domain Dialogue Evaluation with Pairwise Comparison. arXiv 2024, arXiv:2404.01015. [Google Scholar] [CrossRef]
- Chahine, N.; Ferradans, S.; Ponce, J. PICNIQ: Pairwise Comparisons for Natural Image Quality Assessment. arXiv 2024, arXiv:2403.09746. [Google Scholar]
- Wang, M.; Deng, W.; Hu, J.; Tao, X.; Huang, Y. Racial faces in the wild: Reducing racial bias by information maximization adaptation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 692–702. [Google Scholar]
- Wang, Z.; Qinami, K.; Karakozis, I.C.; Genova, K.; Nair, P.; Hata, K.; Russakovsky, O. Towards fairness in visual recognition: Effective strategies for bias mitigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8919–8928. [Google Scholar]
- Robinson, J.P.; Qin, C.; Henon, Y.; Timoner, S.; Fu, Y. Balancing biases and preserving privacy on balanced faces in the wild. IEEE Trans. Image Process. 2023, 32, 4365–4377. [Google Scholar] [CrossRef] [PubMed]
- Serna, I.; Morales, A.; Fierrez, J.; Obradovich, N. Sensitive loss: Improving accuracy and fairness of face representations with discrimination-aware deep learning. Artif. Intell. 2022, 305, 103682. [Google Scholar] [CrossRef]
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 969–977. [Google Scholar]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1341–1360. [Google Scholar] [CrossRef]
- MakeHuman Community. MakeHuman. Version 1.2.0. 2022. Available online: https://github.com/makehumancommunity/makehuman (accessed on 1 August 2022).
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vemulapalli, R.; Agarwala, A. A compact embedding for facial expression similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5683–5692. [Google Scholar]
- Liu, Y.; Yao, X. Ensemble learning via negative correlation. Neural Netw. 1999, 12, 1399–1404. [Google Scholar] [CrossRef]
- Low, C.Y.; Park, J.; Teoh, A.B.J. Stacking-based deep neural network: Deep analytic network for pattern classification. IEEE Trans. Cybern. 2019, 50, 5021–5034. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Niu, X.; Han, H.; Yang, S.; Huang, Y.; Shan, S. Local relationship learning with person-specific shape regularization for facial action unit detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11917–11926. [Google Scholar]
- Tang, Y.; Zeng, W.; Zhao, D.; Zhang, H. PIAP-DF: Pixel-Interested and Anti Person-Specific Facial Action Unit Detection Net with Discrete Feedback Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 12899–12908. [Google Scholar]
- Yin, Y.; Chang, D.; Song, G.; Sang, S.; Zhi, T.; Liu, J.; Luo, L.; Soleymani, M. FG-Net: Facial Action Unit Detection with Generalizable Pyramidal Features. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024; pp. 6099–6108. [Google Scholar]
- Li, X.; Zhang, X.; Wang, T.; Yin, L. Knowledge-Spreader: Learning Semi-Supervised Facial Action Dynamics by Consistifying Knowledge Granularity. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 20979–20989. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems, Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
Figure 1.
The two faces displayed differ by only one AU label, the jaw drop. Many current AU recognition models perform well across one or a few AUs, resulting in an increased average F1 score. To accurately represent the face in many circumstances, the AU recognition model must perform well across all AUs, not just one or a few.
Figure 1.
The two faces displayed differ by only one AU label, the jaw drop. Many current AU recognition models perform well across one or a few AUs, resulting in an increased average F1 score. To accurately represent the face in many circumstances, the AU recognition model must perform well across all AUs, not just one or a few.
Figure 2.
Example images from the BP4D-Spontaneous and DISFA datasets: (a,b) BP4D. (c,d) DISFA.
Figure 2.
Example images from the BP4D-Spontaneous and DISFA datasets: (a,b) BP4D. (c,d) DISFA.
Figure 3.
An overview of our approach. The input image is preprocessed and passed to the heterogeneous, negative correlation, and explicit stacking ensemble. The predictions of each network are then concatenated and passed to our proposed meta-learner, which makes the final prediction.
