3.3.1. Theoretical Basis of SMT Technology
The Satisfiability Modulo Theories (SMT) solver generates feasible schedules by resolving constraints in first-order logic. While SMT alone cannot optimize load balancing, its deterministic solutions provide reliable initial schedules for MADDPG training. By converting SMT solutions into initial experiences, we reduce the exploration burden of MADDPG agents and accelerate convergence.
The SMT solver will first convert all variables in the SMT formula into identifiable variables, and judge whether the formula can be established. If it is, it will carry out the corresponding assignment behavior. During this whole process, a search tree is constructed through the DPLL (Davis–Putnam–Logemann–Loveland) algorithm to continuously assign values, and the termination condition is to obtain a feasible solution or the solver displays no solution.
(1). Rationale for Using SMT Solver as Initial Experience
1. Guaranteed Generation of Feasible Solutions
The SMT (Satisfiability Modulo Theories) solver rigorously enforces all hard constraints of TTE networks (e.g., periodicity and end-to-end deadlines), ensuring the generated schedules are feasible and safe. This provides reinforcement learning (RL) agents with a conflict-free starting point, avoiding frequent constraint violations during early-stage random exploration, which could destabilize training or prevent convergence.
2. Accelerated Convergence
Random exploration in RL (especially in multi-agent settings) is inherently inefficient. By pre-populating the experience replay buffer with SMT solutions: Reduce ineffective exploration: Agents avoid wasting time in invalid action spaces (e.g., conflicting time slots).
High-Quality Demonstrations: SMT solutions, though suboptimal, comply with basic scheduling rules, providing structured prior knowledge. Experiments show SMT initialization reduces training steps by 0.58.
3. Mitigation of Cold-Start Issues
In TTE scheduling, the action space grows exponentially with network scale (e.g., 190 TT messages correspond to ∼ possible scheduling combinations). SMT’s deterministic solutions guide agents toward practical policy directions, eliminating fully random cold starts.
(2). Integration Methodology of SMT and MADDPG
1. Conversion of SMT Solutions and Experience Buffer Initialization
Step 1: Generate a static schedule table using the SMT solver, ensuring all constraints are satisfied.
Step 2: Convert SMT solutions into MADDPG experience tuples :
State s: Current network load and link utilization.
Action a: SMT-assigned
Reward r: Initial reward calculated using and .
Step 3: Pre-fill the experience replay buffer D with samples (e.g., ).
2. Hybrid Training Strategy
Phase 1 (Pre-training): For the first steps (e.g.,K = 5000), update network parameters using only SMT experiences to stabilize Critic’s state-action value estimation.
Phase 2 (Exploitation-Exploration Balance): In subsequent training, sample SMT experiences with probability and new explorations with 1 − . linearly decay (e.g., from 0.5 to 0.1) to reduce dependency on prior knowledge.
3. Dynamic Experience Weight Adjustment
To enhance diversity, add Gaussian noise perturbations to SMT solutions:
where
decreases with training steps (e.g., from 0.1
to 0.01
), gradually phasing out reliance on SMT.
3.3.2. Completion of Initialization
The SMT-generated schedule is decomposed into experience tuples and prefilled into the replay buffer D:
1. State Encoding
Global State s: Link utilization and queued RC/BE messages .
Local Observation : Message period , hop count , and current hypercycle time.
2. Action Extraction
Extract SMT-assigned offsets as actions .
3. Reward Calculation
Load Balancing Reward:
where
is the global load imbalance metric of the SMT solution.
Scheduling Success Reward:
Assumes all messages are scheduled without collisions.
4. Experience Construction
Each TT message’s scheduling decision generates an experience tuple:
Note: The next state is derived by simulating the SMT schedule’s impact on link utilization and message queues.
3.3.3. Hybrid Scheduling Algorithm Flow Based on SMT and MADDPG
Multi-agent reinforcement learning is a method of reinforcement learning, and its essence is to explore and try to learn through multiple agents. Therefore, giving some initial experience guidance to agents is conducive to improving training results and speeding up training efficiency. In the MADDPG algorithm, the initial stage of agent training is inefficient in message planning because there is no experience guidance, which leads to a slow execution rate and long consumption time of the algorithm. SMT’s mathematical algorithm has high efficiency in solving message scheduling, but the solution obtained by this algorithm is only feasible, and there is a problem in that it cannot be optimized. Therefore, the feasible solution obtained by SMT mathematical algorithm is taken as the initial accumulated experience of algorithm training, and the scheduling schedule obtained by SMT mathematical algorithm is transformed into the weights in MADPG algorithm, and the weight ratio is adjusted based on the effect of algorithm training, and the obtained basic solution is used to guide MADPG algorithm training.
In the algorithm flow, firstly, the network configuration information, network scheduling constraint parameters and neural network parameters are initialized, and at the same time, the message cluster needs to be initialized. After that, the messages to be scheduled and the conditions to be met are combined into the corresponding formula, and the formula is input into the solver to obtain a feasible solution. Finally, the solution is used as the initial weight value of the algorithm training, and the weight ratio is adjusted based on the effect of the algorithm training.
In the training stage, each message is explored according to the current state S and the strategy selection action a; after each action selection, it is necessary to judge whether the action meets the constraint conditions, and if not, give a negative return value and return to re-schedule; if yes, the reward value r and the state at the next moment are observed after the action is executed, and the experience vectors are stored in the experience pool D to update the state S; by sampling the data in the empirical area D randomly in small batches, and updating the critic network with the sampled data and the loss minimization function, and updating the actor network with the sampled data and the strategic gradient function; after the training is completed, it is necessary to reset the training environment to prevent the next training from being affected by the training results; based on the training effect of the algorithm, the training times of the algorithm are determined.
In the execution stage, the message agent relies on the optimized policy network to guide the agent’s policy network, inputs the local observation , and outputs the scheduling action through the operation of the policy network. After each action selection, it is necessary to judge whether the action meets the constraint conditions; if not, it will give a negative return value and restart the message scheduling. After all messages are successfully scheduled, the scheduled result is obtained.
The algorithm flow is described as follows (Algorithm 1):



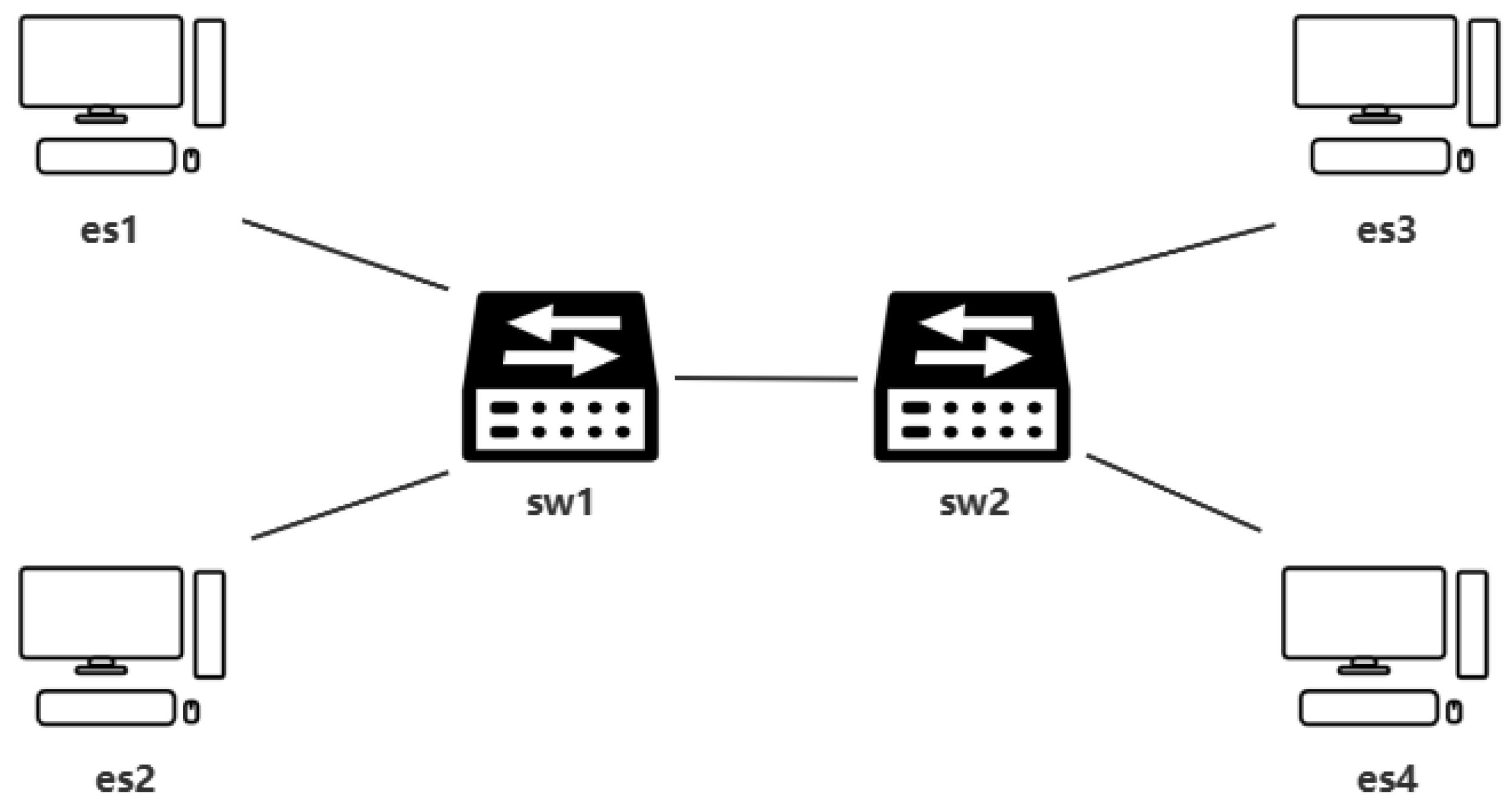