Figure 3.
An overview of our approach. The input image is preprocessed and passed to the heterogeneous, negative correlation, and explicit stacking ensemble. The predictions of each network are then concatenated and passed to our proposed meta-learner, which makes the final prediction.
Figure 4.
Comparison of meta-learners. The two meta-learners (a,b) on the left are common neural network-based approaches for combining the predictions of a stacking ensemble. Our solution’s meta-learner (c) on the right proposes using an MoE as the meta-learner for combining the stacking ensemble’s predictions.
Figure 4.
Comparison of meta-learners. The two meta-learners (a,b) on the left are common neural network-based approaches for combining the predictions of a stacking ensemble. Our solution’s meta-learner (c) on the right proposes using an MoE as the meta-learner for combining the stacking ensemble’s predictions.
Figure 5.
AU distributions across the BP4D (a) and DISFA (b) datasets. The SynAU dataset distribution is included in both datasets as a reference.
Figure 5.
AU distributions across the BP4D (a) and DISFA (b) datasets. The SynAU dataset distribution is included in both datasets as a reference.
Figure 6.
Example images from our released SynAU dataset. Examples are given of variation across gender and race. Although the images are noticeably not realistic, they adequately represent AUs of interest that are included in the BP4D and DISFA datasets.
Figure 6.
Example images from our released SynAU dataset. Examples are given of variation across gender and race. Although the images are noticeably not realistic, they adequately represent AUs of interest that are included in the BP4D and DISFA datasets.
Figure 7.
Overview of the base learner architecture. The variation in each base learner makes it a heterogeneous ensemble and is optimized for one AU at a time, making it a negative correlation ensemble. The heterogeneous variation comes from using or not using pretraining, the synAU dataset, and the Contrastive AU-co-prediction Landmark (COAL) learning module discussed in the next section. The heterogeneous variation also includes using a Swin transformer or a Resnet and having 1 or 3 layers in the AGG module. The negative correlation optimization comes from the loss being weighted to specific AUs.
Figure 7.
Overview of the base learner architecture. The variation in each base learner makes it a heterogeneous ensemble and is optimized for one AU at a time, making it a negative correlation ensemble. The heterogeneous variation comes from using or not using pretraining, the synAU dataset, and the Contrastive AU-co-prediction Landmark (COAL) learning module discussed in the next section. The heterogeneous variation also includes using a Swin transformer or a Resnet and having 1 or 3 layers in the AGG module. The negative correlation optimization comes from the loss being weighted to specific AUs.
Figure 8.
Demonstrationof stacking base learners before our proposed meta-learner. Each AU has two base learners that are optimized for the specific AU. The base learner is selected from the various available models given its performance on the other training fold. This allows the selection of a model that has generalized to the rest of the training dataset. In this figure, folds 1 and 2 are for training, and fold 3 is for evaluation.
Figure 8.
Demonstrationof stacking base learners before our proposed meta-learner. Each AU has two base learners that are optimized for the specific AU. The base learner is selected from the various available models given its performance on the other training fold. This allows the selection of a model that has generalized to the rest of the training dataset. In this figure, folds 1 and 2 are for training, and fold 3 is for evaluation.
Figure 9.
Selected weight distribution on the BP4D (a) and DISFA (b) datasets. Each of the 11 available weights is used in our solution for both datasets.
Figure 9.
Selected weight distribution on the BP4D (a) and DISFA (b) datasets. Each of the 11 available weights is used in our solution for both datasets.
Table 1.
Description of labels contained in the BP4D and DISFA datasets.
Table 1.