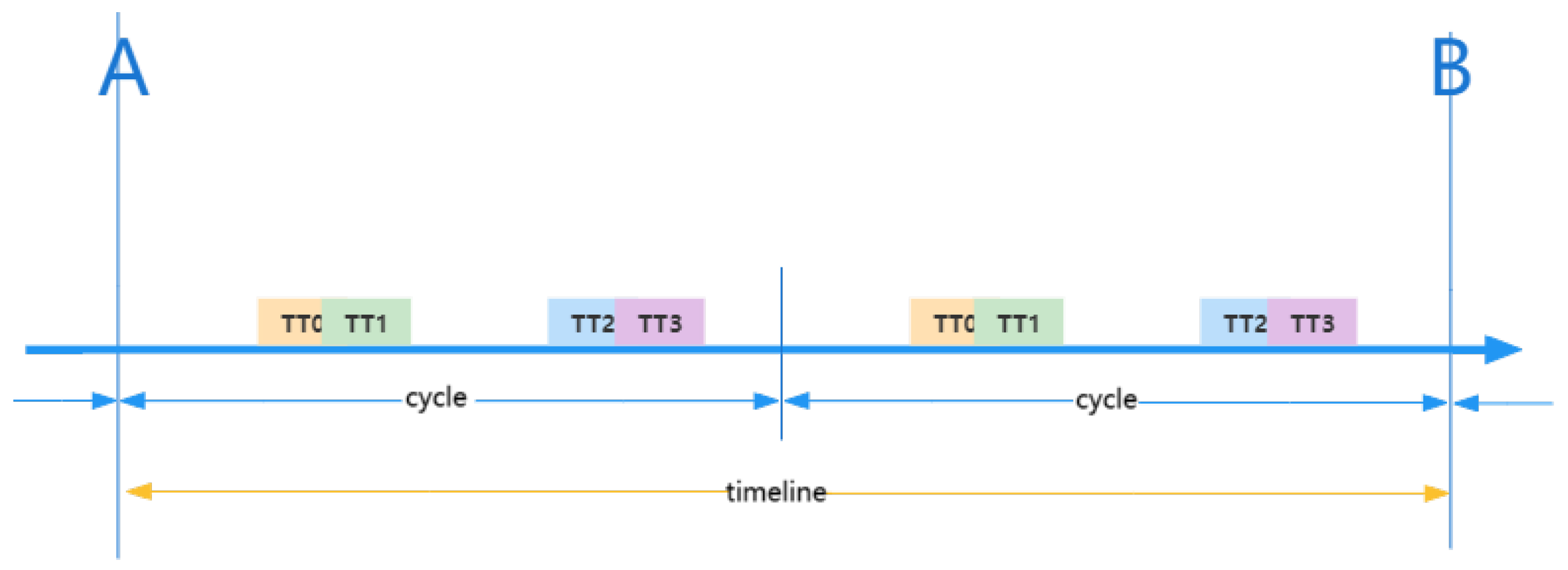
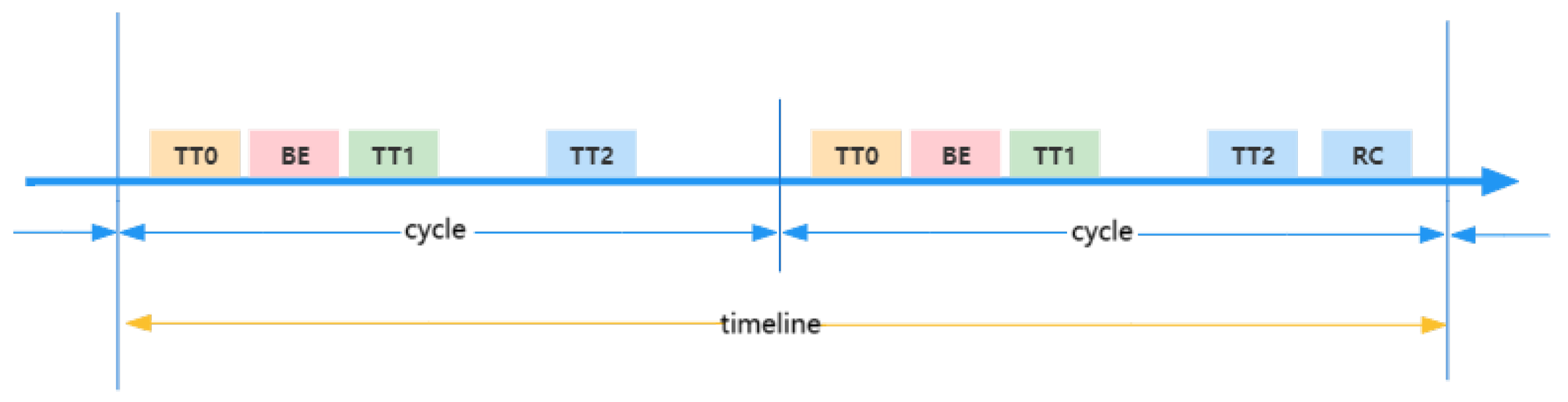
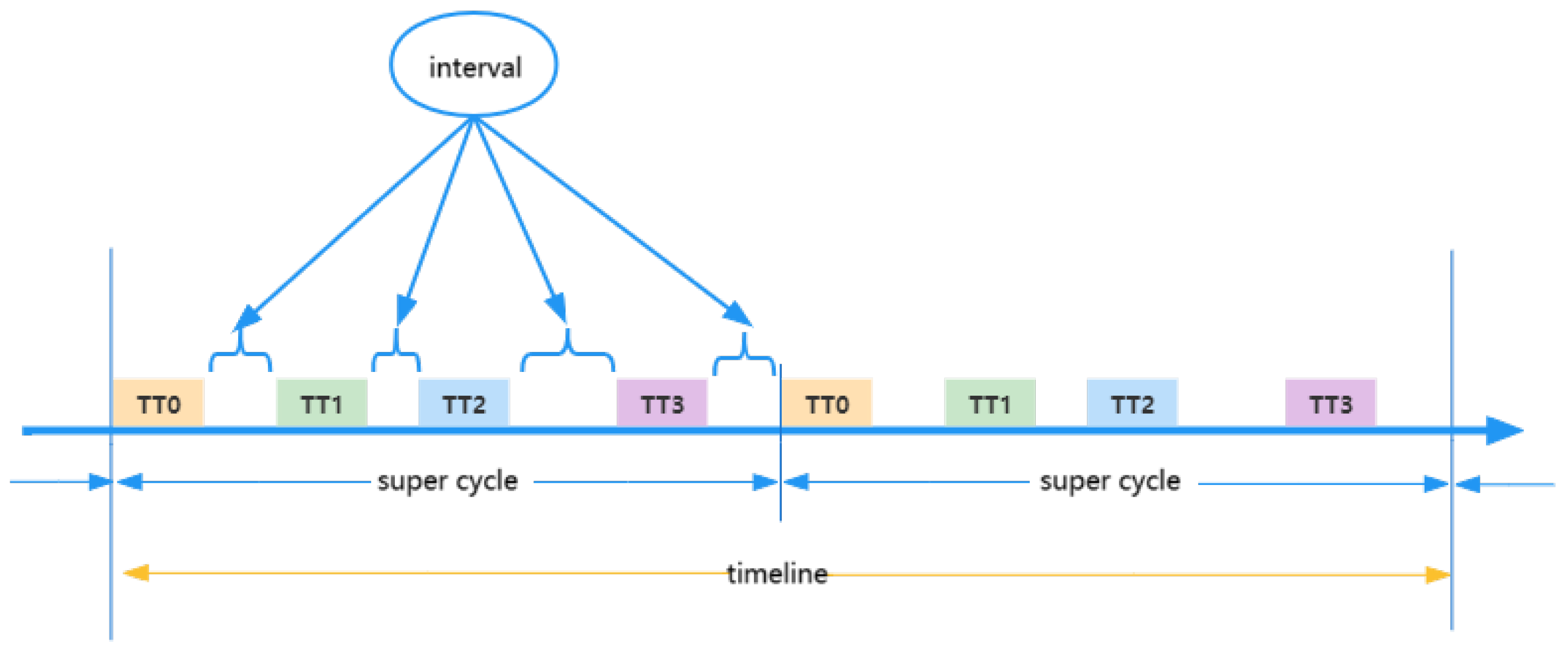
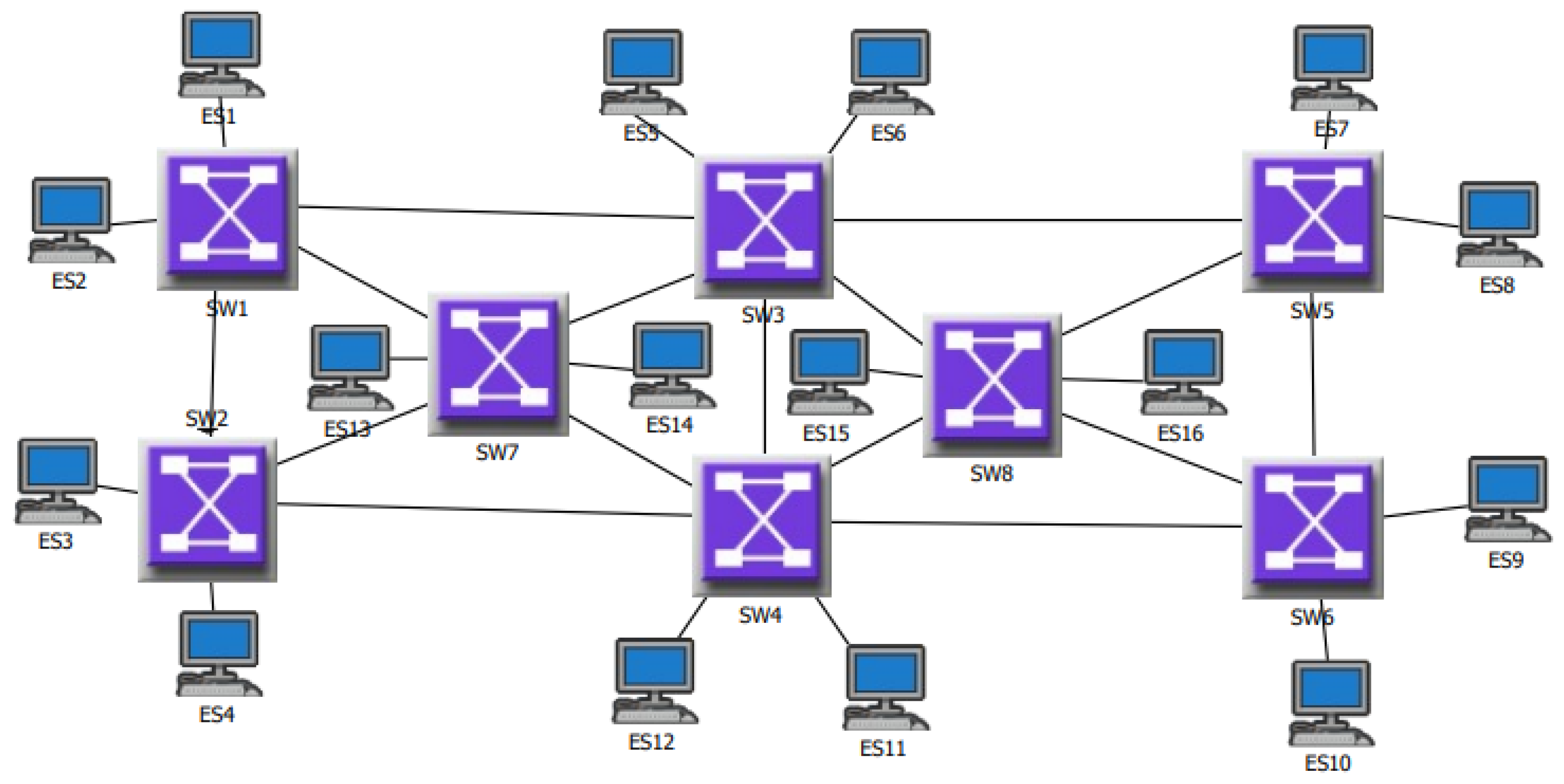