Description of labels contained in the BP4D and DISFA datasets.
| AU Number | FACS Name | BP4D | DISFA |
|---|
| 1 | Inner brow raiser | Yes | Yes |
| 2 | Outer brow raiser | Yes | Yes |
| 4 | Brow lowerer | Yes | Yes |
| 6 | Cheek raiser | Yes | Yes |
| 7 | Lid tightener | Yes | No |
| 9 | Nose wrinkler | No | Yes |
| 10 | Upper lip raiser | Yes | No |
| 12 | Lip corner puller | Yes | Yes |
| 14 | Dimpler | Yes | No |
| 15 | Lip corner depressor | Yes | No |
| 17 | Chin raiser | Yes | No |
| 23 | Lip tightener | Yes | No |
| 24 | Lip pressor | Yes | No |
| 25 | Lips part | No | Yes |
| 26 | Jaw drop | No | Yes |
Table 2.
Gender and racial distributions across our SynAU dataset. The number of individuals in each combination of gender and the three races is represented in our released dataset. The gender and race were randomly selected, and using the law of large numbers, the distribution approached approximately equal distributions.
Table 2.
Gender and racial distributions across our SynAU dataset. The number of individuals in each combination of gender and the three races is represented in our released dataset. The gender and race were randomly selected, and using the law of large numbers, the distribution approached approximately equal distributions.
| Gender | Race | Distribution |
|---|
|
Female
|
Male
|
African
|
Asian
|
Caucasian
|
Count
|
Proportion
|
|---|
| ✓ | | ✓ | | | 35 | 0.175 |
| ✓ | | | ✓ | | 30 | 0.150 |
| ✓ | | | | ✓ | 31 | 0.155 |
| | ✓ | ✓ | | | 30 | 0.150 |
| | ✓ | | ✓ | | 40 | 0.200 |
| | ✓ | | | ✓ | 34 | 0.170 |
| | | | | | 200 | 1.000 |
Table 3.
Comparison of results on the BP4D dataset. Our proposed solution achieves the highest improvement (87.5%) across all AUs as given by the Borda rank while achieving comparable results on the average F1 score. The top-1 in each column is bolded, with the top-2 [bracketed], and the top-3 is underlined.
Table 3.
Comparison of results on the BP4D dataset. Our proposed solution achieves the highest improvement (87.5%) across all AUs as given by the Borda rank while achieving comparable results on the average F1 score. The top-1 in each column is bolded, with the top-2 [bracketed], and the top-3 is underlined.
| Method | Individual AU F1 Scores | Avg. F1 | Borda Rank |
|---|
| |
1
|
2
|
4
|
6
|
7
|
10
|
12
|
14
|
15
|
17
|
23
|
24
|
(↑)
|
(↑)
|
|---|
| DRML [16] | 36.4 | 41.8 | 43.0 | 55.0 | 67.0 | 66.3 | 65.8 | 54.1 | 33.2 | 48.0 | 31.7 | 30.0 | 48.3 | 1.9 |
| EAC-Net [17] | 39.1 | 35.2 | 48.6 | 76.1 | 72.9 | 81.9 | 86.2 | 58.8 | 7.5 | 59.1 | 35.9 | 35.8 | 55.9 | 5.7 |
| JAA-Net [18] | 47.2 | 44.0 | 54.9 | 77.5 | 74.6 | 84.0 | 86.9 | 61.9 | 43.6 | 60.3 | 42.7 | 41.9 | 60.0 | 22.3 |