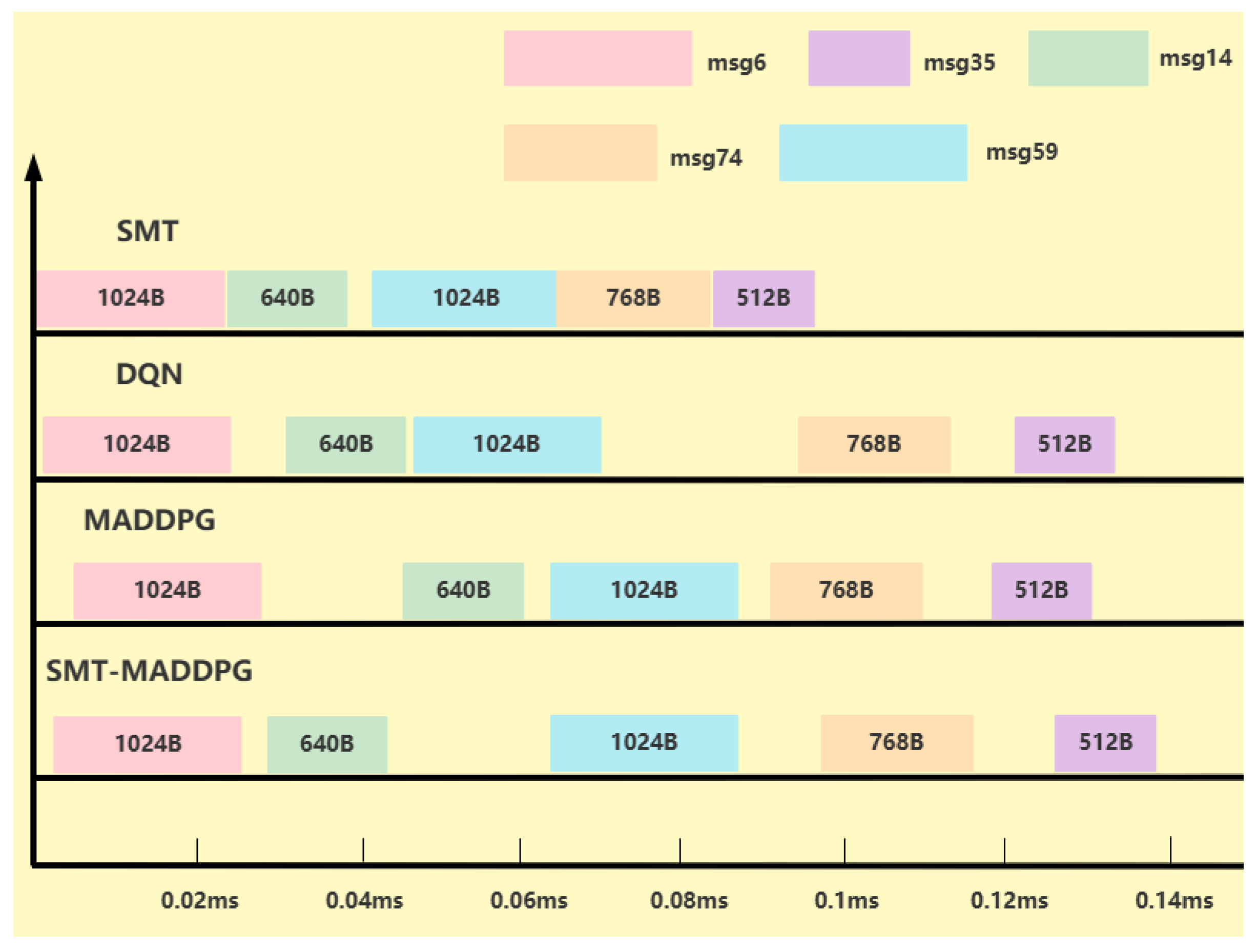


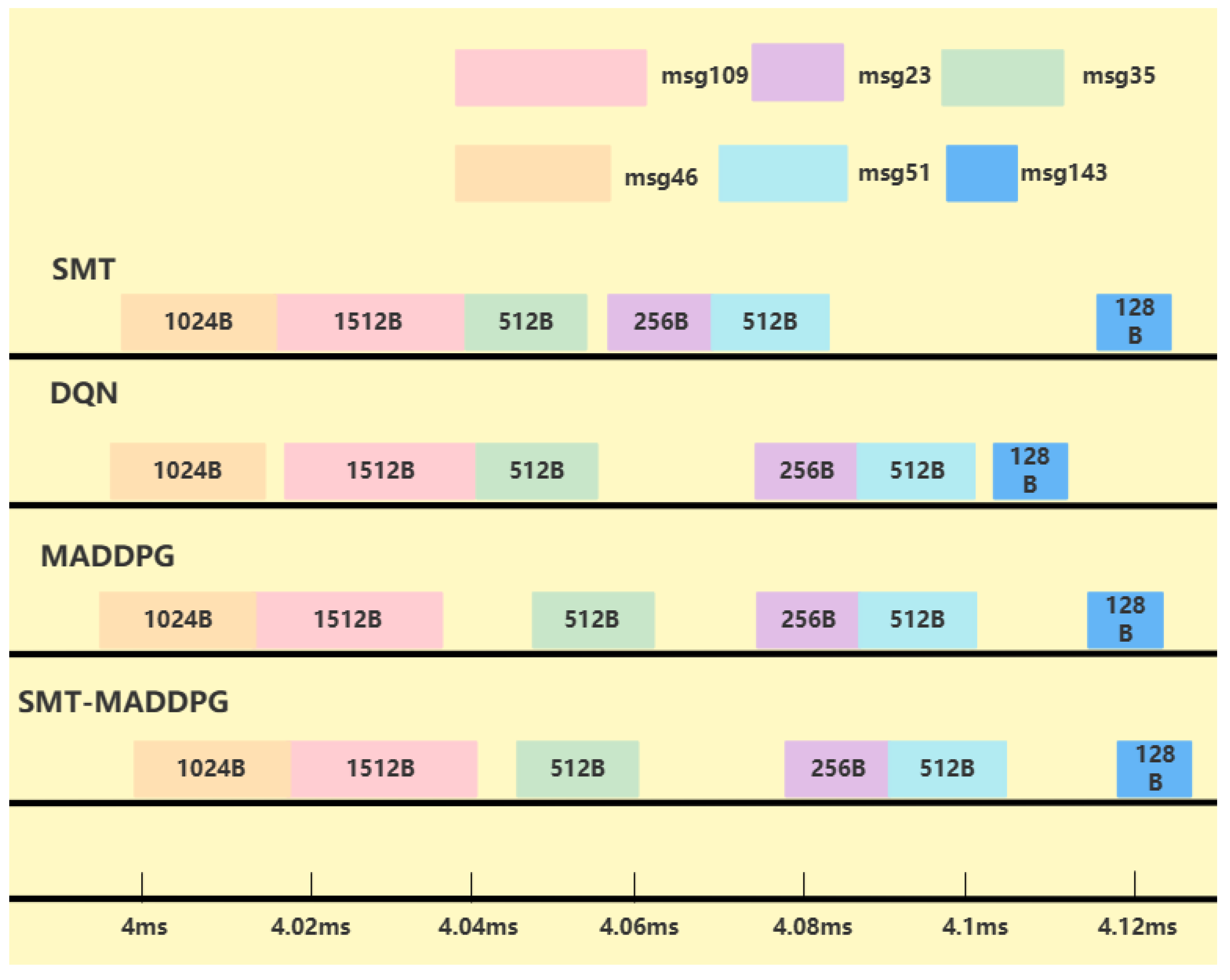
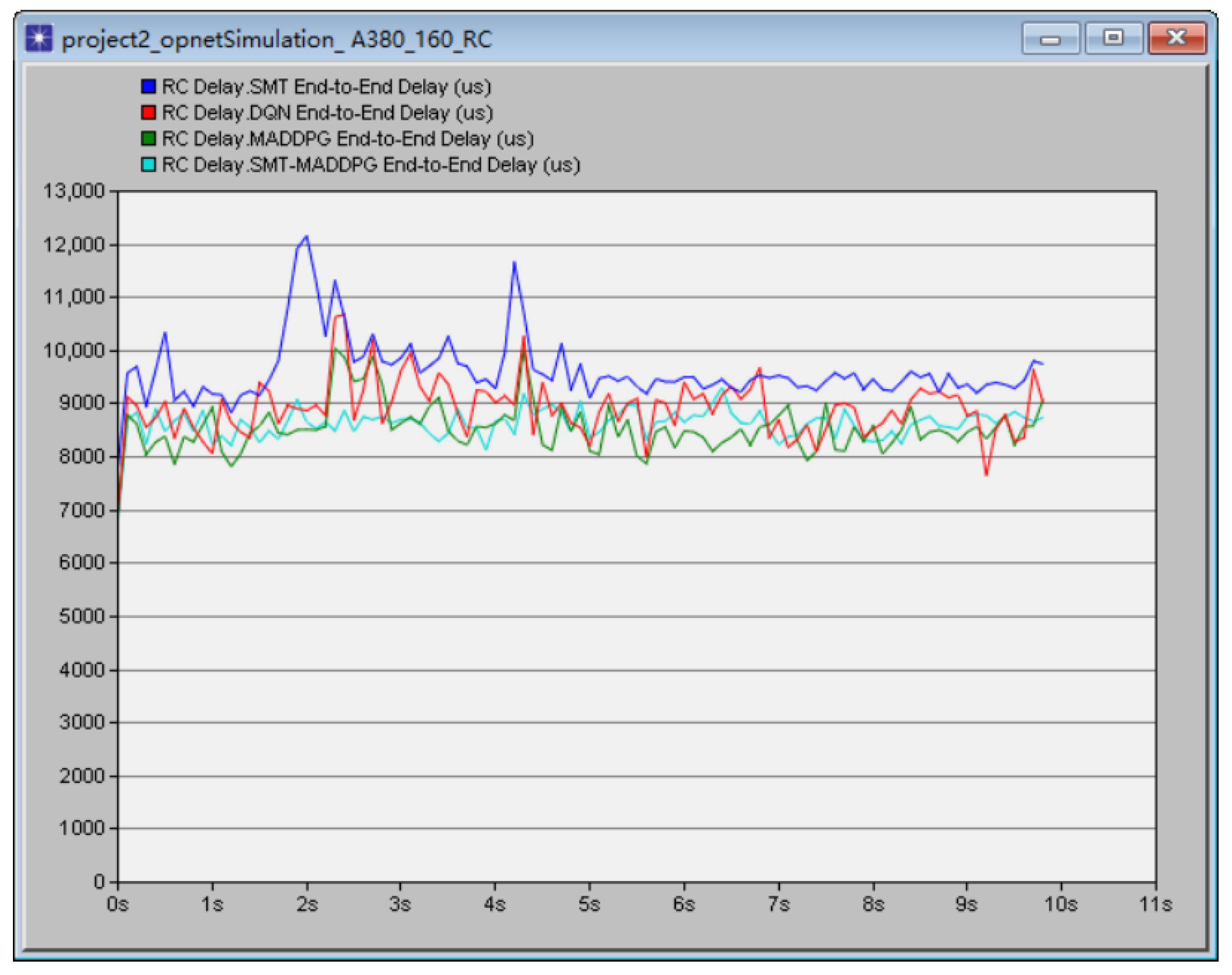

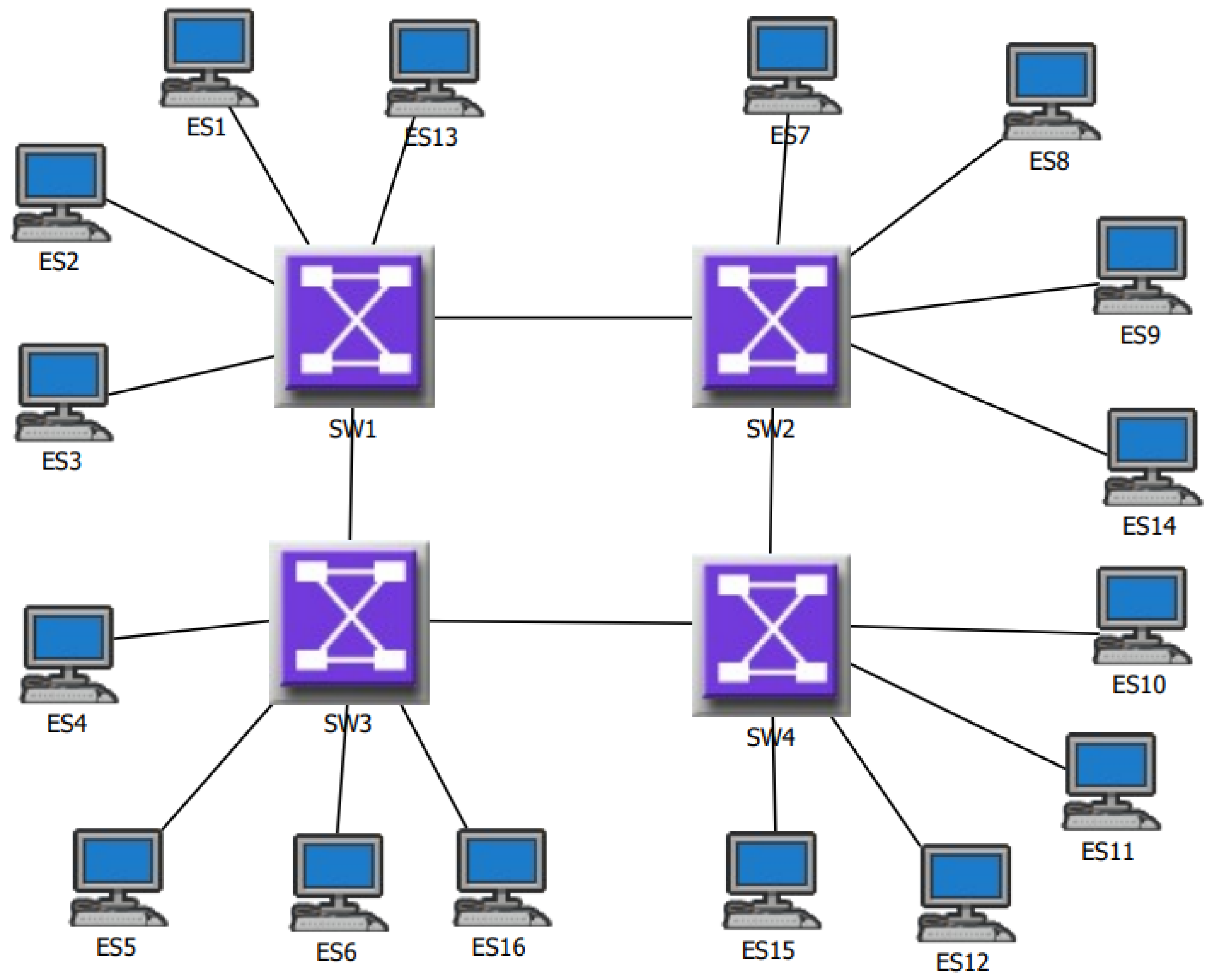