| LP-Net [64] | 43.4 | 38.0 | 54.2 | 77.1 | 76.7 | 83.8 | 87.2 | 63.3 | 45.3 | 60.5 | 48.1 | 54.2 | 61.0 | 26.1 |
| ARL [15] | 45.8 | 39.8 | 55.1 | 75.7 | 77.2 | 82.3 | 86.6 | 58.8 | 47.6 | 62.1 | 47.4 | 55.4 | 61.1 | 26.1 |
| AU-GCN [19] | 46.8 | 38.5 | 60.1 | [80.1] | 79.5 | 84.8 | 88.0 | 67.3 | 52.0 | 63.2 | 40.9 | 52.8 | 62.8 | 50.4 |
| SRERL [14] | 46.9 | 45.3 | 55.6 | 77.1 | 78.4 | 83.5 | 87.6 | 63.9 | 52.2 | 63.9 | 47.1 | 53.3 | 62.9 | 39.4 |
| UGN-B [20] | 54.2 | 46.4 | 56.8 | 76.2 | 76.7 | 82.4 | 86.1 | 64.7 | 51.2 | 63.1 | 48.5 | 53.6 | 63.3 | 36.0 |
| HMP-PS [21] | 53.1 | 46.1 | 56.0 | 76.5 | 76.9 | 82.1 | 86.4 | 64.8 | 51.5 | 63.0 | 49.9 | 54.5 | 63.4 | 38.3 |
| SEV-Net [26] | 58.2 | 50.4 | 58.3 | 81.9 | 73.9 | 87.8 | 87.5 | 61.6 | 52.6 | 62.2 | 44.6 | 47.6 | 63.9 | 54.2 |
| AUFM [28] | 57.4 | 52.6 | [64.6] | 79.3 | [81.5] | 82.7 | 85.6 | 67.9 | 47.3 | 58.0 | 47.0 | 44.9 | 64.1 | 52.7 |
| PIAP [65] | 54.2 | 47.1 | 54.0 | 79.0 | 78.2 | [86.3] | [89.5] | 66.1 | 49.7 | 63.2 | 49.9 | 52.0 | 64.1 | 53.8 |
| FAUDT [25] | 51.7 | 49.3 | 61.0 | 77.8 | 79.5 | 82.9 | 86.3 | 67.6 | 51.9 | 63.0 | 43.7 | 56.3 | 64.2 | 50.8 |
| FG-Net [66] | 52.6 | 48.8 | 57.1 | 79.8 | 77.5 | 85.6 | 89.3 | 68.0 | 45.6 | 64.8 | 46.2 | 55.7 | 64.3 | 62.9 |
| KDSRL [27] | 53.3 | 47.4 | 56.2 | 79.4 | 80.7 | 85.1 | 89.0 | 67.4 | 55.9 | 61.9 | 48.5 | 49.0 | 64.5 | 60.2 |
| KS [67] | 55.3 | 48.6 | 57.1 | 77.5 | 81.8 | 83.3 | 86.4 | 62.8 | 52.3 | 61.3 | [51.6] | [58.3] | 64.7 | 56.1 |
| GMRP [30] | 54.7 | 50.8 | 57.1 | 78.8 | 79.6 | 84.6 | 88.0 | 67.0 | 54.9 | 62.9 | 48.6 | 54.5 | 65.1 | 61.7 |
| ME-GraphAU [22] | 52.7 | 44.3 | 60.9 | 79.9 | 80.1 | 85.3 | 89.2 | [69.4] | 55.4 | 64.4 | 49.8 | 55.1 | 65.5 | 71.2 |
| SACL [23] | 57.8 | 48.8 | 59.4 | 79.1 | 78.8 | 84.0 | 88.2 | 65.2 | [56.1] | 63.8 | 50.8 | 55.2 | 65.6 | 67.8 |
| AUFormer [31] | 55.2 | [52.2] | 63.2 | 79.3 | 79.7 | 84.2 | 88.6 | 67.0 | 53.3 | [65.5] | 50.6 | 55.7 | 66.2 | 76.5 |
| GTLE-Net [29] | 58.2 | 48.7 | 61.5 | 78.7 | 79.2 | 84.2 | 89.8 | 66.3 | 56.7 | 64.8 | 53.5 | 53.6 | 66.3 | 73.9 |
| Our Previous [24] | 57.4 | 50.1 | 66.9 | 79.2 | 80.4 | 84.9 | 89.5 | 68.9 | 55.2 | 65.6 | 50.8 | 59.1 | 67.3 | [86.0] |
| This Solution | 57.6 | 51.6 | 62.2 | 79.1 | 80.8 | 85.7 | 89.2 | 70.0 | 55.6 | 65.1 | 51.0 | 57.9 | [67.2] | 87.5 |
Table 4.
Comparison across results on the DISFA dataset. Our proposed solution achieves the highest improvement (75.6%) across all AUs as given by the Borda rank while achieving comparable results on the average F1 score. The top-1 in each column is bolded, with the top-2 [bracketed], and the top-3 is underlined.