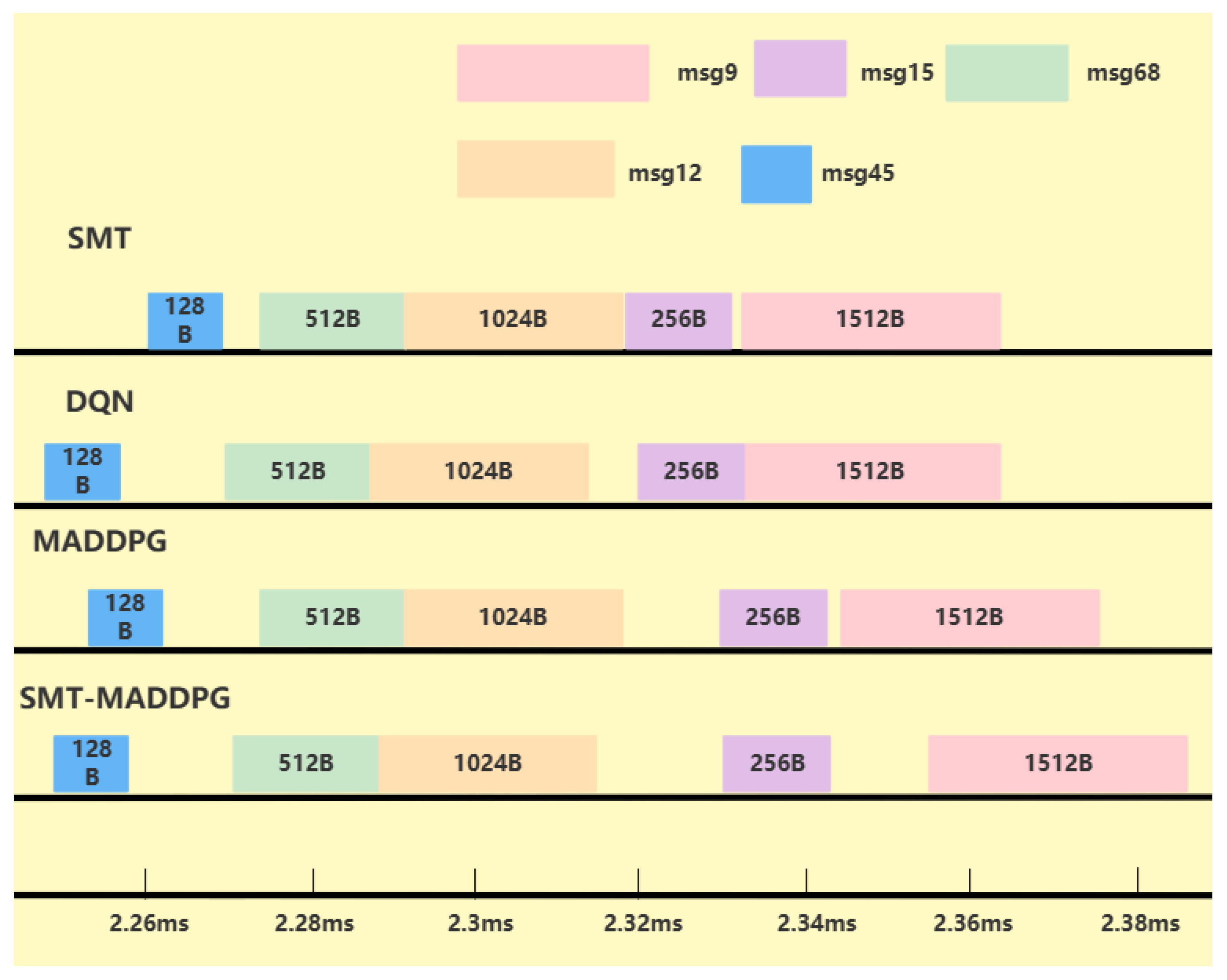

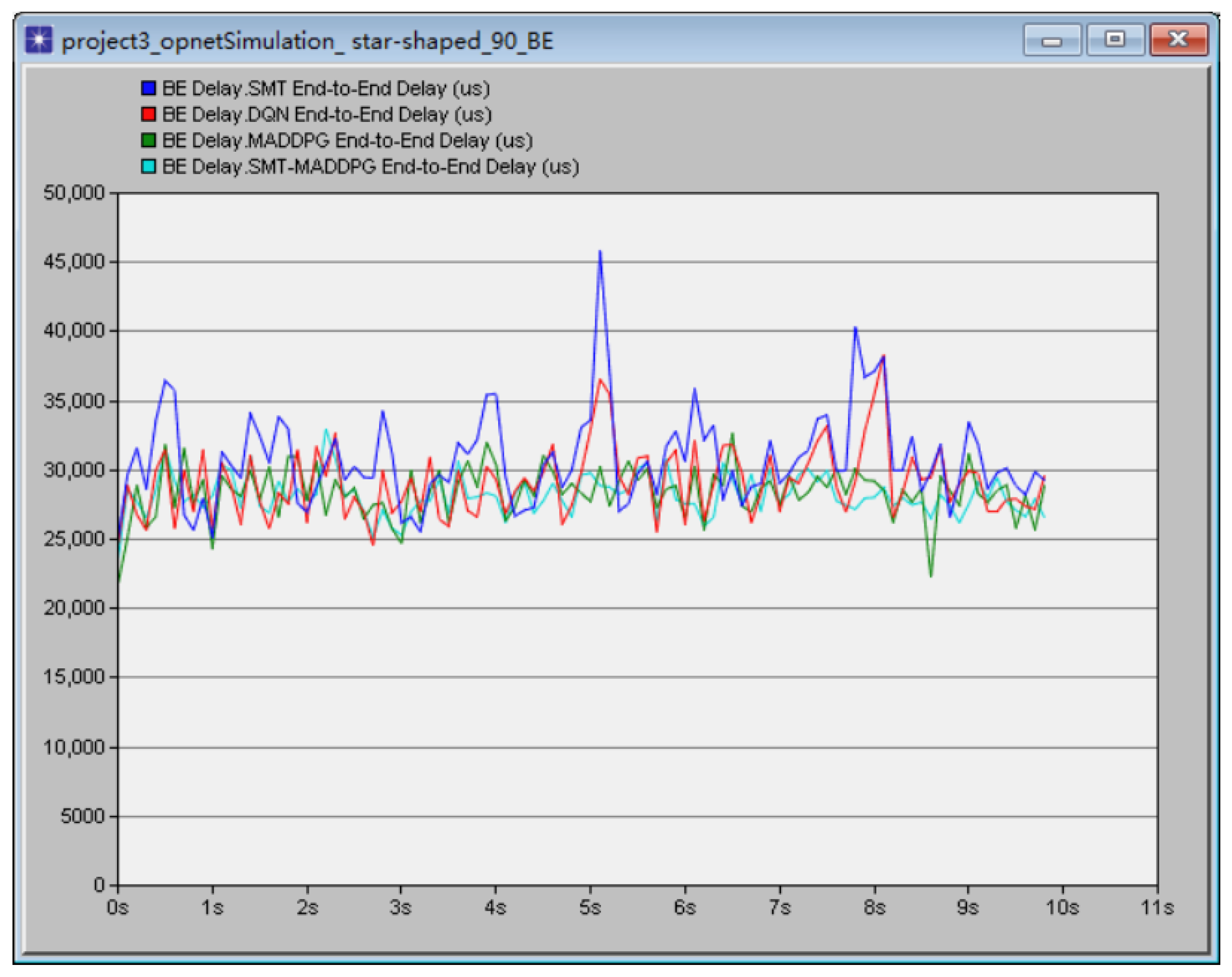
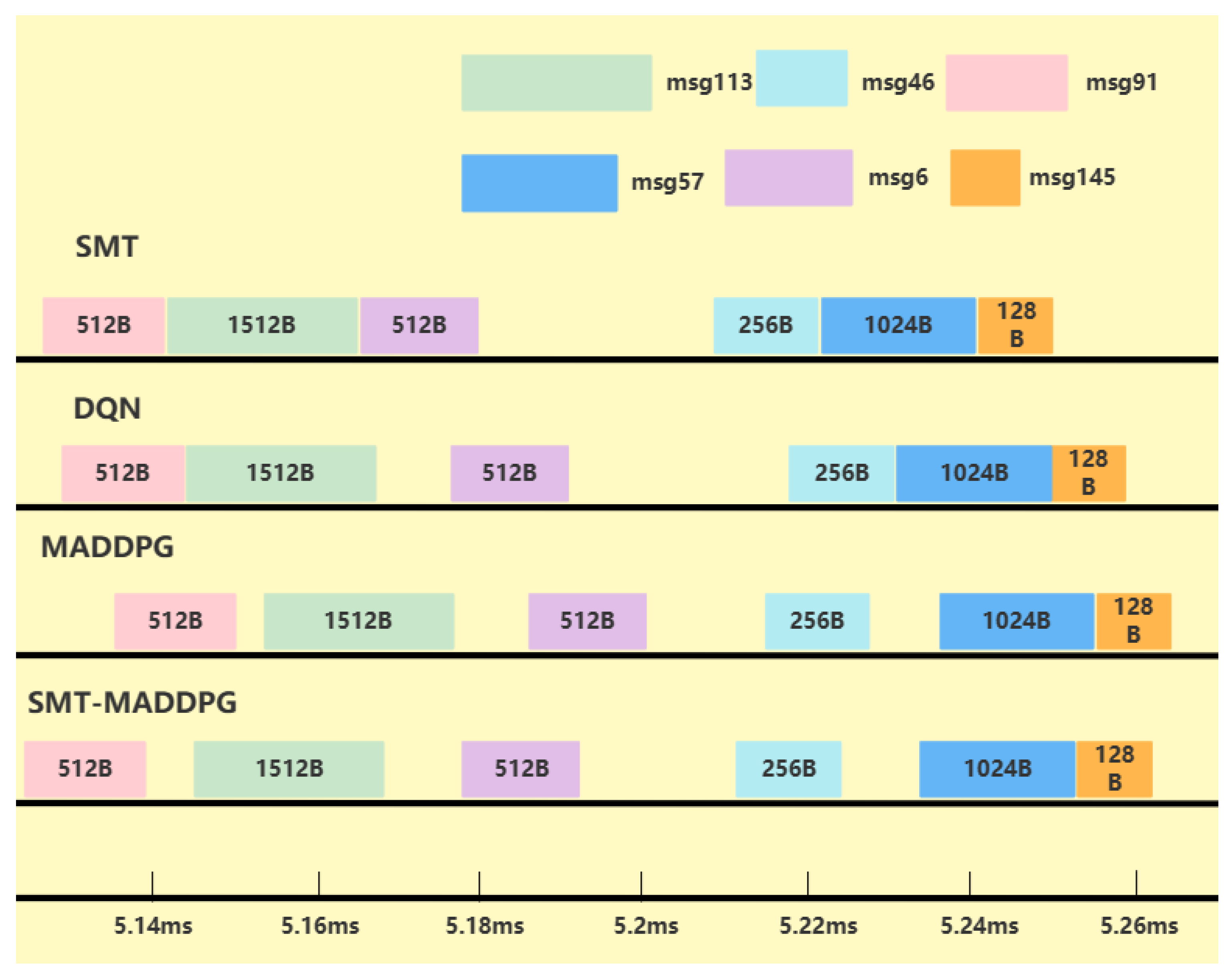


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}