Table 4.
Comparison across results on the DISFA dataset. Our proposed solution achieves the highest improvement (75.6%) across all AUs as given by the Borda rank while achieving comparable results on the average F1 score. The top-1 in each column is bolded, with the top-2 [bracketed], and the top-3 is underlined.
| Method | Individual AU F1 Scores | Avg. F1 | Borda Rank |
|---|
| |
1
|
2
|
4
|
6
|
9
|
12
|
25
|
26
|
(↑)
|
(↑)
|
|---|
| DRML [16] | 17.3 | 17.7 | 37.4 | 29.0 | 10.7 | 37.7 | 38.5 | 20.1 | 26.1 | 0.6 |
| EAC-Net [17] | 41.5 | 26.4 | 66.4 | 50.7 | 80.5 | 89.3 | 88.9 | 15.6 | 48.5 | 42.0 |
| AU-GCN [19] | 32.3 | 19.5 | 55.7 | 57.9 | [61.4] | 62.7 | 90.9 | 60.0 | 55.0 | 39.8 |
| SRERL [14] | 45.7 | 47.8 | 59.6 | 47.1 | 45.6 | 76.5 | 84.3 | 43.6 | 55.9 | 29.5 |
| JAA-Net [18] | 43.7 | 46.2 | 56.0 | 41.4 | 44.7 | 69.6 | 88.3 | 58.4 | 56.0 | 21.0 |
| LP-Net [64] | 29.9 | 24.7 | 72.7 | 46.8 | 49.6 | 72.9 | 93.8 | 65.0 | 56.9 | 40.9 |
| AUFM [28] | 41.5 | 44.9 | 60.3 | 51.5 | 50.3 | 70.4 | 91.3 | 55.3 | 58.2 | 33.5 |
| ARL [15] | 43.9 | 42.1 | 63.6 | 41.8 | 40.0 | 76.2 | 95.2 | 66.8 | 58.7 | 42.6 |
| SEV-Net [26] | 55.3 | 53.1 | 61.5 | 53.6 | 38.2 | 71.6 | 95.7 | 41.5 | 58.8 | 44.9 |
| UGN-B [20] | 43.3 | 48.1 | 63.4 | 49.5 | 48.2 | 72.9 | 90.8 | 59.0 | 60.0 | 35.2 |
| HMP-PS [21] | 38.0 | 45.9 | 65.2 | 50.9 | 50.8 | 76.0 | 93.3 | 67.6 | 61.0 | 48.9 |
| FAUDT [25] | 46.1 | 48.6 | 72.8 | [56.7] | 50.0 | 72.1 | 90.8 | 55.4 | 61.5 | 52.3 |
| KS [67] | 53.8 | 59.9 | 69.2 | 54.2 | 50.8 | 75.8 | 92.2 | 46.8 | 62.8 | 55.7 |
| ME-GraphAU [22] | 54.6 | 47.1 | 72.9 | 54.0 | 55.7 | 76.7 | 91.1 | 53.0 | 63.1 | 63.6 |
| PIAP [65] | 50.2 | 51.8 | 71.9 | 50.6 | 54.5 | [79.7] | 94.1 | 57.2 | 63.8 | 63.6 |
| GMRP [30] | 62.6 | 54.7 | 70.8 | 46.3 | 51.7 | 76.3 | 94.4 | 59.8 | 64.6 | 63.1 |
| KDSRL [27] | 60.4 | 59.2 | 67.5 | 52.7 | 51.5 | 76.1 | 91.3 | 57.7 | 64.5 | 59.1 |
| FG-Net [66] | 63.6 | 66.9 | 72.5 | 50.7 | 48.8 | 76.5 | 94.1 | 50.1 | 65.4 | 64.8 |
| SACL [23] | 62.0 | [65.7] | 74.5 | 53.2 | 43.1 | 76.9 | [95.6] | 53.1 | 65.5 | 72.2 |
| AUFormer [31] | 58.6 | 61.0 | 70.4 | 52.4 | 58.1 | 73.0 | 90.8 | 66.9 | 66.4 | 63.6 |
| GTLE-Net [29] | 64.5 | 63.2 | 70.1 | 47.7 | 53.6 | 76.2 | 94.8 | 65.1 | 66.9 | 69.9 |
| Our previous [24] | [67.2] | 64.1 | [74.2] | 52.2 | 47.0 | 73.1 | 95.1 | 69.8 | [67.8] | [74.4] |
| This Solution | 69.2 | 61.1 | 71.7 | 53.6 | 49.2 | 76.6 | 93.2 | [68.2] | 67.9 | 75.6 |
Table 5.
Results of individually removing each part of the available base learners on the BP4D dataset. refers to the difference from our proposed solution.
Table 5.
Results of individually removing each part of the available base learners on the BP4D dataset. refers to the difference from our proposed solution.
| Model | Avg. F1 | Avg. F1 | Borda | Borda |
|---|
|
Description:
|
Score
|
Score |
Rank
|
Rank |
|---|
| Our Solution | 67.2 | | 87.5 | |
| Linear Meta-learner | 66.7 | −0.5 | 83.7 | −3.8 |
| Transformer Meta-learner | 66.4 | −0.8 | 81.1 | −6.4 |
| AGG Meta-learner | 66.3 | −0.9 | 79.5 | −8.0 |
| No SynAU | 66.9 | −0.3 | 86.0 | −1.5 |
| Only Resnet | 66.5 | −0.7 | 82.2 | −5.3 |
| Only Swin | 66.6 | −0.6 | 83.7 | −3.8 |
| Only AGG 1 Layer | 66.6 | −0.6 | 82.2 | −5.3 |
| Only AGG 3 Layer | 66.9 | −0.3 | 86.7 | −0.8 |
| Never use COAL | 67.0 | −0.2 | 87.9 | 0.4 |
| Only use COAL | 66.8 | −0.4 | 86.4 | −1.1 |
| Not Pretrained | 66.7 | −0.5 | 85.2 | −2.3 |
| Only Pretrained | 66.4 | −0.8 | 81.1 | −6.4 |
Table 6.
Analysis of base learners’ architectural selections. The AUs on the left correspond to both base learners for that AU, as we required both to have the same architecture. Pretrain refers to using pretraining (✓) or not (X). SynAU refers to the use of our SynAU dataset (✓) or not (X). Swin refers to using the Swin Transformer (✓) or the Resnet architecture (X). AGG-3 refers to using three layers (✓) or one layer (X). COAL refers to using the COAL module during training (✓) or not (X). The COAL module is not available for base learners that use the SynAU (—), as it does not provide landmarks.
Table 6.
Analysis of base learners’ architectural selections. The AUs on the left correspond to both base learners for that AU, as we required both to have the same architecture. Pretrain refers to using pretraining (✓) or not (X). SynAU refers to the use of our SynAU dataset (✓) or not (X). Swin refers to using the Swin Transformer (✓) or the Resnet architecture (X). AGG-3 refers to using three layers (✓) or one layer (X). COAL refers to using the COAL module during training (✓) or not (X). The COAL module is not available for base learners that use the SynAU (—), as it does not provide landmarks.
| | Pretrain | SynAU | Swin | AGG-3 | COAL |
|---|
| AU1 | X | X | X | X | X |
| AU2 | ✓ | X | ✓ | ✓ | X |
| AU4 | X | X | X | ✓ | X |
| AU6 | X | ✓ | ✓ | ✓ | — |
| AU7 | ✓ | X | ✓ | X | ✓ |
| AU10 | X | X | ✓ | ✓ | X |
| AU12 | X | ✓ | ✓ | ✓ | — |
| AU14 | ✓ | X | ✓ | ✓ | X |
| AU15 | ✓ | X | ✓ | ✓ | X |
| AU17 | X | ✓ | X | ✓ | — |
| AU23 | X | X | X | X | X |
| AU24 | ✓ | X | ✓ | ✓ | ✓ |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}